Warum Discord von Go nach Rust migriert
 Rust wird zu einer erstklassigen Sprache in einer Vielzahl von Bereichen. Wir bei Discord setzen es erfolgreich sowohl auf Server- als auch auf Clientseite ein. Zum Beispiel auf der Clientseite in der Videokodierungspipeline für Go Live und auf der Serverseite für die Elixir NIF- Funktionen (Native Implemented Functions).Wir haben kürzlich die Leistung eines einzelnen Dienstes dramatisch verbessert und ihn von Go to Rust umgeschrieben. In diesem Artikel wird erläutert, warum es für uns sinnvoll war, den Service neu zu schreiben, wie wir ihn durchgeführt haben und wie stark sich die Produktivität verbessert hat.
Rust wird zu einer erstklassigen Sprache in einer Vielzahl von Bereichen. Wir bei Discord setzen es erfolgreich sowohl auf Server- als auch auf Clientseite ein. Zum Beispiel auf der Clientseite in der Videokodierungspipeline für Go Live und auf der Serverseite für die Elixir NIF- Funktionen (Native Implemented Functions).Wir haben kürzlich die Leistung eines einzelnen Dienstes dramatisch verbessert und ihn von Go to Rust umgeschrieben. In diesem Artikel wird erläutert, warum es für uns sinnvoll war, den Service neu zu schreiben, wie wir ihn durchgeführt haben und wie stark sich die Produktivität verbessert hat.Read State Tracking Service (Status lesen)
Unser Unternehmen basiert auf einem Produkt. Beginnen wir also mit einem Kontext, den wir genau von Go to Rust übertragen haben. Dies ist ein Read States-Dienst. Ihre einzige Aufgabe ist es, zu verfolgen, welche Kanäle und Nachrichten Sie lesen. Auf die Lesezustände wird jedes Mal zugegriffen, wenn Sie eine Verbindung zu Discord herstellen, wenn Sie eine Nachricht senden und wenn Sie die Nachricht lesen. Kurz gesagt, Zustände werden kontinuierlich gelesen und befinden sich auf einem „heißen Pfad“. Wir möchten sicherstellen, dass Discord immer schnell ist, daher sollte die Statusprüfung schnell sein.Die Implementierung des Service on Go erfüllte nicht alle Anforderungen. Die meiste Zeit funktionierte es schnell, aber alle paar Minuten gab es starke Verzögerungen, die für die Benutzer spürbar waren. Nachdem wir die Situation untersucht hatten, stellten wir fest, dass die Verzögerungen auf die Hauptmerkmale von Go zurückzuführen waren: das Speichermodell und den Garbage Collector (GC).Warum gehen, erfüllt unsere Leistungsziele nicht
Um zu erklären, warum Go unsere Leistungsziele nicht erreicht, müssen zunächst Datenstrukturen, Skalierung, Zugriffsmuster und Servicearchitektur erörtert werden.Zum Speichern von Statusinformationen verwenden wir eine Datenstruktur, die als "Status lesen" bezeichnet wird. In Discord gibt es Milliarden davon: einen Status für jeden Benutzer pro Kanal. Jeder Zustand hat mehrere Zähler, die atomar aktualisiert und oft auf Null zurückgesetzt werden müssen. Einer der Zähler ist beispielsweise die Nummer @mentionim Kanal.Um den Atomzähler schnell zu aktualisieren, verfügt jeder Read States-Server über einen LRU-Cache (Least Recent Used). Jeder Cache hat Millionen von Benutzern und zig Millionen von Zuständen. Der Cache wird hunderttausend Mal pro Sekunde aktualisiert.Aus Sicherheitsgründen wird der Cache mit dem Cassandra-Datenbankcluster synchronisiert. Wenn ein Schlüssel aus dem Cache gedrückt wird, geben wir die Status dieses Benutzers in die Datenbank ein. In Zukunft planen wir, die Datenbank bei jeder Statusaktualisierung innerhalb von 30 Sekunden zu aktualisieren. Dies sind Zehntausende von Datensätzen in der Datenbank pro Sekunde.Die folgende Grafik zeigt die Antwortzeit und die CPU-Auslastung im Spitzenzeitintervall für den Go 1- Dienst. Es ist ersichtlich, dass Verzögerungen und Laststöße auf der CPU ungefähr alle zwei Minuten auftreten.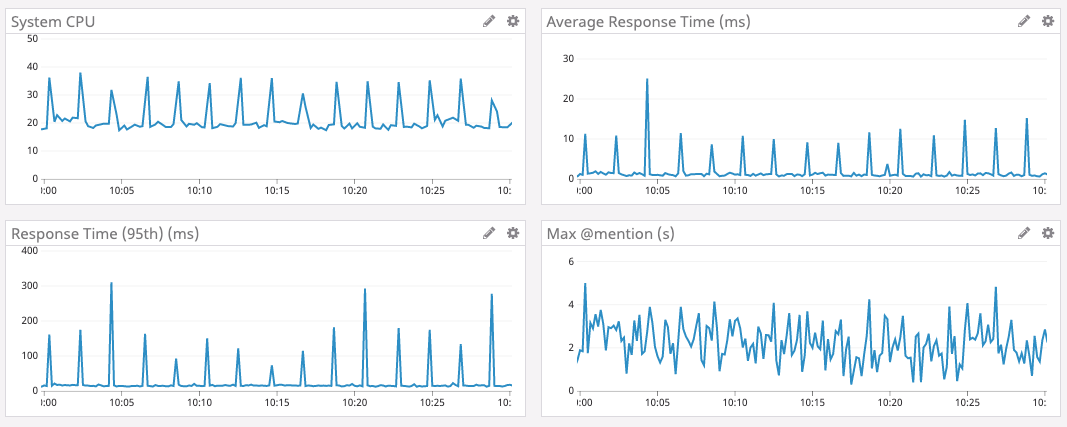
Woher kommt also das Wachstum der Verzögerungen alle zwei Minuten?
In Go wird der Speicher nicht sofort freigegeben, wenn eine Taste aus dem Cache gedrückt wird. Stattdessen wird der Garbage Collector regelmäßig ausgeführt und sucht nach nicht verwendeten Speicherbereichen. Dies ist eine Menge Arbeit, die ein Programm verlangsamen kann.Es ist sehr wahrscheinlich, dass regelmäßige Verlangsamungen unseres Dienstes mit der Speicherbereinigung verbunden sind. Wir haben jedoch einen sehr effizienten Go-Code mit minimaler Speicherzuweisung geschrieben. Es sollte nicht mehr viel Müll übrig sein. Was ist da los?Beim Durchsuchen des Go-Quellcodes haben wir erfahren, dass Go mindestens alle zwei Minuten mit der Speicherbereinigung beginnt . Unabhängig von der Größe des Heapspeichers erzwingt Go den Start, wenn der GC zwei Minuten lang nicht gestartet wurde.Wir haben beschlossen, dass Sie diese Spitzen mit großen Verzögerungen vermeiden können, wenn Sie GC häufiger ausführen. Daher legen wir einen Endpunkt im Service fest, um den GC-Prozentwert im laufenden Betrieb zu ändern . Leider hat die Konfiguration von GC Percent nichts beeinflusst. Wie konnte das passieren? Es stellt sich heraus, dass GC nicht öfter starten wollte, weil wir nicht oft genug Speicher zugewiesen haben.Wir begannen weiter zu graben. Es stellte sich heraus, dass solche großen Verzögerungen nicht aufgrund der großen Menge an freigegebenem Speicher auftreten, sondern weil der Garbage Collector den gesamten LRU-Cache durchsucht, um den gesamten Speicher zu überprüfen. Dann haben wir beschlossen, dass das Scan-Volumen abnimmt, wenn wir den LRU-Cache verringern. Aus diesem Grund haben wir dem Dienst einen weiteren Parameter hinzugefügt, um die Größe des LRU-Cache zu ändern, und die Architektur geändert, wodurch die LRU auf jedem Server in viele separate Caches aufgeteilt wurde.Und so geschah es. Bei kleineren Caches werden Spitzenverzögerungen reduziert.Leider hat der Kompromiss mit der Verringerung des LRU-Cache das 99. Perzentil erhöht (dh der Durchschnittswert für eine Stichprobe von 99% der Verzögerungen hat sich erhöht, mit Ausnahme der Spitzenverzögerungen). Dies liegt daran, dass durch Verringern des Caches die Wahrscheinlichkeit verringert wird, dass sich der Lesestatus des Benutzers im Cache befindet. Wenn es nicht hier ist, müssen wir uns an die Datenbank wenden.Nach einer großen Anzahl von Lasttests für verschiedene Cache-Größen haben wir eine akzeptable Einstellung gefunden. Obwohl nicht ideal, war es eine zufriedenstellende Lösung, so dass wir den Service für eine lange Zeit verlassen haben, um so zu arbeiten.Gleichzeitig haben wir Rust sehr erfolgreich in anderen Discord-Systemen implementiert und daher gemeinsam beschlossen, Frameworks und Bibliotheken für neue Dienste nur in Rust zu schreiben. Und dieser Dienst schien ein ausgezeichneter Kandidat für die Portierung nach Rust zu sein: Er ist klein und autonom, und wir hofften, dass Rust diese Ausbrüche mit Verzögerungen beheben und den Dienst letztendlich für Benutzer angenehmer machen würde 2.Speicherverwaltung in Rust
Rust ist unglaublich schnell und effizient mit Speicher: Da keine Laufzeitumgebung und kein Garbage Collector vorhanden sind, eignet es sich für Hochleistungsdienste, eingebettete Anwendungen und lässt sich problemlos in andere Sprachen integrieren. 3
Rust hat keinen Müllsammler, deshalb haben wir beschlossen, dass es keine solchen Verzögerungen wie Go geben würde.In der Speicherverwaltung verwendet er einen ziemlich einzigartigen Ansatz mit der Idee, Speicher zu "besitzen". Kurz gesagt, Rust verfolgt, wer das Recht hat, aus dem Speicher zu lesen und in den Speicher zu schreiben. Er weiß, wann ein Programm Speicher verwendet, und gibt ihn sofort frei, sobald kein Speicher mehr benötigt wird. Rust erzwingt Speicherregeln zur Kompilierungszeit, wodurch die Möglichkeit von Speicherfehlern zur Laufzeit praktisch ausgeschlossen wird. 4Sie müssen den Speicher nicht manuell verfolgen. Der Compiler wird sich darum kümmern.Wenn in der Rust-Version der Lesestatus aus dem LRU-Cache ausgeschlossen wird, wird der Speicher sofort freigegeben. Dieser Speicher sitzt nicht und wartet nicht auf den Garbage Collector. Rust weiß, dass es nicht mehr verwendet wird und gibt es sofort frei. Zur Laufzeit gibt es keinen Prozess zum Scannen des freizugebenden Speichers.Asynchroner Rost
Es gab jedoch ein Problem mit dem Rust-Ökosystem. Zum Zeitpunkt der Implementierung unseres Dienstes gab es im stabilen Zweig von Rust keine anständigen asynchronen Funktionen. Für einen Netzwerkdienst ist die asynchrone Programmierung ein Muss. Die Community hat mehrere Bibliotheken entwickelt, jedoch mit einer nicht trivialen Verbindung und sehr dummen Fehlermeldungen.Glücklicherweise hat das Rust-Team hart daran gearbeitet, die asynchrone Programmierung zu vereinfachen, und sie war bereits auf dem instabilen Kanal (Nightly) verfügbar.Discord hatte nie Angst, vielversprechende neue Technologien zu lernen. Zum Beispiel waren wir einer der ersten Benutzer von Elixir, React, React Native und Scylla. Wenn eine Technologie vielversprechend aussieht und uns einen Vorteil verschafft, sind wir bereit, uns den unvermeidlichen Schwierigkeiten bei der Implementierung und der Instabilität fortschrittlicher Tools zu stellen. Dies ist einer der Gründe, warum wir so schnell ein Publikum von 250 Millionen Benutzern mit weniger als 50 Programmierern im Bundesstaat erreicht haben.Die Einführung neuer asynchroner Funktionen aus dem instabilen Rust-Kanal ist ein weiteres Beispiel für unsere Bereitschaft, eine neue, vielversprechende Technologie einzuführen. Das Engineering-Team entschied sich, die erforderlichen Funktionen zu implementieren, ohne auf deren Unterstützung in der stabilen Version zu warten. Zusammen mit anderen Vertretern der Gemeinschaft haben wir alle aufgetretenen Probleme überwunden und jetzt asynchrones Rustin einem stabilen Zweig gehalten. Unser Tarif hat sich ausgezahlt.Implementierung, Stresstest und Start
Nur den Code neu zu schreiben war einfach. Wir haben mit einer groben Sendung begonnen und sie dann auf Orte reduziert, an denen es Sinn machte. Zum Beispiel hat Rust ein exzellentes Typsystem mit umfassender Unterstützung für Generika (für die Arbeit mit Daten aller Art), so dass wir den Go-Code leise weggeworfen haben, was den Mangel an Generika kompensierte. Darüber hinaus berücksichtigt das Rust-Speichermodell die Speichersicherheit in verschiedenen Threads, sodass wir die Schutzgoroutinen weggeworfen haben.Belastungstests zeigten sofort ein hervorragendes Ergebnis. Die Serviceleistung von Rust war genauso hoch wie die der Go-Version, jedoch ohne diese Verzögerungen !Normalerweise haben wir die Rust-Version praktisch nicht optimiert. Aber selbst mit den einfachsten Optimierungen konnte Rust eine sorgfältig abgestimmte Version von Go übertreffen.Dies ist ein beredter Beweis dafür, wie einfach es ist, effektive Rust-Programme zu schreiben, anstatt tief in Go einzusteigen.Aber wir haben die einfache Leistung quo nicht erfüllt. Nach ein wenig Profilerstellung und Optimierung haben wir Go in jeder Hinsicht übertroffen . Verzögerung, CPU und Speicher - in der Rust-Version wurde alles besser.Rostleistungsoptimierungen enthalten:- Wechseln zu BTreeMap anstelle von HashMap im LRU-Cache, um die Speichernutzung zu optimieren.
- Ersetzen der ursprünglichen Metrikbibliothek durch eine Version mit Unterstützung für modernes Parallelitäts-Rust.
- Verringern Sie die Anzahl der Kopien im Speicher.
Zufrieden entschieden wir uns, den Service bereitzustellen.Der Start verlief ziemlich reibungslos, da wir Stresstests durchgeführt haben. Wir haben den Service mit einem Testknoten verbunden, mehrere Grenzfälle entdeckt und behoben. Bald darauf rollten sie eine neue Version in den gesamten Serverpark.Die Ergebnisse sind unten gezeigt.Das lila Diagramm ist Go, das blaue Diagramm ist Rust.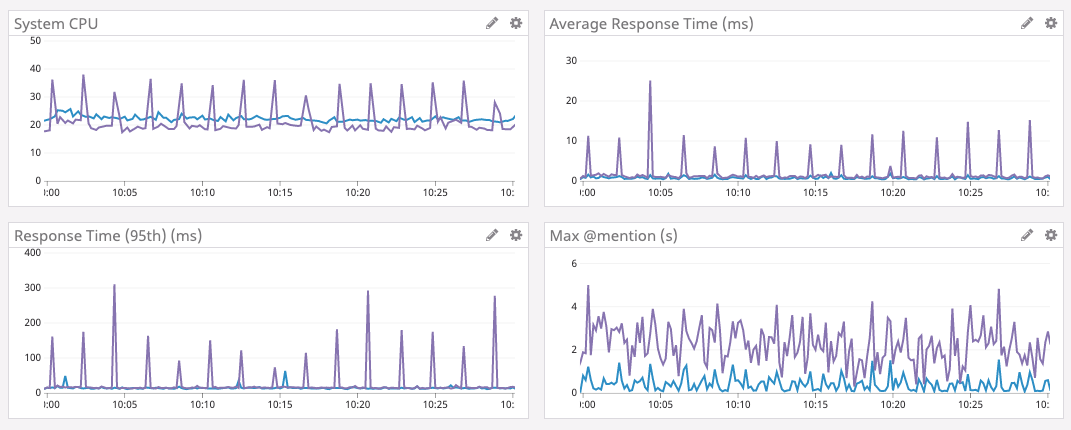
Erhöhen Sie die Cache-Größe
Nachdem der Dienst mehrere Tage erfolgreich funktioniert hatte, haben wir beschlossen, den LRU-Cache erneut zu vergrößern. Wie oben erwähnt, war dies in der Go-Version nicht möglich, da sich die Zeit für die Speicherbereinigung erhöhte. Da wir keine Speicherbereinigung mehr durchführen, können Sie die Cache-Zählung erhöhen, um die Leistung noch weiter zu steigern. Daher haben wir den Speicher auf den Servern erhöht, die Datenstruktur für eine geringere Speichernutzung (zum Spaß) optimiert und die Cache-Größe auf 8 Millionen Lesezustandszustände erhöht.Die folgenden Ergebnisse sprechen für sich. Beachten Sie, dass die durchschnittliche Zeit jetzt in Mikrosekunden und die maximale Verzögerung @mentionin Millisekunden gemessen wird.Ökosystementwicklung
Schließlich hat Rust ein wunderbares Ökosystem, das schnell wächst. Eine neue Version der von uns verwendeten asynchronen Laufzeit ist beispielsweise Tokio 0.2. Wir haben aktualisiert und ohne unser Zutun die Belastung der CPU automatisch reduziert. In der folgenden Grafik können Sie sehen, wie sich die Last seit dem 16. Januar verringert hat.Abschließende Gedanken
Discord verwendet Rust derzeit in vielen Teilen des Software-Stacks: für GameSDK, zum Aufnehmen und Codieren von Videos in Go Live, Elixir NIF , mehreren Backend-Diensten und vielem mehr.Wenn Sie ein neues Projekt oder eine neue Softwarekomponente starten, ziehen wir definitiv die Verwendung von Rust in Betracht. Natürlich nur dort, wo es Sinn macht.Neben der Leistung bietet Rust Entwicklern viele weitere Vorteile. Zum Beispiel vereinfachen die Typensicherheit und der Leihprüfer das Refactoring erheblich, wenn sich die Produktanforderungen ändern oder neue Sprachfunktionen eingeführt werden. Das Ökosystem und die Werkzeuge sind ausgezeichnet und entwickeln sich schnell.Unterhaltsame Tatsache: Das Rust-Team verwendet auch Discord zur Koordinierung. Es gibt sogar eine sehr nützlicheRust Community Server , wo wir manchmal chatten.Fußnoten
- Diagramme aus Go Version 1.9.2. Wir haben die Versionen 1.8, 1.9 und 1.10 ohne Verbesserungen ausprobiert. Die erste Migration von Go nach Rust wurde im Mai 2019 abgeschlossen. [zurückgeben]
- Aus Gründen der Übersichtlichkeit empfehlen wir nicht, alles in Rust ohne Grund neu zu schreiben. [zurückgeben]
- Zitat aus der offiziellen Seite. [zurückgeben]
- Natürlich, bis Sie unsicher verwenden . [zurückgeben]
Source: https://habr.com/ru/post/undefined/
All Articles