Im Vorgriff auf den Beginn des Data Engineer- Kurses haben wir eine Übersetzung eines kleinen, aber interessanten Materials vorbereitet.
In diesem Artikel werde ich darüber sprechen, wie Parkett große Datenmengen in eine kleine Footprint-Datei komprimiert und wie wir mithilfe von Parallelität (Multithreading) eine Bandbreite erreichen können, die weit über der Bandbreite des E / A-Streams liegt.Apache-Parkett: Am besten bei Daten mit niedriger Entropie
Wie Sie der Spezifikation des Apache Parquet- Formats entnehmen können, enthält es mehrere Codierungsebenen, mit denen die Dateigröße erheblich reduziert werden kann. Dazu gehören:- Codierung (Komprimierung) mithilfe eines Wörterbuchs (ähnlich wie bei pandas.Kategoriale Art der Darstellung von Daten, aber die Konzepte selbst sind unterschiedlich);
- Komprimierung von Datenseiten (Snappy, Gzip, LZO oder Brotli);
- Codierung der Ausführungslänge (für Nullzeiger und Indizes des Wörterbuchs) und Ganzzahlbitpackung;
Um Ihnen zu zeigen, wie dies funktioniert, schauen wir uns einen Datensatz an:['banana', 'banana', 'banana', 'banana', 'banana', 'banana',
'banana', 'banana', 'apple', 'apple', 'apple']
Fast alle Parkettimplementierungen verwenden das Standardwörterbuch für die Komprimierung. Somit sind die codierten Daten wie folgt:dictionary: ['banana', 'apple']
indices: [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1]
Indizes im Wörterbuch werden zusätzlich durch den Wiederholungscodierungsalgorithmus komprimiert:dictionary: ['banana', 'apple']
indices (RLE): [(8, 0), (3, 1)]
Wenn Sie dem Rückweg folgen, können Sie das ursprüngliche Array von Zeichenfolgen problemlos wiederherstellen.In meinem vorherigen Artikel habe ich einen Datensatz erstellt, der auf diese Weise sehr gut komprimiert wird. Bei der Arbeit mit pyarrowkönnen wir die Codierung mithilfe des Wörterbuchs (das standardmäßig aktiviert ist) aktivieren und deaktivieren, um festzustellen, wie sich dies auf die Dateigröße auswirkt:import pyarrow.parquet as pq
pq.write_table(dataset, out_path, use_dictionary=True,
compression='snappy)
Ein Datensatz pandas.DataFramemit einer Größe von 1 GB (1024 MB) bei Snappy-Komprimierung und Komprimierung mithilfe eines Wörterbuchs benötigt nur 1,436 MB, dh er kann sogar auf eine Diskette geschrieben werden. Ohne Komprimierung mit dem Wörterbuch belegt es 44,4 MB.Gleichzeitiges Lesen in Parkett-CPP mit PyArrow
Bei der Implementierung von Apache Parquet in C ++ - parquet-cpp , die wir für Python in PyArrow zur Verfügung gestellt haben, wurde die Möglichkeit hinzugefügt, Spalten parallel zu lesen.Um diese Funktion zu testen, installieren Sie PyArrow von conda-forge :conda install pyarrow -c conda-forge
Wenn Sie jetzt die Parkettdatei lesen, können Sie das folgende Argument verwenden nthreads:import pyarrow.parquet as pq
table = pq.read_table(file_path, nthreads=4)
Bei Daten mit geringer Entropie sind Dekomprimierung und Dekodierung stark an den Prozessor gebunden. Da C ++ die ganze Arbeit für uns erledigt, gibt es keine Probleme mit der GIL-Parallelität und wir können eine signifikante Geschwindigkeitssteigerung erzielen. Sehen Sie, was ich durch Lesen eines 1-GB- Datensatzes in einem Pandas-DataFrame auf einem Quad-Core-Laptop (Xeon E3-1505M, NVMe-SSD) erreichen konnte: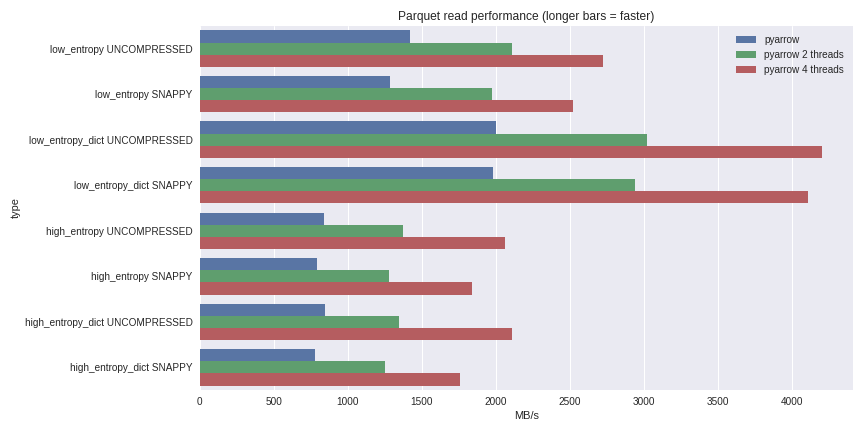 Das vollständige Benchmarking-Szenario finden Sie hier .Ich habe hier die Leistung sowohl für Komprimierungsfälle mit einem Wörterbuch als auch für Fälle ohne Verwendung eines Wörterbuchs aufgenommen. Bei Daten mit geringer Entropie wirkt sich die Komprimierung mithilfe eines Wörterbuchs erheblich auf die Leistung aus, obwohl alle Dateien klein sind (~ 1,5 MB mit Wörterbüchern und ~ 45 MB ohne). Mit 4 Threads erhöht sich die Leseleistung von Pandas auf 4 GB / s. Dies ist viel schneller als das Feather-Format oder jedes andere, das ich kenne.
Das vollständige Benchmarking-Szenario finden Sie hier .Ich habe hier die Leistung sowohl für Komprimierungsfälle mit einem Wörterbuch als auch für Fälle ohne Verwendung eines Wörterbuchs aufgenommen. Bei Daten mit geringer Entropie wirkt sich die Komprimierung mithilfe eines Wörterbuchs erheblich auf die Leistung aus, obwohl alle Dateien klein sind (~ 1,5 MB mit Wörterbüchern und ~ 45 MB ohne). Mit 4 Threads erhöht sich die Leseleistung von Pandas auf 4 GB / s. Dies ist viel schneller als das Feather-Format oder jedes andere, das ich kenne.Fazit
Mit der Version 1.0 parquet-cpp (Apache Parquet in C ++) können Sie sich selbst von der gesteigerten E / A-Leistung überzeugen, die Python-Benutzern jetzt zur Verfügung steht.Da alle grundlegenden Mechanismen in C ++ in anderen Sprachen (z. B. R) implementiert sind, können Sie Schnittstellen für Apache Arrow (säulenförmige Datenstrukturen) und Parkett-CPP erstellen . Die Python-Bindung ist eine kompakte Shell der C ++ - Kernbibliotheken libarrow und libparquet .Das ist alles. Wenn Sie mehr über unseren Kurs erfahren möchten, melden Sie sich für einen Tag der offenen Tür an , der heute stattfinden wird!