Übersetzung des Leitfadens für rekursive neuronale Netze von Tensorflow.org. Das Material beschreibt sowohl die integrierten Funktionen von Keras / Tensorflow 2.0 für eine schnelle Vernetzung als auch die Möglichkeit, Ebenen und Zellen anzupassen. Fälle und Einschränkungen der Verwendung des CuDNN-Kerns werden ebenfalls berücksichtigt, wodurch der Lernprozess des neuronalen Netzwerks beschleunigt werden kann.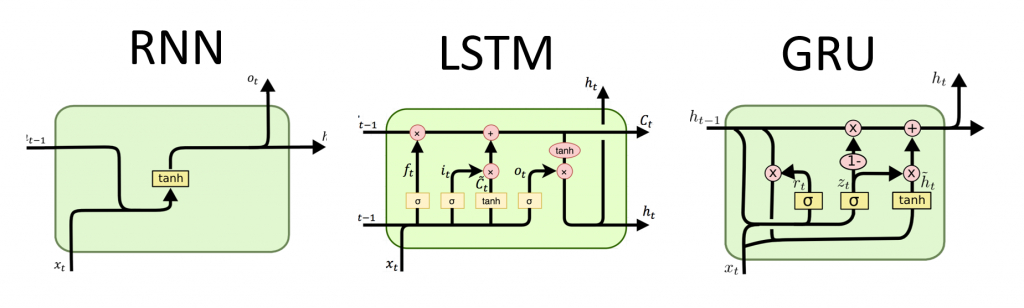 Rekursive neuronale Netze (RNNs) sind eine Klasse von neuronalen Netzen, die sich gut zur Modellierung serieller Daten wie Zeitreihen oder natürlicher Sprache eignen.Wenn schematisch, verwendet die RNN-Schicht eine Schleife
Rekursive neuronale Netze (RNNs) sind eine Klasse von neuronalen Netzen, die sich gut zur Modellierung serieller Daten wie Zeitreihen oder natürlicher Sprache eignen.Wenn schematisch, verwendet die RNN-Schicht eine Schleife for, um über eine zeitlich geordnete Sequenz zu iterieren, während sie in einem internen Zustand codierte Informationen über die Schritte speichert, die er bereits gesehen hat.Keras RNN API ist mit einem Fokus entwickelt , um auf:Einfache Bedienung : Einbau-Schichten tf.keras.layers.RNN, tf.keras.layers.LSTM, tf.keras.layers.GRUkönnen Sie schnell ein rekursive Modell bauen , ohne komplexe Konfigurationseinstellungen vornehmen zu müssen.Einfache Anpassung : Sie können auch Ihre eigene Schicht von RNN-Zellen (innerer Teil der Schleife) definierenfor) mit benutzerdefiniertem Verhalten und verwenden Sie es mit einer gemeinsamen Ebene von `tf.keras.layers.RNN` (die` for`-Schleife selbst). Auf diese Weise können Sie schnell und flexibel verschiedene Forschungsideen mit einem Minimum an Code prototypisieren.Installation
from __future__ import absolute_import, division, print_function, unicode_literals
import collections
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
Ein einfaches Modell bauen
Keras verfügt über drei integrierte RNN-Schichten:tf.keras.layers.SimpleRNNeine vollständig verbundene RNN, in der die Ausgabe des vorherigen Zeitschritts an den nächsten Schritt übergeben werden soll.tf.keras.layers.GRU, zuerst vorgeschlagen im Artikel Studieren von Phrasen mit RNN-Codec für statistische maschinelle Übersetzungtf.keras.layers.LSTM, zuerst vorgeschlagen im Artikel Langzeit-Kurzzeitgedächtnis
Anfang 2015 führte Keras die ersten wiederverwendbaren Open-Source-Python-LSTM- und GRU-Implementierungen in Python ein.Das Folgende ist ein Beispiel eines SequentialModells, das Folgen von ganzen Zahlen verarbeitet, indem jede ganze Zahl in einem 64-dimensionalen Vektor verschachtelt wird und dann Folgen von Vektoren unter Verwendung einer Schicht verarbeitet werden LSTM.model = tf.keras.Sequential()
model.add(layers.Embedding(input_dim=1000, output_dim=64))
model.add(layers.LSTM(128))
model.add(layers.Dense(10))
model.summary()
Ausgänge und Status
Standardmäßig enthält die Ausgabe der RNN-Schicht einen Vektor pro Element. Dieser Vektor ist die Ausgabe der letzten RNN-Zelle, die Informationen über die gesamte Eingabesequenz enthält. Die Dimension dieser Ausgabe (batch_size, units), wobei das an den Layer-Konstruktor übergebene unitsArgument entspricht units.Die RNN-Schicht kann auch die gesamte Ausgabesequenz für jedes Element zurückgeben (ein Vektor für jeden Schritt), wenn Sie dies angeben return_sequences=True. Die Dimension dieser Ausgabe ist (batch_size, timesteps, units).model = tf.keras.Sequential()
model.add(layers.Embedding(input_dim=1000, output_dim=64))
model.add(layers.GRU(256, return_sequences=True))
model.add(layers.SimpleRNN(128))
model.add(layers.Dense(10))
model.summary()
Darüber hinaus kann die RNN-Schicht ihre endgültigen internen Zustände zurückgeben.Die zurückgegebenen Zustände können später verwendet werden, um die Ausführung des RNN fortzusetzen oder ein anderes RNN zu initialisieren . Diese Einstellung wird normalerweise im Codierer-Decodierer-Modell von Sequenz zu Sequenz verwendet, wobei der Endzustand des Codierers für den Anfangszustand des Decodierers verwendet wird.Damit der RNN-Layer seinen internen Status zurückgibt, setzen Sie den Parameter beim Erstellen des Layers return_stateauf value True. Beachten Sie, dass es LSTM2 Zustandstensoren und GRUnur einen gibt.Um den Anfangszustand einer Ebene anzupassen, rufen Sie die Ebene einfach mit einem zusätzlichen Argument auf initial_state.Beachten Sie, dass die Bemaßung mit der Bemaßung des Ebenenelements übereinstimmen muss, wie im folgenden Beispiel.encoder_vocab = 1000
decoder_vocab = 2000
encoder_input = layers.Input(shape=(None, ))
encoder_embedded = layers.Embedding(input_dim=encoder_vocab, output_dim=64)(encoder_input)
output, state_h, state_c = layers.LSTM(
64, return_state=True, name='encoder')(encoder_embedded)
encoder_state = [state_h, state_c]
decoder_input = layers.Input(shape=(None, ))
decoder_embedded = layers.Embedding(input_dim=decoder_vocab, output_dim=64)(decoder_input)
decoder_output = layers.LSTM(
64, name='decoder')(decoder_embedded, initial_state=encoder_state)
output = layers.Dense(10)(decoder_output)
model = tf.keras.Model([encoder_input, decoder_input], output)
model.summary()
RNN-Schichten und RNN-Zellen
Die RNN-API bietet zusätzlich zu den integrierten RNN-Schichten auch APIs auf Zellebene. Im Gegensatz zu RNN-Schichten, die ganze Pakete von Eingabesequenzen verarbeiten, verarbeitet eine RNN-Zelle nur einen Zeitschritt.Die Zelle befindet sich innerhalb des Zyklus der forRNN-Schicht. Wenn Sie eine Zelle mit einer Schicht tf.keras.layers.RNNumwickeln, erhalten Sie eine Schicht, die Sequenzpakete verarbeiten kann, z. RNN(LSTMCell(10)).Mathematisch RNN(LSTMCell(10))ergibt es das gleiche Ergebnis wie LSTM(10). Tatsächlich bestand die Implementierung dieser Schicht in TF v1.x nur darin, die entsprechende RNN-Zelle zu erstellen und sie in die RNN-Schicht einzubinden. Allerdings ist die Verwendung von eingebetteten Schichten GRUund LSTMermöglicht die Verwendung von CuDNN , die Ihnen eine bessere Leistung geben kann.Es gibt drei eingebaute RNN-Zellen, von denen jede ihrer eigenen RNN-Schicht entspricht.tf.keras.layers.SimpleRNNCellpasst zur Ebene SimpleRNN.tf.keras.layers.GRUCellpasst zur Ebene GRU.tf.keras.layers.LSTMCellpasst zur Ebene LSTM.
Die Abstraktion einer Zelle zusammen mit einer gemeinsamen Klasse tf.keras.layers.RNNmacht es sehr einfach, benutzerdefinierte RNN-Architekturen für Ihre Forschung zu implementieren.Stapelübergreifender Speicherstatus
Bei der Verarbeitung langer Sequenzen (möglicherweise endlos) möchten Sie möglicherweise das stapelübergreifende Statefulness- Muster verwenden .Normalerweise wird der interne Zustand der RNN-Schicht mit jedem neuen Datenpaket zurückgesetzt (d. H. Jedes Beispiel, das die Schicht sieht, wird als unabhängig von der Vergangenheit angenommen). Die Ebene behält den Status nur für die Dauer der Verarbeitung dieses Elements bei.Wenn Sie jedoch sehr lange Sequenzen haben, ist es hilfreich, diese in kürzere zu zerlegen und nacheinander auf die RNN-Schicht zu übertragen, ohne den Schichtstatus zurückzusetzen. Somit kann eine Schicht Informationen über die gesamte Sequenz speichern, obwohl jeweils nur eine Teilsequenz angezeigt wird.Sie können dies tun, indem Sie im Konstruktor `stateful = True` setzen.Wenn Sie die Sequenz `s = [t0, t1, ... t1546, t1547]` haben, können Sie sie beispielsweise aufteilen in:s1 = [t0, t1, ... t100]
s2 = [t101, ... t201]
...
s16 = [t1501, ... t1547]
Dann können Sie es verarbeiten mit:lstm_layer = layers.LSTM(64, stateful=True)
for s in sub_sequences:
output = lstm_layer(s)
Wenn Sie den Zustand reinigen möchten, verwenden Sie layer.reset_states().Hinweis: In diesem Fall wird davon ausgegangen, dass das Beispiel iin diesem Paket eine Fortsetzung des Beispiels des ivorherigen Pakets ist. Dies bedeutet, dass alle Pakete die gleiche Anzahl von Elementen enthalten (Paketgröße). Wenn das Paket beispielsweise enthält [sequence_A_from_t0_to_t100, sequence_B_from_t0_to_t100], sollte das nächste Paket enthalten [sequence_A_from_t101_to_t200, sequence_B_from_t101_to_t200].
Hier ist ein vollständiges Beispiel:paragraph1 = np.random.random((20, 10, 50)).astype(np.float32)
paragraph2 = np.random.random((20, 10, 50)).astype(np.float32)
paragraph3 = np.random.random((20, 10, 50)).astype(np.float32)
lstm_layer = layers.LSTM(64, stateful=True)
output = lstm_layer(paragraph1)
output = lstm_layer(paragraph2)
output = lstm_layer(paragraph3)
lstm_layer.reset_states()
Bidirektionale RNN
Bei anderen Sequenzen als Zeitreihen (z. B. Texten) funktioniert das RNN-Modell häufig besser, wenn es die Sequenz nicht nur von Anfang bis Ende verarbeitet, sondern auch umgekehrt. Um beispielsweise das nächste Wort in einem Satz vorherzusagen, ist es oft nützlich, den Kontext um das Wort herum zu kennen und nicht nur die Wörter davor.Keras bietet eine einfache API zum Erstellen solcher bidirektionaler RNNs: einen Wrapper tf.keras.layers.Bidirectional.model = tf.keras.Sequential()
model.add(layers.Bidirectional(layers.LSTM(64, return_sequences=True),
input_shape=(5, 10)))
model.add(layers.Bidirectional(layers.LSTM(32)))
model.add(layers.Dense(10))
model.summary()
Unter der Haube wird die Bidirectionalübertragene RNN-Schicht go_backwardskopiert und das Feld der neu kopierten Schicht wird umgedreht , und somit werden die Eingabedaten in umgekehrter Reihenfolge verarbeitet.Die Ausgabe von ` BidirectionalRNN ist standardmäßig die Summe der Ausgabe der Vorwärtsschicht und der Ausgabe der Rückwärtsschicht. Wenn Sie ein anderes Zusammenführungsverhalten benötigen, z. Verkettung, ändern Sie den Parameter `merge_mode` im Wrapper-Konstruktor` Bidirectional`.Leistungsoptimierung und CuDNN-Kern in TensorFlow 2.0
In TensorFlow 2.0 können die integrierten LSTM- und GRU-Schichten standardmäßig CuDNN-Kerne verwenden, wenn ein Grafikprozessor verfügbar ist. Mit dieser Änderung sind die vorherigen Ebenen keras.layers.CuDNNLSTM/CuDNNGRUveraltet, und Sie können Ihr Modell erstellen, ohne sich Gedanken über die Ausrüstung machen zu müssen, auf der es funktionieren wird.Da der CuDNN-Kernel mit einigen Annahmen erstellt wird, bedeutet dies, dass der Layer den CuDNN-Kernel-Layer nicht verwenden kann, wenn Sie die Standardeinstellungen der integrierten LSTM- oder GRU-Layer ändern . Z.B.- Ändern einer Funktion
activationvon tanhzu etwas anderem. - Ändern einer Funktion
recurrent_activationvon sigmoidzu etwas anderem. - Verwendung
recurrent_dropout> 0. - Setzen Sie es
unrollauf True, wodurch LSTM / GRU das Interne tf.while_loopin eine bereitgestellte Schleife zerlegt for. - Auf
use_biasFalse setzen. - Verwenden von Masken, wenn die Eingabedaten nicht richtig ausgerichtet sind (wenn die Maske mit den genau ausgerichteten Daten übereinstimmt, kann CuDNN weiterhin verwendet werden. Dies ist der häufigste Fall).
Verwenden Sie nach Möglichkeit CuDNN-Kernel
batch_size = 64
input_dim = 28
units = 64
output_size = 10
def build_model(allow_cudnn_kernel=True):
if allow_cudnn_kernel:
lstm_layer = tf.keras.layers.LSTM(units, input_shape=(None, input_dim))
else:
lstm_layer = tf.keras.layers.RNN(
tf.keras.layers.LSTMCell(units),
input_shape=(None, input_dim))
model = tf.keras.models.Sequential([
lstm_layer,
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dense(output_size)]
)
return model
Laden des MNIST-Datasets
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
sample, sample_label = x_train[0], y_train[0]
Erstellen Sie eine Instanz des Modells und kompilieren Sie es
Wir haben sparse_categorical_crossentropyals Funktion der Verluste gewählt. Die Ausgabe des Modells hat eine Dimension [batch_size, 10]. Die Antwort des Modells ist ein ganzzahliger Vektor, jede der Zahlen liegt im Bereich von 0 bis 9.model = build_model(allow_cudnn_kernel=True)
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer='sgd',
metrics=['accuracy'])
model.fit(x_train, y_train,
validation_data=(x_test, y_test),
batch_size=batch_size,
epochs=5)
Erstellen Sie ein neues Modell ohne CuDNN-Kern
slow_model = build_model(allow_cudnn_kernel=False)
slow_model.set_weights(model.get_weights())
slow_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer='sgd',
metrics=['accuracy'])
slow_model.fit(x_train, y_train,
validation_data=(x_test, y_test),
batch_size=batch_size,
epochs=1)
Wie Sie sehen können, ist das mit CuDNN erstellte Modell für das Training viel schneller als das Modell mit dem üblichen TensorFlow-Kern.Das gleiche Modell mit CuDNN-Unterstützung kann für die Ausgabe in einer Einzelprozessorumgebung verwendet werden. Die Anmerkung gibt tf.devicelediglich das verwendete Gerät an. Das Modell wird standardmäßig auf der CPU ausgeführt, wenn die GPU nicht verfügbar ist.Sie müssen sich nur keine Gedanken über die Hardware machen, an der Sie arbeiten. Ist das nicht cool?with tf.device('CPU:0'):
cpu_model = build_model(allow_cudnn_kernel=True)
cpu_model.set_weights(model.get_weights())
result = tf.argmax(cpu_model.predict_on_batch(tf.expand_dims(sample, 0)), axis=1)
print('Predicted result is: %s, target result is: %s' % (result.numpy(), sample_label))
plt.imshow(sample, cmap=plt.get_cmap('gray'))
RNN mit Listen- / Wörterbucheingabe oder verschachtelter Eingabe
Mit verschachtelten Strukturen können Sie mehr Informationen in einem Zeitschritt einfügen. Beispielsweise kann ein Videorahmen gleichzeitig Audio- und Videoeingang enthalten. Die Dimension der Daten kann in diesem Fall sein:[batch, timestep, {\"video\": [height, width, channel], \"audio\": [frequency]}]
In einem anderen Beispiel können handgeschriebene Daten sowohl x- als auch y-Koordinaten für die aktuelle Stiftposition sowie Druckinformationen enthalten. Die Daten können also wie folgt dargestellt werden:[batch, timestep, {\"location\": [x, y], \"pressure\": [force]}]
Der folgende Code erstellt ein Beispiel für eine benutzerdefinierte RNN-Zelle, die mit einer solchen strukturierten Eingabe arbeitet.Definieren Sie eine Benutzerzelle, die verschachtelte Ein- / Ausgabe unterstützt
NestedInput = collections.namedtuple('NestedInput', ['feature1', 'feature2'])
NestedState = collections.namedtuple('NestedState', ['state1', 'state2'])
class NestedCell(tf.keras.layers.Layer):
def __init__(self, unit_1, unit_2, unit_3, **kwargs):
self.unit_1 = unit_1
self.unit_2 = unit_2
self.unit_3 = unit_3
self.state_size = NestedState(state1=unit_1,
state2=tf.TensorShape([unit_2, unit_3]))
self.output_size = (unit_1, tf.TensorShape([unit_2, unit_3]))
super(NestedCell, self).__init__(**kwargs)
def build(self, input_shapes):
input_1 = input_shapes.feature1[1]
input_2, input_3 = input_shapes.feature2[1:]
self.kernel_1 = self.add_weight(
shape=(input_1, self.unit_1), initializer='uniform', name='kernel_1')
self.kernel_2_3 = self.add_weight(
shape=(input_2, input_3, self.unit_2, self.unit_3),
initializer='uniform',
name='kernel_2_3')
def call(self, inputs, states):
input_1, input_2 = tf.nest.flatten(inputs)
s1, s2 = states
output_1 = tf.matmul(input_1, self.kernel_1)
output_2_3 = tf.einsum('bij,ijkl->bkl', input_2, self.kernel_2_3)
state_1 = s1 + output_1
state_2_3 = s2 + output_2_3
output = [output_1, output_2_3]
new_states = NestedState(state1=state_1, state2=state_2_3)
return output, new_states
Erstellen Sie ein RNN-Modell mit verschachtelter Eingabe / Ausgabe
Erstellen wir ein Keras-Modell, das eine Ebene tf.keras.layers.RNNund eine benutzerdefinierte Zelle verwendet, die wir gerade definiert haben.unit_1 = 10
unit_2 = 20
unit_3 = 30
input_1 = 32
input_2 = 64
input_3 = 32
batch_size = 64
num_batch = 100
timestep = 50
cell = NestedCell(unit_1, unit_2, unit_3)
rnn = tf.keras.layers.RNN(cell)
inp_1 = tf.keras.Input((None, input_1))
inp_2 = tf.keras.Input((None, input_2, input_3))
outputs = rnn(NestedInput(feature1=inp_1, feature2=inp_2))
model = tf.keras.models.Model([inp_1, inp_2], outputs)
model.compile(optimizer='adam', loss='mse', metrics=['accuracy'])unit_1 = 10
unit_2 = 20
unit_3 = 30
input_1 = 32
input_2 = 64
input_3 = 32
batch_size = 64
num_batch = 100
timestep = 50
cell = NestedCell(unit_1, unit_2, unit_3)
rnn = tf.keras.layers.RNN(cell)
inp_1 = tf.keras.Input((None, input_1))
inp_2 = tf.keras.Input((None, input_2, input_3))
outputs = rnn(NestedInput(feature1=inp_1, feature2=inp_2))
model = tf.keras.models.Model([inp_1, inp_2], outputs)
model.compile(optimizer='adam', loss='mse', metrics=['accuracy'])
Trainieren Sie das Modell anhand zufällig generierter Daten
Da wir für dieses Modell keinen guten Datensatz haben, verwenden wir zur Demonstration zufällige Daten, die von der Numpy-Bibliothek generiert wurden.input_1_data = np.random.random((batch_size * num_batch, timestep, input_1))
input_2_data = np.random.random((batch_size * num_batch, timestep, input_2, input_3))
target_1_data = np.random.random((batch_size * num_batch, unit_1))
target_2_data = np.random.random((batch_size * num_batch, unit_2, unit_3))
input_data = [input_1_data, input_2_data]
target_data = [target_1_data, target_2_data]
model.fit(input_data, target_data, batch_size=batch_size)
Bei einer Ebene müssen tf.keras.layers.RNNSie nur die mathematische Logik eines einzelnen Schritts innerhalb der Sequenz bestimmen, und die Ebene tf.keras.layers.RNNübernimmt für Sie die Iteration der Sequenz. Dies ist eine unglaublich leistungsstarke Methode, um schnell neue Arten von RNNs (z. B. die LSTM-Variante) zu prototypisieren.Nach der Überprüfung wird die Übersetzung auch auf Tensorflow.org angezeigt. Wenn Sie an der Übersetzung der Dokumentation der Website Tensorflow.org ins Russische teilnehmen möchten, wenden Sie sich bitte persönlich oder in einem Kommentar an. Korrekturen und Kommentare sind willkommen.