In einem früheren Artikel haben wir den Aufmerksamkeitsmechanismus untersucht, eine äußerst verbreitete Methode in modernen Deep-Learning-Modellen, mit der die Leistungsindikatoren neuronaler maschineller Übersetzungsanwendungen verbessert werden können. In diesem Artikel werden wir uns Transformer ansehen, ein Modell, das den Aufmerksamkeitsmechanismus verwendet, um die Lerngeschwindigkeit zu erhöhen. Darüber hinaus übertreffen Transformers bei einer Reihe von Aufgaben das neuronale maschinelle Übersetzungsmodell von Google. Der größte Vorteil von Transformatoren ist jedoch ihre hohe Effizienz unter Parallelisierungsbedingungen. Sogar Google Cloud empfiehlt, Transformer als Modell für die Arbeit an Cloud-TPU zu verwenden . Versuchen wir herauszufinden, woraus das Modell besteht und welche Funktionen es ausführt.
Das Transformer-Modell wurde erstmals in dem Artikel Attention is All You Need vorgeschlagen . Eine Implementierung auf TensorFlow ist als Teil des Tensor2Tensor- Pakets verfügbar. Darüber hinaus hat eine Gruppe von NLP-Forschern aus Harvard eine Annotation des Artikels mit einer Implementierung auf PyTorch erstellt . In demselben Leitfaden werden wir versuchen, die wichtigsten Ideen und Konzepte am einfachsten und konsequentesten zu skizzieren. Wir hoffen, dass sie Menschen, die nicht über fundierte Kenntnisse des Themenbereichs verfügen, helfen, dieses Modell zu verstehen.
High Level Review
Betrachten wir das Modell als eine Art Black Box. In maschinellen Übersetzungsanwendungen akzeptiert es einen Satz in einer Sprache als Eingabe und zeigt einen Satz in einer anderen an.

, , , .
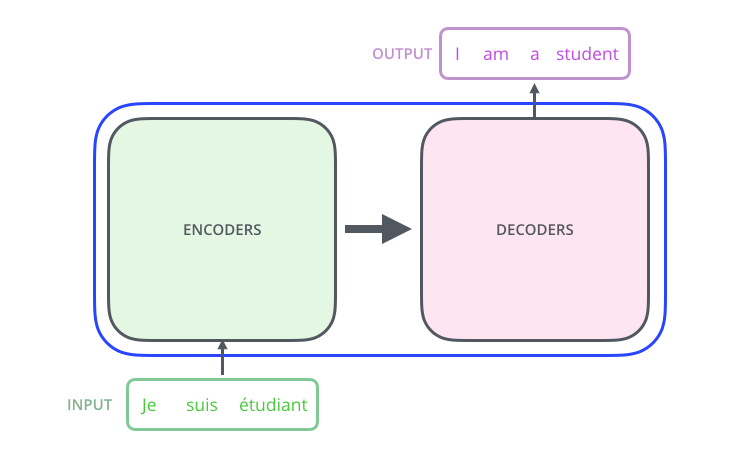
– ; 6 , ( 6 , ). – , .
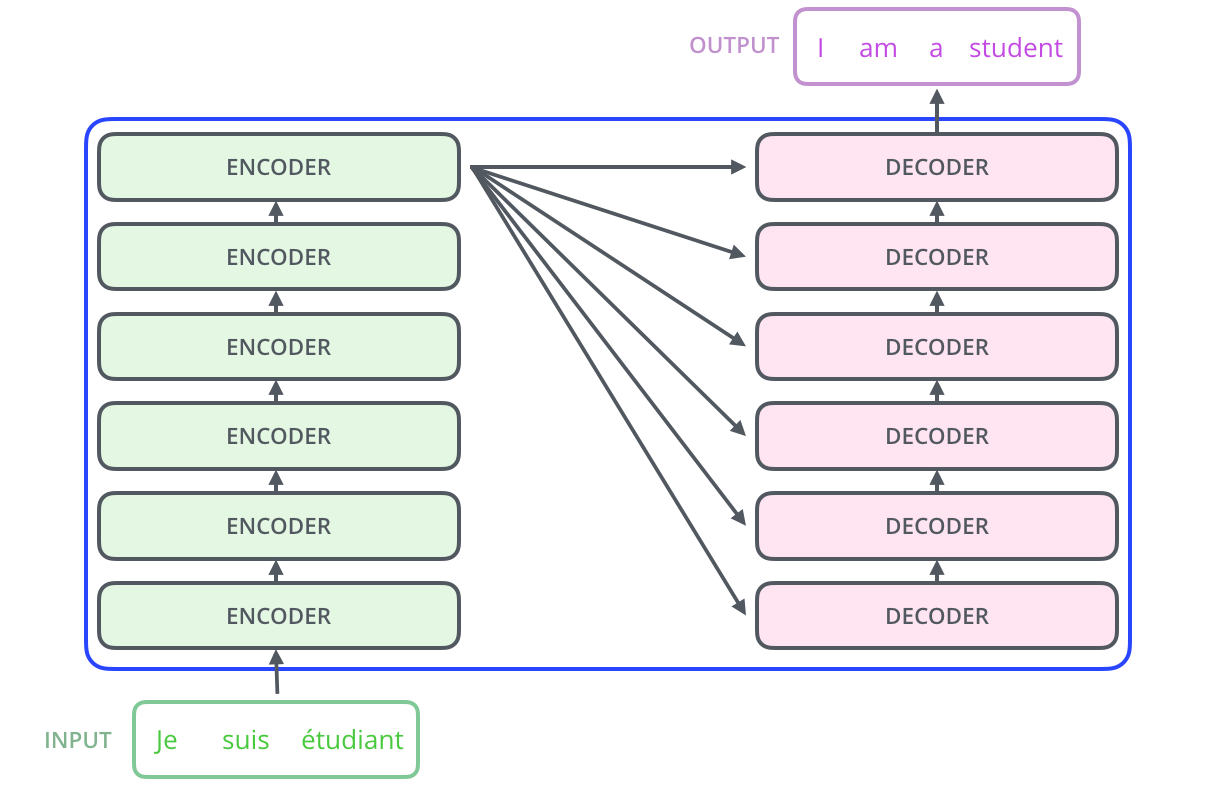
, . :
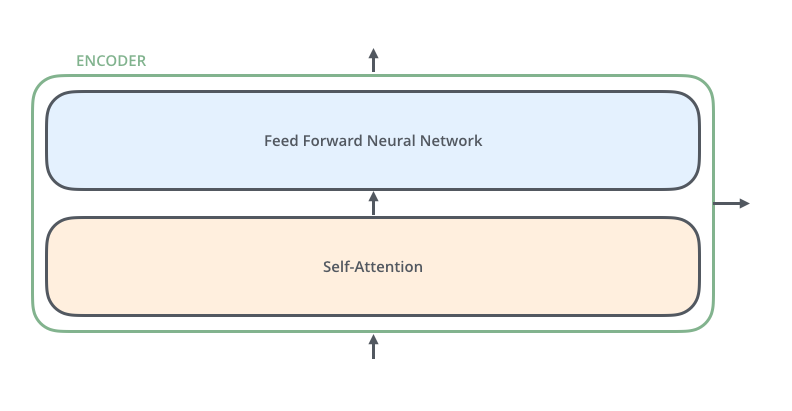
, , (self-attention), . .
(feed-forward neural network). .
, , ( , seq2seq).
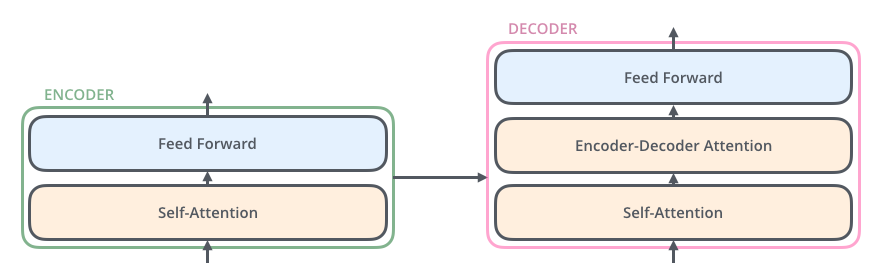
, , /, , .
NLP-, , , (word embeddings).

512. .
. , , : 512 ( , – ). , , , , .
, .
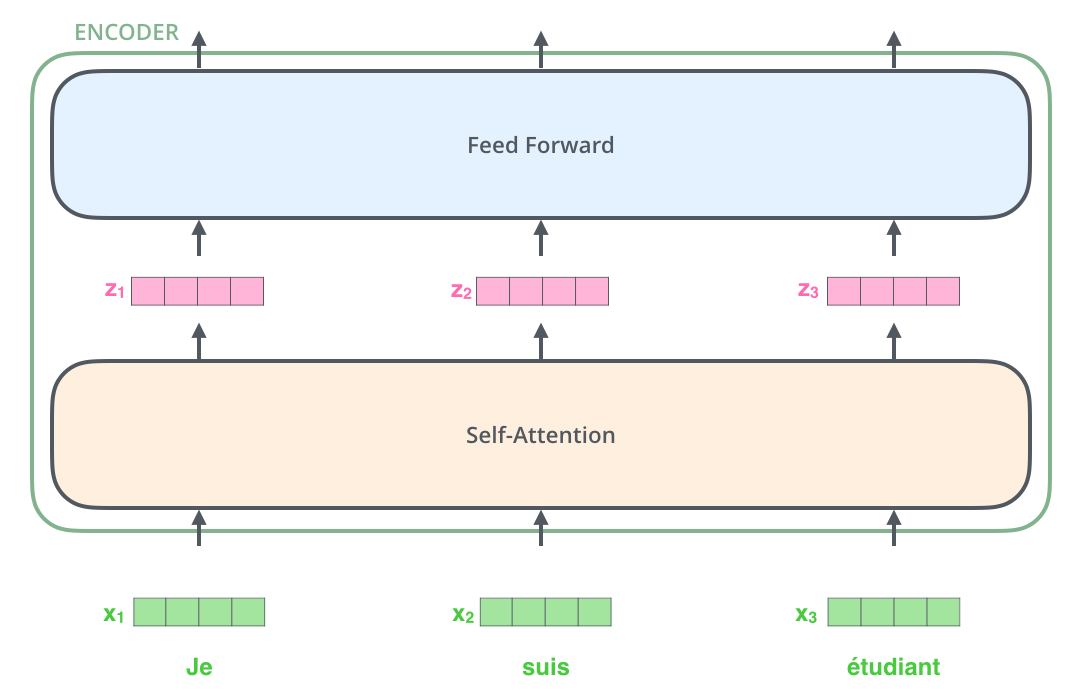
: . , , , .
, .
!
, , – , , , .
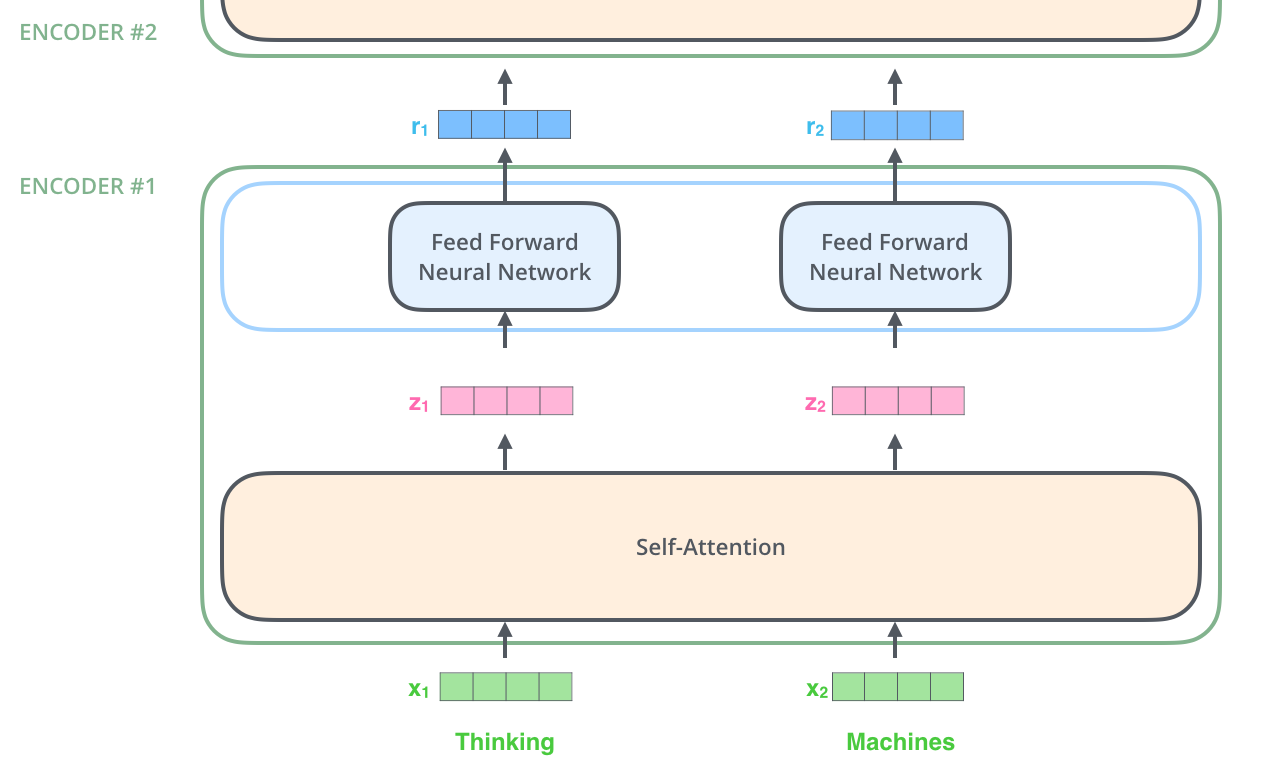
. , .
, « » -, . , «Attention is All You Need». , .
– , :
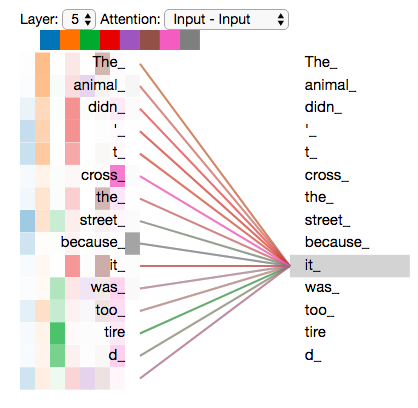
”The animal didn't cross the street because it was too tired”
«it» ? (street) (animal)? .
«it», , «it» «animal».
( ), , .
(RNN), , RNN /, , . – , , «» .

«it» #5 ( ), «The animal» «it».
Tensor2Tensor, , .
, , , .
– ( – ): (Query vector), (Key vector) (Value vector). , .
, , . 64, / 512. , (multi-head attention) .
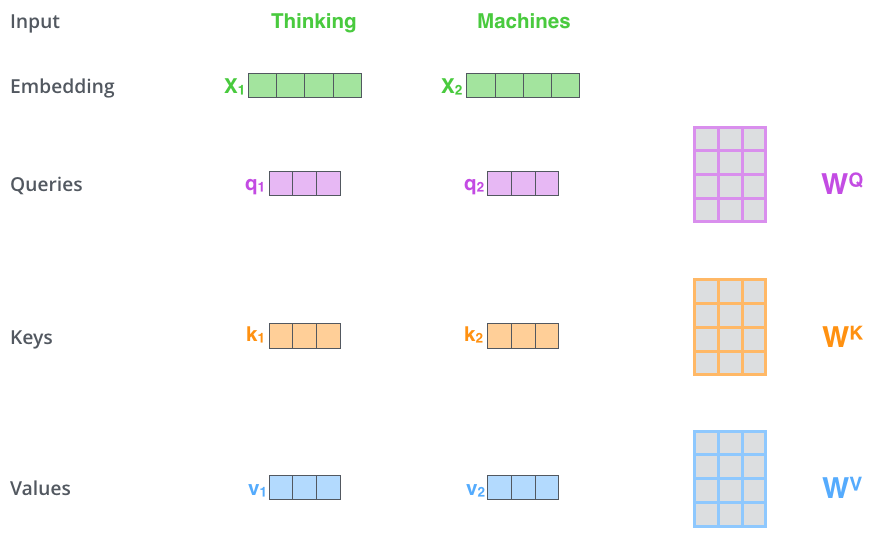
x1 WQ q1, «», . «», «» «» .
«», «» «»?
, . , , , .
– (score). , – «Thinking». . , .
. , #1, q1 k1, — q1 k2.
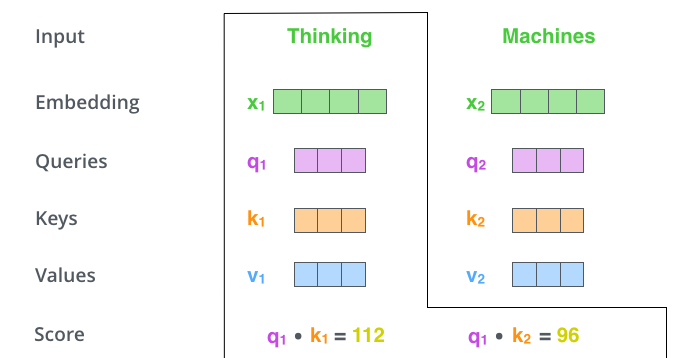
– 8 ( , – 64; , ), (softmax). , 1.
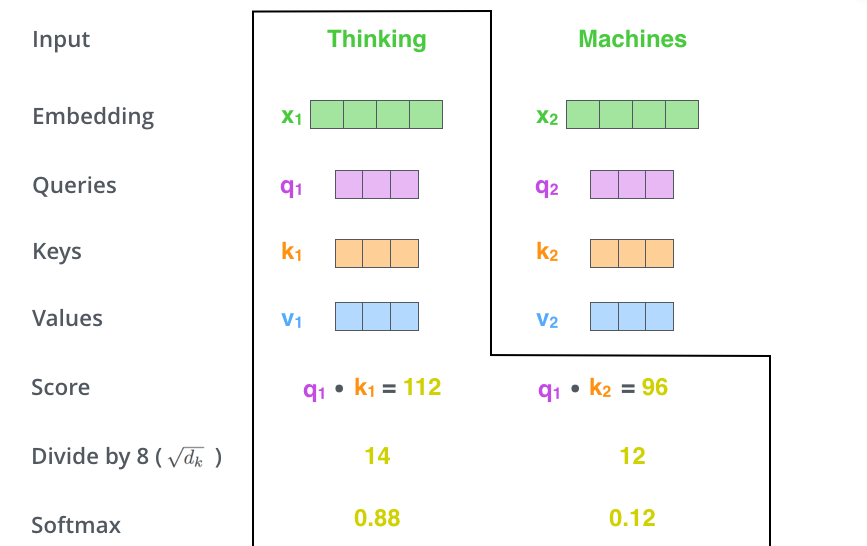
- (softmax score) , . , -, , .
– - ( ). : , , ( , , 0.001).
– . ( ).
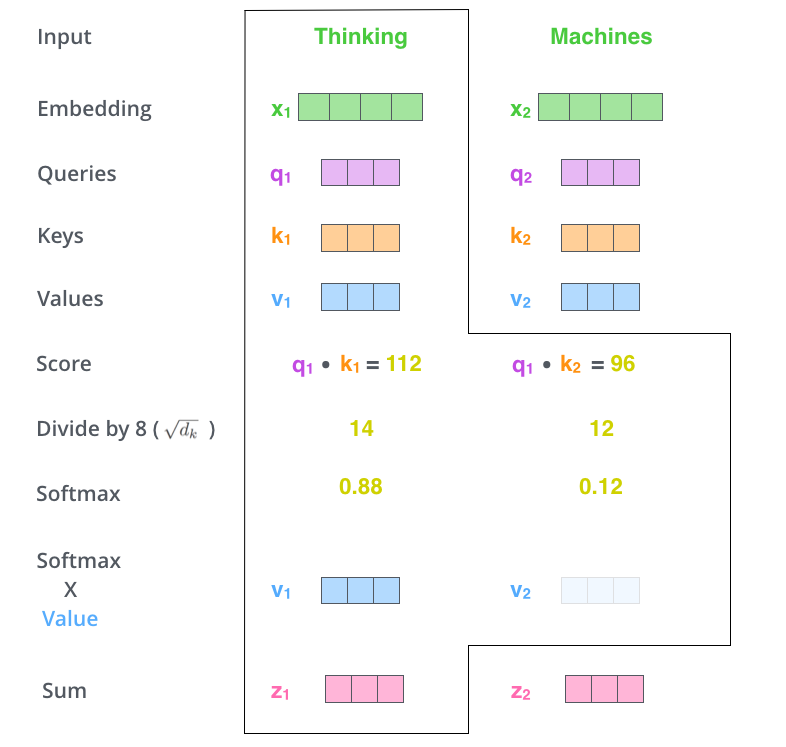
. , . , , . , , .
– , . X , (WQ, WK, WV).

. (512, 4 ) q/k/v (64, 3 ).
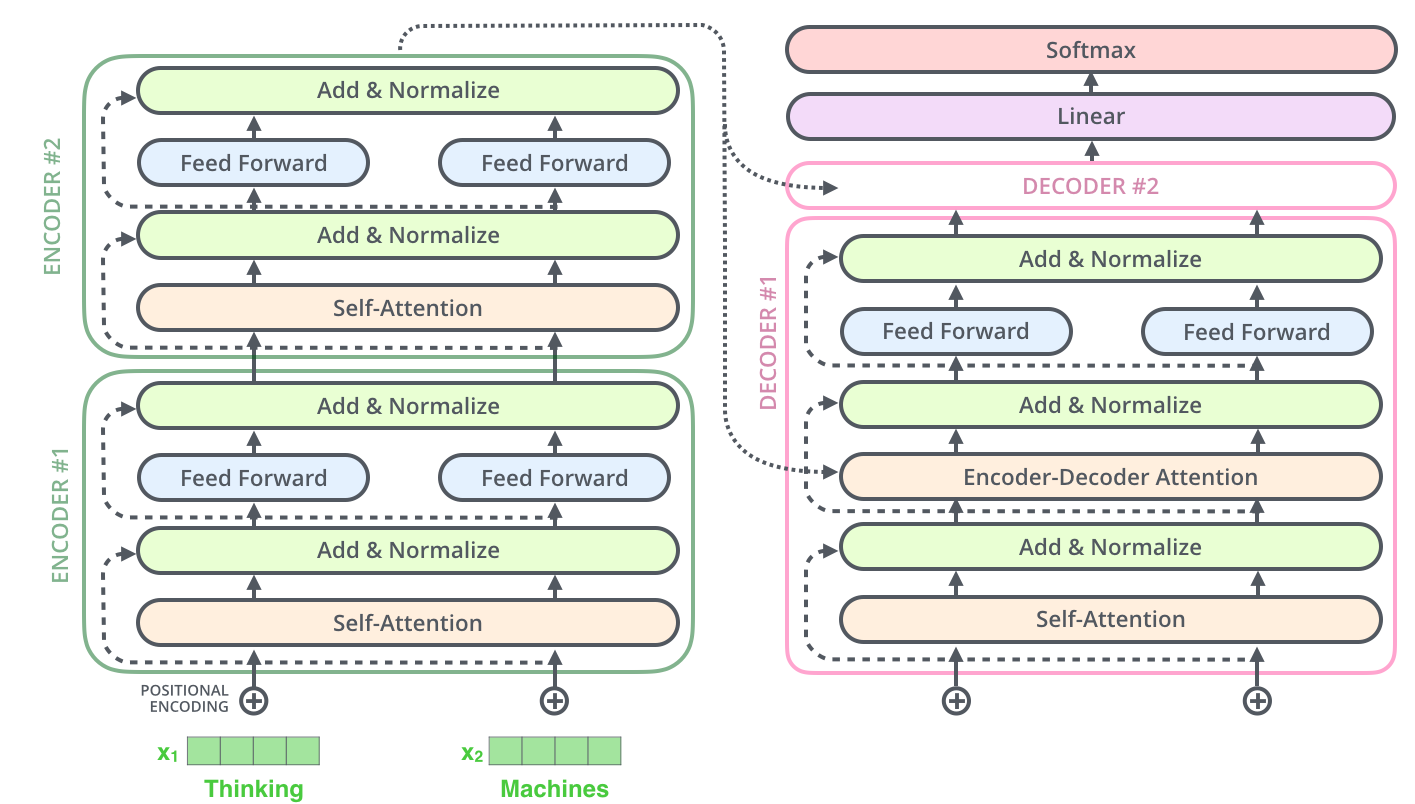
, , 2-6 .
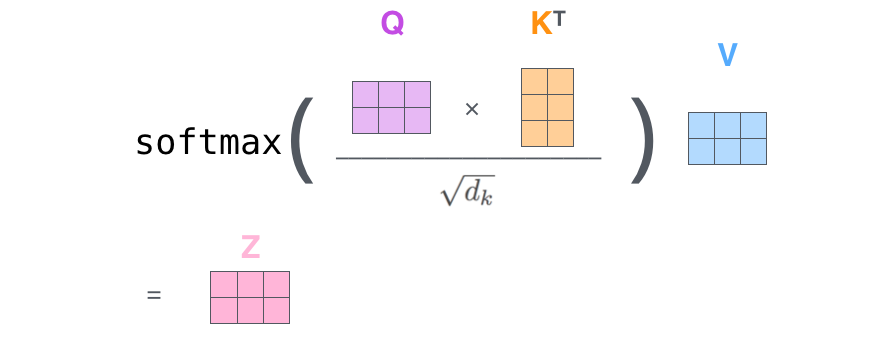
.
, (multi-head attention). :
- . , , z1 , . «The animal didn’t cross the street because it was too tired», , «it».
- « » (representation subspaces). , , // ( 8 «» , 8 /). . ( /) .
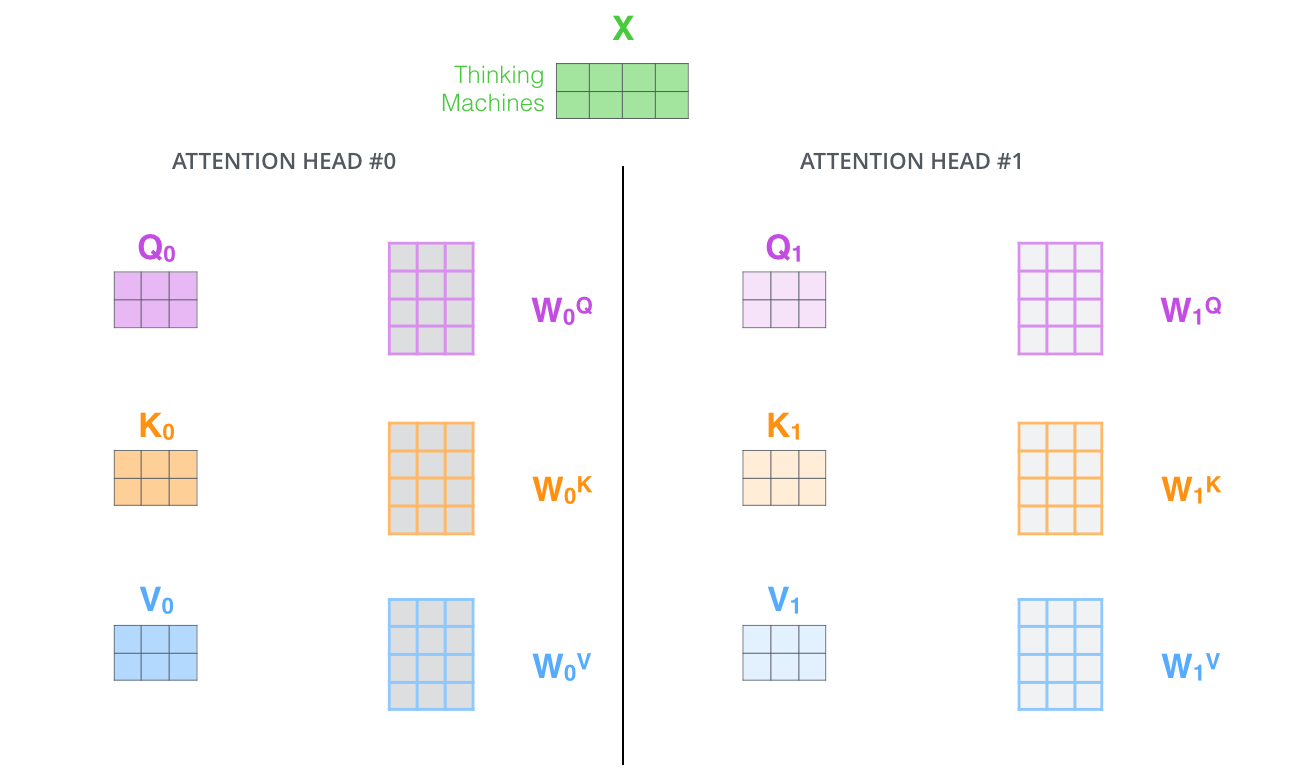
, WQ/WK/WV «», Q/K/V . , WQ/WK/WV Q/K/V .
, , 8 , 8 Z .
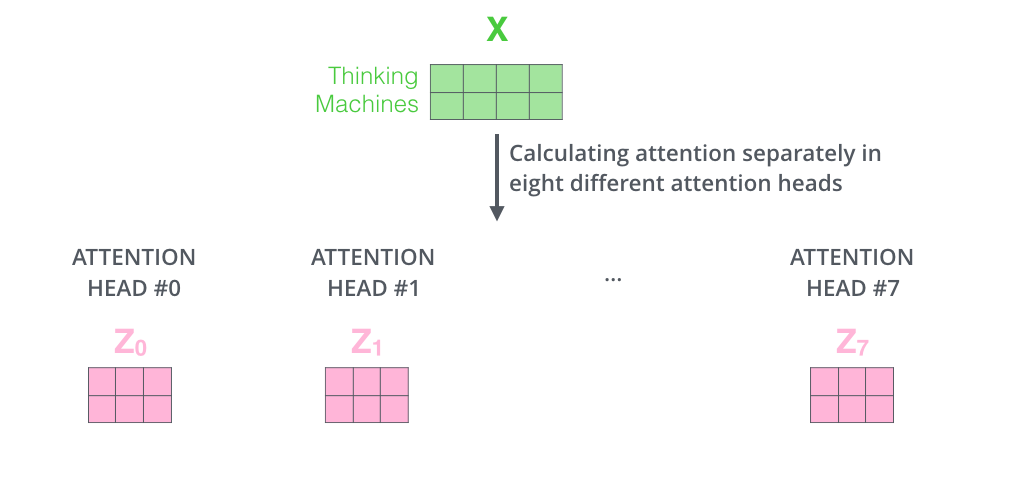
. , 8 – ( ), Z .
? WO.
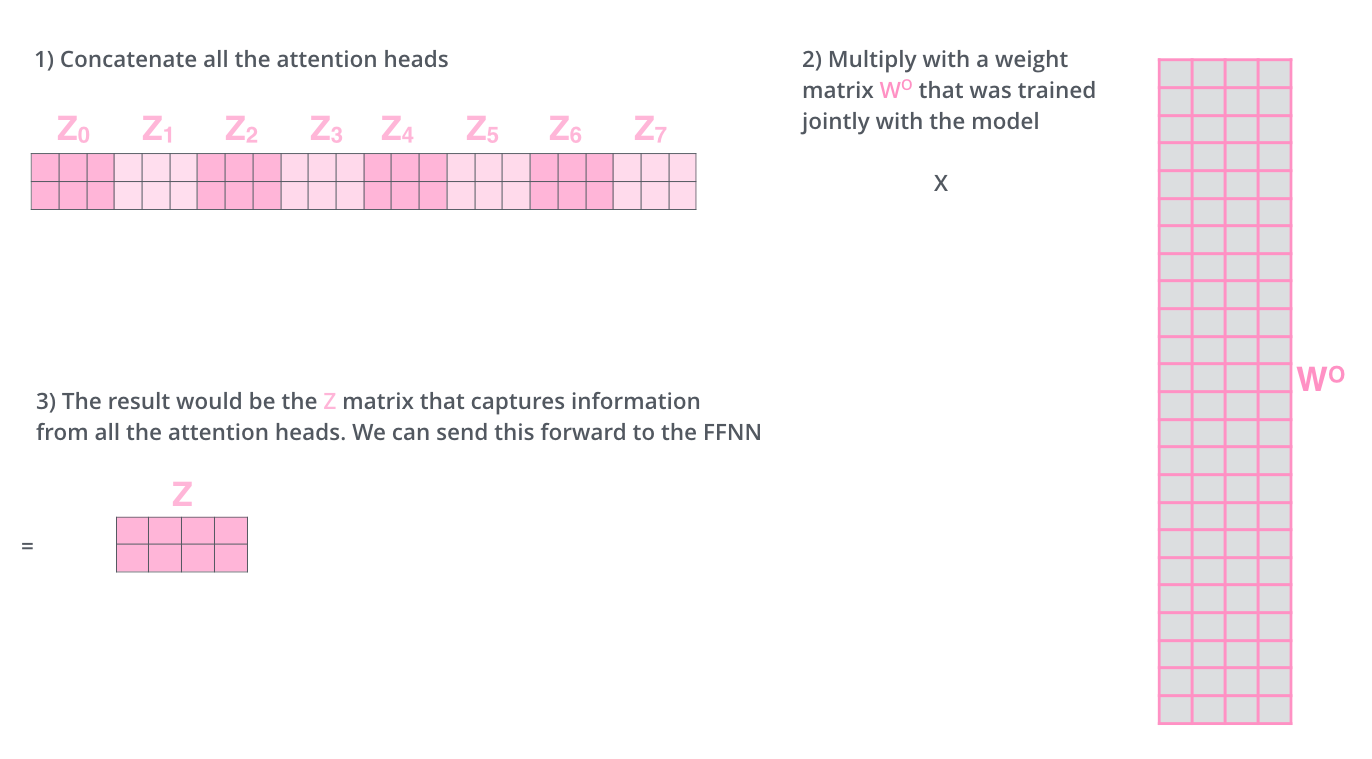
, , . , . , .
, «» , , , «» «it» :

«it», «» «the animal», — «tired». , «it» «animal» «tired».
«» , , .
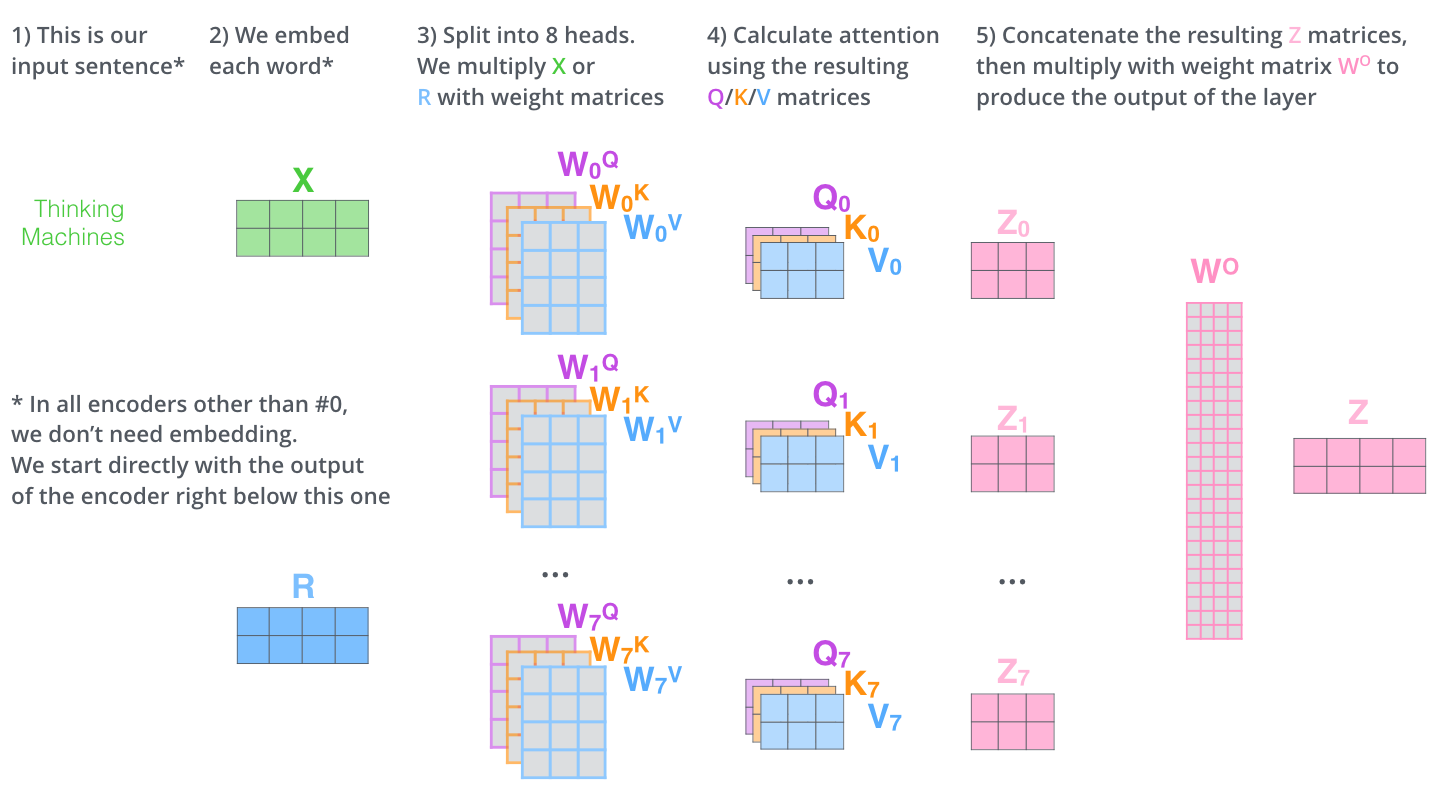
— .
. , . , Q/K/V .
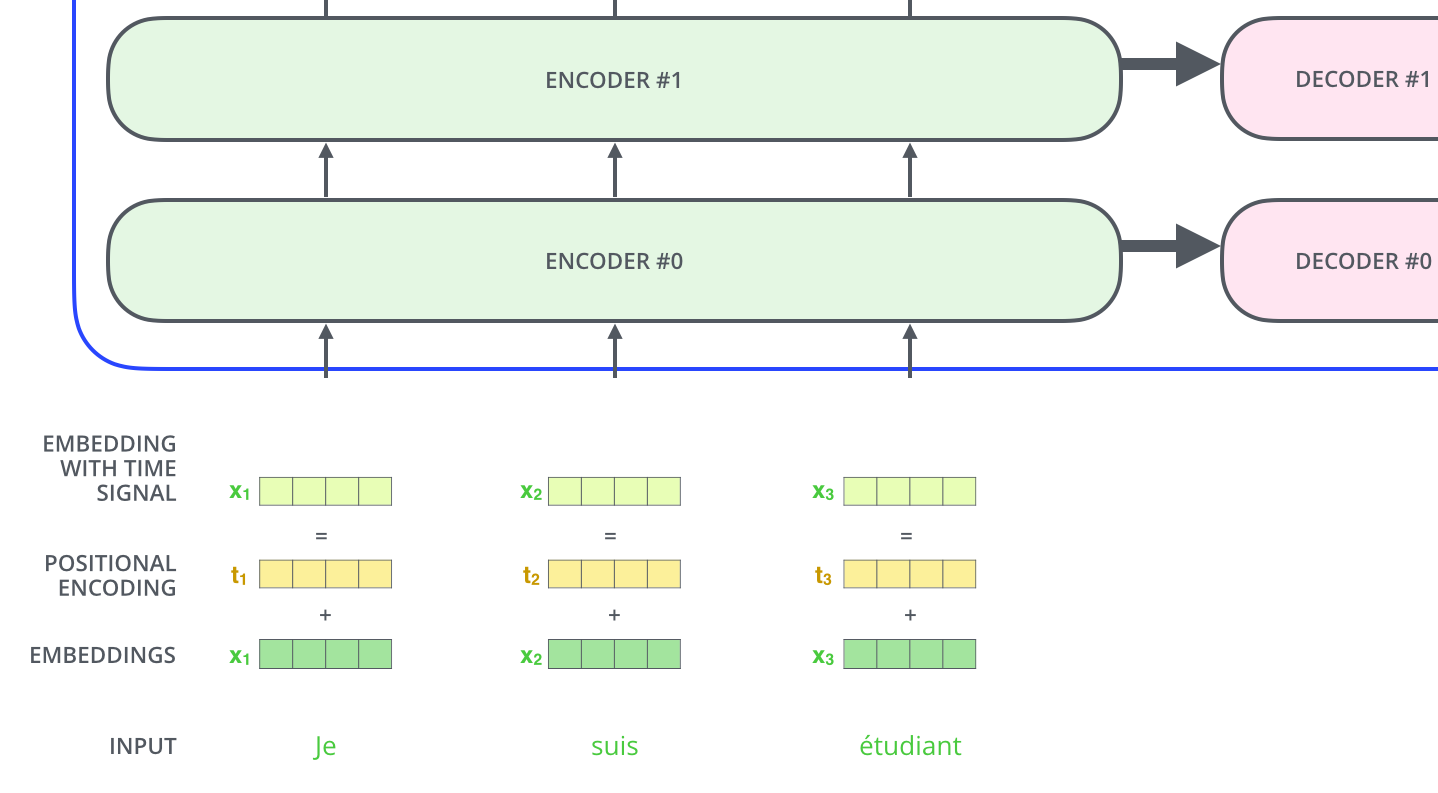
, , , .
, 4, :
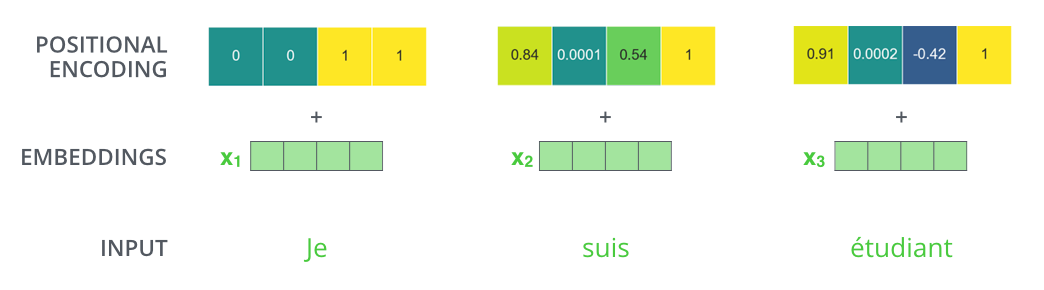
?
: , , , — .. 512 -1 1. , .
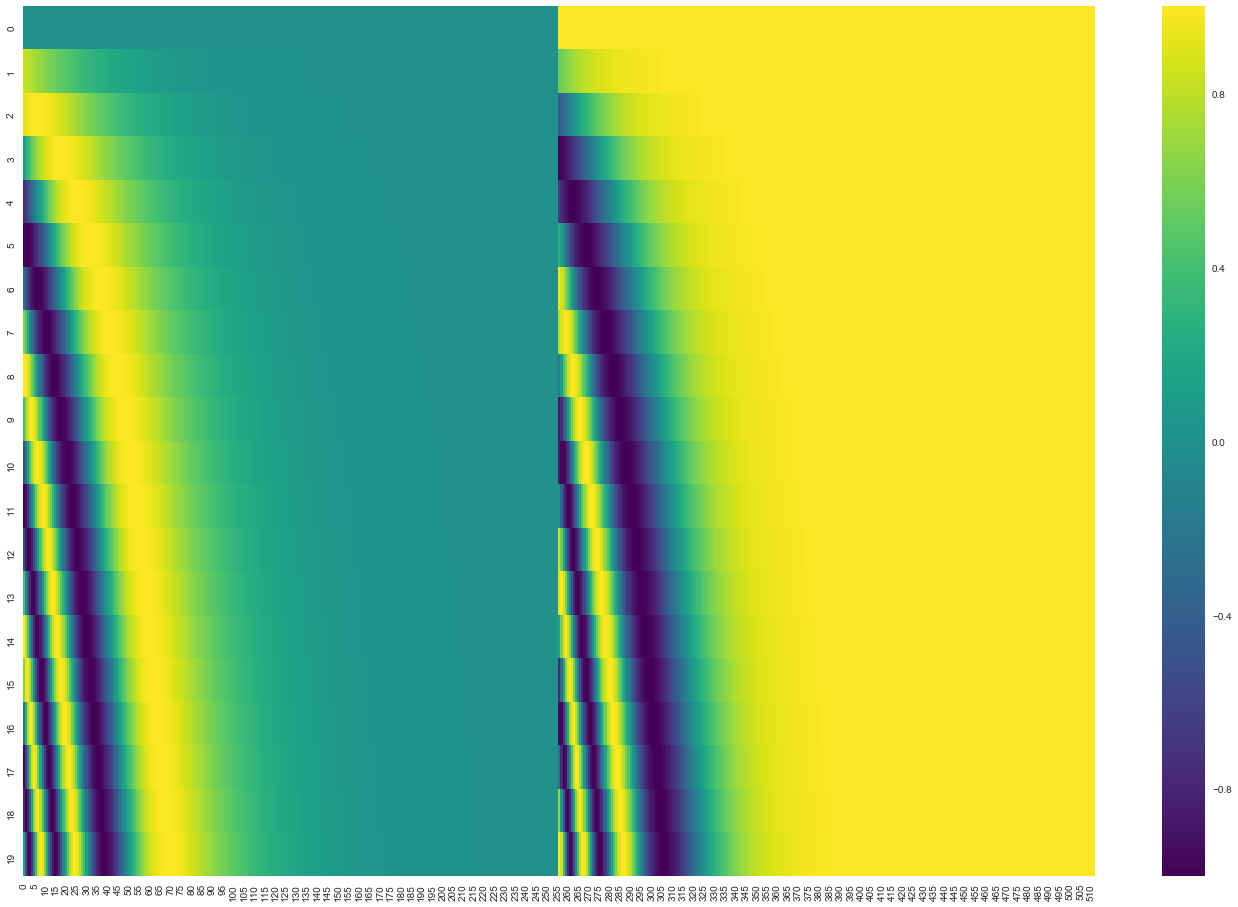
20 () 512 (). , : ( ), – ( ). .
( 3.5). get_timing_signal_1d(). , , (, , , ).
, , , , ( , ) , (layer-normalization step).
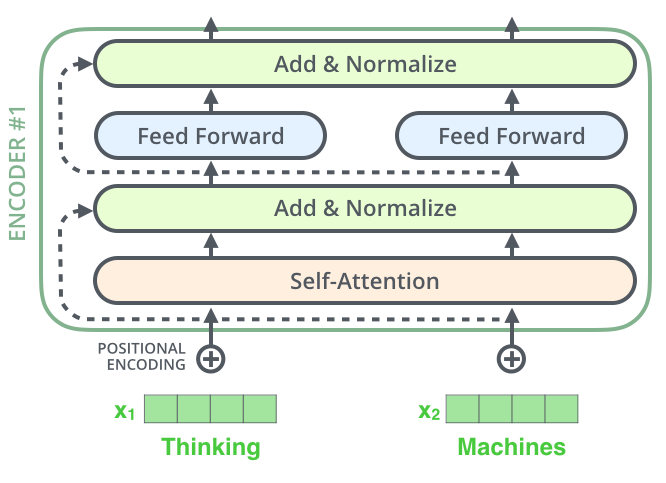
, , :
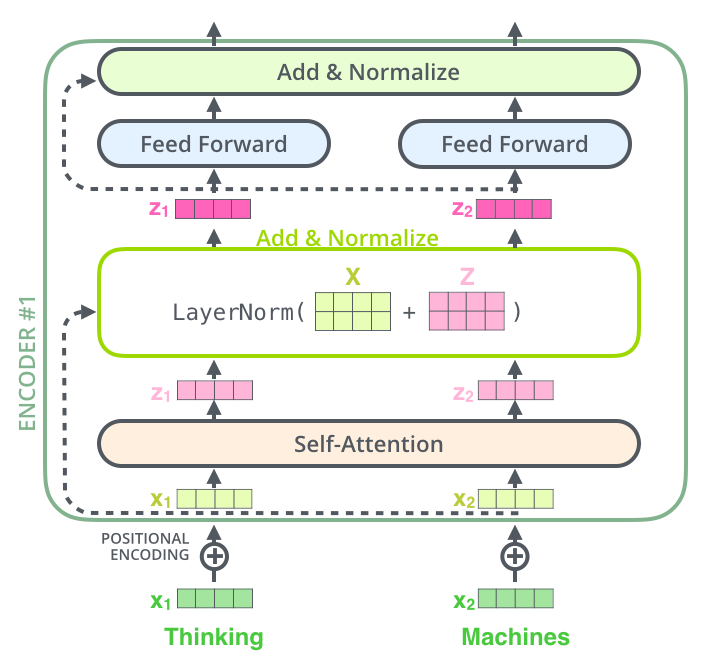
. , :
, , , . , .
. K V. «-» , :
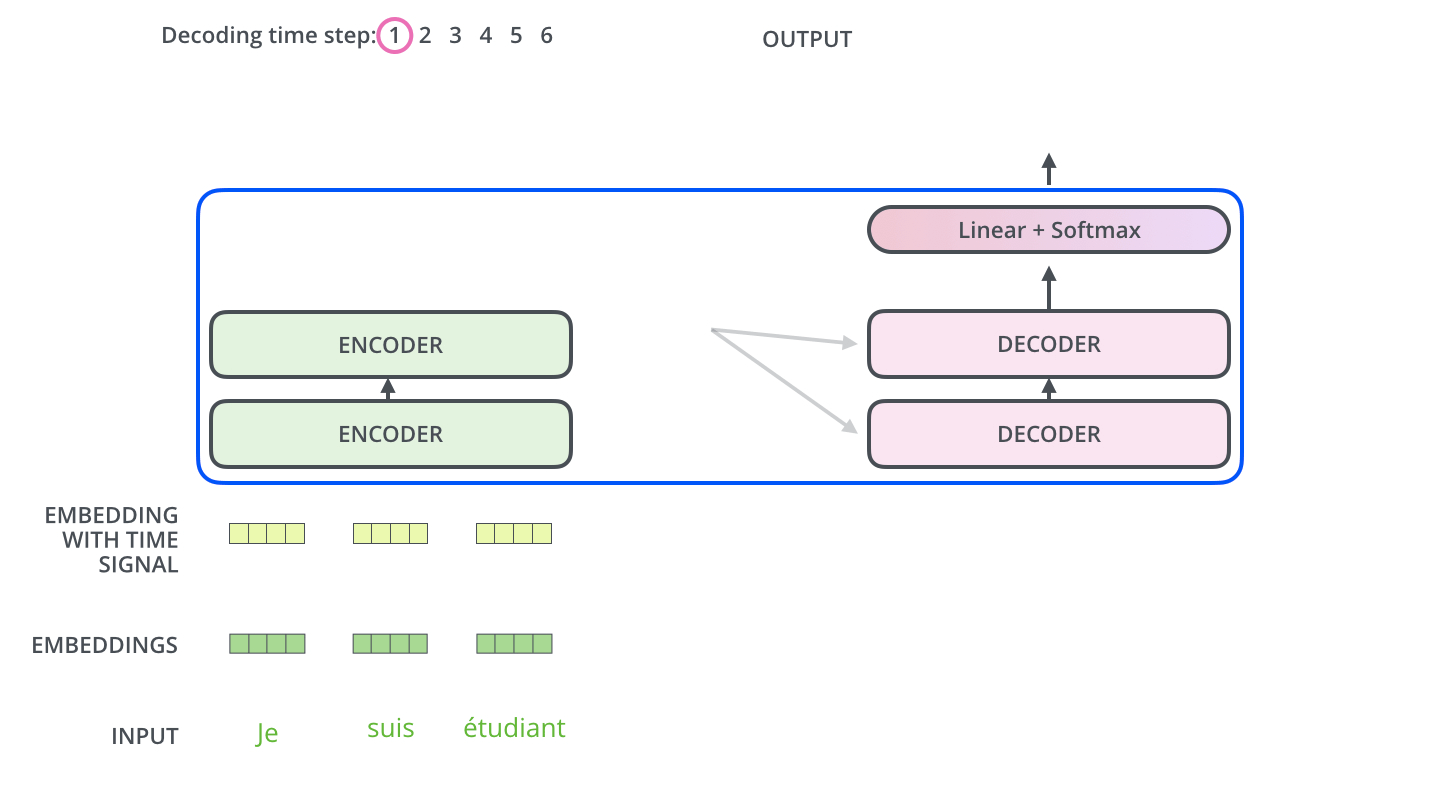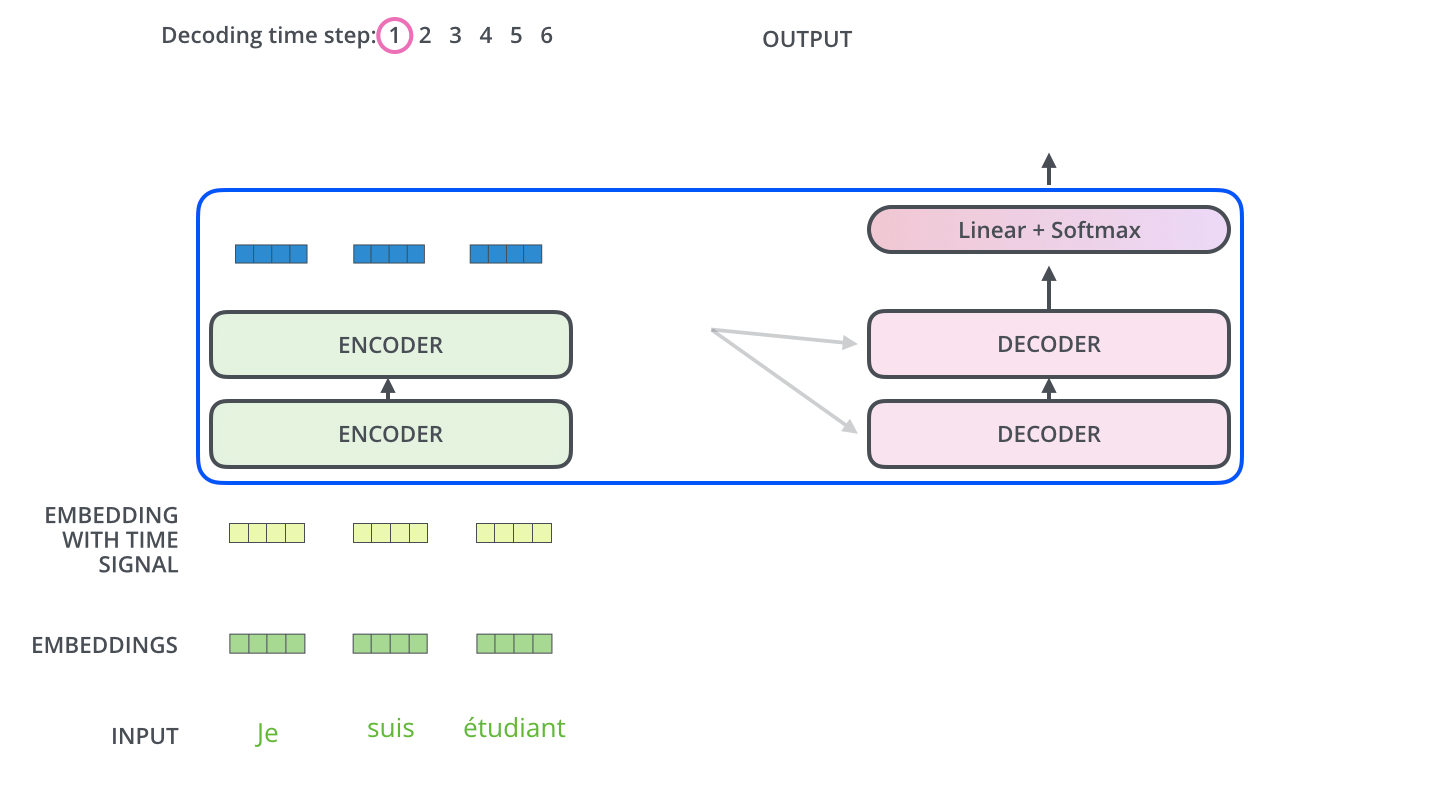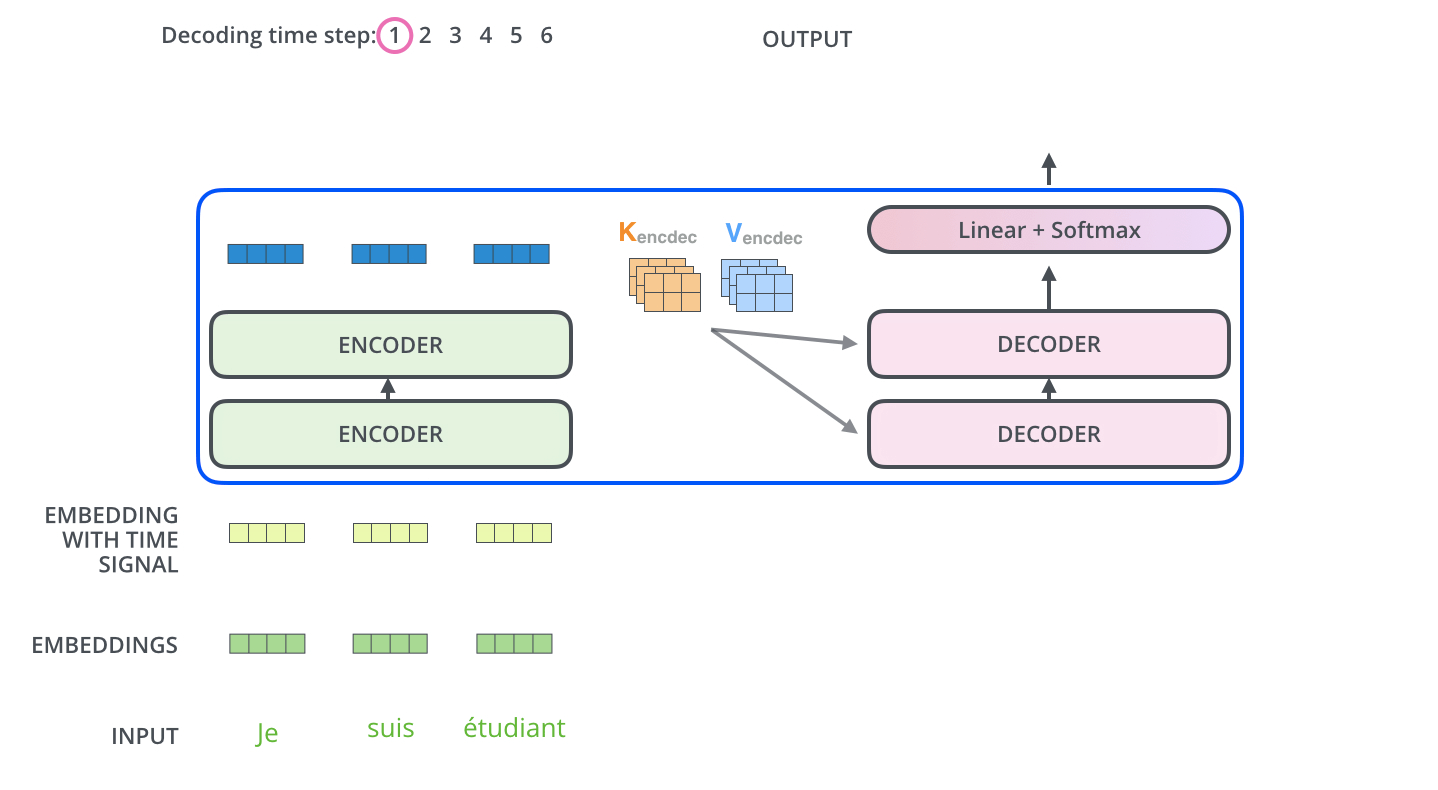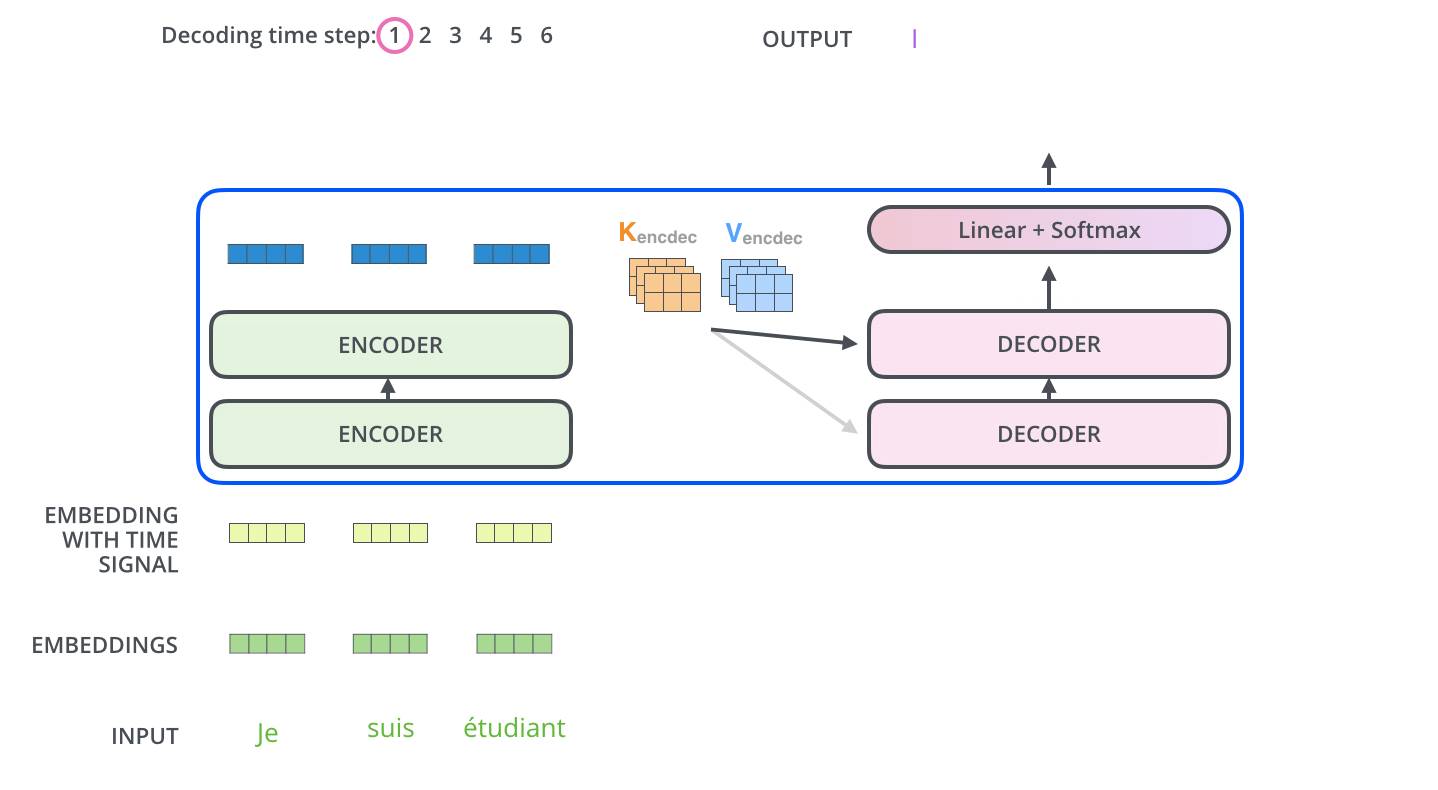
. ( – ).
, , . , , . , , , .
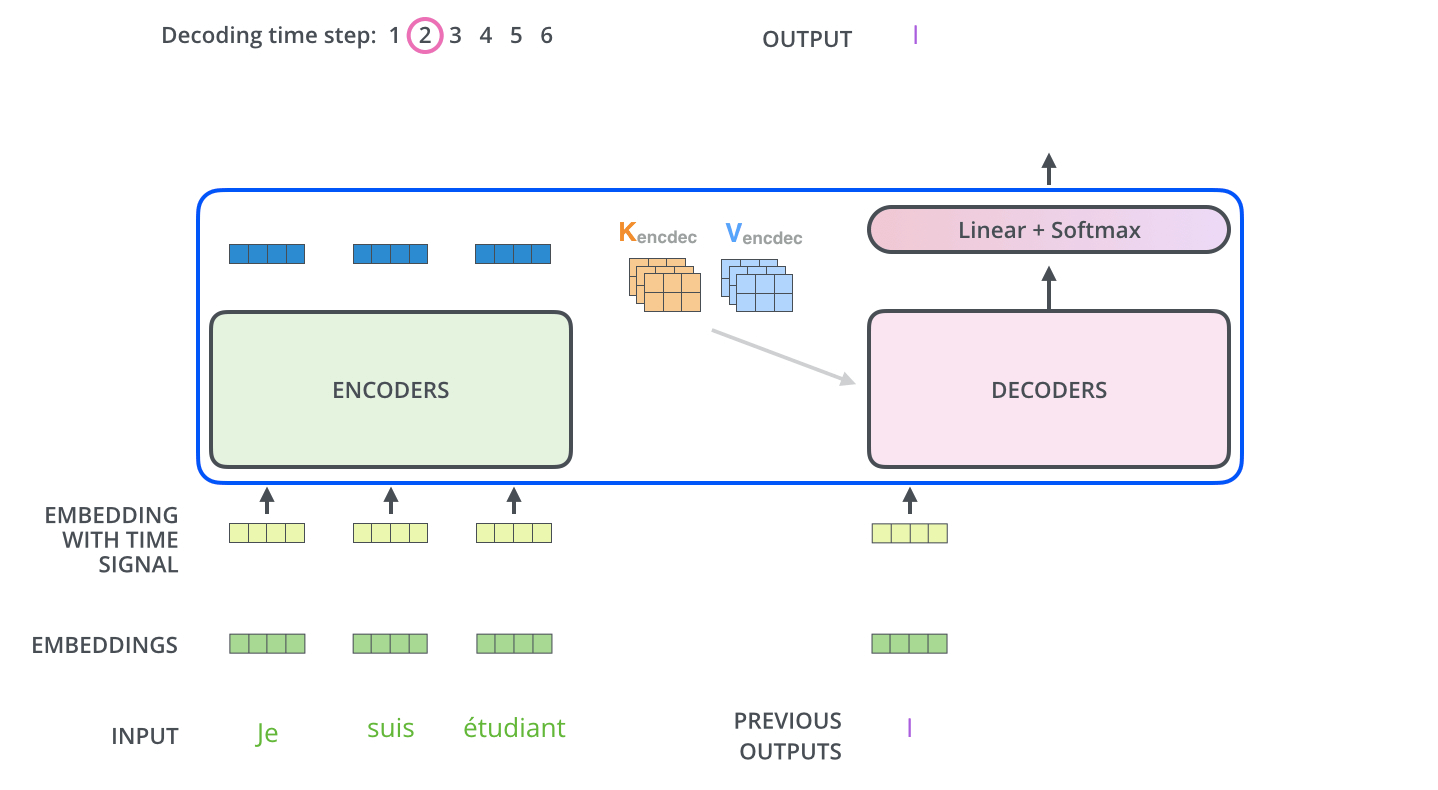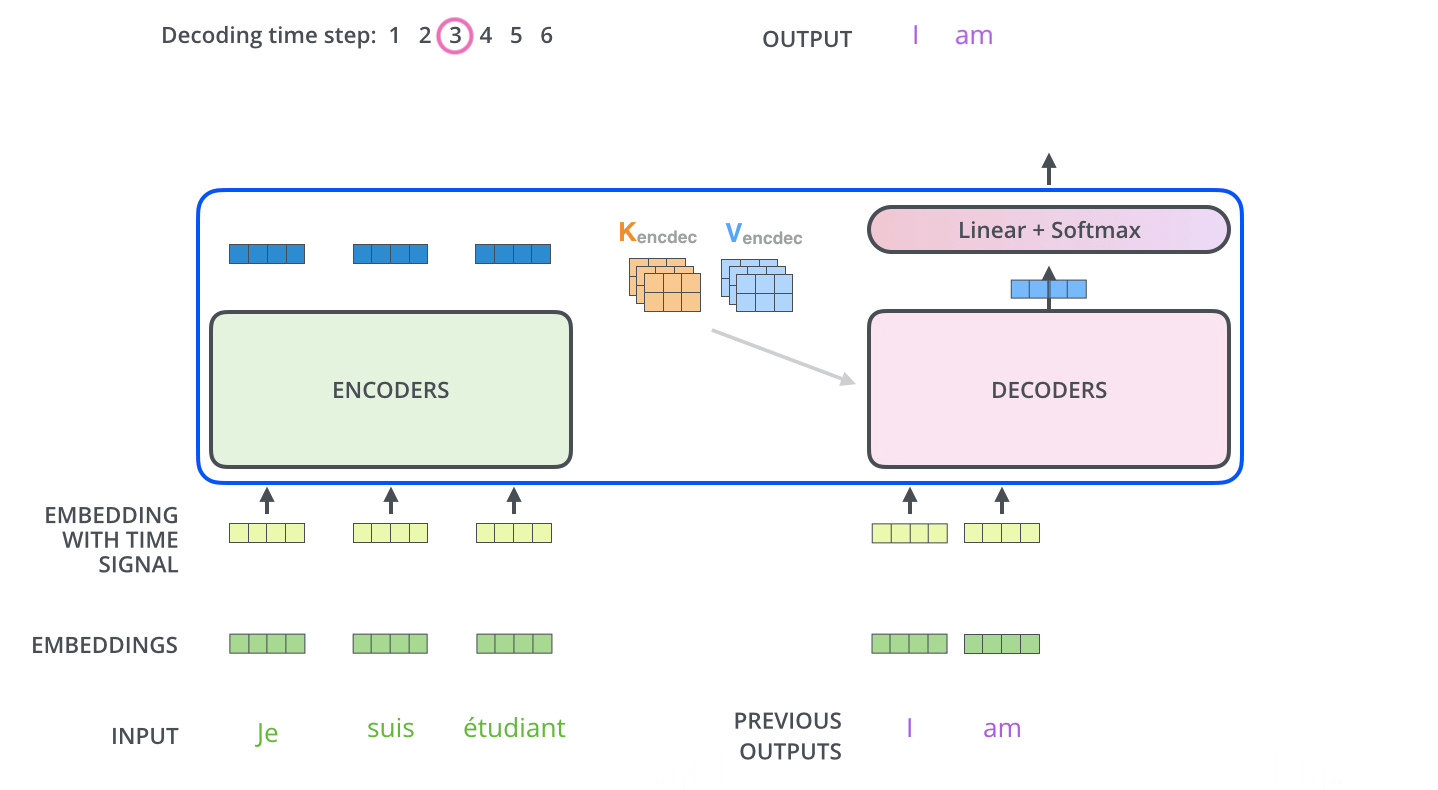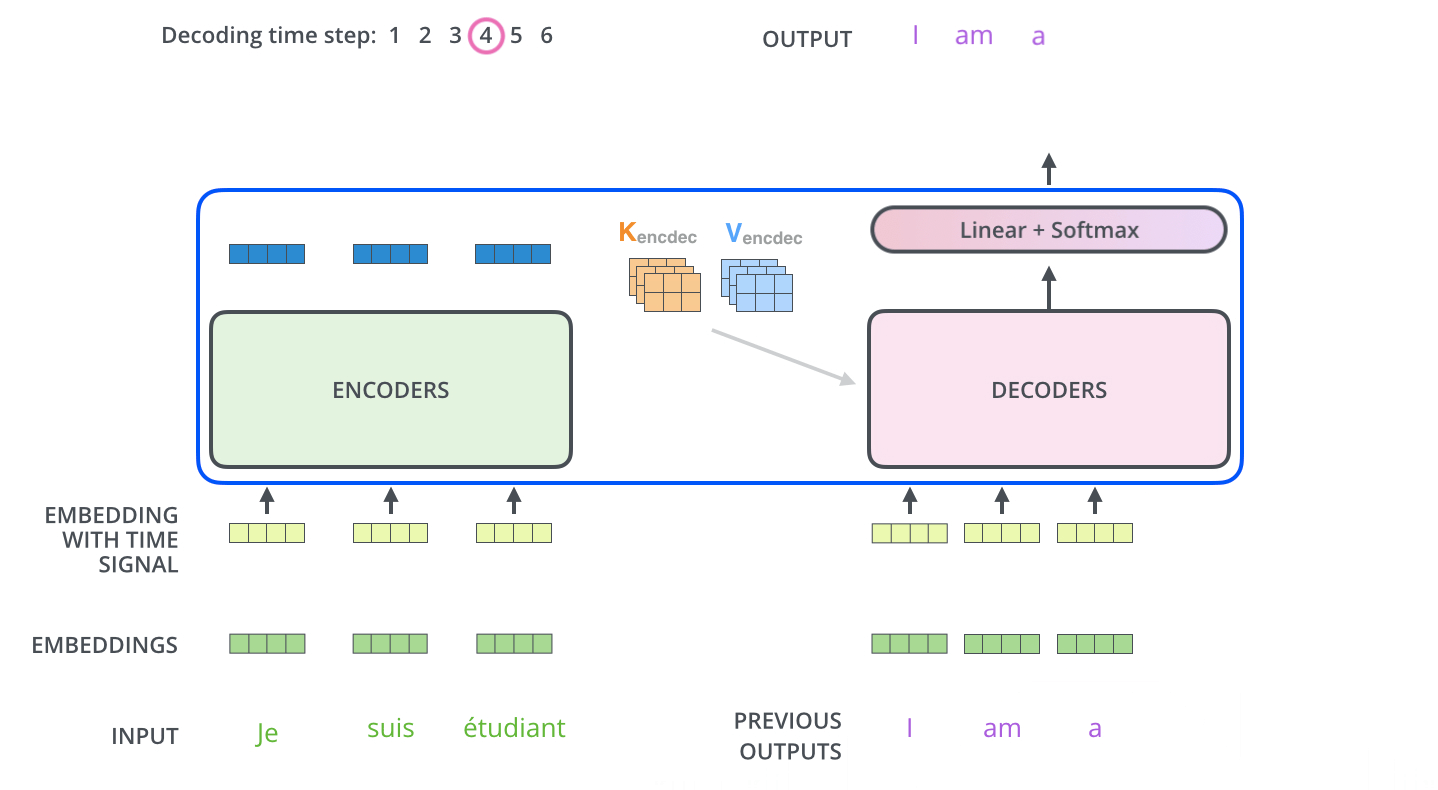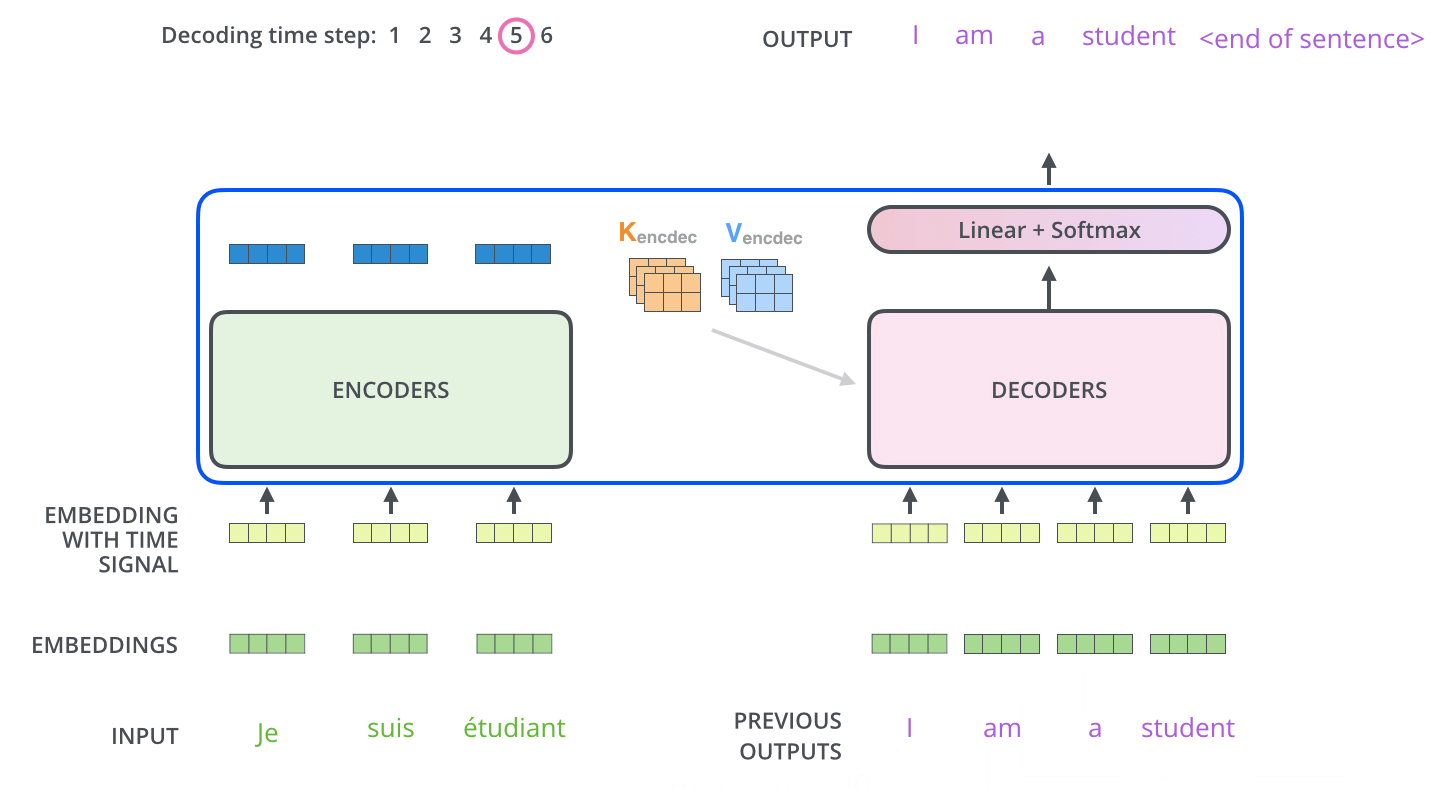
.
. ( –inf) .
«-» , , , , .
. ? .
– , , , , (logits vector).
10 (« » ), . , 10 000 – . .
( , 1). .
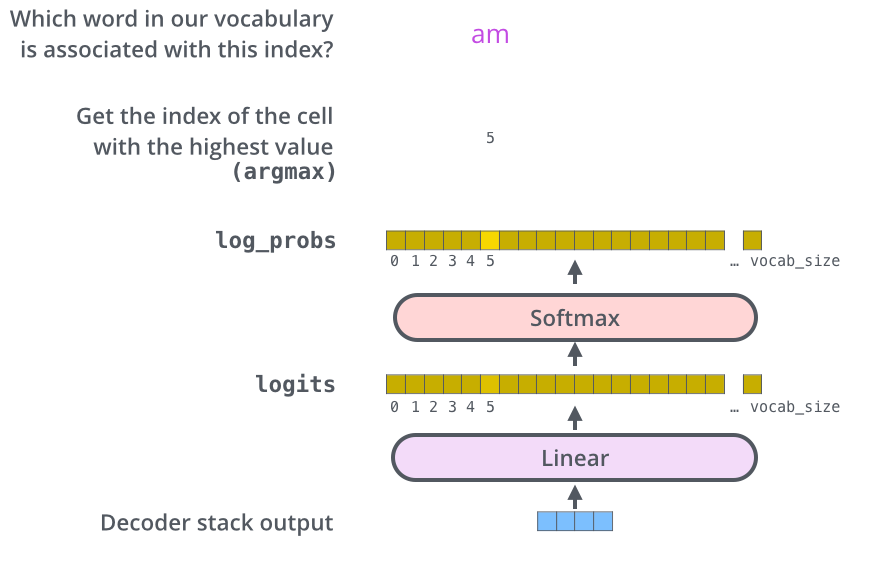
, , .
, , , , .
, . .. , .
, 6 («a», «am», «i», «thanks», «student» «<eos>» (« »).
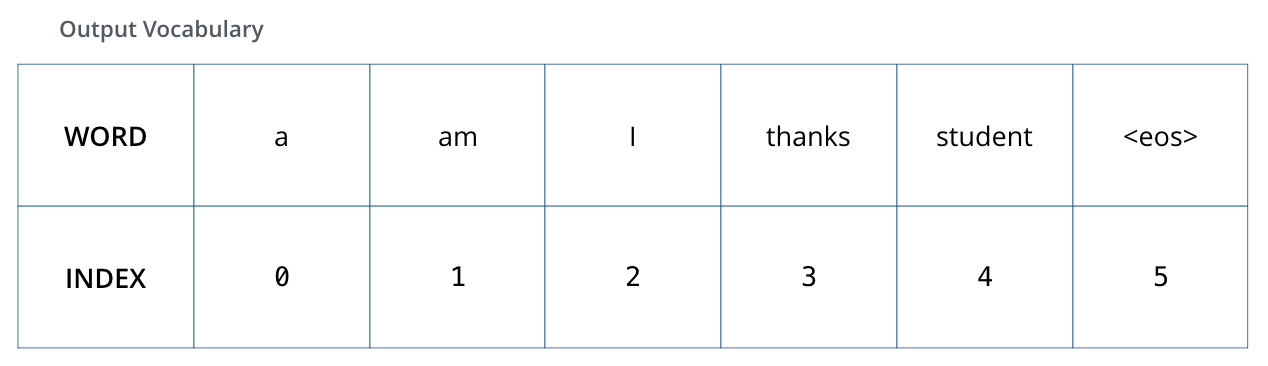
.
, (, one-hot-). , «am», :
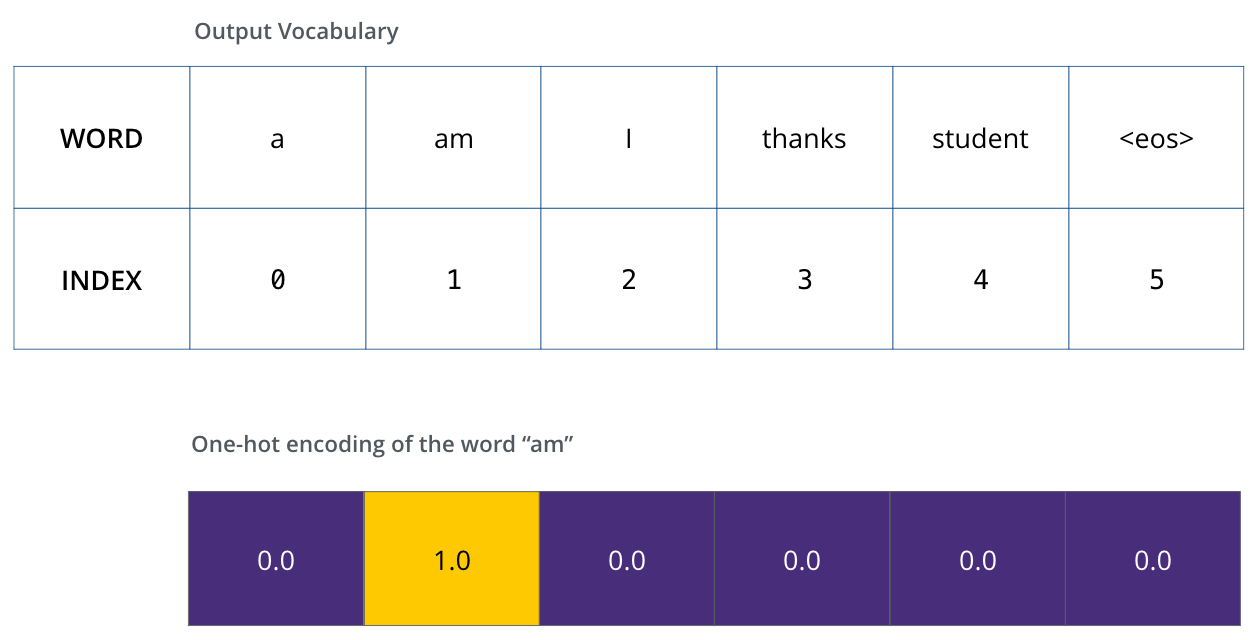
: one-hot- .
(loss function) – , , , .
, . – «merci» «thanks».
, , , «thanks». .. , .
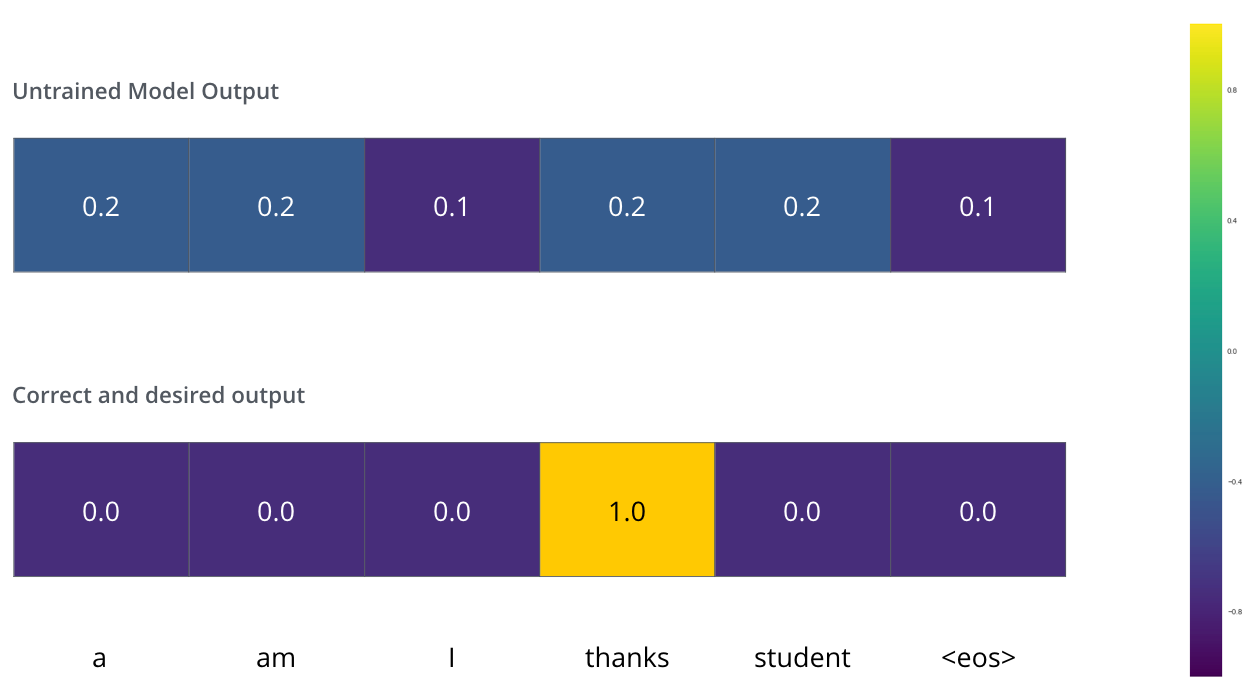
() , /. , , , .
? . , . -.
, . . , «je suis étudiant» – «I am a student». , , , :
- (6 , – 3000 10000);
- , «i»;
- , «am»;
- .. , .
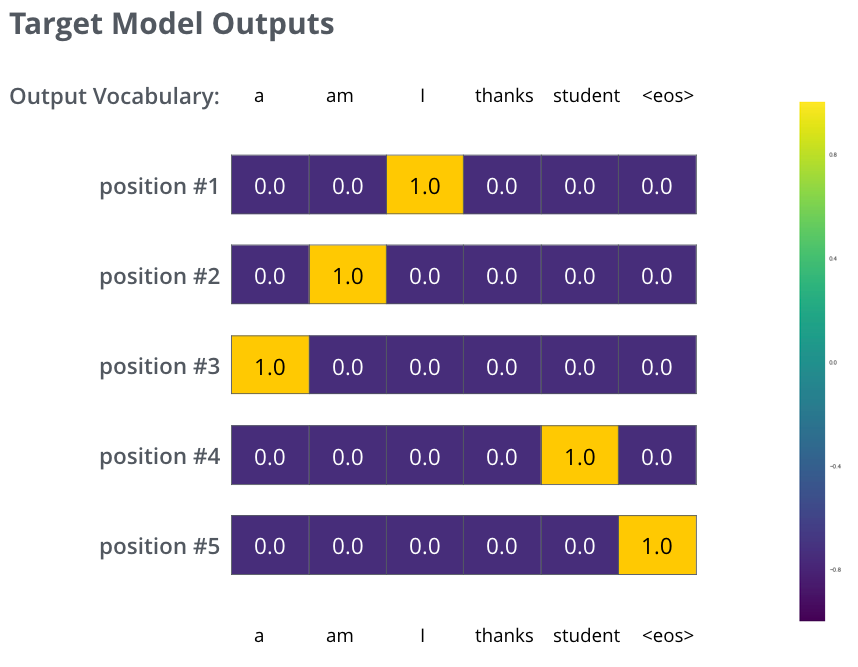
, :
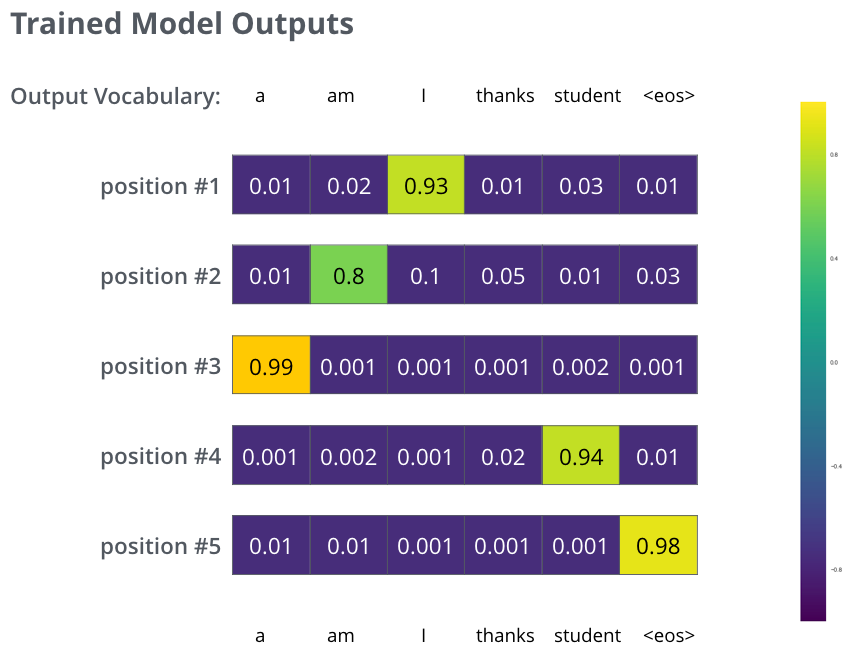
, . , , (.: ). , , , – , .
, , , , . , (greedy decoding). – , , 2 ( , «I» «a») , , : , «I», , , «a». , , . #2 #3 .. « » (beam search). (beam_size) (.. #1 #2), - (top_beams) ( ). .
, . , :
:
Autoren