Ich habe lange über die HIBP-Site (Have I Been Pwned) gewusst . Zwar war er bis vor kurzem noch nie dort gewesen. Ich hatte immer zwei Passwörter. Einer von ihnen wurde wiederholt für Müllpost und ein paar Konten auf seltsamen Websites verwendet. Aber ich musste es ablehnen, weil die Mail gehackt wurde. Und um ehrlich zu sein, bin ich dem Hacker dankbar, weil ich bei diesem Ereignis meine Passwörter überprüft habe - wie ich sie verwende und speichere.Natürlich habe ich die Passwörter für alle Konten geändert, bei denen ein Passwort manipuliert wurde. Dann fragte ich mich, ob das durchgesickerte Passwort in der HIBP-Datenbank war. Ich wollte das Passwort auf der Site nicht eingeben, also habe ich die Datenbank heruntergeladen (pwned-passwords-sha1-ordered-by-count-v5) Die Basis ist sehr beeindruckend. Dies ist eine 22,8-GB-Textdatei mit einer Reihe von SHA-1-Hashes, einer in jeder Zeile mit einem Zähler, wie oft das Kennwort mit diesem Hash in Lecks aufgetreten ist. Ich fand die SHA-1 meines geknackten Passworts heraus und versuchte es zu finden.Inhalt
[G] rep
Wir haben eine Textdatei mit einem Hash in jeder Zeile. Der wahrscheinlich beste Ort ist grep.grep -m 1 '^XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX' pwned-passwords-sha1-ordered-by-count-v5.txtMein Passwort stand mit einer Häufigkeit von mehr als 1.500 Mal ganz oben auf der Liste, also ist es wirklich scheiße. Dementsprechend kehrten die Suchergebnisse fast sofort zurück.Aber nicht jeder hat schwache Passwörter. Ich wollte überprüfen, wie lange es dauern würde, das Worst-Case-Szenario zu finden - den letzten Hash in der Datei:time grep -m 1 '^4541A1E4605EEBF3F4C166329C18502DF75D348A' pwned-passwords-sha1-ordered-by-count-v5.txtErgebnis: 33,35s user 23,39s system 41% cpu 2:15,35 totalDas ist traurig. Schließlich wollte ich, da meine E-Mails gehackt wurden, das Vorhandensein aller meiner alten und neuen Passwörter in der Datenbank überprüfen. Aber ein zweiminütiger Grep erlaubt es Ihnen einfach nicht, dies bequem zu tun. Natürlich könnte ich ein Skript schreiben, es ausführen und spazieren gehen, aber das ist keine Option. Ich wollte eine bessere Lösung finden und etwas lernen.Struktur versuchen
Die erste Idee war die Verwendung einer Trie-Datenstruktur. Die Struktur scheint ideal für die Speicherung von SHA-1-Hashes zu sein. Das Alphabet ist klein, daher sind auch die Knoten klein, ebenso wie die resultierende Datei. Vielleicht passt es sogar in RAM? Die Schlüsselsuche sollte sehr schnell sein.Also habe ich diese Struktur implementiert. Dann nahm er die ersten 1.000.000 Hashes der Quellendatenbank, um die resultierende Datei zu erstellen und zu überprüfen, ob sich alles in der erstellten Datei befindet.Ja, ich konnte alles in der Datei finden, daher funktionierte die Struktur gut. Das Problem war anders.Die resultierende Datei wurde in der Größe 2283686592B (2,2 GB) veröffentlicht. Das ist nicht gut. Lassen Sie uns zählen und sehen, was passiert. Ein Knoten ist eine einfache Struktur aus 16 32-Bit-Werten. Die Werte sind "Zeiger" auf die folgenden Knoten mit dem angegebenen SHA-1-Hash-Symbol. Ein Knoten benötigt also 16 * 4 Bytes = 64 Bytes. Es scheint ein wenig zu sein? Wenn Sie jedoch darüber nachdenken, repräsentiert ein Knoten ein Zeichen in einem Hash. Im schlimmsten Fall benötigt der SHA-1-Hash also 40 * 64 Bytes = 2560 Bytes. Dies ist viel schlimmer als beispielsweise eine Textdarstellung eines Hashs, der nur 40 Bytes belegt.Die Versuchsstruktur hat den Vorteil, dass Knoten wiederverwendet werden. Wenn Sie zwei Wörter aaaund haben abb, wird der Knoten für die ersten Zeichen wiederverwendet, da die Zeichen gleich sind - a.Kommen wir zurück zu unserem Problem. Berechnen wir, wie viele Knoten in der resultierenden Datei gespeichert sind: file_size / node_size = 2283686592 / 64 = 35682603Nun sehen wir, wie viele Knoten im schlimmsten Fall aus einer Million Hashes erstellt werden: Die 1000000 * 40 = 40000000Versuchsstruktur verwendet also nur 40000000 - 35682603 = 4317397Knoten, was 10,8% des Worst-Case-Szenarios entspricht.Mit solchen Indikatoren würde die resultierende Datei für die gesamte HIBP-Datenbank 1421513361920 Bytes (1,02 TB) benötigen. Ich habe nicht einmal genug Festplatte, um die Geschwindigkeit der Schlüsselsuche zu überprüfen.An diesem Tag fand ich heraus, dass die Trie-Struktur nicht für relativ zufällige Daten geeignet ist.Lassen Sie uns nach einer anderen Lösung suchen.Binäre Suche
SHA-1-Hashes haben zwei nette Eigenschaften: Sie sind miteinander vergleichbar und alle gleich groß.Dank dessen können wir die ursprüngliche HIBP-Datenbank verarbeiten und aus den sortierten SHA-1-Werten eine Datei erstellen.Aber wie sortiere ich eine 22-GB-Datei?Frage. Warum die Quelldatei sortieren? HIBP gibt eine Datei mit Zeichenfolgen zurück, die bereits nach Hashes sortiert sind.
Antworten. Ich habe einfach nicht darüber nachgedacht. In diesem Moment wusste ich nichts über die sortierte Datei.Sortierung
Das Sortieren aller Hashes im RAM ist keine Option, ich habe nicht viel RAM. Die Lösung war folgende:- Teilen Sie eine große Datei in kleinere auf, die in den Arbeitsspeicher passen.
- Laden Sie Daten aus kleinen Dateien herunter, sortieren Sie sie im RAM und schreiben Sie sie in Dateien zurück.
- Kombinieren Sie alle kleinen, sortierten Dateien zu einer großen.
Mit einer großen sortierten Datei können Sie unseren Hash mithilfe einer binären Suche durchsuchen. Der Zugriff auf die Festplatte ist wichtig. Berechnen wir, wie viele Treffer für eine binäre Suche erforderlich sind: log2(555278657) = 29.048636703930 Treffer. Nicht so schlecht.In der ersten Phase kann eine Optimierung durchgeführt werden. Konvertieren Sie Text-Hashes in Binärdaten. Dadurch wird die Größe der resultierenden Daten um die Hälfte reduziert: von 22 auf 11 GB. Fein.Warum wieder zusammenführen?
In diesem Moment wurde mir klar, dass man schlauer sein kann. Was ist, wenn Sie kleine Dateien nicht zu einer großen kombinieren, sondern eine binäre Suche in sortierten kleinen Dateien im RAM durchführen? Das Problem besteht darin, die gewünschte Datei zu finden, in der nach dem Schlüssel gesucht werden soll. Die Lösung ist sehr einfach. Neuer Ansatz:- Erstellen Sie 256 Dateien mit den Namen "00" ... "FF".
- Wenn Sie Hashes aus einer großen Datei lesen, schreiben Sie Hashes, die mit "00 .." beginnen, in eine Datei mit dem Namen "00", Hashes, die mit "01 .." beginnen - in eine Datei "01" und so weiter.
- Laden Sie Daten aus kleinen Dateien herunter, sortieren Sie sie im RAM und schreiben Sie sie in Dateien zurück.
Alles ist sehr einfach. Außerdem wird eine weitere Optimierungsoption angezeigt. Wenn der Hash in der Datei "00" gespeichert ist, wissen wir, dass er mit "00" beginnt. Wenn der Hash in der Datei "F2" gespeichert ist, beginnt er mit "F2". Wenn Sie also Hashes in kleine Dateien schreiben, können Sie das erste Byte jedes Hashs weglassen! Dies sind 5% aller Daten. Insgesamt werden 555 MB gespeichert.Parallelität
Die Trennung in kleinere Dateien bietet eine weitere Möglichkeit zur Optimierung. Dateien sind unabhängig voneinander, sodass wir sie parallel sortieren können. Wir erinnern uns, dass alle Ihre Prozessoren gerne gleichzeitig schwitzen;)Sei kein egoistischer Bastard
Als ich die obige Lösung implementierte, stellte ich fest, dass andere Leute wahrscheinlich ein ähnliches Problem hatten. Wahrscheinlich laden auch viele andere die HIBP-Datenbank herunter und durchsuchen sie. Also beschloss ich, meine Arbeit zu teilen.Zuvor habe ich meinen Ansatz noch einmal überarbeitet und einige Probleme gefunden, die ich beheben möchte, bevor ich den Code und die Tools auf Github veröffentliche.Erstens möchte ich als Endbenutzer kein Tool verwenden, das viele seltsame Dateien mit seltsamen Namen erstellt, in denen nicht klar ist, was gespeichert ist usw.Nun, dies kann durch Kombinieren der Dateien "00" .. "FF" in gelöst werden eine große Datei.Leider wirft eine große Datei zum Sortieren ein neues Problem auf. Was ist, wenn ich einen Hash in diese Datei einfügen möchte? Nur ein Hash. Dies sind nur 20 Bytes. Oh, der Hash beginnt mit "000000000 ..". Okay. Lassen Sie uns Speicherplatz dafür freigeben, indem Sie 11 GB anderer Hashes verschieben ...Sie verstehen, wo das Problem liegt. Das Einfügen von Daten in die Mitte einer Datei ist nicht der schnellste Vorgang.Ein weiterer Nachteil dieses Ansatzes besteht darin, dass Sie die ersten Bytes erneut speichern müssen - es sind 555 MB Daten.Und zu guter Letzt ist die binäre Suche nach Daten, die auf Ihrer Festplatte gespeichert sind, viel langsamer als der Zugriff auf RAM. Ich meine, das sind 30 Festplattenlesevorgänge gegenüber 0 Festplattenlesevorgängen.B3
Noch einmal. Was wir haben und was wir erreichen wollen.Wir haben 11 GB Binärwerte. Alle Werte sind vergleichbar und gleich groß. Wir möchten herausfinden, ob ein bestimmter Schlüssel in den gespeicherten Daten vorhanden ist, und möchten auch die Datenbank ändern. Und damit alles schnell geht.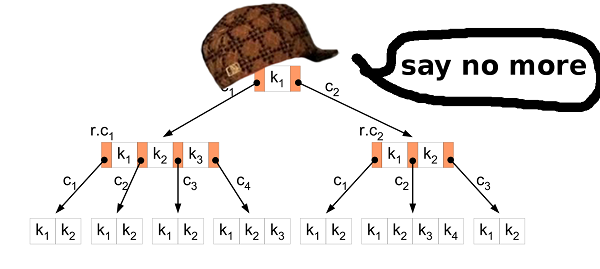 B-Baum? RechtMit dem B-Baum können Sie den Zugriff auf die Festplatte beim Suchen, Ändern usw. minimieren. Er verfügt über viel mehr Funktionen, aber wir benötigen diese beiden.
B-Baum? RechtMit dem B-Baum können Sie den Zugriff auf die Festplatte beim Suchen, Ändern usw. minimieren. Er verfügt über viel mehr Funktionen, aber wir benötigen diese beiden.Sortieren durch Einfügen
Der erste Schritt besteht darin, die Daten aus der HIBP-Quelldatei in den B-Baum zu konvertieren. Dies bedeutet, dass Sie nacheinander alle Hashes extrahieren und in die Struktur einfügen müssen. Hierfür eignet sich der übliche Einfügealgorithmus. Aber in unserem Fall können Sie es besser machen.Das Einfügen vieler Rohdaten in einen B-Baum ist ein bekanntes Szenario. Weise Menschen haben dafür einen besseren Ansatz erfunden als die übliche Beilage. Zunächst müssen Sie die Daten sortieren. Dies kann wie oben beschrieben erfolgen (teilen Sie die Datei in kleinere auf und sortieren Sie sie im RAM). Fügen Sie dann die Daten in den Baum ein.Wenn Sie im üblichen Algorithmus den Blattknoten finden, an dem Sie den Wert einfügen möchten, und dieser gefüllt ist, erstellen Sie einen neuen Knoten (rechts) und verteilen die Werte gleichmäßig auf die beiden Knoten links und rechts (plus ein Wert geht an den übergeordneten Knoten aber hier ist es nicht wichtig). Kurz gesagt, die Werte im linken Knoten sind immer kleiner als die Werte im rechten. Tatsache ist, dass Sie beim Einfügen der sortierten Daten wissen, dass kleinere Werte nicht mehr in den Baum eingefügt werden, sodass keine weiteren Werte an den linken Knoten gesendet werden. Der linke Knoten bleibt die ganze Zeit halb leer. Wenn Sie genügend Werte einfügen, ist der rechte Knoten möglicherweise voll, sodass Sie die Hälfte der Werte auf den neuen rechten Knoten verschieben müssen. Der geteilte Knoten bleibt wie im vorherigen Fall halb leer. Usw…Als Ergebnis erhalten Sie nach allen Einfügungen einen Baum, in dem fast alle Knoten halb leer sind. Dies ist keine sehr effiziente Raumnutzung. Wir können es besser machen.Getrennt oder nicht?
Beim Einfügen sortierter Daten können Sie den Einfügealgorithmus geringfügig ändern. Wenn der Knoten, in den Sie den Wert einfügen möchten, voll ist, brechen Sie ihn nicht. Erstellen Sie einfach einen neuen, leeren Knoten und fügen Sie den Wert in den übergeordneten Knoten ein. Wenn Sie dann die folgenden Werte einfügen (die größer als die vorherigen sind), fügen Sie sie in einen neuen, leeren Knoten ein.Um die Eigenschaften des B-Baums zu erhalten, müssen nach allen Einfügungen die Knoten ganz rechts in jeder Schicht des Baums (mit Ausnahme der Wurzel) aussortiert und die Werte dieses extremen Knotens und seines linken Nachbarn gleichmäßig aufgeteilt werden. So erhalten Sie den kleinstmöglichen Baum.HIBP-Baumeigenschaften
Wenn Sie einen B-Baum entwerfen, müssen Sie dessen Reihenfolge auswählen. Es zeigt, wie viele Werte in einem Knoten gespeichert werden können und wie viele Kinder der Knoten haben kann. Durch Manipulieren dieses Parameters können wir die Höhe des Baums, dieBinärgröße des Knotens usw. manipulieren . In HIBP haben wir 555278657Hashes. Angenommen, wir möchten einen Baum mit einer Höhe von drei (wir benötigen also nicht mehr als drei Leseoperationen, um das Vorhandensein eines Hashs zu überprüfen). Wir müssen einen Wert von M finden, so dass logM(555278657) < 3. Ich habe 1024 gewählt. Dies ist nicht der kleinstmögliche Wert, aber es ist möglich, mehr Hashes einzufügen und die Höhe des Baums beizubehalten.Ausgabedatei
Die HIBP-Quelldatei hat eine Größe von 22,8 GB. Die Ausgabedatei mit dem B-Baum ist 12,4 GB. Die Erstellung auf meinem Computer (Intel Core i7-6700, 3,4 GHz, 16 GB RAM) und auf der Festplatte (nicht auf der SSD) dauert ca. 11 Minuten.Benchmarks
Die B-Tree-Option zeigt ein ziemlich gutes Ergebnis:| | Zeit [μs] | % |
| -----------------: | ------------: | ------------: |
| okon | 49 | 100 |
| grep '^ hash' | 135'350'000 | 276'224'489 |
| grep | 135'480'000 | 276'489'795 |
| C ++ Zeile für Zeile | 135'720'201 | 276'980'002 |
okon - Bibliothek und CLI
Wie gesagt, ich wollte meine Arbeit mit der Welt teilen. Ich habe eine Bibliothek und eine Befehlszeilenschnittstelle implementiert, um die HIBP-Datenbank zu verarbeiten und schnell nach Hashes zu suchen. Die Suche ist so schnell, dass sie beispielsweise in einen Passwort-Manager integriert werden kann und dem Benutzer bei jedem Tastendruck eine Rückmeldung gibt. Es gibt viele Verwendungsmöglichkeiten.Die Bibliothek verfügt über eine C-Schnittstelle, sodass sie fast überall verwendet werden kann. CLI ist eine CLI. Sie können einfach erstellen und ausführen (:Der Code befindet sich in meinem Repository .Haftungsausschluss: okon bietet noch keine Schnittstelle zum Einfügen von Werten in den erstellten B-Baum. Es kann nur die HIBP-Datei verarbeiten, einen B-Baum erstellen und darin suchen. Diese Funktionen funktionieren recht gut, daher habe ich beschlossen, den Code freizugeben und weiter an der Einfügung und anderen möglichen Funktionen zu arbeiten.Links und Diskussion
Danke fürs Lesen
(: