 Im Oktober letzten Jahres fand die erste Yandex Yandex Scale Cloud-Konferenz statt. Es wurde die Einführung vieler neuer Dienste angekündigt, darunter Yandex IoT Core, mit dem Sie Daten mit Millionen von IoT-Geräten austauschen können.In diesem Artikel werde ich darüber sprechen, warum Yandex IoT Core benötigt wird und wie es funktioniert und wie es mit anderen Yandex.Cloud-Diensten interagieren kann. Sie lernen die Architektur, die Feinheiten des Zusammenspiels von Komponenten und die Merkmale der Implementierung von Funktionen kennen - all dies hilft Ihnen, die Nutzung dieser Dienste zu optimieren.Lassen Sie uns zunächst an die Hauptvorteile von Public Clouds und PaaS erinnern - Reduzierung der Entwicklungszeit und -kosten sowie der Support- und Infrastrukturkosten, die auch für IoT-Projekte relevant sind. Es gibt jedoch einige weniger offensichtliche nützliche Funktionen, die Sie in der Cloud erhalten können. Diese effektive Skalierung und Fehlertoleranz sind wichtige Aspekte bei der Arbeit mit Geräten, insbesondere in Projekten für kritische Informationsinfrastrukturen.Effektive Skalierung ist die Möglichkeit, die Anzahl der Geräte frei zu erhöhen oder zu verringern, ohne technische Probleme zu haben und nach den Änderungen eine vorhersehbare Änderung der Systemkosten festzustellen.Fehlertoleranz ist das Vertrauen, dass Services so konzipiert und bereitgestellt werden, dass auch bei Ausfall einiger Ressourcen die höchstmögliche Leistung gewährleistet ist.Kommen wir nun zu den Details.
Im Oktober letzten Jahres fand die erste Yandex Yandex Scale Cloud-Konferenz statt. Es wurde die Einführung vieler neuer Dienste angekündigt, darunter Yandex IoT Core, mit dem Sie Daten mit Millionen von IoT-Geräten austauschen können.In diesem Artikel werde ich darüber sprechen, warum Yandex IoT Core benötigt wird und wie es funktioniert und wie es mit anderen Yandex.Cloud-Diensten interagieren kann. Sie lernen die Architektur, die Feinheiten des Zusammenspiels von Komponenten und die Merkmale der Implementierung von Funktionen kennen - all dies hilft Ihnen, die Nutzung dieser Dienste zu optimieren.Lassen Sie uns zunächst an die Hauptvorteile von Public Clouds und PaaS erinnern - Reduzierung der Entwicklungszeit und -kosten sowie der Support- und Infrastrukturkosten, die auch für IoT-Projekte relevant sind. Es gibt jedoch einige weniger offensichtliche nützliche Funktionen, die Sie in der Cloud erhalten können. Diese effektive Skalierung und Fehlertoleranz sind wichtige Aspekte bei der Arbeit mit Geräten, insbesondere in Projekten für kritische Informationsinfrastrukturen.Effektive Skalierung ist die Möglichkeit, die Anzahl der Geräte frei zu erhöhen oder zu verringern, ohne technische Probleme zu haben und nach den Änderungen eine vorhersehbare Änderung der Systemkosten festzustellen.Fehlertoleranz ist das Vertrauen, dass Services so konzipiert und bereitgestellt werden, dass auch bei Ausfall einiger Ressourcen die höchstmögliche Leistung gewährleistet ist.Kommen wir nun zu den Details.IoT-Skriptarchitektur
Lassen Sie uns zunächst sehen, wie die Gesamtarchitektur des IoT-Skripts aussieht. Darin lassen sich zwei große Teile unterscheiden:
Darin lassen sich zwei große Teile unterscheiden:- Die erste ist die Übermittlung von Daten an den Speicher und die Übermittlung von Befehlen an Geräte. Wenn Sie ein IoT-System erstellen, muss dieses Problem auf jeden Fall gelöst werden, unabhängig davon, welches Projekt Sie ausführen.
- Der zweite arbeitet mit empfangenen Daten. Alles ähnelt jedem anderen Projekt, das auf der Analyse und Visualisierung von Datensätzen basiert. Sie haben ein Repository mit einer anfänglichen Reihe von Informationen, mit denen Sie Ihre Aufgabe realisieren können.
Der erste Teil ist in allen IoT-Systemen ungefähr gleich: Er basiert auf allgemeinen Prinzipien und passt in ein gemeinsames Szenario, das für die meisten IoT-Systeme geeignet ist.Der zweite Teil ist in Bezug auf die ausgeführten Funktionen fast immer einzigartig, obwohl er auf Standardkomponenten basiert. Gleichzeitig wird ohne ein qualitativ hochwertiges, fehlertolerantes und skalierbares Interaktionssystem mit Hardware die Effektivität des analytischen Teils der Architektur auf nahezu Null reduziert, da einfach nichts zu analysieren ist.Aus diesem Grund hat sich das Yandex.Cloud-Team zunächst darauf konzentriert, ein komfortables Ökosystem von Diensten aufzubauen, mit dem Daten schnell, effizient und zuverlässig von Geräten an Speicher übertragen und Befehle an Geräte gesendet werden können. Um diese Probleme zu lösen, arbeiten wir an der Funktionalität und Integration von Yandex IoT Core, Yandex-Funktionen und Datenspeicherdiensten in der Cloud:
Um diese Probleme zu lösen, arbeiten wir an der Funktionalität und Integration von Yandex IoT Core, Yandex-Funktionen und Datenspeicherdiensten in der Cloud:- Der Yandex IoT Core-Dienst ist ein ausfallsicherer skalierbarer MQTT-Broker mit mehreren Mandanten und einer Reihe zusätzlicher nützlicher Funktionen.
- Der Yandex Cloud Functions-Dienst ist ein Vertreter der vielversprechenden Richtung ohne Server und ermöglicht es Ihnen, Ihren Code als Funktion in einer sicheren, fehlertoleranten und automatisch skalierbaren Umgebung auszuführen, ohne virtuelle Maschinen zu erstellen und zu warten.
- Yandex Object Storage ist eine effektive Speicherung großer Datenfelder und eignet sich sehr gut für „historische“ Archivdatensätze.
- , , Yandex Managed Service for ClickHouse, «» . «» , , , .
Wenn es sich bei Datenspeicherungs- und Analysediensten um Allzweckdienste handelt, über die bereits viel geschrieben wurde, werfen Yandex IoT Core und seine Interaktion mit Yandex Cloud-Funktionen in der Regel viele Fragen auf, insbesondere für Personen, die gerade erst anfangen, das Internet der Dinge und Cloud-Technologien zu verstehen. Und da diese Dienste Fehlertoleranz und Skalierung der Arbeit mit Geräten bieten, werden wir zuerst sehen, was sie unter der Haube haben.So funktioniert Yandex IoT Core
Yandex IoT Core ist ein spezialisierter Plattformdienst für den bidirektionalen Datenaustausch zwischen der Cloud und Geräten, auf denen das MQTT-Protokoll ausgeführt wird. Tatsächlich ist dieses Protokoll zum Standard für die Übertragung von Daten an das Internet der Dinge geworden. Es verwendet das Konzept benannter Warteschlangen (Themen), bei denen Sie einerseits Daten schreiben und andererseits asynchron empfangen können, indem Sie Ereignisse dieser Warteschlange abonnieren.Der Yandex IoT Core-Dienst ist mandantenfähig, dh eine einzige Entität, auf die alle Benutzer zugreifen können. Das heißt, alle Geräte und alle Benutzer interagieren mit derselben Dienstinstanz.Dies ermöglicht einerseits die Gewährleistung einer einheitlichen Arbeit für alle Benutzer, andererseits eine effektive Skalierung und Fehlertoleranz, um eine Verbindung mit einer unbegrenzten Anzahl von Geräten aufrechtzuerhalten und eine unbegrenzte Datenmenge sowohl in Bezug auf Volumen als auch Geschwindigkeit zu verarbeiten.Daraus folgt, dass der Dienst sowohl über Redundanzmechanismen als auch über die Fähigkeit verfügen muss, die verwendeten Ressourcen flexibel zu verwalten, um auf Laständerungen reagieren zu können.Darüber hinaus erfordert die Mandantenfähigkeit eine spezielle Logik für die gemeinsame Nutzung von Zugriffsrechten auf MQTT-Themen.Mal sehen, wie das umgesetzt wird.Wie viele andere Yandex.Cloud-Dienste ist Yandex IoT Core logisch in zwei Teile unterteilt - Steuerungsebene und Datenebene: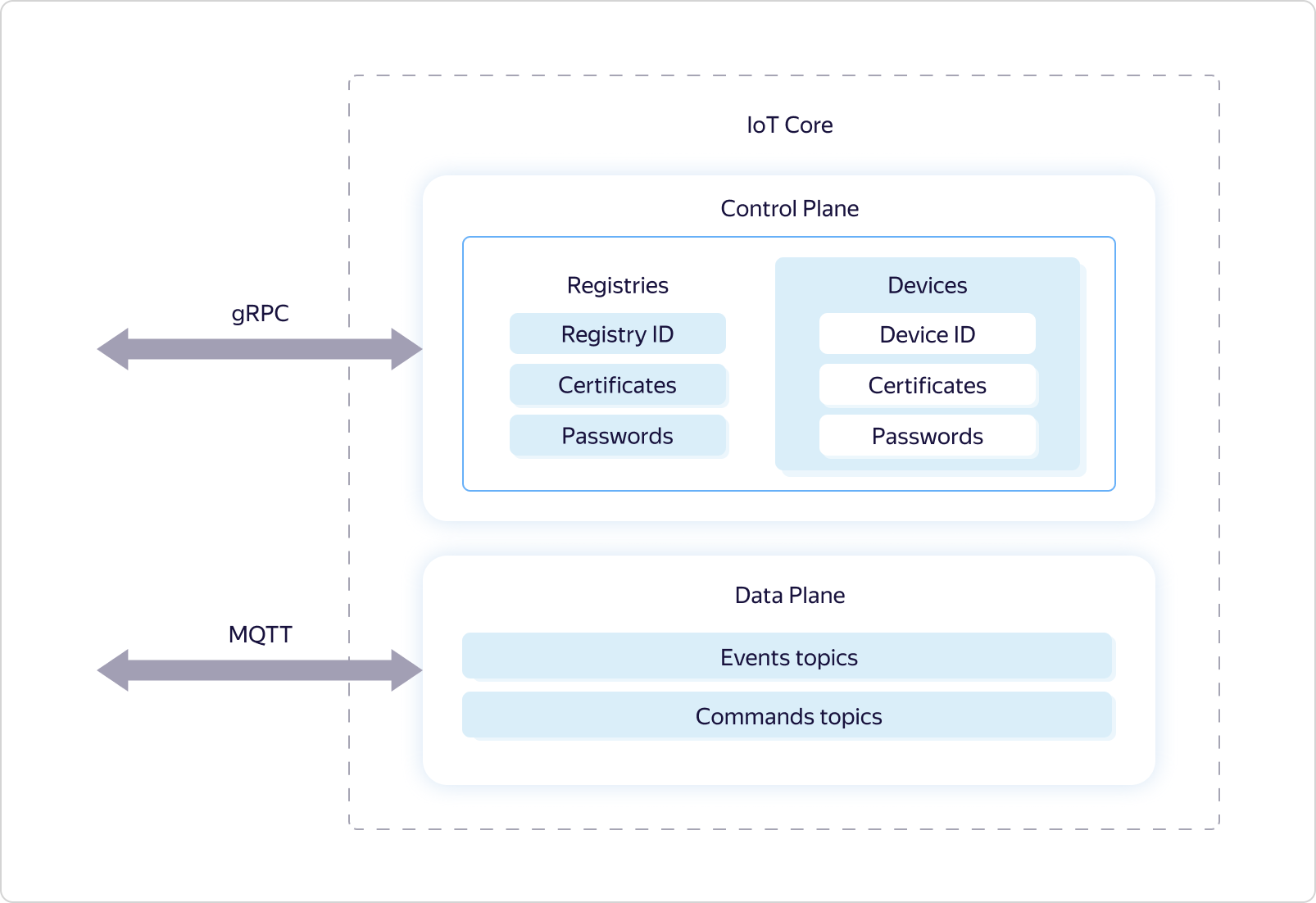 Data Plane ist für die Betriebslogik unter dem MQTT-Protokoll verantwortlich, und Control Plane ist für die Abgrenzung der Zugriffsrechte auf bestimmte Themen verantwortlich und verwendet hierfür die Registrierung und das Gerät für logische Entitäten.
Data Plane ist für die Betriebslogik unter dem MQTT-Protokoll verantwortlich, und Control Plane ist für die Abgrenzung der Zugriffsrechte auf bestimmte Themen verantwortlich und verwendet hierfür die Registrierung und das Gerät für logische Entitäten. Jeder Yandex.Cloud-Benutzer kann über mehrere Registrierungen verfügen, von denen jede eine eigene Teilmenge von Geräten enthalten kann.Der Zugriff auf Themen wird wie folgt bereitgestellt:
Jeder Yandex.Cloud-Benutzer kann über mehrere Registrierungen verfügen, von denen jede eine eigene Teilmenge von Geräten enthalten kann.Der Zugriff auf Themen wird wie folgt bereitgestellt: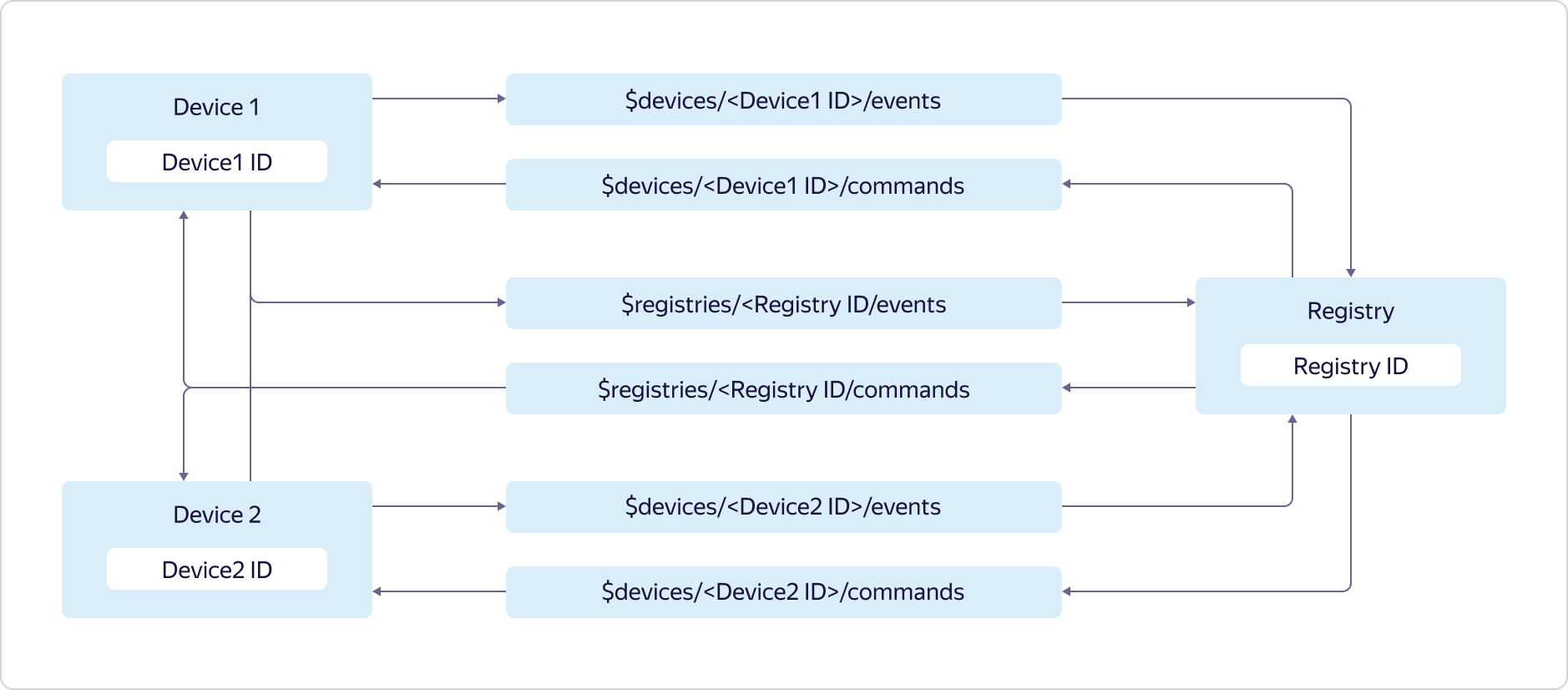 Geräte können Daten nur an ihr Ereignis- und Registrierungsereignisthema senden:
Geräte können Daten nur an ihr Ereignis- und Registrierungsereignisthema senden:$devices/<Device1 ID>/events
$registries/<Registry ID>/events
und abonnieren Sie nur Nachrichten aus Ihrem Befehlsthema und dem Thema Registrierungsbefehle:$devices/<Device1 ID>/commands
$registries/<Registry ID>/commands
Die Registrierung kann Daten an alle Themen der Gerätebefehle und an das Thema der Registrierungsbefehle senden:$devices/<Device1 ID>/commands
$devices/<Device2 ID>/commands
$registries/<Registry ID>/commands
und abonnieren Sie Nachrichten zu allen Themen von Geräteereignissen und zum Thema Registrierungsereignisse:$devices/<Device1 ID>/events
$devices/<Device2 ID>/events
$registries/<Registry ID>/events
Um mit allen oben beschriebenen Entitäten arbeiten zu können, verfügt Data Plane über ein gRPC-Protokoll und ein REST-Protokoll, auf deren Grundlage der Zugriff über die GUI-Konsole von Yandex.Cloud und die CLI-Befehlszeilenschnittstelle erfolgt.Die Datenebene unterstützt das MQTT-Protokoll Version 3.1.1. Es gibt jedoch mehrere Funktionen:- Verwenden Sie beim Herstellen der Verbindung unbedingt TLS.
- Es wird nur die TCP-Verbindung unterstützt. WebSocket ist noch nicht verfügbar.
- Die Autorisierung ist sowohl über die Anmeldung und das Kennwort (wobei die Anmeldung die Geräte- oder Registrierungs-ID ist und die Kennwörter vom Benutzer festgelegt werden) als auch über Zertifikate möglich.
- Das Beibehaltungsflag wird nicht unterstützt, wenn der MQTT-Broker die mit dem Flag gekennzeichnete Nachricht speichert und sie beim nächsten Abonnieren des Themas sendet.
- Persistente Sitzung wird nicht unterstützt, in der der MQTT-Broker Informationen über den Client (Gerät oder Registrierung) speichert, um die erneute Verbindung zu erleichtern.
- Beim Abonnieren und Veröffentlichen werden nur die ersten beiden Serviceebenen unterstützt:
- QoS0 - höchstens einmal. Es gibt keine Zustellgarantie, aber keine erneute Zustellung derselben Nachricht.
- QoS1 - Mindestens einmal. Die Zustellung ist garantiert, es besteht jedoch die Möglichkeit, dass dieselbe Nachricht erneut empfangen wird.
Um die Verbindung zu Yandex IoT Core zu vereinfachen, fügen wir unserem Repository auf GitHub regelmäßig neue Beispiele für verschiedene Plattformen und Sprachen hinzu und beschreiben Skripte in der Dokumentation.Die Servicearchitektur sieht folgendermaßen aus: Die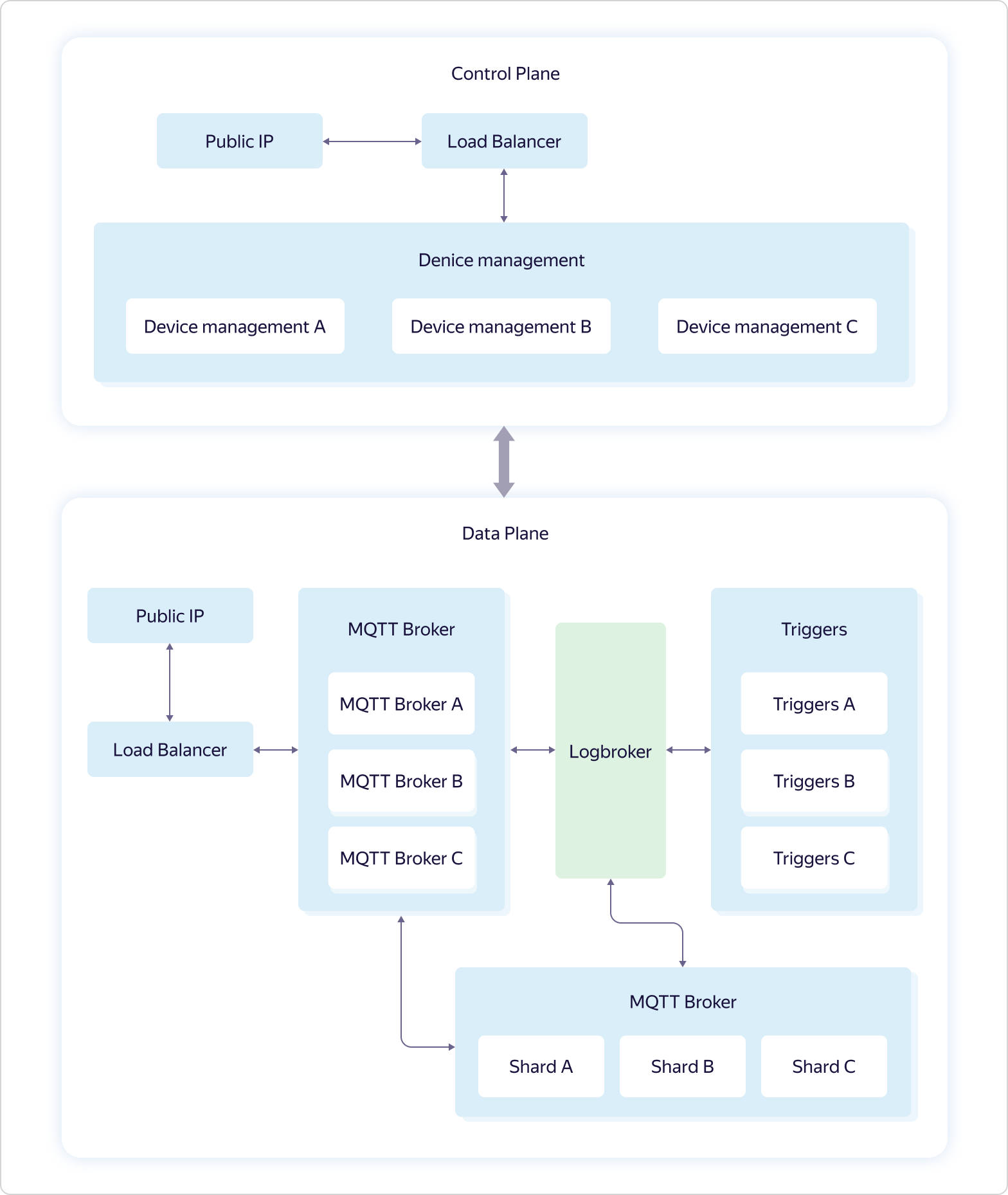 Geschäftslogik des Service besteht aus vier Teilen:
Geschäftslogik des Service besteht aus vier Teilen:- Device management — . Control Plane.
- MQTT Broker — MQTT-. Data Plane.
- Triggers — Yandex Cloud Functions. Data Plane.
- Shards — MQTT- . Data Plane.
Jede Interaktion mit der "Außenwelt" erfolgt über Load Balancer. Darüber hinaus wird gemäß der Hundefutterphilosophie Yandex Load Balancer verwendet, der allen Yandex.Cloud-Benutzern zur Verfügung steht.Jeder Teil der Geschäftslogik besteht aus mehreren Sätzen von drei virtuellen Maschinen - eine in jeder Verfügbarkeitszone (in Schema A, B und C). Virtuelle Maschinen sind genau die gleichen wie alle Yandex.Cloud-Benutzer. Wenn die Last zunimmt, erfolgt die Skalierung mit Hilfe des gesamten Satzes - drei Maschinen werden gleichzeitig im Rahmen eines Teils der Geschäftslogik hinzugefügt. Dies bedeutet, dass, wenn ein Satz von drei MQTT Broker-Maschinen die Last nicht bewältigen kann, ein weiterer Satz von drei MQTT Broker-Maschinen hinzugefügt wird, während die Konfiguration anderer Teile der Geschäftslogik gleich bleibt.Und nur Logbroker ist nicht öffentlich verfügbar. Es ist ein Dienst für einen effizienten ausfallsicheren Betrieb mit Datenströmen. Es basiert auf Apache Kafka, bietet jedoch viele weitere nützliche Funktionen: Es implementiert Disaster Recovery-Prozesse (einschließlich genau einmaliger Semantik, wenn Sie eine Garantie für die Nachrichtenübermittlung ohne Duplizierung haben) und Serviceprozesse (z. B. zentrumsübergreifende Replikation, Datenverteilung an) Berechnungscluster) und verfügt außerdem über einen Mechanismus für die einheitliche, nicht doppelte Verteilung von Daten zwischen Flow-Teilnehmern - eine Art Load Balancer.Die Geräteverwaltungsfunktionen in der Steuerungsebene sind oben beschrieben. Aber mit Data Plane ist alles viel interessanter.Jede Instanz von MQTT Broker arbeitet unabhängig und weiß nichts über andere Instanzen. Alle empfangenen Daten (von Kunden veröffentlichen) werden von Brokern an Logbroker gesendet, von wo sie von Shards and Triggers abgeholt werden. Und in Shards findet die Synchronisation zwischen Instanzen von Brokern statt. Shards kennen alle MQTT-Clients und die Verteilung ihrer Abonnements (Subscribe) auf Instanzen von MQTT-Brokern und bestimmen, wohin die empfangenen Daten gesendet werden sollen.Beispielsweise hat der MQTT-Client A das Thema von Broker A abonniert, und der MQTT-Client B hat dasselbe Thema von Broker B abonniert. Wenn der MQTT-Client C das gleiche Thema veröffentlicht, jedoch an Broker C, überträgt der Shard Daten von Broker C an Broker A und B, wodurch die Daten sowohl vom MQTT-Client A als auch vom MQTT-Client B empfangen werden.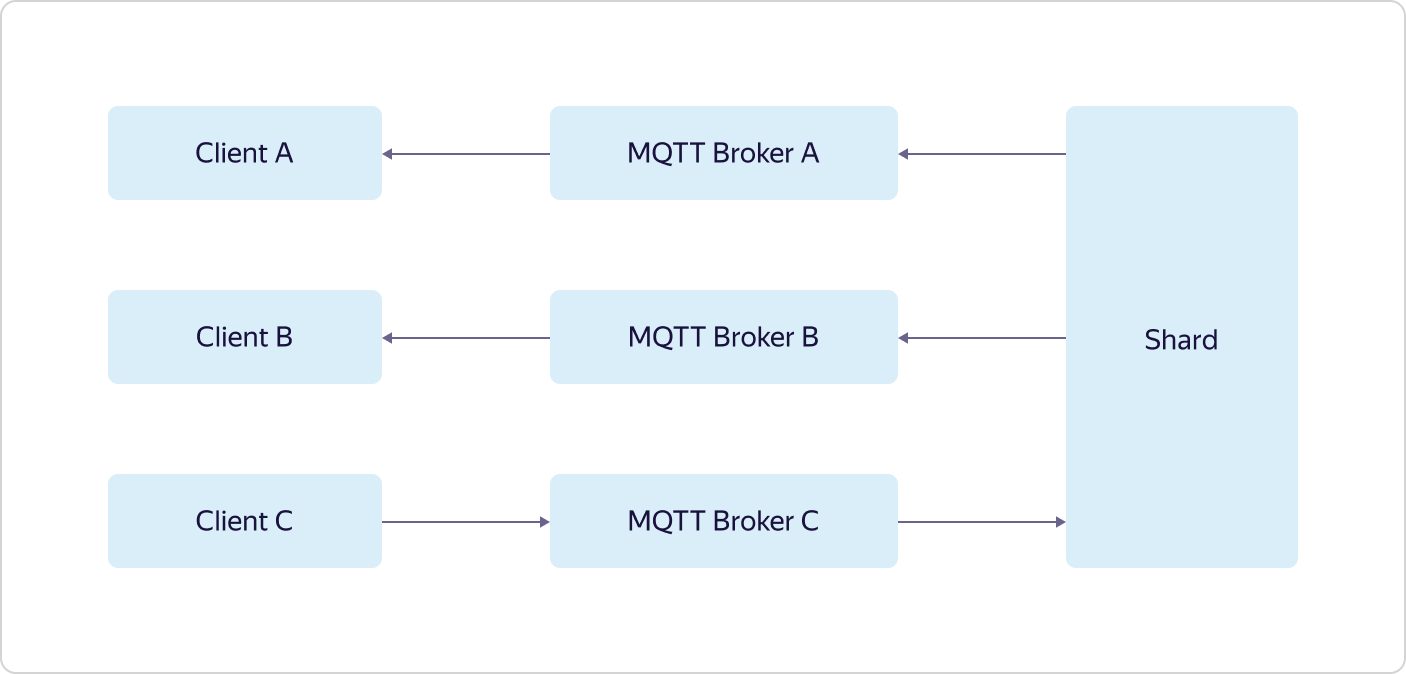 Der letzte Teil der Geschäftslogik, Trigger, empfängt auch alle von MQTT-Clients empfangenen Daten und überträgt sie, wenn dies vom Benutzer konfiguriert wird, an die Trigger des Yandex Cloud Functions-Dienstes.Wie Sie sehen können, verfügt Yandex IoT Core über eine ziemlich komplizierte Architektur und Arbeitslogik, die bei lokalen Installationen nur schwer zu wiederholen ist. Dies ermöglicht es ihm, dem Verlust von sogar zwei der drei Verfügbarkeitszonen standzuhalten und eine unbegrenzte Anzahl von Verbindungen und unbegrenzten Datenmengen zu ermitteln.Darüber hinaus ist all diese Logik dem Benutzer „unter der Haube“ verborgen, aber von außen sieht alles sehr einfach aus - als ob Sie mit einem einzelnen MQTT-Broker arbeiten würden.
Der letzte Teil der Geschäftslogik, Trigger, empfängt auch alle von MQTT-Clients empfangenen Daten und überträgt sie, wenn dies vom Benutzer konfiguriert wird, an die Trigger des Yandex Cloud Functions-Dienstes.Wie Sie sehen können, verfügt Yandex IoT Core über eine ziemlich komplizierte Architektur und Arbeitslogik, die bei lokalen Installationen nur schwer zu wiederholen ist. Dies ermöglicht es ihm, dem Verlust von sogar zwei der drei Verfügbarkeitszonen standzuhalten und eine unbegrenzte Anzahl von Verbindungen und unbegrenzten Datenmengen zu ermitteln.Darüber hinaus ist all diese Logik dem Benutzer „unter der Haube“ verborgen, aber von außen sieht alles sehr einfach aus - als ob Sie mit einem einzelnen MQTT-Broker arbeiten würden.Trigger und Yandex Cloud-Funktionen
Yandex Cloud Functions ist ein Vertreter der sogenannten "serverlosen" (serverlosen) Dienste in Yandex.Cloud. Das Wesentliche an solchen Diensten ist, dass der Benutzer seine Zeit nicht damit verbringt, die Umgebung einzurichten, bereitzustellen und zu skalieren, um Code auszuführen, sondern sich nur mit dem für ihn Wertvollsten befasst - dem Schreiben des Codes selbst, der die erforderliche Aufgabe ausführt. Bei Funktionen ist dies der sogenannte atomare zustandslose Code, der durch ein Ereignis ausgelöst werden kann. "Atomic" und "zustandslos" bedeuten, dass dieser Code eine relativ kleine, aber integrale Aufgabe ausführen sollte, während der Code keine Variablen verwenden sollte, um Werte zwischen Aufrufen zu speichern.Es gibt verschiedene Möglichkeiten, Funktionen aufzurufen: einen direkten HTTP-Aufruf, einen Timer-Aufruf (cron) oder ein Ereignisabonnement. Als letzteres unterstützt der Dienst bereits das Abonnieren von Nachrichtenwarteschlangen (Yandex Message Queue), vom Objektspeicherdienst generierte Ereignisse und (für das IoT-Szenario am wertvollsten) das Abonnieren von Nachrichten in Yandex IoT Core.Trotz der Tatsache, dass Sie mit Yandex IoT Core mit jedem MQTT-kompatiblen Client arbeiten können, ist Yandex Cloud Functions eine der optimalsten und bequemsten Möglichkeiten, Daten zu empfangen und zu verarbeiten. Der Grund dafür ist sehr einfach. Eine Funktion kann für jede eingehende Nachricht von jedem Gerät aufgerufen werden, und die Funktionen werden parallel zueinander ausgeführt (aufgrund der Atomizität und des zustandslosen Ansatzes), und die Anzahl ihrer Anrufe ändert sich natürlich, wenn sich die Anzahl der eingehenden Nachrichten von Geräten ändert. Somit kann der Benutzer die Probleme beim Einrichten der Infrastruktur vollständig ignorieren, und im Gegensatz zu denselben virtuellen Maschinen erfolgt die Zahlung nur für die tatsächlich ausgeführte Arbeit.Auf diese Weise können Sie bei geringer Last erheblich sparen und mit dem Wachstum klare und vorhersehbare Kosten erzielen.Der Mechanismus zum Aufrufen von Funktionen für Ereignisse (Abonnieren von Ereignissen) wird als Trigger (Trigger) bezeichnet. Das Wesentliche ist im Diagramm dargestellt: Ein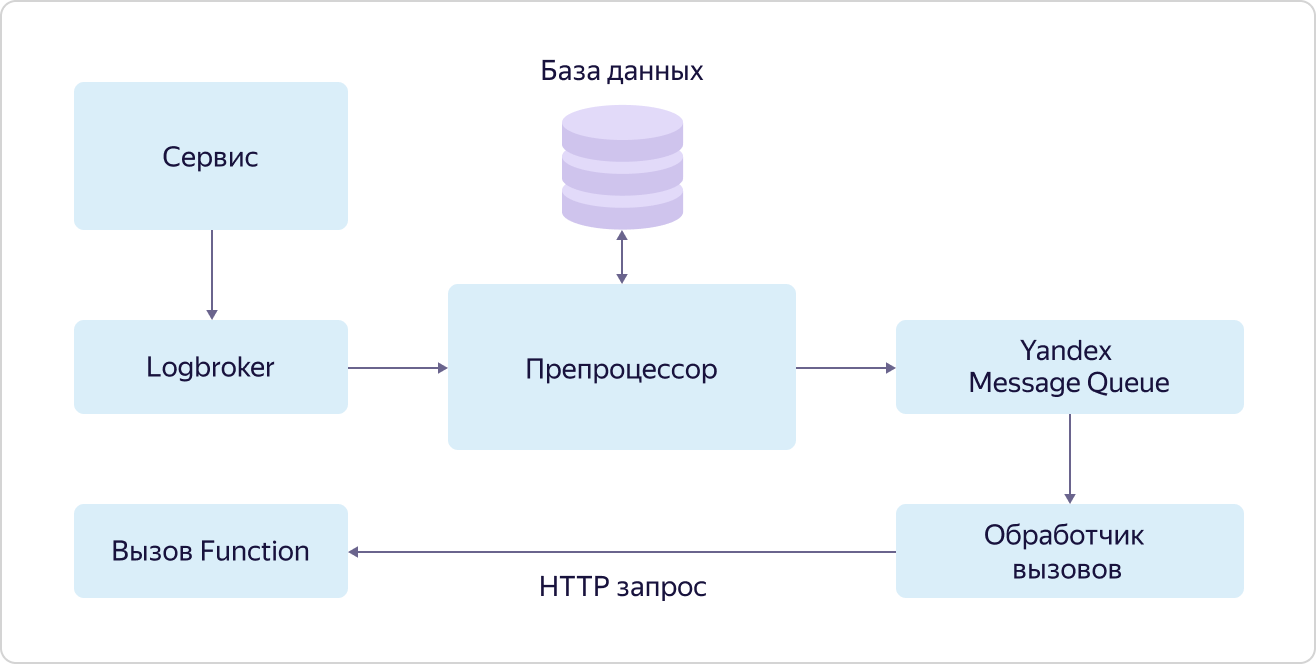 Dienst, der Ereignisse zum Aufrufen von Funktionen generiert, stellt diese in eine Warteschlange in Logbroker. Im Fall von Yandex IoT Core tun dies Trigger aus der Datenebene. Ferner werden diese Ereignisse vom Präprozessor erfasst, der nach einem Datensatz in der Datenbank für dieses Ereignis sucht, der die aufzurufende Funktion angibt. Wenn ein solcher Eintrag gefunden wird, stellt der Präprozessor die Informationen über den Funktionsaufruf (Funktions-ID und Aufrufparameter) in die Warteschlange des Yandex Message Queue-Dienstes, von wo aus der Anrufbearbeiter sie abholt. Der Handler sendet seinerseits eine HTTP-Anforderung zum Aufrufen der Funktion an den Yandex Cloud Functions-Dienst.Gleichzeitig wird wiederum gemäß der Hundefutterphilosophie der Yandex Message Queue-Dienst verwendet, auf den alle Benutzer zugreifen können, und die Funktionen werden genauso aufgerufen, wie alle anderen Benutzer ihre Funktionen aufrufen können.Lassen Sie uns ein paar Worte zur Yandex Message Queue sagen. Trotz der Tatsache, dass dies wie Logbroker ein Warteschlangendienst ist, gibt es einen signifikanten Unterschied zwischen ihnen. Bei der Verarbeitung von Nachrichten aus Warteschlangen informiert der Handler die Warteschlange darüber, dass sie beendet wurde, und die Nachricht kann gelöscht werden. Dies ist ein wichtiger Zuverlässigkeitsmechanismus in solchen Diensten, erschwert jedoch die Logik der Arbeit mit Nachrichten.Mit der Yandex-Nachrichtenwarteschlange können Sie die Verarbeitung jeder Nachricht in der Warteschlange "parallelisieren". Mit anderen Worten, die Nachricht aus der Warteschlange, die gerade verarbeitet wird, blockiert nicht die Möglichkeit eines anderen "Threads", das nächste Ereignis zur Verarbeitung aus der Warteschlange aufzunehmen. Dies wird als Parallelität auf Nachrichtenebene bezeichnet.Und LogBroker bearbeitet Nachrichtengruppen, und bis die gesamte Gruppe verarbeitet ist, kann die nächste Gruppe nicht zur Verarbeitung abgeholt werden. Dieser Ansatz wird auf Partitionsebene als Parallelität bezeichnet.Und genau die Verwendung der Yandex Message Queue ermöglicht es Ihnen, viele Anforderungen zum Aufrufen von Funktionen für Ereignisse eines bestimmten Dienstes schnell und effizient parallel zu verarbeiten.Trotz der Tatsache, dass Trigger eine separate unabhängige Einheit sind, sind sie Teil des Yandex Cloud Functions-Dienstes. Wir müssen nur genau herausfinden, wie die Funktionen aufgerufen werden.
Dienst, der Ereignisse zum Aufrufen von Funktionen generiert, stellt diese in eine Warteschlange in Logbroker. Im Fall von Yandex IoT Core tun dies Trigger aus der Datenebene. Ferner werden diese Ereignisse vom Präprozessor erfasst, der nach einem Datensatz in der Datenbank für dieses Ereignis sucht, der die aufzurufende Funktion angibt. Wenn ein solcher Eintrag gefunden wird, stellt der Präprozessor die Informationen über den Funktionsaufruf (Funktions-ID und Aufrufparameter) in die Warteschlange des Yandex Message Queue-Dienstes, von wo aus der Anrufbearbeiter sie abholt. Der Handler sendet seinerseits eine HTTP-Anforderung zum Aufrufen der Funktion an den Yandex Cloud Functions-Dienst.Gleichzeitig wird wiederum gemäß der Hundefutterphilosophie der Yandex Message Queue-Dienst verwendet, auf den alle Benutzer zugreifen können, und die Funktionen werden genauso aufgerufen, wie alle anderen Benutzer ihre Funktionen aufrufen können.Lassen Sie uns ein paar Worte zur Yandex Message Queue sagen. Trotz der Tatsache, dass dies wie Logbroker ein Warteschlangendienst ist, gibt es einen signifikanten Unterschied zwischen ihnen. Bei der Verarbeitung von Nachrichten aus Warteschlangen informiert der Handler die Warteschlange darüber, dass sie beendet wurde, und die Nachricht kann gelöscht werden. Dies ist ein wichtiger Zuverlässigkeitsmechanismus in solchen Diensten, erschwert jedoch die Logik der Arbeit mit Nachrichten.Mit der Yandex-Nachrichtenwarteschlange können Sie die Verarbeitung jeder Nachricht in der Warteschlange "parallelisieren". Mit anderen Worten, die Nachricht aus der Warteschlange, die gerade verarbeitet wird, blockiert nicht die Möglichkeit eines anderen "Threads", das nächste Ereignis zur Verarbeitung aus der Warteschlange aufzunehmen. Dies wird als Parallelität auf Nachrichtenebene bezeichnet.Und LogBroker bearbeitet Nachrichtengruppen, und bis die gesamte Gruppe verarbeitet ist, kann die nächste Gruppe nicht zur Verarbeitung abgeholt werden. Dieser Ansatz wird auf Partitionsebene als Parallelität bezeichnet.Und genau die Verwendung der Yandex Message Queue ermöglicht es Ihnen, viele Anforderungen zum Aufrufen von Funktionen für Ereignisse eines bestimmten Dienstes schnell und effizient parallel zu verarbeiten.Trotz der Tatsache, dass Trigger eine separate unabhängige Einheit sind, sind sie Teil des Yandex Cloud Functions-Dienstes. Wir müssen nur genau herausfinden, wie die Funktionen aufgerufen werden. Alle Anforderungen zum Aufrufen von Funktionen (sowohl externe als auch interne) fallen in den Load Balancer, der sie an Router in verschiedenen Zugriffszonen (AZ) verteilt. In jeder Zone werden mehrere Teile bereitgestellt. Nach Erhalt einer Anforderung geht der Router zunächst zum IAM-Dienst (Identity and Access Manager), um sicherzustellen, dass die Anforderungsquelle über die Berechtigung zum Aufrufen dieser Funktion verfügt. Dann wendet er sich an den Scheduler und fragt, auf welchem Worker die Funktion ausgeführt werden soll. Worker ist eine virtuelle Maschine mit einer angepassten Laufzeit isolierter Funktionen. Ferner sendet der Router, der vom Scheduler die Adresse des Workers erhalten hat, auf dem die Funktion ausgeführt werden soll, einen Befehl an diesen Worker, um die Funktion mit bestimmten Parametern zu starten.Woher kommt der Arbeiter? Hier geschieht die ganze Magie ohne Server. Scheduler analysieren die Last (Anzahl und Dauer der Funktionen) und verwalten (starten und stoppen) virtuelle Maschinen mit einer bestimmten Laufzeit. NodeJS und Python werden jetzt unterstützt. Und hier ist ein Parameter extrem wichtig - die Geschwindigkeit des Startens von Funktionen. Das Service-Entwicklungsteam hat großartige Arbeit geleistet, und jetzt startet die virtuelle Maschine in maximal 250 ms, während die sicherste Umgebung zum Isolieren von Funktionen voneinander verwendet wird - die QEMU-Virtualisierung, auf der die gesamte Yandex. Cloud ausgeführt wird. Wenn gleichzeitig bereits ein Mitarbeiter für die eingehende Anforderung vorhanden ist, wird die Funktion fast sofort gestartet.Entsprechend dem gleichen Hundefutter-Ansatz verwendet der Load Balancer einen öffentlichen Dienst, auf den alle Benutzer zugreifen können, und der Worker, der Scheduler und der Router sind normale virtuelle Maschinen, genau wie alle Benutzer.Somit wird die Fehlertoleranz des Dienstes auf der Ebene des Load Balancers und der Redundanz der wichtigsten Systemkomponenten (Router und Scheduler) implementiert, und die Skalierung erfolgt aufgrund der Bereitstellung oder Reduzierung der Anzahl der Mitarbeiter. Darüber hinaus arbeitet jede Zugänglichkeitszone unabhängig voneinander, wodurch der Verlust von sogar zwei der drei Zonen überlebt werden kann.
Alle Anforderungen zum Aufrufen von Funktionen (sowohl externe als auch interne) fallen in den Load Balancer, der sie an Router in verschiedenen Zugriffszonen (AZ) verteilt. In jeder Zone werden mehrere Teile bereitgestellt. Nach Erhalt einer Anforderung geht der Router zunächst zum IAM-Dienst (Identity and Access Manager), um sicherzustellen, dass die Anforderungsquelle über die Berechtigung zum Aufrufen dieser Funktion verfügt. Dann wendet er sich an den Scheduler und fragt, auf welchem Worker die Funktion ausgeführt werden soll. Worker ist eine virtuelle Maschine mit einer angepassten Laufzeit isolierter Funktionen. Ferner sendet der Router, der vom Scheduler die Adresse des Workers erhalten hat, auf dem die Funktion ausgeführt werden soll, einen Befehl an diesen Worker, um die Funktion mit bestimmten Parametern zu starten.Woher kommt der Arbeiter? Hier geschieht die ganze Magie ohne Server. Scheduler analysieren die Last (Anzahl und Dauer der Funktionen) und verwalten (starten und stoppen) virtuelle Maschinen mit einer bestimmten Laufzeit. NodeJS und Python werden jetzt unterstützt. Und hier ist ein Parameter extrem wichtig - die Geschwindigkeit des Startens von Funktionen. Das Service-Entwicklungsteam hat großartige Arbeit geleistet, und jetzt startet die virtuelle Maschine in maximal 250 ms, während die sicherste Umgebung zum Isolieren von Funktionen voneinander verwendet wird - die QEMU-Virtualisierung, auf der die gesamte Yandex. Cloud ausgeführt wird. Wenn gleichzeitig bereits ein Mitarbeiter für die eingehende Anforderung vorhanden ist, wird die Funktion fast sofort gestartet.Entsprechend dem gleichen Hundefutter-Ansatz verwendet der Load Balancer einen öffentlichen Dienst, auf den alle Benutzer zugreifen können, und der Worker, der Scheduler und der Router sind normale virtuelle Maschinen, genau wie alle Benutzer.Somit wird die Fehlertoleranz des Dienstes auf der Ebene des Load Balancers und der Redundanz der wichtigsten Systemkomponenten (Router und Scheduler) implementiert, und die Skalierung erfolgt aufgrund der Bereitstellung oder Reduzierung der Anzahl der Mitarbeiter. Darüber hinaus arbeitet jede Zugänglichkeitszone unabhängig voneinander, wodurch der Verlust von sogar zwei der drei Zonen überlebt werden kann.Nützliche Links
Abschließend möchte ich einige Links geben, mit denen Sie die Dienste genauer untersuchen können: