Mein Name ist Pavel Parkhomenko, ich bin ein ML-Entwickler. In diesem Artikel möchte ich über das Design des Yandex.Zen-Dienstes sprechen und technische Verbesserungen mitteilen, deren Einführung es ermöglichte, die Qualität der Empfehlungen zu verbessern. In diesem Beitrag erfahren Sie, wie Sie in wenigen Millisekunden unter Millionen von Dokumenten das für den Benutzer relevanteste finden. wie man eine große Matrix (bestehend aus Millionen von Spalten und zig Millionen von Zeilen) kontinuierlich zerlegt, damit neue Dokumente ihren Vektor in zig Minuten erhalten; Wie wird die Benutzerartikel-Matrixzerlegung wiederverwendet, um eine gute Vektordarstellung für Videos zu erhalten? Unsere Empfehlungsdatenbank enthält Millionen von Dokumenten in verschiedenen Formaten: Textartikel, die auf unserer Plattform erstellt und von externen Websites, Videos, Erzählungen und Kurzbeiträgen stammen. Die Entwicklung eines solchen Dienstes ist mit einer Vielzahl technischer Herausforderungen verbunden. Hier sind einige davon:
Unsere Empfehlungsdatenbank enthält Millionen von Dokumenten in verschiedenen Formaten: Textartikel, die auf unserer Plattform erstellt und von externen Websites, Videos, Erzählungen und Kurzbeiträgen stammen. Die Entwicklung eines solchen Dienstes ist mit einer Vielzahl technischer Herausforderungen verbunden. Hier sind einige davon:- Separate Rechenaufgaben: Führen Sie alle schweren Operationen offline aus und führen Sie in Echtzeit nur eine schnelle Anwendung von Modellen durch, um für 100-200 ms verantwortlich zu sein.
- Berücksichtigen Sie schnell Benutzeraktionen. Dazu ist es erforderlich, dass alle Ereignisse sofort an den Empfehlungsgeber übermittelt werden und das Ergebnis der Modelle beeinflussen.
- Machen Sie das Band so, dass sich neue Benutzer schnell an ihr Verhalten anpassen. Personen, die gerade in das System eingetreten sind, sollten das Gefühl haben, dass ihr Feedback die Empfehlungen beeinflusst.
- Verstehe schnell, wen du einen neuen Artikel empfehlen sollst.
- Reagieren Sie schnell auf das ständige Auftauchen neuer Inhalte. Täglich werden Zehntausende von Artikeln veröffentlicht, und viele von ihnen haben eine begrenzte Lebensdauer (z. B. Nachrichten). Dies ist ihr Unterschied zu Filmen, Musik und anderen langlebigen und teuren Inhalten.
- Übertragen Sie Wissen von einer Domain Domain auf eine andere. Wenn das Empfehlungssystem Modelle für Textartikel trainiert hat und wir Videos hinzufügen, können Sie vorhandene Modelle wiederverwenden, damit der neue Inhaltstyp besser eingestuft wird.
Ich werde Ihnen sagen, wie wir diese Probleme gelöst haben.Kandidatenauswahl
Wie kann in wenigen Millisekunden die Anzahl der betrachteten Dokumente um das Tausendfache reduziert werden, praktisch ohne die Qualität des Rankings zu beeinträchtigen?Angenommen, wir haben viele ML-Modelle trainiert, darauf basierende Attribute generiert und ein anderes Modell trainiert, das Dokumente für den Benutzer bewertet. Alles wäre in Ordnung, aber Sie können nicht alle Zeichen für alle Dokumente in Echtzeit erfassen und zählen, wenn Millionen dieser Dokumente vorhanden sind und Empfehlungen in 100 bis 200 ms erstellt werden müssen. Die Aufgabe besteht darin, aus Millionen eine bestimmte Teilmenge auszuwählen, die für den Benutzer eingestuft wird. Dieser Schritt wird allgemein als Kandidatenauswahl bezeichnet. Es hat mehrere Anforderungen. Erstens muss die Auswahl sehr schnell erfolgen, damit so viel Zeit wie möglich im Ranking selbst verbleibt. Zweitens müssen wir die für den Benutzer relevanten Dokumente so vollständig wie möglich halten, indem wir die Anzahl der für das Ranking relevanten Dokumente stark reduzieren.Unser Prinzip der Kandidatenauswahl hat sich evolutionär weiterentwickelt, und im Moment sind wir zu einem mehrstufigen Schema gekommen: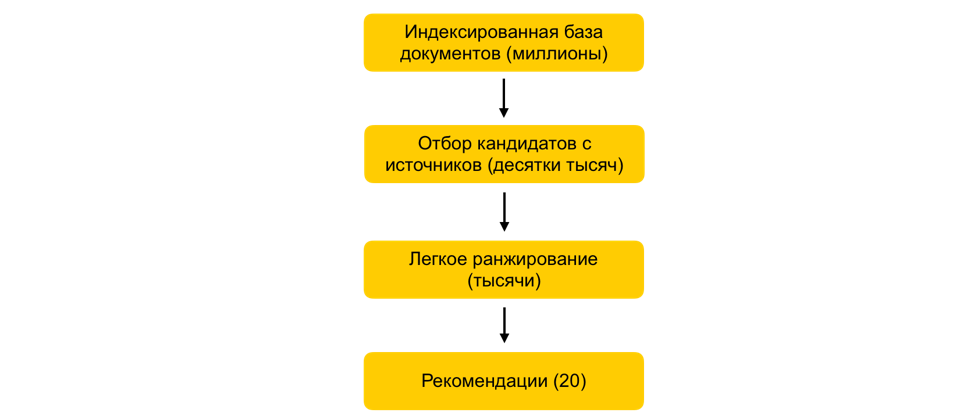 Zunächst werden alle Dokumente in Gruppen unterteilt und die beliebtesten Dokumente aus jeder Gruppe entnommen. Gruppen können Sites, Themen, Cluster sein. Für jeden Benutzer werden basierend auf seiner Geschichte die ihm am nächsten stehenden Gruppen ausgewählt und die besten Dokumente werden ihnen bereits entnommen. Wir verwenden den kNN-Index auch, um die dem Benutzer am nächsten gelegenen Dokumente in Echtzeit auszuwählen. Es gibt verschiedene Methoden zur Erstellung des kNN-Index. Wir haben den am besten verdienten HNSW(Hierarchisch navigierbare Diagramme der kleinen Welt). Dies ist ein hierarchisches Modell, mit dem Sie in wenigen Millisekunden N nächstgelegene Vektoren für einen Benutzer aus einer millionsten Datenbank finden können. Zuvor haben wir unsere gesamte Dokumentendatenbank offline indiziert. Da die Suche im Index recht schnell funktioniert, können Sie bei mehreren starken Einbettungen mehrere Indizes erstellen (einen Index für jede Einbettung) und in Echtzeit auf jeden dieser Indizes zugreifen.Wir haben immer noch Zehntausende von Dokumenten für jeden Benutzer. Dies ist immer noch eine Menge, um alle Attribute zu zählen. Daher wenden wir in dieser Phase ein einfaches Ranking an - ein leichtes, schweres Ranking-Modell mit weniger Attributen. Die Aufgabe besteht darin, vorherzusagen, welche Dokumente das schwere Modell oben haben wird. Die Dokumente mit der höchsten Vorhersage werden im schweren Modell verwendet, dh in der letzten Phase des Rankings. Dieser Ansatz ermöglicht es zehn Millisekunden, die Datenbank der für den Benutzer berücksichtigten Dokumente von Millionen auf Tausende zu reduzieren.
Zunächst werden alle Dokumente in Gruppen unterteilt und die beliebtesten Dokumente aus jeder Gruppe entnommen. Gruppen können Sites, Themen, Cluster sein. Für jeden Benutzer werden basierend auf seiner Geschichte die ihm am nächsten stehenden Gruppen ausgewählt und die besten Dokumente werden ihnen bereits entnommen. Wir verwenden den kNN-Index auch, um die dem Benutzer am nächsten gelegenen Dokumente in Echtzeit auszuwählen. Es gibt verschiedene Methoden zur Erstellung des kNN-Index. Wir haben den am besten verdienten HNSW(Hierarchisch navigierbare Diagramme der kleinen Welt). Dies ist ein hierarchisches Modell, mit dem Sie in wenigen Millisekunden N nächstgelegene Vektoren für einen Benutzer aus einer millionsten Datenbank finden können. Zuvor haben wir unsere gesamte Dokumentendatenbank offline indiziert. Da die Suche im Index recht schnell funktioniert, können Sie bei mehreren starken Einbettungen mehrere Indizes erstellen (einen Index für jede Einbettung) und in Echtzeit auf jeden dieser Indizes zugreifen.Wir haben immer noch Zehntausende von Dokumenten für jeden Benutzer. Dies ist immer noch eine Menge, um alle Attribute zu zählen. Daher wenden wir in dieser Phase ein einfaches Ranking an - ein leichtes, schweres Ranking-Modell mit weniger Attributen. Die Aufgabe besteht darin, vorherzusagen, welche Dokumente das schwere Modell oben haben wird. Die Dokumente mit der höchsten Vorhersage werden im schweren Modell verwendet, dh in der letzten Phase des Rankings. Dieser Ansatz ermöglicht es zehn Millisekunden, die Datenbank der für den Benutzer berücksichtigten Dokumente von Millionen auf Tausende zu reduzieren.ALS Schritt in der Laufzeit
Wie kann man das Feedback des Benutzers unmittelbar nach einem Klick berücksichtigen?Ein wichtiger Faktor in den Empfehlungen ist die Reaktionszeit auf das Feedback des Benutzers. Dies ist besonders wichtig für neue Benutzer: Wenn eine Person gerade erst anfängt, das Empfehlungssystem zu verwenden, erhält sie einen nicht personalisierten Strom von Dokumenten zu verschiedenen Themen. Sobald er den ersten Klick macht, müssen Sie dies sofort berücksichtigen und sich an seine Interessen anpassen. Wenn alle Faktoren offline berechnet werden, wird eine schnelle Systemreaktion aufgrund der Verzögerung unmöglich. Sie müssen Benutzeraktionen also in Echtzeit verarbeiten. Zu diesem Zweck verwenden wir den ALS-Schritt zur Laufzeit, um eine Vektordarstellung des Benutzers zu erstellen.Angenommen, wir haben eine Vektordarstellung für alle Dokumente. Zum Beispiel können wir offline auf der Grundlage der Artikeltext-Einbettungen mit ELMo, BERT oder anderen Modellen des maschinellen Lernens erstellen. Wie kann man eine Vektordarstellung von Benutzern im selben Raum basierend auf ihrer Interaktion im System erhalten?Das allgemeine Prinzip der Bildung und Zerlegung der Benutzerdokumentmatrixm n . . m x n: , — . , ́ , . (, , ) - — , 1, –1.
: P (m x d) Q (d x n), d — ( ). d- ( — P, — Q). . , , .

Eine der möglichen Arten der Matrixzerlegung ist ALS (Alternating Least Squares). Wir werden die folgende Verlustfunktion optimieren:
Hier ist r ui die Interaktion des Benutzers u mit dem Dokument i, q i ist der Vektor des Dokuments i, p u ist der Vektor des Benutzers u.Dann wird der Benutzervektor, der unter dem Gesichtspunkt des mittleren quadratischen Fehlers (für feste Dokumentvektoren) optimal ist, analytisch gefunden, indem die entsprechende lineare Regression gelöst wird.Dies wird als ALS-Schritt bezeichnet. Und der ALS-Algorithmus selbst besteht darin, dass wir abwechselnd eine der Matrizen (Benutzer und Artikel) reparieren und die andere aktualisieren, um die optimale Lösung zu finden.Glücklicherweise ist das Finden der Vektordarstellung eines Benutzers eine ziemlich schnelle Operation, die zur Laufzeit mithilfe von Vektoranweisungen ausgeführt werden kann. Mit diesem Trick können Sie das Feedback des Benutzers im Ranking sofort berücksichtigen. Die gleiche Einbettung kann im kNN-Index verwendet werden, um die Auswahl der Kandidaten zu verbessern.Verteilte kollaborative Filterung
Wie kann man eine inkrementelle verteilte Matrixfaktorisierung durchführen und schnell eine Vektordarstellung neuer Artikel finden?Inhalt ist nicht die einzige Signalquelle für Empfehlungen. Kollaborative Informationen sind eine weitere wichtige Quelle. Gute Zeichen im Ranking können traditionell aus der Zerlegung der Benutzerdokumentmatrix erhalten werden. Bei dem Versuch, diese Zerlegung durchzuführen, stießen wir jedoch auf folgende Probleme:1. Wir haben Millionen von Dokumenten und zig Millionen Benutzer. Die Matrix passt nicht vollständig auf eine Maschine und die Zersetzung ist sehr lang.2. Der größte Teil des Inhalts im System hat eine kurze Lebensdauer: Dokumente bleiben nur wenige Stunden lang relevant. Daher ist es notwendig, ihre Vektordarstellung so schnell wie möglich zu konstruieren.3. Wenn Sie die Zerlegung unmittelbar nach der Veröffentlichung des Dokuments erstellen, hat eine ausreichende Anzahl von Benutzern keine Zeit, es auszuwerten. Daher ist seine Vektordarstellung wahrscheinlich nicht sehr gut.4. Wenn der Benutzer mag oder nicht mag, können wir dies bei der Erweiterung nicht sofort berücksichtigen.Um diese Probleme zu lösen, haben wir eine verteilte Zerlegung der Benutzerdokumentmatrix mit einer häufigen inkrementellen Aktualisierung implementiert. Wie genau funktioniert es?Angenommen, wir haben einen Cluster von N Maschinen (N zu Hunderten) und möchten eine verteilte Zerlegung der Matrix auf ihnen vornehmen, die nicht auf eine Maschine passt. Die Frage ist, wie diese Zerlegung durchgeführt werden soll, damit einerseits genügend Daten auf jeder Maschine vorhanden sind und andererseits die Berechnungen unabhängig sind.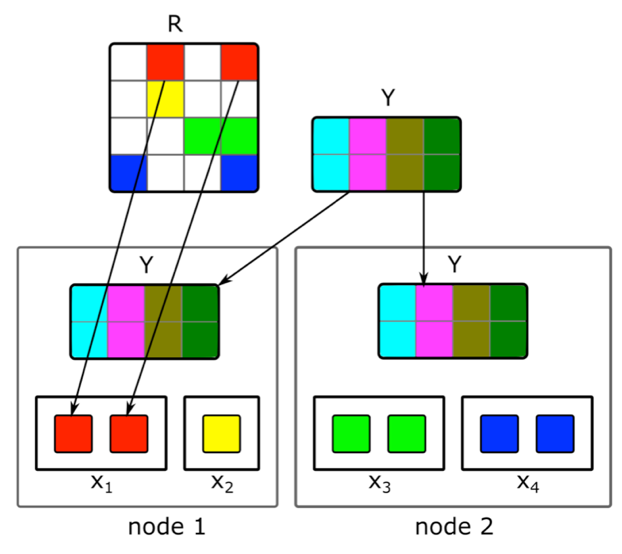 Wir werden den oben beschriebenen ALS-Zerlegungsalgorithmus verwenden. Überlegen Sie, wie Sie einen ALS-Schritt verteilt ausführen - der Rest der Schritte ist ähnlich. Angenommen, wir haben eine feste Matrix von Dokumenten und möchten eine Matrix von Benutzern erstellen. Dazu teilen wir es in N Teile in Zeilen auf, wobei jeder Teil ungefähr die gleiche Anzahl von Zeilen enthält. Wir senden an jede Maschine nicht leere Zellen der entsprechenden Zeilen sowie eine Matrix von Dokumenteinbettungen (insgesamt). Da es nicht sehr groß ist und die Benutzerdokumentmatrix normalerweise sehr spärlich ist, passen diese Daten auf einen normalen Computer.Ein solcher Trick kann für mehrere Epochen wiederholt werden, bis das Modell konvergiert und abwechselnd die feste Matrix geändert wird. Aber selbst dann kann die Zersetzung der Matrix mehrere Stunden dauern. Dies löst nicht das Problem der Notwendigkeit, schnell Einbettungen neuer Dokumente zu erhalten und die Einbettungen derjenigen zu aktualisieren, über die beim Erstellen des Modells nur wenige Informationen vorhanden waren.Die Einführung eines schnellen inkrementellen Updates des Modells hat uns geholfen. Angenommen, wir haben ein aktuell trainiertes Modell. Seit ihrer Schulung sind neue Artikel erschienen, mit denen unsere Benutzer interagiert haben, sowie Artikel, die wenig mit der Schulung zu tun hatten. Um solche Artikel schnell einzubetten, verwenden wir Benutzereinbettungen, die während des ersten großen Trainings des Modells erhalten wurden, und berechnen mit einem ALS-Schritt die Dokumentmatrix mit einer festen Benutzermatrix. Auf diese Weise können Sie Einbettungen sehr schnell erhalten - innerhalb weniger Minuten nach Veröffentlichung eines Dokuments - und häufig Einbettungen neuer Dokumente aktualisieren.Um menschliche Handlungen für Empfehlungen sofort zu berücksichtigen, verwenden wir zur Laufzeit keine offline empfangenen Benutzereinbettungen. Stattdessen machen wir den ALS-Schritt und erhalten den aktuellen Benutzervektor.
Wir werden den oben beschriebenen ALS-Zerlegungsalgorithmus verwenden. Überlegen Sie, wie Sie einen ALS-Schritt verteilt ausführen - der Rest der Schritte ist ähnlich. Angenommen, wir haben eine feste Matrix von Dokumenten und möchten eine Matrix von Benutzern erstellen. Dazu teilen wir es in N Teile in Zeilen auf, wobei jeder Teil ungefähr die gleiche Anzahl von Zeilen enthält. Wir senden an jede Maschine nicht leere Zellen der entsprechenden Zeilen sowie eine Matrix von Dokumenteinbettungen (insgesamt). Da es nicht sehr groß ist und die Benutzerdokumentmatrix normalerweise sehr spärlich ist, passen diese Daten auf einen normalen Computer.Ein solcher Trick kann für mehrere Epochen wiederholt werden, bis das Modell konvergiert und abwechselnd die feste Matrix geändert wird. Aber selbst dann kann die Zersetzung der Matrix mehrere Stunden dauern. Dies löst nicht das Problem der Notwendigkeit, schnell Einbettungen neuer Dokumente zu erhalten und die Einbettungen derjenigen zu aktualisieren, über die beim Erstellen des Modells nur wenige Informationen vorhanden waren.Die Einführung eines schnellen inkrementellen Updates des Modells hat uns geholfen. Angenommen, wir haben ein aktuell trainiertes Modell. Seit ihrer Schulung sind neue Artikel erschienen, mit denen unsere Benutzer interagiert haben, sowie Artikel, die wenig mit der Schulung zu tun hatten. Um solche Artikel schnell einzubetten, verwenden wir Benutzereinbettungen, die während des ersten großen Trainings des Modells erhalten wurden, und berechnen mit einem ALS-Schritt die Dokumentmatrix mit einer festen Benutzermatrix. Auf diese Weise können Sie Einbettungen sehr schnell erhalten - innerhalb weniger Minuten nach Veröffentlichung eines Dokuments - und häufig Einbettungen neuer Dokumente aktualisieren.Um menschliche Handlungen für Empfehlungen sofort zu berücksichtigen, verwenden wir zur Laufzeit keine offline empfangenen Benutzereinbettungen. Stattdessen machen wir den ALS-Schritt und erhalten den aktuellen Benutzervektor.In einen anderen Domainbereich übertragen
Wie kann man das Feedback eines Benutzers zu Textartikeln verwenden, um eine Vektordarstellung eines Videos zu erstellen?Anfangs haben wir nur Textartikel empfohlen, daher konzentrieren sich viele unserer Algorithmen auf diese Art von Inhalten. Beim Hinzufügen von Inhalten eines anderen Typs mussten wir jedoch Modelle anpassen. Wie haben wir dieses Problem anhand des Beispielvideos gelöst? Eine Möglichkeit besteht darin, alle Modelle von Grund auf neu zu trainieren. Dies ist jedoch eine lange Zeit, außerdem fordern einige der Algorithmen das Volumen des Trainingsmusters, das in den ersten Momenten seines Lebens im Service noch nicht in der richtigen Menge für eine neue Art von Inhalten vorhanden ist.Wir sind in die andere Richtung gegangen und haben Textmodelle für das Video wiederverwendet. Bei der Erstellung von Vektordarstellungen des Videos hat uns der gleiche Trick mit ALS geholfen. Wir haben eine Vektordarstellung von Benutzern basierend auf Textartikeln erstellt und den ALS-Schritt unter Verwendung von Informationen zu Videoansichten ausgeführt. So haben wir leicht eine Vektordarstellung des Videos erhalten. Und zur Laufzeit berechnen wir einfach die Nähe zwischen dem aus Textartikeln erhaltenen Benutzervektor und dem Videovektor.Fazit
Die Entwicklung des Kerns eines Echtzeit-Empfehlungssystems ist mit vielen Aufgaben verbunden. Es ist notwendig, Daten schnell zu verarbeiten und ML-Methoden anzuwenden, um diese Daten effektiv zu nutzen. Erstellen Sie komplexe verteilte Systeme, die Benutzersignale und neue Inhaltseinheiten in kürzester Zeit verarbeiten können. und viele andere Aufgaben.In dem aktuellen System, dessen Gerät ich beschrieben habe, wächst die Qualität der Empfehlungen für den Benutzer mit seiner Aktivität und der Dauer des Dienstes. Aber hier liegt natürlich die Hauptschwierigkeit: Es ist für das System schwierig, die Interessen einer Person, die wenig mit Inhalten interagierte, sofort zu verstehen. Die Verbesserung der Empfehlungen für neue Benutzer ist unser Hauptanliegen. Wir werden die Algorithmen weiter optimieren, damit der für die Person relevante Inhalt schneller in ihren Feed gelangt und der irrelevante nicht erscheint.