Hallo Habr.Mein Name ist Misha Butrimov, ich möchte ein wenig über Cassandra sprechen. Meine Geschichte wird für diejenigen nützlich sein, die noch nie auf NoSQL-Datenbanken gestoßen sind - sie enthält viele Implementierungsfunktionen und Fallstricke, die Sie kennen müssen. Und wenn Sie außer Oracle oder einer anderen relationalen Basis nichts gesehen haben, werden diese Dinge Ihr Leben retten.Was ist gut an Cassandra? Dies ist eine NoSQL-Datenbank, die ohne einen einzigen Fehlerpunkt entwickelt wurde und sich gut skalieren lässt. Wenn Sie für eine Basis ein paar Terabyte hinzufügen müssen, fügen Sie dem Ring einfach Knoten hinzu. Erweitern Sie es auf ein anderes Rechenzentrum? Fügen Sie dem Cluster Knoten hinzu. Verarbeitete RPS erhöhen? Fügen Sie dem Cluster Knoten hinzu. Der andere Weg funktioniert auch. Was kann sie sonst noch? Es geht darum, viele Anfragen zu bearbeiten. Aber wie viel ist wie viel? 10, 20, 30, 40 Tausend Anfragen pro Sekunde - das ist nicht viel. Auch 100.000 Anfragen pro Sekunde zur Aufnahme. Es gibt Unternehmen, die angeben, 2 Millionen Anfragen pro Sekunde zu haben. Hier müssen sie wahrscheinlich glauben.Und im Prinzip hat Cassandra einen großen Unterschied zu relationalen Daten - es sieht überhaupt nicht so aus. Und das ist sehr wichtig zu beachten.
Was kann sie sonst noch? Es geht darum, viele Anfragen zu bearbeiten. Aber wie viel ist wie viel? 10, 20, 30, 40 Tausend Anfragen pro Sekunde - das ist nicht viel. Auch 100.000 Anfragen pro Sekunde zur Aufnahme. Es gibt Unternehmen, die angeben, 2 Millionen Anfragen pro Sekunde zu haben. Hier müssen sie wahrscheinlich glauben.Und im Prinzip hat Cassandra einen großen Unterschied zu relationalen Daten - es sieht überhaupt nicht so aus. Und das ist sehr wichtig zu beachten.Nicht alles, was gleich aussieht, funktioniert gleich
Einmal kam ein Kollege zu mir und fragte: „Hier ist die CQL Cassandra-Abfragesprache, und sie hat eine select-Anweisung, sie hat wo, sie hat und. Ich schreibe Briefe und es funktioniert nicht. Warum?". Wenn Sie Cassandra als relationale Datenbank behandeln, ist dies ein idealer Weg, um Ihr Leben durch brutalen Selbstmord zu beenden. Und ich befürworte nicht, es ist in Russland verboten. Sie entwerfen nur etwas Falsches.Zum Beispiel kommt ein Kunde zu uns und sagt: „Erstellen wir eine Datenbank für Fernsehsendungen oder eine Datenbank für ein Verzeichnis von Rezepten. Wir werden dort Speisen oder eine Liste von Serien und Schauspielern haben. “ Wir sagen freudig: "Komm schon!". Dies sind zwei Bytes zum Senden, ein paar Platten und alles ist fertig, alles wird sehr schnell und zuverlässig funktionieren. Und alles ist in Ordnung, bis die Kunden kommen und sagen, dass die Hausfrauen auch das umgekehrte Problem lösen: Sie haben eine Liste von Produkten und wollen wissen, welches Gericht sie kochen möchten. Du bist tot.Das liegt daran, dass Cassandra eine hybride Datenbank ist: Sie ist sowohl ein Schlüsselwert als auch speichert Daten in breiten Spalten. In Java oder Kotlin könnte es folgendermaßen beschrieben werden:Map<RowKey, SortedMap<ColumnKey, ColumnValue>>Das heißt, eine Karte, in der sich auch eine sortierte Karte befindet. Der erste Schlüssel zu dieser Zuordnung ist der Zeilenschlüssel oder Partitionsschlüssel - der Partitionsschlüssel. Der zweite Schlüssel, der der Schlüssel zur bereits sortierten Karte ist, ist der Clustering-Schlüssel.Um die Verteilung der Datenbank zu veranschaulichen, zeichnen wir drei Knoten. Jetzt müssen Sie verstehen, wie Daten in Knoten zerlegt werden. Denn wenn wir alles in eins schieben (es können übrigens tausend, zweitausend, fünf sein - so viele, wie Sie möchten), geht es nicht wirklich um Verteilung. Daher benötigen wir eine mathematische Funktion, die eine Zahl zurückgibt. Nur eine Zahl, ein langer Int, der in einen Bereich fällt. Und wir haben einen Knoten, der für einen Bereich verantwortlich ist, den zweiten - für den zweiten, n-ten - für den n-ten. Diese Nummer wird mit einer Hash-Funktion verwendet, die nur für den Partitionsschlüssel gilt. Dies ist die Spalte, die in der Primärschlüsselanweisung angegeben ist, und dies ist die Spalte, die der erste und grundlegendste Zuordnungsschlüssel ist. Es bestimmt, welcher Knoten welche Daten erhält. In Cassandra wird eine Tabelle mit fast derselben Syntax wie in SQL erstellt:
Diese Nummer wird mit einer Hash-Funktion verwendet, die nur für den Partitionsschlüssel gilt. Dies ist die Spalte, die in der Primärschlüsselanweisung angegeben ist, und dies ist die Spalte, die der erste und grundlegendste Zuordnungsschlüssel ist. Es bestimmt, welcher Knoten welche Daten erhält. In Cassandra wird eine Tabelle mit fast derselben Syntax wie in SQL erstellt:CREATE TABLE users (
user_id uu id,
name text,
year int,
salary float,
PRIMARY KEY(user_id)
)
Der Primärschlüssel besteht in diesem Fall aus einer Spalte und ist auch ein Partitionsschlüssel.Wie werden Benutzer mit uns fallen? Ein Teil wird auf eine Note fallen, ein Teil auf eine andere und ein Teil auf eine dritte. Es stellt sich heraus, dass es sich um eine gewöhnliche Hash-Tabelle handelt, es ist auch eine Map, es ist auch ein Wörterbuch in Python, es ist auch eine einfache Schlüsselwertstruktur, aus der wir alle Werte lesen, lesen und schreiben können.
Wählen Sie: Wenn das Zulassen des Filterns zum vollständigen Scan wird oder nicht
Lassen Sie uns eine Aussage schreiben select * from users where, userid = . Es stellt sich heraus, wie es in Oracle scheint: Wir schreiben select, wir geben Bedingungen an und alles funktioniert, Benutzer bekommen es. Wenn Sie beispielsweise einen Benutzer mit einem bestimmten Geburtsjahr auswählen, schwört Cassandra, dass sie die Anforderung nicht erfüllen kann. Da sie nichts darüber weiß, wie wir Daten zum Geburtsjahr verteilen, hat sie nur eine Spalte als Schlüssel angegeben. Dann sagt sie: „Okay, ich kann diese Bitte immer noch erfüllen. Hinzufügen erlauben Filterung. " Wir fügen eine Richtlinie hinzu, alles funktioniert. Und in diesem Moment passiert etwas Schreckliches.Wenn wir mit Testdaten fahren, ist alles in Ordnung. Und wenn Sie die Anfrage in der Produktion erfüllen, wo wir zum Beispiel 4 Millionen Platten haben, dann ist bei uns nicht alles sehr gut. Da das Zulassen von Filtern eine Anweisung ist, die es Cassandra ermöglicht, alle Daten aus dieser Tabelle von allen Knoten, allen Rechenzentren (wenn sich viele davon in diesem Cluster befinden) zu erfassen und erst dann zu filtern. Dies ist ein Analogon zu Full Scan, und kaum jemand ist davon begeistert.Wenn wir nur Benutzer nach Kennungen benötigen würden, würde dies zu uns passen. Aber manchmal müssen wir andere Abfragen schreiben und der Auswahl andere Einschränkungen auferlegen. Deshalb erinnern wir uns: Wir haben alle eine Karte, die einen Partitionsschlüssel hat, aber darin befindet sich eine sortierte Karte.Und sie hat auch einen Schlüssel, den wir Clustering Key nennen. Dieser Schlüssel, der wiederum aus den von uns ausgewählten Spalten besteht, mit denen Cassandra versteht, wie ihre Daten physisch sortiert sind und auf jedem Knoten liegen. Das heißt, für einige Partitionsschlüssel gibt der Clustering-Schlüssel genau an, wie die Daten in diesen Baum verschoben werden und an welcher Stelle sie dort platziert werden.Dies ist wirklich ein Baum, ein Komparator wird dort einfach genannt, in den wir eine bestimmte Menge von Spalten in Form eines Objekts übergeben, und es wird auch in Form einer Spaltenliste gesetzt.CREATE TABLE users_by_year_salary_id (
user_id uuid,
name text,
year int,
salary float,
PRIMARY KEY((year), salary, user_id)
Beachten Sie die Primärschlüssel-Direktive. Das erste Argument (in unserem Fall das Jahr) ist immer der Partitionsschlüssel. Es kann aus einer oder mehreren Spalten bestehen, es spielt keine Rolle. Wenn mehrere Spalten vorhanden sind, müssen Sie sie erneut in Klammern entfernen, damit der Sprachpräprozessor versteht, dass dies der Primärschlüssel ist, und dahinter alle anderen Spalten - der Clustering-Schlüssel. In diesem Fall werden sie im Komparator in der Reihenfolge übertragen, in der sie sich befinden. Das heißt, die erste Spalte ist bedeutender, die zweite ist weniger bedeutsam und so weiter. Wenn wir beispielsweise für Datenklassen schreiben, sind Felder gleich: Wir listen Felder auf und für sie schreiben wir, welche größer und welche kleiner sind. In Cassandra ist dies relativ gesehen das Datenklassenfeld, auf das die dafür geschriebenen Gleichungen angewendet werden.Wir legen die Sortierung fest, legen Einschränkungen fest
Es muss beachtet werden, dass die Sortierreihenfolge (abnehmend, ansteigend, es spielt keine Rolle) gleichzeitig mit der Erstellung des Schlüssels festgelegt wird und Sie sie später nicht mehr ändern können. Es bestimmt physikalisch, wie die Daten sortiert werden und wie sie liegen werden. Wenn Sie den Clustering-Schlüssel oder die Sortierreihenfolge ändern müssen, müssen Sie eine neue Tabelle erstellen und Daten in diese Tabelle einfügen. Mit dem vorhandenen wird dies nicht funktionieren.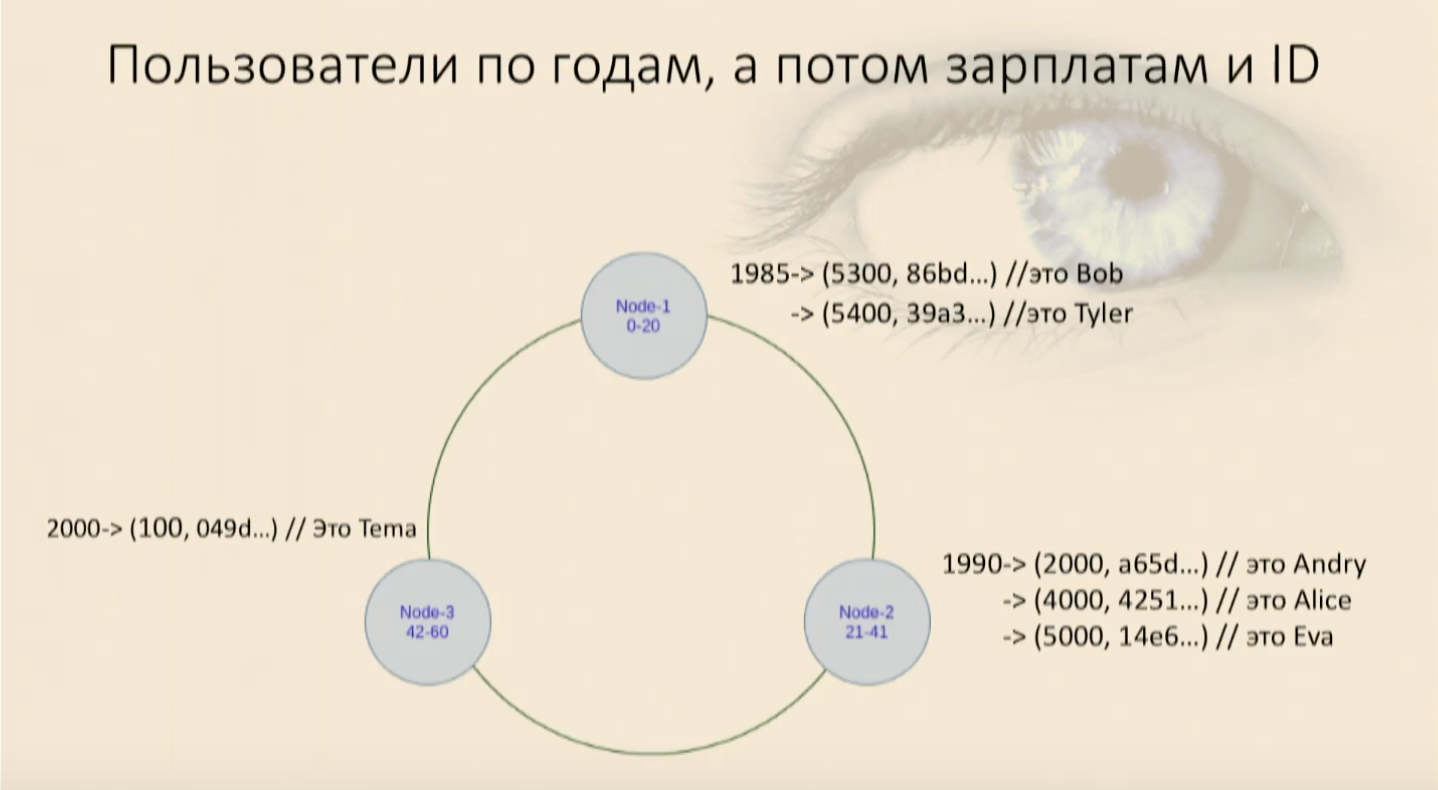 Wir füllten unseren Tisch mit Benutzern und stellten fest, dass sie zuerst nach Geburtsjahr und dann nach Gehalt und Benutzer-ID auf jedem Knoten in einen Ring gingen. Jetzt können wir auswählen und Einschränkungen auferlegen.Unsere Arbeit erscheint wieder
Wir füllten unseren Tisch mit Benutzern und stellten fest, dass sie zuerst nach Geburtsjahr und dann nach Gehalt und Benutzer-ID auf jedem Knoten in einen Ring gingen. Jetzt können wir auswählen und Einschränkungen auferlegen.Unsere Arbeit erscheint wiederwhere, andund Benutzer kommen zu uns, und alles ist wieder in Ordnung. Wenn wir jedoch versuchen, nur den weniger wichtigen Clustering-Schlüsselteil zu verwenden, schwört Cassandra sofort, dass wir in unserer Karte nicht finden können, wo dieses Objekt diese Felder für den Komparator null hat, sondern dieses, das Sie gerade festgelegt haben - wo es liegt. Ich muss alle Daten von diesem Knoten erneut aufnehmen und filtern. Und dies ist ein Analogon von Full Scan innerhalb des Knotens, das ist schlecht.Erstellen Sie in jeder unverständlichen Situation eine neue Tabelle
Was sollen wir tun, wenn wir Benutzer nach ID, Alter oder Gehalt erhalten möchten? Nichts. Verwenden Sie einfach zwei Tabellen. Wenn Sie Benutzer auf drei verschiedene Arten abrufen müssen, gibt es drei Tabellen. Vorbei sind die Zeiten, in denen wir Platz auf der Schraube gespart haben. Dies ist die billigste Ressource. Es kostet viel weniger als die Antwortzeit, was für den Benutzer fatal sein kann. Der Benutzer ist viel netter, in einer Sekunde etwas zu bekommen als in 10 Minuten.Wir tauschen übermäßigen Speicherplatz aus, denormalisierte Daten gegen die Fähigkeit, gut zu skalieren und zuverlässig zu arbeiten. Tatsächlich kann ein Cluster, der aus drei Rechenzentren besteht, von denen jeder fünf Knoten hat, mit einer akzeptablen Datenspeicherung (wenn nichts sicher verloren geht), den Tod eines Rechenzentrums vollständig überleben. Und zwei weitere Knoten in jedem der beiden verbleibenden. Und erst danach beginnen die Probleme. Dies ist eine ziemlich gute Redundanz, sie kostet ein paar unnötige SSD-Laufwerke und Prozessoren. Um Cassandra zu verwenden, das niemals SQL ist, in dem es keine Beziehungen, keine Fremdschlüssel gibt, müssen Sie daher einfache Regeln kennen.Wir gestalten alles auf Anfrage. Die Hauptsache sind nicht die Daten, sondern wie die Anwendung mit ihnen arbeiten wird. Wenn er unterschiedliche Daten auf unterschiedliche Weise oder dieselben Daten auf unterschiedliche Weise empfangen muss, müssen wir sie so platzieren, wie es für die Anwendung bequem ist. Andernfalls schlagen wir bei Full Scan fehl und Cassandra verschafft uns keinen Vorteil.Denormalisierung von Daten ist die Norm. Vergessen Sie normale Formen, wir haben keine relationalen Datenbanken mehr. Wir setzen etwas 100 mal, es wird 100 mal liegen. Es ist sowieso billiger als es zu stoppen.Wir wählen die Schlüssel für die Partitionierung so aus, dass sie normal verteilt sind. Wir brauchen den Hash von unseren Schlüsseln nicht, um in einen engen Bereich zu fallen. Das heißt, das Geburtsjahr im obigen Beispiel ist ein schlechtes Beispiel. Es ist eher gut, wenn unsere Benutzer normalerweise nach Geburtsjahr verteilt sind, und schlecht, wenn wir über Schüler der 5. Klasse sprechen - es wird nicht sehr gut sein, dort zu partitionieren.Die Sortierung wird einmal beim Erstellen des Clustering-Schlüssels ausgewählt. Wenn Sie es ändern müssen, müssen Sie unsere Tabelle mit einem anderen Schlüssel überfüllen.Und das Wichtigste: Wenn wir dieselben Daten auf 100 verschiedene Arten erfassen müssen, haben wir 100 verschiedene Tabellen.