Massive PostgreSQL-Abfrageoptimierung. Kirill Borovikov (Tensor)
Der Bericht enthält einige Ansätze, mit denen Sie die Leistung von SQL-Abfragen überwachen können, wenn Millionen von Abfragen pro Tag und Hunderte von kontrollierten PostgreSQL-Servern vorhanden sind.Welche technischen Lösungen ermöglichen es uns, ein solches Informationsvolumen effizient zu verarbeiten, und wie erleichtert es das Leben eines normalen Entwicklers?Wer interessiert sich für die Analyse spezifischer Probleme und verschiedener Techniken zur Optimierung von SQL-Abfragen und zur Lösung typischer DBA-Probleme in PostgreSQL ? Sie können auch eine Reihe von Artikeln zu diesem Thema lesen . Mein Name ist Kirill Borovikov, ich vertrete die Firma "Tensor" . Insbesondere bin ich auf die Arbeit mit Datenbanken in unserem Unternehmen spezialisiert.Heute werde ich Ihnen sagen, wie wir die Abfrageoptimierung durchführen, wenn Sie nicht die Leistung einer einzelnen Anforderung "erfassen" müssen, sondern das Problem massenhaft lösen müssen. Wenn es Millionen von Anfragen gibt und Sie einige Ansätze zur Lösung dieses großen Problems finden müssen.Im Allgemeinen ist „Tensor“ für unsere Millionen Kunden VLSI - unsere Anwendung : ein soziales Unternehmensnetzwerk, Videokommunikationslösungen für das interne und externe Dokumentenmanagement, Buchhaltungssysteme für die Buchhaltung und Speicherung ... Das heißt, ein solcher „Mega-Mähdrescher“ für die integrierte Geschäftsführung, Das sind mehr als 100 verschiedene interne Projekte.Um sicherzustellen, dass alle normal funktionieren und sich normal entwickeln, haben wir 10 Entwicklungszentren im ganzen Land und mehr als 1000 Entwickler .Wir arbeiten seit 2008 mit PostgreSQL zusammen und haben eine große Menge von dem, was wir verarbeiten - dies sind Kundendaten , statistische, analytische Daten von externen Informationssystemen - mehr als 400 TB gesammelt . Nur "in Produktion" gibt es ungefähr 250 Server, und insgesamt sind die von uns überwachten Datenbankserver ungefähr 1000.
Mein Name ist Kirill Borovikov, ich vertrete die Firma "Tensor" . Insbesondere bin ich auf die Arbeit mit Datenbanken in unserem Unternehmen spezialisiert.Heute werde ich Ihnen sagen, wie wir die Abfrageoptimierung durchführen, wenn Sie nicht die Leistung einer einzelnen Anforderung "erfassen" müssen, sondern das Problem massenhaft lösen müssen. Wenn es Millionen von Anfragen gibt und Sie einige Ansätze zur Lösung dieses großen Problems finden müssen.Im Allgemeinen ist „Tensor“ für unsere Millionen Kunden VLSI - unsere Anwendung : ein soziales Unternehmensnetzwerk, Videokommunikationslösungen für das interne und externe Dokumentenmanagement, Buchhaltungssysteme für die Buchhaltung und Speicherung ... Das heißt, ein solcher „Mega-Mähdrescher“ für die integrierte Geschäftsführung, Das sind mehr als 100 verschiedene interne Projekte.Um sicherzustellen, dass alle normal funktionieren und sich normal entwickeln, haben wir 10 Entwicklungszentren im ganzen Land und mehr als 1000 Entwickler .Wir arbeiten seit 2008 mit PostgreSQL zusammen und haben eine große Menge von dem, was wir verarbeiten - dies sind Kundendaten , statistische, analytische Daten von externen Informationssystemen - mehr als 400 TB gesammelt . Nur "in Produktion" gibt es ungefähr 250 Server, und insgesamt sind die von uns überwachten Datenbankserver ungefähr 1000. SQL ist eine deklarative Sprache. Sie beschreiben nicht, wie etwas funktionieren soll, sondern was Sie erhalten möchten. DBMS weiß besser, wie man JOIN macht - wie man seine Tablets verbindet, welche Bedingungen auferlegt werden müssen, was nach Index geht, was nicht ...Einige DBMS akzeptieren Hinweise: "Nein, verbinden Sie diese beiden Tablets in der einen oder anderen Warteschlange", PostgreSQL jedoch nicht. Dies ist die bewusste Position der führenden Entwickler: "Besser, wir beenden den Abfrageoptimierer, als die Entwickler einen Hinweis verwenden zu lassen."Trotz der Tatsache, dass PostgreSQL es nicht zulässt, dass sich "außen" selbst kontrolliert, können Sie perfekt sehen, was "innen" passiert, wenn Sie Ihre Abfrage ausführen und wo es Probleme gibt.
SQL ist eine deklarative Sprache. Sie beschreiben nicht, wie etwas funktionieren soll, sondern was Sie erhalten möchten. DBMS weiß besser, wie man JOIN macht - wie man seine Tablets verbindet, welche Bedingungen auferlegt werden müssen, was nach Index geht, was nicht ...Einige DBMS akzeptieren Hinweise: "Nein, verbinden Sie diese beiden Tablets in der einen oder anderen Warteschlange", PostgreSQL jedoch nicht. Dies ist die bewusste Position der führenden Entwickler: "Besser, wir beenden den Abfrageoptimierer, als die Entwickler einen Hinweis verwenden zu lassen."Trotz der Tatsache, dass PostgreSQL es nicht zulässt, dass sich "außen" selbst kontrolliert, können Sie perfekt sehen, was "innen" passiert, wenn Sie Ihre Abfrage ausführen und wo es Probleme gibt. Mit welchen klassischen Problemen kommt der Entwickler normalerweise zu DBA? "Hier haben wir die Anfrage erfüllt, und alles ist langsam , alles hängt, etwas passiert ... irgendeine Art von Ärger!"Die Gründe sind fast immer dieselben:
Mit welchen klassischen Problemen kommt der Entwickler normalerweise zu DBA? "Hier haben wir die Anfrage erfüllt, und alles ist langsam , alles hängt, etwas passiert ... irgendeine Art von Ärger!"Die Gründe sind fast immer dieselben:
: « SQL 10 JOIN...» — , «», . , (10 FROM) - . []
PostgreSQL, «» , — «» . 10 , 10 , PostgreSQL , . []- «»
, , , . … - , .
, (INSERT, UPDATE, DELETE) — .
... und für alles andere brauchen wir einen Plan ! Wir müssen sehen, was im Server passiert. Der Abfrageausführungsplan für PostgreSQL ist ein Baum des Abfrageausführungsalgorithmus in einer Textdarstellung. Es ist der Algorithmus, der als Ergebnis der Analyse durch den Planer als der effektivste erkannt wurde.Jeder Baumknoten ist eine Operation: Daten aus einer Tabelle oder einem Index extrahieren, eine Bitmap erstellen, zwei Tabellen verbinden, Stichproben verbinden, schneiden oder entfernen. Die Erfüllung der Anfrage ist eine Passage durch die Knoten dieses Baumes.Um einen Abfrageplan zu erhalten, ist es am einfachsten, die Anweisung auszuführen
Der Abfrageausführungsplan für PostgreSQL ist ein Baum des Abfrageausführungsalgorithmus in einer Textdarstellung. Es ist der Algorithmus, der als Ergebnis der Analyse durch den Planer als der effektivste erkannt wurde.Jeder Baumknoten ist eine Operation: Daten aus einer Tabelle oder einem Index extrahieren, eine Bitmap erstellen, zwei Tabellen verbinden, Stichproben verbinden, schneiden oder entfernen. Die Erfüllung der Anfrage ist eine Passage durch die Knoten dieses Baumes.Um einen Abfrageplan zu erhalten, ist es am einfachsten, die Anweisung auszuführen EXPLAIN. Um alle realen Attribute zu erhalten, führen Sie eine Abfrage aus, die auf - basiert EXPLAIN (ANALYZE, BUFFERS) SELECT ....Der schlechte Punkt: Wenn Sie es ausführen, geschieht es "hier und jetzt", daher ist es nur für das lokale Debuggen geeignet. Wenn Sie einen hoch geladenen Server nehmen, der einem starken Strom von Datenänderungen ausgesetzt ist, und Sie sehen: „Ay! Hier sind wir langsamer zu Xia eine Anfrage. " Vor einer halben Stunde, einer Stunde - während Sie diese Anforderung ausgeführt und aus den Protokollen abgerufen und erneut auf den Server übertragen haben, haben sich Ihr gesamter Datensatz und Ihre Statistiken geändert. Sie führen es zum Debuggen aus - und es läuft schnell! Und Sie können nicht verstehen, warum, warum es langsam war. Um zu verstehen, was genau zu dem Zeitpunkt war, als die Anforderung auf dem Server ausgeführt wurde, haben intelligente Personen das Modul auto_explain geschrieben. Es ist in fast allen gängigen PostgreSQL-Distributionen vorhanden und kann einfach in der Konfigurationsdatei aktiviert werden.Wenn er versteht, dass eine Anfrage länger ausgeführt wird als die Grenze, die Sie ihm mitgeteilt haben, macht er einen „Schnappschuss“ des Plans für diese Anfrage und schreibt sie zusammen in ein Protokoll .
Um zu verstehen, was genau zu dem Zeitpunkt war, als die Anforderung auf dem Server ausgeführt wurde, haben intelligente Personen das Modul auto_explain geschrieben. Es ist in fast allen gängigen PostgreSQL-Distributionen vorhanden und kann einfach in der Konfigurationsdatei aktiviert werden.Wenn er versteht, dass eine Anfrage länger ausgeführt wird als die Grenze, die Sie ihm mitgeteilt haben, macht er einen „Schnappschuss“ des Plans für diese Anfrage und schreibt sie zusammen in ein Protokoll . Jetzt scheint alles in Ordnung zu sein, wir gehen zum Protokoll und sehen dort ... [Textschritt]. Aber wir können nichts über ihn sagen, außer der Tatsache, dass dies ein ausgezeichneter Plan ist, da die Fertigstellung 11 ms gedauert hat.Alles scheint in Ordnung zu sein - aber nichts ist klar darüber, was wirklich passiert ist. Neben der Gesamtzeit sehen wir nicht viel. Denn einen solchen "Latuha" Klartext anzuschauen ist im Allgemeinen beliebt.Aber selbst wenn es geliebt wird, wenn auch unangenehm, gibt es größere Probleme:
Jetzt scheint alles in Ordnung zu sein, wir gehen zum Protokoll und sehen dort ... [Textschritt]. Aber wir können nichts über ihn sagen, außer der Tatsache, dass dies ein ausgezeichneter Plan ist, da die Fertigstellung 11 ms gedauert hat.Alles scheint in Ordnung zu sein - aber nichts ist klar darüber, was wirklich passiert ist. Neben der Gesamtzeit sehen wir nicht viel. Denn einen solchen "Latuha" Klartext anzuschauen ist im Allgemeinen beliebt.Aber selbst wenn es geliebt wird, wenn auch unangenehm, gibt es größere Probleme:- . , Index Scan — , - . , «» , CTE — « ».
- : , , — . , , , , loops — . . , , , — - « ».
Verstehen Sie unter diesen Umständen "Wer ist das schwächste Glied?" fast unrealistisch. Daher schreiben selbst die Entwickler im "Handbuch", dass "Den Plan zu verstehen eine Kunst ist, die gelernt, erlebt ... werden muss" .Aber wir haben 1000 Entwickler, und jeder von ihnen wird diese Erfahrung nicht in seinen Kopf geben. Ich, du, er - sie wissen, und jemand da drüben - ist nicht mehr da. Vielleicht lernt er oder vielleicht auch nicht, aber er muss jetzt arbeiten - und woher würde er diese Erfahrung machen.Visualisierung planen
Daher haben wir erkannt, dass wir eine gute Visualisierung des Plans benötigen, um diese Probleme zu lösen . [Artikel]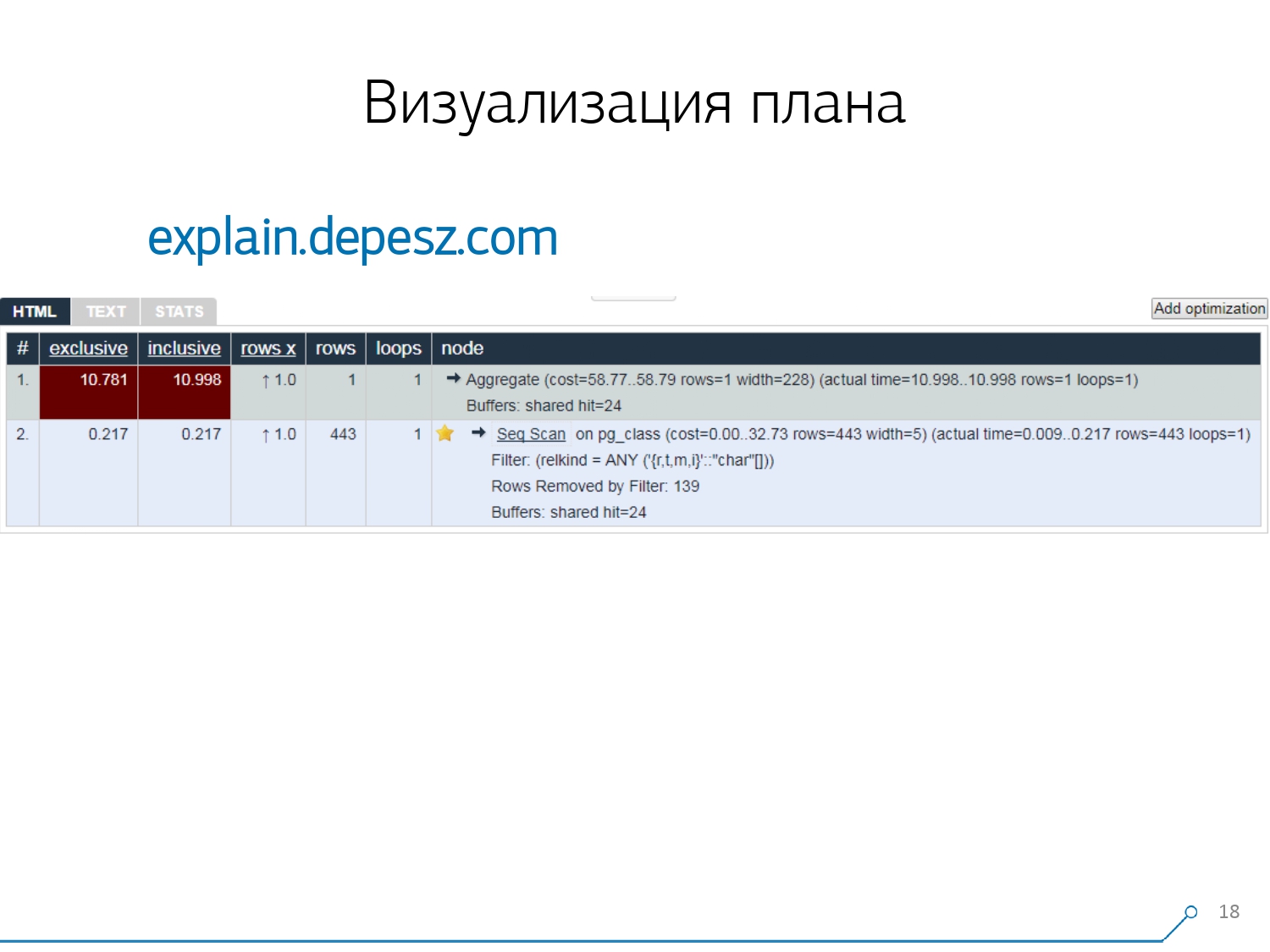 Wir gingen zuerst „um den Markt“ - schauen wir uns im Internet an, was im Allgemeinen existiert.Es stellte sich jedoch heraus, dass es relativ wenige „Live“ -Lösungen gibt, die sich mehr oder weniger entwickeln. Es gibt buchstäblich nur eines: EXPLAIN.depesz.com von Hubert Lubaczewski. Am Eingang zum Feld "Feed" eine Textdarstellung des Plans, zeigt es Ihnen eine Platte mit den analysierten Daten:
Wir gingen zuerst „um den Markt“ - schauen wir uns im Internet an, was im Allgemeinen existiert.Es stellte sich jedoch heraus, dass es relativ wenige „Live“ -Lösungen gibt, die sich mehr oder weniger entwickeln. Es gibt buchstäblich nur eines: EXPLAIN.depesz.com von Hubert Lubaczewski. Am Eingang zum Feld "Feed" eine Textdarstellung des Plans, zeigt es Ihnen eine Platte mit den analysierten Daten:- richtige Knotenarbeitszeit
- Gesamtzeit über den gesamten Teilbaum
- die Anzahl der Datensätze, die abgerufen wurden und die statistisch erwartet wurden
- der Knotenkörper selbst
Dieser Dienst kann auch das Archiv von Links freigeben. Du hast deinen Plan dorthin geworfen und gesagt: "Hey, Vasya, hier ist ein Link für dich, da stimmt etwas nicht." Es gibt jedoch einige kleinere Probleme.Erstens eine große Menge an Copy-Paste. Sie nehmen ein Stück des Protokolls, legen es dort ab und immer wieder.Zweitens gibt es keine Analyse der gelesenen Datenmenge - genau die Puffer, die angezeigt werden
Es gibt jedoch einige kleinere Probleme.Erstens eine große Menge an Copy-Paste. Sie nehmen ein Stück des Protokolls, legen es dort ab und immer wieder.Zweitens gibt es keine Analyse der gelesenen Datenmenge - genau die Puffer, die angezeigt werden EXPLAIN (ANALYZE, BUFFERS), sehen wir hier nicht. Er weiß einfach nicht, wie er sie zerlegen, verstehen und damit arbeiten soll. Wenn Sie viele Daten lesen und verstehen, dass Sie auf einer Festplatte und einem Cache im Speicher falsch "zerlegen" können, sind diese Informationen sehr wichtig.Der dritte negative Punkt ist die sehr schwache Entwicklung dieses Projekts. Die Commits sind sehr klein, es ist gut, wenn alle sechs Monate, und der Code in Perl.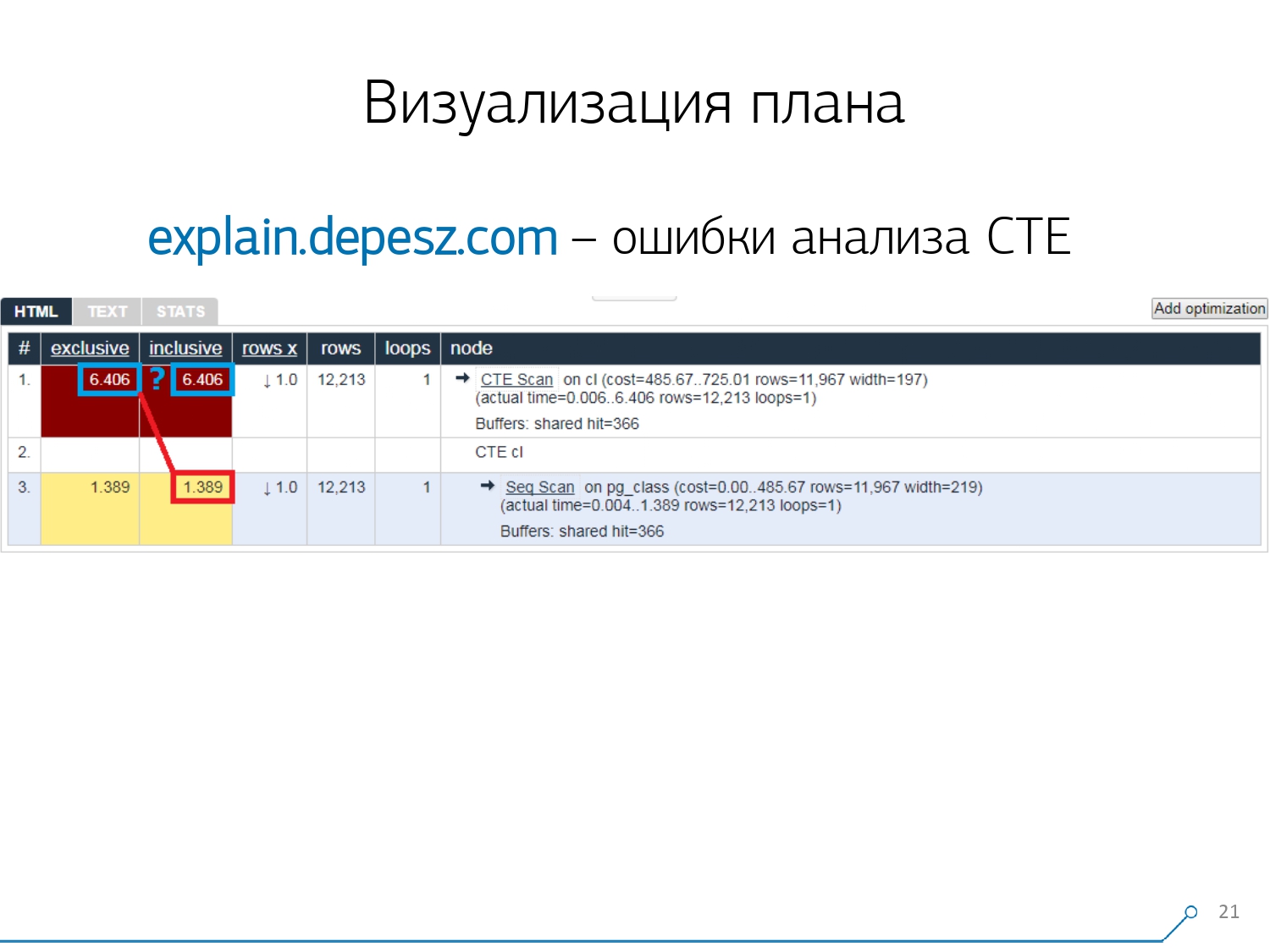 Aber das sind alles "Texte", man könnte irgendwie damit leben, aber eines hat uns von diesem Service abgewandt. Dies sind Analysefehler der Common Table Expression (CTE) und verschiedene dynamische Knoten wie InitPlan / SubPlan.Wenn Sie diesem Bild glauben, ist die Gesamtausführungszeit jedes einzelnen Knotens größer als die Gesamtausführungszeit der gesamten Anforderung. Es ist ganz einfach: Die Generierungszeit dieses CTE wurde nicht vom CTE-Scan-Knoten abgezogen . Daher wissen wir nicht mehr die richtige Antwort, wie viel der CTE-Scan selbst gekostet hat.
Aber das sind alles "Texte", man könnte irgendwie damit leben, aber eines hat uns von diesem Service abgewandt. Dies sind Analysefehler der Common Table Expression (CTE) und verschiedene dynamische Knoten wie InitPlan / SubPlan.Wenn Sie diesem Bild glauben, ist die Gesamtausführungszeit jedes einzelnen Knotens größer als die Gesamtausführungszeit der gesamten Anforderung. Es ist ganz einfach: Die Generierungszeit dieses CTE wurde nicht vom CTE-Scan-Knoten abgezogen . Daher wissen wir nicht mehr die richtige Antwort, wie viel der CTE-Scan selbst gekostet hat. Dann wurde uns klar, dass es Zeit war, unser eigenes zu schreiben - Hurra! Jeder Entwickler sagt: "Jetzt werden wir unsere eigenen schreiben, es wird einfach super!"Sie nahmen einen typischen Webdienst-Stack: den Kern auf Node.js + Express, zog Bootstrap und für schöne Diagramme - D3.js. Und unsere Erwartungen waren berechtigt - wir haben den ersten Prototyp seit 2 Wochen erhalten:
Dann wurde uns klar, dass es Zeit war, unser eigenes zu schreiben - Hurra! Jeder Entwickler sagt: "Jetzt werden wir unsere eigenen schreiben, es wird einfach super!"Sie nahmen einen typischen Webdienst-Stack: den Kern auf Node.js + Express, zog Bootstrap und für schöne Diagramme - D3.js. Und unsere Erwartungen waren berechtigt - wir haben den ersten Prototyp seit 2 Wochen erhalten:- eigener Plan-Parser
Das heißt, jetzt können wir im Allgemeinen jeden Plan aus den von PostgreSQL generierten Plänen analysieren. - korrekte Analyse dynamischer Knoten - CTE Scan, InitPlan, SubPlan
- Analyse der Verteilung von Puffern - wo Seiten mit Daten aus dem Speicher gelesen werden, wo aus dem lokalen Cache, wo von der Festplatte
- Sichtbarkeit erhalten
Damit es nicht "im Protokoll" ist, dass es "gräbt", sondern dass Sie das "schwächste Glied" sofort im Bild sehen.
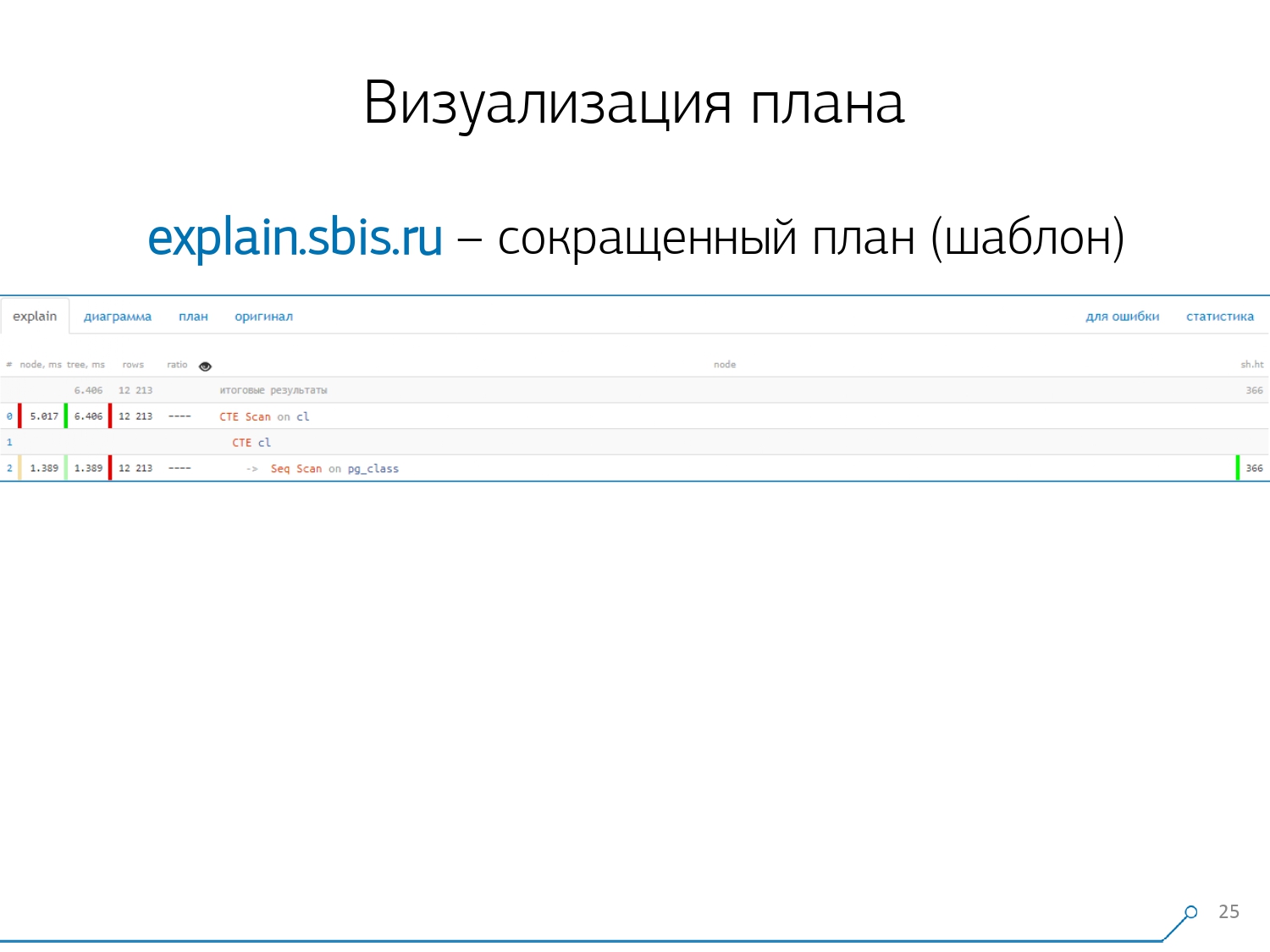 Wir haben so etwas - sofort mit Syntaxhervorhebung. Normalerweise arbeiten unsere Entwickler jedoch nicht mehr mit einer vollständigen Präsentation des Plans, sondern mit einer kürzeren. Immerhin haben wir bereits alle Ziffern analysiert und nach links und rechts geworfen, und in der Mitte haben wir nur die erste Zeile gelassen: Was für ein Knoten ist das: CTE-Scan, CTE- oder Seq-Scan-Generierung durch eine Art Etikett.Diese abgekürzte Ansicht nennen wir die Planvorlage .
Wir haben so etwas - sofort mit Syntaxhervorhebung. Normalerweise arbeiten unsere Entwickler jedoch nicht mehr mit einer vollständigen Präsentation des Plans, sondern mit einer kürzeren. Immerhin haben wir bereits alle Ziffern analysiert und nach links und rechts geworfen, und in der Mitte haben wir nur die erste Zeile gelassen: Was für ein Knoten ist das: CTE-Scan, CTE- oder Seq-Scan-Generierung durch eine Art Etikett.Diese abgekürzte Ansicht nennen wir die Planvorlage .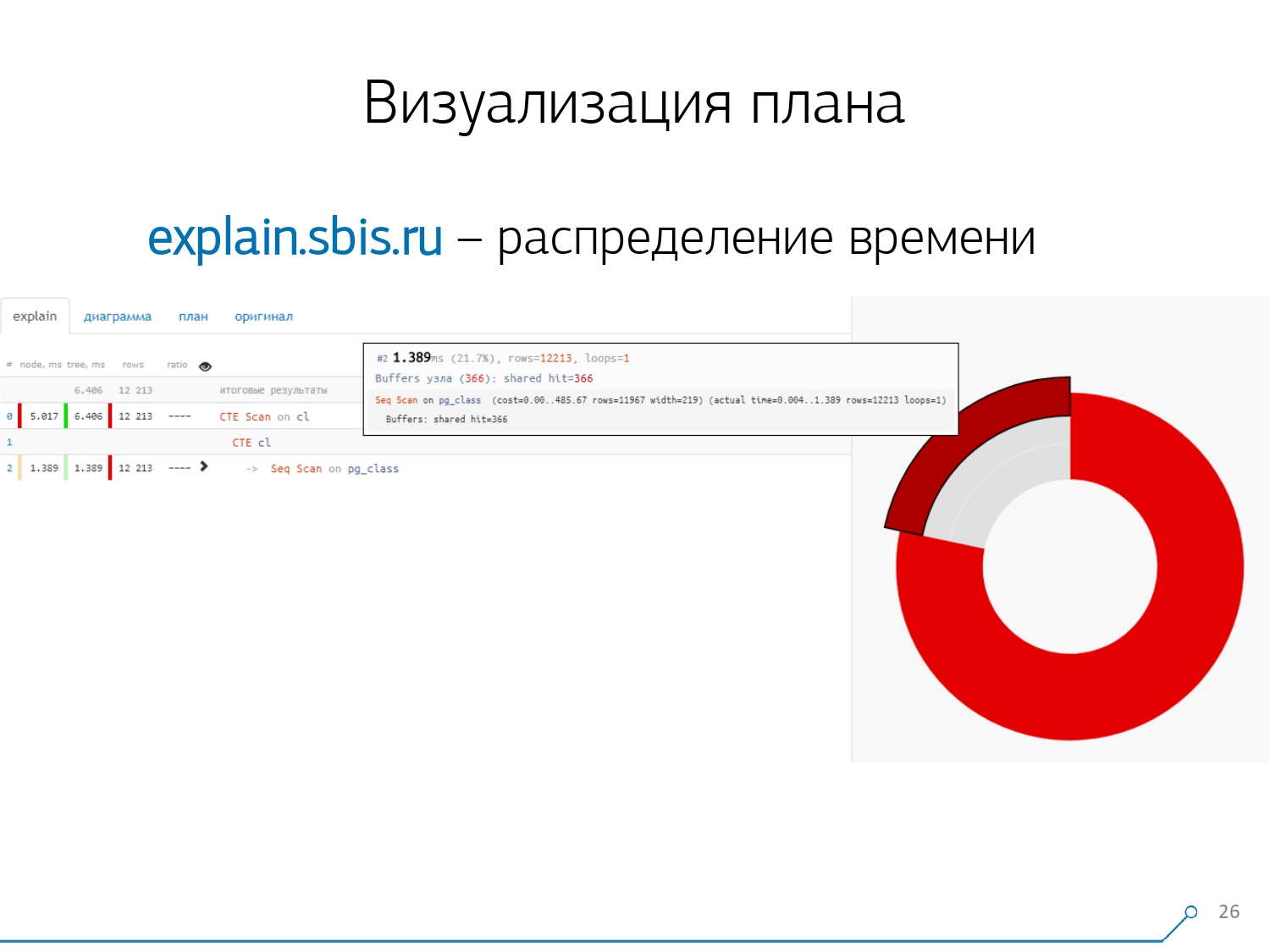 Was wäre sonst noch bequem? Es wäre praktisch zu sehen, welcher Anteil von welchem Knoten der Gesamtzeit uns zugewiesen ist - und einfach das Kreisdiagramm auf der Seite „festzuhalten“ .Wir zeigen auf den Knoten und sehen - bei uns hat sich herausgestellt, dass Seq Scan weniger als ein Viertel der gesamten Zeit in Anspruch genommen hat und die restlichen 3/4 CTE Scan. Grusel! Dies ist eine kleine Bemerkung zur „Feuerrate“ von CTE Scan, wenn Sie diese aktiv in Ihren Abfragen verwenden. Sie sind nicht sehr schnell - sie verlieren sogar gegenüber dem üblichen Tabellenscan. [Artikel] [Artikel]Aber normalerweise sind solche Diagramme interessanter und komplizierter, wenn wir sofort auf ein Segment zeigen, und wir sehen zum Beispiel, dass mehr als die Hälfte der Zeit ein Seq-Scan „gegessen“ hat. Außerdem war eine Art Filter drin, ein paar Datensätze wurden darauf abgelegt ... Sie können dieses Bild direkt an den Entwickler werfen und sagen: „Vasya, hier ist alles schlecht mit Ihnen! Verstehe, schau - etwas stimmt nicht! “
Was wäre sonst noch bequem? Es wäre praktisch zu sehen, welcher Anteil von welchem Knoten der Gesamtzeit uns zugewiesen ist - und einfach das Kreisdiagramm auf der Seite „festzuhalten“ .Wir zeigen auf den Knoten und sehen - bei uns hat sich herausgestellt, dass Seq Scan weniger als ein Viertel der gesamten Zeit in Anspruch genommen hat und die restlichen 3/4 CTE Scan. Grusel! Dies ist eine kleine Bemerkung zur „Feuerrate“ von CTE Scan, wenn Sie diese aktiv in Ihren Abfragen verwenden. Sie sind nicht sehr schnell - sie verlieren sogar gegenüber dem üblichen Tabellenscan. [Artikel] [Artikel]Aber normalerweise sind solche Diagramme interessanter und komplizierter, wenn wir sofort auf ein Segment zeigen, und wir sehen zum Beispiel, dass mehr als die Hälfte der Zeit ein Seq-Scan „gegessen“ hat. Außerdem war eine Art Filter drin, ein paar Datensätze wurden darauf abgelegt ... Sie können dieses Bild direkt an den Entwickler werfen und sagen: „Vasya, hier ist alles schlecht mit Ihnen! Verstehe, schau - etwas stimmt nicht! “ Natürlich gab es einen "Rechen".Das erste, worauf sie „getreten“ sind, ist das Problem der Rundung. Die Knotenzeit jedes Individuums im Plan wird mit einer Genauigkeit von 1 μs angegeben. Und wenn die Anzahl der Knotenzyklen beispielsweise 1000 überschreitet - nach der Ausführung hat PostgreSQL sie "bis zu" aufgeteilt, dann erhalten wir in der umgekehrten Berechnung die Gesamtzeit "irgendwo zwischen 0,95 ms und 1,05 ms". Wenn das Konto in Mikrosekunden ausgegeben wird - noch nichts, aber bereits für [Millisekunden] -, müssen diese Informationen berücksichtigt werden, wenn Ressourcen auf den Knoten des "Wer hat wie viel verbraucht" "gelöst" werden.
Natürlich gab es einen "Rechen".Das erste, worauf sie „getreten“ sind, ist das Problem der Rundung. Die Knotenzeit jedes Individuums im Plan wird mit einer Genauigkeit von 1 μs angegeben. Und wenn die Anzahl der Knotenzyklen beispielsweise 1000 überschreitet - nach der Ausführung hat PostgreSQL sie "bis zu" aufgeteilt, dann erhalten wir in der umgekehrten Berechnung die Gesamtzeit "irgendwo zwischen 0,95 ms und 1,05 ms". Wenn das Konto in Mikrosekunden ausgegeben wird - noch nichts, aber bereits für [Millisekunden] -, müssen diese Informationen berücksichtigt werden, wenn Ressourcen auf den Knoten des "Wer hat wie viel verbraucht" "gelöst" werden. Der zweite, komplexere Punkt ist die Verteilung von Ressourcen (dieselben Puffer) auf dynamische Knoten. Dies kostete uns die ersten 2 Wochen des Prototyps plus das Plus von Woche 4.Dieses Problem zu lösen ist ganz einfach - wir machen einen CTE und lesen angeblich etwas darin. Tatsächlich ist PostgreSQL intelligent und liest dort nichts. Dann nehmen wir die erste Aufzeichnung davon und die ersten hundert vom gleichen CTE dazu.
Der zweite, komplexere Punkt ist die Verteilung von Ressourcen (dieselben Puffer) auf dynamische Knoten. Dies kostete uns die ersten 2 Wochen des Prototyps plus das Plus von Woche 4.Dieses Problem zu lösen ist ganz einfach - wir machen einen CTE und lesen angeblich etwas darin. Tatsächlich ist PostgreSQL intelligent und liest dort nichts. Dann nehmen wir die erste Aufzeichnung davon und die ersten hundert vom gleichen CTE dazu.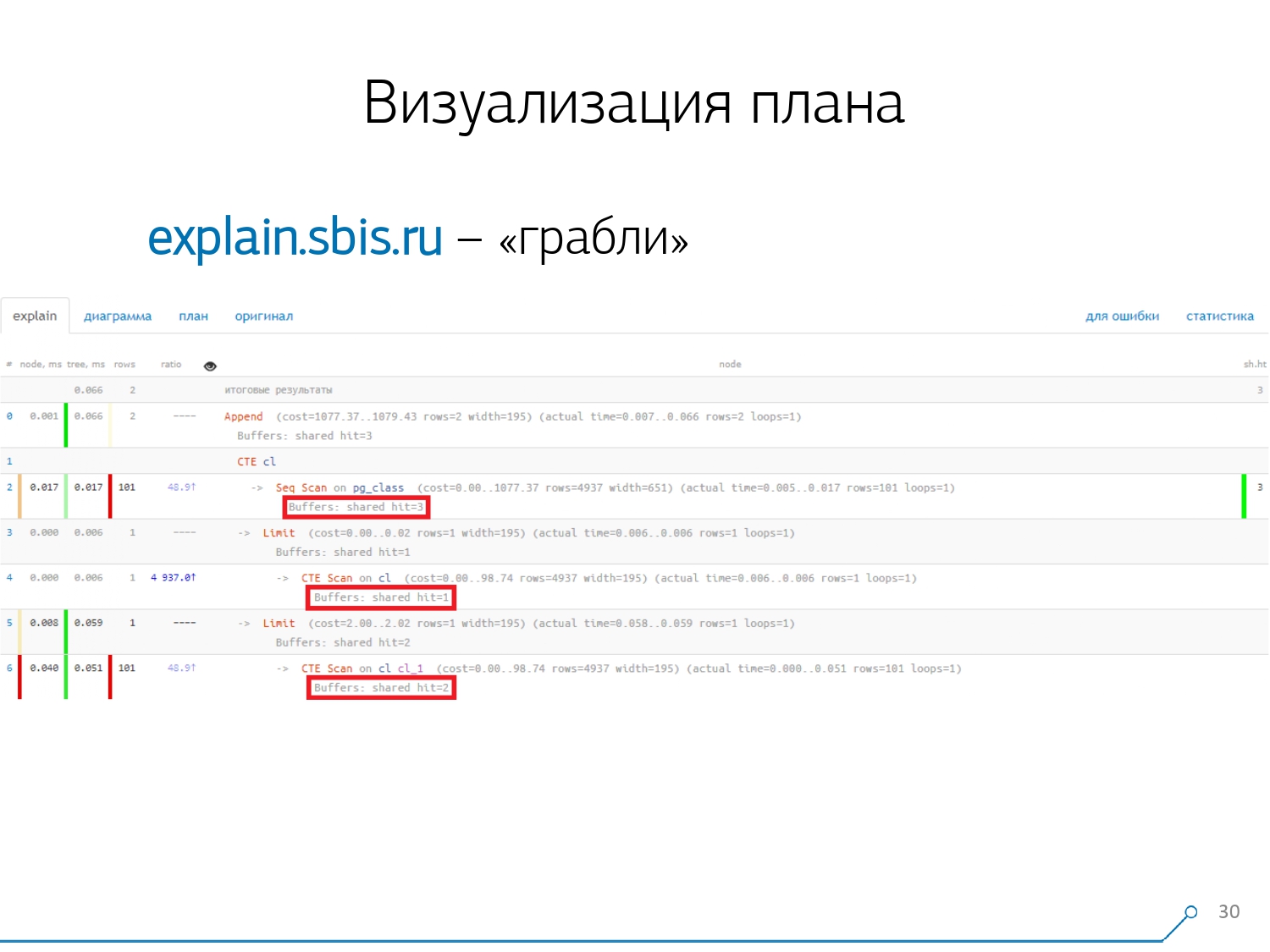 Wir schauen uns den Plan an und verstehen - seltsam, wir haben 3 Puffer (Datenseiten), die im Seq Scan "verbraucht" wurden, einen weiteren im CTE Scan und zwei weitere im zweiten CTE Scan. Das heißt, wenn alles einfach zusammengefasst wird, erhalten wir 6, aber von der Platte lesen wir nur 3! CTE Scan liest nichts von irgendwoher, sondern arbeitet direkt mit dem Prozessspeicher. Das heißt, hier stimmt eindeutig etwas nicht!Tatsächlich stellt sich heraus, dass hier alle 3 Seiten mit Daten, die von Seq Scan angefordert wurden, zuerst 1 nach dem 1. CTE-Scan und dann nach dem 2. gefragt wurden und weitere 2 gelesen wurden. Das heißt, insgesamt wurden 3 Seiten gelesen Daten, nicht 6.
Wir schauen uns den Plan an und verstehen - seltsam, wir haben 3 Puffer (Datenseiten), die im Seq Scan "verbraucht" wurden, einen weiteren im CTE Scan und zwei weitere im zweiten CTE Scan. Das heißt, wenn alles einfach zusammengefasst wird, erhalten wir 6, aber von der Platte lesen wir nur 3! CTE Scan liest nichts von irgendwoher, sondern arbeitet direkt mit dem Prozessspeicher. Das heißt, hier stimmt eindeutig etwas nicht!Tatsächlich stellt sich heraus, dass hier alle 3 Seiten mit Daten, die von Seq Scan angefordert wurden, zuerst 1 nach dem 1. CTE-Scan und dann nach dem 2. gefragt wurden und weitere 2 gelesen wurden. Das heißt, insgesamt wurden 3 Seiten gelesen Daten, nicht 6.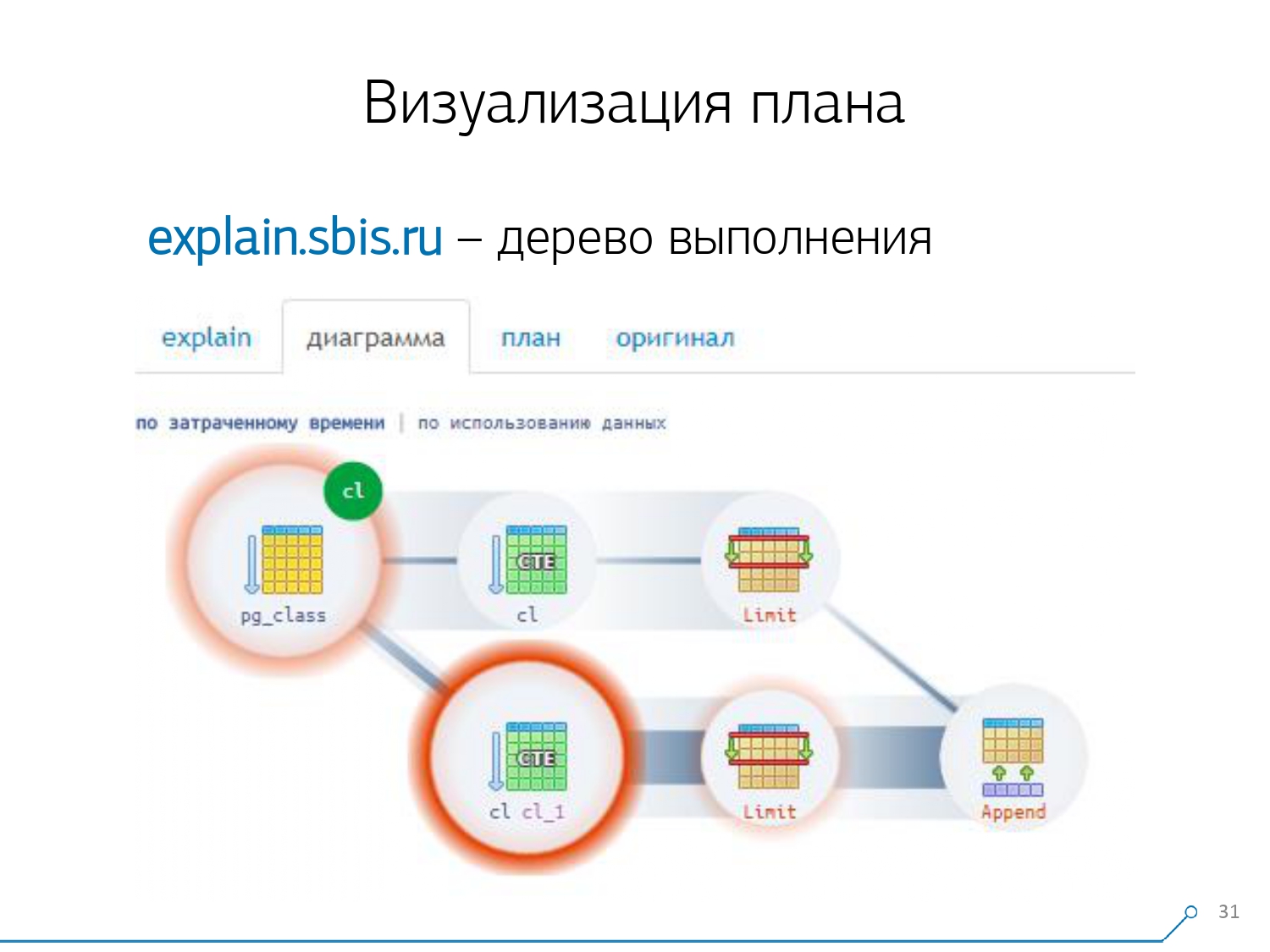 Und dieses Bild hat uns zu dem Verständnis geführt, dass die Umsetzung des Plans kein Baum mehr ist, sondern nur eine Art azyklischer Graph. Und wir haben ein Diagramm wie dieses, damit wir verstehen, "woher es überhaupt kam". Das heißt, hier haben wir einen CTE aus pg_class erstellt und zweimal danach gefragt, und fast die ganze Zeit haben wir den Zweig in Anspruch genommen, als wir das zweite Mal danach gefragt haben. Es ist klar, dass das Lesen der 101. Aufzeichnung viel teurer ist als nur die 1. des Tablets.
Und dieses Bild hat uns zu dem Verständnis geführt, dass die Umsetzung des Plans kein Baum mehr ist, sondern nur eine Art azyklischer Graph. Und wir haben ein Diagramm wie dieses, damit wir verstehen, "woher es überhaupt kam". Das heißt, hier haben wir einen CTE aus pg_class erstellt und zweimal danach gefragt, und fast die ganze Zeit haben wir den Zweig in Anspruch genommen, als wir das zweite Mal danach gefragt haben. Es ist klar, dass das Lesen der 101. Aufzeichnung viel teurer ist als nur die 1. des Tablets. Wir atmeten eine Weile aus. Sie sagten: „Nun, Neo, du kennst Kung Fu! Jetzt ist unsere Erfahrung direkt auf Ihrem Bildschirm. Jetzt kannst du es benutzen. “ [Artikel]
Wir atmeten eine Weile aus. Sie sagten: „Nun, Neo, du kennst Kung Fu! Jetzt ist unsere Erfahrung direkt auf Ihrem Bildschirm. Jetzt kannst du es benutzen. “ [Artikel]Protokollkonsolidierung
Unsere 1000 Entwickler atmeten erleichtert auf. Wir haben jedoch verstanden, dass wir nur Hunderte von "Battle" -Servern haben, und all dieses "Copy-Paste" durch die Entwickler ist überhaupt nicht bequem. Wir erkannten, dass wir es selbst sammeln mussten. Im Allgemeinen gibt es ein reguläres Modul, das Statistiken erfassen kann. Es muss jedoch auch in der Konfiguration aktiviert werden - dies ist das Modul pg_stat_statements . Aber er passte nicht zu uns.Erstens weist es denselben Abfragen in verschiedenen Schemata innerhalb derselben Datenbank unterschiedliche QueryId zu . Das heißt, wenn Sie zuerst dieselbe Anfrage stellen
Im Allgemeinen gibt es ein reguläres Modul, das Statistiken erfassen kann. Es muss jedoch auch in der Konfiguration aktiviert werden - dies ist das Modul pg_stat_statements . Aber er passte nicht zu uns.Erstens weist es denselben Abfragen in verschiedenen Schemata innerhalb derselben Datenbank unterschiedliche QueryId zu . Das heißt, wenn Sie zuerst dieselbe Anfrage stellen SET search_path = '01'; SELECT * FROM user LIMIT 1;und dann SET search_path = '02';dieselbe, haben die Statistiken dieses Moduls unterschiedliche Einträge, und ich kann keine allgemeinen Statistiken genau im Kontext dieses Anforderungsprofils erfassen, ohne die Schemata zu berücksichtigen.Der zweite Punkt, der uns daran gehindert hat, es zu benutzen, ist das Fehlen von Plänen . Das heißt, es gibt keinen Plan, es gibt nur die Anfrage selbst. Wir sehen, was sich verlangsamt hat, aber wir verstehen nicht warum. Und hier kehren wir zum Problem eines sich schnell ändernden Datensatzes zurück.Und der letzte Punkt ist der Mangel an „Fakten . “ Das heißt, es ist unmöglich, eine bestimmte Instanz der Abfrageausführung zu adressieren - sie ist nicht vorhanden, es gibt nur aggregierte Statistiken. Obwohl es möglich ist, damit zu arbeiten, ist es nur sehr schwierig.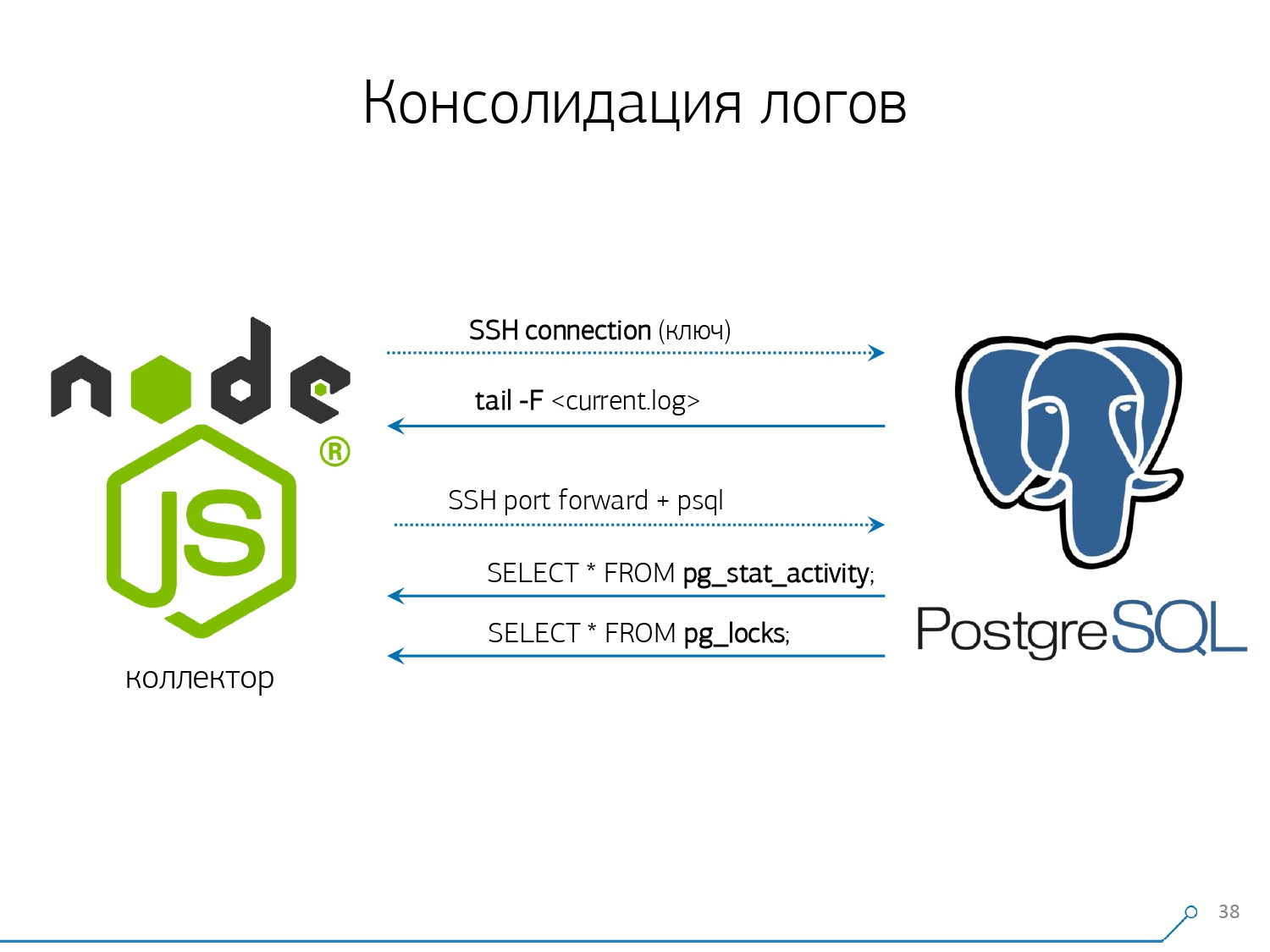 Aus diesem Grund haben wir uns entschlossen, gegen das Kopieren und Einfügen zu kämpfen, und haben begonnen, einen Sammler zu schreiben .Der Kollektor ist über SSH verbunden, "zieht" eine sichere Verbindung zum Server mit der Datenbank unter Verwendung des Zertifikats und
Aus diesem Grund haben wir uns entschlossen, gegen das Kopieren und Einfügen zu kämpfen, und haben begonnen, einen Sammler zu schreiben .Der Kollektor ist über SSH verbunden, "zieht" eine sichere Verbindung zum Server mit der Datenbank unter Verwendung des Zertifikats und tail -F"klammert" sich an die Protokolldatei. Also in dieser SitzungWir erhalten einen vollständigen "Spiegel" der gesamten Protokolldatei , die der Server generiert. Die Belastung des Servers selbst ist minimal, da wir dort nichts analysieren, sondern lediglich den Datenverkehr spiegeln.Da wir bereits begonnen haben, die Schnittstelle auf Node.js zu schreiben, haben wir den Kollektor weiter darauf geschrieben. Diese Technologie hat sich ausgezahlt, da es sehr praktisch ist, JavaScript für die Arbeit mit schlecht formatierten Textdaten zu verwenden. Dies ist das Protokoll. Und die Node.js-Infrastruktur selbst als Backend-Plattform ermöglicht es Ihnen, einfach und bequem mit Netzwerkverbindungen und tatsächlich mit Datenströmen zu arbeiten.Dementsprechend "ziehen" wir zwei Verbindungen: Die erste besteht darin, das Protokoll selbst "abzuhören" und es zu uns zu nehmen, und die zweite besteht darin, die Datenbank regelmäßig zu fragen. "Aber im Protokoll ist angekommen, dass die Platte mit OID 123 blockiert wurde", aber es sagt dem Entwickler nichts, und es wäre schön, die Basis zu fragen: "Was ist OID = 123?" Deshalb fragen wir die Basis regelmäßig nach etwas, das wir zu Hause noch nicht kennen. "Sie haben es einfach nicht berücksichtigt, es gibt eine Art elefantenähnliche Bienen!" Wir begannen mit der Entwicklung dieses Systems, als wir 10 Server überwachen wollten. Das kritischste in unserem Verständnis, bei dem es einige Probleme gab, die schwer zu lösen waren. Aber im ersten Quartal haben wir hundert für die Überwachung bekommen - weil das System „reingegangen“ ist, jeder es wollte, jeder sich wohl fühlte.All dies muss hinzugefügt werden, der Datenstrom ist groß, aktiv. Eigentlich überwachen wir, was wir können - dann nutzen wir es. Wir verwenden PostgreSQL auch als Data Warehouse. Aber nichts ist schneller, um Daten darin zu "gießen", als
"Sie haben es einfach nicht berücksichtigt, es gibt eine Art elefantenähnliche Bienen!" Wir begannen mit der Entwicklung dieses Systems, als wir 10 Server überwachen wollten. Das kritischste in unserem Verständnis, bei dem es einige Probleme gab, die schwer zu lösen waren. Aber im ersten Quartal haben wir hundert für die Überwachung bekommen - weil das System „reingegangen“ ist, jeder es wollte, jeder sich wohl fühlte.All dies muss hinzugefügt werden, der Datenstrom ist groß, aktiv. Eigentlich überwachen wir, was wir können - dann nutzen wir es. Wir verwenden PostgreSQL auch als Data Warehouse. Aber nichts ist schneller, um Daten darin zu "gießen", als COPYes noch keinen Operator gibt .Aber nur die Daten zu „gießen“, ist nicht wirklich unsere Technologie. Wenn Sie auf 100.000 Servern ungefähr 50.000 Anfragen pro Sekunde haben, werden dadurch 100 bis 150 GB Protokolle pro Tag für Sie generiert. Deshalb mussten wir die Basis sorgfältig „sägen“.Erstens haben wir die Partitionierung jeden Tag durchgeführt , da im Großen und Ganzen niemand an der Korrelation zwischen den Tagen interessiert ist. Was ist der Unterschied, den Sie gestern hatten, wenn Sie heute Abend eine neue Version der Anwendung herausgebracht haben - und bereits einige neue Statistiken.Zweitens haben wir gelernt (waren gezwungen) , sehr, sehr schnell mit zu schreibenCOPY . Das heißt, nicht nur, COPYweil es schneller ist als INSERT, sondern noch schneller. Der dritte Punkt - ich musste die Auslöser bzw. die Fremdschlüssel aufgeben . Das heißt, wir haben keine absolut referenzielle Integrität. Denn wenn Sie eine Tabelle haben, in der sich ein Paar von FK befindet, und Sie in der Datenbankstruktur sagen, dass "hier ein Protokolleintrag sich auf FK bezieht, zum Beispiel eine Gruppe von Datensätzen", hat PostgreSQL beim Einfügen nichts anderes zu tun, als wie man
Der dritte Punkt - ich musste die Auslöser bzw. die Fremdschlüssel aufgeben . Das heißt, wir haben keine absolut referenzielle Integrität. Denn wenn Sie eine Tabelle haben, in der sich ein Paar von FK befindet, und Sie in der Datenbankstruktur sagen, dass "hier ein Protokolleintrag sich auf FK bezieht, zum Beispiel eine Gruppe von Datensätzen", hat PostgreSQL beim Einfügen nichts anderes zu tun, als wie man SELECT 1 FROM master_fk1_table WHERE ...mit der Kennung, die Sie einfügen möchten, nimmt und ehrlich ausführt - nur um zu überprüfen, ob dieser Eintrag vorhanden ist, dass Sie diesen Fremdschlüssel nicht mit Ihrer Einfügung "abbrechen".Wir erhalten anstelle eines Datensatzes in der Zieltabelle und ihrer Indizes ein weiteres Plus des Lesens aus allen Tabellen, auf die es verweist. Und wir brauchen es überhaupt nicht - unsere Aufgabe ist es, so viel wie möglich und so schnell wie möglich mit der geringsten Belastung aufzuschreiben. Also FK - runter!Der nächste Punkt ist Aggregation und Hashing. Ursprünglich wurden sie bei uns in der Datenbank implementiert. Schließlich ist es praktisch, sofort, wenn der Datensatz eintrifft, "plus eins" in einer Art Platte direkt im Trigger einzugeben . Es ist gut, praktisch, aber das Gleiche ist schlecht - fügen Sie einen Datensatz ein, aber Sie müssen etwas anderes aus einer anderen Tabelle lesen und schreiben. Darüber hinaus nicht nur das, lesen und schreiben - und das jedes Mal.Stellen Sie sich nun vor, Sie haben ein Schild, auf dem Sie einfach die Anzahl der Anfragen zählen, die an einen bestimmten Host weitergeleitet wurden:+1, +1, +1, ..., +1. Und Sie brauchen es im Prinzip nicht - all dies kann im Speicher des Kollektors zusammengefasst und gleichzeitig an die Datenbank gesendet werden +10.Ja, Ihre logische Integrität kann bei einigen Problemen "auseinanderfallen", aber dies ist fast ein unrealistischer Fall - da Sie einen normalen Server haben, eine Batterie im Controller vorhanden ist, Sie ein Transaktionsprotokoll haben, ein Protokoll im Dateisystem ... Im Allgemeinen nicht es ist es wert. Es ist den Produktivitätsverlust nicht wert, den Sie durch die Arbeit von Triggern / FK erhalten, die Kosten, die Ihnen gleichzeitig entstehen.Gleiches gilt für Hashing. Eine bestimmte Anfrage fliegt zu Ihnen, Sie berechnen eine bestimmte Kennung aus der Datenbank daraus, schreiben in die Datenbank und teilen sie dann allen mit. Alles ist gut, bis zum Zeitpunkt der Aufnahme eine zweite Person zu Ihnen kommt, die es aufnehmen möchte - und Sie haben eine Sperre, und das ist schon schlecht. Wenn Sie daher die Generierung einiger IDs auf dem Client (relativ zur Datenbank) durchführen können, ist es besser, dies zu tun.Wir waren einfach ideal geeignet, um MD5 aus dem Text zu verwenden - eine Anfrage, einen Plan, eine Vorlage, ... Wir berechnen sie auf der Sammlerseite und "gießen" die bereits vorbereitete ID in die Datenbank. Die MD5-Länge und die tägliche Partitionierung ermöglichen es uns, uns keine Gedanken über mögliche Kollisionen zu machen.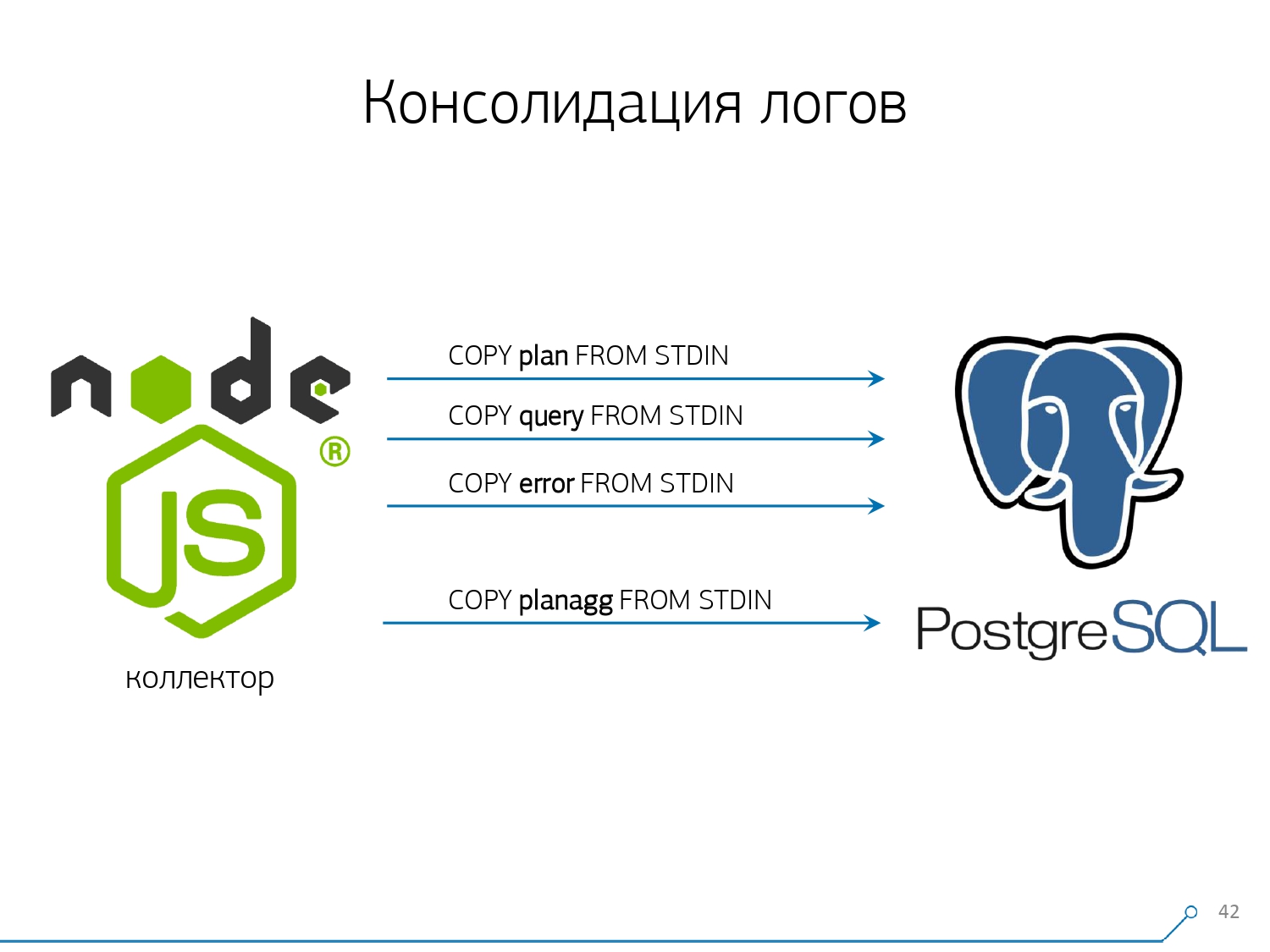 Um dies alles schnell aufzuzeichnen, mussten wir das Aufnahmeverfahren selbst ändern.Wie schreibt man normalerweise Daten? Wir haben eine Art Datensatz, zerlegen ihn in mehrere Tabellen und kopieren ihn dann - zuerst in der ersten, dann in der zweiten, in der dritten ... Es ist unpraktisch, weil wir einen Datenstrom in drei Schritten nacheinander schreiben. Unangenehm. Ist es möglich, schneller zu machen? Kann!Dazu reicht es aus, diese Ströme nur parallel zu zerlegen. Es stellt sich heraus, dass wir Fehler, Anforderungen, Vorlagen, Sperren haben, in separaten Streams fliegen ... - und wir schreiben alles parallel. Halten Sie dazu einfach den COPY-Kanal für jede einzelne Zieltabelle permanent offen .
Um dies alles schnell aufzuzeichnen, mussten wir das Aufnahmeverfahren selbst ändern.Wie schreibt man normalerweise Daten? Wir haben eine Art Datensatz, zerlegen ihn in mehrere Tabellen und kopieren ihn dann - zuerst in der ersten, dann in der zweiten, in der dritten ... Es ist unpraktisch, weil wir einen Datenstrom in drei Schritten nacheinander schreiben. Unangenehm. Ist es möglich, schneller zu machen? Kann!Dazu reicht es aus, diese Ströme nur parallel zu zerlegen. Es stellt sich heraus, dass wir Fehler, Anforderungen, Vorlagen, Sperren haben, in separaten Streams fliegen ... - und wir schreiben alles parallel. Halten Sie dazu einfach den COPY-Kanal für jede einzelne Zieltabelle permanent offen . Das heißt, der Sammler hat immer einen Streamin die ich die Daten schreiben kann, die ich brauche. Damit die Datenbank diese Daten sieht und jemand nicht in den Schlössern hängt und darauf wartet, dass diese Daten geschrieben werden, muss COPY mit einer bestimmten Häufigkeit unterbrochen werden . Für uns erwies sich ein Zeitraum in der Größenordnung von 100 ms als am effektivsten - schließen Sie ihn und öffnen Sie ihn sofort wieder auf demselben Tisch. Und wenn wir an einigen Spitzen keinen Stream haben, bündeln wir bis zu einem bestimmten Limit.Darüber hinaus haben wir herausgefunden, dass für ein solches Lastprofil jede Aggregation, wenn Datensätze in Paketen gesammelt werden, böse ist. Das klassische Böse ist
Das heißt, der Sammler hat immer einen Streamin die ich die Daten schreiben kann, die ich brauche. Damit die Datenbank diese Daten sieht und jemand nicht in den Schlössern hängt und darauf wartet, dass diese Daten geschrieben werden, muss COPY mit einer bestimmten Häufigkeit unterbrochen werden . Für uns erwies sich ein Zeitraum in der Größenordnung von 100 ms als am effektivsten - schließen Sie ihn und öffnen Sie ihn sofort wieder auf demselben Tisch. Und wenn wir an einigen Spitzen keinen Stream haben, bündeln wir bis zu einem bestimmten Limit.Darüber hinaus haben wir herausgefunden, dass für ein solches Lastprofil jede Aggregation, wenn Datensätze in Paketen gesammelt werden, böse ist. Das klassische Böse ist INSERT ... VALUESjenseits von 1000 Aufzeichnungen. Denn in diesem Moment haben Sie eine Spitzenaufnahme auf den Medien, und alle anderen, die versuchen, etwas auf die Festplatte zu schreiben, warten.Um solche Anomalien zu beseitigen, aggregieren Sie einfach nichts, puffern Sie überhaupt nicht . Und wenn eine Pufferung auf die Festplatte auftritt (zum Glück können Sie dies mithilfe der Stream-API in Node.js herausfinden) - verschieben Sie diese Verbindung. Dann kommt das Ereignis zu Ihnen, dass es wieder kostenlos ist - schreiben Sie aus der angesammelten Warteschlange darauf. In der Zwischenzeit ist viel los - nehmen Sie den nächsten kostenlosen aus dem Pool und schreiben Sie ihm.Vor der Implementierung dieses Ansatzes für die Datenaufzeichnung hatten wir ungefähr 4K-Schreiboperationen und auf diese Weise haben wir die Last um das 4-fache reduziert. Jetzt sind sie aufgrund neuer beobachtbarer Basen weitere 6-mal gewachsen - bis zu 100 MB / s. Und jetzt speichern wir Protokolle der letzten 3 Monate in einer Menge von etwa 10-15 TB, in der Hoffnung, dass jeder Entwickler in nur drei Monaten jedes Problem lösen kann.Wir verstehen die Probleme
Aber all diese Daten zu sammeln ist gut, nützlich, angemessen, aber nicht genug - Sie müssen es verstehen. Weil es täglich Millionen verschiedener Pläne gibt. Aber Millionen sind unkontrollierbar, Sie müssen zuerst "weniger" tun. Und zuallererst muss entschieden werden, wie Sie diese „kleinere“ organisieren.Wir haben drei wichtige Punkte für uns identifiziert:
Aber Millionen sind unkontrollierbar, Sie müssen zuerst "weniger" tun. Und zuallererst muss entschieden werden, wie Sie diese „kleinere“ organisieren.Wir haben drei wichtige Punkte für uns identifiziert:- Wer hat diese Anfrage gesendet?
Das heißt, von welcher Anwendung er "geflogen" ist: Webinterface, Backend, Zahlungssystem oder etwas anderes. - Wo ist das passiert?
Auf welchem Server? Denn wenn Sie mehrere Server unter einer Anwendung haben und plötzlich einer "langweilig" wird (weil die "Festplatte verrottet" ist, "der Speicher durchgesickert ist", einige andere Probleme), müssen Sie den Server speziell ansprechen. - wie sich das Problem auf die eine oder andere Weise manifestierte
Um zu verstehen, wer uns die Anfrage gesendet hat, verwenden wir ein reguläres Tool, das eine Sitzungsvariable festlegt: SET application_name = '{bl-host}:{bl-method}';- Senden Sie den Hostnamen der Geschäftslogik, von der die Anfrage gesendet wird, und den Namen der Methode oder Anwendung, die sie initiiert hat.Nachdem wir den "Eigentümer" der Anfrage übergeben haben, muss diese im Protokoll angezeigt werden - dafür konfigurieren wir die Variable log_line_prefix = ' %m [%p:%v] [%d] %r %a'. Jeder Interessierte kann im Handbuch sehen, was dies alles bedeutet. Es stellt sich heraus, dass wir im Protokoll sehen:- Zeit
- Prozess- und Transaktionskennungen
- Basisname
- IP der Person, die diese Anfrage gesendet hat
- und Methodenname
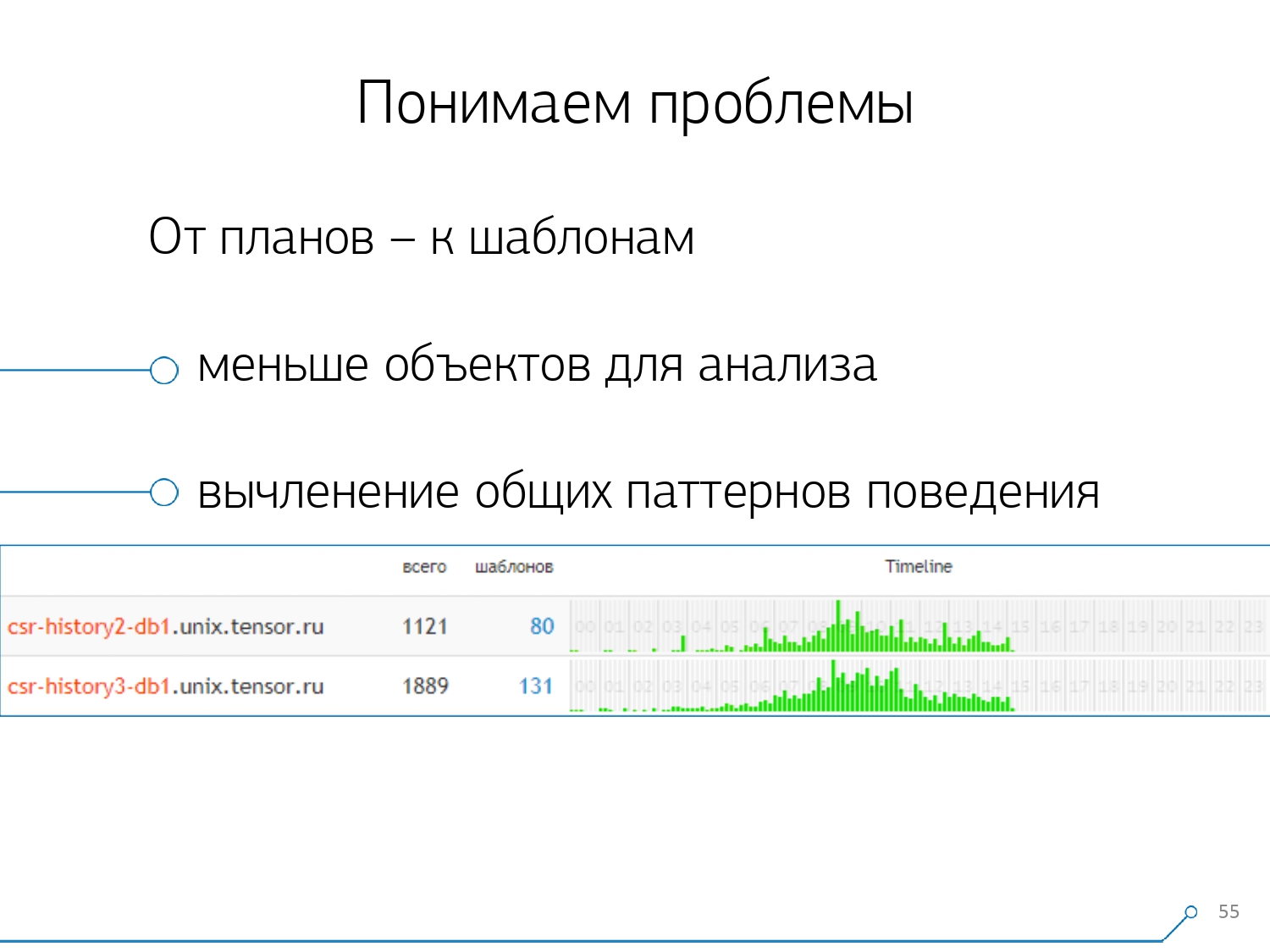 Dann haben wir festgestellt, dass es nicht sehr interessant ist, die Korrelation einer Anfrage zwischen verschiedenen Servern zu untersuchen. Es kommt selten vor, wenn Sie eine Anwendung haben, die hier und da gleichermaßen scheißt. Aber auch wenn es dasselbe ist, schauen Sie sich einen dieser Server an.Der Abschnitt „Ein Server - ein Tag“ hat sich für jede Analyse als ausreichend erwiesen.Der erste analytische Abschnitt ist die „Vorlage“ - eine abgekürzte Form der Darstellung des Plans, die von allen numerischen Indikatoren befreit ist. Der zweite Abschnitt ist die Anwendung oder Methode, und der dritte ist der spezifische Knoten des Plans, der uns Probleme verursacht hat.Beim Wechsel von bestimmten Instanzen zu Vorlagen haben wir sofort zwei Vorteile erhalten:
Dann haben wir festgestellt, dass es nicht sehr interessant ist, die Korrelation einer Anfrage zwischen verschiedenen Servern zu untersuchen. Es kommt selten vor, wenn Sie eine Anwendung haben, die hier und da gleichermaßen scheißt. Aber auch wenn es dasselbe ist, schauen Sie sich einen dieser Server an.Der Abschnitt „Ein Server - ein Tag“ hat sich für jede Analyse als ausreichend erwiesen.Der erste analytische Abschnitt ist die „Vorlage“ - eine abgekürzte Form der Darstellung des Plans, die von allen numerischen Indikatoren befreit ist. Der zweite Abschnitt ist die Anwendung oder Methode, und der dritte ist der spezifische Knoten des Plans, der uns Probleme verursacht hat.Beim Wechsel von bestimmten Instanzen zu Vorlagen haben wir sofort zwei Vorteile erhalten:
, .
, «» - , . , - , , , — , , — , , . , , .
 Die übrigen Methoden basieren auf den Indikatoren, die wir aus dem Plan extrahieren: Wie oft ist eine solche Vorlage aufgetreten, wie lange und durchschnittlich insgesamt, wie viel Daten von der Festplatte gelesen wurden und wie viel aus dem Speicher ...Weil Sie beispielsweise vom Host auf die Analyseseite gelangen, siehe - etwas zu viel auf der Festplatte, um den Anfang zu lesen. Die Festplatte auf dem Server kommt nicht zurecht - und wer liest daraus?Und Sie können nach jeder Spalte sortieren und entscheiden, was Sie gerade tun - mit der Belastung des Prozessors oder der Festplatte oder mit der Gesamtzahl der Anforderungen ... Sortiert, „top“, repariert - haben eine neue Version der Anwendung eingeführt.[Videovorlesung]Und sofort können Sie verschiedene Anwendungen sehen, die mit der gleichen Vorlage aus einer Anfrage wie kommen
Die übrigen Methoden basieren auf den Indikatoren, die wir aus dem Plan extrahieren: Wie oft ist eine solche Vorlage aufgetreten, wie lange und durchschnittlich insgesamt, wie viel Daten von der Festplatte gelesen wurden und wie viel aus dem Speicher ...Weil Sie beispielsweise vom Host auf die Analyseseite gelangen, siehe - etwas zu viel auf der Festplatte, um den Anfang zu lesen. Die Festplatte auf dem Server kommt nicht zurecht - und wer liest daraus?Und Sie können nach jeder Spalte sortieren und entscheiden, was Sie gerade tun - mit der Belastung des Prozessors oder der Festplatte oder mit der Gesamtzahl der Anforderungen ... Sortiert, „top“, repariert - haben eine neue Version der Anwendung eingeführt.[Videovorlesung]Und sofort können Sie verschiedene Anwendungen sehen, die mit der gleichen Vorlage aus einer Anfrage wie kommenSELECT * FROM users WHERE login = 'Vasya'. Frontend, Backend, Verarbeitung ... Und Sie fragen sich, warum der Benutzer die Verarbeitung lesen sollte, wenn er nicht mit ihm interagiert.Der umgekehrte Weg besteht darin, sofort anhand der Anwendung zu sehen, was sie tut. Ein Frontend ist beispielsweise dies, dies, dies und das einmal pro Stunde (nur die Zeitleiste hilft). Und sofort stellt sich die Frage: Es scheint nicht die Aufgabe des Frontends zu sein, einmal pro Stunde etwas zu tun ... Nach einiger Zeit stellten wir fest, dass uns aggregierte Statistiken in Bezug auf Plan-Knoten fehlten . Wir haben aus den Plänen nur diejenigen Knoten isoliert, die etwas mit den Daten der Tabellen selbst tun (sie nach Index lesen / schreiben oder nicht). Im Vergleich zum vorherigen Bild wird nur ein Aspekt hinzugefügt - wie viele Datensätze dieser Knoten zu uns gebracht hat und wie viele er gelöscht hat (Zeilen durch Filter entfernt).Sie haben keinen geeigneten Index auf der Platte, Sie stellen eine Anfrage, sie fliegt am Index vorbei, fällt in Seq Scan ... Sie haben alle Datensätze außer einem herausgefiltert. Und warum benötigen Sie 100 Millionen gefilterte Datensätze pro Tag? Ist es besser, den Index zu rollen?
Nach einiger Zeit stellten wir fest, dass uns aggregierte Statistiken in Bezug auf Plan-Knoten fehlten . Wir haben aus den Plänen nur diejenigen Knoten isoliert, die etwas mit den Daten der Tabellen selbst tun (sie nach Index lesen / schreiben oder nicht). Im Vergleich zum vorherigen Bild wird nur ein Aspekt hinzugefügt - wie viele Datensätze dieser Knoten zu uns gebracht hat und wie viele er gelöscht hat (Zeilen durch Filter entfernt).Sie haben keinen geeigneten Index auf der Platte, Sie stellen eine Anfrage, sie fliegt am Index vorbei, fällt in Seq Scan ... Sie haben alle Datensätze außer einem herausgefiltert. Und warum benötigen Sie 100 Millionen gefilterte Datensätze pro Tag? Ist es besser, den Index zu rollen? Nachdem wir alle Pläne nach Knoten untersucht hatten, stellten wir fest, dass die Pläne einige typische Strukturen enthalten, die sehr wahrscheinlich verdächtig aussehen. Und es wäre schön, dem Entwickler zu sagen: „Freund, hier liest du zuerst nach Index, sortierst ihn dann und schneidest ihn dann ab“ - in der Regel gibt es einen Datensatz.Jeder, der Abfragen mit diesem Muster schrieb, stieß wahrscheinlich auf Folgendes: „Gib mir die letzte Bestellung für Vasya, sein Datum“. Und wenn Sie keinen Index nach Datum haben oder der verwendete Index kein Datum hat, dann gehen Sie genau auf einen solchen „Rechen“ und treten Sie ein .Aber wir wissen, dass dies ein "Rechen" ist - warum also nicht sofort dem Entwickler sagen, was er tun soll? Dementsprechend sieht unser Entwickler beim Öffnen des Plans sofort ein schönes Bild mit Eingabeaufforderungen, auf dem ihm sofort gesagt wird: „Sie haben hier und hier Probleme, aber sie werden auf diese und jene Weise gelöst.“Infolgedessen ist die Menge an Erfahrung, die zu Beginn und jetzt zur Lösung von Problemen benötigt wurde, erheblich gesunken. Hier haben wir ein solches Werkzeug.
Nachdem wir alle Pläne nach Knoten untersucht hatten, stellten wir fest, dass die Pläne einige typische Strukturen enthalten, die sehr wahrscheinlich verdächtig aussehen. Und es wäre schön, dem Entwickler zu sagen: „Freund, hier liest du zuerst nach Index, sortierst ihn dann und schneidest ihn dann ab“ - in der Regel gibt es einen Datensatz.Jeder, der Abfragen mit diesem Muster schrieb, stieß wahrscheinlich auf Folgendes: „Gib mir die letzte Bestellung für Vasya, sein Datum“. Und wenn Sie keinen Index nach Datum haben oder der verwendete Index kein Datum hat, dann gehen Sie genau auf einen solchen „Rechen“ und treten Sie ein .Aber wir wissen, dass dies ein "Rechen" ist - warum also nicht sofort dem Entwickler sagen, was er tun soll? Dementsprechend sieht unser Entwickler beim Öffnen des Plans sofort ein schönes Bild mit Eingabeaufforderungen, auf dem ihm sofort gesagt wird: „Sie haben hier und hier Probleme, aber sie werden auf diese und jene Weise gelöst.“Infolgedessen ist die Menge an Erfahrung, die zu Beginn und jetzt zur Lösung von Problemen benötigt wurde, erheblich gesunken. Hier haben wir ein solches Werkzeug.
Source: https://habr.com/ru/post/undefined/
All Articles