Tausende von Managern aus Vertriebsbüros im ganzen Land zeichnen täglich Zehntausende von Kontakten in unserem CRM-System auf - Fakten zur Kommunikation mit potenziellen oder bereits mit uns zusammenarbeitenden Kunden. Und für diesen Kunden müssen Sie zuerst und vorzugsweise sehr schnell finden. Und das passiert meistens mit Namen. Daher ist es nicht verwunderlich, dass ich bei der erneuten Analyse „schwerer“ Anfragen in einer der am stärksten ausgelasteten Datenbanken - unserem eigenen VLSI-Unternehmenskonto - „oben“ eine Anfrage nach einer „schnellen“ Namenssuche nach Firmenkarten gefunden habe. Darüber hinaus ergab eine weitere Untersuchung ein interessantes Beispiel für die Optimierung und anschließende Verschlechterung der LeistungAnfrage in seiner anschließenden Verfeinerung durch mehrere Teams, von denen jedes ausschließlich aus wohlmeinenden Gründen handelte.0: Was wollte der Benutzer?
[KDPV von hier ]Was bedeutet der Benutzer normalerweise, wenn er "schnelle" Suche nach Namen sagt? Fast nie stellt sich heraus, dass es sich um eine „ehrliche“ Suche nach einem Teilstring handelt ... LIKE '%%'- denn dann nicht nur und , sondern sogar das Ergebnis . Der Benutzer impliziert auf Haushaltsebene, dass Sie ihm am Anfang eines Wortes im Titel eine Suche anbieten und relevanter zeigen, was mit dem eingegebenen beginnt . Und das fast augenblicklich - mit interlinearer Eingabe.''' '''' '1: Begrenzen Sie die Aufgabe
Und noch mehr, eine Person wird nicht speziell eingeben, ' 'so dass Sie nach jedem Wortpräfix suchen müssen. Nein, es ist für den Benutzer viel einfacher, auf einen kurzen Hinweis auf das letzte Wort zu antworten, als die vorherigen absichtlich zu "verpassen" - sehen Sie, wie eine Suchmaschine funktioniert.Im Allgemeinen ist die korrekte Formulierung von Anforderungen für eine Aufgabe mehr als die halbe Lösung. Manchmal kann eine sorgfältige Analyse des Anwendungsfalls das Ergebnis erheblich beeinflussen .Was macht der abstrakte Entwickler?1.0: externe Suchmaschine
Oh, die Suche ist schwierig, ich möchte überhaupt nichts tun - geben wir es den Devops! Lassen Sie sie uns eine externe Suchmaschine in Bezug auf die Datenbank bereitstellen: Sphinx, ElasticSearch, ... Einefunktionierende, wenn auch zeitaufwändige Option in Bezug auf Synchronisation und Änderungsgeschwindigkeit. In unserem Fall jedoch nicht, da die Suche für jeden Kunden nur im Rahmen seiner Kontodaten durchgeführt wird. Und die Daten haben eine ziemlich hohe Variabilität - und wenn der Manager die Karte jetzt eingelegt hat ' ', kann er sich bereits nach 5-10 Sekunden daran erinnern, dass er vergessen hat, die E-Mail dort anzugeben und sie finden und korrigieren möchte.Deshalb - sie sucht „direkt in der Datenbank . “ Glücklicherweise ermöglicht uns PostgreSQL dies und nicht nur eine Option - wir werden sie in Betracht ziehen.1.1: "ehrlicher" Teilstring
Wir klammern uns an das Wort "Teilzeichenfolge". Aber genau für die Indexsuche nach Teilzeichenfolgen (und sogar nach regulären Ausdrücken!) Gibt es ein hervorragendes Modul pg_trgm ! Nur dann muss richtig sortiert werden.Versuchen wir zur Vereinfachung des Modells, eine Platte zu nehmen:CREATE TABLE firms(
id
serial
PRIMARY KEY
, name
text
);
Wir füllen dort 7,8 Millionen Datensätze von realen Organisationen und Index aus:CREATE EXTENSION pg_trgm;
CREATE INDEX ON firms USING gin(lower(name) gin_trgm_ops);
Suchen wir nach den ersten 10 Einträgen für die Interline-Suche:SELECT
*
FROM
firms
WHERE
lower(name) ~ ('(^|\s)' || '')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10;
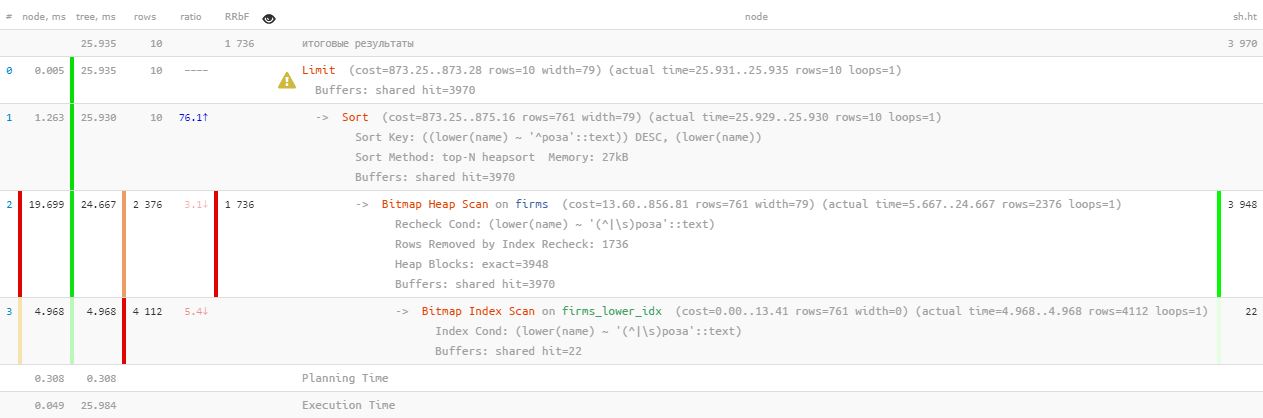 [werfen Sie einen Blick auf EXPLAIN.tensor.ru]Nun, das sind ... 26 ms, 31 MB gelesene Daten und mehr als 1,7 KB gefilterte Datensätze - für 10 Personen. Der Overhead ist zu hoch, ist es möglich, irgendwie effizienter zu sein?
[werfen Sie einen Blick auf EXPLAIN.tensor.ru]Nun, das sind ... 26 ms, 31 MB gelesene Daten und mehr als 1,7 KB gefilterte Datensätze - für 10 Personen. Der Overhead ist zu hoch, ist es möglich, irgendwie effizienter zu sein?1.2: Textsuche? es ist FTS!
In der Tat bietet PostgreSQL einen sehr leistungsfähigen Mechanismus für die Volltextsuche (Volltextsuche), einschließlich der Möglichkeit der Präfixsuche. Eine großartige Option, auch Erweiterungen müssen nicht installiert werden! Lass es uns versuchen:CREATE INDEX ON firms USING gin(to_tsvector('simple'::regconfig, lower(name)));
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', ':*')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10;
 [siehe EXPLAIN.tensor.ru]Hier hat uns die Parallelisierung der Abfrageausführung ein wenig geholfen und die Zeit um die Hälfte auf 11 ms reduziert . Ja, und wir mussten 1,5 mal weniger lesen - nur 20 MB . Und hier, je kleiner desto besser, denn je größer der von uns subtrahierte Betrag ist, desto höher ist die Wahrscheinlichkeit, dass ein Cache-Fehler auftritt, und jede zusätzliche Datenseite, die von der Festplatte gelesen wird, ist eine potenzielle „Bremse“ für die Anforderung.
[siehe EXPLAIN.tensor.ru]Hier hat uns die Parallelisierung der Abfrageausführung ein wenig geholfen und die Zeit um die Hälfte auf 11 ms reduziert . Ja, und wir mussten 1,5 mal weniger lesen - nur 20 MB . Und hier, je kleiner desto besser, denn je größer der von uns subtrahierte Betrag ist, desto höher ist die Wahrscheinlichkeit, dass ein Cache-Fehler auftritt, und jede zusätzliche Datenseite, die von der Festplatte gelesen wird, ist eine potenzielle „Bremse“ für die Anforderung.1.3: Immer noch WIE?
Die vorherige Anforderung ist für alle gut, aber nur wenn Sie sie hunderttausend Mal am Tag abrufen , werden 2 TB der gelesenen Daten ausgeführt . Bestenfalls - aus dem Speicher, aber wenn Sie kein Glück haben, dann von der Festplatte. Versuchen wir also, es kleiner zu machen.Denken Sie daran, dass der Benutzer zuerst "das beginnen mit ..." sehen möchte . Das ist also in seiner reinen Form eine Präfixsuche mit text_pattern_ops! Und nur wenn wir bis zu 10 erforderliche Datensätze "nicht genug" sind, müssen wir sie mithilfe der FTS-Suche lesen:CREATE INDEX ON firms(lower(name) text_pattern_ops);
SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
LIMIT 10;
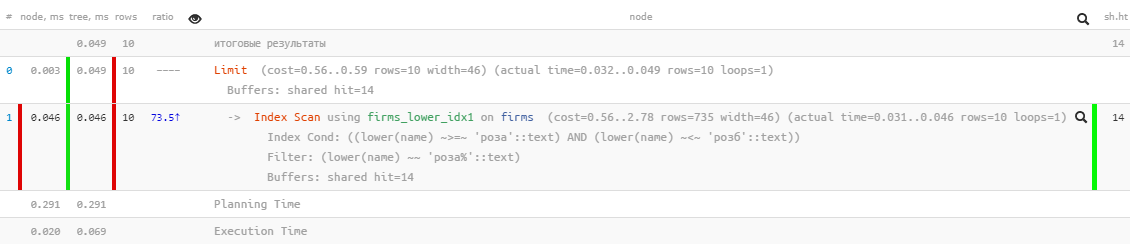 [siehe EXPLAIN.tensor.ru]Hervorragende Leistung - nur 0,05 ms und etwas mehr als 100 KB gelesen! Nur haben wir vergessen, nach Namen zu sortieren, damit der Benutzer nicht in den Ergebnissen verloren geht:
[siehe EXPLAIN.tensor.ru]Hervorragende Leistung - nur 0,05 ms und etwas mehr als 100 KB gelesen! Nur haben wir vergessen, nach Namen zu sortieren, damit der Benutzer nicht in den Ergebnissen verloren geht:SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
ORDER BY
lower(name)
LIMIT 10;
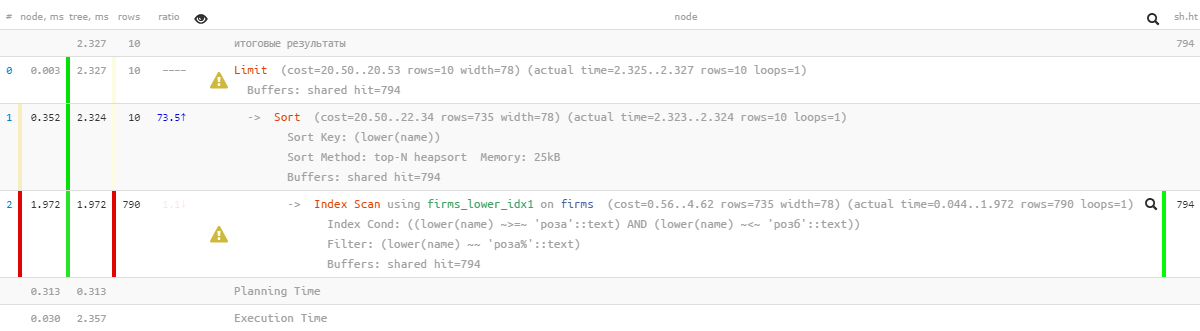 [siehe EXPLAIN.tensor.ru]Oh, etwas ist nicht mehr so hübsch - es scheint, dass es einen Index gibt, aber die Sortierung fliegt daran vorbei ... Es ist natürlich um ein Vielfaches effektiver als die vorherige Version, aber ...
[siehe EXPLAIN.tensor.ru]Oh, etwas ist nicht mehr so hübsch - es scheint, dass es einen Index gibt, aber die Sortierung fliegt daran vorbei ... Es ist natürlich um ein Vielfaches effektiver als die vorherige Version, aber ...1.4: "Mit einer Datei ändern"
Es gibt jedoch einen Index, mit dem Sie nach Bereich suchen können, und es ist normal, die Sortierung zu verwenden - normaler btree !CREATE INDEX ON firms(lower(name));
Nur eine Anfrage dafür muss „manuell zusammengestellt“ werden:SELECT
*
FROM
firms
WHERE
lower(name) >= '' AND
lower(name) <= ('' || chr(65535))
ORDER BY
lower(name)
LIMIT 10;
 [siehe EXPLAIN.tensor.ru]Großartig - sowohl die Sortierarbeiten als auch der Ressourcenverbrauch bleiben "mikroskopisch", tausende Male effizienter als "reine" FTS ! Es bleibt in einer einzigen Anfrage zu sammeln:
[siehe EXPLAIN.tensor.ru]Großartig - sowohl die Sortierarbeiten als auch der Ressourcenverbrauch bleiben "mikroskopisch", tausende Male effizienter als "reine" FTS ! Es bleibt in einer einzigen Anfrage zu sammeln:(
SELECT
*
FROM
firms
WHERE
lower(name) >= '' AND
lower(name) <= ('' || chr(65535))
ORDER BY
lower(name)
LIMIT 10
)
UNION ALL
(
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', ':*') AND
lower(name) NOT LIKE ('' || '%')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10
)
LIMIT 10;
Ich stelle fest, dass die zweite Unterabfrage nur ausgeführt wird, wenn die erste weniger als die vom letzten erwarteteLIMIT Anzahl von Zeilen zurückgibt . Ich habe bereits über diese Methode der Abfrageoptimierung geschrieben .Also ja, wir haben jetzt btree und gin gleichzeitig auf dem Tisch, aber statistisch gesehen hat sich herausgestellt, dass weniger als 10% der Anfragen den zweiten Block erreichen . Das heißt, mit solch bekannten typischen Einschränkungen für die Aufgabe konnten wir den gesamten Serverressourcenverbrauch um fast das Tausendfache reduzieren!1.5 *: Auf die Datei verzichten
Oben wurde LIKEuns daran gehindert, die falsche Sorte zu verwenden. Sie kann jedoch durch Angabe der USING-Anweisung "auf den wahren Pfad gesetzt" werden:Die Standardeinstellung ist impliziert ASC. Darüber hinaus können Sie den Namen eines bestimmten Sortieroperators in einem Satz angeben USING. Der Sortieroperator muss Mitglied einer bestimmten Familie von B-Tree-Operatoren sein, die kleiner oder größer als diese ist. ASCnormalerweise gleichwertig USING <und DESCnormalerweise gleichwertig USING >.
In unserem Fall ist "weniger" ~<~:SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
ORDER BY
lower(name) USING ~<~
LIMIT 10;
 [siehe EXPLAIN.tensor.ru]
[siehe EXPLAIN.tensor.ru]2: wie man Anfragen "sauer" macht
Jetzt verlassen wir unsere Bitte, ein halbes Jahr oder ein Jahr lang darauf zu bestehen, und überraschenderweise finden wir sie wieder „ganz oben“ mit Indikatoren für das tägliche „Pumpen“ des Speichers ( gemeinsam genutzte Puffer ) in 5,5 TB - das heißt sogar mehr als ursprünglich.Nein, natürlich ist unser Geschäft gewachsen und die Last hat zugenommen, aber nicht so sehr! Hier ist also etwas schmutzig - lass es uns herausfinden.2.1: die Geburt des Paging
Irgendwann wollte ein anderes Entwicklungsteam es ermöglichen, von einer schnellen Indexsuche mit denselben, aber erweiterten Ergebnissen in die Registrierung zu „springen“. Und welche Registrierung ohne Seitennavigation? Lass es uns vermasseln!( ... LIMIT <N> + 10)
UNION ALL
( ... LIMIT <N> + 10)
LIMIT 10 OFFSET <N>;
Jetzt war es für den Entwickler ohne Anstrengung möglich, die Registrierung der Suchergebnisse mit "Typ-Seite" -Ladung anzuzeigen.Tatsächlich wird für jede nächste Datenseite immer mehr gelesen (die gesamte vorherige Zeit, die wir verwerfen, plus den gewünschten „Schwanz“) - das heißt, dies ist ein eindeutiges Antimuster. Und es wäre richtiger, die Suche bei der nächsten Iteration von dem in der Schnittstelle gespeicherten Schlüssel aus zu starten, aber darüber - ein anderes Mal.2.2: will exotisch
Irgendwann wollte der Entwickler die resultierende Auswahl mit Daten aus einer anderen Tabelle diversifizieren. Zu diesem Zweck wurde die gesamte vorherige Anforderung an den CTE gesendet:WITH q AS (
...
LIMIT <N> + 10
)
SELECT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET <N>;
Und trotzdem - nicht schlecht, denn eine Unterabfrage wird nur für 10 zurückgegebene Datensätze berechnet, wenn nicht ...2.3: UNTERSCHIEDLICH bedeutungslos und gnadenlos
Irgendwo in den Prozess der eine solche Entwicklung, eine war Bedingung verlorenNOT LIKE aus der zweiten Unterabfrage . Es ist klar, dass ich danach zweimalUNION ALL angefangen habe, einige Datensätze zurückzugeben - zuerst am Anfang der Zeile und dann wieder - am Anfang des ersten Wortes dieser Zeile. Im Limit könnten alle Datensätze der 2. Unterabfrage mit den Datensätzen der ersten übereinstimmen.Was macht ein Entwickler, anstatt nach einem Grund zu suchen? Keine Frage!- Verdoppeln Sie die Größe der Originalmuster
- Setzen Sie DISTINCT so, dass wir nur einzelne Instanzen jeder Zeile erhalten
WITH q AS (
( ... LIMIT <2 * N> + 10)
UNION ALL
( ... LIMIT <2 * N> + 10)
LIMIT <2 * N> + 10
)
SELECT DISTINCT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET <N>;
Das heißt, es ist klar, dass das Ergebnis am Ende genau das gleiche ist, aber die Chance, zur 2. CTE-Unterabfrage zu „fliegen“, ist viel höher geworden, und ohne dies wird deutlich mehr gelesen .Aber das ist nicht das Traurigste. Da der Entwickler mich gebeten hat, DISTINCTnicht nach bestimmten, sondern sofort nach allen Feldern des Datensatzes auszuwählen, wurde das Feld sub_query, das Ergebnis der Unterabfrage, ebenfalls automatisch angezeigt. Für die Ausführung DISTINCTmusste die Datenbank nun nicht 10 Unterabfragen ausführen , sondern alle <2 * N> + 10 !2.4: vor allem kooperation!
Die Entwickler haben also gelebt - sie haben sich nicht darum gekümmert, weil sie in der Registrierung auf signifikante N-Werte "gepatcht" wurden, mit einer chronischen Verlangsamung beim Empfang jeder nächsten "Seite".Bis Entwickler aus einer anderen Abteilung zu ihnen kamen und keine so bequeme Methode für die iterative Suche verwenden wollten - das heißt, wir nehmen ein Stück aus einem Beispiel, filtern nach zusätzlichen Bedingungen, zeichnen das Ergebnis und dann das nächste Stück (was in unserem Fall durch erreicht wird) Erhöhen Sie N) und so weiter, bis wir den Bildschirm ausfüllen.Im Allgemeinen erreichte die gefangene Probe N Werte von fast 17 K, und in nur 24 Stunden wurden mindestens 4 K solche Anforderungen „in der Kette“ ausgeführt. Der letzte von ihnen hat bereits kühn gescannt1 GB Speicher bei jeder Iteration ...