Wie ABLYY NLP Technologies lernen, Nachrichten zu überwachen und Risiken zu managen
 Das Spektrum der Aufgaben, die mit ABBYY-Technologien gelöst werden können, hat sich mit einer weiteren interessanten Gelegenheit ergänzt. Wir haben unseren Motor in der Arbeit eines Bank-Underwriters geschult - einer Person, die Ereignisse von Gegenparteien aus einem riesigen Nachrichtenstrom erfasst und Risiken bewertet.Solche Systeme, die auf ABBYY-Technologien basieren, werden bereits von mehreren großen russischen Banken eingesetzt. Wir möchten über die Nuancen der Implementierung dieser Lösung sprechen - eher nicht triviale und unerwartete Herausforderungen, denen sich unsere Ontologen gestellt haben.
Das Spektrum der Aufgaben, die mit ABBYY-Technologien gelöst werden können, hat sich mit einer weiteren interessanten Gelegenheit ergänzt. Wir haben unseren Motor in der Arbeit eines Bank-Underwriters geschult - einer Person, die Ereignisse von Gegenparteien aus einem riesigen Nachrichtenstrom erfasst und Risiken bewertet.Solche Systeme, die auf ABBYY-Technologien basieren, werden bereits von mehreren großen russischen Banken eingesetzt. Wir möchten über die Nuancen der Implementierung dieser Lösung sprechen - eher nicht triviale und unerwartete Herausforderungen, denen sich unsere Ontologen gestellt haben.Den Nachrichtenfluss eindämmen
Um erfolgreich zu sein, muss eine Bank genau wissen, mit wem sie es zu tun hat, und schnell auf wichtige Veränderungen im Leben ihrer Gegenparteien reagieren. Besonders wenn es sich um andere Banken oder große Firmenkunden handelt - IT-Unternehmen, landwirtschaftliche Unternehmen und andere. Dafür haben die meisten russischen Banken spezielle Experten - Underwriter. Sie analysieren Informationen aus verschiedenen Quellen, einschließlich Nachrichten, auf Risikofaktoren für die Bank. Es ist nicht nur notwendig, die Nachrichten zu lesen, sondern auch zu bewerten, wie sich dies auf die Bank und ihre Kunden auswirkt.Risikofaktoren können variieren:- Konkurs,
- Aktionärskonflikt
- Eigentümer- oder Managementstrukturwechsel,
- Fakten über Betrug, drohende Geschäftsverluste eines Kunden,
- Informationen über Ansprüche und außerplanmäßige Inspektionen durch Aufsichtsbehörden,
- das Vorhandensein von Ansprüchen
- ,
- .
Wenn der Underwriter einen Risikofaktor identifiziert, kann die langfristige Zusammenarbeit mit einer solchen Gegenpartei der Bank bis zum Prozess Probleme bereiten. Und die Wahrscheinlichkeit eines negativen Ergebnisses ist wichtig, um dies so schnell wie möglich herauszufinden. Warum ist es nicht so einfach? In den Nachrichten ist nicht nur die Erwähnung von Gegenparteien wichtig, sondern auch der Kontext. Sie müssen verstehen, in welcher Beziehung eine Person oder ein Unternehmen zu den Faktoren steht, die die Bank mit Risikoquellen in Beziehung setzt.In der Zwischenzeit ist der Nachrichtenfluss, insbesondere unter Berücksichtigung nicht nur der föderalen, sondern auch der regionalen Medien, riesig und wächst weiter. Allein Medialogy, ein Nachrichtenüberwachungsdienst, sammelt Inhalte aus 52.000 Quellen. Laut Roskomnadzor war es ab September 2019 im russischen Medienregister eingetragenmehr als 67.000 aktive Medien. Eine Person ist physisch nicht in der Lage, alle Nachrichten schnell zu lesen, auch wenn es nur ein Thema ist, das sie interessiert. Banken müssen also entweder ständig die Mitarbeiter der Underwriter auffüllen oder nach einer alternativen Lösung im Bereich der Informationstechnologie suchen.Lösungsoptionen
Der naheliegendste Weg besteht darin, den Nachrichtenfluss durch kostenpflichtige Abonnements auf geschlossene Newsfeeds zu verschiedenen Themen zu beschränken. Solche Bänder werden von Interfax, Prime, Thomson Reuters, Bloomberg und anderen Nachrichtenagenturen angeboten. Die Nachrichten in ihnen sind bereits teilweise strukturiert: Es gibt Tags mit Firmennamen, Schlüsselpersonen, die an den Nachrichten beteiligt sind. Dies löst das Problem jedoch nicht vollständig: Die Arbeit mit dem Kontext liegt immer noch bei den Underwritern.Viele in Unternehmen vorhandene Medienüberwachungssysteme suchen nach Schlüsselwörtern im Text. Dieser Ansatz liefert viel informatives „Rauschen“ und funktioniert nicht ohne zusätzliche Tricks in Form von Filtern. Die Vollständigkeit und Genauigkeit des Szenarios mit Schlüsselwörtern lässt zu wünschen übrig, weil:- Das Schlüsselwort und seine zugehörigen Variationen können im Text erwähnt werden, sind jedoch nicht relevant. Beispielsweise kann ein Unternehmen in einer historischen Referenz aufgeführt sein, die nicht direkt mit der Nachricht zusammenhängt.
- In den Nachrichten ist es wichtig, nicht nur Gegenparteien zu erwähnen, sondern auch den Kontext. Sie müssen verstehen, in welcher Beziehung eine Person oder ein Unternehmen zu den Faktoren steht, die die Bank mit Risikoquellen in Beziehung setzt. Wenn Sie sich Beispiele für Risikofaktoren in Nachrichtentexten ansehen, können Sie sehen, wie viele potenziell wichtige Nachrichten bei der Suche nach Schlüsselwörtern übersehen werden können. Daher wird der Ausdruck „Konflikt der Aktionäre“ in den Nachrichten nicht immer erwähnt. Wenn Sie sich das folgende Beispiel ansehen, ist für den Underwriter der Konflikt oder sein Potenzial offensichtlich:

Erste Proben
Eine der größten russischen Banken entschied sich daher zu entscheiden, welche der beiden Technologien die Aufgabe, Risiken zu finden, besser bewältigen würde. Ein intelligenter Dokumentklassifizierer bestimmte Risikofaktoren basierend auf dem Inhalt der Nachrichten. Die auf Textanalysen basierende Lösung extrahierte die erforderlichen Daten aus den Nachrichten. Wie sich herausstellte, ist die beste Option eine Symbiose aus zwei Lösungen: Der Klassifizierer hat dazu beigetragen, die Anzahl der vom Band kommenden Dokumente zu verringern, völlig irrelevante Informationen zu entfernen, und dann wurden Datenextraktionstechnologien in die Arbeit aufgenommen.In der ersten Phase - Proof of Concept (POC) - wurde die Möglichkeit getestet, mit diesen Tools nach Risiken zu suchen. Der Kunde wählte einen Risikofaktor - eine Konfliktsituation. Die Technologie sollte Nachrichten identifizieren, die von einem Konflikt der Aktionäre sprachen - Einzelpersonen oder juristische Personen, Top-Manager einer Bank oder einem Konflikt einer Bank mit Aufsichtsbehörden. ABBYY Onto-Engineers erstellte ein Testmodell, für dessen Entwicklung eine Auswahl von 1000 Nachrichten verwendet wurde. Sie extrahierte den Text des Konflikts, das Datum der Nachrichten und eine Liste seiner Teilnehmer. Das Modell bewies die Realisierbarkeit des vorgeschlagenen Ansatzes: In der POC-Phase wurden anhand der von einer der Banken bereitgestellten Kontrollstichprobe (Nachrichten, die nicht für die Entwicklung verwendet wurden) die folgenden Ergebnisse aus 50 Dokumenten erhalten: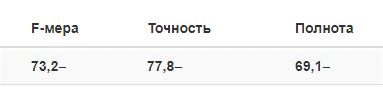
Das Ergebnis verbessern
Bei der Entwicklung von Modellen orientieren sich Ontologen an den Ergebnissen regelmäßiger Selbsttests, bei denen alle Abweichungen zwischen dem Ziel und den erhaltenen Werten aufgezeichnet werden. Um solche Berichte zu erstellen, wurden die Nachrichten gemäß den Anweisungen des Kunden markiert. Markierte Dateien im XML-Format, die Zielwerte enthalten, wurden mit XML-Dateien verglichen, die aufgrund der Verwendung der aktuellen Version des Ontomodells erhalten wurden. Autotest-Ergebnisse enthalten sowohl zusammenfassende Informationen mit den Qualitätsindikatoren für die Analyse der gesamten Nachrichtensammlung als auch private Informationen für jedes extrahierte Objekt und Dokument separat. So können Sie bewerten, wie sich die Genauigkeit des Modells in der Dynamik erhöht.Hier ist ein Beispiel für eine solche Tabelle: Die Modellergebnisse können auch mit der Genauigkeitsmetrik gemessen werden, einer Ableitung der Vollständigkeit und Genauigkeit:Die Genauigkeitsmetrik kann als Basis bezeichnet werden. Es misst die Anzahl korrekt klassifizierter Objekte im Verhältnis zur Gesamtzahl aller Objekte. Die Genauigkeitsmetrik hat einige Nachteile: Sie ist nicht ideal für unausgeglichene Klassen, bei denen es viele Instanzen einer Klasse und wenige andere geben kann.Diese Metrik wird von einer anderen großen Bank verwendet, auch von unserem Kunden. Die Genauigkeitsmetrik betrug 85%.In Zukunft haben die Banken die Integration von ABBYY-Produkten, in denen unser Modell funktioniert hat, unabhängig durchgeführt und in ihrem Kreislauf verwendet. Unsere Produkte sind in das Bankrisikomanagementsystem integriert: Sie übertragen Dokumente zur Analyse und sammeln die Ergebnisse.
Die Modellergebnisse können auch mit der Genauigkeitsmetrik gemessen werden, einer Ableitung der Vollständigkeit und Genauigkeit:Die Genauigkeitsmetrik kann als Basis bezeichnet werden. Es misst die Anzahl korrekt klassifizierter Objekte im Verhältnis zur Gesamtzahl aller Objekte. Die Genauigkeitsmetrik hat einige Nachteile: Sie ist nicht ideal für unausgeglichene Klassen, bei denen es viele Instanzen einer Klasse und wenige andere geben kann.Diese Metrik wird von einer anderen großen Bank verwendet, auch von unserem Kunden. Die Genauigkeitsmetrik betrug 85%.In Zukunft haben die Banken die Integration von ABBYY-Produkten, in denen unser Modell funktioniert hat, unabhängig durchgeführt und in ihrem Kreislauf verwendet. Unsere Produkte sind in das Bankrisikomanagementsystem integriert: Sie übertragen Dokumente zur Analyse und sammeln die Ergebnisse.Wie das System funktioniert
Aus technischer Sicht funktioniert das System folgendermaßen: Wenn der Text in die ABBYY-Lösung verarbeitet wird, wird seine mehrstufige sprachliche Analyse durchgeführt. Im lexikalisch-morphologischen Stadium werden die einfachsten Eigenschaften von Wörtern bestimmt: Geschlecht, Anzahl, Fall. Dann wird in der Analysephase bestimmt, wo das Subjekt, das Prädikat, wie die Wörter miteinander in Beziehung stehen. Wenn Sie die Syntax kennen, können Sie mit der Definition der Semantik fortfahren. Für jedes Wort wird seine Bedeutung bestimmt. Zusätzlich zu dieser sprachlichen Analyse gelten die Regeln zum Extrahieren von Informationen, die von unseren Ontologen entwickelt wurden. Das Ontomodell enthält eine Beschreibung der Datenstruktur, die aus Kundendokumenten abgerufen werden soll, sowie Regeln, mit denen diese Datenstruktur abgerufen werden kann.

Unerwartete Schwierigkeiten
Risiko ist ein abstraktes Konzept. Dies ist ein sehr spezifisches Berufsfeld, und es ist wichtig, die Meinungen von Spezialisten zu berücksichtigen, die jeden Tag mit Risiken arbeiten. Benutzer unserer Kunden können für die Nachrichten stimmen und ein bedingtes "Gefällt mir" setzen: ob das System das Vorhandensein von Risiken in den Nachrichten korrekt bestimmt hat oder nicht.Beim Debuggen des Systems wurden wir mit der Tatsache konfrontiert, dass Underwriter häufig die Bedeutung der Nachrichten und das Vorhandensein eines Risikofaktors darin interpretieren. Ein Benutzer möchte, dass eine bestimmte Art von Nachrichten in seinem Feed angezeigt wird, und ein anderer Benutzer betrachtet solche Nachrichten als nicht relevant. Dieses Problem wird wie folgt gelöst: Die Bank sammelt von den Underwritern eine Liste von Nachrichten, die von den Experten anders interpretiert wurden, und trifft die endgültige Entscheidung über die Interpretation bestimmter Nachrichten: Gibt es einen Risikofaktor oder nicht? Abhängig von der Rückmeldung werden Änderungen am Ontomodell vorgenommen.Was ist, wenn die Nachrichten auf Englisch sind?
Viele russische Banken verwenden Quellen wie Dow Jones, Bloomberg, Financial Times. Einer der Vorteile unseres Ansatzes zur Entwicklung von Ontomodellen auf der Basis von ABLYY NLP-Technologien war die schnelle Anpassung von Modellen zur Analyse von Nachrichten auf Russisch für die Arbeit mit englischen Texten. Dies erfordert das Debuggen des Modells in den englischen Originalnachrichten.Bewerten Sie die Ergebnisse
Jetzt können Underwriter die Nachrichten in Echtzeit verfolgen, ohne alle 100.500 Nachrichten lesen zu müssen. Im Prinzip müssen Sie nicht einmal die gesamten Nachrichten lesen, in denen das System einen Risikofaktor gefunden hat: Das Fragment mit dem wichtigsten (Snippet) wird im Programm hervorgehoben. In wenigen Minuten können Sie automatisch einen Bericht für eine Bank erstellen, nur einen oder mehrere wichtige Risikofaktoren hervorheben. Bei diesem Ansatz ist es schwieriger, etwas Wichtiges zu übersehen. Ferner kann der Versicherer die Kontrahentenkarte öffnen und Nachrichten auswählen, die er für wichtig hält. Auf dieser Grundlage kann die Bonität des Unternehmens geändert, der Zinssatz geändert oder ein Grund zur Kontaktaufnahme mit dem Management des Unternehmens angegeben werden. Diese Nachrichten werden an das Workflow-System weitergeleitet.Sie können fragen, wie viele Nachrichten die Technologie verarbeitet. Alles hängt vom Nachrichtenfluss ab: Im Januar und Mai beispielsweise gibt es traditionell weniger Nachrichten. Eine Bank kann über unser System bis zu 2,5 Millionen Nachrichten pro Monat abrufen. Und diese Anzahl ist nur durch Lizenz und Rechenleistung begrenzt.Übrigens ähnliche Technologienkann nicht nur in Banken arbeiten, sondern auch in Unternehmen, die einen großen Nachrichtenfluss über Wettbewerber, Kunden, Partner verfolgen und Nutzerbewertungen in sozialen Netzwerken lesen. Zum Beispiel können Risikofonds, die NLP-Technologien verwenden, Informationen über vielversprechende Start-ups in Bezug auf potenzielle Investitionen und Regierungsorganisationen nachverfolgen - wichtige Nachrichten darüber, was in einer bestimmten Region passiert, welche Probleme auftreten, wer verantwortlich ist usw. Darüber hinaus können Sie nicht nur Nachrichten in den Medien analysieren, sondern auch Blogs und Bewertungen in sozialen Netzwerken.
Und vor welchen Aufgaben standen Sie bei Projekten zur Verarbeitung unstrukturierter Dokumente für Banken und Unternehmen anderer Branchen?Source: https://habr.com/ru/post/undefined/
All Articles