يكتسب NiFi المزيد والمزيد من الشعبية ومع كل إصدار جديد يحصل على المزيد والمزيد من الأدوات للعمل مع البيانات. ومع ذلك ، قد يكون من الضروري أن يكون لديك أداة خاصة بك لحل مشكلة معينة. لدى Apache Nifi أكثر من 300 معالج في الحزمة الأساسية. معالج نيفي إنها لبنة البناء الرئيسية لإنشاء تدفق البيانات في نظام NiFi البيئي. توفر المعالجات واجهة تتيح من خلالها NiFi الوصول إلى ملف التدفق وسماته ومحتواه. سيوفر المعالج المخصص الطاقة والوقت واهتمام المستخدم ، لأنه بدلاً من العديد من عناصر المعالج البسيطة ، سيتم عرض عنصر واحد فقط في الواجهة وسيتم تنفيذ عنصر واحد فقط (جيدًا ، أو كم تكتب). مثل المعالجات القياسية ، يسمح لك المعالج المخصص بإجراء عمليات مختلفة ومعالجة محتويات ملف التدفق. سنتحدث اليوم عن الأدوات القياسية لتوسيع الوظائف.
إنها لبنة البناء الرئيسية لإنشاء تدفق البيانات في نظام NiFi البيئي. توفر المعالجات واجهة تتيح من خلالها NiFi الوصول إلى ملف التدفق وسماته ومحتواه. سيوفر المعالج المخصص الطاقة والوقت واهتمام المستخدم ، لأنه بدلاً من العديد من عناصر المعالج البسيطة ، سيتم عرض عنصر واحد فقط في الواجهة وسيتم تنفيذ عنصر واحد فقط (جيدًا ، أو كم تكتب). مثل المعالجات القياسية ، يسمح لك المعالج المخصص بإجراء عمليات مختلفة ومعالجة محتويات ملف التدفق. سنتحدث اليوم عن الأدوات القياسية لتوسيع الوظائف.تنفيذ
ExecuteScript هو معالج عالمي مصمم لتطبيق منطق الأعمال بلغة برمجة (Groovy ، Jython ، Javascript ، JRuby). يسمح لك هذا النهج بالحصول بسرعة على الوظيفة المطلوبة. لتوفير الوصول إلى مكونات NiFi في برنامج نصي ، من الممكن استخدام المتغيرات التالية:الجلسة : متغير من نوع org.apache.nifi.processor.ProcessSession. يتيح لك المتغير تنفيذ العمليات باستخدام ملف التدفق ، مثل إنشاء () و putAttribute () و Transfer () ، وكذلك قراءة () والكتابة ().السياق : org.apache.nifi.processor.ProcessContext. يمكن استخدامه للحصول على خصائص المعالج والعلاقات وخدمات التحكم و StateManager.REL_SUCCESS : العلاقة "النجاح".REL_FAILURE : علاقة الفشلالخصائص الديناميكية : يتم تمرير الخصائص الديناميكية المحددة في ExecuteScript إلى محرك البرنامج النصي كمتغيرات ، يتم تعيينها كخاصية PropertyValue. هذا يسمح لك بالحصول على قيمة الخاصية ، وتحويل القيمة إلى نوع البيانات المناسب ، على سبيل المثال ، المنطقي ، وماإلى ذلك. للاستخدام ، ما عليك سوى تحديد Script Engineوتحديد موقع الملف Script Fileباستخدام البرنامج النصي أو البرنامج النصي نفسه Script Body.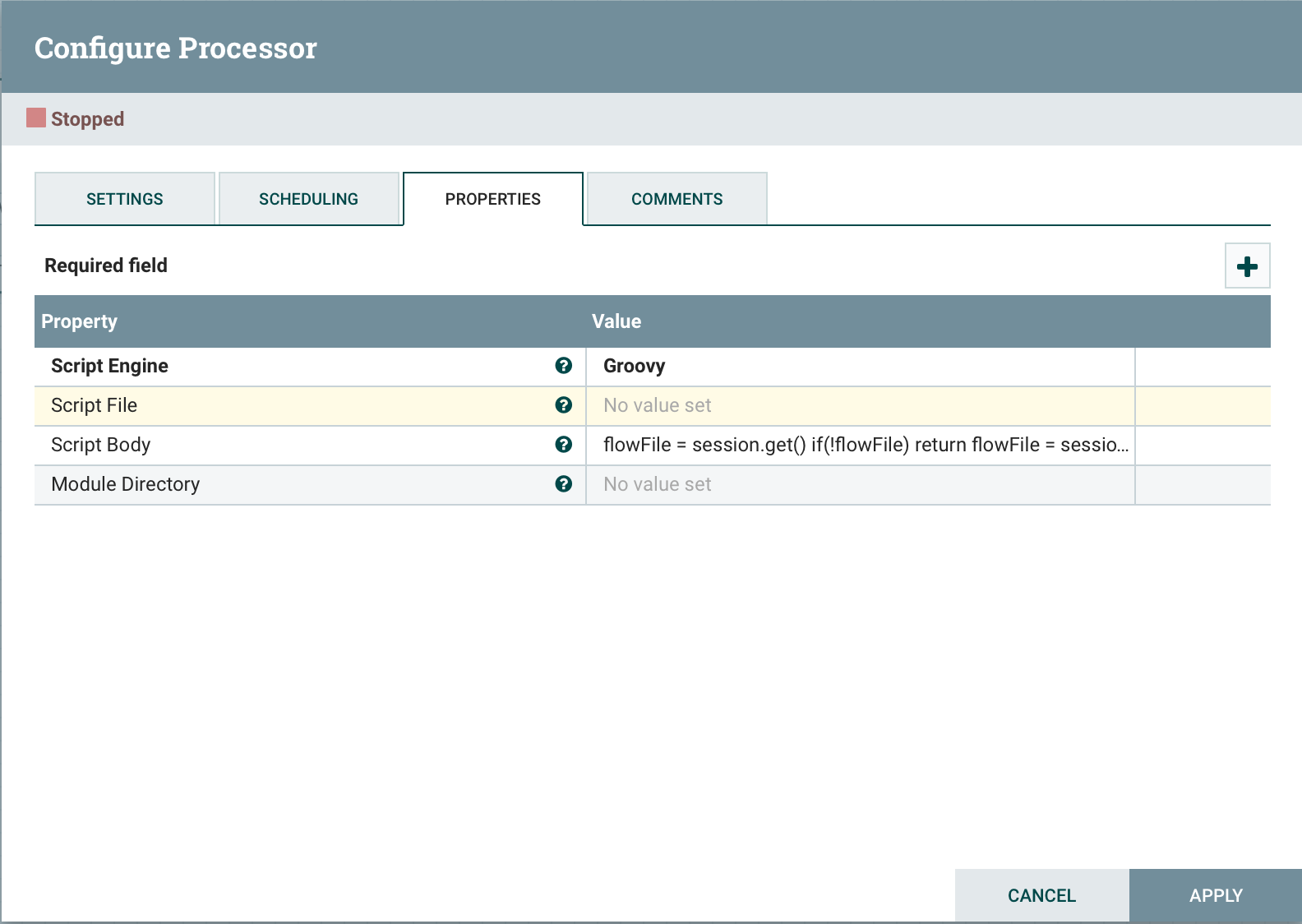 دعونا نلقي نظرة على بضعة أمثلة:احصل على ملف دفق واحد من قائمة الانتظار
دعونا نلقي نظرة على بضعة أمثلة:احصل على ملف دفق واحد من قائمة الانتظارflowFile = session.get()
if(!flowFile) return
إنشاء ملف FlowFile جديدflowFile = session.create()
// Additional processing here
أضف السمة إلى FlowFileflowFile = session.get()
if(!flowFile) return
flowFile = session.putAttribute(flowFile, 'myAttr', 'myValue')
استخراج ومعالجة جميع السمات.flowFile = session.get() if(!flowFile) return
flowFile.getAttributes().each { key,value ->
// Do something with the key/value pair
}
مسجلlog.info('Found these things: {} {} {}', ['Hello',1,true] as Object[])
يمكنك استخدام الميزات المتقدمة في ExecuteScript ، ويمكن العثور على مزيد من المعلومات حول ذلك في المقالة ExecuteScript Cookbook.تنفيذ GroovyScript
يحتوي ExecuteGroovyScript على نفس الوظيفة مثل ExecuteScript ، ولكن بدلاً من حديقة حيوانات للغات الصالحة ، يمكنك استخدام واحد فقط - رائع. الميزة الرئيسية لهذا المعالج هي استخدامه الأكثر ملاءمة لخدمات الخدمة. بالإضافة إلى المجموعة القياسية من المتغيرات الجلسة ، السياق ، إلخ. يمكنك تحديد الخصائص الديناميكية باستخدام البادئة CTL و SQL. بدءًا من الإصدار 1.11 ، ظهر دعم RecordReader و Record Writer. جميع الخصائص هي HashMap ، والتي تستخدم "اسم الخدمة" كمفتاح ، والقيمة هي كائن محدد اعتمادًا على الخاصية:RecordWriter HashMap<String,RecordSetWriterFactory>
RecordReader HashMap<String,RecordReaderFactory>
SQL HashMap<String,groovy.sql.Sql>
CTL HashMap<String,ControllerService>
هذه المعلومات تجعل الحياة أسهل بالفعل. يمكننا البحث في المصادر أو البحث عن وثائق لفئة معينة.العمل مع قاعدة البياناتإذا قمنا بتعريف خاصية SQL.DB وربط DBCPService ، فسوف نصل إلى الخاصية من الرمز. SQL.DB.rows('select * from table')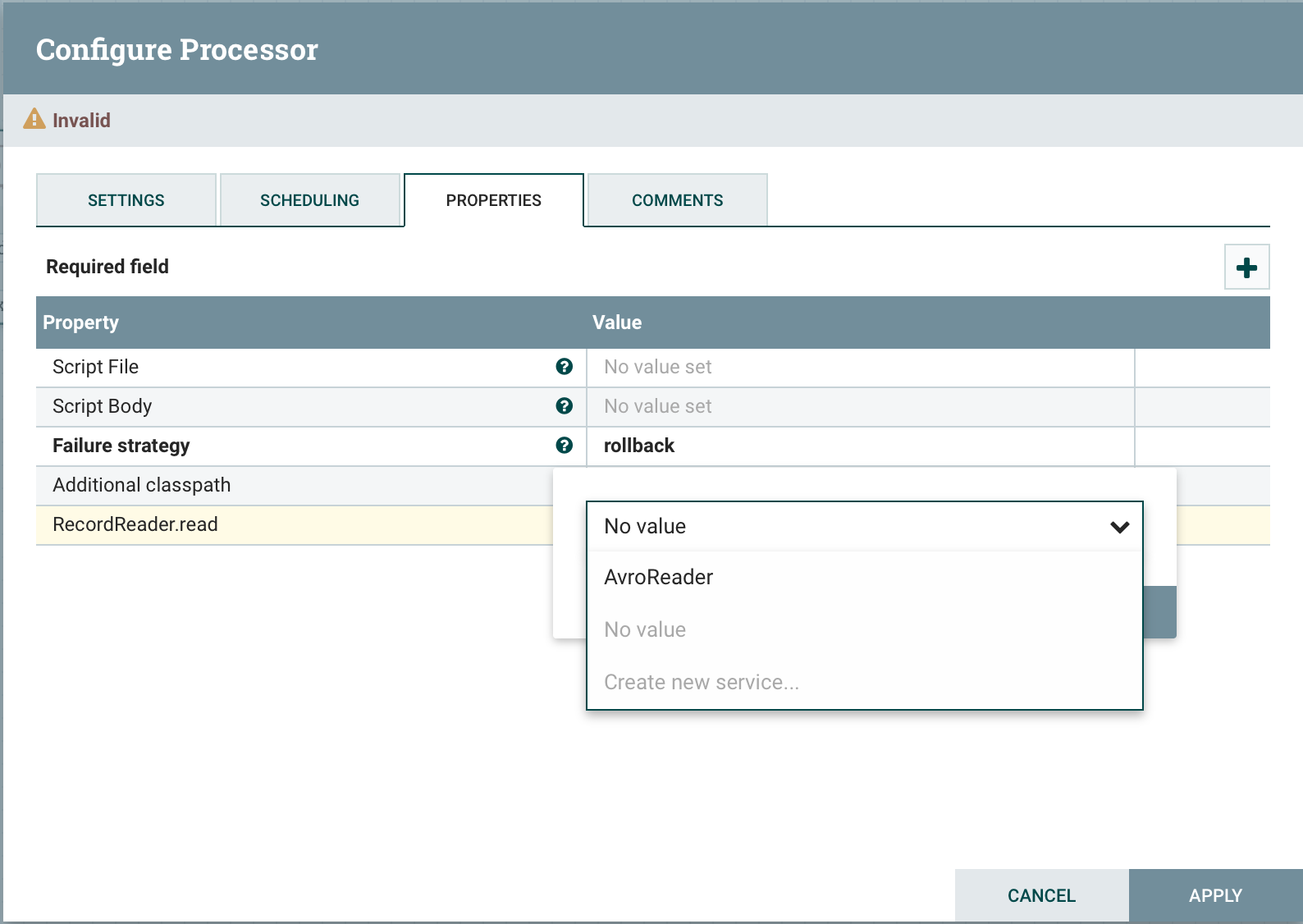 يقبل المعالج تلقائيًا اتصالاً من خدمة dbcp قبل التنفيذ ويعالج المعاملة. يتم إرجاع معاملات قاعدة البيانات تلقائيًا عند حدوث خطأ ويتم الالتزام بها في حالة نجاحها. في ExecuteGroovyScript ، يمكنك اعتراض بدء وإيقاف الأحداث من خلال تطبيق الأساليب الثابتة المناسبة.
يقبل المعالج تلقائيًا اتصالاً من خدمة dbcp قبل التنفيذ ويعالج المعاملة. يتم إرجاع معاملات قاعدة البيانات تلقائيًا عند حدوث خطأ ويتم الالتزام بها في حالة نجاحها. في ExecuteGroovyScript ، يمكنك اعتراض بدء وإيقاف الأحداث من خلال تطبيق الأساليب الثابتة المناسبة.import org.apache.nifi.processor.ProcessContext
...
static onStart(ProcessContext context){
// your code
}
static onStop(ProcessContext context){
// your code
}
REL_SUCCESS << flowFile
InvokeScriptedProcessor
معالج آخر مثير للاهتمام. لاستخدامه ، تحتاج إلى تعريف فئة تقوم بتنفيذ واجهة التطبيق وتحديد متغير المعالج. يمكنك تحديد أي PropertyDescriptor أو علاقة ، وكذلك الوصول إلى ComponentLog الأصل وتحديد الأساليب غير الصالحة onScheduled (سياق ProcessContext) وباطلة onStopped (سياق ProcessContext). سيتم استدعاء هذه الطرق عند حدوث حدث بدء مجدول في NiFi (onScheduled) وعندما يتوقف (onScheduled).class GroovyProcessor implements Processor {
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
يجب تنفيذ المنطق في الطريقة void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) @Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) throw s ProcessException {
final ProcessSession session = sessionFactory.createSession(); def
flowFile = session.create()
if (!flowFile) return
// your code
try
{ session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
ليس من الضروري وصف جميع الطرق المعلنة في الواجهة ، لذلك دعونا نتجاوز فئة مجردة واحدة نعلن فيها الطريقة التالية:abstract void executeScript(ProcessContext context, ProcessSession session)
الطريقة التي سنتصل بهاvoid onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory)
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.components.ValidationContext import org.apache.nifi.components.ValidationResult import org.apache.nifi.logging.ComponentLog
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.ProcessSessionFactory import org.apache.nifi.processor.Processor
import org.apache.nifi.processor.ProcessorInitializationContext import org.apache.nifi.processor.Relationship
import org.apache.nifi.processor.exception.ProcessException
abstract class BaseGroovyProcessor implements Processor {
public ComponentLog log
public Set<Relationship> relationships;
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr final ProcessSession session = sessionFactory.createSession();
try {
executeScript(context, session);
session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
abstract void executeScript(ProcessContext context, ProcessSession session) thro
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null }
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
الآن نعلن عن فئة BaseGroovyProcessorتالية ونصف تنفيذنا ، ونضيف أيضًا العلاقة RELSUCCESS و RELFAILURE.import org.apache.commons.lang3.tuple.Pair
import org.apache.nifi.expression.ExpressionLanguageScope import org.apache.nifi.processor.util.StandardValidators import ru.rt.nifi.common.BaseGroovyProcessor
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.dbcp.DBCPService
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.exception.ProcessException import org.quartz.CronExpression
import java.sql.Connection
import java.sql.PreparedStatement import java.sql.ResultSet
import java.sql.SQLException import java.sql.Statement
class InvokeScripted extends BaseGroovyProcessor {
public static final REL_SUCCESS = new Relationship.Builder()
.name("success")
.description("If the cache was successfully communicated with it will be rou
.build()
public static final REL_FAILURE = new Relationship.Builder()
.name("failure")
.description("If unable to communicate with the cache or if the cache entry
.build()
@Override
void executeScript(ProcessContext context, ProcessSession session) throws Proces def flowFile = session.create()
if (!flowFile) return
try {
// your code
session.transfer(flowFile, REL_SUCCESS)
} catch(ProcessException | SQLException e) {
session.transfer(flowFile, REL_FAILURE)
log.error("Unable to execute SQL select query {} due to {}. No FlowFile
}
}
}
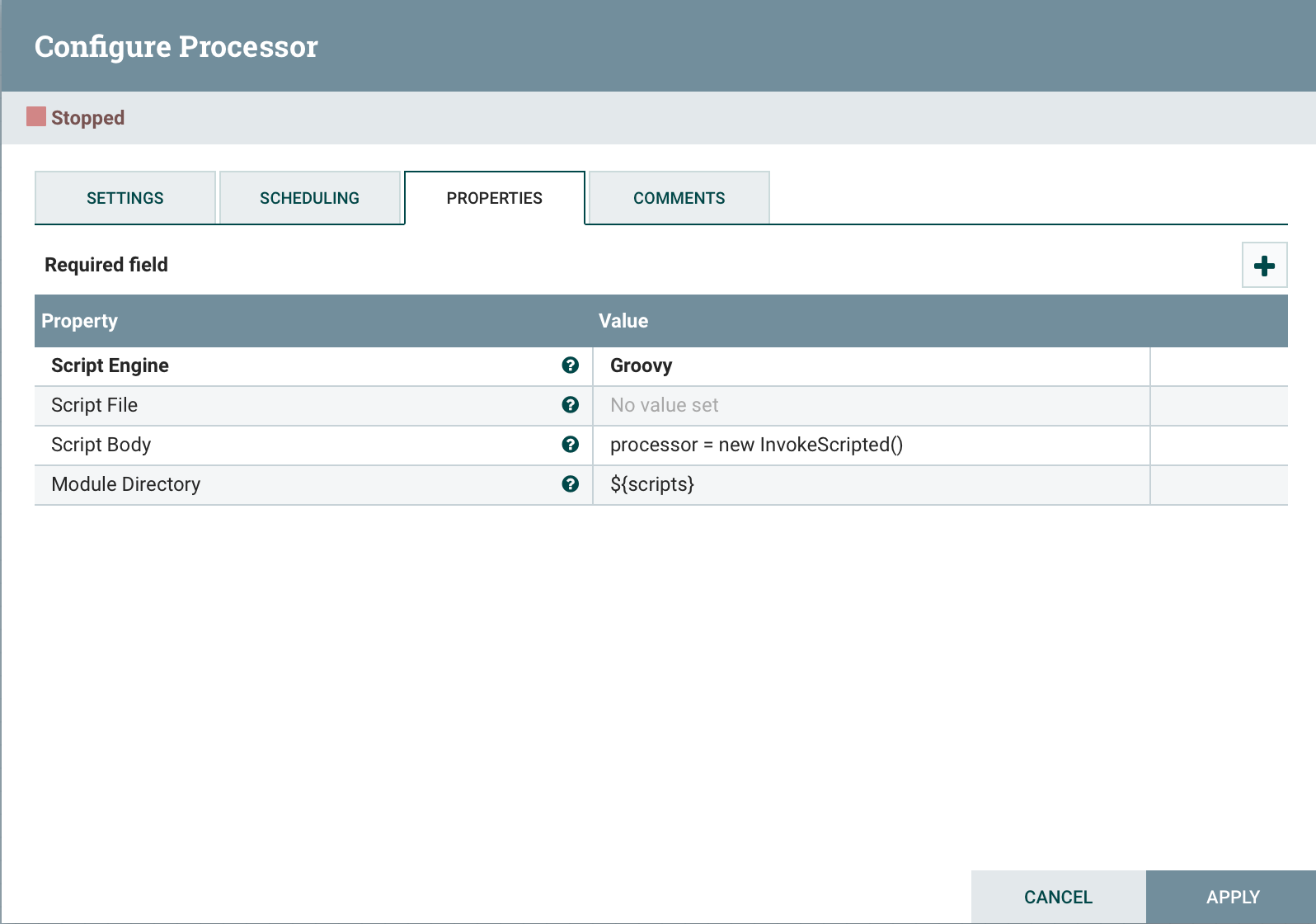 إضافة إلى نهاية التعليمات البرمجية.
إضافة إلى نهاية التعليمات البرمجية. processor = new InvokeScripted()يشبه هذا الأسلوب إنشاء معالج مخصص.استنتاج
إن إنشاء معالج مخصص ليس أسهل شيء - للمرة الأولى سيكون عليك العمل بجد لاكتشافه ، ولكن فوائد هذا الإجراء لا يمكن إنكارها.منشور أعده فريق إدارة بيانات Rostelecom