Hinweis perev. : In diesem Artikel gibt Banzai Cloud ein Beispiel für die Verwendung seiner speziellen Dienstprogramme, um den Betrieb von Kafka innerhalb von Kubernetes zu erleichtern. Diese Anweisungen veranschaulichen, wie Sie die optimale Infrastrukturgröße ermitteln und Kafka selbst konfigurieren können, um den erforderlichen Durchsatz zu erzielen. Apache Kafka ist eine verteilte Streaming-Plattform zur Erstellung zuverlässiger, skalierbarer und leistungsstarker Echtzeit-Streaming-Systeme. Seine beeindruckenden Funktionen können mit Kubernetes erweitert werden. Zu diesem Zweck haben wir den Kafka Open Source-Operator und ein Tool namens Supertubes entwickelt. Mit ihnen können Sie Kafka in Kubernetes ausführen und die verschiedenen Funktionen verwenden, z. B. die Feinabstimmung der Brokerkonfiguration, die Skalierung basierend auf Metriken mit Neuausrichtung, Rack-Erkennung (Kenntnis der Hardwareressourcen), „weiche“ (ordnungsgemäße) fortlaufende Updates usw.
Apache Kafka ist eine verteilte Streaming-Plattform zur Erstellung zuverlässiger, skalierbarer und leistungsstarker Echtzeit-Streaming-Systeme. Seine beeindruckenden Funktionen können mit Kubernetes erweitert werden. Zu diesem Zweck haben wir den Kafka Open Source-Operator und ein Tool namens Supertubes entwickelt. Mit ihnen können Sie Kafka in Kubernetes ausführen und die verschiedenen Funktionen verwenden, z. B. die Feinabstimmung der Brokerkonfiguration, die Skalierung basierend auf Metriken mit Neuausrichtung, Rack-Erkennung (Kenntnis der Hardwareressourcen), „weiche“ (ordnungsgemäße) fortlaufende Updates usw.Probieren Sie Supertubes in Ihrem Cluster aus:
curl https://getsupertubes.sh | sh supertubes install -a --no-democluster --kubeconfig <path-to-eks-cluster-kubeconfig-file>
Oder beziehen Sie sich auf die Dokumentation . Sie können auch einige der Funktionen von Kafka lesen, die mithilfe von Supertubes und dem Kafka-Operator automatisiert werden. Wir haben bereits im Blog darüber geschrieben:
Wenn Sie sich für die Bereitstellung eines Kafka-Clusters in Kubernetes entscheiden, werden Sie wahrscheinlich auf das Problem stoßen, die optimale Größe der zugrunde liegenden Infrastruktur zu ermitteln und die Kafka-Konfiguration an die Bandbreitenanforderungen anzupassen. Die maximale Leistung jedes Brokers wird durch die Leistung der Infrastrukturkomponenten in seinem Kern bestimmt, z. B. Speicher, Prozessor, Festplattengeschwindigkeit, Netzwerkbandbreite usw.Im Idealfall sollte die Konfiguration des Brokers so sein, dass alle Elemente der Infrastruktur maximal genutzt werden. Im wirklichen Leben ist dieses Setup jedoch sehr kompliziert. Es ist wahrscheinlicher, dass Benutzer Broker so konfigurieren, dass die Verwendung von einer oder zwei Komponenten (Festplatte, Speicher oder Prozessor) maximiert wird. Im Allgemeinen zeigt ein Broker maximale Leistung, wenn seine Konfiguration es Ihnen ermöglicht, die langsamste Komponente "vollständig" zu verwenden. So können wir eine ungefähre Vorstellung von der Last bekommen, die ein Broker bewältigen kann.Theoretisch können wir auch die Anzahl der Broker schätzen, die für die Arbeit mit einer bestimmten Last benötigt werden. In der Praxis gibt es jedoch so viele Konfigurationsoptionen auf verschiedenen Ebenen, dass es sehr schwierig (wenn nicht unmöglich) ist, die potenzielle Leistung einer bestimmten Konfiguration zu bewerten. Mit anderen Worten, es ist sehr schwierig, die Konfiguration ausgehend von einer bestimmten Leistung zu planen.Für Supertubes-Benutzer verwenden wir normalerweise den folgenden Ansatz: Beginnen Sie mit einer Konfiguration (Infrastruktur + Einstellungen), messen Sie dann die Leistung, passen Sie die Brokereinstellungen an und wiederholen Sie den Vorgang erneut. Dies geschieht so lange, bis das Potenzial der langsamsten Infrastrukturkomponente voll ausgeschöpft ist.Auf diese Weise erhalten wir eine klarere Vorstellung davon, wie viele Broker ein Cluster benötigt, um mit einer bestimmten Last fertig zu werden (die Anzahl der Broker hängt auch von anderen Faktoren ab, z. B. der Mindestanzahl von Nachrichtenreplikaten, um Stabilität zu gewährleisten, der Anzahl der Partitionsleiter usw.). Darüber hinaus erhalten wir eine Vorstellung davon, welche vertikale Skalierung der Infrastrukturkomponente gewünscht wird.In diesem Artikel werden die Schritte erläutert, die wir unternehmen, um aus den langsamsten Komponenten in den Anfangskonfigurationen „alles herauszuholen“ und den Durchsatz des Kafka-Clusters zu messen. Für eine hoch belastbare Konfiguration sind mindestens drei Arbeitsmakler erforderlich (min.insync.replicas=3) in drei verschiedenen Zugänglichkeitszonen angeordnet. Zur Konfiguration, Skalierung und Überwachung der Kubernetes-Infrastruktur verwenden wir unsere eigene Hybrid-Cloud-Container-Management-Plattform - Pipeline . Es unterstützt On-Premise (Bare Metal, VMware) und fünf Arten von Clouds (Alibaba, AWS, Azure, Google, Oracle) sowie eine beliebige Kombination davon.Gedanken zur Infrastruktur und Konfiguration des Kafka-Clusters
In den folgenden Beispielen haben wir AWS als Cloud-Dienstanbieter und EKS als Kubernetes-Distribution ausgewählt. Eine ähnliche Konfiguration kann mit PKE implementiert werden , einer von CNCF zertifizierten Kubernetes-Distribution von Banzai Cloud.Platte
Amazon bietet verschiedene Arten von EBS-Volumes an . SSDs sind die Basis von gp2 und io1. Um jedoch einen hohen Durchsatz zu gewährleisten, verbraucht gp2 akkumulierte Kredite (E / A-Gutschriften) . Daher bevorzugen wir den Typ io1 , der einen stabilen hohen Durchsatz bietet.Instanztypen
Die Leistung von Kafka hängt stark vom Seiten-Cache des Betriebssystems ab. Daher benötigen wir Instanzen mit genügend Speicher für Broker (JVMs) und Seiten-Cache. Instanz c5.2xlarge ist ein guter Anfang, da sie über 16 GB Arbeitsspeicher verfügt und für die Arbeit mit EBS optimiert ist . Der Nachteil ist, dass alle 24 Stunden eine maximale Leistung von nicht mehr als 30 Minuten erzielt werden kann. Wenn Ihre Arbeitslast über einen längeren Zeitraum maximale Leistung erfordert, sehen Sie sich andere Arten von Instanzen an. Wir haben genau das getan und bei c5.4xlarge angehalten . Es bietet einen maximalen Durchsatz von 593,75 Mb / s.. Der maximale Durchsatz des EBS io1-Volumes ist höher als der der c5.4xlarge- Instanz . Das langsamste Infrastrukturelement ist daher wahrscheinlich der E / A-Durchsatz dieses Instanztyps (was auch durch die Ergebnisse unserer Auslastungstests bestätigt werden sollte).Netzwerk
Die Netzwerkbandbreite sollte im Vergleich zur Leistung der VM-Instanz und der Festplatte recht groß sein, da sonst das Netzwerk zu einem Engpass wird. In unserem Fall unterstützt die c5.4xlarge- Netzwerkschnittstelle Geschwindigkeiten von bis zu 10 Gbit / s, was erheblich über der Bandbreite der E / A-Instanz der VM liegt.Broker-Bereitstellung
Broker sollten auf dedizierten Knoten bereitgestellt (in Kubernetes geplant) werden, um den Wettbewerb mit anderen Prozessen um Prozessor-, Speicher-, Netzwerk- und Festplattenressourcen zu vermeiden.Java-Version
Die logische Wahl ist Java 11, da es mit Docker in dem Sinne kompatibel ist, dass die JVM die Prozessoren und den Speicher, die für den Container, in dem der Broker ausgeführt wird, verfügbar sind, korrekt bestimmt. In dem Wissen, dass Prozessorlimits wichtig sind, legt die JVM intern und transparent die Anzahl der GC-Threads und JIT-Compiler-Threads fest. Wir haben ein Kafka-Image verwendet banzaicloud/kafka:2.13-2.4.0, das Kafka Version 2.4.0 (Scala 2.13) in Java 11 enthält.Wenn Sie mehr über Java / JVM auf Kubernetes erfahren möchten, lesen Sie unsere folgenden Veröffentlichungen:
Broker-Speichereinstellungen
Das Einstellen des Broker-Speichers hat zwei Hauptaspekte: Einstellungen für die JVM und für den Kubernetes-Pod. Das für den Pod festgelegte Speicherlimit muss größer als die maximale Heap-Größe sein, damit die JVM genügend Speicherplatz für den Java-Metaspace in ihrem eigenen Speicher und für den von Kafka aktiv verwendeten Seitencache des Betriebssystems hat. In unseren Tests haben wir Kafka-Broker mit Parametern ausgeführt -Xmx4G -Xms2G, und das Speicherlimit für den Pod war 10 Gi. Bitte beachten Sie, dass die Speichereinstellungen für die JVM automatisch mit -XX:MaxRAMPercentageund -X:MinRAMPercentagebasierend auf dem Speicherlimit für den Pod abgerufen werden können .Broker-Prozessoreinstellungen
Im Allgemeinen können Sie die Produktivität steigern, indem Sie die Parallelität erhöhen, indem Sie die Anzahl der von Kafka verwendeten Threads erhöhen. Je mehr Prozessoren für Kafka verfügbar sind, desto besser. In unserem Test haben wir mit einem Limit von 6 Prozessoren begonnen und deren Anzahl schrittweise (iteriert) auf 15 erhöht. Außerdem haben wir num.network.threads=12in den Brokereinstellungen festgelegt, wie viele Streams Daten vom Netzwerk empfangen und senden. Nachdem sie sofort festgestellt hatten, dass Follower-Broker Replikate nicht schnell genug erhalten können, erhöhten sie sich num.replica.fetchersauf 4, um die Geschwindigkeit zu erhöhen, mit der Follower-Broker Nachrichten von Führungskräften replizierten.Tool zur Lasterzeugung
Stellen Sie sicher, dass das Potenzial des ausgewählten Lastgenerators nicht ausgeht, bevor der Kafka-Cluster (dessen Benchmark ausgeführt wird) seine maximale Last erreicht. Mit anderen Worten, es ist erforderlich, eine vorläufige Bewertung der Funktionen des Lastgenerierungswerkzeugs durchzuführen und Instanztypen mit einer ausreichenden Anzahl von Prozessoren und Speicher auszuwählen. In diesem Fall erzeugt unser Tool mehr Last, als der Kafka-Cluster verdauen kann. Nach vielen Experimenten haben wir uns für drei Kopien von c5.4xlarge entschieden , in denen jeweils der Generator gestartet wurde.Benchmarking
Die Leistungsmessung ist ein iterativer Prozess, der die folgenden Schritte umfasst:- Einrichtung der Infrastruktur (EKS-Cluster, Kafka-Cluster, Lastgenerierungstool sowie Prometheus und Grafana);
- Lastgenerierung für einen bestimmten Zeitraum, um zufällige Abweichungen in den gesammelten Leistungsindikatoren zu filtern;
- Feinabstimmung der Infrastruktur und Konfiguration des Brokers anhand der beobachteten Leistungsindikatoren;
- Wiederholen des Vorgangs, bis die erforderliche Kafka-Cluster-Bandbreite erreicht ist. Gleichzeitig sollte es stabil reproduzierbar sein und minimale Bandbreitenschwankungen aufweisen.
Im nächsten Abschnitt werden die Schritte beschrieben, die während des Benchmark-Testclusters ausgeführt wurden.Werkzeuge
Die folgenden Tools wurden verwendet, um die Basiskonfiguration, die Lastgenerierung und die Leistungsmessung schnell bereitzustellen:- Banzai Cloud Pipeline EKS Amazon c Prometheus ( Kafka ) Grafana ( ). Pipeline , , , , , .
- Sangrenel — Kafka.
- Grafana Kafka : Kubernetes Kafka, Node Exporter.
- Supertubes CLI für die einfachste Möglichkeit, einen Kafka-Cluster in Kubernetes zu konfigurieren. Zookeeper, Kafka-Operator, Envoy und viele andere Komponenten sind installiert und ordnungsgemäß konfiguriert, um den Kafka-Cluster für die Produktion in Kubernetes auszuführen.
- Verwenden Sie die hier angegebenen Anweisungen, um die Supertubes-CLI zu installieren .

EKS-Cluster
Bereiten
Sie einen EKS-Cluster mit dedizierten c5.4xlarge- Arbeitsknoten in verschiedenen Verfügbarkeitszonen für Pods mit Kafka-Brokern sowie dedizierten Knoten für den Lastgenerator und die Überwachungsinfrastruktur vor.banzai cluster create -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/cluster_eks_202001.json
Wenn der EKS-Cluster betriebsbereit ist, aktivieren Sie seinen integrierten Überwachungsdienst. Prometheus und Grafana werden im Cluster bereitgestellt.Kafka-Systemkomponenten
Installieren Sie die Kafka-Systemkomponenten (Zookeeper, Kafka-Operator) mithilfe der Supertubes-CLI in der EKS:supertubes install -a --no-democluster --kubeconfig <path-to-eks-cluster-kubeconfig-file>
Kafka Cluster
Standardmäßig verwendet EKS gp2- EBS- Volumes. Daher müssen Sie für den Kafka-Cluster eine separate Speicherklasse erstellen, die auf io1- Volumes basiert :kubectl create -f - <<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast-ssd
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
iopsPerGB: "50"
fsType: ext4
volumeBindingMode: WaitForFirstConsumer
EOF
Legen Sie einen Parameter für Broker fest min.insync.replicas=3und stellen Sie Broker-Pods auf Knoten in drei verschiedenen Verfügbarkeitszonen bereit:supertubes cluster create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/kafka_202001_3brokers.yaml --wait --timeout 600
Themen
Wir haben gleichzeitig drei Instanzen des Lastgenerators gestartet. Jeder von ihnen schreibt in einem eigenen Thema, das heißt, wir brauchen nur drei Themen:supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest1
spec:
name: perftest1
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest2
spec:
name: perftest2
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest3
spec:
name: perftest3
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
Für jedes Thema beträgt der Replikationsfaktor 3 - der empfohlene Mindestwert für hochverfügbare Produktionssysteme.Tool zur Lasterzeugung
Wir haben drei Instanzen des Lastgenerators gestartet (jede in einem separaten Thema geschrieben). Für Pods des Lastgenerators müssen Sie die Knotenaffinität registrieren, damit sie nur auf den ihnen zugewiesenen Knoten geplant werden:apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
app: loadtest
name: perf-load1
namespace: kafka
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: loadtest
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: loadtest
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nodepool.banzaicloud.io/name
operator: In
values:
- loadgen
containers:
- args:
- -brokers=kafka-0:29092,kafka-1:29092,kafka-2:29092,kafka-3:29092
- -topic=perftest1
- -required-acks=all
- -message-size=512
- -workers=20
image: banzaicloud/perfload:0.1.0-blog
imagePullPolicy: Always
name: sangrenel
resources:
limits:
cpu: 2
memory: 1Gi
requests:
cpu: 2
memory: 1Gi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
Einige Punkte, die Sie beachten sollten:- Der Lastgenerator generiert 512-Byte-Nachrichten und veröffentlicht diese in Stapeln von 500 Nachrichten an Kafka.
-required-acks=all , Kafka. , , , , . (consumers) , , , .- 20 worker' (
-workers=20). worker 5 producer', worker' Kafka. 100 producer', Kafka.
Clusterüberwachung
Während der Stresstests des Kafka-Clusters haben wir auch dessen Zustand überwacht, um sicherzustellen, dass keine Pod-Neustarts, nicht synchronen Replikate und maximaler Durchsatz bei minimalen Schwankungen aufgetreten sind:Messergebnisse
3 Broker, Nachrichtengröße - 512 Bytes
Mit gleichmäßig auf drei Broker verteilten Partitionen konnten wir eine Leistung von ~ 500 Mbit / s (ca. 990.000 Nachrichten pro Sekunde) erzielen :

 Der Speicherverbrauch der virtuellen JVM-Maschine überschritt 2 GB nicht:
Der Speicherverbrauch der virtuellen JVM-Maschine überschritt 2 GB nicht:

 Die Festplattenbandbreite erreichte die maximale E / A-Bandbreite Der Knoten in allen drei Instanzen, an denen die Broker gearbeitet haben:
Die Festplattenbandbreite erreichte die maximale E / A-Bandbreite Der Knoten in allen drei Instanzen, an denen die Broker gearbeitet haben: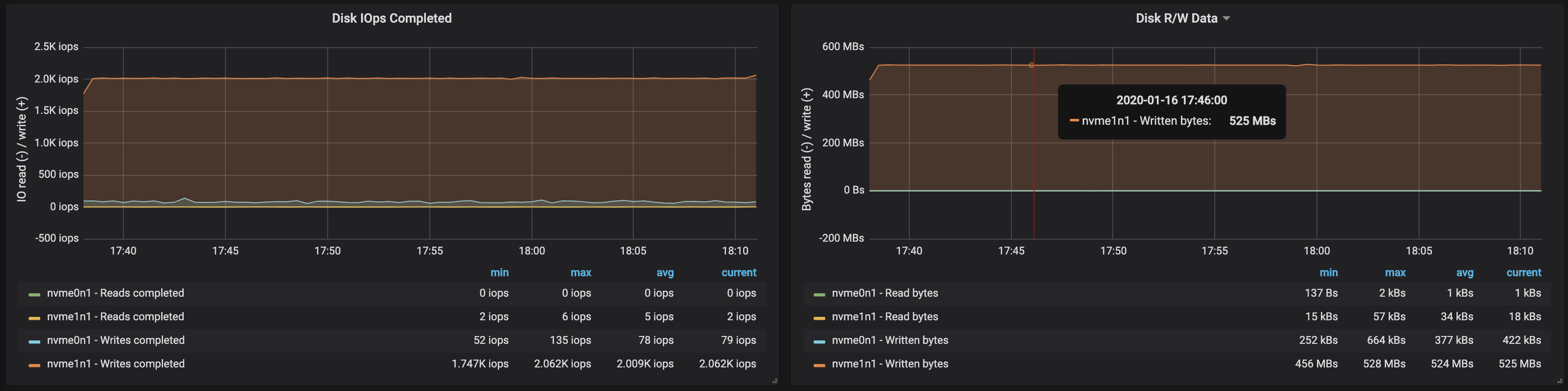

 Aus den Daten zur Speichernutzung durch die Knoten folgt, dass das Puffern und Zwischenspeichern des Systems ~ 10-15 GB dauerte:
Aus den Daten zur Speichernutzung durch die Knoten folgt, dass das Puffern und Zwischenspeichern des Systems ~ 10-15 GB dauerte:


3 Broker, Nachrichtengröße - 100 Bytes
Mit einer Verringerung der Nachrichtengröße verringert sich der Durchsatz um etwa 15 bis 20%: Die für die Verarbeitung jeder Nachricht aufgewendete Zeit ist betroffen. Außerdem hat sich die Prozessorlast fast verdoppelt.

 Da Brokerknoten noch nicht verwendete Kernel haben, können Sie die Leistung verbessern, indem Sie die Konfiguration von Kafka ändern. Dies ist keine leichte Aufgabe. Um den Durchsatz zu erhöhen, ist es daher besser, mit größeren Nachrichten zu arbeiten.
Da Brokerknoten noch nicht verwendete Kernel haben, können Sie die Leistung verbessern, indem Sie die Konfiguration von Kafka ändern. Dies ist keine leichte Aufgabe. Um den Durchsatz zu erhöhen, ist es daher besser, mit größeren Nachrichten zu arbeiten.4 Broker, Nachrichtengröße - 512 Bytes
Sie können die Leistung des Kafka-Clusters problemlos steigern, indem Sie einfach neue Broker hinzufügen und das Gleichgewicht der Partitionen beibehalten (dies gewährleistet eine gleichmäßige Lastverteilung zwischen den Brokern). In unserem Fall stieg der Cluster-Durchsatz nach dem Hinzufügen eines Brokers auf ~ 580 Mbit / s (~ 1,1 Millionen Nachrichten pro Sekunde) . Das Wachstum erwies sich als geringer als erwartet: Dies ist hauptsächlich auf das Ungleichgewicht der Partitionen zurückzuführen (nicht alle Broker arbeiten auf dem Höhepunkt der Chancen).


 Der Speicherverbrauch des JVM-Computers bleibt unter 2 GB: Das
Der Speicherverbrauch des JVM-Computers bleibt unter 2 GB: Das


 Partitionsungleichgewicht hat den Betrieb von Brokern mit Laufwerken beeinträchtigt:
Partitionsungleichgewicht hat den Betrieb von Brokern mit Laufwerken beeinträchtigt:



Ergebnisse
Der oben vorgestellte iterative Ansatz kann erweitert werden, um komplexere Szenarien abzudecken, einschließlich Hunderten von Verbrauchern, Neupartitionierung, fortlaufenden Aktualisierungen, Pod-Neustarts usw. All dies ermöglicht es uns, die Grenzen der Fähigkeiten des Kafka-Clusters unter verschiedenen Bedingungen zu bewerten, Engpässe in seiner Arbeit zu identifizieren und Wege zu finden, um mit ihnen umzugehen.Wir haben Supertubes entwickelt, um einen Cluster schnell und einfach bereitzustellen, zu konfigurieren, Broker und Themen hinzuzufügen / zu entfernen, auf Warnungen zu reagieren und sicherzustellen, dass Kafka in Kubernetes insgesamt ordnungsgemäß funktioniert. Unser Ziel ist es, uns auf die Hauptaufgabe zu konzentrieren (Kafka-Nachrichten zu „generieren“ und zu „konsumieren“) und dem Bediener die ganze harte Arbeit für Supertubes und Kafka zur Verfügung zu stellen.Wenn Sie an Banzai Cloud-Technologien und Open Source-Projekten interessiert sind, abonnieren Sie das Unternehmen auf GitHub , LinkedIn oder Twitter .PS vom Übersetzer
Lesen Sie auch in unserem Blog: