Hallo alle zusammen. Am 26. Februar begann der Unterricht in OTUS in einer neuen Gruppe im Kurs "MS SQL Server Developer" . In diesem Zusammenhang möchte ich Ihnen meine Veröffentlichung über Fensterfunktionen mitteilen. Übrigens kannst du in der kommenden Woche noch der Gruppe beitreten ;-).
Fensterfunktionen sind in unserer Praxis gut etabliert, aber nur wenige Menschen wissen, wie die Rahmen RANGE und ROWS funktionieren.Vielleicht sind sie deshalb etwas seltener. Der Zweck dieses Artikels ist es, Anwendungsbeispiele bereitzustellen, damit Sie definitiv keine Fragen haben: "Wer ist wer?" und "Wie man es anwendet?". Die Frage "Warum?" Der Artikel bleibt unbeleuchtet.Schauen wir uns an, was ein Frame ist und wie Sie mit ORDER By in der OVER () -Klausel einen ähnlichen Effekt erzielen.Zur Demonstration verwenden wir eine einfache Tabelle, damit Sie Beispiele ohne Verwendung eines Compilers berechnen können. Im Allgemeinen empfehle ich es sehr - schauen Sie nach und überlegen Sie, was das Ergebnis der Ausführung sein wird, und überprüfen Sie sich dann selbst -, damit Sie weiße Flecken in der Wahrnehmung der Fensterfunktionen finden, die beim Lesen der fertigen Ergebnisse möglicherweise nicht offensichtlich sind.TabelleCreate table sales
(sales_id INT PRIMARY KEY, sales_dt DATETIME2 DEFAULT GETUTCDATE(), customer_id INT, item_id INT, cnt INT, price_per_item DECIMAL(19,4));
INSERT INTO sales
(sales_id, sales_dt, customer_id, item_id, cnt, price_per_item)
VALUES
(1, '2020-01-10T10:00:00', 100, 200, 2, 30.15),
(2, '2020-01-11T11:00:00', 100, 311, 1, 5.00),
(3, '2020-01-12T14:00:00', 100, 400, 1, 50.00),
(4, '2020-01-12T20:00:00', 100, 311, 5, 5.00),
(5, '2020-01-13T10:00:00', 150, 311, 1, 5.00),
(6, '2020-01-13T11:00:00', 100, 315, 1, 17.00),
(7, '2020-01-14T10:00:00', 150, 200, 2, 30.15),
(8, '2020-01-14T15:00:00', 100, 380, 1, 8.00),
(9, '2020-01-14T18:00:00', 170, 380, 3, 8.00),
(10, '2020-01-15T09:30:00', 100, 311, 1, 5.00),
(11, '2020-01-15T12:45:00', 150, 311, 5, 5.00),
(12, '2020-01-15T21:30:00', 170, 200, 1, 30.15);
Beginnen wir mit einem einfachen Moment - den Unterschieden in der SUMME-Funktion mit und ohne SortierungSELECT sales_id, customer_id, count,
SUM(count) OVER () as total,
SUM(count) OVER (ORDER BY customer_id) AS cum,
SUM(count) OVER (ORDER BY customer_id, sales_id) AS cum_uniq
FROM sales
ORDER BY customer_id, sales_id;
 Schauen wir uns den ersten unauffälligen Rechen an. Wie denken Sie, wie viele Entwickler denken, dass cum und cum_uniq beim Lesen des Codes gleich sind? Ein bisschen nachdenken? Vielleicht, aber weil es hier offensichtlich ist und es so offensichtlich ist, wenn der Code in der Anwendung gelesen wird, und sogar mit der nicht so offensichtlichen Nicht-Eindeutigkeit des Sortierfeldes.Jetzt öffne unser wundervolles Fenster.Das Fenster, oder besser gesagt der Rahmen, besteht aus 2 Arten von REIHEN und BEREICH. Lernen Sie zuerst REIHEN kennen.Optionen für Rahmenbeschränkungen:
Schauen wir uns den ersten unauffälligen Rechen an. Wie denken Sie, wie viele Entwickler denken, dass cum und cum_uniq beim Lesen des Codes gleich sind? Ein bisschen nachdenken? Vielleicht, aber weil es hier offensichtlich ist und es so offensichtlich ist, wenn der Code in der Anwendung gelesen wird, und sogar mit der nicht so offensichtlichen Nicht-Eindeutigkeit des Sortierfeldes.Jetzt öffne unser wundervolles Fenster.Das Fenster, oder besser gesagt der Rahmen, besteht aus 2 Arten von REIHEN und BEREICH. Lernen Sie zuerst REIHEN kennen.Optionen für Rahmenbeschränkungen:- Alles vor der aktuellen Zeile / dem aktuellen Bereich und dem tatsächlichen Wert der aktuellen Zeile
ZWISCHEN UNBEGRENZTEM VORHERIGEM
ZWISCHEN UNBEGRENZTEM VORHERIGEM UND AKTUELLER REIHE
- Aktuelle Zeile / Bereich und alles danach
ZWISCHEN AKTUELLER REIHE UND UNBEGRENZTEM FOLGENDEM - Festlegen , wie viele Zeilen vor und nach zu (nicht für RANGE unterstützt)
zwischen N vor und N Nach
ZWISCHEN CURRENT ROW UND N Nach
Vorstehende UND AKTUELLE REIHE VON N
Aber lassen Sie uns den Rahmen in Aktion sehen.Wir öffnen das „Fenster“ in der aktuellen und allen vorherigen Zeilen. Für die SUMME-Funktion fällt dies, wie Sie sehen können, mit der ASC-Sortierung zusammenSELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id) AS cum_uniq,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_and_all_before2
FROM sales
ORDER BY customer_id, sales_id;
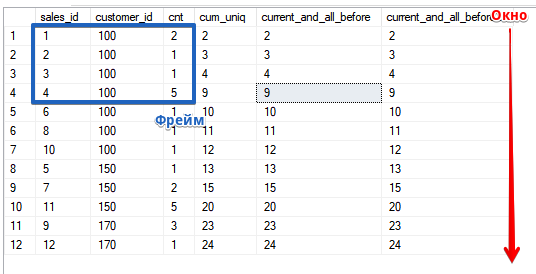 Gleichzeitig möchte ich Sie daran erinnern, dass die Sortierreihenfolge im Fenster (in der OVER () -Klausel) nicht mit der Sortierreihenfolge in der Abfrage selbst zusammenhängt. Im Beispiel ist dies dieselbe, um die Berechnung zu vereinfachen, wenn Sie die Berechnung überprüfen und die Funktionsweise verstehen möchten
Gleichzeitig möchte ich Sie daran erinnern, dass die Sortierreihenfolge im Fenster (in der OVER () -Klausel) nicht mit der Sortierreihenfolge in der Abfrage selbst zusammenhängt. Im Beispiel ist dies dieselbe, um die Berechnung zu vereinfachen, wenn Sie die Berechnung überprüfen und die Funktionsweise verstehen möchtenSELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id) AS cum_uniq,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_and_all_before2
FROM sales
ORDER BY cnt;
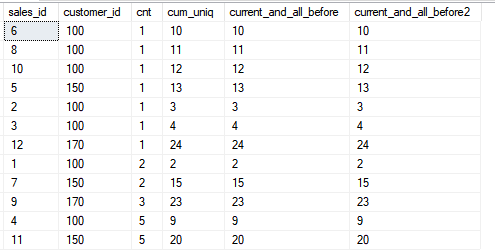 Schauen wir uns nun die Funktionalität des Rahmens an, wenn wir alle nachfolgenden Zeilen einschließen.
Schauen wir uns nun die Funktionalität des Rahmens an, wenn wir alle nachfolgenden Zeilen einschließen.SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_frame,
SUM(cnt) OVER (ORDER BY customer_id DESC, sales_id DESC) AS current_and_all_order_desc
FROM sales
ORDER BY customer_id, sales_id;
 Wie Sie hier sehen können, können Sie das gleiche Ergebnis auch für eine Aggregatfunktion erhalten, wenn Sie die umgekehrte Sortierung verwenden. ROWS ist jedoch etwas stabiler, da Sie eine Überraschung in Form derselben Werte erhalten können, wenn Ihre Sortierfelder nicht eindeutig sind.Und schließlich eine Option, die nicht mehr sortiert werden kann, wenn wir eine bestimmte Anzahl von Zeilen angeben, die in den Frame aufgenommen werden sollen
Wie Sie hier sehen können, können Sie das gleiche Ergebnis auch für eine Aggregatfunktion erhalten, wenn Sie die umgekehrte Sortierung verwenden. ROWS ist jedoch etwas stabiler, da Sie eine Überraschung in Form derselben Werte erhalten können, wenn Ihre Sortierfelder nicht eindeutig sind.Und schließlich eine Option, die nicht mehr sortiert werden kann, wenn wir eine bestimmte Anzahl von Zeilen angeben, die in den Frame aufgenommen werden sollenSELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS before_and_current,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS current_and_1_next,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING) AS before2_and_2_next
FROM sales
ORDER BY customer_id, sales_id;
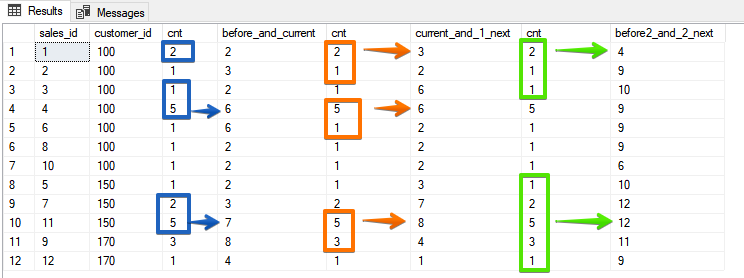 In dieser Option geben Sie bereits spezifisch an, welche Linien sich im Bereich befinden, und meiner Meinung nach ist dies aus den Ergebnissen am offensichtlichsten.
In dieser Option geben Sie bereits spezifisch an, welche Linien sich im Bereich befinden, und meiner Meinung nach ist dies aus den Ergebnissen am offensichtlichsten.Der Unterschied zwischen ROWS und RANGE
Der Unterschied besteht darin, dass ROWS in einer Zeile und RANGE in einem Bereich ausgeführt wird. Das ist zwar aus dem Namen ersichtlich, erklärt aber in der Praxis wenig?Schauen wir uns das Bild an (Quelle am Ende des Artikels)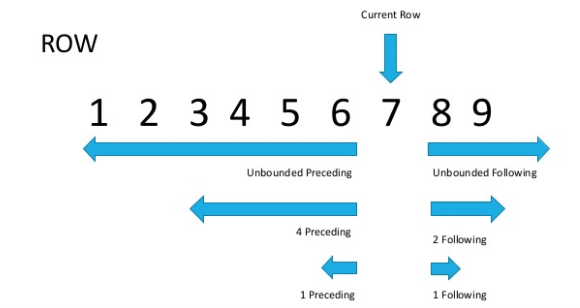
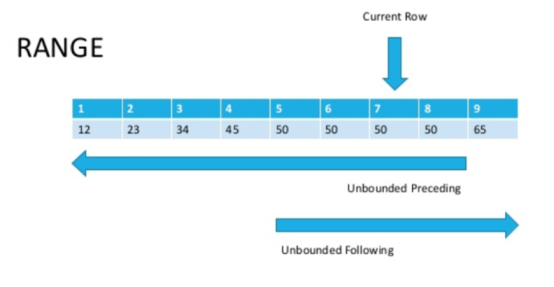 . Wenn wir nun genau hinschauen, wird klar, dass Zeilen mit demselben Wert des Sortierparameters als Bereich bezeichnet werden.Wie bereits oben erwähnt, ist ROWS auf eine Zeichenfolge beschränkt, während RANGE den gesamten Bereich übereinstimmender Werte erfasst, die Sie in der Fensterfunktion ORDER BY angeben.
. Wenn wir nun genau hinschauen, wird klar, dass Zeilen mit demselben Wert des Sortierparameters als Bereich bezeichnet werden.Wie bereits oben erwähnt, ist ROWS auf eine Zeichenfolge beschränkt, während RANGE den gesamten Bereich übereinstimmender Werte erfasst, die Sie in der Fensterfunktion ORDER BY angeben.SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id RANGE UNBOUNDED PRECEDING) AS current_and_all_before2
FROM sales
ORDER BY 2, sales_id;
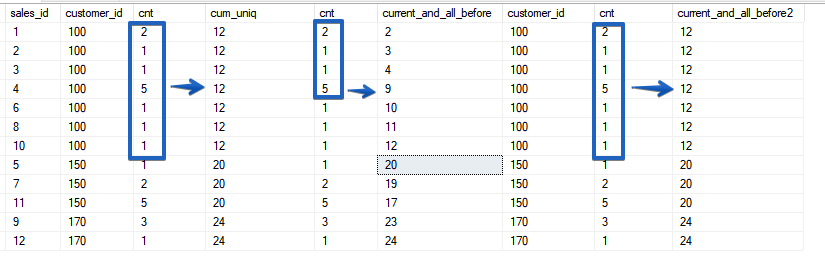 ROWS - arbeitet immer mit einer bestimmten Zeile, auch wenn die Sortierung nicht eindeutig ist. RANGE kombiniert jedoch nur Perioden in Bereichen mit den übereinstimmenden Werten der Sortierfelder. In diesem Sinne ist die Funktionalität dem Verhalten der SUM () - Funktion beim Sortieren nach einem nicht eindeutigen Feld sehr ähnlich. Sehen wir uns ein anderes Beispiel an.
ROWS - arbeitet immer mit einer bestimmten Zeile, auch wenn die Sortierung nicht eindeutig ist. RANGE kombiniert jedoch nur Perioden in Bereichen mit den übereinstimmenden Werten der Sortierfelder. In diesem Sinne ist die Funktionalität dem Verhalten der SUM () - Funktion beim Sortieren nach einem nicht eindeutigen Feld sehr ähnlich. Sehen wir uns ein anderes Beispiel an.SELECT sales_id, customer_id, price_per_item, cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item RANGE UNBOUNDED PRECEDING) AS current_and_all_before2
FROM sales
ORDER BY 2, price_per_item;
 Es gibt bereits 2 Felder und der Bereich wird durch einen Bereich mit übereinstimmenden Werten für beide Felder bestimmt.Und die Option ist, wenn wir alle nachfolgenden Zeilen aus der aktuellen in die Berechnung einbeziehen, die im Fall der SUMME-Funktion mit dem Wert übereinstimmen, der durch umgekehrte Sortierung erhalten werden kann:
Es gibt bereits 2 Felder und der Bereich wird durch einen Bereich mit übereinstimmenden Werten für beide Felder bestimmt.Und die Option ist, wenn wir alle nachfolgenden Zeilen aus der aktuellen in die Berechnung einbeziehen, die im Fall der SUMME-Funktion mit dem Wert übereinstimmen, der durch umgekehrte Sortierung erhalten werden kann:SELECT sales_id, customer_id, price_per_item, cnt,
SUM(cnt) OVER (ORDER BY customer_id DESC, price_per_item DESC) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_before2
FROM sales
ORDER BY 2, price_per_item, sales_id desc;
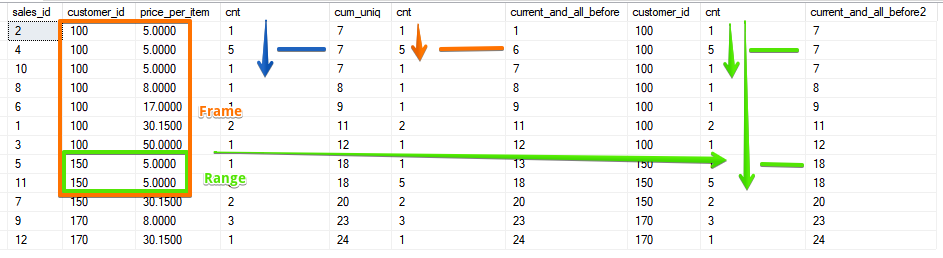 Wie Sie sehen können, erfasst RANGE erneut den gesamten Bereich übereinstimmender Paare.Trotz der Tatsache, dass die Funktionalität von ROWS und RANGE jedes Mal alles andere als neu ist, stellen sich Fragen zur Verwendung. Ich hoffe, dieser Artikel hat das Verständnis dafür erweitert, wie sich ROWS und RANGE unterscheiden, und jetzt werden Sie nicht zweifeln, in welchem Fall dieser oder jener Rahmen benötigt wird.Illustration Source BEREICH über den Unterschied und die REIHENder Fensterfunktionen Mit dem SQL Server 2016 kann Mark Tabladillopünktlich zum Kurs sein
Wie Sie sehen können, erfasst RANGE erneut den gesamten Bereich übereinstimmender Paare.Trotz der Tatsache, dass die Funktionalität von ROWS und RANGE jedes Mal alles andere als neu ist, stellen sich Fragen zur Verwendung. Ich hoffe, dieser Artikel hat das Verständnis dafür erweitert, wie sich ROWS und RANGE unterscheiden, und jetzt werden Sie nicht zweifeln, in welchem Fall dieser oder jener Rahmen benötigt wird.Illustration Source BEREICH über den Unterschied und die REIHENder Fensterfunktionen Mit dem SQL Server 2016 kann Mark Tabladillopünktlich zum Kurs sein