Katastrophale Wolke: Wie es funktioniert
Hallo Habr!Nach den Neujahrsferien haben wir eine katastrophenresistente Cloud basierend auf zwei Standorten neu gestartet. Heute erklären wir Ihnen, wie es funktioniert, und zeigen, was mit virtuellen Clientmaschinen passiert, wenn einzelne Clusterelemente ausfallen und die gesamte Site ausfällt (Spoiler - mit ihnen ist alles in Ordnung). Katastrophensicherer Cloud-Speicher am OST-Standort.
Katastrophensicherer Cloud-Speicher am OST-Standort.Was ist innen
Unter der Haube des Clusters befinden sich Cisco UCS-Server mit VMware ESXi-Hypervisor, zwei INFINIDAT InfiniBox F2240-Speichersysteme, Cisco Nexus-Netzwerkgeräte sowie Brocade SAN-Switches. Der Cluster ist in zwei Standorte unterteilt - OST und NORD, d. H. In jedem Rechenzentrum ein identischer Satz von Geräten. Eigentlich macht es das katastrophal.Innerhalb einer Plattform werden auch die Hauptelemente dupliziert (Hosts, SAN-Switches, Netzwerkkarte).Zwei Standorte sind durch dedizierte Glasfaserpfade verbunden, die ebenfalls reserviert sind.Ein paar Worte zur Lagerung. Die erste katastrophenresistente Cloud, die wir auf NetApp aufgebaut haben. Hier wurde INFINIDAT ausgewählt, und hier ist der Grund:- Aktiv-Aktiv-Replikationsoption. Dadurch bleibt die virtuelle Maschine auch dann betriebsbereit, wenn eines der Speichersysteme vollständig ausfällt. Ich werde Ihnen später mehr über die Replikation erzählen.
- Drei Festplattencontroller für erhöhte Systemstabilität. Normalerweise gibt es zwei.
- Fertige Lösung. Zu uns kam ein bereits montiertes Rack, das nur mit dem Netzwerk verbunden und konfiguriert werden muss.
- Aufmerksamer technischer Support. Die INFINIDAT-Ingenieure analysieren ständig Protokolle und Ereignisse von Speichersystemen, installieren neue Versionen in der Firmware und helfen bei der Konfiguration.
Hier einige Fotos vom Auspacken:

Wie funktioniert es
Die Cloud ist bereits in sich selbst belastbar. Es schützt den Client vor einzelnen Hardware- und Softwarefehlern. Katastrophal hilft beim Schutz vor Massenfehlern am selben Standort: zum Beispiel Ausfall des Speichersystems (oder des SDS-Clusters, was häufig vorkommt :)), Massenfehler im Speichernetzwerk und vieles mehr. Gut und vor allem: Eine solche Wolke wird gespeichert, wenn ein ganzer Standort aufgrund von Feuer, Stromausfall, Raider-Gefangennahme und außerirdischen Landungen nicht mehr zugänglich ist .In all diesen Fällen werden virtuelle Client-Maschinen weiterhin ausgeführt, und hier ist der Grund dafür.Das Cluster-Schema ist so konzipiert, dass jeder ESXi-Host mit virtuellen Client-Maschinen auf eines von zwei Speichersystemen zugreifen kann. Wenn der Speicher am OST-Standort ausfällt, funktionieren die virtuellen Maschinen weiterhin: Die Hosts, auf denen sie arbeiten, greifen auf den Speicher in NORD für Daten zu. So sieht das Verbindungsdiagramm im Cluster aus.Dies ist möglich, weil zwischen den SAN-Fabriken der beiden Standorte eine Inter-Switch-Verbindung konfiguriert ist: Der Fabric A OST SAN-Switch ist ähnlich wie Fabric B SAN-Switches mit dem Fabric A NORD SAN-Switch verbunden.Damit all diese Feinheiten von SAN-Fabriken sinnvoll sind, wird die Active-Active-Replikation zwischen den beiden Speichersystemen konfiguriert: Informationen werden fast gleichzeitig in das lokale und das Remote-Speichersystem geschrieben, RPO = 0. Es stellt sich heraus, dass auf einem SHD die Originaldaten gespeichert sind, auf dem anderen - ihrer Replik. Daten werden auf Speichervolumebene repliziert, und VM-Daten (Festplatten, Konfigurationsdatei, Auslagerungsdatei usw.) sind bereits auf ihnen gespeichert.Der ESXi-Host sieht das primäre Volume und sein Replikat als ein einzelnes Speichergerät. Es gibt 24 Pfade vom ESXi-Host zu jedem Festplattengerät:12 Pfade ordnen es dem lokalen Speicher zu (optimale Pfade) und die restlichen 12 - dem Remote-Speicher (nicht optimale Pfade). In einer normalen Situation greift ESXi über „optimale“ Pfade auf Daten im lokalen Speicher zu. Wenn dieses Speichersystem ausfällt, verliert ESXi seine optimalen Pfade und wechselt zu „nicht optimalen“. So sieht es im Diagramm aus.
So sieht das Verbindungsdiagramm im Cluster aus.Dies ist möglich, weil zwischen den SAN-Fabriken der beiden Standorte eine Inter-Switch-Verbindung konfiguriert ist: Der Fabric A OST SAN-Switch ist ähnlich wie Fabric B SAN-Switches mit dem Fabric A NORD SAN-Switch verbunden.Damit all diese Feinheiten von SAN-Fabriken sinnvoll sind, wird die Active-Active-Replikation zwischen den beiden Speichersystemen konfiguriert: Informationen werden fast gleichzeitig in das lokale und das Remote-Speichersystem geschrieben, RPO = 0. Es stellt sich heraus, dass auf einem SHD die Originaldaten gespeichert sind, auf dem anderen - ihrer Replik. Daten werden auf Speichervolumebene repliziert, und VM-Daten (Festplatten, Konfigurationsdatei, Auslagerungsdatei usw.) sind bereits auf ihnen gespeichert.Der ESXi-Host sieht das primäre Volume und sein Replikat als ein einzelnes Speichergerät. Es gibt 24 Pfade vom ESXi-Host zu jedem Festplattengerät:12 Pfade ordnen es dem lokalen Speicher zu (optimale Pfade) und die restlichen 12 - dem Remote-Speicher (nicht optimale Pfade). In einer normalen Situation greift ESXi über „optimale“ Pfade auf Daten im lokalen Speicher zu. Wenn dieses Speichersystem ausfällt, verliert ESXi seine optimalen Pfade und wechselt zu „nicht optimalen“. So sieht es im Diagramm aus. Das Schema eines katastrophenresistenten Clusters.Alle Client-Netzwerke werden an beiden Standorten über eine gemeinsame Netzwerkfactory eingerichtet. Provider Edge (PE) wird an jedem Standort ausgeführt, an dem Client-Netzwerke beendet werden. PEs werden zu einem einzigen Cluster zusammengefasst. Wenn PE an einem Standort fehlschlägt, wird der gesamte Datenverkehr an den zweiten Standort umgeleitet. Dank dessen bleiben virtuelle Maschinen von der Site ohne PE über das Netzwerk für den Client verfügbar.Lassen Sie uns nun sehen, was mit den virtuellen Client-Maschinen bei verschiedenen Fehlern passieren wird. Beginnen wir mit den leichtesten Optionen und enden mit den schwerwiegendsten - dem Ausfall der gesamten Site. In den Beispielen ist der Hauptstandort OST und die Sicherung mit Datenreplikaten NORD.
Das Schema eines katastrophenresistenten Clusters.Alle Client-Netzwerke werden an beiden Standorten über eine gemeinsame Netzwerkfactory eingerichtet. Provider Edge (PE) wird an jedem Standort ausgeführt, an dem Client-Netzwerke beendet werden. PEs werden zu einem einzigen Cluster zusammengefasst. Wenn PE an einem Standort fehlschlägt, wird der gesamte Datenverkehr an den zweiten Standort umgeleitet. Dank dessen bleiben virtuelle Maschinen von der Site ohne PE über das Netzwerk für den Client verfügbar.Lassen Sie uns nun sehen, was mit den virtuellen Client-Maschinen bei verschiedenen Fehlern passieren wird. Beginnen wir mit den leichtesten Optionen und enden mit den schwerwiegendsten - dem Ausfall der gesamten Site. In den Beispielen ist der Hauptstandort OST und die Sicherung mit Datenreplikaten NORD.Was passiert mit einer virtuellen Client-Maschine, wenn ...
Replikationsverbindung schlägt fehl. Die Replikation zwischen den Speichersystemen der beiden Standorte wird gestoppt.ESXi funktioniert nur mit lokalen Festplattengeräten (entlang der optimalen Pfade).Virtuelle Maschinen funktionieren weiterhin. Es gibt eine Lücke ISL (Inter-Switch Link). Der Fall ist unwahrscheinlich. Es sei denn, ein verrückter Bagger gräbt mehrere optische Routen gleichzeitig aus, die über unabhängige Routen verlaufen und über verschiedene Eingänge zu den Standorten gebracht werden. Aber wie auch immer. In diesem Fall verlieren ESXi-Hosts die Hälfte ihrer Pfade und können nur auf ihren lokalen Speicher zugreifen. Replikate werden gesammelt, aber Hosts können nicht darauf zugreifen.Virtuelle Maschinen funktionieren normal.
Es gibt eine Lücke ISL (Inter-Switch Link). Der Fall ist unwahrscheinlich. Es sei denn, ein verrückter Bagger gräbt mehrere optische Routen gleichzeitig aus, die über unabhängige Routen verlaufen und über verschiedene Eingänge zu den Standorten gebracht werden. Aber wie auch immer. In diesem Fall verlieren ESXi-Hosts die Hälfte ihrer Pfade und können nur auf ihren lokalen Speicher zugreifen. Replikate werden gesammelt, aber Hosts können nicht darauf zugreifen.Virtuelle Maschinen funktionieren normal. Verweigert einen SAN-Switch an einem der Standorte.ESXi-Hosts verlieren einige ihrer Speicherpfade. In diesem Fall funktionieren die Hosts auf der Site, auf der der Switch fehlgeschlagen ist, nur über ihren eigenen HBA.Gleichzeitig funktionieren virtuelle Maschinen weiterhin normal.
Verweigert einen SAN-Switch an einem der Standorte.ESXi-Hosts verlieren einige ihrer Speicherpfade. In diesem Fall funktionieren die Hosts auf der Site, auf der der Switch fehlgeschlagen ist, nur über ihren eigenen HBA.Gleichzeitig funktionieren virtuelle Maschinen weiterhin normal. Alle SAN-Switches an einem der Standorte schlagen fehl. Nehmen wir an, eine solche Katastrophe ist am OST-Standort passiert. In diesem Fall verlieren ESXi-Hosts auf dieser Site alle Pfade zu ihren Festplattengeräten. Der Standard-VMware vSphere HA-Mechanismus kommt ins Spiel: Er startet alle virtuellen Maschinen der OST-Plattform in NORD nach maximal 140 Sekunden neu.Virtuelle Maschinen, die auf den Hosts der NORD-Site ausgeführt werden, funktionieren normal.
Alle SAN-Switches an einem der Standorte schlagen fehl. Nehmen wir an, eine solche Katastrophe ist am OST-Standort passiert. In diesem Fall verlieren ESXi-Hosts auf dieser Site alle Pfade zu ihren Festplattengeräten. Der Standard-VMware vSphere HA-Mechanismus kommt ins Spiel: Er startet alle virtuellen Maschinen der OST-Plattform in NORD nach maximal 140 Sekunden neu.Virtuelle Maschinen, die auf den Hosts der NORD-Site ausgeführt werden, funktionieren normal.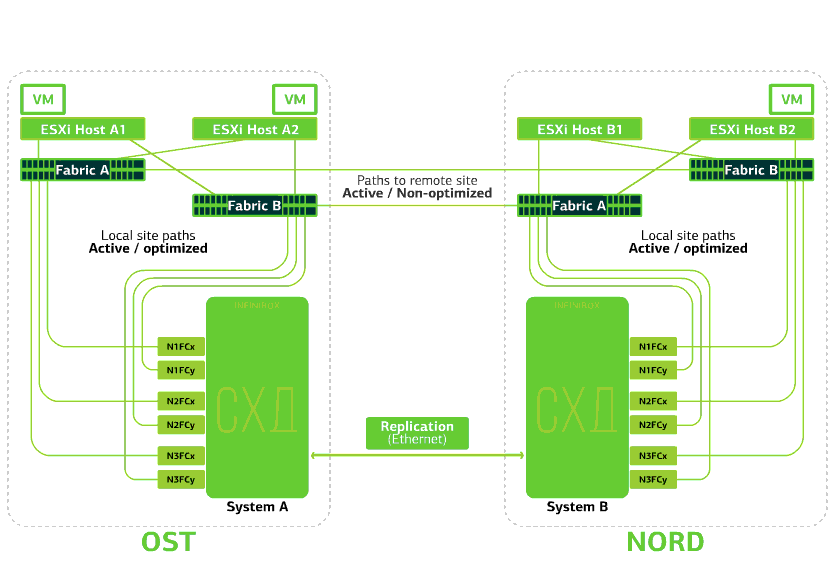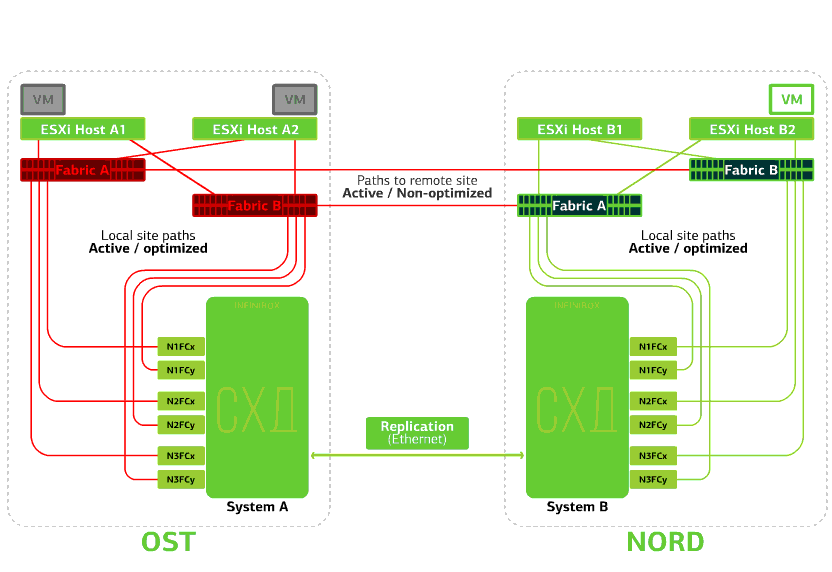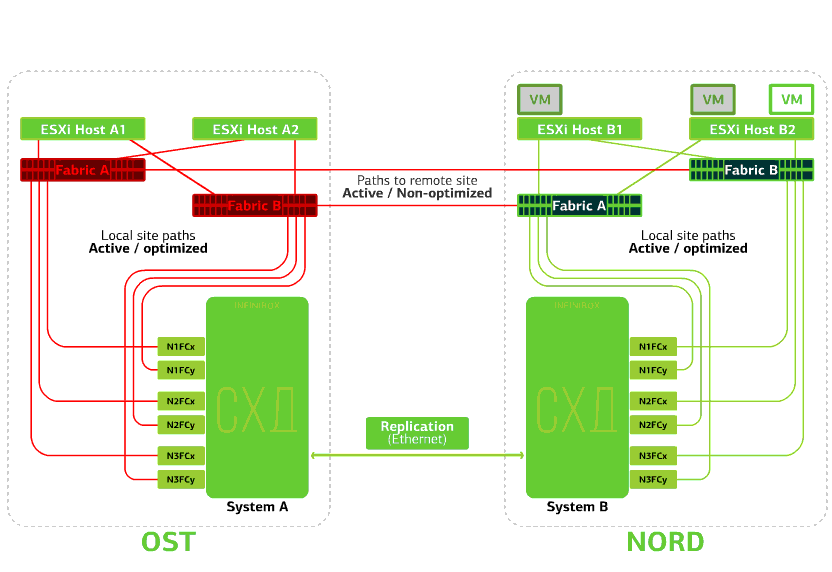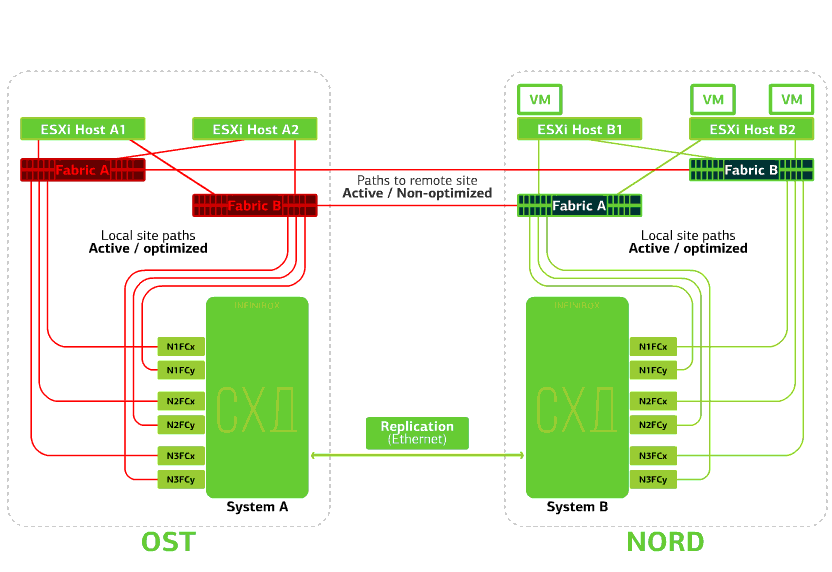 Verweigert den ESXi-Host an einer Site.Hier funktioniert der vSphere HA-Mechanismus wieder: Virtuelle Maschinen von einem ausgefallenen Host werden auf anderen Hosts neu gestartet - auf demselben oder einem Remote-Standort. Die Neustartzeit der virtuellen Maschine beträgt bis zu 1 Minute.Wenn alle ESXi-Hosts der OST-Plattform ausfallen, gibt es keine Optionen: VMs werden auf einem anderen neu gestartet. Die Neustartzeit ist dieselbe.
Verweigert den ESXi-Host an einer Site.Hier funktioniert der vSphere HA-Mechanismus wieder: Virtuelle Maschinen von einem ausgefallenen Host werden auf anderen Hosts neu gestartet - auf demselben oder einem Remote-Standort. Die Neustartzeit der virtuellen Maschine beträgt bis zu 1 Minute.Wenn alle ESXi-Hosts der OST-Plattform ausfallen, gibt es keine Optionen: VMs werden auf einem anderen neu gestartet. Die Neustartzeit ist dieselbe.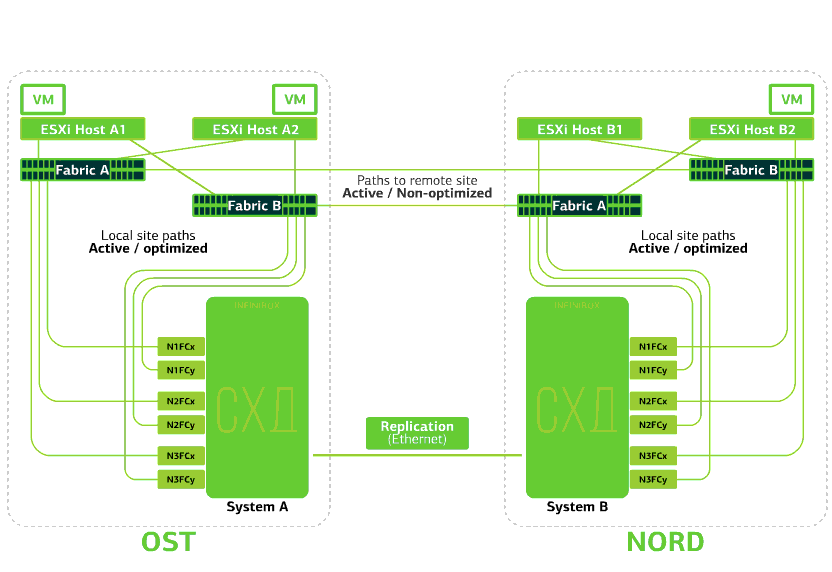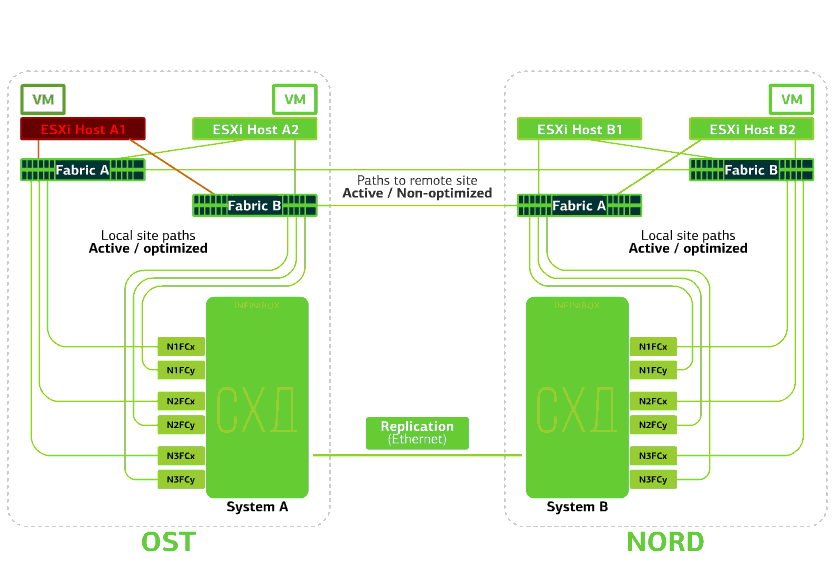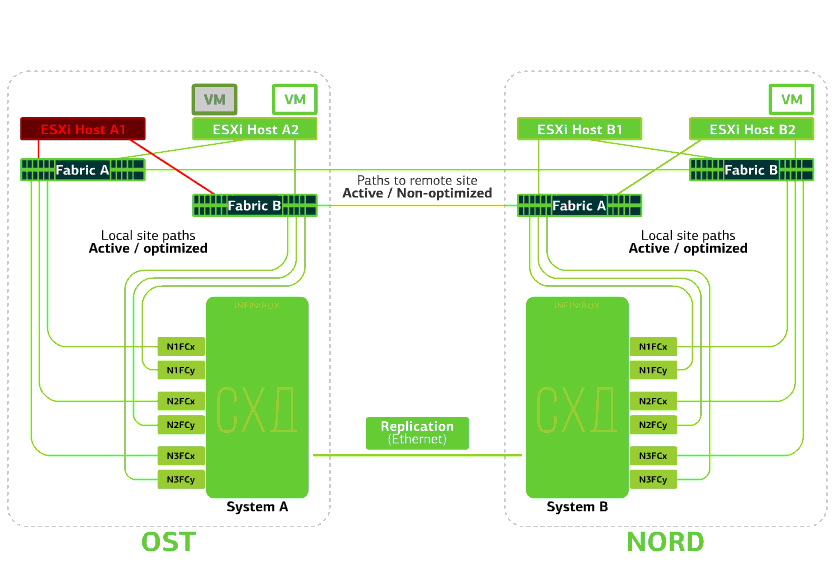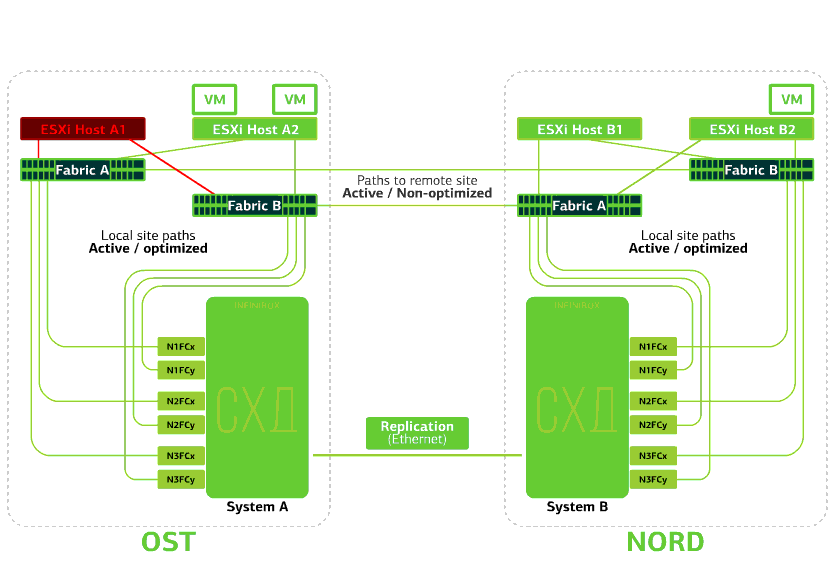 Verweigert die Speicherung auf derselben Site. Angenommen, das Speichersystem wurde am OST-Standort abgelehnt. Anschließend wechseln die OST ESXi-Hosts zur Arbeit mit Speicherreplikaten in NORD. Nachdem das ausgefallene Speichersystem zum System zurückgekehrt ist, findet eine erzwungene Replikation statt. Die OST ESXi-Hosts beginnen erneut mit der Kontaktaufnahme mit dem lokalen Speichersystem.Virtuelle Maschinen haben die ganze Zeit gearbeitet.
Verweigert die Speicherung auf derselben Site. Angenommen, das Speichersystem wurde am OST-Standort abgelehnt. Anschließend wechseln die OST ESXi-Hosts zur Arbeit mit Speicherreplikaten in NORD. Nachdem das ausgefallene Speichersystem zum System zurückgekehrt ist, findet eine erzwungene Replikation statt. Die OST ESXi-Hosts beginnen erneut mit der Kontaktaufnahme mit dem lokalen Speichersystem.Virtuelle Maschinen haben die ganze Zeit gearbeitet. Schlägt eine der Sites fehl.In diesem Fall werden alle virtuellen Maschinen am Sicherungsstandort über den vSphere HA-Mechanismus neu gestartet. VM-Neustartzeit - 140 Sekunden. In diesem Fall werden alle Netzwerkeinstellungen der virtuellen Maschine gespeichert und stehen dem Client über das Netzwerk zur Verfügung.Um die Computer auf dem Sicherungsstandort problemlos neu zu starten, ist jeder Standort nur halb voll. Die zweite Hälfte ist die Reserve für den Fall, dass alle virtuellen Maschinen vom zweiten verletzten Standort entfernt werden.
Schlägt eine der Sites fehl.In diesem Fall werden alle virtuellen Maschinen am Sicherungsstandort über den vSphere HA-Mechanismus neu gestartet. VM-Neustartzeit - 140 Sekunden. In diesem Fall werden alle Netzwerkeinstellungen der virtuellen Maschine gespeichert und stehen dem Client über das Netzwerk zur Verfügung.Um die Computer auf dem Sicherungsstandort problemlos neu zu starten, ist jeder Standort nur halb voll. Die zweite Hälfte ist die Reserve für den Fall, dass alle virtuellen Maschinen vom zweiten verletzten Standort entfernt werden.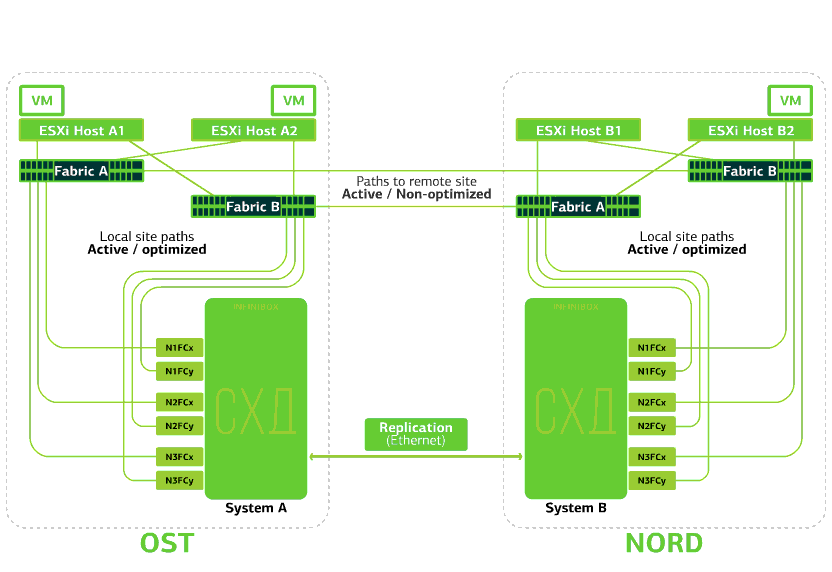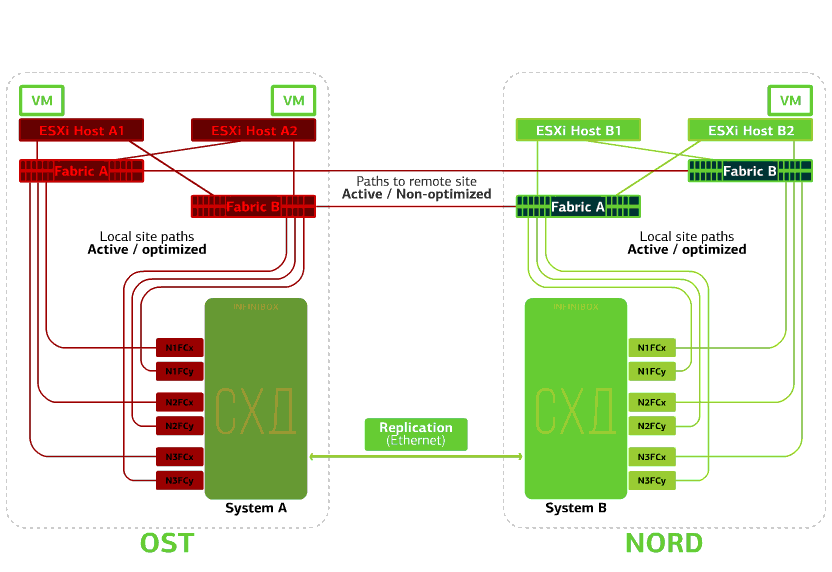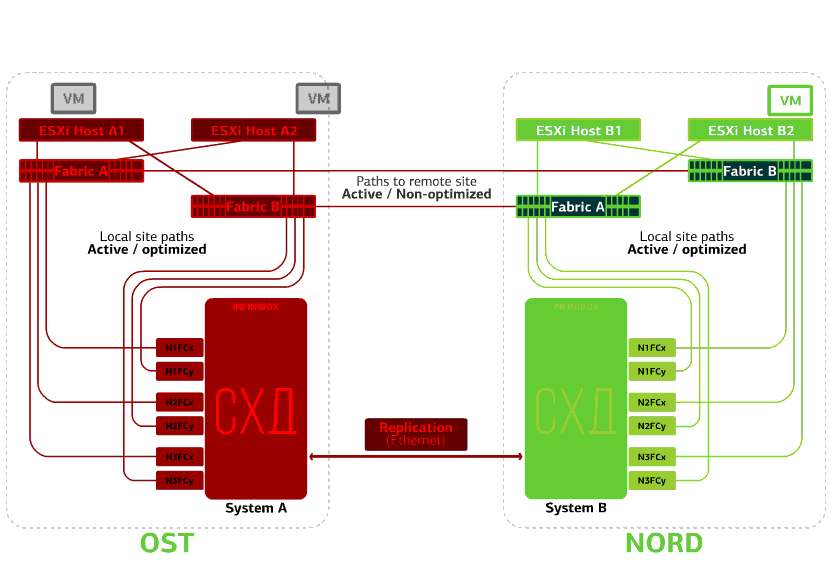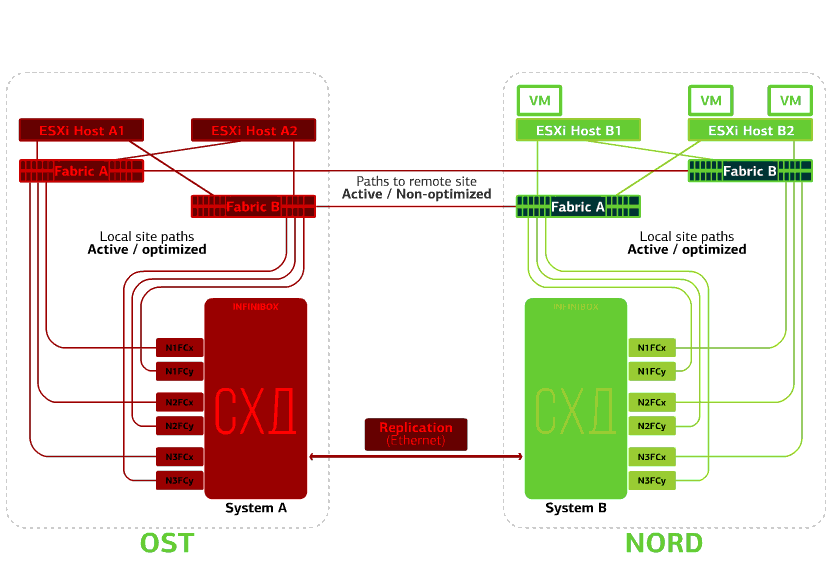 Eine katastrophensichere Cloud, die auf zwei Rechenzentren basiert, schützt vor solchen Fehlern.Dieses Vergnügen ist nicht billig, da Sie zusätzlich zu den Hauptressourcen eine Reserve auf dem zweiten Standort benötigen. Daher platzieren sie geschäftskritische Services in einer solchen Cloud, deren lange Ausfallzeit große finanzielle und Reputationsverluste verursacht, oder wenn dem Informationssystem von den Aufsichtsbehörden oder internen Vorschriften des Unternehmens Anforderungen an die Katastrophenverträglichkeit auferlegt werden.Quellen:
Eine katastrophensichere Cloud, die auf zwei Rechenzentren basiert, schützt vor solchen Fehlern.Dieses Vergnügen ist nicht billig, da Sie zusätzlich zu den Hauptressourcen eine Reserve auf dem zweiten Standort benötigen. Daher platzieren sie geschäftskritische Services in einer solchen Cloud, deren lange Ausfallzeit große finanzielle und Reputationsverluste verursacht, oder wenn dem Informationssystem von den Aufsichtsbehörden oder internen Vorschriften des Unternehmens Anforderungen an die Katastrophenverträglichkeit auferlegt werden.Quellen:- www.infinidat.com/sites/default/files/resource-pdfs/DS-INFBOX-190331-US_0.pdf
- support.infinidat.com/hc/en-us/articles/207057109-InfiniBox-best-practices-guides
Source: https://habr.com/ru/post/undefined/
All Articles