Wenn Facebook „lügt“, denken die Leute, dass es an Hackern oder DDoS-Angriffen liegt, aber nicht. Alle „Stürze“ in den letzten Jahren wurden durch interne Änderungen oder Ausfälle verursacht. Um neuen Mitarbeitern beizubringen, Facebook nicht mit Beispielen zu brechen, werden alle wichtigen Vorfälle mit Namen versehen, z. B. "Call the Cops" oder "CAPSLOCK". Der erste wurde benannt, weil eines Tages, als das soziale Netzwerk ausfiel, Benutzer die Polizei von Los Angeles anriefen und darum baten, das Problem zu beheben, und der Sheriff auf Twitter verzweifelt darum bat, sie nicht zu stören. Während des zweiten Vorfalls auf den Cache-Computern fiel die Netzwerkschnittstelle aus und stieg nicht an, und alle Computer wurden von Hand neu gestartet.Elina Lobanovaarbeitet seit 4 Jahren auf Facebook im Web Foundation-Team. Die Teammitglieder werden als Produktionsingenieure bezeichnet und überwachen die Zuverlässigkeit und Leistung des gesamten Backends, veröffentlichen Facebook, wenn es eingeschaltet ist, schreiben Überwachung und Automatisierung, um sich und anderen das Leben zu erleichtern. In einem Artikel, der auf Elinas Bericht über HighLoad ++ 2019 basiert , zeigen wir , wie Produktionsingenieure das Facebook-Backend überwachen, welche Tools sie verwenden, was zu schweren Abstürzen führt und wie sie damit umgehen.Mein Name ist Elina, vor fast 5 Jahren wurde ich als gewöhnlicher Entwickler auf Facebook angerufen, wo ich zum ersten Mal auf wirklich stark ausgelastete Systeme stieß - dies wird an Instituten nicht gelehrt. Das Unternehmen stellt kein Team ein, sondern ein Büro. Deshalb bin ich in London angekommen, habe ein Team ausgewählt, das die Arbeit von facebook.com überwacht und unter den Produktionsingenieuren war.
In einem Artikel, der auf Elinas Bericht über HighLoad ++ 2019 basiert , zeigen wir , wie Produktionsingenieure das Facebook-Backend überwachen, welche Tools sie verwenden, was zu schweren Abstürzen führt und wie sie damit umgehen.Mein Name ist Elina, vor fast 5 Jahren wurde ich als gewöhnlicher Entwickler auf Facebook angerufen, wo ich zum ersten Mal auf wirklich stark ausgelastete Systeme stieß - dies wird an Instituten nicht gelehrt. Das Unternehmen stellt kein Team ein, sondern ein Büro. Deshalb bin ich in London angekommen, habe ein Team ausgewählt, das die Arbeit von facebook.com überwacht und unter den Produktionsingenieuren war.Produktionsingenieure
Zunächst möchte ich Ihnen sagen, was wir tun und warum wir als Produktionsingenieure bezeichnet werden und nicht wie Google beispielsweise SRE.2009. SRE
Das Standardmodell, das in vielen Unternehmen noch verwendet wird, ist "Entwickler - Tester - Betrieb". Oft sind sie geteilt: Sie sitzen auf verschiedenen Etagen, manchmal sogar in verschiedenen Ländern, und kommunizieren nicht miteinander.Im Jahr 2009 hatte Facebook bereits SRE. Bei Google hat SRE früher begonnen, sie wissen, wie man DevOps erreicht, und haben es in ihrem Buch „ Site Reliability Engineering “ geschrieben. Auf Facebook gab es 2009 nichts Vergleichbares. Wir hießen SRE, aber wir haben die gleiche Arbeit wie Ops im Rest der Welt geleistet: Handarbeit, keine Automatisierung, Bereitstellung aller Dienste mit Ihren Händen, Überwachung irgendwie, Oncall für alles, eine Reihe von Shell-Skripten.
Auf Facebook gab es 2009 nichts Vergleichbares. Wir hießen SRE, aber wir haben die gleiche Arbeit wie Ops im Rest der Welt geleistet: Handarbeit, keine Automatisierung, Bereitstellung aller Dienste mit Ihren Händen, Überwachung irgendwie, Oncall für alles, eine Reihe von Shell-Skripten.2010. SRO und AppOps
Dies alles wurde nicht skaliert, da die Anzahl der Benutzer zu diesem Zeitpunkt dreimal pro Jahr zunahm und die Anzahl der Dienste entsprechend zunahm. Im Jahr 2010 wurde die willensstarke Entscheidung Ops in zwei Gruppen aufgeteilt.Die erste Gruppe ist die SRO , wobei „O“ „Betrieb“ ist und sich mit der Entwicklung, Automatisierung und Überwachung des Standorts befasst.Die zweite Gruppe ist AppOps . Sie wurden in Teams für große Services integriert. AppOps steht der Idee von DevOps bereits nahe.Die Trennung für eine Weile rettete alle.2012. Produktionsingenieure
Im Jahr 2012 hat AppOps die Produktionsingenieure einfach umbenannt . Neben dem Namen hat sich nichts geändert, aber es ist bequemer geworden. Wie Sie eine Yacht nennen, wird sie segeln, und wir wollten nicht wie Ops segeln.Es gab immer noch SROs, Facebook wuchs und die gleichzeitige Überwachung aller Dienste war schwierig. Eine Person, die angerufen wurde, durfte nicht einmal auf die Toilette gehen: Er bat jemanden, ihn zu ersetzen, weil er ständig brannte.2014. Schließung der SRO
Irgendwann haben die Behörden alle zu einem Anruf weitergeleitet. "Jeder" bedeutet auch die Entwickler: Sie schreiben Ihren Code, hier sind Sie und antworten auf diesen Code!Produktionsingenieure wurden bereits in die wichtigsten Hilfeteams integriert, der Rest hat Pech. Wir haben mit großen Teams angefangen und in ein paar Jahren alle auf Facebook auf oncall übertragen. Unter den Entwicklern herrschte große Aufregung: Jemand kündigte, jemand schrieb schlechte Beiträge. Aber alles beruhigte sich und 2014 wurde die SRO geschlossen, weil sie nicht mehr benötigt wurden. Wir leben also bis heute.Das Wort "SRE" im Unternehmen ist berüchtigt, aber wir sehen aus wie SRE bei Google. Es gibt Unterschiede.- Wir sind immer in Teams eingebaut. Wir haben im Allgemeinen keine SRE-Suche, wie bei Google, sondern für jeden Suchdienst separat.
- Wir sind nicht in den Produkten , sondern nur in der Infrastruktur, die das Produkt selbst verwaltet.
- Wir sind oncall zusammen mit den Entwicklern.
- Wir haben etwas mehr Erfahrung mit Systemen und Netzwerken, daher konzentrieren wir uns darauf, Dienste zu überwachen und zu löschen, wenn sie hell brennen. Wir beheben Fehler im Voraus, die von Anfang an zu Abstürzen führen und die Architektur neuer Dienste beeinflussen können, damit diese später in der Produktion reibungslos funktionieren.
Überwachung
Es ist das Wichtigste. Wie machen wir das? Wie jeder: ohne schwarze Magie, in seinem eigenen Zuhause. Aber der Teufel wird Ihnen wie immer ausführlich davon erzählen.OBEN AUF
Beginnen wir von unten. Jeder kennt TOP unter Linux, und wir verwenden ATOP, wobei "A" "fortgeschritten" ist - ein Systemleistungsmonitor. Der Hauptvorteil von ATOP besteht darin, dass der Verlauf gespeichert wird: Sie können ihn so konfigurieren, dass Snapshots auf der Festplatte gespeichert werden. Unser ATOP läuft alle 5 Sekunden auf allen Maschinen.Hier ist ein Beispielserver, auf dem das PHP-Backend für facebook.com ausgeführt wird. Wir haben unsere virtuelle Maschine geschrieben, um PHP-Code auszuführen. Sie heißt HHVM (HipHop Virtual Machine). Laut exportierten Metriken haben wir festgestellt, dass mehrere Maschinen nicht fast eine einzige Anfrage in einer Minute verarbeitet haben. Mal sehen, warum, öffnen Sie ATOP 30 Sekunden bevor es hängt. Es ist zu sehen, dass wir bei den Prozessorproblemen zu viel laden. Es gibt auch Probleme mit dem Speicher, es sind nur noch 1,5 GB im Cache und nach 5 Sekunden nur noch 800 MB.
Es ist zu sehen, dass wir bei den Prozessorproblemen zu viel laden. Es gibt auch Probleme mit dem Speicher, es sind nur noch 1,5 GB im Cache und nach 5 Sekunden nur noch 800 MB. Nach weiteren 5 Sekunden wird die CPU freigegeben, nichts wird ausgeführt. ATOP sagt, schauen Sie sich das Endergebnis an, wir schreiben auf die Festplatte, aber was? Es stellt sich heraus, dass wir Swap schreiben.
Nach weiteren 5 Sekunden wird die CPU freigegeben, nichts wird ausgeführt. ATOP sagt, schauen Sie sich das Endergebnis an, wir schreiben auf die Festplatte, aber was? Es stellt sich heraus, dass wir Swap schreiben. Wer macht das? Prozesse, die aus dem Speicher 0,5 GB entnommen und in Swap gestellt wurden. An ihre Stelle traten zwei verdächtige Python-Prozesse, die dann als Befehlszeile angesehen werden können.
Wer macht das? Prozesse, die aus dem Speicher 0,5 GB entnommen und in Swap gestellt wurden. An ihre Stelle traten zwei verdächtige Python-Prozesse, die dann als Befehlszeile angesehen werden können.
ATOP ist wunderschön, wir benutzen es ständig.
Wenn Sie es nicht haben, empfehle ich dringend, es zu verwenden. Haben Sie keine Angst um das Laufwerk, ATOP frisst alle 5 Sekunden nur 200-300 MB pro Tag.Malloc HTTP
Den Bahamas und den großen Zwischenfällen geben wir Namen. Es gibt einen lustigen Fehler im Zusammenhang mit ATOP namens Malloc HTTP. Wir haben es mit ATOP und Strace debütiert.Wir verwenden Thrift überall als RPC. In den frühen Versionen des Parsers gab es einen erstaunlichen Fehler, der so funktionierte: Es kam eine Nachricht an, bei der die ersten 4 Bytes der Größe der Daten entsprechen, dann die Daten selbst und die ersten Bytes der nächsten Nachricht hinzugefügt werden.Aber einmal eines der Programme, anstatt zum Thrift-Dienst zu gehen, ging ich zu HTTP und erhielt eine Antwort «das HTTP Bad the Request» : HTTP/1.1 400.Nachdem es HTTP genommen und mit malloc HTTP die Anzahl der Bytes zugewiesen hat.Thrift message
HTTP/1.1 400
"HTTP" == 0x48545450
Es ist okay, wir haben Overcommit, lassen Sie uns mehr Speicher zuweisen! Wir haben mit malloc zugeteilt, und bis wir dort schreiben und lesen, werden sie uns keine wirkliche Erinnerung geben.Aber es war nicht da! Wenn wir gabeln wollen, gibt die Gabel einen Fehler zurück - es ist nicht genug Speicher vorhanden.malloc("HTTP")
pid = fork(); // errno = ENOMEM
Aber warum gibt es eine Erinnerung? Beim Verständnis der Handbücher haben wir festgestellt, dass alles sehr einfach ist: Die aktuelle Overcommit-Konfiguration ist so, dass es sich um eine magische Heuristik handelt, und der Kernel selbst entscheidet, wann viel und wann nicht:malloc("HTTP")
pid = fork(); // errno = ENOMEM
// 0: heuristic overcommit
vm.overcommit_memory = 0
Für einen Arbeitsprozess ist dies normal. Sie können malloc bis TB auswählen, für einen neuen Prozess jedoch - nein. Ein Teil der Überwachung bei uns war mit der Tatsache verbunden, dass der Hauptprozess kleine Skripte für die Datenerfassung gabelte. Infolgedessen fiel unser Überwachungsteil aus, weil wir uns nicht mehr gabeln konnten.FB303
FB303 ist unser grundlegendes Überwachungssystem. Es wurde nach dem 1982er Standard-Bass-Synthesizer benannt. Das Prinzip ist einfach, daher funktioniert es immer noch: Jeder Dienst implementiert die Thrift getCounters-Schnittstelle.
Das Prinzip ist einfach, daher funktioniert es immer noch: Jeder Dienst implementiert die Thrift getCounters-Schnittstelle.Service FacebookService {
map<string, i64> getCounters()
}
Tatsächlich implementiert er es nicht, da die Bibliotheken bereits geschrieben sind, alles im Code incrementoder erledigt ist set.incrementCounter(string& key);
setCounter(string& key, int64_t value);
Infolgedessen exportiert jeder Dienst Zähler an den Port, den er bei Service Discovery registriert. Unten sehen Sie ein Beispiel für eine Maschine, die einen Newsfeed generiert und ungefähr 5,5 Tausend Paare (Zeichenfolge, Nummer) exportiert: Speicher, Produktion, alles. Jeder Computer führt einen Binärprozess aus, der alle Dienste durchläuft, diese Zähler sammelt und speichert.So sieht die Speicher-GUI aus .
Jeder Computer führt einen Binärprozess aus, der alle Dienste durchläuft, diese Zähler sammelt und speichert.So sieht die Speicher-GUI aus . Prometheus und Grafana sehr ähnlich, aber nicht. Der erste FB303-Eintrag auf GitHub war 2009 und Prometheus 2012. Dies ist eine Erklärung für alle „Heimwerker“ von Facebook: Wir haben sie gemacht, als es in Open Source nichts Normales gab.Beispielsweise wird nach den Namen von Zählern gesucht.
Prometheus und Grafana sehr ähnlich, aber nicht. Der erste FB303-Eintrag auf GitHub war 2009 und Prometheus 2012. Dies ist eine Erklärung für alle „Heimwerker“ von Facebook: Wir haben sie gemacht, als es in Open Source nichts Normales gab.Beispielsweise wird nach den Namen von Zählern gesucht.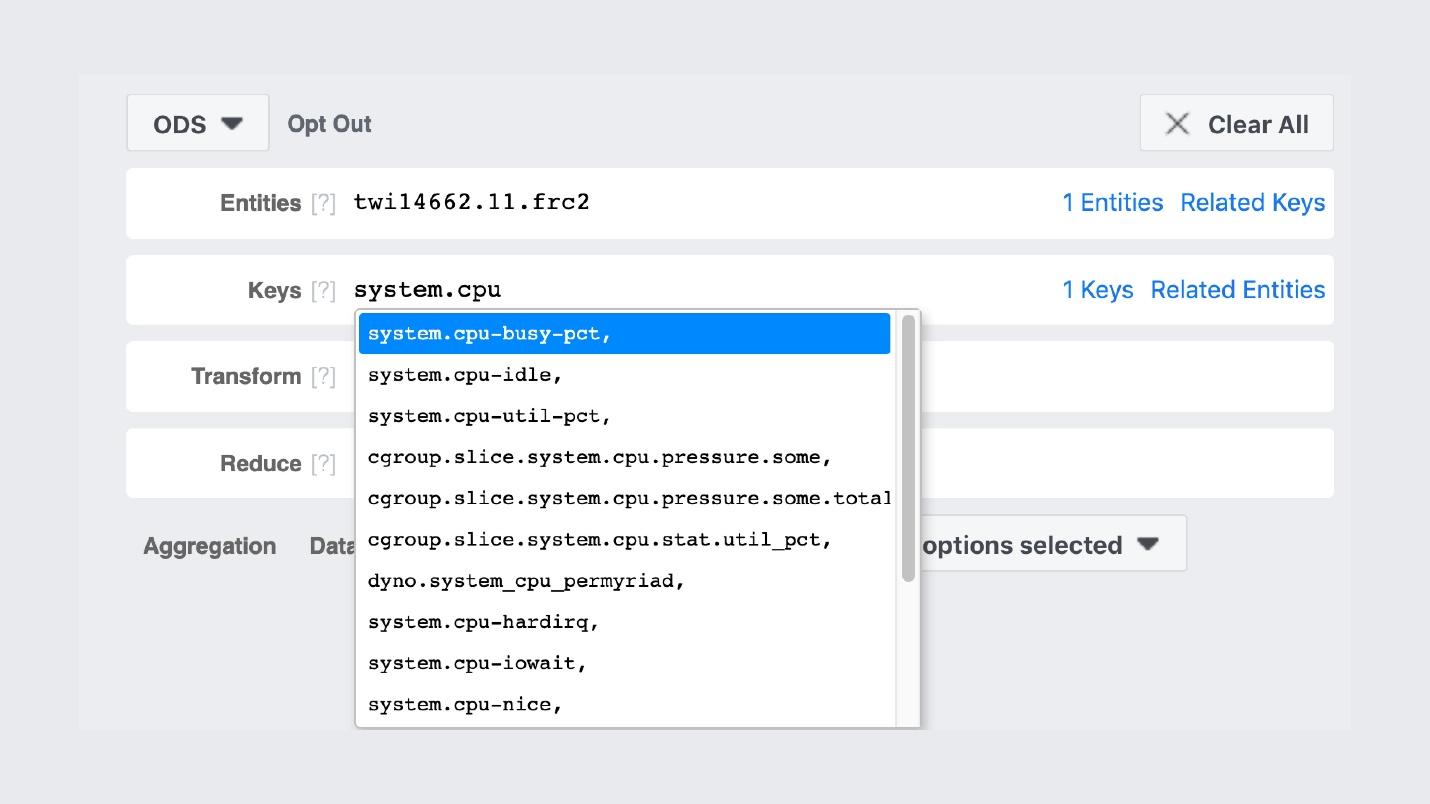 Die Grafiken selbst sehen ungefähr so aus.
Die Grafiken selbst sehen ungefähr so aus. Ein Bild aus der inneren Gruppe, in dem wir schöne Grafiken posten.Ein wichtiger Unterschied zwischen unserem Überwachungsstapel und Prometheus und Grafana besteht darin, dass wir Daten für immer speichern . Unsere Überwachung wird die Daten erneut abtasten und nach 2 Wochen haben wir alle 5 Minuten einen Punkt und nach einem Jahr für jede Stunde. Daher können sie so viel gespeichert werden. Automatisch wird dies nirgendwo konfiguriert.Wenn wir jedoch über die Funktionen der Überwachung von Facebook sprechen, würde ich dies mit einem englischen Wort „ Beobachtbarkeit“ beschreiben .
Ein Bild aus der inneren Gruppe, in dem wir schöne Grafiken posten.Ein wichtiger Unterschied zwischen unserem Überwachungsstapel und Prometheus und Grafana besteht darin, dass wir Daten für immer speichern . Unsere Überwachung wird die Daten erneut abtasten und nach 2 Wochen haben wir alle 5 Minuten einen Punkt und nach einem Jahr für jede Stunde. Daher können sie so viel gespeichert werden. Automatisch wird dies nirgendwo konfiguriert.Wenn wir jedoch über die Funktionen der Überwachung von Facebook sprechen, würde ich dies mit einem englischen Wort „ Beobachtbarkeit“ beschreiben .Beobachtbarkeit
Es gibt eine "Black Box", es gibt eine "White Box" und wir haben eine transparente "Box" aus Glas. Dies bedeutet, dass wir beim Schreiben von Code alles Mögliche in die Protokolle schreiben und nicht selektiv. Das Sampling ist überall gut abgestimmt, sodass das Backend für Speicher, Zähler und alles andere gut funktioniert.Gleichzeitig können wir unsere Dashboards bereits auf vorhandenen Zählern aufbauen. Wenn Sie diese Dashboards studieren, ist dies nicht der Endpunkt mit 10 Diagrammen, sondern der erste, von dem aus wir zu unserer Benutzeroberfläche gehen und dort alles finden, was möglich ist.Tauchen
Dies ist der Höhepunkt der Idee der Beobachtbarkeit. Dies ist unser ELK-Stack. Das Prinzip ist dasselbe: Wir schreiben in JSON ohne ein bestimmtes Schema und fordern dann in Form einer Tabelle , Zeitreihen von Daten oder 10 weitere Visualisierungsoptionen an.Scuba protokolliert in der Größenordnung von Hunderten von Gigabyte pro Sekunde. Alles wird sehr schnell angefordert, da es sich nicht um Elasticsearch handelt und sich auf leistungsstarken Maschinen alles im Speicher befindet. Ja, dafür wird Geld ausgegeben, aber wie wunderbar ist es!Unterhalb der Benutzeroberfläche von Scuba wird beispielsweise eine der beliebtesten Tabellen geöffnet, in die alle Clients aller Thrift-Dienste Protokolle schreiben.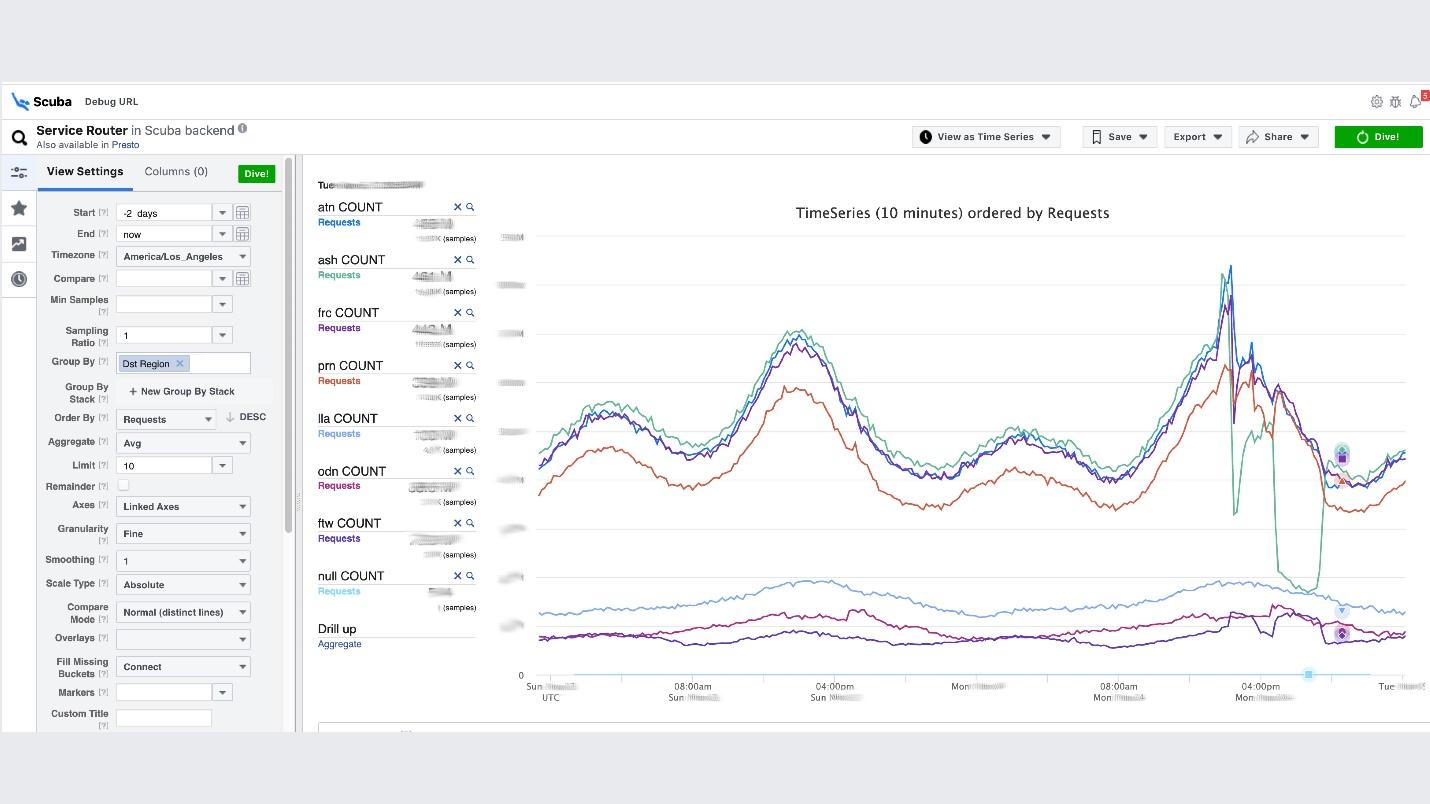 Die Grafik zeigt, dass am Ende im Service ein Fehler aufgetreten ist. Um die Verzögerung herauszufinden, gehen Sie zur Liste der Zähler, wählen Sie die Verzögerung und Aggregation aus und klicken Sie auf "Tauchen".
Die Grafik zeigt, dass am Ende im Service ein Fehler aufgetreten ist. Um die Verzögerung herauszufinden, gehen Sie zur Liste der Zähler, wählen Sie die Verzögerung und Aggregation aus und klicken Sie auf "Tauchen".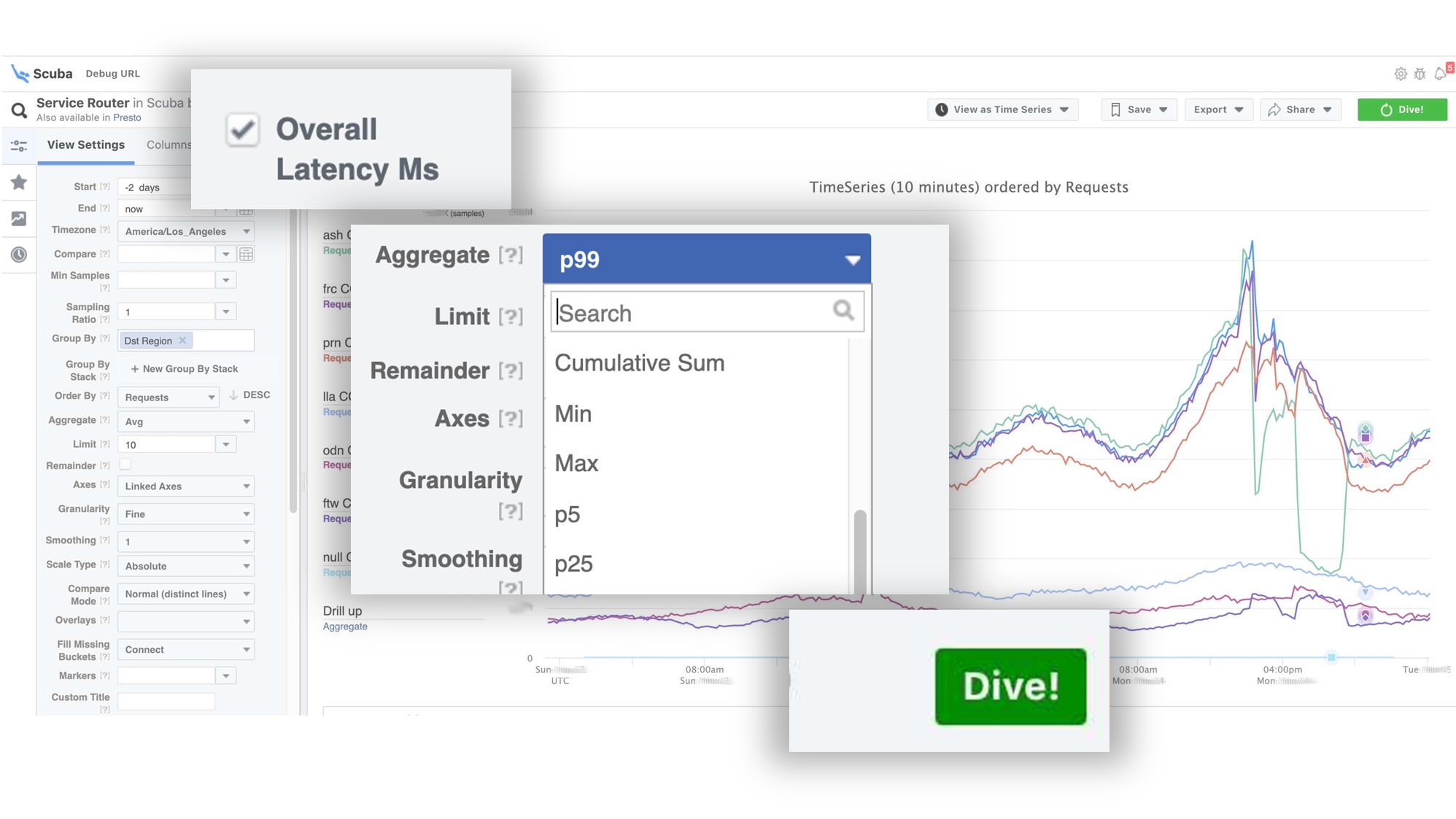 Die Antwort kommt in 2 Sekunden.
Die Antwort kommt in 2 Sekunden.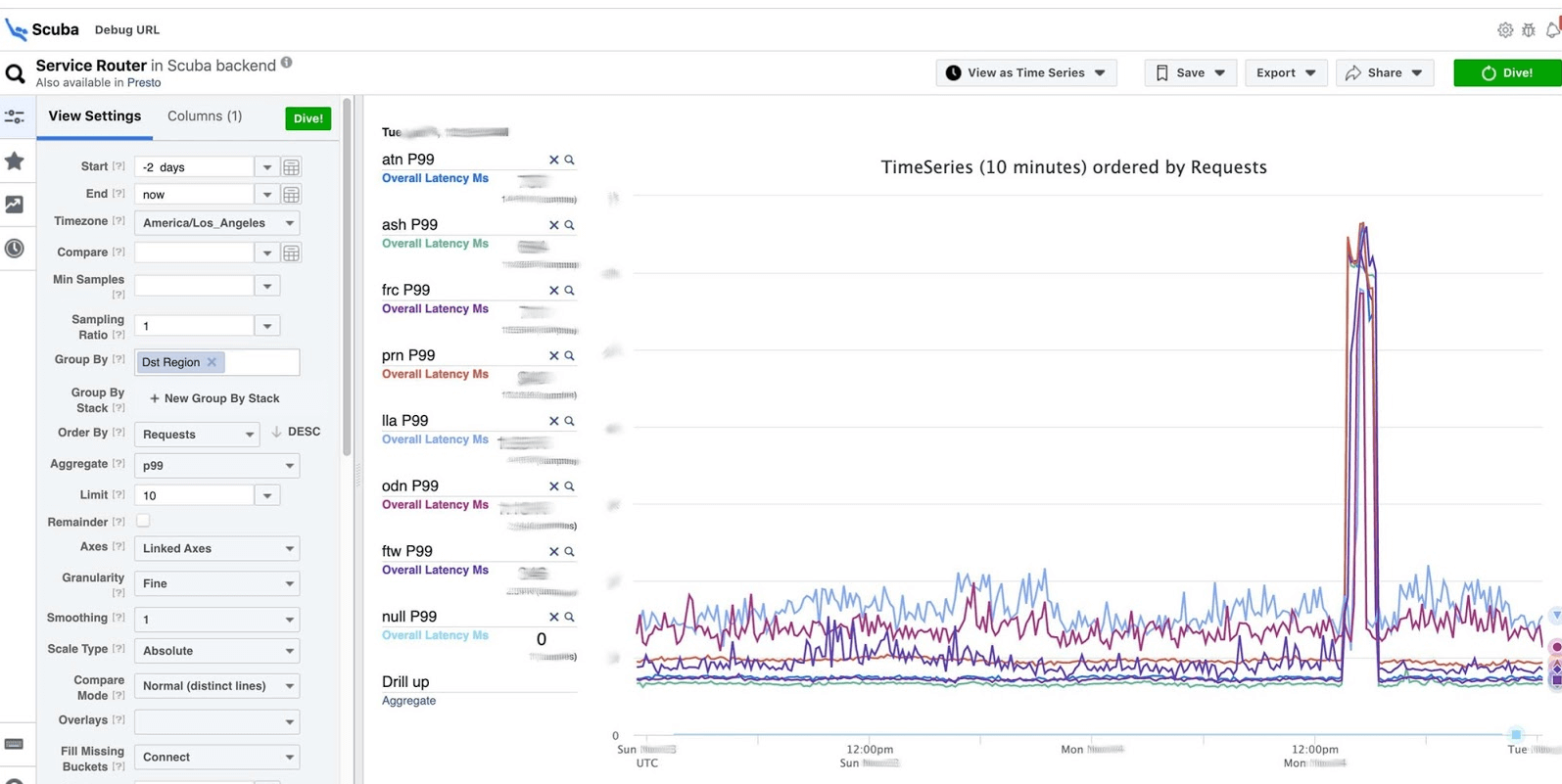 Es ist zu sehen, dass in diesem Moment etwas passiert ist und die Verzögerung erheblich zugenommen hat. Um mehr zu erfahren, können Sie nach verschiedenen Parametern gruppieren.Es gibt Hunderte solcher Tabellen.
Es ist zu sehen, dass in diesem Moment etwas passiert ist und die Verzögerung erheblich zugenommen hat. Um mehr zu erfahren, können Sie nach verschiedenen Parametern gruppieren.Es gibt Hunderte solcher Tabellen.- Eine Tabelle, die die Versionen von Binärdateien und Paketen zeigt, wie viel Speicher auf allen Millionen von Computern belegt ist. Auf jedem Host wird einmal pro Stunde eine PS erstellt und an Scuba gesendet.
- Alle dmesg, alle Speicherabbilder werden an andere Tabellen gesendet. Wir führen Perf einmal alle 10 Minuten auf jedem Computer aus, damit wir wissen, welche Stack-Traces wir auf dem Kernel haben und was die globale CPU laden kann.
PHP-Debug
Scuba bietet auch ein Backend für unser Kern-PHP-Debugging-Tool. Tausende von Ingenieuren schreiben PHP-Code, und irgendwie müssen Sie das globale Repository vor schlechten Dingen schützen.Wie funktioniert es? PHP schreibt auch einen Stack-Trace in jedes Protokoll. Scuba (unsere Elasticsearch) kann einfach keine Stapelverfolgung von allen Protokollen von allen Maschinen aufnehmen. Bevor wir das Protokoll in Scuba ablegen, konvertieren wir den Stack-Trace in einen Hash, probieren ihn durch Hashes aus und speichern nur sie. Die Stack-Traces selbst werden an Memcached gesendet. Anschließend können Sie im internen Tool schnell genug eine bestimmte Stapelverfolgung aus Memcached abrufen. Visualisierung mit Hash-Gruppierung aus Protokollen und Stack-Traces.Wir debuggen den Code mit der Pattern Matching- Methode : Öffnen Sie Scuba und sehen Sie, wie das Fehlerdiagramm aussieht.
Visualisierung mit Hash-Gruppierung aus Protokollen und Stack-Traces.Wir debuggen den Code mit der Pattern Matching- Methode : Öffnen Sie Scuba und sehen Sie, wie das Fehlerdiagramm aussieht.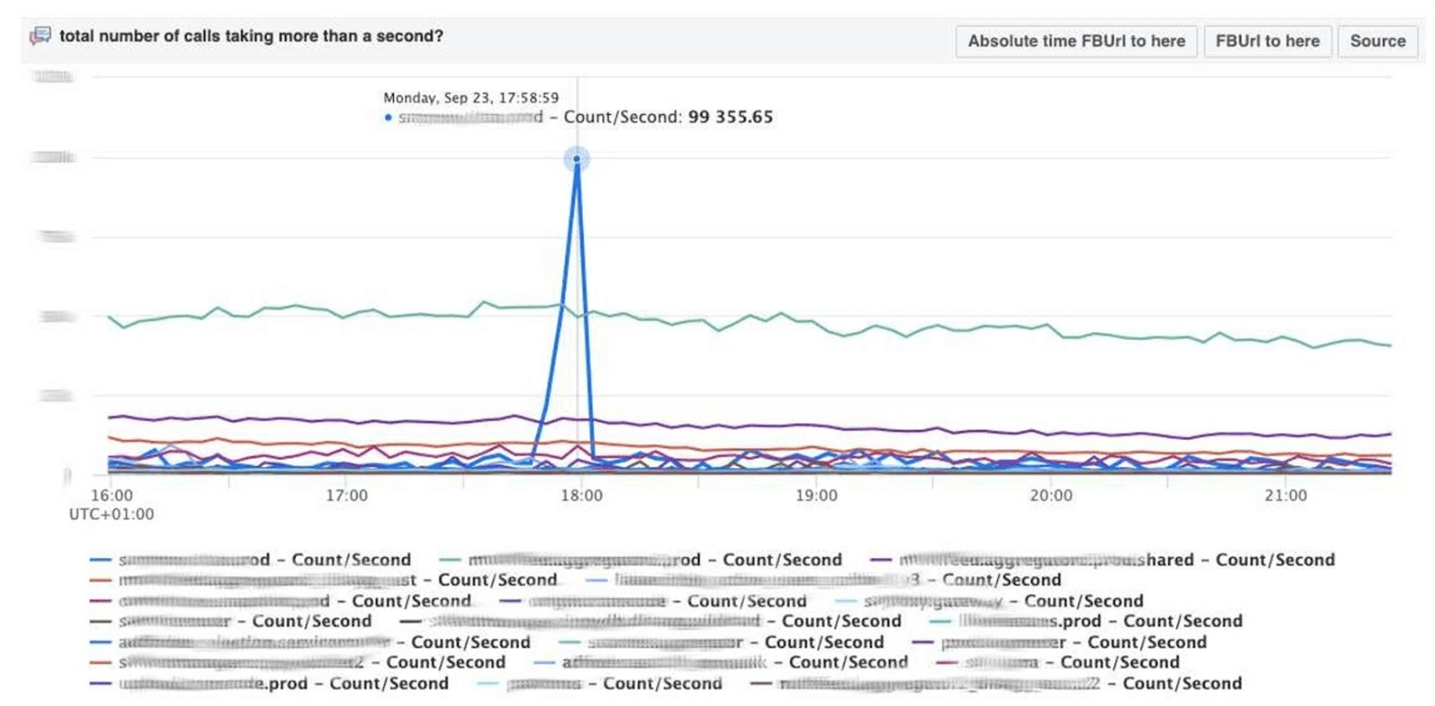 Wir gehen zu LogView, dort sind Fehler bereits nach Stack-Traces gruppiert.
Wir gehen zu LogView, dort sind Fehler bereits nach Stack-Traces gruppiert. Ein Stack-Trace wird aus Memcached geladen, und bereits darauf können Sie diff (Commit im PHP-Repository) finden, das ungefähr zur gleichen Zeit veröffentlicht wurde, und es zurücksetzen. Jeder kann ein Rollback durchführen und sich bei uns festlegen. Hierfür sind keine Berechtigungen erforderlich.
Ein Stack-Trace wird aus Memcached geladen, und bereits darauf können Sie diff (Commit im PHP-Repository) finden, das ungefähr zur gleichen Zeit veröffentlicht wurde, und es zurücksetzen. Jeder kann ein Rollback durchführen und sich bei uns festlegen. Hierfür sind keine Berechtigungen erforderlich.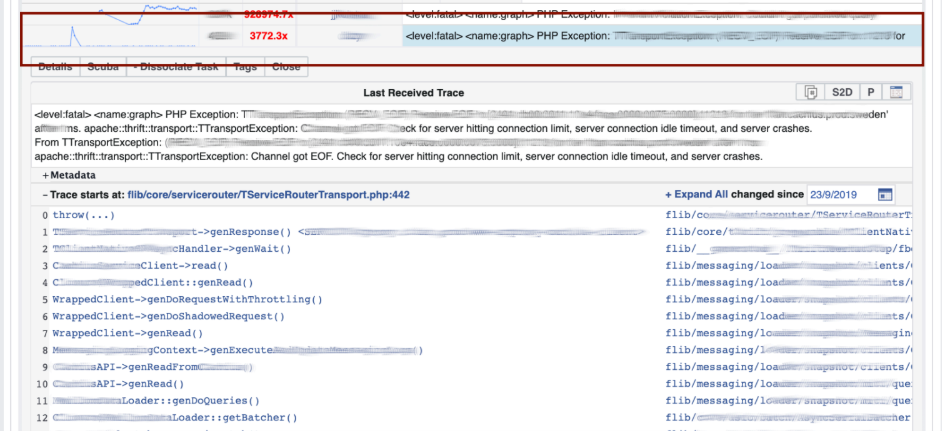
Dashboards
Ich beende das Überwachungsthema mit Dashboards. Wir haben nur wenige davon - nur zwei von drei Indikatoren. Das Dashboard selbst ist eher ungewöhnlich. Ich würde gerne mehr über ihn sprechen. Unten finden Sie ein Standard-Dashboard mit einer Reihe von Grafiken.Leider ist es bei ihm nicht so einfach. Tatsache ist, dass die violette Linie in einem Diagramm derselbe Dienst ist, dem die blaue Linie im anderen Diagramm entspricht, und dass sich ein anderes Diagramm an einem Tag und ein anderes in einem Monat befinden kann.Wir verwenden unser auf Kubismus basierendes Dashboard - die Open Source JS-Bibliothek. Es wurde auf Square geschrieben und unter der Apache-Lizenz veröffentlicht. Sie haben integrierte Unterstützung für Graphit und Würfel. Aber es ist leicht zu erweitern, was wir getan haben.Das Dashboard unten zeigt einen Tag mit einem Pixel pro Minute. Jede Linie ist eine Region: Rechenzentren in der Nähe. Sie zeigen die Anzahl der Protokolle, die das Facebook-Backend schreibt, in Bytes pro Sekunde an. Unten finden Sie Anmerkungen für Teams in Amerika, um zu sehen, was wir bereits von den Ereignissen während des Tages behoben haben. In diesem Bild ist es leicht, nach Korrelationen zu suchen.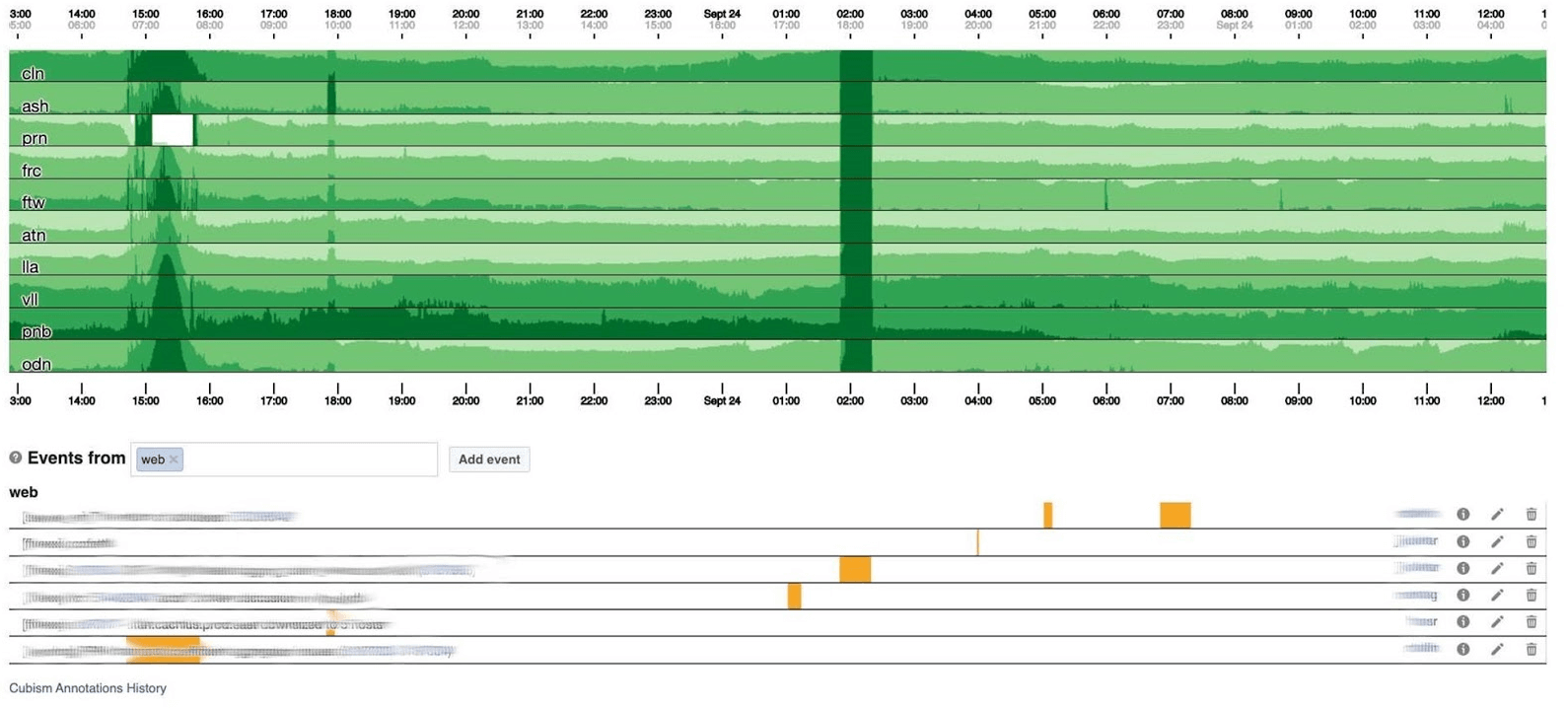 Unten ist die Anzahl der Fehler 500 angegeben. Was auf der linken Seite für die Benutzer nicht wichtig war, und offensichtlich gefiel ihnen der dunkelgrüne Streifen in der Mitte nicht.
Unten ist die Anzahl der Fehler 500 angegeben. Was auf der linken Seite für die Benutzer nicht wichtig war, und offensichtlich gefiel ihnen der dunkelgrüne Streifen in der Mitte nicht.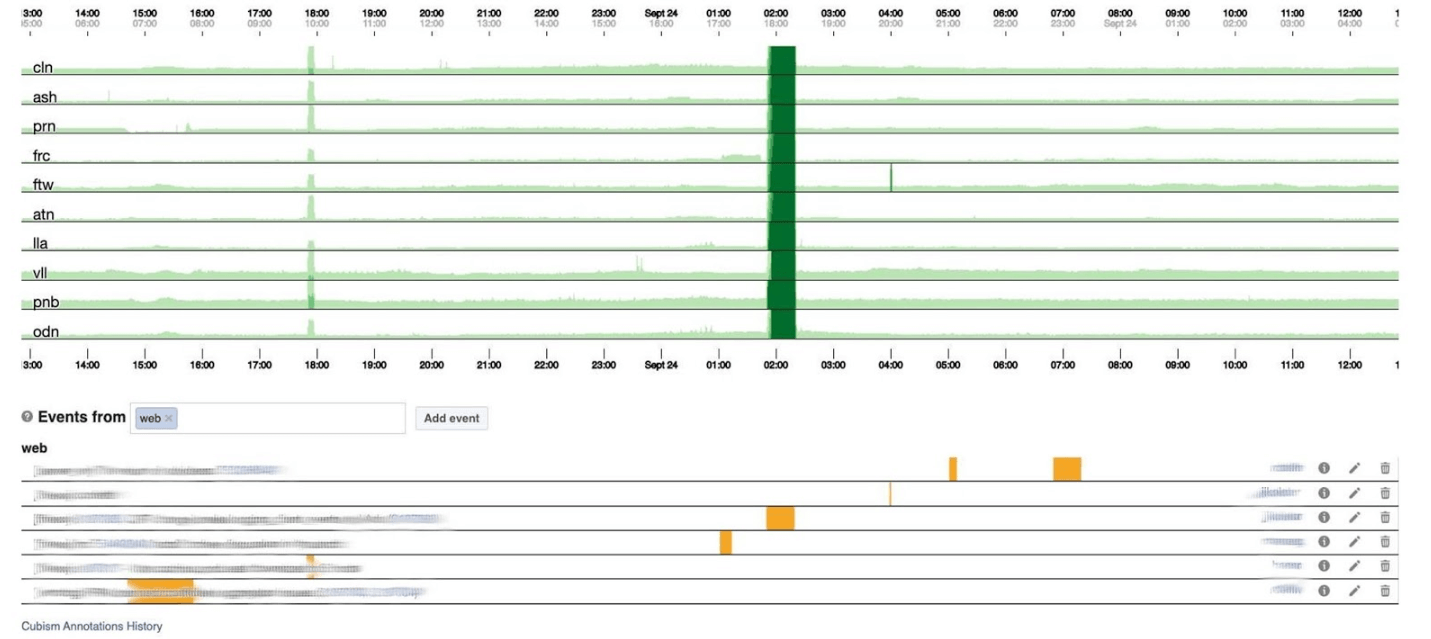 Als nächstes folgt die Latenzzeit des 99. Perzentils. Gleichzeitig ist, wie in der obigen Tabelle, zu sehen, dass die Latenz gesunken ist. Um einen Fehler zurückzugeben, muss nicht viel Zeit aufgewendet werden.
Als nächstes folgt die Latenzzeit des 99. Perzentils. Gleichzeitig ist, wie in der obigen Tabelle, zu sehen, dass die Latenz gesunken ist. Um einen Fehler zurückzugeben, muss nicht viel Zeit aufgewendet werden.
Wie es funktioniert
In einem 120 Pixel hohen Diagramm ist alles sichtbar. Viele davon können jedoch nicht auf einem Dashboard platziert werden, sodass wir uns auf 30 drücken. Leider erhalten wir dann eine Art Boa Constrictor. Gehen wir zurück und sehen, was der Kubismus damit macht. Er zerlegt das Diagramm in vier Teile: Je höher, desto dunkler und dann kollabiert er.
Leider erhalten wir dann eine Art Boa Constrictor. Gehen wir zurück und sehen, was der Kubismus damit macht. Er zerlegt das Diagramm in vier Teile: Je höher, desto dunkler und dann kollabiert er. Jetzt haben wir den gleichen Zeitplan wie zuvor, aber alles ist deutlich sichtbar: Je dunkler das Grün, desto schlechter. Jetzt ist viel klarer, was passiert.Links sieht man die Welle, als sie aufstieg, und in der Mitte, wo sie dunkelgrün ist, ist alles sehr schlecht.
Jetzt haben wir den gleichen Zeitplan wie zuvor, aber alles ist deutlich sichtbar: Je dunkler das Grün, desto schlechter. Jetzt ist viel klarer, was passiert.Links sieht man die Welle, als sie aufstieg, und in der Mitte, wo sie dunkelgrün ist, ist alles sehr schlecht.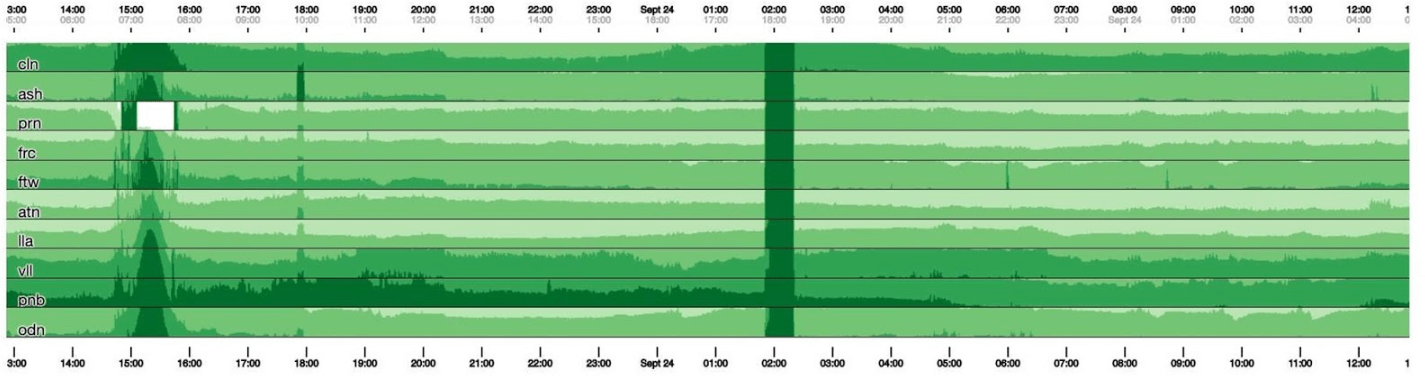 Kubismus ist nur der Anfang. Es wird für die Visualisierung benötigt, um zu verstehen, ob jetzt alles schlecht ist oder nicht. Für jede Tabelle gibt es bereits Dashboards mit detaillierten Grafiken.
Kubismus ist nur der Anfang. Es wird für die Visualisierung benötigt, um zu verstehen, ob jetzt alles schlecht ist oder nicht. Für jede Tabelle gibt es bereits Dashboards mit detaillierten Grafiken. Die Überwachung selbst hilft, den Status des Systems zu verstehen und zu reagieren, wenn es ausfällt. Auf Facebook muss jeder Oncall-Mitarbeiter in der Lage sein, alles zu reparieren. Wenn es hell brennt, schaltet sich alles ein, vor allem aber Produktionsingenieure mit der Erfahrung eines Systemadministrators, weil sie wissen, wie man das Problem schnell löst.
Die Überwachung selbst hilft, den Status des Systems zu verstehen und zu reagieren, wenn es ausfällt. Auf Facebook muss jeder Oncall-Mitarbeiter in der Lage sein, alles zu reparieren. Wenn es hell brennt, schaltet sich alles ein, vor allem aber Produktionsingenieure mit der Erfahrung eines Systemadministrators, weil sie wissen, wie man das Problem schnell löst.Wenn Facebook lag
Manchmal passieren Vorfälle und Facebook lügt. Normalerweise denken die Leute, dass Facebook wegen DDoS lügt oder Hacker angegriffen werden, aber in 5 Jahren ist es nie passiert. Der Grund waren immer unsere Ingenieure. Sie sind nicht absichtlich: Die Systeme sind sehr komplex und können dort ausfallen, wo Sie nicht warten.Wir geben allen wichtigen Vorfällen Namen, damit Neulinge bequem erwähnt und darüber informiert werden können, um Fehler in Zukunft nicht zu wiederholen. Der Champion mit dem lustigsten Namen ist der Vorfall Call the Cops . Die Leute riefen die Polizei in Los Angeles an und baten darum, Facebook zu reparieren, weil es lügt. Der Sheriff von Los Angeles hatte es so satt, dass er twitterte: "Bitte rufen Sie uns nicht an!" Wir sind dafür nicht verantwortlich! “ Mein Lieblingsvorfall, an dem ich teilgenommen habe, hieß CAPSLOCK.. Es ist insofern interessant, als es zeigt, dass alles passieren kann. Und genau das ist passiert. Es obychnyyIP Adresse :
Mein Lieblingsvorfall, an dem ich teilgenommen habe, hieß CAPSLOCK.. Es ist insofern interessant, als es zeigt, dass alles passieren kann. Und genau das ist passiert. Es obychnyyIP Adresse : fd3b:5679:92eb:9ce4::1.Facebook verwendet Chef, um das Betriebssystem anzupassen. Service Inventory speichert die Hostkonfiguration in seiner Datenbank, und Chef empfängt eine Konfigurationsdatei vom Service. Sobald der Dienst seine Version geändert hatte, begann er sofort, IP-Adressen aus der Datenbank im MySQL-Format zu lesen und in eine Datei zu kopieren. Die neue Adresse ist jetzt in Großbuchstaben geschrieben : FD3B:5679:92EB:9CE4::1.Shef sieht sich die neue Datei an und stellt fest, dass sich die IP-Adresse „geändert“ hat, da sie nicht in binärer Form, sondern mit einer Zeichenfolge verglichen wird. Die IP-Adresse ist "neu", was bedeutet, dass Sie die Schnittstelle absenken und die Schnittstelle anheben müssen. Bei allen Millionen Autos in 15 Minuten ging die Schnittstelle auf und ab.Es scheint in Ordnung zu sein - die Kapazität hat abgenommen, während das Netzwerk auf einigen Computern lag. Im Netzwerktreiber unserer benutzerdefinierten Netzwerkkarten trat jedoch plötzlich ein Fehler auf: Beim Start benötigten sie 0,5 GB sequentiellen physischen Speicher. Auf Cache-Computern verschwanden diese 0,5 GB, während wir die Schnittstelle absenkten und anhoben. Daher ist auf Cache-Computern die Netzwerkschnittstelle ausgefallen und nicht gestiegen, und ohne Caches funktioniert nichts. Wir setzten uns und starteten diese Maschinen mit unseren Händen neu. Es hat Spaß gemacht.Incident Manager Portal
Wenn Facebook „brennt“, ist es erforderlich, die Arbeit der „Feuerwehr“ zu organisieren und vor allem zu verstehen, wo es brennt, denn in einem großen Unternehmen kann es an einem Ort „verbrannt riechen“, aber das Problem liegt an einem anderen. Das UI-Tool namens Incident Manager Portal hilft uns dabei . Es wurde von Produktionsingenieuren geschrieben und steht allen offen. Sobald etwas passiert, starten wir dort einen Vorfall: Name, Anfang, Beschreibung.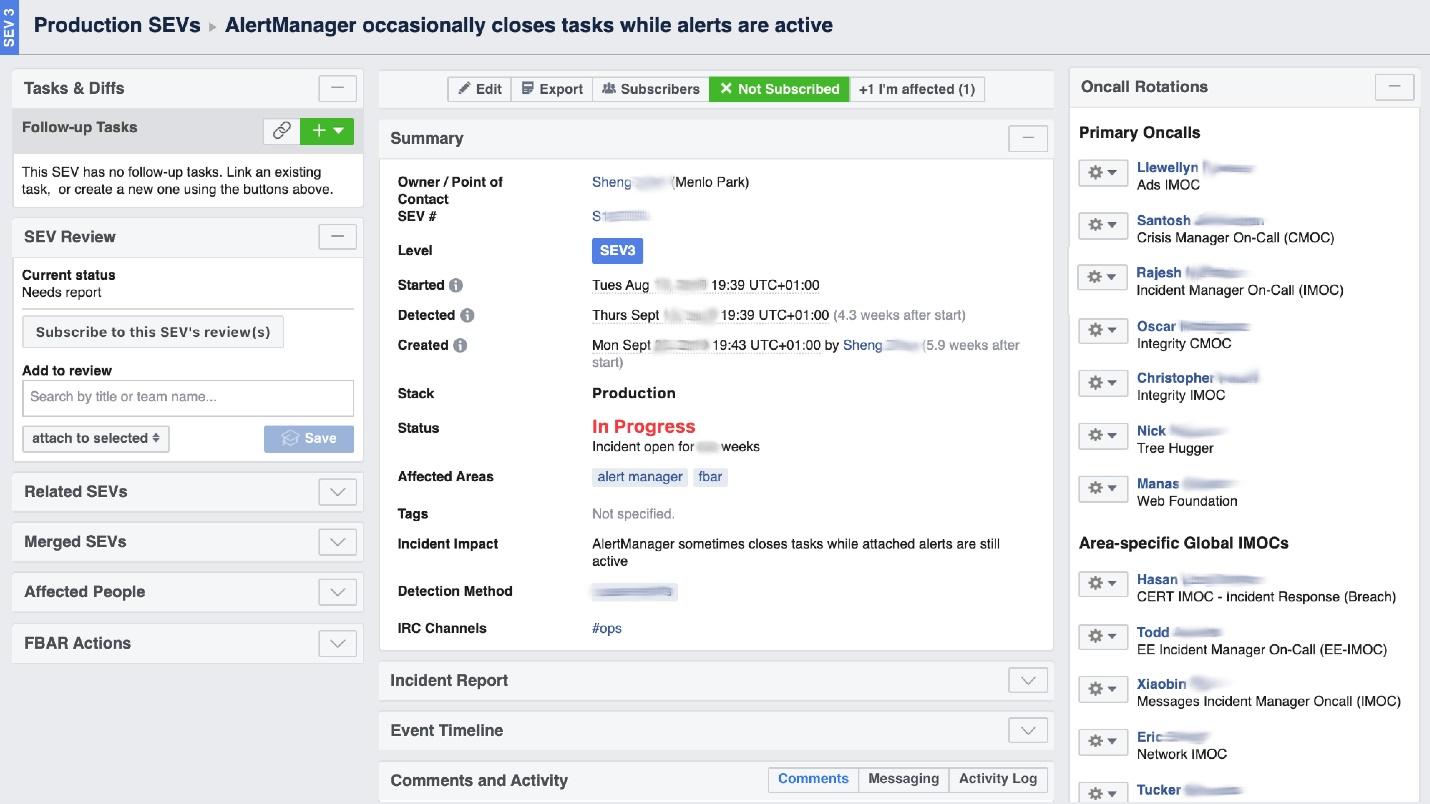 Wir haben eine speziell geschulte Person - Incident Manager On-Call (IMOC). Dies ist keine unbefristete Stelle, Manager wechseln regelmäßig. Bei großen Bränden organisiert und koordiniert IMOC Personen zur Reparatur, muss diese jedoch nicht selbst reparieren. Sobald ein Vorfall mit einem hohen Gefährdungsgrad erstellt wird, empfängt IMOC SMS und hilft bei der Organisation. In einem großen System kann auf solche Menschen nicht verzichtet werden.
Wir haben eine speziell geschulte Person - Incident Manager On-Call (IMOC). Dies ist keine unbefristete Stelle, Manager wechseln regelmäßig. Bei großen Bränden organisiert und koordiniert IMOC Personen zur Reparatur, muss diese jedoch nicht selbst reparieren. Sobald ein Vorfall mit einem hohen Gefährdungsgrad erstellt wird, empfängt IMOC SMS und hilft bei der Organisation. In einem großen System kann auf solche Menschen nicht verzichtet werden.Verhütung
Facebook ist nicht so verbreitet. Meistens löschen wir keine Brände und starten die Cache-Maschinen nicht neu, aber wir beheben Fehler im Voraus und wenn möglich für alle gleichzeitig.Sobald wir das "Warteschlangenproblem" gefunden und behoben haben. Die Anzahl der Anforderungen erhöht sich um 50% und die Fehler um 100%, da niemand die Drosselung im Voraus implementiert, insbesondere bei kleinen Diensten.Wir haben ein Beispiel für mehrere Dienste herausgefunden und ein Verhaltensmodell grob definiert.- Unter normaler Last kommt die Anforderung an, wird verarbeitet und an den Client zurückgegeben.
- Bei hoher Auslastung warten Anforderungen in einer Warteschlange, da alle Threads für die Verarbeitung von Anforderungen ausgelastet sind. Die Verzögerung nimmt zu, aber bisher ist alles in Ordnung.
- Die Linie wächst, die Last steigt. Irgendwann endet alles, was der Server auf dem Client ausführt, mit einem Antwortzeitlimit, und der Client fällt mit einem Fehler aus. Zu diesem Zeitpunkt kann das Ergebnis des Servers einfach weggeworfen werden.
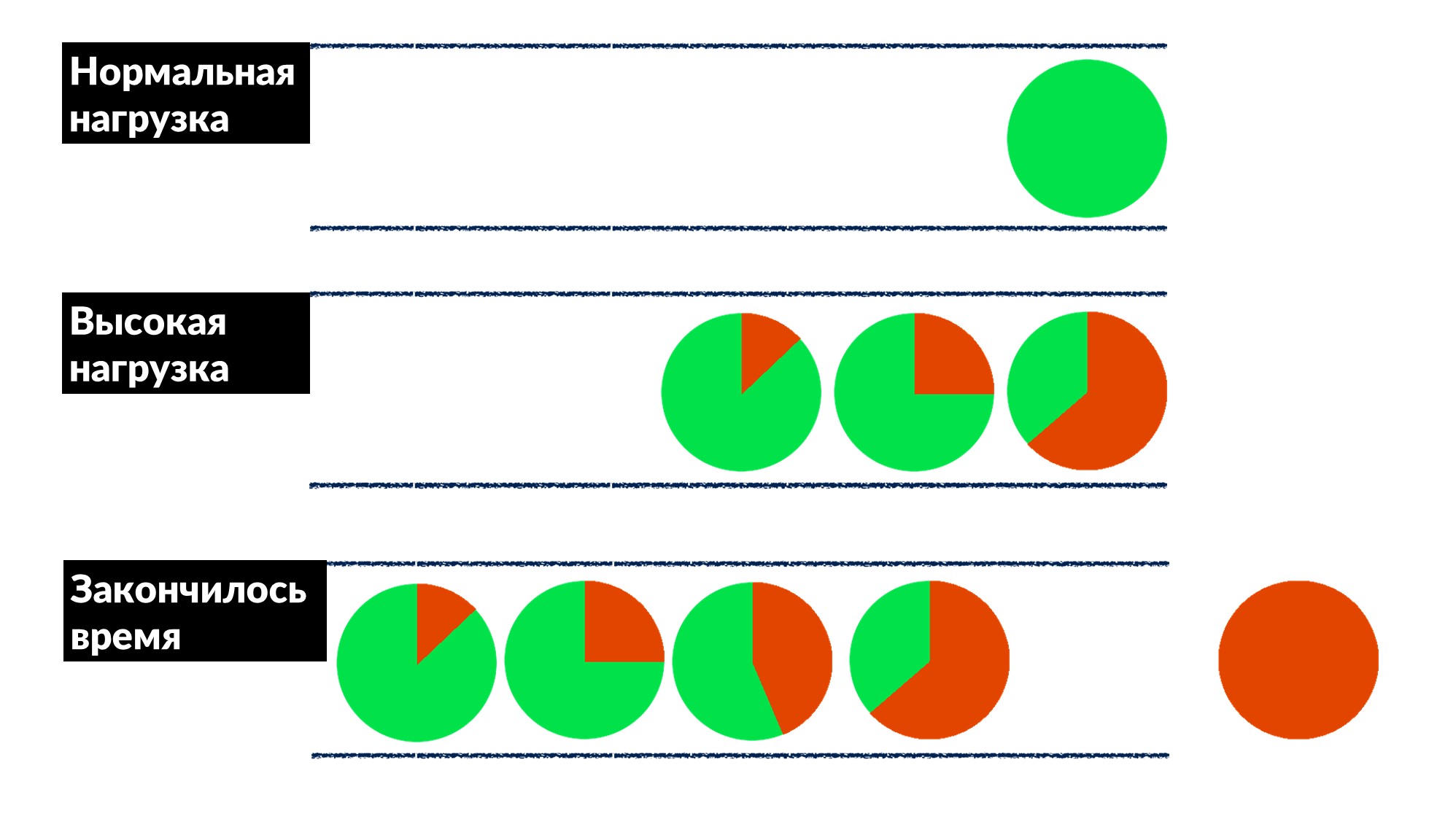 Das Client-Timeout wird rot hervorgehoben.Und der Kunde wiederholt noch einmal! Es stellt sich heraus, dass alle von uns ausgeführten Anforderungen in den Papierkorb geworfen werden und niemand mehr benötigt wird.Wie kann man dieses Problem für alle gleichzeitig lösen? Führen Sie eine Begrenzung der Wartezeit in der Warteschlange ein. Wenn sich die Anforderung mehr als erwartet in der Warteschlange befindet, wird sie verworfen und nicht auf dem Server verarbeitet. Wir verschwenden keine CPU darauf. Wir bekommen ein ehrliches Spiel: Wir werfen alles weg, was wir nicht verarbeiten können, und alles, was wir können - verarbeitet.Die Einschränkung ermöglichte es, die Last um 50% über das Maximum zu erhöhen, aber dennoch 66% der Anfragen zu verarbeiten und nur 33% der Fehler zu erhalten. Die Entwickler des Frameworks für Dispatch haben dies auf der Serverseite implementiert, und wir, die Produktionsingenieure, haben das Zeitlimit von 100 ms in der Warteschlange für alle sanft festgelegt. So erhielten alle Dienste sofort eine günstige Grunddrosselung.
Das Client-Timeout wird rot hervorgehoben.Und der Kunde wiederholt noch einmal! Es stellt sich heraus, dass alle von uns ausgeführten Anforderungen in den Papierkorb geworfen werden und niemand mehr benötigt wird.Wie kann man dieses Problem für alle gleichzeitig lösen? Führen Sie eine Begrenzung der Wartezeit in der Warteschlange ein. Wenn sich die Anforderung mehr als erwartet in der Warteschlange befindet, wird sie verworfen und nicht auf dem Server verarbeitet. Wir verschwenden keine CPU darauf. Wir bekommen ein ehrliches Spiel: Wir werfen alles weg, was wir nicht verarbeiten können, und alles, was wir können - verarbeitet.Die Einschränkung ermöglichte es, die Last um 50% über das Maximum zu erhöhen, aber dennoch 66% der Anfragen zu verarbeiten und nur 33% der Fehler zu erhalten. Die Entwickler des Frameworks für Dispatch haben dies auf der Serverseite implementiert, und wir, die Produktionsingenieure, haben das Zeitlimit von 100 ms in der Warteschlange für alle sanft festgelegt. So erhielten alle Dienste sofort eine günstige Grunddrosselung.Werkzeuge
Die Ideologie von SRE besagt, dass Sie automatisieren müssen, wenn Sie eine große Flotte von Autos, eine Reihe von Diensten und nichts mit Ihren Händen zu tun haben. Daher schreiben wir die Hälfte der Zeit Code und erstellen Tools.- Integrierter Kubismus in das System.
- FBAR ist ein „Arbeitstier“, das kommt und repariert, sodass sich niemand Sorgen um ein kaputtes Auto macht. Dies ist die Hauptaufgabe des FBAR, aber jetzt hat es noch mehr Aufgaben.
- Coredumper , den wir mit zwei Kollegen geschrieben haben . Es überwacht Coredumps auf allen Maschinen und legt sie zusammen mit Stack-Traces mit allen Host-Informationen an einem Ort ab: Wo liegt sie, wie findet man welche Größe? Vor allem aber sind Stack-Traces kostenlos, ohne GDB mit BPF-Programmen zu starten.
Umfragen
Das Letzte, was wir tun, ist mit Leuten zu reden, sie zu interviewen. Dies scheint uns sehr wichtig zu sein.Eine nützliche Umfrage betrifft die Zuverlässigkeit. In den wichtigsten Zitaten unseres Fragebogens fragen wir nach bereits laufenden Diensten:"Die Hauptverantwortung der Systemsoftware muss darin bestehen, weiter zu laufen. Die Erbringung von Dienstleistungen sollte als vorteilhafter Nebeneffekt des fortgesetzten Betriebs angesehen werden »
Dies bedeutet, dass die Hauptaufgabe des Systems darin besteht, weiter zu arbeiten, und die Tatsache, dass es irgendeine Art von Service bietet, ist ein zusätzlicher Bonus.Umfragen sind nur für mittlere Dienste gedacht, große selbst verstehen. Wir geben einen Fragebogen, in dem wir grundlegende Fragen zu Architektur, SLO und zum Beispiel zum Testen stellen.- "Was passiert, wenn Ihr System 10% der Last erhält?" Wenn die Leute denken: "Aber wirklich, was?" - Einsichten erscheinen und viele regieren sogar ihre Systeme. Früher haben sie nicht darüber nachgedacht, aber nach der Frage gibt es einen Grund.
- "Wer ist der erste, der normalerweise Probleme mit Ihrem Dienst bemerkt - Sie oder Ihre Benutzer?" Entwickler beginnen sich zu erinnern, wann dies passiert ist und: "... Vielleicht müssen Sie Warnungen hinzufügen."
- "Was ist dein größter Oncall-Schmerz?" Dies ist ungewöhnlich für Entwickler, insbesondere für neue. Sie sagen sofort: „Wir haben viele Warnungen! Lassen Sie uns sie reinigen und diejenigen entfernen, die nicht der Fall sind. “
- "Wie häufig sind deine Veröffentlichungen?" Zuerst erinnern sie sich daran, dass sie es mit ihren Händen freigeben, und dann haben sie ihre eigene benutzerdefinierte Bereitstellung.
Der Fragebogen enthält keine Kodierung, er ist standardisiert und ändert sich alle sechs Monate. Dies ist ein zweiseitiges Dokument, das wir in 2-3 Wochen ausfüllen können. Und dann arrangieren wir eine zweistündige Kundgebung und finden Lösungen für viele Probleme. Dieses einfache Tool funktioniert gut mit uns und kann Ihnen helfen.6-7 Saint HighLoad++, . (, , ).
telegram- . !