In letzter Zeit ist die Aufgabe der Zeichenerkennung in Anwendungsprogrammen nicht besonders schwierig - Sie können viele vorgefertigte OCR-Bibliotheken verwenden, von denen viele nahezu perfektioniert sind. Trotzdem kann es manchmal schwierig sein, einen eigenen Erkennungsalgorithmus zu entwickeln, ohne „hoch entwickelte“ OCR-Bibliotheken von Drittanbietern zu verwenden.
Dies ist genau die Aufgabe, die sich während meiner Arbeit ergeben hat, und es gibt mehrere Gründe, warum es besser ist, keine vorgefertigten Bibliotheken zu verwenden: Das geschlossene Projekt mit seiner weiteren Zertifizierung, eine gewisse Einschränkung der Anzahl der Codezeilen und der Größe der verbundenen Bibliotheken, umso mehr, als Sie im Themenbereich genug erkennen müssen spezifischer Zeichensatz.
Der Erkennungsalgorithmus ist einfach und gibt natürlich nicht vor, der genaueste, schnellste und effektivste zu sein, sondern bewältigt seine kleine Aufgabe gut.
Angenommen, wir haben Eingaben in Form von gescannten Bildern von Dokumenten in strukturierter Form. Diese Dokumente haben einen speziellen einstelligen Code in der oberen linken Ecke. Unsere Aufgabe ist es, dieses Symbol zu erkennen und dann einige Aktionen auszuführen, z. B. das Quelldokument gemäß den angegebenen Regeln zu klassifizieren.

Das Algorithmusdiagramm lautet wie folgt:
 Da wir im Voraus wissen, wo sich unser Symbol befindet, ist es nicht schwierig, einen bestimmten Bereich zu schneiden. Um alle „Unregelmäßigkeiten“ an den Rändern des Symbols zu beseitigen, übersetzen wir das Bild in Schwarzweiß (Schwarzweiß).
Da wir im Voraus wissen, wo sich unser Symbol befindet, ist es nicht schwierig, einen bestimmten Bereich zu schneiden. Um alle „Unregelmäßigkeiten“ an den Rändern des Symbols zu beseitigen, übersetzen wir das Bild in Schwarzweiß (Schwarzweiß).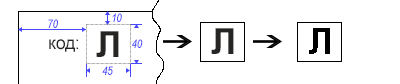
short width = 45, height = 40, offsetTop = -10, offsetLeft = -70;
BufferedImage image = ImageIO.read(file);
BufferedImage symbol = new BufferedImage(width, height, BufferedImage.TYPE_BYTE_BINARY);
Graphics2D g = symbol.createGraphics();
g.drawImage(image, offsetLeft, offsetTop, null);
Als nächstes müssen Sie das resultierende Fragment "Pixel für Pixel" in eine binäre Zeichenfolge konvertieren, dh eine Zeichenfolge, bei der beispielsweise "*" einem schwarzen Pixel und ein Leerzeichen einem weißen entspricht.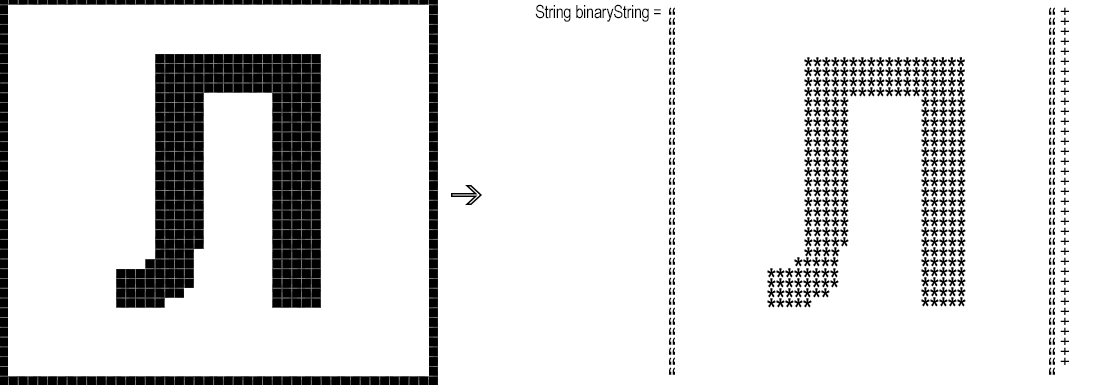
short whiteBg = -1;
StringBuilder binaryString = new StringBuilder();
for (short y = 1; y < height; y++)
for (short x = 1; x < width; x++) {
int rgb = symbol.getRGB(x, y);
binaryString.append(rgb == whiteBg ? " " : "*");
}
Als nächstes müssen Sie den minimalen Levenshtein-Abstand zwischen der empfangenen Zeichenfolge und den vorbereiteten Referenzzeichenfolgen ermitteln (Sie können sogar eine beliebige Zeichenfolgenvergleichsmethode verwenden).int min = 1000000;
char findSymbol = "";
for (Map.Entry<Character, String> entry : originalMap.entrySet()) {
int levenshtein = levenshtein(binaryString.toString(), entry.getValue());
if (levenshtein < min) {
min = levenshtein;
findSymbol = entry.getKey();
}
}
Die Funktion zum Ermitteln der Levenshtein-Entfernung wird als Methode gemäß dem Standardalgorithmus implementiert:public static int levenshtein(String targetStr, String sourceStr) {
int m = targetStr.length(), n = sourceStr.length();
int[][] delta = new int[m + 1][n + 1];
for (int i = 1; i <= m; i++)
delta[i][0] = i;
for (int j = 1; j <= n; j++)
delta[0][j] = j;
for (int j = 1; j <= n; j++)
for (int i = 1; i <= m; i++) {
if (targetStr.charAt(i - 1) == sourceStr.charAt(j - 1))
delta[i][j] = delta[i - 1][j - 1];
else
delta[i][j] = Math.min(delta[i - 1][j] + 1,
Math.min(delta[i][j - 1] + 1, delta[i - 1][j - 1] + 1));
}
return delta[m][n];
}
Das resultierende findSymbol wird unser anerkannter Charakter sein.Dieser Algorithmus kann optimiert werden, um die Leistung zu verbessern, und durch verschiedene Überprüfungen ergänzt werden, um die Erkennungseffizienz zu verbessern. Viele Indikatoren hängen vom spezifischen Themenbereich des zu lösenden Problems ab (Anzahl der Zeichen, Vielfalt der Schriftarten, Bildqualität usw.).Es wurde auf praktische Weise festgestellt, dass die Methode auch problematische Probleme wie „Ähnlichkeit“ der Zeichen, z. B. „L“ <->, qualitativ bewältigt "P", "5" <-> "S", "O" <-> "0". Da beispielsweise der Abstand zwischen den Binärzeichenfolgen "L" und "P" auch bei einigen "Unregelmäßigkeiten" immer größer ist als zwischen dem erkannten "L" und der Referenzzeichenfolge "L".Wenn Sie ein ähnliches Problem (z. B. das Erkennen von Spielkarten) mit einer Reihe von Einschränkungen bei der Verwendung von Neuronen und anderen vorgefertigten Lösungen lösen müssen, können Sie diese Methode im Allgemeinen sicher anwenden und ändern.