Eine Übersetzung des Artikels wurde vor Beginn des Kurses für maschinelles Lernen von OTUS erstellt.
Aufgabe
In diesem Handbuch verwenden wir den Datensatz Bitcoin vs USD .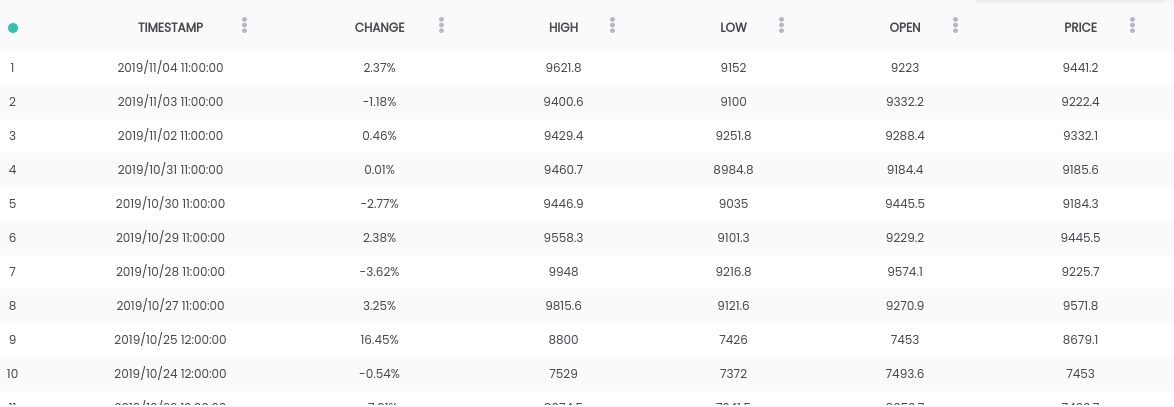 Der obige Datensatz enthält einen Tagespreis Zusammenfassung, in dem die Änderung Spalt die Preisänderung in Prozent des Vortagespreises (ist PREIS ) im Vergleich zu neu ( OPEN ).Ziel: Um die Aufgabe zu vereinfachen, konzentrieren wir uns darauf, vorherzusagen, ob der Preis am nächsten Tag steigen ( ÄNDERN> 0 ) oder fallen ( ÄNDERN <0 ) wird. (So können wir möglicherweise Vorhersagen "im wirklichen Leben" verwenden).Bedarf
Der obige Datensatz enthält einen Tagespreis Zusammenfassung, in dem die Änderung Spalt die Preisänderung in Prozent des Vortagespreises (ist PREIS ) im Vergleich zu neu ( OPEN ).Ziel: Um die Aufgabe zu vereinfachen, konzentrieren wir uns darauf, vorherzusagen, ob der Preis am nächsten Tag steigen ( ÄNDERN> 0 ) oder fallen ( ÄNDERN <0 ) wird. (So können wir möglicherweise Vorhersagen "im wirklichen Leben" verwenden).Bedarf- Python 2.6+ oder 3.1+ muss auf dem System installiert sein
- Installiere Pandas , Sklearn und Openblender (mit pip)
$ pip install pandas OpenBlender scikit-learn
Schritt 1. Bitcoin-Daten abrufen
Importieren Sie zunächst die erforderlichen Bibliotheken:import OpenBlender
import pandas as pd
import json
Ziehen Sie nun die Daten über die OpenBlender-API .Definieren wir zunächst die Parameter (in unserem Fall ist dies nur die ID des Bitcoin-Datensatzes ):
parameters = {
'id_dataset':'5d4c3af79516290b01c83f51'
}
Hinweis: Sie müssen ein Konto auf openblender.io erstellen (kostenlos) und ein Token hinzufügen (Sie finden es auf der Registerkarte "Konto"):parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51'
}
Fügen wir nun die Daten in den Datenrahmen 'df' ein :
def pullObservationsToDF(parameters):
action = 'API_getObservationsFromDataset'
df = pd.read_json(json.dumps(OpenBlender.call(action,parameters)['sample']), convert_dates=False,convert_axes=False) .sort_values('timestamp', ascending=False)
df.reset_index(drop=True, inplace=True)
return df
df = pullObservationsToDF(parameters)
Und schauen Sie sie sich an: Hinweis: Die Werte können variieren, da der Datensatz täglich aktualisiert wird !
Hinweis: Die Werte können variieren, da der Datensatz täglich aktualisiert wird !Schritt 2. Datenvorbereitung
Zunächst müssen wir ein Prognoseziel erstellen, das besagt, ob „ ÄNDERN “ zunimmt oder abnimmt. Fügen Sie dazu 'success_thr_over': 0 zu den Zielschwellenwertparametern hinzu :parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold':{'feature':'change', 'success_thr_over': 0}
}
Wenn wir die Daten erneut aus der API abrufen:df = pullObservationsToDF(parameters)
df.head()
 Das Attribut "CHANGE" wurde durch ein neues Attribut "change_over_0" ersetzt, das 1 wird, wenn "CHANGE" positiv ist, und 0, wenn nicht. Dies wird ein Ziel für maschinelles Lernen sein.Wenn wir die Beobachtung für "morgen" vorhersagen möchten, können wir die Informationen von morgen nicht verwenden. Fügen wir also eine Verzögerung von einem Zeitraum hinzu.
Das Attribut "CHANGE" wurde durch ein neues Attribut "change_over_0" ersetzt, das 1 wird, wenn "CHANGE" positiv ist, und 0, wenn nicht. Dies wird ein Ziel für maschinelles Lernen sein.Wenn wir die Beobachtung für "morgen" vorhersagen möchten, können wir die Informationen von morgen nicht verwenden. Fügen wir also eine Verzögerung von einem Zeitraum hinzu.parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold':{'feature':'change','success_thr_over' : 0},
'lag_target_feature':{'feature':'change_over_0', 'periods' : 1}
}
df = pullObservationsToDF(parameters)
df.head()
 Dadurch wird 'change_over_0' einfach an den Daten des vorherigen Tages (Zeitraums) ausgerichtet und der Name in 'TARGET_change_over_0' geändert .Schauen wir uns die Abhängigkeit an:
Dadurch wird 'change_over_0' einfach an den Daten des vorherigen Tages (Zeitraums) ausgerichtet und der Name in 'TARGET_change_over_0' geändert .Schauen wir uns die Abhängigkeit an:target_variable = 'TARGET_change_over_0'
df = df.dropna()
df.corr()[target_variable].sort_values()
 Sie sind linear unabhängig und wahrscheinlich nicht nützlich.
Sie sind linear unabhängig und wahrscheinlich nicht nützlich.Schritt 3. Abrufen von Wirtschaftsnachrichtendaten
Nachdem ich in OpenBlender nach Abhängigkeiten gesucht hatte , fand ich das Fox Business News- Dataset , mit dessen Hilfe gute Prognosen für unser Ziel erstellt werden können. Wir müssen einen Weg finden, die Werte der Spalte "Titel" in numerische Merkmale umzuwandeln , die Wiederholungen von Wörtern und Wortgruppen in der Nachrichtenzusammenfassung zu zählen und sie rechtzeitig mit unserem Bitcoin-Datensatz zu vergleichen. Es ist einfacher als es klingt.Zuerst müssen Sie einen TextVectorizer für das Attribut 'title' der Nachrichten erstellen :
Wir müssen einen Weg finden, die Werte der Spalte "Titel" in numerische Merkmale umzuwandeln , die Wiederholungen von Wörtern und Wortgruppen in der Nachrichtenzusammenfassung zu zählen und sie rechtzeitig mit unserem Bitcoin-Datensatz zu vergleichen. Es ist einfacher als es klingt.Zuerst müssen Sie einen TextVectorizer für das Attribut 'title' der Nachrichten erstellen :action = 'API_createTextVectorizer'
vectorizer_parameters = {
'token' : 'your_token',
'name' : 'Fox Business TextVectorizer',
'sources':[{'id_dataset' : '5d571f9e9516293a12ad4f6d',
'features' : ['title']}],
'ngram_range' : {'min' : 1, 'max' : 2},
'language' : 'en',
'remove_stop_words' : 'on',
'min_count_limit' : 2
}
Wir werden einen Vektorisierer erstellen, um alle Zeichen als Token-Wörter in Form von Zahlen zu erhalten. Oben haben wir Folgendes angegeben:- Name : Nennen wir es "Fox Business TextVectorizer" .
- Anker : ID des Datensatzes und Name der Merkmale, die wir als Quelle verwenden müssen (in unserem Fall nur die Spalte "Titel" );
- ngram_range : minimale und maximale Länge einer Reihe von Wörtern für die Tokenisierung;
- Sprache : Englisch
- remove_stop_words : um Stoppwörter aus der Quelle zu entfernen;
- min_count_limit : Die Mindestanzahl von Wiederholungen, die als Token betrachtet werden sollten (einzelne Vorkommen sind selten nützlich).
Führen Sie nun Folgendes aus:res = OpenBlender.call(action, vectorizer_parameters)
res
Antworten:{
'message' : 'TextVectorizer created successfully.'
'id_textVectorizer' : '5dc1a404951629331f6359dd',
'num_ngrams': 4270
}
Es
wurde ein TextVectorizer erstellt , der gemäß unserer Konfiguration 4270 n-Gramm generiert. Wenig später benötigen wir die generierte ID:5dc1a404951629331f6359ddSchritt 4. Kompatible News-Zusammenfassung mit Bitcoin-Datensatz
Jetzt müssen wir die Nachrichtenübersicht und die Bitcoin-Wechselkursdaten rechtzeitig vergleichen. Im Allgemeinen bedeutet dies, dass Sie zwei Datensätze mit einem Zeitstempel als Schlüssel kombinieren müssen. Fügen wir die kombinierten Daten zu unseren ursprünglichen Datenextraktionsoptionen hinzu:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold' : {'feature':'change','success_thr_over':0},
'lag_target_feature' : {'feature':'change_over_0', 'periods':1},
'blends':[{'id_blend':'5dc1a404951629331f6359dd',
'blend_type' : 'text_ts',
'restriction' : 'predictive',
'specifications':{'time_interval_size' : 3600*12 }}]
}
Oben haben wir Folgendes angegeben:- id_blend : id unseres textVectorizer;
- blend_type : 'text_ts', damit Python versteht, dass es sich um eine Mischung aus Text und Zeitstempel handelt;
- Einschränkung : "vorausschauend" , so dass es keine "Vermischung" von Nachrichten aus der Zukunft mit allen Beobachtungen gibt, sondern nur mit denen, die früher als zum angegebenen Zeitpunkt veröffentlicht wurden.
- blend_class : 'next_observation' , so dass nur die nächsten Beobachtungen "gemischt" werden;
- Spezifikationen : Die maximal mögliche verstrichene Zeit für die Übertragung der Beobachtung, in diesem Fall 12 Stunden (3600 * 12). Dies bedeutet, dass jede Beobachtung des Bitcoin-Preises basierend auf den Nachrichten der letzten 12 Stunden vorhergesagt wird.
Schließlich fügen wir ab dem 20. August einen Filter nach dem Datum 'date_filter' hinzu , da Fox News zu diesem Zeitpunkt mit der Datenerfassung begann, und 'drop_non_numeric', sodass wir nur Zahlen erhalten:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold' : {'feature':'change','success_thr_over':0},
'lag_target_feature' : {'feature':'change_over_0', 'periods':1},
'blends':[{'id_blend':'5dc1a404951629331f6359dd',
'blend_type' : 'text_ts',
'restriction' : 'predictive',
'blend_class' : 'closest_observation',
'specifications':{'time_interval_size' : 3600*12 }}],
'date_filter':{'start_date':'2019-08-20T16:59:35.825Z',
'end_date':'2019-11-04T17:59:35.825Z'},
'drop_non_numeric' : 1
}
Hinweis : Ich habe den 4. November als 'end_date' angegeben . Da es der Tag war, an dem ich diesen Code geschrieben habe, können Sie das Datum ändern.Lassen Sie uns die Daten erneut abrufen:df = pullObservationsToDF(parameters)
print(df.shape)
df.head()
(57, 2115) Jetzt haben wir mehr als 2000 Zeichen mit Token und 57 Beobachtungen.
Jetzt haben wir mehr als 2000 Zeichen mit Token und 57 Beobachtungen.Schritt 5. Wenden Sie ML auf das Vorhersageziel an
Jetzt haben wir endlich einen sauberen Datensatz, der genau so aussieht, wie wir ihn brauchen, mit einem Zeitversatz des Ziels und der zugehörigen numerischen Daten.Schauen wir uns die höchsten Korrelationen mit 'Target_change_over_0' an : Jetzt haben wir einige korrelierende Attribute. Teilen wir den Datensatz in Training und Test in chronologischer Reihenfolge auf, damit wir das Modell in frühen Beobachtungen trainieren und in späteren testen können.
Jetzt haben wir einige korrelierende Attribute. Teilen wir den Datensatz in Training und Test in chronologischer Reihenfolge auf, damit wir das Modell in frühen Beobachtungen trainieren und in späteren testen können.X = df.loc[:, df.columns != target_variable].values
y = df.loc[:,[target_variable]].values
div = int(round(len(X) * 0.29))
X_test = X[:div]
y_test = y[:div]
print(X_test.shape)
print(y_test.shape)
X_train = X[div:]
y_train = y[div:]
print(X_train.shape)
print(y_train.shape)
 Wir haben 40 Beobachtungen zum Training und 17 zum Testen.Jetzt importieren wir die notwendigen Bibliotheken:
Wir haben 40 Beobachtungen zum Training und 17 zum Testen.Jetzt importieren wir die notwendigen Bibliotheken:from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_auc_score
from sklearn import metrics
Verwenden wir nun eine zufällige Gesamtstruktur (RandomForest) und machen eine Vorhersage:rf = RandomForestRegressor(n_estimators = 1000)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
Fügen wir zur Vereinfachung die Vorhersagen und y_test in den Datenrahmen ein:df_res = pd.DataFrame({'y_test':y_test[:,0], 'y_pred':y_pred})
df_res.head()
Unser realer 'y_test' ist binär, aber unsere Prognosen sind vom Typ float . Runden wir sie also auf, vorausgesetzt, wenn sie größer als 0,5 sind, bedeutet dies einen Preisanstieg und wenn weniger als 0,5 - einen Rückgang.threshold = 0.5
preds = [1 if val > threshold else 0 for val in df_res['y_pred']]
Um die Ergebnisse besser zu verstehen, erhalten wir jetzt die AUC, die Fehlermatrix und den Genauigkeitsindikator:print(roc_auc_score(preds, df_res['y_test']))
print(metrics.confusion_matrix(preds, df_res['y_test']))
print(accuracy_score(preds, df_res['y_test']))
 Wir haben 64,7% der korrekten Vorhersagen mit 0,65 AUC erhalten.
Wir haben 64,7% der korrekten Vorhersagen mit 0,65 AUC erhalten.- 9 Mal haben wir einen Rückgang vorhergesagt und der Preis ist gesunken (rechts);
- 5-mal haben wir einen Rückgang vorhergesagt und der Preis ist gestiegen (falsch);
- 1 Mal haben wir einen Anstieg vorhergesagt, aber der Preis ist falsch gesunken);
- 2 Mal haben wir einen Anstieg vorhergesagt und der Preis ist gestiegen (wahr).
Erfahren Sie mehr über den Kurs .