Kafka Streams ist eine Java-Bibliothek zum Analysieren und Verarbeiten von in Apache Kafka gespeicherten Daten. Wie bei jeder anderen Streaming-Verarbeitungsplattform kann die Datenverarbeitung mit und / oder ohne Zustandserhaltung in Echtzeit durchgeführt werden. In diesem Beitrag werde ich versuchen zu beschreiben, warum das Erreichen einer hohen Verfügbarkeit (99,99%) in Kafka Streams problematisch ist und was wir tun können, um dies zu erreichen.Was müssen wir wissen?
Bevor wir das Problem und mögliche Lösungen beschreiben, schauen wir uns die Grundkonzepte von Kafka Streams an. Wenn Sie mit Kafka-APIs für Verbraucher / Produzenten gearbeitet haben, sind Ihnen die meisten dieser Paradigmen vertraut. In den folgenden Abschnitten werde ich versuchen, die Speicherung von Daten in Partitionen, die Neuverteilung von Verbrauchergruppen und die Anpassung der Grundkonzepte von Kafka-Clients in die Kafka Streams-Bibliothek in wenigen Worten zu beschreiben.Kafka: Partitionieren von Daten
In der Kafka-Welt senden Produzentenanwendungen Daten als Schlüssel-Wert-Paare an ein bestimmtes Thema. Das Thema selbst ist in Kafka-Brokern in eine oder mehrere Partitionen unterteilt. Kafka verwendet einen Nachrichtenschlüssel, um anzugeben, in welche Partition die Daten geschrieben werden sollen. Folglich landen Nachrichten mit demselben Schlüssel immer auf derselben Partition.Verbraucheranwendungen sind in Verbrauchergruppen organisiert, und jede Gruppe kann eine oder mehrere Instanzen von Verbrauchern haben.Jede Instanz eines Verbrauchers in der Verbrauchergruppe ist für die Verarbeitung von Daten aus einem eindeutigen Satz von Partitionen des Eingabethemas verantwortlich.
Consumer-Instanzen sind im Wesentlichen ein Mittel zur Skalierung der Verarbeitung in Ihrer Consumer-Gruppe.Kafka: Verbrauchergruppe neu ausbalancieren
Wie bereits erwähnt, erhält jede Instanz der Verbrauchergruppe eine Reihe eindeutiger Partitionen, von denen Daten verarbeitet werden. Immer wenn ein neuer Verbraucher einer Gruppe beitritt, muss ein Neuausgleich stattfinden, damit er eine Partition erhält. Dasselbe passiert, wenn der Verbraucher stirbt. Der Rest des Verbrauchers sollte seine Partitionen nehmen, um sicherzustellen, dass alle Partitionen verarbeitet werden.Kafka Streams: Streams
Zu Beginn dieses Beitrags haben wir festgestellt, dass die Kafka Streams-Bibliothek auf APIs von Herstellern und Verbrauchern basiert und die Datenverarbeitung genauso organisiert ist wie die Standardlösung von Kafka. In der Kafka Streams-Konfiguration entspricht das Feld application.id der Datei group.idin der Consumer-API. Kafka Streams erstellt eine bestimmte Anzahl von Threads vorab und jeder von ihnen führt die Datenverarbeitung von einer oder mehreren Partitionen von Eingabethemen aus. In der Terminologie der Consumer-API stimmen Streams im Wesentlichen mit Instanzen von Consumer aus derselben Gruppe überein. Threads sind die Hauptmethode zum Skalieren der Datenverarbeitung in Kafka Streams. Dies kann vertikal erfolgen, indem die Anzahl der Threads für jede Kafka Streams-Anwendung auf einem Computer erhöht wird, oder horizontal, indem ein zusätzlicher Computer mit derselben application.id hinzugefügt wird.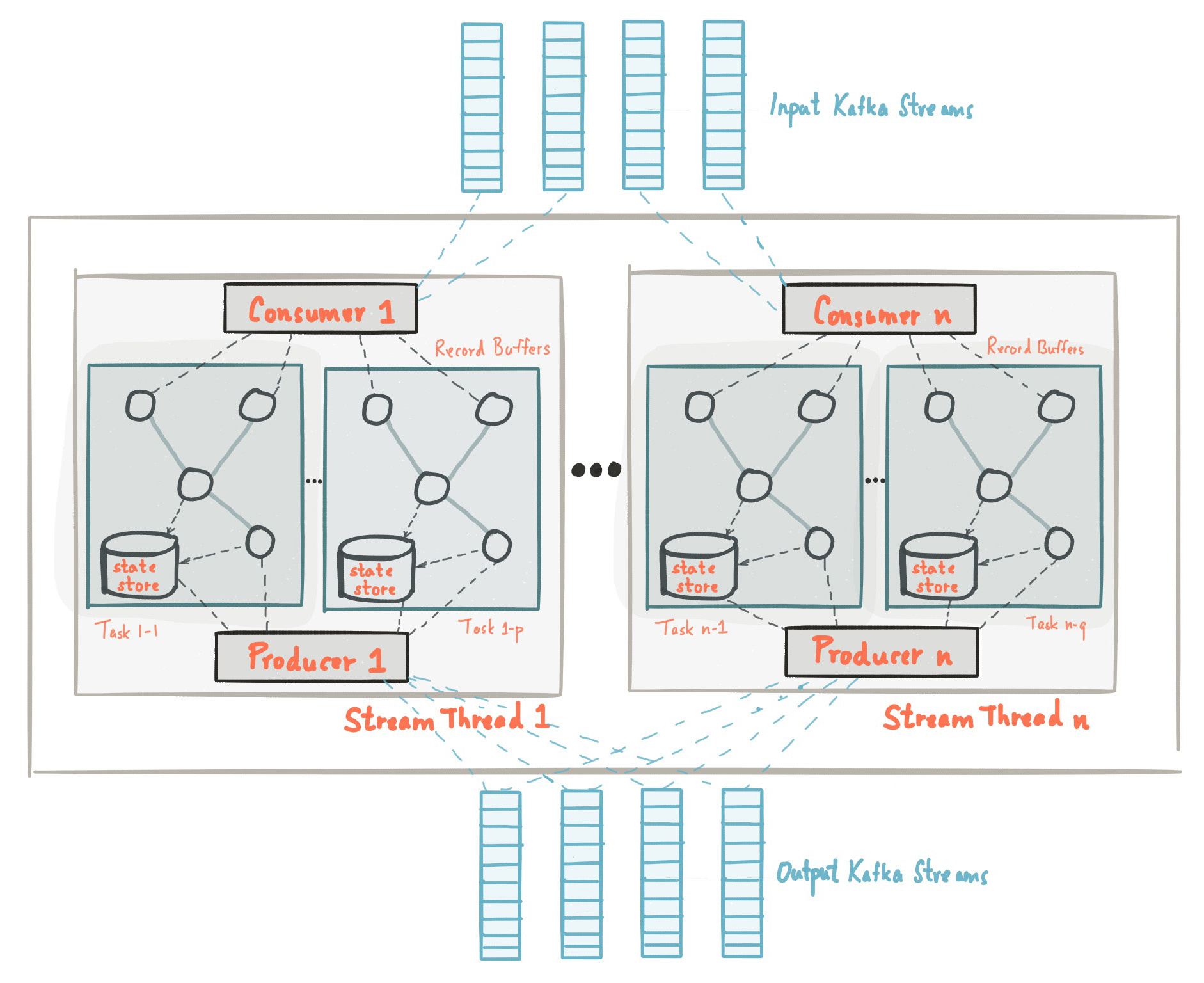 Quelle: kafka.apache.org/21/documentation/streams/architectureIn Kafka Streams gibt es viele weitere Elemente wie Aufgaben, Verarbeitungstopologie, Threading-Modell usw., die in diesem Beitrag nicht behandelt werden. Weitere Informationen finden Sie hier.
Quelle: kafka.apache.org/21/documentation/streams/architectureIn Kafka Streams gibt es viele weitere Elemente wie Aufgaben, Verarbeitungstopologie, Threading-Modell usw., die in diesem Beitrag nicht behandelt werden. Weitere Informationen finden Sie hier.Kafka Streams: Staatsspeicher
Bei der Stream-Verarbeitung gibt es Operationen mit und ohne Zustandserhaltung. Der Status ermöglicht es der Anwendung, sich die erforderlichen Informationen zu merken, die über den Umfang des aktuell verarbeiteten Datensatzes hinausgehen.Zustandsoperationen wie Anzahl, jede Art von Aggregation, Verknüpfungen usw. sind viel komplizierter. Dies liegt an der Tatsache, dass Sie mit nur einem Datensatz nicht den letzten Status (z. B. Anzahl) für einen bestimmten Schlüssel ermitteln können. Daher müssen Sie den Status Ihres Streams in Ihrer Anwendung speichern. Wie bereits erwähnt, verarbeitet jeder Thread eine Reihe eindeutiger Partitionen. Daher verarbeitet ein Thread nur eine Teilmenge des gesamten Datensatzes. Dies bedeutet, dass jeder Kafka Streams-Anwendungsthread mit derselben application.id seinen eigenen isolierten Status beibehält. Wir werden nicht näher darauf eingehen, wie der Status in Kafka Streams gebildet wird. Es ist jedoch wichtig zu verstehen, dass Status mithilfe des Änderungsprotokollthemas (Änderungsprotokollthema) wiederhergestellt und nicht nur auf der lokalen Festplatte, sondern auch in Kafka Broker gespeichert werden.Das Speichern des Statusänderungsprotokolls in Kafka Broker als separates Thema dient nicht nur der Fehlertoleranz, sondern auch der einfachen Bereitstellung neuer Instanzen von Kafka Streams mit derselben application.id. Da der Status auf der Brokerseite als Änderungsprotokollthema gespeichert ist, kann eine neue Instanz aus diesem Thema einen eigenen Status laden.Weitere Informationen zum Zustandsspeicher finden Sie hier .Warum ist Hochverfügbarkeit bei Kafka Streams problematisch?
Wir haben die grundlegenden Konzepte und Prinzipien der Datenverarbeitung mit Kafka Streams überprüft. Versuchen wir nun, alle Teile miteinander zu kombinieren und zu analysieren, warum das Erreichen einer hohen Verfügbarkeit problematisch sein kann. Aus den vorherigen Abschnitten müssen wir uns erinnern:- Die Daten im Kafka-Thema sind in Partitionen unterteilt, die auf die Kafka-Streams verteilt sind.
- Kafka Streams-Anwendungen mit derselben application.id sind in der Tat eine Gruppe von Verbrauchern, und jeder seiner Threads ist eine separate isolierte Instanz des Verbrauchers.
- Für Statusoperationen behält der Thread seinen eigenen Status bei, der vom Kafka-Thema in Form eines Änderungsprotokolls „reserviert“ wird.
- , Kafka , .
TransferWise SPaaS (Stream Processing as a Service)
Bevor ich das Wesentliche dieses Beitrags hervorhole, möchte ich Ihnen zunächst erläutern, was wir in TransferWise erstellt haben und warum Hochverfügbarkeit für uns sehr wichtig ist.In TransferWise haben wir mehrere Knoten für die Streaming-Verarbeitung, und jeder Knoten enthält mehrere Instanzen von Kafka-Streams für jedes Produktteam. Kafka Streams-Instanzen, die für ein bestimmtes Entwicklungsteam entwickelt wurden, haben eine spezielle application.id und normalerweise mehr als 5 Threads. Im Allgemeinen haben Teams im gesamten Cluster 10 bis 20 Threads (entsprechend der Anzahl der Instanzen von Verbrauchern). Anwendungen, die auf Knoten bereitgestellt werden, überwachen Eingabethemen und führen verschiedene Arten von Vorgängen mit und ohne Status für Eingabedaten aus und bieten Echtzeit-Datenaktualisierungen für nachfolgende nachgeschaltete Mikrodienste.Produktteams müssen aggregierte Daten in Echtzeit aktualisieren. Dies ist notwendig, um unseren Kunden die Möglichkeit zu geben, sofort Geld zu überweisen. Unsere übliche SLA:An einem bestimmten Tag sollten 99,99% der aggregierten Daten in weniger als 10 Sekunden verfügbar sein.
Um Ihnen eine Vorstellung zu geben, konnte Kafka Streams während Stresstests 20.085 Eingabenachrichten pro Sekunde verarbeiten und aggregieren. Somit klangen 10 Sekunden SLA unter normaler Last durchaus erreichbar. Leider wurde unser SLA während des fortlaufenden Updates der Knoten, auf denen die Anwendungen bereitgestellt werden, nicht erreicht. Im Folgenden werde ich beschreiben, warum dies passiert ist.Sliding Node Update
Wir bei TransferWise glauben fest an die kontinuierliche Bereitstellung unserer Software und veröffentlichen in der Regel mehrmals täglich neue Versionen unserer Dienste. Schauen wir uns ein Beispiel für ein einfaches kontinuierliches Service-Update an und sehen, was während des Release-Prozesses passiert. Auch hier müssen wir uns daran erinnern:- Die Daten im Kafka-Thema sind in Partitionen unterteilt, die auf die Kafka-Streams verteilt sind.
- Kafka Streams-Anwendungen mit derselben application.id sind in der Tat eine Gruppe von Verbrauchern, und jeder seiner Threads ist eine separate isolierte Instanz des Verbrauchers.
- Für Statusoperationen behält der Thread seinen eigenen Status bei, der vom Kafka-Thema in Form eines Änderungsprotokolls „reserviert“ wird.
- , Kafka , .
Ein Freigabeprozess auf einem einzelnen Knoten dauert normalerweise acht bis neun Sekunden. Während der Veröffentlichung werden Instanzen von Kafka Streams auf dem Knoten „sanft neu gestartet“. Für einen einzelnen Knoten beträgt die zum korrekten Neustart des Dienstes erforderliche Zeit ungefähr acht bis neun Sekunden. Das Herunterfahren einer Kafka Streams-Instanz auf einem Knoten führt offensichtlich zu einem Neuausgleich der Verbrauchergruppe. Da die Daten partitioniert sind, müssen alle Partitionen, die zur bootfähigen Instanz gehörten, auf aktive Kafka Streams-Anwendungen mit derselben application.id verteilt werden. Dies gilt auch für aggregierte Daten, die auf der Festplatte gespeichert wurden. Bis dieser Vorgang abgeschlossen ist, werden keine Daten verarbeitet.Standby-Repliken
Um die Neuausgleichszeit für Kafka Streams-Anwendungen zu verkürzen, gibt es ein Konzept für Sicherungsreplikate, die in der Konfiguration als num.standby.replicas definiert sind. Sicherungsreplikate sind Kopien des lokalen Statusspeichers. Dieser Mechanismus ermöglicht es, den Statusspeicher von einer Instanz von Kafka Streams auf eine andere zu replizieren. Wenn der Kafka Streams-Thread aus irgendeinem Grund stirbt, kann die Dauer des Statuswiederherstellungsprozesses minimiert werden. Leider helfen aus den unten erläuterten Gründen selbst Backup-Replikate bei einem fortlaufenden Service-Update nicht weiter.Angenommen, wir haben zwei Instanzen von Kafka-Streams auf zwei verschiedenen Computern: Knoten-a und Knoten-b. Für jede der Kafka Streams-Instanzen wird auf diesen beiden Knoten num.standby.replicas = 1 angegeben. Bei dieser Konfiguration verwaltet jede Kafka Streams-Instanz ihre eigene Kopie des Repositorys auf einem anderen Knoten. Während eines fortlaufenden Updates haben wir die folgende Situation:- Die neue Version des Dienstes wurde auf Knoten-a bereitgestellt.
- Die Kafka Streams-Instanz auf Knoten a ist deaktiviert.
- Das Rebalancing hat begonnen.
- Das Repository von Knoten-a wurde bereits auf Knoten-b repliziert, da wir die Konfiguration num.standby.replicas = 1 angegeben haben.
- Knoten-b verfügt bereits über eine Schattenkopie von Knoten-a, sodass der Neuausgleichsprozess fast sofort erfolgt.
- Knoten-a startet erneut.
- node-a tritt einer Gruppe von Verbrauchern bei.
- Kafka Broker sieht eine neue Instanz von Kafka Streams und beginnt mit dem Ausgleich.
Wie wir sehen können, hilft num.standby.replicas nur in Szenarien eines vollständigen Herunterfahrens eines Knotens. Dies bedeutet, dass bei einem Absturz von Knoten-a Knoten-b fast sofort ordnungsgemäß weiterarbeiten kann. In einer fortlaufenden Aktualisierungssituation wird Node-a nach dem Trennen der Verbindung wieder der Gruppe beitreten, und dieser letzte Schritt führt zu einem Neuausgleich. Wenn Node-a nach einem Neustart der Consumer-Gruppe beitritt, wird dies als neue Instanz des Consumer betrachtet. Auch hier müssen wir uns daran erinnern, dass die Echtzeitdatenverarbeitung angehalten wird, bis eine neue Instanz ihren Status aus dem Änderungsprotokollthema wiederherstellt.Beachten Sie, dass das Neuausgleichen von Partitionen, wenn eine neue Instanz einer Gruppe hinzugefügt wird, nicht für die Kafka Streams-API gilt, da genau das Protokoll der Apache Kafka-Verbrauchergruppe funktioniert.Leistung: Hochverfügbarkeit mit Kafka Streams
Trotz der Tatsache, dass Kafka-Clientbibliotheken keine integrierte Funktionalität für das oben erwähnte Problem bieten, gibt es einige Tricks, mit denen eine hohe Clusterverfügbarkeit während eines fortlaufenden Updates erreicht werden kann. Die Idee hinter Backup-Replikaten bleibt gültig, und Backup-Maschinen zum richtigen Zeitpunkt zu haben, ist eine gute Lösung, die wir verwenden, um im Falle eines Instanzausfalls eine hohe Verfügbarkeit sicherzustellen.Das Problem bei unserer Ersteinrichtung war, dass wir eine Gruppe von Verbrauchern für alle Teams auf allen Knoten hatten. Anstelle einer Gruppe von Verbrauchern haben wir jetzt zwei, und die zweite Gruppe fungiert als „heißer“ Cluster. In prod haben Knoten eine spezielle Variable CLUSTER_ID, die der application.id von Kafka Streams-Instanzen hinzugefügt wird. Hier ist ein Beispiel für eine Spring Boot application.yml-Konfiguration:application.ymlspring.profiles: production
streaming-pipelines:
team-a-stream-app-id: "${CLUSTER_ID}-team-a-stream-app"
team-b-stream-app-id: "${CLUSTER_ID}-team-b-stream-app"
Zu einem bestimmten Zeitpunkt befindet sich jeweils nur einer der Cluster im aktiven Modus. Der Sicherungscluster sendet keine Nachrichten in Echtzeit an nachgeschaltete Mikrodienste. Während der Veröffentlichung der Version wird der Sicherungscluster aktiv, wodurch ein fortlaufendes Update des ersten Clusters ermöglicht wird. Da es sich um eine völlig andere Gruppe von Verbrauchern handelt, bemerken unsere Kunden nicht einmal Verstöße bei der Verarbeitung, und nachfolgende Dienste empfangen weiterhin Nachrichten vom kürzlich aktiven Cluster. Einer der offensichtlichen Nachteile der Verwendung einer Sicherungsgruppe von Verbrauchern ist der zusätzliche Overhead und Ressourcenverbrauch. Diese Architektur bietet jedoch zusätzliche Garantien, Kontrolle und Fehlertoleranz für unser Streaming-Verarbeitungssystem.Neben dem Hinzufügen eines zusätzlichen Clusters gibt es auch Tricks, mit denen das Problem durch häufiges Neuausgleichen behoben werden kann.Erhöhen Sie group.initial.rebalance.delay.ms
Ab Kafka 0.11.0.0 wurde die Konfigurationsgruppe.initial.rebalance.delay.ms hinzugefügt. Laut Dokumentation ist diese Einstellung verantwortlich für:Die Zeit in Millisekunden, die GroupCoordinator für die anfängliche Neuausrichtung des Verbrauchers der Gruppe verzögert.
Wenn wir in dieser Einstellung beispielsweise 60.000 Millisekunden festlegen, haben wir bei einem fortlaufenden Update möglicherweise ein Minutenfenster für die Veröffentlichung der Version. Wenn die Kafka Streams-Instanz in diesem Zeitfenster erfolgreich neu gestartet wird, wird kein Neuausgleich aufgerufen. Beachten Sie, dass die Daten, für die die neu gestartete Kafka Streams-Instanz verantwortlich war, weiterhin nicht verfügbar sind, bis der Knoten in den Online-Modus zurückkehrt. Wenn ein Neustart einer Instanz beispielsweise etwa acht Sekunden dauert, haben Sie acht Sekunden Ausfallzeit für die Daten, für die diese Instanz verantwortlich ist.Es ist zu beachten, dass der Hauptnachteil dieses Konzepts darin besteht, dass Sie im Falle eines Knotenausfalls unter Berücksichtigung der aktuellen Konfiguration eine zusätzliche Verzögerung von einer Minute während der Wiederherstellung erhalten.Verkleinern der Segmentgröße in Änderungsprotokollthemen
Die große Verzögerung bei der Neuausrichtung von Kafka Stream ist auf die Wiederherstellung staatlicher Geschäfte aus Änderungsprotokollthemen zurückzuführen. Änderungsprotokollthemen sind komprimierte Themen, mit denen Sie den neuesten Datensatz für einen bestimmten Schlüssel im Thema speichern können. Ich werde dieses Konzept im Folgenden kurz beschreiben.Die Themen in Kafka Broker sind in Segmente unterteilt. Wenn ein Segment die konfigurierte Schwellengröße erreicht, wird ein neues Segment erstellt und das vorherige komprimiert. Standardmäßig ist dieser Schwellenwert auf 1 GB festgelegt. Wie Sie wahrscheinlich wissen, ist die Hauptdatenstruktur, die den Kafka-Themen und ihren Partitionen zugrunde liegt, die Protokollstruktur mit einem Vorwärtsschreibvorgang. Wenn also Nachrichten an das Thema gesendet werden, werden sie immer zum letzten „aktiven“ Segment hinzugefügt, die Komprimierung jedoch nicht los.Daher befinden sich die meisten gespeicherten Speicherzustände im Änderungsprotokoll immer in der Datei "Aktives Segment" und werden nie komprimiert, was zu Millionen unkomprimierter Änderungsprotokollnachrichten führt. Für Kafka Streams bedeutet dies, dass die Kafka Streams-Instanz während des Neuausgleichs, wenn sie ihren Status aus dem Changelog-Thema wiederherstellt, viele redundante Einträge aus dem Changelog-Thema lesen muss. Da sich State Stores nur um den letzten Status und nicht um den Verlauf kümmern, wird diese Verarbeitungszeit verschwendet. Das Reduzieren der Größe des Segments führt zu einer aggressiveren Datenkomprimierung, sodass neue Instanzen von Kafka Streams-Anwendungen viel schneller wiederhergestellt werden können.Fazit
Auch wenn Kafka Streams keine integrierte Möglichkeit bietet, während eines fortlaufenden Service-Updates eine hohe Verfügbarkeit bereitzustellen, kann dies dennoch auf Infrastrukturebene erfolgen. Wir müssen uns daran erinnern, dass Kafka Streams im Gegensatz zu Apache Flink oder Apache Spark kein „Cluster-Framework“ ist. Es handelt sich um eine kompakte Java-Bibliothek, mit der Entwickler skalierbare Anwendungen für das Streaming von Daten erstellen können. Trotzdem bietet es die notwendigen Bausteine, um so ehrgeizige Streaming-Ziele wie die Verfügbarkeit von „99,99%“ zu erreichen.