Wenn ein weiteres fruchtbares Jahr zu Ende geht, möchte ich zurückblicken, Bilanz ziehen und zeigen, was wir in dieser Zeit konnten. Die # DeepPavlov-Bibliothek ist für eine Minute bereits zwei Jahre alt und wir freuen uns, dass unsere Community jeden Tag wächst.Im Laufe der Arbeit an der Bibliothek haben wir Folgendes erreicht:- Die Bibliotheksdownloads stiegen im Vergleich zum Vorjahr um ein Drittel. Jetzt hat DeepPavlov mehr als 100.000 Installationen und mehr als 10.000 Containerinstallationen.
- Die Anzahl kommerzieller Lösungen hat aufgrund modernster Technologien, die in DeepPavlov in verschiedenen Branchen von Einzelhandel zu Industrie implementiert wurden, zugenommen.
- Die erste Version von DeepPavlov Agent wurde veröffentlicht .
- Die Anzahl der aktiven Community-Mitglieder hat sich verfünffacht.
- Unser Team aus Studenten und Doktoranden wurde ausgewählt, um an der Alexa Prize Socialbot Grand Challenge 3 teilzunehmen .
- Die Bibliothek wurde zum Gewinner des Wettbewerbs der Firma Google «Powered by TensorFlow Challenge».
Was hat zu solchen Ergebnissen beigetragen und warum ist DeepPavlov die beste Open Source für den Aufbau von Konversations-KI? Wir werden in unserem Artikel erzählen.
#DeepPavlov zielt auf das Ergebnis
In letzter Zeit sind Dialogsysteme zum Standard für die Mensch-Maschine-Interaktion geworden. Chatbots werden in fast allen Branchen eingesetzt und vereinfachen die Interaktion zwischen Menschen und Computern. Sie lassen sich nahtlos in Websites, Messaging-Plattformen und Geräte integrieren. Viele Unternehmen ziehen es heute vor, Routineaufgaben an interaktive Systeme zu delegieren, die mehrere Benutzeranforderungen gleichzeitig bearbeiten können, wodurch Arbeitskosten gespart werden.Oft wissen Unternehmen jedoch nicht, wo sie anfangen sollen, wenn sie einen Bot entwickeln, der den Anforderungen ihres Unternehmens entspricht. In der Vergangenheit können Chatbots in zwei große Gruppen unterteilt werden: basierend auf Regeln und basierend auf Daten. Der erste Typ basiert auf vordefinierten Befehlen und Vorlagen. Jeder dieser Befehle sollte vom Chatbot-Entwickler mit regulären Ausdrücken und Textdatenanalyse geschrieben werden. Im Gegensatz dazu basieren datengesteuerte Chat-Bots auf maschinellen Lernmodellen, die auf Dialogdaten vorab trainiert wurden.Open Source Bibliothek - DeepPavlovbietet eine kostenlose und benutzerfreundliche Lösung zum Erstellen interaktiver Systeme. DeepPavlov wird mit mehreren vorgefertigten Komponenten geliefert, um Probleme im Zusammenhang mit der Verarbeitung natürlicher Sprache (NLP) zu lösen. DeepPavlov löst Probleme wie: Klassifizierung von Text, Korrektur von Tippfehlern, Erkennung benannter Entitäten, Antworten auf Fragen zur Wissensbasis und viele andere. Und Sie können DeepPavlov in einer Zeile installieren, indem Sie Folgendes ausführen:pip install -q deeppavlov
* Mit dem Framework können Sie Modelle trainieren und testen sowie deren Hyperparameter anpassen. Die Bibliothek unterstützt Linux- und Windows-Plattformen. Sie können dieses und andere Modelle in der Demoversion der Bibliothek ausprobieren .Derzeit wurden moderne Ergebnisse bei vielen Aufgaben durch die Verwendung von auf BERT basierenden Modellen erzielt. Das DeepPavlov- Team hat BERT in die folgenden drei Aufgaben integriert: Textklassifizierung, Erkennung benannter Entitäten und Antworten auf Fragen. Infolgedessen haben wir bei all diesen Aufgaben erhebliche Verbesserungen vorgenommen.1. BERT DeepPavlov-Modelle
BERT für die Textklassifizierung Ein
auf BERT DeepPavlov basierendes Textklassifizierungsmodell dient beispielsweise dazu, das Problem der Erkennung von Beleidigungen zu lösen. Das Modell beinhaltet die Vorhersage, ob ein in einer öffentlichen Diskussion veröffentlichter Kommentar für einen der Teilnehmer als anstößig angesehen wird. In diesem Fall wird die Klassifizierung nur in zwei Klassen durchgeführt: Beleidigung und nicht Beleidigung.Jedes vorab trainierte Modell kann für die Ausgabe sowohl über die Befehlszeilenschnittstelle (CLI) als auch über Python verwendet werden. Stellen Sie vor der Verwendung des Modells sicher, dass alle erforderlichen Pakete mit dem folgenden Befehl installiert sind:python -m deeppavlov install insults_kaggle_bert
python -m deeppavlov interact insults_kaggle_bert -d
BERT für die Erkennung benannter Entitäten
Zusätzlich zu Textklassifizierungsmodellen enthält DeepPavlov ein BERT-basiertes Modell für die Erkennung benannter Entitäten (NER). Dies ist eine der häufigsten Aufgaben in NLP und das am häufigsten verwendete Modell unserer Bibliothek. Gleichzeitig verfügt NER über viele Geschäftsanwendungen. Beispielsweise kann ein Modell wichtige Informationen aus einem Lebenslauf extrahieren, um die Arbeit von Personalfachleuten zu erleichtern. Darüber hinaus kann NER verwendet werden, um relevante Entitäten in Kundenanfragen zu identifizieren, z. B. Produktspezifikationen, Firmennamen oder Informationen zu Unternehmenszweigen.Das DeepPavlov-Team hat das NER-Modell im englischsprachigen OntoNotes-Paket geschult, das 19 Arten von Markups enthält, darunter PER (Person), LOC (Standort), ORG (Organisation) und viele andere. Um mit zu interagieren, müssen Sie es mit dem folgenden Befehl installieren:python -m deeppavlov install ner_ontonotes_bert_mult
python -m deeppavlov interact ner_ontonotes_bert_mult [-d]
BERT zur Beantwortung von Fragen Eine
kontextbezogene Antwort auf eine Frage ist die Aufgabe, eine Antwort auf eine Frage in einem bestimmten Kontext (z. B. einem Wikipedia-Absatz) zu finden, wobei die Antwort auf jede Frage ein Kontextsegment ist. Zum Beispiel bildet das Dreifache von Kontext, Frage und Antwort unten das richtige Triplett für die Aufgabe, die Frage zu beantworten.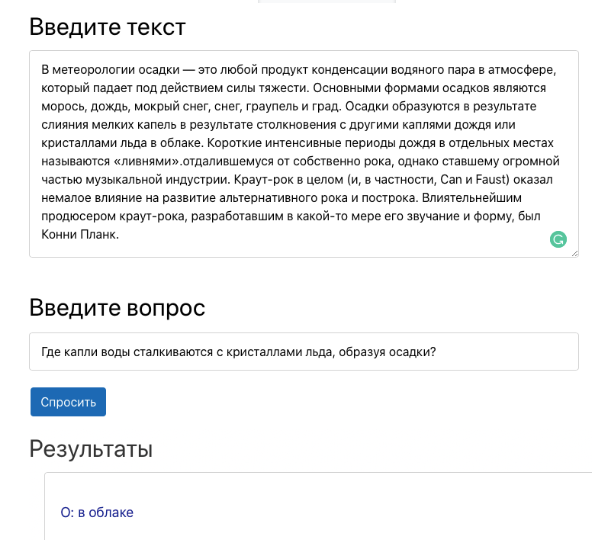 Präsentation der Arbeit des Frage-Antwort-Systems in einer Demo.Ein System zur Beantwortung von Fragen kann viele Prozesse in einem Unternehmen automatisieren. Dies kann beispielsweise Arbeitgebern helfen, Antworten auf der Grundlage der internen Unternehmensdokumentation zu erhalten. Darüber hinaus hilft das Modell dabei, die Fähigkeit der Schüler zu testen, den Text im Lernprozess zu verstehen. In jüngster Zeit hat die Aufgabe, kontextbezogene Fragen zu beantworten, jedoch große Aufmerksamkeit bei Wissenschaftlern auf sich gezogen. Einer der wichtigsten Wendepunkte in diesem Bereich war die Veröffentlichung des Stanford Question Answer Set (SQuAD). Der SQuAD-Datensatz hat zu unzähligen Ansätzen zur Lösung des Problems des Frage-Antwort-Systems geführt. Eines der erfolgreichsten ist das DeepPavlov BERT-Modell. Es übertrifft alle anderen und liefert derzeit Ergebnisse, die an menschliche Eigenschaften grenzen.Um das BERT-basierte QS-Modell mit DeepPavlov zu verwenden, müssen Sie:
Präsentation der Arbeit des Frage-Antwort-Systems in einer Demo.Ein System zur Beantwortung von Fragen kann viele Prozesse in einem Unternehmen automatisieren. Dies kann beispielsweise Arbeitgebern helfen, Antworten auf der Grundlage der internen Unternehmensdokumentation zu erhalten. Darüber hinaus hilft das Modell dabei, die Fähigkeit der Schüler zu testen, den Text im Lernprozess zu verstehen. In jüngster Zeit hat die Aufgabe, kontextbezogene Fragen zu beantworten, jedoch große Aufmerksamkeit bei Wissenschaftlern auf sich gezogen. Einer der wichtigsten Wendepunkte in diesem Bereich war die Veröffentlichung des Stanford Question Answer Set (SQuAD). Der SQuAD-Datensatz hat zu unzähligen Ansätzen zur Lösung des Problems des Frage-Antwort-Systems geführt. Eines der erfolgreichsten ist das DeepPavlov BERT-Modell. Es übertrifft alle anderen und liefert derzeit Ergebnisse, die an menschliche Eigenschaften grenzen.Um das BERT-basierte QS-Modell mit DeepPavlov zu verwenden, müssen Sie:python -m deeppavlov install squad_bert
python -m deeppavlov interact squad_bert -d
Weitere Modelle finden Sie in der Dokumentation . Wenn Sie Tutorials zur Verwendung von Bibliothekskomponenten benötigen, suchen Sie diese in unserem offiziellen Blog .2. DeepPavlov Agent - eine Plattform zum Erstellen von Multitasking-Chat-Bots
Heute gibt es verschiedene Ansätze zur Entwicklung interaktiver Agenten. Bei der Entwicklung von Konversationsagenten wird die modulare Architektur hauptsächlich für einen fokussierten Dialog verwendet, in dem sich das Skript entfaltet. Oft muss der Benutzer jedoch einen fokussierten Dialog kombinieren, beispielsweise mit einer anderen Funktion - Beantwortung von Fragen oder Suche nach Informationen sowie Aufrechterhaltung eines Gesprächs. Somit ist der ideale Dialogagent ein persönlicher Assistent, der verschiedene Arten von Agenten kombiniert und zwischen seinen Funktionen und Charakteren wechselt, je nachdem, in welcher Aufgabe er verwendet wird. Gleichzeitig muss der Agent Informationen über sein Wesen sammeln und seine Algorithmen an einen bestimmten Benutzer anpassen. Andererseits sollte es in der Lage sein, sich in externe Dienste zu integrieren. Zum Beispiel,Fragen an externe Datenbanken stellen, Informationen von dort abrufen, verarbeiten, das Wichtige hervorheben und an den Benutzer weiterleiten. Um dieses Problem zu lösen, wurde im Oktober 2019 die erste Version von DeepPavlov Agent 1.0 veröffentlicht, einer Plattform zum Erstellen von Multitasking-Chat-Bots. Der Agent hilft Entwicklern von Produktions-Chatbots, mehrere NLP-Modelle in einer Pipeline zu organisieren.Weitere Informationen zur Plattform und zu den Funktionen finden Sie in der Dokumentation .3. Implementierung von DeepPavlov NLP SaaS
Um die Arbeit mit vorgefertigten NLP-Modellen von DeepPavlov zu vereinfachen, wurde im September 2019 ein SaaS-Dienst gestartet. Mit DeepPavlov Cloud können Sie Text analysieren und Dokumente in der Cloud speichern. Um die Modelle nutzen zu können, müssen Sie sich in unserem Service registrieren und einen Token im Bereich Tokens Ihres persönlichen Kontos erhalten. Derzeit unterstützt der Dienst mehrere vorab geschulte NLP-Modelle in russischer Sprache und testet derzeit das System.4. Teilnahme an DSCT8 oder einem gezielten Dialogsystem
Die Verwendung von virtuellen Assistenten wie Amazon Alexa und Google Assistant hat Möglichkeiten für die Entwicklung von Anwendungen eröffnet, mit denen wir die Implementierung vieler alltäglicher Aufgaben vereinfachen können, z. B. die Bestellung eines Taxis, die Buchung eines Tisches in einem Restaurant und viele andere. Um solche Probleme zu lösen, werden fokussierte Dialogsysteme verwendet.Dialogue State Traking (DST) ist eine Schlüsselkomponente in solchen Dialogsystemen. DST ist dafür verantwortlich, Äußerungen in der menschlichen Sprache in eine semantische Darstellung der Sprache zu übersetzen, insbesondere um Absichten und Slot-Wert-Paare zu extrahieren, die dem Ziel des Benutzers entsprechen.Während der Teambeteiligung an DSTC8Das GOLOMB-Modell (GOaL-orientierter Multi-Task-BERT-basierter Dialogstatus-Tracker) wurde entwickelt - ein zielorientiertes Multi-Task-Modell, das auf BERT basiert, um den Status des Dialogs zu verfolgen. Um den Zustand des Dialogs vorherzusagen, löst das Modell verschiedene Klassifizierungsprobleme und die Aufgabe, einen Teilstring zu finden. Bald wird dieses Modell in der DeepPavlov-Bibliothek erscheinen. In der Zwischenzeit können Sie den vollständigen Artikel hier lesen . Präsentation des Posters auf der AAAI-20-Konferenz in New York (USA).
Präsentation des Posters auf der AAAI-20-Konferenz in New York (USA).
5. Teilnahme an der Alexa Prize Socialbot Grand Challenge
Das Team von DeepPavlov, bestehend aus Studenten und Doktoranden des Moskauer Instituts für Physik und Technologie, wurde ausgewählt, um an der Alexa Prize Socialbot Grand Challenge 3 teilzunehmen - einem internationalen Wettbewerb, der sich der Entwicklung der Konversations-KI-Technologie widmet. Ziel des Wettbewerbs ist es, einen Bot zu schaffen, der frei mit Menschen über relevante Themen kommunizieren kann. Aus den 375 Bewerbungen wählte das Alexa-Preiskomitee 10 Finalisten aus, darunter unser Team - DREAM. Im Moment hat das Team das Viertelfinale des Wettbewerbs erreicht und kämpft um das Halbfinale. Sie können die Nachrichten verfolgen und unsere auf der offiziellen Seite anfeuern , und vergessen Sie nicht, Twitter zu abonnieren . Teamzusammensetzung Dream Team.
Teamzusammensetzung Dream Team.
6. Teilnahme an der Powered by TF Challenge
Wie bereits erwähnt, enthält DeepPavlov mehrere vorgefertigte Komponenten, die von TensorFlow und Keras unterstützt werden. In diesem Jahr gewann das DeepPavlov-Team den Google Powered by TF Challenge-Wettbewerb für das beste maschinelle Lernprojekt, das die TensorFlow-Bibliothek verwendet. Unter den mehr als 600 Wettbewerbsteilnehmern wählte Google die fünf besten Projekte aus, darunter die DeepPavlov-Bibliothek. Das Projekt wurde auf dem offiziellen TensorFlow-Blog vorgestellt . Es ist erwähnenswert, dass die Flexibilität von TensorFlow es uns ermöglicht, jede erdenkliche neuronale Netzwerkarchitektur zu erstellen. Insbesondere verwenden wir TensorFlow für die nahtlose Integration in BERT-basierte Modelle.
7. Entwicklung der Gemeinschaft
Das globale Ziel unseres Projekts ist es, Entwicklern und Forschern auf dem Gebiet der künstlichen Konversationsintelligenz die Möglichkeit zu geben, die fortschrittlichsten Werkzeuge zur Erstellung interaktiver Systeme der nächsten Generation zu verwenden und eine international bedeutende Plattform im Bereich der KI für den Erfahrungsaustausch und die Vermittlung modernster Technologien zu werden.Um dies zu erreichen, arbeiten DeepPavlov- MitarbeiterDurchführung von kostenlosen Semesterschulungen für Studierende und Mitarbeiter der Informatik. Einer davon ist der Kurs „Deep Learning in der Verarbeitung natürlicher Sprache“, der Seminare und Workshops umfasst. Der Unterricht umfasst Themen wie: Aufbau von Dialogsystemen, Methoden zur Bewertung eines Dialogsystems mit der Fähigkeit, eine Antwort zu generieren, verschiedene Rahmenbedingungen für Dialogsysteme, Methoden zur Schätzung der Höhe der Vergütung aufgrund der Optimierung von Dialogrichtlinien, Arten von Benutzeranforderungen, Berücksichtigung der Modellierung von Call-Center-Anrufen. Im Jahr 2020 haben wir eine neue Rekrutierung gestartet und bereits 900 Studenten und Mitarbeiter werden kostenlos geschult. Sie können die Nachrichten und das Set für diesen und andere Kurse auf unserer Website verfolgen . Und wenn Sie die Kurse verpasst haben, aber mehr erfahren möchten - dann auf unsererYoutube- Kanal finden Sie sie immer in der Aufzeichnung.Heute bietet die DeepPavlov- Bibliothek AI-fähige Komponenten für die Arbeit mit Text, die in 92 Ländern der Welt verwendet werden. Ab Februar 2020 erreichte die Anzahl der Downloads der Bibliothek 100.000.000, und die Dynamik der Installationen gewinnt an Dynamik. Darüber hinaus haben bereits mehr als 30 Unternehmen in Russland bereits Lösungen implementiert und setzen diese erfolgreich auf DeepPavlov-Basis ein. Dies zeigt, dass solche Lösungen auf der ganzen Welt sehr beliebt sind.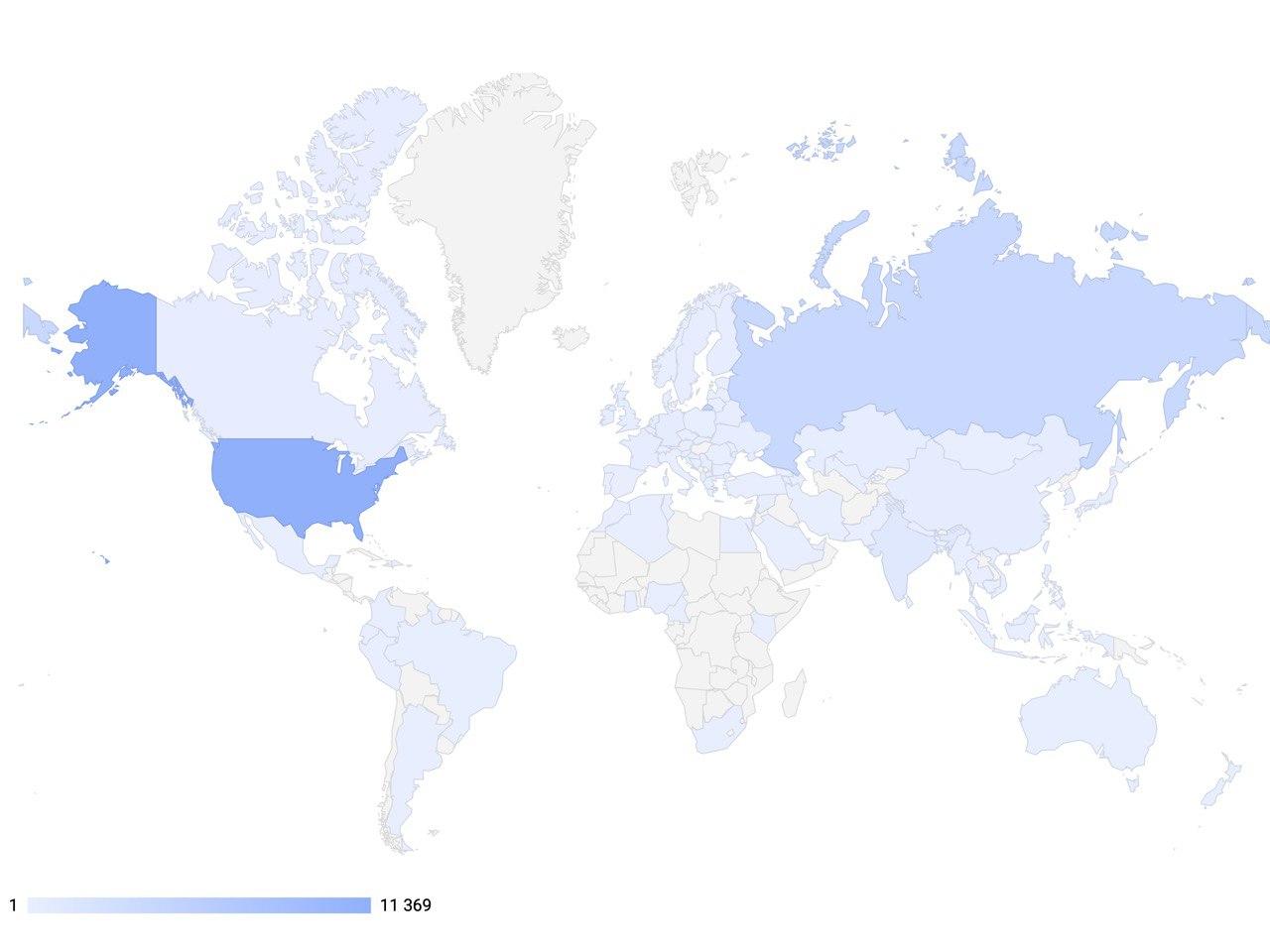
Was weiter?
Wir freuen uns, unsere Erfolge mit Ihnen zu teilen, deshalb haben wir eine Veranstaltung für unsere Community vorbereitet. Wir möchten Erfahrungen und Wissen aus realen Produktionsprojekten darüber austauschen, wie die besten KI-Assistenten erstellt werden können. Nehmen Sie am 28. Februar an dem Treffen von Benutzern und Entwicklern der offenen DeepPavlov-Bibliothek teil, um über künstliche Intelligenz und ihre Anwendung zu sprechen und andere Mitglieder der Community zu treffen. Die Veranstaltung findet im Rahmen der AI-Woche vom 25. bis 28. Februar statt. Wir warten auf alle, die DeepPavlov nutzen oder unsere Technologie kennenlernen möchten.Alle Informationen zu den Referenten und zum Programm finden Sie auf der Website. Für die Teilnahme an der Veranstaltung ist eine Registrierung erforderlich.Beitritt: DeepPavlov 2 Jahre
Die KI-Branche wird sich weiterentwickeln, und wir glauben, dass DeepPavlov zu einer fortschrittlichen Technologie wird, mit der jeder Entwickler die natürliche Sprache verstehen wird. Nächstes Jahr werden wir daran arbeiten, unsere Community zu verdoppeln, Open Source-Tools zu erweitern und die Forschung zum maschinellen Lernen zu verbessern. Und vergessen Sie nicht, dass DeepPavlov ein Forum hat - stellen Sie Ihre Fragen bezüglich der Bibliothek und der Modelle. Vielen Dank für Ihre Aufmerksamkeit!