Verständnis des maschinellen Lernmodells, das CAPTCHA bricht
Hallo alle zusammen! Diesen Monat rekrutiert OTUS eine neue Gruppe für den Kurs für maschinelles Lernen . Nach gängiger Tradition teilen wir Ihnen am Vorabend des Kursbeginns die Übersetzung von interessantem Material zum Thema mit. Computer Vision ist eines der relevantesten und am besten erforschten Themen der KI [1]. Aktuelle Methoden zur Lösung von Problemen mit Faltungs-Neuronalen Netzen werden jedoch ernsthaft kritisiert, da solche Netze leicht zu täuschen sind. Um nicht unbegründet zu sein, möchte ich Ihnen einige Gründe nennen: Netzwerke dieses Typs liefern mit hoher Sicherheit ein falsches Ergebnis für natürlich vorkommende Bilder, die keine statistischen Signale enthalten [2], auf die sich Faltungs-Neuronale Netzwerke stützen, für Bilder, die zuvor korrekt klassifiziert wurden. aber in denen sich ein Pixel [3] oder Bilder mit physischen Objekten, die der Szene hinzugefügt wurden, aber das Klassifizierungsergebnis nicht ändern mussten [4], geändert haben. Tatsache ist, wenn wir wirklich intelligente Maschinen schaffen wollen,Es sollte uns vernünftig erscheinen, in das Studium neuer Ideen zu investieren.Eine dieser neuen Ideen ist Vicarious 'Anwendung des Recursive Cortical Network (RCN), das sich von den Neurowissenschaften inspirieren lässt. Dieses Modell behauptete, es sei äußerst effektiv beim Brechen von Text-Captcha, wodurch viel um sich herum geredet werde . Aus diesem Grund habe ich beschlossen, mehrere Artikel zu schreiben, von denen jeder einen bestimmten Aspekt dieses Modells erklärt. In diesem Artikel werden wir über seine Struktur sprechen und wie die Erzeugung von Bildern, die in den Materialien des Hauptartikels über RCN [5] dargestellt werden, erzeugt wird.In diesem Artikel wird davon ausgegangen, dass Sie bereits mit Faltungs-Neuronalen Netzen vertraut sind, daher werde ich viele Analogien mit ihnen ziehen.Um sich auf die RCN-Erkennung vorzubereiten, müssen Sie verstehen, dass RCNs auf der Idee basieren, die Form (Skizze des Objekts) vom Erscheinungsbild (seiner Textur) zu trennen, und dass es sich um ein generatives Modell handelt, nicht um ein diskriminierendes Modell, sodass wir damit Bilder wie in einem generativen generieren können gegnerische Netzwerke. Zusätzlich wird eine parallele hierarchische Struktur verwendet, ähnlich der Architektur von Faltungs-Neuronalen Netzen, die mit dem Stadium der Bestimmung der Form des Zielobjekts in den unteren Schichten beginnt, und dann wird sein Aussehen auf der oberen Schicht hinzugefügt. Im Gegensatz zu Faltungs-Neuronalen Netzen basiert das Modell, das wir betrachten, auf einer reichen theoretischen Basis grafischer Modelle anstelle von gewichteten Summen und Gradientenabstieg. Lassen Sie uns nun die Merkmale der RCN-Struktur untersuchen.
Computer Vision ist eines der relevantesten und am besten erforschten Themen der KI [1]. Aktuelle Methoden zur Lösung von Problemen mit Faltungs-Neuronalen Netzen werden jedoch ernsthaft kritisiert, da solche Netze leicht zu täuschen sind. Um nicht unbegründet zu sein, möchte ich Ihnen einige Gründe nennen: Netzwerke dieses Typs liefern mit hoher Sicherheit ein falsches Ergebnis für natürlich vorkommende Bilder, die keine statistischen Signale enthalten [2], auf die sich Faltungs-Neuronale Netzwerke stützen, für Bilder, die zuvor korrekt klassifiziert wurden. aber in denen sich ein Pixel [3] oder Bilder mit physischen Objekten, die der Szene hinzugefügt wurden, aber das Klassifizierungsergebnis nicht ändern mussten [4], geändert haben. Tatsache ist, wenn wir wirklich intelligente Maschinen schaffen wollen,Es sollte uns vernünftig erscheinen, in das Studium neuer Ideen zu investieren.Eine dieser neuen Ideen ist Vicarious 'Anwendung des Recursive Cortical Network (RCN), das sich von den Neurowissenschaften inspirieren lässt. Dieses Modell behauptete, es sei äußerst effektiv beim Brechen von Text-Captcha, wodurch viel um sich herum geredet werde . Aus diesem Grund habe ich beschlossen, mehrere Artikel zu schreiben, von denen jeder einen bestimmten Aspekt dieses Modells erklärt. In diesem Artikel werden wir über seine Struktur sprechen und wie die Erzeugung von Bildern, die in den Materialien des Hauptartikels über RCN [5] dargestellt werden, erzeugt wird.In diesem Artikel wird davon ausgegangen, dass Sie bereits mit Faltungs-Neuronalen Netzen vertraut sind, daher werde ich viele Analogien mit ihnen ziehen.Um sich auf die RCN-Erkennung vorzubereiten, müssen Sie verstehen, dass RCNs auf der Idee basieren, die Form (Skizze des Objekts) vom Erscheinungsbild (seiner Textur) zu trennen, und dass es sich um ein generatives Modell handelt, nicht um ein diskriminierendes Modell, sodass wir damit Bilder wie in einem generativen generieren können gegnerische Netzwerke. Zusätzlich wird eine parallele hierarchische Struktur verwendet, ähnlich der Architektur von Faltungs-Neuronalen Netzen, die mit dem Stadium der Bestimmung der Form des Zielobjekts in den unteren Schichten beginnt, und dann wird sein Aussehen auf der oberen Schicht hinzugefügt. Im Gegensatz zu Faltungs-Neuronalen Netzen basiert das Modell, das wir betrachten, auf einer reichen theoretischen Basis grafischer Modelle anstelle von gewichteten Summen und Gradientenabstieg. Lassen Sie uns nun die Merkmale der RCN-Struktur untersuchen.Feature-Layer
Der erste Layertyp in RCN wird als Feature-Layer bezeichnet. Wir werden das Modell schrittweise betrachten. Nehmen wir daher zunächst an, dass die gesamte Hierarchie des Modells nur aus übereinander gestapelten Schichten dieses Typs besteht. Wir werden von abstrakten Konzepten auf hoher Ebene zu spezifischeren Merkmalen der unteren Ebenen übergehen, wie in Abbildung 1 dargestellt . Eine Schicht dieses Typs besteht aus mehreren Knoten, die sich im zweidimensionalen Raum befinden, ähnlich wie Merkmalskarten in Faltungs-Neuronalen Netzen. Abbildung 1 : Mehrere übereinander angeordnete Feature-Layer mit Knoten im zweidimensionalen Raum. Der Übergang von der vierten zur ersten Schicht bedeutet den Übergang vom Allgemeinen zum Besonderen.Jeder Knoten besteht aus mehreren Kanälen, von denen jeder ein separates Merkmal darstellt. Kanäle sind binäre Variablen, die den Wert True oder False annehmen und angeben, ob ein diesem Kanal entsprechendes Objekt im endgültig erzeugten Bild in der Koordinate (x, y) des Knotens vorhanden ist. Auf jeder Ebene haben Knoten den gleichen Kanaltyp.Nehmen wir als Beispiel eine Zwischenschicht und sprechen über ihre Kanäle und die obigen Schichten, um die Erklärung zu vereinfachen. Die Liste der Kanäle auf dieser Ebene besteht aus einer Hyperbel, einem Kreis und einer Parabel. Bei einem bestimmten Lauf beim Erzeugen des Bildes erforderten die Berechnungen der darüber liegenden Ebenen einen Kreis in der Koordinate (1,1). Somit hat der Knoten (1, 1) einen Kanal, der dem Objekt "Kreis" im Wert True entspricht. Dies wirkt sich direkt auf einige Knoten in der darunter liegenden Ebene aus, dh, die Features der unteren Ebene, die dem Kreis in der Nachbarschaft (1,1) zugeordnet sind, werden auf True gesetzt. Diese Objekte niedrigerer Ebene können beispielsweise vier Bögen mit unterschiedlichen Ausrichtungen sein. Wenn die Merkmale der unteren Ebene aktiviert sind, aktivieren sie die Kanäle auf den Ebenen noch tiefer, bis die letzte Ebene erreicht ist.Bilderzeugung. Die Aktivierungsvisualisierung wird in angezeigtAbbildung 2 .Sie fragen sich vielleicht, wie wird klar, dass die Darstellung eines Kreises 4 Bögen beträgt? Und woher weiß RCN, dass es einen Kanal benötigt, um den Kreis darzustellen? Kanäle und ihre Bindungen an andere Schichten werden in der RCN-Trainingsphase gebildet.
Abbildung 1 : Mehrere übereinander angeordnete Feature-Layer mit Knoten im zweidimensionalen Raum. Der Übergang von der vierten zur ersten Schicht bedeutet den Übergang vom Allgemeinen zum Besonderen.Jeder Knoten besteht aus mehreren Kanälen, von denen jeder ein separates Merkmal darstellt. Kanäle sind binäre Variablen, die den Wert True oder False annehmen und angeben, ob ein diesem Kanal entsprechendes Objekt im endgültig erzeugten Bild in der Koordinate (x, y) des Knotens vorhanden ist. Auf jeder Ebene haben Knoten den gleichen Kanaltyp.Nehmen wir als Beispiel eine Zwischenschicht und sprechen über ihre Kanäle und die obigen Schichten, um die Erklärung zu vereinfachen. Die Liste der Kanäle auf dieser Ebene besteht aus einer Hyperbel, einem Kreis und einer Parabel. Bei einem bestimmten Lauf beim Erzeugen des Bildes erforderten die Berechnungen der darüber liegenden Ebenen einen Kreis in der Koordinate (1,1). Somit hat der Knoten (1, 1) einen Kanal, der dem Objekt "Kreis" im Wert True entspricht. Dies wirkt sich direkt auf einige Knoten in der darunter liegenden Ebene aus, dh, die Features der unteren Ebene, die dem Kreis in der Nachbarschaft (1,1) zugeordnet sind, werden auf True gesetzt. Diese Objekte niedrigerer Ebene können beispielsweise vier Bögen mit unterschiedlichen Ausrichtungen sein. Wenn die Merkmale der unteren Ebene aktiviert sind, aktivieren sie die Kanäle auf den Ebenen noch tiefer, bis die letzte Ebene erreicht ist.Bilderzeugung. Die Aktivierungsvisualisierung wird in angezeigtAbbildung 2 .Sie fragen sich vielleicht, wie wird klar, dass die Darstellung eines Kreises 4 Bögen beträgt? Und woher weiß RCN, dass es einen Kanal benötigt, um den Kreis darzustellen? Kanäle und ihre Bindungen an andere Schichten werden in der RCN-Trainingsphase gebildet.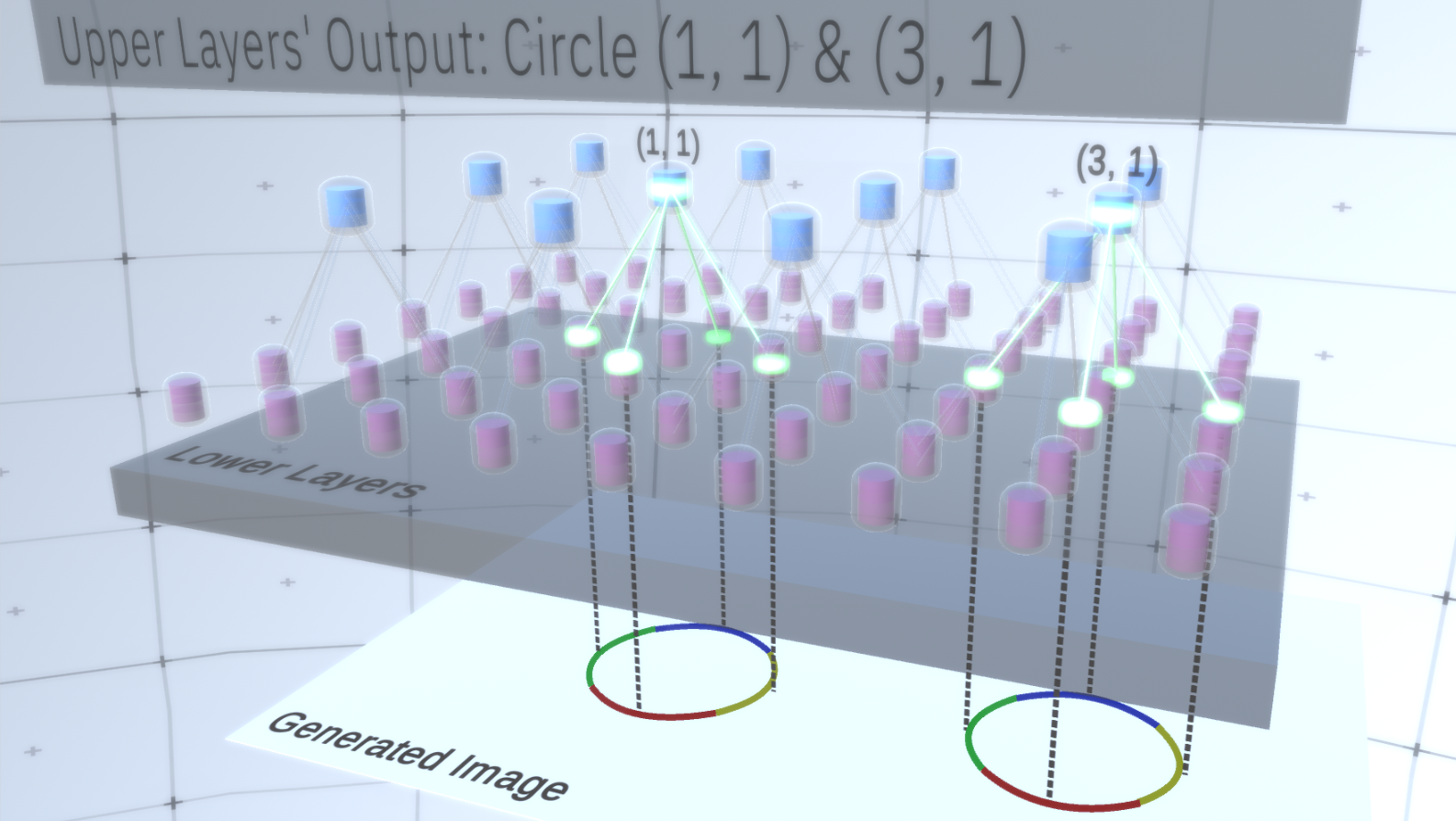 Abbildung 2: Informationsfluss in Feature-Layern. Zeichenknoten sind Kapseln, die Scheiben enthalten, die Kanäle darstellen. Einige der oberen und unteren Schichten wurden der Einfachheit halber in Form eines Parallelepipeds dargestellt, in Wirklichkeit bestehen sie jedoch auch aus Merkmalsknoten als Zwischenschichten. Bitte beachten Sie, dass die obere Zwischenschicht aus 3 Kanälen und die zweite Schicht aus 4 Kanälen besteht.Sie können eine sehr starre und deterministische Methode zur Erzeugung des angenommenen Modells angeben, aber für Menschen werden kleine Störungen der Krümmung des Kreises immer noch als Kreis betrachtet, wie Sie in Abbildung 3 sehen können .
Abbildung 2: Informationsfluss in Feature-Layern. Zeichenknoten sind Kapseln, die Scheiben enthalten, die Kanäle darstellen. Einige der oberen und unteren Schichten wurden der Einfachheit halber in Form eines Parallelepipeds dargestellt, in Wirklichkeit bestehen sie jedoch auch aus Merkmalsknoten als Zwischenschichten. Bitte beachten Sie, dass die obere Zwischenschicht aus 3 Kanälen und die zweite Schicht aus 4 Kanälen besteht.Sie können eine sehr starre und deterministische Methode zur Erzeugung des angenommenen Modells angeben, aber für Menschen werden kleine Störungen der Krümmung des Kreises immer noch als Kreis betrachtet, wie Sie in Abbildung 3 sehen können .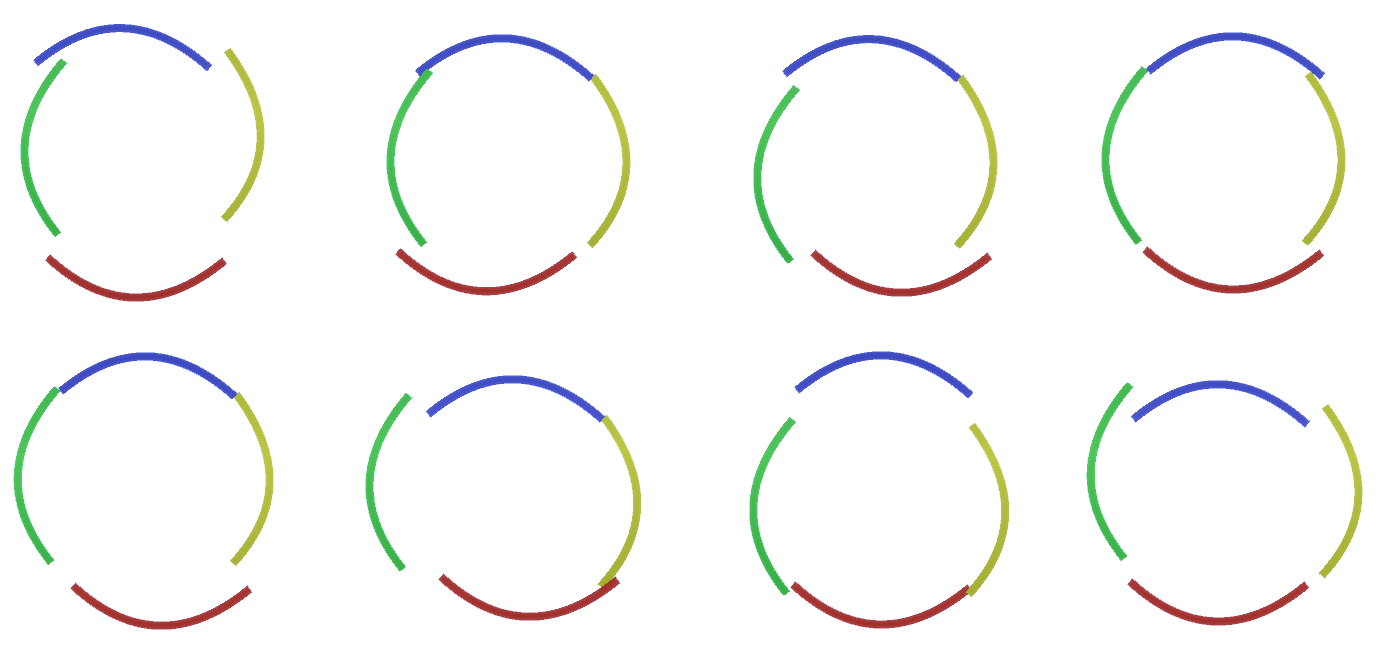 Abbildung 3: Viele Variationen der Konstruktion eines Kreises aus vier gekrümmten Bögen aus Abbildung 2.Es wäre schwierig, jede dieser Variationen als separaten neuen Kanal in der Schicht zu betrachten. In ähnlicher Weise wird das Gruppieren von Variationen in dieselbe Entität die Verallgemeinerung in neue Variationen erheblich erleichtern, wenn wir RCN etwas später an die Klassifizierung anpassen, anstatt sie zu generieren. Aber wie ändern wir RCN, um diese Gelegenheit zu bekommen?
Abbildung 3: Viele Variationen der Konstruktion eines Kreises aus vier gekrümmten Bögen aus Abbildung 2.Es wäre schwierig, jede dieser Variationen als separaten neuen Kanal in der Schicht zu betrachten. In ähnlicher Weise wird das Gruppieren von Variationen in dieselbe Entität die Verallgemeinerung in neue Variationen erheblich erleichtern, wenn wir RCN etwas später an die Klassifizierung anpassen, anstatt sie zu generieren. Aber wie ändern wir RCN, um diese Gelegenheit zu bekommen?Unterabtastungsebenen
Dazu benötigen Sie einen neuen Layertyp - den Pooling-Layer. Es befindet sich zwischen zwei beliebigen Zeichenschichten und fungiert als Vermittler zwischen ihnen. Es besteht auch aus Kanälen, sie haben jedoch ganzzahlige Werte, keine binären.Um zu veranschaulichen, wie diese Ebenen funktionieren, kehren wir zum Kreisbeispiel zurück. Anstatt 4 Bögen mit festen Koordinaten von der darüber liegenden Merkmalsebene als Merkmal eines Kreises zu benötigen, wird die Suche auf der Unterabtastungsebene durchgeführt. Dann wählt jeder aktivierte Kanal in der Unterabtastschicht einen Knoten auf der darunter liegenden Schicht in seiner Nähe aus, um eine leichte Verzerrung des Merkmals zu ermöglichen. Wenn wir also eine Kommunikation mit 9 Knoten direkt unter dem Unterabtastknoten herstellen, wählt der Unterabtastungskanal bei jeder Aktivierung gleichmäßig einen dieser 9 Knoten aus und aktiviert ihn, und der Index des ausgewählten Knotens ist der Status des Unterabtastkanals - eine Ganzzahl. In Abbildung 4Sie können mehrere Läufe sehen, bei denen jeder Lauf einen anderen Satz von Knoten niedrigerer Ebene verwendet, sodass Sie auf verschiedene Arten einen Kreis erstellen können. Abbildung 4: Betrieb von Unterabtastschichten. Jeder Frame in diesem GIF-Bild ist ein separater Start. Unterabtastknoten werden gewürfelt. In diesem Bild haben die Unterabtastknoten 4 Kanäle, die 4 Kanälen der darunter liegenden Merkmalsebene entsprechen. Die obere und untere Schicht wurden vollständig aus dem Bild entfernt.Trotz der Tatsache, dass wir die Variabilität unseres Modells brauchten, wäre es besser, wenn es zurückhaltender und fokussierter bleiben würde. In den beiden vorhergehenden Abbildungen sehen einige Kreise zu seltsam aus, um sie wirklich als Kreise zu interpretieren, da die Bögen nicht miteinander verbunden sind, wie aus Abbildung 5 ersichtlich ist. Wir möchten vermeiden, sie zu generieren. Wenn wir also einen Mechanismus für Unterabtastungskanäle hinzufügen könnten, um die Auswahl von Merkmalsknoten zu koordinieren und uns auf kontinuierliche Formen zu konzentrieren, wäre unser Modell genauer.
Abbildung 4: Betrieb von Unterabtastschichten. Jeder Frame in diesem GIF-Bild ist ein separater Start. Unterabtastknoten werden gewürfelt. In diesem Bild haben die Unterabtastknoten 4 Kanäle, die 4 Kanälen der darunter liegenden Merkmalsebene entsprechen. Die obere und untere Schicht wurden vollständig aus dem Bild entfernt.Trotz der Tatsache, dass wir die Variabilität unseres Modells brauchten, wäre es besser, wenn es zurückhaltender und fokussierter bleiben würde. In den beiden vorhergehenden Abbildungen sehen einige Kreise zu seltsam aus, um sie wirklich als Kreise zu interpretieren, da die Bögen nicht miteinander verbunden sind, wie aus Abbildung 5 ersichtlich ist. Wir möchten vermeiden, sie zu generieren. Wenn wir also einen Mechanismus für Unterabtastungskanäle hinzufügen könnten, um die Auswahl von Merkmalsknoten zu koordinieren und uns auf kontinuierliche Formen zu konzentrieren, wäre unser Modell genauer. Abbildung 5: Viele Optionen zum Erstellen eines Kreises. Die Optionen, die wir löschen möchten, sind mit roten Kreuzen markiert.RCN-Autoren verwendeten zu diesem Zweck eine laterale Verbindung in Unterabtastungsschichten. Im Wesentlichen haben Unterabtastkanäle Verbindungen mit anderen Unterabtastkanälen aus der unmittelbaren Umgebung, und diese Verbindungen ermöglichen es nicht, dass einige Zustandspaare gleichzeitig in zwei Kanälen koexistieren. Tatsächlich wird der Abtastbereich dieser beiden Kanäle einfach begrenzt. In verschiedenen Versionen des Kreises erlauben diese Verbindungen beispielsweise nicht, dass sich zwei benachbarte Bögen voneinander entfernen. Dieser Mechanismus ist in Abbildung 6 dargestellt.. Auch diese Beziehungen werden in der Trainingsphase hergestellt. Es sollte beachtet werden, dass moderne künstliche neuronale Vanille-Netze keine lateralen Verbindungen in ihren Schichten haben, obwohl sie in biologischen neuronalen Netzen existieren, und es wird angenommen, dass sie eine Rolle bei der Konturintegration im visuellen Kortex spielen (aber offen gesagt hat der visuelle Kortex wo komplexeres Gerät, als es aus der vorherigen Aussage hervorgeht).
Abbildung 5: Viele Optionen zum Erstellen eines Kreises. Die Optionen, die wir löschen möchten, sind mit roten Kreuzen markiert.RCN-Autoren verwendeten zu diesem Zweck eine laterale Verbindung in Unterabtastungsschichten. Im Wesentlichen haben Unterabtastkanäle Verbindungen mit anderen Unterabtastkanälen aus der unmittelbaren Umgebung, und diese Verbindungen ermöglichen es nicht, dass einige Zustandspaare gleichzeitig in zwei Kanälen koexistieren. Tatsächlich wird der Abtastbereich dieser beiden Kanäle einfach begrenzt. In verschiedenen Versionen des Kreises erlauben diese Verbindungen beispielsweise nicht, dass sich zwei benachbarte Bögen voneinander entfernen. Dieser Mechanismus ist in Abbildung 6 dargestellt.. Auch diese Beziehungen werden in der Trainingsphase hergestellt. Es sollte beachtet werden, dass moderne künstliche neuronale Vanille-Netze keine lateralen Verbindungen in ihren Schichten haben, obwohl sie in biologischen neuronalen Netzen existieren, und es wird angenommen, dass sie eine Rolle bei der Konturintegration im visuellen Kortex spielen (aber offen gesagt hat der visuelle Kortex wo komplexeres Gerät, als es aus der vorherigen Aussage hervorgeht).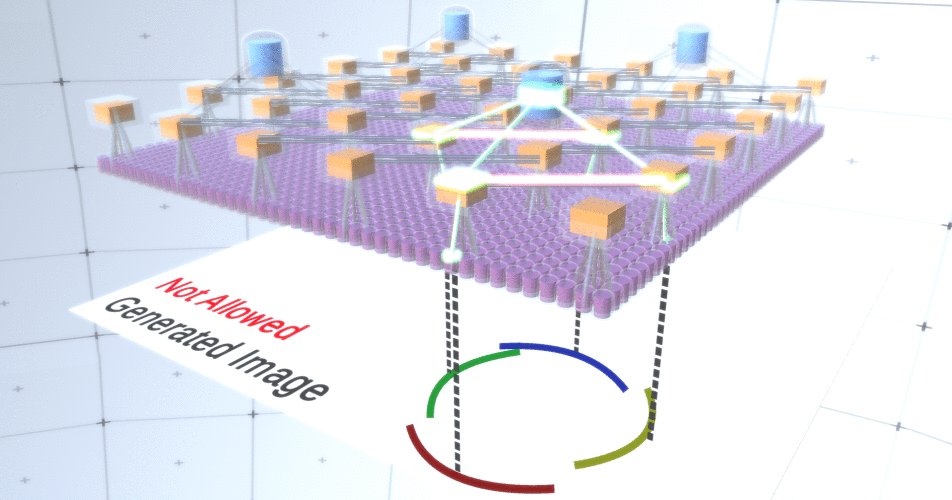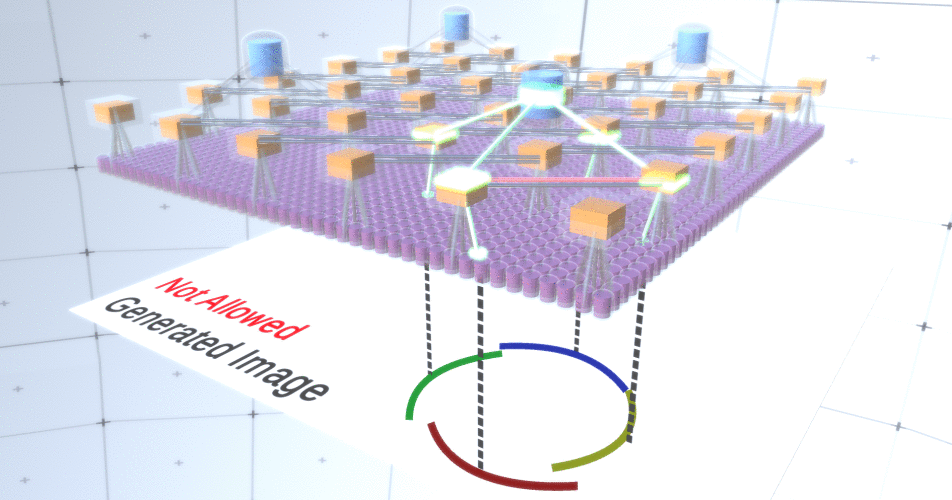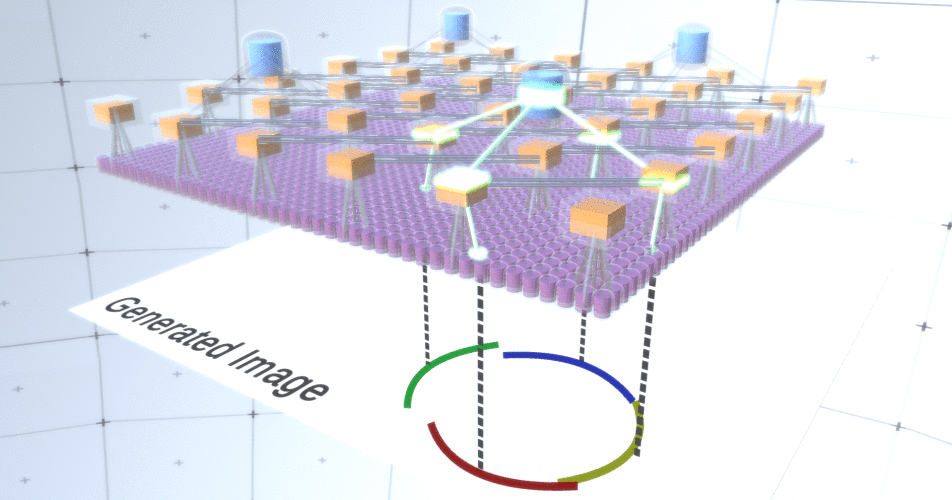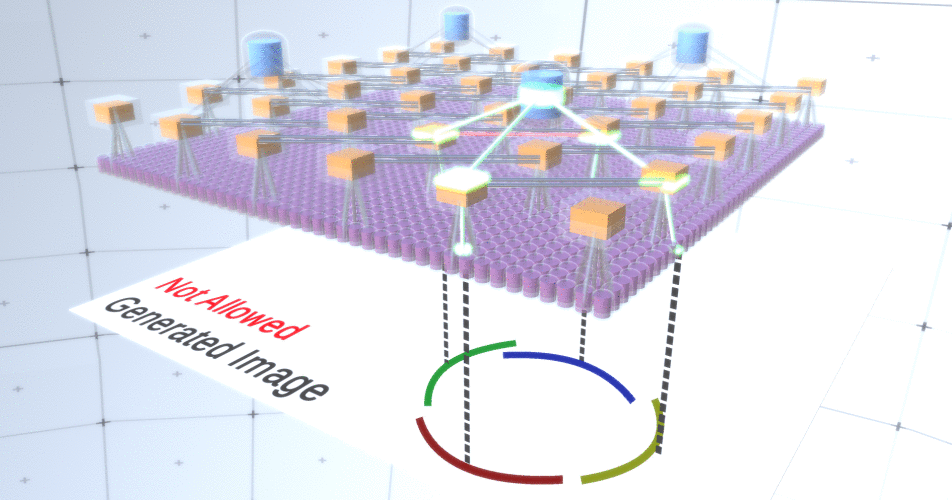 Abbildung 6: GIF- RCN . , . , RCN , , . .Bisher haben wir über Zwischenschichten von RCN gesprochen, wir haben nur die oberste Schicht und die unterste Schicht, die mit den Pixeln des erzeugten Bildes interagiert. Die oberste Ebene ist eine reguläre Feature-Ebene, in der die Kanäle jedes Knotens Klassen unseres beschrifteten Datensatzes sind. Beim Generieren wählen wir einfach den Speicherort und die Klasse aus, die wir erstellen möchten, gehen zum Knoten mit dem angegebenen Speicherort und sagen, dass er den Kanal der von uns ausgewählten Klasse aktiviert. Dadurch werden einige der Kanäle in der darunter liegenden Unterabtastebene, dann die darunter liegende Feature-Ebene usw. aktiviert, bis die letzte Feature-Ebene erreicht ist. Basierend auf Ihrem Wissen über Faltungs-Neuronale Netze sollten Sie denken, dass die oberste Schicht einen einzelnen Knoten hat, aber dies ist nicht der Fall, und dies ist einer der Vorteile von RCN.Eine Diskussion dieses Themas würde jedoch den Rahmen dieses Artikels sprengen.Der letzte Feature-Layer ist eindeutig. Erinnerst du dich, ich habe darüber gesprochen, wie RCNs Form und Aussehen trennen? Es ist diese Schicht, die für das Erhalten der Form des erzeugten Objekts verantwortlich ist. Daher sollte diese Ebene mit Features auf sehr niedriger Ebene arbeiten, den grundlegendsten Bausteinen jeder Form, die uns helfen, jede gewünschte Form zu erzeugen. Kleine Ränder, die sich in verschiedenen Winkeln drehen, sind durchaus geeignet, und genau diese verwenden die Autoren der Technologie.Die Autoren haben die Attribute der letzten Ebene ausgewählt, um ein 3x3-Fenster mit einem Rand mit einem bestimmten Drehwinkel darzustellen, den sie als Patch-Deskriptor bezeichnen. Die Anzahl der ausgewählten Drehwinkel beträgt 16. Um später ein Erscheinungsbild hinzufügen zu können, benötigen Sie außerdem zwei Ausrichtungen für jede Drehung, um feststellen zu können, ob sich der Hintergrund am linken oder am rechten Rand befindet, wenn es sich um Außenränder handelt und zusätzliche Orientierung im Fall von inneren Grenzen (d. h. innerhalb des Objekts). In Abbildung 7 sind die Eigenschaften der letzten Schichtanordnung dargestellt, und in Abbildung 8 ist dargestellt , wie die Deskriptoren von Patches eine bestimmte Form erzeugen können.
Abbildung 6: GIF- RCN . , . , RCN , , . .Bisher haben wir über Zwischenschichten von RCN gesprochen, wir haben nur die oberste Schicht und die unterste Schicht, die mit den Pixeln des erzeugten Bildes interagiert. Die oberste Ebene ist eine reguläre Feature-Ebene, in der die Kanäle jedes Knotens Klassen unseres beschrifteten Datensatzes sind. Beim Generieren wählen wir einfach den Speicherort und die Klasse aus, die wir erstellen möchten, gehen zum Knoten mit dem angegebenen Speicherort und sagen, dass er den Kanal der von uns ausgewählten Klasse aktiviert. Dadurch werden einige der Kanäle in der darunter liegenden Unterabtastebene, dann die darunter liegende Feature-Ebene usw. aktiviert, bis die letzte Feature-Ebene erreicht ist. Basierend auf Ihrem Wissen über Faltungs-Neuronale Netze sollten Sie denken, dass die oberste Schicht einen einzelnen Knoten hat, aber dies ist nicht der Fall, und dies ist einer der Vorteile von RCN.Eine Diskussion dieses Themas würde jedoch den Rahmen dieses Artikels sprengen.Der letzte Feature-Layer ist eindeutig. Erinnerst du dich, ich habe darüber gesprochen, wie RCNs Form und Aussehen trennen? Es ist diese Schicht, die für das Erhalten der Form des erzeugten Objekts verantwortlich ist. Daher sollte diese Ebene mit Features auf sehr niedriger Ebene arbeiten, den grundlegendsten Bausteinen jeder Form, die uns helfen, jede gewünschte Form zu erzeugen. Kleine Ränder, die sich in verschiedenen Winkeln drehen, sind durchaus geeignet, und genau diese verwenden die Autoren der Technologie.Die Autoren haben die Attribute der letzten Ebene ausgewählt, um ein 3x3-Fenster mit einem Rand mit einem bestimmten Drehwinkel darzustellen, den sie als Patch-Deskriptor bezeichnen. Die Anzahl der ausgewählten Drehwinkel beträgt 16. Um später ein Erscheinungsbild hinzufügen zu können, benötigen Sie außerdem zwei Ausrichtungen für jede Drehung, um feststellen zu können, ob sich der Hintergrund am linken oder am rechten Rand befindet, wenn es sich um Außenränder handelt und zusätzliche Orientierung im Fall von inneren Grenzen (d. h. innerhalb des Objekts). In Abbildung 7 sind die Eigenschaften der letzten Schichtanordnung dargestellt, und in Abbildung 8 ist dargestellt , wie die Deskriptoren von Patches eine bestimmte Form erzeugen können.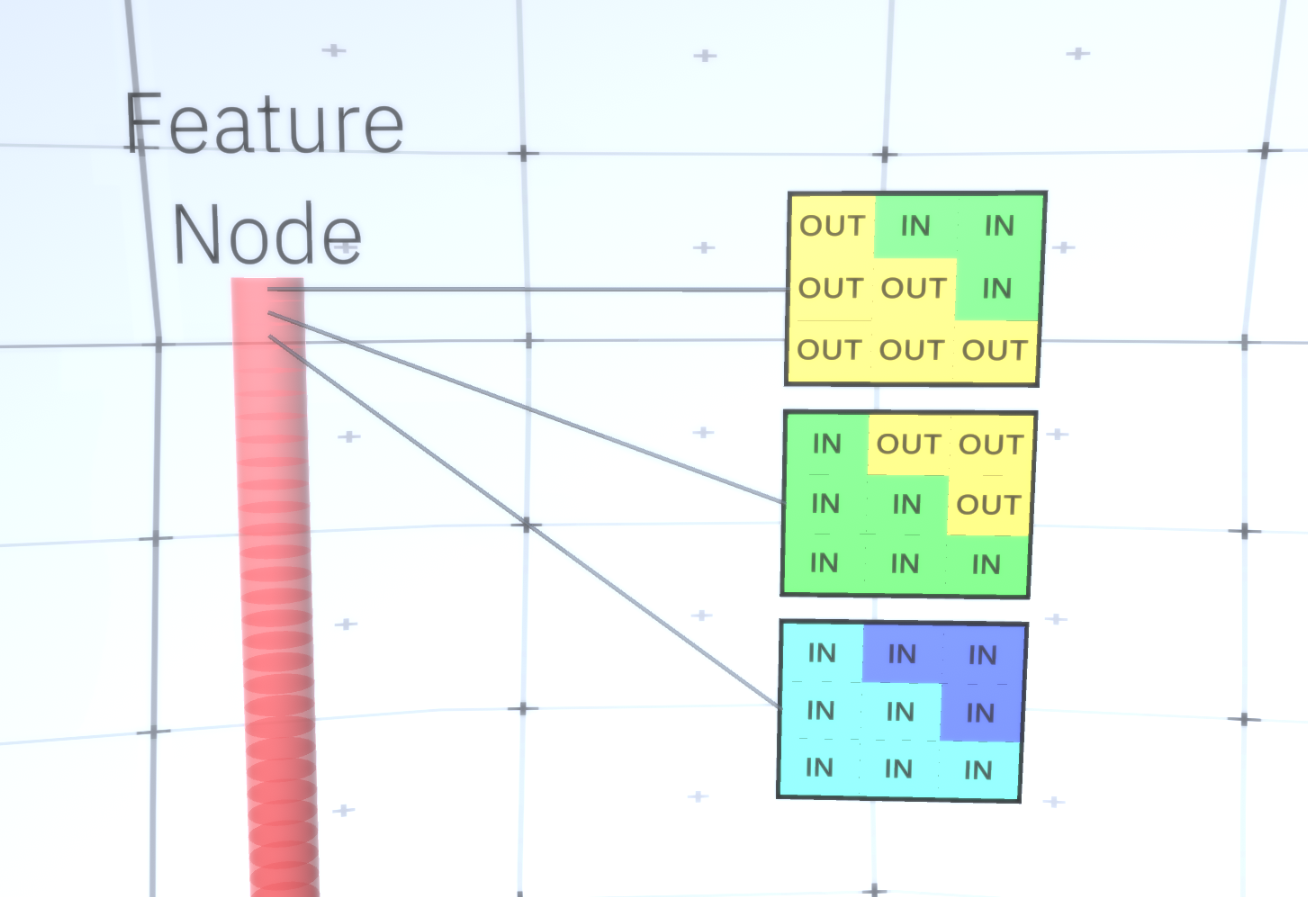 Abbildung 7: . 48 ( ) , 16 3 . – 45 . “IN " , “OUT” — .
Abbildung 7: . 48 ( ) , 16 3 . – 45 . “IN " , “OUT” — . 8: «i» .Nachdem wir die letzte Zeichenebene erreicht haben, haben wir ein Diagramm, in dem die Grenzen des Objekts bestimmt werden und das Verständnis, ob sich der Bereich außerhalb der Grenze befindet, intern oder extern ist. Es bleibt ein Erscheinungsbild hinzuzufügen, das jeden verbleibenden Bereich im Bild als IN oder OUT kennzeichnet und den Bereich übermalt. Ein bedingtes Zufallsfeld kann hier helfen. Ohne auf mathematische Details einzugehen, weisen wir einfach jedem Pixel im endgültigen Bild eine Wahrscheinlichkeitsverteilung nach Farbe und Zustand (IN oder OUT) zu. Diese Verteilung spiegelt Informationen wider, die am Rand der Karte abgerufen wurden. Wenn beispielsweise zwei benachbarte Pixel vorhanden sind, von denen eines IN und das andere OUT ist, steigt die Wahrscheinlichkeit, dass sie eine andere Farbe haben, stark an. Wenn sich zwei benachbarte Pixel auf gegenüberliegenden Seiten des inneren Randes befinden, ist die Wahrscheinlichkeitdas wird eine andere Farbe haben wird auch zunehmen. Wenn die Pixel innerhalb des Rahmens liegen und durch nichts voneinander getrennt sind, steigt die Wahrscheinlichkeit, dass sie dieselbe Farbe haben, aber die externen Pixel können geringfügig voneinander abweichen und so weiter. Um das endgültige Bild zu erhalten, treffen Sie einfach eine Auswahl aus der soeben installierten gemeinsamen Wahrscheinlichkeitsverteilung. Um das erzeugte Bild interessanter zu machen, können wir die Farben durch die Textur ersetzen. Wir werden diese Ebene nicht diskutieren, da RCN die Klassifizierung durchführen kann, ohne auf dem Erscheinungsbild zu basieren.Um das endgültige Bild zu erhalten, treffen Sie einfach eine Auswahl aus der soeben installierten gemeinsamen Wahrscheinlichkeitsverteilung. Um das erzeugte Bild interessanter zu machen, können wir die Farben durch die Textur ersetzen. Wir werden diese Ebene nicht diskutieren, da RCN die Klassifizierung durchführen kann, ohne auf dem Erscheinungsbild zu basieren.Um das endgültige Bild zu erhalten, treffen Sie einfach eine Auswahl aus der soeben installierten gemeinsamen Wahrscheinlichkeitsverteilung. Um das erzeugte Bild interessanter zu machen, können wir die Farben durch die Textur ersetzen. Wir werden diese Ebene nicht diskutieren, da RCN die Klassifizierung durchführen kann, ohne auf dem Erscheinungsbild zu basieren.Nun, wir werden heute hier enden. Wenn Sie mehr über RCN erfahren möchten, lesen Sie diesen Artikel [5] und den Anhang mit zusätzlichen Materialien, oder lesen Sie meine anderen Artikel über die logischen Schlussfolgerungen , Schulungen und Ergebnisse der Verwendung von RCN für verschiedene Datensätze .
8: «i» .Nachdem wir die letzte Zeichenebene erreicht haben, haben wir ein Diagramm, in dem die Grenzen des Objekts bestimmt werden und das Verständnis, ob sich der Bereich außerhalb der Grenze befindet, intern oder extern ist. Es bleibt ein Erscheinungsbild hinzuzufügen, das jeden verbleibenden Bereich im Bild als IN oder OUT kennzeichnet und den Bereich übermalt. Ein bedingtes Zufallsfeld kann hier helfen. Ohne auf mathematische Details einzugehen, weisen wir einfach jedem Pixel im endgültigen Bild eine Wahrscheinlichkeitsverteilung nach Farbe und Zustand (IN oder OUT) zu. Diese Verteilung spiegelt Informationen wider, die am Rand der Karte abgerufen wurden. Wenn beispielsweise zwei benachbarte Pixel vorhanden sind, von denen eines IN und das andere OUT ist, steigt die Wahrscheinlichkeit, dass sie eine andere Farbe haben, stark an. Wenn sich zwei benachbarte Pixel auf gegenüberliegenden Seiten des inneren Randes befinden, ist die Wahrscheinlichkeitdas wird eine andere Farbe haben wird auch zunehmen. Wenn die Pixel innerhalb des Rahmens liegen und durch nichts voneinander getrennt sind, steigt die Wahrscheinlichkeit, dass sie dieselbe Farbe haben, aber die externen Pixel können geringfügig voneinander abweichen und so weiter. Um das endgültige Bild zu erhalten, treffen Sie einfach eine Auswahl aus der soeben installierten gemeinsamen Wahrscheinlichkeitsverteilung. Um das erzeugte Bild interessanter zu machen, können wir die Farben durch die Textur ersetzen. Wir werden diese Ebene nicht diskutieren, da RCN die Klassifizierung durchführen kann, ohne auf dem Erscheinungsbild zu basieren.Um das endgültige Bild zu erhalten, treffen Sie einfach eine Auswahl aus der soeben installierten gemeinsamen Wahrscheinlichkeitsverteilung. Um das erzeugte Bild interessanter zu machen, können wir die Farben durch die Textur ersetzen. Wir werden diese Ebene nicht diskutieren, da RCN die Klassifizierung durchführen kann, ohne auf dem Erscheinungsbild zu basieren.Um das endgültige Bild zu erhalten, treffen Sie einfach eine Auswahl aus der soeben installierten gemeinsamen Wahrscheinlichkeitsverteilung. Um das erzeugte Bild interessanter zu machen, können wir die Farben durch die Textur ersetzen. Wir werden diese Ebene nicht diskutieren, da RCN die Klassifizierung durchführen kann, ohne auf dem Erscheinungsbild zu basieren.Nun, wir werden heute hier enden. Wenn Sie mehr über RCN erfahren möchten, lesen Sie diesen Artikel [5] und den Anhang mit zusätzlichen Materialien, oder lesen Sie meine anderen Artikel über die logischen Schlussfolgerungen , Schulungen und Ergebnisse der Verwendung von RCN für verschiedene Datensätze .Quellen:
- [1] R. Perrault, Y. Shoham, E. Brynjolfsson et al., Jahresbericht 2019 des AI Index 2019 (2019), Human-Centered AI Institute - Stanford University.
- [2] D. Hendrycks, K. Zhao, S. Basart et al., Natural Adversarial Examples (2019), arXiv: 1907.07174.
- [3] J. Su, D. Vasconcellos Vargas und S. Kouichi, Ein-Pixel-Angriff zur Täuschung tiefer neuronaler Netze (2017), arXiv: 1710.08864.
- [4] M. Sharif, S. Bhagavatula, L. Bauer, Ein allgemeiner Rahmen für kontroverse Beispiele mit Zielen (2017), arXiv: 1801.00349.
- [5] D. George, W. Lehrach, K. Kansky, et al., A Generative Vision Model that Trains with High Data Efficiency and Break Text-based CAPTCHAs (2017), Science Mag (Vol 358 — Issue 6368).
- [6] H. Liang, X. Gong, M. Chen, et al., Interactions Between Feedback and Lateral Connections in the Primary Visual Cortex (2017), Proceedings of the National Academy of Sciences of the United States of America.
: « : ». Source: https://habr.com/ru/post/undefined/
All Articles