Hallo alle zusammen.Wir, Victor Antipov und Ilya Aleshin, werden heute über unsere Erfahrungen mit USB-Geräten über Python PyUSB und ein wenig über Reverse Engineering sprechen.
Hintergrund
Im Jahr 2019 trat das Dekret der Regierung der Russischen Föderation Nr. 224 „Über die Genehmigung der Vorschriften für die Kennzeichnung von Tabakerzeugnissen durch Identifizierung und die Besonderheiten der Einführung eines staatlichen Informationssystems zur Überwachung des Warenverkehrs, für den eine Kennzeichnung durch Tabakerzeugnisse vorgeschrieben ist“ in Kraft.In dem Dokument wird erklärt, dass die Hersteller ab dem 1. Juli 2019 jede Packung Tabak kennzeichnen müssen. Direktvertriebshändler sollten diese Produkte mit dem Design eines Universal Transfer Document (UPD) erhalten. Geschäfte wiederum müssen den Verkauf von gekennzeichneten Produkten über die Registrierkasse registrieren.Ab dem 1. Juli 2020 sind auch nicht gekennzeichnete Tabakerzeugnisse verboten. Dies bedeutet, dass alle Zigarettenpackungen mit einem speziellen Datamatrix-Barcode gekennzeichnet sein müssen. Und - ein wichtiger Punkt - es stellte sich heraus, dass Datamatrix nicht gewöhnlich, sondern umgekehrt sein wird. Das heißt, kein schwarzer Code auf weiß, sondern umgekehrt.Wir haben unsere Scanner getestet und es stellte sich heraus, dass die meisten von ihnen neu geflasht / umgeschult werden müssen, da sie sonst einfach nicht normal mit diesem Barcode arbeiten können. Diese Wendung der Ereignisse garantierte uns starke Kopfschmerzen, da unser Unternehmen viele Geschäfte hat, die über ein weites Gebiet verstreut sind. Mehrere Zehntausende von Kassen - und extrem wenig Zeit.Was war zu tun? Es gibt zwei Möglichkeiten. Erstens: Die Ingenieure in der Einrichtung blinken die Scanner manuell neu ein und passen sie an. Zweitens: Wir arbeiten remote und decken vorzugsweise viele Scanner gleichzeitig in einer Iteration ab.Die erste Option passte natürlich nicht zu uns: Wir müssten Geld für Exkursionen von Ingenieuren ausgeben, und es ist in diesem Fall schwierig, den Prozess zu kontrollieren und zu koordinieren. Aber das Wichtigste ist, dass die Leute arbeiten, das heißt, wir würden möglicherweise viele Fehler bekommen und höchstwahrscheinlich nicht die Frist einhalten.Die zweite Option ist gut für alle, wenn nicht für eine, aber. Einige Anbieter verfügten nicht über die für alle erforderlichen Betriebssysteme erforderlichen Remote-Flashing-Tools. Und da die Fristen abgelaufen waren, musste ich mit meinem eigenen Kopf denken.Als nächstes werden wir beschreiben, wie wir Tools für Handscanner für das Debian 9.x-Betriebssystem entwickelt haben (wir haben alle Debian-Kassen).:
Sagt Victor Antipov.Das offizielle Dienstprogramm des Anbieters funktioniert unter Windows und nur mit IE. Das Dienstprogramm kann den Scanner flashen und konfigurieren.Da das Zielsystem Debian ist, haben wir den USB-Redirector-Server auf dem Debian-Server und den USB-Redirector-Client unter Windows installiert. Mit den Dienstprogrammen usb-redirector wurde der Scanner vom Linux-Computer an den Windows-Computer weitergeleitet.Das Dienstprogramm des Windows-Anbieters hat den Scanner gesehen und sogar normal geflasht. Somit wurde die erste Schlussfolgerung gezogen: Nichts hängt vom Betriebssystem ab, die Angelegenheit steht im Flashing-Protokoll.OK. Auf einem Windows-Computer wurde ein Flashen gestartet, und auf einem Linux-Computer wurde ein Speicherauszug entfernt.Sie haben den Dump in WireShark gestopft und ... waren traurig (ich werde einen Teil der Dump-Details weglassen, sie sind nicht von Interesse).Welche Müllkippe hat uns gezeigt: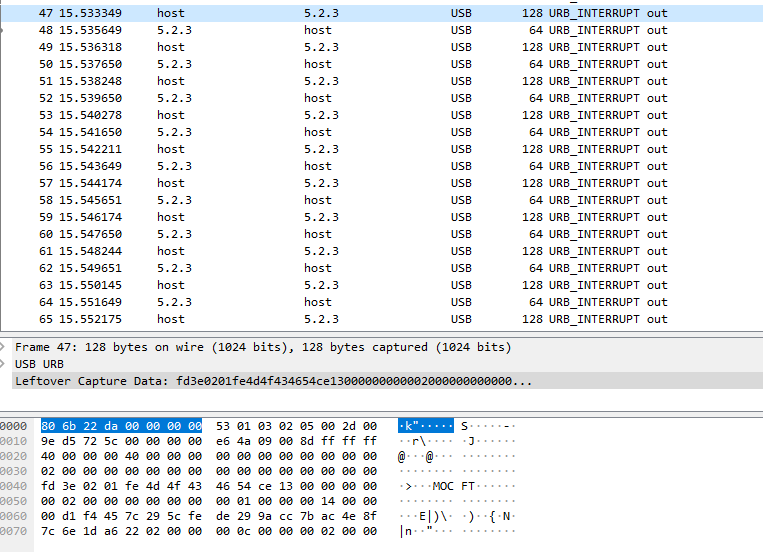
 Die Adressen 0000-0030 sind nach Wireshark USB-Serviceinformationen.Wir waren an Teil 0040-0070 interessiert.Aus einem Übertragungsrahmen war nichts klar, außer MOCFT-Zeichen. Diese Symbole erwiesen sich als Symbole aus der Firmware-Datei sowie den übrigen Symbolen bis zum Ende des Frames (die Firmware-Datei ist hervorgehoben):
Die Adressen 0000-0030 sind nach Wireshark USB-Serviceinformationen.Wir waren an Teil 0040-0070 interessiert.Aus einem Übertragungsrahmen war nichts klar, außer MOCFT-Zeichen. Diese Symbole erwiesen sich als Symbole aus der Firmware-Datei sowie den übrigen Symbolen bis zum Ende des Frames (die Firmware-Datei ist hervorgehoben): Was bedeuteten die Symbole fd 3e 02 01 fe, ich persönlich hatte wie Ilya keine Ahnung.Ich habe mir den nächsten Frame angesehen (Serviceinformationen werden hier gelöscht, die Firmware-Datei wird hervorgehoben):
Was bedeuteten die Symbole fd 3e 02 01 fe, ich persönlich hatte wie Ilya keine Ahnung.Ich habe mir den nächsten Frame angesehen (Serviceinformationen werden hier gelöscht, die Firmware-Datei wird hervorgehoben): Was wurde klar? Dass die ersten beiden Bytes eine Art Konstante sind. Alle nachfolgenden Blöcke bestätigten dies, jedoch vor dem Ende des Übertragungsblocks:
Was wurde klar? Dass die ersten beiden Bytes eine Art Konstante sind. Alle nachfolgenden Blöcke bestätigten dies, jedoch vor dem Ende des Übertragungsblocks: Dieser Frame geriet ebenfalls in einen Stupor, da sich die Konstante änderte (hervorgehoben) und seltsamerweise ein Teil der Datei vorhanden war. Die Größe der übertragenen Bytes der Datei zeigte an, dass 1024 Bytes übertragen wurden. Was die restlichen Bytes bedeuteten - ich wusste es nicht noch einmal.Zunächst habe ich wie ein alter BBS-Spitzname die Standardübertragungsprotokolle überarbeitet. 1024 Bytes, kein Protokoll übergeben. Er begann das Material zu studieren und stieß auf das 1K Xmodem-Protokoll. Es erlaubte die Übertragung von 1024, jedoch mit einer Nuance: Zuerst nur 128, und nur in Abwesenheit von Fehlern erhöhte das Protokoll die Anzahl der übertragenen Bytes. Ich hatte sofort eine Übertragung von 1024 Bytes. Ich beschloss, die Übertragungsprotokolle und speziell das X-Modem zu studieren.Es gab zwei Varianten des Modems.Zunächst das Format des XMODEM-Pakets mit CRC8-Unterstützung (Original XMODEM):
Dieser Frame geriet ebenfalls in einen Stupor, da sich die Konstante änderte (hervorgehoben) und seltsamerweise ein Teil der Datei vorhanden war. Die Größe der übertragenen Bytes der Datei zeigte an, dass 1024 Bytes übertragen wurden. Was die restlichen Bytes bedeuteten - ich wusste es nicht noch einmal.Zunächst habe ich wie ein alter BBS-Spitzname die Standardübertragungsprotokolle überarbeitet. 1024 Bytes, kein Protokoll übergeben. Er begann das Material zu studieren und stieß auf das 1K Xmodem-Protokoll. Es erlaubte die Übertragung von 1024, jedoch mit einer Nuance: Zuerst nur 128, und nur in Abwesenheit von Fehlern erhöhte das Protokoll die Anzahl der übertragenen Bytes. Ich hatte sofort eine Übertragung von 1024 Bytes. Ich beschloss, die Übertragungsprotokolle und speziell das X-Modem zu studieren.Es gab zwei Varianten des Modems.Zunächst das Format des XMODEM-Pakets mit CRC8-Unterstützung (Original XMODEM):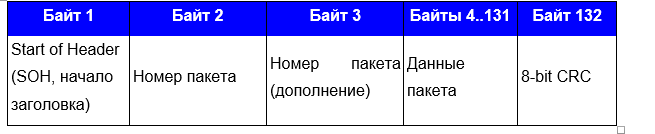 Zweitens das XMODEM-Paketformat mit CRC16-Unterstützung (XmodemCRC):
Zweitens das XMODEM-Paketformat mit CRC16-Unterstützung (XmodemCRC):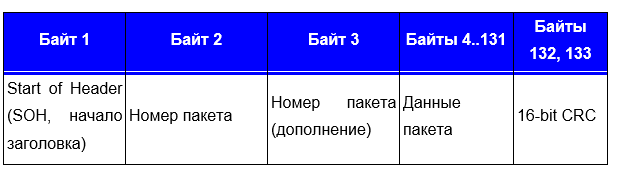 Es sieht ähnlich aus, mit Ausnahme von SOH, Paketnummer und CRC und der Länge des Pakets.Ich habe mir den Anfang des zweiten Übertragungsblocks angesehen (und wieder die Firmware-Datei gesehen, aber mit einem Einzug von 1024 Bytes):
Es sieht ähnlich aus, mit Ausnahme von SOH, Paketnummer und CRC und der Länge des Pakets.Ich habe mir den Anfang des zweiten Übertragungsblocks angesehen (und wieder die Firmware-Datei gesehen, aber mit einem Einzug von 1024 Bytes): Ich habe den bekannten Header fd 3e 02 gesehen, aber die nächsten zwei Bytes haben sich bereits geändert: Es war 01 fe und es wurde 02 fd. Dann habe ich bemerkt, dass der zweite Block jetzt 02 nummeriert ist und somit verstanden hat: Vor mir liegt die Nummerierung des Übertragungsblocks. Die erste 1024-Übertragung ist 01, die zweite 02, die dritte 03 usw. (aber natürlich hexadezimal). Aber was bedeutet der Wechsel von fe zu fd? Die Augen sahen eine Abnahme von 1, das Gehirn erinnerte daran, dass Programmierer von 0 zählen, nicht von 1. Aber warum ist dann der erste Block 1 nicht 0? Ich habe die Antwort auf diese Frage nicht gefunden. Aber ich habe verstanden, wie der zweite Block betrachtet wird. Der zweite Block ist nichts anderes als FF - (minus) die Nummer des ersten Blocks. Somit wurde der zweite Block als = 02 (FF-02) = 02 FD bezeichnet. Das anschließende Lesen der Müllkippe bestätigte meine Vermutung.Dann tauchte das folgende Bild des Programms auf:Der Beginn des Programmsfd 3e 02 - Start01 FE - ÜbertragungszählerÜbertragung (34 Blöcke, 1024 Bytes werden übertragen)fd 3e 1024 Datenbytes (unterteilt in Blöcke von 30 Bytes).Ende der Übertragungfd 25Datenreste, die an 1024 Bytes ausgerichtet werden sollen.Wie sieht der
Ich habe den bekannten Header fd 3e 02 gesehen, aber die nächsten zwei Bytes haben sich bereits geändert: Es war 01 fe und es wurde 02 fd. Dann habe ich bemerkt, dass der zweite Block jetzt 02 nummeriert ist und somit verstanden hat: Vor mir liegt die Nummerierung des Übertragungsblocks. Die erste 1024-Übertragung ist 01, die zweite 02, die dritte 03 usw. (aber natürlich hexadezimal). Aber was bedeutet der Wechsel von fe zu fd? Die Augen sahen eine Abnahme von 1, das Gehirn erinnerte daran, dass Programmierer von 0 zählen, nicht von 1. Aber warum ist dann der erste Block 1 nicht 0? Ich habe die Antwort auf diese Frage nicht gefunden. Aber ich habe verstanden, wie der zweite Block betrachtet wird. Der zweite Block ist nichts anderes als FF - (minus) die Nummer des ersten Blocks. Somit wurde der zweite Block als = 02 (FF-02) = 02 FD bezeichnet. Das anschließende Lesen der Müllkippe bestätigte meine Vermutung.Dann tauchte das folgende Bild des Programms auf:Der Beginn des Programmsfd 3e 02 - Start01 FE - ÜbertragungszählerÜbertragung (34 Blöcke, 1024 Bytes werden übertragen)fd 3e 1024 Datenbytes (unterteilt in Blöcke von 30 Bytes).Ende der Übertragungfd 25Datenreste, die an 1024 Bytes ausgerichtet werden sollen.Wie sieht der Blockübertragungs-Endrahmen aus : fd 25 - Signal zum Ende der Blockübertragung. Weiter 2f 52 - die Reste der Datei bis zu 1024 Bytes. 2f 52 ist nach dem Protokoll eine 16-Bit-CRC-Prüfsumme.Basierend auf dem alten Speicher habe ich ein Programm in C erstellt, das 1024 Bytes aus einer Datei gezogen und 16-Bit-CRC gelesen hat. Der Start des Programms hat gezeigt, dass dies kein 16-Bit-CRC ist. Wieder Stupor - für ungefähr drei Tage. Die ganze Zeit habe ich versucht zu verstehen, was es sein könnte, wenn nicht eine Prüfsumme. Beim Studium englischsprachiger Websites stellte ich fest, dass das X-Modem eine eigene Prüfsummenberechnung verwendet - CRC-CCITT (XModem). Ich habe keine Implementierungen in C für diese Berechnung gefunden, aber ich habe eine Site gefunden, die diese Prüfsumme online liest. Durch das Hochladen von 1024 Bytes meiner Datei auf die Webseite zeigte mir die Site eine Prüfsumme, die vollständig mit der Prüfsumme aus der Datei übereinstimmte.Hurra! Das letzte Rätsel ist gelöst, jetzt mussten Sie Ihre eigene Firmware erstellen. Dann übertrug ich mein Wissen (und sie blieben nur in meinem Kopf) auf Ilya, die mit mächtigen Werkzeugen vertraut ist - Python.
Blockübertragungs-Endrahmen aus : fd 25 - Signal zum Ende der Blockübertragung. Weiter 2f 52 - die Reste der Datei bis zu 1024 Bytes. 2f 52 ist nach dem Protokoll eine 16-Bit-CRC-Prüfsumme.Basierend auf dem alten Speicher habe ich ein Programm in C erstellt, das 1024 Bytes aus einer Datei gezogen und 16-Bit-CRC gelesen hat. Der Start des Programms hat gezeigt, dass dies kein 16-Bit-CRC ist. Wieder Stupor - für ungefähr drei Tage. Die ganze Zeit habe ich versucht zu verstehen, was es sein könnte, wenn nicht eine Prüfsumme. Beim Studium englischsprachiger Websites stellte ich fest, dass das X-Modem eine eigene Prüfsummenberechnung verwendet - CRC-CCITT (XModem). Ich habe keine Implementierungen in C für diese Berechnung gefunden, aber ich habe eine Site gefunden, die diese Prüfsumme online liest. Durch das Hochladen von 1024 Bytes meiner Datei auf die Webseite zeigte mir die Site eine Prüfsumme, die vollständig mit der Prüfsumme aus der Datei übereinstimmte.Hurra! Das letzte Rätsel ist gelöst, jetzt mussten Sie Ihre eigene Firmware erstellen. Dann übertrug ich mein Wissen (und sie blieben nur in meinem Kopf) auf Ilya, die mit mächtigen Werkzeugen vertraut ist - Python.Programmerstellung
Erzählt von Ilya Aleshin.Nachdem ich die entsprechenden Anweisungen erhalten hatte, war ich sehr „glücklich“.Wo soll ich anfangen? Von Anfang an. Vom Dumping von einem USB-Anschluss.Führen Sie USB-pcap https://desowin.org/usbpcap/tour.html aus.Wählen Sie den Port, an den das Gerät angeschlossen ist, und die Datei, in der der Speicherauszug gespeichert werden soll. Wir verbinden den Scanner mit dem Computer, auf dem die native EZConfigScanning-Software für Windows installiert ist.
Wir verbinden den Scanner mit dem Computer, auf dem die native EZConfigScanning-Software für Windows installiert ist.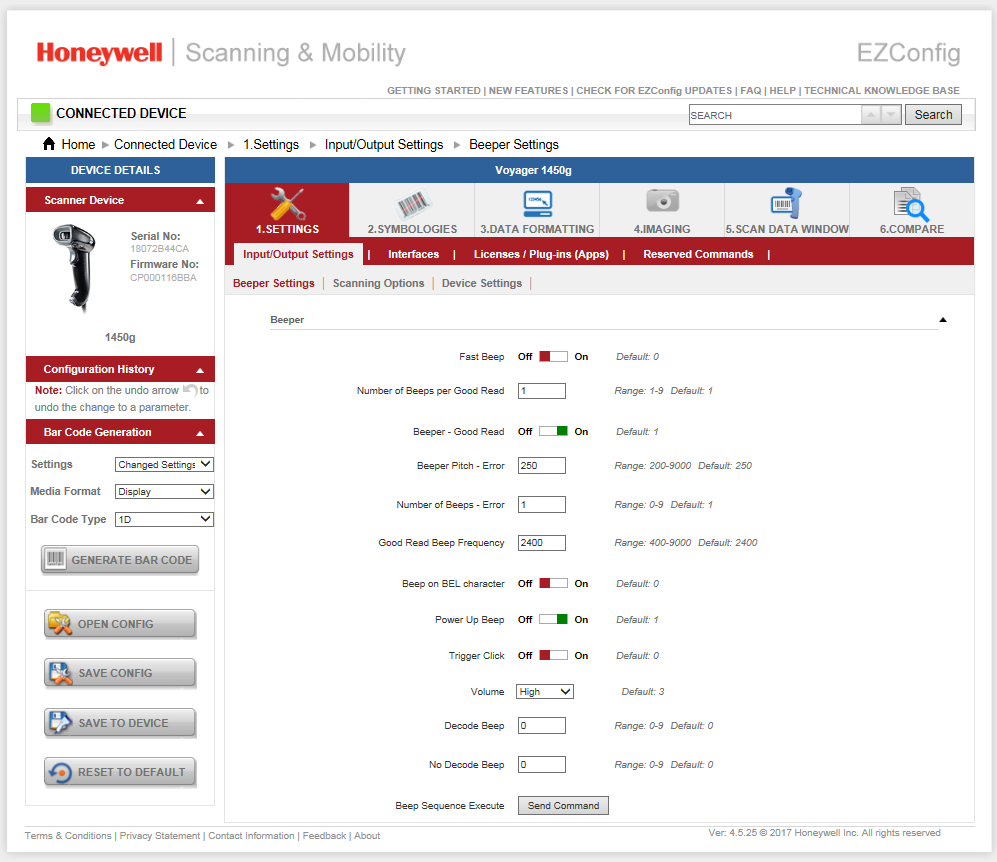 Darin finden wir den Punkt, an dem Befehle an das Gerät gesendet werden. Aber was ist mit den Teams? Wo bekommt man sie?Wenn das Programm startet, wird das Gerät automatisch abgefragt (wir werden dies etwas später sehen). Und es gab Schulungs-Barcodes aus offiziellen Ausrüstungsdokumenten. DEFALT. Das ist unser Team.
Darin finden wir den Punkt, an dem Befehle an das Gerät gesendet werden. Aber was ist mit den Teams? Wo bekommt man sie?Wenn das Programm startet, wird das Gerät automatisch abgefragt (wir werden dies etwas später sehen). Und es gab Schulungs-Barcodes aus offiziellen Ausrüstungsdokumenten. DEFALT. Das ist unser Team. Die notwendigen Daten werden empfangen. Öffnen Sie dump.pcap durch wireshark.Block beim Start EZConfigScanning. Die roten Punkte sind Orte, auf die Sie achten sollten.
Die notwendigen Daten werden empfangen. Öffnen Sie dump.pcap durch wireshark.Block beim Start EZConfigScanning. Die roten Punkte sind Orte, auf die Sie achten sollten.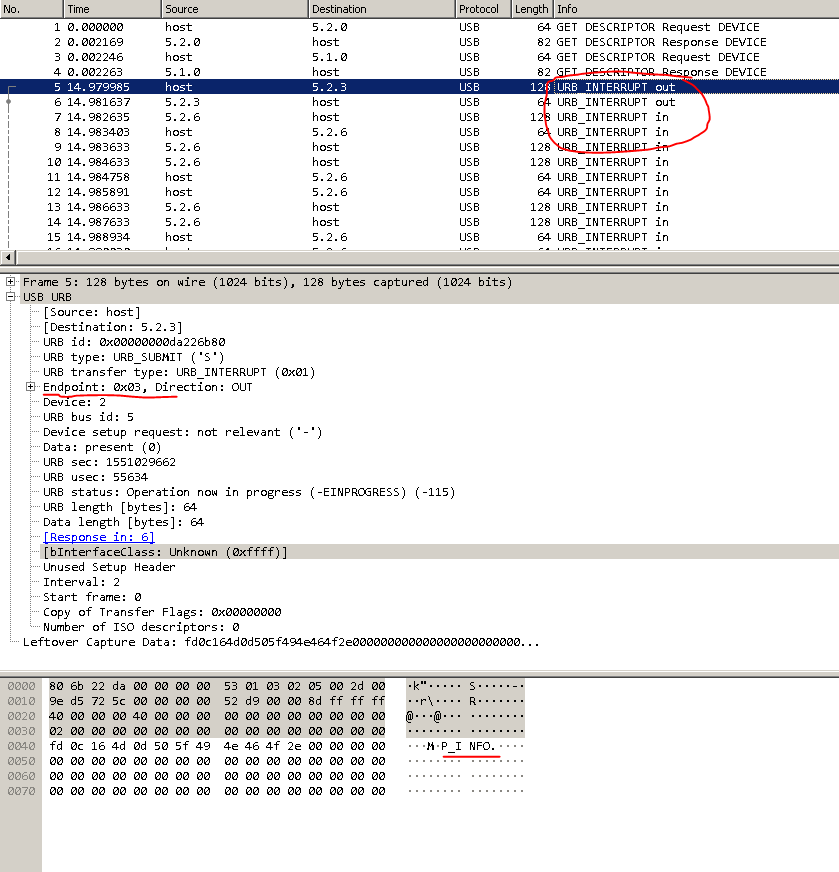
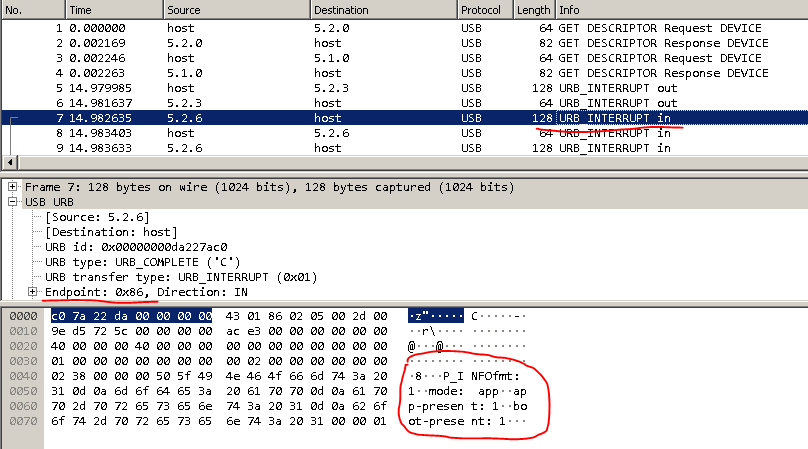 Als ich das alles zum ersten Mal sah, verlor ich den Mut. Wo man weiter graben kann, ist unklar.Ein bisschen Brainstorming und ... und ... Aha! In einer Müllhalde, aus ist in , und in ist aus .Googelte, was URB_INTERRUPT ist. Es wurde festgestellt, dass dies eine Datenübertragungsmethode ist. Und es gibt 4 solcher Methoden: Kontrolle, Interrupt, isochron, Bulk. Sie können separat darüber lesen.Die Endpunktadressen in der USB-Geräteschnittstelle können entweder über den Befehl „lsusb –v“ oder über pyusb abgerufen werden.Jetzt müssen Sie alle Geräte mit dieser VID finden. Sie können gezielt nach VID: PID suchen.
Als ich das alles zum ersten Mal sah, verlor ich den Mut. Wo man weiter graben kann, ist unklar.Ein bisschen Brainstorming und ... und ... Aha! In einer Müllhalde, aus ist in , und in ist aus .Googelte, was URB_INTERRUPT ist. Es wurde festgestellt, dass dies eine Datenübertragungsmethode ist. Und es gibt 4 solcher Methoden: Kontrolle, Interrupt, isochron, Bulk. Sie können separat darüber lesen.Die Endpunktadressen in der USB-Geräteschnittstelle können entweder über den Befehl „lsusb –v“ oder über pyusb abgerufen werden.Jetzt müssen Sie alle Geräte mit dieser VID finden. Sie können gezielt nach VID: PID suchen. Es sieht aus wie das:
Es sieht aus wie das: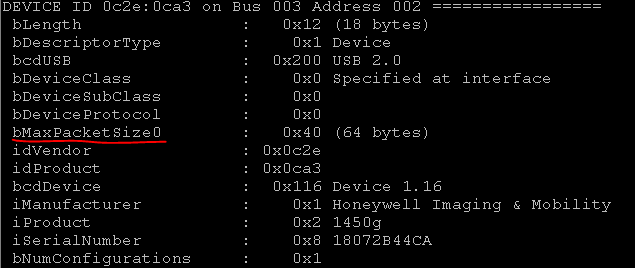
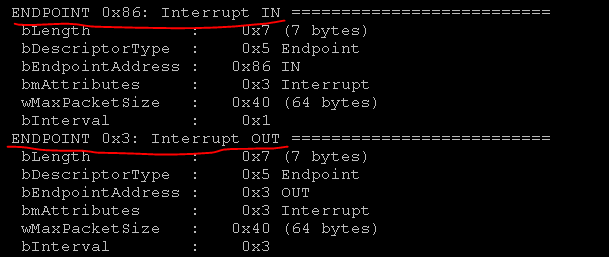 Wir haben also die notwendigen Informationen: P_INFO-Befehle. oder DEFALT, Adressen, an die der Befehlsendpunkt = 03 geschrieben und der Antwortendpunkt = 86 abgerufen werden soll. Es bleibt nur, die Befehle in hex zu übersetzen.
Wir haben also die notwendigen Informationen: P_INFO-Befehle. oder DEFALT, Adressen, an die der Befehlsendpunkt = 03 geschrieben und der Antwortendpunkt = 86 abgerufen werden soll. Es bleibt nur, die Befehle in hex zu übersetzen.
 Da wir das Gerät bereits gefunden haben, trennen Sie es vom Kernel ...
Da wir das Gerät bereits gefunden haben, trennen Sie es vom Kernel ...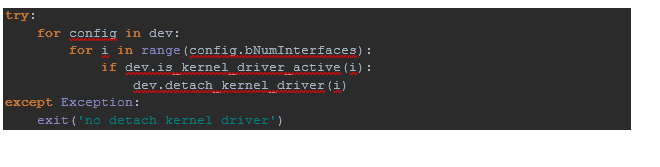 ... und schreiben Sie auf den Endpunkt mit der Adresse 0x03,
... und schreiben Sie auf den Endpunkt mit der Adresse 0x03, ... und lesen Sie dann die Antwort vom Endpunkt mit der Adresse 0x86.
... und lesen Sie dann die Antwort vom Endpunkt mit der Adresse 0x86. Strukturierte Antwort:
Strukturierte Antwort:P_INFOfmt: 1
mode: app
app-present: 1
boot-present: 1
hw-sn: 18072B44CA
hw-rev: 0x20
cbl: 4
app-sw-rev: CP000116BBA
boot-sw-rev: CP000014BAD
flash: 3
app-m_name: Voyager 1450g
boot-m_name: Voyager 1450g
app-p_name: 1450g
boot-p_name: 1450g
boot-time: 16:56:02
boot-date: Oct 16 2014
app-time: 08:49:30
app-date: Mar 25 2019
app-compat: 289
boot-compat: 288
csum: 0x6986
Wir sehen diese Daten in dump.pcap.

 Fein! Wir übersetzen System-Barcodes in Hex. Alles, die Trainingsfunktionalität ist fertig.Was tun mit Firmware? Es scheint, dass alles gleich ist, aber es gibt eine Nuance.Nachdem wir einen vollständigen Speicherauszug des Flash-Prozesses entfernt hatten, verstanden wir ungefähr, womit wir es zu tun hatten. Hier ist ein Artikel über XMODEM, der wirklich dazu beigetragen hat, zu verstehen, wie diese Kommunikation abläuft, wenn auch allgemein: http://microsin.net/adminstuff/others/xmodem-protocol-overview.html Ich empfehle, ihn zu lesen.Wenn Sie in den
Fein! Wir übersetzen System-Barcodes in Hex. Alles, die Trainingsfunktionalität ist fertig.Was tun mit Firmware? Es scheint, dass alles gleich ist, aber es gibt eine Nuance.Nachdem wir einen vollständigen Speicherauszug des Flash-Prozesses entfernt hatten, verstanden wir ungefähr, womit wir es zu tun hatten. Hier ist ein Artikel über XMODEM, der wirklich dazu beigetragen hat, zu verstehen, wie diese Kommunikation abläuft, wenn auch allgemein: http://microsin.net/adminstuff/others/xmodem-protocol-overview.html Ich empfehle, ihn zu lesen.Wenn Sie in den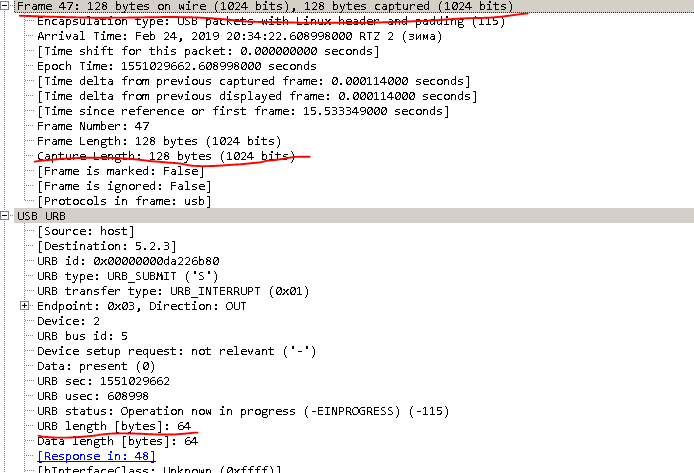 Speicherauszug schauen, können Sie sehen, dass die Rahmengröße 1024 und die Größe der URB-Daten 64 beträgt. Daher erhalten wir 1024/64 16 Zeilen in einem Block, lesen die Firmware-Datei mit 1 Zeichen und bilden einen Block. Ergänzung von 1 Zeile in einem Block mit Sonderzeichen fd3e02 + Blocknummer.Die nächsten 14 Zeilen werden mit fd25 + ergänzt. Mit XMODEM.calc_crc () berechnen wir die Prüfsumme des gesamten Blocks (es hat viel Zeit gedauert, um zu verstehen, dass „FF - 1“ CSUM ist), und die letzte 16. Zeile wird mit fd3e ergänzt.Es scheint, dass alles, die Firmware-Datei lesen, die Blöcke treffen, den Scanner vom Kernel trennen und an das Gerät senden. Aber nicht so einfach. Der Scanner muss durchSenden von NEWAPP = '\\ xfd \\ x0a \\ x16 \\ x4e \\ x2c \\ x4e \\ x45 \\ x57 \\ x41 \\ x50 \\ x50 \\ x0d' in den Firmware-Modus versetzt werden .Woher kommt dieser Befehl? Von der Müllkippe.
Speicherauszug schauen, können Sie sehen, dass die Rahmengröße 1024 und die Größe der URB-Daten 64 beträgt. Daher erhalten wir 1024/64 16 Zeilen in einem Block, lesen die Firmware-Datei mit 1 Zeichen und bilden einen Block. Ergänzung von 1 Zeile in einem Block mit Sonderzeichen fd3e02 + Blocknummer.Die nächsten 14 Zeilen werden mit fd25 + ergänzt. Mit XMODEM.calc_crc () berechnen wir die Prüfsumme des gesamten Blocks (es hat viel Zeit gedauert, um zu verstehen, dass „FF - 1“ CSUM ist), und die letzte 16. Zeile wird mit fd3e ergänzt.Es scheint, dass alles, die Firmware-Datei lesen, die Blöcke treffen, den Scanner vom Kernel trennen und an das Gerät senden. Aber nicht so einfach. Der Scanner muss durchSenden von NEWAPP = '\\ xfd \\ x0a \\ x16 \\ x4e \\ x2c \\ x4e \\ x45 \\ x57 \\ x41 \\ x50 \\ x50 \\ x0d' in den Firmware-Modus versetzt werden .Woher kommt dieser Befehl? Von der Müllkippe. Aufgrund der Einschränkung von 64 können wir jedoch nicht den gesamten Block an den Scanner senden:
Aufgrund der Einschränkung von 64 können wir jedoch nicht den gesamten Block an den Scanner senden: Nun, der Scanner im NEWAPP-Blinkmodus akzeptiert auch kein Hex. Daher ist es notwendig, jede Zeile bytes_array zu übersetzen
Nun, der Scanner im NEWAPP-Blinkmodus akzeptiert auch kein Hex. Daher ist es notwendig, jede Zeile bytes_array zu übersetzen[253, 10, 22, 78, 44, 78, 69, 87, 65, 80, 80, 13, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Und senden Sie diese Daten bereits an den Scanner.Wir bekommen die Antwort:[2, 1, 0, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Wenn Sie den Artikel über XMODEM lesen, wird klar: Die Daten wurden akzeptiert.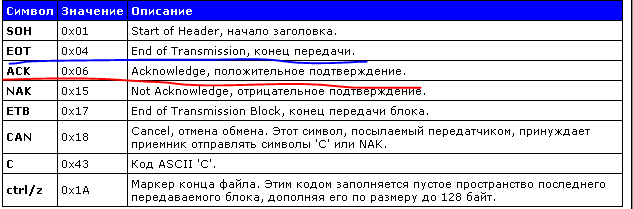 Nachdem alle Blöcke übertragen wurden, schließen wir die Übertragung END_TRANSFER = '\ xfd \ x01 \ x04' ab.Da diese Blöcke keine Informationen für normale Benutzer enthalten, wird die Firmware standardmäßig im versteckten Modus erstellt. Und für alle Fälle organisieren wir über tqdm einen Fortschrittsbalken.
Nachdem alle Blöcke übertragen wurden, schließen wir die Übertragung END_TRANSFER = '\ xfd \ x01 \ x04' ab.Da diese Blöcke keine Informationen für normale Benutzer enthalten, wird die Firmware standardmäßig im versteckten Modus erstellt. Und für alle Fälle organisieren wir über tqdm einen Fortschrittsbalken. Eigentlich ist der Rest klein. Es bleibt nur, die Lösung zu einem klar definierten Zeitpunkt in Skripte für die Massenreplikation zu verpacken, um den Arbeitsprozess an der Abendkasse nicht zu verlangsamen und die Protokollierung hinzuzufügen.
Eigentlich ist der Rest klein. Es bleibt nur, die Lösung zu einem klar definierten Zeitpunkt in Skripte für die Massenreplikation zu verpacken, um den Arbeitsprozess an der Abendkasse nicht zu verlangsamen und die Protokollierung hinzuzufügen.Gesamt
Nachdem wir viel Zeit, Energie und Haare auf dem Kopf verbracht hatten , konnten wir die Lösungen entwickeln, die wir brauchten. Außerdem haben wir die Frist eingehalten. Gleichzeitig werden die Scanner jetzt zentral neu geflasht und umgeschult. Wir steuern den gesamten Prozess klar. Das Unternehmen sparte Zeit und Geld und wir sammelten wertvolle Erfahrungen im Reverse Engineering dieser Art von Geräten.