Eine typische Bedingung für die Implementierung von CI / CD in Kubernetes: Die Anwendung muss in der Lage sein, neue Clientanforderungen nicht mehr zu akzeptieren, bevor vorhandene angehalten und vor allem erfolgreich abgeschlossen werden. Durch die Einhaltung dieser Bedingung können Sie während der Bereitstellung keine Ausfallzeiten erzielen. Selbst wenn Sie sehr beliebte Bundles (wie NGINX und PHP-FPM) verwenden, können Schwierigkeiten auftreten, die bei jeder Bereitstellung zu einer Vielzahl von Fehlern führen ...
Durch die Einhaltung dieser Bedingung können Sie während der Bereitstellung keine Ausfallzeiten erzielen. Selbst wenn Sie sehr beliebte Bundles (wie NGINX und PHP-FPM) verwenden, können Schwierigkeiten auftreten, die bei jeder Bereitstellung zu einer Vielzahl von Fehlern führen ...Theorie. Wie Pod lebt
Wir haben diesen Artikel bereits ausführlich über den Pod-Lebenszyklus veröffentlicht . Im Zusammenhang mit diesem Thema interessiert uns Folgendes: In dem Moment, in dem der Pod in den Status " Beenden" wechselt, werden keine neuen Anforderungen mehr an ihn gesendet (der Pod wird aus der Liste der Endpunkte für den Dienst entfernt). Um Ausfallzeiten während der Bereitstellung zu vermeiden, reicht es unsererseits aus, das Problem des korrekten Stopps der Anwendung zu lösen.Es sollte auch beachtet werden, dass die Kulanzfrist standardmäßig 30 Sekunden beträgt : Danach wird der Pod beendet und die Anwendung sollte es schaffen, alle Anforderungen vor dieser Frist zu verarbeiten. Hinweis: Obwohl jede Anforderung, die länger als 5-10 Sekunden ausgeführt wird, bereits problematisch ist und ein ordnungsgemäßes Herunterfahren ihm nicht mehr hilft ...Um besser zu verstehen, was passiert, wenn der Pod seine Arbeit beendet, reicht es aus, das folgende Schema zu studieren: A1, B1 - Änderungen vornehmen Status von Sub
A1, B1 - Änderungen vornehmen Status von Sub
A2: Senden von SIGTERM
B2 - Entfernen des Pods von Endpunkten
B3 - Abrufen von Änderungen (Endpunktliste wurde geändert)
B4 - Aktualisieren der iptables-RegelnHinweis: Das Entfernen des Endpunkt-Pods und das Senden von SIGTERM erfolgt nicht nacheinander, sondern parallel. Aufgrund der Tatsache, dass Ingress nicht sofort eine aktualisierte Liste der Endpunkte erhält, werden neue Anforderungen von Clients an den Pod gesendet, was zu 500 Fehlern beim Beenden des Pods führt(wir übersetzten ausführlichere Material zu diesem Thema ) . Sie müssen dieses Problem auf folgende Weise lösen:- Senden Sie die Header der Verbindung: Antwort schließen (wenn es sich um eine HTTP-Anwendung handelt).
- Wenn es keine Möglichkeit gibt, Änderungen am Code vorzunehmen, beschreibt der Artikel eine Lösung, mit der Sie Anforderungen bis zum Ende des Kulanzzeitraums verarbeiten können.
Theorie. Wie NGINX und PHP-FPM ihre Prozesse beenden
Nginx
Beginnen wir mit NGINX, da damit alles mehr oder weniger offensichtlich ist. Eingebettet in die Theorie erfahren wir, dass NGINX einen Master-Prozess und mehrere "Worker" hat - dies sind untergeordnete Prozesse, die Client-Anforderungen verarbeiten. Eine praktische Funktion wird bereitgestellt: Verwenden des Befehls zum nginx -s <SIGNAL>Beenden von Prozessen entweder im Schnellabschaltmodus oder im ordnungsgemäßen Herunterfahren. Offensichtlich interessieren wir uns genau für die letztere Option.Dann ist alles einfach: Sie müssen dem preStop-Hook einen Befehl hinzufügen, der ein Signal für ein ordnungsgemäßes Herunterfahren sendet. Dies kann in der Bereitstellung im Containerblock erfolgen: lifecycle:
preStop:
exec:
command:
- /usr/sbin/nginx
- -s
- quit
In dem Moment, in dem der Pod seine Arbeit in den NGINX-Containerprotokollen abgeschlossen hat, sehen wir Folgendes:2018/01/25 13:58:31 [notice] 1#1: signal 3 (SIGQUIT) received, shutting down
2018/01/25 13:58:31 [notice] 11#11: gracefully shutting down
Und das bedeutet, was wir brauchen: NGINX wartet auf den Abschluss von Abfragen und beendet dann den Prozess. Im Folgenden wird jedoch ein häufiges Problem erläutert, aufgrund dessen der nginx -s quitVorgang selbst bei einem Befehl nicht ordnungsgemäß abgeschlossen wird.Und zu diesem Zeitpunkt sind wir mit NGINX fertig: Zumindest können Sie anhand der Protokolle verstehen, dass alles so funktioniert, wie es sollte.Was ist mit PHP-FPM? Wie geht es mit dem ordnungsgemäßen Herunterfahren um? Lass es uns richtig machen.PHP-FPM
Im Fall von PHP-FPM etwas weniger Informationen. Wenn Sie sich auf das offizielle Handbuch zu PHP-FPM konzentrieren, werden Sie darüber informiert, dass die folgenden POSIX-Signale empfangen werden:SIGINT, SIGTERM- schnelles Herunterfahren;SIGQUIT - anmutiges Herunterfahren (was wir brauchen).
Der Rest der Signale in diesem Problem ist nicht erforderlich, daher wird ihre Analyse weggelassen. Um den Vorgang korrekt abzuschließen, müssen Sie den folgenden PreStop-Hook schreiben: lifecycle:
preStop:
exec:
command:
- /bin/kill
- -SIGQUIT
- "1"
Auf den ersten Blick ist dies alles, was erforderlich ist, um in beiden Containern ein ordnungsgemäßes Herunterfahren durchzuführen. Die Aufgabe ist jedoch komplizierter als es scheint. Als Nächstes untersuchten wir zwei Fälle, in denen das ordnungsgemäße Herunterfahren nicht funktionierte und eine kurzfristige Unzugänglichkeit des Projekts während der Bereitstellung verursachte.Trainieren. Mögliche Probleme beim ordnungsgemäßen Herunterfahren
Nginx
Zuallererst ist es nützlich, sich daran zu erinnern: Neben der Ausführung des Befehls nginx -s quitgibt es noch einen weiteren Schritt, auf den Sie achten sollten. Wir hatten ein Problem, als NGINX anstelle eines SIGQUIT-Signals trotzdem SIGTERM sendete, aufgrund dessen die Anforderungen nicht korrekt abgeschlossen wurden. Ähnliche Fälle finden Sie beispielsweise hier . Leider konnten wir keinen konkreten Grund für dieses Verhalten feststellen: Es gab einen Verdacht auf die NGINX-Version, der jedoch nicht bestätigt wurde. Die Symptomatik war, dass in den Protokollen des NGINX-Containers die Meldungen "offener Socket Nr. 10 in Verbindung 5" beobachtet wurden , wonach der Pod gestoppt wurde.Wir können ein solches Problem beispielsweise anhand der Antworten auf den von uns benötigten Eingang beobachten: Statuscode-Anzeigen zum Zeitpunkt der BereitstellungIn diesem Fall erhalten wir nur den 503-Fehlercode von Ingress selbst: Er kann nicht auf den NGINX-Container zugreifen, da er nicht mehr verfügbar ist. Wenn Sie sich die Protokolle des Containers mit NGINX ansehen, enthalten sie Folgendes:
Statuscode-Anzeigen zum Zeitpunkt der BereitstellungIn diesem Fall erhalten wir nur den 503-Fehlercode von Ingress selbst: Er kann nicht auf den NGINX-Container zugreifen, da er nicht mehr verfügbar ist. Wenn Sie sich die Protokolle des Containers mit NGINX ansehen, enthalten sie Folgendes:[alert] 13939#0: *154 open socket #3 left in connection 16
[alert] 13939#0: *168 open socket #6 left in connection 13
Nach dem Ändern des Stoppsignals beginnt der Container korrekt zu stoppen: Dies wird durch die Tatsache bestätigt, dass ein 503-Fehler nicht mehr beobachtet wird.Wenn Sie auf ein ähnliches Problem stoßen, ist es sinnvoll herauszufinden, welches Stoppsignal im Container verwendet wird und wie der preStop-Hook genau aussieht. Es ist möglich, dass der Grund genau darin liegt.PHP-FPM ... und mehr
Das Problem mit PHP-FPM wird trivial beschrieben: Es wartet nicht auf den Abschluss untergeordneter Prozesse, sondern beendet diese, wodurch während der Bereitstellung und anderer Vorgänge 502 Fehler auftreten. Seit 2005 gab es auf bugs.php.net (zum Beispiel hier und hier ) mehrere Fehlermeldungen , die dieses Problem beschreiben. Aber Sie werden wahrscheinlich nichts in den Protokollen sehen: PHP-FPM wird den Abschluss seines Prozesses ohne Fehler oder Benachrichtigungen von Drittanbietern bekannt geben.Es sollte klargestellt werden, dass das Problem selbst in geringerem oder größerem Maße von der Anwendung selbst abhängt und beispielsweise nicht bei der Überwachung auftritt. Wenn Sie immer noch darauf stoßen, fällt Ihnen eine einfache Problemumgehung ein: Fügen Sie einen PreStop-Hook mit hinzusleep(30). Auf diese Weise können Sie alle vorherigen Anforderungen ausführen (wir akzeptieren keine neuen, da sich der Pod bereits im Status " Beenden" befindet ). Nach 30 Sekunden endet der Pod selbst mit einem Signal SIGTERM.Es stellt sich heraus, dass lifecycleder Container folgendermaßen aussehen wird: lifecycle:
preStop:
exec:
command:
- /bin/sleep
- "30"
Aufgrund der 30-Sekunden-Anzeige sleepwird die Bereitstellungszeit jedoch erheblich verlängert , da jeder Pod für mindestens 30 Sekunden beendet wird, was schlecht ist. Was kann man damit machen?Wenden wir uns an die Partei, die für die direkte Ausführung des Antrags verantwortlich ist. In unserem Fall ist dies PHP-FPM , das standardmäßig die Ausführung seiner untergeordneten Prozesse nicht überwacht : Der Master-Prozess wird sofort beendet. Dieses Verhalten kann mithilfe einer Anweisung geändert werden process_control_timeout, die Zeitlimits für das Warten auf Signale vom Master durch untergeordnete Prozesse festlegt. Wenn Sie den Wert auf 20 Sekunden festlegen, werden die meisten im Container ausgeführten Anforderungen abgedeckt, und nach deren Abschluss wird der Master-Prozess gestoppt.Mit diesem Wissen werden wir zu unserem letzten Problem zurückkehren. Wie bereits erwähnt, ist Kubernetes keine monolithische Plattform: Die Interaktion zwischen den verschiedenen Komponenten dauert einige Zeit. Dies gilt insbesondere dann, wenn wir die Arbeit von Ingresss und anderen verwandten Komponenten betrachten, da aufgrund einer solchen Verzögerung zum Zeitpunkt der Bereitstellung leicht 500 Fehler auftreten können. Beispielsweise kann ein Fehler in der Phase des Sendens einer Anforderung an den Upstream auftreten, aber die „Zeitverzögerung“ der Interaktion zwischen Komponenten ist eher kurz - weniger als eine Sekunde.Daher kann in Verbindung mit der bereits erwähnten Richtlinie process_control_timeoutdie folgende Konstruktion verwendet werden für lifecycle:lifecycle:
preStop:
exec:
command: ["/bin/bash","-c","/bin/sleep 1; kill -QUIT 1"]
In diesem Fall kompensieren wir die Verzögerung durch das Team sleepund erhöhen die Bereitstellungszeit nicht wesentlich: Gibt es einen spürbaren Unterschied zwischen 30 Sekunden und eins? .. Tatsächlich wird die „Hauptaufgabe“ erledigt process_control_timeout, aber lifecycleim Falle einer Verzögerung nur als „Sicherheitsnetz“ verwendet.Im Allgemeinen betreffen das beschriebene Verhalten und die entsprechende Problemumgehung nicht nur PHP-FPM . Eine ähnliche Situation kann auf die eine oder andere Weise auftreten, wenn andere Sprachen / Frameworks verwendet werden. Wenn Sie das ordnungsgemäße Herunterfahren nicht auf andere Weise beheben können, z. B. den Code neu schreiben, damit die Anwendung die Abschlusssignale korrekt verarbeitet, können Sie die beschriebene Methode verwenden. Es ist vielleicht nicht das Schönste, aber es funktioniert.Trainieren. Laden Sie Tests, um die Pod-Leistung zu überprüfen
Lasttests sind eine Möglichkeit, die Funktionsweise des Containers zu überprüfen, da Sie mit diesem Verfahren den tatsächlichen Kampfbedingungen näher kommen, wenn Benutzer die Site besuchen. Sie können Yandex.Tank verwenden , um die oben genannten Empfehlungen zu testen : Es deckt alle unsere Anforderungen perfekt ab. Das Folgende sind Tipps und Tricks zum Testen mit einem klaren - dank der Grafiken von Grafana und Yandex.Tank selbst - ein Beispiel aus unserer Erfahrung.Das Wichtigste dabei ist , stufenweise nach Änderungen zu suchen.. Führen Sie nach dem Hinzufügen eines neuen Fixes den Test aus und prüfen Sie, ob sich die Ergebnisse im Vergleich zum vorherigen Start geändert haben. Andernfalls ist es schwierig, ineffektive Lösungen zu identifizieren, und in Zukunft können Sie nur noch Schaden anrichten (z. B. die Bereitstellungszeit verlängern).Eine weitere Einschränkung: Sehen Sie sich die Protokolle des Containers während seiner Beendigung an. Werden dort ordnungsgemäße Informationen zum Herunterfahren aufgezeichnet? Gibt es Fehler in den Protokollen beim Zugriff auf andere Ressourcen (z. B. einen benachbarten PHP-FPM-Container)? Fehler der Anwendung selbst (wie im oben beschriebenen Fall von NGINX)? Ich hoffe, dass die einleitenden Informationen aus diesem Artikel dazu beitragen, besser zu verstehen, was mit dem Container während seiner Beendigung passiert.Der erste Testlauf fand also ohne lifecycleund ohne zusätzliche Anweisungen für den Anwendungsserver statt (process_control_timeoutin PHP-FPM). Der Zweck dieses Tests war es, die ungefähre Anzahl von Fehlern zu identifizieren (und ob sie überhaupt existieren). Aus zusätzlichen Informationen sollte auch bekannt sein, dass die durchschnittliche Bereitstellungszeit jedes Herdes etwa 5 bis 10 Sekunden bis zum Zustand der vollständigen Bereitschaft betrug. Die Ergebnisse lauten wie folgt: Im Yandex.Tank-Informationsfenster, das zum Zeitpunkt der Bereitstellung auftrat und durchschnittlich bis zu 5 Sekunden dauerte, ist ein Spritzer von 502 Fehlern sichtbar. Vermutlich wurden dadurch die vorhandenen Anforderungen an den alten Pod beendet, als dieser beendet wurde. Danach traten 503 Fehler auf, die das Ergebnis eines gestoppten NGINX-Containers waren, der ebenfalls aufgrund des Backends getrennt wurde (aufgrund dessen Ingress keine Verbindung herstellen konnte).Mal sehen wie
Im Yandex.Tank-Informationsfenster, das zum Zeitpunkt der Bereitstellung auftrat und durchschnittlich bis zu 5 Sekunden dauerte, ist ein Spritzer von 502 Fehlern sichtbar. Vermutlich wurden dadurch die vorhandenen Anforderungen an den alten Pod beendet, als dieser beendet wurde. Danach traten 503 Fehler auf, die das Ergebnis eines gestoppten NGINX-Containers waren, der ebenfalls aufgrund des Backends getrennt wurde (aufgrund dessen Ingress keine Verbindung herstellen konnte).Mal sehen wieprocess_control_timeoutin PHP-FPM hilft uns, auf den Abschluss untergeordneter Prozesse zu warten, d. h. Beheben Sie solche Fehler. Wiederholte Bereitstellung mit dieser Anweisung: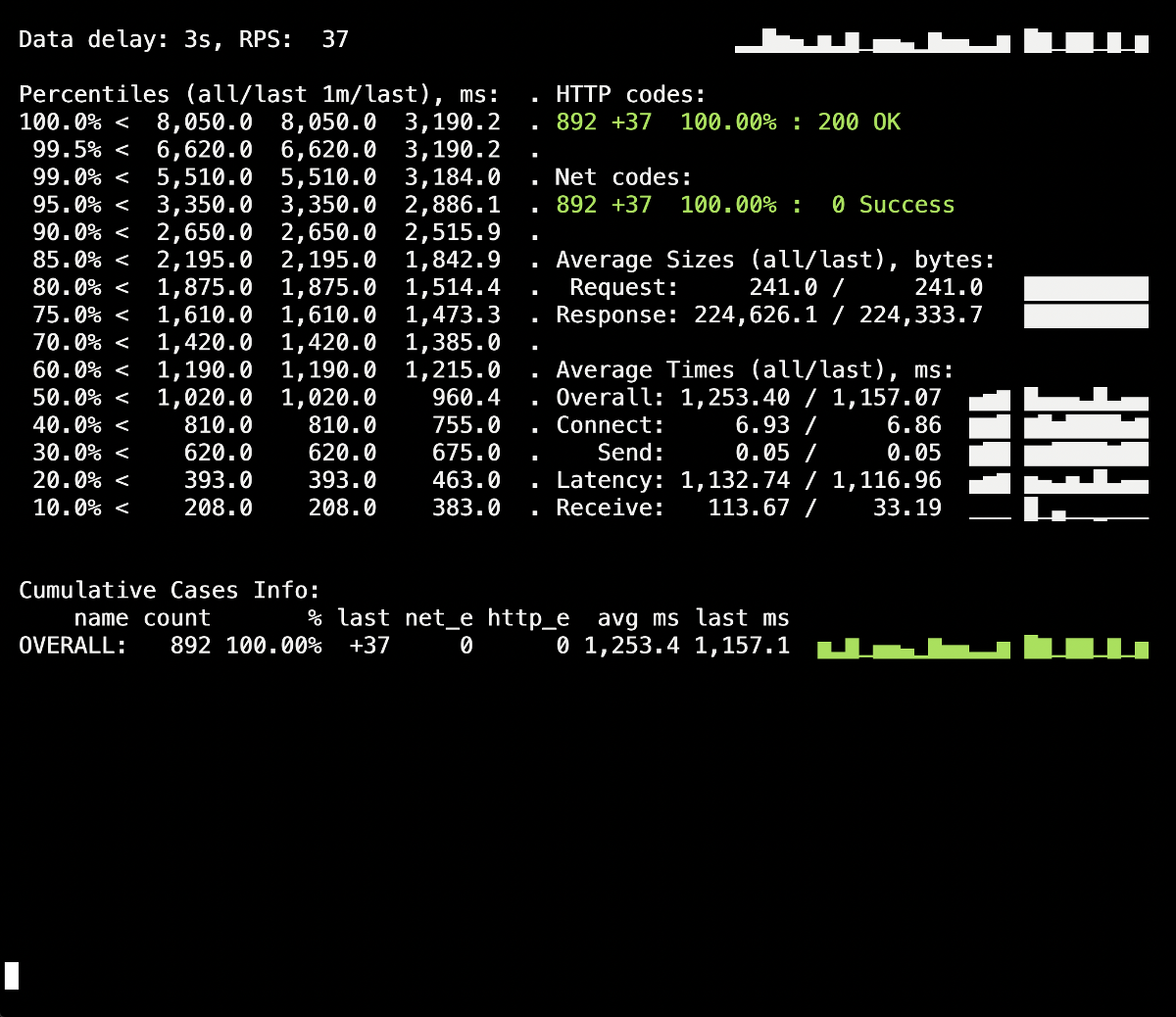 Während der Bereitstellung der 500er treten keine Fehler mehr auf! Die Bereitstellung ist erfolgreich, das ordnungsgemäße Herunterfahren funktioniert.Es lohnt sich jedoch, sich an den Moment mit Ingress-Containern zu erinnern, einem kleinen Prozentsatz von Fehlern, die aufgrund einer Zeitverzögerung auftreten können. Um sie zu vermeiden, müssen Sie die Konstruktion hinzufügen
Während der Bereitstellung der 500er treten keine Fehler mehr auf! Die Bereitstellung ist erfolgreich, das ordnungsgemäße Herunterfahren funktioniert.Es lohnt sich jedoch, sich an den Moment mit Ingress-Containern zu erinnern, einem kleinen Prozentsatz von Fehlern, die aufgrund einer Zeitverzögerung auftreten können. Um sie zu vermeiden, müssen Sie die Konstruktion hinzufügen sleepund die Bereitstellung wiederholen. In unserem speziellen Fall waren jedoch keine Änderungen sichtbar (wieder keine Fehler).Fazit
Für den korrekten Abschluss des Prozesses erwarten wir von der Anwendung das folgende Verhalten:- Warten Sie einige Sekunden und akzeptieren Sie dann keine neuen Verbindungen mehr.
- Warten Sie, bis alle Anforderungen abgeschlossen sind, und schließen Sie alle Keepalive-Verbindungen, die keine Anforderungen ausführen.
- Schließen Sie Ihren Prozess ab.
Es können jedoch nicht alle Anwendungen auf diese Weise funktionieren. Eine Lösung für das Problem in der Realität von Kubernetes ist:- Hinzufügen eines Pre-Stop-Hakens, der einige Sekunden wartet
- Studieren Sie die Konfigurationsdatei unseres Backends auf die relevanten Parameter.
Das NGINX-Beispiel lässt uns verstehen, dass selbst eine Anwendung, die Signale zum Abschluss zunächst korrekt verarbeiten muss, dies möglicherweise nicht tut. Daher ist es wichtig, während der Bereitstellung der Anwendung auf 500 Fehler zu prüfen. Außerdem können Sie das Problem umfassender betrachten und sich nicht auf einen separaten Pod oder Container konzentrieren, sondern die gesamte Infrastruktur als Ganzes.Yandex.Tank kann als Testwerkzeug in Verbindung mit jedem Überwachungssystem verwendet werden (in unserem Fall wurden Daten von Grafana mit einem Backend in Form von Prometheus für den Test verwendet). Probleme mit dem ordnungsgemäßen Herunterfahren sind unter schweren Lasten, die der Benchmark erzeugen kann, deutlich sichtbar, und die Überwachung hilft, die Situation während oder nach dem Test genauer zu analysieren.Antwort auf das Feedback zum Artikel: Es ist erwähnenswert, dass die Probleme und Lösungen hier in Bezug auf NGINX Ingress beschrieben werden. Für andere Fälle gibt es andere Lösungen, die wir möglicherweise in den folgenden Materialien des Zyklus berücksichtigen werden.PS
Andere aus dem K8s Tipps & Tricks-Zyklus: