Er war sich nicht sicher, ob er richtig gehört hatte. So viel hing davon ab! Aber nicht nochmal fragen? (c) Boris Akunin. Die ganze Welt ist ein Theater.
Während ich an dem im vorherigen Artikel erwähnten Sprachassistenten arbeitete, wurde mir klar, dass ich einfach nicht anders kann, als die schöne FuzzyWuzzy- Bibliothek mit Ihnen zu teilen .Kurz gesagt, dank ihr ist es möglich, einen Fuzzy-String-Vergleich ohne Leiden durchzuführen.Erste Schritte
Um loszulegen, müssen Sie zwei Schritteausführen : / WICHTIG! Python Version 2.7 und höher /Schritt 1. Installation.Öffnen Sie die Befehlszeile und geben Sie Folgendes ein:pip install fuzzywuzzy
Drücken Sie Enter.Installieren Sie anschließend Python-Levenshtein auf die gleiche Weise , um den String-Abgleich um das 3-10-fache zu beschleunigen.pip install python-Levenshtein
Nach Abschluss der Installation kann die Bibliothek importiert werden.Schritt 2. Importieren in das Projekt.from fuzzywuzzy import fuzz
from fuzzywuzzy import process
Funktionell
1. Der häufigste Vergleich:a = fuzz.ratio(' ', ' ')
print(a)
Wenn wir ein paar Zeichen ändern, erhält die Ausgabe eine andere Nummer.a = fuzz.ratio(' ', ' ')
print(a)
2. Teilvergleich:Diese Art des Vergleichs in der gesamten zweiten Zeile sucht nach einer Übereinstimmung mit der ursprünglichen, zum Beispiel:a = fuzz.partial_ratio(' ', ' !')
print(a)
Odera = fuzz.partial_ratio(' ', ' , ')
print(a)
Aber Sie sollten sich an das Register erinnern, daa = fuzz.partial_ratio(' ', ' , ')
print(a)
3.Token- Vergleich 1) Token-SortierverhältnisWörter werden unabhängig von Groß- und Kleinschreibung oder Reihenfolge miteinander verglichena = fuzz.token_sort_ratio(' ', ' ')
print(a)
a = fuzz.token_sort_ratio(' ', ' ')
print(a)
a = fuzz.token_sort_ratio('1 2 ', '1 2 ')
print(a)
2) Token Set RatioDieser Vergleich entspricht im Gegensatz zur Vergangenheit Zeichenfolgen, wenn ihr Unterschied in der Wiederholung von Wörtern besteht.a = fuzz.token_set_ratio(' ', ' ')
print(a)
4. Erweiterter regelmäßiger VergleichIn vielen Fällen ist es ratsamer, genau WRatio zu verwenden , da zwischen Groß- und Kleinschreibung und Interpunktion unterschieden wird (ohne die Zeichenfolge zu teilen).a = fuzz.WRatio(' ', '! !')
print(a)
a = fuzz.WRatio(' ', '!, !')
print(a)
5. Arbeiten mit der ListeUm die Zeilen mit den Zeilen aus der Liste zu vergleichen, wird das Prozessmodul verwendetcity = ["", "-", "", "", "", "", "", "", "", "", ""]
a = process.extract("", city, limit=2)
print(a)
Wenn nur der erste in der Liste benötigt wird, ist es besser, extractOne zu verwendencity = ["", "-", "", "", "", "", "", "", "", "", ""]
a = process.extractOne("", city)
print(a)
Anwendung
Wie und wo Sie all das anwenden können, liegt bei Ihnen, aber hier ist ein Beispiel aus meiner Hausarbeit :
try:
files = os.listdir('C:\\Users\\hartp\\Desktop\\')
filestart = process.extractOne(namerec, files)
if filestart[1] >= 80:
os.startfile('C:\\Users\\hartp\\Desktop\\' + filestart[0])
else:
speak(' ')
except FileNotFoundError:
speak(' ')
Lassen Sie uns den Code durchgehen und verstehen, was was ist. Mit demBefehl os.listdir erhalten wir eine Liste aller Dateien, die am Ende des angegebenen Pfads (in unserem Fall zum Desktop) vorhanden sind.files = os.listdir('C:\\Users\\hartp\\Desktop\\')
print(files)
Als nächstes werden die Zeilen der Dateiliste mit dem Namen der Datei verglichen , die der Benutzer benannt hat (Variable namerec ). Ich hoffe, Sie haben bemerkt, dass das Ergebnis der Funktion extractOne ein Tupel aus Zeichenfolge und Zahl ist (Ähnlichkeitsindex).Beispiel aus dem letzten Kapitelcity = ["", "-", "", "", "", "", "", "", "", "", ""]
a = process.extractOne("", city)
print(a)
. Basierend darauf überprüfen wir den Ähnlichkeitsindex filestart [1]> = 80 ([1], da das Tupel wie in einem Array von 0 nummeriert ist) und führen die Funktion os.startfile mit einer Datei namens filestart [0 aus , wenn die Bedingung erfüllt ist ]. Andernfalls, wenn der Ähnlichkeitsindex kleiner als 80 ist oder ein Fehler auftritt , dass die Datei nicht gefunden wurde, informieren wir den Benutzer durch die sprechen Funktion .Alle Wege führen nach Matan
Versteckt vor Leuten, die Angst vor Mathe haben, , ().
, .
( , ) — , .
S1 i S2 j
S1=vrhk
S2=rhgr
3 :
- : r → v
- : -r
- : rVhgr
:

0 1? ( — «0»), r , r ( , — «1»). v .
rh h, r ( ), , :
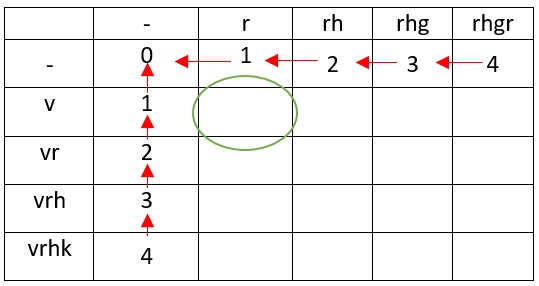
v r ( ).
, — v.
1. ? r , v. r , v, rv. , v v.
v rh
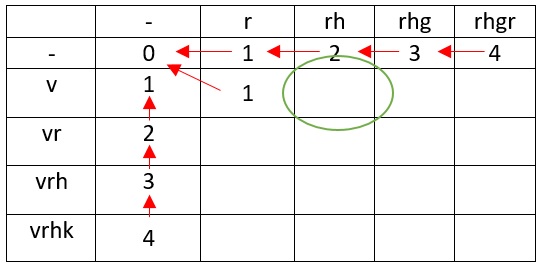
— v h r .
.
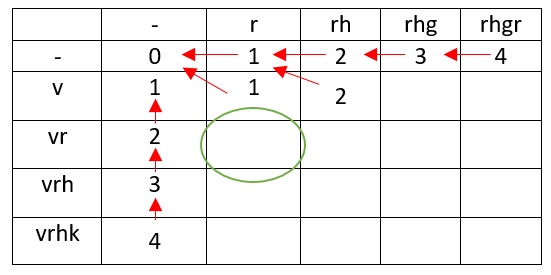
vr r , , , , .
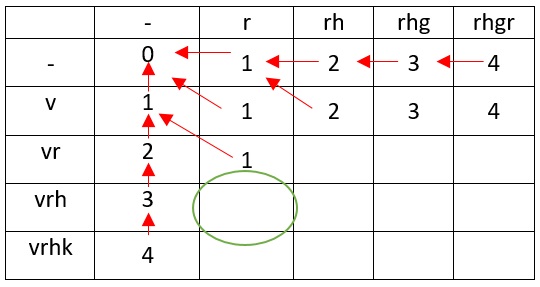
vrh r h ( vr r), 2

vr r vrh rh, , .
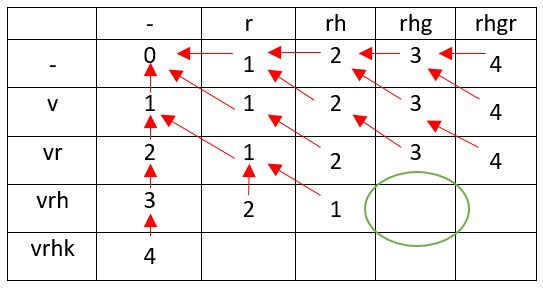
, vrh rhg , , , - ( ).
, , ( ) — vrhk rhgr.
Vielen Dank für Ihre Aufmerksamkeit! Ich hoffe, dieser Artikel ist für jemanden nützlich.