 Hallo alle zusammen!An Leistungstests beteiligt. Und ich mag es wirklich, die Überwachung einzurichten und die Metriken in Grafana zu genießen . Der Standard zum Speichern von Metriken in Lastwerkzeugen ist InfluxDB . In InfluxDB können Sie Metriken aus so beliebten Tools wie den folgenden speichern:In Arbeit mit Leistungstest-Tools und deren Metriken habe ich eine Auswahl von Programmierrezepten für das Bundle von Grafana und InfluxDB zusammengestellt . Ich schlage vor, ein interessantes Problem zu betrachten, das auftritt, wenn es eine Metrik mit zwei oder mehr Tags gibt. Ich denke, das ist nicht ungewöhnlich. Und im allgemeinen Fall klingt die Aufgabe so: Berechnung der Gesamtmetrik für eine Gruppe, die in Untergruppen unterteilt ist .
Hallo alle zusammen!An Leistungstests beteiligt. Und ich mag es wirklich, die Überwachung einzurichten und die Metriken in Grafana zu genießen . Der Standard zum Speichern von Metriken in Lastwerkzeugen ist InfluxDB . In InfluxDB können Sie Metriken aus so beliebten Tools wie den folgenden speichern:In Arbeit mit Leistungstest-Tools und deren Metriken habe ich eine Auswahl von Programmierrezepten für das Bundle von Grafana und InfluxDB zusammengestellt . Ich schlage vor, ein interessantes Problem zu betrachten, das auftritt, wenn es eine Metrik mit zwei oder mehr Tags gibt. Ich denke, das ist nicht ungewöhnlich. Und im allgemeinen Fall klingt die Aufgabe so: Berechnung der Gesamtmetrik für eine Gruppe, die in Untergruppen unterteilt ist .Es gibt drei Möglichkeiten:
- Nur der Betrag, der nach Typ-Tag gruppiert ist
- Grafana-Weg. Wir verwenden einen Stapel von Werten
- Summe der Höhen mit Unterabfrage
Wie alles begann
Konfigurierte JVM-MBean-Überwachung mit Jolokia , Telegraf , InfluxDB und Grafana . Und er visualisierte Metriken für Speicherpools - wie viel Speicher von jedem Speicherpool in HEAP und darüber hinaus zugewiesen wird.Diagramme zu JVM-Speicherpools und Garbage Collector-Aktivitäten von 13:00 Uhr des Vortages bis 01:00 Uhr der Nacht des aktuellen Tages (Zeitraum von 12 Stunden). Hier sehen Sie, dass die Speicherpools in zwei Gruppen unterteilt sind: HEAP und NON_HEAP . Und dass es gegen 17:00 Uhr eine Speicherbereinigung gab, nach der die Größe der Speicherpools abnahm: Um Metriken für Speicherpools zu erfassen, habe ich die folgenden Einstellungen in der Telegraf- Konfigurationsdatei angegeben : telegraf.conf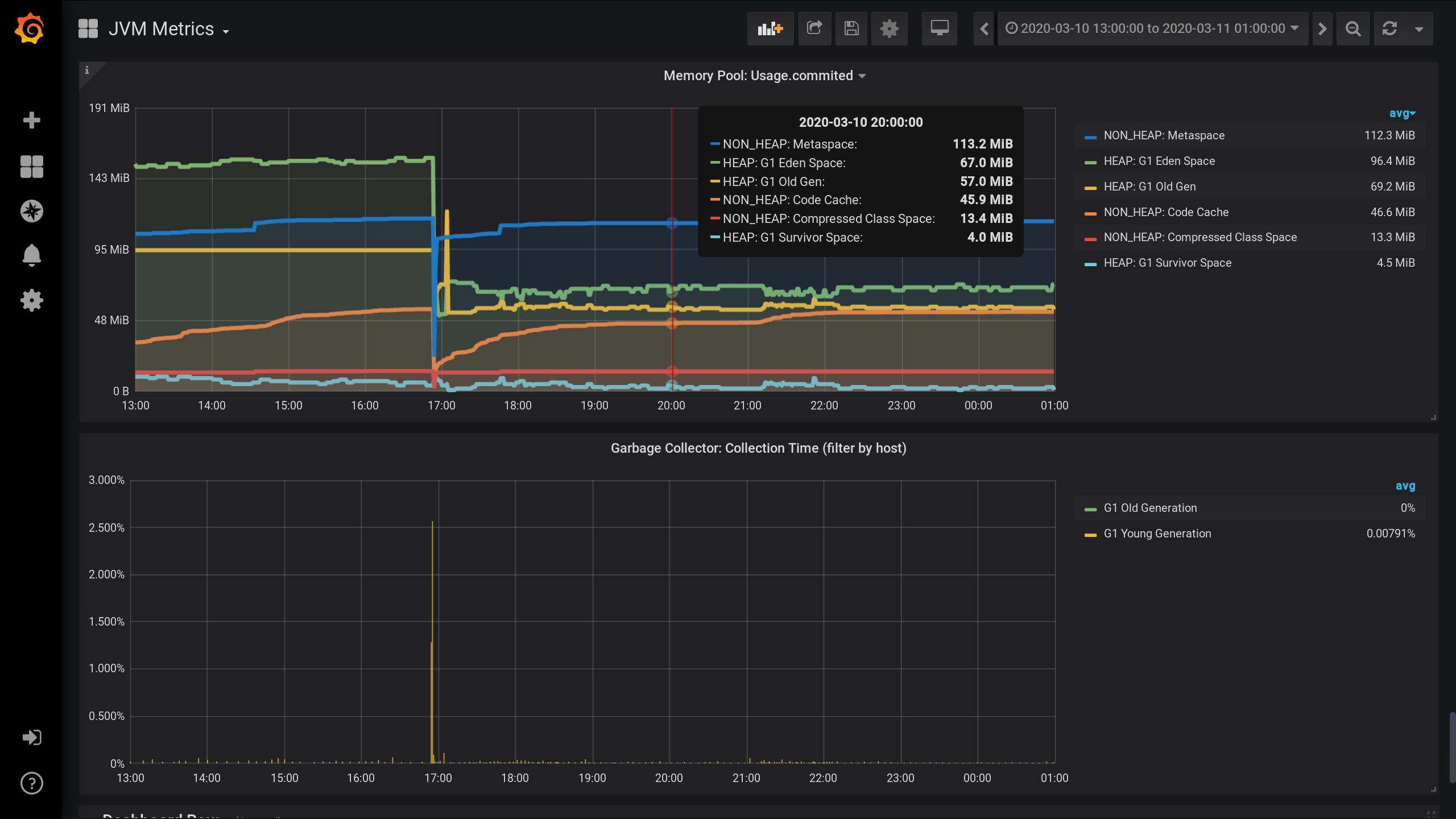
[outputs.influxdb]
urls = ["http://influxdb_server:8086"]
database = "telegraf"
username = "login-InfluxDb"
password = "*****"
retention_policy = "month"
influx_uint_support = false
[agent]
collection_jitter = "2s"
interval = "2s"
precision = "s"
[[inputs.jolokia2_agent]]
username = "login-Jolokia"
password = "*****"
urls = ["http://127.0.0.1:7777/jvm-service"]
[[inputs.jolokia2_agent.metric]]
paths = ["Usage","PeakUsage","CollectionUsage","Type"]
name = "java_memory_pool"
mbean = "java.lang:name=*,type=MemoryPool"
tag_keys = ["name"]
[[processors.converter]]
[processors.converter.fields]
integer = ["CollectionUsage.*", "PeakUsage.*", "Usage.*"]
tag = ["Type"]
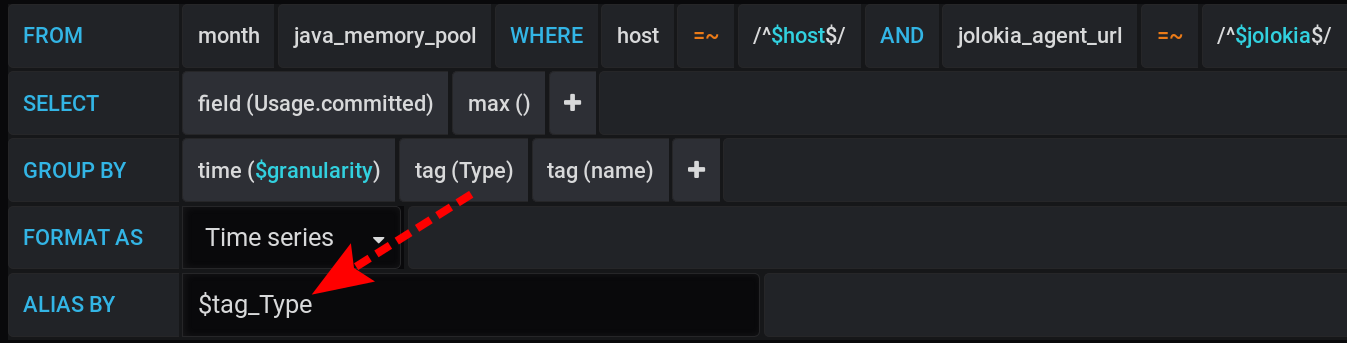
Und in Grafana habe ich eine Anfrage an InfluxDB erstellt , um den maximalen MetrikwertUsage.Committed für einen bestimmten Zeitraum mit einem Schritt $granularity(1 m) in Diagrammen anzuzeigen und nach zwei Tags Type(HEAP oder NON_HEAP) und name(Metaspace, G1 Old Gen, ...) zu gruppieren: Dieselbe Anfrage in Textform unter Berücksichtigung aller Grafana- Variablen (achten Sie darauf, dass die Variablenwerte nicht mit - dies ist wichtig, damit die Abfrage ordnungsgemäß funktioniert):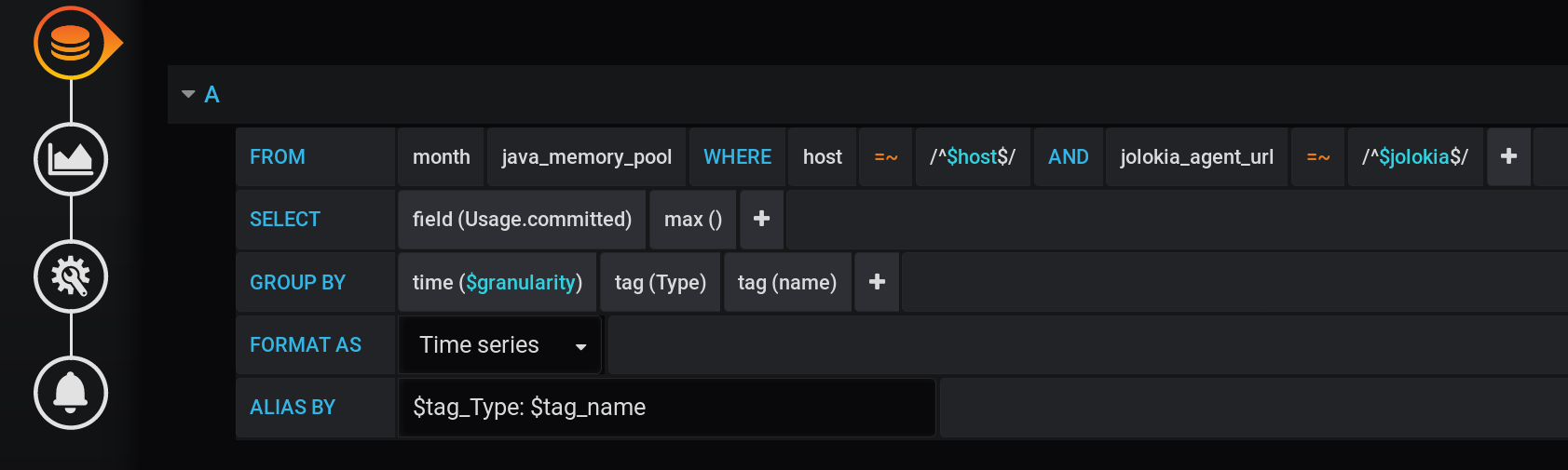
:regexSELECT max("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^${host:regex}$/ AND
jolokia_agent_url =~ /^${jolokia:regex}$/ AND
$timeFilter
GROUP BY
"Type", "name", time($granularity)
Dieselbe
Abfrage in Textform unter Berücksichtigung der spezifischen Werte der Grafana- Variablen :SELECT max("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^serverName$/ AND
jolokia_agent_url =~ /^http:\/\/127\.0\.0\.1:7777\/jvm-service$/ AND
time >= 1583834400000ms and time <= 1583877600000ms
GROUP BY
"Type", "name", time(1m)
Gruppieren nach Zeit GROUP BY time($granularity)oder wird GROUP BY time(1m)verwendet, um die Anzahl der Punkte im Diagramm zu reduzieren. Für einen Zeitraum von 12 Stunden und einen Gruppierungsschritt von 1 Minute erhalten wir: 12 x 60 = 720 mal oder 721 Punkte (der letzte Punkt mit dem Wert null).Denken Sie daran, dass 721 die erwartete Anzahl von Punkten als Antwort auf Anforderungen an InfluxDB mit den aktuellen Einstellungen für das Zeitintervall (12 Stunden) und den Gruppierungsschritt (1 Minute) ist.
NON_HEAP-
Speicherpool : Metaspace (blau) liegt beim Speicherverbrauch um 20:00 Uhr an der Spitze. Und laut HEAP: G1 Old Gen (gelb) gab es um 17:03 Uhr einen kleinen lokalen Anstieg. Insgesamt verließen alle NON_HEAP- Pools zum Zeitpunkt 20:00 172,5 MiB (113,2 + 45,9 + 13,4) und die HEAP- Pools 128 MiB (67 + 57 + 4).
Beachten Sie die Werte für 20:00: NON_HEAP- Pools 172,5 MiB und HEAP- Pools 128 MiB . Wir werden uns in Zukunft auf diese Werte konzentrieren.
Im Kontext von Typ : Name haben wir den Metrikwert leicht erhalten.Nur im Zusammenhang mit dem Namensschild ist der Metrikwert ebenfalls leicht zu erhalten, da alle Namen der Speicherpools eindeutig sind und es ausreicht, die Gruppierung der Ergebnisse nur nach Namen zu belassen .Die Frage bleibt: Wie erhält man die Größe, die allen HEAP-Pools und allen NON_HEAP-Pools insgesamt zugewiesen ist?
1. Nur der Betrag, der nach Typ-Tag gruppiert ist
1.1. Summe gruppiert nach Tag
Die erste Lösung, die in den Sinn kommen könnte, besteht darin, die Werte nach dem Type- Tag zu gruppieren und die Summe der Werte in jeder Gruppe zu berechnen. Eine solche Abfrage sieht folgendermaßen aus: Eine Textdarstellung einer Summenberechnungsanforderung, gruppiert nach Typ- Tag mit allen Grafana- Variablen :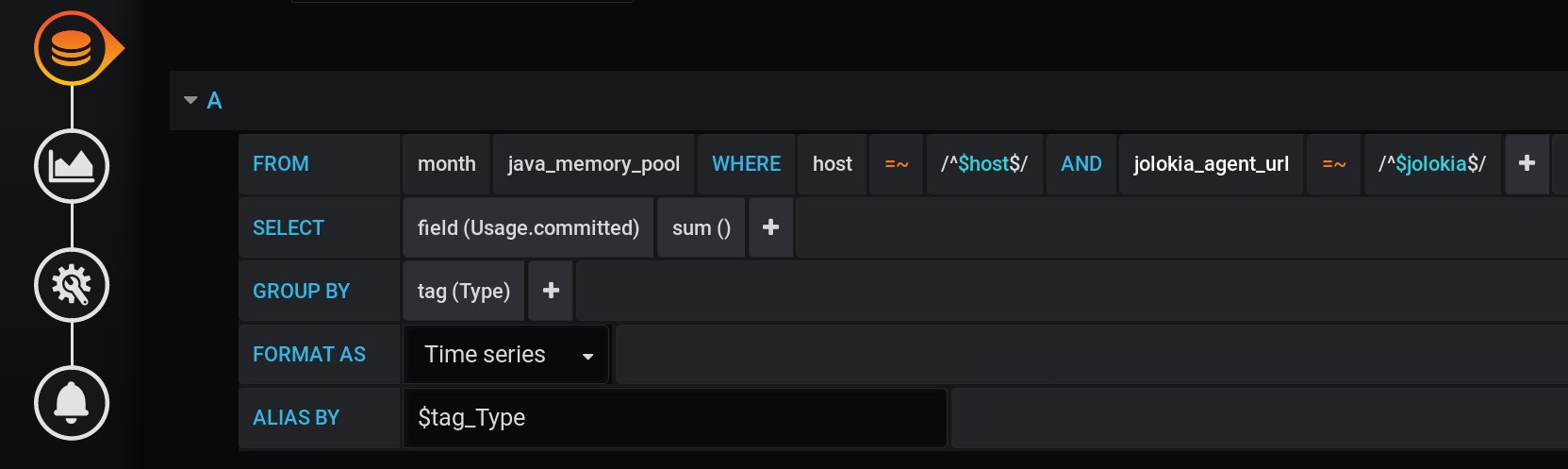
SELECT sum("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^${host:regex}$/ AND
jolokia_agent_url =~ /^${jolokia:regex}$/ AND
$timeFilter
GROUP BY
"Type"
Dies ist eine gültige Abfrage, die jedoch nur zwei Punkte zurückgibt : Die Summe wird bei Gruppierung nur durch das Type- Tag mit zwei Werten (HEAP und NON_HEAP) berechnet. Wir werden nicht einmal den Zeitplan sehen. Es gibt zwei freistehende Punkte mit einer großen Wertesumme (mehr als 3 TiB): Eine solche Summe ist nicht geeignet, eine Aufteilung in Zeitintervalle ist erforderlich.
1.2. Betrag gruppiert nach Tag pro Minute
In der ursprünglichen Abfrage haben wir Metriken nach einem benutzerdefinierten $ Granularitätsintervall gruppiert . Lassen Sie uns jetzt die Gruppierung nach einem benutzerdefinierten Intervall durchführen.Diese Abfrage wird sich herausstellen, fügte sie hinzu GROUP BY time($granularity): Wir erhalten aufgeblasene Werte, anstatt 172,5 MiB von NON_HEAP sehen wir 4,88 GiB: Da Metriken alle 2 Sekunden einmal an InfluxDB gesendet werden (siehe telegraf.conf oben), gibt die Summe der Messwerte in einer Minute nicht den Betrag an im Moment und die Summe von dreißig solchen Beträgen. Wir können das Ergebnis auch nicht durch die Konstante 30 teilen . Da $ granularity ein Parameter ist, kann er sowohl auf 1 Minute als auch auf 10 Minuten eingestellt werden. Und der Wert des Betrags ändert sich.
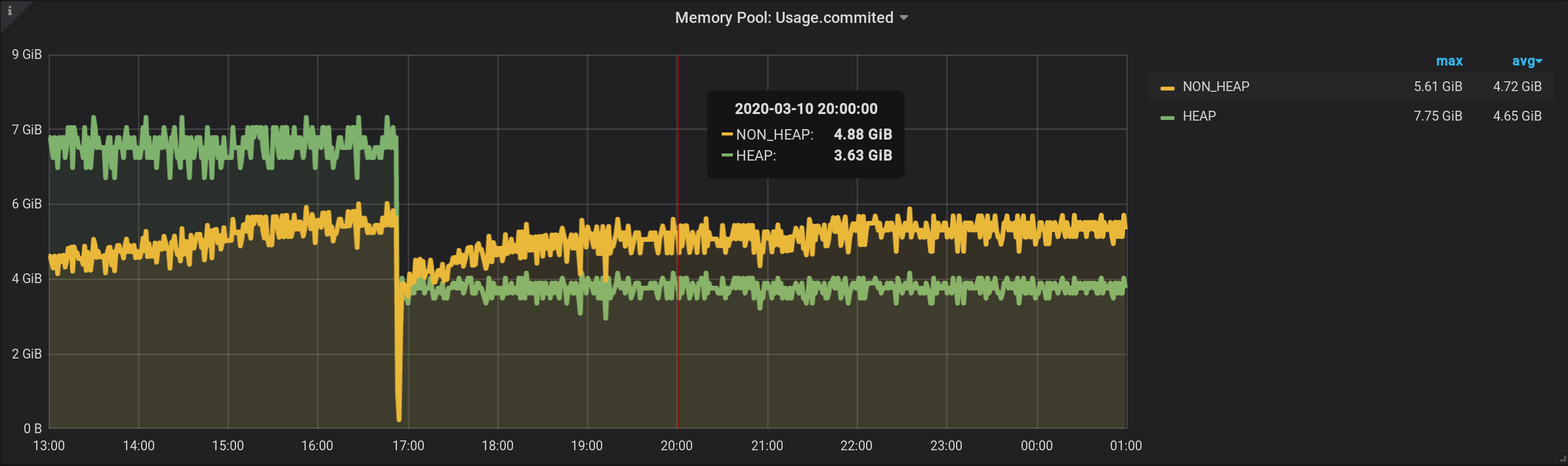
1.3. Tag pro Sekunde gruppiert
Um den Metrikwert für die aktuelle Intensität der Metriksammlung (2 Sekunden) korrekt zu erhalten, müssen Sie den Betrag für ein festes Intervall berechnen, das die Intensität der Metriksammlung nicht überschreitet.Versuchen wir, Statistiken mit einer Gruppierung in Sekunden anzuzeigen. Zur GROUP BYGruppierung hinzufügen time(1s): Mit einer so kleinen Granularität erhalten wir eine große Anzahl von Punkten für unser Zeitintervall von 12 Stunden (12 Stunden * 60 Minuten * 60 Sekunden = 43.200 Intervalle, 43.201 Punkte pro Zeile, von denen der letzte null ist): 43.201 Punkte in jeder Zeile des Diagramms. Es gibt so viele Punkte, dass InfluxDB für eine lange Zeit eine Antwort bildet, Grafana eine Antwort länger benötigt und der Browser dann für eine lange Zeit eine so große Anzahl von Punkten zieht.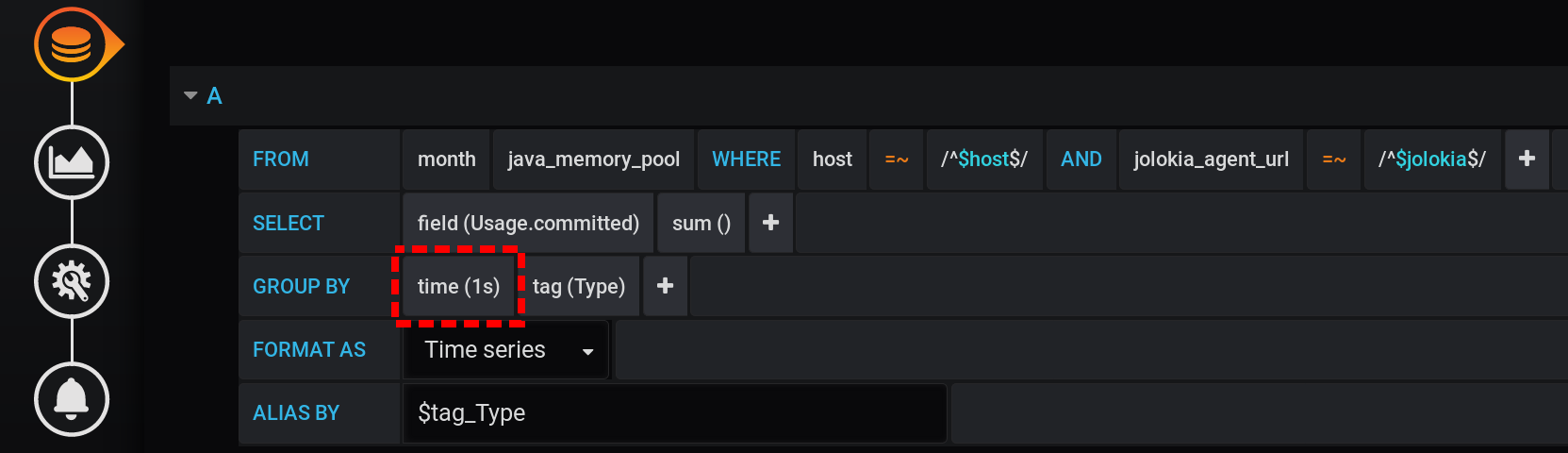
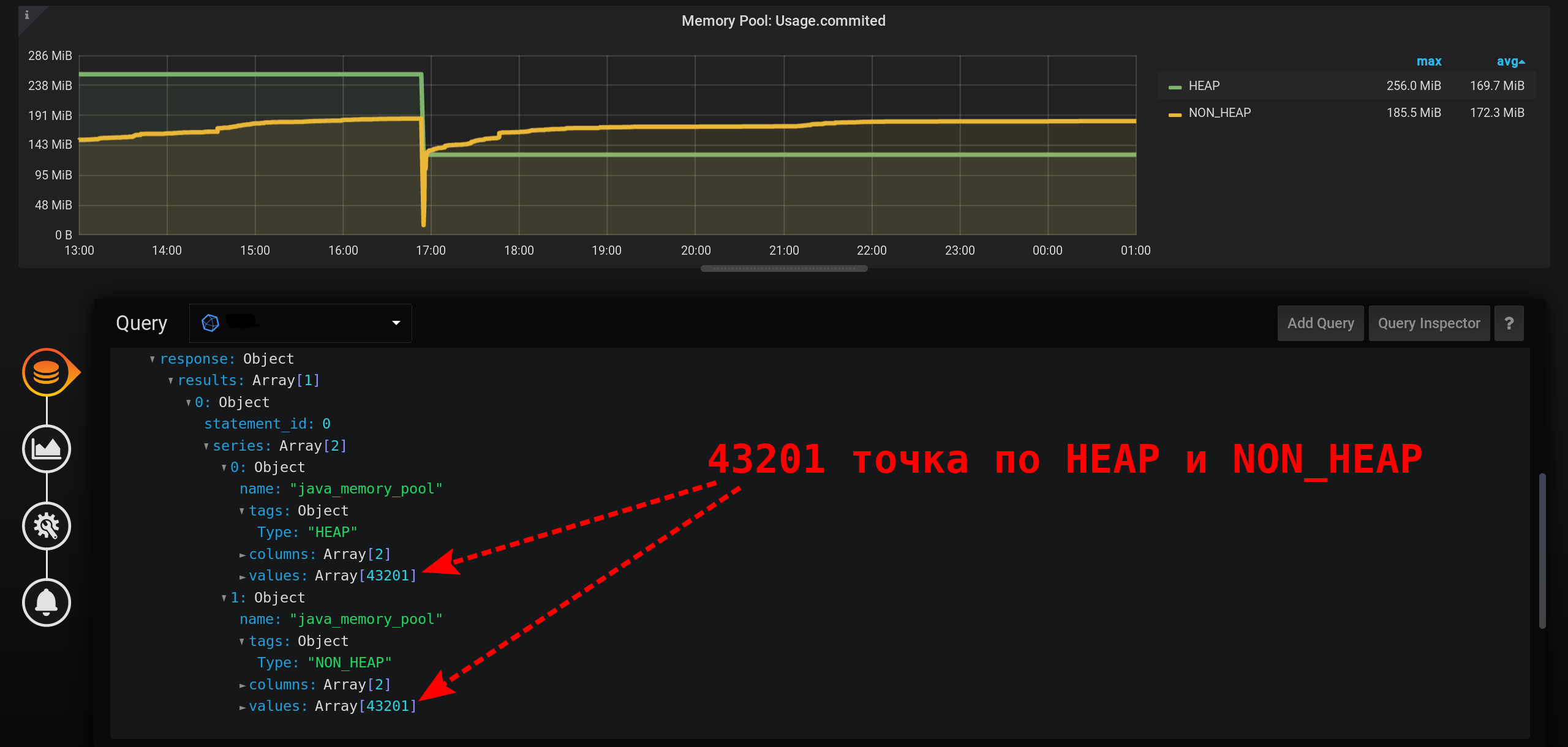 Und nicht in jeder Sekunde gibt es Punkte: Metriken wurden alle 2 Sekunden gesammelt und nach jeder Sekunde gruppiert, was bedeutet, dass jeder zweite Punkt null ist. Konfigurieren Sie die Verbindung nicht leerer Werte, um eine glatte Linie anzuzeigen. Andernfalls werden die Grafiken nicht angezeigt : Bisher war Grafana so, dass der Browser beim Zeichnen einer großen Anzahl von Punkten hängen blieb. Jetzt kann die Version von Grafana mehrere Zehntausend Punkte zeichnen: Der Browser überspringt einfach einige davon und zeichnet anhand der ausgedünnten Daten ein Diagramm. Das Diagramm wird jedoch geglättet. Hochs werden als Durchschnittshochs angezeigt.
Und nicht in jeder Sekunde gibt es Punkte: Metriken wurden alle 2 Sekunden gesammelt und nach jeder Sekunde gruppiert, was bedeutet, dass jeder zweite Punkt null ist. Konfigurieren Sie die Verbindung nicht leerer Werte, um eine glatte Linie anzuzeigen. Andernfalls werden die Grafiken nicht angezeigt : Bisher war Grafana so, dass der Browser beim Zeichnen einer großen Anzahl von Punkten hängen blieb. Jetzt kann die Version von Grafana mehrere Zehntausend Punkte zeichnen: Der Browser überspringt einfach einige davon und zeichnet anhand der ausgedünnten Daten ein Diagramm. Das Diagramm wird jedoch geglättet. Hochs werden als Durchschnittshochs angezeigt. Als Ergebnis gibt es ein Diagramm, das genau angezeigt wird, die Metriken um 20:00 Uhr werden korrekt berechnet, die Metriken in der Diagrammlegende werden korrekt berechnet. Das Diagramm wird jedoch geglättet: Bursts sind mit einer Genauigkeit von 1 Sekunde nicht sichtbar. Insbesondere der HEAP- Anstieg um 17:03 Uhr verschwand aus dem Diagramm, das HEAP- Diagramm ist sehr glatt: Das Minus in der Leistung wird sich über ein längeres Zeitintervall deutlich manifestieren. Wenn Sie versuchen, ein Diagramm in einem Monat (720 Stunden) und nicht in 12 Stunden zu erstellen, friert alles mit einer so geringen Granularität (1 Sekunde) ein, dass zu viele Punkte vorhanden sind. Und es gibt ein Minus in Abwesenheit von Peaks, ein Paradoxon - aufgrund der hohen Genauigkeit beim Erhalten von Metriken erhalten wir eine geringe Genauigkeit ihrer Anzeige .
Als Ergebnis gibt es ein Diagramm, das genau angezeigt wird, die Metriken um 20:00 Uhr werden korrekt berechnet, die Metriken in der Diagrammlegende werden korrekt berechnet. Das Diagramm wird jedoch geglättet: Bursts sind mit einer Genauigkeit von 1 Sekunde nicht sichtbar. Insbesondere der HEAP- Anstieg um 17:03 Uhr verschwand aus dem Diagramm, das HEAP- Diagramm ist sehr glatt: Das Minus in der Leistung wird sich über ein längeres Zeitintervall deutlich manifestieren. Wenn Sie versuchen, ein Diagramm in einem Monat (720 Stunden) und nicht in 12 Stunden zu erstellen, friert alles mit einer so geringen Granularität (1 Sekunde) ein, dass zu viele Punkte vorhanden sind. Und es gibt ein Minus in Abwesenheit von Peaks, ein Paradoxon - aufgrund der hohen Genauigkeit beim Erhalten von Metriken erhalten wir eine geringe Genauigkeit ihrer Anzeige .
2. Grafana-Weg. Wir verwenden einen Stapel von Werten
Mit InfluxDB und dem Grafana- Abfrage- Designer konnte keine einfache und produktive Lösung erstellt werden . Wir werden nur versuchen, Grafana- Tools zu verwenden , um die im Originaldiagramm angezeigten Metriken zusammenzufassen. Und ja, das ist möglich!2.1. Machen Sie einfach den Hover-Tooltip / Stacked-Wert: kumulativ
Wir werden die Anforderung zur Auswahl von Metriken unverändert lassen, wie im Abschnitt „Wie alles begann“: Metriken werden nach Typ und Name gruppiert . Das Type- Tag wird jedoch nur in den Namen der Diagramme angezeigt : In den Visualisierungseinstellungen werden die Metriken nach Grafana- Stapeln gruppiert : Fügen
Sie zunächst die Trennung zweier Tags in zwei verschiedene Stapel A und B hinzu, damit sich ihre Werte nicht überschneiden: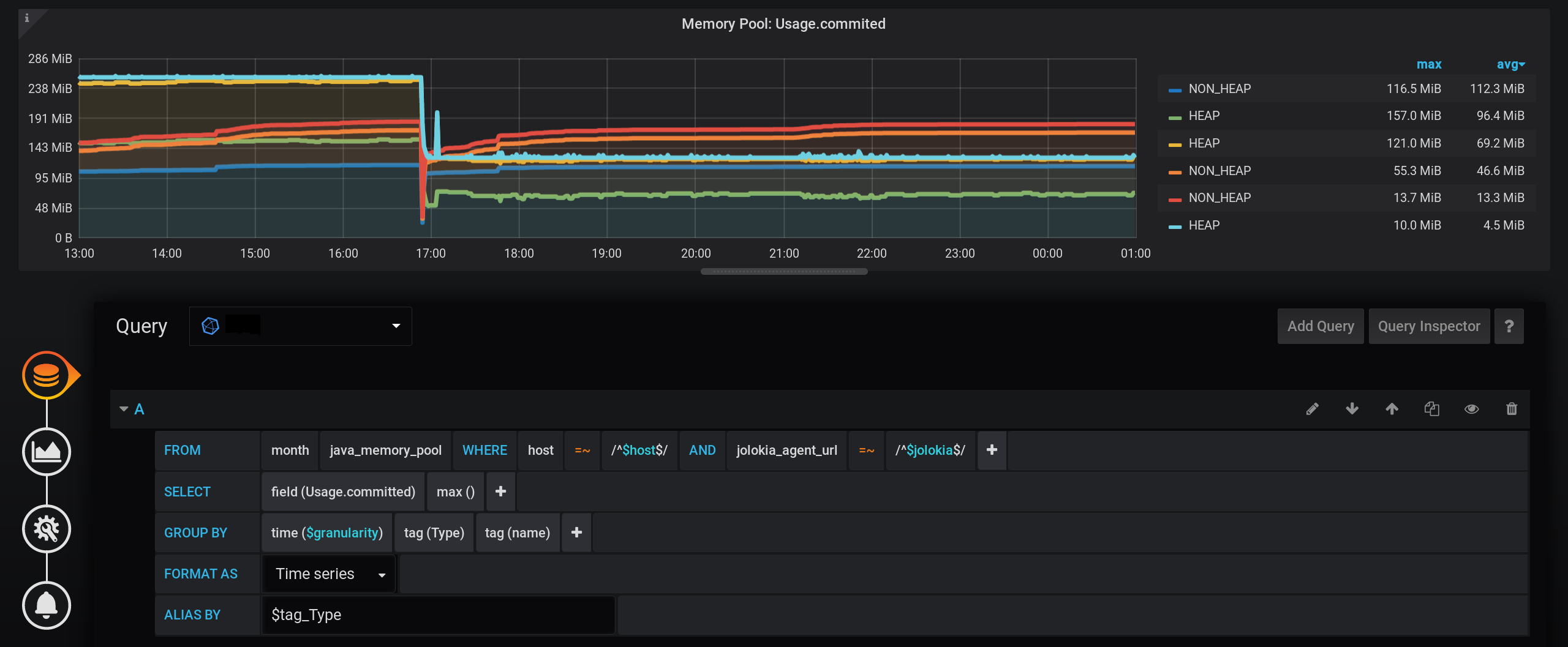
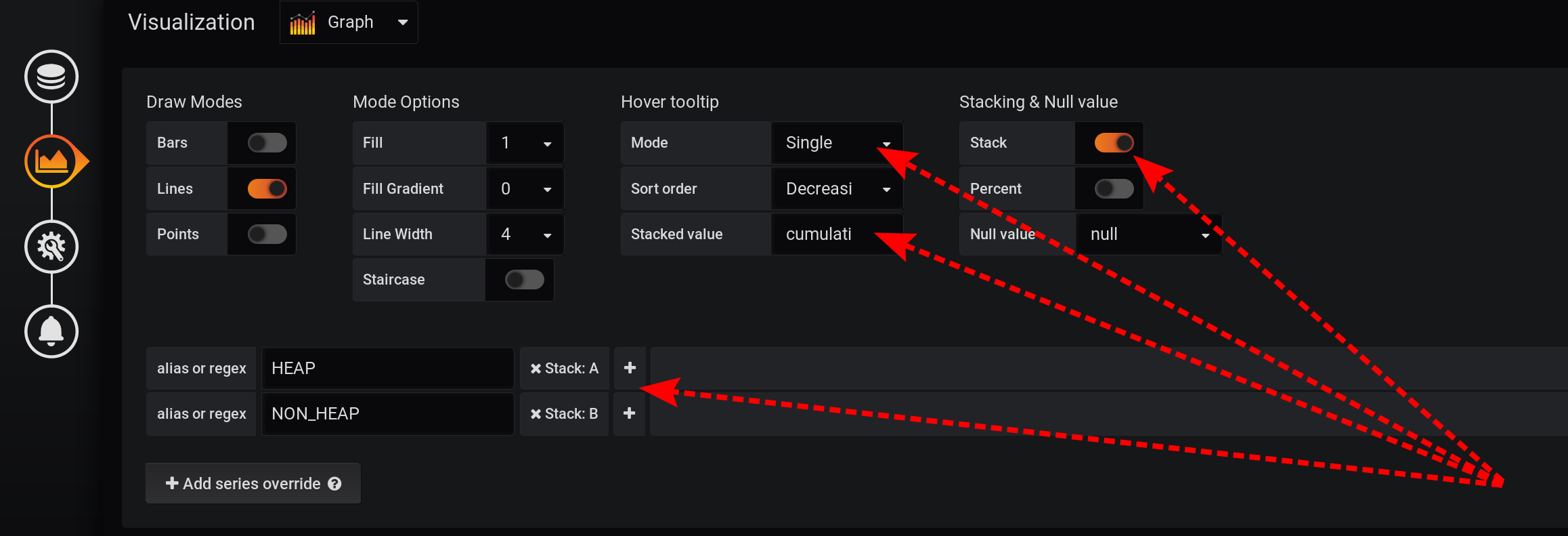
- In Serie überschreiben / HEAP / Stapel : A
- In Serie überschreiben / NON_HEAP / Stapel : B
Konfigurieren Sie anschließend die Visualisierung von Metriken so, dass die Gesamtwerte in einem Tooltip mit Diagrammen angezeigt werden:- Stacking & Nullwert / Stapel : On
- Hover-Tooltip / gestapelter Wert : kumulativ
- Hover-Tooltip / Modus : Single
Aufgrund der verschiedenen Funktionen von Grafana müssen Sie Aktionen in dieser Reihenfolge ausführen. Wenn Sie die Reihenfolge der Aktionen ändern oder einige Felder mit Standardeinstellungen belassen, funktioniert etwas nicht:- Stack A B Stacking & Null value / Stack: On, ;
- Hover tooltip / Mode , Single, Hover tooltip .
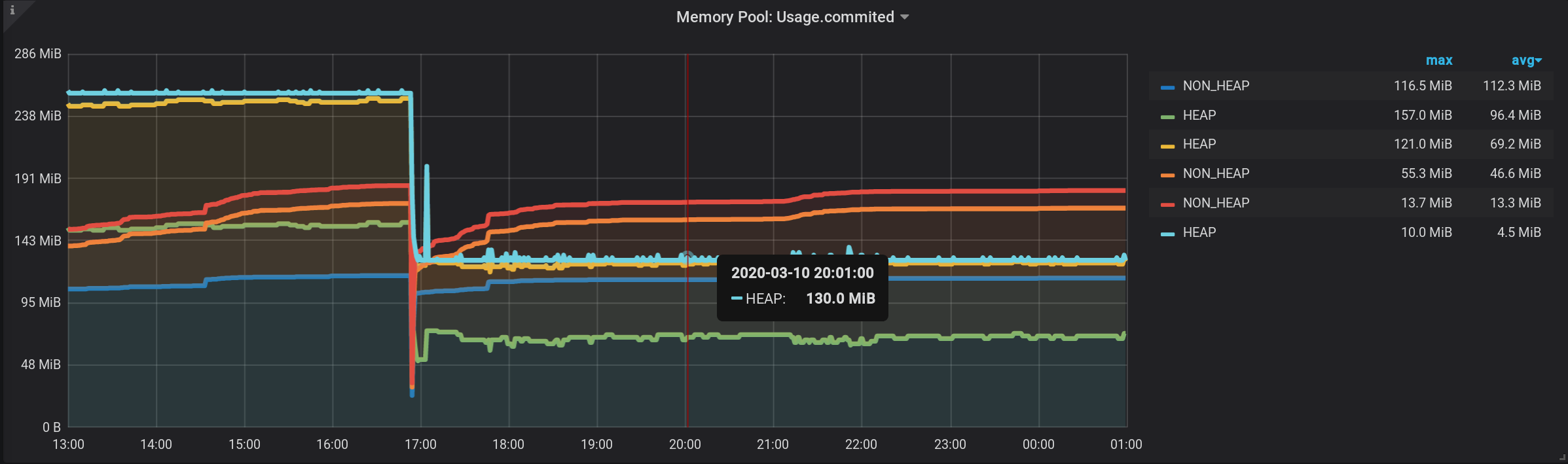
Und jetzt sehen wir viele Linien, solche für uns. Aber! Wenn Sie den Mauszeiger über den obersten NON_HEAP bewegen , wird in der QuickInfo die Summe der Werte aller NON_HEAPs angezeigt . Der Betrag gilt als wahr, die bereits von Grafana Mitteln : Und wenn Sie schweben über den obersten Plan mit dem Namen HEAP , werden wir den Betrag , um sehen HEAP . Das Diagramm wird korrekt angezeigt. Sogar der HEAP- Anstieg um 17:03 Uhr ist sichtbar: Formal ist die Aufgabe erledigt. Aber es gibt Nachteile - viele zusätzliche Diagramme werden angezeigt. Sie müssen den Cursor ganz nach oben bewegen. Und in der Legende zum Diagramm werden nicht kumulative, sondern einzelne Werte angezeigt, sodass die Legende unbrauchbar geworden ist.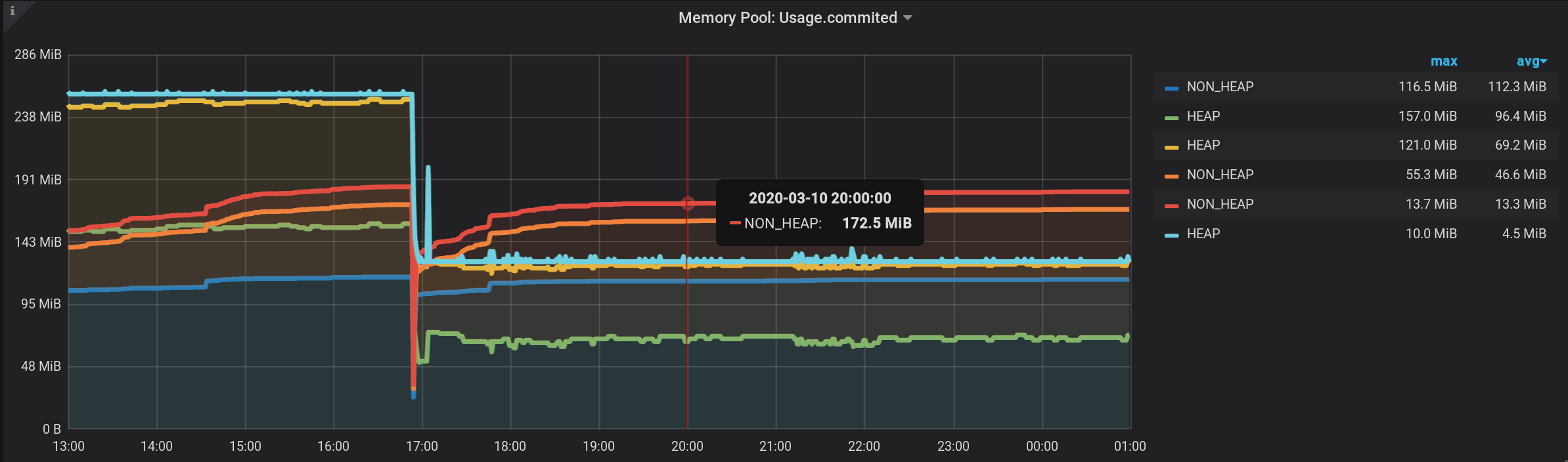
2.2. Gestapelter Wert: kumulativ mit ausgeblendeten Zwischenzeilen
Beheben wir das erste Minus der vorherigen Lösung: Stellen Sie sicher, dass keine zusätzlichen Diagramme angezeigt werden.Dafür:- Fügen Sie den Ergebnissen neue Metriken mit einem anderen Namen und Wert 0 hinzu.
- Fügen Sie Stapel A und Stapel B oben im Stapel neue Metriken hinzu .
- Aus der Anzeige ausblenden - die ursprünglichen Zeilen von HEAP und NON_HEAP .
Nach der Hauptanforderung fügen wir zwei neue hinzu: Anforderung B zum Empfangen einer Reihe mit den Werten 0 und Name [NON_HEAP] und Anforderung C zum Empfangen einer Reihe mit den Werten 0 und Name [HEAP] . Um 0 zu erhalten, nehmen wir den ersten Wert des Felds "Usage.committed" in jeder Zeitgruppe und subtrahieren ihn: first ("Usage.committed") - first ("Usage.committed") - wir erhalten eine stabile 0. Die Namen der Diagramme werden geändert, ohne an Bedeutung zu verlieren Aufgrund der eckigen Klammern: [NON_HEAP] und [HEAP] : [HEAP] und HEAP werden in Stapel A kombiniert und verbergen auch alle HEAP . [NON_HEAP]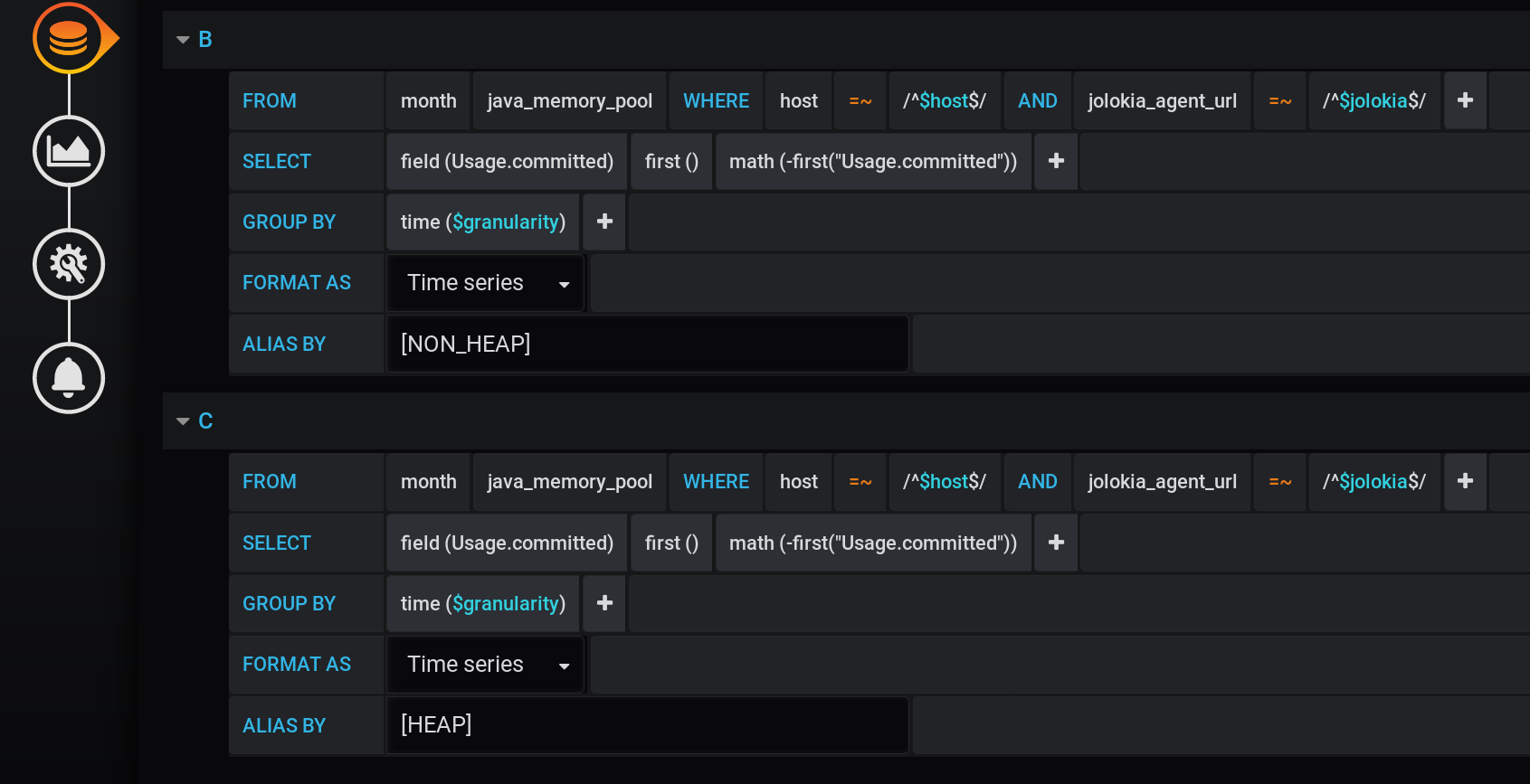 und kombinieren Sie NON_HEAP in Stapel B und verbergen Sie NON_HEAP : Ermitteln Sie den
korrekten Betrag mit [NON_HEAP] in der QuickInfo, wenn Sie den Mauszeiger über das Diagramm halten: Ermitteln
Sie den korrekten Betrag mit [HEAP] in der QuickInfo, wenn Sie mit der Maus über das Diagramm fahren. Und sogar alle Bursts sind sichtbar: Und der Zeitplan wird schnell erstellt. Aber die Legende zeigt immer 0 an, die Legende ist unbrauchbar geworden. Es hat alles geklappt! Echter Bypass ist durch die Grafana- Stapel . Aus diesem Grund wurde der Artikel der Kategorie Abnormale Programmierung hinzugefügt .
und kombinieren Sie NON_HEAP in Stapel B und verbergen Sie NON_HEAP : Ermitteln Sie den
korrekten Betrag mit [NON_HEAP] in der QuickInfo, wenn Sie den Mauszeiger über das Diagramm halten: Ermitteln
Sie den korrekten Betrag mit [HEAP] in der QuickInfo, wenn Sie mit der Maus über das Diagramm fahren. Und sogar alle Bursts sind sichtbar: Und der Zeitplan wird schnell erstellt. Aber die Legende zeigt immer 0 an, die Legende ist unbrauchbar geworden. Es hat alles geklappt! Echter Bypass ist durch die Grafana- Stapel . Aus diesem Grund wurde der Artikel der Kategorie Abnormale Programmierung hinzugefügt .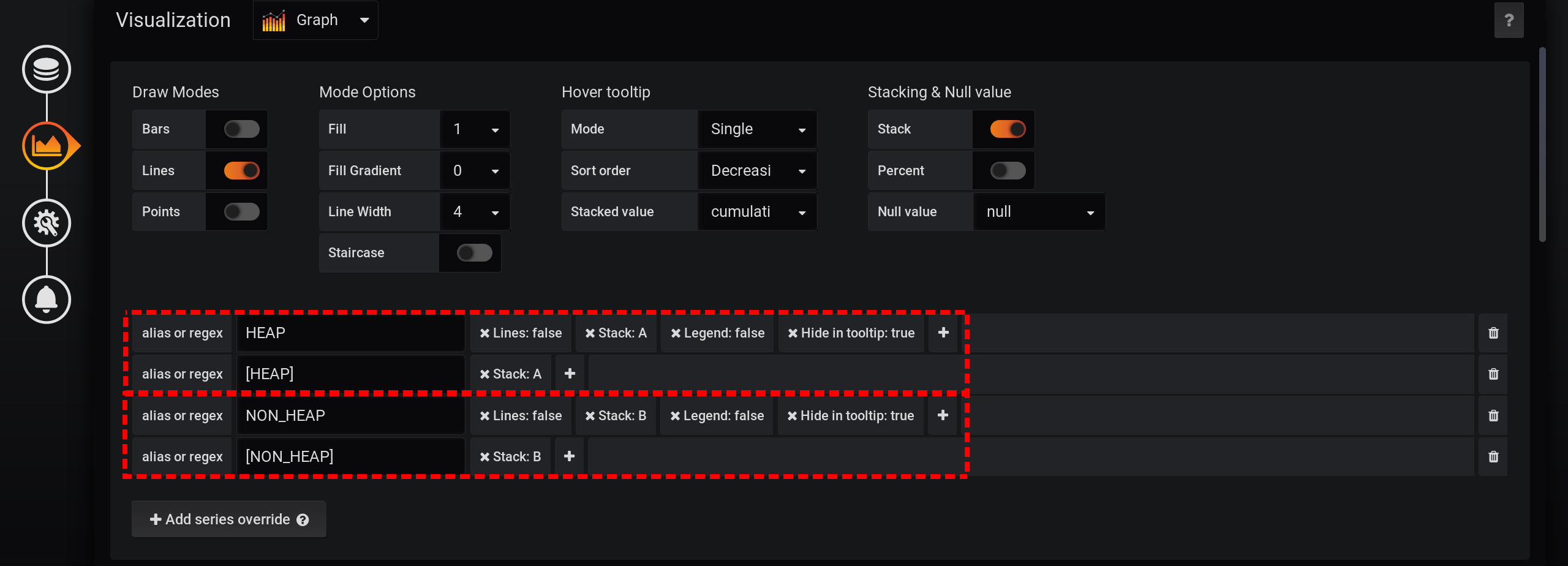


3. Die Summe der Höhen mit der Unterabfrage
Da wir bereits mit einer Reihe von Grafana und InfluxDB den Weg der abnormalen Programmierung eingeschlagen haben , fahren wir fort. Lassen Sie InfluxDB eine kleine Anzahl von Punkten zurückgeben und die Legende erscheinen.3.1 Summe der Inkremente der kumulierten Summe der Maxima
Lassen Sie uns die Möglichkeiten von InfluxDB untersuchen . Früher habe ich oft geholfen, indem ich die Ableitung des kumulierten Betrags genommen habe. Deshalb werden wir jetzt versuchen, diesen Ansatz anzuwenden. Wechseln wir in den Modus der manuellen Bearbeitung von Anfragen: Stellen wir eine solche Anfrage:
SELECT sum("U") FROM (
SELECT non_negative_difference(cumulative_sum(max("Usage.committed"))) AS "U"
FROM "month"."java_memory_pool"
WHERE
(
"host" =~ /^${host:regex}$/ AND
"jolokia_agent_url" =~ /^${jolokia:regex}$/
) AND
$timeFilter
GROUP BY time($granularity), "Type", "name"
)
GROUP BY "Type", time($granularity)
Hier wird der Maximalwert der Metrik in der Gruppe nach Zeit genommen und die Summe dieser Werte ab dem Zeitpunkt, zu dem die Referenz beginnt, gruppiert nach den Tags Typ und Name . Infolgedessen wird zu jedem Zeitpunkt eine Summe aller Angaben nach Typ ( HEAP oder NON_HEAP ) mit Trennung nach Poolname angezeigt , es werden jedoch nicht 30 Werte summiert, wie dies in Version 1.2 der Fall war, sondern nur einer ist das Maximum.Und wenn wir die nehmen non_negative_difference Zuwachs von solchen kumulativen Summe für den letzten Schritt, dann werden wir den Summenwert aller Datenpools gruppiert nach erhalten Typ und Name - Tags zu Beginn des Zeitintervalls.Nun, um den Betrag nur per Tag zu erhaltenGeben Sie ohne Gruppierung nach Namensschild eine Anforderung der obersten Ebene mit ähnlichen Gruppierungsparametern ein, jedoch ohne Gruppierung nach Namen .Als Ergebnis einer solch komplexen Abfrage erhalten wir die Summe aller Typen.Perfekter Zeitplan. Die Summe der Maxima wird korrekt berechnet. Es gibt eine Legende mit den richtigen Werten ungleich Null. In der QuickInfo können Sie alle Metriken anzeigen, nicht nur Single. Sogar HEAP- Bursts werden angezeigt : Eine Sache, aber - die Anforderung stellte sich als schwierig heraus: die Summe des Inkrements der kumulierten Summe von Maxima mit einer Änderung der Gruppierungsstufe.
3.2 Summe der Höhen mit Änderung der Gruppierungsstufe
Können Sie etwas einfacher machen als in Version 3.1? Die Büchse der Pandora ist bereits geöffnet. Wir haben in den manuellen Bearbeitungsmodus für Abfragen gewechselt.Es besteht der Verdacht, dass der Erhalt eines Inkrements aus dem kumulierten Betrag zu einem Null-Effekt führt - einer löscht den anderen aus. Entfernen Sie non_negative_difference (cumulative_sum (...)) .Vereinfachen Sie die Anfrage.Wir belassen einfach die Summe der Maxima mit einer Abnahme der Gruppierungsstufe:SELECT sum("A")
FROM (
SELECT max("Usage.committed") as "A"
FROM "month"."java_memory_pool"
WHERE
(
"host" =~ /^${host:regex}$/ AND
"jolokia_agent_url" =~ /^${jolokia:regex}$/
) AND
$timeFilter
GROUP BY time($granularity), "Type", "name"
)
WHERE $timeFilter
GROUP BY time($granularity), "Type"
Dies ist eine schnelle, einfache Abfrage, die in 12 Stunden nur 721 Punkte pro Serie zurückgibt, gruppiert nach Minuten: 12 (Stunden) * 60 (Minuten) = 720 Intervalle, 721 Punkte (zuletzt leer). Bitte beachten Sie, dass der Zeitfilter doppelt vorhanden ist. Es befindet sich in der Unterabfrage und in der Gruppierungsanforderung: Ohne $ timeFilter beträgt die Anzahl der zurückgegebenen Punkte in der externen Gruppierungsanforderung in 12 Stunden nicht 721, sondern mehr. Da die Unterabfrage für das Intervall von ... bis gruppiert ist und die Gruppierung einer externen Anforderung ohne Filter für das Intervall von ... jetzt erfolgt . Und wenn in Grafana ein Zeitintervall ausgewählt ist, das nicht die letzten X Stunden beträgt (nicht so, dass bis = jetzt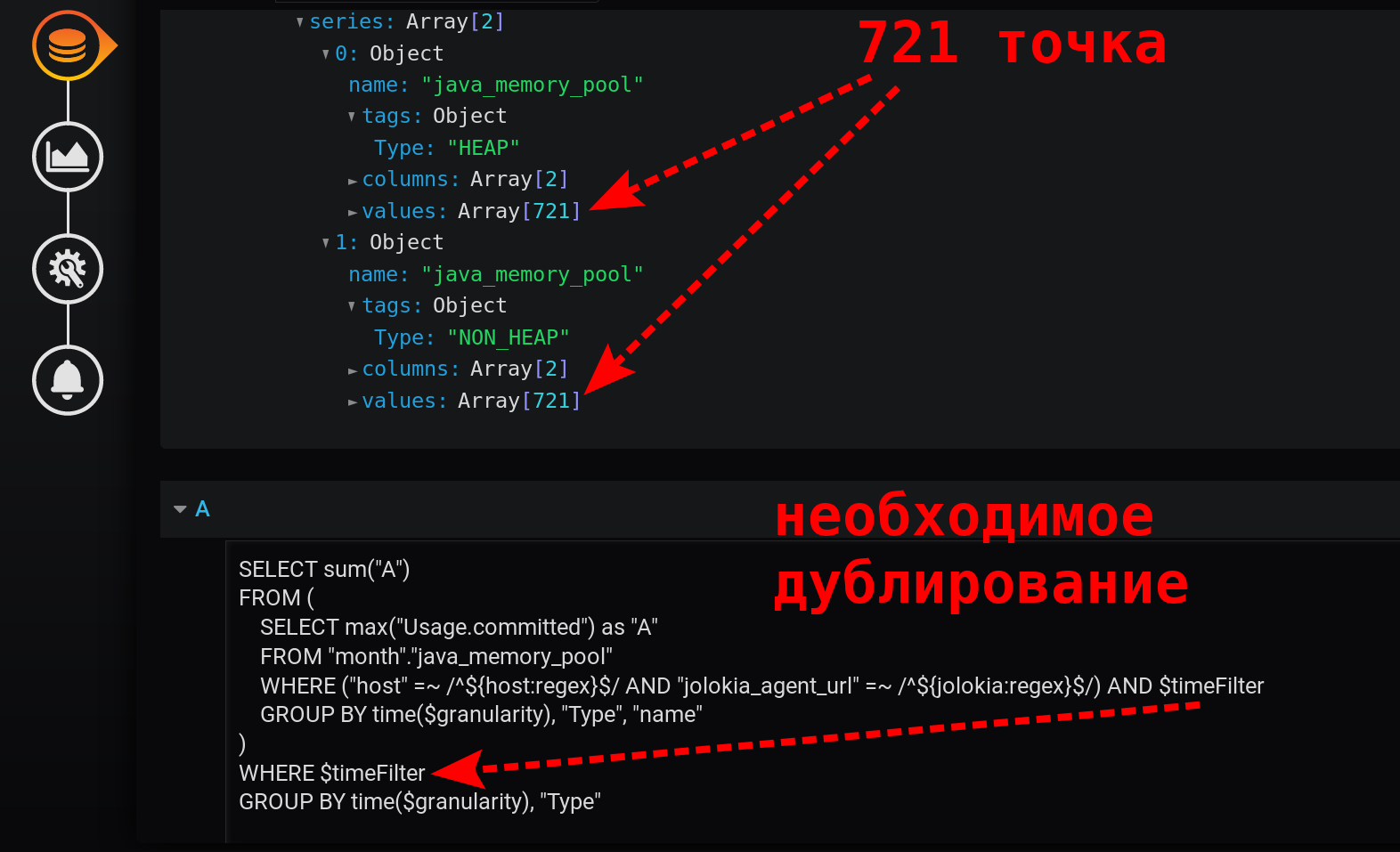 ), aber für das Intervall von der Vergangenheit ( bis < jetzt ) werden leere Punkte mit einem Nullwert am Ende der Auswahl angezeigt.Das resultierende Diagramm erwies sich als einfach, schnell und korrekt. Mit einer Legende, die zusammenfassende Metriken anzeigt. Mit Tooltip für mehrere Zeilen gleichzeitig. Und auch mit der Anzeige aller Wertestöße: Das Ergebnis ist erreicht!
), aber für das Intervall von der Vergangenheit ( bis < jetzt ) werden leere Punkte mit einem Nullwert am Ende der Auswahl angezeigt.Das resultierende Diagramm erwies sich als einfach, schnell und korrekt. Mit einer Legende, die zusammenfassende Metriken anzeigt. Mit Tooltip für mehrere Zeilen gleichzeitig. Und auch mit der Anzeige aller Wertestöße: Das Ergebnis ist erreicht!Referenzen (anstelle von Referenzen)
Verteilungen der im Artikel verwendeten Tools:Dokumentation zu den Funktionen der im Artikel verwendeten Tools:Die Kombination von Grafana und InfluxDB sollte den Leistungstestingenieuren bekannt sein. Und in diesem Bundle sind viele einfache Aufgaben sehr interessant und können mit normalen Programmiermethoden nicht immer gelöst werden.Manchmal sind bei den Grafana- Funktionen und Feinheiten der InfluxDB- Abfragesprache abnormale Programmierkenntnisse erforderlich .In dem Artikel wurden vier Optionen zum Implementieren der Summierung einer Metrik berücksichtigt, die nach einem Tag gruppiert ist, jedoch mehrere Tags enthält. Die Aufgabe war interessant. Und es gibt viele solche Aufgaben.Ich bereite einen Bericht über die Feinheiten der Programmierung mit Grafana und InfluxDB vor. Ich werde regelmäßig Materialien zu diesem Thema veröffentlichen. In der Zwischenzeit freue ich mich über Ihre Fragen zum aktuellen Artikel.