HighLoad ++, Anastasia Tsymbalyuk, Stanislav Tselovalnikov (Sberbank): Wie wir zu MDA wurden
Die nächste HighLoad ++ - Konferenz findet am 6. und 7. April 2020 in St. Petersburg statt.Details und Tickets hier . HighLoad ++ Sibirien 2019. Halle "Krasnojarsk". 25. Juni, 14 Uhr Abstracts und Präsentation .Die Entwicklung eines industriellen Datenverwaltungs- und -verbreitungssystems von Grund auf ist keine leichte Aufgabe. Insbesondere bei einem vollständigen Rückstand beträgt die Arbeitszeit ein Viertel, und die Produktanforderungen sind ständige Turbulenzen. Wir werden am Beispiel des Aufbaus eines Metadatenverwaltungssystems erläutern, wie in kurzer Zeit ein industriell skalierbares System aufgebaut werden kann, das die Speicherung und Verteilung von Daten umfasst.Unser Ansatz nutzt Metadaten, dynamischen SQL-Code und Codegenerierung basierend auf Swagger-Codegen und Lenker voll aus. Diese Lösung reduziert die Entwicklungs- und Rekonfigurationszeit des Systems und das Hinzufügen neuer Verwaltungsobjekte erfordert keine einzige Zeile neuen Codes.Wir werden Ihnen sagen, wie es in unserem Team funktioniert: Welche Regeln halten wir ein, welche Tools verwenden wir, auf welche Schwierigkeiten wir gestoßen sind und wie wir sie heldenhaft überwinden.Anastasia Tsymbalyuk (im Folgenden - AC): - Mein Name ist Nastya und das ist Stas!Stas Tselovalnikov (im Folgenden - SC): - Hallo allerseits!AC: - Heute werden wir Ihnen etwas über MDA erzählen und wie wir mit diesem Ansatz die Entwicklungszeit verkürzt und der Welt ein industriell skalierbares Metadatenmanagementsystem vorgestellt haben. Hurra!SC: - Nastya, was ist MDA?AC: - Stas, ich denke, wir werden jetzt reibungslos weitermachen. Genauer gesagt werde ich am Ende der Präsentation ein wenig darüber sprechen. Lassen Sie uns zuerst über uns sprechen:
Wir werden am Beispiel des Aufbaus eines Metadatenverwaltungssystems erläutern, wie in kurzer Zeit ein industriell skalierbares System aufgebaut werden kann, das die Speicherung und Verteilung von Daten umfasst.Unser Ansatz nutzt Metadaten, dynamischen SQL-Code und Codegenerierung basierend auf Swagger-Codegen und Lenker voll aus. Diese Lösung reduziert die Entwicklungs- und Rekonfigurationszeit des Systems und das Hinzufügen neuer Verwaltungsobjekte erfordert keine einzige Zeile neuen Codes.Wir werden Ihnen sagen, wie es in unserem Team funktioniert: Welche Regeln halten wir ein, welche Tools verwenden wir, auf welche Schwierigkeiten wir gestoßen sind und wie wir sie heldenhaft überwinden.Anastasia Tsymbalyuk (im Folgenden - AC): - Mein Name ist Nastya und das ist Stas!Stas Tselovalnikov (im Folgenden - SC): - Hallo allerseits!AC: - Heute werden wir Ihnen etwas über MDA erzählen und wie wir mit diesem Ansatz die Entwicklungszeit verkürzt und der Welt ein industriell skalierbares Metadatenmanagementsystem vorgestellt haben. Hurra!SC: - Nastya, was ist MDA?AC: - Stas, ich denke, wir werden jetzt reibungslos weitermachen. Genauer gesagt werde ich am Ende der Präsentation ein wenig darüber sprechen. Lassen Sie uns zuerst über uns sprechen: Ich kann mich als Synergiesucher in industriellen IT-Lösungen bezeichnen.SC: - Und ich?
Ich kann mich als Synergiesucher in industriellen IT-Lösungen bezeichnen.SC: - Und ich?Was macht das SberData-Team?
AC: - Und du bist nur ein industrieller Mastodon, weil du mehr als eine Lösung zum Abschlussball gebracht hast!SC: - Tatsächlich arbeiten wir bei Sberbank im selben Team zusammen und verwalten SberData-Metadaten: AC: - SberData, wenn auch auf einfache Weise - Dies ist eine Analyseplattform, auf der alle digitalen Spuren jedes Kunden fließen. Wenn Sie Kunde der Sberbank sind, fließen alle Informationen über Sie genau dorthin. Dort werden viele Datensätze gespeichert, aber wir verstehen, dass die Datenmenge nicht deren Qualität bedeutet. Und Daten ohne Kontext sind manchmal völlig nutzlos, weil wir sie nicht anwenden, interpretieren, schützen und anreichern können.Gerade diese Aufgaben werden durch Metadaten gelöst. Sie zeigen uns den Geschäftskontext und die technische Komponente der Daten, dh wo sie erschienen sind, wie sie transformiert wurden, an welchem Punkt die minimale Beschreibung, das Markup jetzt ist. Dies reicht bereits aus, um die Daten zu verwenden und ihnen zu vertrauen. Dies ist genau die Aufgabe, die Metadaten lösen.SC: - Mit anderen Worten, die Mission unseres Teams ist es, die Effizienz der Sberbank-Informationsanalyseplattform zu steigern, da die Informationen, über die Sie gerade gesprochen haben, zur richtigen Zeit am richtigen Ort an die richtigen Personen geliefert werden sollten. Und denken Sie daran, Sie sagten auch, wenn Daten modernes Öl sind, dann sind Metadaten eine Karte der Ablagerungen dieses Öls.AC:- In der Tat ist dies eine meiner brillanten Aussagen, auf die ich sehr stolz bin. Technisch gesehen wurde diese Aufgabe auf die Tatsache reduziert, dass wir ein Metadaten-Management-Tool innerhalb unserer Plattform erstellen und dessen vollständigen Lebenszyklus sicherstellen mussten.Aber um in die Probleme unseres Themenbereichs einzutauchen und zu verstehen, an welchem Punkt wir uns befinden, schlage ich vor, vor 9 Monaten einen Rollback durchzuführen.Stellen Sie sich also vor: Vor dem Fenster ist der Monat November, die Vögel flogen alle nach Süden, wir sind traurig ... Und als wir einen erfolgreichen Piloten mit dem Team hatten, gab es Kunden - wir blieben alle in der Komfortzone, bis es zu keiner Rückkehr kam.
AC: - SberData, wenn auch auf einfache Weise - Dies ist eine Analyseplattform, auf der alle digitalen Spuren jedes Kunden fließen. Wenn Sie Kunde der Sberbank sind, fließen alle Informationen über Sie genau dorthin. Dort werden viele Datensätze gespeichert, aber wir verstehen, dass die Datenmenge nicht deren Qualität bedeutet. Und Daten ohne Kontext sind manchmal völlig nutzlos, weil wir sie nicht anwenden, interpretieren, schützen und anreichern können.Gerade diese Aufgaben werden durch Metadaten gelöst. Sie zeigen uns den Geschäftskontext und die technische Komponente der Daten, dh wo sie erschienen sind, wie sie transformiert wurden, an welchem Punkt die minimale Beschreibung, das Markup jetzt ist. Dies reicht bereits aus, um die Daten zu verwenden und ihnen zu vertrauen. Dies ist genau die Aufgabe, die Metadaten lösen.SC: - Mit anderen Worten, die Mission unseres Teams ist es, die Effizienz der Sberbank-Informationsanalyseplattform zu steigern, da die Informationen, über die Sie gerade gesprochen haben, zur richtigen Zeit am richtigen Ort an die richtigen Personen geliefert werden sollten. Und denken Sie daran, Sie sagten auch, wenn Daten modernes Öl sind, dann sind Metadaten eine Karte der Ablagerungen dieses Öls.AC:- In der Tat ist dies eine meiner brillanten Aussagen, auf die ich sehr stolz bin. Technisch gesehen wurde diese Aufgabe auf die Tatsache reduziert, dass wir ein Metadaten-Management-Tool innerhalb unserer Plattform erstellen und dessen vollständigen Lebenszyklus sicherstellen mussten.Aber um in die Probleme unseres Themenbereichs einzutauchen und zu verstehen, an welchem Punkt wir uns befinden, schlage ich vor, vor 9 Monaten einen Rollback durchzuführen.Stellen Sie sich also vor: Vor dem Fenster ist der Monat November, die Vögel flogen alle nach Süden, wir sind traurig ... Und als wir einen erfolgreichen Piloten mit dem Team hatten, gab es Kunden - wir blieben alle in der Komfortzone, bis es zu keiner Rückkehr kam.Modell-Metadaten-Management-System
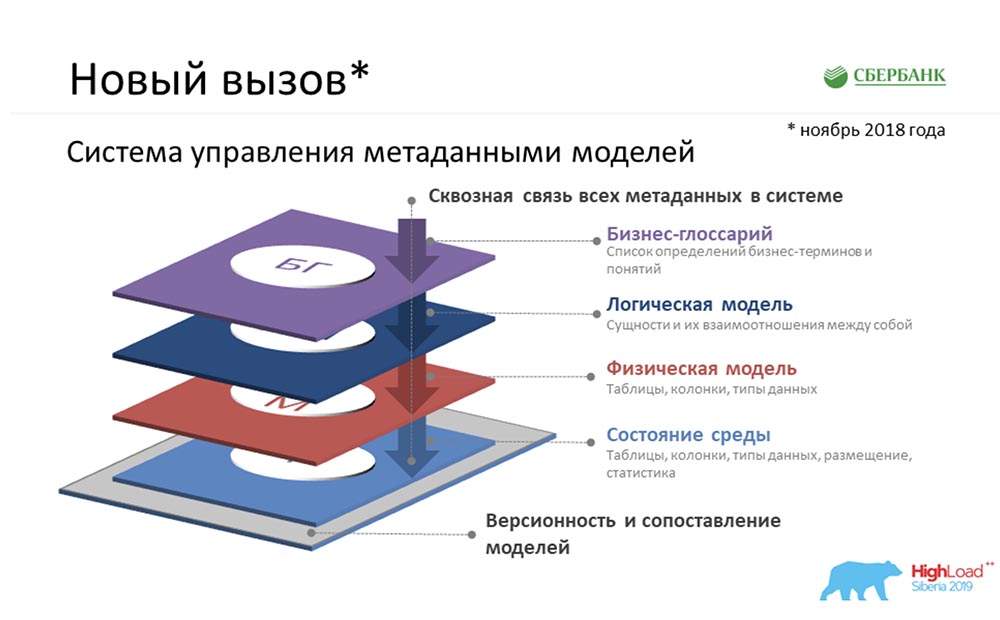 SC: - Sie hatten noch etwas anderes an einer Komfortzone ... Tatsächlich hatten wir die Aufgabe, einen Metadaten-Broker zu erstellen, der die Möglichkeit bieten sollte, mit unseren Kunden, Programmen und Systemen zu kommunizieren. Unsere Kunden hätten auf Backend-Ebene die Möglichkeit haben sollen, entweder eine Art Metadatenpaket zu senden oder zu empfangen. Und wir, die diese Funktion bereitstellen, mussten auf unserer Ebene die konsistentesten und relevantesten Informationen zu Metadaten auf vier logischen Ebenen sammeln:
SC: - Sie hatten noch etwas anderes an einer Komfortzone ... Tatsächlich hatten wir die Aufgabe, einen Metadaten-Broker zu erstellen, der die Möglichkeit bieten sollte, mit unseren Kunden, Programmen und Systemen zu kommunizieren. Unsere Kunden hätten auf Backend-Ebene die Möglichkeit haben sollen, entweder eine Art Metadatenpaket zu senden oder zu empfangen. Und wir, die diese Funktion bereitstellen, mussten auf unserer Ebene die konsistentesten und relevantesten Informationen zu Metadaten auf vier logischen Ebenen sammeln:- Business Glossary Level.
- Die Ebene des logischen Modells.
- Die Ebene des physikalischen Modells.
- Der Zustand der Umwelt, den wir aufgrund der Umkehrung der industriellen Umgebung erhalten haben.
Und das alles muss konsequent sein.AC: - Ja, wirklich. Aber hier würde ich es auch irgendwie auf einfache Weise erklären, denn ich schließe nicht aus, dass der Themenbereich unklar und unverständlich ist ... In einemBusiness-Glossar geht es darum, was kluge Leute in Anzügen stundenlang finden ... wie man einen Begriff benennt, wie man eine Formel entwickelt Berechnung. Sie denken lange nach und haben am Ende nur ein Business-Glossar.Das logische Modell handelt davon, wie sich der Analytiker in der Welt sieht, der in der Lage ist, mit diesen klugen Leuten in Anzügen und Krawatten zu kommunizieren, aber gleichzeitig versteht, wie es möglich wäre, zu landen. Weit entfernt von den Details der physischen Verwirklichung.Das physikalische Modell handelt davon, wann harte Programmierer an der Reihe sind, Architekten, die wirklich verstehen, wie man diese Objekte landet - in welche Tabelle zu legen, welche Felder zu erstellen sind, welche Indizes zu hängen sind ... DerZustand der Umgebung ist eine Art Besetzung. Dies ist wie ein Zeugnis aus einem Auto. Ein Programmierer möchte der Maschine manchmal eines sagen, aber sie versteht es falsch. Allein der Zustand der Umwelt zeigt uns den tatsächlichen Zustand, und wir vergleichen ständig alles; und wir verstehen, dass es einen Unterschied zwischen dem, was der Programmierer gesagt hat, und dem tatsächlichen Zustand der Umgebung gibt.Fall zur Beschreibung von Metadaten
SC: - Lassen Sie es uns anhand eines konkreten Beispiels erklären. Zum Beispiel haben wir vier dieser festgelegten Ebenen. Nehmen wir an, wir haben diese ernsthaften Leute in Beziehungen, die auf der Ebene eines Geschäftsglossars arbeiten - sie verstehen überhaupt nicht, wie und was darin angeordnet ist. Sie verstehen jedoch, dass sie ein obligatorisches Berichtsformular erstellen müssen, sie müssen beispielsweise den durchschnittlichen Kontostand auf persönlichen Konten ermitteln: Auf dieser Ebene sollte eine Person bereits über ein Geschäftsglossar (Bedingungen für die obligatorische Berichterstattung) verfügen oder über einen durchschnittlichen Kontostand auf einem persönlichen Konto verfügen. Als nächstes kommt der Analytiker, der ihn perfekt versteht, mit ihm dieselbe Sprache sprechen kann, aber er kann auch mit Programmierern dieselbe Sprache sprechen.Er sagt: "Hören Sie, hier haben Sie die ganze Geschichte in separate Konten als Entitäten unterteilt, und sie haben ein Attribut - das durchschnittliche Gleichgewicht."Als nächstes kommt der Architekt und sagt: „Wir werden diese Präsentation von Darlehen an juristische Personen durchführen. Dementsprechend erstellen wir eine physische Tabelle mit persönlichen Konten. Wir erstellen eine physische Tabelle mit täglichen Guthaben auf persönlichen Konten (da diese jeden Tag zum Handelsschluss eingehen). Und einmal im Monat zum Stichtag berechnen wir den Durchschnitt (Tabelle der monatlichen Salden) wie gewünscht. “Gesagt, getan. Und dann kam unser Parser, der zum Industriekreis ging und sagte: "Ja, ich verstehe - es gibt notwendige Tische ..." Was hat diesen Tisch noch bereichert? Hier (als Beispiel) - Partitionen und Indizes, obwohl genau genommen sowohl Partitionen als auch Indizes auf der Entwurfsebene des physischen Modells liegen könnten, könnte es aber noch etwas anderes geben (zum Beispiel Datenvolumen).
Auf dieser Ebene sollte eine Person bereits über ein Geschäftsglossar (Bedingungen für die obligatorische Berichterstattung) verfügen oder über einen durchschnittlichen Kontostand auf einem persönlichen Konto verfügen. Als nächstes kommt der Analytiker, der ihn perfekt versteht, mit ihm dieselbe Sprache sprechen kann, aber er kann auch mit Programmierern dieselbe Sprache sprechen.Er sagt: "Hören Sie, hier haben Sie die ganze Geschichte in separate Konten als Entitäten unterteilt, und sie haben ein Attribut - das durchschnittliche Gleichgewicht."Als nächstes kommt der Architekt und sagt: „Wir werden diese Präsentation von Darlehen an juristische Personen durchführen. Dementsprechend erstellen wir eine physische Tabelle mit persönlichen Konten. Wir erstellen eine physische Tabelle mit täglichen Guthaben auf persönlichen Konten (da diese jeden Tag zum Handelsschluss eingehen). Und einmal im Monat zum Stichtag berechnen wir den Durchschnitt (Tabelle der monatlichen Salden) wie gewünscht. “Gesagt, getan. Und dann kam unser Parser, der zum Industriekreis ging und sagte: "Ja, ich verstehe - es gibt notwendige Tische ..." Was hat diesen Tisch noch bereichert? Hier (als Beispiel) - Partitionen und Indizes, obwohl genau genommen sowohl Partitionen als auch Indizes auf der Entwurfsebene des physischen Modells liegen könnten, könnte es aber noch etwas anderes geben (zum Beispiel Datenvolumen).Registrierung und Speicherung auf Metadatenebene
AC: - Wie wird alles bei uns gespeichert? Dies ist eine super vereinfachte Form des Beispiels, das Stas zuvor gemalt hat! Wie wird das alles bei uns liegen?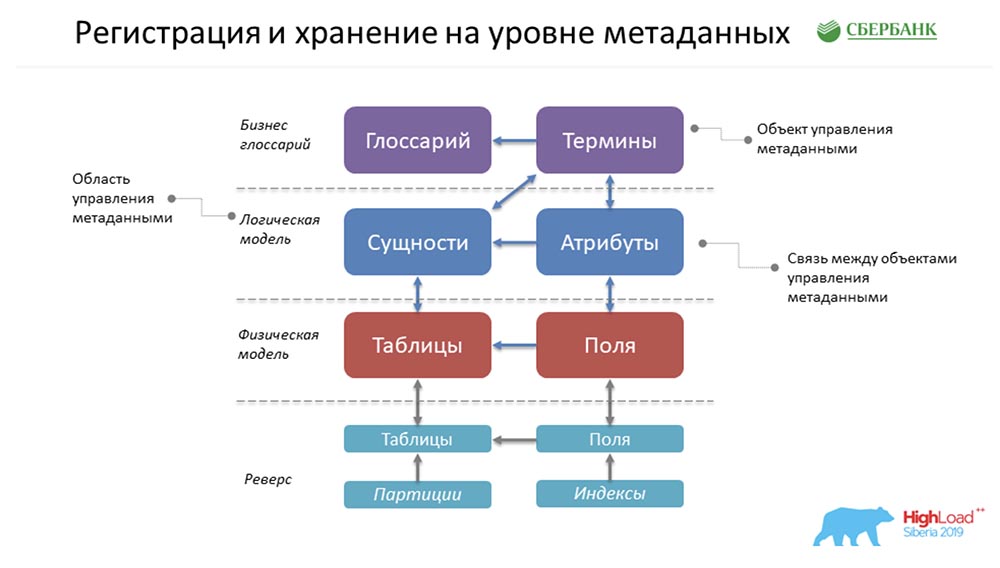 Tatsächlich ist es eine Zeile im Glossarobjekt, eine im Terms-Objekt, eine in den Entities, eine in den Attributen und so weiter. In der obigen Abbildung ist jedes Rechteck ein Objekt in unserem Steuerungssystem, das diese oder jene dort gespeicherten Informationen darstellt.Um Sie langsam in die Terminologie einzuführen, bitte ich Sie, Folgendes zu beachten ... Was ist ein Metadatenverwaltungsobjekt? Physikalisch wird dies in Form einer Tabelle dargestellt, tatsächlich werden dort jedoch bestimmte Informationen zu Begriffen, Glossaren, Entitäten, Attributen usw. gespeichert. Diesen Begriff „Objekt“ werden wir in unserer Präsentation weiterhin verwenden.SC: - Hier muss gesagt werden, dass jeder Cube nur eine Tabelle in unserem System ist, in der wir Metadaten speichern, und wir nennen dies das Steuerobjekt.
Tatsächlich ist es eine Zeile im Glossarobjekt, eine im Terms-Objekt, eine in den Entities, eine in den Attributen und so weiter. In der obigen Abbildung ist jedes Rechteck ein Objekt in unserem Steuerungssystem, das diese oder jene dort gespeicherten Informationen darstellt.Um Sie langsam in die Terminologie einzuführen, bitte ich Sie, Folgendes zu beachten ... Was ist ein Metadatenverwaltungsobjekt? Physikalisch wird dies in Form einer Tabelle dargestellt, tatsächlich werden dort jedoch bestimmte Informationen zu Begriffen, Glossaren, Entitäten, Attributen usw. gespeichert. Diesen Begriff „Objekt“ werden wir in unserer Präsentation weiterhin verwenden.SC: - Hier muss gesagt werden, dass jeder Cube nur eine Tabelle in unserem System ist, in der wir Metadaten speichern, und wir nennen dies das Steuerobjekt.Metadatenanforderungen
Was hatten wir am Eingang? Am Eingang erhielten wir recht interessante Anforderungen. Es gab viele von ihnen, aber hier wollen wir drei Hauptmerkmale zeigen: Die erste Anforderung ist ziemlich klassisch. Uns wird gesagt: "Leute, alles, was einmal zu dir gekommen ist, muss für immer kommen." Die Historisierung ist abgeschlossen und jede Änderung in Ihrem Metadatensystem, die zu Ihnen gekommen ist (es spielt keine Rolle, ob ein Paket mit 100 Feldern eingetroffen ist (100 Änderungen) oder ein Feld in einer Tabelle geändert wurde), erfordert eine neue Registrierung der Metadaten. Sie erfordern auch die Rückgabe einer Antwort:
Die erste Anforderung ist ziemlich klassisch. Uns wird gesagt: "Leute, alles, was einmal zu dir gekommen ist, muss für immer kommen." Die Historisierung ist abgeschlossen und jede Änderung in Ihrem Metadatensystem, die zu Ihnen gekommen ist (es spielt keine Rolle, ob ein Paket mit 100 Feldern eingetroffen ist (100 Änderungen) oder ein Feld in einer Tabelle geändert wurde), erfordert eine neue Registrierung der Metadaten. Sie erfordern auch die Rückgabe einer Antwort:- Standardmäßig - aktueller Status;
- Nach Datum;
- nach Revisionsnummer.
Die zweite Anforderung war interessanter: Uns wurde gesagt, dass sie mit uns an Objekten arbeiten können, aber sie müssen viel in Java programmieren, aber sie wollen nicht. Sie schlugen vor, 100 Objekte (oder 10) gleichzeitig zu mischen, und wir sollten dieses Geschäft abwickeln (weil wir können). Was bedeutet das Mischen? Zum Beispiel kamen 10 Spalten. Sie haben einen Link zur Tabellenkennung, aber wir haben die Tabelle selbst nicht - sie wurde am Ende von JSON erstellt. "Sie denken und verarbeiten - es ist notwendig, dass Sie können"!In der Reihenfolge des zunehmenden Interesses - das dritte: „Wir möchten nicht nur die API verwenden können, die Sie uns erstellen, sondern uns selbst verstehen wollen ...“ Und in einer willkürlichen Reihenfolge sagen Sie: „Geben Sie uns die Vereinigung von diesem Objekt zu dem durch das dritte Objekt. Lassen Sie Ihr System selbst verstehen, wie das alles funktioniert, fragen Sie die Datenbank und geben Sie das Ergebnis in JSON zurück. “Wir hatten eine solche Geschichte am Eingang.Geschätzte Schätzungen
 AC: - Nach unseren ungefähren Berechnungen musste jedes Steuerobjekt zur Implementierung dieses gesamten Konzepts an sieben Schnittstellen teilnehmen: einfach (einfach), für objektweites Schreiben / Lesen und Löschen ...Drei weitere - für universelles Schreiben / Lesen / Löschen, t Das heißt, wir können alles in beliebiger Reihenfolge werfen und wie das Suppenset auf das System übertragen wird, und sie wird herausfinden, in welcher Reihenfolge es gelöscht, abgelegt, gelesen werden soll.Eine weitere Sache - eine Hierarchie aufzubauen, damit wir dem System anzeigen können - „Gib uns von Objekt zu Objekt zurück“; und es gibt einen Baum verschachtelter Objekte zurück.
AC: - Nach unseren ungefähren Berechnungen musste jedes Steuerobjekt zur Implementierung dieses gesamten Konzepts an sieben Schnittstellen teilnehmen: einfach (einfach), für objektweites Schreiben / Lesen und Löschen ...Drei weitere - für universelles Schreiben / Lesen / Löschen, t Das heißt, wir können alles in beliebiger Reihenfolge werfen und wie das Suppenset auf das System übertragen wird, und sie wird herausfinden, in welcher Reihenfolge es gelöscht, abgelegt, gelesen werden soll.Eine weitere Sache - eine Hierarchie aufzubauen, damit wir dem System anzeigen können - „Gib uns von Objekt zu Objekt zurück“; und es gibt einen Baum verschachtelter Objekte zurück.Komplexität der Implementierung
SC: - Zusätzlich zu den technischen Anforderungen, die uns zum Zeitpunkt des Beginns dieser Geschichte gestellt wurden, hatten wir zusätzliche Schwierigkeiten. Erstens ist dies eine gewisse Unsicherheit der Anforderungen. Nicht jedes Team konnte nicht immer klar artikulieren, was es vom Service benötigt, und oft wurde der Moment der Wahrheit im Moment des Prototyping einer Geschichte auf der Def-Rennstrecke geboren. Und während es den Abschlussball erreichte, konnte es mehrere Zyklen geben.AC: - Dies sind genau die Turbulenzen, die zu Beginn angekündigt wurden.SC: - Weiter ...Es gab eine unzulässige Frist, da selbst zum Zeitpunkt des Starts mehr als fünf Teams von uns abhängig waren. Klassiker des Genres: Das Ergebnis wurde gestern gebraucht. Die Arbeitsoption ist im Verbrühungsmodus, was wir auch getan haben.Der dritte ist eine große Menge an Entwicklung. Nastya auf ihrer Folie hat gezeigt, dass wir bei der Betrachtung der Anforderungen, was und wie zu tun ist, festgestellt haben: 1 Objekt erfordert sieben APIs (entweder dafür oder die Teilnahme an sieben APIs). Dies bedeutet, dass wenn wir einen Patch (6 Objekte, Modell, 42 API) in einer Woche haben ...
Erstens ist dies eine gewisse Unsicherheit der Anforderungen. Nicht jedes Team konnte nicht immer klar artikulieren, was es vom Service benötigt, und oft wurde der Moment der Wahrheit im Moment des Prototyping einer Geschichte auf der Def-Rennstrecke geboren. Und während es den Abschlussball erreichte, konnte es mehrere Zyklen geben.AC: - Dies sind genau die Turbulenzen, die zu Beginn angekündigt wurden.SC: - Weiter ...Es gab eine unzulässige Frist, da selbst zum Zeitpunkt des Starts mehr als fünf Teams von uns abhängig waren. Klassiker des Genres: Das Ergebnis wurde gestern gebraucht. Die Arbeitsoption ist im Verbrühungsmodus, was wir auch getan haben.Der dritte ist eine große Menge an Entwicklung. Nastya auf ihrer Folie hat gezeigt, dass wir bei der Betrachtung der Anforderungen, was und wie zu tun ist, festgestellt haben: 1 Objekt erfordert sieben APIs (entweder dafür oder die Teilnahme an sieben APIs). Dies bedeutet, dass wenn wir einen Patch (6 Objekte, Modell, 42 API) in einer Woche haben ...Standardansatz
AC: - Ja, tatsächlich sind 42 APIs pro Woche nur die Spitze des Eisbergs. Wir sind uns bewusst, dass wir Folgendes benötigen, um sicherzustellen, dass diese 42 APIs funktionieren:- Erstellen Sie zunächst eine Speicherstruktur für das Objekt.
- zweitens, um die Logik seiner Verarbeitung sicherzustellen;
- drittens schreiben Sie genau die API, an der das Objekt teilnimmt (oder speziell dafür konfiguriert ist);
- viertens wäre es schön, all dies idealerweise mit den Konturen des Testens abzudecken, zu testen und zu sagen, dass alles in Ordnung ist;
- fünftens (die gleiche Kirsche auf dem Kuchen), um diese ganze Geschichte zu dokumentieren.
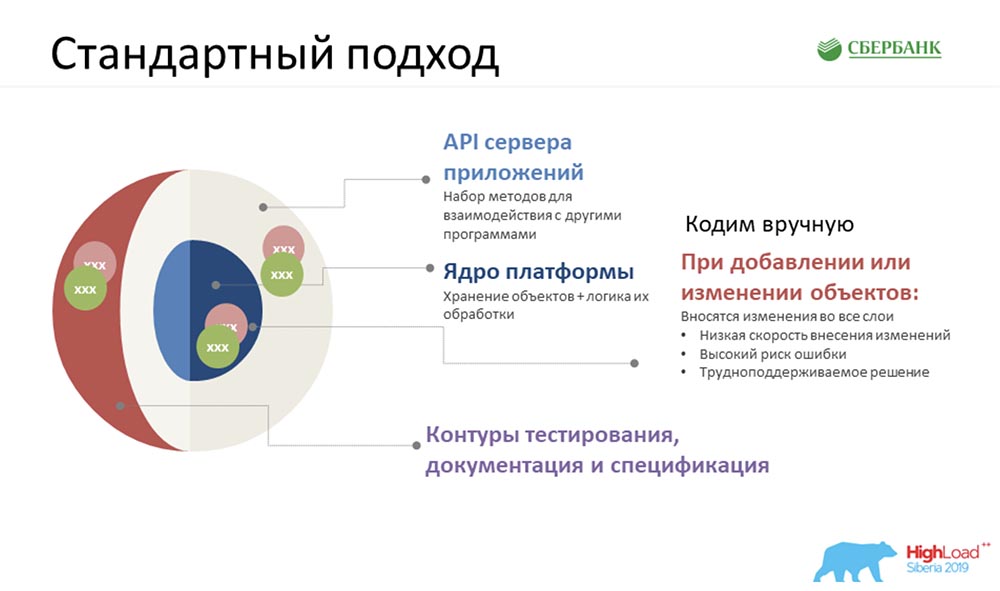 Das erste, was uns einfiel (zu Beginn haben wir Ihnen ein ungefähres Diagramm gezeigt) - wir hatten natürlich ungefähr 35 Objekte. Mit ihnen musste etwas getan werden, all dies musste abgeleitet werden, und es blieb sehr wenig Zeit. Und die erste Idee, die uns einfiel, war, uns hinzusetzen, die Ärmel hochzukrempeln und mit dem Codieren zu beginnen.Selbst nachdem wir ein paar Tage in diesem Modus gearbeitet hatten (wir hatten drei Teams), erreichten wir eine so glühende Temperatur ... Alle waren nervös ... Und wir erkannten, dass wir nach einem anderen Ansatz suchen mussten.
Das erste, was uns einfiel (zu Beginn haben wir Ihnen ein ungefähres Diagramm gezeigt) - wir hatten natürlich ungefähr 35 Objekte. Mit ihnen musste etwas getan werden, all dies musste abgeleitet werden, und es blieb sehr wenig Zeit. Und die erste Idee, die uns einfiel, war, uns hinzusetzen, die Ärmel hochzukrempeln und mit dem Codieren zu beginnen.Selbst nachdem wir ein paar Tage in diesem Modus gearbeitet hatten (wir hatten drei Teams), erreichten wir eine so glühende Temperatur ... Alle waren nervös ... Und wir erkannten, dass wir nach einem anderen Ansatz suchen mussten.Benutzerdefinierter Ansatz
Wir begannen darauf zu achten, was wir tun. Die Idee dieses Ansatzes war schon immer vor unseren Augen, weil wir uns schon sehr lange mit Metadaten beschäftigt haben. Irgendwie ist es uns nicht sofort in den Sinn gekommen ...Wie Sie sich vorstellen können, besteht die Essenz dieser Idee darin, Metadaten zu verwenden. Es besteht in der Tatsache, dass wir die Struktur unseres Repositorys erfassen (dies sind bestimmte Metadaten), sobald wir eine Vorlage für einen Code erstellt haben (z. B. mehrere APIs oder Prozeduren zur Verarbeitung von Logik, Skripte zum Erstellen von Strukturen). Sobald wir diese Vorlage erstellt haben, werden alle Metadaten durchlaufen. Durch Tags werden Eigenschaften in den Code eingesetzt (Objektnamen, Felder, wichtige Merkmale), und der resultierende Code ist fertig. Das heißt, es reicht aus, einmal verwirrt zu sein - erstellen Sie eine Vorlage und verwenden Sie dann alle diese Informationen sowohl für vorhandene als auch für neue Objekte. Hier stellen wir ein anderes Konzept vor - #META_META. Ich werde erklären warum, um Sie nicht zu verwirren.Unser System befasst sich mit der Verwaltung von Metadaten, und der von uns verwendete Ansatz beschreibt ein Metadatenverwaltungssystem, d. H. Zwei Metas. "MetaMeta" - wir haben es zu Hause im Team genannt. Um die anderen nicht weiter zu verwirren, werden wir genau diesen Begriff verwenden.
Das heißt, es reicht aus, einmal verwirrt zu sein - erstellen Sie eine Vorlage und verwenden Sie dann alle diese Informationen sowohl für vorhandene als auch für neue Objekte. Hier stellen wir ein anderes Konzept vor - #META_META. Ich werde erklären warum, um Sie nicht zu verwirren.Unser System befasst sich mit der Verwaltung von Metadaten, und der von uns verwendete Ansatz beschreibt ein Metadatenverwaltungssystem, d. H. Zwei Metas. "MetaMeta" - wir haben es zu Hause im Team genannt. Um die anderen nicht weiter zu verwirren, werden wir genau diesen Begriff verwenden.Mechanismus zur Sicherstellung der Historisierung und Überarbeitung
SC: - Sie haben den Rest unserer Rede zusammengefasst. Wir werden es genauer erzählen.Ich muss sagen, dass wir bei der Vorbereitung der Rede gebeten wurden, technische Informationen zu geben, die für Kollegen von Interesse sein könnten. Wir werden es tun. Außerdem werden die Folien technischer - vielleicht sieht jemand etwas Interessantes für sich.Erstens, wie wir das Problem der Historisierung und Revision gelöst haben. Vielleicht ist das ähnlich wie bei vielen. Betrachten Sie dies anhand von Metadaten als Beispiel, die ein einzelnes Feld in der Buchungstabelle beschreiben (als Beispiel):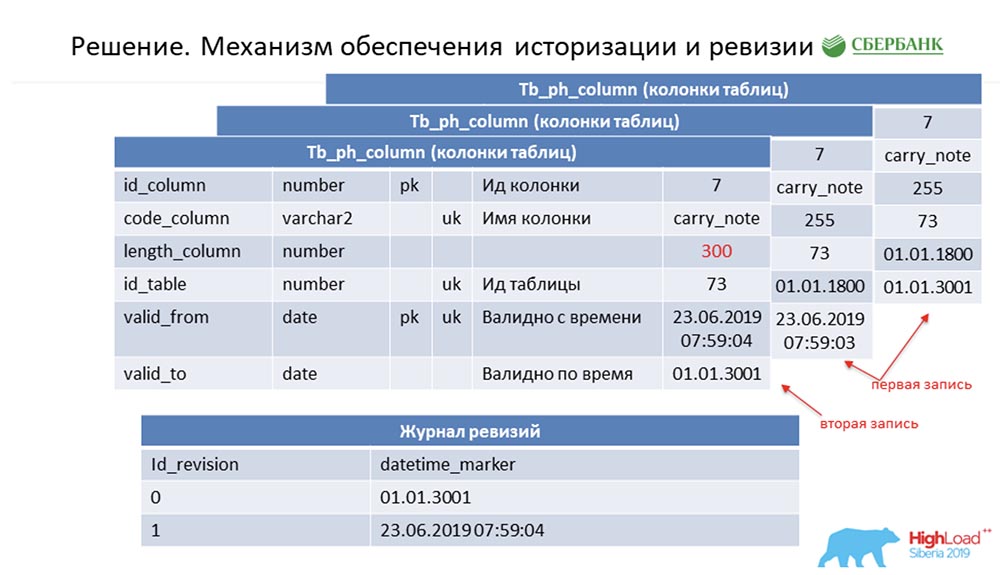 Es hat eine ID - "7", einen Namen - Carry_note, eine Link-ID_Tabelle 73 und ein Feld - 255. Wir geben im Primär- und Alternativschlüssel ein Feld (vom Typ Datum) ab dem Zeitpunkt ein, ab dem dieser Eintrag gültig wird - valid_from. Und noch ein Feld - bis zu welchem Datum dieser Datensatz gültig ist (valid_to). In diesem Fall werden sie standardmäßig ausgefüllt - es ist klar, dass dieser Eintrag grundsätzlich immer gültig ist. Und dies geschieht so lange, bis wir beispielsweise die Länge des Feldes ändern möchten.Sobald wir dies tun möchten, schließen wir den Datensatz valid_to (wir legen den Zeitstempel fest, zu dem das Ereignis aufgetreten ist). Gleichzeitig machen wir einen neuen Rekord ("300"). Es ist leicht zu bemerken, dass in dieser Situation, wenn Sie die Datenbank von einem bestimmten Zeitpunkt an durch den „Kampf“ (zwischen) zwischen valid_from und valid_to betrachten, wir einen einzigen Datensatz erhalten, der jedoch zu diesem Zeitpunkt relevant ist. Gleichzeitig haben wir gleichzeitig ein Revisionsprotokoll geführt:
Es hat eine ID - "7", einen Namen - Carry_note, eine Link-ID_Tabelle 73 und ein Feld - 255. Wir geben im Primär- und Alternativschlüssel ein Feld (vom Typ Datum) ab dem Zeitpunkt ein, ab dem dieser Eintrag gültig wird - valid_from. Und noch ein Feld - bis zu welchem Datum dieser Datensatz gültig ist (valid_to). In diesem Fall werden sie standardmäßig ausgefüllt - es ist klar, dass dieser Eintrag grundsätzlich immer gültig ist. Und dies geschieht so lange, bis wir beispielsweise die Länge des Feldes ändern möchten.Sobald wir dies tun möchten, schließen wir den Datensatz valid_to (wir legen den Zeitstempel fest, zu dem das Ereignis aufgetreten ist). Gleichzeitig machen wir einen neuen Rekord ("300"). Es ist leicht zu bemerken, dass in dieser Situation, wenn Sie die Datenbank von einem bestimmten Zeitpunkt an durch den „Kampf“ (zwischen) zwischen valid_from und valid_to betrachten, wir einen einzigen Datensatz erhalten, der jedoch zu diesem Zeitpunkt relevant ist. Gleichzeitig haben wir gleichzeitig ein Revisionsprotokoll geführt: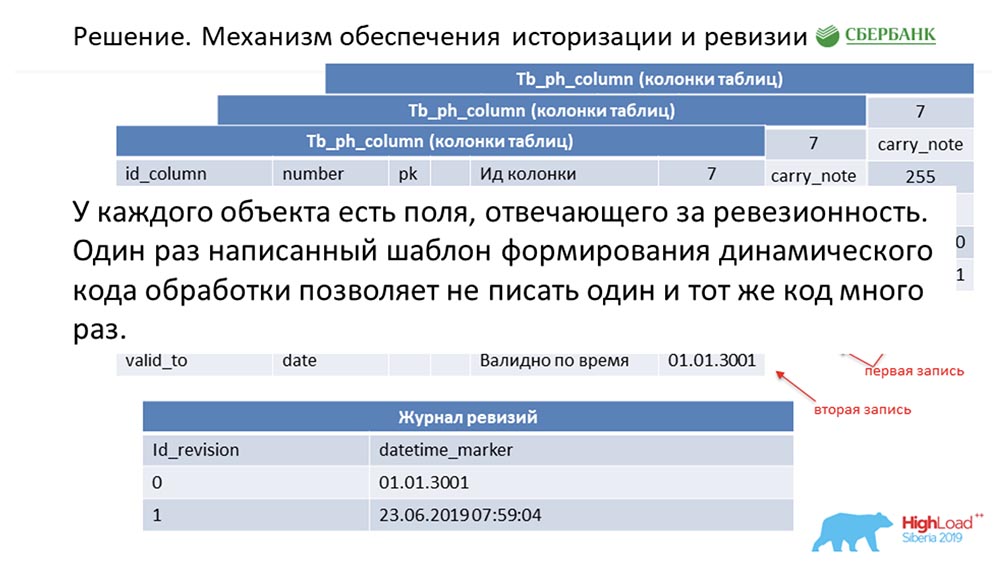 Darin haben wir Revisionen aufgezeichnet , deren Sequenz (Sequenz) id zunimmt, und den Zeitpunkt, der dieser Revisions-ID entspricht. So konnten wir die erste Nachfrage schließen.AC:- Ich denke ja! Hier ist der Ansatz der gleiche. Wir verstehen, dass jedes Objekt im System diese beiden erforderlichen Felder hat. Sobald wir verwirrt sind, codieren wir die Verarbeitungslogik dieser Vorlage und ersetzen dann (beim Generieren des dynamischen Codes) einfach die Namen der entsprechenden Objekte. So wird jedes Objekt in unserem System überarbeitet, und all dies kann verarbeitet werden - wir schreiben im Allgemeinen keine einzige Codezeile.
Darin haben wir Revisionen aufgezeichnet , deren Sequenz (Sequenz) id zunimmt, und den Zeitpunkt, der dieser Revisions-ID entspricht. So konnten wir die erste Nachfrage schließen.AC:- Ich denke ja! Hier ist der Ansatz der gleiche. Wir verstehen, dass jedes Objekt im System diese beiden erforderlichen Felder hat. Sobald wir verwirrt sind, codieren wir die Verarbeitungslogik dieser Vorlage und ersetzen dann (beim Generieren des dynamischen Codes) einfach die Namen der entsprechenden Objekte. So wird jedes Objekt in unserem System überarbeitet, und all dies kann verarbeitet werden - wir schreiben im Allgemeinen keine einzige Codezeile.Batch-Update
SC: - Die zweite Anforderung war für mich etwas interessanter. Ehrlich gesagt, als es um den Eingang ging, war ich zuerst nur betäubt. Aber die Entscheidung ist gekommen!Ich erinnere Sie daran, dass dies der gleiche Fall ist, als JSON mit einem Paket für die n-te Anzahl von Objekten zu uns kam, die in das System eingefügt werden müssen. Gleichzeitig haben wir zu Beginn 10 Spalten, die auf eine nicht vorhandene Tabelle verweisen, und die Tabelle wurde in den JSON-Tail aufgenommen. Was zu tun ist? Wir haben einen Ausweg gefunden, indem wir den Mechanismus rekursiver hierarchischer Abfragen verwendet haben - dies ist mit Sicherheit die bekannte Verbindung durch vorherige Konstruktion. Wir haben es wie folgt gemacht: Hier ist ein Fragment unseres Produktionscodes:
Wir haben einen Ausweg gefunden, indem wir den Mechanismus rekursiver hierarchischer Abfragen verwendet haben - dies ist mit Sicherheit die bekannte Verbindung durch vorherige Konstruktion. Wir haben es wie folgt gemacht: Hier ist ein Fragment unseres Produktionscodes: An dieser Stelle (ein Codeabschnitt, der in einem roten Oval eingekreist ist) ist der Hauptpunkt, der eine Idee gibt. Und hier ist das Objekt mit einem anderen Objekt verknüpft, das durch einen Fremdschlüssel im System verknüpft ist.Zum Verständnis: Wenn jemand Code in Oracle schreibt, gibt es All_columns, All_all_-Tabellen, All_constraint-Tabellen - dies ist das Wörterbuch, das von den Skripten verarbeitet wird (wie die auf der Folie oben gezeigten).Bei der Ausgabe erhalten wir Felder, die uns die Priorität der Verarbeitung von Objekten geben, und zusätzlich einen Deskriptor - es ist im Wesentlichen eine eindeutige Zeichenfolgenkennung für jeden Metadatensatz. Der Code, mit dem der Deskriptor empfangen wird, ist auch auf der Folie oben angegeben.Zum Beispiel ein Feld - wie könnte es aussehen? Dies ist der Plattformcode: oracle KP., Production. KP, my_scheme. KP, my_table. KP usw., wobei KP der Feldcode ist. Es wird also einen solchen Deskriptor geben.AC: - Was sind die Probleme hier? Wir haben Objekte im System und die Reihenfolge ihrer Einfügung ist für uns sehr wichtig. Beispielsweise können wir keine Spalten vor Tabellen einfügen, da eine Spalte auf eine bestimmte Tabelle verweisen muss. Wie gewohnt: Zuerst fügen wir die Tabellen ein, als Antwort erhalten wir ein ID-Array, durch diese IDs werfen wir die Spalten und führen die zweite Einfügeoperation aus.In Wirklichkeit erreicht die Länge dieser Kette, wie Stas gezeigt hat, 8-9 Objekte. Der Benutzer muss unter Verwendung des Standardansatzes alle diese Operationen nacheinander ausführen (alle diese 9 Operationen) und ihre Reihenfolge klar verstehen, damit kein Fehler auftritt.Soweit ich Stas richtig interpretiere, können wir alle diese Objekte in beliebiger Reihenfolge auf das System übertragen und kümmern uns nicht darum, wie wir dies einfügen müssen. Wir haben nur ein Suppenset in das System geworfen und alles bestimmt, in welcher Reihenfolge es eingefügt werden soll.Ich habe nur die Frage: Was ist, wenn wir das Objekt zum ersten Mal einfügen? Wir haben die Tabelle bereits eingefügt und kennen ihre ID nicht. Wie geben wir an (ein rein hypothetisches Beispiel), dass wir zwei Tabellen einfügen müssen, von denen jede eine Spalte hat? Wie geben wir an, dass sich diese JSON-Spalte auf Tabelle1 bezieht, nicht auf Tabelle2?SC: - Ein Deskriptor! Der Griff, den wir auf dieser Folie angegeben haben (vorher).Und auf dieser Folie ist genau die Lösung angegeben:
An dieser Stelle (ein Codeabschnitt, der in einem roten Oval eingekreist ist) ist der Hauptpunkt, der eine Idee gibt. Und hier ist das Objekt mit einem anderen Objekt verknüpft, das durch einen Fremdschlüssel im System verknüpft ist.Zum Verständnis: Wenn jemand Code in Oracle schreibt, gibt es All_columns, All_all_-Tabellen, All_constraint-Tabellen - dies ist das Wörterbuch, das von den Skripten verarbeitet wird (wie die auf der Folie oben gezeigten).Bei der Ausgabe erhalten wir Felder, die uns die Priorität der Verarbeitung von Objekten geben, und zusätzlich einen Deskriptor - es ist im Wesentlichen eine eindeutige Zeichenfolgenkennung für jeden Metadatensatz. Der Code, mit dem der Deskriptor empfangen wird, ist auch auf der Folie oben angegeben.Zum Beispiel ein Feld - wie könnte es aussehen? Dies ist der Plattformcode: oracle KP., Production. KP, my_scheme. KP, my_table. KP usw., wobei KP der Feldcode ist. Es wird also einen solchen Deskriptor geben.AC: - Was sind die Probleme hier? Wir haben Objekte im System und die Reihenfolge ihrer Einfügung ist für uns sehr wichtig. Beispielsweise können wir keine Spalten vor Tabellen einfügen, da eine Spalte auf eine bestimmte Tabelle verweisen muss. Wie gewohnt: Zuerst fügen wir die Tabellen ein, als Antwort erhalten wir ein ID-Array, durch diese IDs werfen wir die Spalten und führen die zweite Einfügeoperation aus.In Wirklichkeit erreicht die Länge dieser Kette, wie Stas gezeigt hat, 8-9 Objekte. Der Benutzer muss unter Verwendung des Standardansatzes alle diese Operationen nacheinander ausführen (alle diese 9 Operationen) und ihre Reihenfolge klar verstehen, damit kein Fehler auftritt.Soweit ich Stas richtig interpretiere, können wir alle diese Objekte in beliebiger Reihenfolge auf das System übertragen und kümmern uns nicht darum, wie wir dies einfügen müssen. Wir haben nur ein Suppenset in das System geworfen und alles bestimmt, in welcher Reihenfolge es eingefügt werden soll.Ich habe nur die Frage: Was ist, wenn wir das Objekt zum ersten Mal einfügen? Wir haben die Tabelle bereits eingefügt und kennen ihre ID nicht. Wie geben wir an (ein rein hypothetisches Beispiel), dass wir zwei Tabellen einfügen müssen, von denen jede eine Spalte hat? Wie geben wir an, dass sich diese JSON-Spalte auf Tabelle1 bezieht, nicht auf Tabelle2?SC: - Ein Deskriptor! Der Griff, den wir auf dieser Folie angegeben haben (vorher).Und auf dieser Folie ist genau die Lösung angegeben: Die Deskriptoren werden im System als eine Art Gedächtnisfeld verwendet, das nicht existiert, aber id ersetzt. In diesem Moment, wenn das System zunächst versteht, dass die Tabelle eingefügt werden muss, erhält es eine ID. und bereits in der Phase der Generierung der SQL-Abfrage für die Einfügung und Spalte wird die ID verarbeitet. Der Benutzer kann kein Dampfbad nehmen: „Griff geben und ausführen!“. Das System wird es tun.
Die Deskriptoren werden im System als eine Art Gedächtnisfeld verwendet, das nicht existiert, aber id ersetzt. In diesem Moment, wenn das System zunächst versteht, dass die Tabelle eingefügt werden muss, erhält es eine ID. und bereits in der Phase der Generierung der SQL-Abfrage für die Einfügung und Spalte wird die ID verarbeitet. Der Benutzer kann kein Dampfbad nehmen: „Griff geben und ausführen!“. Das System wird es tun.Universelle Abfrage für eine Gruppe verwandter Objekte
Vielleicht mein Lieblingsfall. Dies ist die bevorzugte technische Anforderung, die wir hatten. Sie kamen zu uns und sagten: „Leute, macht es so, dass das System alles kann! Bitte von Objekt zu Objekt. Ratet mal, wie sich alles untereinander verbindet. Gib uns zurück, JSON, bitte. Wir möchten mit Ihrem Service nicht viel programmieren. "...Frage:" Wie ?! "Wir sind tatsächlich den gleichen Weg gegangen. Genau die gleiche Konstruktion: Sie wurde verwendet, um dieses Problem zu lösen. Der einzige Unterschied besteht darin, dass es einen gültigen Filter gab, der diesen hierarchischen Baum nur für die Storys abwickelte, für die ein Deskriptor erforderlich war. Relativ gesehen war es für jedes Objekt einzigartig. Hier sind alle möglichen Verbindungen im System ungedreht (wir haben ungefähr 50 Objekte).Alle möglichen Verbindungen zwischen Objekten werden im Voraus vorbereitet. Wenn wir ein Objekt haben, das an drei Beziehungen beteiligt ist, werden drei Zeilen vorbereitet, damit der Algorithmus verstehen kann. Und sobald die JSON-Anfrage bei uns eintrifft, gehen wir zu dem Ort, an dem diese Geschichte im Voraus in MeteMet vorbereitet wurde. Wir suchen nach dem Weg, den wir brauchen. Wenn wir nicht finden, ist dies eine Geschichte. Wenn wir sie finden, bilden wir eine Abfrage in der Datenbank. Wird ausgeführt - JSON wird zurückgegeben (wie angefordert).AC: - Infolgedessen können wir auf das System übertragen, von welchem Objekt wir empfangen möchten. Wenn Sie eine eindeutige Verbindung zwischen zwei Objekten skizzieren können, ermittelt das System selbst, auf welcher Verschachtelungsebene das Objekt im Baum zu Ihnen zurückkehrt:Es ist sehr flexibel! Unsere Benutzer sind wieder einmal in einem Zustand der „Turbulenzen“: Heute brauchen sie eine Sache, morgen brauchen sie eine andere. Und diese Lösung ermöglicht es uns, die Struktur sehr flexibel anzupassen. Dies waren drei Schlüsselfälle, die auf unserer Kernseite verwendet wurden.SC: - Lassen Sie uns einige zusammenfassen. Es ist klar, dass wir jetzt aufgrund der begrenzten Zeit nicht alle Chips erzählen werden. Drei Fälle haben wir unserer Meinung nach durchgeführt und erzählt. Es ist uns gelungen, die komplexeste Logik und die Logik, die für jedes Metadatenverwaltungsobjekt einheitlich funktionieren sollte, in den Kernelcode zu integrieren.Wir konnten diesen Code nicht 100% dynamisch gestalten, was bedeutet, dass bei erstellten Objekten (es spielt keine Rolle, ob sie bereits erstellt wurden oder später erstellt werden; die Hauptsache ist, dass sie gemäß den Regeln erstellt werden) das System funktionieren kann - es muss nichts hinzugefügt und neu geschrieben werden. Nur testen ist genug. Wir haben diese ganze Geschichte in drei universelle Methoden geparkt. Meiner Meinung nach gibt es genug davon, um fast jedes geschäftliche Problem zu lösen:
Sie wurde verwendet, um dieses Problem zu lösen. Der einzige Unterschied besteht darin, dass es einen gültigen Filter gab, der diesen hierarchischen Baum nur für die Storys abwickelte, für die ein Deskriptor erforderlich war. Relativ gesehen war es für jedes Objekt einzigartig. Hier sind alle möglichen Verbindungen im System ungedreht (wir haben ungefähr 50 Objekte).Alle möglichen Verbindungen zwischen Objekten werden im Voraus vorbereitet. Wenn wir ein Objekt haben, das an drei Beziehungen beteiligt ist, werden drei Zeilen vorbereitet, damit der Algorithmus verstehen kann. Und sobald die JSON-Anfrage bei uns eintrifft, gehen wir zu dem Ort, an dem diese Geschichte im Voraus in MeteMet vorbereitet wurde. Wir suchen nach dem Weg, den wir brauchen. Wenn wir nicht finden, ist dies eine Geschichte. Wenn wir sie finden, bilden wir eine Abfrage in der Datenbank. Wird ausgeführt - JSON wird zurückgegeben (wie angefordert).AC: - Infolgedessen können wir auf das System übertragen, von welchem Objekt wir empfangen möchten. Wenn Sie eine eindeutige Verbindung zwischen zwei Objekten skizzieren können, ermittelt das System selbst, auf welcher Verschachtelungsebene das Objekt im Baum zu Ihnen zurückkehrt:Es ist sehr flexibel! Unsere Benutzer sind wieder einmal in einem Zustand der „Turbulenzen“: Heute brauchen sie eine Sache, morgen brauchen sie eine andere. Und diese Lösung ermöglicht es uns, die Struktur sehr flexibel anzupassen. Dies waren drei Schlüsselfälle, die auf unserer Kernseite verwendet wurden.SC: - Lassen Sie uns einige zusammenfassen. Es ist klar, dass wir jetzt aufgrund der begrenzten Zeit nicht alle Chips erzählen werden. Drei Fälle haben wir unserer Meinung nach durchgeführt und erzählt. Es ist uns gelungen, die komplexeste Logik und die Logik, die für jedes Metadatenverwaltungsobjekt einheitlich funktionieren sollte, in den Kernelcode zu integrieren.Wir konnten diesen Code nicht 100% dynamisch gestalten, was bedeutet, dass bei erstellten Objekten (es spielt keine Rolle, ob sie bereits erstellt wurden oder später erstellt werden; die Hauptsache ist, dass sie gemäß den Regeln erstellt werden) das System funktionieren kann - es muss nichts hinzugefügt und neu geschrieben werden. Nur testen ist genug. Wir haben diese ganze Geschichte in drei universelle Methoden geparkt. Meiner Meinung nach gibt es genug davon, um fast jedes geschäftliche Problem zu lösen:- Erstens ist derselbe universelle „Updater“ eine Methode, mit der ein oder eine Gruppe von Objekten, die in zufälliger Reihenfolge übertragen werden, aktualisiert / eingefügt / gelöscht werden kann (Löschen schließt einen Datensatz).
- Die zweite Methode ist eine Methode, die universelle Informationen zu nur einem Objekt zurückgeben kann.
- Die dritte Methode ist dieselbe Methode, die Join-Informationen zurückgeben kann, die durch Gruppen von Objekten verbunden sind.
So stellte sich heraus, und wir machten den Kern. Und dann gehen wir zu Ihrem Lieblingsteil über.Anwendungseinstiegspunkt
AC: - Ja, dies ist mein Lieblingsteil, da dies mein Verantwortungsbereich ist - Application Server. Um zu verstehen, in welcher Situation ich mich befand, werde ich versuchen, Sie erneut in ein Problem zu stürzen.Stas hat gute Arbeit geleistet und mir diese drei Standardmethoden übergeben, mit denen diese Objekte manipuliert wurden. Dies ist eine rein skizzenhafte Beschreibung - in Wirklichkeit gibt es noch viel mehr: Gehen wir zurück zum Anfang, um Sie zu vertiefen ... Wie werden die Metadaten im System hier dargestellt?
Gehen wir zurück zum Anfang, um Sie zu vertiefen ... Wie werden die Metadaten im System hier dargestellt?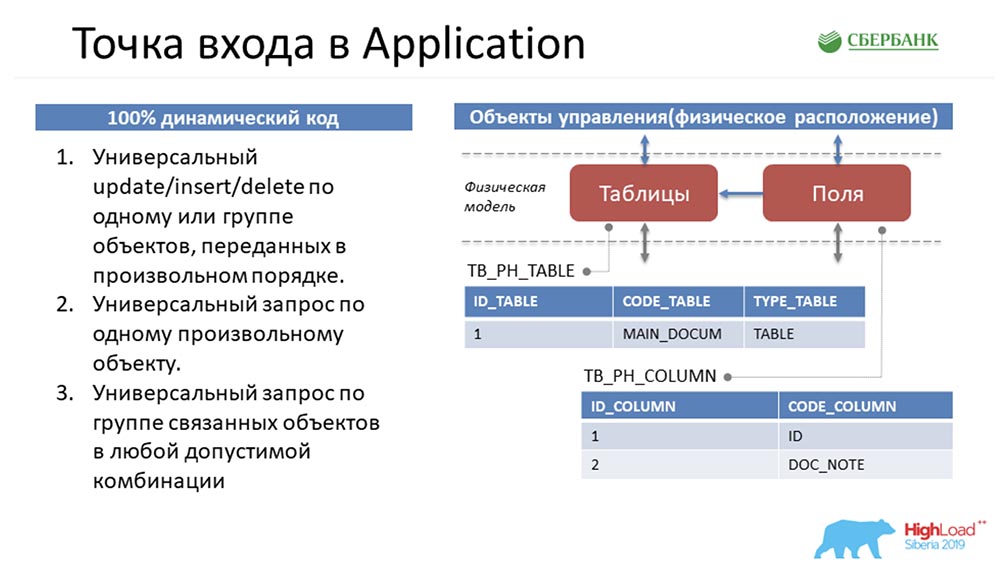 Wenn wir sehen, dass sich in der Umgebung eine Tabelle befindet, fällt diese als ein Datensatz im Tabellenobjekt und einige Datensätze im Feldobjekt in unser System. Im Wesentlichen haben wir eine Struktur zusammengestellt.Wir können feststellen, dass die Menge dieser Objekte unterschiedlich ist. Um diese Objekte zu manipulieren und alles in eine universelle Struktur zu bringen, damit alle drei Methoden verstehen, worüber gesprochen wird, bewegt sich Stas mit dem Pferd. Es nimmt alle Objekte und dreht sie um, das heißt, es repräsentiert jedes Objekt in unserem Metadatenverwaltungssystem als vier Zeilen:
Wenn wir sehen, dass sich in der Umgebung eine Tabelle befindet, fällt diese als ein Datensatz im Tabellenobjekt und einige Datensätze im Feldobjekt in unser System. Im Wesentlichen haben wir eine Struktur zusammengestellt.Wir können feststellen, dass die Menge dieser Objekte unterschiedlich ist. Um diese Objekte zu manipulieren und alles in eine universelle Struktur zu bringen, damit alle drei Methoden verstehen, worüber gesprochen wird, bewegt sich Stas mit dem Pferd. Es nimmt alle Objekte und dreht sie um, das heißt, es repräsentiert jedes Objekt in unserem Metadatenverwaltungssystem als vier Zeilen: Da jedes Objekt in unserem Metadatenverwaltungssystem physisch eine Tabelle ist, kann jedes Objekt gemäß diesen vier Zeichen zerlegt werden: Zeilennummer , Tabelle, Feld und Feldwert. Es war Stas, der sich all das ausgedacht hat, und ich musste es irgendwie implementieren und den Benutzern geben.SC:- Entschuldigung, aber wie kann ich Ihnen beispielsweise in einer flachen Antwortspalte, die noch nicht erstellt wurde, irgendwann erstellen, und Gott weiß, was sie sein können? .. Daher besteht die einzige Option unter den Bedingungen des dynamischen Codes darin, die Interaktion zwischen zu konfigurieren Kern und Anwendung, um diese Informationen an Sie zu übermitteln - nur so, wie wir es sehen. Ich glaube, dass diese Entscheidung aus meiner Sicht genial war, weil sie nur von Ihnen kam.AC: - Jetzt werden wir nicht darüber streiten. Zwei Wochen vor Ablauf der Frist blieb ich bei der Tatsache, dass ich diese drei Methoden an meinen Händen hatte (links auf der vorherigen Folie), die die universelle Struktur manipulierten (rechts auf derselben Folie).Mein erster Gedanke war, einfach alles auf API-Ebene zusammenzufassen und damit zum Benutzer zu gehen und zu sagen: „Schau, was für eine brillante Sache! Du kannst alles machen! Übertragen Sie alle oder sogar nicht vorhandene Objekte. Cool, ja "?!
Da jedes Objekt in unserem Metadatenverwaltungssystem physisch eine Tabelle ist, kann jedes Objekt gemäß diesen vier Zeichen zerlegt werden: Zeilennummer , Tabelle, Feld und Feldwert. Es war Stas, der sich all das ausgedacht hat, und ich musste es irgendwie implementieren und den Benutzern geben.SC:- Entschuldigung, aber wie kann ich Ihnen beispielsweise in einer flachen Antwortspalte, die noch nicht erstellt wurde, irgendwann erstellen, und Gott weiß, was sie sein können? .. Daher besteht die einzige Option unter den Bedingungen des dynamischen Codes darin, die Interaktion zwischen zu konfigurieren Kern und Anwendung, um diese Informationen an Sie zu übermitteln - nur so, wie wir es sehen. Ich glaube, dass diese Entscheidung aus meiner Sicht genial war, weil sie nur von Ihnen kam.AC: - Jetzt werden wir nicht darüber streiten. Zwei Wochen vor Ablauf der Frist blieb ich bei der Tatsache, dass ich diese drei Methoden an meinen Händen hatte (links auf der vorherigen Folie), die die universelle Struktur manipulierten (rechts auf derselben Folie).Mein erster Gedanke war, einfach alles auf API-Ebene zusammenzufassen und damit zum Benutzer zu gehen und zu sagen: „Schau, was für eine brillante Sache! Du kannst alles machen! Übertragen Sie alle oder sogar nicht vorhandene Objekte. Cool, ja "?! Und sie sagen: „Aber Sie verstehen, dass Ihr Service überhaupt nicht spezialisiert ist? Als Benutzer verstehe ich nicht, welche Objekte ich auf das System übertragen kann, wie ich sie bearbeiten kann ... Für mich ist es eine Black Box, ich habe generell Angst, dass ich Daten übermitteln werde. Ich kann mich irren - ich habe Angst. Stellen Sie sicher, dass ich den Anweisungen klar folgen und sehen kann, welche Objekte sich im System befinden und welche Manipulationsmethoden ich verwenden kann. “
Und sie sagen: „Aber Sie verstehen, dass Ihr Service überhaupt nicht spezialisiert ist? Als Benutzer verstehe ich nicht, welche Objekte ich auf das System übertragen kann, wie ich sie bearbeiten kann ... Für mich ist es eine Black Box, ich habe generell Angst, dass ich Daten übermitteln werde. Ich kann mich irren - ich habe Angst. Stellen Sie sicher, dass ich den Anweisungen klar folgen und sehen kann, welche Objekte sich im System befinden und welche Manipulationsmethoden ich verwenden kann. “Fleck. Ein Ansatz
Dann wurde uns klar, dass es cool war, eine Spezifikation für unseren Service zu erstellen. Kurz gesagt, um eine Liste der Objekte unseres Systems zu erstellen, eine Liste der Punkte, Manipulationen und welche Objekte sie miteinander jonglieren. So kam es, dass wir in unserer Firma Swagger für diese Zwecke als eine Art architektonische Lösung verwenden. Nachdem ich mir die Swagger-Struktur angesehen hatte, wurde mir klar, dass ich die Struktur von Objekten, die sich im System befinden, irgendwohin bringen muss. Vom Kernel erhielt ich nur drei Standardmethoden und einen Tabellenwechsler. Sonst nichts. Für mich schien es dann eine unmögliche Aufgabe zu sein, die gesamte Struktur, die sich im Repository befindet, aus diesen vier Standardfeldern zu erhalten. Ich habe aufrichtig nicht verstanden, woher ich alle Beschreibungen von Objekten, alle zulässigen Werte, alle Logik ...SC:- Was bedeutet es wo? Sie und ich haben MetaMeta, das den Kernel im Echtzeitmodus bereitstellt. Der Kernel in Echtzeitausführung generiert eine SQL-Abfrage, die mit der Datenbank kommuniziert. Alles ist da, nicht nur was Sie brauchen. Es gibt auch Verknüpfungen zwischen Objekten.AC: - Auf Anraten von Stas ging ich dann zu MetaMetu und war überrascht, weil dort alle notwendigen Gentleman-Kits zur Erstellung von Standardspezifikationen vorhanden waren. Dann kam die Idee auf, dass Sie eine Vorlage erstellen und alles nach sieben möglichen Szenarien malen müssen - 7 Standard-APIs für jedes Objekt.
Nachdem ich mir die Swagger-Struktur angesehen hatte, wurde mir klar, dass ich die Struktur von Objekten, die sich im System befinden, irgendwohin bringen muss. Vom Kernel erhielt ich nur drei Standardmethoden und einen Tabellenwechsler. Sonst nichts. Für mich schien es dann eine unmögliche Aufgabe zu sein, die gesamte Struktur, die sich im Repository befindet, aus diesen vier Standardfeldern zu erhalten. Ich habe aufrichtig nicht verstanden, woher ich alle Beschreibungen von Objekten, alle zulässigen Werte, alle Logik ...SC:- Was bedeutet es wo? Sie und ich haben MetaMeta, das den Kernel im Echtzeitmodus bereitstellt. Der Kernel in Echtzeitausführung generiert eine SQL-Abfrage, die mit der Datenbank kommuniziert. Alles ist da, nicht nur was Sie brauchen. Es gibt auch Verknüpfungen zwischen Objekten.AC: - Auf Anraten von Stas ging ich dann zu MetaMetu und war überrascht, weil dort alle notwendigen Gentleman-Kits zur Erstellung von Standardspezifikationen vorhanden waren. Dann kam die Idee auf, dass Sie eine Vorlage erstellen und alles nach sieben möglichen Szenarien malen müssen - 7 Standard-APIs für jedes Objekt.Fleck. OAS + Lenker
Es ist also leicht zu erkennen, woraus die Spezifikation besteht: Sie können auf der OAS-Website und im Lenker (unten auf der Folie) nachsehen, woraus sie bestehen sollte - es gibt eine Reihe von Endpunkten, eine Reihe von Methoden und am Ende gibt es Modelle. Der Code wird von Zeit zu Zeit wiederholt. Für jedes Objekt müssen wir get, put schreiben. löschen; Für eine Gruppe von Objekten müssen wir dies und so weiter schreiben.Der Trick bestand darin, die ganze Geschichte einmal zu schreiben und nicht mehr zu baden. Die Folie zeigt ein Beispiel für echten Code. Blaue Objekte sind Tags im Lenker. Dies ist eine Vorlagen-Engine. Sehr flexibel, rate ich jedem - Sie können es selbst anpassen, benutzerdefinierte Tag-Handler schreiben ...Anstelle dieser blauen Tags werden beim Ausführen dieser Vorlage über alle Metadaten alle wichtigen Eigenschaften ersetzt - der Name des Objekts, seine Beschreibung, eine Art Logik (zum Beispiel, dass wir abhängig von der Eigenschaft einen zusätzlichen Parameter hinzufügen müssen) und so weiter. Am Ende steht ein Link zu dem Modell, das er interpretiert.
Sie können auf der OAS-Website und im Lenker (unten auf der Folie) nachsehen, woraus sie bestehen sollte - es gibt eine Reihe von Endpunkten, eine Reihe von Methoden und am Ende gibt es Modelle. Der Code wird von Zeit zu Zeit wiederholt. Für jedes Objekt müssen wir get, put schreiben. löschen; Für eine Gruppe von Objekten müssen wir dies und so weiter schreiben.Der Trick bestand darin, die ganze Geschichte einmal zu schreiben und nicht mehr zu baden. Die Folie zeigt ein Beispiel für echten Code. Blaue Objekte sind Tags im Lenker. Dies ist eine Vorlagen-Engine. Sehr flexibel, rate ich jedem - Sie können es selbst anpassen, benutzerdefinierte Tag-Handler schreiben ...Anstelle dieser blauen Tags werden beim Ausführen dieser Vorlage über alle Metadaten alle wichtigen Eigenschaften ersetzt - der Name des Objekts, seine Beschreibung, eine Art Logik (zum Beispiel, dass wir abhängig von der Eigenschaft einen zusätzlichen Parameter hinzufügen müssen) und so weiter. Am Ende steht ein Link zu dem Modell, das er interpretiert.Anwendungscode. Swagger Codegen + Lenker
All dies haben wir codiert, aufgezeichnet und eine Spezifikation erstellt. Alles war sehr cool und gut. Wir haben alle 7 möglichen Szenarien für jedes Objekt.Hat es dem Benutzer gegeben. Er sagte: „Wow! Cool! Jetzt wollen wir es nutzen! “ Was ist wieder das Problem?Wir haben eine Spezifikation, die jede Methode im Detail beschreibt, was damit zu tun ist, welche Objekte zu manipulieren sind. Und es gibt drei Standard-Kernel-Methoden, die die oben beschriebene invertierte Tabelle als Eingabe verwenden.Dann musste man einfach eins mit dem anderen kreuzen (jetzt scheint es mir einfach). Das heißt, wenn ein Benutzer eine Methode in der Benutzeroberfläche aufruft, mussten wir sie korrekt und korrekt an den Kernel weiterleiten und das Modell (wo wir schöne Spezifikationen haben) in diese vier Standardfelder umwandeln. Das war alles was getan werden musste. Um all dies in die Praxis umzusetzen, brauchten wir "nominative" Transformationen ...
Um all dies in die Praxis umzusetzen, brauchten wir "nominative" Transformationen ...Konvertierungen
Swagger hat zunächst ein solches Werkzeug - Swagger Codegen. Wenn Sie sich jemals mit erfundenen Spezifikationen befasst haben, gibt es eine Schaltfläche „Serverteil generieren“. Klicken Sie auf, wählen Sie eine Sprache aus - ein fertiges Projekt wird für Sie generiert.Es wird bemerkenswert generiert: Es gibt alle Klassenbeschreibungen, alle Endpunktbeschreibungen ... - es funktioniert. Sie können es lokal ausführen - es wird funktionieren. Das Problem ist eines: Es gibt Stubs zurück - jede Methode wird nicht inkrementiert.Die Idee war, Logik basierend auf diesen sieben Szenarien in den Codegenerator einzufügen - eine der Standardvorlagen zu „verderben“ und selbst zu konfigurieren. Hier ist nur ein Beispiel für echten Code, den wir in der Vorlagen-Engine verwenden, und eine Liste der Aktionen, die wir ausführen mussten, um diesen Codegenerator für uns selbst zu konfigurieren: Das Wichtigste war, die erforderlichen Bibliotheken zu verbinden, Klassen für die Kommunikation mit dem Kernel zu schreiben und (je nach Szenario) den Aufruf einer oder mehrerer Methoden auf der Kernelseite zu interpretieren. Das Modell wurde ebenfalls umgedreht: von dem in der Spezifikation angegebenen schönen auf vier Felder und dann zurück transformiert.Der wahrscheinlich schwierigste Fall war hier, dem Benutzer einen Baum zu geben, da der Kernel auch vier Zeilen an uns zurückgibt - sehen Sie, auf welcher Ebene sich die Hierarchie befindet. Wir haben den Mechanismus der Außenbeziehungen verwendet, der in der IDE enthalten ist, dh wir sind zu MetaMetu gegangen, haben alle Pfade von einem zum anderen untersucht und dynamisch einen Baum durch sie generiert. Der Benutzer kann uns von jedem Objekt nach dem fragen, was er will - am Ausgang wird ihm ein schöner Baum zurückgegeben, in dem bereits alles strukturell angelegt ist.SC: - Ich werde dich für eine Sekunde aufhalten, weil ich mich schon verlaufen habe. Ich werde Sie im Stil von "Verstehe ich das richtig" fragen ...Sie möchten sagen, dass wir den kompliziertesten und komplexesten Code berechnet haben, der für ein neues Objekt geschrieben werden müsste. Und um Zeit zu sparen, um es nicht zu tun, haben wir es geschafft, alles in den Kernel zu schieben und diese Geschichte dynamisch zu machen ... Aber diese API (wie sie scherzten, "hartnäckig") ist so "alles", dass es beängstigend ist, sie herauszugeben: unpassende Adressierung Damit können Sie Metadaten beschädigen. Dies ist einerseits.Andererseits haben wir festgestellt, dass wir nur dann mit unseren Kunden kommunizieren können, wenn wir ihnen eine API geben, die eine eindeutige Projektion der im System eingebetteten Metadatenverwaltungsobjekte darstellt (tatsächlich einen bestimmten Vertrag für unseren Service ausführen). Es scheint, dass alles - wir treffen: Wenn das Objekt nicht da ist - es noch nicht da ist, und wenn es erscheint - erscheint die Vertragsverlängerung bereits ein neuer Code.Wir scheinen in vermeidbare manuelle Codierung geraten zu sein, aber hier schlagen Sie vor, diesen Code per Button auszuführen. Wieder schaffen wir es, von der Geschichte wegzukommen, wenn wir etwas mit unseren Händen schreiben müssen. Ist das so?AC: - Ja, das ist es wirklich. Im Allgemeinen war meine Idee, ein für alle Mal mit der Programmierung zu beginnen, zumindest mit Hilfe von Template-Engines. Schreiben Sie den Code einmal und entspannen Sie sich dann. Und selbst wenn ein neues Objekt im System erscheint - durch die Schaltfläche, mit der wir das Update starten, wird alles verschärft, wir haben eine neue Struktur, neue Methoden werden generiert, alles ist in Ordnung und in Ordnung.
Das Wichtigste war, die erforderlichen Bibliotheken zu verbinden, Klassen für die Kommunikation mit dem Kernel zu schreiben und (je nach Szenario) den Aufruf einer oder mehrerer Methoden auf der Kernelseite zu interpretieren. Das Modell wurde ebenfalls umgedreht: von dem in der Spezifikation angegebenen schönen auf vier Felder und dann zurück transformiert.Der wahrscheinlich schwierigste Fall war hier, dem Benutzer einen Baum zu geben, da der Kernel auch vier Zeilen an uns zurückgibt - sehen Sie, auf welcher Ebene sich die Hierarchie befindet. Wir haben den Mechanismus der Außenbeziehungen verwendet, der in der IDE enthalten ist, dh wir sind zu MetaMetu gegangen, haben alle Pfade von einem zum anderen untersucht und dynamisch einen Baum durch sie generiert. Der Benutzer kann uns von jedem Objekt nach dem fragen, was er will - am Ausgang wird ihm ein schöner Baum zurückgegeben, in dem bereits alles strukturell angelegt ist.SC: - Ich werde dich für eine Sekunde aufhalten, weil ich mich schon verlaufen habe. Ich werde Sie im Stil von "Verstehe ich das richtig" fragen ...Sie möchten sagen, dass wir den kompliziertesten und komplexesten Code berechnet haben, der für ein neues Objekt geschrieben werden müsste. Und um Zeit zu sparen, um es nicht zu tun, haben wir es geschafft, alles in den Kernel zu schieben und diese Geschichte dynamisch zu machen ... Aber diese API (wie sie scherzten, "hartnäckig") ist so "alles", dass es beängstigend ist, sie herauszugeben: unpassende Adressierung Damit können Sie Metadaten beschädigen. Dies ist einerseits.Andererseits haben wir festgestellt, dass wir nur dann mit unseren Kunden kommunizieren können, wenn wir ihnen eine API geben, die eine eindeutige Projektion der im System eingebetteten Metadatenverwaltungsobjekte darstellt (tatsächlich einen bestimmten Vertrag für unseren Service ausführen). Es scheint, dass alles - wir treffen: Wenn das Objekt nicht da ist - es noch nicht da ist, und wenn es erscheint - erscheint die Vertragsverlängerung bereits ein neuer Code.Wir scheinen in vermeidbare manuelle Codierung geraten zu sein, aber hier schlagen Sie vor, diesen Code per Button auszuführen. Wieder schaffen wir es, von der Geschichte wegzukommen, wenn wir etwas mit unseren Händen schreiben müssen. Ist das so?AC: - Ja, das ist es wirklich. Im Allgemeinen war meine Idee, ein für alle Mal mit der Programmierung zu beginnen, zumindest mit Hilfe von Template-Engines. Schreiben Sie den Code einmal und entspannen Sie sich dann. Und selbst wenn ein neues Objekt im System erscheint - durch die Schaltfläche, mit der wir das Update starten, wird alles verschärft, wir haben eine neue Struktur, neue Methoden werden generiert, alles ist in Ordnung und in Ordnung.MetaMeta optimieren
Um unseren Service noch besser zu machen, haben wir das Standard-MetaMeta bereichert. Am Eingang hatten wir, was vom Kern übrig war. Wir haben den Objekten auch eine zusätzliche Beschreibung hinzugefügt. Objekte sind in Bereichen gruppiert. Wir zeigen dies alles in der Spezifikation an, damit der Benutzer versteht, was er manipuliert und mit welchem Objekt er gerade kommuniziert.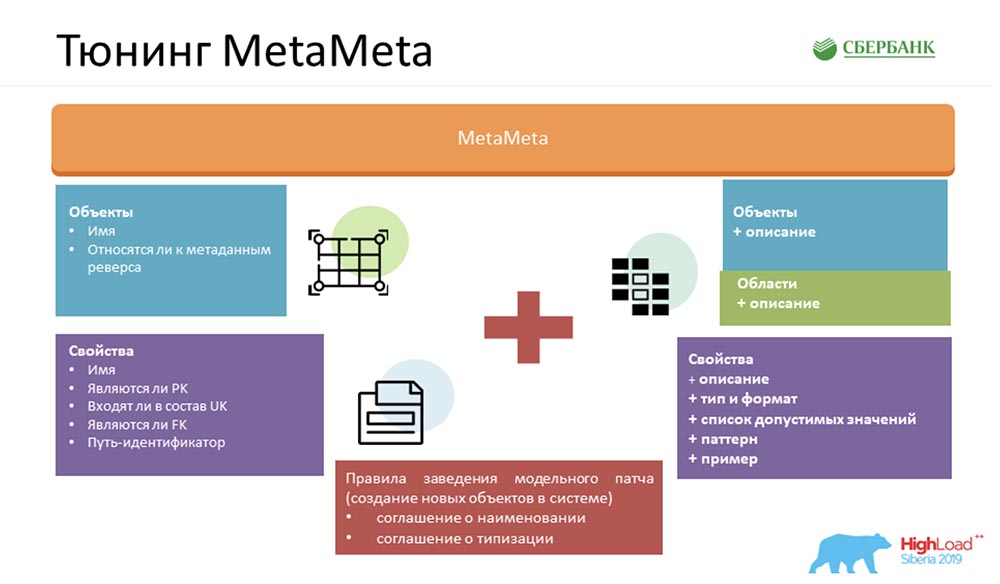 Nur haben wir dort einige Kleinigkeiten hinzugefügt - Typen, Formate, Listen akzeptabler Werte, Muster, Beispiele. Dies freut auch die Benutzer - sie verstehen bereits klar, was eingefügt werden kann, was nicht. Wir stellen dem Benutzer auch ein Client-Artefakt zur Verfügung, mit dem wir Fehler bei der Kommunikation mit unserem Service abfangen können (genau nach Format, bereits in der Kompilierungsphase).Aber vor allem, damit all diese Magie funktioniert, mussten wir uns auf das Innere einigen: eine Reihe bestimmter Regeln erstellen. Es gibt nicht viele von ihnen - ich habe drei gezählt (es gibt zwei von ihnen auf der Folie, also muss man sich an eine erinnern):
Nur haben wir dort einige Kleinigkeiten hinzugefügt - Typen, Formate, Listen akzeptabler Werte, Muster, Beispiele. Dies freut auch die Benutzer - sie verstehen bereits klar, was eingefügt werden kann, was nicht. Wir stellen dem Benutzer auch ein Client-Artefakt zur Verfügung, mit dem wir Fehler bei der Kommunikation mit unserem Service abfangen können (genau nach Format, bereits in der Kompilierungsphase).Aber vor allem, damit all diese Magie funktioniert, mussten wir uns auf das Innere einigen: eine Reihe bestimmter Regeln erstellen. Es gibt nicht viele von ihnen - ich habe drei gezählt (es gibt zwei von ihnen auf der Folie, also muss man sich an eine erinnern):- Namenskonvention. Wir benennen Objekte im System speziell, um das Erkennen von Szenarien für ihre weitere Verwendung zu erleichtern.
- Schreibvereinbarung. Um die Typen, Formate und den Kampf zwischen dem Kernel und dem Anwendungsserver korrekt zu bestimmen, verwenden wir das Prüfsystem, mit dem wir verstehen, zu welchem Format eine bestimmte Eigenschaft gehört.
- Gültige Fremdschlüssel. Wenn das Objekt einen ungültigen Link zu einem anderen Objekt erhält, funktioniert all diese Magie falsch.
Ergebnis
SC: - Es ist cool, aber viel Theorie. Können Sie ein praktisches Beispiel geben?AC: - Ja, ich habe es speziell vorbereitet. Bevor Stas am Freitagabend, buchstäblich 5 Minuten vor Ende des Arbeitstages, zur Konferenz aufbrach, sagte er zu mir: „Oh, sieh mal! Ich habe einen Modell-Patch veröffentlicht - wie cool! Es wäre schön, unseren Service zu aktualisieren. " Der Patch enthielt nur zwei Objekte, aber ich verstehe, dass ich mit dem alten Ansatz verwirrt werden und 7 APIs schreiben oder hinzufügen müsste.Sofort hatte ich nur einen Knopfdruck, um all diese Magie zum Laufen zu bringen. Ich habe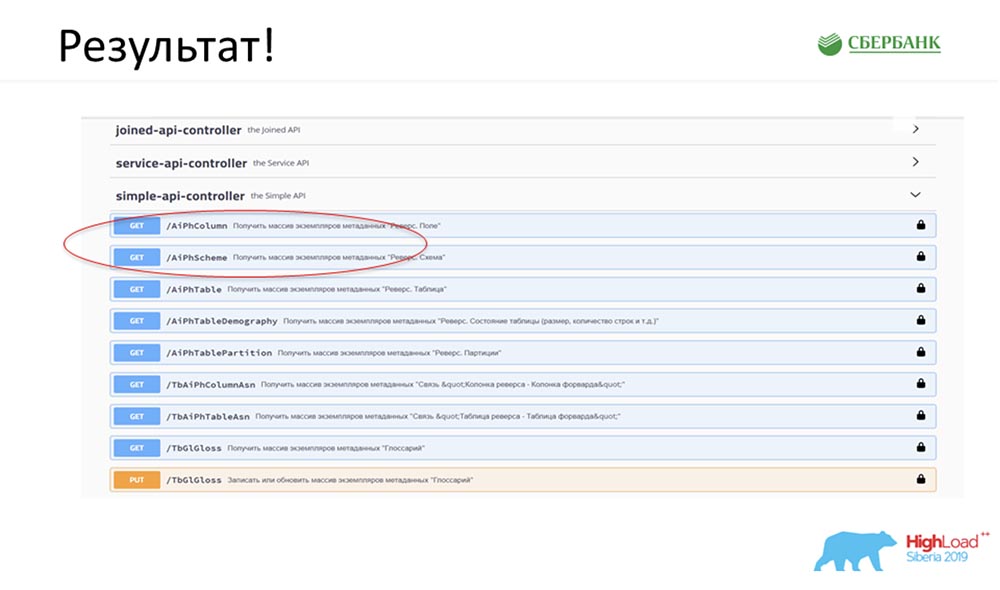 den Ort, an dem die Magie stattfinden soll, speziell rot eingekreist : Ich klicke auf den Button ... Dies sind natürlich Screenshots, aber in Wirklichkeit funktioniert alles so:
den Ort, an dem die Magie stattfinden soll, speziell rot eingekreist : Ich klicke auf den Button ... Dies sind natürlich Screenshots, aber in Wirklichkeit funktioniert alles so: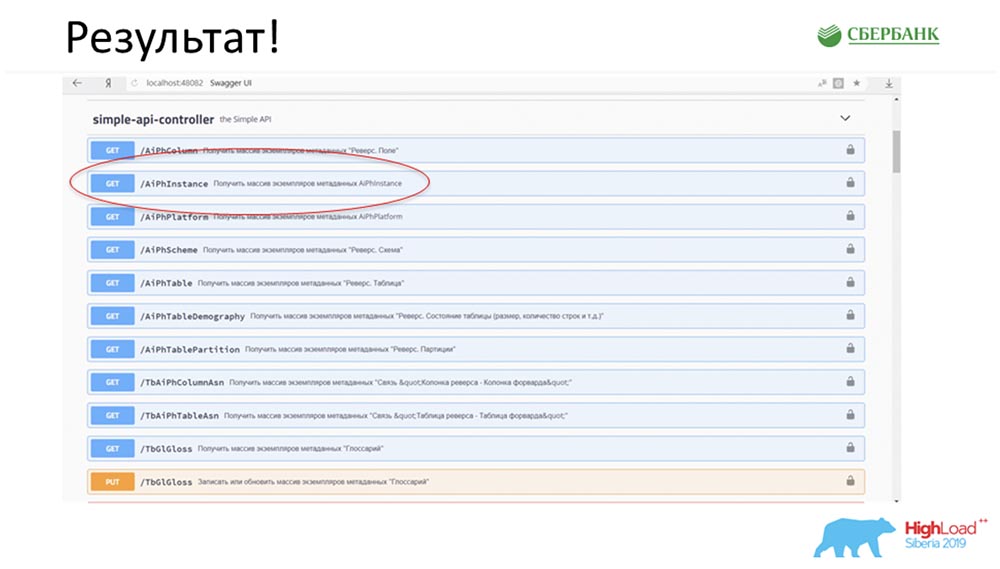 Wir haben eine neue Methode (zwischen den beiden), die bereits Daten liefert, mit denen wir in der Hierarchie die gesamte Struktur abfragen können, alle verschachtelten Objekte:
Wir haben eine neue Methode (zwischen den beiden), die bereits Daten liefert, mit denen wir in der Hierarchie die gesamte Struktur abfragen können, alle verschachtelten Objekte: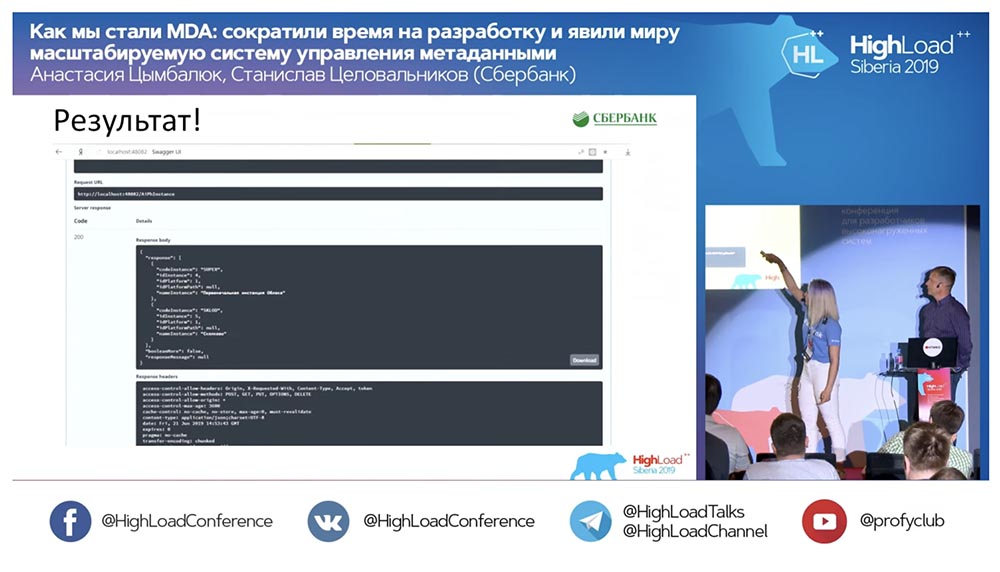
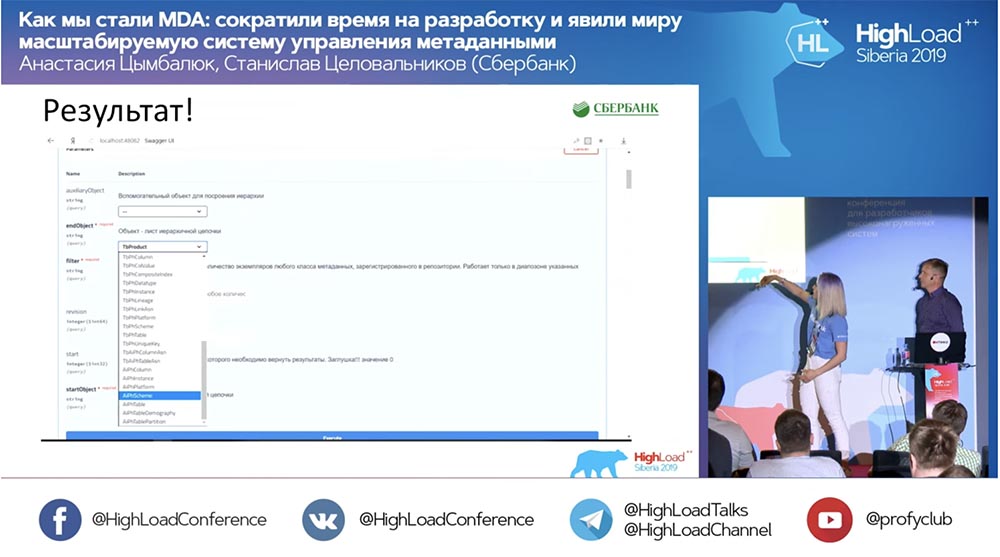
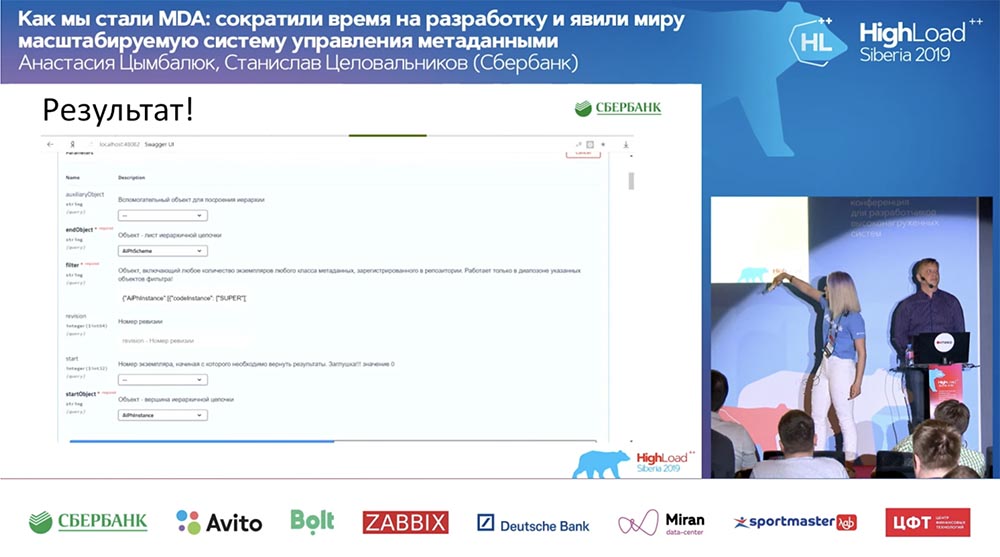 Und alles funktioniert! Ich habe überhaupt keine einzige Codezeile geschrieben.
Und alles funktioniert! Ich habe überhaupt keine einzige Codezeile geschrieben.Zusammenfassung
SC: - Erstens, was ist die Tatsache? Wir haben die komplexeste Logik verwaltet, die unsere Programmierer am meisten Zeit in Anspruch nehmen würden, um 100% dynamischen Kernel-Code zu packen, der mit Objekten arbeiten kann - diejenigen, die es sind und diejenigen, die es sein werden: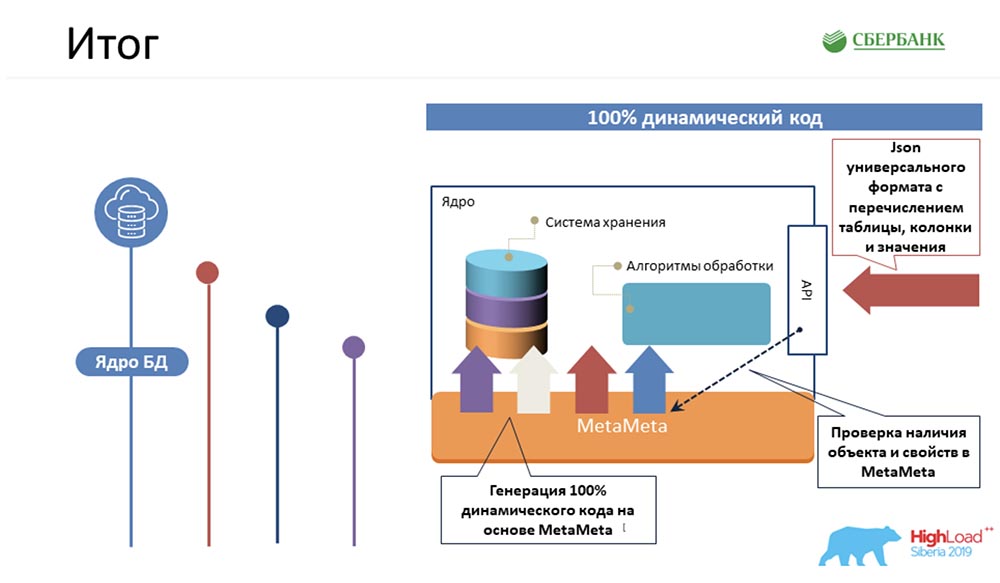 Zweitens haben wir es auf der Ebene des Anwendungsservers geschafft (wo es nicht möglich ist), um auch die Programmierung aufgrund der Codegenerierung zu vermeiden - dieselbe Schaltfläche, die Sie demonstriert haben:
Zweitens haben wir es auf der Ebene des Anwendungsservers geschafft (wo es nicht möglich ist), um auch die Programmierung aufgrund der Codegenerierung zu vermeiden - dieselbe Schaltfläche, die Sie demonstriert haben: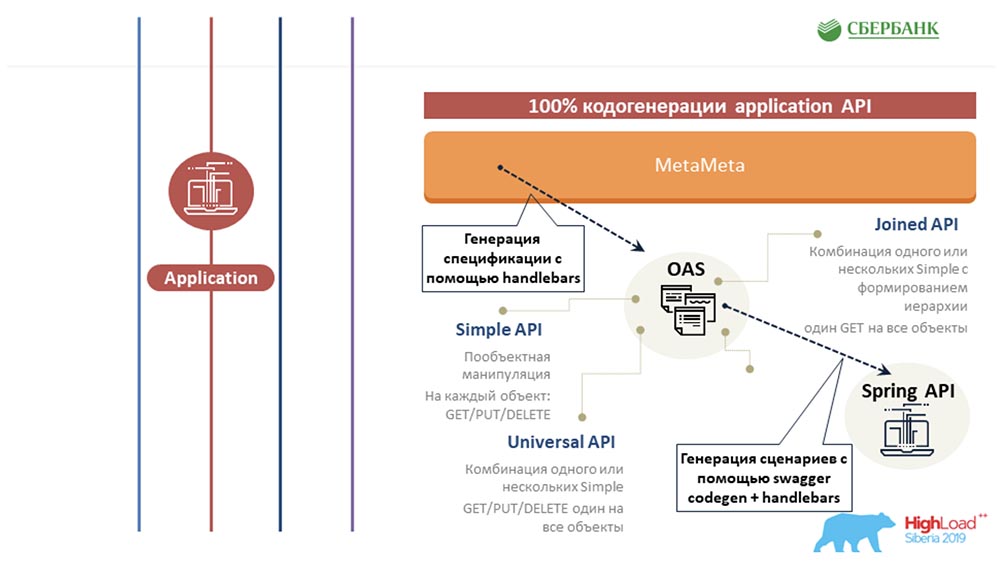 AC: - Wir haben versucht, denselben Ansatz basierend auf Metadaten auf andere Bereiche, auf den Testbereich, auszudehnen. Wir schreiben auch einmal eine Vorlage für ein Objekt und fügen dort Tags ein. Wenn diese Vorlage entlang der Metadaten ausgeführt wird, wird ein fertiges Blatt mit allen Testszenarien erstellt. Das heißt, wir decken alle Objekte mit Tests ab.
AC: - Wir haben versucht, denselben Ansatz basierend auf Metadaten auf andere Bereiche, auf den Testbereich, auszudehnen. Wir schreiben auch einmal eine Vorlage für ein Objekt und fügen dort Tags ein. Wenn diese Vorlage entlang der Metadaten ausgeführt wird, wird ein fertiges Blatt mit allen Testszenarien erstellt. Das heißt, wir decken alle Objekte mit Tests ab.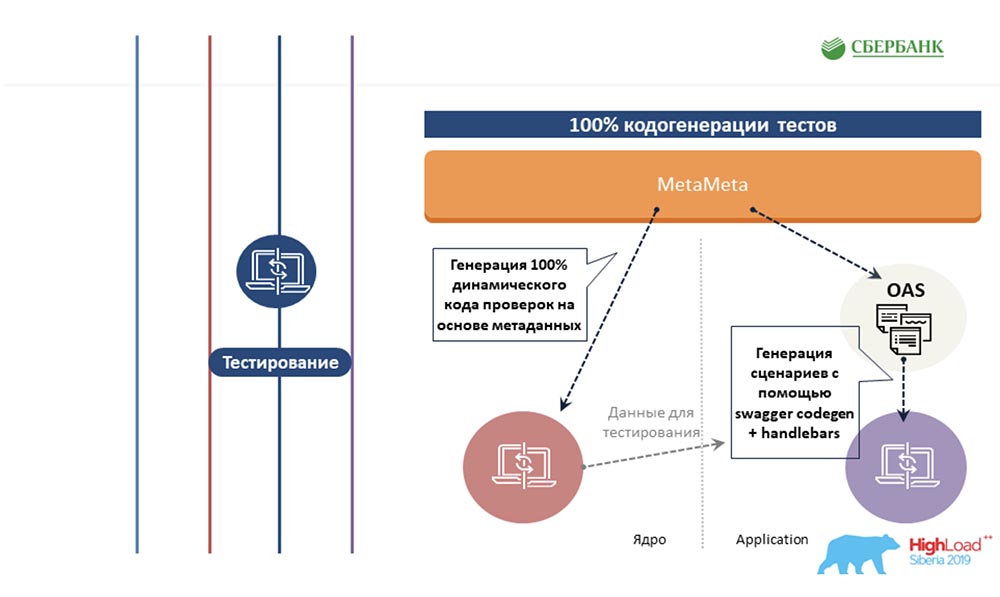 Als nächstes ist die Kirsche auf dem Kuchen. Ich weiß, dass nur wenige Leute gerne dokumentieren, was sie tun. Wir haben diesen Schmerz auch anhand von Metadaten gelöst. Nachdem wir eine Vorlage mit HTML-Markup vorbereitet hatten, markierten wir sie. Wenn wir die Metadaten durchgehen, werden alle diese Tags durch ihre Eigenschaften ersetzt, die den Objekten entsprechen.
Als nächstes ist die Kirsche auf dem Kuchen. Ich weiß, dass nur wenige Leute gerne dokumentieren, was sie tun. Wir haben diesen Schmerz auch anhand von Metadaten gelöst. Nachdem wir eine Vorlage mit HTML-Markup vorbereitet hatten, markierten wir sie. Wenn wir die Metadaten durchgehen, werden alle diese Tags durch ihre Eigenschaften ersetzt, die den Objekten entsprechen. Die Ausgabe ist eine schöne fertige HTML-Seite. Dann veröffentlichen wir in Confluence und können unseren Benutzern ein für Menschen lesbares Format zur Verfügung stellen, damit sie sehen können, was wir im System haben, wie wir damit arbeiten, einige minimale Beschreibungen, akzeptable Werte, erforderliche Eigenschaften, Schlüssel ... Sie alle können dies tun sehen und kann es ganz leicht herausfinden.Infolgedessen haben wir vier Hauptpunkte, und dieser Ansatz wird als MDA (Model Driven Architecture) bezeichnet. Aus irgendeinem Grund bedeutet dies „modellgetriebene Architektur“, obwohl ich es als „Softwareentwicklungsmethode“ bezeichnen würde.
Die Ausgabe ist eine schöne fertige HTML-Seite. Dann veröffentlichen wir in Confluence und können unseren Benutzern ein für Menschen lesbares Format zur Verfügung stellen, damit sie sehen können, was wir im System haben, wie wir damit arbeiten, einige minimale Beschreibungen, akzeptable Werte, erforderliche Eigenschaften, Schlüssel ... Sie alle können dies tun sehen und kann es ganz leicht herausfinden.Infolgedessen haben wir vier Hauptpunkte, und dieser Ansatz wird als MDA (Model Driven Architecture) bezeichnet. Aus irgendeinem Grund bedeutet dies „modellgetriebene Architektur“, obwohl ich es als „Softwareentwicklungsmethode“ bezeichnen würde. Was ist der Sinn? Sie erstellen ein Modell, einigen bestimmten Regeln. Anschließend erstellen Sie einmal Transformationsmuster dieses Modells in einer Programmiersprache, die Ihnen zur Verfügung steht. All dies funktioniert, um alte Objekte zu ändern und neue hinzuzufügen. Sie schreiben den Code einmal und kümmern sich nicht mehr darum.SC: - Ich habe ehrlich auf den gesamten Bericht gewartet, als Sie diese Frage beantwortet haben. Kommen wir zu meinen Lieblingsfolien.
Was ist der Sinn? Sie erstellen ein Modell, einigen bestimmten Regeln. Anschließend erstellen Sie einmal Transformationsmuster dieses Modells in einer Programmiersprache, die Ihnen zur Verfügung steht. All dies funktioniert, um alte Objekte zu ändern und neue hinzuzufügen. Sie schreiben den Code einmal und kümmern sich nicht mehr darum.SC: - Ich habe ehrlich auf den gesamten Bericht gewartet, als Sie diese Frage beantwortet haben. Kommen wir zu meinen Lieblingsfolien.Entscheidung. Prozess. Vor
AC: - „Der Prozess. Vorher “- das ist unser Stolz, weil wir viel programmiert haben, fast nichts gegessen haben - waren wir sehr böse. Ich musste all diese 5 Schritte für jedes Objekt ausführen: Es war sehr traurig und hat uns viel Zeit gekostet. Jetzt haben wir diese Nahrungskette auf drei Glieder reduziert, von denen das wichtigste einfach darin besteht, das Objekt korrekt zu erstellen, und nicht mehr:
Es war sehr traurig und hat uns viel Zeit gekostet. Jetzt haben wir diese Nahrungskette auf drei Glieder reduziert, von denen das wichtigste einfach darin besteht, das Objekt korrekt zu erstellen, und nicht mehr: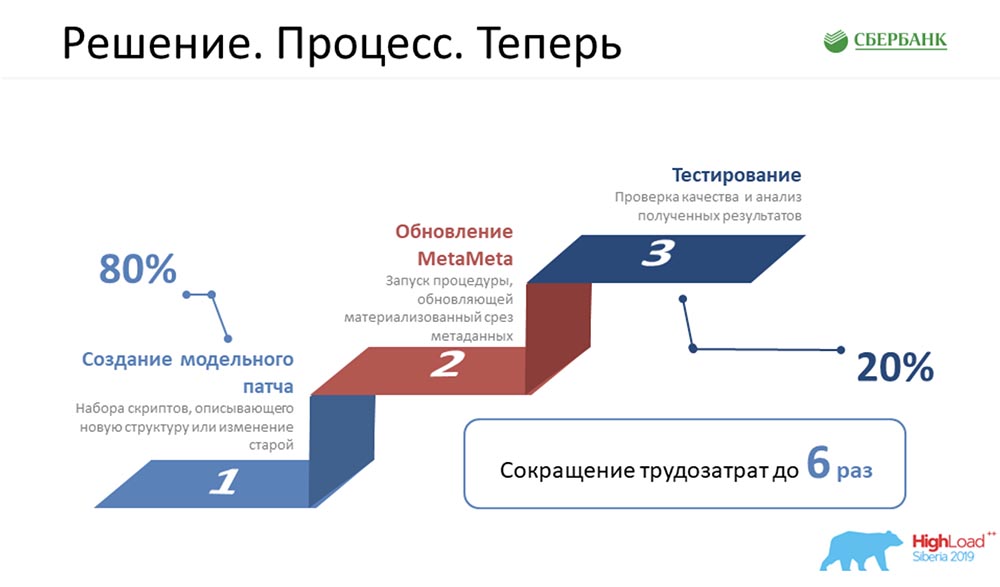 MetaMeta wird durch eine Schaltfläche (Aktualisierung) gestartet und anschließend getestet. Wir versuchen derzeit sicherzustellen, dass nichts von uns abfällt, da wir diesen Ansatz kürzlich angewendet haben. Wir versuchen, diesen gesamten Prozess zu kontrollieren.Schätzungen zufolge wurden alle unsere Arbeitskosten für die Entwicklung unserer gesamten Software um das Sechsfache gesenkt.SC:- Von mir selbst möchte ich aufrichtig sagen, dass die Nummer 6 nicht durchgebrannt ist, sondern sogar konservativ. In der Tat ist der Wirkungsgrad sogar noch höher.
MetaMeta wird durch eine Schaltfläche (Aktualisierung) gestartet und anschließend getestet. Wir versuchen derzeit sicherzustellen, dass nichts von uns abfällt, da wir diesen Ansatz kürzlich angewendet haben. Wir versuchen, diesen gesamten Prozess zu kontrollieren.Schätzungen zufolge wurden alle unsere Arbeitskosten für die Entwicklung unserer gesamten Software um das Sechsfache gesenkt.SC:- Von mir selbst möchte ich aufrichtig sagen, dass die Nummer 6 nicht durchgebrannt ist, sondern sogar konservativ. In der Tat ist der Wirkungsgrad sogar noch höher.Zukunftspläne
Sie haben am Ende des Berichts gebeten, sich mit unseren Plänen zu befassen. Zunächst scheint es, dass wir nicht nur eine vollständige, sondern auch eine entfremdete und verpackte Lösung erreichen müssen. Diese Technologien können gegebenenfalls irgendwo in der Nähe angewendet werden. Ich möchte ein fertiges Produkt erzielen, das entwickelt wird und das wir im Auftrag der Sberbank anbieten können.Wenn wir über unmittelbare Aufgaben sprechen, werden diese natürlich alle mit Aufzählungszeichen auf den Folien angezeigt. Trotz der Optimierung, die wir erhalten haben, ist die Belastung des Teams immer noch sehr ernst. Ich kann nicht mit Sicherheit sagen, ab welchem Quartal wir mit der Umsetzung dieser Schritte fortfahren können.Nummer 6 und der Fall, den Nastya gebracht hat - sie sind ehrlich. Es war wirklich am Freitag, als wir Dokumente (Flugzeug, Reisen usw.) besorgen mussten. Das benachbarte Team sollte am Montag getestet werden, und wir mussten diesen Patch veröffentlichen, um die Jungs nicht einzurichten. Es funktionierte! Dies ist ein realer Fall. Ich würde mich freuen, wenn dies für einen von Ihnen nützlich sein könnte. Bei Fragen stehen wir Ihnen gerne zur Verfügung. Und nach dem Bericht ist auch hier noch etwas Zeit. Fragen. Wir helfen Ihnen gerne weiter!AC:- In der Tat kann dieser Ansatz, glaube ich, von allen genutzt werden. Nicht unbedingt in unserer Form (wir beschäftigen uns mit der Verwaltung von Metadaten). Es kann ein Kontrollsystem für alles sein. Alles, was Sie zur Hand haben müssen, ist eine relationale Sicht der Dinge, Metadaten von dort zu nehmen, einige Template-Engines zu verstehen und eine Programmiersprache zu verstehen (wie es funktioniert).Alle diese Tools sind gemeinfrei - Sie können bereits mit dem Googeln beginnen und verstehen, wie Sie sie verwenden. Ich bin sicher, dass ihre Verwendung Ihr Leben einfacher, besser und im Allgemeinen Zeit für neue, ehrgeizige und coole Aufgaben machen wird. Danke!
Ich würde mich freuen, wenn dies für einen von Ihnen nützlich sein könnte. Bei Fragen stehen wir Ihnen gerne zur Verfügung. Und nach dem Bericht ist auch hier noch etwas Zeit. Fragen. Wir helfen Ihnen gerne weiter!AC:- In der Tat kann dieser Ansatz, glaube ich, von allen genutzt werden. Nicht unbedingt in unserer Form (wir beschäftigen uns mit der Verwaltung von Metadaten). Es kann ein Kontrollsystem für alles sein. Alles, was Sie zur Hand haben müssen, ist eine relationale Sicht der Dinge, Metadaten von dort zu nehmen, einige Template-Engines zu verstehen und eine Programmiersprache zu verstehen (wie es funktioniert).Alle diese Tools sind gemeinfrei - Sie können bereits mit dem Googeln beginnen und verstehen, wie Sie sie verwenden. Ich bin sicher, dass ihre Verwendung Ihr Leben einfacher, besser und im Allgemeinen Zeit für neue, ehrgeizige und coole Aufgaben machen wird. Danke!Fragen
Frage des Publikums (im Folgenden - A): - Verstehe ich richtig, dass alles gestapelt ist, weil Sie eine relationale Datenbank verwenden? Mir scheint, wenn Sie sich die dokumentenorientierte Datenbank ansehen, wäre all diese Lösung für Sie viel einfacher als ich jetzt sehe.SC: - Nicht wirklich. Womit wir angefangen haben, als wir über Leute gesprochen haben, die auf Glossarebene arbeiten, und die Spinne, die zum Abschlussball geht, diese Geschichten liest und prüft - tatsächlich findet die Tabelle mit dem Feld, das für diesen Glossarbegriff verantwortlich ist, beim Abschlussball statt . Sie sagten von unserem Service: „Leute, ihr solltet eine REST-API haben. Wie Sie es tun, ist Ihr Problem. Hier ist eine Liste der zulässigen Technologien - verwenden Sie etwas aus dieser Liste (das können wir in der Sberbank verwenden). “Dies ist die Ebene unserer Lösung, angewandte Architektur. Im Gegenteil, für uns war es einfacher, dies nicht relational zu tun. Warum? Ich werde ein Beispiel geben, eines von vielen ... Zum Beispiel muss ich beim Schreiben eines Feldes sicherstellen, dass es nirgendwo auf eine Tabelle verweist, die nicht existiert. Ich mache nur einen Fremdschlüssel in der Datenbank und mache mir keine Sorgen. Ich schreibe keine Zeile - sie lässt mich diese Aufnahme nicht machen. Und es gibt viele solche Beispiele!Hier sollten wir lieber über etwas anderes sprechen. Eine kompliziertere Geschichte: Wir werden einen Modell-Patch mit einem Anpassungs- / Zertifizierungsdatensatz veröffentlichen, und dort gibt es 6 Objekte. Und um diese Gentleman-APIs bereitzustellen, benötigen Sie zwangsläufig drei Monate, um (ohne weiteres) zu arbeiten. Wir werden anderthalb Wochen brauchen. Ohne diese Technologien war es einfach unmöglich, unter diesen Bedingungen zu überleben. Wir würden einfach keinen solchen Service bieten!Dies ist möglich, wenn Sie die Produktion so erstellt haben, dass Sie einen Modell-Patch (neues Objekt), eine Schaltfläche „Alles gut machen“ und eine Software haben, die im Client-Emulationsmodus getestet wird. Ein neues verdient, das alte fiel nicht ab - dies musste erreicht werden, aber wie - es war die Wahl des Teams. A: - Ich habe eine zweite Frage. Und was ist ein Beispiel für die Verwendung aus dem Leben? Ich verstehe, dass es theoretisch so aussieht, als könnten Sie mit Ihrem META_META-Objekt zumindest die ganze Welt beschreiben ... Aber wie verwenden Sie es im Leben? Gemessen an der Implementierung (alles sollte ineinander gesteckt werden) sollte es langsamer werden!SC:- Übrigens nein (überraschend)! Eine andere Anwendung dieser Geschichte sind Codegeneratoren. Hier werden einige Storefronts, Speicher erstellt und Sie sind ETL. Sie versuchen, alle möglichen Optionen auf neun Vorlagen zu parken, neun Template-Engines, die im Voraus beschrieben wurden. Mithilfe von Metadaten beschreiben Sie diese Umwandlung, indem Sie diese Vorlagen als Stubs verwenden. Außerdem gibt diese Maschine ohne Programmierung einen ETL-Code aus und generiert Code basierend auf Metadaten. Ich glaube, dass es auch solche Technologien gibt, Ansätze werden angemessen und korrekt sein.A: - Ich habe mit einem genaueren Beispiel gerechnet.A: - Sagen Sie mir bitte, es wurde in Ihren Anforderungen geschrieben, dass Sie komplexe strukturelle Abfragen durchführen müssen (Join und dergleichen). In welcher Sprache ist es implementiert oder beschreiben Sie es irgendwie logisch?SC:- Zugriff über die REST-API, meistens Java, obwohl es sich um eine beliebige Sprache handeln kann. Unser Service wurde veröffentlicht (dhttps, fragen Sie https - Sie erhalten JSON zurück). Die Code-Teile, die wir gezeigt haben, sind SQL. Um zu verstehen, in welcher Reihenfolge es verarbeitet werden soll, haben wir einige SQL-Optimierungen an den DBMS-Wörterbüchern vorgenommen und es in Form von materialisierten Darstellungen in einem separaten Schema geparkt. Wenn ein Modell-Patch veröffentlicht wird, wird dementsprechend auf die Schaltfläche "Materialisierte Ansicht aktualisieren" geklickt (+ Felder werden angezeigt). Aber unser Code ist wirklich Java und Oracle.AC:- Hier ist anzumerken, dass wir beschlossen haben, die Verantwortungsbereiche aufzuteilen. Wir haben die ganze Magie absichtlich auf den Kernel übertragen, und Application interpretiert diese Antworten einfach richtig. Das heißt, der Join-Mechanismus selbst tritt im Kernel auf, und Java streut einfach alles kompetent in den Baum und gibt dem Benutzer das Endergebnis.A: - Und was macht Code Gens - schreiben Sie dort bereits die Logik komplexer Abfragen auf? Oder wird es auf der Client-Seite gemacht? Wir müssen verstehen, welche Seite beschrieben wird ... Sie haben, wie sich herausstellt, Code Gen vorgestellt, auf dem es notwendig ist, in einer bestimmten Struktur genau zu beschreiben: Ich möchte zum Beispiel, dass meine API so und so Join lernt, gehe die Liste durch; Dann sagen Sie, ob es drinnen ist oder nicht ... - komplexe Abfragen sind genug. Wann ist das geschrieben?SC:- Wenn ich Ihre Frage richtig verstehe, ist dies genau die Geschichte, in der unsere Kunden, unsere Kunden (dies ist ein Team innerhalb des Kernels, der Plattform) sagen: "Hören Sie, wir wollen nicht programmieren - geben Sie uns dies." "Das ist es" alles wurde im Kern gemacht. Der Kern - im Wesentlichen was? 80 Prozent, vielleicht 90 - dies ist die Generierung von dynamischem Code, dem Text, der unter PL / SQL aufgerufen, aber an die Datenbank weitergeleitet wird. Dort wird diese Zeile auch mit der Zeit länger generiert, dann wird auf die Datenbank zugegriffen (z. B. die Join-Anforderung), sie wird zurückgegeben, in JSON eingeschlossen und verkehrt herum angezeigt. Darüber hinaus wandelt Java all dies in einen Vertrag um, der von der Struktur abhängt.UND:- Enthüllte eine Batch-Update-Lösung. Und wie erfolgt die Liefergarantie - ist das gesamte Paket oder ein Teil des Pakets angekommen? Haben sie ein bestimmtes Cachend? Und wie kann sichergestellt werden, dass weder der Dienst ausfällt noch die Datenstrukturen kohärent sind, damit keine Fehler auftreten?SC: - Wir haben ein Protokoll - es gibt zwei Aktualisierungsmodi. In einem von ihnen können Sie das Flag "Wenden Sie alles an, was Sie können" setzen. Es gibt eine Software, die Excel in JSON konvertiert - möglicherweise sind 10.000 Zeilen vorhanden. Und genau genommen können zwei Zeilen ungültig sein (Fehler). Und entweder sagst du: "Wende alles an, was du kannst"; oder "Nur anwenden, wenn die ganze Geschichte keinen einzigen Fehler enthält." Dort wird der Integralstatus beispielsweise ein Rollback sein. Tatsächlich wird eine Einfügung in die Datenbank vorgenommen, aber das Festschreiben wird nicht aufgerufen.Im Fehlerfall - es ruft Rollback auf, befindet es sich im Protokoll; Sie erhalten das Protokoll trotzdem. Sie erhalten in jeder Zeile einen Status und haben eine Kennung in einem separaten Feld - entweder eine Nummer (Objekt-ID) oder einen alternativen Schlüssel oder beides. Das Protokoll macht es möglich zu verstehen, was mit meiner Anfrage passiert ist.AC: - Der Benutzer selbst gibt an, in welche der Optionen er sich bewegen soll. Wir übergeben diesen Parameter an die Seite des Kerns, und der Kern erzeugt bereits die gesamte Magie, gibt uns die Antwort und interpretiert sie.UND:"Warum haben Sie keinen integrierten Ausdrucks-Compiler verwendet, mit dem Sie die Regel definieren können?" Angenommen, wir haben eine Vorlage. Ich blogge in einer Sprache (getippte / nicht getippte Skriptsprache). schrieb: "Ich möchte eine Liste." Hat dieses Snippet übergeben, damit ein Code-Prozessor alles zerkaut und in eine NoSQL-Datenbank stellt, wie in der ersten Frage vorgeschlagen ... Es ist jedoch nicht klar, warum eine relationale Datenbank und warum und wie mit Datenredundanz umzugehen ist. Ein Mann schickt Ihnen eine Vorlage mit einer Milliarde Müll ... Wie werden diese Vereinbarungen getroffen, wenn eine Person sie braucht?
A: - Ich habe eine zweite Frage. Und was ist ein Beispiel für die Verwendung aus dem Leben? Ich verstehe, dass es theoretisch so aussieht, als könnten Sie mit Ihrem META_META-Objekt zumindest die ganze Welt beschreiben ... Aber wie verwenden Sie es im Leben? Gemessen an der Implementierung (alles sollte ineinander gesteckt werden) sollte es langsamer werden!SC:- Übrigens nein (überraschend)! Eine andere Anwendung dieser Geschichte sind Codegeneratoren. Hier werden einige Storefronts, Speicher erstellt und Sie sind ETL. Sie versuchen, alle möglichen Optionen auf neun Vorlagen zu parken, neun Template-Engines, die im Voraus beschrieben wurden. Mithilfe von Metadaten beschreiben Sie diese Umwandlung, indem Sie diese Vorlagen als Stubs verwenden. Außerdem gibt diese Maschine ohne Programmierung einen ETL-Code aus und generiert Code basierend auf Metadaten. Ich glaube, dass es auch solche Technologien gibt, Ansätze werden angemessen und korrekt sein.A: - Ich habe mit einem genaueren Beispiel gerechnet.A: - Sagen Sie mir bitte, es wurde in Ihren Anforderungen geschrieben, dass Sie komplexe strukturelle Abfragen durchführen müssen (Join und dergleichen). In welcher Sprache ist es implementiert oder beschreiben Sie es irgendwie logisch?SC:- Zugriff über die REST-API, meistens Java, obwohl es sich um eine beliebige Sprache handeln kann. Unser Service wurde veröffentlicht (dhttps, fragen Sie https - Sie erhalten JSON zurück). Die Code-Teile, die wir gezeigt haben, sind SQL. Um zu verstehen, in welcher Reihenfolge es verarbeitet werden soll, haben wir einige SQL-Optimierungen an den DBMS-Wörterbüchern vorgenommen und es in Form von materialisierten Darstellungen in einem separaten Schema geparkt. Wenn ein Modell-Patch veröffentlicht wird, wird dementsprechend auf die Schaltfläche "Materialisierte Ansicht aktualisieren" geklickt (+ Felder werden angezeigt). Aber unser Code ist wirklich Java und Oracle.AC:- Hier ist anzumerken, dass wir beschlossen haben, die Verantwortungsbereiche aufzuteilen. Wir haben die ganze Magie absichtlich auf den Kernel übertragen, und Application interpretiert diese Antworten einfach richtig. Das heißt, der Join-Mechanismus selbst tritt im Kernel auf, und Java streut einfach alles kompetent in den Baum und gibt dem Benutzer das Endergebnis.A: - Und was macht Code Gens - schreiben Sie dort bereits die Logik komplexer Abfragen auf? Oder wird es auf der Client-Seite gemacht? Wir müssen verstehen, welche Seite beschrieben wird ... Sie haben, wie sich herausstellt, Code Gen vorgestellt, auf dem es notwendig ist, in einer bestimmten Struktur genau zu beschreiben: Ich möchte zum Beispiel, dass meine API so und so Join lernt, gehe die Liste durch; Dann sagen Sie, ob es drinnen ist oder nicht ... - komplexe Abfragen sind genug. Wann ist das geschrieben?SC:- Wenn ich Ihre Frage richtig verstehe, ist dies genau die Geschichte, in der unsere Kunden, unsere Kunden (dies ist ein Team innerhalb des Kernels, der Plattform) sagen: "Hören Sie, wir wollen nicht programmieren - geben Sie uns dies." "Das ist es" alles wurde im Kern gemacht. Der Kern - im Wesentlichen was? 80 Prozent, vielleicht 90 - dies ist die Generierung von dynamischem Code, dem Text, der unter PL / SQL aufgerufen, aber an die Datenbank weitergeleitet wird. Dort wird diese Zeile auch mit der Zeit länger generiert, dann wird auf die Datenbank zugegriffen (z. B. die Join-Anforderung), sie wird zurückgegeben, in JSON eingeschlossen und verkehrt herum angezeigt. Darüber hinaus wandelt Java all dies in einen Vertrag um, der von der Struktur abhängt.UND:- Enthüllte eine Batch-Update-Lösung. Und wie erfolgt die Liefergarantie - ist das gesamte Paket oder ein Teil des Pakets angekommen? Haben sie ein bestimmtes Cachend? Und wie kann sichergestellt werden, dass weder der Dienst ausfällt noch die Datenstrukturen kohärent sind, damit keine Fehler auftreten?SC: - Wir haben ein Protokoll - es gibt zwei Aktualisierungsmodi. In einem von ihnen können Sie das Flag "Wenden Sie alles an, was Sie können" setzen. Es gibt eine Software, die Excel in JSON konvertiert - möglicherweise sind 10.000 Zeilen vorhanden. Und genau genommen können zwei Zeilen ungültig sein (Fehler). Und entweder sagst du: "Wende alles an, was du kannst"; oder "Nur anwenden, wenn die ganze Geschichte keinen einzigen Fehler enthält." Dort wird der Integralstatus beispielsweise ein Rollback sein. Tatsächlich wird eine Einfügung in die Datenbank vorgenommen, aber das Festschreiben wird nicht aufgerufen.Im Fehlerfall - es ruft Rollback auf, befindet es sich im Protokoll; Sie erhalten das Protokoll trotzdem. Sie erhalten in jeder Zeile einen Status und haben eine Kennung in einem separaten Feld - entweder eine Nummer (Objekt-ID) oder einen alternativen Schlüssel oder beides. Das Protokoll macht es möglich zu verstehen, was mit meiner Anfrage passiert ist.AC: - Der Benutzer selbst gibt an, in welche der Optionen er sich bewegen soll. Wir übergeben diesen Parameter an die Seite des Kerns, und der Kern erzeugt bereits die gesamte Magie, gibt uns die Antwort und interpretiert sie.UND:"Warum haben Sie keinen integrierten Ausdrucks-Compiler verwendet, mit dem Sie die Regel definieren können?" Angenommen, wir haben eine Vorlage. Ich blogge in einer Sprache (getippte / nicht getippte Skriptsprache). schrieb: "Ich möchte eine Liste." Hat dieses Snippet übergeben, damit ein Code-Prozessor alles zerkaut und in eine NoSQL-Datenbank stellt, wie in der ersten Frage vorgeschlagen ... Es ist jedoch nicht klar, warum eine relationale Datenbank und warum und wie mit Datenredundanz umzugehen ist. Ein Mann schickt Ihnen eine Vorlage mit einer Milliarde Müll ... Wie werden diese Vereinbarungen getroffen, wenn eine Person sie braucht? SC:"Ich werde versuchen zu antworten, sobald ich die Frage verstanden habe." Der größte Teil des Programms kommuniziert jetzt mit uns. Wenn der Mechanismus der Integrationsinteraktion eingerichtet ist, kommunizieren nicht so viele Menschen mit uns als Programme. Es gibt natürlich Fälle, in denen Leute a la exelniks für die primäre Verschüttung senden: Wir erstellen JSONs aus ihnen, laden sie hoch, aber dies ist eher eine primäre Einstellung.Und wir haben einen Modus, in dem Sie 5.000 Zeilen gesendet haben, von denen 4.900 mit dem Status "Ich habe verarbeitet, ich habe keine Änderungen gefunden, ich habe nichts getan" zurückgegeben wurden. Dies spiegelt sich jedoch im Protokoll wider und es liegt kein Fehler vor. Dies ist einerseits Redundanz.Wir haben diese ganze Geschichte ungefähr in der dritten, normalen Form gespeichert, was im Gegensatz zu einigen denormalisierten Strukturen, die beispielsweise für Schaufenster verwendet werden, keine Redundanz bedeutet.Warum relational? Codegeneratoren arbeiten für uns und die Sensibilität für die Qualität der Metadaten im System ist sehr hoch. Und wenn wir die Möglichkeit haben, Fremdschlüssel mithilfe von relationalen Konfigurationen zu konfigurieren und sicherzustellen ... Der Datensatz legt sich einfach nicht hin - es tritt ein Fehler auf, wenn im System etwas nicht stimmt, wenn ein Fehler auftritt. Und wir wollen, aber wir suchen keine zusätzliche Arbeit ...Wir werden nicht daran gemessen, wie viele Codezeilen wir geschrieben haben: "Haben Sie die Frage nach dem Dienst und seiner Stabilität gelöst oder nicht?" Sie können überhaupt nicht schreiben - die Hauptsache ist, dass es funktioniert. In diesem Sinne war es für uns einfach schneller und bequemer.Ich nehme keinen bestimmten Anbieter, aber relationale Datenbanken werden seit 20 Jahren entwickelt! Es ist nicht einfach so. Nehmen Sie zum Beispiel Word oder Excel unter Windows - Sie programmieren dort nicht den Code, der mit Hilfe von "Assembler" auf die Köpfe der Festplatte zugreift und diese bewegt, um eine Datei zu schreiben ... Das gleiche ist hier! Wir haben nur die Entwicklungen in RDBMS verwendet, und es war praktisch.AC:- Um alle unsere Anforderungen zu gewährleisten, war uns die Integrität der Metadaten wichtig. Und hier wollten wir wahrscheinlich auch vermitteln, dass wir uns überhaupt nicht festhalten müssen - wir verwenden relational, nicht relational ... Das Wesentliche des Berichts ist, dass Sie ihn auch verwenden können. Nicht unbedingt auf relationaler Basis, denn sicher haben auch andere Metadaten, die gesammelt werden können: zumindest, welche Tabellen, Felder und dies alles programmiert ist.A: - Das System erfordert eine gewisse Verwendung. Wie planen Sie die Übermittlung von Daten an Ihr System (oder haben Sie dies bereits getan)? Es ist klar, dass eine Art Aktualisierung der Datenstruktur im Lebensmittelgeschäft stattfindet. Wie kommt das alles zu dir? Automatisch oder Ihr Agent steht oder biegen Sie alle Entwicklungsteams, damit Sie Updates erhalten?AC:- Wir haben zwei Betriebsarten. Eine davon ist, wenn die Entwickler selbst oder die Teams selbst gezwungen sind, Metadaten über REST-Services in das System einzutragen. Die zweite Betriebsart ist der gleiche „Staubsauger“: Wir gehen selbst in die Umwelt und nehmen von dort alle möglichen Metadaten. Wir machen das einmal am Tag und überprüfen nur, was uns die Entwickler geschickt haben.
SC:"Ich werde versuchen zu antworten, sobald ich die Frage verstanden habe." Der größte Teil des Programms kommuniziert jetzt mit uns. Wenn der Mechanismus der Integrationsinteraktion eingerichtet ist, kommunizieren nicht so viele Menschen mit uns als Programme. Es gibt natürlich Fälle, in denen Leute a la exelniks für die primäre Verschüttung senden: Wir erstellen JSONs aus ihnen, laden sie hoch, aber dies ist eher eine primäre Einstellung.Und wir haben einen Modus, in dem Sie 5.000 Zeilen gesendet haben, von denen 4.900 mit dem Status "Ich habe verarbeitet, ich habe keine Änderungen gefunden, ich habe nichts getan" zurückgegeben wurden. Dies spiegelt sich jedoch im Protokoll wider und es liegt kein Fehler vor. Dies ist einerseits Redundanz.Wir haben diese ganze Geschichte ungefähr in der dritten, normalen Form gespeichert, was im Gegensatz zu einigen denormalisierten Strukturen, die beispielsweise für Schaufenster verwendet werden, keine Redundanz bedeutet.Warum relational? Codegeneratoren arbeiten für uns und die Sensibilität für die Qualität der Metadaten im System ist sehr hoch. Und wenn wir die Möglichkeit haben, Fremdschlüssel mithilfe von relationalen Konfigurationen zu konfigurieren und sicherzustellen ... Der Datensatz legt sich einfach nicht hin - es tritt ein Fehler auf, wenn im System etwas nicht stimmt, wenn ein Fehler auftritt. Und wir wollen, aber wir suchen keine zusätzliche Arbeit ...Wir werden nicht daran gemessen, wie viele Codezeilen wir geschrieben haben: "Haben Sie die Frage nach dem Dienst und seiner Stabilität gelöst oder nicht?" Sie können überhaupt nicht schreiben - die Hauptsache ist, dass es funktioniert. In diesem Sinne war es für uns einfach schneller und bequemer.Ich nehme keinen bestimmten Anbieter, aber relationale Datenbanken werden seit 20 Jahren entwickelt! Es ist nicht einfach so. Nehmen Sie zum Beispiel Word oder Excel unter Windows - Sie programmieren dort nicht den Code, der mit Hilfe von "Assembler" auf die Köpfe der Festplatte zugreift und diese bewegt, um eine Datei zu schreiben ... Das gleiche ist hier! Wir haben nur die Entwicklungen in RDBMS verwendet, und es war praktisch.AC:- Um alle unsere Anforderungen zu gewährleisten, war uns die Integrität der Metadaten wichtig. Und hier wollten wir wahrscheinlich auch vermitteln, dass wir uns überhaupt nicht festhalten müssen - wir verwenden relational, nicht relational ... Das Wesentliche des Berichts ist, dass Sie ihn auch verwenden können. Nicht unbedingt auf relationaler Basis, denn sicher haben auch andere Metadaten, die gesammelt werden können: zumindest, welche Tabellen, Felder und dies alles programmiert ist.A: - Das System erfordert eine gewisse Verwendung. Wie planen Sie die Übermittlung von Daten an Ihr System (oder haben Sie dies bereits getan)? Es ist klar, dass eine Art Aktualisierung der Datenstruktur im Lebensmittelgeschäft stattfindet. Wie kommt das alles zu dir? Automatisch oder Ihr Agent steht oder biegen Sie alle Entwicklungsteams, damit Sie Updates erhalten?AC:- Wir haben zwei Betriebsarten. Eine davon ist, wenn die Entwickler selbst oder die Teams selbst gezwungen sind, Metadaten über REST-Services in das System einzutragen. Die zweite Betriebsart ist der gleiche „Staubsauger“: Wir gehen selbst in die Umwelt und nehmen von dort alle möglichen Metadaten. Wir machen das einmal am Tag und überprüfen nur, was uns die Entwickler geschickt haben. SC: - Von den vier Ebenen, die wir untersucht haben, sind die drei obersten Ebenen (Glossar, logische Modelle, physische Modelle) die Geschichte, die uns standardmäßig im Metadata Broker-Modus einfällt, und wir sind ein passiver Teilnehmer. Sie rufen uns an, geben uns etwas, fragen; Unsere Aufgabe ist es, konsequent zu parken. Obwohl es Fälle gibt, in denen wir einige Storys mit den Ressourcen des Teams erstellen, sind wir sehr daran interessiert, diese Metadaten zu haben.Wie Nastya sagte, gehen wir in Bezug auf die Geschichte mit der Umkehrung (im Fachjargon nennen wir sie „Staubsauger“) in die industrielle Umgebung und lesen einige Daten. Es gibt verschiedene Fälle - wir sind bereit, später zu diskutieren, wir sind bereit, viele interessante Geschichten zu erzählen.A: - Ich komme aus dem Zentrum der Finanztechnologie. Ich habe dort ein bekanntes Wort gesehen - Haupt-DACUM. Unsere Plattform verfügt über eigene Metadaten. Wie sind Sie befreundet - in diesem Fall direkt mit den Oracle-Tabellen oder mit unseren Metadaten? In unserem Fall ist es nicht ganz bezeichnend, mit Oracle-Tabellen befreundet zu sein.SC:- Es gibt eine solche Tabelle Haupt-DACUM, die die Verkabelung enthält. Dies ist kein Geheimnis: Es gab und gibt Produkte, die an dieser Geschichte arbeiten. Dies ist eine der Informationsquellen im Repository. Es gibt eine Art System, das ein Datenanbieter ist. Natürlich steht es in Bezug auf Metadaten im Mittelpunkt unserer Aufmerksamkeit, denn eine der Geschichten, die wir hier zeigen sollten und die wir (aufgrund des Themas des Berichts) überhaupt nicht berührt haben, ist die Datenlinie. Sie müssen zeigen, woher der Datenverlauf dieses Felds stammt. In diesem Sinne wissen wir Bescheid, wenn es eine DACUM-Haupttabelle gibt.
SC: - Von den vier Ebenen, die wir untersucht haben, sind die drei obersten Ebenen (Glossar, logische Modelle, physische Modelle) die Geschichte, die uns standardmäßig im Metadata Broker-Modus einfällt, und wir sind ein passiver Teilnehmer. Sie rufen uns an, geben uns etwas, fragen; Unsere Aufgabe ist es, konsequent zu parken. Obwohl es Fälle gibt, in denen wir einige Storys mit den Ressourcen des Teams erstellen, sind wir sehr daran interessiert, diese Metadaten zu haben.Wie Nastya sagte, gehen wir in Bezug auf die Geschichte mit der Umkehrung (im Fachjargon nennen wir sie „Staubsauger“) in die industrielle Umgebung und lesen einige Daten. Es gibt verschiedene Fälle - wir sind bereit, später zu diskutieren, wir sind bereit, viele interessante Geschichten zu erzählen.A: - Ich komme aus dem Zentrum der Finanztechnologie. Ich habe dort ein bekanntes Wort gesehen - Haupt-DACUM. Unsere Plattform verfügt über eigene Metadaten. Wie sind Sie befreundet - in diesem Fall direkt mit den Oracle-Tabellen oder mit unseren Metadaten? In unserem Fall ist es nicht ganz bezeichnend, mit Oracle-Tabellen befreundet zu sein.SC:- Es gibt eine solche Tabelle Haupt-DACUM, die die Verkabelung enthält. Dies ist kein Geheimnis: Es gab und gibt Produkte, die an dieser Geschichte arbeiten. Dies ist eine der Informationsquellen im Repository. Es gibt eine Art System, das ein Datenanbieter ist. Natürlich steht es in Bezug auf Metadaten im Mittelpunkt unserer Aufmerksamkeit, denn eine der Geschichten, die wir hier zeigen sollten und die wir (aufgrund des Themas des Berichts) überhaupt nicht berührt haben, ist die Datenlinie. Sie müssen zeigen, woher der Datenverlauf dieses Felds stammt. In diesem Sinne wissen wir Bescheid, wenn es eine DACUM-Haupttabelle gibt.Ein bisschen Werbung :)
Vielen Dank für Ihren Aufenthalt bei uns. Gefällt dir unser Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung aufgeben oder Ihren Freunden Cloud-basiertes VPS für Entwickler ab 4,99 US-Dollar empfehlen , ein einzigartiges Analogon von Einstiegsservern, das von uns für Sie erfunden wurde: Die ganze Wahrheit über VPS (KVM) E5-2697 v3 (6 Kerne) 10 GB DDR4 480 GB SSD 1 Gbit / s ab 19 $ oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).Dell R730xd 2-mal günstiger im Equinix Tier IV-Rechenzentrum in Amsterdam? Nur wir haben 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2,6 GHz 14C 64 GB DDR4 4 x 960 GB SSD 1 Gbit / s 100 TV von 199 US-Dollar in den Niederlanden!Dell R420 - 2x E5-2430 2,2 GHz 6C 128 GB DDR3 2x960 GB SSD 1 Gbit / s 100 TB - ab 99 US-Dollar! Lesen Sie mehr über den Aufbau eines Infrastrukturgebäudes. Klasse C mit Dell R730xd E5-2650 v4-Servern für 9.000 Euro pro Cent? Source: https://habr.com/ru/post/undefined/
All Articles