Vor einigen Wochen beschwerte sich ein Kollege in einem Gespräch beim Abendessen über einen langsamen Prozess. Er berechnete die Anzahl der generierten Bytes, die Anzahl der Verarbeitungszyklen und letztendlich die Größe des RAM. Ein Kollege sagte, dass eine moderne GPU mit einer Speicherbandbreite von mehr als 500 GB / s ihre Aufgabe verschlingen und nicht ersticken würde.Es schien mir, dass dies ein interessanter Ansatz ist. Persönlich habe ich Leistungsziele aus dieser Perspektive bisher nicht bewertet. Ja, ich kenne den Unterschied in der Prozessor- und Speicherleistung. Ich weiß, wie man Code schreibt, der den Cache stark nutzt. Ich kenne die ungefähren Verzögerungszahlen. Dies reicht jedoch nicht aus, um die Speicherbandbreite sofort zu bewerten.Hier ist ein Gedankenexperiment. Stellen Sie sich im Speicher ein kontinuierliches Array von einer Milliarde 32-Bit-Ganzzahlen vor. Das sind 4 Gigabyte. Wie lange dauert es, dieses Array zu durchlaufen und die Werte zu addieren? Wie viele Bytes pro Sekunde kann die CPU aus dem RAM lesen? Kontinuierliche Daten? Direktzugriff? Wie gut kann dieser Prozess parallelisiert werden?Sie werden sagen, dass dies nutzlose Fragen sind. Echte Programme sind zu komplex, um einen so naiven Meilenstein zu setzen. So ist es! Die eigentliche Antwort lautet "je nach Situation".Ich denke jedoch, dass es sich lohnt, dieses Problem zu untersuchen. Ich versuche nicht, die Antwort zu finden . Aber ich denke, wir können einige obere und untere Grenzen definieren, einige interessante Punkte in der Mitte und dabei etwas lernen.
Ich weiß, wie man Code schreibt, der den Cache stark nutzt. Ich kenne die ungefähren Verzögerungszahlen. Dies reicht jedoch nicht aus, um die Speicherbandbreite sofort zu bewerten.Hier ist ein Gedankenexperiment. Stellen Sie sich im Speicher ein kontinuierliches Array von einer Milliarde 32-Bit-Ganzzahlen vor. Das sind 4 Gigabyte. Wie lange dauert es, dieses Array zu durchlaufen und die Werte zu addieren? Wie viele Bytes pro Sekunde kann die CPU aus dem RAM lesen? Kontinuierliche Daten? Direktzugriff? Wie gut kann dieser Prozess parallelisiert werden?Sie werden sagen, dass dies nutzlose Fragen sind. Echte Programme sind zu komplex, um einen so naiven Meilenstein zu setzen. So ist es! Die eigentliche Antwort lautet "je nach Situation".Ich denke jedoch, dass es sich lohnt, dieses Problem zu untersuchen. Ich versuche nicht, die Antwort zu finden . Aber ich denke, wir können einige obere und untere Grenzen definieren, einige interessante Punkte in der Mitte und dabei etwas lernen.Die Zahlen, die jeder Programmierer kennen sollte
Wenn Sie Programmierblogs lesen, sind Sie wahrscheinlich auf "Zahlen gestoßen, die jeder Programmierer kennen sollte". Sie sehen ungefähr so aus:Link zum L1-Cache 0,5 ns
Falsche 5 ns Vorhersage
Link zum L2-Cache 7 ns 14x zum L1-Cache
Mutex Capture / Release 25 ns
Verbindung zum Hauptspeicher 100 ns 20x zum L2-Cache, 200x zum L1-Cache
Komprimieren Sie 1000 Bytes mit Zippy 3000 ns 3 μs
Senden von 1000 Bytes über ein 1-Gbit / s-Netzwerk 10.000 ns 10 μs
Random Read 4000 mit SSD 150.000 ns 150 μs ~ 1 GB / s SSD
Lesen Sie nacheinander 1 MB aus 250.000 ns und 250 μs
Roundtrip-Paket im Rechenzentrum 500.000 ns 500 μs
1 MB sequentielles Einlesen der SSD 1.000.000 ns 1.000 μs 1 ms ~ 1 GB / s SSD, 4x Speicher
Festplattensuche 10.000.000 ns 10.000 μs 10 ms 20x zum Rechenzentrum
Lesen Sie 1 MB nacheinander von der Festplatte 20.000.000 ns 20.000 μs 20 ms 80x in den Speicher, 20x in die SSD
Paket senden CA-> Niederlande-> CA 150.000.000 ns 150.000 μs 150 ms
Quelle: Jonas BonerGroße Liste. Er taucht mindestens einmal im Jahr bei HackerNews auf. Jeder Programmierer sollte diese Zahlen kennen.Aber diese Zahlen handeln von etwas anderem. Latenz und Bandbreite sind nicht dasselbe.Verzögerung im Jahr 2020
Diese Liste wurde 2012 erstellt, und dieser Artikel von 2020 hat sich geändert. Hier sind die Zahlen für Intel i7 mit StackOverflow .Treffer im L1-Cache, ~ 4 Zyklen (2,1 - 1,2 ns)
Treffer im L2-Cache, ~ 10 Zyklen (5,3 - 3,0 ns)
Hit im L3-Cache für einen einzelnen Kern ~ 40 Zyklen (21,4 - 12,0 ns)
Hit im L3-Cache, zusammen für einen weiteren Kernel ~ 65 Zyklen (34,8 - 19,5 ns)
Treffen Sie den L3-Cache mit einer Änderung für einen weiteren Kernel ~ 75 Zyklen (40,2 - 22,5 ns)
Lokaler RAM ~ 60 ns
Interessant! Was hat sich geändert?- L1 ist langsamer geworden;
0,5 → 1,5
- L2 schneller;
7 → 4,2
- Das Verhältnis von L1 und L2 ist stark reduziert;
2,5x 14(Beeindruckend!)
- Der L3-Cache ist mittlerweile zum Standard geworden.
12 40
- RAM ist schneller geworden;
100 → 60
Wir werden keine weitreichenden Schlussfolgerungen ziehen. Es ist unklar, wie die ursprünglichen Zahlen berechnet wurden. Wir werden Äpfel nicht mit Orangen vergleichen.Hier sind einige Zahlen von Wikichip zur Bandbreite und Cache-Größe meines Prozessors.Speicherbandbreite: 39,74 Gigabyte pro Sekunde
L1-Cache: 192 Kilobyte (32 KB pro Kern)
L2-Cache: 1,5 Megabyte (256 KB pro Kern)
L3-Cache: 12 Megabyte (gemeinsam genutzt; 2 MB pro Kern)
Was ich wissen will:- Obergrenze der RAM-Leistung
- untere Grenze
- L1 / L2 / L3-Cache-Grenzen
Naives Benchmarking
Lassen Sie uns einige Tests machen. Um die Bandbreite zu messen, habe ich ein einfaches C ++ - Programm geschrieben. Sehr ungefähr sieht sie so aus.
std::vector<int> nums;
for (size_t i = 0; i < 1024*1024*1024; ++i)
nums.push_back(rng() % 1024);
for (int thread_count = 1; thread_count <= MAX_THREADS; ++thread_count) {
auto slice_len = nums.size() / thread_count;
for (size_t thread = 0; thread < thread_count; ++thread) {
auto begin = nums.begin() + thread * slice_len;
auto end = (thread == thread_count - 1)
? nums.end() : begin + slice_len;
futures.push_back(std::async([begin, end] {
int64_t sum = 0;
for (auto ptr = begin; ptr < end; ++ptr)
sum += *ptr;
return sum;
}));
}
int64_t sum = 0;
for (auto& future : futures)
sum += future.get();
}
Einige Details werden weggelassen. Aber du hast die Idee verstanden. Erstellen Sie ein großes, kontinuierliches Array von Elementen. Teilen Sie das Array in separate Fragmente. Verarbeiten Sie jedes Fragment in einem separaten Thread. Ergebnisse akkumulieren.Sie müssen auch den Direktzugriff messen. Das ist sehr schwer. Ich habe verschiedene Möglichkeiten ausprobiert und mich schließlich entschlossen, vorberechnete Indizes zu mischen. Jeder Index existiert genau einmal. Dann durchläuft die innere Schleife die Indizes und berechnet sum += nums[index].std::vector<int> nums = ;
std::vector<uint32_t> indices = ;
int64_t sum = 0;
for (auto ptr = indices.begin(); ptr < indices.end(); ++ptr) {
auto idx = *ptr;
sum += nums[idx];
}
return sum;
Bei der Berechnung des Durchsatzes berücksichtige ich nicht den Speicher des Indexarrays. Es werden nur Bytes gezählt, die zur Gesamtsumme beitragen sum. Ich vergleiche meine Hardware nicht, sondern bewerte die Fähigkeit, mit Datensätzen unterschiedlicher Größe und mit unterschiedlichen Zugriffsschemata zu arbeiten.Wir werden Tests mit drei Datentypen durchführen:int- Die 32-Bit-Hauptzahlmatri4x4- enthält int[16]; passt in eine 64-Byte-Cache-Zeilematrix4x4_simd- verwendet integrierte Tools__m256iGroßer Block
Mein erster Test funktioniert mit einem großen Speicherblock. Ein 1-GB-Block von NElementen wird hervorgehoben und mit kleinen Zufallswerten gefüllt. Eine einfache Schleife durchläuft ein Array N-mal, sodass sie mit einem Volume auf den Speicher zugreift N , um die Summe zu berechnen int64_t. Mehrere Threads teilen das Array auf und jeder erhält Zugriff auf die gleiche Anzahl von Elementen.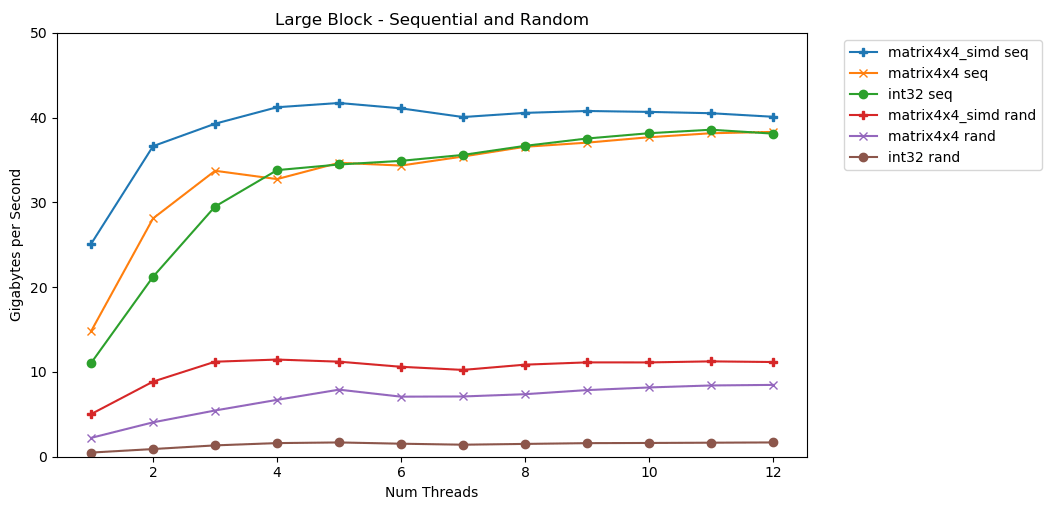 TA Dah! In diesem Diagramm nehmen wir die durchschnittliche Ausführungszeit der Summierungsoperation und konvertieren sie von
TA Dah! In diesem Diagramm nehmen wir die durchschnittliche Ausführungszeit der Summierungsoperation und konvertieren sie von runtime_in_nanosecondsnach gigabytes_per_second.Ziemlich gutes Ergebnis. int32kann nacheinander 11 GB / s in einem einzelnen Stream lesen. Es skaliert linear, bis es 38 GB / s erreicht. Tests matrix4x4und matrix4x4_simdschneller, aber an der gleichen Decke ruhen.Es gibt eine klare und offensichtliche Obergrenze dafür, wie viele Daten pro Sekunde aus dem RAM gelesen werden können. Auf meinem System sind dies ungefähr 40 GB / s. Dies entspricht den oben aufgeführten aktuellen Spezifikationen.Gemessen an den unteren drei Diagrammen ist der Direktzugriff langsam. Sehr sehr langsam. Die Single-Threaded-Leistung int32beträgt vernachlässigbare 0,46 GB / s. Dies ist 24-mal langsamer als sequentielles Stapeln mit 11,03 GB / s! Der Test matrix4x4zeigt das beste Ergebnis, da er in vollen Cache-Zeilen ausgeführt wird. Es ist jedoch immer noch vier- bis siebenmal langsamer als der sequentielle Zugriff und erreicht Spitzenwerte von nur 8 GB / s.Kleiner Block: sequentielles Lesen
Auf meinem System beträgt die L1 / L2 / L3-Cache-Größe für jeden Stream 32 KB, 256 KB und 2 MB. Was passiert, wenn Sie einen 32-Kilobyte-Block von Elementen nehmen und 125.000 Mal darüber iterieren? Dies sind 4 GB Speicher, aber wir werden immer in den Cache gehen.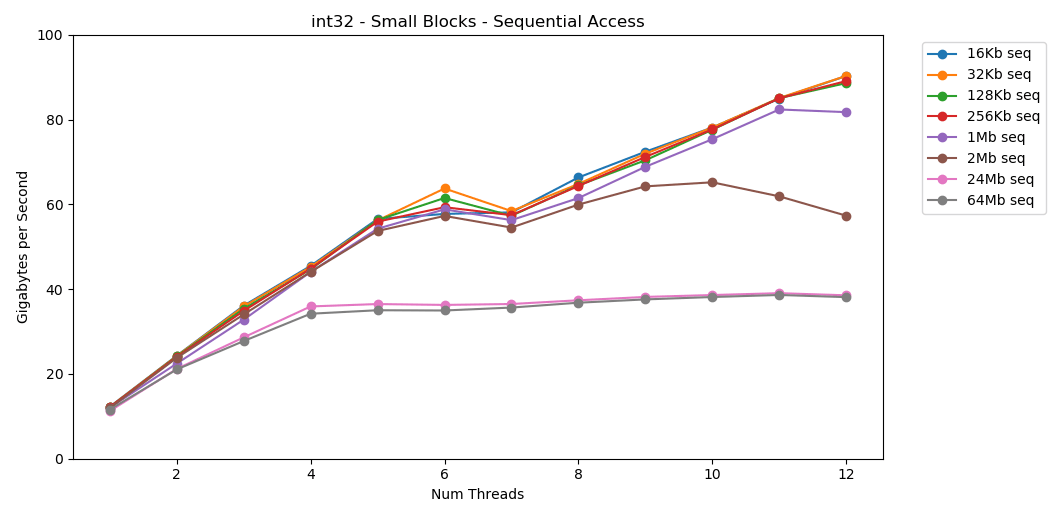 Genial! Die Single-Thread-Leistung ähnelt dem Lesen eines großen Blocks mit etwa 12 GB / s. Abgesehen davon, dass diesmal Multithreading die Obergrenze von 40 GB / s durchbricht. Es ergibt Sinn. Die Daten verbleiben im Cache, sodass der RAM-Engpass nicht auftritt. Für Daten, die nicht in den L3-Cache passen, gilt die gleiche Obergrenze von ca. 38 GB / s.Der Test
Genial! Die Single-Thread-Leistung ähnelt dem Lesen eines großen Blocks mit etwa 12 GB / s. Abgesehen davon, dass diesmal Multithreading die Obergrenze von 40 GB / s durchbricht. Es ergibt Sinn. Die Daten verbleiben im Cache, sodass der RAM-Engpass nicht auftritt. Für Daten, die nicht in den L3-Cache passen, gilt die gleiche Obergrenze von ca. 38 GB / s.Der Test matrix4x4zeigt ähnliche Ergebnisse wie die Schaltung, jedoch noch schneller; 31 GB / s im Single-Thread-Modus, 171 GB / s im Multithread-Modus.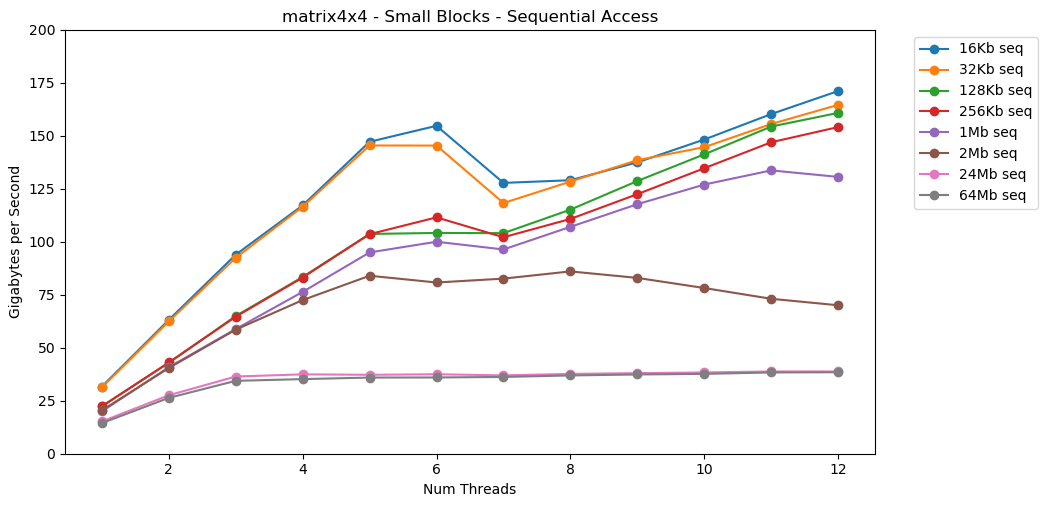 Nun schauen wir uns an
Nun schauen wir uns an matrix4x4_simd. Achten Sie auf die y-Achse.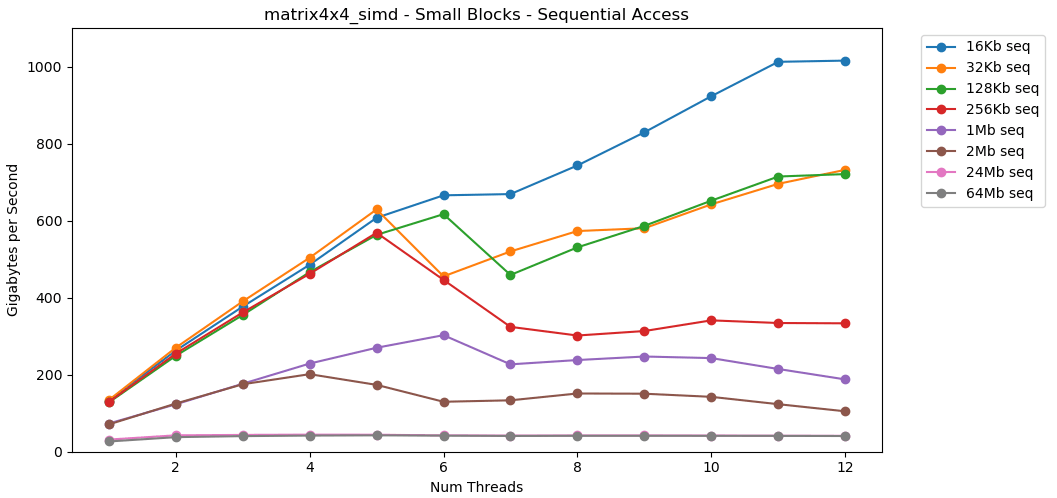
matrix4x4_simdaußergewöhnlich schnell durchgeführt. Es ist 10 mal schneller als int32. Bei einem 16-KB-Block werden sogar 1000 GB / s durchbrochen!Offensichtlich ist dies ein Oberflächensynthesetest. Die meisten Anwendungen führen nicht millionenfach hintereinander denselben Vorgang mit denselben Daten aus. Der Test zeigt keine Leistung in der realen Welt.Aber die Lektion ist klar. Im Cache werden Daten schnell verarbeitet . Mit einer sehr hohen Obergrenze bei Verwendung von SIMD: mehr als 100 GB / s im Single-Thread-Modus, mehr als 1000 GB / s im Multithread-Modus. Das Schreiben von Daten in den Cache ist langsam und mit einer harten Grenze von etwa 40 GB / s.Kleiner Block: zufälliges Lesen
Machen wir dasselbe, aber jetzt mit wahlfreiem Zugriff. Dies ist mein Lieblingsteil des Artikels.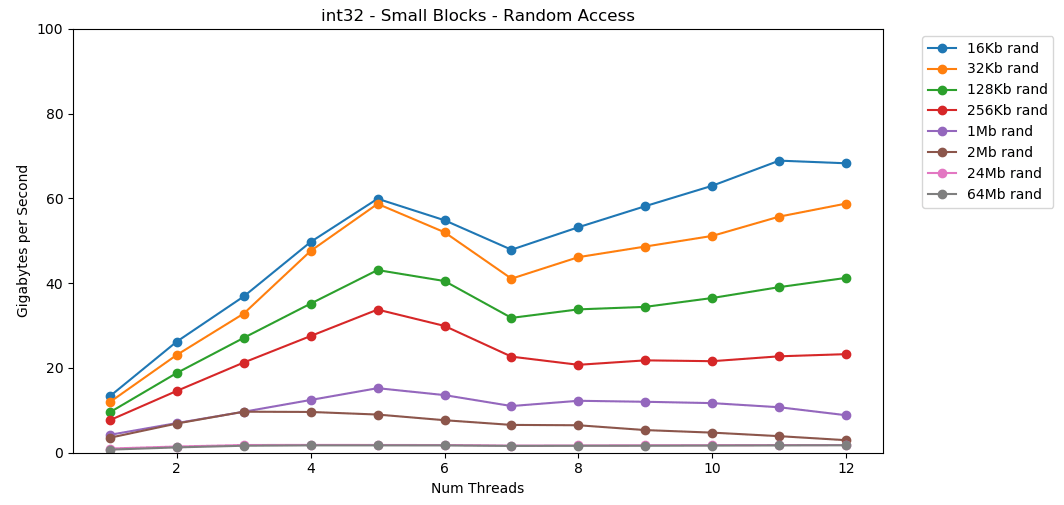 Das Lesen von Zufallswerten aus dem RAM ist langsam, nur 0,46 GB / s. Das Lesen von Zufallswerten aus dem L1-Cache ist sehr schnell: 13 GB / s. Dies ist schneller als das Lesen serieller Daten
Das Lesen von Zufallswerten aus dem RAM ist langsam, nur 0,46 GB / s. Das Lesen von Zufallswerten aus dem L1-Cache ist sehr schnell: 13 GB / s. Dies ist schneller als das Lesen serieller Daten int32aus dem RAM (11 GB / s).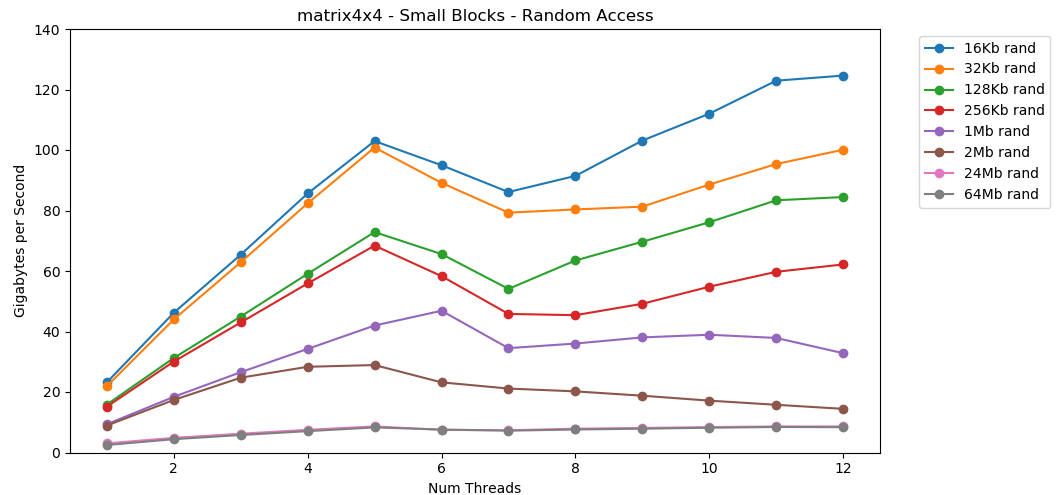 Der Test
Der Test matrix4x4zeigt ein ähnliches Ergebnis für dieselbe Vorlage, jedoch ungefähr doppelt so schnell wie int.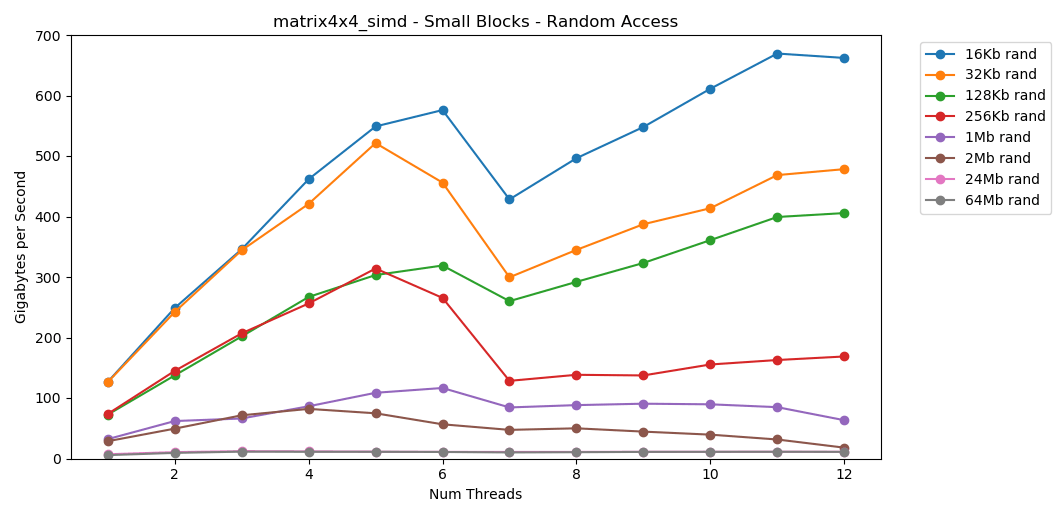 Der Direktzugriff ist
Der Direktzugriff ist matrix4x4_simdwahnsinnig schnell.Ergebnisse des wahlfreien Zugriffs
Das freie Lesen aus dem Speicher ist langsam. Katastrophal langsam. Weniger als 1 GB / s für beide Testfälle int32. Gleichzeitig sind zufällige Lesevorgänge aus dem Cache überraschend schnell. Es ist vergleichbar mit dem sequentiellen Lesen aus dem RAM.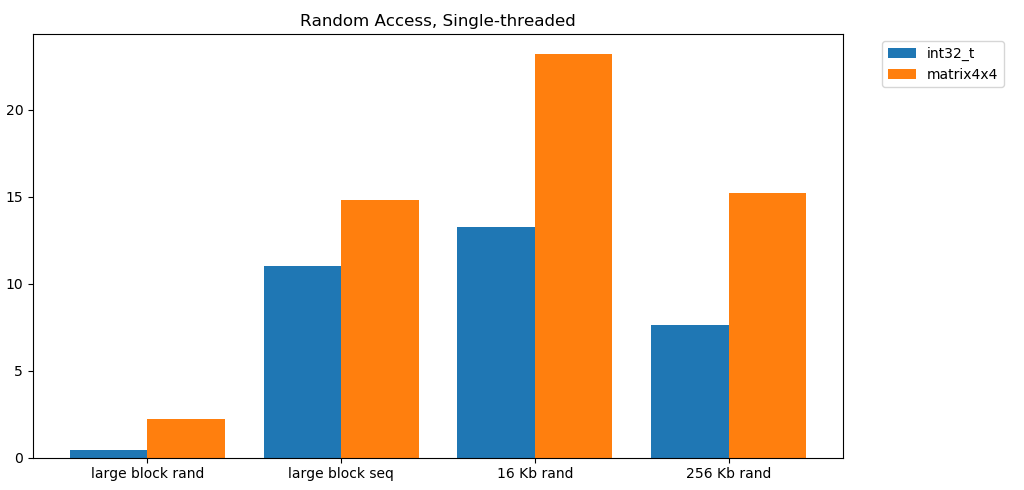 Es muss verdaut werden. Der zufällige Zugriff auf den Cache ist in seiner Geschwindigkeit mit dem sequentiellen Zugriff auf den RAM vergleichbar. Der Rückgang von L1 16 KB auf L2 256 KB beträgt nur die Hälfte oder weniger.Ich denke, dass dies tiefgreifende Konsequenzen haben wird.
Es muss verdaut werden. Der zufällige Zugriff auf den Cache ist in seiner Geschwindigkeit mit dem sequentiellen Zugriff auf den RAM vergleichbar. Der Rückgang von L1 16 KB auf L2 256 KB beträgt nur die Hälfte oder weniger.Ich denke, dass dies tiefgreifende Konsequenzen haben wird.Verknüpfte Listen gelten als schädlich
Das Verfolgen eines Zeigers (Springen auf Zeiger) ist schlecht. Sehr sehr schlecht. Um wie viel nimmt die Leistung ab? Überzeugen Sie sich selbst. Ich habe einen zusätzlichen Test, wickelt matrix4x4in std::unique_ptr. Jeder Zugriff erfolgt über einen Zeiger. Hier ist ein schreckliches, nur katastrophales Ergebnis. 1 Thread | matrix4x4 | unique_ptr | diff |
-------------------- | --------------- | ------------ | -------- |
Großer Block - Seq | 14,8 GB / s | 0,8 GB / s | 19x |
16 KB - Seq | 31,6 GB / s | 2,2 GB / s | 14x |
256 KB - Seq | 22,2 GB / s | 1,9 GB / s | 12x |
Großer Block - Rand | 2,2 GB / s | 0,1 GB / s | 22x |
16 KB - Rand | 23,2 GB / s | 1,7 GB / s | 14x |
256 KB - Rand | 15,2 GB / s | 0,8 GB / s | 19x |
6 Fäden | matrix4x4 | unique_ptr | diff |
-------------------- | --------------- | ------------ | -------- |
Großer Block - Seq | 34,4 GB / s | 2,5 GB / s | 14x |
16 KB - Seq | 154,8 GB / s | 8,0 GB / s | 19x |
256 KB - Seq | 111,6 GB / s | 5,7 GB / s | 20x |
Großer Block - Rand | 7,1 GB / s | 0,4 GB / s | 18x |
16 KB - Rand | 95,0 GB / s | 7,8 GB / s | 12x |
256 KB - Rand | 58,3 GB / s | 1,6 GB / s | 36x |Die sequentielle Summierung der Werte hinter dem Zeiger erfolgt mit einer Geschwindigkeit von weniger als 1 GB / s. Die doppelt übersprungene Direktzugriffsgeschwindigkeit des Caches beträgt nur 0,1 GB / s.Das Verfolgen eines Zeigers verlangsamt die Codeausführung 10 bis 20 Mal. Lassen Sie Ihre Freunde keine verknüpften Listen verwenden. Bitte denken Sie an den Cache.Budgetschätzung für Frames
Es ist üblich, dass Spieleentwickler ein Limit (Budget) für die Belastung der CPU und die Speichermenge festlegen. Aber ich habe noch nie ein Bandbreitenbudget gesehen.In modernen Spielen wächst FPS weiter. Jetzt ist es bei 60 FPS. VR arbeitet mit einer Frequenz von 90 Hz. Ich habe einen 144-Hz-Gaming-Monitor. Es ist großartig, also scheinen die 60 FPS wie Scheiße zu sein. Ich werde niemals zum alten Monitor zurückkehren. Esports und Streamer Twitch überwacht 240 Hz. In diesem Jahr stellte Asus auf der CES ein 360-Hz-Monster vor.Mein Prozessor hat eine Obergrenze von ca. 40 GB / s. Das scheint eine große Zahl zu sein! Bei einer Frequenz von 240 Hz werden jedoch nur 167 MB pro Bild erhalten. Eine realistische Anwendung kann 5 GB / s Verkehr mit 144 Hz erzeugen, was nur 69 MB pro Frame entspricht.Hier ist eine Tabelle mit einigen Zahlen. | 1 | 10 | 30 | 60 | 90 | 144 | 240 | 360 |
-------- | ------- | -------- | -------- | -------- | ------ - | -------- | -------- | -------- |
40 GB / s | 40 GB | 4 GB | 1,3 GB | 667 MB | 444 MB | 278 MB | 167 MB | 111 MB |
10 GB / s | 10 GB | 1 GB | 333 MB | 166 MB | 111 MB | 69 MB | 42 MB | 28 MB |
1 GB / s | 1 GB | 100 MB | 33 MB | 17 MB | 11 MB | 7 MB | 4 MB | 3 MB |
Es scheint mir nützlich, Probleme aus dieser Perspektive zu bewerten. Dies macht deutlich, dass einige Ideen nicht realisierbar sind. 240 Hz zu erreichen ist nicht einfach. Dies wird nicht von alleine passieren.Die Zahlen, die jeder Programmierer kennen sollte (2020)
Die vorherige Liste ist veraltet. Jetzt muss es aktualisiert und bis 2020 in Übereinstimmung gebracht werden.Hier sind einige Zahlen für meinen Heimcomputer. Dies ist eine Mischung aus AIDA64, Sandra und meinen Benchmarks. Die Zahlen geben kein vollständiges Bild und sind nur ein Ausgangspunkt.Latenz L1: 1 ns
L2-Verzögerung: 2,5 ns
Verzögerung L3: 10 ns
RAM-Latenz: 50 ns
(pro Thread)
L1-Band: 210 GB / s
L2-Band: 80 GB / s
L3-Band: 60 GB / s
(das ganze System)
RAM-Band: 45 GB / s
Es wäre schön, einen kleinen, einfachen Open-Source-Benchmark zu erstellen. Einige C-Dateien, die auf Desktop-Computern, Servern, Mobilgeräten, Konsolen usw. ausgeführt werden können. Aber ich bin nicht die Art von Person, die ein solches Tool schreibt.Verweigerung der Verantwortung
Das Messen der Speicherbandbreite ist schwierig. Sehr kompliziert. Es gibt wahrscheinlich Fehler in meinem Code. Viele unerklärliche Faktoren. Wenn Sie Kritik an meiner Technik haben, haben Sie wahrscheinlich Recht.Letztendlich halte ich das für normal. In diesem Artikel geht es nicht um die genaue Leistung meines Desktops. Dies ist unter bestimmten Gesichtspunkten eine Problemstellung. Und darüber, wie man lernt, wie man grobe mathematische Berechnungen durchführt.Fazit
Ein Kollege teilte mir eine interessante Meinung über die GPU-Speicherbandbreite und die Anwendungsleistung mit. Dies veranlasste mich, die Speicherleistung auf modernen Computern zu untersuchen.Für ungefähre Berechnungen sind hier einige Zahlen für einen modernen Desktop:- RAM-Leistung
- Maximal:
45 / - Im Durchschnitt ungefähr:
5 / - Minimum:
1 /
- L1 / L2 / L3-Cache-Leistung (pro Kern)
- Maximum (c simd):
210 // 80 //60 / - Im Durchschnitt ungefähr:
25 // 15 //9 / - Minimum:
13 // 8 //3,5 /
Die Stichprobenbewertungen beziehen sich auf die Leistung matrix4x4. Echter Code wird niemals so einfach sein. Für Berechnungen auf einer Serviette ist dies jedoch ein vernünftiger Ausgangspunkt. Sie müssen diese Zahl basierend auf den Speicherzugriffsmustern in Ihrem Programm, den Eigenschaften Ihrer Ausrüstung und dem Code anpassen.Das Wichtigste ist jedoch eine neue Art, über Probleme nachzudenken. Die Darstellung des Problems in Bytes pro Sekunde oder Bytes pro Frame ist eine weitere Linse, durch die man schauen muss. Dies ist ein nützliches Werkzeug für alle Fälle.Danke fürs Lesen.Quelle
Benchmark C ++Python Graphdata.jsonWeitere Nachforschungen
Dieser Artikel hat das Thema nur geringfügig berührt. Ich werde wahrscheinlich nicht darauf eingehen. Wenn er dies tun würde, könnte er einige der folgenden Aspekte abdecken:Systemspezifikationen
Tests wurden auf meinem Heim-PC durchgeführt. Nur Lagereinstellungen, kein Übertakten.- Betriebssystem: Windows 10 v1903 Build 18362
- CPU: Intel i7-8700k bei 3,70 GHz
- RAM: 2x16 GSkill Ripjaw DDR4-3200 (16-18-18-38 bei 1600 MHz)
- Hauptplatine: Asus TUF Z370-Plus Gaming