 Illustration von melmagazine.com (Quelle: melmagazine.com/wp-content/uploads/2019/11/DNA-1280x533.jpg )Derzeit werden öffentliche Netzwerke mit Kanälen, die nicht vor dem Eindringling geschützt sind, häufig für den Informationsaustausch verwendet. Messaging in einem solchen verbundenen Netzwerk und Benutzern eines Computernetzwerks sind gezwungen, sich selbst zu schützen. Da der Benutzer die Nachrichtenkanäle selbst nicht schützen kann, schützt er die Nachricht.Was ist in der Nachricht geschützt? Erstens verwendet die Syntax (Integrität) für diesen Zweck dieCodierung(Codierung und Analyse von Codes) und zweitens die Semantik (Vertraulichkeit), für dieKryptologieverwendet wird(Kryptographie und kryptographische Analyse) Drittens kann der Übertreter indirekt die Verfügbarkeit der Nachricht einschränken, indem er die Tatsache ihrer Übertragung verbirgt , die Steganologie (Steganographie und Steganalyse) verwendet.Die aufgeführten Möglichkeiten werden theoretisch und praktisch in unterschiedlichem Maße bereitgestellt, und obwohl sich jede Richtung schon ziemlich lange entwickelt hat, sind sie noch lange nicht vollständig. In der vorliegenden Arbeit werden wir nur ein bestimmtes Thema ansprechen - die Analyse von Nachrichtencodes.
Illustration von melmagazine.com (Quelle: melmagazine.com/wp-content/uploads/2019/11/DNA-1280x533.jpg )Derzeit werden öffentliche Netzwerke mit Kanälen, die nicht vor dem Eindringling geschützt sind, häufig für den Informationsaustausch verwendet. Messaging in einem solchen verbundenen Netzwerk und Benutzern eines Computernetzwerks sind gezwungen, sich selbst zu schützen. Da der Benutzer die Nachrichtenkanäle selbst nicht schützen kann, schützt er die Nachricht.Was ist in der Nachricht geschützt? Erstens verwendet die Syntax (Integrität) für diesen Zweck dieCodierung(Codierung und Analyse von Codes) und zweitens die Semantik (Vertraulichkeit), für dieKryptologieverwendet wird(Kryptographie und kryptographische Analyse) Drittens kann der Übertreter indirekt die Verfügbarkeit der Nachricht einschränken, indem er die Tatsache ihrer Übertragung verbirgt , die Steganologie (Steganographie und Steganalyse) verwendet.Die aufgeführten Möglichkeiten werden theoretisch und praktisch in unterschiedlichem Maße bereitgestellt, und obwohl sich jede Richtung schon ziemlich lange entwickelt hat, sind sie noch lange nicht vollständig. In der vorliegenden Arbeit werden wir nur ein bestimmtes Thema ansprechen - die Analyse von Nachrichtencodes.Einführung
Der genetische Code (HA) wurde als Untersuchungsobjekt ausgewählt. Hier können Sie ein merkwürdiges Beispiel für die Anwendung des Bürgerlichen Gesetzbuchs im Bereich der Informationssicherheit kennenlernen (anscheinend unprofessionell und daher nicht erfolgreich) .In der Codierungstheorie können zwei wichtige Richtungen unterschieden werden: Codierung der Informationsquelle und Kanalcodierung. Die erste davon wird in der Regel von der sendenden Partei implementiert und hat das Ziel, die Nachrichtenredundanz (z. B. Morsecode) zu beseitigen. Die zweite dient dazu, Fehler in Nachrichten zu erkennen und zu beseitigen. Vor dem Erscheinen der Korrekturcodes wurde das Problem der Fehlerbeseitigung durch erneute Übertragung des verzerrten Fragmentes der Nachricht auf Anforderung der empfangenden Seite gelöst.Hier stellen wir fest, dass es für die empfangende Seite unmöglich ist, das Chiffriergramm korrekt zu entschlüsseln, wenn Fehler in seinem Text auftreten. Chiffren erlauben es nicht, Fehler zu erkennen oder gar zu beheben. Aus diesem Grund wird auf der sendenden Seite des Kommunikationssystems das Nachrichtenverschlüsselungsgramm mit einem Korrekturcode codiert, und auf der empfangenden Seite erkennt der Decoder in der empfangenen Nachricht (falls vorhanden) und korrigiert die Fehler.Danach kommt das Kryptosystem ins Spiel und der legitime Empfänger erhält eine entschlüsselte Nachricht. Dies ist im Allgemeinen die Funktionsweise von Netzwerken, die sichere Nachrichten austauschen.In dieser Arbeit werden wir den sehr wichtigen genetischen Code, der nicht vom menschlichen Verstand, sondern von der Natur selbst erstellt wurde (ein seltener Fall), detailliert analysieren.Die Geschichte einer Entdeckung und des Nobelpreises
Wir fragen uns, wie die Natur auf der Ebene der Genetik und des Stoffwechsels von Organismen (Zellen) solche Bestimmungen des Informationsaustauschs im Leben der Arten und ihrer einzelnen Vertreter umsetzt.Vor dem Zweiten Weltkrieg wusste die wissenschaftliche Welt, dass in lebenden Organismen die Übertragung erblicher Merkmale von Generation zu Generation über relativ einfache chemische Einheiten (Gene) erfolgt, die eine große Menge an Informationen enthalten, die für die Fortführung und Reproduktion des Lebens erforderlich sind.Alle Gene (keine Proteine) binden in Ketten (Chromosomen) und materialisieren sich in Desoxyribonukleinsäure (DNA). Die Experten hatten keine Klarheit darüber, wie alles passiert und wie die DNA selbst strukturiert ist.Junge Forscher, der britische Physiker F. Crick und der amerikanische Biologe J. Watson, veröffentlichten 1953 (25.4) in der Zeitschrift Nature einen Artikel über die Struktur von Desoxyribonukleinsäure. Zu Beginn ihrer Arbeit im Jahr 1949 war James Watson 23 Jahre alt, Francis Crick und Maurice Wilkins, jeweils 33 Jahre alt.In dem Artikel beschrieben die Autoren ein Modell der räumlichen Struktur der DNA in Form einer Doppelhelix, von der zwei Stränge nach rechts gedreht waren. Es stellte sich heraus, dass die Stränge selbst durch aus Nukleotiden gebildete transversale "Schritte" verbunden waren.Definition . Nukleotide sind Verbindungen, die aus Zucker, stickstoffhaltigen Basen (Purin oder Pyrimidin) und Phosphorsäure bestehen. Nukleotide sind die „Bausteine“ für DNA und RNA.
Diese DNA-Helix ist der Träger des genetischen Codes - des Vererbungscodes der Merkmale von Organismen von Tieren und Pflanzen. Dies war eine völlig ungewöhnliche neue Arbeit über die Struktur und Eigenschaften eines Desoxyribonukleinsäuremoleküls.Das DNA-Modell junger Autoren wurde durch Vergleich mit einem Röntgenbeugungsmuster der Kristallstruktur der DNA des englischen Biophysikers Maurice Wilkins bestätigt. Später wurde ein genetischer Code entdeckt, der Informationen über die Synthese der Struktur und Zusammensetzung von Proteinen enthält und überträgt - die Hauptkomponenten jeder Zelle lebender Organismen, die den Zellzyklus implementieren.Definition . Der Zellzyklus ist der korrekte Wechsel von Perioden relativer Ruhe mit Perioden der Zellteilung.
Im selben Jahr veröffentlichten die Autoren später einen weiteren Artikel, in dem ein möglicher Mechanismus zum Kopieren von DNA durch Matrixsynthese bei der Teilung lebender Zellen beschrieben wurde. Die Doppelhelix der DNA wurde mit einem „Blitzschloss“ verglichen.Jeder Faden der Spirale wurde nach dem „Lösen der Verriegelung“ und dem Verdünnen der Fäden zu einer Synthesematrix und wurde mit einem zweiten Materialfaden aus dem Zytoplasma der Zelle nach dem Prinzip der Komplementarität zur vollständigen DNA vervollständigt. Es wurde auch gesagt, dass eine bestimmte Sequenz von Basen (Codons, Triplets) ein Code ist, der genetische Informationen enthält.Die Idee, den Code zu mathematisieren, wurde erstmals 1954 von G. Gamov in einem Artikel als das Problem ausgedrückt, Wörter aus einem Alphabet (System) mit vier Buchstaben in Wörter eines Alphabets mit zwanzig Buchstaben zu übersetzen. Er stellte das Problem der Kodierung von Lebensphänomenen nicht als biochemisches, sondern als kombinatorisches mathematisches Problem vor. Die vorläufigen, lang anhaltenden Bemühungen der Autoren dieser Arbeit sind in D. Watsons Buch The Thread of Life gut beschrieben.1962 erhielten Watson, Crick und Wilkins den Nobelpreis für Physiologie oder Medizin "für Entdeckungen in der Molekülstruktur von Nukleinsäuren und für die Bestimmung ihrer Rolle bei der Übertragung von Informationen in lebender Materie".Sie hatten Informationen über die folgenden Fakten:- Im Jahr 1866 formulierte Gregor Mendel die Bestimmungen, dass die "Elemente", später Gene genannt, die Vererbung der physikalischen Eigenschaften von Individuen der Spezies bestimmen.
- , , () , , .
- 1869 . , . . () (). . 4- ( ): (), (), (G), (); (), (U) , (G), (), ( ) .
- , , – , .
- 1950 . , 4- .
- , , .
- , 20- , (), .
- 1944 « ? ». : « - , , ?».
- 1954 , () 4- 20- , , .
Die Forscher mussten den nächsten Schritt machen, und es wurde getan.Es gab keinen Mangel an Hypothesen und Annahmen, aber jemand musste seine Wahrheit überprüfen.Überlappende Codes (ein Nukleotidbuchstabe ist Teil von mehr als einem Codon): dreieckig, Dur-Moll und sequentiell, vorgeschlagen von Gamov und Kollegen;Nicht überlappende Codes: Kombination von Gamow und Ichas, dem "kommafreien Code" von Scream, Griffith und Orgel. Im Kombinationscode werden Aminosäuren (20) von Tripletts mit 4 Nukleotiden codiert, aber ihre Reihenfolge ist nicht wichtig, sondern nur ihre Zusammensetzung: Die Tripletts TTA, TAT, ATT codieren dieselbe Aminosäure in Proteinen.Der kommafreie Code erklärte, wie der „Leserahmen“ ausgewählt wird. Ein solches „Schiebefenster“ entlang des DNA-Strangs, in dem die Buchstaben nacheinander ohne Trennzeichen (Kommas) in Wörter folgen, deutet darauf hin, dass die Wörter irgendwie unterschiedlich sind. Gemäß dem Modell von F. Crick wurde eine Annahme getroffen: Alle Tripletts sind in bedeutungsvolle unterteilt, d. H. Sie entsprechen bestimmten Aminosäuren und haben keine Bedeutung.Wenn nur bedeutungsvolle Drillinge DNA bilden, werden sich solche Drillinge in einem anderen „Leserahmen“ als bedeutungslos herausstellen. Die Autoren dieses Codes haben gezeigt, dass es möglich ist, Drillinge auszuwählen, die diese Anforderungen erfüllen, und dass es genau 20 gibt. Natürlich hatten die Autoren kein volles Vertrauen in ihre Richtigkeit.In der Tat wurde nach 1960 gezeigt, dass die Codons, die von Crick als sinnlos angesehen wurden, die Proteinsynthese in vitro durchführten, und bis 1965 wurde die Bedeutung aller 64 Triplett-Codons festgestellt. Es stellte sich auch heraus, dass eine Anzahl von Aminosäuren von zwei, drei, vier und sogar sechs verschiedenen Tripletts codiert wird, d. H. Es gibt eine gewisse Redundanz, deren Zweck noch zu bestimmen ist.Genetischer Code des Lebens. Geerbte Informationen
. – , ( , G, C, T), , . ( ) – . . .
Um jede der 20 Arten kanonischer Aminosäuren, aus denen fast alle Proteine weiter konstruiert sind, und das terminale Stoppsignal zu codieren, ist ein Satz von drei Nukleotiden (Buchstaben), die als Triplett (Codon) bezeichnet werden, ausreichend. Die Codonsequenz bildet ein Gen im Chromosomenstrang und bestimmt die Aminosäuresequenz in der Polypeptidkette des von diesem Gen codierten Proteins. Es gab ein Konzept von "einem Gen - einem Enzym".Die klassische Darstellung von Informationen (Linearität ihrer Aufzeichnung) besteht aus Texten im weitesten Sinne (Sprache, Buchstaben, Bücher, Bilder, Filme, Musik usw.) dieses Wortes in einer natürlichen Sprache (EY). Die Sprache enthält ein umfangreiches Vokabular (Vokabular), und wenn es neben der gesprochenen Sprache auch eine geschriebene Sprache gibt, dann das Alphabet mit einer Grammatik.Um Informationen für lange Zeit aufzubewahren und Kopien davon zu übertragen, ist ein solides, gut geschütztes Speicher- und Schriftsystem erforderlich. Die Erbinformation lebender Organismen wird vom EY der Natur in Langtexten mit Wörtern in einem bestimmten „molekularen“ Alphabet geschrieben, die in Form von Chromosomen in den Kernen aller Zellen lebender Organismen gespeichert sind.Die Prozesse und Wege zur Übertragung von Informationen, die auf seinen natürlichen Trägermolekülen aufgezeichnet sind, werden von F. Crick (1958) in Form des zentralen Dogmas der Molekularbiologie formuliert . Drei Hauptprozesse steuern alle anderen Prozesse der Zellfunktion und des Lebens der Organismen insgesamt.Diese Prozesse sind: Replikation , Transkription und Übersetzung. Ferner werden sie ausführlicher erörtert. Informationen in Organismen werden nur in einer Richtung von Nukleinsäuren (DNA → RNA → Protein) zu einem Protein übertragen, eine umgekehrte Übertragung besteht nicht. Sonderfälle von DNA → Protein, RNA → RNA, RNA → DNA sind möglich.Das Lesen von Informationen entlang molekularer Ketten ist nur in einer Vorwärtsrichtung zulässig. Der Begriff "Leserahmen" wird verwendet.Definition . Ein Leserahmen (offen) ist eine Sequenz von nicht überlappenden Codons, die ein Protein synthetisieren können, beginnend mit einem Startcodon und endend mit einem Stoppcodon. Der Rahmen wird durch das allererste Triplett bestimmt, von dem aus die Sendung beginnt.
Um mit der Übertragung zu beginnen, reicht ein Startcodon nicht aus, Sie benötigen auch ein Initiationscodon (es gibt drei davon: AUG, GUG, UUG). Nach dem Lesen erfolgt die Translation, indem die Codons der ribosomalen rRNA nacheinander gelesen und die Aminosäuren durch das Ribosom aneinander gebunden werden, bis das Stopcodon erreicht ist.Während der Übersetzung werden Codons immer von einem Startinitiierungssymbol (AUG) „gelesen“ und überlappen sich nicht. Das Lesen nach dem Beginn des Tripletts nach dem Triplett geht zum Stoppcodon des Abschlusses der Synthese der Proteinpolypeptidkette.Diese Fakten sind in einer Tabelle mit Methoden zur Übertragung genetischer Informationen zusammengefasst.Tabelle 1 - Das zentrale Dogma der Molekularbiologie Die Geschichte des Studiums von Texten über die Vererbung von Organismen, ihr Verständnis, ist lang und reich an Entdeckungen, Errungenschaften, Wahnvorstellungen und Enttäuschungen. Die Liste der Ereignisse in der Geschichte des Verstehens (Erkennen) der Naturtexte ist zweifellos sowohl für die Wissenschaft als auch für jeden einzelnen Menschen von Interesse.Die Wörter der Texte sind sehr lang, aber das Alphabet der Schrift „EYA nature“ enthält nur vier Buchstaben - dies sind molekulare Basen: In RNA sind es A (Adenin), C (Cytosin), G (Guanin), U (Uracil) (in DNA wird Uracil ersetzt auf T (Thymin)). Die Sprache der Wildtiere ist die Sprache der Moleküle.Biologen haben festgestellt, dass jedes Wort des Vererbungstextes von einem Polymer-DNA-Molekül (Desoxyribonukleinsäure, entdeckt 1868 vom Arzt I. F. Misher) gebildet wird, das aus 4 Basen besteht (Nukleotide - aus Kern - Kern).Die Basen sind paarweise miteinander verbunden (verbunden), A ← → T, T ← → A, G ← → C, C ← → G mit speziellen Wasserstoffbrücken, die das Prinzip der Komplementarität (Komplementarität) implementieren. Diese Tatsachen wurden zu verschiedenen Zeiten von verschiedenen Wissenschaftlern und Methoden vieler Wissenschaften (Physik, Chemie, Biologie, Zytologie, Genetik usw.) festgestellt. Die Schwierigkeiten, diesen NJ zu kennen, traten ständig auf.DNA-Moleküle kristallisierten nicht, aber als dies geschah, wurde die Aufgabe, die DNA-Struktur zu etablieren, auf die Lösung des inversen Problems der Röntgenbeugungsanalyse (Fourier-Transformation des Beugungsmusters des auf dem Bildschirm durch Röntgenstrahlen erzeugten Kristalls) reduziert.Das Modell, das 1953 von J. Watson und Francis Crick berechnet und von Hand zusammengestellt wurde, ähnelt dem LEGO-Kinderspiel, bei dem die Elemente molekulare Basen waren und die interatomaren Abstände und Drehwinkel sehr genau eingehalten wurden. Die Chromosomenstruktur wurde in großem Maßstab reproduziert.Dieses Modell bestätigte praktisch die verschiedenen Hypothesen der Theoretiker und bewies überzeugend das Fehlen von Diskrepanzen mit praktischen Experimenten und den Ergebnissen der Röntgenbeugungsanalyse kristalliner DNA.Die wichtigsten detaillierten Daten zur chemischen Struktur der DNA und zu den numerischen Eigenschaften des Modells wurden 1953 von Rosalinda Franklin und M. Wilkins im Labor für Röntgenanalyse erhalten. Der Konflikt der Wissenschaftler wird in dem Roman "Einsamkeit im Netz" von Janusz Leon Wisniewski beschrieben.Das Vorhandensein der visuellen Struktur der DNA und ihrer quantitativen Eigenschaften gab Impulse für die Entwicklung der Genetik und aller Biowissenschaften, aus denen die Idee des Humangenomprojekts im Jahr 2000 hervorging. Watson wurde der erste Leiter dieses Projekts. Der Chromosomensatz des menschlichen Homo sapiens wurde innerhalb des Projekts vollständig entschlüsselt. Die vollständige genetische Karte des 1. Chromosoms wurde 2006 fertiggestellt. Die Karte enthält 3141 Gene und 991 Pseudogene.Aus mathematischer Sicht können vier Elemente des Alphabets vier Elementen eines endlichen erweiterten Galois-Feldes GF (2 2 ) = ( 0, 1, α, β ) zugeordnet werden, wobei die Operationen modulo des irreduziblen Polynoms p (x) = x 2 + x + 1 durchgeführt werden . Dann ist α + β = 1, α ∙ β = 1und die Abbildung der Feldelemente , um Buchstaben nimmt die Form
Die Geschichte des Studiums von Texten über die Vererbung von Organismen, ihr Verständnis, ist lang und reich an Entdeckungen, Errungenschaften, Wahnvorstellungen und Enttäuschungen. Die Liste der Ereignisse in der Geschichte des Verstehens (Erkennen) der Naturtexte ist zweifellos sowohl für die Wissenschaft als auch für jeden einzelnen Menschen von Interesse.Die Wörter der Texte sind sehr lang, aber das Alphabet der Schrift „EYA nature“ enthält nur vier Buchstaben - dies sind molekulare Basen: In RNA sind es A (Adenin), C (Cytosin), G (Guanin), U (Uracil) (in DNA wird Uracil ersetzt auf T (Thymin)). Die Sprache der Wildtiere ist die Sprache der Moleküle.Biologen haben festgestellt, dass jedes Wort des Vererbungstextes von einem Polymer-DNA-Molekül (Desoxyribonukleinsäure, entdeckt 1868 vom Arzt I. F. Misher) gebildet wird, das aus 4 Basen besteht (Nukleotide - aus Kern - Kern).Die Basen sind paarweise miteinander verbunden (verbunden), A ← → T, T ← → A, G ← → C, C ← → G mit speziellen Wasserstoffbrücken, die das Prinzip der Komplementarität (Komplementarität) implementieren. Diese Tatsachen wurden zu verschiedenen Zeiten von verschiedenen Wissenschaftlern und Methoden vieler Wissenschaften (Physik, Chemie, Biologie, Zytologie, Genetik usw.) festgestellt. Die Schwierigkeiten, diesen NJ zu kennen, traten ständig auf.DNA-Moleküle kristallisierten nicht, aber als dies geschah, wurde die Aufgabe, die DNA-Struktur zu etablieren, auf die Lösung des inversen Problems der Röntgenbeugungsanalyse (Fourier-Transformation des Beugungsmusters des auf dem Bildschirm durch Röntgenstrahlen erzeugten Kristalls) reduziert.Das Modell, das 1953 von J. Watson und Francis Crick berechnet und von Hand zusammengestellt wurde, ähnelt dem LEGO-Kinderspiel, bei dem die Elemente molekulare Basen waren und die interatomaren Abstände und Drehwinkel sehr genau eingehalten wurden. Die Chromosomenstruktur wurde in großem Maßstab reproduziert.Dieses Modell bestätigte praktisch die verschiedenen Hypothesen der Theoretiker und bewies überzeugend das Fehlen von Diskrepanzen mit praktischen Experimenten und den Ergebnissen der Röntgenbeugungsanalyse kristalliner DNA.Die wichtigsten detaillierten Daten zur chemischen Struktur der DNA und zu den numerischen Eigenschaften des Modells wurden 1953 von Rosalinda Franklin und M. Wilkins im Labor für Röntgenanalyse erhalten. Der Konflikt der Wissenschaftler wird in dem Roman "Einsamkeit im Netz" von Janusz Leon Wisniewski beschrieben.Das Vorhandensein der visuellen Struktur der DNA und ihrer quantitativen Eigenschaften gab Impulse für die Entwicklung der Genetik und aller Biowissenschaften, aus denen die Idee des Humangenomprojekts im Jahr 2000 hervorging. Watson wurde der erste Leiter dieses Projekts. Der Chromosomensatz des menschlichen Homo sapiens wurde innerhalb des Projekts vollständig entschlüsselt. Die vollständige genetische Karte des 1. Chromosoms wurde 2006 fertiggestellt. Die Karte enthält 3141 Gene und 991 Pseudogene.Aus mathematischer Sicht können vier Elemente des Alphabets vier Elementen eines endlichen erweiterten Galois-Feldes GF (2 2 ) = ( 0, 1, α, β ) zugeordnet werden, wobei die Operationen modulo des irreduziblen Polynoms p (x) = x 2 + x + 1 durchgeführt werden . Dann ist α + β = 1, α ∙ β = 1und die Abbildung der Feldelemente , um Buchstaben nimmt die Form und der zusätzliche (ergänzende) Nukleotid berechnet wird nach der Regel ¬ → x + 1 , von wo aus T → A + 1, C → G + 1.Konstruktiv ist das DNA - Modell stellt zwei äquidistante Polymerketten von paarweise verbundenen Nukleotiden (von das Prinzip einer Strickleiter) und zu einer rechten Doppelspirale verdreht. Unten im Text entsprechen vertikal geschriebene Buchstabenpaare den Schritten der "Leiter":T A GGTTCG T ...
und der zusätzliche (ergänzende) Nukleotid berechnet wird nach der Regel ¬ → x + 1 , von wo aus T → A + 1, C → G + 1.Konstruktiv ist das DNA - Modell stellt zwei äquidistante Polymerketten von paarweise verbundenen Nukleotiden (von das Prinzip einer Strickleiter) und zu einer rechten Doppelspirale verdreht. Unten im Text entsprechen vertikal geschriebene Buchstabenpaare den Schritten der "Leiter":T A GGTTCG T ...
ATCCAAGCA ...Zwei Ketten wiederholen die Buchstabenfolge, aber der Anfang der einen befindet sich gegenüber dem Ende der anderen. Informationen in DNA-Molekülen werden mit einem hohen Grad an Redundanz aufgezeichnet, was natürlich ein hohes Maß an Zuverlässigkeit beim Lesen und Kopieren von Informationen bietet (Replikation: DNA → DNA). Ein weiteres Wort wird dem ursprünglichen Wort zugeordnet, jedoch in zusätzlichem Code.Alle Chromosomen enthalten Gene in ihrer Zusammensetzung und sind in jeder Zelle in einem sehr kleinen Volumen (im Zellkern) enthalten und kurz und sehr lang. Der Abstand zwischen DNA-Strängen beträgt 2 nm, zwischen den "Schritten" - 0,31 nm, eine vollständige Umdrehung der "Helix" alle 10 Paare. Die Gesamtlänge aller in einen Strang gestreckten DNA erreicht 2 m. Menschliche Erbinformationen werden auf 23 Chromosomen aufgezeichnet. Die Länge des Chromosoms beträgt ca. 10 9Nukleotide, und der Durchmesser des Kerns ist kleiner als ein Mikrometer. Somit wird die DNA in der Zelle verdichtet.Definition . Gen (Griechisch.γενοζ - Gattung). Die strukturelle und funktionelle Einheit der Vererbung lebender Organismen. Gene (genauer Allele) bestimmen die erblichen Merkmale von Organismen, die während der Fortpflanzung von den Eltern auf die Nachkommen übertragen werden.
Mit den Worten der DNA ist es möglich, einzelne Unterteile (Gene) zu isolieren und zu betrachten, die integrale Informationen über die Struktur eines Proteinmoleküls oder eines RNA-Moleküls enthalten. Darüber hinaus sind Gene durch regulatorische Sequenzen (Promotoren) gekennzeichnet.Promotoren können sich sowohl in unmittelbarer Nähe eines offenen Leserasters, der ein Protein codiert, oder am Anfang einer RNA-Sequenz befinden, als auch in einem Abstand von vielen Millionen Basenpaaren (Nukleotiden), beispielsweise in Fällen mit Enhancern, Isolatoren und Suppressoren.Jedes Gen ist dafür verantwortlich, ein spezifisches Protein zu erzeugen, das für das Leben des Körpers notwendig ist. Das Konzept des Genotyps bezeichnet die erbliche Konstitution von Gameten (Keimzellen) und Zygoten (somatische Zellen) im Gegensatz zum Phänotyp, der erworbene Zeichen beschreibt, die nicht vererbt werden.Blockcodes
Code ist ein mehrwertiges Konzept. Zunächst kann ein Code als Code-Satz von Codewörtern bezeichnet werden, die den Code selbst bilden. Es sind diese Wörter, die der Decodierer beim Senden von Nachrichten auf der Empfangsseite erkennt, und auf der Sendeseite bildet der Codierer sie.Bei der Erzeugung von Codewörtern wird eine eindeutige Zuordnung eines endlich geordneten Zeichensatzes, der zu einem bestimmten endlichen Alphabet gehört, zu einem anderen, nicht unbedingt geordneten, normalerweise umfangreicheren Zeichensatz zum Codieren der Übertragung, Speicherung oder Transformation von Informationen verwendet. Wirlisten die Eigenschaften des betrachteten genetischen Codes auf:- . . in Vitro ( ). () () .
- . , .
- . . ( ) – , , .
. . 4- , , 20 , , ( ) .
, (), 4; 2- (), 42 =16 ; () 43 = 64 > 20 . .
- . . , -, , - . .
. 64 1965 . , . , (). .
2 —

20 61 , . , . AUG – .
. . AGC, GCU, CUA,… , . , . .
- . - .
, . ( ) ( ) .
- . - , . : AUG ( ) , – .
- . . . 1961 . .
- – ;
- – ( ) .
Betrachten Sie zwei diskrete Mengen X und n, die jeweils | enthalten X | und | n | Elemente und Mapping φ : n → X . Bei der Darstellung beliebiger Zuordnungen von Mengen mit Wörtern im Alphabet X erhalten wir eine Menge von X n Wörtern mit jeweils n Zeichen Länge aus dem verfügbaren q = | X |, die das Alphabet der Textnachrichten bilden. Es ist zweckmäßig , alle Wörter X n in lexikographischer Reihenfolge in einer allgemeinen Liste anzuordnen.Unser Ziel in diesem Teil der Arbeit ist es, einen Code zu generieren, der die Codierung (Konvertierung) der übertragenen Daten in eine Form ermöglicht, die für die räumliche und zeitliche Übertragung und die Übertragung (Übersetzung) von einer Sprache in eine andere für den Nachrichtenempfänger verständlich ist.Das Generieren eines Codes umfasst das Auswählen des Alphabets, das Bestimmen der Regelmäßigkeit und bei der Auswahl eines regulären Codes das Bestimmen der Länge des Codeworts, das Bestimmen der Anzahl der Codewörter und das Bestimmen der buchstabenweisen Zusammensetzung jedes Wortes.Tabelle 3 - Der genetische Code besteht aus 64 Codewörtern mit jeweils 3 Buchstaben. Tabelle 4 - Inverse Werte der Codesequenz von RNA-Tripletts
Tabelle 4 - Inverse Werte der Codesequenz von RNA-Tripletts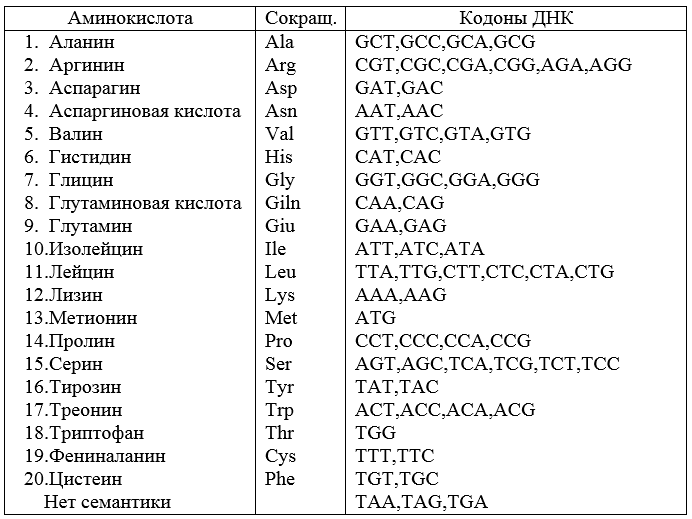 Zusätzliche Eigenschaften des Codes, z. B. sollte der Code kein Komma haben, werden durch strengere Anforderungen an die genannten Codeparameter bestimmt. Ein kommafreier Code muss Wörter mit einer maximalen Periode enthalten. Solche Anforderungen konzentrieren sich auf die Bequemlichkeit der nachfolgenden Synthese des Codecs. Eng verwandt mit diesen Bestimmungen der Codesynthese sind Fragen der Codierung von Informationen und ihrer Decodierung.
Zusätzliche Eigenschaften des Codes, z. B. sollte der Code kein Komma haben, werden durch strengere Anforderungen an die genannten Codeparameter bestimmt. Ein kommafreier Code muss Wörter mit einer maximalen Periode enthalten. Solche Anforderungen konzentrieren sich auf die Bequemlichkeit der nachfolgenden Synthese des Codecs. Eng verwandt mit diesen Bestimmungen der Codesynthese sind Fragen der Codierung von Informationen und ihrer Decodierung.Code-Analyse
Die Aufgabe der Codeanalyse klingt völlig anders, wenn der Code bereits vorhanden ist und verwendet wird, aber selbst wenig darüber bekannt ist. Codierte Nachrichten stehen zum Anzeigen und Studieren zur Verfügung, sind jedoch so vielfältig und zahlreich, dass das Prinzip ihrer Erstellung selbst bei einer sehr umfassenden Analyse nicht sichtbar ist.Tatsächlich steht das Codierungssystem selbst auch zur Beobachtung und Untersuchung zur Verfügung, aber die Komplexität seiner Konstruktion und Funktionsweise erlaubt es nicht, eine vollständige qualitative und zuverlässige Beschreibung zu erhalten.Information (Daten) ist eine Nachricht, d.h. eine Zeichenkette des Alphabets, die von einer Startposition aus in Segmente (Blöcke) mit einer Länge von n Zeichen unterteilt werden kann, und jedes dieser Segmente ist ein Codewort. Der Code ist in diesem Fall Block.Auf der Empfangsseite des Nachrichtenkanals sollte der Empfänger in der Lage sein, die fortlaufende Zeichenfolge von Nachrichtenzeichen korrekt in separate Wörter zu unterteilen. Die Verwendung von Worttrennzeichen (Kommas) ist unerwünscht, da Ressourcen erforderlich sind.Synchronisation . Ohne Synchronisation ist die korrekte Übersetzung der Nachricht nicht möglich. Dies impliziert eine der Anforderungen für den generierten Code: Der Code muss so gestaltet sein, dass die Synchronisation eindeutig durch die Mittel (Eigenschaften) des Codes selbst und des Informationsempfangsgeräts bereitgestellt wird.Definition . Das Einrichten einer Position, die das Startzeichen (Anfangszeichen) eines Codeworts enthält, wird als Synchronisation bezeichnet.
Die Synchronisationsaufgabe wird einfach gelöst, wenn das Alphabet ein spezielles Worttrennzeichen verwendet, beispielsweise ein Komma. Der Leserahmen des nächsten Codeworts wird unmittelbar nach dem Trennzeichen festgelegt.
Ein solcher Abscheider ist praktisch, aber aus mehreren Gründen unerwünscht.- Erstens muss der Code so sein, dass er am Ankunftsort der Nachricht genau dieselbe Form hat wie am Abfahrtsort (Gewährleistung der Integrität).
- Zweitens sollten die Codierungs-, Decodierungszeit und Übertragungsdauer so kurz wie möglich sein, da dies die Möglichkeit verringert, Umwelteinflüsse auf den Nachrichtentext zu verzerren.
- Drittens ist es wünschenswert, eine kleine Menge an Nachrichtenträgern zu haben, da weniger Speicher, Schutz und andere Ressourcen erforderlich sind.
Zur besseren Unterscheidbarkeit von Codewörtern sollten sie in der vollständigen Liste möglicher Wörter, d. H. unterscheiden sich in der Zusammensetzung der Bedeutungen der Symbole, da die Vektoren des Vektorraums Komponenten sind.Daher können Codewörter nicht alle und keine Wörter der Menge X n sein , sondern nur eine Teilmenge von ihnen D є X n . Die Wahl der symbolischen Zusammensetzung der Codewörter stellt die Hauptaufgabe ihrer Bildung dar, da die Zusammensetzung der Codewörter die Erfüllung der formulierten Anforderungen an den Code sicherstellen muss. Daher werden wir den Code ohne Komma weiter betrachten.. , . = (1, 2, …, n) = (1, 2, …, n). || = (1, 2, …, n, 1, 2, …, n). n – 1 n n . .
. (2, …, n, 1), (3, …, n, 1, 2)…( n, 1,…, n-2, n-1), .
Wenn alle Überlappungen in der Verkettung für ein Paar von Codewörtern keine Codewörter sind, kann der Mechanismus der Empfangsseite (Decoder) des Informationsübertragungskanals eine eindeutige Startposition festlegen. Dies ist möglich, wenn der Decodierer der Liste D alle Codewörter und die Möglichkeit hat, sie mit gelesenen n Zeichen aus der empfangenen Nachricht abzugleichen.Wir zeigen, wie das geht. Lassen Sie ein Symbol in der empfangenen Zeichenfolge auswählen und fixieren. Nachdem der Decoder n Zeichen vom festen gezählt hat, vergleicht er das herausgestellte Wort mit den Wörtern in der Codeliste. Wenn eine Übereinstimmung mit einem der Wörter in der Codeliste vorliegt, wird die Synchronisation hergestellt. Das feste Symbol und seine Position beginnen.Wenn es keine Übereinstimmung mit einem der Wörter in der Codeliste gibt, d. H. Das überlappende Wort trifft, bedeutet dies, dass sich die Startposition links von der festen Position befindet.Wir bewegen uns von der festen Position nach links und wiederholen die Aktionen des vorherigen Schritts, bis wir bei einem Schritt eine Übereinstimmung mit einem der Codewörter erhalten. Dieser Prozess hat notwendigerweise einen erfolgreichen Abschluss in der richtigen Startposition, d. H. Die Synchronisation wird im Durchschnitt für die Anzahl von n / 2 Schritten hergestellt.. () D є n n , , єD .
Wir haben bereits festgestellt, dass ein solcher Code eine korrekte Synchronisation in langen Ketten von Codewörtern ohne Trennzeichen zwischen ihnen gewährleistet. Welche Wörter aus der Menge X n sind in der Teilmenge D є X n enthalten ? Wenn die Kardinalität der Menge X n durch ganze Zahlen geteilt wird, kann die Kardinalität D einer dieser Teiler sein (der Lagrange-Gruppensatz) und der Code wird als Gruppenblockcode ohne Komma bezeichnet ., , D. , D n ( n D), . , D.
Kommen wir zum Thema der Anzahl der Wörter im generierten Code.Die Potenz des Codes ist ohne Komma. Wir finden die größtmögliche Anzahl von Wörtern im Code D , den wir mit | bezeichnen D | = W n ( q) . Es ist nicht möglich, die genaue Bedeutung zu erhalten, aber eine obere Schätzung für die Anzahl der Wörter kann unter Verwendung des Konzepts der Wortperiode erhalten werden . Bezeichne mit T k x die zyklische Verschiebung eines Wortes der Länge n um k Schritte, k < n .. d ( ) k, k = d ≤ n, d | n. d = n (). .
, = (1, 2, 3, 1, 2, 3 ) d < n. || . || = (1, 2, 3 ; 1, 2, 3 , 1, 2, 3 ; 1, 2, 3). , (;) , . , n.
n(q) q . D Wn(q) ≤ n(q)/n .


 Somit können Sie für die Quelldaten von Beispiel 1 aus einem Satz beliebiger 64 Wörter mit einer Länge von 3 Zeichen einen Code erstellen, der 20 Wörter enthält und eine Synchronisation bereitstellt. Dieser Code ist nicht ohne Mängel. Wenn ein Fehler in eines der Wörter in einem einzelnen Zeichen eingefügt wird, wird der Code nicht synchronisiert. Mit anderen Worten, der Code ist gegen Fehler instabil.Das gegebene numerische Beispiel kann verwendet werden, um den genetischen Code lebender Organismen zu veranschaulichen und zu erklären, der von der Natur auf einem langen Weg der Evolution geschaffen und 1966 von der modernen Wissenschaft vollständig entschlüsselt wurde. Es wird festgestellt, dass sich der genetische Code nicht überlappt, und die Bedeutung (Interpretation) jedes Codons wird offenbart.Der endgültige Tisch sieht wie folgt aus (Abb. 2).Aus der Tabelle folgt, dass der Code entartet ist. Dies bedeutet, dass der Code Synonyme enthält, z. B. GUU = GUC = Val, CGG = AGA = Arg usw. Drei Codons UAA, UAG, UGA tragen keinen Unsinn. Dies sind Terminationscodons, deren Auftreten in einer Folge von Zeichen das Ende der Übersetzung (Übertragung) bedeutet. Ein Organismus stirbt, wenn infolge eines Fehlers der Buchstabe des semantischen Codons in ein Terminationscodon geändert wird.Solche Veränderungen sind möglich und werden Mutationen genannt.
Somit können Sie für die Quelldaten von Beispiel 1 aus einem Satz beliebiger 64 Wörter mit einer Länge von 3 Zeichen einen Code erstellen, der 20 Wörter enthält und eine Synchronisation bereitstellt. Dieser Code ist nicht ohne Mängel. Wenn ein Fehler in eines der Wörter in einem einzelnen Zeichen eingefügt wird, wird der Code nicht synchronisiert. Mit anderen Worten, der Code ist gegen Fehler instabil.Das gegebene numerische Beispiel kann verwendet werden, um den genetischen Code lebender Organismen zu veranschaulichen und zu erklären, der von der Natur auf einem langen Weg der Evolution geschaffen und 1966 von der modernen Wissenschaft vollständig entschlüsselt wurde. Es wird festgestellt, dass sich der genetische Code nicht überlappt, und die Bedeutung (Interpretation) jedes Codons wird offenbart.Der endgültige Tisch sieht wie folgt aus (Abb. 2).Aus der Tabelle folgt, dass der Code entartet ist. Dies bedeutet, dass der Code Synonyme enthält, z. B. GUU = GUC = Val, CGG = AGA = Arg usw. Drei Codons UAA, UAG, UGA tragen keinen Unsinn. Dies sind Terminationscodons, deren Auftreten in einer Folge von Zeichen das Ende der Übersetzung (Übertragung) bedeutet. Ein Organismus stirbt, wenn infolge eines Fehlers der Buchstabe des semantischen Codons in ein Terminationscodon geändert wird.Solche Veränderungen sind möglich und werden Mutationen genannt.Definition . Mutationen sind relativ stabile Veränderungen in der erblichen Substanz.
Jedes Chromosom enthält die Gene x1, x2, ..., xn , die ein komplexes Merkmal X des Körpers bilden. Während der Reproduktion wird ein Chromosomenpaar in einer Zelle gebildet, das durch Fusion von väterlichen und mütterlichen Keimzellen erhalten wird: Ein Chromosom wird vom Vater, das andere von der Mutter erhalten (diploides Chromosomenpaar).In homologen Chromosomen stimmen alle Gene in ihrer Funktion überein, können sich jedoch um mehrere Nukleotide unterscheiden. Solche Unterschiede sind häufig das Ergebnis von Mutationen, die durch Chemikalien, Strahlung, radioaktive Exposition, Temperatur und ionisierende Strahlung verursacht werden können.Erbkrankheiten werden durch ähnliche Mutationen verursacht, die im Chromosomensatz der Keimzellen eines der Elternteile fixiert sind. Ein bekanntes Beispiel für ein menschliches Gen, das für Hämoglobin kodiert. Wenn der Buchstabe T durch den Buchstaben A ersetzt wird , erscheint eine alternative Form von Hämoglobin an einer Position des Gens. Dies äußert sich in einer Krankheit namens Sichelanämie.Wenn der Wert des Merkmals in beiden homologen Chromosomen übereinstimmt, wird das Individuum für dieses Gen als homozygot bezeichnet. In anderen Fällen tritt Heterozygotie auf. Homozygotie ist durch diploide Paare vom Typ a) und Heterozygotie durch Paare vom Typ b) gekennzeichnet (Fig. 3). Fig. 3 - diploide Paare von Homozygoten und HeterozygotenAnstelle eines diploiden Paares werden vier homologe Chromosomen A, A, a, a gebildetund sie sind gleichmäßig auf die vier gebildeten Gameten verteilt. Jeder Gamet erhält auch eines der Chromosomen B, B, b, b, das einem komplexen Merkmal entspricht. Diese Verteilung erfolgt für Chromosomen unabhängig zwischen vier Gameten und zwischen verschiedenen Zeichen. Diese Tatsachen wurden von Mendel festgestellt und 1865 veröffentlicht.Das beeindruckendste Merkmal des genetischen Codes ist seine Vielseitigkeit. Das gegebene Schema (1) kann erfolgreich zum Decodieren von RNA von Tieren und Pflanzen verwendet werden. 1979 erschienen Ergebnisse zum mitochondrialen genetischen Code, der sich von den Werten einiger Codons in der Tabelle und mit anderen Codonerkennungsregeln unterscheidet.Die Translation erfolgt durch das Ribosom - ein spezielles Organ der Zelle. Die Synchronisation (Einstellen des Leserahmens) erfolgt mit dem Präfix AGGAGGU , das als Shine-Dolgarno-Sequenz bezeichnet wird. Diese Purinsequenz ist im Wort im Singular vorhanden, und die Wahrscheinlichkeit seiner Verzerrung ist gering. Aber wenn es zu Verzerrungen kommt, ist der Körper in einer Katastrophe.Abbildung 1 - Entsprechung des Codeworts mit Aminosäuren Abbildung 2 - DNA-, mRNA- und Proteinhelix
Fig. 3 - diploide Paare von Homozygoten und HeterozygotenAnstelle eines diploiden Paares werden vier homologe Chromosomen A, A, a, a gebildetund sie sind gleichmäßig auf die vier gebildeten Gameten verteilt. Jeder Gamet erhält auch eines der Chromosomen B, B, b, b, das einem komplexen Merkmal entspricht. Diese Verteilung erfolgt für Chromosomen unabhängig zwischen vier Gameten und zwischen verschiedenen Zeichen. Diese Tatsachen wurden von Mendel festgestellt und 1865 veröffentlicht.Das beeindruckendste Merkmal des genetischen Codes ist seine Vielseitigkeit. Das gegebene Schema (1) kann erfolgreich zum Decodieren von RNA von Tieren und Pflanzen verwendet werden. 1979 erschienen Ergebnisse zum mitochondrialen genetischen Code, der sich von den Werten einiger Codons in der Tabelle und mit anderen Codonerkennungsregeln unterscheidet.Die Translation erfolgt durch das Ribosom - ein spezielles Organ der Zelle. Die Synchronisation (Einstellen des Leserahmens) erfolgt mit dem Präfix AGGAGGU , das als Shine-Dolgarno-Sequenz bezeichnet wird. Diese Purinsequenz ist im Wort im Singular vorhanden, und die Wahrscheinlichkeit seiner Verzerrung ist gering. Aber wenn es zu Verzerrungen kommt, ist der Körper in einer Katastrophe.Abbildung 1 - Entsprechung des Codeworts mit Aminosäuren Abbildung 2 - DNA-, mRNA- und Proteinhelix Abbildung 2 zeigt, wie die Aminosäuresequenz in einem Proteinmolekül von einer Codonsequenz in einem DNA-Molekül codiert wird. Hier ist Matrix-mRNA ein Zwischenmolekül. Seine Ketten divergieren nach dem Prinzip des „Reißverschlusses“, bei dem die Rolle des Schlosses von einem Enzym gespielt wird, das das Molekül durch Wasserstoffbrückenbindungen aufbricht.In Zellen wird der genetische Code durch drei Matrixprozesse ausgeführt: Replikation (tritt im Kern auf), Transkription und Translation .Die Transkription (buchstabenweise Aufzeichnung von DNA → mRNA) ist ein biologischer Prozess in eukaryotischen Zellen, der im Zellkern abläuft (durch eine Kernmembran vom Zytoplasma getrennt) und eine Synthese von i-RNA-Molekülen in den entsprechenden DNA-Regionen darstellt. Die DNA-Nukleotidsequenz wird in dieselbe RNA-Sequenz "umgeschrieben".Translation (Lesen und Translation von RNA → Protein) Der biologische Prozess in prokaryotischen Zellen wird mit dem Transkriptionsprozess kombiniert, der im Zellzytoplasma auf den Ribosomen stattfindet. Die Sequenz der mRNA-Nukleotide wird vom Kern transportiert und in die Aminosäuresequenz übersetzt (Synthese der Polypeptidkette auf der mRNA-Matrix): Diese Stufe erfolgt unter Beteiligung der Transport-RNA (tRNA) und der entsprechenden Enzyme.Somit ist die Translation eine Proteinsynthese durch das Ribosom basierend auf Informationen, die in Matrix-mRNA aufgezeichnet sind. Um 20 Aminosäuren sowie ein Stoppsignal zu erhalten, das das Ende einer Proteinsequenz anzeigt, sind drei aufeinanderfolgende Nukleotide, die als Triplett bezeichnet werden, ausreichend.Lebende Organismen sind nach Arten auf Pflanzen und Tiere verteilt.
Abbildung 2 zeigt, wie die Aminosäuresequenz in einem Proteinmolekül von einer Codonsequenz in einem DNA-Molekül codiert wird. Hier ist Matrix-mRNA ein Zwischenmolekül. Seine Ketten divergieren nach dem Prinzip des „Reißverschlusses“, bei dem die Rolle des Schlosses von einem Enzym gespielt wird, das das Molekül durch Wasserstoffbrückenbindungen aufbricht.In Zellen wird der genetische Code durch drei Matrixprozesse ausgeführt: Replikation (tritt im Kern auf), Transkription und Translation .Die Transkription (buchstabenweise Aufzeichnung von DNA → mRNA) ist ein biologischer Prozess in eukaryotischen Zellen, der im Zellkern abläuft (durch eine Kernmembran vom Zytoplasma getrennt) und eine Synthese von i-RNA-Molekülen in den entsprechenden DNA-Regionen darstellt. Die DNA-Nukleotidsequenz wird in dieselbe RNA-Sequenz "umgeschrieben".Translation (Lesen und Translation von RNA → Protein) Der biologische Prozess in prokaryotischen Zellen wird mit dem Transkriptionsprozess kombiniert, der im Zellzytoplasma auf den Ribosomen stattfindet. Die Sequenz der mRNA-Nukleotide wird vom Kern transportiert und in die Aminosäuresequenz übersetzt (Synthese der Polypeptidkette auf der mRNA-Matrix): Diese Stufe erfolgt unter Beteiligung der Transport-RNA (tRNA) und der entsprechenden Enzyme.Somit ist die Translation eine Proteinsynthese durch das Ribosom basierend auf Informationen, die in Matrix-mRNA aufgezeichnet sind. Um 20 Aminosäuren sowie ein Stoppsignal zu erhalten, das das Ende einer Proteinsequenz anzeigt, sind drei aufeinanderfolgende Nukleotide, die als Triplett bezeichnet werden, ausreichend.Lebende Organismen sind nach Arten auf Pflanzen und Tiere verteilt.. – , . , , .
Es gibt zwei Arten der Zellteilung: eine zur Bildung somatischer Zellen (Körperzellen) und eine zur Bildung von Keimzellen (Gameten). Die Art des Organismus wird durch das Vorhandensein, die Anzahl und die Zusammensetzung der Chromosomen in den Zellen von Organismen bestimmt, die unverändert (konstant) sind. Das normale Wachstum und die normale Entwicklung des Körpers wird durch die Bildung und das Wachstum somatischer Zellen infolge von Mitose sichergestellt. Bei der Mitose verdoppeln sich alle im Zellkern befindlichen Chromosomen vor Beginn der Zellteilung (DNA-Replikation) und sind gleichmäßig auf zwei Tochterzellen verteilt. Der Satz von 2n2c- Chromosomen in jeder Körperzelle ist genau der gleiche. Mitose hält eine konstante diploide Anzahl von Chromosomen in Zellen aufrecht.Ein weiterer Prozess der Meiose ist die Bildung von Gameten, die für die Fortführung der Gattung der Organismen notwendig sind. Bei der Meiose teilt sich jede Zelle zweimal und die Anzahl der Chromosomen verdoppelt sich einmal. Meiose führt zur Bildung diploider Zellen mit haploiden Gameten mit einem Satz von n2c . Bei der anschließenden Befruchtung bilden Gameten einen Organismus der neuen Generation mit einem diploiden Karyotyp (nc + nc = 2n2c) .Dieser Mechanismus wird bei allen Arten realisiert, die sich sexuell vermehren. Meiose stellt die Konstanz der Chromosomensätze (Karyotypen) - Vererbung und die Schaffung neuer Kombinationen der genotypischen Variabilität väterlicher und mütterlicher Gene sicher.Die vorgeschlagene Arbeit eröffnet die Möglichkeit, den genetischen Code zur Lösung der Aufgaben des Informationsschutzes zu verwenden. Ein korrektes Verständnis des Naturphänomens und seiner Verwendung ist nur mit dem Aufwand des Forschers möglich, der nicht durch Schwierigkeiten bei der tiefen Kenntnis der uns umgebenden Natur und ihrer Erscheinungsformen aufgehalten wird.
Das normale Wachstum und die normale Entwicklung des Körpers wird durch die Bildung und das Wachstum somatischer Zellen infolge von Mitose sichergestellt. Bei der Mitose verdoppeln sich alle im Zellkern befindlichen Chromosomen vor Beginn der Zellteilung (DNA-Replikation) und sind gleichmäßig auf zwei Tochterzellen verteilt. Der Satz von 2n2c- Chromosomen in jeder Körperzelle ist genau der gleiche. Mitose hält eine konstante diploide Anzahl von Chromosomen in Zellen aufrecht.Ein weiterer Prozess der Meiose ist die Bildung von Gameten, die für die Fortführung der Gattung der Organismen notwendig sind. Bei der Meiose teilt sich jede Zelle zweimal und die Anzahl der Chromosomen verdoppelt sich einmal. Meiose führt zur Bildung diploider Zellen mit haploiden Gameten mit einem Satz von n2c . Bei der anschließenden Befruchtung bilden Gameten einen Organismus der neuen Generation mit einem diploiden Karyotyp (nc + nc = 2n2c) .Dieser Mechanismus wird bei allen Arten realisiert, die sich sexuell vermehren. Meiose stellt die Konstanz der Chromosomensätze (Karyotypen) - Vererbung und die Schaffung neuer Kombinationen der genotypischen Variabilität väterlicher und mütterlicher Gene sicher.Die vorgeschlagene Arbeit eröffnet die Möglichkeit, den genetischen Code zur Lösung der Aufgaben des Informationsschutzes zu verwenden. Ein korrektes Verständnis des Naturphänomens und seiner Verwendung ist nur mit dem Aufwand des Forschers möglich, der nicht durch Schwierigkeiten bei der tiefen Kenntnis der uns umgebenden Natur und ihrer Erscheinungsformen aufgehalten wird.