Ich stoße regelmäßig auf eine Situation, in der viele Entwickler aufrichtig glauben, dass der Index in PostgreSQL ein solches Schweizer Messer ist, das allgemein bei Problemen mit der Abfrageleistung hilft. Es reicht aus, der Tabelle einen neuen Index hinzuzufügen oder das Feld irgendwo in den vorhandenen aufzunehmen, und dann (Magie-Magie!) Werden alle Abfragen diesen Index effektiv verwenden. Erstens werden sie entweder nicht oder nicht effizient oder nicht alle. Zweitens führen zusätzliche Indizes nur zu Leistungsproblemen beim Schreiben.In den meisten Fällen treten solche Situationen während der "Langzeit" -Entwicklung auf, wenn kein benutzerdefiniertes Produkt nach dem Modell "einmal geschrieben, gegeben, vergessen" hergestellt wird, sondern wie in unserem Fall erstellt wirdService mit einem langen Lebenszyklus .Verbesserungen erfolgen iterativ durch die Kräfte vieler verteilter Teams , die nicht nur räumlich, sondern auch zeitlich verteilt sind. Und wenn Sie nicht die gesamte Geschichte der Projektentwicklung oder die Merkmale der angewandten Verteilung von Daten in der Datenbank kennen, können Sie die Indizes leicht "durcheinander bringen". Überlegungen und Testanforderungen im Rahmen des Schnitts ermöglichen es Ihnen jedoch, einen Teil der Probleme im Voraus vorherzusagen und zu erkennen:
Erstens werden sie entweder nicht oder nicht effizient oder nicht alle. Zweitens führen zusätzliche Indizes nur zu Leistungsproblemen beim Schreiben.In den meisten Fällen treten solche Situationen während der "Langzeit" -Entwicklung auf, wenn kein benutzerdefiniertes Produkt nach dem Modell "einmal geschrieben, gegeben, vergessen" hergestellt wird, sondern wie in unserem Fall erstellt wirdService mit einem langen Lebenszyklus .Verbesserungen erfolgen iterativ durch die Kräfte vieler verteilter Teams , die nicht nur räumlich, sondern auch zeitlich verteilt sind. Und wenn Sie nicht die gesamte Geschichte der Projektentwicklung oder die Merkmale der angewandten Verteilung von Daten in der Datenbank kennen, können Sie die Indizes leicht "durcheinander bringen". Überlegungen und Testanforderungen im Rahmen des Schnitts ermöglichen es Ihnen jedoch, einen Teil der Probleme im Voraus vorherzusagen und zu erkennen:- nicht verwendete Indizes
- Präfix "Klone"
- Zeitstempel "in der Mitte"
- indexierbarer Boolescher Wert
- Arrays im Index
- Null Müll
Am einfachsten ist es, Indizes zu finden, für die es überhaupt keine Pässe gab . Sie müssen nur sicherstellen, dass das Zurücksetzen von statistics ( pg_stat_reset()) vor langer Zeit erfolgt ist, und Sie möchten das verwendete "selten, aber passend" nicht löschen. Wir verwenden die Systemansicht pg_stat_user_indexes:SELECT * FROM pg_stat_user_indexes WHERE idx_scan = 0;
Aber selbst wenn der Index verwendet wird und nicht in diese Auswahl fällt, bedeutet dies keineswegs, dass er für Ihre Abfragen gut geeignet ist.Welche Indizes sind [nicht] geeignet?
Um zu verstehen, warum einige Abfragen im Index "schlecht" werden, werden wir uns die Struktur eines regulären btree- Index überlegen , der in der Natur am häufigsten vorkommenden Instanz. Indizes aus einem einzelnen Feld verursachen normalerweise keine Probleme. Daher betrachten wir die Probleme, die bei einem Verbund aus zwei Feldern auftreten.Ein extrem vereinfachter Weg, wie man sich vorstellen kann, ist ein „Schichtkuchen“, bei dem in jeder Schicht Bäume nach den Werten des entsprechenden Feldes in der richtigen Reihenfolge angeordnet sind.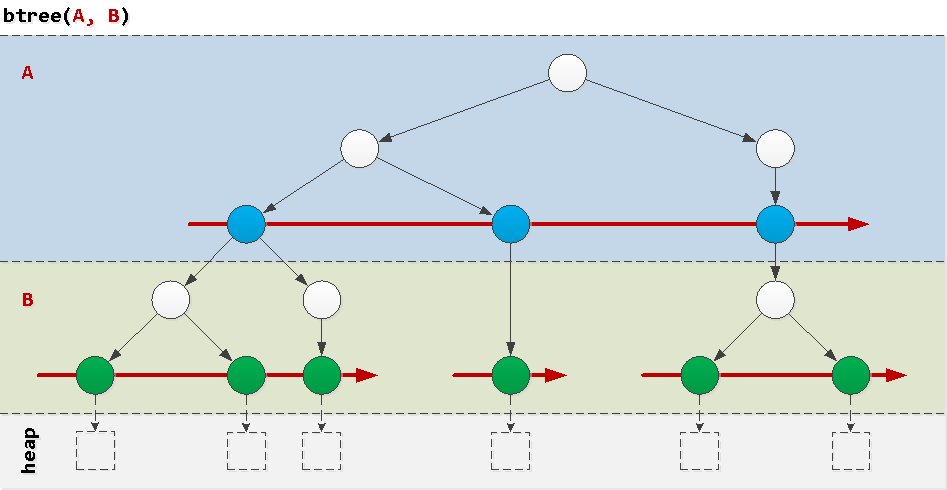 Nun ist es klar , dass das Feld A global geordnet und B - nur innerhalb eines bestimmten Werts A . Schauen wir uns Beispiele für Bedingungen an, die in realen Abfragen auftreten, und wie sie den Index "durchlaufen".
Nun ist es klar , dass das Feld A global geordnet und B - nur innerhalb eines bestimmten Werts A . Schauen wir uns Beispiele für Bedingungen an, die in realen Abfragen auftreten, und wie sie den Index "durchlaufen".Gut: Präfixbedingung
Beachten Sie, dass der Index btree(A, B)einen „Subindex“ enthält btree(A). Dies bedeutet, dass alle unten beschriebenen Regeln für jeden Präfixindex funktionieren.Das heißt, wenn Sie einen komplexeren Index als in unserem Beispiel erstellen, der vom Typ ist btree(A, B, C), können Sie davon ausgehen, dass Ihre Datenbank automatisch "angezeigt" wird:btree(A, B, C)btree(A, B)btree(A)
Dies bedeutet, dass das „physische“ Vorhandensein des Präfixindex in der Datenbank in den meisten Fällen redundant ist. Immerhin hat die mehr Indizes eine Tabelle zu schreiben - desto schlechter ist es für PostgreSQL, da es Write Amplification nennt - Uber darüber beschwert (und hier können Sie eine Analyse ihrer Ansprüche finden ).Und wenn etwas die Basis daran hindert, gut zu leben, lohnt es sich, sie zu finden und zu beseitigen. Schauen wir uns ein Beispiel an:CREATE TABLE tbl(A integer, B integer, val integer);
CREATE INDEX ON tbl(A, B)
WHERE val IS NULL;
CREATE INDEX ON tbl(A)
WHERE val IS NULL;
CREATE INDEX ON tbl(A, B, val);
CREATE INDEX ON tbl(A);
Präfix-Index-SuchabfrageWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid AND
idx.indexprs IS NULL
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
, CASE
WHEN def ~ ' WHERE ' THEN regexp_replace(def, E'.* WHERE ', '')
END wh
FROM
def
)
, pre AS (
SELECT
nmt
, wh
, nmf$
, tpf$
, nmi
, def
FROM
fld
ORDER BY
1, 2, 3
)
SELECT DISTINCT
Y.*
FROM
pre X
JOIN
pre Y
ON Y.nmi <> X.nmi AND
(Y.nmt, Y.wh) IS NOT DISTINCT FROM (X.nmt, X.wh) AND
(
Y.nmf$[1:array_length(X.nmf$, 1)] = X.nmf$ OR
X.nmf$[1:array_length(Y.nmf$, 1)] = Y.nmf$
)
ORDER BY
1, 2, 3;
Idealerweise sollten Sie eine leere Auswahl erhalten, aber schauen Sie - dies sind unsere verdächtigen Indexgruppen:nmt | wh | nmf$ | tpf$ | nmi | def
---------------------------------------------------------------------------------------
tbl | (val IS NULL) | {a} | {int4} | tbl_a_idx | CREATE INDEX ...
tbl | (val IS NULL) | {a,b} | {int4,int4} | tbl_a_b_idx | CREATE INDEX ...
tbl | | {a} | {int4} | tbl_a_idx1 | CREATE INDEX ...
tbl | | {a,b,val} | {int4,int4,int4} | tbl_a_b_val_idx | CREATE INDEX ...
Dann entscheiden Sie für jede Gruppe selbst, ob es sich gelohnt hat, den kürzeren oder den längeren Index zu entfernen, der überhaupt nicht benötigt wurde.Gut: alle Konstanten außer dem letzten Feld
Wenn die Werte aller Felder des Index mit Ausnahme des letzten durch Konstanten festgelegt werden (in unserem Beispiel ist dies Feld A), kann der Index normal verwendet werden. In diesem Fall kann der Wert des letzten Feldes beliebig eingestellt werden: Konstante, Ungleichung, Intervall, Durchwahl IN (...)oder = ANY(...). Und es kann auch danach sortiert werden.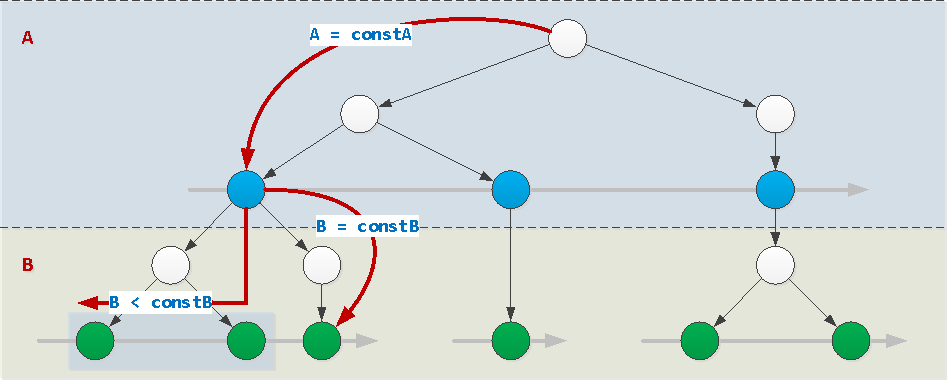
WHERE A = constA AND B [op] constB / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }WHERE A = constA AND B BETWEEN constB1 AND constB2WHERE A = constA ORDER BY B
Basierend auf den oben beschriebenen Präfixindizes funktioniert dies gut:WHERE A [op] const / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }WHERE A BETWEEN const1 AND const2ORDER BY AWHERE (A, B) [op] (constA, constB) / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }ORDER BY A, B
Schlecht: vollständige Aufzählung der "Ebene"
Bei einem Teil der Abfragen wird die einzige Aufzählung der Bewegung im Index zu einer vollständigen Aufzählung aller Werte in einer der „Ebenen“. Es ist ein Glück, wenn es eine Einheit solcher Werte gibt - und wenn es Tausende gibt? ..Normalerweise tritt ein solches Problem auf, wenn Ungleichheit in der Abfrage verwendet wird , die Bedingung nicht die Felder bestimmt , die in der Indexreihenfolge vorher waren , oder diese Reihenfolge während der Sortierung verletzt wird .WHERE A <> constWHERE B [op] const / = ANY(...) / IN (...)ORDER BY BORDER BY B, A
Schlecht: Intervall oder Satz befindet sich nicht im letzten Feld
Als Konsequenz des vorherigen - Wenn Sie mehrere Werte oder deren Bereich auf einer Zwischenebene finden und dann nach den Feldern filtern oder sortieren müssen, die "tiefer" im Index liegen, treten Probleme auf, wenn die Anzahl der eindeutigen Werte "in der Mitte" des Index liegt groß.WHERE A BETWEEN constA1 AND constA2 AND B BETWEEN constB1 AND constB2WHERE A = ANY(...) AND B = constWHERE A = ANY(...) ORDER BY BWHERE A = ANY(...) AND B = ANY(...)
Schlecht: Ausdruck statt Feld
Manchmal verwandelt ein Entwickler eine Spalte in einer Abfrage unbewusst in etwas anderes - in einen Ausdruck, für den es keinen Index gibt. Dies kann behoben werden, indem ein Index aus dem gewünschten Ausdruck erstellt oder die inverse Transformation durchgeführt wird:WHERE A - const1 [op] const2
Fix: WHERE A [op] const1 + const2WHERE A::typeOfConst = const
Fix: WHERE A = const::typeOfA
Wir berücksichtigen die Kardinalität der Felder
Angenommen, Sie benötigen einen Index (A, B)und möchten nur nach Gleichheit auswählen : (A, B) = (constA, constB). Die Verwendung eines Hash-Index wäre ideal , aber ... Zusätzlich zum Nicht-Journaling (Wal-Logging) solcher Indizes bis Version 10 können sie auch nicht in mehreren Feldern vorhanden sein:CREATE INDEX ON tbl USING hash(A, B);
Im Allgemeinen haben Sie btree gewählt. Was ist also der beste Weg, um Spalten darin anzuordnen - (A, B)oder (B, A)? Um diese Frage zu beantworten, muss ein Parameter wie die Kardinalität der Daten in der entsprechenden Spalte berücksichtigt werden , dh wie viele eindeutige Werte sie enthalten.Stellen wir uns das vor A = {1,2}, B = {1,2,3,4}und zeichnen einen Umriss des Indexbaums für beide Optionen: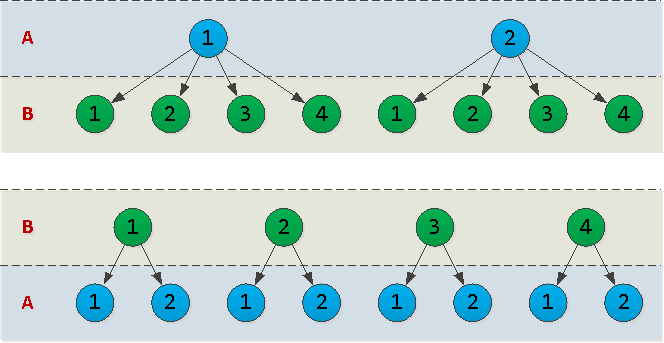 Tatsächlich ist jeder Knoten im Baum, den wir zeichnen, eine Seite im Index. Und je mehr vorhanden sind, desto mehr Speicherplatz belegt der Index, desto länger dauert das Lesen.In unserem Beispiel hat die Option
Tatsächlich ist jeder Knoten im Baum, den wir zeichnen, eine Seite im Index. Und je mehr vorhanden sind, desto mehr Speicherplatz belegt der Index, desto länger dauert das Lesen.In unserem Beispiel hat die Option (A, B)10 Knoten und (B, A)- 12. Das heißt, es ist rentabler, die "Felder" mit so wenig eindeutigen Werten wie möglich "zuerst" zu setzen .Schlecht: viel und fehl am Platz (Zeitstempel "in der Mitte")
Genau aus diesem Grund sieht es immer verdächtig aus, wenn ein Feld mit offensichtlich großer Variabilität wie Zeitstempel [tz] nicht das letzte in Ihrem Index ist . In der Regel steigen die Werte des Zeitstempelfelds monoton an, und die folgenden Indexfelder haben zu jedem Zeitpunkt nur einen Wert.CREATE TABLE tbl(A integer, B timestamp);
CREATE INDEX ON tbl(A, B);
CREATE INDEX ON tbl(B, A);

Suchabfrage für nicht endgültige Zeitstempel [tz] -IndizesWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
, (
SELECT
array_agg(replace(opcname::text, '_ops', '') ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indclass[i] ik
FROM
generate_subscripts(idx.indclass, 1) i
) f
JOIN
pg_opclass T
ON T.oid = f.ik
) opc$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, def
, nmf$
, tpf$
, opc$
FROM
fld
WHERE
'timestamp' = ANY(tpf$[1:array_length(tpf$, 1) - 1]) OR
'timestamptz' = ANY(tpf$[1:array_length(tpf$, 1) - 1]) OR
'timestamp' = ANY(opc$[1:array_length(opc$, 1) - 1]) OR
'timestamptz' = ANY(opc$[1:array_length(opc$, 1) - 1])
ORDER BY
1, 2;
Hier analysieren wir sofort sowohl die Typen der Eingabefelder selbst als auch die auf sie angewendeten Klassen von Operatoren - da sich einige timestamptz-Funktionen wie date_trunc als Indexfeld herausstellen können.nmt | nmi | def | nmf$ | tpf$ | opc$
----------------------------------------------------------------------------------
tbl | tbl_b_a_idx | CREATE INDEX ... | {b,a} | {timestamp,int4} | {timestamp,int4}
Schlecht: zu wenig (boolesch)
Die Kehrseite derselben Münze wird zu einer Situation, in der der Index ein Boolesches Feld ist , das nur 3 Werte annehmen kann NULL, FALSE, TRUE. Das Vorhandensein ist natürlich sinnvoll, wenn Sie es für die angewandte Sortierung verwenden möchten, indem Sie sie beispielsweise als Knotentyp in der Baumhierarchie festlegen, unabhängig davon, ob es sich um einen Ordner oder ein Blatt handelt („Ordner zuerst“).CREATE TABLE tbl(
id
serial
PRIMARY KEY
, leaf_pid
integer
, leaf_type
boolean
, public
boolean
);
CREATE INDEX ON tbl(leaf_pid, leaf_type);
CREATE INDEX ON tbl(public, id);
In den meisten Fällen ist dies jedoch nicht der Fall, und Anforderungen haben einen bestimmten Wert für das boolesche Feld. Und dann wird es möglich, den Index durch dieses Feld durch seine bedingte Version zu ersetzen:CREATE INDEX ON tbl(id) WHERE public;
Boolesche Suchabfrage in IndizesWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
, (
SELECT
array_agg(replace(opcname::text, '_ops', '') ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indclass[i] ik
FROM
generate_subscripts(idx.indclass, 1) i
) f
JOIN
pg_opclass T
ON T.oid = f.ik
) opc$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, def
, nmf$
, tpf$
, opc$
FROM
fld
WHERE
(
'bool' = ANY(tpf$) OR
'bool' = ANY(opc$)
) AND
NOT(
ARRAY(
SELECT
nmf$[i:i+1]::text
FROM
generate_series(1, array_length(nmf$, 1) - 1) i
) &&
ARRAY[
'{leaf_pid,leaf_type}'
]
)
ORDER BY
1, 2;
nmt | nmi | def | nmf$ | tpf$ | opc$
------------------------------------------------------------------------------------
tbl | tbl_public_id_idx | CREATE INDEX ... | {public,id} | {bool,int4} | {bool,int4}
Arrays in btree
Ein separater Punkt ist der Versuch, das Array mithilfe des btree-Index zu "indizieren". Dies ist durchaus möglich, da für sie die entsprechenden Operatoren gelten :(<, >, = . .) , B-, , . ( ). , , .
Das Problem ist jedoch, dass er etwas verwendet, das er für Operatoren von Inklusion und Schnittmenge verwenden möchte : <@, @>, &&. Dies funktioniert natürlich nicht - da sie andere Arten von Indizes benötigen . Wie ein solcher Baum für die Funktion des Zugriffs auf ein bestimmtes Element nicht funktioniertarr[i] .Wir lernen solche zu finden:CREATE TABLE tbl(
id
serial
PRIMARY KEY
, pid
integer
, list
integer[]
);
CREATE INDEX ON tbl(pid);
CREATE INDEX ON tbl(list);
Array-Suchabfrage in btreeWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid AND
cli.relam = (
SELECT
oid
FROM
pg_am
WHERE
amname = 'btree'
LIMIT 1
)
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, nmf$
, tpf$
, def
FROM
fld
WHERE
tpf$ && ARRAY(
SELECT
typname
FROM
pg_type
WHERE
typname ~ '^_'
)
ORDER BY
1, 2;
nmt | nmi | nmf$ | tpf$ | def
--------------------------------------------------------
tbl | tbl_list_idx | {list} | {_int4} | CREATE INDEX ...
NULL-Indexeinträge
Das letzte häufig auftretende Problem besteht darin, den Index mit vollständig NULL-Einträgen zu „verschmutzen“. Das heißt, Datensätze, bei denen der indizierte Ausdruck in jeder der Spalten NULL ist . Solche Aufzeichnungen haben keinen praktischen Nutzen, aber sie fügen jedem Einsatz Schaden zu.Normalerweise werden sie angezeigt, wenn Sie ein FK-Feld oder eine Wertebeziehung mit optionalem Auffüllen in der Tabelle erstellen. Dann rollen Sie den Index, damit FK schnell funktioniert ... und hier sind sie. Je seltener die Verbindung gefüllt wird, desto mehr „Müll“ fällt in den Index. Wir werden simulieren:CREATE TABLE tbl(
id
serial
PRIMARY KEY
, fk
integer
);
CREATE INDEX ON tbl(fk);
INSERT INTO tbl(fk)
SELECT
CASE WHEN i % 10 = 0 THEN i END
FROM
generate_series(1, 1000000) i;
In den meisten Fällen kann ein solcher Index in einen bedingten Index konvertiert werden, der auch weniger benötigt:CREATE INDEX ON tbl(fk) WHERE (fk) IS NOT NULL;
_tmp=# \di+ tbl*
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+----------------+-------+----------+----------+---------+-------------
public | tbl_fk_idx | index | postgres | tbl | 36 MB |
public | tbl_fk_idx1 | index | postgres | tbl | 2208 kB |
public | tbl_pkey | index | postgres | tbl | 21 MB |
Um solche Indizes zu finden, müssen wir die tatsächliche Verteilung der Daten kennen - das heißt, wir müssen den gesamten Inhalt der Tabellen lesen und ihn gemäß den WHERE-Bedingungen des Auftretens überlagern (wir werden dies mit dblink tun ), was sehr lange dauern kann .Suchabfrage nach NULL-Einträgen in IndizesWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisprimary AND
idx.indisready AND
idx.indisvalid AND
NOT EXISTS(
SELECT
NULL
FROM
pg_constraint
WHERE
conindid = cli.oid
LIMIT 1
) AND
pg_relation_size(cli.oid) > 1 << 20
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, regexp_replace(
CASE
WHEN def ~ ' USING btree ' THEN
regexp_replace(def, E'.* USING btree (.*?)($| WHERE .*)', E'\\1')
END
, E' ([a-z]*_pattern_ops|(ASC|DESC)|NULLS\\s?(?:FIRST|LAST))'
, ''
, 'ig'
) fld
, CASE
WHEN def ~ ' WHERE ' THEN regexp_replace(def, E'.* WHERE ', '')
END wh
FROM
def
)
, q AS (
SELECT
nmt
, $q$
SET search_path = $q$ || quote_ident((TABLE sch)) || $q$, public;
SELECT
ARRAY[
count(*)
$q$ || string_agg(
', coalesce(sum((' || coalesce(wh, 'TRUE') || ')::integer), 0)' || E'\n' ||
', coalesce(sum(((' || coalesce(wh, 'TRUE') || ') AND (' || fld || ' IS NULL))::integer), 0)' || E'\n'
, '' ORDER BY nmi) || $q$
]
FROM
$q$ || quote_ident((TABLE sch)) || $q$.$q$ || quote_ident(nmt) || $q$
$q$ q
, array_agg(clioid ORDER BY nmi) oid$
, array_agg(nmi ORDER BY nmi) idx$
, array_agg(fld ORDER BY nmi) fld$
, array_agg(wh ORDER BY nmi) wh$
FROM
fld
WHERE
fld IS NOT NULL
GROUP BY
1
ORDER BY
1
)
, res AS (
SELECT
*
, (
SELECT
qty
FROM
dblink(
'dbname=' || current_database() || ' port=' || current_setting('port')
, q
) T(qty bigint[])
) qty
FROM
q
)
, iter AS (
SELECT
*
, generate_subscripts(idx$, 1) i
FROM
res
)
, stat AS (
SELECT
nmt table_name
, idx$[i] index_name
, pg_relation_size(oid$[i]) index_size
, pg_size_pretty(pg_relation_size(oid$[i])) index_size_humanize
, regexp_replace(fld$[i], E'^\\((.*)\\)$', E'\\1') index_fields
, regexp_replace(wh$[i], E'^\\((.*)\\)$', E'\\1') index_cond
, qty[1] table_rec_count
, qty[i * 2] index_rec_count
, qty[i * 2 + 1] index_rec_count_null
FROM
iter
)
SELECT
*
, CASE
WHEN table_rec_count > 0
THEN index_rec_count::double precision / table_rec_count::double precision * 100
ELSE 0
END::numeric(32,2) index_cover_prc
, CASE
WHEN index_rec_count > 0
THEN index_rec_count_null::double precision / index_rec_count::double precision * 100
ELSE 0
END::numeric(32,2) index_null_prc
FROM
stat
WHERE
index_rec_count_null * 4 > index_rec_count
ORDER BY
1, 2;
-[ RECORD 1 ]--------+--------------
table_name | tbl
index_name | tbl_fk_idx
index_size | 37838848
index_size_humanize | 36 MB
index_fields | fk
index_cond |
table_rec_count | 1000000
index_rec_count | 1000000
index_rec_count_null | 900000
index_cover_prc | 100.00 -- 100%
index_null_prc | 90.00 -- 90% NULL-""
Ich hoffe, einige der Fragen in diesem Artikel werden Ihnen helfen.