 Wenn Analyseprobleme über vorgefertigte Tools hinausgehen, ist es wahrscheinlich an der Zeit, eine Datenbank für die Analyse auszuwählen. Sie sollten keine Skripts von Abfragen in die Arbeitsdatenbank schreiben, da Sie die Reihenfolge der Daten ändern und höchstwahrscheinlich die Anwendung verlangsamen können.Sie können wichtige Informationen auch versehentlich löschen, wenn dort Analysten oder Ingenieure arbeiten.Für die Analyse benötigen Sie einen separaten Datenbanktyp. Aber welches ist wahr?In diesem Beitrag werden Angebote und Best Practices für ein durchschnittliches Unternehmen betrachtet, das gerade erst anfängt zu arbeiten. Unabhängig davon, für welche Einstellung Sie sich entscheiden, können Sie in Zukunft einen Kompromiss finden, um die Leistung gegenüber dem, was wir hier diskutieren, zu verbessern.Bei der Arbeit mit einer großen Anzahl von Kunden haben wir festgestellt, dass die wichtigsten Kriterien, die berücksichtigt werden müssen, sind:
Wenn Analyseprobleme über vorgefertigte Tools hinausgehen, ist es wahrscheinlich an der Zeit, eine Datenbank für die Analyse auszuwählen. Sie sollten keine Skripts von Abfragen in die Arbeitsdatenbank schreiben, da Sie die Reihenfolge der Daten ändern und höchstwahrscheinlich die Anwendung verlangsamen können.Sie können wichtige Informationen auch versehentlich löschen, wenn dort Analysten oder Ingenieure arbeiten.Für die Analyse benötigen Sie einen separaten Datenbanktyp. Aber welches ist wahr?In diesem Beitrag werden Angebote und Best Practices für ein durchschnittliches Unternehmen betrachtet, das gerade erst anfängt zu arbeiten. Unabhängig davon, für welche Einstellung Sie sich entscheiden, können Sie in Zukunft einen Kompromiss finden, um die Leistung gegenüber dem, was wir hier diskutieren, zu verbessern.Bei der Arbeit mit einer großen Anzahl von Kunden haben wir festgestellt, dass die wichtigsten Kriterien, die berücksichtigt werden müssen, sind:- Art der analysierten Daten
- Wie viele Daten haben Sie?
- Der Fokus Ihres Engineering-Teams
- Wie schnell brauchen Sie Informationen?
Welche Arten von Daten analysieren Sie?
Denken Sie an die Daten, die Sie analysieren möchten. Passen sie gut in Zeilen und Spalten wie eine riesige Excel-Tabelle? Oder wäre es sinnvoller, wenn Sie sie in ein Word-Dokument einfügen?Wenn Sie auf Excel geantwortet haben, entspricht eine relationale Datenbank wie Postgres, MySQL, Amazon Redshift oder BigQuery Ihren Anforderungen. Diese strukturierten relationalen Datenbanken eignen sich hervorragend, wenn Sie genau wissen, welche Daten Sie erhalten und in welcher Beziehung sie zueinander stehen - im Grunde genommen, wie Zeilen und Spalten zusammenhängen. Für die meisten Arten der Benutzeranalyse funktionieren relationale Datenbanken gut. Benutzerattribute wie Namen, E-Mails und Abrechnungspläne passen perfekt in die Tabelle, z. B. Benutzerereignisse und deren Eigenschaften .Wenn Ihre Daten jedoch besser auf ein Blatt Papier passen, sollten Sie auf eine nicht relationale (NoSQL) Datenbank wie Hadoop oder Mongo verweisen.Nicht relationale Datenbanken zeichnen sich durch eine extrem große Anzahl privater Werte (Millionen) von halbstrukturierten Daten aus. Klassische Beispiele für halbstrukturierte Daten sind Texte wie E-Mail, Bücher und soziale Netzwerke, audiovisuelle Daten und geografische Daten. Wenn Sie viel Text Mining, Sprachverarbeitung oder Bildverarbeitung durchführen, müssen Sie höchstwahrscheinlich nicht relationale Datenspeicher verwenden.
Mit wie vielen Daten haben Sie es zu tun?
Die nächste Frage, die Sie sich stellen müssen, ist, mit wie vielen Daten Sie es zu tun haben. Je mehr Daten Sie haben, desto nützlicher ist die nicht relationale Datenbank, da sie keine Einschränkungen für eingehende Daten auferlegt, sodass Sie schneller in die Datenbank schreiben können. Dies sind keine strengen Einschränkungen, und jeder kann abhängig von verschiedenen Faktoren mehr oder weniger Daten verarbeiten. Wir haben jedoch festgestellt, dass jede der Datenbanken innerhalb dieser Grenzen einwandfrei funktioniert.Wenn Sie weniger als 1 TB Daten haben, erhalten Sie mit Postgres eine gute Leistung. Aber es verlangsamt sich bei etwa 6 TB. Wenn Sie MySQL mögen, aber einen etwas größeren Maßstab benötigen, kann Aurora (Amazon-eigene Version) 64 TB erreichen. Für eine Petabyte-Größe ist Amazon Redshift normalerweise eine gute Wahl, da es für Analysen bis zu 2PB optimiert ist. Für die parallele Verarbeitung oder sogar für MOAR-Daten ist es wahrscheinlich an der Zeit, sich Hadoop anzusehen.AWS teilte uns jedoch mit, dass Amazon.com auf Redshift ausgeführt wird. Wenn Sie also ein erstklassiges DBA-Team haben, können Sie möglicherweise über das 2PB-Limit hinaus skalieren.
Dies sind keine strengen Einschränkungen, und jeder kann abhängig von verschiedenen Faktoren mehr oder weniger Daten verarbeiten. Wir haben jedoch festgestellt, dass jede der Datenbanken innerhalb dieser Grenzen einwandfrei funktioniert.Wenn Sie weniger als 1 TB Daten haben, erhalten Sie mit Postgres eine gute Leistung. Aber es verlangsamt sich bei etwa 6 TB. Wenn Sie MySQL mögen, aber einen etwas größeren Maßstab benötigen, kann Aurora (Amazon-eigene Version) 64 TB erreichen. Für eine Petabyte-Größe ist Amazon Redshift normalerweise eine gute Wahl, da es für Analysen bis zu 2PB optimiert ist. Für die parallele Verarbeitung oder sogar für MOAR-Daten ist es wahrscheinlich an der Zeit, sich Hadoop anzusehen.AWS teilte uns jedoch mit, dass Amazon.com auf Redshift ausgeführt wird. Wenn Sie also ein erstklassiges DBA-Team haben, können Sie möglicherweise über das 2PB-Limit hinaus skalieren.Worauf konzentriert sich Ihr Engineering-Team?
Dies ist eine weitere wichtige Frage, die Sie sich bei der Erörterung der Datenbank stellen sollten. Je kleiner Ihr Gesamtteam ist, desto größer ist die Wahrscheinlichkeit, dass sich Ihre Ingenieure in erster Linie auf die Produkterstellung und nicht auf die Datenverarbeitung und -verwaltung konzentrieren. Die Anzahl der Personen, die Sie diesen Projekten widmen können, wirkt sich stark auf Ihre Optionen aus.Mit einigen technischen Ressourcen haben Sie mehr Auswahlmöglichkeiten - Sie können zu einer relationalen oder nicht relationalen Datenbank wechseln. Relationale Datenbanken benötigen weniger Zeit als NoSQL.Wenn Sie mehrere Ingenieure haben, die an der Installation arbeiten, aber niemanden zum Dienst bringen können, wählen Sie beispielsweise Postgres , Google SQL (optionales MySQL-Hosting) oder Segment Warehouses(Redshift-Hosting) ist wahrscheinlich eine bessere Option als Redshift, Aurora oder BigQuery, da sie eine regelmäßige Korrektur der Datenverarbeitung erfordern. Wenn Sie mehr Zeit für den Service haben, können Sie durch Auswahl von Redshift oder BigQuery schnellere und umfangreichere Abfragen durchführen.Relationale Datenbanken haben einen weiteren Vorteil: Sie können sie mit SQL abfragen. SQL ist sowohl Analysten als auch Ingenieuren bekannt und leichter zu erlernen als die meisten Programmiersprachen.Andererseits erfordert die Analyse von halbstrukturierten Daten in der Regel mindestens Erfahrung in der objektorientierten Programmierung oder besser Erfahrung im Schreiben von Code für die Arbeit mit Big Data. Auch mit dem Aufkommen von Analysetools wie HunkFür Hadoop oder Slamdata für MongoDB benötigen Sie einen erfahrenen Analysten oder Datenspezialisten, um diese Arten von Datenbanken zu analysieren.Wie schnell benötigen Sie diese Daten?
Während „Echtzeitanalysen“ in Fällen wie Betrugserkennung und Systemüberwachung sehr beliebt sind, erfordern die meisten Analysen keine Echtzeitdaten oder sofortige Analysen.Wenn Sie beispielsweise Fragen beantworten, was den Abfluss von Benutzern verursacht oder wie Personen von Ihrer Anwendung auf Ihre Website wechseln, ist der Zugriff auf Ihre Daten mit einer leichten Verzögerung (stündliche oder tägliche Intervalle) durchaus akzeptabel. Ihre Daten ändern sich nicht von Minute zu Minute.Wenn Sie hauptsächlich an der eigentlichen Analyse arbeiten, sollten Sie sich daher auf eine für Analysen optimierte Datenbank wie Redshift oder BigQuery beziehen. Solche Datenbanken sind so konzipiert, dass sie eine große Datenmenge aufnehmen und Daten schnell lesen und kombinieren können, wodurch Abfragen schnell erfolgen. Sie können Daten auch schnell genug (stündlich) herunterladen, während jemand den Reinigungsprozess durchführt, die Größe ändert und den Cluster überwacht.Wenn Sie unbedingt Echtzeitdaten benötigen, sollten Sie sich an eine unstrukturierte Datenbank wie Hadoop wenden. Sie können Ihre Hadoop-Datenbank so gestalten, dass Daten sehr schnell in sie geladen werden. Die Abfrage kann jedoch je nach RAM-Auslastung, verfügbarem Speicherplatz und Datenstruktur länger dauern.Postgres vs. Amazon Redshift vs. Google Bigquery
Sie haben wahrscheinlich bereits erkannt, dass eine relationale Datenbank die beste Wahl für die Analyse der meisten Arten von Benutzerverhalten ist. Informationen darüber, wie Ihre Benutzer mit Ihrer Website und Ihren Anwendungen interagieren, können problemlos in ein strukturiertes Format eingepasst werden.analytics.track('Completed Order') — select * from ios.completed_order
 Die Frage ist also, welche SQL-Datenbank verwendet werden soll. Es müssen vier Kriterien berücksichtigt werden.
Die Frage ist also, welche SQL-Datenbank verwendet werden soll. Es müssen vier Kriterien berücksichtigt werden.Größe vs. Geschwindigkeit
Wenn Sie Geschwindigkeit benötigen, sollten Sie Postgres in Betracht ziehen: Für eine Datenbank mit weniger als 1 TB ist Postgres ziemlich schnell zum Laden von Daten und Abfragen. Plus, es ist verfügbar. Wenn Sie sich 6 TB nähern (von Amazon RDS geerbt), werden Ihre Abfragen langsamer ausgeführt.Wenn Sie eine größere Größe benötigen, empfehlen wir daher normalerweise Redshift. Unsere Erfahrung zeigt, dass Redshift das beste Preis-Leistungs-Verhältnis bietet.SQL-Highlight
Redshift basiert auf einer Variation von Postgres und beide unterstützen das gute alte SQL. Redshift unterstützt nicht alle von postgres unterstützten Datentypen und Funktionen , ist jedoch dem Industriestandard viel näher als BigQuery, das über eigenes SQL verfügt.Im Gegensatz zu vielen anderen SQL-basierten Systemen verwendet BigQuery eine durch Kommas getrennte Syntax, um Tabellenverknüpfungen zu kennzeichnen, und nicht gemäß der SQL-Dokumentation . Dies bedeutet, dass SQL-Abfragen ohne Vorsicht zu Fehlern oder unerwarteten Ergebnissen führen können. Daher können viele der Teams, die wir getroffen haben, ihre Analysten nicht davon überzeugen, BigQuery SQL zu lernen.Ökosystem von Drittanbietern
Selten lebt Ihr Data Warehouse alleine. Sie müssen die Daten in eine Datenbank stellen und außerdem eine Software verwenden, um sie zu analysieren. (Es sei denn, Sie führen die SQL-Abfrage über die Befehlszeile aus.)Daher gefällt Redshift häufig ein sehr großes Ökosystem an Tools von Drittanbietern. AWS verfügt über Funktionen wie das Segment Data Warehouse zum Laden von Daten aus der Analyse-API in Redshift und funktioniert auch mit fast allen Datenvisualisierungstools auf dem Markt. Es stellen weniger Dienste von Drittanbietern eine Verbindung zu Google her. Daher kann die Entwicklung derselben Daten zu BigQuery länger dauern, und Sie haben nicht so viele Optionen für BI-Software.Sie können Amazon-Partner sehenhier und google hier .Wenn Sie jedoch bereits Google Cloud Storage anstelle von Amazon S3 verwenden, kann es für Sie von Vorteil sein, im Google-Ökosystem zu bleiben. Beide Dienste vereinfachen das Laden von Daten, wenn sie bereits im entsprechenden Cloud-Speicher-Repository vorhanden sind. Obwohl sie nicht gegen die Nutzungsbedingungen verstoßen, ist es viel einfacher, wenn Sie einen dieser Anbieter nicht mehr verwenden.Ausbildung
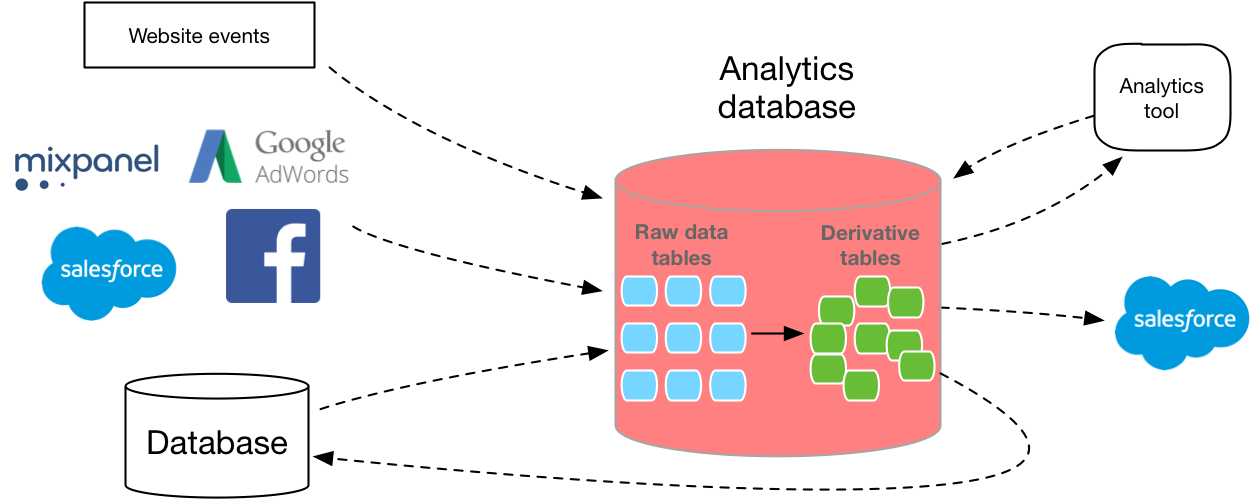
Nachdem Sie eine klarere Vorstellung davon haben, welche Datenbank verwendet werden soll, müssen Sie im nächsten Schritt herausfinden, wie Sie die Daten in der Datenbank erfassen.Viele neue Datenbankentwickler unterschätzen, wie schwierig es ist, eine skalierbare Datenpipeline aufzubauen. Sie müssen Ihre eigene Extraktionsschicht, Datenerfassungs-API, Abfrage- und Konvertierungsschicht schreiben. Und jeder muss skalieren. Darüber hinaus müssen Sie das richtige Layout basierend auf der Größe und dem Typ jeder Spalte bestimmen. MVP repliziert Ihre Produktionsdatenbank auf eine neue Instanz. Dies bedeutet jedoch normalerweise die Verwendung einer Datenbank, die nicht für die Analyse optimiert ist.Glücklicherweise gibt es auf dem Markt verschiedene Optionen, mit denen Sie einige dieser Hindernisse umgehen und automatisch eine ETL für Sie erstellen können.Unabhängig davon, ob es sich um Ihre eigene Entwicklung oder Ihren Kauf handelt, lohnt es sich, Daten in SQL abzurufen.Basierend auf den anfänglichen Benutzerdaten können Sie nur mit Hilfe eines flexiblen SQL-Formats detaillierte Fragen zu den Aktivitäten Ihrer Kunden beantworten, die Verteilung genau bewerten, das plattformübergreifende Verhalten verstehen, Dashboards für ein bestimmtes Unternehmen erstellen und vieles mehr.