Hallo, ich arbeite im Projektteam des RRP KP (verteiltes Datenregister zur Überwachung des Lebenszyklus von Radsätzen). Hier möchte ich die Erfahrungen unseres Teams bei der Entwicklung einer Unternehmensblockchain für dieses Projekt unter den von der Technologie vorgegebenen Bedingungen teilen. Zum größten Teil werde ich über Hyperledger Fabric sprechen, aber der hier beschriebene Ansatz kann auf jede erlaubte Blockchain extrapoliert werden. Das ultimative Ziel unserer Forschung ist es, Blockchain-Lösungen für Unternehmen so vorzubereiten, dass das Endprodukt angenehm zu verwenden und nicht zu schwer zu warten ist.Es wird keine Entdeckungen geben, unerwartete Lösungen und keine einzigartigen Entwicklungen werden hier behandelt (weil ich sie nicht habe). Ich möchte nur meine bescheidenen Erfahrungen teilen, um zu zeigen, dass „es möglich war“, und vielleicht in den Kommentaren über die Erfahrungen anderer lesen, gute und weniger gute Entscheidungen zu treffen.Problem: Blockchains sind noch nicht skaliert
Heutzutage zielen die Bemühungen vieler Entwickler darauf ab, die Blockchain zu einer wirklich praktischen Technologie zu machen und nicht zu einer Zeitbombe in einem schönen Wrapper. Zustandskanäle, optimistisches Rollup, Plasma und Sharding können alltäglich werden. Irgendwann mal. Oder vielleicht wird TON den Start erneut um sechs Monate verzögern und die nächste Plasmagruppe wird aufhören zu existieren. Wir können an eine andere Roadmap glauben und brillante White Papers für die Nacht lesen, aber hier und jetzt müssen wir etwas mit dem tun, was wir haben. Scheiße fertig machen.Die Aufgabe, die unserem Team im aktuellen Projekt gestellt wird, sieht im Allgemeinen so aus: Es gibt viele Unternehmen, die mehrere Tausend erreichen und keine vertrauensvollen Beziehungen aufbauen möchten. Es ist erforderlich, eine DLT-Lösung zu erstellen, die auf normalen PCs ohne besondere Leistungsanforderungen funktioniert und eine Benutzererfahrung bietet, die nicht schlechter ist als bei jedem zentralen Buchhaltungssystem. Die der Lösung zugrunde liegende Technologie sollte die Möglichkeit einer böswilligen Manipulation von Daten minimieren. Deshalb befindet sich hier die Blockchain.Slogans aus Whitepapers und den Medien versprechen uns, dass Sie mit der nächsten Entwicklung Millionen von Transaktionen pro Sekunde durchführen können. Was ist das wirklich?Das Mainnet Ethereum läuft jetzt mit ~ 30 tps. Bereits deshalb ist es schwierig, es als eine Blockchain zu erkennen, die für Unternehmensanforderungen geeignet ist. Unter den genehmigten Lösungen sind Benchmarks bekannt, die 2000 tps ( Quorum ) oder 3000 tps ( Hyperledger Fabric , die Veröffentlichung ist etwas kleiner, aber Sie müssen berücksichtigen, dass der Benchmark mit der alten Consensus-Engine durchgeführt wurde) anzeigen . Es wurde versucht, Fabric radikal zu überarbeiten , was mit 20.000 tps nicht zu den schlechtesten Ergebnissen führte. Bisher ist dies jedoch nur akademische Forschung, die auf seine stabile Implementierung wartet. Es ist unwahrscheinlich, dass ein Unternehmen, das es sich leisten kann, eine Abteilung von Blockchain-Entwicklern zu unterhalten, solche Indikatoren in Kauf nimmt. Das Problem ist jedoch nicht nur der Durchsatz, sondern auch die Latenz.Latenz
Die Verzögerung vom Beginn der Transaktion bis zur endgültigen Genehmigung durch das System hängt nicht nur von der Geschwindigkeit der Nachricht ab, die alle Phasen der Validierung und Bestellung durchläuft, sondern auch von den Parametern der Blockbildung. Selbst wenn unsere Blockchain es uns ermöglicht, mit einer Geschwindigkeit von 1.000.000 tps festzuschreiben, die Bildung eines 488-MB-Blocks jedoch 10 Minuten dauert, wird es für uns einfacher?Schauen wir uns den Transaktionslebenszyklus in Hyperledger Fabric genauer an, um zu verstehen, wofür die Zeit aufgewendet wird und wie sie sich auf die Parameter der Blockbildung auswirkt.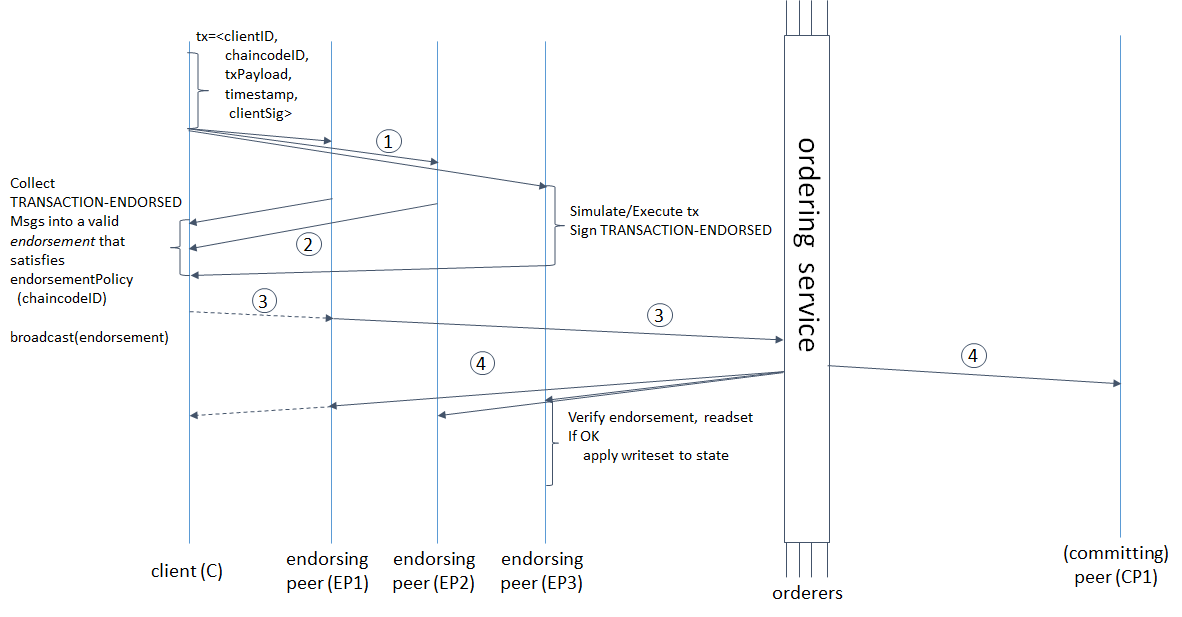 von hier genommen : hyperledger-fabric.readthedocs.io/en/release-1.4/arch-deep-dive.html#swimlane(1) Der Client bildet die Transaktion, sendet sie an unterstützende Peers. Letztere simulieren die Transaktion (wenden die vom Kettencode vorgenommenen Änderungen auf den aktuellen Status an, verpflichten sich jedoch nicht zum Hauptbuch) und erhalten RWSet - Schlüsselnamen, Versionen und Werte aus der Sammlung in CouchDB. 2) Endorser senden das signierte RWSet an den Client zurück. (3) Der Client prüft entweder die Signaturen aller erforderlichen Peers (Endorser) und sendet die Transaktion dann an den Bestellservice oder sendet sie ohne Bestätigung (die Überprüfung erfolgt später noch). Der Bestellservice bildet einen Block. 4) sendet an alle Peers zurück, nicht nur an Endorser; Peers überprüfen, ob die Schlüsselversionen im Lesesatz mit den Versionen in der Datenbank und den Signaturen aller Endorser übereinstimmen, und schreiben den Block schließlich fest.Aber das ist nicht alles. Die Wörter "Reihenfolge bildet einen Block" verbergen nicht nur die Reihenfolge der Transaktionen, sondern auch 3 aufeinanderfolgende Netzwerkanforderungen vom Leiter an die Follower und umgekehrt: Der Leiter fügt dem Protokoll eine Nachricht hinzu, sendet Anhänger, letzterer fügt seinem Protokoll hinzu, sendet eine Bestätigung der erfolgreichen Replikation an den Leiter, der Leiter schreibt eine Nachricht , sendet eine Commit-Bestätigung an Follower, Follower-Commit. Je kleiner die Größe und die Zeit der Blockbildung sind, desto häufiger muss der Bestellservice einen Konsens herstellen. Hyperledger Fabric verfügt über zwei Parameter für die Blockbildung: BatchTimeout - Zeitpunkt der Blockbildung und BatchSize - Blockgröße (Anzahl der Transaktionen und Größe des Blocks selbst in Byte). Sobald einer der Parameter das Limit erreicht, wird ein neuer Block freigegeben. Je mehr Warrant-Knoten vorhanden sind, desto länger dauert es. Daher müssen Sie BatchTimeout und BatchSize erhöhen. Da RWSets jedoch versioniert sind, ist die Wahrscheinlichkeit von MVCC-Konflikten umso höher, je mehr wir einen Block erstellen. Darüber hinaus verschlechtert sich UX mit einem Anstieg von BatchTimeout katastrophal. Das folgende Schema erscheint mir vernünftig und offensichtlich, um diese Probleme zu lösen.
von hier genommen : hyperledger-fabric.readthedocs.io/en/release-1.4/arch-deep-dive.html#swimlane(1) Der Client bildet die Transaktion, sendet sie an unterstützende Peers. Letztere simulieren die Transaktion (wenden die vom Kettencode vorgenommenen Änderungen auf den aktuellen Status an, verpflichten sich jedoch nicht zum Hauptbuch) und erhalten RWSet - Schlüsselnamen, Versionen und Werte aus der Sammlung in CouchDB. 2) Endorser senden das signierte RWSet an den Client zurück. (3) Der Client prüft entweder die Signaturen aller erforderlichen Peers (Endorser) und sendet die Transaktion dann an den Bestellservice oder sendet sie ohne Bestätigung (die Überprüfung erfolgt später noch). Der Bestellservice bildet einen Block. 4) sendet an alle Peers zurück, nicht nur an Endorser; Peers überprüfen, ob die Schlüsselversionen im Lesesatz mit den Versionen in der Datenbank und den Signaturen aller Endorser übereinstimmen, und schreiben den Block schließlich fest.Aber das ist nicht alles. Die Wörter "Reihenfolge bildet einen Block" verbergen nicht nur die Reihenfolge der Transaktionen, sondern auch 3 aufeinanderfolgende Netzwerkanforderungen vom Leiter an die Follower und umgekehrt: Der Leiter fügt dem Protokoll eine Nachricht hinzu, sendet Anhänger, letzterer fügt seinem Protokoll hinzu, sendet eine Bestätigung der erfolgreichen Replikation an den Leiter, der Leiter schreibt eine Nachricht , sendet eine Commit-Bestätigung an Follower, Follower-Commit. Je kleiner die Größe und die Zeit der Blockbildung sind, desto häufiger muss der Bestellservice einen Konsens herstellen. Hyperledger Fabric verfügt über zwei Parameter für die Blockbildung: BatchTimeout - Zeitpunkt der Blockbildung und BatchSize - Blockgröße (Anzahl der Transaktionen und Größe des Blocks selbst in Byte). Sobald einer der Parameter das Limit erreicht, wird ein neuer Block freigegeben. Je mehr Warrant-Knoten vorhanden sind, desto länger dauert es. Daher müssen Sie BatchTimeout und BatchSize erhöhen. Da RWSets jedoch versioniert sind, ist die Wahrscheinlichkeit von MVCC-Konflikten umso höher, je mehr wir einen Block erstellen. Darüber hinaus verschlechtert sich UX mit einem Anstieg von BatchTimeout katastrophal. Das folgende Schema erscheint mir vernünftig und offensichtlich, um diese Probleme zu lösen.Vermeiden Sie es, auf die Block-Finalisierung zu warten, und verlieren Sie nicht die Fähigkeit, den Transaktionsstatus zu verfolgen
Je länger die Formationszeit und die Blockgröße sind, desto höher ist der Durchsatz der Blockchain. Einer der anderen folgt nicht direkt, aber es sollte beachtet werden, dass für die Konsensbildung in RAFT drei Netzwerkanforderungen vom Leiter an die Follower und umgekehrt erforderlich sind. Je mehr Auftragsknoten vorhanden sind, desto länger dauert es. Je kleiner die Größe und die Bildungszeit des Blocks sind, desto mehr solche Wechselwirkungen treten auf. Wie kann die Formationszeit und die Blockgröße erhöht werden, ohne die Wartezeit für eine Systemantwort für den Endbenutzer zu verlängern?Erstens müssen Sie MVCC-Konflikte irgendwie lösen, die durch eine große Blockgröße verursacht werden, die verschiedene RWSets mit derselben Version enthalten kann. Auf der Clientseite (in Bezug auf das Blockchain-Netzwerk ist dies möglicherweise das Backend, und ich meine es auch so) benötigen Sie natürlich einen MVCC-KonfliktbehandlerDies kann entweder ein separater Dienst oder ein regulärer Dekorateur über einen transaktionsauslösenden Aufruf mit Wiederholungslogik sein.Wiederholungsversuche können mit einer exponentiellen Strategie implementiert werden, aber dann verringert sich die Latenz ebenso exponentiell. Sie sollten also entweder einen zufälligen oder einen permanenten Wiederholungsversuch innerhalb bestimmter kleiner Grenzen verwenden. Mit Blick auf mögliche Konflikte in der ersten Ausführungsform.Der nächste Schritt besteht darin, die Interaktion des Clients mit dem System asynchron zu gestalten, damit es nicht 15, 30 oder 10.000.000 Sekunden wartet, die wir als BatchTimeout festlegen. Gleichzeitig müssen Sie die Gelegenheit speichern, um sicherzustellen, dass die durch die Transaktion initiierten Änderungen in die Blockchain geschrieben / nicht geschrieben werden.Sie können eine Datenbank verwenden, um den Transaktionsstatus zu speichern. Die einfachste Option ist CouchDB, da sie einfach zu bedienen ist: Die Datenbank verfügt über eine sofort einsatzbereite Benutzeroberfläche und eine REST-API, und Sie können Replikation und Sharding einfach dafür konfigurieren. Sie können nur eine separate Sammlung in derselben CouchDB-Instanz erstellen, in der Fabric seinen Weltstatus speichert. Wir müssen Dokumente dieser Art speichern.{
Status string
TxID: string
Error: string
}
Dieses Dokument wird in die Datenbank geschrieben, bevor die Transaktion an Peers übertragen wird. Eine Entitäts-ID wird an den Benutzer zurückgegeben (dieselbe ID wird als Schlüssel verwendet), wenn dies eine Operation zum Erstellen von Daten ist. Anschließend werden die Felder Status, TxID und Fehler aktualisiert, sobald relevante Informationen von Peers empfangen werden. In diesem Schema wartet der Benutzer nicht auf die endgültige Bildung des Blocks und beobachtet 10 Sekunden lang das sich drehende Rad auf dem Bildschirm. Er erhält eine sofortige Antwort vom System und arbeitet weiter.Wir haben BoltDB zum Speichern von Transaktionsstatus ausgewählt, da wir Speicherplatz sparen müssen und keine Zeit für die Netzwerkinteraktion mit einem eigenständigen Datenbankserver aufwenden möchten, insbesondere wenn diese Interaktion über das Nur-Text-Protokoll erfolgt. Übrigens verwenden Sie CouchDB, um das oben beschriebene Schema zu implementieren oder nur um den Weltzustand zu speichern. In jedem Fall ist es sinnvoll, die Art und Weise zu optimieren, wie Daten in CouchDB gespeichert werden. In CouchDB beträgt die Größe der B-Tree-Knoten standardmäßig 1279 Byte, was viel kleiner ist als die Größe des Sektors auf der Festplatte. Dies bedeutet, dass sowohl das Lesen als auch das Neuausgleichen des Baums mehr physischen Zugriff auf die Festplatte erfordern. Die optimale Größe entspricht dem Advanced Format- Standard und beträgt 4 Kilobyte. Zur Optimierung müssen wir den Parameter btree_chunk_size auf 4096 setzenin der CouchDB-Konfigurationsdatei. Für BoltDB ist ein solcher manueller Eingriff nicht erforderlich .
In diesem Schema wartet der Benutzer nicht auf die endgültige Bildung des Blocks und beobachtet 10 Sekunden lang das sich drehende Rad auf dem Bildschirm. Er erhält eine sofortige Antwort vom System und arbeitet weiter.Wir haben BoltDB zum Speichern von Transaktionsstatus ausgewählt, da wir Speicherplatz sparen müssen und keine Zeit für die Netzwerkinteraktion mit einem eigenständigen Datenbankserver aufwenden möchten, insbesondere wenn diese Interaktion über das Nur-Text-Protokoll erfolgt. Übrigens verwenden Sie CouchDB, um das oben beschriebene Schema zu implementieren oder nur um den Weltzustand zu speichern. In jedem Fall ist es sinnvoll, die Art und Weise zu optimieren, wie Daten in CouchDB gespeichert werden. In CouchDB beträgt die Größe der B-Tree-Knoten standardmäßig 1279 Byte, was viel kleiner ist als die Größe des Sektors auf der Festplatte. Dies bedeutet, dass sowohl das Lesen als auch das Neuausgleichen des Baums mehr physischen Zugriff auf die Festplatte erfordern. Die optimale Größe entspricht dem Advanced Format- Standard und beträgt 4 Kilobyte. Zur Optimierung müssen wir den Parameter btree_chunk_size auf 4096 setzenin der CouchDB-Konfigurationsdatei. Für BoltDB ist ein solcher manueller Eingriff nicht erforderlich .Gegendruck: Pufferstrategie
Aber es kann viele Nachrichten geben. Mehr als das System kann verarbeiten und Ressourcen mit einem Dutzend anderer Dienste als den im Diagramm gezeigten gemeinsam nutzen - und all dies sollte auch auf Computern funktionieren, auf denen das Starten von Intellij Idea äußerst mühsam sein wird.Das Problem der unterschiedlichen Durchsätze von Kommunikationssystemen, Hersteller und Verbraucher, wird auf unterschiedliche Weise gelöst. Mal sehen, was wir tun können.Löschen : Wir können behaupten, nicht mehr als X Transaktionen in T Sekunden verarbeiten zu können. Alle Anforderungen, die dieses Limit überschreiten, werden zurückgesetzt. Es ist ziemlich einfach, aber dann können Sie UX vergessen.Steuern: Der Verbraucher sollte über eine Schnittstelle verfügen, über die er je nach Belastung die tps des Herstellers steuern kann. Nicht schlecht, aber es verpflichtet die Entwickler des Clients, die Last für die Implementierung dieser Schnittstelle zu erstellen. Für uns ist dies inakzeptabel, da die Blockchain in Zukunft in eine Vielzahl von seit langem bestehenden Systemen integriert wird.Pufferung : Anstatt dem Eingangsdatenstrom zu widerstehen, können wir diesen Strom puffern und mit der erforderlichen Geschwindigkeit verarbeiten. Dies ist natürlich die beste Lösung, wenn wir eine gute Benutzererfahrung bieten möchten. Wir haben den Puffer mithilfe der Warteschlange in RabbitMQ implementiert. Dem Schema wurden zwei neue Aktionen hinzugefügt: (1) Nach dem Empfang der Anforderung für die API wird eine Nachricht mit den zum Aufrufen der Transaktion erforderlichen Parametern in die Warteschlange gestellt, und der Client erhält eine Nachricht, dass die Transaktion vom System akzeptiert wurde. (2) Das Backend liest die Daten mit der in der Konfiguration angegebenen Geschwindigkeit aus der Warteschlange; initiiert eine Transaktion und aktualisiert die Daten im Statusspeicher.Jetzt können Sie die Formationszeit erhöhen und die Kapazität beliebig blockieren, um Verzögerungen vor dem Benutzer zu verbergen.
Dem Schema wurden zwei neue Aktionen hinzugefügt: (1) Nach dem Empfang der Anforderung für die API wird eine Nachricht mit den zum Aufrufen der Transaktion erforderlichen Parametern in die Warteschlange gestellt, und der Client erhält eine Nachricht, dass die Transaktion vom System akzeptiert wurde. (2) Das Backend liest die Daten mit der in der Konfiguration angegebenen Geschwindigkeit aus der Warteschlange; initiiert eine Transaktion und aktualisiert die Daten im Statusspeicher.Jetzt können Sie die Formationszeit erhöhen und die Kapazität beliebig blockieren, um Verzögerungen vor dem Benutzer zu verbergen.Andere Werkzeuge
Über den Kettencode wurde hier nichts gesagt, da in der Regel nichts zu optimieren ist. Chaincode sollte so einfach und sicher wie möglich sein - das ist alles, was dazu benötigt wird. Das einfache und sichere Schreiben von Cheynkod hilft uns dabei, SSKit von S7 Techlab und dem statischen Analysator Revive ^ CC zu optimieren .Darüber hinaus entwickelt unser Team eine Reihe von Dienstprogrammen, um die Arbeit mit Fabric einfach und unterhaltsam zu gestalten: einen Blockchain-Explorer , ein Dienstprogramm zum automatischen Ändern der Netzwerkkonfiguration (Hinzufügen / Entfernen von Organisationen, RAFT-Knoten), ein Dienstprogramm zum Widerrufen von Zertifikaten und zum Entfernen der Identität . Wenn Sie dazu beitragen möchten - willkommen.Fazit
Dieser Ansatz macht es einfach, Hyperledger Fabric durch Quorum, andere private Ethereum-Netzwerke (PoA oder sogar PoW), zu ersetzen, die reale Bandbreite erheblich zu reduzieren und gleichzeitig die normale Benutzeroberfläche beizubehalten (sowohl für Benutzer im Browser als auch für integrierte Systeme). Wenn Sie Fabric im Schema durch Ethereum ersetzen, müssen Sie nur die Logik des Wiederholungsdienstes / Dekorators von der Verarbeitung von MVCC-Konflikten in das atomare Inkrement nonce und das erneute Senden ändern. Durch Pufferung und Statusspeicherung kann die Antwortzeit von der Blockbildungszeit entkoppelt werden. Jetzt können Sie Tausende von Auftragsknoten hinzufügen und haben keine Angst, dass zu oft Blöcke gebildet werden, und laden den Bestellservice.Im Allgemeinen war das alles, was ich teilen wollte. Ich würde mich freuen, wenn dies jemandem bei seiner Arbeit hilft.