HighLoad ++, Mikhail Makurov, Maxim Chernetsov (Intersvyaz): Zabbix, 100 kNVPS auf einem Server
Die nächste HighLoad ++ - Konferenz findet am 6. und 7. April 2020 in St. Petersburg statt. Details und Tickets hier . HighLoad ++ Moskau 2018. Moskauer Halle. 9. November, 15 Uhr Abstracts und Präsentation . * Überwachung - Online und Analyse.* Die Hauptbeschränkungen der ZABBIX-Plattform.* Lösung zur Skalierung des Analytics-Speichers.* ZABBIX-Serveroptimierung.* UI-Optimierung.* Erfahrung im Betrieb des Systems mit Lasten von mehr als 40.000 NVPS.* Kurz Schlussfolgerungen.Mikhail Makurov (im Folgenden - MM): - Hallo allerseits!Maxim Chernetsov (im Folgenden - MCH): - Guten Tag!MM: - Lassen Sie mich Maxim vorstellen. Max ist ein talentierter Ingenieur, der beste Netzwerker, den ich kenne. Maxim befasst sich mit Netzwerken und Diensten, deren Entwicklung und Betrieb.
* Überwachung - Online und Analyse.* Die Hauptbeschränkungen der ZABBIX-Plattform.* Lösung zur Skalierung des Analytics-Speichers.* ZABBIX-Serveroptimierung.* UI-Optimierung.* Erfahrung im Betrieb des Systems mit Lasten von mehr als 40.000 NVPS.* Kurz Schlussfolgerungen.Mikhail Makurov (im Folgenden - MM): - Hallo allerseits!Maxim Chernetsov (im Folgenden - MCH): - Guten Tag!MM: - Lassen Sie mich Maxim vorstellen. Max ist ein talentierter Ingenieur, der beste Netzwerker, den ich kenne. Maxim befasst sich mit Netzwerken und Diensten, deren Entwicklung und Betrieb. MCH: - Und ich würde gerne über Michael sprechen. Michael ist ein C-Entwickler. Er hat einige hoch geladene Verkehrsverarbeitungslösungen für unser Unternehmen geschrieben. Wir leben und arbeiten im Ural, in der Stadt der strengen Bauern von Tscheljabinsk, in der Firma Intersvyaz. Unser Unternehmen ist ein Anbieter von Internet- und Kabelfernsehdiensten für eine Million Menschen in 16 Städten.MM:- Und es ist erwähnenswert, dass Intersvyaz viel mehr als nur ein Anbieter ist, es ist ein IT-Unternehmen. Die meisten unserer Entscheidungen werden von unserer IT-Abteilung getroffen.A: Von Servern, die Datenverkehr verarbeiten, bis zum Call Center und zur mobilen Anwendung. In der IT-Abteilung gibt es etwa 80 Mitarbeiter mit sehr, sehr unterschiedlichen Kompetenzen.
MCH: - Und ich würde gerne über Michael sprechen. Michael ist ein C-Entwickler. Er hat einige hoch geladene Verkehrsverarbeitungslösungen für unser Unternehmen geschrieben. Wir leben und arbeiten im Ural, in der Stadt der strengen Bauern von Tscheljabinsk, in der Firma Intersvyaz. Unser Unternehmen ist ein Anbieter von Internet- und Kabelfernsehdiensten für eine Million Menschen in 16 Städten.MM:- Und es ist erwähnenswert, dass Intersvyaz viel mehr als nur ein Anbieter ist, es ist ein IT-Unternehmen. Die meisten unserer Entscheidungen werden von unserer IT-Abteilung getroffen.A: Von Servern, die Datenverkehr verarbeiten, bis zum Call Center und zur mobilen Anwendung. In der IT-Abteilung gibt es etwa 80 Mitarbeiter mit sehr, sehr unterschiedlichen Kompetenzen.Über Zabbix und seine Architektur
MCH: - Und jetzt werde ich versuchen, einen persönlichen Rekord aufzustellen und in einer Minute zu sagen, was Zabbix ist (im Folgenden "Zabbiks").Zabbix positioniert sich auf Unternehmensebene als „out of the box“ -Überwachungssystem. Es verfügt über viele lebensvereinfachende Funktionen: erweiterte Eskalationsregeln, APIs für die Integration, Gruppierung und automatische Erkennung von Hosts und Metriken. In Zabbix gibt es sogenannte Skalierungswerkzeuge - Proxys. Zabbix ist ein Open Source System.Kurz über Architektur. Wir können sagen, dass es aus drei Komponenten besteht: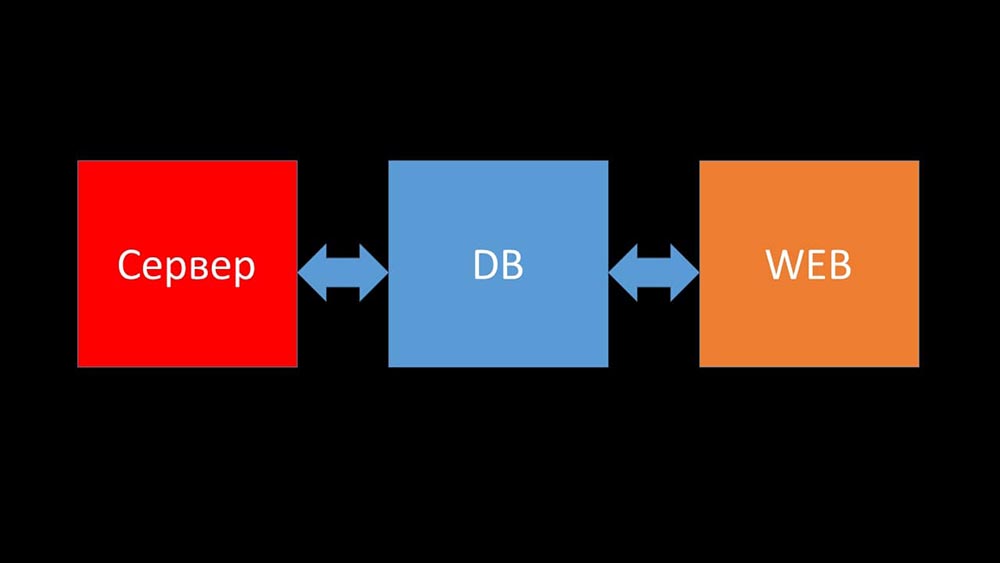
- Server. Es ist in C geschrieben. Mit ziemlich komplizierter Verarbeitung und Übertragung von Informationen zwischen Streams. Die gesamte Verarbeitung findet darin statt: vom Empfang bis zum Speichern in der Datenbank.
- Alle Daten werden in der Datenbank gespeichert. Zabbix unterstützt MySQL, PostreSQL und Oracle.
- Das Webinterface ist in PHP geschrieben. Auf den meisten Systemen wird ein Apache-Server mitgeliefert, der jedoch im nginx + php-Bundle effizienter arbeitet.
Heute möchten wir aus dem Leben unseres Unternehmens eine Geschichte über Zabbix erzählen ...Lebensgeschichte der Firma Intersvyaz. Was haben wir und was wird benötigt?
 Vor 5 oder 6 Monaten. Einmal nach der Arbeit ...MCH: - Mischa, hallo! Ich bin froh, dass ich dich erwischt habe - es gibt ein Gespräch. Wir hatten wieder Probleme mit der Überwachung. Während eines schweren Unfalls verlangsamte sich alles und es gab keine Informationen über den Status des Netzwerks. Leider wird dies nicht das erste Mal wiederholt. Ich brauche deine Hilfe. Lassen Sie unsere Überwachung unter keinen Umständen funktionieren!MM: - Aber lassen Sie uns zuerst synchronisieren. Ich habe dort seit ein paar Jahren nicht mehr gesucht. Soweit ich mich erinnere, haben wir Nagios abgelehnt und sind vor 8 Jahren zu Zabbix gewechselt. Und jetzt scheinen wir 6 leistungsstarke Server und ungefähr ein Dutzend Proxys zu haben. Verwechsle ich etwas?MCH:- Fast. 15 Server, von denen einige virtuelle Maschinen sind. Vor allem rettet uns dies nicht in dem Moment, in dem wir es am dringendsten brauchen. Wie ein Unfall - die Server werden langsamer und nichts ist sichtbar. Wir haben versucht, die Konfiguration zu optimieren, dies führt jedoch nicht zu einem optimalen Leistungsgewinn.MM: - Ich verstehe. Hast du etwas gesucht, hast du etwas aus der Diagnose herausgegraben?MCH:- Das erste, was Sie tun müssen, ist nur die Datenbank. MySQL wird so ständig geladen, dass neue Metriken erhalten bleiben. Wenn Zabbix eine Reihe von Ereignissen generiert, wird die Datenbank buchstäblich mehrere Stunden lang in sich selbst gespeichert. Ich habe Ihnen bereits von der Optimierung der Konfiguration erzählt, aber dieses Jahr haben wir die Hardware buchstäblich aktualisiert: Auf den Servern und Festplatten-Arrays von SSD RAID-ahs befinden sich mehr als hundert Gigabyte Speicher - es macht keinen Sinn, sie linear zu erweitern. Was werden wir machen?MM: - Ich verstehe. Im Allgemeinen ist MySQL eine LTP-Datenbank. Anscheinend ist es nicht mehr zum Speichern eines Archivs von Metriken unserer Größe geeignet. Lass es uns herausfinden.MCH: - Komm schon!
Vor 5 oder 6 Monaten. Einmal nach der Arbeit ...MCH: - Mischa, hallo! Ich bin froh, dass ich dich erwischt habe - es gibt ein Gespräch. Wir hatten wieder Probleme mit der Überwachung. Während eines schweren Unfalls verlangsamte sich alles und es gab keine Informationen über den Status des Netzwerks. Leider wird dies nicht das erste Mal wiederholt. Ich brauche deine Hilfe. Lassen Sie unsere Überwachung unter keinen Umständen funktionieren!MM: - Aber lassen Sie uns zuerst synchronisieren. Ich habe dort seit ein paar Jahren nicht mehr gesucht. Soweit ich mich erinnere, haben wir Nagios abgelehnt und sind vor 8 Jahren zu Zabbix gewechselt. Und jetzt scheinen wir 6 leistungsstarke Server und ungefähr ein Dutzend Proxys zu haben. Verwechsle ich etwas?MCH:- Fast. 15 Server, von denen einige virtuelle Maschinen sind. Vor allem rettet uns dies nicht in dem Moment, in dem wir es am dringendsten brauchen. Wie ein Unfall - die Server werden langsamer und nichts ist sichtbar. Wir haben versucht, die Konfiguration zu optimieren, dies führt jedoch nicht zu einem optimalen Leistungsgewinn.MM: - Ich verstehe. Hast du etwas gesucht, hast du etwas aus der Diagnose herausgegraben?MCH:- Das erste, was Sie tun müssen, ist nur die Datenbank. MySQL wird so ständig geladen, dass neue Metriken erhalten bleiben. Wenn Zabbix eine Reihe von Ereignissen generiert, wird die Datenbank buchstäblich mehrere Stunden lang in sich selbst gespeichert. Ich habe Ihnen bereits von der Optimierung der Konfiguration erzählt, aber dieses Jahr haben wir die Hardware buchstäblich aktualisiert: Auf den Servern und Festplatten-Arrays von SSD RAID-ahs befinden sich mehr als hundert Gigabyte Speicher - es macht keinen Sinn, sie linear zu erweitern. Was werden wir machen?MM: - Ich verstehe. Im Allgemeinen ist MySQL eine LTP-Datenbank. Anscheinend ist es nicht mehr zum Speichern eines Archivs von Metriken unserer Größe geeignet. Lass es uns herausfinden.MCH: - Komm schon!Integration von Zabbix und Clickhouse als Ergebnis eines Hackathons
Nach einiger Zeit erhielten wir interessante Daten: Der größte Teil des Speicherplatzes in unserer Datenbank wurde vom Archiv der Metriken belegt, und weniger als 1% wurden für Konfiguration, Vorlagen und Einstellungen verwendet. Zu diesem Zeitpunkt betreiben wir seit mehr als einem Jahr die Big-Data-Lösung auf Basis von Clickhouse. Die Bewegungsrichtung war für uns offensichtlich. Bei unserem Frühjahrs-Hackathon schrieb er die Integration von Zabbix mit Clickhouse für den Server und das Frontend. Zu diesem Zeitpunkt hatte Zabbix bereits Unterstützung für ElasticSearch, und wir haben beschlossen, diese zu vergleichen.
größte Teil des Speicherplatzes in unserer Datenbank wurde vom Archiv der Metriken belegt, und weniger als 1% wurden für Konfiguration, Vorlagen und Einstellungen verwendet. Zu diesem Zeitpunkt betreiben wir seit mehr als einem Jahr die Big-Data-Lösung auf Basis von Clickhouse. Die Bewegungsrichtung war für uns offensichtlich. Bei unserem Frühjahrs-Hackathon schrieb er die Integration von Zabbix mit Clickhouse für den Server und das Frontend. Zu diesem Zeitpunkt hatte Zabbix bereits Unterstützung für ElasticSearch, und wir haben beschlossen, diese zu vergleichen.
Vergleichen Sie Clickhouse und Elasticsearch
MM: - Zum Vergleich haben wir dieselbe Last generiert, die der Zabbix-Server bereitstellt, und uns angesehen, wie sich die Systeme verhalten würden. Wir haben Daten in Stapeln von 1000 Zeilen geschrieben und CURL verwendet. Wir haben zuvor vorgeschlagen, dass das Clickhouse für das Lastprofil von Zabbix effektiver ist. Die Ergebnisse übertrafen sogar unsere Erwartungen: Unter den gleichen Testbedingungen schrieb das Clickhouse dreimal so viele Daten. Gleichzeitig verbrauchten beide Systeme beim Lesen von Daten sehr effizient (eine kleine Menge an Ressourcen). Für „Elastix“ war jedoch bei der Aufnahme eine große Menge an Prozessor erforderlich:Insgesamt hat Clickhouse Elastix in Bezug auf Prozessorverbrauch und -geschwindigkeit deutlich übertroffen. Gleichzeitig verwendet „Clickhouse“ aufgrund der Datenkomprimierung 11-mal weniger Festplattenlaufwerke und führt etwa 30-mal weniger Festplattenvorgänge aus:
Unter den gleichen Testbedingungen schrieb das Clickhouse dreimal so viele Daten. Gleichzeitig verbrauchten beide Systeme beim Lesen von Daten sehr effizient (eine kleine Menge an Ressourcen). Für „Elastix“ war jedoch bei der Aufnahme eine große Menge an Prozessor erforderlich:Insgesamt hat Clickhouse Elastix in Bezug auf Prozessorverbrauch und -geschwindigkeit deutlich übertroffen. Gleichzeitig verwendet „Clickhouse“ aufgrund der Datenkomprimierung 11-mal weniger Festplattenlaufwerke und führt etwa 30-mal weniger Festplattenvorgänge aus: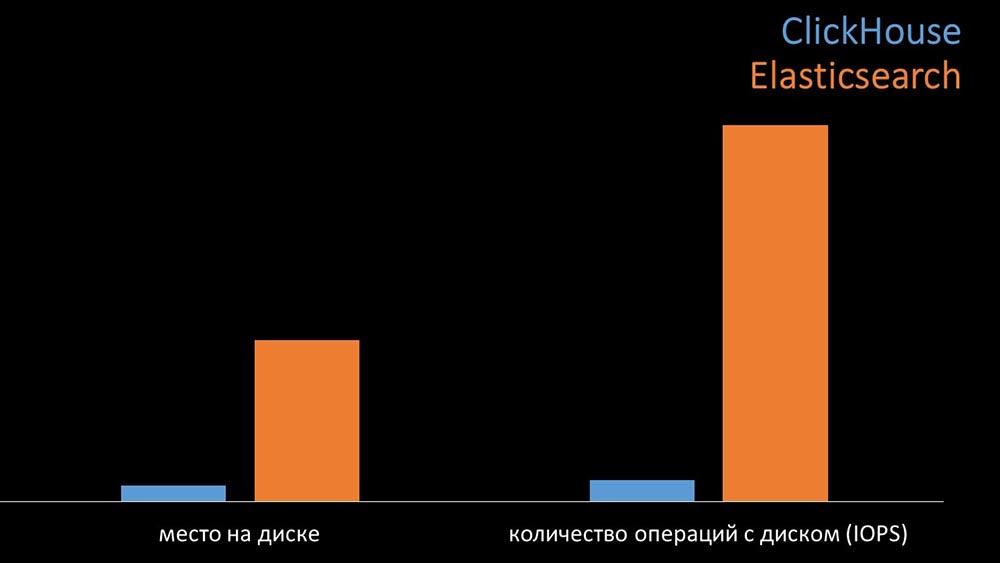 MCH: - Ja, die Arbeit mit dem Festplattensubsystem bei „Clickhouse“ ist sehr effektiv. Unter den Basen können Sie riesige SATA-Festplatten verwenden und eine Schreibgeschwindigkeit von Hunderttausenden von Zeilen pro Sekunde erreichen. Das System "out of the box" unterstützt Sharding, Replikation, es ist sehr einfach zu konfigurieren. Wir sind mehr als zufrieden mit dem Betrieb seit einem Jahr.Um die Ressourcen zu optimieren, können Sie "Clickhouse" neben der vorhandenen Hauptbasis installieren und so viel Prozessorzeit und Festplattenvorgänge sparen. Wir haben das Metrikarchiv für die vorhandenen „Clickhouse“ -Cluster herausgenommen:
MCH: - Ja, die Arbeit mit dem Festplattensubsystem bei „Clickhouse“ ist sehr effektiv. Unter den Basen können Sie riesige SATA-Festplatten verwenden und eine Schreibgeschwindigkeit von Hunderttausenden von Zeilen pro Sekunde erreichen. Das System "out of the box" unterstützt Sharding, Replikation, es ist sehr einfach zu konfigurieren. Wir sind mehr als zufrieden mit dem Betrieb seit einem Jahr.Um die Ressourcen zu optimieren, können Sie "Clickhouse" neben der vorhandenen Hauptbasis installieren und so viel Prozessorzeit und Festplattenvorgänge sparen. Wir haben das Metrikarchiv für die vorhandenen „Clickhouse“ -Cluster herausgenommen: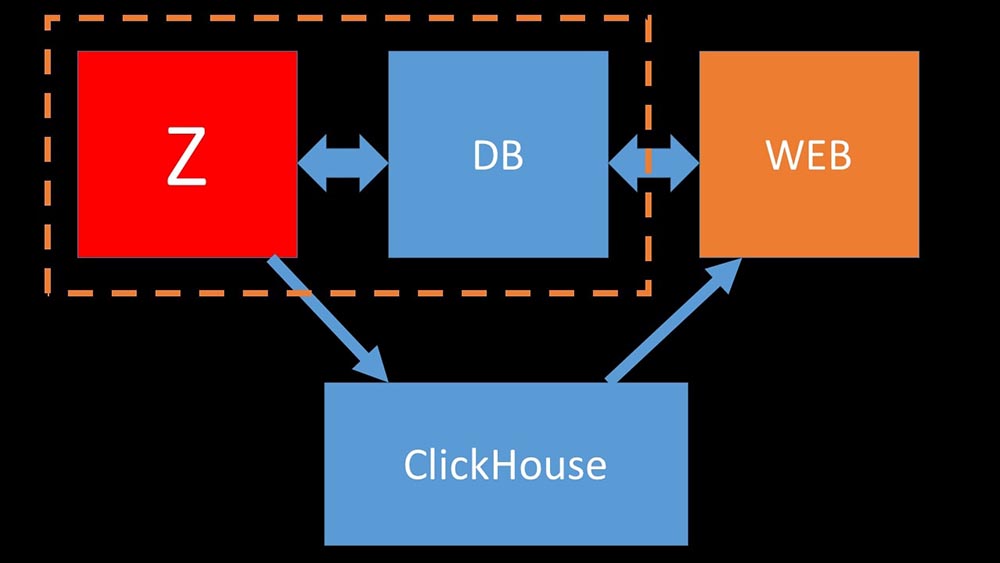 Wir haben die MySQL-Hauptdatenbank so weit entladen, dass wir sie auf demselben Computer mit dem Zabbix-Server kombinieren und den dedizierten Server für MySQL aufgeben konnten.
Wir haben die MySQL-Hauptdatenbank so weit entladen, dass wir sie auf demselben Computer mit dem Zabbix-Server kombinieren und den dedizierten Server für MySQL aufgeben konnten.Wie funktioniert das Polling in Zabbix?
Vor 4 MonatenMM: - Nun, Sie können die Probleme mit der Basis vergessen?MCH: - Das ist sicher! Ein weiteres Problem, das wir lösen müssen, ist die langsame Datenerfassung. Jetzt sind alle unsere 15 Proxys mit SNMP- und Polling-Prozessen überlastet. Und es gibt nichts anderes als das Einrichten neuer und neuer Server.MM: - Großartig. Aber sagen Sie mir zuerst, wie Polling in Zabbix funktioniert.MCH: - Kurz gesagt, es gibt 20 Arten von Metriken und ein Dutzend Möglichkeiten, diese zu erhalten. Zabbix kann Daten entweder im "Request-Response" -Modus erfassen oder neue Daten über die "Trapper-Schnittstelle" erwarten. Es ist erwähnenswert, dass diese Methode (Trapper) im ursprünglichen Zabbix die schnellste ist.Es gibt Proxys für den Lastausgleich:
Es ist erwähnenswert, dass diese Methode (Trapper) im ursprünglichen Zabbix die schnellste ist.Es gibt Proxys für den Lastausgleich: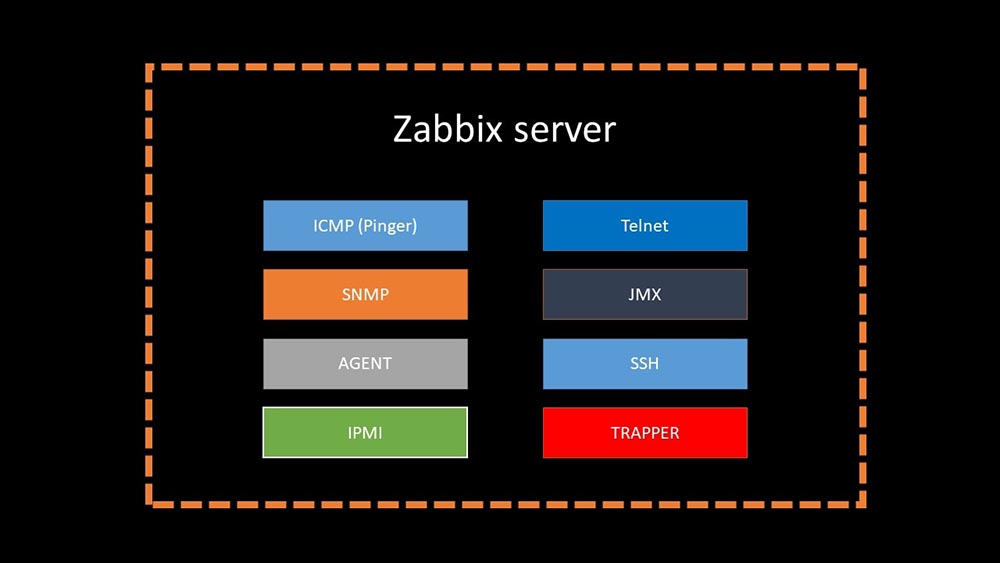 Proxies können dieselben Erfassungsfunktionen wie der Zabbix-Server ausführen, Aufgaben von ihm empfangen und erfasste Metriken über die Trapper-Schnittstelle senden. Dies ist die offiziell empfohlene Lastausgleichsmethode. Proxys sind auch nützlich für die Überwachung einer Remote-Infrastruktur, die über NAT oder einen langsamen Kanal funktioniert:
Proxies können dieselben Erfassungsfunktionen wie der Zabbix-Server ausführen, Aufgaben von ihm empfangen und erfasste Metriken über die Trapper-Schnittstelle senden. Dies ist die offiziell empfohlene Lastausgleichsmethode. Proxys sind auch nützlich für die Überwachung einer Remote-Infrastruktur, die über NAT oder einen langsamen Kanal funktioniert: MM: - Mit der Architektur ist alles klar. Wir müssen uns die Quelle ansehen ...Ein paar Tage später
MM: - Mit der Architektur ist alles klar. Wir müssen uns die Quelle ansehen ...Ein paar Tage späterGeschichte, wie nmap fping gewonnen hat
MM: - Es scheint, dass ich etwas ausgegraben habe.MCH: - Sag es mir!MM: - Ich habe festgestellt, dass Zabbix bei Verfügbarkeitsprüfungen bis zu 128 Hosts gleichzeitig überprüft. Ich habe versucht, diese Zahl auf 500 zu erhöhen, und das Intervall zwischen den Paketen in ihrem Ping (Ping) entfernt - dies hat die Leistung um den Faktor zwei erhöht. Aber ich hätte gerne große Zahlen.MCH: - In meiner Praxis muss ich manchmal die Verfügbarkeit von Tausenden von Hosts überprüfen, und ich habe nichts schnelleres als nmap gesehen. Ich bin sicher, dass dies der schnellste Weg ist. Lass es uns versuchen! Sie müssen die Anzahl der Hosts in einer Iteration erheblich erhöhen.MM: - Mehr als fünfhundert prüfen? 600?MCH: - Mindestens ein paar Tausend.MM:- Okay. Das Wichtigste, was ich sagen wollte: Ich stellte fest, dass die meisten Umfragen in Zabbix synchron durchgeführt wurden. Wir müssen es asynchron wiederholen. Dann können wir die Anzahl der von den Pollern gesammelten Metriken drastisch erhöhen, insbesondere wenn wir die Anzahl der Metriken in einer Iteration erhöhen.MCH: - Großartig! Und wann?MM: - Wie immer gestern.MCH: - Wir haben beide Versionen von fping und nmap verglichen: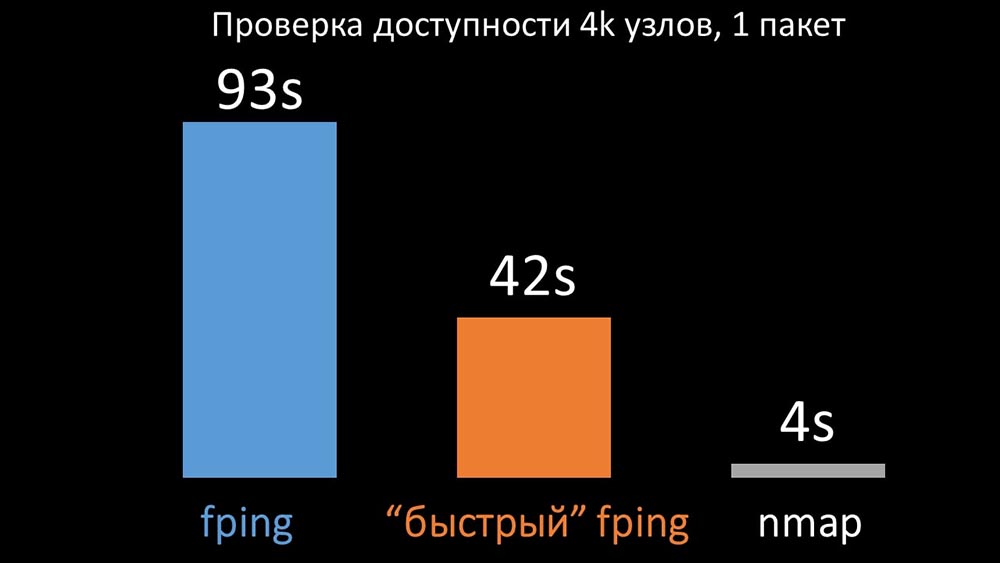 Auf einer großen Anzahl von Hosts wurde erwartet, dass nmap bis zu fünfmal effizienter ist. Da nmap nur die Verfügbarkeit und die Antwortzeit überprüft, haben wir die Verlustberechnung auf Trigger übertragen und die Intervalle für die Verfügbarkeitsprüfung erheblich reduziert. Wir haben die optimale Anzahl von Hosts für nmap im Bereich von 4.000 pro Iteration gefunden. Mit Nmap konnten wir die CPU-Kosten für Verfügbarkeitsprüfungen um das Dreifache reduzieren und das Intervall von 120 Sekunden auf 10 Sekunden verkürzen.
Auf einer großen Anzahl von Hosts wurde erwartet, dass nmap bis zu fünfmal effizienter ist. Da nmap nur die Verfügbarkeit und die Antwortzeit überprüft, haben wir die Verlustberechnung auf Trigger übertragen und die Intervalle für die Verfügbarkeitsprüfung erheblich reduziert. Wir haben die optimale Anzahl von Hosts für nmap im Bereich von 4.000 pro Iteration gefunden. Mit Nmap konnten wir die CPU-Kosten für Verfügbarkeitsprüfungen um das Dreifache reduzieren und das Intervall von 120 Sekunden auf 10 Sekunden verkürzen.Polling-Optimierung
MM: - Dann haben wir uns für Meinungsforscher entschieden. Wir waren hauptsächlich an SNMP-Entfernung und Agenten interessiert. In Zabbix wurden die Abfragen synchron durchgeführt und spezielle Maßnahmen ergriffen, um die Effizienz des Systems zu erhöhen. Im synchronen Modus führt die Nichtverfügbarkeit des Hosts zu einer erheblichen Verschlechterung der Abfrage. Es gibt ein ganzes System von Zuständen, es gibt spezielle Prozesse - die sogenannten nicht erreichbaren Poller, die nur mit unzugänglichen Hosts arbeiten: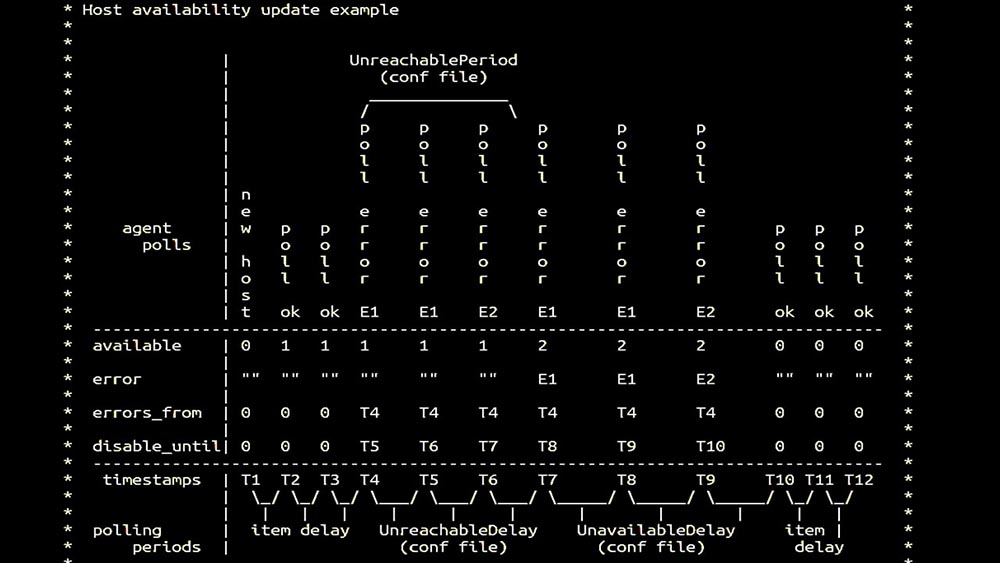 Dies ist ein Kommentar, der die Zustandsmatrix zeigt, die Komplexität des Übergangssystems, die erforderlich ist, damit das System effektiv bleibt. Darüber hinaus ist die synchrone Abfrage selbst eher langsam:
Dies ist ein Kommentar, der die Zustandsmatrix zeigt, die Komplexität des Übergangssystems, die erforderlich ist, damit das System effektiv bleibt. Darüber hinaus ist die synchrone Abfrage selbst eher langsam: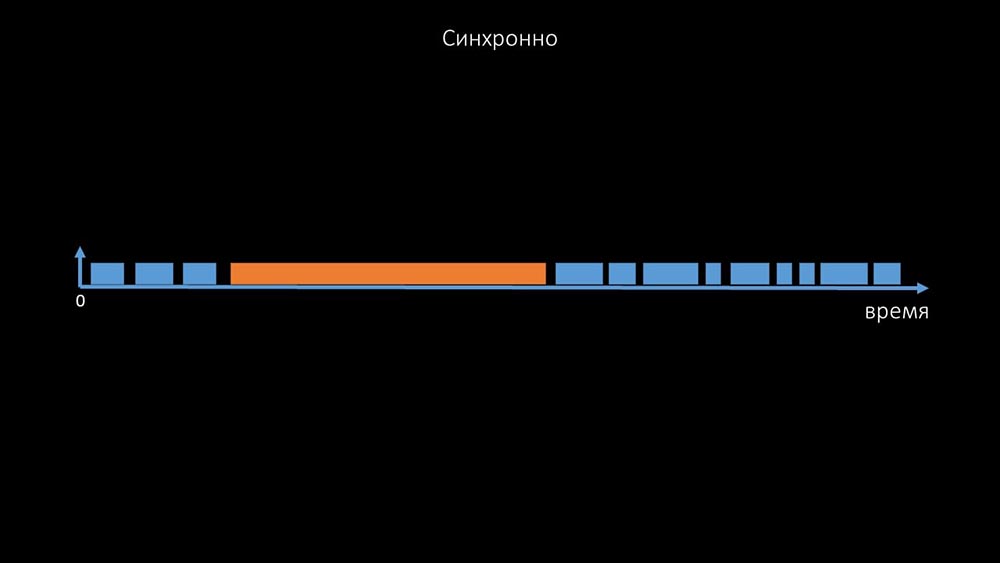 Aus diesem Grund konnten Tausende von Poller-Threads auf einem Dutzend Proxys nicht die erforderliche Datenmenge für uns erfassen. Die asynchrone Implementierung löste nicht nur die Probleme mit der Anzahl der Threads, sondern vereinfachte auch das
Aus diesem Grund konnten Tausende von Poller-Threads auf einem Dutzend Proxys nicht die erforderliche Datenmenge für uns erfassen. Die asynchrone Implementierung löste nicht nur die Probleme mit der Anzahl der Threads, sondern vereinfachte auch das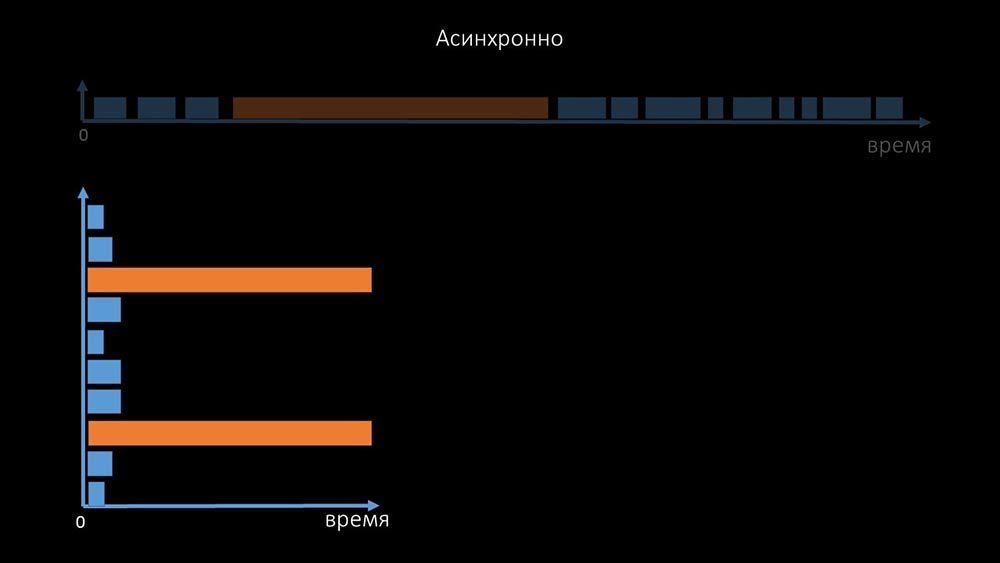 Statussystem unzugänglicher Hosts erheblich, da für jede in einer Iteration der Abfrage überprüfte Anzahl die maximale Wartezeit 1 Zeitüberschreitung betrug: Zusätzlich haben wir das Abfragesystem für SNMP- modifiziert und verbessert. Anfragen. Tatsache ist, dass die meisten nicht gleichzeitig auf mehrere SNMP-Anfragen antworten können. Aus diesem Grund haben wir einen Hybridmodus erstellt, wenn die SNMP-Abfrage desselben Hosts asynchron erfolgt:
Statussystem unzugänglicher Hosts erheblich, da für jede in einer Iteration der Abfrage überprüfte Anzahl die maximale Wartezeit 1 Zeitüberschreitung betrug: Zusätzlich haben wir das Abfragesystem für SNMP- modifiziert und verbessert. Anfragen. Tatsache ist, dass die meisten nicht gleichzeitig auf mehrere SNMP-Anfragen antworten können. Aus diesem Grund haben wir einen Hybridmodus erstellt, wenn die SNMP-Abfrage desselben Hosts asynchron erfolgt: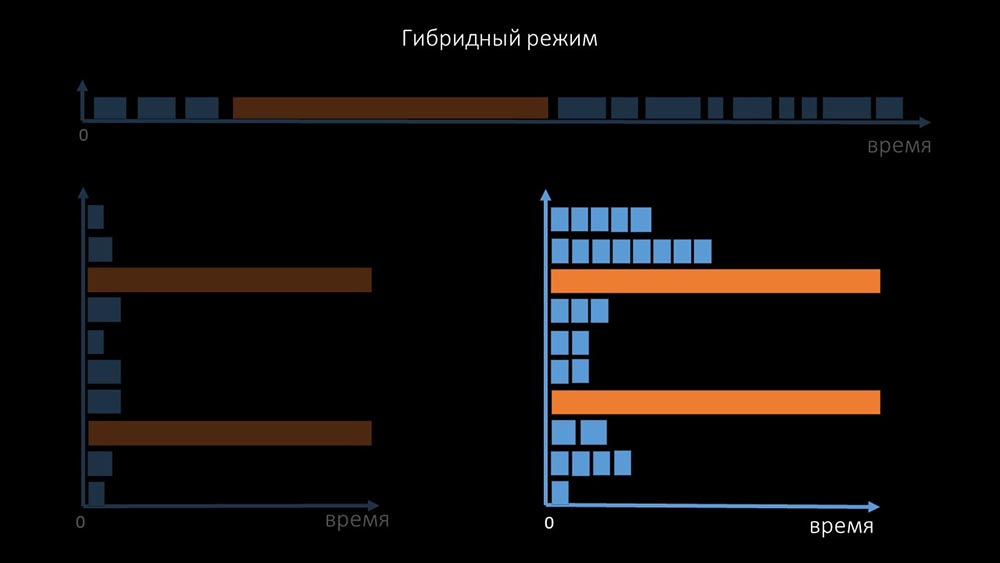 Dies erfolgt für das gesamte Host-Bundle. Dieser Modus ist am Ende nicht langsamer als vollständig asynchron, da das Abrufen von eineinhalb hundert SNMP-Werten immer noch viel schneller als eine Zeitüberschreitung ist.Unsere Experimente haben gezeigt, dass die optimale Anzahl von Anforderungen in einer Iteration bei SNMP-Abfragen etwa 8.000 beträgt. Insgesamt konnte durch den Übergang in den asynchronen Modus die Abfrageleistung um das 200-fache, mehrere hundertfache beschleunigt werden.MCH: - Die erhaltenen Abfrageoptimierungen haben gezeigt, dass wir nicht nur alle Proxys entfernen, sondern auch die Intervalle für viele Überprüfungen verkürzen können und keine Proxys benötigt werden, um die Last zu teilen.Vor ungefähr drei Monaten
Dies erfolgt für das gesamte Host-Bundle. Dieser Modus ist am Ende nicht langsamer als vollständig asynchron, da das Abrufen von eineinhalb hundert SNMP-Werten immer noch viel schneller als eine Zeitüberschreitung ist.Unsere Experimente haben gezeigt, dass die optimale Anzahl von Anforderungen in einer Iteration bei SNMP-Abfragen etwa 8.000 beträgt. Insgesamt konnte durch den Übergang in den asynchronen Modus die Abfrageleistung um das 200-fache, mehrere hundertfache beschleunigt werden.MCH: - Die erhaltenen Abfrageoptimierungen haben gezeigt, dass wir nicht nur alle Proxys entfernen, sondern auch die Intervalle für viele Überprüfungen verkürzen können und keine Proxys benötigt werden, um die Last zu teilen.Vor ungefähr drei MonatenÄndern Sie die Architektur - erhöhen Sie die Last!
MM: - Nun, Max, ist es Zeit, produktiv zu sein? Ich brauche einen leistungsstarken Server und einen guten Ingenieur.MCH: - Nun, wir planen. Es ist Zeit, mit 5.000 Metriken pro Sekunde loszulegen.Morgen nach demMCH- Upgrade : - Mischa, wir haben aktualisiert, aber am Morgen zurückgesetzt ... Ratet mal, welche Geschwindigkeit Sie erreicht haben?MM: - Maximal tausend.MCH: - Ja, 25! Leider sind wir dort, wo wir angefangen haben.MM: - Und so? Haben Sie eine Diagnose erhalten?MCH: - Ja natürlich! Hier zum Beispiel ein interessantes Top: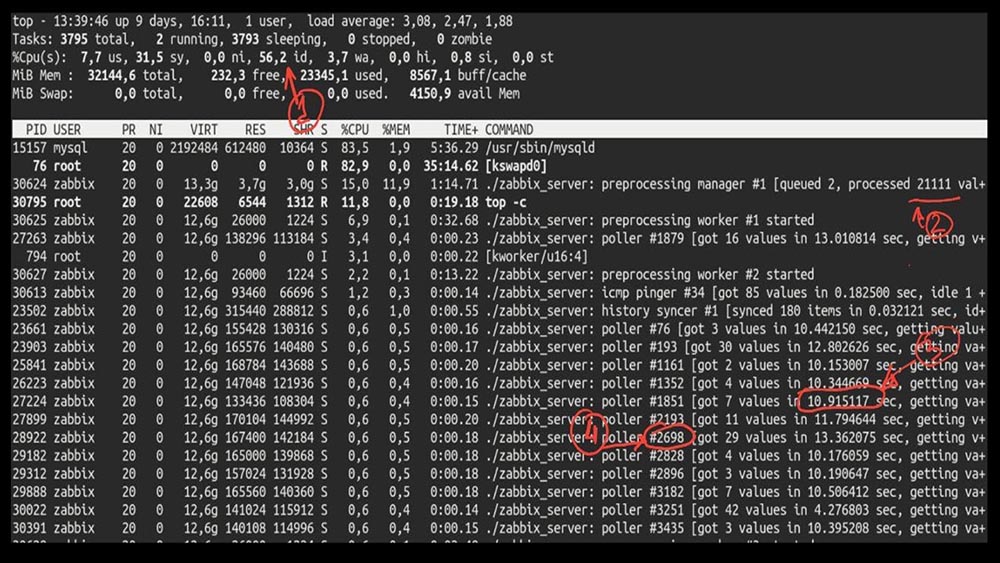 MM: - Mal sehen. Ich sehe, dass wir eine große Anzahl von Abfragethreads ausprobiert haben:
MM: - Mal sehen. Ich sehe, dass wir eine große Anzahl von Abfragethreads ausprobiert haben: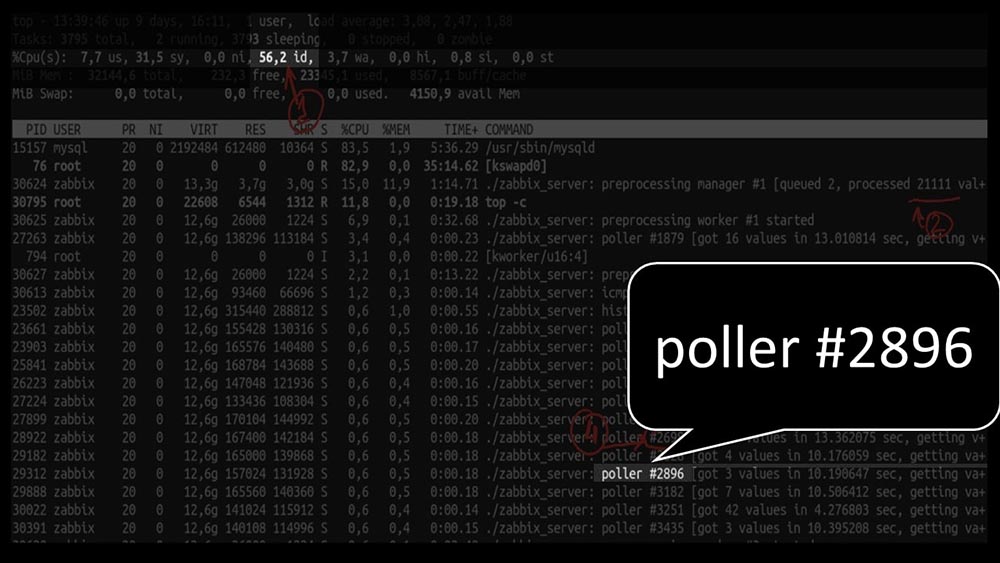 Gleichzeitig konnten wir das System nicht einmal zur Hälfte nutzen:
Gleichzeitig konnten wir das System nicht einmal zur Hälfte nutzen: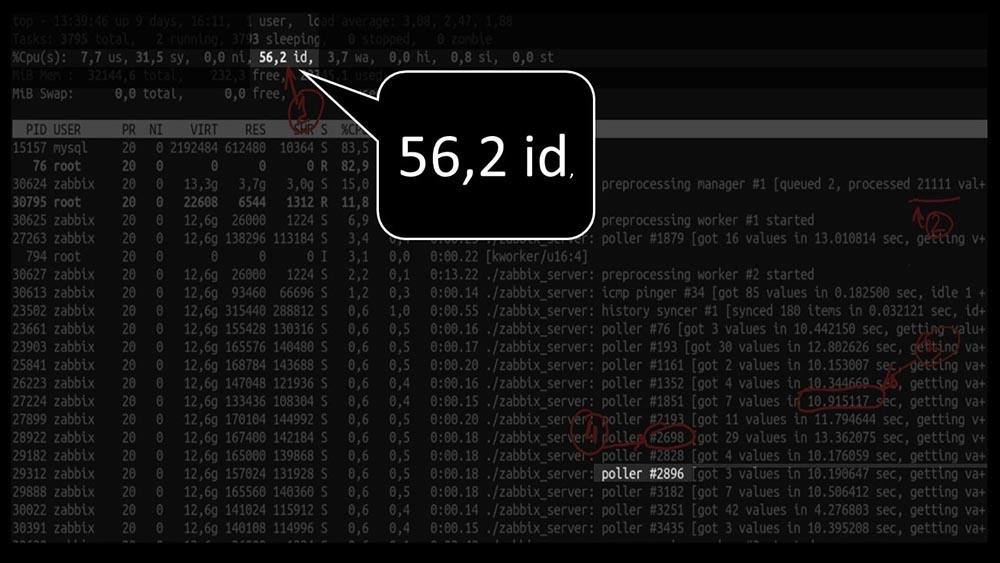 Und die Gesamtleistung ist mit etwa 4.000 Metriken pro Sekunde recht gering:
Und die Gesamtleistung ist mit etwa 4.000 Metriken pro Sekunde recht gering: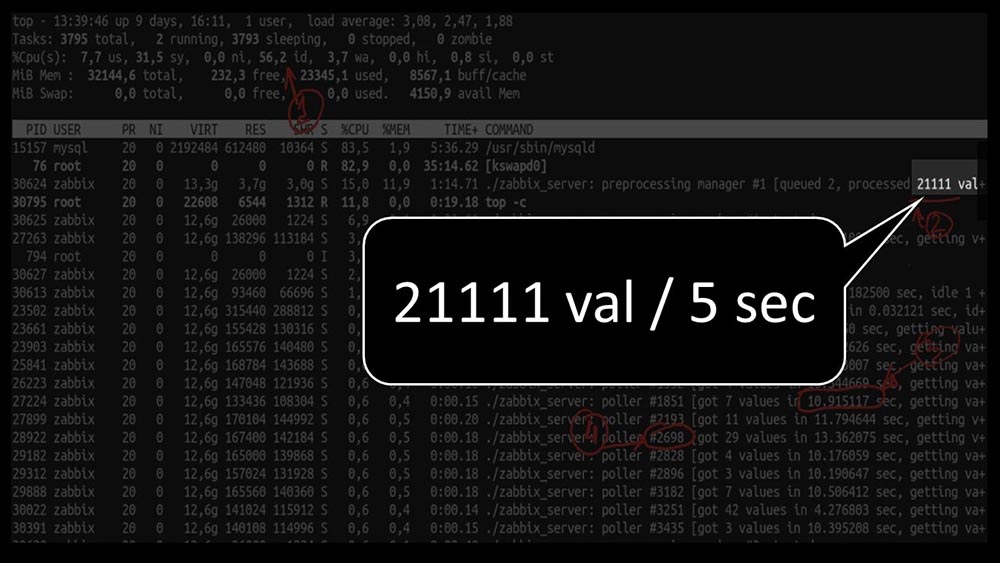 Gibt es noch etwas?MCH: - Ja, Strace eines der Poller:
Gibt es noch etwas?MCH: - Ja, Strace eines der Poller: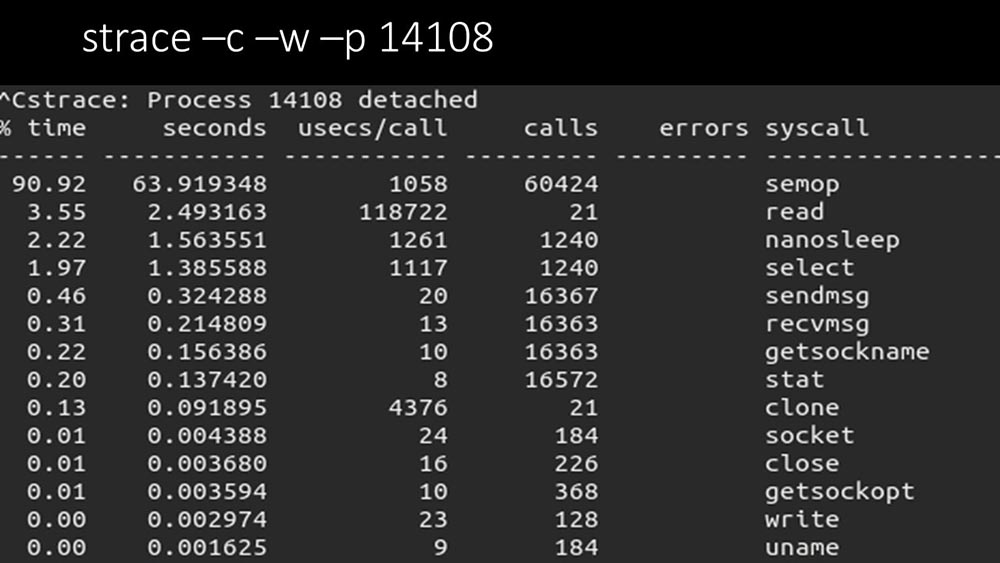 MM: - Hier ist deutlich zu sehen, dass der Polling-Prozess auf „Semaphoren“ wartet. Dies sind Sperren:
MM: - Hier ist deutlich zu sehen, dass der Polling-Prozess auf „Semaphoren“ wartet. Dies sind Sperren: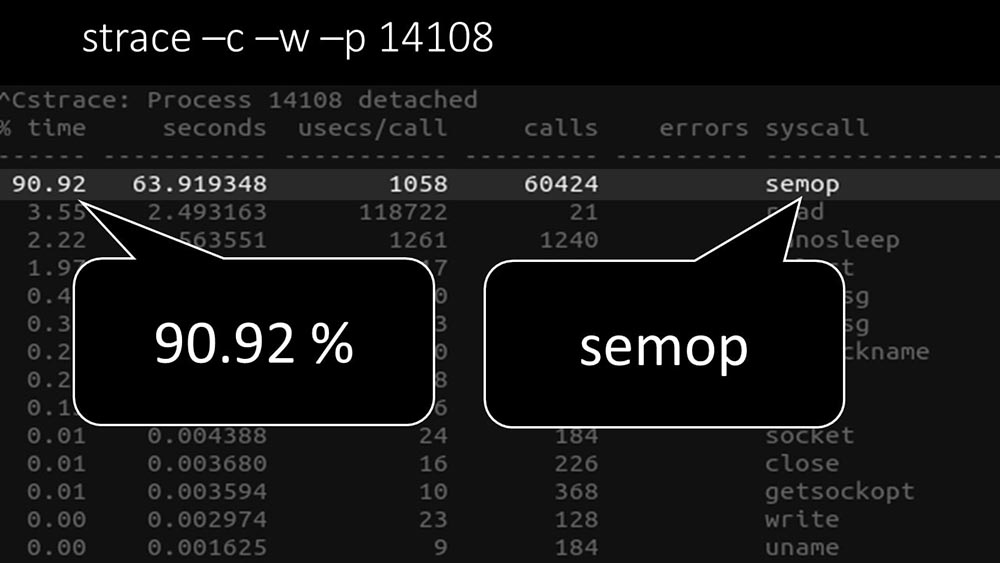 MCH: - Es ist nicht klar.MM: - Sehen Sie, dies ist wie eine Situation, in der eine Reihe von Threads versuchen, mit Ressourcen zu arbeiten, mit denen jeweils nur einer arbeiten kann. Dann können sie diese Ressource nur noch nach Zeit teilen:
MCH: - Es ist nicht klar.MM: - Sehen Sie, dies ist wie eine Situation, in der eine Reihe von Threads versuchen, mit Ressourcen zu arbeiten, mit denen jeweils nur einer arbeiten kann. Dann können sie diese Ressource nur noch nach Zeit teilen: Die Gesamtproduktivität der Arbeit mit einer solchen Ressource wird durch die Geschwindigkeit eines Kerns begrenzt: Es
Die Gesamtproduktivität der Arbeit mit einer solchen Ressource wird durch die Geschwindigkeit eines Kerns begrenzt: Es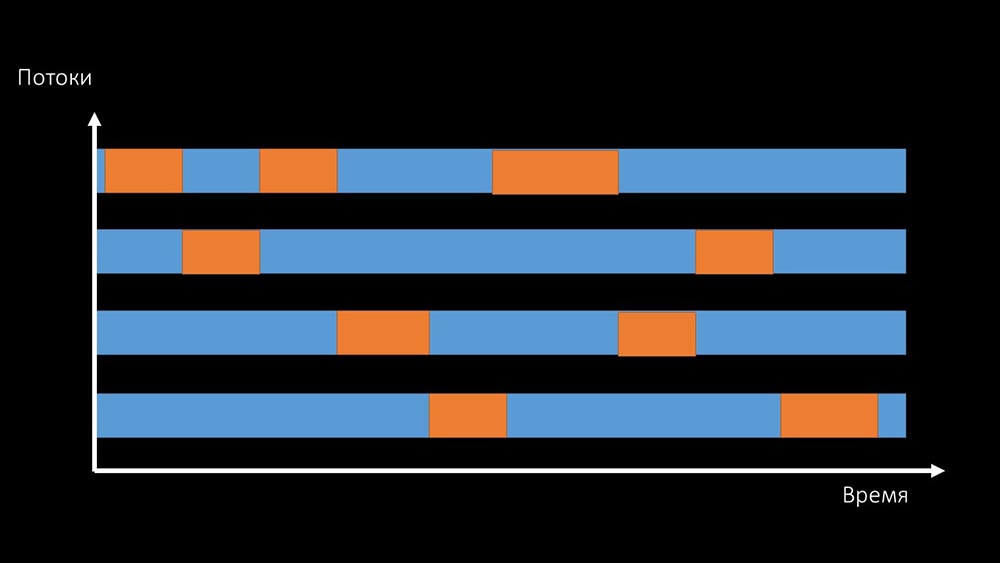 gibt zwei Möglichkeiten, dieses Problem zu lösen.Aktualisieren Sie das Maschineneisen und wechseln Sie zu schnelleren Kerneln:
gibt zwei Möglichkeiten, dieses Problem zu lösen.Aktualisieren Sie das Maschineneisen und wechseln Sie zu schnelleren Kerneln: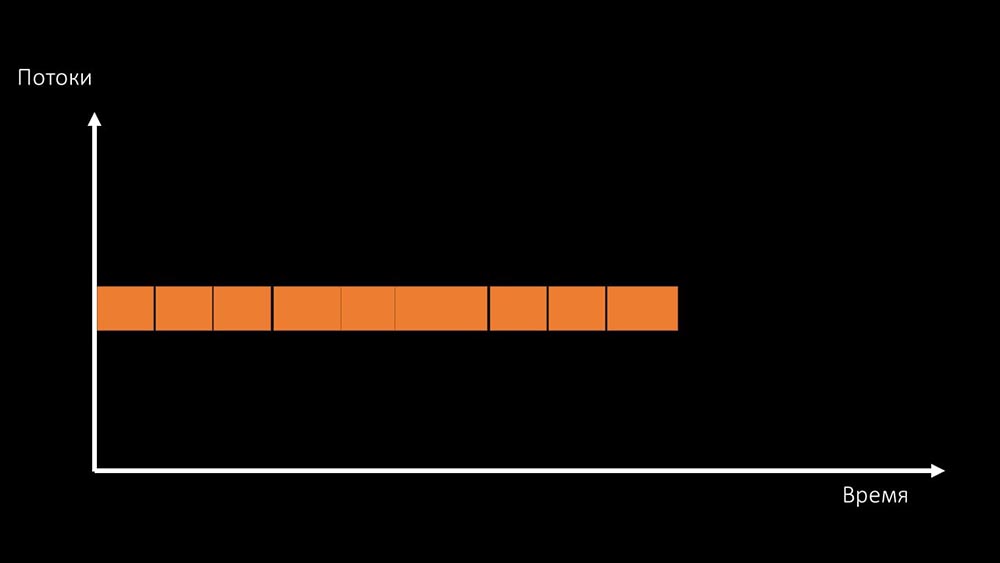 Oder ändern Sie die Architektur und gleichzeitig die Last:
Oder ändern Sie die Architektur und gleichzeitig die Last: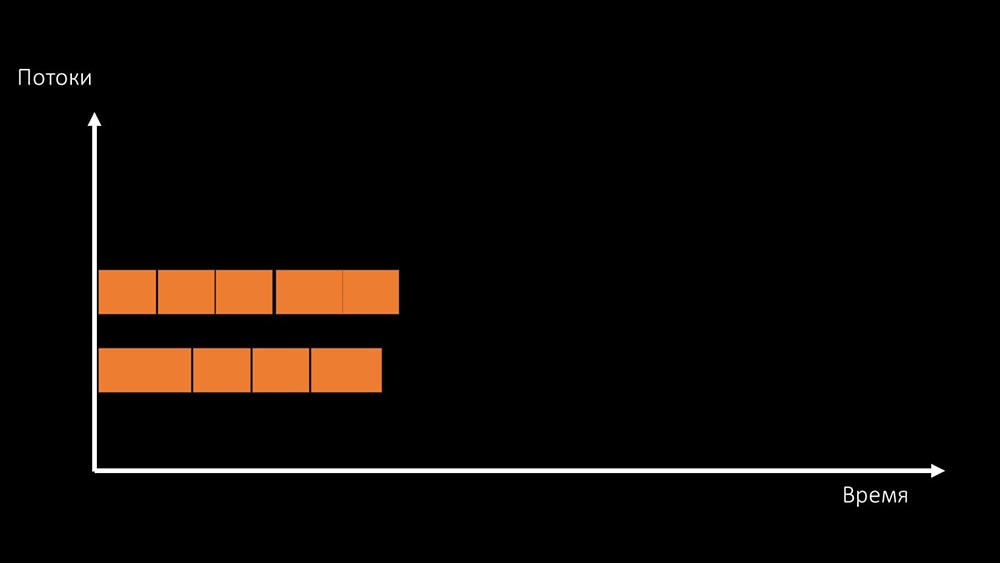 MCH: - Übrigens verwenden wir auf einer Testmaschine weniger Kerne als auf einer Kampfmaschine, aber die Frequenz pro Kern ist 1,5-mal schneller!MM: - Ist das klar? Es ist notwendig, den Servercode zu überprüfen.
MCH: - Übrigens verwenden wir auf einer Testmaschine weniger Kerne als auf einer Kampfmaschine, aber die Frequenz pro Kern ist 1,5-mal schneller!MM: - Ist das klar? Es ist notwendig, den Servercode zu überprüfen.Datenpfad in Zabbix Server
MCH: - Um zu verstehen, haben wir angefangen zu analysieren, wie die Daten innerhalb des Zabbix-Servers übertragen werden: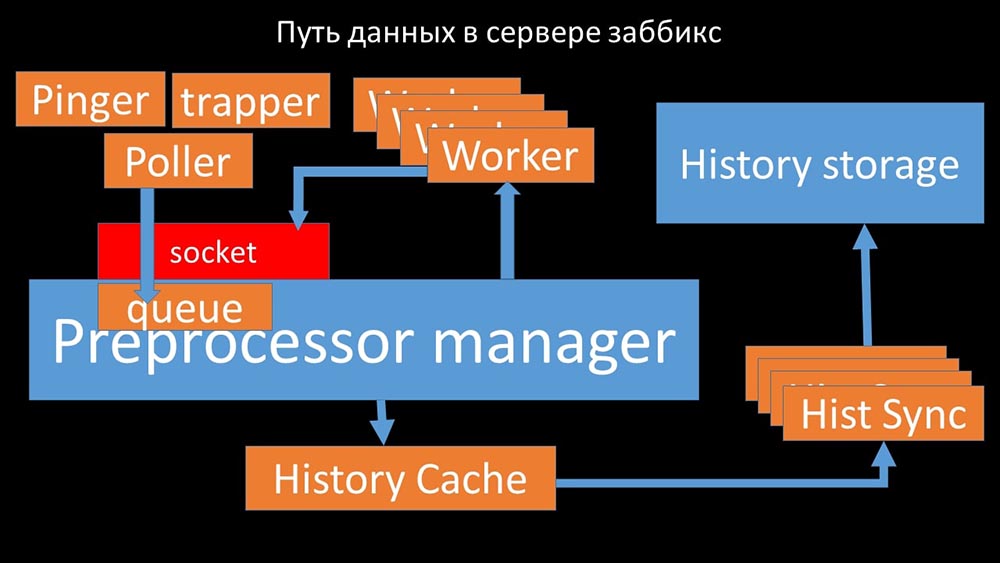 Cooles Bild, richtig? Lassen Sie uns Schritt für Schritt durchgehen, um mehr oder weniger zu klären. Es gibt Streams und Dienste, die für das Sammeln von Daten verantwortlich sind:
Cooles Bild, richtig? Lassen Sie uns Schritt für Schritt durchgehen, um mehr oder weniger zu klären. Es gibt Streams und Dienste, die für das Sammeln von Daten verantwortlich sind: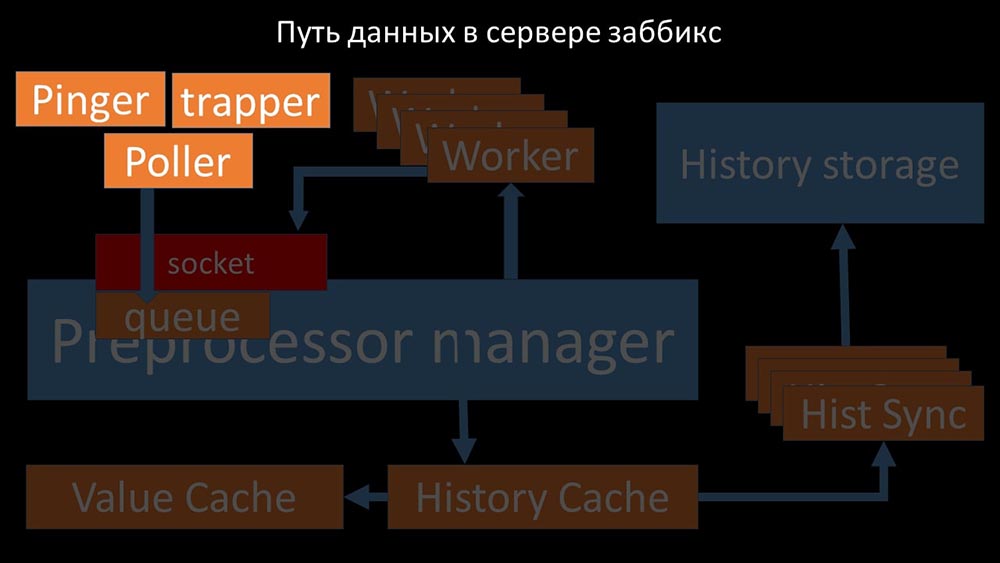 Sie übertragen die gesammelten Metriken über den Socket an den Präprozessor-Manager, wo sie in die Warteschlange gestellt werden: Der
Sie übertragen die gesammelten Metriken über den Socket an den Präprozessor-Manager, wo sie in die Warteschlange gestellt werden: Der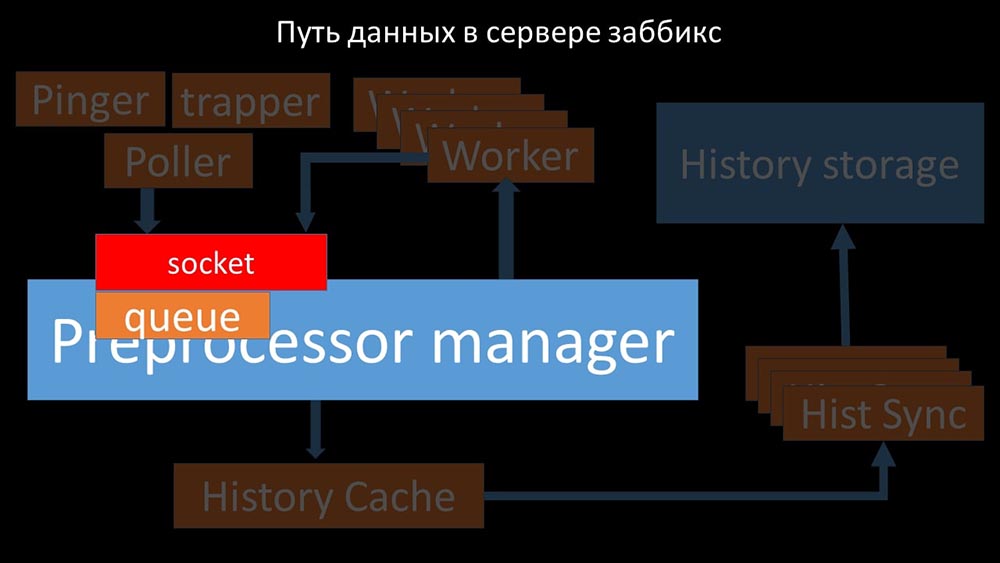 Präprozessor-Manager überträgt Daten an seine Mitarbeiter, die die Vorverarbeitungsanweisungen ausführen, und gibt sie über denselben Socket zurück:
Präprozessor-Manager überträgt Daten an seine Mitarbeiter, die die Vorverarbeitungsanweisungen ausführen, und gibt sie über denselben Socket zurück: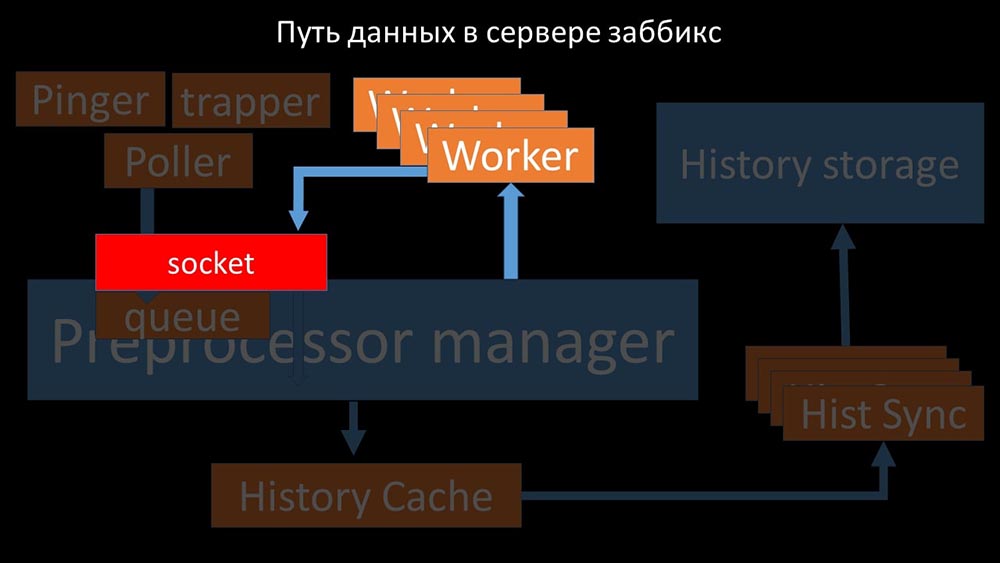 Danach den Präprozessor -manager speichert sie im Verlaufs-Cache:
Danach den Präprozessor -manager speichert sie im Verlaufs-Cache: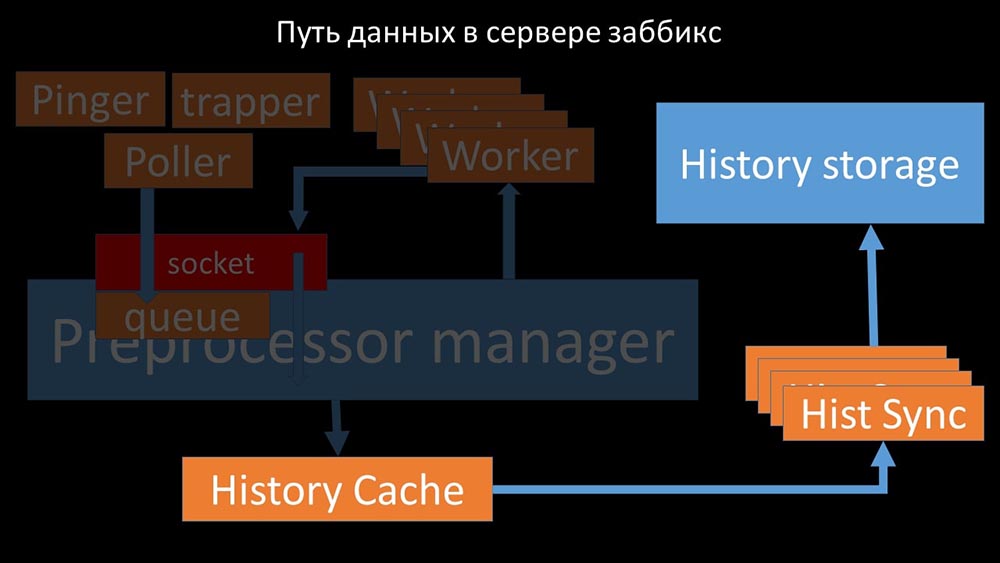 Von dort aus werden sie von Verlaufssenkern erfasst, die eine Vielzahl von Funktionen ausführen: zum Beispiel das Berechnen von Triggern, das Füllen des Wertecaches und vor allem das Speichern von Metriken im Verlaufsspeicher. Im Allgemeinen ist der Prozess komplex und sehr verwirrend.
Von dort aus werden sie von Verlaufssenkern erfasst, die eine Vielzahl von Funktionen ausführen: zum Beispiel das Berechnen von Triggern, das Füllen des Wertecaches und vor allem das Speichern von Metriken im Verlaufsspeicher. Im Allgemeinen ist der Prozess komplex und sehr verwirrend. MM: - Das erste, was wir gesehen haben, ist, dass die meisten Threads um den sogenannten "Konfigurationscache" konkurrieren (ein Speicherbereich, in dem alle Serverkonfigurationen gespeichert sind). Besonders viele Sperren werden von den für die Datenerfassung verantwortlichen Streams vorgenommen:
MM: - Das erste, was wir gesehen haben, ist, dass die meisten Threads um den sogenannten "Konfigurationscache" konkurrieren (ein Speicherbereich, in dem alle Serverkonfigurationen gespeichert sind). Besonders viele Sperren werden von den für die Datenerfassung verantwortlichen Streams vorgenommen: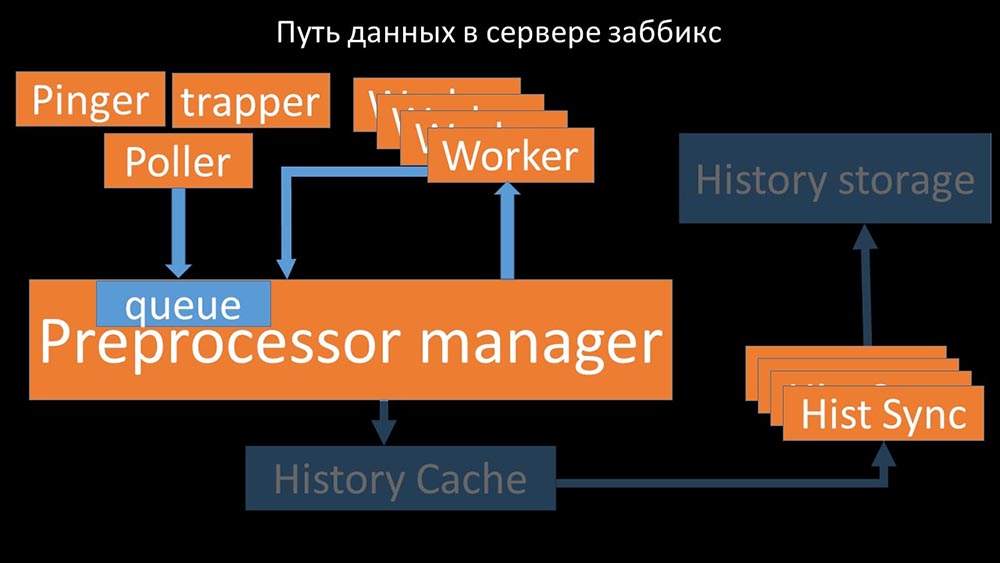 ... da in der Konfiguration nicht nur Metriken mit ihren Parametern gespeichert werden, sondern auch Warteschlangen, aus denen die Poller Informationen darüber abrufen, was als Nächstes zu tun ist. Wenn es viele Poller gibt und einer die Konfiguration blockiert, warten die anderen auf Anfragen:
... da in der Konfiguration nicht nur Metriken mit ihren Parametern gespeichert werden, sondern auch Warteschlangen, aus denen die Poller Informationen darüber abrufen, was als Nächstes zu tun ist. Wenn es viele Poller gibt und einer die Konfiguration blockiert, warten die anderen auf Anfragen:
Meinungsforscher dürfen nicht in Konflikt geraten
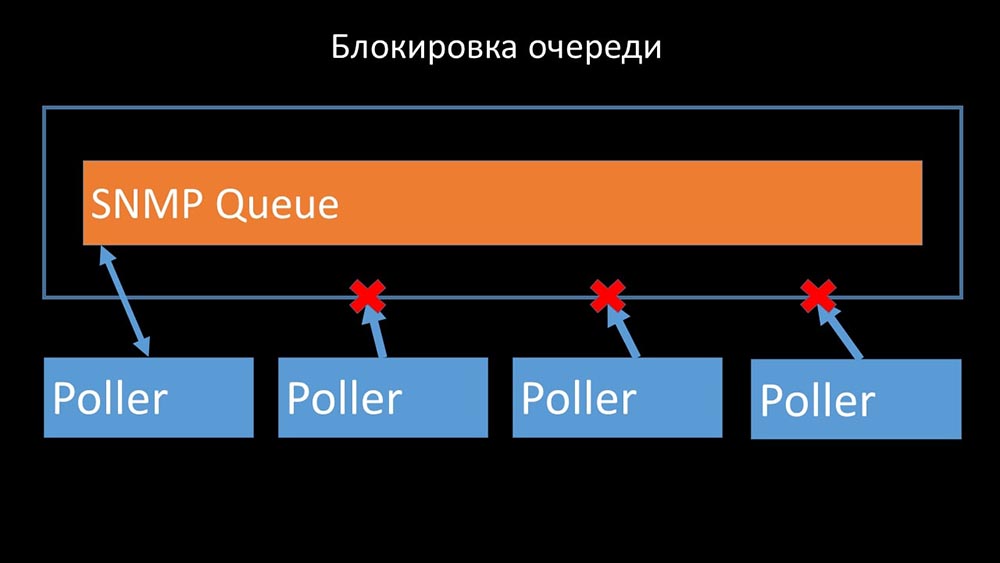 Daher haben wir als erstes die Warteschlange in vier Teile unterteilt und den Pollern ermöglicht, diese Warteschlangen gleichzeitig sicher zu blockieren:
Daher haben wir als erstes die Warteschlange in vier Teile unterteilt und den Pollern ermöglicht, diese Warteschlangen gleichzeitig sicher zu blockieren: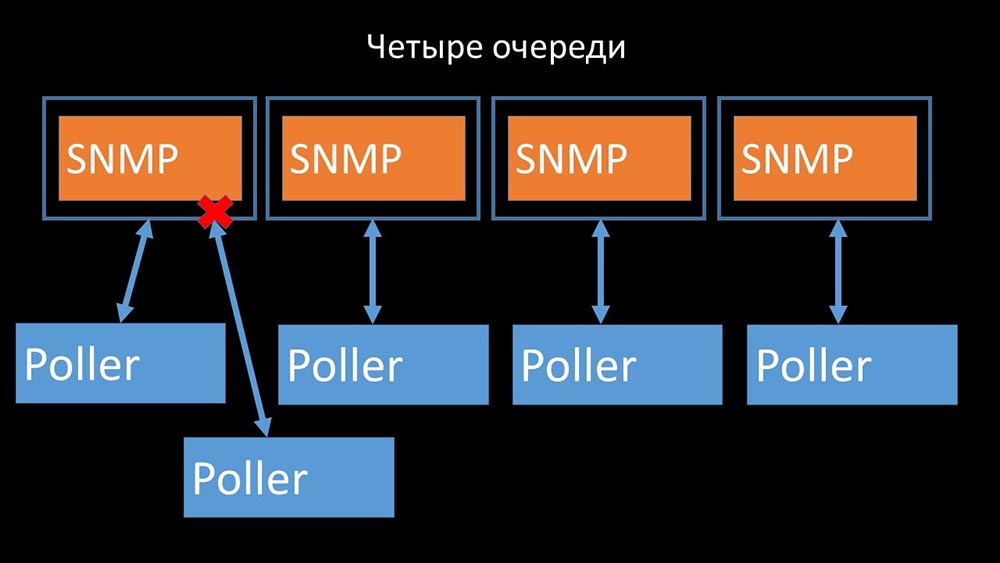 Dadurch wurde die Konkurrenz um den Konfigurationscache beseitigt und die Geschwindigkeit der Poller wurde erheblich erhöht. Aber dann wurden wir mit der Tatsache konfrontiert, dass der Präprozessor-Manager begann, eine Job-Warteschlange aufzubauen:
Dadurch wurde die Konkurrenz um den Konfigurationscache beseitigt und die Geschwindigkeit der Poller wurde erheblich erhöht. Aber dann wurden wir mit der Tatsache konfrontiert, dass der Präprozessor-Manager begann, eine Job-Warteschlange aufzubauen:
Der Präprozessor-Manager sollte Prioritäten setzen können
Dies geschah, als ihm die Produktivität fehlte. Dann konnte er nur noch Anforderungen aus den Datenerfassungsprozessen sammeln und deren Puffer hinzufügen, bis er den gesamten Speicher verbraucht und abstürzt: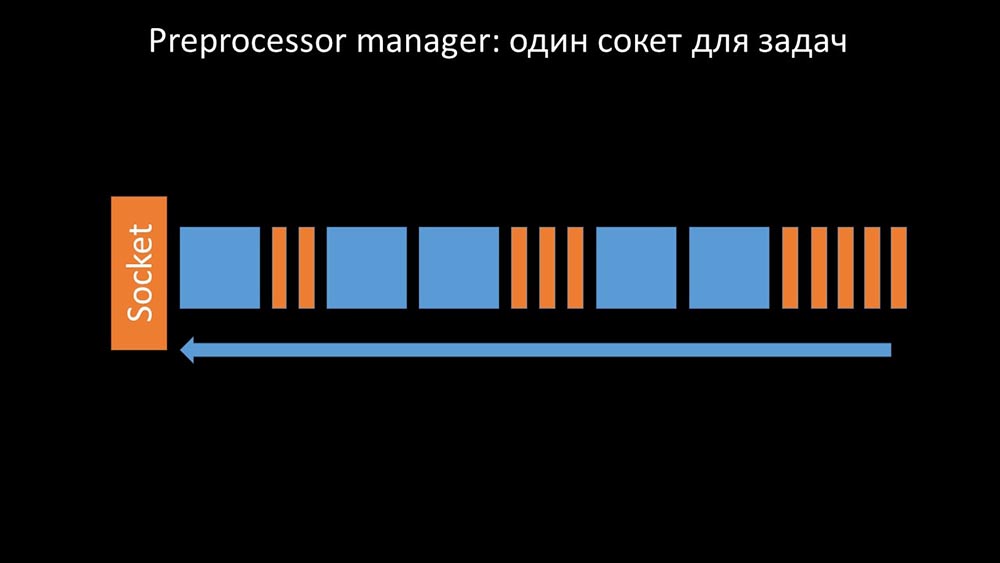 Um dieses Problem zu lösen, haben wir einen zweiten Socket hinzugefügt, der speziell für Mitarbeiter zugewiesen wurde:
Um dieses Problem zu lösen, haben wir einen zweiten Socket hinzugefügt, der speziell für Mitarbeiter zugewiesen wurde: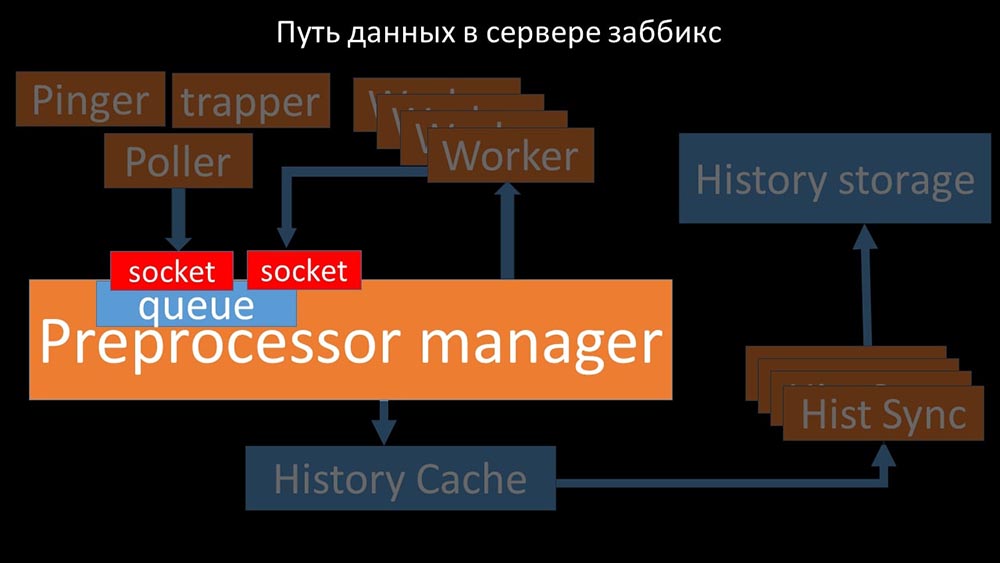 So. Der Präprozessor-Manager hatte die Möglichkeit, seine Arbeit zu priorisieren, und falls der Puffer wächst, besteht die Aufgabe darin, das Essen zu verlangsamen und den Arbeitern die Möglichkeit zu geben, diesen Puffer aufzunehmen:
So. Der Präprozessor-Manager hatte die Möglichkeit, seine Arbeit zu priorisieren, und falls der Puffer wächst, besteht die Aufgabe darin, das Essen zu verlangsamen und den Arbeitern die Möglichkeit zu geben, diesen Puffer aufzunehmen: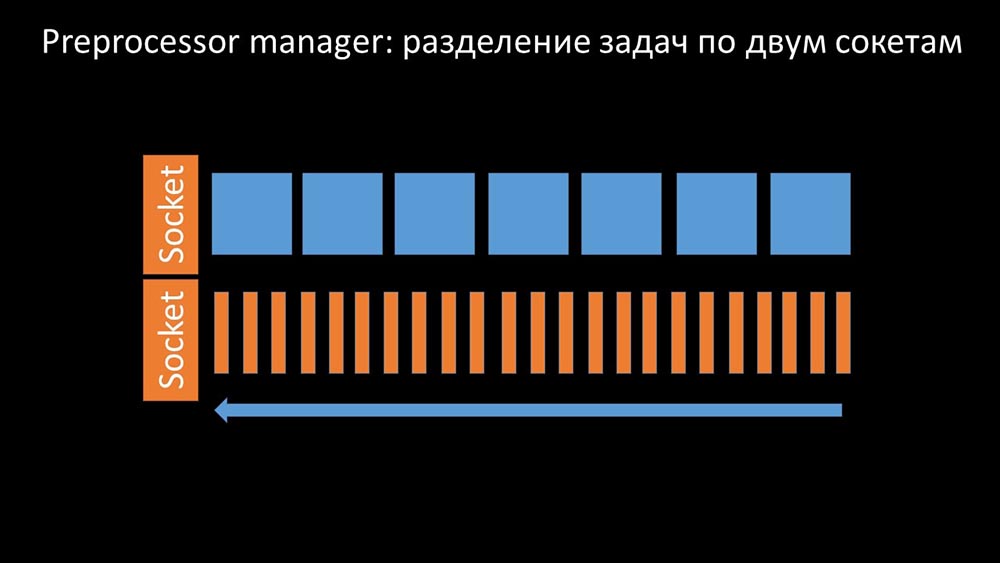 Dann stellten wir fest, dass einer der Gründe für die Verlangsamung darin bestand, dass die Arbeiter selbst im Wettbewerb standen wichtige Ressource für ihre Arbeit. Wir haben dieses Problem mit einer Fehlerbehebung registriert und in den neuen Versionen von Zabbix wurde es bereits behoben:
Dann stellten wir fest, dass einer der Gründe für die Verlangsamung darin bestand, dass die Arbeiter selbst im Wettbewerb standen wichtige Ressource für ihre Arbeit. Wir haben dieses Problem mit einer Fehlerbehebung registriert und in den neuen Versionen von Zabbix wurde es bereits behoben: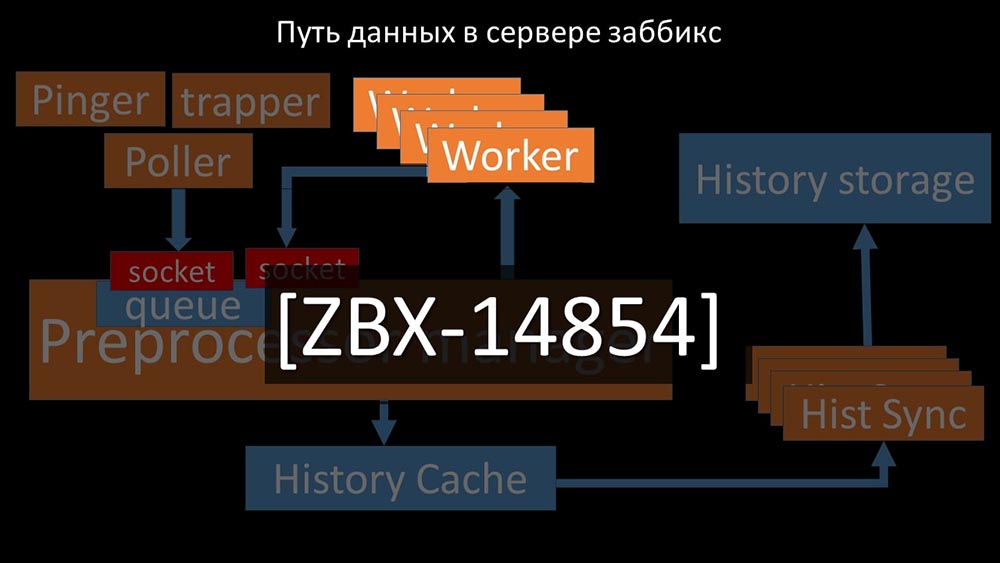
Wir erhöhen die Anzahl der Steckdosen - wir erhalten das Ergebnis
Außerdem wurde der Präprozessor-Manager selbst zu einem engen Link, da es sich um einen einzelnen Thread handelt. Es beruhte auf der Geschwindigkeit des Kerns und ergab eine maximale Geschwindigkeit von ungefähr 70.000 Metriken pro Sekunde: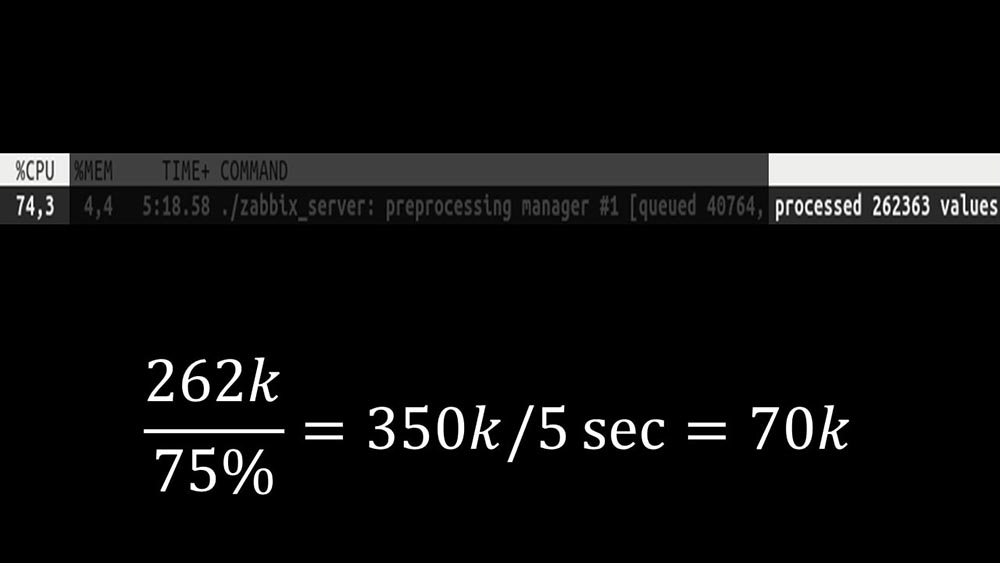 Deshalb haben wir vier mit vier Sockelsätzen als Arbeiter erstellt:
Deshalb haben wir vier mit vier Sockelsätzen als Arbeiter erstellt: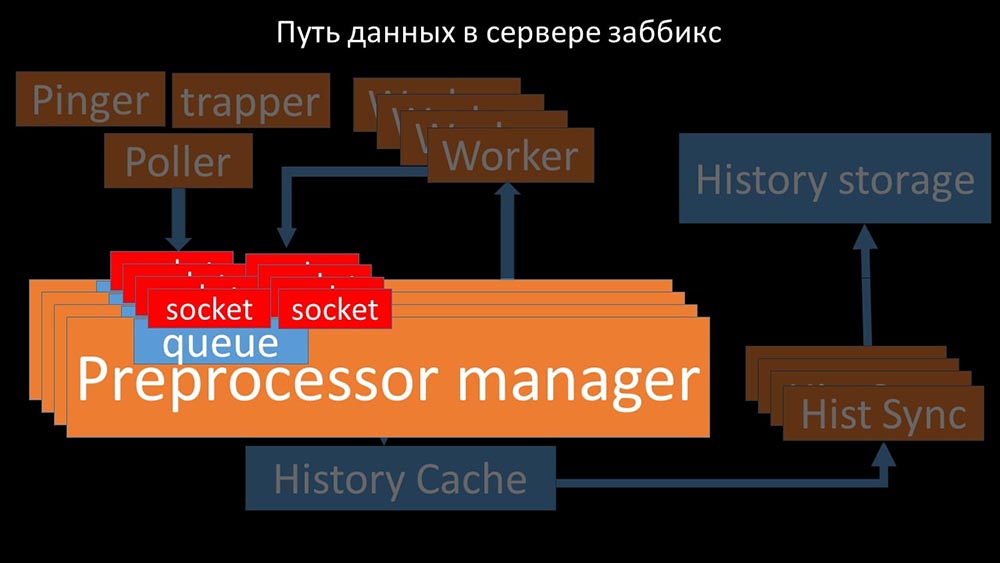 Und dies ermöglichte es uns, die Geschwindigkeit auf ungefähr 130.000 Metriken zu erhöhen: Die
Und dies ermöglichte es uns, die Geschwindigkeit auf ungefähr 130.000 Metriken zu erhöhen: Die Nichtlinearität des Wachstums erklärt sich aus der Tatsache, dass es Konkurrenz um den Cache gab Geschichten. Für ihn traten 4 Präprozessor-Manager und historische Synker an. Zu diesem Zeitpunkt haben wir auf einer Testmaschine ungefähr 130.000 Metriken pro Sekunde erhalten, die zu 95% auf dem Prozessor verwendet wurden: vor
Nichtlinearität des Wachstums erklärt sich aus der Tatsache, dass es Konkurrenz um den Cache gab Geschichten. Für ihn traten 4 Präprozessor-Manager und historische Synker an. Zu diesem Zeitpunkt haben wir auf einer Testmaschine ungefähr 130.000 Metriken pro Sekunde erhalten, die zu 95% auf dem Prozessor verwendet wurden: vor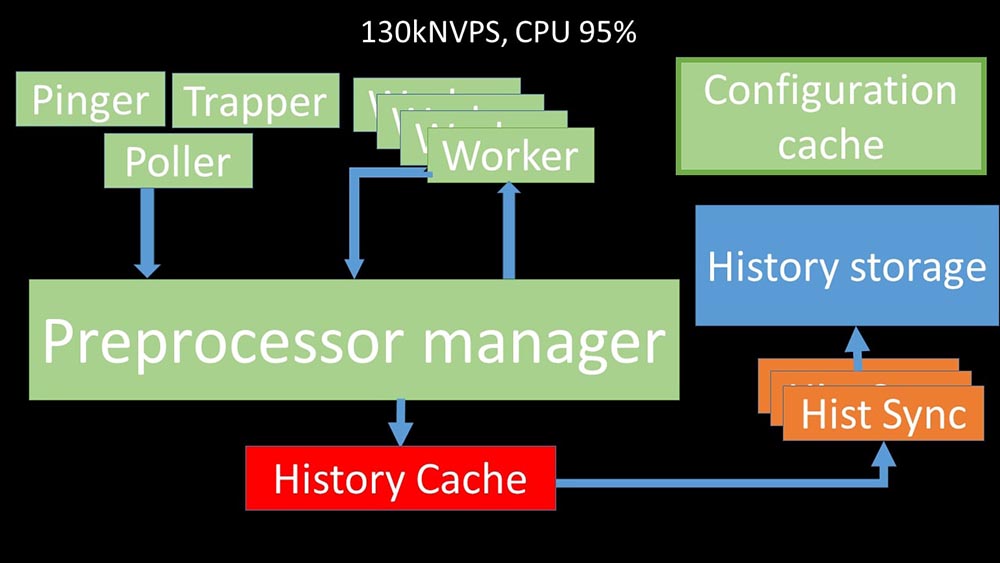 ungefähr 2,5 Monaten
ungefähr 2,5 MonatenDie Ablehnung der snmp-Community erhöhte die NVPs um das Eineinhalbfache
MM: - Max, ich brauche eine neue Testmaschine! Wir passen nicht mehr in die aktuelle.MCH: - Und was ist jetzt?MM: - Jetzt - 130.000 NVPs und ein "Regal" -Prozessor.MCH: - Wow! Cool! Warten Sie, ich habe zwei Fragen. Nach meinen Berechnungen liegt unser Bedarf im Bereich von 15 bis 20.000 Metriken pro Sekunde. Warum brauchen wir mehr?MM: - Ich möchte den Job bis zum Ende beenden. Ich möchte sehen, wie viel wir aus diesem System herausholen können.MCH: - Aber ...MM: - Aber es ist für das Geschäft nutzlos.MCH: - Ich verstehe. Und die zweite Frage: Was wir jetzt haben, können wir uns ohne die Hilfe eines Entwicklers selbst unterstützen?MM:- Ich denke nicht. Das Ändern des Konfigurationscaches ist ein Problem. Es behandelt Änderungen in den meisten Threads und ist schwer zu pflegen. Höchstwahrscheinlich wird es sehr schwierig sein, sie zu unterstützen.MCH: - Dann brauchen Sie eine Alternative.MM: - Es gibt eine solche Option. Wir können auf schnelle Kerne umsteigen und gleichzeitig das neue Schließsystem aufgeben. Wir erhalten immer noch die Leistung von 60-80.000 Metriken. In diesem Fall können wir den Rest des Codes belassen. Clickhouse, asynchrones Polling funktioniert. Und es wird leicht zu warten sein.MCH: - Großartig! Ich schlage vor, darauf einzugehen.Nachdem wir die Serverseite optimiert hatten, konnten wir den neuen Code endlich produktiv ausführen. Wir haben einen Teil der Änderungen zugunsten des Wechsels zu einem Computer mit schnellen Kerneln und der Minimierung der Anzahl der Änderungen im Code aufgegeben. Wir haben auch die Konfiguration vereinfacht und die Makros in den Datenelementen nach Möglichkeit aufgegeben, da sie die Quelle zusätzlicher Sperren sind. Die Ablehnung des snmp-community-Makros, das häufig in Dokumentationen und Beispielen zu finden ist, ermöglichte es uns in unserem Fall, NVPs zusätzlich um das 1,5-fache zu beschleunigen.Nach zwei Tagen in der Produktion
Die Ablehnung des snmp-community-Makros, das häufig in Dokumentationen und Beispielen zu finden ist, ermöglichte es uns in unserem Fall, NVPs zusätzlich um das 1,5-fache zu beschleunigen.Nach zwei Tagen in der ProduktionEntfernen Sie Popups zum Vorfallverlauf
MCH: - Mischa, wir benutzen das System zwei Tage lang und alles funktioniert. Aber nur wenn alles funktioniert! Wir hatten die Arbeit mit der Übertragung eines ausreichend großen Teils des Netzwerks geplant und erneut mit unseren Händen überprüft, ob es gestiegen war, nicht.MM: - Das kann nicht sein! Wir haben alles 10 mal überprüft. Der Server verarbeitet sogar die vollständige Unzugänglichkeit des Netzwerks sofort.MCH: - Ja, ich verstehe alles: Server, Basis, Top, Austat, Protokolle - alles ist schnell ... Aber wir schauen uns die Weboberfläche an und dort haben wir den Prozessor "im Regal" auf dem Server und dies: MM: - Ich verstehe. Schauen wir uns das Web an. Wir haben festgestellt, dass in einer Situation mit einer großen Anzahl aktiver Vorfälle die meisten betrieblichen Widgets sehr langsam zu arbeiten begannen:
MM: - Ich verstehe. Schauen wir uns das Web an. Wir haben festgestellt, dass in einer Situation mit einer großen Anzahl aktiver Vorfälle die meisten betrieblichen Widgets sehr langsam zu arbeiten begannen: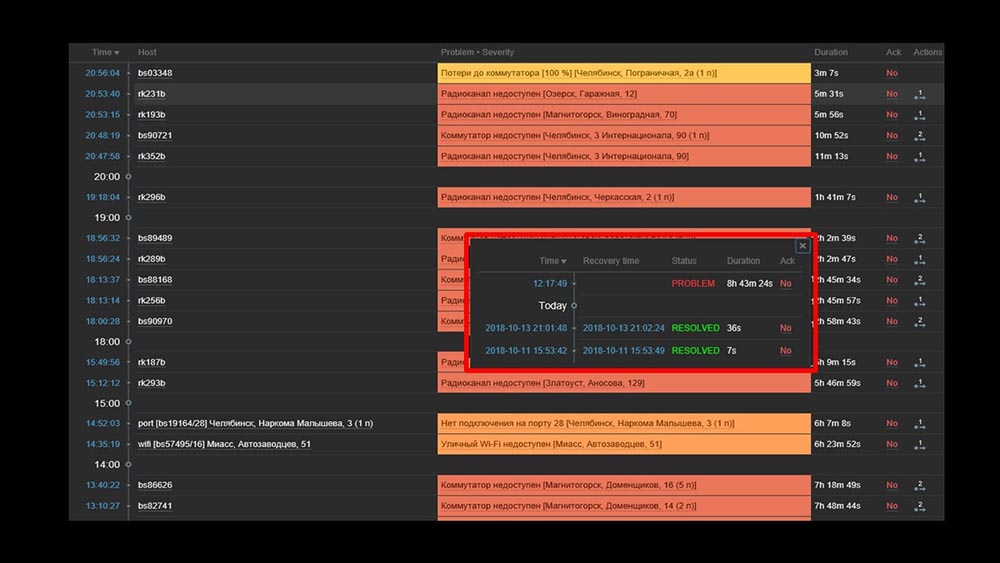 Der Grund dafür war die Generierung von Popups mit einer Historie von Vorfällen, die für jedes Element in der Liste generiert werden. Daher haben wir uns geweigert, diese Fenster zu generieren (5 Zeilen im Code auskommentiert), und dies hat unsere Probleme gelöst.Die Ladezeit des Widgets wurde, selbst wenn sie nicht zugänglich war, von einigen Minuten auf 10-15 Sekunden reduziert, und der Verlauf kann weiterhin angezeigt werden, indem Sie auf die Zeit klicken:
Der Grund dafür war die Generierung von Popups mit einer Historie von Vorfällen, die für jedes Element in der Liste generiert werden. Daher haben wir uns geweigert, diese Fenster zu generieren (5 Zeilen im Code auskommentiert), und dies hat unsere Probleme gelöst.Die Ladezeit des Widgets wurde, selbst wenn sie nicht zugänglich war, von einigen Minuten auf 10-15 Sekunden reduziert, und der Verlauf kann weiterhin angezeigt werden, indem Sie auf die Zeit klicken: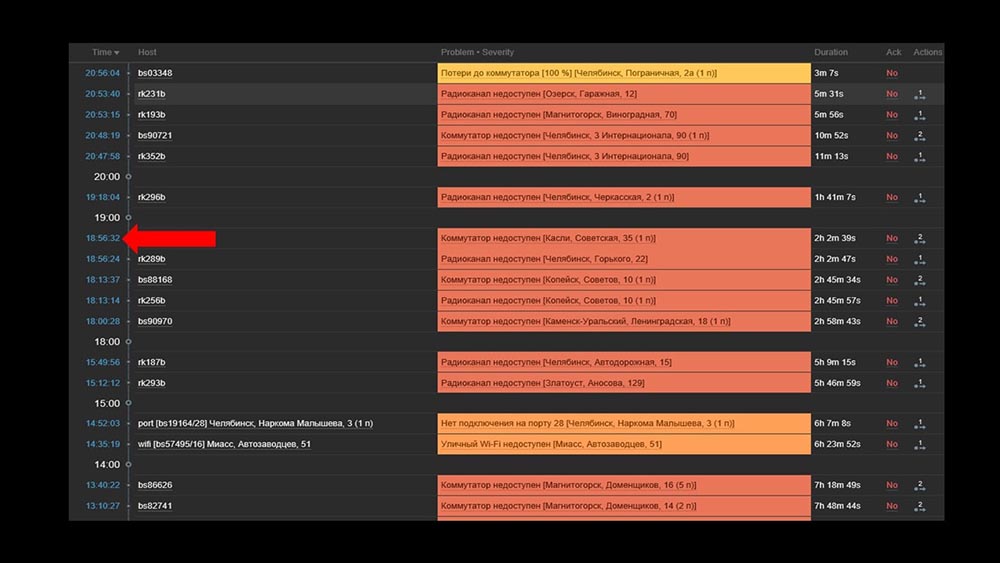 Nach der Arbeit. Vor 2 MonatenMCH: - Mischa, gehst du? Wir müssen reden.MM: - Ich werde nicht. Wieder etwas mit Zabbix?MCH: - Oh nein, entspann dich! Ich wollte nur sagen: alles funktioniert, danke! Bier mit mir.
Nach der Arbeit. Vor 2 MonatenMCH: - Mischa, gehst du? Wir müssen reden.MM: - Ich werde nicht. Wieder etwas mit Zabbix?MCH: - Oh nein, entspann dich! Ich wollte nur sagen: alles funktioniert, danke! Bier mit mir.Zabbix ist wirksam
Zabbix ist ein ziemlich vielseitiges und reichhaltiges System und Funktion. Es kann sofort für kleine Installationen verwendet werden, muss jedoch mit zunehmendem Bedarf optimiert werden. Verwenden Sie den entsprechenden Speicher, um ein großes Archiv von Metriken zu speichern:- Sie können die integrierten Tools in Form einer Integration mit Elastixerch oder des Hochladens des Verlaufs in Textdateien (verfügbar ab der vierten Version) verwenden.
- Sie können unsere Erfahrung und Integration mit Clickhouse nutzen.
Um die Geschwindigkeit beim Sammeln von Metriken drastisch zu erhöhen, erfassen Sie diese asynchron und übertragen Sie sie über die Trapper-Schnittstelle an den Zabbix-Server. oder Sie können den Patch für asynchrone Poller von Zabbix selbst verwenden.Zabbix ist in C geschrieben und sehr effektiv. Die Lösung mehrerer enger architektonischer Bereiche ermöglicht es, die Produktivität weiter zu steigern und nach unserer Erfahrung mehr als 100.000 Metriken auf einem Computer mit einem Prozessor zu erhalten.
Der gleiche Zabbix-Patch
MM: - Ich möchte ein paar Punkte hinzufügen. Der gesamte aktuelle Bericht, alle Tests und Nummern sind für die Konfiguration angegeben, die bei uns verwendet wird. Wir nehmen jetzt ungefähr 20.000 Metriken pro Sekunde davon. Wenn Sie versuchen zu verstehen, ob dies für Sie funktioniert, können Sie vergleichen. Worüber sie heute gesprochen haben, wird auf GitHub als Patch veröffentlicht: github.com/miklert/zabbix Der Patch enthält:
Der Patch enthält:- vollständige Integration mit Clickhouse (sowohl Zabbix-Server als auch Frontend);
- Lösen von Problemen mit dem Präprozessor-Manager;
- asynchrones Polling.
Der Patch ist mit allen Versionen 4 kompatibel, einschließlich lts. Höchstwahrscheinlich funktioniert es mit minimalen Änderungen unter Version 3.4.Vielen Dank für Ihre Aufmerksamkeit.Fragen
Frage des Publikums (im Folgenden - A): - Guten Tag! Bitte sagen Sie mir, haben Sie Pläne für eine intensive Interaktion mit dem Zabbix-Team oder haben sie mit Ihnen, damit dies kein Patch ist, sondern das normale Verhalten von Zabbix?MM: - Ja, wir werden sicherlich einen Teil der Änderungen vornehmen. Etwas wird sein, etwas wird im Patch bleiben.A: - Vielen Dank für den hervorragenden Bericht! Sagen Sie mir bitte, nachdem Sie den Patch angewendet haben, bleibt die Unterstützung von der Seite von Zabbix bestehen und wie können Sie weiterhin auf höhere Versionen aktualisieren? Wird es möglich sein, Zabbix nach Ihrem Patch auf 4.2, 5.0 zu aktualisieren?MM:- Ich kann nichts über Unterstützung sagen. Wenn ich der technische Support von Zabbix wäre, würde ich wahrscheinlich nein sagen, da dies der Code eines anderen ist. In Bezug auf die Codebasis 4.2 lautet unsere Position wie folgt: "Wir werden mit der Zeit gehen und wir werden auf die nächste Version aktualisiert." Daher werden wir den Patch für einige Zeit auf aktualisierte Versionen hochladen. Ich habe bereits im Bericht gesagt: Die Anzahl der Änderungen an den Versionen ist immer noch recht gering. Ich denke, der Übergang von 3,4 auf 4 hat anscheinend 15 Minuten gedauert. Dort hat sich etwas geändert, aber nicht sehr wichtig.A: - Sie planen also, Ihren Patch zu warten und können ihn sicher in Betrieb nehmen, um in Zukunft auf irgendeine Weise Updates zu erhalten?MM: - Wir empfehlen es dringend. Dies löst viele Probleme für uns.MCH:- Ich möchte noch einmal betonen, dass Änderungen, die sich nicht auf die Architektur und nicht auf Sperren und Warteschlangen beziehen, modular sind und sich in separaten Modulen befinden. Selbst mit geringfügigen Änderungen können sie problemlos gewartet werden.MM: - Wenn die Details interessant sind, verwendet „Clickhouse“ die sogenannte Verlaufsbibliothek. Es ist nicht gebunden - dies ist eine Kopie der Unterstützung von Elastic, dh es ist konfigurierbar. Durch das Abrufen werden nur die Poller geändert. Wir glauben, dass dies noch lange funktionieren wird.A: - Vielen Dank. Aber sagen Sie mir, gibt es eine Dokumentation der vorgenommenen Änderungen? MM:- Dokumentation ist ein Patch. Offensichtlich ergeben sich mit der Einführung von „Clickhouse“ und der Einführung neuer Poller-Typen neue Konfigurationsoptionen. Der Link von der letzten Folie enthält eine kurze Beschreibung der Verwendung.
MM:- Dokumentation ist ein Patch. Offensichtlich ergeben sich mit der Einführung von „Clickhouse“ und der Einführung neuer Poller-Typen neue Konfigurationsoptionen. Der Link von der letzten Folie enthält eine kurze Beschreibung der Verwendung.Über das Ersetzen von fping durch nmap
A: - Wie haben Sie das letztendlich umgesetzt? Können Sie konkrete Beispiele nennen: Sind es Ihre Strapper und ein externes Skript? Was überprüft schließlich so viele Hosts so schnell? Wie bekommt man diese Gastgeber? Muss nmap sie irgendwie füttern, von irgendwoher holen, hineinstecken, etwas anfangen? ..MM:- Cool. Sehr richtige Frage! Der Punkt ist dies. Wir haben die Bibliothek (ICMP-Ping, Teil von Zabbix) für ICMP-Überprüfungen geändert, die die Anzahl der Pakete - Einheit (1) angeben, und der Code versucht, nmap zu verwenden. Das heißt, dies ist die interne Arbeit von Zabbix, es ist die interne Arbeit des Pingers geworden. Dementsprechend ist keine Synchronisation oder Verwendung eines Trappers erforderlich. Dies wurde absichtlich gemacht, um das System kohärent zu lassen und nicht an der Synchronisation zweier Basissysteme teilzunehmen: Was ist zu überprüfen, durch den Poller auszufüllen und ob die Füllung in uns gebrochen ist? Dies ist viel einfacher.A: - Funktioniert es auch für einen Proxy?MM: - Ja, aber wir haben es nicht überprüft. Der Abrufcode ist sowohl in Zabbix als auch auf dem Server gleich. Sollte arbeiten. Ich betone noch einmal: Die Systemleistung ist so, dass wir keinen Proxy benötigen.MCH: - Die richtige Antwort auf die Frage lautet: "Warum brauchen Sie einen Proxy mit einem solchen System?" Nur wegen NAT'a oder um über einen langsamen Kanal einige zu überwachen ...A: - Und Sie verwenden Zabbix als Allergen, wenn ich das richtig verstehe. Oder die Grafiken (wo befindet sich die Archivschicht), die Sie für ein anderes System wie Grafana hinterlassen haben? Oder nutzen Sie diese Funktionalität nicht?MM: - Ich werde noch einmal betonen: Wir haben die vollständige Integration vorgenommen. Wir gießen Geschichte in "Clickhouse", haben aber gleichzeitig das PHP-Frontend geändert. Das PHP-Frontend geht zu "Clickhouse" und macht alle Grafiken von dort. Gleichzeitig haben wir, um ehrlich zu sein, einen Teil, der aus demselben „Clickhouse“, denselben Zabbix-Daten und Daten in anderen grafischen Anzeigesystemen besteht.MCH: - Auch in "Grafan".Wie wurde die Entscheidung getroffen, Ressourcen zuzuweisen?
A: - Teilen Sie eine kleine innere Küche. Wie wurde die Entscheidung getroffen, Ressourcen für eine ernsthafte Produktverarbeitung bereitzustellen? Dies sind im Allgemeinen bestimmte Risiken. Und bitte sagen Sie mir im Zusammenhang mit der Tatsache, dass Sie neue Versionen unterstützen werden: Wie ist diese Entscheidung aus Managementsicht gerechtfertigt?MM: - Anscheinend haben wir das Drama der Geschichte nicht sehr gut erzählt. Wir befanden uns in einer Situation, in der etwas getan werden musste, und gingen im Wesentlichen zwei parallele Befehle aus:- Einer war damit beschäftigt, ein Überwachungssystem mit neuen Methoden zu starten: Monitoring as a Service, ein Standardsatz von Open Source-Lösungen, die wir kombinieren und dann versuchen, den Geschäftsprozess zu ändern, um mit dem neuen Überwachungssystem zu arbeiten.
- Parallel dazu hatten wir einen begeisterten Programmierer, der dies tat (über sich selbst). So kam es, dass er gewann.
A: - Und wie groß ist das Team?MCH: - Sie ist vor dir.A: - Das heißt, wie immer wird ein Leidenschaftlicher gebraucht?MM: - Ich weiß nicht, was ein Leidenschaftlicher ist.A: - In diesem Fall anscheinend Sie. Vielen Dank, du bist cool.MM: - Danke.Über Patches für Zabbix
A: - Bei einem System, das Proxys verwendet (z. B. in einigen verteilten Systemen), können Sie beispielsweise Poller, Proxys und teilweise den Präprozessor von Zabbix selbst anpassen und patchen. und ihre Interaktion? Ist es möglich, bestehende Entwicklungen für ein System mit mehreren Proxys zu optimieren?MM: - Ich weiß, dass der Zabbix-Server mithilfe eines Proxys zusammengestellt wird (er wird kompiliert und der Code wird abgerufen). Wir haben dies im Produkt nicht getestet. Ich bin mir nicht sicher, aber meiner Meinung nach wird der Präprozessor-Manager nicht im Proxy verwendet. Die Aufgabe des Proxys besteht darin, eine Reihe von Metriken von Zabbix zu übernehmen, sie auszufüllen (es schreibt auch die Konfiguration und die lokale Datenbank) und sie an den Zabbix-Server zurückzugeben. Dann führt der Server selbst die Vorverarbeitung durch, wenn er sie empfängt.Das Interesse an Stimmrechtsvertretern ist verständlich. Wir werden dies überprüfen. Dies ist ein interessantes Thema.A: - Die Idee war folgende: Wenn Sie Poller patchen können, können sie auf Proxys gepatcht und die Interaktion mit dem Server gepatcht werden, und der Präprozessor kann nur auf dem Server für diese Zwecke angepasst werden.MM: - Ich denke, alles ist noch einfacher. Sie nehmen den Code, wenden den Patch an und konfigurieren ihn nach Bedarf. Sammeln Sie die Proxyserver (z. B. mit ODBC) und verteilen Sie den gepatchten Code an die Systeme. Wo nötig - Proxies sammeln, wo nötig - Server.A: - Außerdem müssen Sie die Proxy-Übertragung höchstwahrscheinlich nicht auf den Server patchen?MCH: - Nein, es ist Standard.MM:- Eigentlich klang eine der Ideen nicht. Wir haben immer ein Gleichgewicht zwischen einer Explosion von Ideen und der Anzahl der Änderungen und der Leichtigkeit der Unterstützung gehalten.Ein bisschen Werbung :)
Vielen Dank für Ihren Aufenthalt bei uns. Gefällt dir unser Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung aufgeben oder Ihren Freunden Cloud-basiertes VPS für Entwickler ab 4,99 US-Dollar empfehlen , ein einzigartiges Analogon von Einstiegsservern, das von uns für Sie erfunden wurde: Die ganze Wahrheit über VPS (KVM) E5-2697 v3 (6 Kerne) 10 GB DDR4 480 GB SSD 1 Gbit / s ab 19 $ oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).Dell R730xd 2-mal günstiger im Equinix Tier IV-Rechenzentrum in Amsterdam? Nur wir haben 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2,6 GHz 14C 64 GB DDR4 4 x 960 GB SSD 1 Gbit / s 100 TV von 199 US-Dollar in den Niederlanden!Dell R420 - 2x E5-2430 2,2 GHz 6C 128 GB DDR3 2x960 GB SSD 1 Gbit / s 100 TB - ab 99 US-Dollar! Lesen Sie mehr über den Aufbau eines Infrastrukturgebäudes. Klasse C mit Dell R730xd E5-2650 v4-Servern für 9.000 Euro für einen Cent? Source: https://habr.com/ru/post/undefined/
All Articles