HighLoad ++, Mikhail Tyulenev (MongoDB): Kausale Konsistenz: von der Theorie zur Praxis
Die nächste HighLoad ++ - Konferenz findet am 6. und 7. April 2020 in St. Petersburg statt.Details und Tickets hier . HighLoad ++ Sibirien 2019. Halle "Krasnojarsk". 25. Juni, 12:00 Uhr. Abstracts und Präsentation . Es kommt vor, dass praktische Anforderungen im Widerspruch zu einer Theorie stehen, bei der Aspekte, die für ein kommerzielles Produkt wichtig sind, nicht berücksichtigt werden. In diesem Bericht wird der Prozess der Auswahl und Kombination verschiedener Ansätze zur Erstellung kausaler Konsistenzkomponenten auf der Grundlage akademischer Forschung auf der Grundlage der Anforderungen eines kommerziellen Produkts vorgestellt. Die Schüler lernen die bestehenden theoretischen Ansätze für logische Uhren, Abhängigkeitsverfolgung, Systemsicherheit, Uhrensynchronisation und warum MongoDB diese oder jene Lösungen eingestellt hat.Mikhail Tyulenev (im Folgenden - MT): - Ich werde über kausale Konsistenz sprechen - Dies ist eine Funktion, an der wir in MongoDB gearbeitet haben. Ich arbeite in einer Gruppe verteilter Systeme, wir haben es vor ungefähr zwei Jahren gemacht.
Es kommt vor, dass praktische Anforderungen im Widerspruch zu einer Theorie stehen, bei der Aspekte, die für ein kommerzielles Produkt wichtig sind, nicht berücksichtigt werden. In diesem Bericht wird der Prozess der Auswahl und Kombination verschiedener Ansätze zur Erstellung kausaler Konsistenzkomponenten auf der Grundlage akademischer Forschung auf der Grundlage der Anforderungen eines kommerziellen Produkts vorgestellt. Die Schüler lernen die bestehenden theoretischen Ansätze für logische Uhren, Abhängigkeitsverfolgung, Systemsicherheit, Uhrensynchronisation und warum MongoDB diese oder jene Lösungen eingestellt hat.Mikhail Tyulenev (im Folgenden - MT): - Ich werde über kausale Konsistenz sprechen - Dies ist eine Funktion, an der wir in MongoDB gearbeitet haben. Ich arbeite in einer Gruppe verteilter Systeme, wir haben es vor ungefähr zwei Jahren gemacht. Dabei musste ich mich mit viel akademischer Forschung vertraut machen, da diese Funktion gut untersucht ist. Es stellte sich heraus, dass kein einziger Artikel in die Anforderungen der Produktion passt, die Datenbank angesichts der sehr spezifischen Anforderungen, die wahrscheinlich in Produktionsanwendungen gestellt werden.Ich werde darüber sprechen, wie wir als Verbraucher akademischer Forschung etwas daraus zubereiten, das wir unseren Benutzern dann als fertiges Gericht präsentieren können, das bequem und sicher zu verwenden ist.
Dabei musste ich mich mit viel akademischer Forschung vertraut machen, da diese Funktion gut untersucht ist. Es stellte sich heraus, dass kein einziger Artikel in die Anforderungen der Produktion passt, die Datenbank angesichts der sehr spezifischen Anforderungen, die wahrscheinlich in Produktionsanwendungen gestellt werden.Ich werde darüber sprechen, wie wir als Verbraucher akademischer Forschung etwas daraus zubereiten, das wir unseren Benutzern dann als fertiges Gericht präsentieren können, das bequem und sicher zu verwenden ist.Kausale Konsistenz. Definieren wir Konzepte
Zunächst möchte ich allgemein skizzieren, was kausale Konsistenz ist. Es gibt zwei Charaktere - Leonard und Penny (die Serie „The Big Bang Theory“):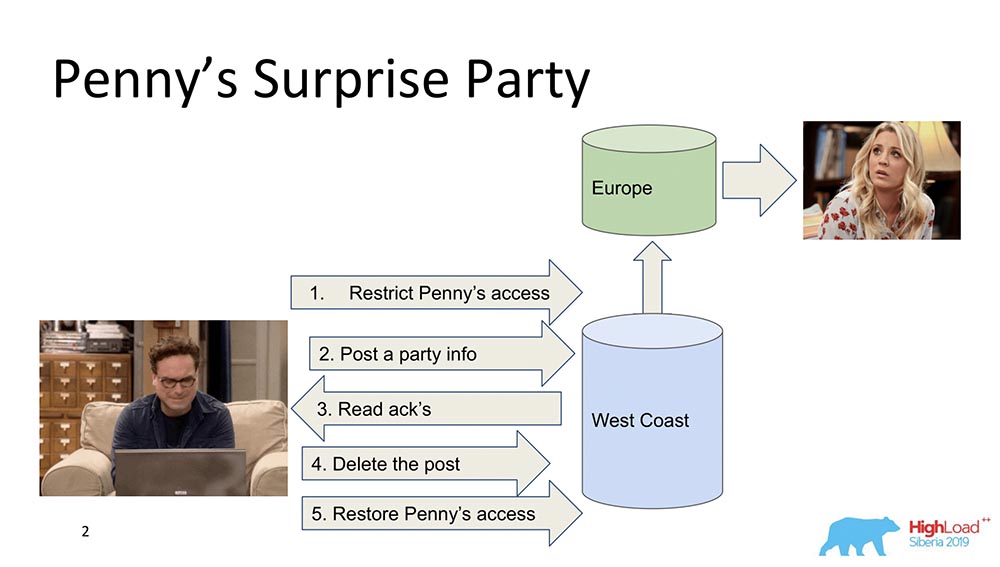 Angenommen, Penny ist in Europa und Leonard möchte eine Art Überraschung für sie machen, eine Party. Und er hat nichts Besseres gefunden, als sie von der Freundesliste zu streichen und Updates zu senden, um alle Freunde zu füttern: "Lass uns Penny glücklich machen!" (Sie in Europa sieht im Schlaf nicht alles und kann nicht sehen, weil sie nicht da ist.) Am Ende wird dieser Beitrag gelöscht, aus dem "Feed" gelöscht und der Zugriff wiederhergestellt, sodass nichts bemerkt wird und kein Skandal auftritt.Das ist alles in Ordnung, aber nehmen wir an, dass das System verteilt ist und die Ereignisse etwas schief gelaufen sind. Möglicherweise kommt es beispielsweise vor, dass die Penny-Zugriffsbeschränkung nach dem Erscheinen dieses Beitrags aufgetreten ist, wenn die Ereignisse nicht durch einen Kausalzusammenhang verbunden sind. Tatsächlich ist dies ein Beispiel dafür, wann kausale Konsistenz erforderlich ist, um eine Geschäftsfunktion zu erfüllen (in diesem Fall).Tatsächlich sind dies nicht triviale Eigenschaften der Datenbank - nur sehr wenige Menschen unterstützen sie. Kommen wir zu den Modellen.
Angenommen, Penny ist in Europa und Leonard möchte eine Art Überraschung für sie machen, eine Party. Und er hat nichts Besseres gefunden, als sie von der Freundesliste zu streichen und Updates zu senden, um alle Freunde zu füttern: "Lass uns Penny glücklich machen!" (Sie in Europa sieht im Schlaf nicht alles und kann nicht sehen, weil sie nicht da ist.) Am Ende wird dieser Beitrag gelöscht, aus dem "Feed" gelöscht und der Zugriff wiederhergestellt, sodass nichts bemerkt wird und kein Skandal auftritt.Das ist alles in Ordnung, aber nehmen wir an, dass das System verteilt ist und die Ereignisse etwas schief gelaufen sind. Möglicherweise kommt es beispielsweise vor, dass die Penny-Zugriffsbeschränkung nach dem Erscheinen dieses Beitrags aufgetreten ist, wenn die Ereignisse nicht durch einen Kausalzusammenhang verbunden sind. Tatsächlich ist dies ein Beispiel dafür, wann kausale Konsistenz erforderlich ist, um eine Geschäftsfunktion zu erfüllen (in diesem Fall).Tatsächlich sind dies nicht triviale Eigenschaften der Datenbank - nur sehr wenige Menschen unterstützen sie. Kommen wir zu den Modellen.Konsistenzmodelle
Was ist ein Konsistenzmodell in Datenbanken im Allgemeinen? Dies sind einige der Garantien, die ein verteiltes System in Bezug darauf gibt, welche Daten und in welcher Reihenfolge der Client empfangen kann.Grundsätzlich kommt es bei allen Konsistenzmodellen darauf an, wie verteilt das System wie ein System ist, das beispielsweise auf einem Laptop mit demselben Nicken funktioniert. Und so sehr ähnelt das System, das auf Tausenden von geoverteilten „Knoten“ funktioniert, einem Laptop, bei dem alle diese Eigenschaften im Prinzip automatisch ausgeführt werden.Daher gelten Konsistenzmodelle nur für verteilte Systeme. Bei allen Systemen, die zuvor mit derselben vertikalen Skalierung existierten und arbeiteten, traten solche Probleme nicht auf. Es gab einen Puffer-Cache, aus dem immer alles gelesen wurde.Starkes Modell
Tatsächlich ist das allererste Modell Stark (oder die Linie der Aufstiegsfähigkeit, wie sie oft genannt wird). Dies ist ein Konsistenzmodell, das sicherstellt, dass jede Änderung für alle Benutzer des Systems sichtbar ist, sobald eine Bestätigung eingeht, dass sie stattgefunden hat.Dadurch wird eine globale Reihenfolge aller Ereignisse in der Datenbank erstellt. Dies ist eine sehr starke Konsistenz-Eigenschaft und im Allgemeinen sehr teuer. Es ist jedoch sehr gut gepflegt. Es ist einfach sehr teuer und langsam - sie werden einfach selten verwendet. Dies nennt man Aufstiegsfähigkeit.Es gibt eine weitere, leistungsstärkere Eigenschaft, die im "Spanner" unterstützt wird - die externe Konsistenz. Wir werden etwas später über ihn sprechen.Kausal
Das Folgende ist Kausal, genau das, worüber ich gesprochen habe. Es gibt mehrere Unterebenen zwischen Stark und Kausal, über die ich nicht sprechen werde, aber alle sind auf Kausal zurückzuführen. Dies ist ein wichtiges Modell, da es das stärkste aller Modelle ist und die stärkste Konsistenz bei Vorhandensein eines Netzwerks oder von Partitionen aufweist.Kausale ist eigentlich eine Situation, in der Ereignisse durch einen Kausalzusammenhang verbunden sind. Sehr oft werden sie aus Sicht des Kunden als Read your on-Rechte wahrgenommen. Wenn der Kunde einige Werte beobachtet hat, kann er die Werte in der Vergangenheit nicht sehen. Er beginnt bereits, Präfixablesungen zu sehen. Es kommt alles auf dasselbe an.Kausale als Konsistenzmodell sind eine Teilreihenfolge von Ereignissen auf dem Server, bei der Ereignisse von allen Clients in derselben Reihenfolge beobachtet werden. In diesem Fall Leonard und Penny.Eventuell
Das dritte Modell ist die eventuelle Konsistenz. Dies unterstützt absolut alle verteilten Systeme, ein Minimalmodell, das im Allgemeinen Sinn macht. Dies bedeutet Folgendes: Wenn sich die Daten ändern, werden sie irgendwann konsistent.In einem solchen Moment sagt sie nichts, sonst würde sie sich in externe Konsistenz verwandeln - es würde eine ganz andere Geschichte geben. Trotzdem ist dies ein sehr beliebtes Modell, das häufigste. Standardmäßig verwenden alle Benutzer verteilter Systeme Eventual Consistency.Ich möchte einige vergleichende Beispiele geben: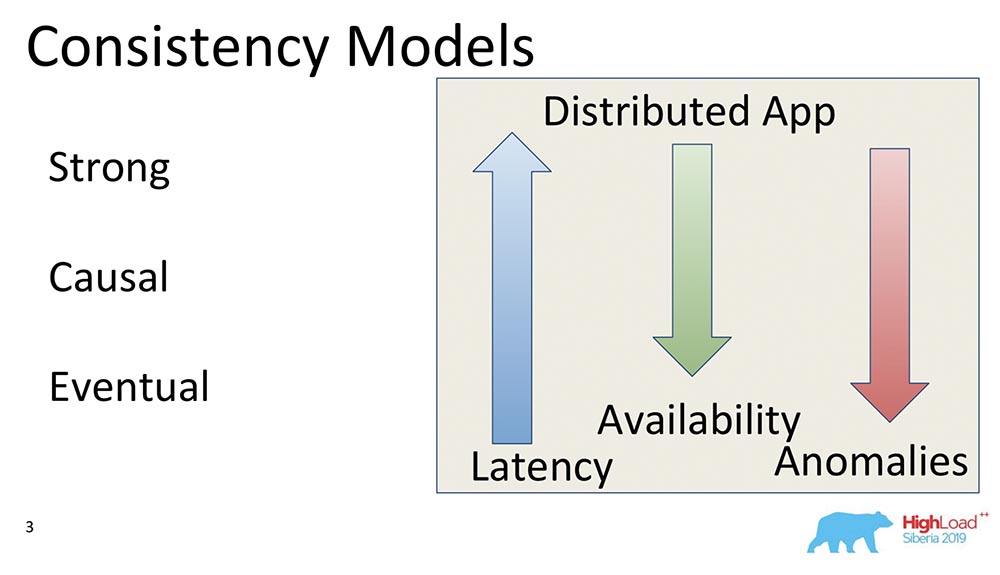 Was bedeuten diese Pfeile?
Was bedeuten diese Pfeile?- Latency. : , , , . Eventual Consistency , , , memory .
- Availability. , partitions, - – , , - . Eventual Consistency – , .
- Anomalies. , , . Strong Consistency , Eventual Consistency . : Eventual Consistency, ? , Eventual Consistency- , , , ; - ; . , .
CAP
Wenn Sie die Wörter Konsistenz, Verfügbarkeit sehen - woran denken Sie? Richtig - CAP-Theorem! Jetzt möchte ich den Mythos zerstreuen ... Ich bin es nicht - da ist Martin Kleppman, der einen wunderbaren Artikel geschrieben hat, ein wundervolles Buch. Das CAP-Theorem ist ein in den 2000er Jahren formuliertes Prinzip: Konsistenz, Verfügbarkeit, Partitionen: Nehmen Sie zwei, und Sie können nicht drei auswählen. Es war ein bestimmtes Prinzip. Einige Jahre später wurde es von Gilbert und Lynch als Theorem bewiesen. Dann wurde es als Mantra verwendet - Systeme wurden in CA, CP, AP usw. unterteilt.Dieser Satz wurde tatsächlich aus folgenden Gründen bewiesen ... Erstens wurde Verfügbarkeit nicht als kontinuierlicher Wert von Null bis Hundert betrachtet (0 - das System ist "tot", 100 - Antworten schnell; wir sind es gewohnt, ihn zu berücksichtigen), sondern als eine Eigenschaft des Algorithmus Dies stellt sicher, dass bei allen Ausführungen Daten zurückgegeben werden.Es gibt kein Wort über die Reaktionszeit! Es gibt einen Algorithmus, der Daten nach 100 Jahren zurückgibt - einen perfekt verfügbaren Algorithmus, der Teil des CAP-Theorems ist.Zweitens: Es wurde ein Satz für Änderungen der Werte desselben Schlüssels bewiesen, obwohl diese Änderungen eine veränderbare Linie sind. Dies bedeutet, dass sie tatsächlich praktisch nicht verwendet werden, da die Modelle unterschiedliche mögliche Konsistenz, starke Konsistenz (möglicherweise) aufweisen.Warum ist das alles? Darüber hinaus wird der CAP-Satz in der Form, in der er bewiesen ist, dass er praktisch nicht anwendbar ist, selten verwendet. In einer theoretischen Form schränkt es irgendwie alles ein. Es stellt sich heraus, dass ein bestimmtes Prinzip intuitiv wahr ist, aber im Allgemeinen in keiner Weise bewiesen wird.
Das CAP-Theorem ist ein in den 2000er Jahren formuliertes Prinzip: Konsistenz, Verfügbarkeit, Partitionen: Nehmen Sie zwei, und Sie können nicht drei auswählen. Es war ein bestimmtes Prinzip. Einige Jahre später wurde es von Gilbert und Lynch als Theorem bewiesen. Dann wurde es als Mantra verwendet - Systeme wurden in CA, CP, AP usw. unterteilt.Dieser Satz wurde tatsächlich aus folgenden Gründen bewiesen ... Erstens wurde Verfügbarkeit nicht als kontinuierlicher Wert von Null bis Hundert betrachtet (0 - das System ist "tot", 100 - Antworten schnell; wir sind es gewohnt, ihn zu berücksichtigen), sondern als eine Eigenschaft des Algorithmus Dies stellt sicher, dass bei allen Ausführungen Daten zurückgegeben werden.Es gibt kein Wort über die Reaktionszeit! Es gibt einen Algorithmus, der Daten nach 100 Jahren zurückgibt - einen perfekt verfügbaren Algorithmus, der Teil des CAP-Theorems ist.Zweitens: Es wurde ein Satz für Änderungen der Werte desselben Schlüssels bewiesen, obwohl diese Änderungen eine veränderbare Linie sind. Dies bedeutet, dass sie tatsächlich praktisch nicht verwendet werden, da die Modelle unterschiedliche mögliche Konsistenz, starke Konsistenz (möglicherweise) aufweisen.Warum ist das alles? Darüber hinaus wird der CAP-Satz in der Form, in der er bewiesen ist, dass er praktisch nicht anwendbar ist, selten verwendet. In einer theoretischen Form schränkt es irgendwie alles ein. Es stellt sich heraus, dass ein bestimmtes Prinzip intuitiv wahr ist, aber im Allgemeinen in keiner Weise bewiesen wird.Kausale Konsistenz - das stärkste Modell
Was jetzt passiert - Sie können alle drei Dinge erhalten: Konsistenz, Verfügbarkeit kann über Partitionen erhalten werden. Insbesondere ist die kausale Konsistenz das stärkste Konsistenzmodell, das bei vorhandenen Partitionen (Netzwerkunterbrechungen) immer noch funktioniert. Deshalb ist es von so großem Interesse, und deshalb beschäftigen wir uns damit. Erstens vereinfacht es die Arbeit der Anwendungsentwickler. Insbesondere der Server bietet viel Unterstützung: Wenn garantiert ist, dass alle Datensätze, die in einem Client vorkommen, in dieser Reihenfolge auf dem anderen Client eintreffen. Zweitens hält es Partitionen stand.
Erstens vereinfacht es die Arbeit der Anwendungsentwickler. Insbesondere der Server bietet viel Unterstützung: Wenn garantiert ist, dass alle Datensätze, die in einem Client vorkommen, in dieser Reihenfolge auf dem anderen Client eintreffen. Zweitens hält es Partitionen stand.Innenküche MongoDB
Wir erinnern uns an das Mittagessen und gehen in die Küche. Ich werde über das Systemmodell sprechen, nämlich was ist MongoDB für diejenigen, die zuerst von einer solchen Datenbank hören.
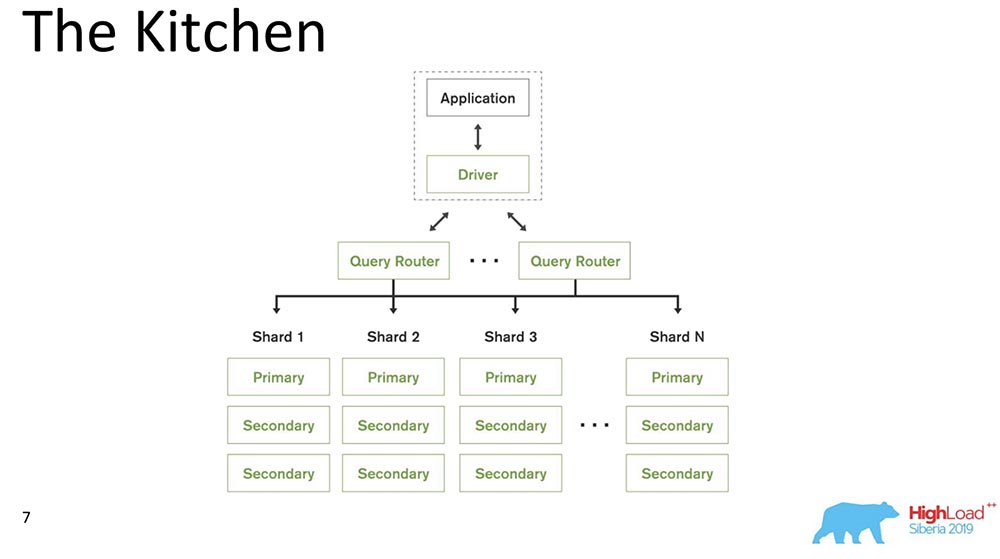 MongoDB (im Folgenden als "MongoBD" bezeichnet) ist ein verteiltes System, das horizontale Skalierung, dh Sharding, unterstützt. und innerhalb jedes Shards unterstützt es auch Datenredundanz, d. h. Replikation.Das Sharding in "MongoBD" (nicht relationale Datenbank) führt einen automatischen Ausgleich durch, dh jede Sammlung von Dokumenten (oder "Tabelle" in Bezug auf relationale Daten) in Teile, und der Server verschiebt sie bereits automatisch zwischen Shards.Der Abfrage-Router, der Abfragen für den Client verteilt, ist ein Client, über den er funktioniert. Er weiß bereits, wo und welche Daten sich befinden, sendet alle Anfragen an den richtigen Shard.Ein weiterer wichtiger Punkt: MongoDB ist ein einzelner Master. Es gibt eine Primärdatenbank - sie kann Datensätze aufnehmen, die die darin enthaltenen Schlüssel unterstützen. Sie können nicht mit mehreren Mastern schreiben.Wir haben Release 4.2 gemacht - dort sind neue interessante Dinge aufgetaucht. Insbesondere fügten sie Lucene - die Suche - ein, es war ausführbares Java direkt in "Mongo", und dort wurde es möglich, Lucene zu durchsuchen, genau wie in "Elastic".Und sie haben ein neues Produkt entwickelt - Charts, das auch auf Atlas (Mongos eigene Cloud) verfügbar ist. Sie haben Free Tier - damit können Sie herumspielen. Die Diagramme haben mir sehr gut gefallen - die Datenvisualisierung ist sehr intuitiv.
MongoDB (im Folgenden als "MongoBD" bezeichnet) ist ein verteiltes System, das horizontale Skalierung, dh Sharding, unterstützt. und innerhalb jedes Shards unterstützt es auch Datenredundanz, d. h. Replikation.Das Sharding in "MongoBD" (nicht relationale Datenbank) führt einen automatischen Ausgleich durch, dh jede Sammlung von Dokumenten (oder "Tabelle" in Bezug auf relationale Daten) in Teile, und der Server verschiebt sie bereits automatisch zwischen Shards.Der Abfrage-Router, der Abfragen für den Client verteilt, ist ein Client, über den er funktioniert. Er weiß bereits, wo und welche Daten sich befinden, sendet alle Anfragen an den richtigen Shard.Ein weiterer wichtiger Punkt: MongoDB ist ein einzelner Master. Es gibt eine Primärdatenbank - sie kann Datensätze aufnehmen, die die darin enthaltenen Schlüssel unterstützen. Sie können nicht mit mehreren Mastern schreiben.Wir haben Release 4.2 gemacht - dort sind neue interessante Dinge aufgetaucht. Insbesondere fügten sie Lucene - die Suche - ein, es war ausführbares Java direkt in "Mongo", und dort wurde es möglich, Lucene zu durchsuchen, genau wie in "Elastic".Und sie haben ein neues Produkt entwickelt - Charts, das auch auf Atlas (Mongos eigene Cloud) verfügbar ist. Sie haben Free Tier - damit können Sie herumspielen. Die Diagramme haben mir sehr gut gefallen - die Datenvisualisierung ist sehr intuitiv.Zutaten mit kausaler Konsistenz
Ich habe ungefähr 230 Artikel gezählt, die zu diesem Thema veröffentlicht wurden - von Leslie Lampert. Aus meiner Erinnerung werde ich Ihnen einige Teile dieser Materialien bringen. Alles begann mit einem Artikel von Leslie Lampert, der in den 1970er Jahren geschrieben wurde. Wie Sie sehen, sind einige Untersuchungen zu diesem Thema noch nicht abgeschlossen. Jetzt ist die kausale Konsistenz im Zusammenhang mit der Entwicklung verteilter Systeme von Interesse.
Alles begann mit einem Artikel von Leslie Lampert, der in den 1970er Jahren geschrieben wurde. Wie Sie sehen, sind einige Untersuchungen zu diesem Thema noch nicht abgeschlossen. Jetzt ist die kausale Konsistenz im Zusammenhang mit der Entwicklung verteilter Systeme von Interesse.Einschränkungen
Was sind die Einschränkungen? Dies ist tatsächlich einer der Hauptpunkte, da sich die Einschränkungen, die Produktionssysteme auferlegen, stark von den Einschränkungen unterscheiden, die in wissenschaftlichen Artikeln bestehen. Oft sind sie ziemlich künstlich.
- Erstens ist „MongoDB“, wie ich bereits sagte, ein einzelner Master (dies vereinfacht sich erheblich).
- , 10 . - , .
- , , , binary, , .
- , Research : . «» – . , , – . , .
- , – : , performance degradation .
- Ein weiterer Punkt ist im Allgemeinen antiakademisch: Kompatibilität früherer und zukünftiger Versionen. Alte Treiber müssen neue Updates unterstützen, und die Datenbank muss alte Treiber unterstützen.
All dies bringt im Allgemeinen Einschränkungen mit sich.Kausale Konsistenzkomponenten
Ich werde jetzt über einige der Komponenten sprechen. Wenn wir die allgemeine kausale Konsistenz berücksichtigen, können wir Blöcke unterscheiden. Wir haben aus den Werken ausgewählt, die zu einem bestimmten Block gehören: Abhängigkeitsverfolgung, Auswahl der Stunden, wie diese Uhren miteinander synchronisiert werden können und wie wir die Sicherheit gewährleisten - dies ist ein ungefährer Plan dessen, worüber ich sprechen werde:
Vollständige Abhängigkeitsverfolgung
Warum wird es benötigt? Damit bei der Replikation der Daten - jeder Datensatz - jede Datenänderung Informationen darüber enthält, von welchen Änderungen sie abhängt. Die allererste und naive Änderung ist, wenn jede Nachricht, die einen Datensatz enthält, Informationen zu vorherigen Nachrichten enthält: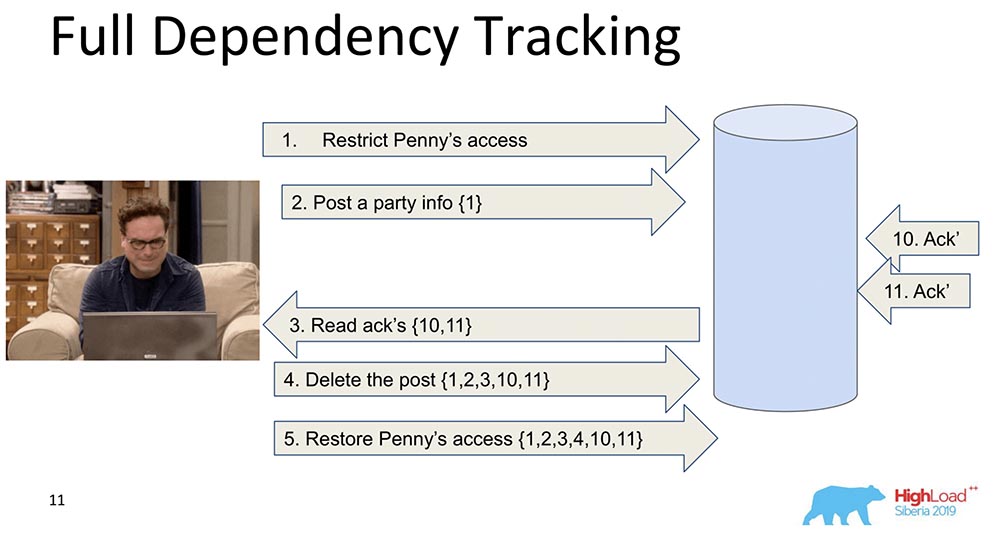 In diesem Beispiel ist die Zahl in geschweiften Klammern die Anzahl der Datensätze. Manchmal werden diese Datensätze mit Werten sogar vollständig übertragen, manchmal werden einige Versionen übertragen. Die Quintessenz ist, dass jede Änderung Informationen über die vorherige enthält (offensichtlich trägt sie alles in sich).Warum haben wir uns entschieden, diesen Ansatz nicht zu verwenden (vollständige Verfolgung)? Weil dieser Ansatz unpraktisch ist: Jede Änderung im sozialen Netzwerk hängt von allen vorherigen Änderungen in diesem sozialen Netzwerk ab und überträgt beispielsweise Facebook oder Vkontakte in jedem Update. Trotzdem gibt es eine Menge Forschung, nämlich Full Dependency Tracking - dies sind soziale Netzwerke, in einigen Situationen funktioniert es wirklich.
In diesem Beispiel ist die Zahl in geschweiften Klammern die Anzahl der Datensätze. Manchmal werden diese Datensätze mit Werten sogar vollständig übertragen, manchmal werden einige Versionen übertragen. Die Quintessenz ist, dass jede Änderung Informationen über die vorherige enthält (offensichtlich trägt sie alles in sich).Warum haben wir uns entschieden, diesen Ansatz nicht zu verwenden (vollständige Verfolgung)? Weil dieser Ansatz unpraktisch ist: Jede Änderung im sozialen Netzwerk hängt von allen vorherigen Änderungen in diesem sozialen Netzwerk ab und überträgt beispielsweise Facebook oder Vkontakte in jedem Update. Trotzdem gibt es eine Menge Forschung, nämlich Full Dependency Tracking - dies sind soziale Netzwerke, in einigen Situationen funktioniert es wirklich.Explizite Abhängigkeitsverfolgung
Der nächste ist begrenzter. Auch hier wird die Übermittlung von Informationen berücksichtigt, aber nur das, was eindeutig davon abhängt. Was davon abhängt, wird in der Regel bereits von der Anwendung festgelegt. Wenn Daten repliziert werden, werden nur Antworten zurückgegeben, wenn eine Anforderung gestellt wird, wenn vorherige Abhängigkeiten erfüllt wurden, dh angezeigt werden. Dies ist die Essenz der Funktionsweise der kausalen Konsistenz.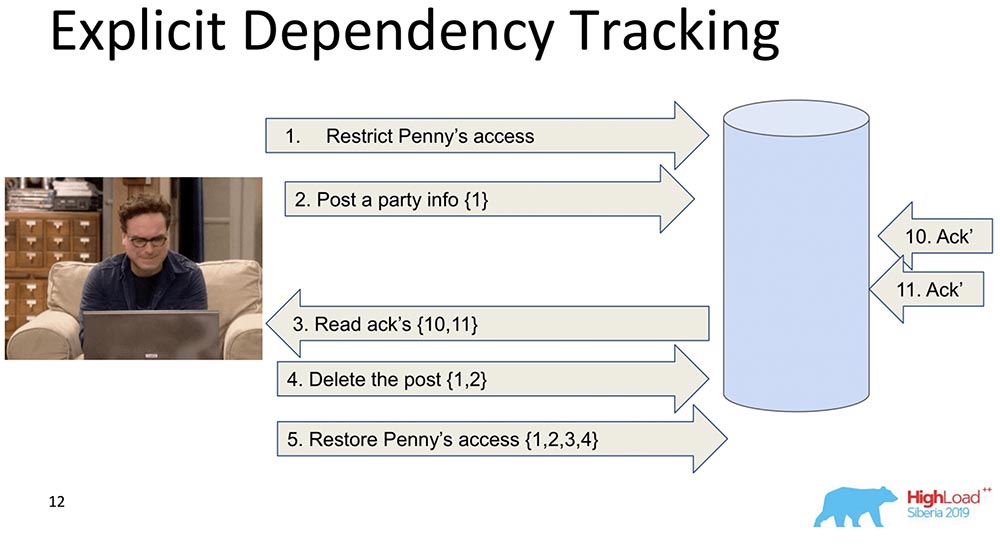 Sie sieht, dass Datensatz 5 von Datensatz 1, 2, 3, 4 abhängt. Sie wartet, bis der Client Zugriff auf die Änderungen erhält, die durch Pennys Zugriffsverordnung vorgenommen wurden, wenn alle vorherigen Änderungen bereits an die Datenbank übergeben wurden.Dies passt auch nicht zu uns, weil es sowieso zu viele Informationen gibt, und dies wird sich verlangsamen. Es gibt einen anderen Ansatz ...
Sie sieht, dass Datensatz 5 von Datensatz 1, 2, 3, 4 abhängt. Sie wartet, bis der Client Zugriff auf die Änderungen erhält, die durch Pennys Zugriffsverordnung vorgenommen wurden, wenn alle vorherigen Änderungen bereits an die Datenbank übergeben wurden.Dies passt auch nicht zu uns, weil es sowieso zu viele Informationen gibt, und dies wird sich verlangsamen. Es gibt einen anderen Ansatz ...Lamport Uhr
Sie sind sehr alt. Lamport Clock impliziert, dass diese Abhängigkeiten zu einer Skalarfunktion namens Lamport Clock zusammengefasst werden.Eine Skalarfunktion ist eine abstrakte Zahl. Oft als logische Zeit bezeichnet. Bei jedem Ereignis erhöht sich dieser Zähler. Der dem Prozess derzeit bekannte Zähler sendet jede Nachricht. Es ist klar, dass Prozesse möglicherweise nicht synchron sind und völlig unterschiedliche Zeiten haben können. Trotzdem gleicht das System die Uhr irgendwie mit solchen Nachrichten aus. Was passiert in diesem Fall?Ich habe diese große Scherbe in zwei Teile zerbrochen, so dass klar war: Freunde können in einem Knoten leben, der einen Teil der Sammlung enthält, und Feed kann in einem anderen Knoten leben, der einen Teil dieser Sammlung enthält. Es ist klar, wie sie aus der Reihe kommen können? Zuerst sagt Feed "Repliziert" und dann Freunde. Wenn das System keine Garantie dafür bietet, dass der Feed erst angezeigt wird, wenn auch die Friends-Abhängigkeiten in der Friends-Sammlung geliefert werden, haben wir nur eine Situation, die ich erwähnt habe.Sie sehen, wie sich die logische Zählerzeit im Feed erhöht: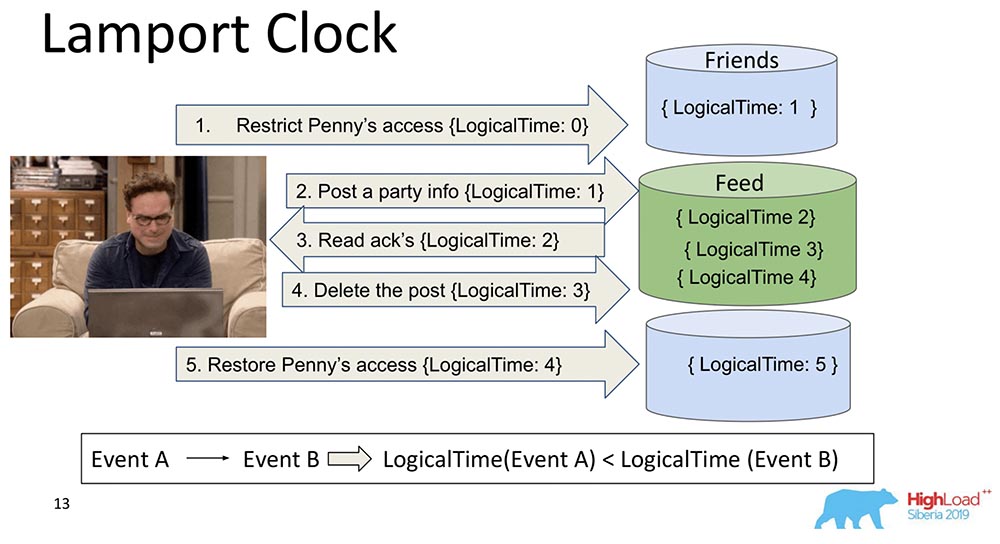 Daher ist die Haupteigenschaft dieser Lamport-Uhr- und Kausalkonsistenz (erklärt durch Lamport-Uhr) wie folgt: Wenn wir Ereignisse A und B haben und Ereignis B von Ereignis A * abhängt, ist die LogicalTime von Ereignis A geringer als die LogicalTime von Ereignis B.* Manchmal sagen sie sogar, dass A vor B passiert ist, dh A vor B passiert ist - dies ist eine Art Beziehung, die teilweise die gesamte Menge von Ereignissen ordnet, die im Allgemeinen passiert sind.Das Gegenteil ist falsch. Dies ist tatsächlich einer der Hauptnachteile von Lamport Clock - Teilbestellung. Es gibt ein Konzept für gleichzeitige Ereignisse, dh Ereignisse, bei denen weder (A vor B) noch (A vor B) aufgetreten sind. Ein Beispiel ist die parallele Hinzufügung von Leonard zu Freunden eines anderen (nicht einmal Leonard, sondern Sheldon zum Beispiel).Dies ist die Eigenschaft, die häufig bei der Arbeit mit Lamport-Uhren verwendet wird: Sie sehen sich die Funktion genau an und ziehen daraus eine Schlussfolgerung - möglicherweise sind diese Ereignisse abhängig. Denn in einer Richtung ist dies wahr: Wenn LogicalTime A kleiner als LogicalTime B ist, kann B nicht vor A auftreten; und wenn mehr, dann vielleicht.
Daher ist die Haupteigenschaft dieser Lamport-Uhr- und Kausalkonsistenz (erklärt durch Lamport-Uhr) wie folgt: Wenn wir Ereignisse A und B haben und Ereignis B von Ereignis A * abhängt, ist die LogicalTime von Ereignis A geringer als die LogicalTime von Ereignis B.* Manchmal sagen sie sogar, dass A vor B passiert ist, dh A vor B passiert ist - dies ist eine Art Beziehung, die teilweise die gesamte Menge von Ereignissen ordnet, die im Allgemeinen passiert sind.Das Gegenteil ist falsch. Dies ist tatsächlich einer der Hauptnachteile von Lamport Clock - Teilbestellung. Es gibt ein Konzept für gleichzeitige Ereignisse, dh Ereignisse, bei denen weder (A vor B) noch (A vor B) aufgetreten sind. Ein Beispiel ist die parallele Hinzufügung von Leonard zu Freunden eines anderen (nicht einmal Leonard, sondern Sheldon zum Beispiel).Dies ist die Eigenschaft, die häufig bei der Arbeit mit Lamport-Uhren verwendet wird: Sie sehen sich die Funktion genau an und ziehen daraus eine Schlussfolgerung - möglicherweise sind diese Ereignisse abhängig. Denn in einer Richtung ist dies wahr: Wenn LogicalTime A kleiner als LogicalTime B ist, kann B nicht vor A auftreten; und wenn mehr, dann vielleicht.Vektoruhr
Die logische Entwicklung von Lamport-Uhren ist die Vektoruhr. Sie unterscheiden sich darin, dass jeder Knoten, der sich hier befindet, eine eigene Uhr enthält und als Vektor übertragen wird.In diesem Fall sehen Sie, dass der Nullindex des Vektors für den Feed verantwortlich ist und der erste Index des Vektors für Freunde (jeder dieser Knoten). Und jetzt werden sie zunehmen: Der Nullindex des "Feeds" steigt bei der Aufnahme - 1, 2, 3: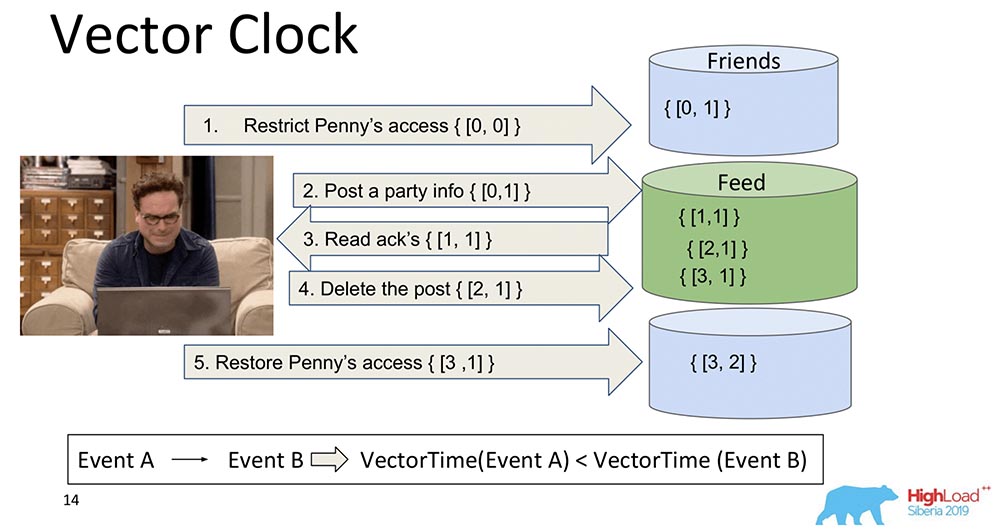 Wie ist die Vektoruhr besser? Die Tatsache, dass sie herausfinden können, welche Ereignisse gleichzeitig auftreten und wann sie auf verschiedenen Knoten auftreten. Dies ist sehr wichtig für ein Sharding-System wie das MongoBD. Wir haben uns jedoch nicht dafür entschieden, obwohl es eine wunderbare Sache ist und großartig funktioniert und wahrscheinlich zu uns passen würde ...Wenn wir zehntausend Shards haben, können wir nicht zehntausend Komponenten übertragen, selbst wenn wir komprimieren, denken wir uns etwas anderes aus - trotzdem ist die Nutzlast um ein Vielfaches geringer als das Volumen dieses gesamten Vektors. Deshalb haben wir unsere Herzen und Zähne zusammengebissen, diesen Ansatz aufgegeben und sind zu einem anderen übergegangen.
Wie ist die Vektoruhr besser? Die Tatsache, dass sie herausfinden können, welche Ereignisse gleichzeitig auftreten und wann sie auf verschiedenen Knoten auftreten. Dies ist sehr wichtig für ein Sharding-System wie das MongoBD. Wir haben uns jedoch nicht dafür entschieden, obwohl es eine wunderbare Sache ist und großartig funktioniert und wahrscheinlich zu uns passen würde ...Wenn wir zehntausend Shards haben, können wir nicht zehntausend Komponenten übertragen, selbst wenn wir komprimieren, denken wir uns etwas anderes aus - trotzdem ist die Nutzlast um ein Vielfaches geringer als das Volumen dieses gesamten Vektors. Deshalb haben wir unsere Herzen und Zähne zusammengebissen, diesen Ansatz aufgegeben und sind zu einem anderen übergegangen.Spanner TrueTime. Atomuhr
Ich sagte, dass es eine Geschichte über Spanner geben wird. Das ist eine coole Sache, genau im 21. Jahrhundert: Atomuhren, GPS-Synchronisation.Welche Idee? Spanner ist ein Google-System, das seit kurzem sogar für Benutzer verfügbar ist (sie haben SQL daran angehängt). Jede Transaktion dort hat einen Zeitstempel. Da die Zeit synchronisiert ist *, kann jedem Ereignis eine bestimmte Zeit zugewiesen werden - die Atomuhr hat eine Wartezeit, nach der garantiert wird, dass eine andere Zeit auftritt. Durch einfaches Schreiben in die Datenbank und Warten auf einen bestimmten Zeitraum wird die Serialisierung des Ereignisses automatisch garantiert. Sie haben das stärkste Konsistenzmodell, das man sich im Prinzip vorstellen kann - es ist externe Konsistenz.* Dies ist das Hauptproblem von Lampart-Uhren - sie sind auf verteilten Systemen niemals synchron. Sie können divergieren, auch mit NTP funktionieren sie immer noch nicht sehr gut. "Spanner" hat eine Atomuhr und die Synchronisation scheint dann Mikrosekunden zu sein.Warum haben wir uns nicht entschieden? Wir gehen nicht davon aus, dass unsere Benutzer eine eingebaute Atomuhr haben. Wenn sie erscheinen und in jeden Laptop eingebaut sind, wird es eine Art super coole GPS-Synchronisation geben - dann ja ... In der Zwischenzeit ist Amazon, Basisstationen für Fanatiker das Beste, was möglich ist ... Deshalb haben wir andere Uhren verwendet.
Durch einfaches Schreiben in die Datenbank und Warten auf einen bestimmten Zeitraum wird die Serialisierung des Ereignisses automatisch garantiert. Sie haben das stärkste Konsistenzmodell, das man sich im Prinzip vorstellen kann - es ist externe Konsistenz.* Dies ist das Hauptproblem von Lampart-Uhren - sie sind auf verteilten Systemen niemals synchron. Sie können divergieren, auch mit NTP funktionieren sie immer noch nicht sehr gut. "Spanner" hat eine Atomuhr und die Synchronisation scheint dann Mikrosekunden zu sein.Warum haben wir uns nicht entschieden? Wir gehen nicht davon aus, dass unsere Benutzer eine eingebaute Atomuhr haben. Wenn sie erscheinen und in jeden Laptop eingebaut sind, wird es eine Art super coole GPS-Synchronisation geben - dann ja ... In der Zwischenzeit ist Amazon, Basisstationen für Fanatiker das Beste, was möglich ist ... Deshalb haben wir andere Uhren verwendet.Hybriduhr
Dies ist tatsächlich das, was den „MongoBD“ ankreuzt und gleichzeitig die kausale Konsistenz sicherstellt. Was sind sie Hybrid? Ein Hybrid ist ein Skalarwert, besteht jedoch aus zwei Komponenten:
- Die erste ist die Unix-Ära (wie viele Sekunden sind seit dem "Beginn der Computerwelt" vergangen).
- Das zweite ist ein Inkrement, ebenfalls ein 32-Bit-Int ohne Vorzeichen.
Das ist eigentlich alles. Es gibt einen solchen Ansatz: Der Teil, der für die Zeit verantwortlich ist, wird ständig mit der Uhr synchronisiert; Jedes Mal, wenn eine Aktualisierung erfolgt, wird dieser Teil mit der Uhr synchronisiert und es stellt sich heraus, dass die Zeit immer mehr oder weniger korrekt ist. Mit Inkrement können Sie zwischen Ereignissen unterscheiden, die zur gleichen Zeit aufgetreten sind.Warum ist das für MongoBD wichtig? Da Sie zu einem bestimmten Zeitpunkt Sicherungswiederherstellungen erstellen können, wird das Ereignis nach Zeit indiziert. Dies ist wichtig, wenn einige Ereignisse benötigt werden. Bei einer Datenbank sind Ereignisse Änderungen an der Datenbank, die zu bestimmten Zeitpunkten auftreten.Ich werde Ihnen nur den wichtigsten Grund nennen (bitte sagen Sie es niemandem)! Wir haben dies getan, weil geordnete, indizierte Daten in MongoDB OpLog so aussehen. OpLog ist eine Datenstruktur, die absolut alle Änderungen in der Datenbank enthält: Sie gehen zuerst zu OpLog und werden dann bereits auf Storage selbst angewendet, wenn es sich um ein repliziertes Datum oder einen Shard handelt.Das war der Hauptgrund. Es gibt jedoch auch praktische Anforderungen für die Entwicklung der Datenbank, was bedeutet, dass es einfach sein sollte - es gibt wenig Code, so wenig kaputte Dinge wie möglich, die neu geschrieben und getestet werden müssen. Die Tatsache, dass unsere Oplogs von einer Hybriduhr indiziert wurden, hat uns sehr geholfen und es uns ermöglicht, die richtige Wahl zu treffen. Es hat sich wirklich ausgezahlt und irgendwie magisch funktioniert, beim allerersten Prototyp. Es war sehr cool!Uhrensynchronisation
In der wissenschaftlichen Literatur sind mehrere Synchronisationsmethoden beschrieben. Ich spreche von Synchronisation, wenn wir zwei verschiedene Shards haben. Wenn ein Replikatsatz vorhanden ist, ist dort keine Synchronisierung erforderlich: Es handelt sich um einen „einzelnen Master“. Wir haben ein OpLog, in das alle Änderungen eingehen - in diesem Fall ist alles bereits im "Oplog" selbst sequentiell geordnet. Wenn wir jedoch zwei verschiedene Shards haben, ist hier die Zeitsynchronisation wichtig. Hier haben Vektoruhren mehr geholfen! Aber wir haben sie nicht. Der zweite ist Heartbeats. Sie können einige Signale austauschen, die in jeder Zeiteinheit auftreten. Aber Hartbits sind zu langsam, wir können unserem Kunden keine Latenz gewähren.Wahre Zeit ist natürlich eine wunderbare Sache. Aber auch dies ist wahrscheinlich die Zukunft ... Obwohl der Atlas bereits erstellt werden kann, gibt es bereits schnelle "amazonische" Zeitsynchronisierer. Aber es wird nicht jedem zur Verfügung stehen.Klatschen ist, wenn alle Nachrichten Zeit enthalten. Dies ist ungefähr das, was wir verwenden. Jede Nachricht zwischen Knoten, einem Treiber, einem Router von Datenknoten, absolut alles für MongoDB sind einige Elemente, Datenbankkomponenten, die Stunden enthalten, die fließen. Überall dort, wo sie die Bedeutung von Hybridzeit haben, wird sie übertragen. 64 Bit? Es erlaubt, es ist möglich.
Der zweite ist Heartbeats. Sie können einige Signale austauschen, die in jeder Zeiteinheit auftreten. Aber Hartbits sind zu langsam, wir können unserem Kunden keine Latenz gewähren.Wahre Zeit ist natürlich eine wunderbare Sache. Aber auch dies ist wahrscheinlich die Zukunft ... Obwohl der Atlas bereits erstellt werden kann, gibt es bereits schnelle "amazonische" Zeitsynchronisierer. Aber es wird nicht jedem zur Verfügung stehen.Klatschen ist, wenn alle Nachrichten Zeit enthalten. Dies ist ungefähr das, was wir verwenden. Jede Nachricht zwischen Knoten, einem Treiber, einem Router von Datenknoten, absolut alles für MongoDB sind einige Elemente, Datenbankkomponenten, die Stunden enthalten, die fließen. Überall dort, wo sie die Bedeutung von Hybridzeit haben, wird sie übertragen. 64 Bit? Es erlaubt, es ist möglich.Wie funktioniert das alles zusammen?
Hier schaue ich mir ein Replikatset an, um es ein bisschen einfacher zu machen. Es gibt primäre und sekundäre. Secondary führt die Replikation durch und ist nicht immer vollständig mit Primary synchronisiert.In den "Primärfarben" befindet sich eine Einfügung (Einfügung) mit einem bestimmten Zeitwert. Dieser Einsatz erhöht den internen Zähler um 11, wenn er maximal ist. Oder es überprüft die Uhrwerte und synchronisiert mit der Uhr, wenn die Uhr größer ist. Auf diese Weise können Sie nach Zeit sortieren.Nachdem er eine Aufzeichnung gemacht hat, tritt ein wichtiger Moment ein. Die Stunden sind in "MongoDB" und werden nur erhöht, wenn sie im "Oplog" aufgezeichnet sind. Dies ist ein Ereignis, das den Status des Systems ändert. In allen klassischen Artikeln wird ein Ereignis als eine Nachricht betrachtet, die in einen Knoten eingeht: Eine Nachricht ist eingetroffen - das heißt, das System hat seinen Status geändert.Dies liegt an der Tatsache, dass es während der Studie nicht vollständig möglich ist zu verstehen, wie diese Nachricht interpretiert wird. Wir wissen mit Sicherheit, dass wenn es nicht im „Oplog“ wiedergegeben wird, es in keiner Weise interpretiert wird und nur der Eintrag im „Oplog“ eine Änderung des Systemzustands darstellt. Dies vereinfacht alles für uns: Das Modell vereinfacht und ermöglicht es uns, im Rahmen eines Replikatsatzes und vieler anderer nützlicher Dinge zu organisieren.Es gibt den Wert zurück, der bereits im „Oplog“ aufgezeichnet wurde - wir wissen, dass dieser Wert im „Oplog“ bereits liegt und seine Zeit 12 ist. Jetzt beginnt der Lesevorgang beispielsweise an einem anderen Knoten (sekundär) und wird bereits nach ClusterTime selbst übertragen Botschaft. Er sagt: „Ich brauche alles, was nach mindestens 12 oder zwölf passiert ist“ (siehe Abb. Oben).Dies wird als Causal a Consistent (CAT) bezeichnet. Theoretisch gibt es ein solches Konzept, dass es sich um eine Zeitscheibe handelt, die an sich konsistent ist. In diesem Fall können wir sagen, dass dies der Zustand des Systems ist, der zum Zeitpunkt 12 beobachtet wurde.Jetzt gibt es hier nichts mehr, da es die Situation zu imitieren scheint, in der Secondary Daten von Primary replizieren muss. Er wartet ... Und jetzt sind die Daten gekommen - geben diese Werte zurück.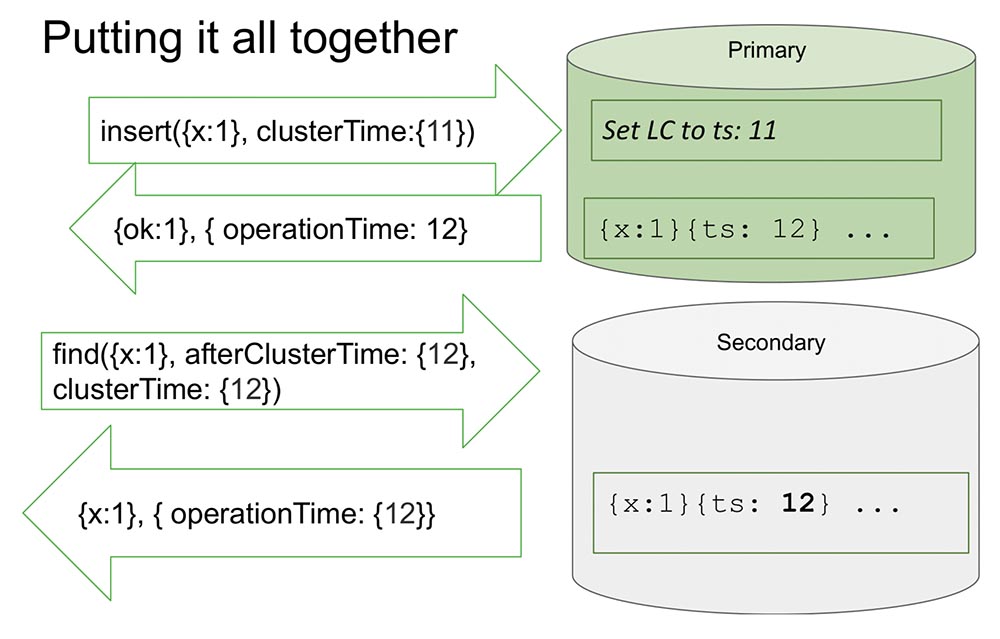 So funktioniert alles. Fast.Was bedeutet "fast"? Nehmen wir an, es gibt jemanden, der gelesen und verstanden hat, wie das alles funktioniert. Ich habe festgestellt, dass jedes Mal, wenn ClusterTime auftritt, die interne logische Uhr aktualisiert wird und der nächste Datensatz um eins erhöht wird. Diese Funktion nimmt 20 Zeilen ein. Angenommen, diese Person überträgt die größtmögliche 64-Bit-Zahl minus eins.Warum ist minus eins? Da die interne Uhr durch diesen Wert ersetzt wird (dies ist offensichtlich die größtmögliche und mehr als die aktuelle Zeit), wird im „Olog“ ein Eintrag angezeigt, und die Uhr wird um einen weiteren erhöht - und es gibt bereits einen Maximalwert (es gibt einfach alle Einheiten, es gibt keinen Weg mehr , vorzeichenlose Ints).Es ist klar, dass das System danach für nichts völlig unzugänglich wird. Es kann nur entladen, gereinigt werden - viel Handarbeit. Volle Verfügbarkeit:
So funktioniert alles. Fast.Was bedeutet "fast"? Nehmen wir an, es gibt jemanden, der gelesen und verstanden hat, wie das alles funktioniert. Ich habe festgestellt, dass jedes Mal, wenn ClusterTime auftritt, die interne logische Uhr aktualisiert wird und der nächste Datensatz um eins erhöht wird. Diese Funktion nimmt 20 Zeilen ein. Angenommen, diese Person überträgt die größtmögliche 64-Bit-Zahl minus eins.Warum ist minus eins? Da die interne Uhr durch diesen Wert ersetzt wird (dies ist offensichtlich die größtmögliche und mehr als die aktuelle Zeit), wird im „Olog“ ein Eintrag angezeigt, und die Uhr wird um einen weiteren erhöht - und es gibt bereits einen Maximalwert (es gibt einfach alle Einheiten, es gibt keinen Weg mehr , vorzeichenlose Ints).Es ist klar, dass das System danach für nichts völlig unzugänglich wird. Es kann nur entladen, gereinigt werden - viel Handarbeit. Volle Verfügbarkeit: Wenn dies an einem anderen Ort repliziert wird, legt sich der gesamte Cluster einfach hin. Eine absolut inakzeptable Situation, die jeder sehr schnell und einfach organisieren kann! Daher haben wir diesen Moment als einen der wichtigsten angesehen. Wie kann man das verhindern?
Wenn dies an einem anderen Ort repliziert wird, legt sich der gesamte Cluster einfach hin. Eine absolut inakzeptable Situation, die jeder sehr schnell und einfach organisieren kann! Daher haben wir diesen Moment als einen der wichtigsten angesehen. Wie kann man das verhindern?Unser Weg ist es, clusterTime zu signieren
So wird es in der Nachricht übertragen (vor dem blauen Text). Wir haben aber auch begonnen, eine Signatur (blauer Text) zu generieren: Die Signatur wird von einem Schlüssel generiert, der in der Datenbank innerhalb des geschützten Bereichs gespeichert ist. es wird generiert, aktualisiert (Benutzer sehen nichts). Hash wird generiert und jede Nachricht wird während der Erstellung signiert und nach Erhalt validiert.Wahrscheinlich stellt sich bei Menschen die Frage: "Wie sehr verlangsamt es sich?" Ich sagte, dass es schnell funktionieren sollte, insbesondere wenn diese Funktion nicht vorhanden ist.Was bedeutet es in diesem Fall, die kausale Konsistenz zu verwenden? Dies zeigt den Parameter afterClusterTime an. Und ohne es werden ohnehin einfach Werte übergeben. Klatschen funktioniert seit Version 3.6 immer.Wenn wir die ständige Generierung von Signaturen verlassen, verlangsamt dies das System auch ohne Funktionen, die unseren Ansätzen und Anforderungen nicht entsprechen. Und was haben wir getan?
Signatur wird von einem Schlüssel generiert, der in der Datenbank innerhalb des geschützten Bereichs gespeichert ist. es wird generiert, aktualisiert (Benutzer sehen nichts). Hash wird generiert und jede Nachricht wird während der Erstellung signiert und nach Erhalt validiert.Wahrscheinlich stellt sich bei Menschen die Frage: "Wie sehr verlangsamt es sich?" Ich sagte, dass es schnell funktionieren sollte, insbesondere wenn diese Funktion nicht vorhanden ist.Was bedeutet es in diesem Fall, die kausale Konsistenz zu verwenden? Dies zeigt den Parameter afterClusterTime an. Und ohne es werden ohnehin einfach Werte übergeben. Klatschen funktioniert seit Version 3.6 immer.Wenn wir die ständige Generierung von Signaturen verlassen, verlangsamt dies das System auch ohne Funktionen, die unseren Ansätzen und Anforderungen nicht entsprechen. Und was haben wir getan?Mach es schnell!
Eine einfache Sache, aber der Trick ist interessant - ich werde es teilen, vielleicht wird jemand interessiert sein.Wir haben einen Hash, der signierte Daten speichert. Alle Daten durchlaufen den Cache. Der Cache signiert nicht speziell die Zeit, sondern den Bereich. Wenn ein bestimmter Wert erreicht ist, generieren wir einen Bereich, maskieren die letzten 16 Bits und signieren diesen Wert: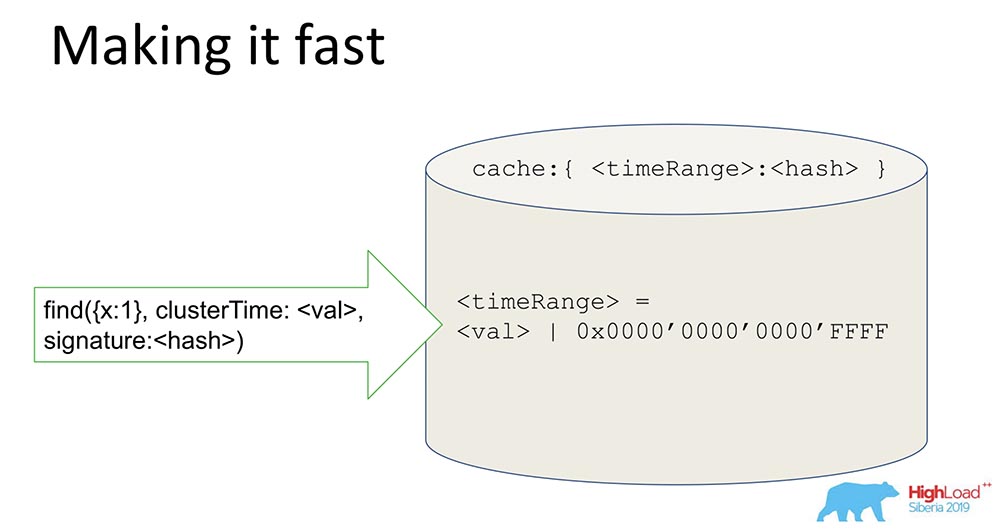 Durch den Empfang einer solchen Signatur beschleunigen wir das System (bedingt) um das 65.000-fache. Es funktioniert großartig: Als sie die Experimente durchgeführt haben, wurde die Zeit, in der wir ein konsistentes Update hatten, dort wirklich um das Zehntausendfache reduziert. Es ist klar, dass dies nicht funktioniert, wenn sie uneins sind. In den meisten praktischen Fällen funktioniert dies jedoch. Die Kombination der Range-Signatur mit der Signatur löste das Sicherheitsproblem.
Durch den Empfang einer solchen Signatur beschleunigen wir das System (bedingt) um das 65.000-fache. Es funktioniert großartig: Als sie die Experimente durchgeführt haben, wurde die Zeit, in der wir ein konsistentes Update hatten, dort wirklich um das Zehntausendfache reduziert. Es ist klar, dass dies nicht funktioniert, wenn sie uneins sind. In den meisten praktischen Fällen funktioniert dies jedoch. Die Kombination der Range-Signatur mit der Signatur löste das Sicherheitsproblem.Was haben wir gelernt?
Lehren daraus haben wir gezogen:- , , , . - ( , . .), , . , , , . – .
, , («», ) – . ? . , . – , . - . , «» , , , availability, latency .
- Das letzte ist, dass wir verschiedene Ideen berücksichtigen und mehrere allgemein unterschiedliche Artikel zu einem Ansatz zusammenfassen mussten. Die Idee zum Signieren kam zum Beispiel aus einem Artikel, in dem das Paxos-Protokoll untersucht wurde, das für nicht-byzantinisches Faylor innerhalb des Autorisierungsprotokolls und für byzantinische außerhalb des Autorisierungsprotokolls gilt. Im Allgemeinen haben wir dies letztendlich genau getan.
Hier gibt es absolut nichts Neues! Aber sobald wir alles zusammengemischt haben ... Es ist wie zu sagen, dass das Olivier-Salatrezept Unsinn ist, weil Eier, Mayonnaise und Gurken bereits erfunden wurden ... Es geht um die gleiche Geschichte.
 Damit werde ich enden. Danke!
Damit werde ich enden. Danke!Fragen
Frage des Publikums (im Folgenden - B): - Danke, Michael für den Bericht! Das Thema Zeit ist interessant. Sie verwenden Klatschen. Sie sagten, dass jeder seine eigene Zeit hat, jeder seine Ortszeit kennt. So wie ich es verstehe, haben wir einen Treiber - es kann viele Clients mit Treibern geben, auch Abfrageplaner, viele Shards ... Aber was wird das System tun, wenn wir plötzlich eine Diskrepanz haben: Jemand entscheidet, dass er für eine Minute ist voraus, jemand - eine Minute dahinter? Wo werden wir uns befinden?MT: - Wirklich eine gute Frage! Ich wollte nur über Scherben sagen. Wenn ich die Frage richtig verstehe, haben wir diese Situation: Es gibt Shard 1 und Shard 2, das Lesen erfolgt von diesen beiden Shards - sie haben eine Diskrepanz, sie interagieren nicht miteinander, weil die Zeit, die sie kennen, unterschiedlich ist, insbesondere die Zeit, die Sie existieren in Oplogs.Angenommen, Shard 1 hat eine Million Datensätze gemacht, Shard 2 hat überhaupt nichts getan, und die Anfrage kam in zwei Shards. Und der erste hat afterClusterTime über eine Million. In einer solchen Situation wird Shard 2, wie ich bereits erklärt habe, niemals reagieren.F: - Ich wollte wissen, wie sie synchronisieren und eine logische Zeit auswählen.MT: - Sehr einfach zu synchronisieren. Shard, wenn afterClusterTime zu ihm kommt und er die Zeit nicht im "Catch" findet - initiiert keine genehmigte. Das heißt, er hebt seine Hände mit seinen Händen auf diesen Wert. Dies bedeutet, dass keine Ereignisse vorhanden sind, die dieser Abfrage entsprechen. Er schafft dieses Ereignis künstlich und wird so zum Causal Consistent.F: - Und wenn danach noch einige andere Ereignisse zu ihm kommen, die irgendwo im Netzwerk verloren gegangen sind?MT:- Die Scherbe ist so angeordnet, dass sie nicht mehr kommt, da es sich um einen einzelnen Meister handelt. Wenn er bereits aufgenommen hat, werden sie nicht kommen, sondern danach sein. Es kann nicht passieren, dass irgendwo etwas steckt, dann wird er nicht schreiben, und dann sind diese Ereignisse eingetroffen - und die kausale Konsistenz wurde verletzt. Wenn er nicht schreibt, müssen sie alle als nächstes kommen (er wird auf sie warten). BEIM:- Ich habe ein paar Fragen zu den Zeilen. Die kausale Konsistenz setzt voraus, dass eine bestimmte Warteschlange von Aktionen ausgeführt werden muss. Was passiert, wenn wir ein Paket verlieren? Also ging der 10., der 11. ... der 12. verschwand und alle anderen warten darauf, dass er erfüllt wird. Und plötzlich ist unser Auto gestorben, wir können nichts mehr tun. Gibt es eine maximale Warteschlangenlänge, die sich ansammelt, bevor sie ausgeführt wird? Welcher fatale Fehler tritt auf, wenn ein Zustand verloren geht? Wenn wir darüber hinaus aufschreiben, dass es einen früheren Zustand gibt, sollten wir dann irgendwie davon ausgehen? Und sie haben nicht von ihm gestoßen!MT:- Auch eine wunderbare Frage! Was machen wir? MongoDB hat das Konzept von Quorum-Datensätzen, Quorum liest. Wann kann eine Nachricht verschwinden? Wenn der Datensatz nicht beschlussfähig ist oder wenn der Messwert nicht beschlussfähig ist (etwas Müll kann auch haften bleiben).In Bezug auf die kausale Konsistenz haben wir einen großen experimentellen Test durchgeführt. Das Ergebnis war, dass Verstöße gegen die kausale Konsistenz auftreten, wenn Aufzeichnung und Lesen nicht beschlussfähig sind. Genau das, was du sagst!Unser Tipp: Verwenden Sie bei Verwendung der kausalen Konsistenz mindestens das Quorum. In diesem Fall geht nichts verloren, auch wenn der Quorumdatensatz verloren geht ... Dies ist eine orthogonale Situation: Wenn der Benutzer nicht möchte, dass die Daten verloren gehen, müssen Sie den Quorumdatensatz verwenden. Die kausale Konsistenz garantiert keine Haltbarkeit. Die Haltbarkeitsgarantie wird durch Replikation und mit der Replikation verbundene Maschinen gewährleistet.F: - Wenn wir eine Instanz erstellen, die Sharding für uns erledigt (nicht Master, sondern Slave), hängt sie von der Unix-Zeit ihrer eigenen Maschine oder von der Zeit des „Masters“ ab. zum ersten Mal oder regelmäßig synchronisiert?MT:- Jetzt mache ich es klar. Scherbe (d. H. Horizontale Trennwand) - es gibt immer Primär. Und in einer Scherbe kann es einen „Meister“ geben und es kann Repliken geben. Der Shard unterstützt jedoch immer das Schreiben, da er eine bestimmte Domäne unterstützen muss (Primary befindet sich im Shard).F: - Das heißt, alles hängt nur vom "Meister" ab? Immer die "Master" -Zeit verwenden?MT: - Ja. Sie können im übertragenen Sinne sagen: Die Uhr tickt, wenn es eine Aufnahme im "Master", im "Olog" gibt.F: - Wir haben einen Kunden, der eine Verbindung herstellt und der nichts über die Zeit wissen muss.MT:- Im Allgemeinen müssen Sie nichts wissen! Wenn wir darüber sprechen, wie es auf dem Client funktioniert: Wenn er auf dem Client die kausale Konsistenz verwenden möchte, muss er eine Sitzung öffnen. Jetzt ist alles da: beide Transaktionen in der Sitzung und das Abrufen von Rechten ... Eine Sitzung ist eine Reihenfolge von logischen Ereignissen, die mit einem Client auftreten.Wenn er diese Sitzung öffnet und dort sagt, dass er kausale Konsistenz wünscht (wenn die Sitzung standardmäßig kausale Konsistenz unterstützt), funktioniert alles automatisch. Der Fahrer merkt sich diese Zeit und erhöht sie, wenn er eine neue Nachricht erhält. Es merkt sich, welche Antwort die vorherige vom Server zurückgegeben hat, der die Daten zurückgegeben hat. Die folgende Anforderung enthält afterCluster ("Zeit ist größer als diese").Der Kunde muss absolut nichts wissen! Das ist für ihn absolut undurchsichtig. Was kann ich tun, wenn Benutzer diese Funktionen verwenden? Erstens können Sie Secondaries sicher lesen: Sie können in Primary schreiben und aus geografisch replizierten Secondaries lesen und sicherstellen, dass es funktioniert. Gleichzeitig können die auf Primary aufgezeichneten Sitzungen sogar auf Secondary übertragen werden, dh Sie können nicht eine Sitzung, sondern mehrere verwenden.F: - Das Thema "Eventuelle Konsistenz" ist stark mit der neuen Compute Science-Schicht verknüpft - CRDT-Datentypen (Conflict-free Replicated Data Types). Haben Sie über die Integration dieser Datentypen in die Datenbank nachgedacht und was können Sie dazu sagen?MT: - Gute Frage! CRDT ist sinnvoll für Schreibkonflikte: in MongoDB - Single Master.BEIM:- Ich habe eine Frage von den Devops. In der realen Welt gibt es solche Jesuitensituationen, in denen das byzantinische Versagen eintritt und die bösen Menschen innerhalb des geschützten Bereichs beginnen, sich an das Protokoll zu halten und Handwerkspakete auf besondere Weise zu senden?
BEIM:- Ich habe ein paar Fragen zu den Zeilen. Die kausale Konsistenz setzt voraus, dass eine bestimmte Warteschlange von Aktionen ausgeführt werden muss. Was passiert, wenn wir ein Paket verlieren? Also ging der 10., der 11. ... der 12. verschwand und alle anderen warten darauf, dass er erfüllt wird. Und plötzlich ist unser Auto gestorben, wir können nichts mehr tun. Gibt es eine maximale Warteschlangenlänge, die sich ansammelt, bevor sie ausgeführt wird? Welcher fatale Fehler tritt auf, wenn ein Zustand verloren geht? Wenn wir darüber hinaus aufschreiben, dass es einen früheren Zustand gibt, sollten wir dann irgendwie davon ausgehen? Und sie haben nicht von ihm gestoßen!MT:- Auch eine wunderbare Frage! Was machen wir? MongoDB hat das Konzept von Quorum-Datensätzen, Quorum liest. Wann kann eine Nachricht verschwinden? Wenn der Datensatz nicht beschlussfähig ist oder wenn der Messwert nicht beschlussfähig ist (etwas Müll kann auch haften bleiben).In Bezug auf die kausale Konsistenz haben wir einen großen experimentellen Test durchgeführt. Das Ergebnis war, dass Verstöße gegen die kausale Konsistenz auftreten, wenn Aufzeichnung und Lesen nicht beschlussfähig sind. Genau das, was du sagst!Unser Tipp: Verwenden Sie bei Verwendung der kausalen Konsistenz mindestens das Quorum. In diesem Fall geht nichts verloren, auch wenn der Quorumdatensatz verloren geht ... Dies ist eine orthogonale Situation: Wenn der Benutzer nicht möchte, dass die Daten verloren gehen, müssen Sie den Quorumdatensatz verwenden. Die kausale Konsistenz garantiert keine Haltbarkeit. Die Haltbarkeitsgarantie wird durch Replikation und mit der Replikation verbundene Maschinen gewährleistet.F: - Wenn wir eine Instanz erstellen, die Sharding für uns erledigt (nicht Master, sondern Slave), hängt sie von der Unix-Zeit ihrer eigenen Maschine oder von der Zeit des „Masters“ ab. zum ersten Mal oder regelmäßig synchronisiert?MT:- Jetzt mache ich es klar. Scherbe (d. H. Horizontale Trennwand) - es gibt immer Primär. Und in einer Scherbe kann es einen „Meister“ geben und es kann Repliken geben. Der Shard unterstützt jedoch immer das Schreiben, da er eine bestimmte Domäne unterstützen muss (Primary befindet sich im Shard).F: - Das heißt, alles hängt nur vom "Meister" ab? Immer die "Master" -Zeit verwenden?MT: - Ja. Sie können im übertragenen Sinne sagen: Die Uhr tickt, wenn es eine Aufnahme im "Master", im "Olog" gibt.F: - Wir haben einen Kunden, der eine Verbindung herstellt und der nichts über die Zeit wissen muss.MT:- Im Allgemeinen müssen Sie nichts wissen! Wenn wir darüber sprechen, wie es auf dem Client funktioniert: Wenn er auf dem Client die kausale Konsistenz verwenden möchte, muss er eine Sitzung öffnen. Jetzt ist alles da: beide Transaktionen in der Sitzung und das Abrufen von Rechten ... Eine Sitzung ist eine Reihenfolge von logischen Ereignissen, die mit einem Client auftreten.Wenn er diese Sitzung öffnet und dort sagt, dass er kausale Konsistenz wünscht (wenn die Sitzung standardmäßig kausale Konsistenz unterstützt), funktioniert alles automatisch. Der Fahrer merkt sich diese Zeit und erhöht sie, wenn er eine neue Nachricht erhält. Es merkt sich, welche Antwort die vorherige vom Server zurückgegeben hat, der die Daten zurückgegeben hat. Die folgende Anforderung enthält afterCluster ("Zeit ist größer als diese").Der Kunde muss absolut nichts wissen! Das ist für ihn absolut undurchsichtig. Was kann ich tun, wenn Benutzer diese Funktionen verwenden? Erstens können Sie Secondaries sicher lesen: Sie können in Primary schreiben und aus geografisch replizierten Secondaries lesen und sicherstellen, dass es funktioniert. Gleichzeitig können die auf Primary aufgezeichneten Sitzungen sogar auf Secondary übertragen werden, dh Sie können nicht eine Sitzung, sondern mehrere verwenden.F: - Das Thema "Eventuelle Konsistenz" ist stark mit der neuen Compute Science-Schicht verknüpft - CRDT-Datentypen (Conflict-free Replicated Data Types). Haben Sie über die Integration dieser Datentypen in die Datenbank nachgedacht und was können Sie dazu sagen?MT: - Gute Frage! CRDT ist sinnvoll für Schreibkonflikte: in MongoDB - Single Master.BEIM:- Ich habe eine Frage von den Devops. In der realen Welt gibt es solche Jesuitensituationen, in denen das byzantinische Versagen eintritt und die bösen Menschen innerhalb des geschützten Bereichs beginnen, sich an das Protokoll zu halten und Handwerkspakete auf besondere Weise zu senden? MT: - Böse Menschen im Umkreis sind wie ein trojanisches Pferd! Böse Menschen im Umkreis können viele schlechte Dinge tun.F: - Es ist klar, dass Sie grob gesagt ein Loch im Server lassen, durch das Sie den Elefantenzoo stecken und den gesamten Cluster für immer zusammenbrechen können. Die manuelle Wiederherstellung wird einige Zeit in Anspruch nehmen. Dies ist, gelinde gesagt, falsch. Auf der anderen Seite ist dies merkwürdig: In der Praxis gibt es in der Praxis Situationen, in denen natürlich ähnliche interne Angriffe auftreten?MT:- Da ich im wirklichen Leben selten auf Sicherheitsverletzungen stoße, kann ich nicht sagen - vielleicht passieren sie. Aber wenn wir über Entwicklungsphilosophie sprechen, dann denken wir so: Wir haben einen Umkreis, der den Leuten Sicherheit bietet - es ist eine Burg, eine Mauer; und innerhalb des Perimeters können Sie alles tun, was Sie wollen. Es ist klar, dass es Benutzer gibt, die nur schauen können, und es gibt Benutzer, die das Verzeichnis löschen können.Abhängig von den Rechten kann der Schaden, den Benutzer anrichten können, eine Maus oder ein Elefant sein. Es ist klar, dass ein Benutzer mit vollen Rechten überhaupt alles tun kann. Ein Benutzer mit nicht weitreichenden Schadensrechten kann erheblich weniger verursachen. Insbesondere kann er das System nicht brechen.BEIM:- Im sicheren Bereich kletterte jemand, um unerwartete Protokolle für den Server zu erstellen, um den Server mit Krebs einzurichten, und wenn Sie Glück haben, dann den gesamten Cluster ... Kommt es jemals so "gut" vor?MT: - Ich habe noch nie von solchen Dingen gehört. Die Tatsache, dass Sie auf diese Weise den Server füllen können, ist kein Geheimnis. Um sich darin zu füllen, aus dem Protokoll zu stammen, ein autorisierter Benutzer zu sein, der so etwas in eine Nachricht schreiben kann ... Eigentlich ist es unmöglich, weil es sowieso überprüft wird. Es ist möglich, diese Authentifizierung für Benutzer zu deaktivieren, die dies nicht möchten. Dies ist dann ihr Problem. Grob gesagt haben sie selbst die Mauern zerstört und Sie können dort einen Elefanten stopfen, der mit Füßen treten wird ... Im Allgemeinen können Sie sich als Handwerker verkleiden, kommen und ihn holen!BEIM:- Danke für den Bericht. Sergey (Yandex). In „Mong“ gibt es eine Konstante, die die Anzahl der stimmberechtigten Mitglieder im Replikatsatz begrenzt, und diese Konstante beträgt 7 (sieben). Warum ist das eine Konstante? Warum ist das kein Parameter?MT: - Replica Set Wir haben auch 40 Knoten. Es gibt immer eine Mehrheit. Ich weiß nicht, welche Version ...F: - Im Replikatset können Sie nicht stimmberechtigte Mitglieder ausführen, aber maximal 7 abstimmen. Wie können Sie dann deaktivieren, wenn das Replikatset in 3 Rechenzentren gezogen wird? Ein Rechenzentrum kann leicht ausgeschaltet werden, und ein anderer Computer fällt aus.MT: - Dies liegt bereits etwas außerhalb des Berichtsbereichs. Dies ist eine häufige Frage. Vielleicht kann ich es ihm dann sagen.
MT: - Böse Menschen im Umkreis sind wie ein trojanisches Pferd! Böse Menschen im Umkreis können viele schlechte Dinge tun.F: - Es ist klar, dass Sie grob gesagt ein Loch im Server lassen, durch das Sie den Elefantenzoo stecken und den gesamten Cluster für immer zusammenbrechen können. Die manuelle Wiederherstellung wird einige Zeit in Anspruch nehmen. Dies ist, gelinde gesagt, falsch. Auf der anderen Seite ist dies merkwürdig: In der Praxis gibt es in der Praxis Situationen, in denen natürlich ähnliche interne Angriffe auftreten?MT:- Da ich im wirklichen Leben selten auf Sicherheitsverletzungen stoße, kann ich nicht sagen - vielleicht passieren sie. Aber wenn wir über Entwicklungsphilosophie sprechen, dann denken wir so: Wir haben einen Umkreis, der den Leuten Sicherheit bietet - es ist eine Burg, eine Mauer; und innerhalb des Perimeters können Sie alles tun, was Sie wollen. Es ist klar, dass es Benutzer gibt, die nur schauen können, und es gibt Benutzer, die das Verzeichnis löschen können.Abhängig von den Rechten kann der Schaden, den Benutzer anrichten können, eine Maus oder ein Elefant sein. Es ist klar, dass ein Benutzer mit vollen Rechten überhaupt alles tun kann. Ein Benutzer mit nicht weitreichenden Schadensrechten kann erheblich weniger verursachen. Insbesondere kann er das System nicht brechen.BEIM:- Im sicheren Bereich kletterte jemand, um unerwartete Protokolle für den Server zu erstellen, um den Server mit Krebs einzurichten, und wenn Sie Glück haben, dann den gesamten Cluster ... Kommt es jemals so "gut" vor?MT: - Ich habe noch nie von solchen Dingen gehört. Die Tatsache, dass Sie auf diese Weise den Server füllen können, ist kein Geheimnis. Um sich darin zu füllen, aus dem Protokoll zu stammen, ein autorisierter Benutzer zu sein, der so etwas in eine Nachricht schreiben kann ... Eigentlich ist es unmöglich, weil es sowieso überprüft wird. Es ist möglich, diese Authentifizierung für Benutzer zu deaktivieren, die dies nicht möchten. Dies ist dann ihr Problem. Grob gesagt haben sie selbst die Mauern zerstört und Sie können dort einen Elefanten stopfen, der mit Füßen treten wird ... Im Allgemeinen können Sie sich als Handwerker verkleiden, kommen und ihn holen!BEIM:- Danke für den Bericht. Sergey (Yandex). In „Mong“ gibt es eine Konstante, die die Anzahl der stimmberechtigten Mitglieder im Replikatsatz begrenzt, und diese Konstante beträgt 7 (sieben). Warum ist das eine Konstante? Warum ist das kein Parameter?MT: - Replica Set Wir haben auch 40 Knoten. Es gibt immer eine Mehrheit. Ich weiß nicht, welche Version ...F: - Im Replikatset können Sie nicht stimmberechtigte Mitglieder ausführen, aber maximal 7 abstimmen. Wie können Sie dann deaktivieren, wenn das Replikatset in 3 Rechenzentren gezogen wird? Ein Rechenzentrum kann leicht ausgeschaltet werden, und ein anderer Computer fällt aus.MT: - Dies liegt bereits etwas außerhalb des Berichtsbereichs. Dies ist eine häufige Frage. Vielleicht kann ich es ihm dann sagen.
Ein bisschen Werbung :)
Vielen Dank für Ihren Aufenthalt bei uns. Gefällt dir unser Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung aufgeben oder Ihren Freunden Cloud-basiertes VPS für Entwickler ab 4,99 US-Dollar empfehlen , ein einzigartiges Analogon von Einstiegsservern, das von uns für Sie erfunden wurde: Die ganze Wahrheit über VPS (KVM) E5-2697 v3 (6 Kerne) 10 GB DDR4 480 GB SSD 1 Gbit / s ab 19 $ oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).Dell R730xd 2-mal günstiger im Equinix Tier IV-Rechenzentrum in Amsterdam? Nur wir haben 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2,6 GHz 14C 64 GB DDR4 4 x 960 GB SSD 1 Gbit / s 100 TV von 199 US-Dollar in den Niederlanden!Dell R420 - 2x E5-2430 2,2 GHz 6C 128 GB DDR3 2x960 GB SSD 1 Gbit / s 100 TB - ab 99 US-Dollar! Lesen Sie mehr über den Aufbau eines Infrastrukturgebäudes. Klasse C mit Dell R730xd E5-2650 v4-Servern für 9.000 Euro pro Cent? Source: https://habr.com/ru/post/undefined/
All Articles