In diesem Artikel werde ich Ihnen erklären, wie Sie in 30 Minuten eine maschinelle Lernumgebung einrichten, ein neuronales Netzwerk für die Bilderkennung erstellen und dann dasselbe Netzwerk auf einem Grafikprozessor (GPU) ausführen.Definieren wir zunächst, was ein neuronales Netzwerk ist.In unserem Fall handelt es sich um ein mathematisches Modell sowie dessen Software- oder Hardware-Implementierung, das auf dem Prinzip der Organisation und Funktionsweise biologischer neuronaler Netze basiert - Netze von Nervenzellen eines lebenden Organismus. Dieses Konzept entstand bei der Untersuchung von Prozessen im Gehirn und bei dem Versuch, diese Prozesse zu simulieren.Neuronale Netze werden nicht im üblichen Sinne des Wortes programmiert, sondern trainiert. Die Lernfähigkeit ist einer der Hauptvorteile neuronaler Netze gegenüber herkömmlichen Algorithmen. Technisch gesehen besteht das Training darin, die Verbindungskoeffizienten zwischen Neuronen zu finden. Während des Lernprozesses kann das neuronale Netzwerk komplexe Beziehungen zwischen Eingabe und Ausgabe identifizieren und eine Verallgemeinerung durchführen.Unter dem Gesichtspunkt des maschinellen Lernens ist ein neuronales Netzwerk ein Sonderfall von Mustererkennungsverfahren, Diskriminanzanalyse, Clustering-Verfahren und anderen Verfahren.Ausrüstung
Lassen Sie uns zunächst die Ausrüstung behandeln. Wir benötigen einen Server, auf dem das Linux-Betriebssystem installiert ist. Geräte für den Betrieb von maschinellen Lernsystemen erfordern eine ausreichend leistungsfähige und folglich teure. Für diejenigen, die kein gutes Auto zur Hand haben, empfehle ich, auf das Angebot von Cloud-Anbietern zu achten. Der benötigte Server kann schnell gemietet werden und nur für die Nutzungsdauer bezahlen.In Projekten, in denen neuronale Netze erstellt werden müssen, verwende ich die Server eines der russischen Cloud-Anbieter. Das Unternehmen bietet Miet-Cloud-Server speziell für maschinelles Lernen mit leistungsstarken Tesla V100-Grafikprozessoren (GPUs) von NVIDIA an. Kurz gesagt: Die Verwendung eines Servers mit einer GPU kann Dutzende Male effizienter (schnell) sein als ein Server mit ähnlichen Kosten, bei dem eine CPU für Berechnungen verwendet wird (ein bekannter Zentralprozessor). Dies wird durch die Besonderheiten der GPU-Architektur erreicht, die Berechnungen schneller abwickelt.Um die unten beschriebenen Beispiele auszuführen, haben wir den folgenden Server mehrere Tage lang gekauft:- 150 GB SSD
- RAM 32 GB
- Tesla V100 16 Gb Prozessor mit 4 Kernen
Ubuntu 18.04 wurde auf dem Computer installiert.Stellen Sie die Umgebung ein
Installieren Sie nun auf dem Server alles, was Sie zum Arbeiten benötigen. Da unser Artikel in erster Linie für Anfänger gedacht ist, werde ich darin auf einige Punkte eingehen, die für sie nützlich sein werden.Über die Befehlszeile wird viel Arbeit beim Einrichten der Umgebung geleistet. Die meisten Benutzer verwenden Windows als funktionierendes Betriebssystem. Die Standardkonsole in diesem Betriebssystem lässt zu wünschen übrig. Daher werden wir das praktische Cmder / Tool verwenden . Laden Sie die Mini-Version herunter und führen Sie Cmder.exe aus. Als Nächstes müssen Sie über SSH eine Verbindung zum Server herstellen:ssh root@server-ip-or-hostname
Geben Sie anstelle von Server-IP- oder Hostname die IP-Adresse oder den DNS-Namen Ihres Servers an. Geben Sie als nächstes das Passwort ein und nach erfolgreicher Verbindung sollten wir so etwas bekommen.Welcome to Ubuntu 18.04.3 LTS (GNU/Linux 4.15.0-74-generic x86_64)
Die Hauptsprache für die Entwicklung von ML-Modellen ist Python. Die beliebteste Plattform für die Verwendung unter Linux ist Anaconda .Installieren Sie es auf unserem Server.Wir beginnen mit der Aktualisierung des lokalen Paketmanagers:sudo apt-get update
Installieren Sie curl (Befehlszeilenprogramm):sudo apt-get install curl
Laden Sie die neueste Version von Anaconda Distribution herunter:cd /tmp
curl –O https://repo.anaconda.com/archive/Anaconda3-2019.10-Linux-x86_64.sh
Wir starten die Installation:bash Anaconda3-2019.10-Linux-x86_64.sh
Während des Installationsvorgangs müssen Sie die Lizenzvereinbarung bestätigen. Bei erfolgreicher Installation sollte Folgendes angezeigt werden:Thank you for installing Anaconda3!
Um ML-Modelle zu entwickeln, werden jetzt viele Frameworks erstellt. Wir arbeiten mit den beliebtesten: PyTorch und Tensorflow .Durch die Verwendung des Frameworks können Sie die Entwicklungsgeschwindigkeit erhöhen und vorgefertigte Tools für Standardaufgaben verwenden.In diesem Beispiel arbeiten wir mit PyTorch. Es installieren:conda install pytorch torchvision cudatoolkit=10.1 -c pytorch
Jetzt müssen wir das Jupyter Notebook starten - ein beliebtes Entwicklungstool unter ML-Spezialisten. Sie können Code schreiben und sofort die Ergebnisse seiner Ausführung sehen. Jupyter Notebook ist Teil von Anaconda und bereits auf unserem Server installiert. Sie müssen von unserem Desktop-System aus eine Verbindung herstellen.Dazu führen wir zunächst Jupyter auf dem Server aus, indem wir Port 8080 angeben:jupyter notebook --no-browser --port=8080 --allow-root
Öffnen Sie anschließend eine weitere Registerkarte in unserer Cmder-Konsole (das Hauptmenü ist das Dialogfeld "Neue Konsole") und stellen Sie über Port 8080 eine Verbindung zum Server über SSH her:ssh -L 8080:localhost:8080 root@server-ip-or-hostname
Wenn Sie den ersten Befehl eingeben, werden uns Links zum Öffnen von Jupyter in unserem Browser angeboten:To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-18788-open.html
Or copy and paste one of these URLs:
http://localhost:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
or http://127.0.0.1:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
Verwenden Sie den Link für localhost: 8080. Kopieren Sie den vollständigen Pfad und fügen Sie ihn in die Adressleiste des lokalen Browsers Ihres PCs ein. Das Jupyter-Notizbuch wird geöffnet.Erstellen wir einen neuen Laptop: Neu - Notebook - Python 3.Überprüfen Sie den korrekten Betrieb aller von uns installierten Komponenten. Wir führen ein PyTorch-Codebeispiel in Jupyter ein und starten die Ausführung (Schaltfläche Ausführen):from __future__ import print_function
import torch
x = torch.rand(5, 3)
print(x)
Das Ergebnis sollte ungefähr so aussehen: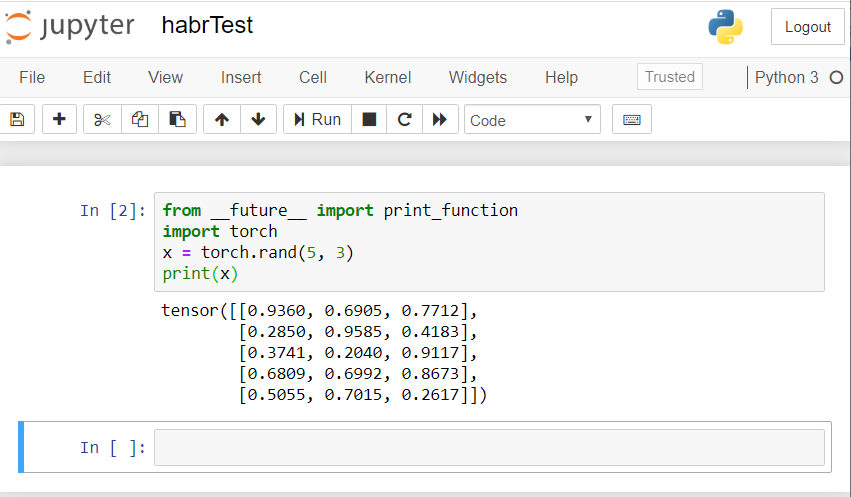 Wenn Sie ein ähnliches Ergebnis haben, dann haben wir uns alle richtig eingerichtet und können beginnen, ein neuronales Netzwerk aufzubauen!
Wenn Sie ein ähnliches Ergebnis haben, dann haben wir uns alle richtig eingerichtet und können beginnen, ein neuronales Netzwerk aufzubauen!Erstellen Sie ein neuronales Netzwerk
Wir werden ein neuronales Netzwerk für die Bilderkennung erstellen. Wir nehmen diesen Leitfaden als Grundlage .Um das Netzwerk zu trainieren, verwenden wir den öffentlich verfügbaren CIFAR10-Datensatz. Er hat Klassen: "Flugzeug", "Auto", "Vogel", "Katze", "Hirsch", "Hund", "Frosch", "Pferd", "Schiff", "LKW". Bilder in CIFAR10 haben eine Größe von 3 × 32 × 32, d. H. 3-Kanal-Farbbilder von 32 × 32 Pixel.Für die Arbeit verwenden wir das erstellte PyTorch-Paket für die Arbeit mit Bildern - Torchvision.Wir werden die folgenden Schritte der Reihe nach ausführen:- Laden Sie Trainings- und Testdatensätze herunter und normalisieren Sie sie
- Definition des neuronalen Netzes
- Netzwerktraining zu Trainingsdaten
- Testen des Netzwerks mit Testdaten
- Wiederholen Sie das GPU-Training und -Test
Der gesamte folgende Code wird im Jupyter-Notizbuch ausgeführt.Laden Sie CIFAR10 herunter und normalisieren Sie es
Kopieren Sie den folgenden Code in Jupyter und führen Sie ihn aus:
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
Die Antwort sollte so lauten:Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
Extracting ./data/cifar-10-python.tar.gz to ./data
Files already downloaded and verified
Wir werden verschiedene Trainingsbilder zur Überprüfung ableiten:
import matplotlib.pyplot as plt
import numpy as np
def imshow(img):
img = img / 2 + 0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
dataiter = iter(trainloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

Definition des neuronalen Netzes
Lassen Sie uns zunächst untersuchen, wie ein neuronales Netzwerk zur Bilderkennung funktioniert. Dies ist ein einfaches Direktverbindungsnetzwerk. Es nimmt Eingaben auf, durchläuft sie nacheinander durch mehrere Ebenen und gibt schließlich die Ausgabe aus.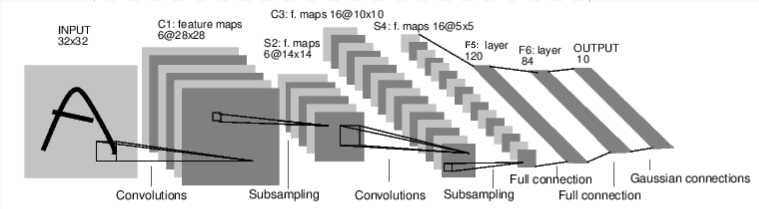 Erstellen wir ein ähnliches Netzwerk in unserer Umgebung:
Erstellen wir ein ähnliches Netzwerk in unserer Umgebung:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
Wir definieren auch die Verlustfunktion und den Optimierer
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
Netzwerktraining zu Trainingsdaten
Wir beginnen unser neuronales Netzwerk zu trainieren. Ich mache Sie darauf aufmerksam, dass Sie danach beim Ausführen dieses Codes eine Weile warten müssen, bis die Arbeit abgeschlossen ist. Ich habe 5 Minuten gebraucht. Vernetzung braucht Zeit. for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
Wir erhalten folgendes Ergebnis: Wir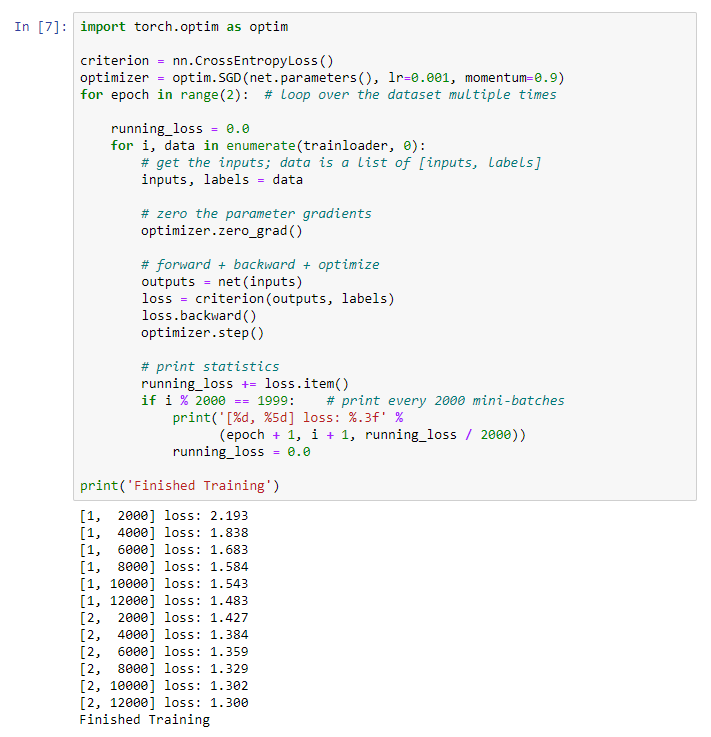 speichern unser trainiertes Modell:
speichern unser trainiertes Modell:PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)
Testen des Netzwerks mit Testdaten
Wir haben das Netzwerk anhand einer Reihe von Trainingsdaten trainiert. Wir müssen jedoch überprüfen, ob das Netzwerk überhaupt etwas gelernt hat.Wir werden dies überprüfen, indem wir die Klassenbezeichnung vorhersagen, die das neuronale Netzwerk ausgibt, und auf Wahrheit prüfen. Wenn die Prognose korrekt ist, fügen wir die Stichprobe der Liste der korrekten Prognosen hinzu.Lassen Sie uns das Bild aus der Testsuite zeigen:dataiter = iter(testloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
 Bitten Sie nun das neuronale Netz, uns zu sagen, was auf diesen Bildern zu sehen ist:
Bitten Sie nun das neuronale Netz, uns zu sagen, was auf diesen Bildern zu sehen ist:
net = Net()
net.load_state_dict(torch.load(PATH))
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(4)))
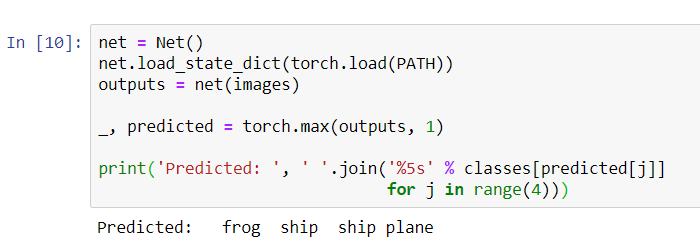 Die Ergebnisse scheinen ziemlich gut zu sein: Das Netzwerk hat drei der vier Bilder korrekt identifiziert.Mal sehen, wie das Netzwerk im gesamten Datensatz funktioniert.
Die Ergebnisse scheinen ziemlich gut zu sein: Das Netzwerk hat drei der vier Bilder korrekt identifiziert.Mal sehen, wie das Netzwerk im gesamten Datensatz funktioniert.
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
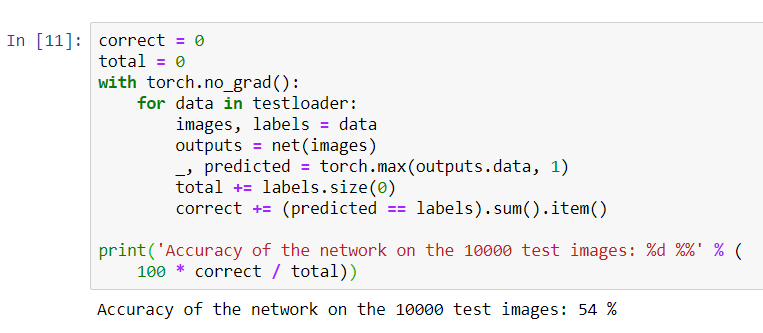 Es sieht so aus, als ob das Netzwerk es weiß und funktioniert. Wenn er Klassen zufällig definiert, beträgt die Genauigkeit 10%.Nun wollen wir sehen, welche Klassen das Netzwerk besser definiert:
Es sieht so aus, als ob das Netzwerk es weiß und funktioniert. Wenn er Klassen zufällig definiert, beträgt die Genauigkeit 10%.Nun wollen wir sehen, welche Klassen das Netzwerk besser definiert:class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
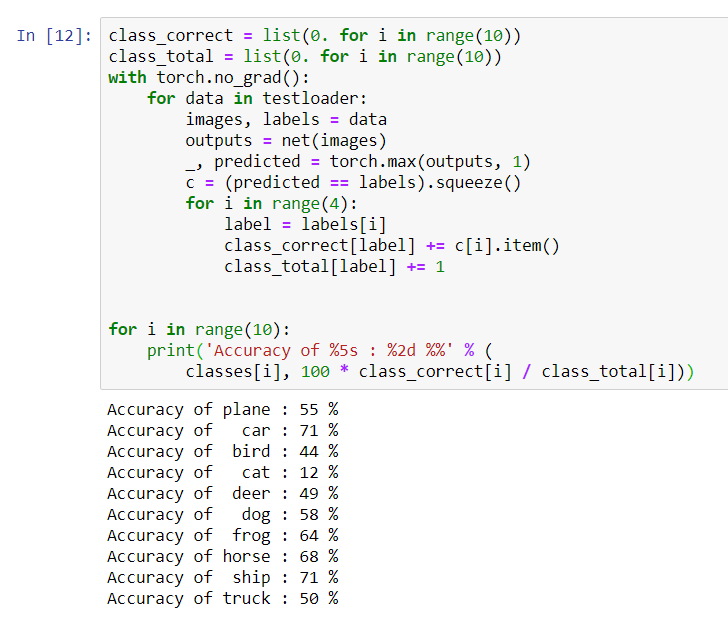 Es scheint, dass das Netzwerk Autos und Schiffe am besten bestimmt: 71% Genauigkeit.Das Netzwerk funktioniert also. Versuchen wir nun, seine Arbeit auf den Grafikprozessor (GPU) zu übertragen und zu sehen, was sich ändert.
Es scheint, dass das Netzwerk Autos und Schiffe am besten bestimmt: 71% Genauigkeit.Das Netzwerk funktioniert also. Versuchen wir nun, seine Arbeit auf den Grafikprozessor (GPU) zu übertragen und zu sehen, was sich ändert.GPU-Training für neuronale Netze
Zunächst erkläre ich kurz, was CUDA ist. CUDA (Compute Unified Device Architecture) ist eine von NVIDIA entwickelte Parallel-Computing-Plattform für das allgemeine Computing auf GPUs. Mit CUDA können Entwickler mithilfe der Funktionen von GPUs Computeranwendungen erheblich beschleunigen. Auf unserem von uns gekauften Server ist diese Plattform bereits installiert.Definieren wir zunächst unsere GPU als das erste sichtbare Cuda-Gerät.device = torch . device ( "cuda:0" if torch . cuda . is_available () else "cpu" )
print ( device )
 Senden Sie das Netzwerk an die GPU:
Senden Sie das Netzwerk an die GPU:net.to(device)
Wir müssen auch bei jedem Schritt Eingaben und Ziele an die GPU senden:inputs, labels = data[0].to(device), data[1].to(device)
Führen Sie das Netzwerk-Retraining bereits auf der GPU aus:import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
Dieses Mal dauerte das Netzwerktraining etwa 3 Minuten. Denken Sie daran, dass dieselbe Phase auf einem normalen Prozessor 5 Minuten dauerte. Der Unterschied ist nicht signifikant, weil unser Netzwerk nicht so groß ist. Wenn Sie große Arrays für das Training verwenden, erhöht sich der Unterschied zwischen der Geschwindigkeit der GPU und dem herkömmlichen Prozessor.Das scheint alles zu sein. Was wir geschafft haben:- Wir haben die GPU untersucht und den Server ausgewählt, auf dem sie installiert ist.
- Wir haben eine Softwareumgebung zum Erstellen eines neuronalen Netzwerks eingerichtet.
- Wir haben ein neuronales Netzwerk für die Bilderkennung erstellt und trainiert.
- Wir haben das Training des Netzwerks mit der GPU wiederholt und eine Geschwindigkeitssteigerung erhalten.
Gerne beantworte ich Fragen in den Kommentaren.