Was ist eine Datenstruktur?Einfach ausgedrückt ist eine Datenstruktur ein Container, in dem Daten in einem bestimmten Layout (Format oder Art und Weise, wie sie im Speicher organisiert sind) gespeichert werden. Dieses „Layout“ ermöglicht es, dass die Datenstruktur in einigen Operationen effektiv und in anderen ineffektiv ist. Ihr Ziel ist es, die Datenstrukturen zu verstehen, damit Sie die Datenstruktur auswählen können, die für das betreffende Problem am optimalsten ist.Warum brauchen wir Datenstrukturen?Da Datenstrukturen zum organisierten Speichern von Daten verwendet werden und Daten das wichtigste Element der Informatik sind, ist der wahre Wert von Datenstrukturen offensichtlich.Unabhängig davon, welches Problem Sie lösen, müssen Sie auf die eine oder andere Weise mit Daten umgehen - sei es das Gehalt eines Mitarbeiters, die Aktienkurse, die Einkaufsliste oder sogar ein einfaches Telefonverzeichnis.Basierend auf verschiedenen Szenarien sollten die Daten in einem bestimmten Format gespeichert werden. Wir haben mehrere Datenstrukturen, die die Notwendigkeit abdecken, Daten in verschiedenen Formaten zu speichern.Häufig verwendete DatenstrukturenLassen Sie uns zunächst die am häufigsten verwendeten Datenstrukturen auflisten und sie dann einzeln betrachten:- Arrays - Arrays
- Stapel - Stapel
- Warteschlangen - Warteschlangen
- Verknüpfte Listen - Verwandte Listen
- Bäume - Bäume
- Grafiken - Grafiken
- Versuche (es sind im Wesentlichen Bäume, aber es ist immer noch schön, sie separat zu benennen). - Priorität
- Hash-Tabellen - Hash-Tabellen
Arrays - ArraysEin Array ist die einfachste und am weitesten verbreitete Datenstruktur. Andere Datenstrukturen wie Stapel und Warteschlangen werden von Arrays abgeleitet.Hier ist ein Bild eines einfachen Arrays der Größe 4, das Elemente (1, 2, 3 und 4) enthält.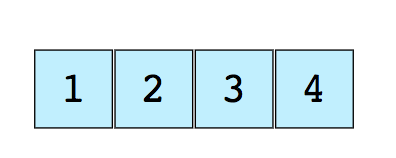 Jedem Datenelement wird ein positiver numerischer Wert zugewiesen, der als Index bezeichnet wird und der Position dieses Elements im Array entspricht. Die meisten Sprachen definieren den Startindex eines Arrays als 0.Es gibt zwei Arten von Arrays:
Jedem Datenelement wird ein positiver numerischer Wert zugewiesen, der als Index bezeichnet wird und der Position dieses Elements im Array entspricht. Die meisten Sprachen definieren den Startindex eines Arrays als 0.Es gibt zwei Arten von Arrays:- Eindimensionale Arrays (wie oben gezeigt)
- Mehrdimensionale Arrays (Arrays innerhalb von Arrays) Mehrdimensionale Arrays
Grundlegende Operationen für Arrays.Einfügen - Fügt einElement an einem angegebenen Index ein.Löschen (Löschen) - Entfernt ein Element an einem angegebenen Index.Größe - Ermittelt die Gesamtzahl der Elemente in einem Array.Zum Selbststudium:1 Suchen Sie das zweite minimale Element des Arrays.2. Die ersten sich nicht wiederholenden Ganzzahlen im Array.3. Führen Sie zwei sortierte Arrays zusammen.4. Ordnen Sie die positiven und negativen Werte im Array neu an.StapelWir alle kennen die berühmte Option Rückgängig (Abbrechen), die in fast jeder Anwendung vorhanden ist. Haben Sie sich jemals gefragt, wie das funktioniert? Das Wesentliche des Mechanismus ist, dass Sie die vorherigen Zustände Ihrer Arbeit (die durch eine bestimmte Anzahl begrenzt sind) so im Speicher speichern, dass die letzte Aktion zuerst angezeigt wird. Dies kann nicht nur mit Arrays durchgeführt werden. Hier kommt der Stapel zum Einsatz!Ein echtes Beispiel für einen Stapel ist ein Stapel vertikal angeordneter Bücher. Um ein Buch irgendwo in der Mitte zu erhalten, müssen Sie alle darüber liegenden Bücher löschen. So funktioniert die LIFO- Methode (Last In First Out) .Hier ist ein Bild eines Stapels mit drei Datenelementen (1, 2 und 3), wobei 3 oben steht und zuerst gelöscht wird: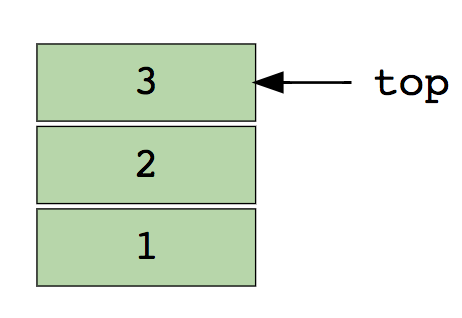 Die grundlegenden Operationen mit Stapeln:Push - fügt ein Element über andere ein.Pull (Pop) - Gibt das oberste Element nach dem Entfernen vom Stapel zurück.Leeren? (IsEmpty) - gibt true (true) zurück, wenn der Stapel leer ist.Top (Top) - Gibt das oberste Element zurück, ohne es vom Stapel zu löschen.Für unabhängige Studien:1. Bewerten Sie den Postfix-Ausdruck mithilfe des Stapels.2. Sortieren Sie die Werte auf dem Stapel.3. Überprüfen Sie die ausgeglichenen Klammern im Ausdruck.WarteschlangenWie ein Stapel ist eine Warteschlange eine weitere lineare Datenstruktur, in der Elemente nacheinander gespeichert werden. Der einzige signifikante Unterschied zwischen dem Stapel und der Warteschlange besteht darin, dass die Warteschlange anstelle der LIFO-Methode eine Methode implementiertFIFO, kurz für First in First Out .Ein großartiges Beispiel für eine Linie im wirklichen Leben: eine Reihe von Personen, die an der Kasse warten. Wenn eine neue Person ankommt, tritt sie von Anfang an und nicht von Anfang an in die Leitung ein - und die Person, die davor steht, erhält als erste ein Ticket und verlässt daher die Leitung.Hier ist ein Bild einer Warteschlange mit vier Datenelementen (1, 2, 3 und 4), wobei 1 oben steht und zuerst gelöscht wird:
Die grundlegenden Operationen mit Stapeln:Push - fügt ein Element über andere ein.Pull (Pop) - Gibt das oberste Element nach dem Entfernen vom Stapel zurück.Leeren? (IsEmpty) - gibt true (true) zurück, wenn der Stapel leer ist.Top (Top) - Gibt das oberste Element zurück, ohne es vom Stapel zu löschen.Für unabhängige Studien:1. Bewerten Sie den Postfix-Ausdruck mithilfe des Stapels.2. Sortieren Sie die Werte auf dem Stapel.3. Überprüfen Sie die ausgeglichenen Klammern im Ausdruck.WarteschlangenWie ein Stapel ist eine Warteschlange eine weitere lineare Datenstruktur, in der Elemente nacheinander gespeichert werden. Der einzige signifikante Unterschied zwischen dem Stapel und der Warteschlange besteht darin, dass die Warteschlange anstelle der LIFO-Methode eine Methode implementiertFIFO, kurz für First in First Out .Ein großartiges Beispiel für eine Linie im wirklichen Leben: eine Reihe von Personen, die an der Kasse warten. Wenn eine neue Person ankommt, tritt sie von Anfang an und nicht von Anfang an in die Leitung ein - und die Person, die davor steht, erhält als erste ein Ticket und verlässt daher die Leitung.Hier ist ein Bild einer Warteschlange mit vier Datenelementen (1, 2, 3 und 4), wobei 1 oben steht und zuerst gelöscht wird: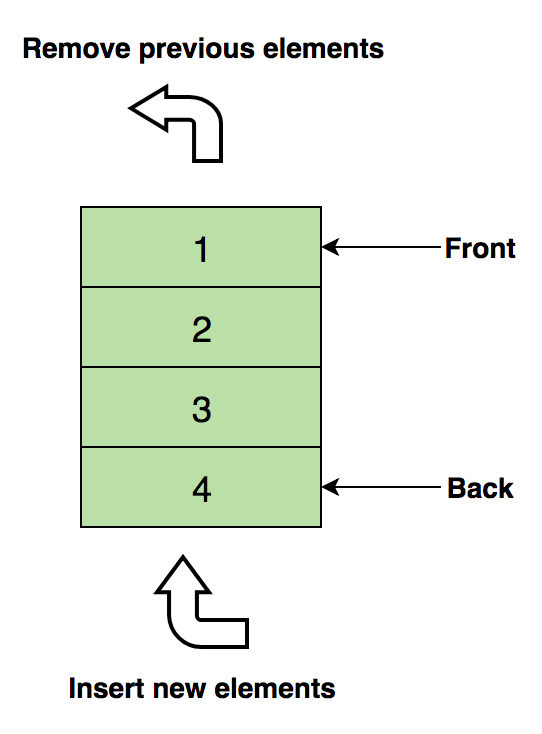 Grundlegende Operationen mit der Warteschlange:Enqueue - Fügt ein Element am Ende der Warteschlange ein.Dequeue - Löscht ein Element am Anfang der Warteschlange.Leeren? (IsEmpty) - gibt true (true) zurück, wenn die Warteschlange leer ist.Oben (Oben) - Gibt das erste Element der Warteschlange zurück.Für unabhängige Studien:1. Implementierung des Stacks über die Warteschlange.2. Die inversen ersten k Elemente der Warteschlange.3. Generierung von Binärzahlen von 1 bis n mithilfe der Warteschlange.Verknüpfte ListeEine verknüpfte Liste ist eine weitere wichtige lineare Datenstruktur, die auf den ersten Blick Arrays ähnelt, sich jedoch in der Speicherzuordnung, der internen Struktur und der Ausführung der grundlegenden Einfüge- und Löschvorgänge unterscheidet.Eine verknüpfte Liste ähnelt einer Knotenkette, in der jeder Knoten Informationen wie Daten und einen Zeiger auf den nächsten Knoten in der Kette enthält. Es gibt einen Kopfzeiger, der auf das erste Element der verknüpften Liste zeigt. Wenn die Liste leer ist, zeigt sie einfach auf Null oder nichts.Verknüpfte Listen werden zum Implementieren von Dateisystemen, Hash-Tabellen und Adjazenzlisten verwendet.Hier ist eine visuelle Darstellung der internen Struktur einer verknüpften Liste:
Grundlegende Operationen mit der Warteschlange:Enqueue - Fügt ein Element am Ende der Warteschlange ein.Dequeue - Löscht ein Element am Anfang der Warteschlange.Leeren? (IsEmpty) - gibt true (true) zurück, wenn die Warteschlange leer ist.Oben (Oben) - Gibt das erste Element der Warteschlange zurück.Für unabhängige Studien:1. Implementierung des Stacks über die Warteschlange.2. Die inversen ersten k Elemente der Warteschlange.3. Generierung von Binärzahlen von 1 bis n mithilfe der Warteschlange.Verknüpfte ListeEine verknüpfte Liste ist eine weitere wichtige lineare Datenstruktur, die auf den ersten Blick Arrays ähnelt, sich jedoch in der Speicherzuordnung, der internen Struktur und der Ausführung der grundlegenden Einfüge- und Löschvorgänge unterscheidet.Eine verknüpfte Liste ähnelt einer Knotenkette, in der jeder Knoten Informationen wie Daten und einen Zeiger auf den nächsten Knoten in der Kette enthält. Es gibt einen Kopfzeiger, der auf das erste Element der verknüpften Liste zeigt. Wenn die Liste leer ist, zeigt sie einfach auf Null oder nichts.Verknüpfte Listen werden zum Implementieren von Dateisystemen, Hash-Tabellen und Adjazenzlisten verwendet.Hier ist eine visuelle Darstellung der internen Struktur einer verknüpften Liste: Die folgenden Arten von verknüpften Listen sind:
Die folgenden Arten von verknüpften Listen sind:- Single Link List (unidirektional)
- Doppelt verknüpfte Liste (bidirektional)
Grundlegende Operationen für eine verknüpfte ListeInsertAtEnd - Fügt ein Element am Ende einer verknüpften Liste ein.InsertB Start (InsertAtHead) - Fügt ein Element am Anfang einer verknüpften Liste ein.Löschen - Entfernt dieses Element aus der verknüpften Liste.DeleteBeginning (DeleteAtHead) - löscht das erste Element der verknüpften Liste.Suchen - Gibt das gefundene Element aus der verknüpften Liste zurück.Leeren? (IsEmpty) - gibt true (true) zurück, wenn die verknüpfte Liste leer ist.Für ein unabhängiges Studium:1. Drehen Sie die verknüpfte Liste um (invertieren, umkehren, rückwärts anzeigen).2. Definieren Sie eine Schleife in einer verknüpften Liste.3. Geben Sie den N-ten Knoten vom Ende in der verknüpften Liste zurück.4. Entfernen Sie Duplikate aus der verknüpften Liste.DiagrammeDiagramme sind eine Sammlung von Knoten, die in Form eines Netzwerks miteinander verbunden sind. Knoten werden auch als Eckpunkte bezeichnet. Das Paar (x, y) wird als Kante bezeichnet, was anzeigt, dass der Scheitelpunkt x mit dem Scheitelpunkt y verbunden ist. Eine Kante kann Gewicht / Kosten enthalten und zeigt an, wie viel Kosten erforderlich sind, um von oben x nach y zu gelangen.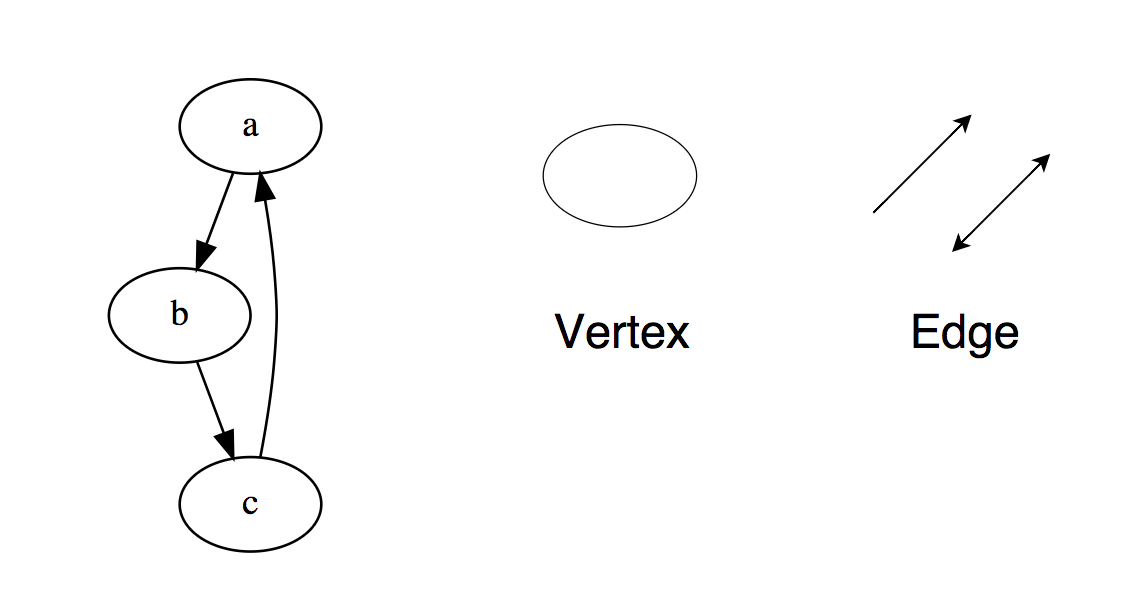 Arten von Diagrammen:
Arten von Diagrammen:- Ungerichtete Grafik
- Gerichteter Graph
In Programmiersprachen werden Diagramme in zwei Formen dargestellt:Das Folgende ist ein Beispiel für eine zusammenhängende Adjazenzliste (ungerichteter Graph).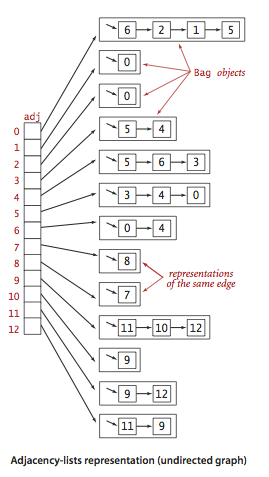 Bekannte Beispiele für Bewegungsalgorithmen entlang von Graphen:Für unabhängige Studien:1. Implementierung der Suche "Breite und Tiefe"2. Überprüfen Sie, ob das Diagramm ein Baum ist oder nicht.3. Zählen Sie die Anzahl der Kanten im Diagramm.4. Finden Sie den kürzesten Weg zwischen den Gipfeln.BäumeEin Baum ist eine hierarchische Datenstruktur, die aus Eckpunkten (Knoten) und Kanten besteht, die sie verbinden. Bäume sehen aus wie Diagramme, aber der entscheidende Punkt, der einen Baum von einem Diagramm unterscheidet, ist, dass in einem Baum keine Schleife vorhanden sein kann. Ein Baum ist ein zerrissener Graph.Bäume werden häufig in der künstlichen Intelligenz und in komplexen Algorithmen verwendet, um einen effizienten Speichermechanismus für Algorithmen zur Problemlösung bereitzustellen.Hier ist ein Bild eines einfachen Baums und der in der Baumdatenstruktur verwendeten Grundbegriffe:
Bekannte Beispiele für Bewegungsalgorithmen entlang von Graphen:Für unabhängige Studien:1. Implementierung der Suche "Breite und Tiefe"2. Überprüfen Sie, ob das Diagramm ein Baum ist oder nicht.3. Zählen Sie die Anzahl der Kanten im Diagramm.4. Finden Sie den kürzesten Weg zwischen den Gipfeln.BäumeEin Baum ist eine hierarchische Datenstruktur, die aus Eckpunkten (Knoten) und Kanten besteht, die sie verbinden. Bäume sehen aus wie Diagramme, aber der entscheidende Punkt, der einen Baum von einem Diagramm unterscheidet, ist, dass in einem Baum keine Schleife vorhanden sein kann. Ein Baum ist ein zerrissener Graph.Bäume werden häufig in der künstlichen Intelligenz und in komplexen Algorithmen verwendet, um einen effizienten Speichermechanismus für Algorithmen zur Problemlösung bereitzustellen.Hier ist ein Bild eines einfachen Baums und der in der Baumdatenstruktur verwendeten Grundbegriffe: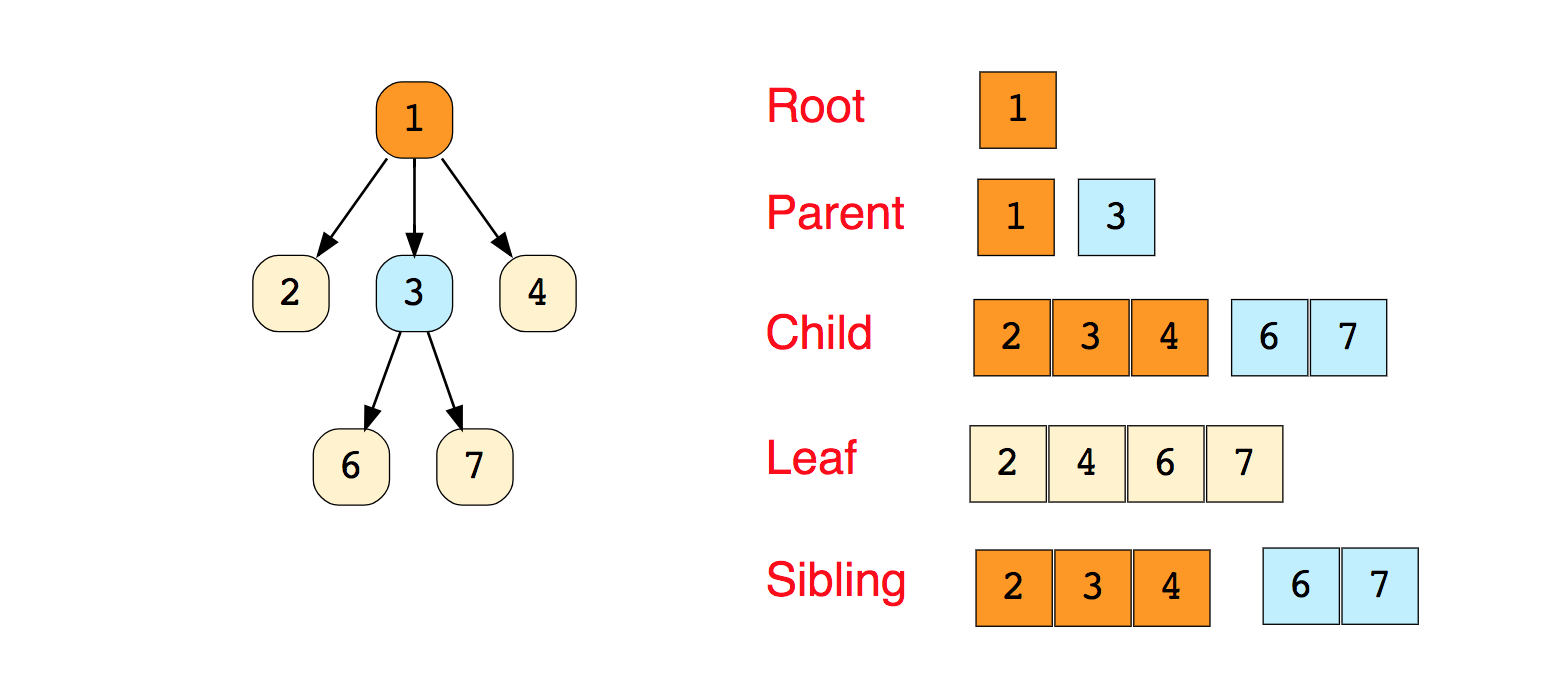 Es gibt Baumarten:
Es gibt Baumarten:- N-
- (Balanced Tree)
- (Binary Tree)
- (Binary Search Tree)
- AVL
- - (Red Black Tree)
- 2–3
Aus dem oben Gesagten sind der Binärbaum und der Binärsuchbaum die am häufigsten verwendeten Bäume.Für unabhängige Studien:1. Ermitteln Sie die Höhe des Binärbaums.2. Suchen Sie den k-ten Maximalwert im binären Suchbaum.3. Finden Sie die Knoten in einem Abstand von "k" von der Wurzel.4. Suchen Sie die Vorfahren des angegebenen Knotens im Binärbaum.Praktische Beispiele:1. Facebook: Jeder Benutzer ist ein Scheitelpunkt, und zwei Personen sind Freunde, wenn zwischen zwei Scheitelpunkten eine Kante liegt. Auch Empfehlungen an Freunde werden auf Basis der Graphentheorie berechnet.2. Google Maps: Verschiedene Orte werden durch Spitzen und Straßen durch Kanten dargestellt. Die Graphentheorie wird verwendet, um den kürzesten Weg zwischen zwei Spitzen zu finden.3. Verkehrsnetze: In ihnen sind die Gipfel die Kreuzungen von Straßen und Rippen - dies sind die Straßensegmente zwischen ihren Kreuzungen.4. Darstellung molekularer Strukturen, bei denen die Eckpunkte Moleküle und die Kanten die Bindungen zwischen den Molekülen sind.5. Diskrete Signalisierungsprozesse in Graphen. ( Und dann gibt es einen guten Artikel , und gleichzeitig ist es das )6. Empirische Beobachtungen zeigen, dass die meisten Gene durch eine kleine Anzahl anderer Gene reguliert werden, normalerweise weniger als zehn. Daher kann ein genetisches Netzwerk als ein spärlicher Graph betrachtet werden, dh ein Graph, in dem ein Knoten mit mehreren anderen Knoten verbunden ist. Wenn orientierte (azyklische) Graphen oder ungerichtete Graphen mit Wahrscheinlichkeiten gesättigt sind, sind das Ergebnis probabilistisch orientierte grafische Modelle bzw. probabilistische ungerichtete grafische Modelle.7. Theorie der Mayer-Cluster-Erweiterung der VolatilitätsfunktionGas (Z) in der Thermodynamik erfordert die Berechnung von zwei, drei, vier Bedingungen und so weiter. Es gibt eine systematische Möglichkeit, dies kombinatorisch mit Diagrammen zu tun, und es hilft, die Konnektivität solcher Diagramme herauszufinden. Die Kenntnis der Graphentheorie kann hilfreich sein, wenn Sie eine Teilmenge dieser Diagramme zusammenfassen möchten.8. Kartenfärbung: Das berühmte Vierfarben-Theorem besagt, dass Sie Kartenregionen immer korrekt färben können, sodass nicht zwei benachbarten Regionen dieselbe Farbe zugewiesen wird, wobei nicht mehr als vier verschiedene Farben verwendet werden. In diesem Modell sind Regionen mit Farben Knoten und Nachbarschaften Kanten des Diagramms.9. Die Aufgabe mit drei Hütten ist ein bekanntes mathematisches Rätsel. Es kann wie folgt formuliert werden: Drei Hütten in einer Ebene (oder Kugel), von denen jede mit Gas-, Wasser- und Elektrizitätsunternehmen verbunden sein muss. Das Problem wird mithilfe eines Diagramms in der Ebene gelöst .10. Suchen Sie nach der Mitte des Diagramms: Ermitteln Sie für jeden Scheitelpunkt die Länge des kürzesten Pfades zum am weitesten entfernten Scheitelpunkt. Die Mitte des Diagramms ist der Scheitelpunkt, für den dieser Wert minimal ist. Dies ist wichtig für die architektonische Planung von Siedlungen, in denen sich ein Krankenhaus, eine Feuerwehr oder eine Polizeistation befinden sollte, damit der am weitesten entfernte Punkt so nah wie möglich ist.Für # Liebhaber C, wie ich, eine Verbindung mit Beispielen von C # grafischer Darstellung Code ist hier. Für die fortschrittlichste Bibliothek mit der Implementierung von Graphen in C ++ hier . Für Fans von AI und Skynet stampfen Sie hier .Sequenzen (Trie)Sequenzen, auch als Bäume mit Präfixen (Präfixbäume) bezeichnet, sind eine baumartige Datenstruktur, die effektiv genug ist, um Probleme im Zusammenhang mit Zeichenfolgen zu lösen. Sie bieten eine schnelle Suche und werden hauptsächlich zum Suchen von Wörtern in einem Wörterbuch, für automatische Sätze in einer Suchmaschine und sogar für das IP-Routing verwendet.Hier ist eine Illustration, wie die drei Wörter "oben", "also" und "ihre" in der Priorität gespeichert werden: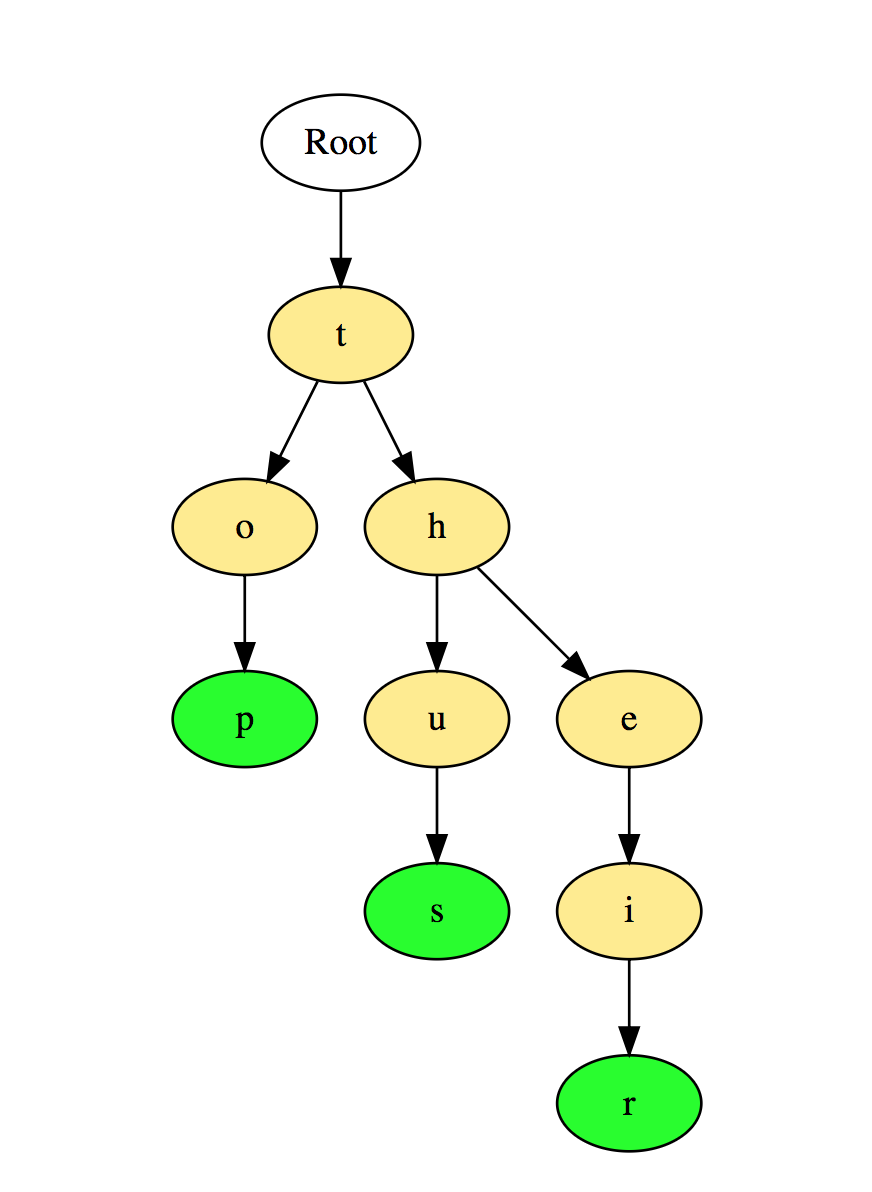 Wörter werden von oben nach unten gespeichert, wobei die grünen Knoten "p", "s" und "r" auf das Ende von "oben", "oben" zeigen. also “bzw.„ ihre “.Für unabhängige Studien:1. Zählen Sie die Gesamtzahl der Wörter in der Priorität.2. Drucken Sie alle in der Priorität gespeicherten Wörter aus.3. Sortieren von Array-Elementen mit Priorität.4. Generieren Sie Wörter aus dem Wörterbuch mithilfe von Warteschlangen.5. Erstellen Sie das T9-Wörterbuch.Praktische Anwendungsbeispiele:1. Auswahl aus dem Wörterbuch oder Vervollständigung beim Eingeben eines Wortes.2. Suchen Sie in Kontakten im Telefon oder im Telefonwörterbuch.Hash-tabelleHashing ist ein Prozess, mit dem Objekte eindeutig identifiziert und jedes Objekt anhand eines vorberechneten eindeutigen Index gespeichert wird, der als „Schlüssel“ bezeichnet wird. Somit wird das Objekt in Form eines Schlüssel-Wert-Paares gespeichert, und eine Sammlung solcher Elemente wird als Wörterbuch bezeichnet. Jedes Objekt kann mit diesem Schlüssel gefunden werden.Es gibt verschiedene Hash-basierte Datenstrukturen, aber die Hash-Tabelle ist die am häufigsten verwendete Datenstruktur. Eine Hash-Tabelle wird verwendet, wenn Sie mit einem Schlüssel auf Elemente zugreifen müssen, und Sie können den nützlichen Wert des Schlüssels bestimmen.Hash-Tabellen werden normalerweise mithilfe von Arrays implementiert.Die Leistung beim Hashing einer Datenstruktur hängt von diesen drei Faktoren ab:
Wörter werden von oben nach unten gespeichert, wobei die grünen Knoten "p", "s" und "r" auf das Ende von "oben", "oben" zeigen. also “bzw.„ ihre “.Für unabhängige Studien:1. Zählen Sie die Gesamtzahl der Wörter in der Priorität.2. Drucken Sie alle in der Priorität gespeicherten Wörter aus.3. Sortieren von Array-Elementen mit Priorität.4. Generieren Sie Wörter aus dem Wörterbuch mithilfe von Warteschlangen.5. Erstellen Sie das T9-Wörterbuch.Praktische Anwendungsbeispiele:1. Auswahl aus dem Wörterbuch oder Vervollständigung beim Eingeben eines Wortes.2. Suchen Sie in Kontakten im Telefon oder im Telefonwörterbuch.Hash-tabelleHashing ist ein Prozess, mit dem Objekte eindeutig identifiziert und jedes Objekt anhand eines vorberechneten eindeutigen Index gespeichert wird, der als „Schlüssel“ bezeichnet wird. Somit wird das Objekt in Form eines Schlüssel-Wert-Paares gespeichert, und eine Sammlung solcher Elemente wird als Wörterbuch bezeichnet. Jedes Objekt kann mit diesem Schlüssel gefunden werden.Es gibt verschiedene Hash-basierte Datenstrukturen, aber die Hash-Tabelle ist die am häufigsten verwendete Datenstruktur. Eine Hash-Tabelle wird verwendet, wenn Sie mit einem Schlüssel auf Elemente zugreifen müssen, und Sie können den nützlichen Wert des Schlüssels bestimmen.Hash-Tabellen werden normalerweise mithilfe von Arrays implementiert.Die Leistung beim Hashing einer Datenstruktur hängt von diesen drei Faktoren ab:- Hash-Funktion
- Hash-Tabellengröße
- Kollisionsverarbeitungsmethode
Hier ist eine Illustration, wie ein Hash in einem Array angezeigt wird. Der Index dieses Arrays wird mithilfe einer Hash-Funktion berechnet.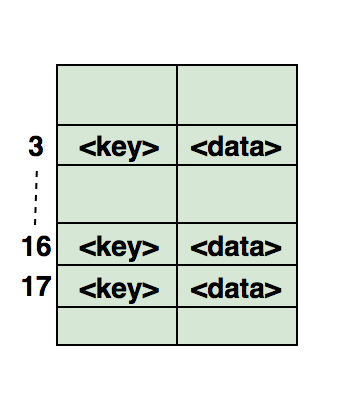 Für unabhängige Studien:1. Finden Sie symmetrische Paare im Array.2. Folgen Sie dem vollständigen Fahrweg.3. Suchen Sie, ob das Array eine Teilmenge eines anderen Arrays ist.4. Überprüfen Sie, ob die angegebenen Arrays nicht zusammenhängend sind.Unten finden Sie einen Beispielcode für die Verwendung von Hash-Tabellen in .Net
Für unabhängige Studien:1. Finden Sie symmetrische Paare im Array.2. Folgen Sie dem vollständigen Fahrweg.3. Suchen Sie, ob das Array eine Teilmenge eines anderen Arrays ist.4. Überprüfen Sie, ob die angegebenen Arrays nicht zusammenhängend sind.Unten finden Sie einen Beispielcode für die Verwendung von Hash-Tabellen in .Netstatic void Main(string[] args)
{
Hashtable ht = new Hashtable
{
{ "001", "Zara Ali" },
{ "002", "Abida Rehman" },
{ "003", "Joe Holzner" },
{ "004", "Mausam Benazir Nur" },
{ "005", "M. Amlan" },
{ "006", "M. Arif" },
{ "007", "Ritesh Saikia" }
};
if (ht.ContainsValue("Nuha Ali"))
{
Console.WriteLine(" !");
}
else
{
ht.Add("008", "Nuha Ali");
}
ICollection key = ht.Keys;
foreach (string k in key)
{
Console.WriteLine(k + ": " + ht[k]);
}
Console.ReadKey();
}
Praktische Beispiele:1. Das Spiel "Leben". Darin ist ein Hash ein Satz von Koordinaten jeder lebenden Zelle.2. Eine primitive Version der Google-Suchmaschine könnte alle vorhandenen Wörter einer Reihe von URLs zuordnen, in denen sie vorkommen. In diesem Fall werden Hash-Tabellen zweimal verwendet: das erste Mal, um Wörter URL-Sätzen zuzuordnen, und das zweite Mal, um jeden URL-Satz zu speichern.3. Bei der Implementierung einer Mehrwegbaumstruktur / eines Mehrwegalgorithmus können Hash-Tabellen für den schnellen Zugriff auf jedes untergeordnete Element des internen Knotens verwendet werden.4. Wenn Sie ein Programm zum Schachspielen schreiben, ist es sehr wichtig, die zuvor bewerteten Positionen im Auge zu behalten, damit Sie bei Bedarf zurückkehren können, wenn Sie sie erneut benötigen.5. Jede Programmiersprache muss den Variablennamen ihrer Adresse im Speicher zuordnen. In Skriptsprachen wie Javascript und Perl können Felder dem Objekt dynamisch hinzugefügt werden, was bedeutet, dass die Objekte selbst wie Hash-Maps sind.