In diesem Artikel werde ich auf einige einfache Tricks eingehen, die nützlich sind, wenn Sie mit Daten arbeiten, die nicht in den lokalen Computer passen, aber immer noch zu klein sind, um als groß bezeichnet zu werden. In Anlehnung an die englischsprachige Analogie (groß, aber nicht groß) werden wir diese Daten als dick bezeichnen. Wir sprechen von Einheitengrößen und zehn Gigabyte.[Haftungsausschluss] Wenn Sie SQL lieben, kann alles, was unten geschrieben steht, zu hellen, höchstwahrscheinlich negativen Emotionen führen. In den Niederlanden gibt es 49262 Tesla, von denen 427 Taxis sind. Lesen Sie besser nicht weiter [/ Haftungsausschluss]. Ausgangspunkt war ein Artikel über die Nabe mit einer Beschreibung eines interessanten Datensatzes - eine vollständige Liste der in den Niederlanden zugelassenen Fahrzeuge, 14 Millionen Linien, von LKW-Traktoren bis hin zu Elektrofahrrädern mit einer Geschwindigkeit von über 25 km / h.Das Set ist interessant, dauert 7 GB, Sie können es auf der Website der zuständigen Organisation herunterladen .Der Versuch, die Daten so zu steuern, wie sie in den Pandas sind, um sie zu filtern und zu bereinigen, endete mit einem Fiasko (Herren der SQL-Husaren, warnte ich!). Pandas fielen aus einem Mangel an Speicher auf dem Desktop mit 8 GB. Mit ein wenig Blutvergießen kann die Frage gelöst werden, wenn Sie sich daran erinnern, dass die Pandas CSV-Dateien in mittelgroßen Stücken lesen können. Die Fragmentgröße in Zeilen wird durch den Parameter chunksize bestimmt.Um die Arbeit zu veranschaulichen, schreiben wir eine einfache Funktion, die eine Anfrage stellt und bestimmt, wie viele Tesla-Autos insgesamt sind und welcher Anteil davon in Taxis arbeitet. Ohne Tricks beim Fragmentlesen verbraucht eine solche Anfrage zuerst den gesamten Speicher, leidet dann lange und am Ende fällt die Rampe ab.Beim Lesen von Fragmenten sieht unsere Funktion ungefähr so aus:
Ausgangspunkt war ein Artikel über die Nabe mit einer Beschreibung eines interessanten Datensatzes - eine vollständige Liste der in den Niederlanden zugelassenen Fahrzeuge, 14 Millionen Linien, von LKW-Traktoren bis hin zu Elektrofahrrädern mit einer Geschwindigkeit von über 25 km / h.Das Set ist interessant, dauert 7 GB, Sie können es auf der Website der zuständigen Organisation herunterladen .Der Versuch, die Daten so zu steuern, wie sie in den Pandas sind, um sie zu filtern und zu bereinigen, endete mit einem Fiasko (Herren der SQL-Husaren, warnte ich!). Pandas fielen aus einem Mangel an Speicher auf dem Desktop mit 8 GB. Mit ein wenig Blutvergießen kann die Frage gelöst werden, wenn Sie sich daran erinnern, dass die Pandas CSV-Dateien in mittelgroßen Stücken lesen können. Die Fragmentgröße in Zeilen wird durch den Parameter chunksize bestimmt.Um die Arbeit zu veranschaulichen, schreiben wir eine einfache Funktion, die eine Anfrage stellt und bestimmt, wie viele Tesla-Autos insgesamt sind und welcher Anteil davon in Taxis arbeitet. Ohne Tricks beim Fragmentlesen verbraucht eine solche Anfrage zuerst den gesamten Speicher, leidet dann lange und am Ende fällt die Rampe ab.Beim Lesen von Fragmenten sieht unsere Funktion ungefähr so aus:def pandas_chunky_query():
print('reading csv file with pandas in chunks')
filtered_chunk_list=[]
for chunk in pd.read_csv('C:\Open_data\RDW_full.CSV', chunksize=1E+6):
filtered_chunk=chunk[chunk['Merk'].isin(['TESLA MOTORS','TESLA'])]
filtered_chunk_list.append(filtered_chunk)
model_df = pd.concat(filtered_chunk_list)
print(model_df['Taxi indicator'].value_counts())
Indem Sie eine absolut vernünftige Million Zeilen angeben, können Sie die Abfrage in 1:46 ausführen und 1965 M Speicher in der Spitze verwenden. Alle Zahlen für einen dummen Desktop mit etwas Altem, acht Kernen, ungefähr 8 GB Speicher und unter dem siebten Windows.
 Wenn Sie die Blockgröße ändern, folgt der maximale Speicherverbrauch buchstäblich darauf, und die Ausführungszeit ändert sich nicht wesentlich. Für 0,5 M Leitungen dauert die Anforderung 1:44 und 1063 MB, für 2M 1:53 und 3762 MB.Die Geschwindigkeit ist nicht sehr erfreulich, noch weniger erfreulich ist, dass Sie beim Lesen der Datei in Fragmenten gezwungen sind, für diese Funktion angepasstes Schreiben zu schreiben und mit Listen von Fragmenten zu arbeiten, die dann in einem Datenrahmen gesammelt werden müssen. Auch das CSV-Format selbst ist nicht sehr zufrieden, was viel Platz einnimmt und langsam gelesen wird.Da wir Daten in eine Rampe treiben können, kann ein viel kompakteres Apachev-Format für die Speicherung verwendet werdenParkett bei Komprimierung und dank des Datenschemas ist das Lesen beim Lesen viel schneller. Und die Rampe kann durchaus mit ihm arbeiten. Nur jetzt können sie nicht in Fragmenten gelesen werden. Was ist zu tun?- Lass uns Spaß haben, nimm das Dask-
Wenn Sie die Blockgröße ändern, folgt der maximale Speicherverbrauch buchstäblich darauf, und die Ausführungszeit ändert sich nicht wesentlich. Für 0,5 M Leitungen dauert die Anforderung 1:44 und 1063 MB, für 2M 1:53 und 3762 MB.Die Geschwindigkeit ist nicht sehr erfreulich, noch weniger erfreulich ist, dass Sie beim Lesen der Datei in Fragmenten gezwungen sind, für diese Funktion angepasstes Schreiben zu schreiben und mit Listen von Fragmenten zu arbeiten, die dann in einem Datenrahmen gesammelt werden müssen. Auch das CSV-Format selbst ist nicht sehr zufrieden, was viel Platz einnimmt und langsam gelesen wird.Da wir Daten in eine Rampe treiben können, kann ein viel kompakteres Apachev-Format für die Speicherung verwendet werdenParkett bei Komprimierung und dank des Datenschemas ist das Lesen beim Lesen viel schneller. Und die Rampe kann durchaus mit ihm arbeiten. Nur jetzt können sie nicht in Fragmenten gelesen werden. Was ist zu tun?- Lass uns Spaß haben, nimm das Dask- Knopfakkordeon und beschleunige!Dask! Ein Ersatz für die sofort einsatzbereite Rampe, die große Dateien lesen, auf mehreren Kernen parallel arbeiten und verzögerte Berechnungen verwenden kann. Zu meiner Überraschung über Dask on Habré gibt es nur 4 Veröffentlichungen .Also nehmen wir den Dask, fahren den Original-CSV hinein und fahren ihn mit minimaler Konvertierung auf den Boden. Beim Lesen schwört dask auf die Mehrdeutigkeit von Datentypen in einigen Spalten, daher setzen wir sie explizit ein (aus Gründen der Klarheit wurde das Gleiche für die Rampe getan, die Betriebszeit ist unter Berücksichtigung dieses Faktors höher, das Wörterbuch mit dtypes wird aus Gründen der Klarheit aus allen Abfragen herausgeschnitten), der Rest ist für sich . Außerdem überprüfen wir zur Überprüfung den Bodenbelag geringfügig, indem wir versuchen, die Datentypen auf die kompaktesten zu reduzieren, ein Spaltenpaar durch Ja / Nein-Text durch Boolesche zu ersetzen und andere Daten in die wirtschaftlichsten Typen umzuwandeln (für die Anzahl der Motorzylinder ist uint8 definitiv ausreichend). Wir speichern den optimierten Boden separat und sehen, was wir bekommen.Das erste, was bei der Arbeit mit Dask gefällt, ist, dass wir nichts Überflüssiges schreiben müssen, nur weil wir dicke Daten haben. Wenn Sie nicht darauf achten, dass das Dask importiert wird und nicht die Rampe, sieht alles so aus, als würde eine Datei mit hundert Zeilen in der Rampe verarbeitet (plus ein paar dekorative Pfeifen für die Profilerstellung).def dask_query():
print('reading CSV file with dask')
with ProgressBar(), ResourceProfiler(dt=0.25) as rprof:
raw_data=dd.read_csv('C:\Open_data\RDW_full.CSV')
model_df=raw_data[raw_data['Merk'].isin(['TESLA MOTORS','TESLA'])]
print(model_df['Taxi indicator'].value_counts().compute())
rprof.visualize()
Vergleichen Sie nun die Auswirkungen der Quelldatei auf die Leistung bei der Arbeit mit dasko. Zuerst lesen wir die gleiche CSV-Datei wie bei der Arbeit mit der Rampe. Das gleiche ungefähr zwei Minuten und zwei Gigabyte Speicher (1:38 2096 Mb). Es schien, war es das wert, sich im Gebüsch zu küssen?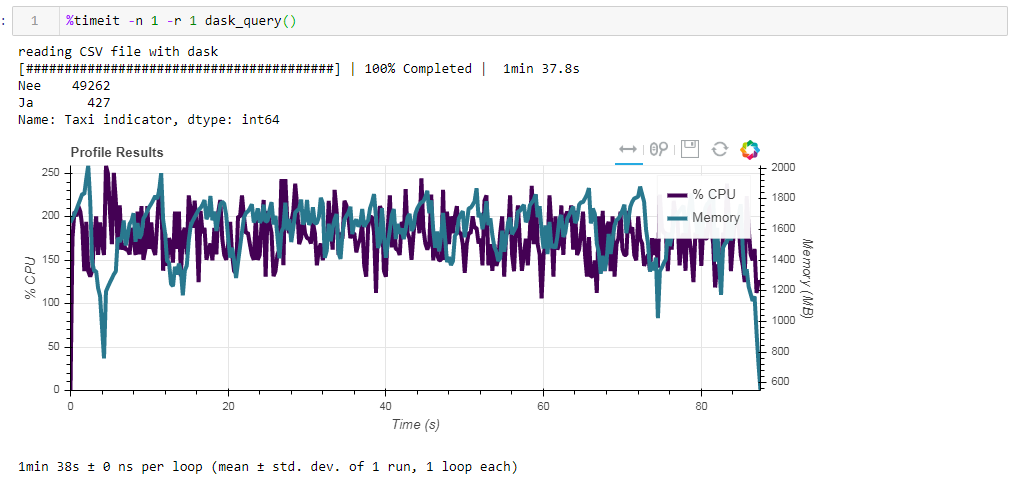 Führen Sie nun die nicht optimierte Parkettdatei des Bretts ein. Die Anfrage wurde in ungefähr 54 Sekunden verarbeitet und verbrauchte 1388 MB Speicher. Die Datei selbst für die Anfrage ist jetzt zehnmal kleiner (ungefähr 700 MB). Hier sind die Boni bereits konvex sichtbar. Eine CPU-Auslastung von Hunderten von Prozent ist eine Parallelisierung über mehrere Kerne.
Führen Sie nun die nicht optimierte Parkettdatei des Bretts ein. Die Anfrage wurde in ungefähr 54 Sekunden verarbeitet und verbrauchte 1388 MB Speicher. Die Datei selbst für die Anfrage ist jetzt zehnmal kleiner (ungefähr 700 MB). Hier sind die Boni bereits konvex sichtbar. Eine CPU-Auslastung von Hunderten von Prozent ist eine Parallelisierung über mehrere Kerne.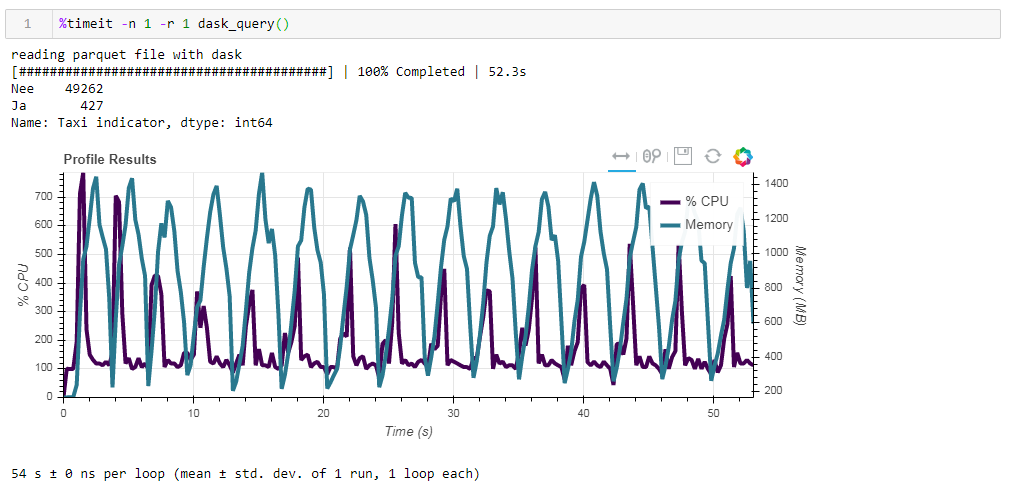 Das zuvor optimierte Parkett mit leicht modifizierten Datentypen in komprimierter Form ist nur 1 MB weniger, was bedeutet, dass ohne Hinweise alles recht effizient komprimiert wird. Die Produktivitätssteigerung ist ebenfalls nicht besonders signifikant. Die Anfrage dauert die gleichen 53 Sekunden und verbraucht etwas weniger Speicher - 1332 MB.Basierend auf den Ergebnissen unserer Übungen können wir Folgendes sagen:
Das zuvor optimierte Parkett mit leicht modifizierten Datentypen in komprimierter Form ist nur 1 MB weniger, was bedeutet, dass ohne Hinweise alles recht effizient komprimiert wird. Die Produktivitätssteigerung ist ebenfalls nicht besonders signifikant. Die Anfrage dauert die gleichen 53 Sekunden und verbraucht etwas weniger Speicher - 1332 MB.Basierend auf den Ergebnissen unserer Übungen können wir Folgendes sagen:- Wenn Ihre Daten „fett“ sind und Sie an eine Rampe gewöhnt sind - Chunksize hilft der Rampe, dieses Volumen zu verdauen, ist die Geschwindigkeit erträglich.
- Wenn Sie mehr Geschwindigkeit herausholen möchten, während der Lagerung Platz sparen und sich nicht nur mit einer Rampe zurückhalten möchten, ist die Dämmerung mit Parkett eine gute Kombination.
Zum Schluss noch über Lazy Computing. Eines der Merkmale des Dasks ist, dass es verzögerte Berechnungen verwendet, dh Berechnungen werden nicht sofort ausgeführt, wie sie im Code enthalten sind, sondern wenn sie wirklich benötigt werden oder wenn Sie sie explizit mithilfe der Berechnungsmethode angefordert haben. In unserer Funktion liest dask beispielsweise nicht alle Daten in den Speicher, wenn wir angeben, die Datei zu lesen. Er liest sie später und nur die Spalten, die sich auf die Anfrage beziehen.Dies ist im folgenden Beispiel leicht zu erkennen. Wir nehmen eine vorgefilterte Datei, in der wir nur 12 Spalten von den anfänglichen 64 übrig gelassen haben. Komprimiertes Parkett benötigt 203 MB. Wenn Sie unsere reguläre Anforderung darauf ausführen, wird sie in 8,8 Sekunden ausgeführt, und die maximale Speicherauslastung beträgt ca. 300 MB, was einem Zehntel der komprimierten Datei entspricht, wenn Sie sie in einer einfachen CSV-Datei überholen.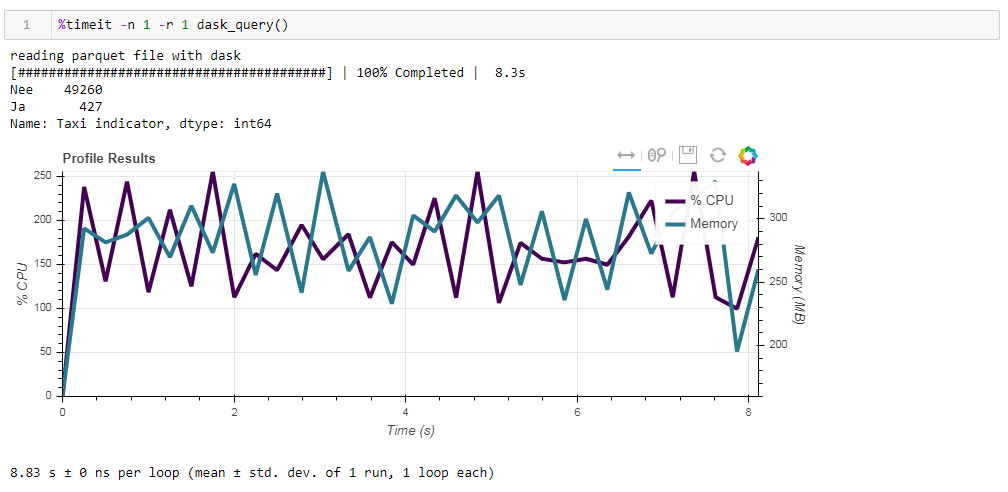 Wenn Sie ausdrücklich aufgefordert werden, die Datei zu lesen und dann die Anforderung auszuführen, beträgt der Speicherverbrauch fast das Zehnfache. Wir ändern unsere Funktion geringfügig, indem wir die Datei explizit lesen:
Wenn Sie ausdrücklich aufgefordert werden, die Datei zu lesen und dann die Anforderung auszuführen, beträgt der Speicherverbrauch fast das Zehnfache. Wir ändern unsere Funktion geringfügig, indem wir die Datei explizit lesen:def dask_query():
print('reading parquet file with dask')
with ProgressBar(), ResourceProfiler(dt=0.25) as rprof:
raw_data=dd.read_parquet('C:\Open_data\RDW_filtered.parquet' ).compute()
model_df=raw_data[raw_data['Merk'].isin(['TESLA MOTORS','TESLA'])]
print(model_df['Taxi indicator'].value_counts())
rprof.visualize()
Und hier ist, was wir bekommen, 10,5 Sekunden und 3568 MB Speicher (!)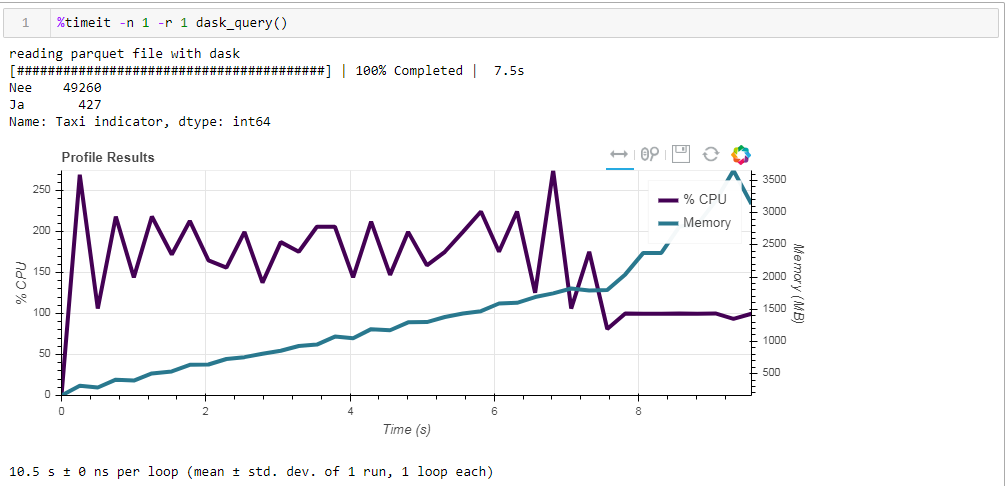 Wieder einmal sind wir davon überzeugt, dass der Dask - er ist kompetent in seinen Aufgaben und es lohnt sich nicht, noch einmal mit Mikromanagement darauf zu klettern.
Wieder einmal sind wir davon überzeugt, dass der Dask - er ist kompetent in seinen Aufgaben und es lohnt sich nicht, noch einmal mit Mikromanagement darauf zu klettern.