Seit Jahren diskutieren Experten in C ++ die Semantik von Werten, Unveränderlichkeit und gemeinsamer Nutzung von Ressourcen durch Kommunikation. Über eine neue Welt ohne Mutexe und Rassen, ohne Befehls- und Beobachtermuster. In der Tat ist nicht alles so einfach. Das Hauptproblem liegt immer noch in unseren Datenstrukturen. Unveränderliche Datenstrukturen ändern ihre Werte nicht. Um etwas mit ihnen zu tun, müssen Sie neue Werte erstellen. Die alten Werte bleiben an derselben Stelle, sodass sie ohne Probleme und Sperren aus verschiedenen Streams gelesen werden können. Infolgedessen können Ressourcen rationaler und geordneter geteilt werden, da alte und neue Werte gemeinsame Daten verwenden können. Dank dessen sind sie viel schneller miteinander zu vergleichen und speichern die Betriebsgeschichte kompakt mit der Möglichkeit der Stornierung. All dies passt perfekt zu Multithread- und interaktiven Systemen: Solche Datenstrukturen vereinfachen die Architektur von Desktop-Anwendungen und ermöglichen eine bessere Skalierung von Diensten. Unveränderliche Strukturen sind das Erfolgsgeheimnis von Clojure und Scala, und sogar die JavaScript-Community nutzt sie jetzt, da sie über die Bibliothek Immutable.js verfügen.geschrieben in den Eingeweiden der Firma Facebook.Unter dem Schnitt - Video und Übersetzung des Juan Puente- Berichts von der C ++ Russia 2019 Moskauer Konferenz. Juan spricht über Immer , eine Bibliothek unveränderlicher Strukturen für C ++. In der Post:
Unveränderliche Datenstrukturen ändern ihre Werte nicht. Um etwas mit ihnen zu tun, müssen Sie neue Werte erstellen. Die alten Werte bleiben an derselben Stelle, sodass sie ohne Probleme und Sperren aus verschiedenen Streams gelesen werden können. Infolgedessen können Ressourcen rationaler und geordneter geteilt werden, da alte und neue Werte gemeinsame Daten verwenden können. Dank dessen sind sie viel schneller miteinander zu vergleichen und speichern die Betriebsgeschichte kompakt mit der Möglichkeit der Stornierung. All dies passt perfekt zu Multithread- und interaktiven Systemen: Solche Datenstrukturen vereinfachen die Architektur von Desktop-Anwendungen und ermöglichen eine bessere Skalierung von Diensten. Unveränderliche Strukturen sind das Erfolgsgeheimnis von Clojure und Scala, und sogar die JavaScript-Community nutzt sie jetzt, da sie über die Bibliothek Immutable.js verfügen.geschrieben in den Eingeweiden der Firma Facebook.Unter dem Schnitt - Video und Übersetzung des Juan Puente- Berichts von der C ++ Russia 2019 Moskauer Konferenz. Juan spricht über Immer , eine Bibliothek unveränderlicher Strukturen für C ++. In der Post:- architektonische Vorteile der Immunität;
- Erstellung eines effektiven persistenten Vektortyps basierend auf RRB-Bäumen;
- Analyse der Architektur am Beispiel eines einfachen Texteditors.
Die Tragödie der wertebasierten Architektur
Um die Bedeutung unveränderlicher Datenstrukturen zu verstehen, diskutieren wir die Semantik von Werten. Dies ist eine sehr wichtige Funktion von C ++. Ich halte sie für einen der Hauptvorteile dieser Sprache. Bei alledem ist es sehr schwierig, die Semantik von Werten so zu verwenden, wie wir es möchten. Ich glaube, dass dies die Tragödie der wertorientierten Architektur ist und der Weg zu dieser Tragödie mit guten Absichten gepflastert ist. Angenommen, wir müssen interaktive Software schreiben, die auf einem Datenmodell mit einer Darstellung eines vom Benutzer bearbeitbaren Dokuments basiert. Wenn Architektur basierend auf den Werten im Zentrum dieses Modells einfach und bequem Arten von Werten verwendet , dass es bereits in der Sprache: vector, map, tuple,struct. Die Anwendungslogik wird aus Funktionen erstellt, die Dokumente nach Wert erfassen und eine neue Version eines Dokuments nach Wert zurückgeben. Dieses Dokument kann sich innerhalb der Funktion ändern (wie unten beschrieben), aber die Semantik der Werte in C ++, die auf das Argument nach Wert und den Rückgabetyp nach Wert angewendet wird, stellt sicher, dass keine Nebenwirkungen auftreten.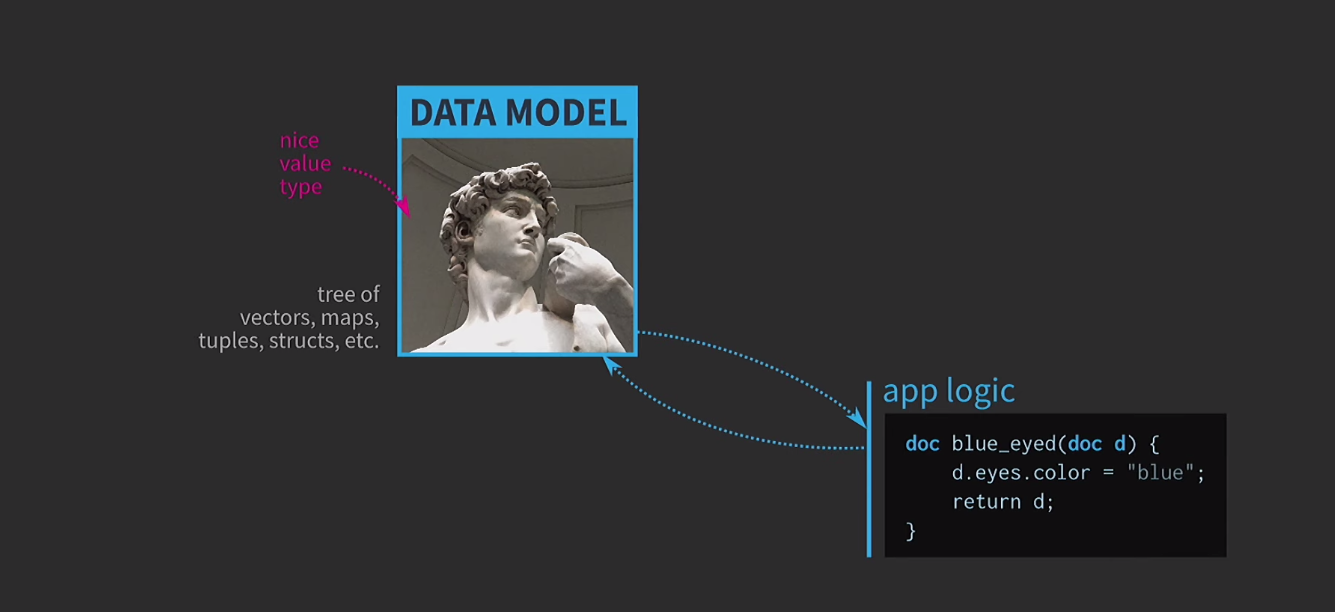 Diese Funktion ist sehr einfach zu analysieren und zu testen.
Diese Funktion ist sehr einfach zu analysieren und zu testen. Da wir mit Werten arbeiten, werden wir versuchen, das Rückgängigmachen der Aktion zu implementieren. Dies kann schwierig sein, aber mit unserem Ansatz ist es eine triviale Aufgabe: Wir haben
Da wir mit Werten arbeiten, werden wir versuchen, das Rückgängigmachen der Aktion zu implementieren. Dies kann schwierig sein, aber mit unserem Ansatz ist es eine triviale Aufgabe: Wir haben std::vectormit verschiedenen Zuständen verschiedene Kopien des Dokuments.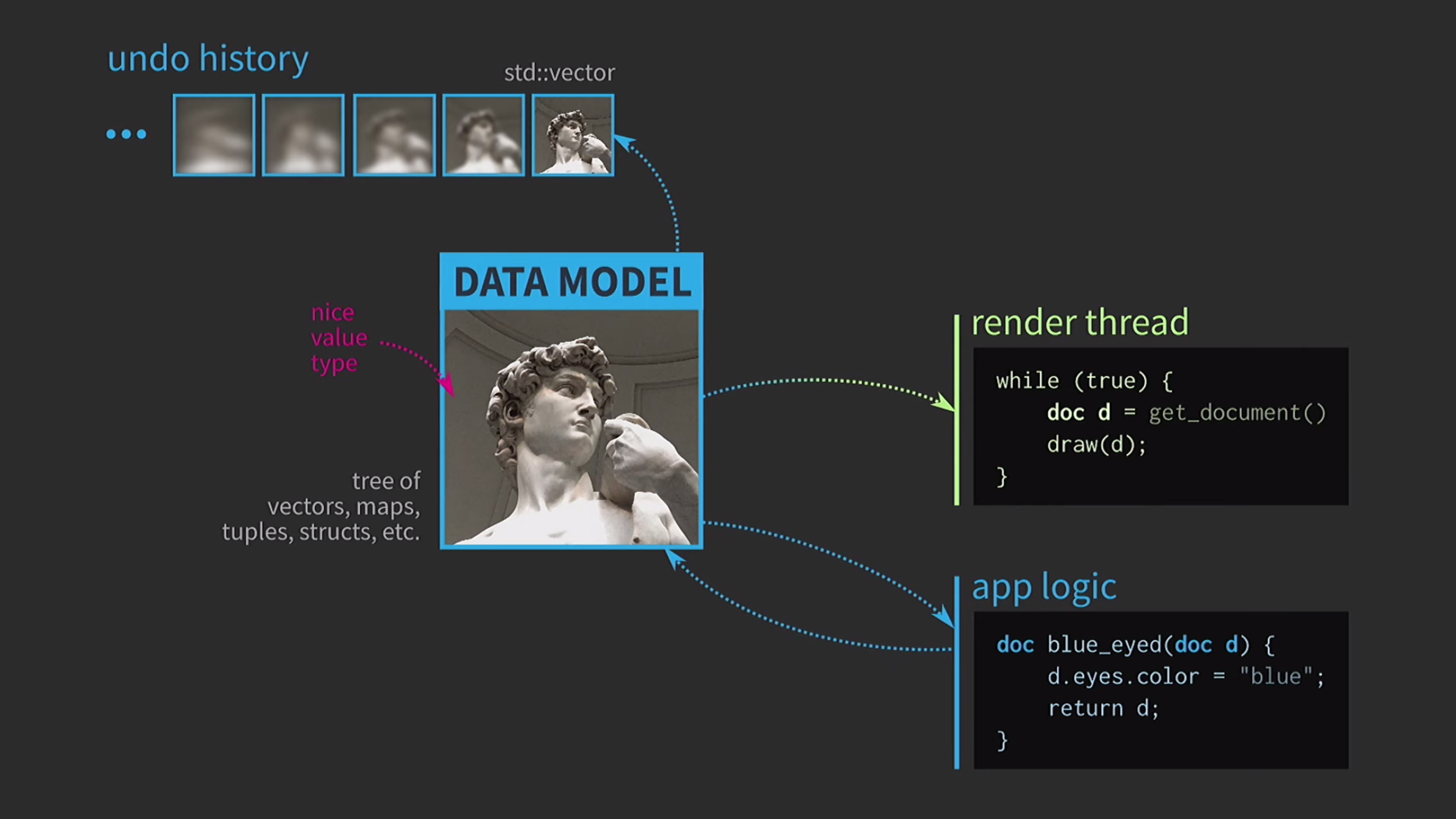 Angenommen, wir haben auch eine Benutzeroberfläche, und um deren Reaktionsfähigkeit sicherzustellen, muss die Zuordnung der Benutzeroberfläche in einem separaten Thread erfolgen. Das Dokument wird per Nachricht an einen anderen Stream gesendet, und die Interaktion erfolgt auch auf der Grundlage von Nachrichten und nicht über die gemeinsame Nutzung des Status mithilfe von
Angenommen, wir haben auch eine Benutzeroberfläche, und um deren Reaktionsfähigkeit sicherzustellen, muss die Zuordnung der Benutzeroberfläche in einem separaten Thread erfolgen. Das Dokument wird per Nachricht an einen anderen Stream gesendet, und die Interaktion erfolgt auch auf der Grundlage von Nachrichten und nicht über die gemeinsame Nutzung des Status mithilfe von mutexes. Wenn die Kopie vom zweiten Stream empfangen wird, können Sie dort alle erforderlichen Vorgänge ausführen. Das Speichern eines Dokuments auf der Festplatte ist häufig sehr langsam, insbesondere wenn das Dokument groß ist. Daher wird die Verwendung
Das Speichern eines Dokuments auf der Festplatte ist häufig sehr langsam, insbesondere wenn das Dokument groß ist. Daher wird die Verwendung std::asyncdieser Operation asynchron ausgeführt. Wir verwenden ein Lambda, setzen ein Gleichheitszeichen ein, um eine Kopie zu erhalten, und jetzt können Sie ohne andere primitive Arten der Synchronisation speichern.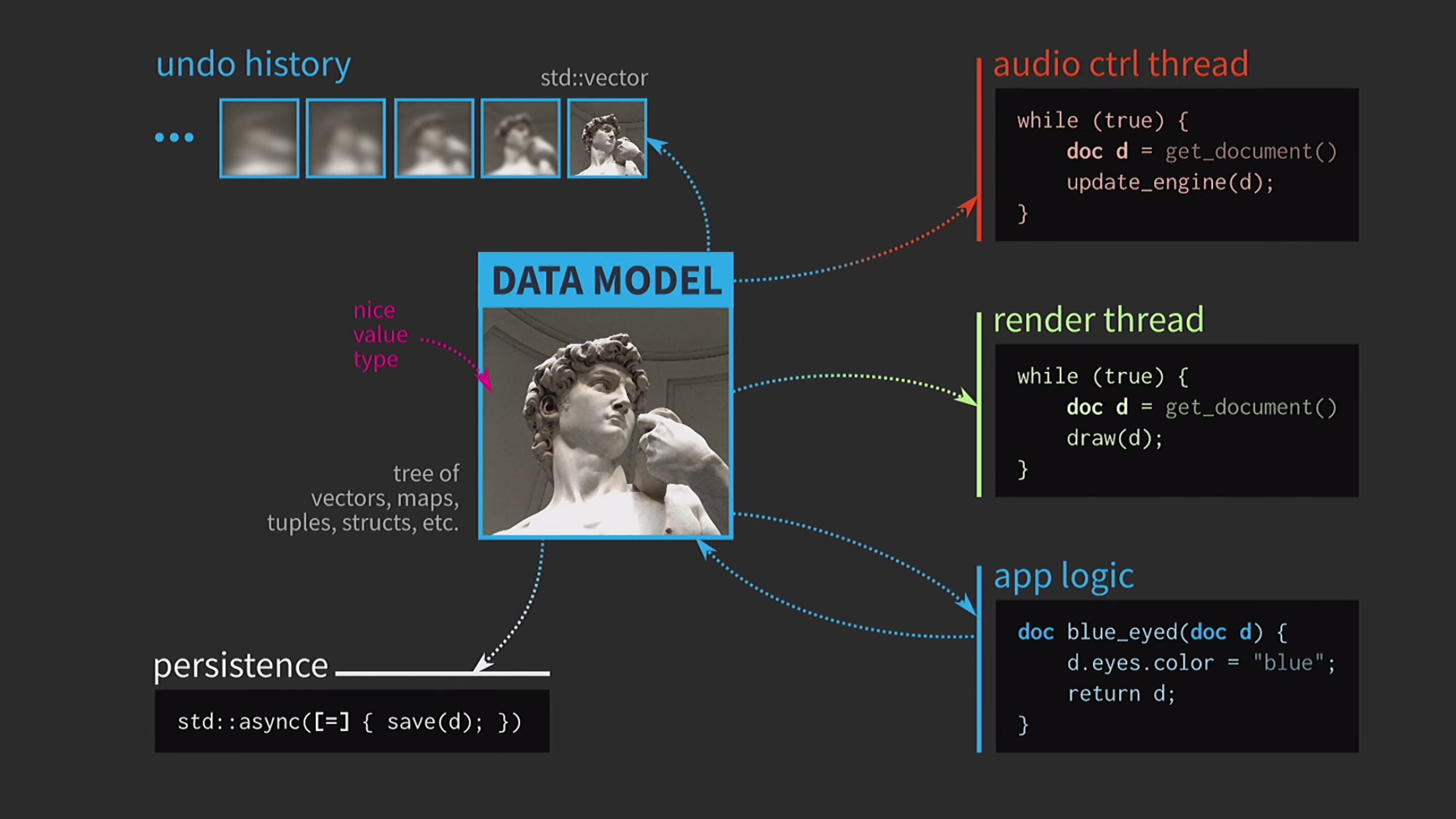 Nehmen wir weiter an, wir haben auch einen Schallkontrollfluss. Wie gesagt, ich habe viel mit Musiksoftware gearbeitet, und Sound ist eine weitere Darstellung unseres Dokuments. Es muss sich in einem separaten Stream befinden. Daher ist für diesen Stream auch eine Kopie des Dokuments erforderlich.Als Ergebnis haben wir ein sehr schönes, aber nicht zu realistisches Schema erhalten.
Nehmen wir weiter an, wir haben auch einen Schallkontrollfluss. Wie gesagt, ich habe viel mit Musiksoftware gearbeitet, und Sound ist eine weitere Darstellung unseres Dokuments. Es muss sich in einem separaten Stream befinden. Daher ist für diesen Stream auch eine Kopie des Dokuments erforderlich.Als Ergebnis haben wir ein sehr schönes, aber nicht zu realistisches Schema erhalten.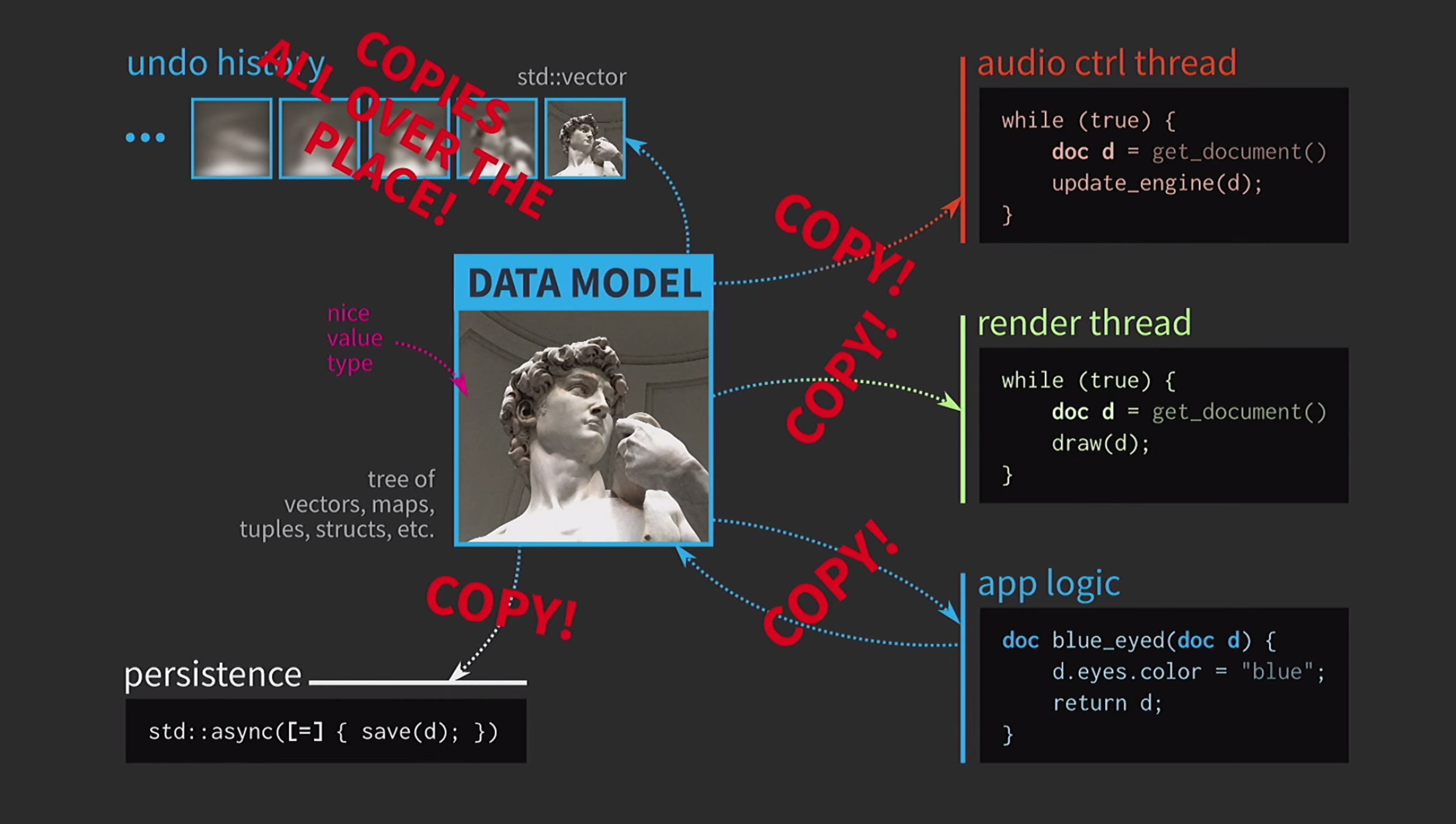 Es müssen ständig Dokumente kopiert werden, der Aktionsverlauf für das Abbrechen dauert Gigabyte, und für jedes Rendern der Benutzeroberfläche müssen Sie eine tiefe Kopie des Dokuments erstellen. Im Allgemeinen sind alle Interaktionen zu kostspielig.
Es müssen ständig Dokumente kopiert werden, der Aktionsverlauf für das Abbrechen dauert Gigabyte, und für jedes Rendern der Benutzeroberfläche müssen Sie eine tiefe Kopie des Dokuments erstellen. Im Allgemeinen sind alle Interaktionen zu kostspielig.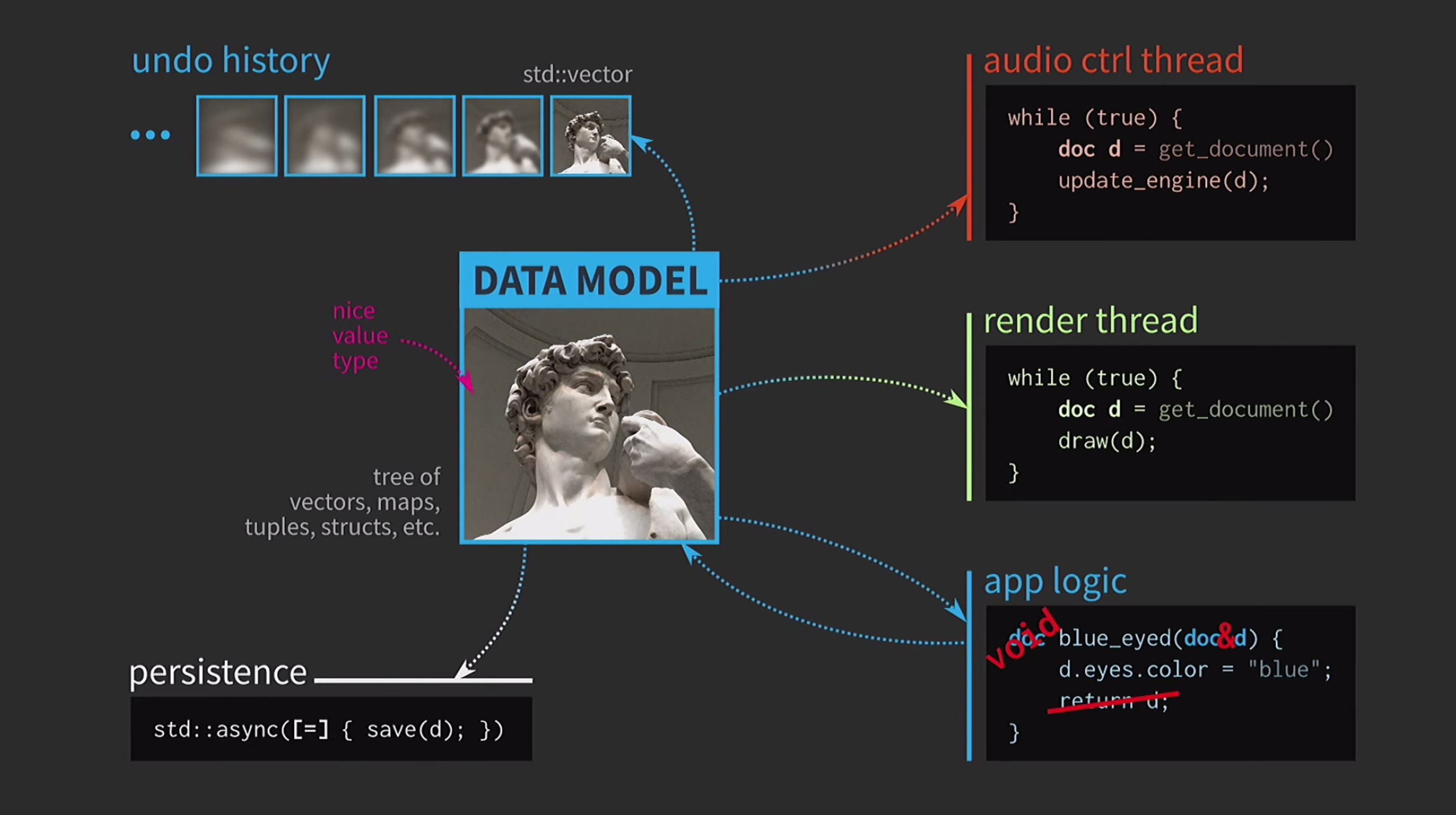 Was macht der C ++ - Entwickler in dieser Situation? Anstatt ein Dokument nach Wert zu akzeptieren, akzeptiert die Anwendungslogik jetzt einen Link zum Dokument und aktualisiert es bei Bedarf. In diesem Fall müssen Sie nichts zurückgeben. Aber jetzt geht es nicht um Werte, sondern um Objekte und Orte. Dies führt zu neuen Problemen: Wenn eine Verbindung zum Status mit gemeinsamem Zugriff besteht, benötigen Sie diese
Was macht der C ++ - Entwickler in dieser Situation? Anstatt ein Dokument nach Wert zu akzeptieren, akzeptiert die Anwendungslogik jetzt einen Link zum Dokument und aktualisiert es bei Bedarf. In diesem Fall müssen Sie nichts zurückgeben. Aber jetzt geht es nicht um Werte, sondern um Objekte und Orte. Dies führt zu neuen Problemen: Wenn eine Verbindung zum Status mit gemeinsamem Zugriff besteht, benötigen Sie diese mutex. Dies ist äußerst kostspielig, daher wird unsere Benutzeroberfläche in Form eines äußerst komplexen Baums aus verschiedenen Widgets dargestellt.Alle diese Elemente sollten aktualisiert werden, wenn sich ein Dokument ändert. Daher ist ein Warteschlangenmechanismus für Änderungssignale erforderlich. Darüber hinaus besteht die Historie des Dokuments nicht mehr aus einer Reihe von Zuständen, sondern aus einer Implementierung des Teammusters. Die Operation muss zweimal in die eine und in die andere Richtung ausgeführt werden und sicherstellen, dass alles symmetrisch ist. Das Speichern in einem separaten Thread ist bereits zu schwierig, daher muss dies abgebrochen werden.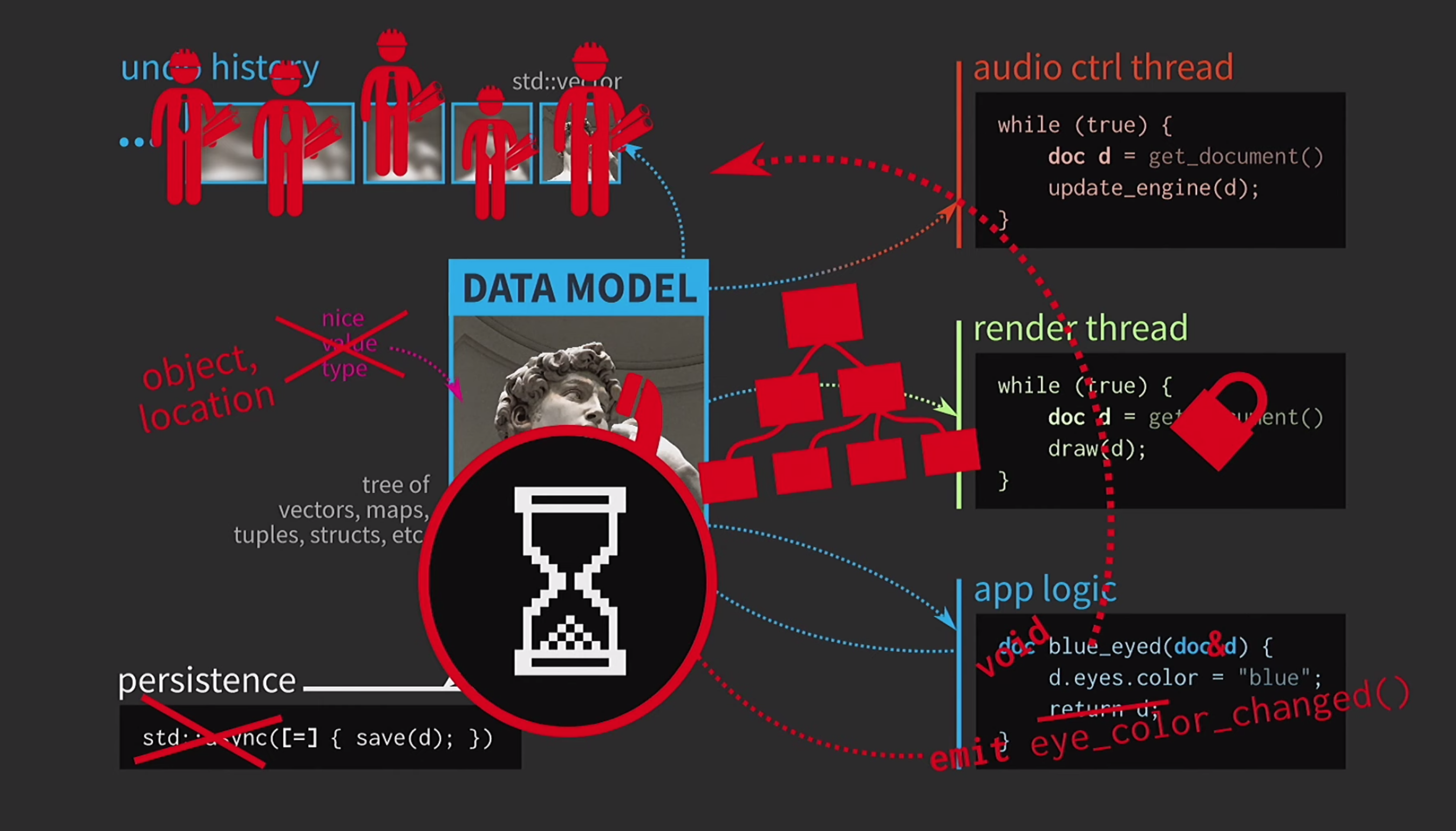 Benutzer sind bereits an das Sanduhrbild gewöhnt, daher ist es in Ordnung, wenn sie etwas warten. Eine andere Sache ist beängstigend - das Pasta-Monster regiert jetzt unseren Code.Ab wann ging es bergab? Wir haben unseren Code sehr gut gestaltet und mussten dann aufgrund des Kopierens Kompromisse eingehen. In C ++ muss das Kopieren jedoch nur für veränderbare Daten als Wert übergeben werden. Wenn das Objekt unveränderlich ist, kann der Zuweisungsoperator so implementiert werden, dass nur der Zeiger auf die interne Darstellung und nichts weiter kopiert wird.
Benutzer sind bereits an das Sanduhrbild gewöhnt, daher ist es in Ordnung, wenn sie etwas warten. Eine andere Sache ist beängstigend - das Pasta-Monster regiert jetzt unseren Code.Ab wann ging es bergab? Wir haben unseren Code sehr gut gestaltet und mussten dann aufgrund des Kopierens Kompromisse eingehen. In C ++ muss das Kopieren jedoch nur für veränderbare Daten als Wert übergeben werden. Wenn das Objekt unveränderlich ist, kann der Zuweisungsoperator so implementiert werden, dass nur der Zeiger auf die interne Darstellung und nichts weiter kopiert wird.const auto v0 = vector<int>{};
Stellen Sie sich eine Datenstruktur vor, die uns helfen könnte. Im folgenden Vektor sind alle Methoden als markiert const, sodass sie unveränderlich sind. Bei der Ausführung .push_backwird der Vektor nicht aktualisiert, sondern es wird ein neuer Vektor zurückgegeben, zu dem die übertragenen Daten hinzugefügt werden. Leider können wir bei diesem Ansatz keine eckigen Klammern verwenden, da diese definiert sind. Stattdessen können Sie die Funktion verwenden.setDies gibt eine neue Version mit einem aktualisierten Element zurück. Unsere Datenstruktur hat jetzt eine Eigenschaft, die in der funktionalen Programmierung als Persistenz bezeichnet wird. Dies bedeutet nicht, dass wir diese Datenstruktur auf der Festplatte speichern, sondern dass beim Aktualisieren der alte Inhalt nicht gelöscht wird. Stattdessen wird ein neuer Zweig unserer Welt erstellt, dh die Struktur. Dank dessen können wir vergangene Werte mit gegenwärtigen vergleichen - dies geschieht mit Hilfe von zwei assert.const auto v0 = vector<int>{};
const auto v1 = v0.push_back(15);
const auto v2 = v1.push_back(16);
const auto v3 = v2.set(0, 42);
assert(v2.size() == v0.size() + 2);
assert(v3[0] - v1[0] == 27);
Änderungen können jetzt direkt überprüft werden, sie sind keine versteckten Eigenschaften der Datenstruktur mehr. Diese Funktion ist besonders in interaktiven Systemen nützlich, in denen wir ständig Daten ändern müssen.Eine weitere wichtige Eigenschaft ist das strukturelle Teilen. Jetzt kopieren wir nicht alle Daten für jede neue Version der Datenstruktur. Auch mit .push_backund.setNicht alle Daten werden kopiert, sondern nur ein kleiner Teil davon. Alle unsere Gabeln haben gemeinsamen Zugriff auf eine kompakte Ansicht, die proportional zur Anzahl der Änderungen und nicht zur Anzahl der Kopien ist. Daraus folgt auch, dass der Vergleich sehr schnell ist: Wenn alles in einem Speicherblock, in einem Zeiger gespeichert ist, können Sie einfach die Zeiger vergleichen und nicht die darin enthaltenen Elemente untersuchen, wenn sie gleich sind.Da ein solcher Vektor meiner Meinung nach äußerst nützlich ist, habe ich ihn in einer separaten Bibliothek implementiert: Dies ist immer - eine Bibliothek unveränderlicher Strukturen, ein Open-Source-Projekt.Beim Schreiben wollte ich, dass die Verwendung den C ++ - Entwicklern vertraut ist. Es gibt viele Bibliotheken, die die Konzepte der funktionalen Programmierung in C ++ implementieren, aber es entsteht der Eindruck, dass die Entwickler für Haskell und nicht für C ++ schreiben. Dies schafft Unannehmlichkeiten. Außerdem habe ich gute Leistungen erzielt. Benutzer verwenden C ++, wenn die verfügbaren Ressourcen begrenzt sind. Schließlich wollte ich, dass die Bibliothek anpassbar ist. Diese Anforderung hängt mit der Leistungsanforderung zusammen.Auf der Suche nach einem magischen Vektor
Im zweiten Teil des Berichts werden wir untersuchen, wie dieser unveränderliche Vektor strukturiert ist. Der einfachste Weg, die Prinzipien einer solchen Datenstruktur zu verstehen, besteht darin, mit einer regulären Liste zu beginnen. Wenn Sie mit der funktionalen Programmierung ein wenig vertraut sind (am Beispiel von Lisp oder Haskell), wissen Sie, dass Listen die häufigsten unveränderlichen Datenstrukturen sind.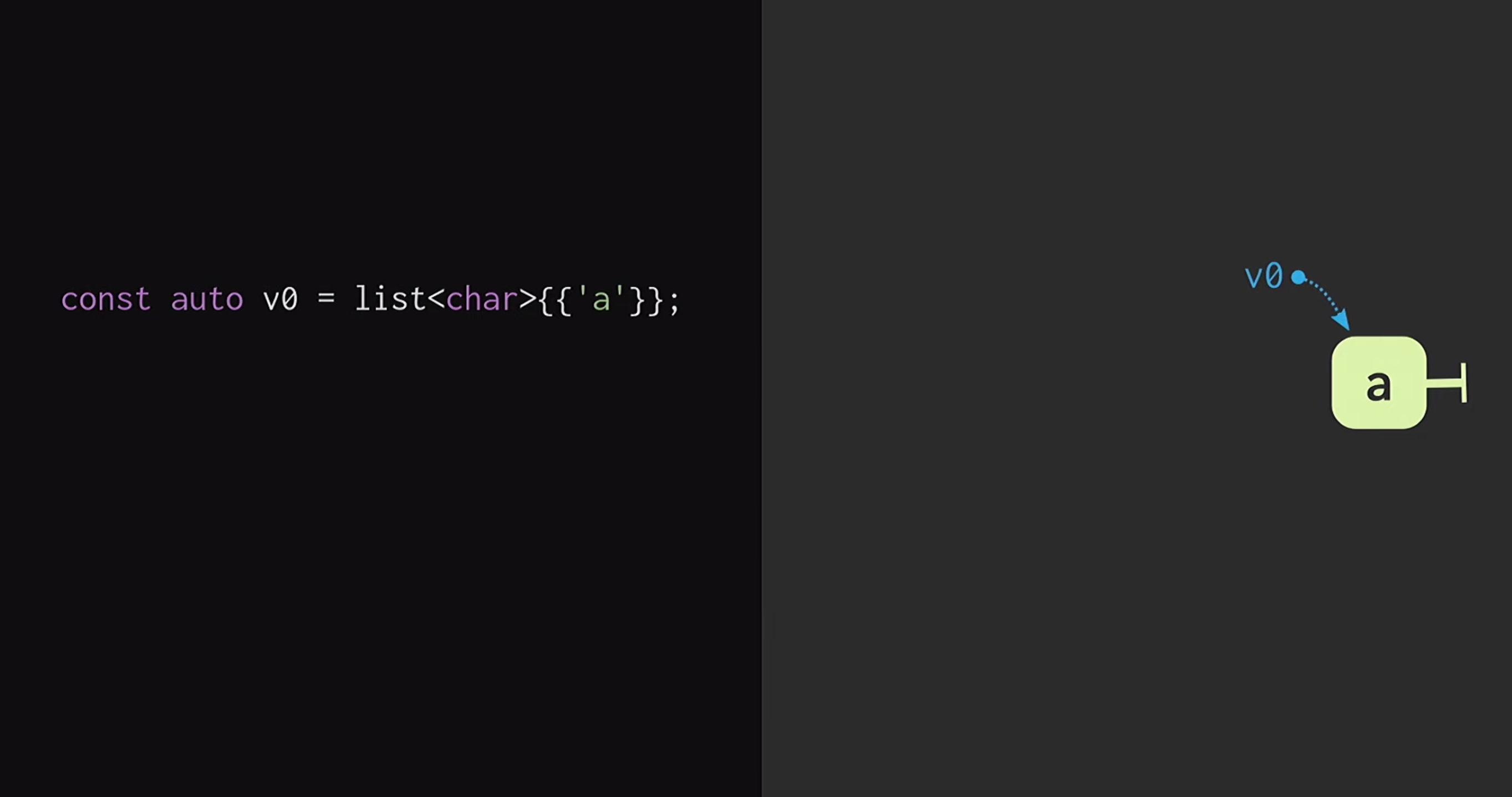 Nehmen wir zunächst an, wir haben eine Liste mit einem einzelnen Knoten
Nehmen wir zunächst an, wir haben eine Liste mit einem einzelnen Knoten v1sie v0zeigen unterschiedliche Elemente an.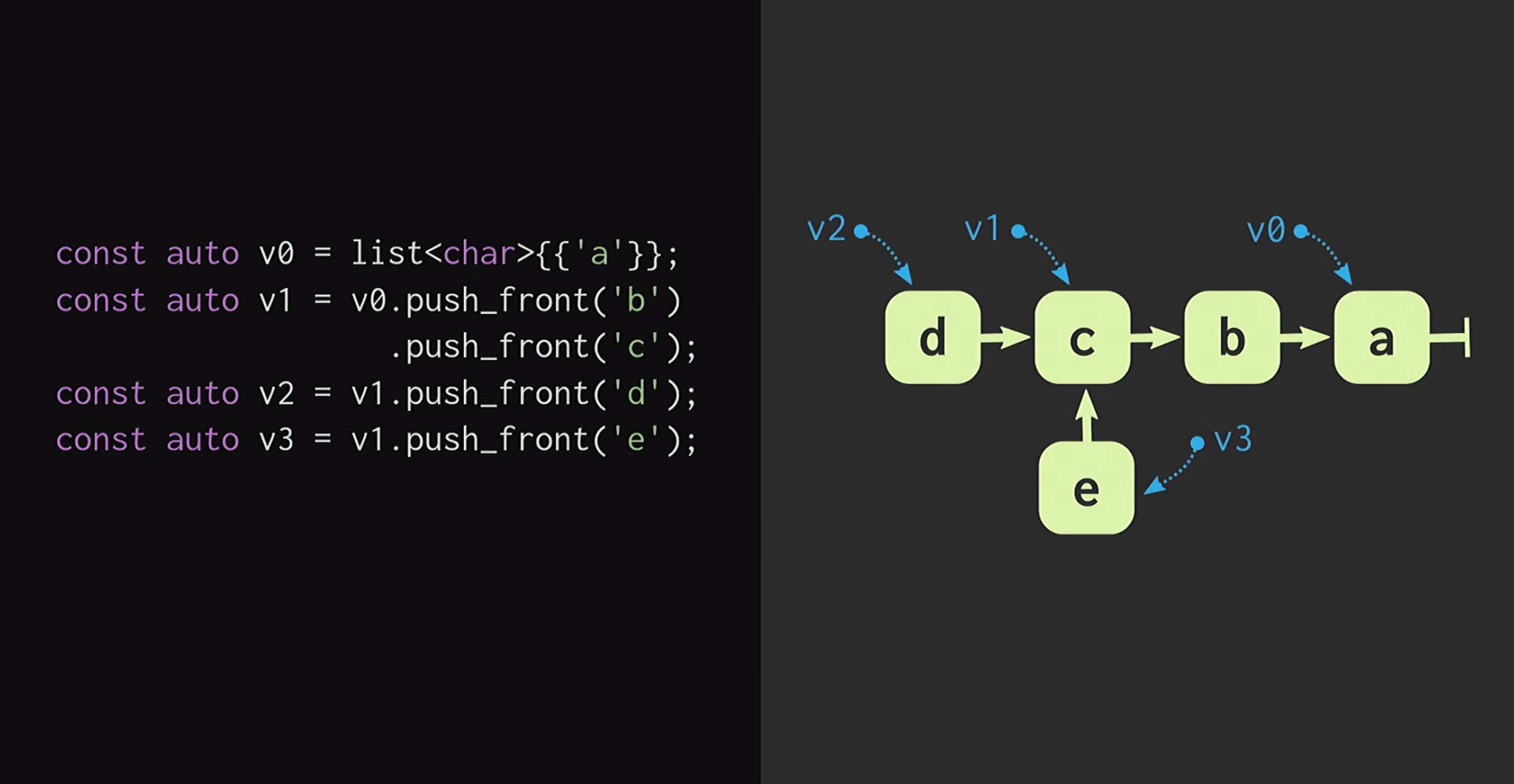 Wir können auch eine Gabelung der Realität erstellen, dh eine neue Liste erstellen, die das gleiche Ende, aber einen anderen Anfang hat.Solche Datenstrukturen wurden lange untersucht: Chris Okasaki schrieb die grundlegende Arbeit von Purely Functional Data Structures . Darüber hinaus ist die von Ralf Hinze und Ross Paterson vorgeschlagene Finger Tree- Datenstruktur sehr interessant . Für C ++ funktionieren solche Datenstrukturen jedoch nicht gut. Sie verwenden kleine Knoten, und wir wissen, dass kleine Knoten in C ++ einen Mangel an Caching-Effizienz bedeuten.Darüber hinaus stützen sie sich häufig auf Eigenschaften, die C ++ nicht besitzt, wie z. B. Faulheit. Daher ist die Arbeit von Phil Bagwell an unveränderlichen Datenstrukturen für uns viel nützlicher - ein Link , der Anfang der 2000er Jahre geschrieben wurde, sowie die Arbeit von Rich Hickey - Link, Autor von Clojure. Rich Hickey hat eine Liste erstellt, die eigentlich keine Liste ist, sondern auf modernen Datenstrukturen basiert: Vektoren und Hash-Maps. Diese Datenstrukturen weisen eine Caching-Effizienz auf und interagieren gut mit modernen Prozessoren, für die es unerwünscht ist, mit kleinen Knoten zu arbeiten. Solche Strukturen können in C ++ verwendet werden.Wie baue ich einen Immunvektor auf? Im Herzen jeder Struktur, die auch nur aus der Ferne einem Vektor ähnelt, muss sich ein Array befinden. Das Array verfügt jedoch nicht über eine strukturelle Freigabe. Um ein Element des Arrays zu ändern, ohne die Persistenz-Eigenschaft zu verlieren, müssen Sie das gesamte Array kopieren. Um dies nicht zu tun, kann das Array in separate Teile aufgeteilt werden.Wenn wir jetzt ein Vektorelement aktualisieren, müssen wir nur ein Stück und nicht den gesamten Vektor kopieren. Aber solche Teile selbst sind keine Datenstruktur, sie müssen auf die eine oder andere Weise kombiniert werden. Legen Sie sie in ein anderes Array. Erneut tritt das Problem auf, dass das Array sehr groß sein kann und das erneute Kopieren zu lange dauert.Wir teilen dieses Array in Teile, platzieren sie erneut in einem separaten Array und wiederholen diesen Vorgang, bis nur noch ein Root-Array vorhanden ist. Die resultierende Struktur wird als Restbaum bezeichnet. Dieser Baum wird durch die Konstante M = 2B, dh den Verzweigungsfaktor, beschrieben. Dieser Verzweigungsindikator sollte eine Zweierpotenz sein, und wir werden sehr bald herausfinden, warum. In dem Beispiel auf der Folie werden Blöcke mit vier Zeichen verwendet, in der Praxis werden jedoch Blöcke mit 32 Zeichen verwendet. Es gibt Experimente, mit denen Sie die optimale Blockgröße für eine bestimmte Architektur finden können. Auf diese Weise können Sie das beste Verhältnis zwischen strukturellem gemeinsamem Zugriff und Zugriffszeit erzielen: Je niedriger der Baum, desto weniger Zugriffszeit.Entwickler, die dies in C ++ schreiben, denken wahrscheinlich: Aber alle baumbasierten Strukturen sind sehr langsam! Bäume wachsen mit zunehmender Anzahl von Elementen in ihnen, und aus diesem Grund werden die Zugriffszeiten verkürzt. Deshalb bevorzugen Programmierer
Wir können auch eine Gabelung der Realität erstellen, dh eine neue Liste erstellen, die das gleiche Ende, aber einen anderen Anfang hat.Solche Datenstrukturen wurden lange untersucht: Chris Okasaki schrieb die grundlegende Arbeit von Purely Functional Data Structures . Darüber hinaus ist die von Ralf Hinze und Ross Paterson vorgeschlagene Finger Tree- Datenstruktur sehr interessant . Für C ++ funktionieren solche Datenstrukturen jedoch nicht gut. Sie verwenden kleine Knoten, und wir wissen, dass kleine Knoten in C ++ einen Mangel an Caching-Effizienz bedeuten.Darüber hinaus stützen sie sich häufig auf Eigenschaften, die C ++ nicht besitzt, wie z. B. Faulheit. Daher ist die Arbeit von Phil Bagwell an unveränderlichen Datenstrukturen für uns viel nützlicher - ein Link , der Anfang der 2000er Jahre geschrieben wurde, sowie die Arbeit von Rich Hickey - Link, Autor von Clojure. Rich Hickey hat eine Liste erstellt, die eigentlich keine Liste ist, sondern auf modernen Datenstrukturen basiert: Vektoren und Hash-Maps. Diese Datenstrukturen weisen eine Caching-Effizienz auf und interagieren gut mit modernen Prozessoren, für die es unerwünscht ist, mit kleinen Knoten zu arbeiten. Solche Strukturen können in C ++ verwendet werden.Wie baue ich einen Immunvektor auf? Im Herzen jeder Struktur, die auch nur aus der Ferne einem Vektor ähnelt, muss sich ein Array befinden. Das Array verfügt jedoch nicht über eine strukturelle Freigabe. Um ein Element des Arrays zu ändern, ohne die Persistenz-Eigenschaft zu verlieren, müssen Sie das gesamte Array kopieren. Um dies nicht zu tun, kann das Array in separate Teile aufgeteilt werden.Wenn wir jetzt ein Vektorelement aktualisieren, müssen wir nur ein Stück und nicht den gesamten Vektor kopieren. Aber solche Teile selbst sind keine Datenstruktur, sie müssen auf die eine oder andere Weise kombiniert werden. Legen Sie sie in ein anderes Array. Erneut tritt das Problem auf, dass das Array sehr groß sein kann und das erneute Kopieren zu lange dauert.Wir teilen dieses Array in Teile, platzieren sie erneut in einem separaten Array und wiederholen diesen Vorgang, bis nur noch ein Root-Array vorhanden ist. Die resultierende Struktur wird als Restbaum bezeichnet. Dieser Baum wird durch die Konstante M = 2B, dh den Verzweigungsfaktor, beschrieben. Dieser Verzweigungsindikator sollte eine Zweierpotenz sein, und wir werden sehr bald herausfinden, warum. In dem Beispiel auf der Folie werden Blöcke mit vier Zeichen verwendet, in der Praxis werden jedoch Blöcke mit 32 Zeichen verwendet. Es gibt Experimente, mit denen Sie die optimale Blockgröße für eine bestimmte Architektur finden können. Auf diese Weise können Sie das beste Verhältnis zwischen strukturellem gemeinsamem Zugriff und Zugriffszeit erzielen: Je niedriger der Baum, desto weniger Zugriffszeit.Entwickler, die dies in C ++ schreiben, denken wahrscheinlich: Aber alle baumbasierten Strukturen sind sehr langsam! Bäume wachsen mit zunehmender Anzahl von Elementen in ihnen, und aus diesem Grund werden die Zugriffszeiten verkürzt. Deshalb bevorzugen Programmierer std::unordered_mapeher als std::map. Ich beeile mich, Sie zu beruhigen: Unser Baum wächst sehr langsam. Ein Vektor, der alle möglichen Werte eines 32-Bit-Int enthält, ist nur 7 Ebenen hoch. Es kann experimentell gezeigt werden, dass bei dieser Datengröße das Verhältnis des Caches zum Lastvolumen die Leistung erheblich beeinflusst als die Tiefe des Baums.Mal sehen, wie ein Zugriff auf ein Element eines Baumes durchgeführt wird. Angenommen, Sie müssen sich Element 17 zuwenden. Wir nehmen eine binäre Darstellung des Index und teilen ihn in Gruppen von der Größe eines Verzweigungsfaktors auf. In jeder Gruppe verwenden wir den entsprechenden Binärwert und gehen so den Baum hinunter.Nehmen wir als nächstes an, wir müssen diese Datenstruktur ändern, dh die Methode ausführen
In jeder Gruppe verwenden wir den entsprechenden Binärwert und gehen so den Baum hinunter.Nehmen wir als nächstes an, wir müssen diese Datenstruktur ändern, dh die Methode ausführen .set.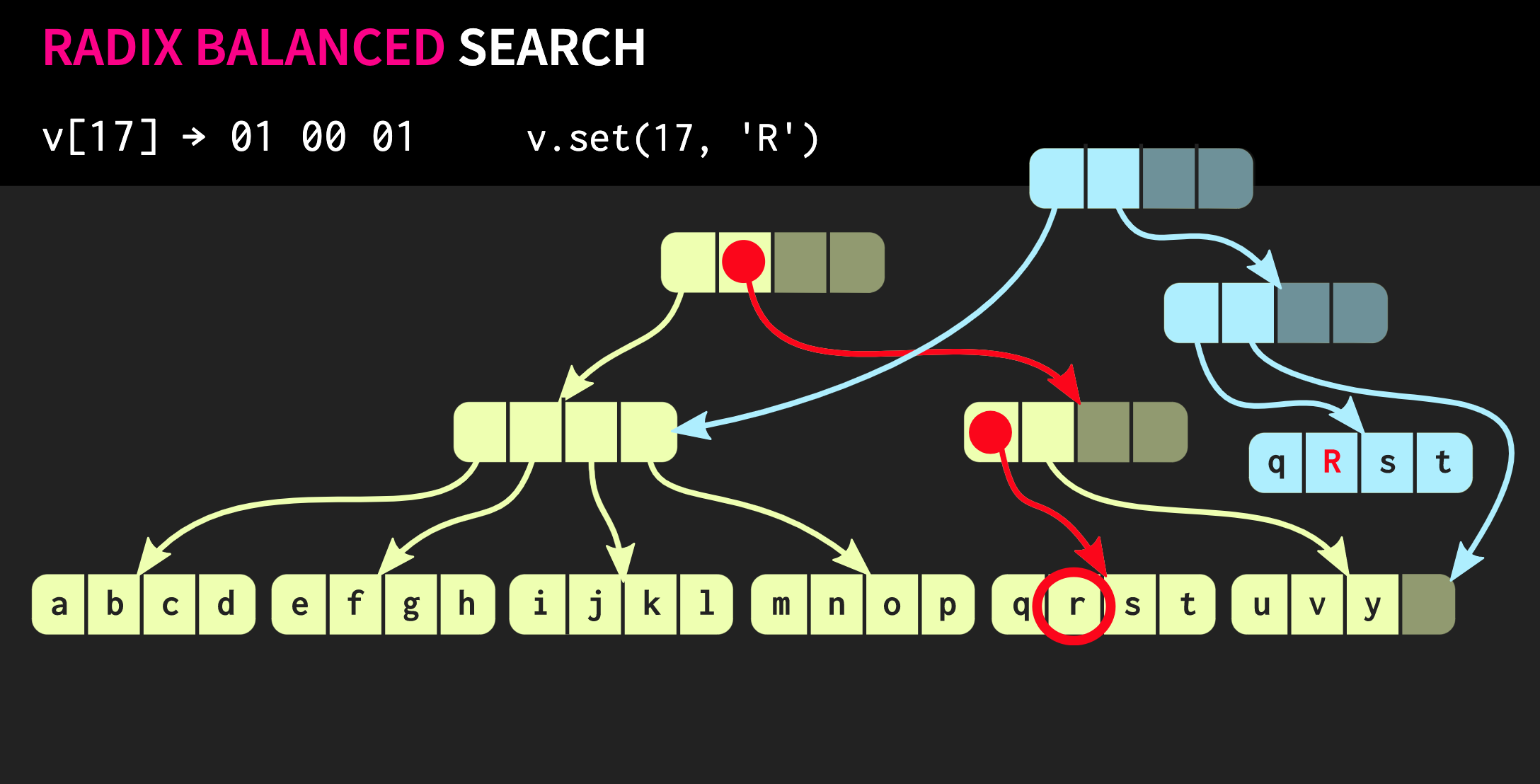 Dazu müssen Sie zuerst den Block kopieren, in dem sich das Element befindet, und dann jeden internen Knoten auf dem Weg zum Element kopieren. Einerseits müssen ziemlich viele Daten kopiert werden, gleichzeitig ist ein erheblicher Teil dieser Daten üblich, dies kompensiert deren Volumen.Übrigens gibt es eine viel ältere Datenstruktur, die der von mir beschriebenen sehr ähnlich ist. Dies sind Speicherseiten mit einem Seitentabellenbaum. Ihre Geschäftsführung erfolgt ebenfalls per Anruf
Dazu müssen Sie zuerst den Block kopieren, in dem sich das Element befindet, und dann jeden internen Knoten auf dem Weg zum Element kopieren. Einerseits müssen ziemlich viele Daten kopiert werden, gleichzeitig ist ein erheblicher Teil dieser Daten üblich, dies kompensiert deren Volumen.Übrigens gibt es eine viel ältere Datenstruktur, die der von mir beschriebenen sehr ähnlich ist. Dies sind Speicherseiten mit einem Seitentabellenbaum. Ihre Geschäftsführung erfolgt ebenfalls per Anruf fork.Versuchen wir, unsere Datenstruktur zu verbessern. Angenommen, wir müssen zwei Vektoren verbinden. Die bisher beschriebene Datenstruktur weist dieselben Einschränkungen auf std::vector:wie leere Zellen ganz rechts. Da die Struktur perfekt ausbalanciert ist, können sich diese leeren Zellen nicht in der Mitte des Baums befinden. Wenn es also einen zweiten Vektor gibt, den wir mit dem ersten kombinieren möchten, müssen wir die Elemente in leere Zellen kopieren, wodurch leere Zellen im zweiten Vektor erstellt werden, und am Ende müssen wir den gesamten zweiten Vektor kopieren. Eine solche Operation hat die Rechenkomplexität O (n), wobei n die Größe des zweiten Vektors ist.Wir werden versuchen, ein besseres Ergebnis zu erzielen. Es gibt eine modifizierte Version unserer Datenstruktur, die als Relaxed Radix Balanced Tree bezeichnet wird. In dieser Struktur können Knoten, die sich nicht ganz links befinden, leere Zellen haben. Daher ist es in solchen unvollständigen (oder entspannten) Knoten erforderlich, die Größe des Teilbaums zu berechnen. Jetzt können Sie eine komplexe, aber logarithmische Verknüpfungsoperation ausführen. Diese Operation mit konstanter Zeitkomplexität ist O (log (32)). Da die Bäume flach sind, ist die Zugriffszeit konstant, wenn auch relativ lang. Aufgrund der Tatsache, dass wir eine solche Vereinigungsoperation haben, wird eine entspannte Version dieser Datenstruktur als konfluent bezeichnet: Zusätzlich zu ihrer Beständigkeit und Sie können sie teilen, können zwei solcher Strukturen zu einer kombiniert werden.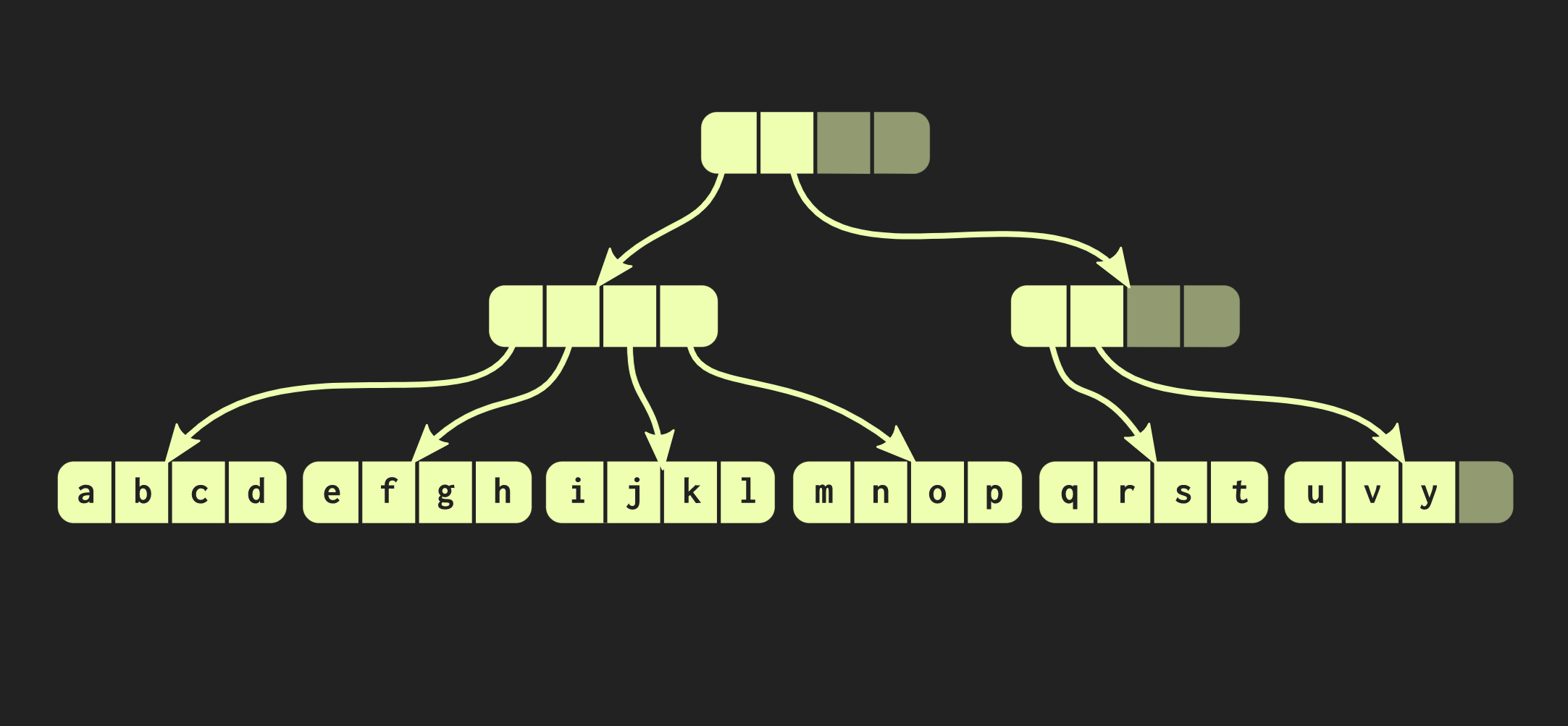 In dem Beispiel, mit dem wir bisher gearbeitet haben, ist die Datenstruktur sehr ordentlich, aber in der Praxis sehen die Implementierungen in Clojure und anderen funktionalen Sprachen anders aus. Sie erstellen Container für jeden Wert, dh jedes Element im Vektor befindet sich in einer separaten Zelle, und Blattknoten enthalten Zeiger auf diese Elemente. Dieser Ansatz ist jedoch äußerst ineffizient. In C ++ wird normalerweise nicht jeder Wert in einen Container eingefügt. Daher ist es besser, wenn sich diese Elemente direkt in Knoten befinden. Dann tritt ein anderes Problem auf: Unterschiedliche Elemente haben unterschiedliche Größen. Wenn das Element dieselbe Größe wie der Zeiger hat, sieht unsere Struktur wie folgt aus:
In dem Beispiel, mit dem wir bisher gearbeitet haben, ist die Datenstruktur sehr ordentlich, aber in der Praxis sehen die Implementierungen in Clojure und anderen funktionalen Sprachen anders aus. Sie erstellen Container für jeden Wert, dh jedes Element im Vektor befindet sich in einer separaten Zelle, und Blattknoten enthalten Zeiger auf diese Elemente. Dieser Ansatz ist jedoch äußerst ineffizient. In C ++ wird normalerweise nicht jeder Wert in einen Container eingefügt. Daher ist es besser, wenn sich diese Elemente direkt in Knoten befinden. Dann tritt ein anderes Problem auf: Unterschiedliche Elemente haben unterschiedliche Größen. Wenn das Element dieselbe Größe wie der Zeiger hat, sieht unsere Struktur wie folgt aus: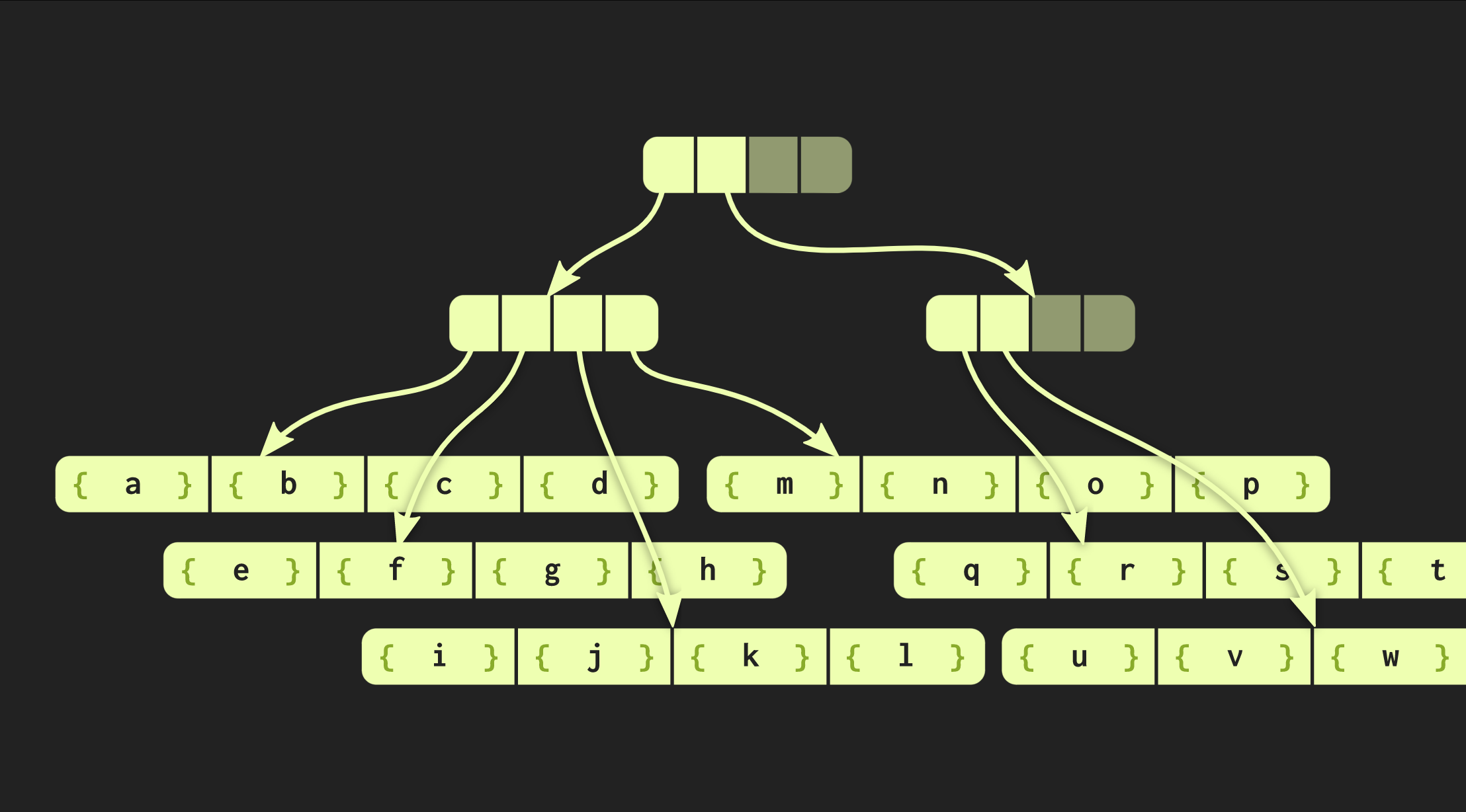 Wenn die Elemente jedoch groß sind, verliert die Datenstruktur die von uns gemessenen Eigenschaften (Zugriffszeit O (log (32) ()), da das Kopieren eines der Blätter jetzt länger dauert. Daher habe ich diese Datenstruktur so geändert, dass sie mit zunehmender Größe zunimmt Die Anzahl der darin enthaltenen Elemente verringerte die Anzahl dieser Elemente in den Blattknoten. Im Gegenteil, wenn die Elemente klein sind, können sie jetzt mehr passen. Die neue Version des Baums wird als Einbetten eines radixausgeglichenen Baums bezeichnet. Sie wird nicht durch eine Konstante beschrieben, sondern durch zwei: eine von ihnen beschreibt interne Knoten und das zweite Blatt. Durch die Implementierung des Baums in C ++ kann die optimale Größe des Blattelements in Abhängigkeit von der Größe der Zeiger und der Elemente selbst berechnet werden.Unser Baum funktioniert bereits recht gut, kann aber noch verbessert werden. Schauen Sie sich eine Funktion ähnlich einer Funktion an
Wenn die Elemente jedoch groß sind, verliert die Datenstruktur die von uns gemessenen Eigenschaften (Zugriffszeit O (log (32) ()), da das Kopieren eines der Blätter jetzt länger dauert. Daher habe ich diese Datenstruktur so geändert, dass sie mit zunehmender Größe zunimmt Die Anzahl der darin enthaltenen Elemente verringerte die Anzahl dieser Elemente in den Blattknoten. Im Gegenteil, wenn die Elemente klein sind, können sie jetzt mehr passen. Die neue Version des Baums wird als Einbetten eines radixausgeglichenen Baums bezeichnet. Sie wird nicht durch eine Konstante beschrieben, sondern durch zwei: eine von ihnen beschreibt interne Knoten und das zweite Blatt. Durch die Implementierung des Baums in C ++ kann die optimale Größe des Blattelements in Abhängigkeit von der Größe der Zeiger und der Elemente selbst berechnet werden.Unser Baum funktioniert bereits recht gut, kann aber noch verbessert werden. Schauen Sie sich eine Funktion ähnlich einer Funktion an iota:vector<int> myiota(vector<int> v, int first, int last)
{
for (auto i = first; i < last; ++i)
v = v.push_back(i);
return v;
}
Es nimmt eine Eingabe entgegen vector, wird push_backam Ende des Vektors für jede Ganzzahl zwischen firstund ausgeführt lastund gibt zurück, was passiert ist. Alles ist in Ordnung mit der Richtigkeit dieser Funktion, aber es funktioniert ineffizient. Jeder Aufruf push_backkopiert den Block ganz links unnötig: Der nächste Aufruf drückt ein anderes Element und die Kopie wird erneut wiederholt, und die von der vorherigen Methode kopierten Daten werden gelöscht.Sie können eine andere Implementierung dieser Funktion ausprobieren, bei der wir die Persistenz innerhalb der Funktion aufgeben. Kann transient vectormit einer veränderlichen API verwendet werden, die mit der regulären API kompatibel ist vector. Innerhalb einer solchen Funktion push_backändert jeder Aufruf die Datenstruktur.vector<int> myiota(vector<int> v, int first, int last)
{
auto t = v.transient();
for (auto i = first; i < last; ++i)
t.push_back(i);
return t.persistent();
}
Diese Implementierung ist effizienter und ermöglicht es Ihnen, neue Elemente auf dem richtigen Weg wiederzuverwenden. Am Ende der Funktion wird ein Aufruf .persistent()getätigt, der unveränderlich zurückgibt vector. Mögliche Nebenwirkungen bleiben von außerhalb der Funktion unsichtbar. Das Original vectorwar und bleibt unveränderlich, nur die innerhalb der Funktion erstellten Daten werden geändert. Wie bereits erwähnt, besteht ein wichtiger Vorteil dieses Ansatzes darin, dass Sie std::back_inserterStandardalgorithmen verwenden können, für die veränderbare APIs erforderlich sind.Betrachten Sie ein anderes Beispiel.vector<char> say_hi(vector<char> v)
{
return v.push_back('h')
.push_back('i')
.push_back('!');
}
Die Funktion akzeptiert nicht und gibt zurück vector, aber eine Aufrufkette wird im Inneren ausgeführt push_back. Hier kann wie im vorherigen Beispiel unnötiges Kopieren innerhalb des Anrufs auftreten push_back. Beachten Sie, dass der erste Wert, der ausgeführt push_backwird, der benannte Wert ist und der Rest ein r-Wert ist, dh anonyme Links. Wenn Sie die Referenzzählung verwenden, kann die Methode push_backauf Referenzzähler für Knoten verweisen, denen im Baum Speicher zugewiesen ist. Und im Fall von r-Wert wird klar, dass kein anderer Teil des Programms auf diese Knoten zugreift, wenn die Anzahl der Verknüpfungen eins ist. Hier ist die Leistung genau die gleiche wie im Fall von transient.vector<char> say_hi(vector<char> v)
{
return v.push_back('h') ⟵ named value: v
.push_back('i') ⟵ r-value value
.push_back('!'); ⟵ r-value value
}
Um dem Compiler zu helfen, können wir ihn außerdem ausführen move(v), da er an vkeiner anderen Stelle in der Funktion verwendet wird. Wir hatten einen wichtigen Vorteil, der nicht in der transientVariante enthalten war: Wenn wir den zurückgegebenen Wert eines anderen say_hi an die Funktion say_hi übergeben, gibt es keine zusätzlichen Kopien. Im Fall von c transientgibt es Grenzen, an denen übermäßiges Kopieren auftreten kann. Mit anderen Worten, wir haben eine dauerhafte, unveränderliche Datenstruktur, deren Leistung von der tatsächlichen Menge des gemeinsam genutzten Zugriffs zur Laufzeit abhängt. Wenn keine Freigabe erfolgt, entspricht die Leistung der einer veränderlichen Datenstruktur. Dies ist eine äußerst wichtige Eigenschaft. Das Beispiel, das ich Ihnen oben bereits gezeigt habe, kann mit einer Methode umgeschrieben werden move(v).vector<int> myiota(vector<int> v, int first, int last)
{
for (auto i = first; i < last; ++i)
v = std::move(v).push_back(i);
return v;
}
Bisher haben wir über Vektoren gesprochen, und zusätzlich gibt es auch Hash-Maps. Sie widmen sich einem sehr nützlichen Bericht von Phil Nash: Der heilige Gral. Ein Hash-Array hat Trie für C ++ zugeordnet . Es beschreibt Hash-Tabellen, die nach denselben Prinzipien implementiert wurden, über die ich gerade gesprochen habe.Ich bin sicher, dass viele von Ihnen Zweifel an der Leistung solcher Strukturen haben. Arbeiten sie in der Praxis schnell? Ich habe viele Tests durchgeführt und kurz gesagt lautet meine Antwort ja. Wenn Sie mehr über die Testergebnisse erfahren möchten, werden diese in meinem Artikel für die Internationale Konferenz für funktionale Programmierung 2017 veröffentlicht. Ich denke, es ist besser, nicht die absoluten Werte zu diskutieren, sondern die Auswirkungen dieser Datenstruktur auf das Gesamtsystem. Natürlich ist die Aktualisierung unseres Vektors langsamer, da Sie mehrere Datenblöcke kopieren und Speicher für andere Daten zuweisen müssen. Das Umgehen unseres Vektors erfolgt jedoch fast mit der gleichen Geschwindigkeit wie bei einem normalen. Für mich war es sehr wichtig, dies zu erreichen, da das Lesen von Daten viel häufiger durchgeführt wird als das Ändern.Aufgrund der langsameren Aktualisierung muss nichts kopiert werden, nur die Datenstruktur wird kopiert. Daher wird die für die Aktualisierung des Vektors aufgewendete Zeit sozusagen für alle im System durchgeführten Kopien amortisiert. Wenn Sie diese Datenstruktur in einer Architektur anwenden, die der zu Beginn des Berichts beschriebenen ähnlich ist, steigt die Leistung daher erheblich.Ewig
Ich werde nicht unbegründet sein und meine Datenstruktur anhand eines Beispiels demonstrieren. Ich habe einen kleinen Texteditor geschrieben. Dies ist ein interaktives Tool namens ewig , bei dem Dokumente durch unveränderliche Vektoren dargestellt werden. Ich habe eine Kopie der gesamten Wikipedia in Esperanto auf meiner Festplatte gespeichert, sie wiegt 1 Gigabyte (zuerst wollte ich die englische Version herunterladen, aber sie ist zu groß). Welchen Texteditor Sie auch verwenden, ich bin sicher, dass ihm diese Datei nicht gefallen wird. Und wenn Sie diese Datei in ewig herunterladen , können Sie sie sofort bearbeiten, da der Download asynchron ist. Die Dateinavigation funktioniert, nichts hängt, nein mutex, keine Synchronisation. Wie Sie sehen können, benötigt die heruntergeladene Datei 20 Millionen Codezeilen.Bevor wir uns mit den wichtigsten Eigenschaften dieses Tools befassen, sollten wir uns mit einem lustigen Detail befassen. Am Anfang der Zeile, die am unteren Rand des Bildes weiß hervorgehoben ist, sehen Sie zwei Bindestriche. Diese Benutzeroberfläche ist Emacs-Benutzern höchstwahrscheinlich vertraut. Bindestriche bedeuten, dass das Dokument in keiner Weise geändert wurde. Wenn Sie Änderungen vornehmen, werden anstelle von Bindestrichen Sternchen angezeigt. Wenn Sie diese Änderungen jedoch im Gegensatz zu anderen Editoren in ewig löschen (nicht rückgängig machen, sondern nur löschen), werden anstelle von Sternchen wieder Bindestriche angezeigt, da alle vorherigen Versionen des Textes in ewig gespeichert sind. Dank dessen wird kein spezielles Flag benötigt, um anzuzeigen, ob das Dokument geändert wurde: Das Vorhandensein von Änderungen wird durch Vergleich mit dem Originaldokument festgestellt.Betrachten Sie eine weitere interessante Eigenschaft des Tools: Kopieren Sie den gesamten Text und fügen Sie ihn einige Male in die Mitte des vorhandenen Textes ein. Wie Sie sehen können, geschieht dies sofort. Das Verbinden von Vektoren ist hier eine logarithmische Operation, und der Logarithmus von mehreren Millionen ist keine so lange Operation. Wenn Sie versuchen, dieses große Dokument auf Ihrer Festplatte zu speichern, dauert es viel länger, da der Text nicht mehr als Vektor dargestellt wird, der aus der vorherigen Version dieses Vektors stammt. Beim Speichern auf der Festplatte erfolgt eine Serialisierung, sodass die Persistenz verloren geht.
Am Anfang der Zeile, die am unteren Rand des Bildes weiß hervorgehoben ist, sehen Sie zwei Bindestriche. Diese Benutzeroberfläche ist Emacs-Benutzern höchstwahrscheinlich vertraut. Bindestriche bedeuten, dass das Dokument in keiner Weise geändert wurde. Wenn Sie Änderungen vornehmen, werden anstelle von Bindestrichen Sternchen angezeigt. Wenn Sie diese Änderungen jedoch im Gegensatz zu anderen Editoren in ewig löschen (nicht rückgängig machen, sondern nur löschen), werden anstelle von Sternchen wieder Bindestriche angezeigt, da alle vorherigen Versionen des Textes in ewig gespeichert sind. Dank dessen wird kein spezielles Flag benötigt, um anzuzeigen, ob das Dokument geändert wurde: Das Vorhandensein von Änderungen wird durch Vergleich mit dem Originaldokument festgestellt.Betrachten Sie eine weitere interessante Eigenschaft des Tools: Kopieren Sie den gesamten Text und fügen Sie ihn einige Male in die Mitte des vorhandenen Textes ein. Wie Sie sehen können, geschieht dies sofort. Das Verbinden von Vektoren ist hier eine logarithmische Operation, und der Logarithmus von mehreren Millionen ist keine so lange Operation. Wenn Sie versuchen, dieses große Dokument auf Ihrer Festplatte zu speichern, dauert es viel länger, da der Text nicht mehr als Vektor dargestellt wird, der aus der vorherigen Version dieses Vektors stammt. Beim Speichern auf der Festplatte erfolgt eine Serialisierung, sodass die Persistenz verloren geht.Zurück zur wertbasierten Architektur
 Beginnen wir damit, wie Sie nicht zu dieser Architektur zurückkehren können: Verwenden Sie den üblichen Controller, das Modell und die Ansicht im Java-Stil, die am häufigsten für interaktive Anwendungen in C ++ verwendet werden. Es ist nichts falsch mit ihnen, aber sie sind nicht für unser Problem geeignet. Einerseits ermöglicht das Model-View-Controller-Muster die Trennung von Aufgaben, andererseits ist jedes dieser Elemente ein Objekt, sowohl aus objektorientierter Sicht als auch aus Sicht von C ++, dh es handelt sich um veränderbare Speicherbereiche Bedingung. View kennt sich mit Model aus; Das ist viel schlimmer - Model kennt View indirekt, da es mit ziemlicher Sicherheit einen Rückruf gibt, über den die View benachrichtigt wird, wenn sich das Modell ändert. Selbst mit der besten Implementierung objektorientierter Prinzipien erhalten wir viele gegenseitige Abhängigkeiten.
Beginnen wir damit, wie Sie nicht zu dieser Architektur zurückkehren können: Verwenden Sie den üblichen Controller, das Modell und die Ansicht im Java-Stil, die am häufigsten für interaktive Anwendungen in C ++ verwendet werden. Es ist nichts falsch mit ihnen, aber sie sind nicht für unser Problem geeignet. Einerseits ermöglicht das Model-View-Controller-Muster die Trennung von Aufgaben, andererseits ist jedes dieser Elemente ein Objekt, sowohl aus objektorientierter Sicht als auch aus Sicht von C ++, dh es handelt sich um veränderbare Speicherbereiche Bedingung. View kennt sich mit Model aus; Das ist viel schlimmer - Model kennt View indirekt, da es mit ziemlicher Sicherheit einen Rückruf gibt, über den die View benachrichtigt wird, wenn sich das Modell ändert. Selbst mit der besten Implementierung objektorientierter Prinzipien erhalten wir viele gegenseitige Abhängigkeiten.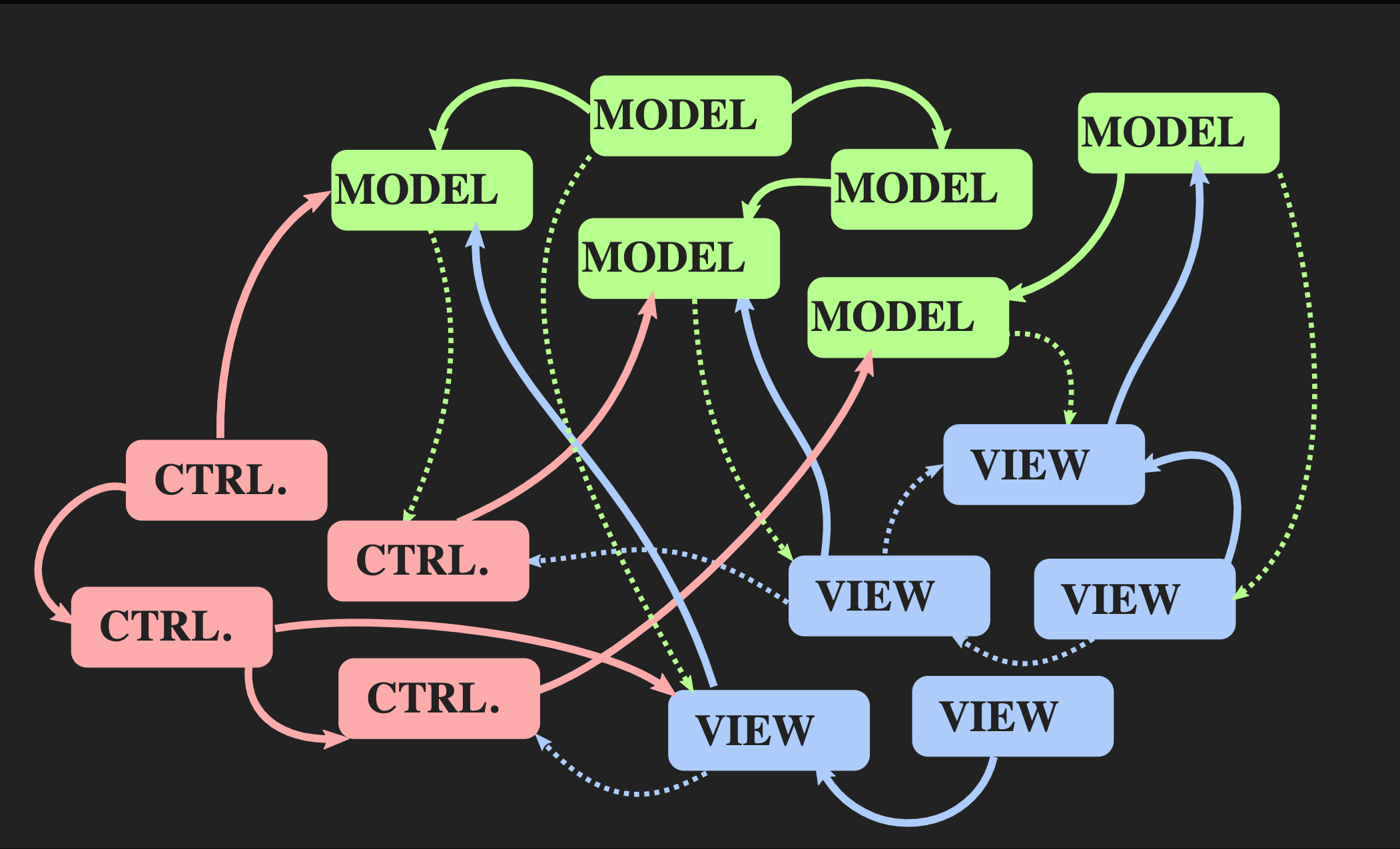 Wenn die Anwendung wächst und neues Modell, Controller und Ansicht hinzugefügt werden, tritt eine Situation auf, in der Sie zum Ändern eines Programmsegments alle damit verbundenen Teile, alle Ansichten kennen müssen, über die Warnungen empfangen
Wenn die Anwendung wächst und neues Modell, Controller und Ansicht hinzugefügt werden, tritt eine Situation auf, in der Sie zum Ändern eines Programmsegments alle damit verbundenen Teile, alle Ansichten kennen müssen, über die Warnungen empfangen callbackwerden usw. Infolgedessen alle Das bekannte Pasta-Monster beginnt, diese Abhängigkeiten zu durchschauen.Ist eine andere Architektur möglich? Es gibt einen alternativen Ansatz für das Model-View-Controller-Muster namens "Unidirectional Data Flow Architecture". Dieses Konzept wurde nicht von mir erfunden, es wird ziemlich oft in der Webentwicklung verwendet. Auf Facebook wird dies als Flux-Architektur bezeichnet, in C ++ jedoch noch nicht.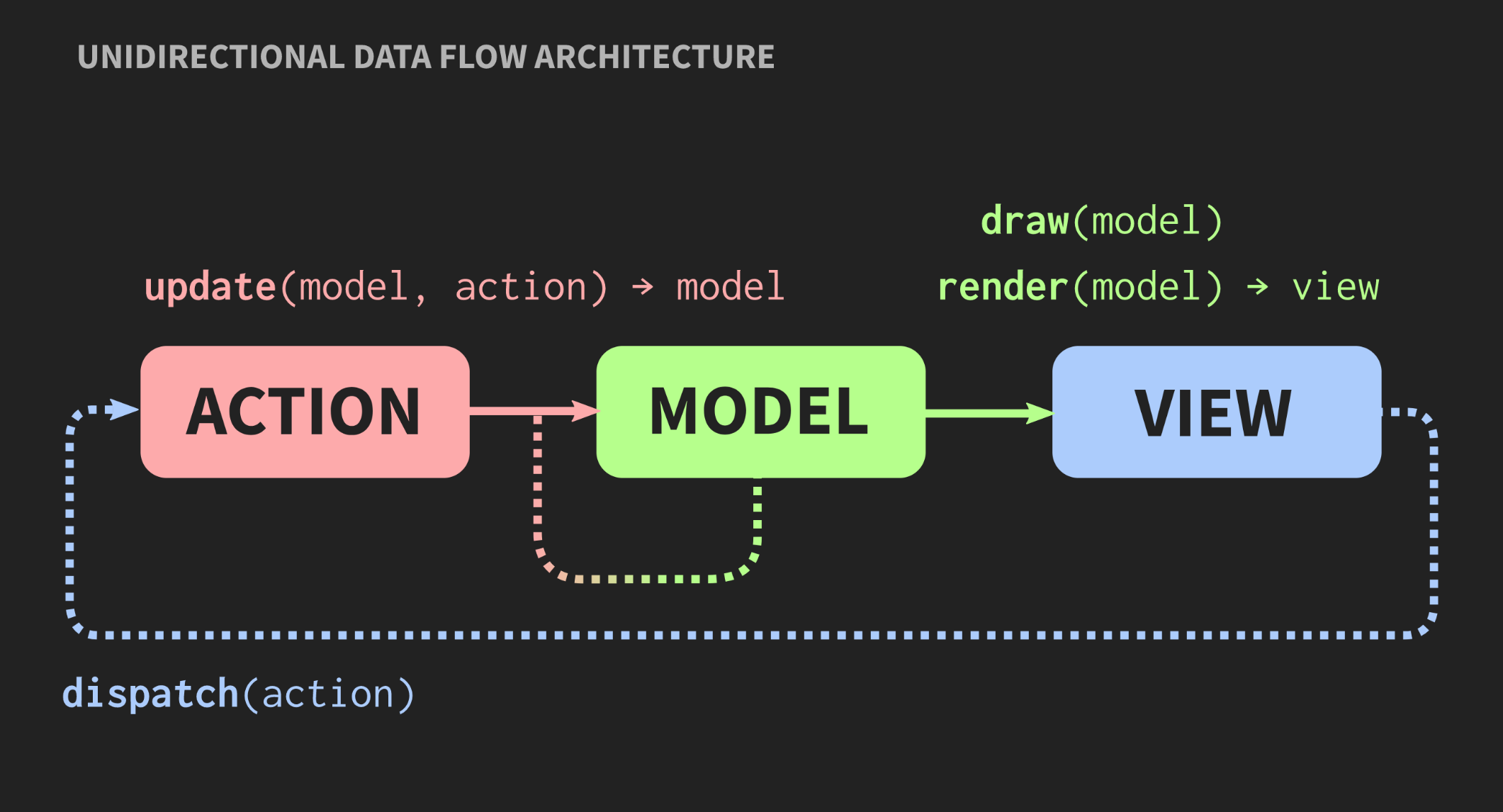 Elemente einer solchen Architektur sind uns bereits bekannt: Aktion, Modell und Ansicht, aber die Bedeutung von Blöcken und Pfeilen ist unterschiedlich. Blöcke sind Werte, keine Objekte und keine Regionen mit veränderlichen Zuständen. Dies gilt auch für View. Außerdem sind Pfeile keine Links, da es ohne Objekte keine Links geben kann. Hier sind die Pfeile Funktionen. Zwischen Aktion und Modell gibt es eine Aktualisierungsfunktion, die das aktuelle Modell, dh den aktuellen Status der Welt, akzeptiert, und Aktion, die ein Ereignis darstellt, z. B. einen Mausklick oder ein Ereignis einer anderen Abstraktionsebene, z. B. das Einfügen eines Elements oder Symbols in ein Dokument. Die Aktualisierungsfunktion aktualisiert das Dokument und gibt den neuen Status der Welt zurück. Das Modell stellt eine Verbindung zum Rendern der Ansichtsfunktion her, die das Modell übernimmt und die Ansicht zurückgibt. Dies erfordert ein Framework, in dem View als Werte dargestellt werden kann.In der Webentwicklung macht React dies, aber in C ++ gibt es noch nichts Vergleichbares, obwohl wer weiß, wenn es Leute gibt, die mich dafür bezahlen wollen, dass ich so etwas schreibe, kann es bald erscheinen. In der Zwischenzeit können Sie die API für den Sofortmodus verwenden, mit der Sie mit der Zeichenfunktion einen Wert als Nebeneffekt erstellen können.Schließlich sollte die Ansicht über einen Mechanismus verfügen, mit dem der Benutzer oder andere Ereignisquellen eine Aktion senden können. Es gibt eine einfache Möglichkeit, dies zu implementieren. Es wird unten dargestellt:
Elemente einer solchen Architektur sind uns bereits bekannt: Aktion, Modell und Ansicht, aber die Bedeutung von Blöcken und Pfeilen ist unterschiedlich. Blöcke sind Werte, keine Objekte und keine Regionen mit veränderlichen Zuständen. Dies gilt auch für View. Außerdem sind Pfeile keine Links, da es ohne Objekte keine Links geben kann. Hier sind die Pfeile Funktionen. Zwischen Aktion und Modell gibt es eine Aktualisierungsfunktion, die das aktuelle Modell, dh den aktuellen Status der Welt, akzeptiert, und Aktion, die ein Ereignis darstellt, z. B. einen Mausklick oder ein Ereignis einer anderen Abstraktionsebene, z. B. das Einfügen eines Elements oder Symbols in ein Dokument. Die Aktualisierungsfunktion aktualisiert das Dokument und gibt den neuen Status der Welt zurück. Das Modell stellt eine Verbindung zum Rendern der Ansichtsfunktion her, die das Modell übernimmt und die Ansicht zurückgibt. Dies erfordert ein Framework, in dem View als Werte dargestellt werden kann.In der Webentwicklung macht React dies, aber in C ++ gibt es noch nichts Vergleichbares, obwohl wer weiß, wenn es Leute gibt, die mich dafür bezahlen wollen, dass ich so etwas schreibe, kann es bald erscheinen. In der Zwischenzeit können Sie die API für den Sofortmodus verwenden, mit der Sie mit der Zeichenfunktion einen Wert als Nebeneffekt erstellen können.Schließlich sollte die Ansicht über einen Mechanismus verfügen, mit dem der Benutzer oder andere Ereignisquellen eine Aktion senden können. Es gibt eine einfache Möglichkeit, dies zu implementieren. Es wird unten dargestellt:application update(application state, action ev);
void run(const char* fname)
{
auto term = terminal{};
auto state = application{load_buffer(fname), key_map_emacs};
while (!state.done) {
draw(state);
auto act = term.next();
state = update(state, act);
}
}
Mit Ausnahme des asynchronen Speicherns und Ladens ist dies der Code, der in dem gerade dargestellten Editor verwendet wird. Hier gibt es ein Objekt terminal, mit dem Sie über die Befehlszeile lesen und schreiben können. Ferner applicationist dies der Wert von Model, speichert er den gesamten Zustand der Anwendung. Wie Sie oben auf dem Bildschirm sehen können, gibt es eine Funktion, die eine neue Version zurückgibt application. Der Zyklus innerhalb der Funktion wird ausgeführt, bis die Anwendung geschlossen werden muss, dh bis !state.done. In der Schleife wird ein neuer Zustand gezeichnet, dann wird das nächste Ereignis angefordert. Schließlich wird der Status in einer lokalen Variablen gespeichert stateund die Schleife beginnt erneut. Dieser Code hat einen sehr wichtigen Vorteil: Während der Ausführung des Programms existiert nur eine veränderbare Variable, es handelt sich um ein Objekt state.Clojure-Entwickler nennen diese Single-Atom-Architektur: Es gibt einen einzigen Punkt in der gesamten Anwendung, über den alle Änderungen vorgenommen werden. Die Anwendungslogik beteiligt sich in keiner Weise an der Aktualisierung dieses Punktes, dies macht einen speziell dafür entworfenen Zyklus. Dank dessen besteht die Anwendungslogik vollständig aus reinen Funktionen, wie Funktionen update.Mit diesem Ansatz zum Schreiben von Anwendungen ändert sich die Denkweise über Software. Die Arbeit beginnt nun nicht mit dem UML-Diagramm der Schnittstellen und Operationen, sondern mit den Daten selbst. Es gibt einige Ähnlichkeiten mit datenorientiertem Design. Richtiges, datenorientiertes Design wird normalerweise verwendet, um maximale Leistung zu erzielen. Hier streben wir neben der Geschwindigkeit nach Einfachheit und Korrektheit. Die Betonung ist etwas anders, aber es gibt wichtige Ähnlichkeiten in der Methodik.using index = int;
struct coord
{
index row = {};
index col = {};
};
using line = immer::flex_vector<char>;
using text = immer::flex_vector<line>;
struct file
{
immer::box<std::string> name;
text content;
};
struct snapshot
{
text content;
coord cursor;
};
struct buffer
{
file from;
text content;
coord cursor;
coord scroll;
std::optional<coord> selection_start;
immer::vector<snapshot> history;
std::optional<std::size_t> history_pos;
};
struct application
{
buffer current;
key_map keys;
key_seq input;
immer::vector<text> clipboard;
immer::vector<message> messages;
};
struct action { key_code key; coord size; };
Oben sind die wichtigsten Datentypen unserer Anwendung aufgeführt. Der Hauptteil der Anwendung besteht aus lineflex_vector, und flex_vector ist vectoreiner, für den Sie eine Verknüpfungsoperation ausführen können. Als nächstes textfolgt der Vektor, in dem er gespeichert ist line. Wie Sie sehen können, ist dies eine sehr einfache Darstellung des Textes. Textgespeichert, mit deren Hilfe fileein Name, dh eine Adresse im Dateisystem, und tatsächlich text. Wie fileein anderer Typ verwendet, ein einfacher, aber sehr nützlicher : box. Dies ist ein Einzelelementcontainer. Sie können einen Heap einfügen und ein Objekt verschieben, wobei das Kopieren möglicherweise zu ressourcenintensiv ist.Ein weiterer wichtiger Typ : snapshot. Basierend auf diesem Typ ist eine Abbruchfunktion aktiv. Es enthält ein Dokument (im Formulartext) und Cursorposition (Koordinate). Auf diese Weise können Sie den Cursor an die Position zurücksetzen, an der er sich während der Bearbeitung befand.Der nächste Typ ist buffer. Dies ist ein Begriff von vim und emacs, wie dort offene Dokumente genannt werden. Darin bufferbefindet sich eine Datei, aus der der Text heruntergeladen wurde, sowie der Inhalt des Textes. Auf diese Weise können Sie nach Änderungen im Dokument suchen. Um einen Teil des Textes hervorzuheben, gibt es eine optionale Variable selection_start, die den Beginn der Auswahl angibt. Der Vektor von snapshotist die Geschichte des Textes. Beachten Sie, dass wir das Teammuster nicht verwenden. Der Verlauf besteht nur aus Status. Wenn die Stornierung gerade abgeschlossen wurde, benötigen wir einen Positionsindex in der Statushistorie history_pos.Der nächste Typ : application. Es enthält ein offenes Dokument (Puffer) key_mapundkey_seqfür Tastaturkürzel sowie einen Vektor aus textfür die Zwischenablage und einen weiteren Vektor für Nachrichten, die am unteren Bildschirmrand angezeigt werden. Bisher wird es in der Debütversion der Anwendung nur einen Thread und eine Art von Aktion geben, die Eingaben key_codeund coord.Höchstwahrscheinlich denken viele von Ihnen bereits darüber nach, wie diese Vorgänge implementiert werden sollen. Wenn nach Wert genommen und nach Wert zurückgegeben, sind die Operationen in den meisten Fällen recht einfach. Der Code meines Texteditors ist auf github veröffentlicht , sodass Sie sehen können, wie er tatsächlich aussieht. Jetzt werde ich nur auf den Code eingehen, der die Stornierungsfunktion implementiert.Stornieren
Das korrekte Schreiben einer Stornierung ohne die entsprechende Infrastruktur ist nicht so einfach. In meinem Editor habe ich es nach dem Vorbild von Emacs implementiert, also zunächst ein paar Worte zu seinen Grundprinzipien. Der Befehl return fehlt hier und dank dessen können Sie keine Arbeit verlieren. Wenn eine Rücksendung erforderlich ist, werden Änderungen am Text vorgenommen, und alle Stornierungsaktionen werden wieder Teil des Stornierungsverlaufs. Dieses Prinzip ist oben dargestellt. Die rote Raute zeigt hier eine Position in der Geschichte: Wenn eine Stornierung gerade nicht abgeschlossen wurde, ist die rote Raute immer ganz am Ende. Wenn Sie abbrechen, verschiebt der Diamant einen Status zurück, aber gleichzeitig wird am Ende der Warteschlange ein weiterer Status hinzugefügt - derselbe, den der Benutzer derzeit sieht (S3). Wenn Sie erneut abbrechen und zum Status S2 zurückkehren, wird der Status S2 am Ende der Warteschlange hinzugefügt. Wenn der Benutzer jetzt eine Änderung vornimmt, wird diese als neuer Status von S5 am Ende der Warteschlange hinzugefügt und eine Raute wird dorthin verschoben. Wenn Sie nun vergangene Aktionen rückgängig machen, werden die vorherigen rückgängig gemachten Aktionen zuerst gescrollt. Um ein solches Stornierungssystem zu implementieren, reicht der folgende Code aus:
Dieses Prinzip ist oben dargestellt. Die rote Raute zeigt hier eine Position in der Geschichte: Wenn eine Stornierung gerade nicht abgeschlossen wurde, ist die rote Raute immer ganz am Ende. Wenn Sie abbrechen, verschiebt der Diamant einen Status zurück, aber gleichzeitig wird am Ende der Warteschlange ein weiterer Status hinzugefügt - derselbe, den der Benutzer derzeit sieht (S3). Wenn Sie erneut abbrechen und zum Status S2 zurückkehren, wird der Status S2 am Ende der Warteschlange hinzugefügt. Wenn der Benutzer jetzt eine Änderung vornimmt, wird diese als neuer Status von S5 am Ende der Warteschlange hinzugefügt und eine Raute wird dorthin verschoben. Wenn Sie nun vergangene Aktionen rückgängig machen, werden die vorherigen rückgängig gemachten Aktionen zuerst gescrollt. Um ein solches Stornierungssystem zu implementieren, reicht der folgende Code aus:buffer record(buffer before, buffer after)
{
if (before.content != after.content) {
after.history = after.history.push_back({before.content, before.cursor});
if (before.history_pos == after.history_pos)
after.history_pos = std::nullopt;
}
return after;
}
buffer undo(buffer buf)
{
auto idx = buf.history_pos.value_or(buf.history.size());
if (idx > 0) {
auto restore = buf.history[--idx];
buf.content = restore.content;
buf.cursor = restore.cursor;
buf.history_pos = idx;
}
return buf;
}
Es gibt zwei Aktionen recordund undo. Recordwährend einer Operation durchgeführt. Dies ist sehr praktisch, da wir nicht wissen müssen, ob das Dokument bearbeitet wurde. Die Funktion ist für die Anwendungslogik transparent. Nach jeder Aktion prüft die Funktion, ob sich das Dokument geändert hat. Wenn eine Änderung aufgetreten ist, werden der push_backInhalt und die Cursorposition für ausgeführt history. Wenn die Aktion nicht zu einer Änderung geführt hat history_pos(dh die empfangene Eingabe wird buffernicht durch die Abbruchaktion verursacht), wird history_posein Wert zugewiesen null. Bei Bedarf undoprüfen wir history_pos. Wenn es keine Bedeutung hat, betrachten wir es history_posals am Ende der Geschichte. Wenn der Stornierungsverlauf nicht leer ist (d. H.history_posnicht ganz am Anfang der Geschichte), wird eine Stornierung durchgeführt. Der aktuelle Inhalt und der Cursor werden ersetzt und geändert history_pos. Die Unwiderruflichkeit des Abbruchvorgangs wird durch die Funktion erreicht record, die auch während des Abbruchvorgangs aufgerufen wird.Wir haben also eine Operation undo, die 10 Codezeilen einnimmt und die ohne Änderungen (oder mit minimalen Änderungen) in fast jeder anderen Anwendung verwendet werden kann.Zeitreise
Über Zeitreisen. Wie wir jetzt sehen werden, ist dies ein Thema im Zusammenhang mit der Stornierung. Ich werde die Arbeit eines Frameworks demonstrieren, das jeder Anwendung mit einer ähnlichen Architektur nützliche Funktionen hinzufügt. Das Framework heißt hier ewig-debug . Diese Version von ewig enthält einige Debugging-Funktionen. Jetzt können Sie über den Browser den Debugger öffnen, in dem Sie den Status der Anwendung überprüfen können. Wir sehen, dass die letzte Aktion die Größe geändert hat, weil ich ein neues Fenster geöffnet habe und mein Fenstermanager die Größe des bereits geöffneten Fensters automatisch geändert hat. Für die automatische Serialisierung in JSON musste ich natürlich Anmerkungen für struct aus der speziellen Reflection-Bibliothek hinzufügen. Der Rest des Systems ist jedoch ziemlich universell und kann mit jeder ähnlichen Anwendung verbunden werden. Jetzt können Sie im Browser alle abgeschlossenen Aktionen sehen. Natürlich gibt es einen Anfangszustand, der keine Aktion hat. Dies ist der Status vor dem Download. Darüber hinaus kann ich durch Doppelklicken die Anwendung in den vorherigen Zustand zurückversetzen. Dies ist ein sehr nützliches Debugging-Tool, mit dem Sie das Auftreten einer Fehlfunktion in der Anwendung verfolgen können.Wenn Sie interessiert sind, können Sie meinen Bericht über CPPCON 19, Die wertvollsten Werte, anhören. Dort werde ich diesen Debugger im Detail untersuchen.Darüber hinaus wird dort die wertebasierte Architektur näher erläutert. Darin erkläre ich Ihnen auch, wie Sie Aktionen implementieren und hierarchisch organisieren. Dies stellt die Modularität des Systems sicher und ermöglicht es Ihnen, nicht alles in einer großen Aktualisierungsfunktion zu behalten. Darüber hinaus wird in diesem Bericht auf Asynchronität und das Herunterladen von Dateien mit mehreren Threads eingegangen. Es gibt eine andere Version dieses Berichts, in der eine halbe Stunde zusätzliches Material postmoderne unveränderliche Datenstrukturen enthält.
Wir sehen, dass die letzte Aktion die Größe geändert hat, weil ich ein neues Fenster geöffnet habe und mein Fenstermanager die Größe des bereits geöffneten Fensters automatisch geändert hat. Für die automatische Serialisierung in JSON musste ich natürlich Anmerkungen für struct aus der speziellen Reflection-Bibliothek hinzufügen. Der Rest des Systems ist jedoch ziemlich universell und kann mit jeder ähnlichen Anwendung verbunden werden. Jetzt können Sie im Browser alle abgeschlossenen Aktionen sehen. Natürlich gibt es einen Anfangszustand, der keine Aktion hat. Dies ist der Status vor dem Download. Darüber hinaus kann ich durch Doppelklicken die Anwendung in den vorherigen Zustand zurückversetzen. Dies ist ein sehr nützliches Debugging-Tool, mit dem Sie das Auftreten einer Fehlfunktion in der Anwendung verfolgen können.Wenn Sie interessiert sind, können Sie meinen Bericht über CPPCON 19, Die wertvollsten Werte, anhören. Dort werde ich diesen Debugger im Detail untersuchen.Darüber hinaus wird dort die wertebasierte Architektur näher erläutert. Darin erkläre ich Ihnen auch, wie Sie Aktionen implementieren und hierarchisch organisieren. Dies stellt die Modularität des Systems sicher und ermöglicht es Ihnen, nicht alles in einer großen Aktualisierungsfunktion zu behalten. Darüber hinaus wird in diesem Bericht auf Asynchronität und das Herunterladen von Dateien mit mehreren Threads eingegangen. Es gibt eine andere Version dieses Berichts, in der eine halbe Stunde zusätzliches Material postmoderne unveränderliche Datenstrukturen enthält.Zusammenfassen
Ich denke, es ist Zeit, Bilanz zu ziehen. Ich werde Andy Wingo zitieren - er ist ein ausgezeichneter Entwickler, er hat viel Zeit für V8 und Compiler im Allgemeinen aufgewendet, schließlich ist er damit beschäftigt, Guile zu unterstützen und das Schema für GNU zu implementieren. Kürzlich schrieb er auf seinem Twitter: „Um eine leichte Beschleunigung des Programms zu erreichen, messen wir jede kleine Änderung und lassen nur diejenigen übrig, die ein positives Ergebnis liefern. Aber wir erreichen wirklich eine signifikante Beschleunigung, blind, investieren viel Mühe, haben kein 100% iges Vertrauen und werden nur von der Intuition geleitet. Was für eine seltsame Zweiteilung. "Es scheint mir, dass C ++ - Entwickler im ersten Genre erfolgreich sind. Geben Sie uns ein geschlossenes System, und wir werden mit unseren Werkzeugen alles ausdrücken, was daraus möglich ist. Aber im zweiten Genre sind wir es nicht gewohnt zu arbeiten. Natürlich ist der zweite Ansatz riskanter und führt oft zu einer Verschwendung großer Anstrengungen. Andererseits kann ein Programm durch einfaches Umschreiben oft einfacher und schneller gemacht werden. Ich hoffe, ich habe es geschafft, Sie davon zu überzeugen, zumindest diesen zweiten Ansatz zu versuchen.Juan Puente sprach auf der C ++ Russia 2019 in Moskau und sprach über Datenstrukturen, mit denen Sie interessante Dinge tun können. Ein Teil der Magie dieser Strukturen liegt in der Auswahl von Kopien - darüber werden Anton Polukhin und Roman Rusyaev auf der kommenden Konferenz sprechen . Folgen Sie den Programmaktualisierungen auf der Website.