Hallo alle zusammen!Ich möchte über ein sehr langweiliges Projekt sprechen, bei dem sich Robotik, maschinelles Lernen (und zusammen ist dies Roboterlernen), virtuelle Realität und ein bisschen Cloud-Technologie kreuzten. Und das alles macht tatsächlich Sinn. Schließlich ist es sehr praktisch, in einen Roboter einzusteigen, zu zeigen, was zu tun ist, und dann anhand der gespeicherten Daten Gewichte auf dem ML-Server zu trainieren.Unter dem Schnitt werden wir erzählen, wie es jetzt funktioniert, und einige Details zu jedem der Aspekte, die entwickelt werden mussten.
Wozu
Für den Anfang lohnt es sich, ein wenig zu enthüllen.Es scheint, dass mit Deep Learning bewaffnete Roboter Menschen überall von ihren Jobs verdrängen werden. In der Tat ist nicht alles so glatt. Wo Aktionen streng wiederholt werden, sind Prozesse bereits sehr gut automatisiert. Wenn es sich um „intelligente Roboter“ handelt, dh um Anwendungen, bei denen Computer Vision und Algorithmen bereits ausreichen. Es gibt aber auch viele äußerst komplizierte Geschichten. Roboter können mit der Vielfalt der Objekte, mit denen sie umgehen müssen, und der Vielfalt der Umgebung kaum fertig werden.Wichtige Punkte
Es gibt drei wichtige Dinge in Bezug auf die Implementierung, die noch nicht überall zu finden sind:- (data-driven learning). .. , , , . , .
- ()
- - (Human-machine collaboration)
Das zweite ist ebenfalls wichtig, da wir im Moment eine Änderung der Lernansätze, der dahinter stehenden Algorithmen und der Computerwerkzeuge beobachten werden. Wahrnehmungs- und Steuerungsalgorithmen werden flexibler. Ein Roboter-Upgrade kostet Geld. Und der Rechner kann effizienter eingesetzt werden, wenn mehrere Roboter gleichzeitig bedient werden. Dieses Konzept nennt man „Cloud Robotics“.Mit letzterem ist alles einfach - AI ist derzeit nicht ausreichend entwickelt, um 100% Zuverlässigkeit und Genauigkeit in allen Situationen zu bieten, die vom Unternehmen gefordert werden. Daher wird der Supervisor-Bediener, der manchmal Robotern helfen kann, nicht verletzt.Planen
Zunächst zu einer Software- / Netzwerkplattform, die alle beschriebenen Funktionen bietet: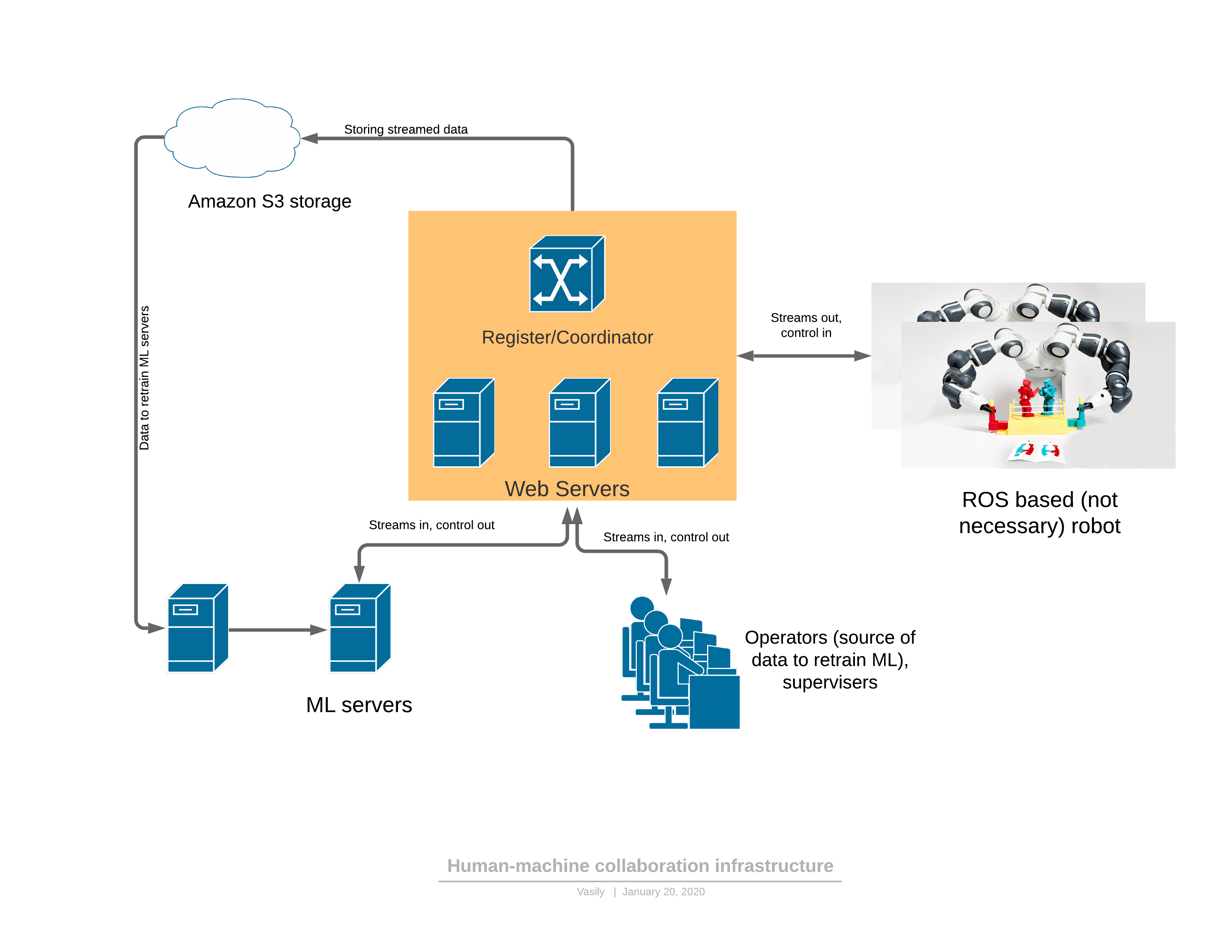 Komponenten:
Komponenten:- Der Roboter sendet einen 3D-Videostream an den Server und erhält als Antwort die Kontrolle.
- : - , (, , , )
- ML ( ), , , . — 3D , .
- - , 3D , UI . — .
Es gibt zwei Funktionsmodi des Roboters: automatisch und manuell.Im manuellen Modus arbeitet der Roboter, wenn der ML-Dienst noch nicht geschult ist. Dann wechselt der Roboter entweder auf Wunsch des Bedieners von automatisch zu manuell (ich habe beim Beobachten des Roboters merkwürdige Verhaltensweisen festgestellt) oder wenn ML-Dienste selbst eine Anomalie feststellen. Über die Erkennung von Anomalien wird später berichtet - dies ist ein sehr wichtiger Teil, ohne den es unmöglich ist, den vorgeschlagenen Ansatz anzuwenden.Die Entwicklung der Kontrolle ist wie folgt:- Die Aufgabe für den Roboter wird in lesbaren Begriffen formuliert und Leistungsindikatoren beschrieben.
- Der Bediener stellt in VR eine Verbindung zum Roboter her und führt die Aufgabe für einige Zeit innerhalb des vorhandenen Workflows aus
- Der ML-Teil wird auf die empfangenen Daten trainiert
- , ML
3D
Sehr oft verwenden Roboter die ROS-Umgebung (Robot Operating System), die in der Tat ein Framework für die Verwaltung von „Knoten“ (Knoten) ist, von denen jeder einen Teil der Funktionalität des Roboters bereitstellt. Im Allgemeinen ist dies eine relativ bequeme Methode zum Programmieren von Robotern, die in gewisser Weise der Microservice-Architektur von Webanwendungen ähnelt. Der Hauptvorteil von ROS ist der Industriestandard, und es wird bereits eine große Anzahl von Modulen benötigt, um einen Roboter zu erstellen. Sogar Industrieroboterarme können ein ROS-Schnittstellenmodul haben.Am einfachsten ist es, ein Brückenmodell zwischen unserem Serverteil und ROS zu erstellen. Zum Beispiel wie z. Jetzt verwendet unser Projekt eine weiterentwickelte Version des ROS- „Knotens“, der sich anmeldet und den Mikrodienst des Registers abfragt, mit dem ein Relay-Server ein bestimmter Roboter verbinden kann. Der Quellcode dient nur als Beispiel für Anweisungen zur Installation des ROS-Moduls. Wenn Sie dieses Framework (ROS) beherrschen, sieht zunächst alles ziemlich unfreundlich aus, aber die Dokumentation ist ziemlich gut, und nach ein paar Wochen beginnen Entwickler, seine Funktionalität recht sicher zu nutzen.Interessant - das Problem der Komprimierung des 3D-Datenstroms, der direkt auf dem Roboter erzeugt werden muss.Es ist nicht so einfach, die Tiefenkarte zu komprimieren. Selbst bei einer geringen Komprimierung des RGB-Streams ist eine sehr schwerwiegende lokale Helligkeitsverzerrung von wahr in Pixel an den Rändern oder beim Bewegen von Objekten zulässig. Das Auge merkt das fast nicht, aber sobald die gleichen Verzerrungen in der Tiefenkarte erlaubt sind, wird beim Rendern von 3D alles sehr schlecht: (aus dem Artikel )Diese Defekte an den Rändern verderben die 3D-Szene stark, weil Es liegt nur viel Müll in der Luft.Wir haben begonnen, Frame-für-Frame-Komprimierung zu verwenden - JPEG für RGB und PNG für eine Tiefenkarte mit kleinen Hacks. Diese Methode komprimiert den 30-FPS-Stream für eine 3D-Scannerauflösung von 640 x 480 bei 25 Mbit / s. Eine bessere Komprimierung kann auch bereitgestellt werden, wenn der Datenverkehr für die Anwendung kritisch ist. Es gibt kommerzielle 3D-Stream-Codecs, mit denen dieser Stream auch komprimiert werden kann.
(aus dem Artikel )Diese Defekte an den Rändern verderben die 3D-Szene stark, weil Es liegt nur viel Müll in der Luft.Wir haben begonnen, Frame-für-Frame-Komprimierung zu verwenden - JPEG für RGB und PNG für eine Tiefenkarte mit kleinen Hacks. Diese Methode komprimiert den 30-FPS-Stream für eine 3D-Scannerauflösung von 640 x 480 bei 25 Mbit / s. Eine bessere Komprimierung kann auch bereitgestellt werden, wenn der Datenverkehr für die Anwendung kritisch ist. Es gibt kommerzielle 3D-Stream-Codecs, mit denen dieser Stream auch komprimiert werden kann.Kontrolle der virtuellen Realität
Nachdem wir den Referenzrahmen der Kamera und des Roboters kalibriert haben (und bereits einen Artikel über die Kalibrierung geschrieben haben ), kann der Roboterarm in der virtuellen Realität gesteuert werden. Der Controller stellt sowohl die Position in 3D XYZ als auch die Ausrichtung ein. Für einige Roboruk sind nur 3 Koordinaten ausreichend, aber bei einer großen Anzahl von Freiheitsgraden muss auch die Ausrichtung des von der Steuerung festgelegten Werkzeugs übertragen werden. Darüber hinaus gibt es genügend Steuerungen an den Steuerungen, um Roboterbefehle auszuführen, z. B. das Ein- und Ausschalten der Pumpe, die Steuerung des Greifers und andere.Zunächst wurde beschlossen, das JavaScript-Framework für Virtual-Reality-A-Frames zu verwenden, das auf der WebVR-Engine basiert. Die ersten Ergebnisse (Videodemonstration am Ende des Artikels für den 4-Koordinaten-Arm) wurden auf dem A-Rahmen erzielt.Tatsächlich stellte sich heraus, dass WebVR (oder A-Frame) aus mehreren Gründen eine erfolglose Lösung war:- Kompatibilität hauptsächlich mit FireFox , während das A-Frame-Framework in FireFox keine Texturressourcen freigab (der Rest der Browser wurde damit fertig), bis der Speicherverbrauch 16 GB erreichte
- begrenzte Interaktion mit VR-Controllern und Helm. So war es beispielsweise nicht möglich, zusätzliche Markierungen hinzuzufügen, mit denen Sie beispielsweise die Position der Ellbogen des Bedieners festlegen können.
- Die Anwendung erforderte Multithreading oder mehrere Prozesse. In einem Thread / Prozess war es notwendig, die Videobilder zu entpacken, in einem anderen - Zeichnen. Infolgedessen wurde alles durch Arbeiter organisiert, aber die Auspackzeit erreichte 30 ms, und das Rendern in VR sollte mit einer Frequenz von 90 FPS erfolgen.
All diese Mängel führten dazu, dass das Rendern des Rahmens in den zugewiesenen 10 ms keine Zeit hatte und es in VR sehr unangenehme Zuckungen gab. Wahrscheinlich konnte alles überwunden werden, aber die Identität jedes Browsers war etwas nervig.Jetzt haben wir uns entschlossen, zum C # -, OpenTK- und C # -Port der OpenVR-Bibliothek zu wechseln. Es gibt noch eine Alternative - Einheit. Sie schreiben, dass Unity für Anfänger ist ... aber schwierig.Das Wichtigste, was gefunden und bekannt sein musste, um Freiheit zu erlangen:VRTextureBounds_t bounds = new VRTextureBounds_t() { uMin = 0, vMin = 0, uMax = 1f, vMax = 1f };
OpenVR.Compositor.Submit(EVREye.Eye_Left, ref leftTexture, ref bounds, EVRSubmitFlags.Submit_Default);
OpenVR.Compositor.Submit(EVREye.Eye_Right, ref rightTexture, ref bounds, EVRSubmitFlags.Submit_Default);
(Dies ist der Code zum Senden von zwei Texturen an das linke und rechte Auge des Helms)d.h. Zeichnen Sie OpenGL in die Textur, die verschiedene Augen sehen, und senden Sie es an eine Brille. Joy kannte keine Grenzen, als sich herausstellte, dass das linke Auge mit Rot und das rechte mit Blau gefüllt war. Nur ein paar Tage und jetzt wurde die über webSocket kommende Tiefen- und RGB-Karte in 10 ms anstelle von 30 in JS auf das polygonale Modell übertragen. Und dann fragen Sie einfach die Koordinaten und Tasten der Controller ab, geben Sie das Ereignissystem für die Tasten ein, verarbeiten Sie Benutzerklicks, geben Sie die Zustandsmaschine für die Benutzeroberfläche ein und jetzt können Sie ein Glas vom Espresso nehmen:Jetzt ist die Qualität des Realsense D435 etwas deprimierend, aber sie wird vergehen, sobald wir mindestens einen so interessanten 3D-Scanner von Microsoft installieren , dessen Punktwolke viel genauer ist.Serverseite
Relay-ServerDas Hauptfunktionselement ist das Server-Relay (Server in der Mitte), das vom Roboter einen Videostream mit 3D-Bildern und Sensorablesungen sowie dem Zustand des Roboters empfängt und unter den Verbrauchern verteilt. Eingabedaten - gepackte Frames und Sensorwerte über TCP / IP. Die Verteilung an Verbraucher erfolgt über Web-Sockets (ein sehr praktischer Mechanismus für das Streaming an mehrere Verbraucher, einschließlich eines Browsers).Darüber hinaus speichert der Staging-Server den Datenstrom im S3-Cloud-Speicher, damit er später für Schulungen verwendet werden kann.Jeder Relay-Server unterstützt die http-API, mit der Sie den aktuellen Status ermitteln können. Dies ist praktisch, um aktuelle Verbindungen zu überwachen.Die Weiterleitungsaufgabe ist sowohl aus rechnerischer als auch aus verkehrstechnischer Sicht recht schwierig. Daher folgten wir hier der Logik, dass Relay-Server auf einer Vielzahl von Cloud-Servern bereitgestellt werden. Und das bedeutet, dass Sie nachverfolgen müssen, wer wo eine Verbindung herstellt (insbesondere wenn sich Roboter und Bediener in verschiedenen Regionen befinden).RegistrierenDie zuverlässigste Version ist jetzt für jeden Roboter schwer festzulegen, mit welchen Servern er eine Verbindung herstellen kann (Redundanz schadet nicht). Der ML-Verwaltungsdienst ist dem Roboter zugeordnet. Er fragt den Relay-Server ab, um festzustellen, mit welchem der Roboter verbunden ist, und stellt eine Verbindung mit dem entsprechenden Server her, wenn er natürlich über genügend Rechte dafür verfügt. Die Anwendung des Bedieners funktioniert auf ähnliche Weise.Das angenehmste! Aufgrund der Tatsache, dass die Ausbildung von Robotern ein Dienst ist, ist der Dienst nur für uns im Inneren sichtbar. So kann sein Frontend für uns so bequem wie möglich sein! Jene. Es handelt sich um eine Konsole im Browser (es gibt eine TerminalJS- Bibliothek , die in ihrer Einfachheit sehr schön ist und sehr einfach zu ändern ist, wenn Sie zusätzliche Funktionen wie die automatische TAB-Vervollständigung oder das Abspielen des Anrufverlaufs wünschen). Sie sieht folgendermaßen aus: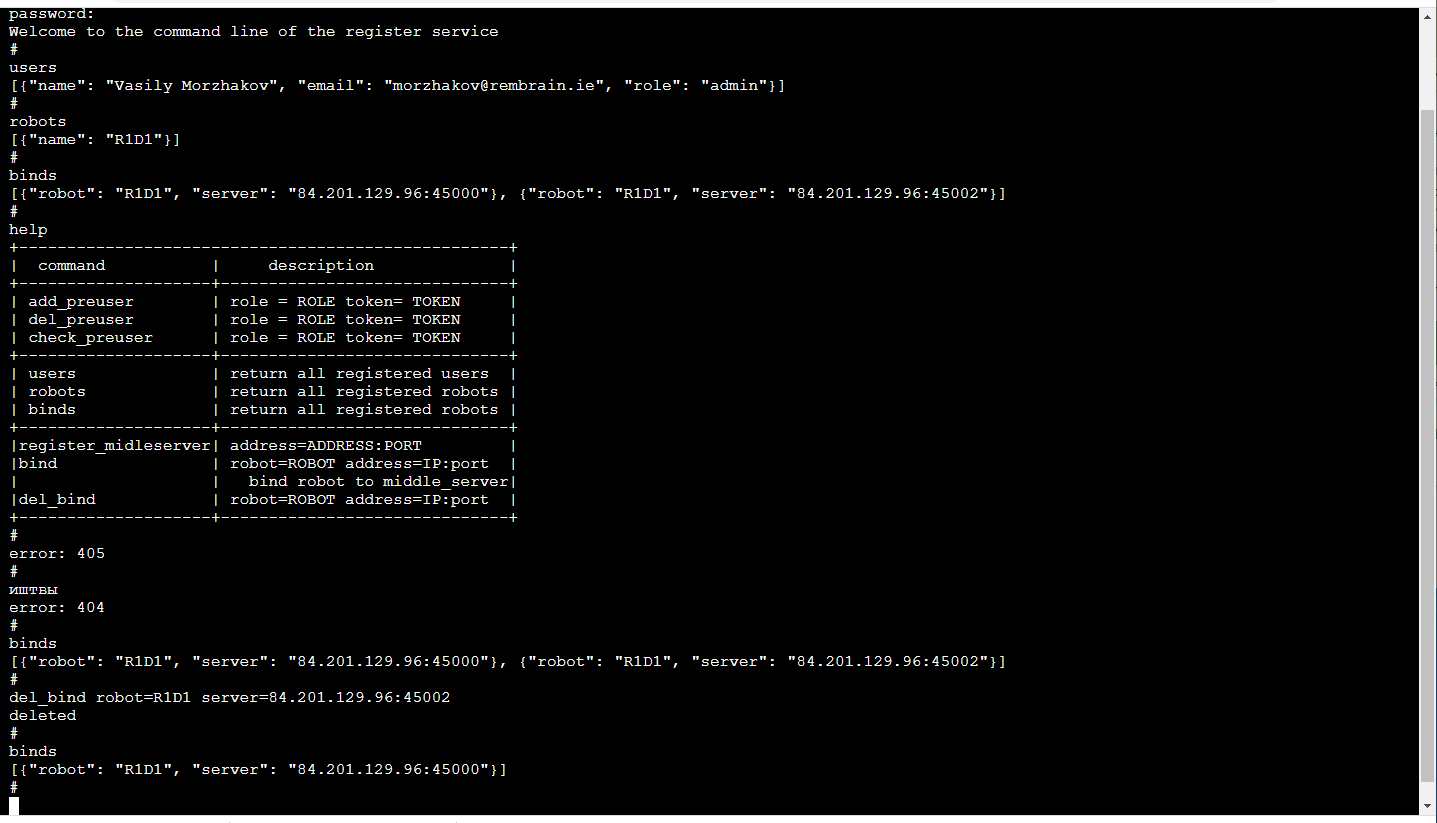 Dies ist natürlich ein separates Diskussionsthema, warum die Befehlszeile so gemütlich. Übrigens ist es besonders praktisch, Unit-Tests eines solchen Frontends durchzuführen.Zusätzlich zur http-API implementiert dieser Dienst einen Mechanismus zum Registrieren von Benutzern mit temporären Token, Anmelde- / Abmeldeoperatoren, Administratoren und Robotern, Sitzungsunterstützung und Sitzungsverschlüsselungsschlüsseln für die Verkehrsverschlüsselung zwischen dem Relay-Server und dem Roboter.All dies geschieht in Python mit Flask - ein sehr enger Stapel für ML-Entwickler (d. H. Uns). Ja, außerdem ist die vorhandene CI / CD-Infrastruktur für Microservices mit Flask befreundet.
Dies ist natürlich ein separates Diskussionsthema, warum die Befehlszeile so gemütlich. Übrigens ist es besonders praktisch, Unit-Tests eines solchen Frontends durchzuführen.Zusätzlich zur http-API implementiert dieser Dienst einen Mechanismus zum Registrieren von Benutzern mit temporären Token, Anmelde- / Abmeldeoperatoren, Administratoren und Robotern, Sitzungsunterstützung und Sitzungsverschlüsselungsschlüsseln für die Verkehrsverschlüsselung zwischen dem Relay-Server und dem Roboter.All dies geschieht in Python mit Flask - ein sehr enger Stapel für ML-Entwickler (d. H. Uns). Ja, außerdem ist die vorhandene CI / CD-Infrastruktur für Microservices mit Flask befreundet.Verzögerungsproblem
Wenn wir die Manipulatoren in Echtzeit steuern möchten, ist die minimale Verzögerung äußerst nützlich. Wenn die Verzögerung zu groß wird (mehr als 300 ms), ist es sehr schwierig, die Manipulatoren basierend auf dem Bild im virtuellen Helm zu steuern. In unserer Lösung beträgt die Verzögerung aufgrund der Frame-für-Frame-Komprimierung (dh ohne Pufferung) und ohne Verwendung von Standardtools wie GStreamer selbst unter Berücksichtigung des Zwischenservers etwa 150 bis 200 ms. Die Übertragungszeit über das Netzwerk von ihnen beträgt etwa 80 ms. Der Rest der Verzögerung wird durch die Realsense D435-Kamera und die begrenzte Aufnahmefrequenz verursacht.Dies ist natürlich ein Problem in voller Höhe, das im Verfolgungsmodus auftritt, wenn der Manipulator in seiner Realität in der virtuellen Realität ständig der Steuerung des Bedieners folgt. In der Art, sich zu einem bestimmten Punkt XYZ zu bewegen, verursacht die Verzögerung keine Probleme für den Bediener.ML Teil
Es gibt zwei Arten von Dienstleistungen: Management und Schulung.Der Trainingsdienst sammelt die im S3-Speicher gespeicherten Daten und beginnt mit dem erneuten Training der Modellgewichte. Am Ende des Trainings werden Gewichte an den Managementdienst gesendet.Der Verwaltungsdienst unterscheidet sich in Bezug auf Eingabe- und Ausgabedaten nicht von der Anwendung des Bedieners. Ebenso der Eingangs-RGBD-Stream (RGB + Depth), die Sensorwerte und der Roboterstatus, die Ausgangssteuerbefehle. Aufgrund dieser Identität erscheint es möglich, im Rahmen des Konzepts des „datengesteuerten Trainings“ zu trainieren.Der Zustand des Roboters (und die Sensorwerte) sind eine Schlüsselgeschichte für ML. Es definiert den Kontext. Beispielsweise verfügt ein Roboter über eine Zustandsmaschine, die für seinen Betrieb charakteristisch ist und weitgehend bestimmt, welche Art von Steuerung erforderlich ist. Diese 2 Werte werden zusammen mit jedem Frame übertragen: der Betriebsmodus und der Zustandsvektor des Roboters.Und ein wenig zum Training:In der Demonstration am Ende des Artikels ging es darum , ein Objekt (einen Kinderwürfel) in einer 3D-Szene zu finden. Dies ist eine grundlegende Aufgabe für Bestückungsanwendungen.Das Training basierte auf einem Paar von Vorher-Nachher-Bildern und der Zielbezeichnung, die mit manueller Steuerung erhalten wurden: Aufgrund des Vorhandenseins von zwei Tiefenkarten war es einfach, die Maske des im Bild bewegten Objekts zu berechnen:
Aufgrund des Vorhandenseins von zwei Tiefenkarten war es einfach, die Maske des im Bild bewegten Objekts zu berechnen: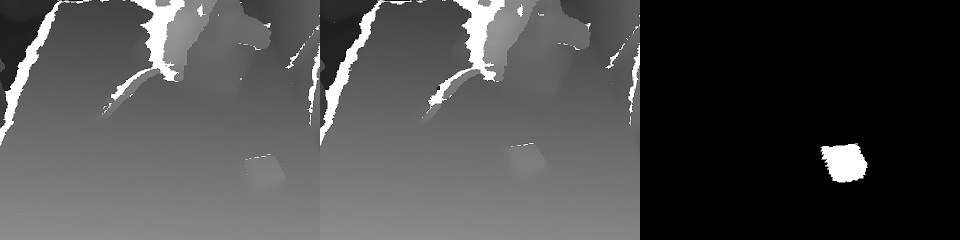 Außerdem werden xyz auf die Kameraebene projiziert und Sie können die Nachbarschaft des erfassten Objekts auswählen:
Außerdem werden xyz auf die Kameraebene projiziert und Sie können die Nachbarschaft des erfassten Objekts auswählen: Eigentlich mit dieser Nachbarschaft und wird funktionieren.Zuerst erhalten wir XY durch Training. Unet ein Faltungsnetzwerk für die Würfelsegmentierung.Dann müssen wir die Tiefe bestimmen und verstehen, ob das Bild vor uns abnormal ist. Dies erfolgt mit einem Auto-Encoder in RGB und einem bedingten Auto-Encoder in der Tiefe.Modellarchitektur für das Training von Auto-Encodern:
Eigentlich mit dieser Nachbarschaft und wird funktionieren.Zuerst erhalten wir XY durch Training. Unet ein Faltungsnetzwerk für die Würfelsegmentierung.Dann müssen wir die Tiefe bestimmen und verstehen, ob das Bild vor uns abnormal ist. Dies erfolgt mit einem Auto-Encoder in RGB und einem bedingten Auto-Encoder in der Tiefe.Modellarchitektur für das Training von Auto-Encodern: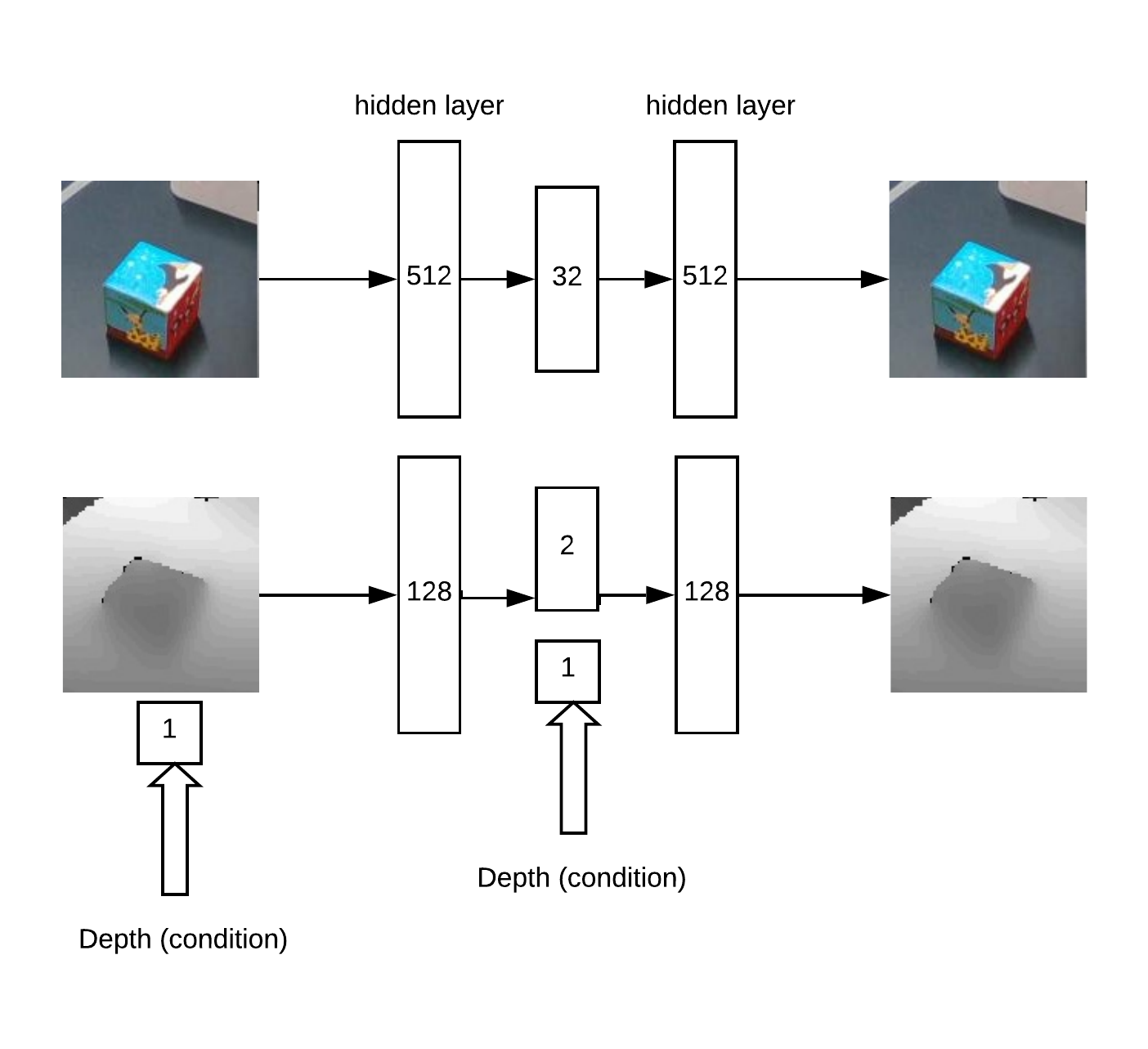 Die Logik der Arbeit:
Die Logik der Arbeit:- Suchen Sie auf der „Wärmekarte“ nach einem Maximum (bestimmen Sie die Winkelkoordinaten u = x / zv = y / z des Objekts), das den Schwellenwert überschreitet
- Dann rekonstruiert der Auto-Encoder die Nachbarschaft des gefundenen Punktes für alle Hypothesen in der Tiefe (mit einem gegebenen Schritt von min_depth bis max_depth) und wählt die Tiefe aus, bei der die Diskrepanz zwischen Rekonstruktion und Eingabe minimal ist
- Mit den Winkelkoordinaten u, v und der Tiefe können Sie die Koordinaten x, y, z erhalten
Ein Beispiel für die Auto-Encoder-Rekonstruktion einer Karte von Würfeltiefen mit einer korrekt definierten Tiefe: Zum Teil basiert die Idee einer Tiefensuchmethode auf einem Artikel über Sätze von Auto-Encodern .Dieser Ansatz eignet sich gut für Objekte mit verschiedenen Formen.Im Allgemeinen gibt es jedoch viele verschiedene Ansätze, um ein XYZ-Objekt aus einem RGBD-Bild zu finden. Natürlich ist es in der Praxis und bei einer großen Datenmenge erforderlich, die genaueste Methode zu wählen.Es gab auch die Aufgabe, Anomalien zu erkennen. Dazu benötigen wir ein Segmentierungs-Faltungsnetzwerk, um aus den verfügbaren Masken zu lernen. Anhand dieser Maske können Sie dann die Genauigkeit der Auto-Encoder-Rekonstruktion in der Tiefenkarte und im RGB bewerten. Aufgrund dieser Diskrepanz kann man über das Vorhandensein einer Anomalie entscheiden.Aufgrund dieser Methode ist es möglich, das Auftreten von zuvor nicht sichtbaren Objekten im Rahmen zu erkennen, die dennoch vom primären Suchalgorithmus erkannt werden.
Zum Teil basiert die Idee einer Tiefensuchmethode auf einem Artikel über Sätze von Auto-Encodern .Dieser Ansatz eignet sich gut für Objekte mit verschiedenen Formen.Im Allgemeinen gibt es jedoch viele verschiedene Ansätze, um ein XYZ-Objekt aus einem RGBD-Bild zu finden. Natürlich ist es in der Praxis und bei einer großen Datenmenge erforderlich, die genaueste Methode zu wählen.Es gab auch die Aufgabe, Anomalien zu erkennen. Dazu benötigen wir ein Segmentierungs-Faltungsnetzwerk, um aus den verfügbaren Masken zu lernen. Anhand dieser Maske können Sie dann die Genauigkeit der Auto-Encoder-Rekonstruktion in der Tiefenkarte und im RGB bewerten. Aufgrund dieser Diskrepanz kann man über das Vorhandensein einer Anomalie entscheiden.Aufgrund dieser Methode ist es möglich, das Auftreten von zuvor nicht sichtbaren Objekten im Rahmen zu erkennen, die dennoch vom primären Suchalgorithmus erkannt werden.Demonstration
Das Überprüfen und Debuggen der gesamten erstellten Softwareplattform wurde am Stand durchgeführt:- 3D-Kamera Realsense D435
- 4 koordinieren Dobot Magier
- VR Helm HTC Vive
- Server in der Yandex Cloud (reduziert die Latenz im Vergleich zur AWS Cloud)
In dem Video lernen wir, wie man einen Würfel in einer 3D-Szene findet, indem man eine Aufgabe in VR Pick & Place ausführt. Etwa 50 Beispiele reichten für das Training auf einem Würfel. Dann ändert sich das Objekt und es werden ungefähr 30 weitere Beispiele gezeigt. Nach der Umschulung kann der Roboter ein neues Objekt finden.Der gesamte Vorgang dauerte ungefähr 15 Minuten, von denen ungefähr die Hälfte das Gewicht des Modells trainierte.Und in diesem Video steuert YuMi in VR. Um zu lernen, wie Objekte bearbeitet werden, müssen Sie die Ausrichtung und Position des Werkzeugs bewerten. Die Mathematik basiert auf einem ähnlichen Prinzip, befindet sich jedoch derzeit in der Test- und Entwicklungsphase.Fazit
Big Data und Deep Learning sind nicht alles.Wir ändern den Lernansatz und bewegen uns dahin, wie Menschen neue Dinge lernen - indem wir wiederholen, was sie sehen.Der mathematische Apparat „unter der Haube“, den wir für reale Anwendungen entwickeln werden, zielt auf das Problem der kontextsensitiven Interpretation und Kontrolle ab. Der Kontext hier sind natürliche Informationen, die von Robotersensoren verfügbar sind, oder externe Informationen über den aktuellen Prozess.Und je mehr technologische Prozesse wir beherrschen, desto mehr wird die Struktur des „Gehirns in den Wolken“ entwickelt und seine Einzelteile trainiert.Stärken dieses Ansatzes:- die Möglichkeit zu lernen, wie man variable Objekte manipuliert
- Lernen in einer sich ändernden Umgebung (z. B. mobile Roboter)
- schlecht strukturierte Aufgaben
- kurze Markteinführungszeit; Sie können das Ziel auch im manuellen Modus mit den Operatoren ausführen
Verjährung:- Bedarf an zuverlässigem und gutem Internet
- Zusätzliche Methoden sind erforderlich, um eine hohe Genauigkeit zu erzielen, z. B. Kameras im Manipulator selbst
Wir arbeiten derzeit daran, unseren Ansatz auf die Standard-Bestückungsaufgabe verschiedener Objekte anzuwenden. Aber es scheint uns (natürlich!), Dass er zu mehr fähig ist. Irgendwelche Ideen, wo Sie sich sonst noch versuchen können?Vielen Dank für Ihre Aufmerksamkeit!