مرحبا مجددا. نواصل اليوم سلسلة الترجمات تحسبًا لبدء الدورة الأساسية "الرياضيات لعلوم البيانات" .
في مقالة حديثة ، تحدثنا عن كيفية إنشاء كاشف شاذ في Power BI من خلال دمج PyCaret فيه ، ومساعدة المحللين ومحللي البيانات على إضافة التعلم الآلي إلى التقارير ولوحات التحكم دون بذل الكثير من الجهد.في هذه المقالة ، سنلقي نظرة على كيفية إجراء تحليل الكتلة باستخدام PyCaret و Power BI. إذا لم تكن قد سمعت بأي شيء عن PyCaret من قبل ، فيمكنك البدء في التعرف عليه هنا .ما سنناقشه في دليل اليوم:- ما هو التجمع؟ أنواع التكتل.
- التعلم بدون معلم وتنفيذ نموذج تجميع في Power BI.
- تحليل النتائج وتصور المعلومات على لوحة القيادة.
- كيفية نشر نموذج تجميع على الإنتاج في Power BI؟
قبل أن نبدأ ...
إذا كنت قد استخدمت Python بالفعل من قبل ، فمن المرجح أن لديك بالفعل Anaconda على جهاز الكمبيوتر الخاص بك. إذا لم يكن كذلك ، يمكنك تنزيل توزيع Anaconda من Python 3.7 أو أعلى من هنا .إعداد البيئة
قبل البدء في استخدام ميزات تعلم الآلة PyCaret في Power BI ، تحتاج إلى إنشاء بيئة افتراضية وتثبيتها فيها pycaret. للقيام بذلك ، نحتاج إلى تنفيذ ثلاث خطوات:الخطوة 1 - إنشاء بيئة افتراضيةافتح موجه أوامر Anaconda وأدخل ما يلي:conda create --name myenv python=3.7
الخطوة 2 - تثبيت PyCaret قمبتشغيل الأمر التالي في موجه أوامر Anaconda:pip install pycaret
قد يستغرق التثبيت 15-20 دقيقة. إذا واجهت أي مشاكل أثناء التثبيت ، يمكنك التعرف على حلها على صفحتنا على GitHub .الخطوة 3 - وضح في Power BI حيث تم تثبيت Python.يجب أن تكون البيئة الافتراضية التي تم إنشاؤها مرتبطة بـ Power BI. يمكنك القيام بذلك باستخدام الإعدادات العامة في Power BI Desktop (ملف -> خيارات -> عام -> برمجة Python). يتم وضع بيئة Anaconda في الدليل افتراضيًا:C:\Users\username\AppData\Local\Continuum\anaconda3\envs\myenv
ما هو التجمع؟
التجميع هو طريقة لتقسيم البيانات إلى مجموعات وفقًا لخصائص متشابهة. يمكن أن تكون هذه المجموعات مفيدة لدراسة البيانات وتحديد الأنماط وتحليل مجموعات فرعية من البيانات. تساعد بيانات التجميع في تحديد هياكل البيانات الأساسية ، وهو أمر مفيد في العديد من الصناعات. فيما يلي بعض الاستخدامات الشائعة للتجمع في الأعمال:- تجزئة عملاء التسويق.
- تحليل سلوك المستهلك للترقيات والخصومات.
- تحديد الكتل الأرضية أثناء تفشي المرض ، على سبيل المثال ، COVID-19.
أنواع التجميع
بالنظر إلى الطبيعة الذاتية لمهام التجميع ، هناك العديد من الخوارزميات الأكثر ملاءمة لحل أنواع معينة من المهام. كل خوارزمية لها خصائصها الخاصة ومبرراتها الرياضية ، التي تكمن وراء توزيع المجموعات.في البرنامج التعليمي اليوم ، نتحدث عن تحليل الكتلة في Power BI باستخدام مكتبة Python تسمى PyCaret ولن نتعمق في الرياضيات. سنستخدم اليوم طريقة k- الوسائل - وهي واحدة من أبسط طرق التدريس وأكثرها شعبية بدون معلم. يمكنك العثور على مزيد من المعلومات حول طريقة k-يعني هنا .
سنستخدم اليوم طريقة k- الوسائل - وهي واحدة من أبسط طرق التدريس وأكثرها شعبية بدون معلم. يمكنك العثور على مزيد من المعلومات حول طريقة k-يعني هنا .سياق العمل
في هذا الدليل ، سنستخدم مجموعة بيانات مسبقة الصنع من قاعدة بيانات الإنفاق الصحي العالمي لمنظمة الصحة العالمية. يحتوي على النفقات الصحية كنسبة مئوية من الناتج المحلي الإجمالي الوطني لأكثر من 200 دولة من 2000 إلى 2017.مهمتنا هي العثور على الأنماط والمجموعات في هذه البيانات باستخدام طريقة k-الوسائل.يمكن العثور على البيانات هنا .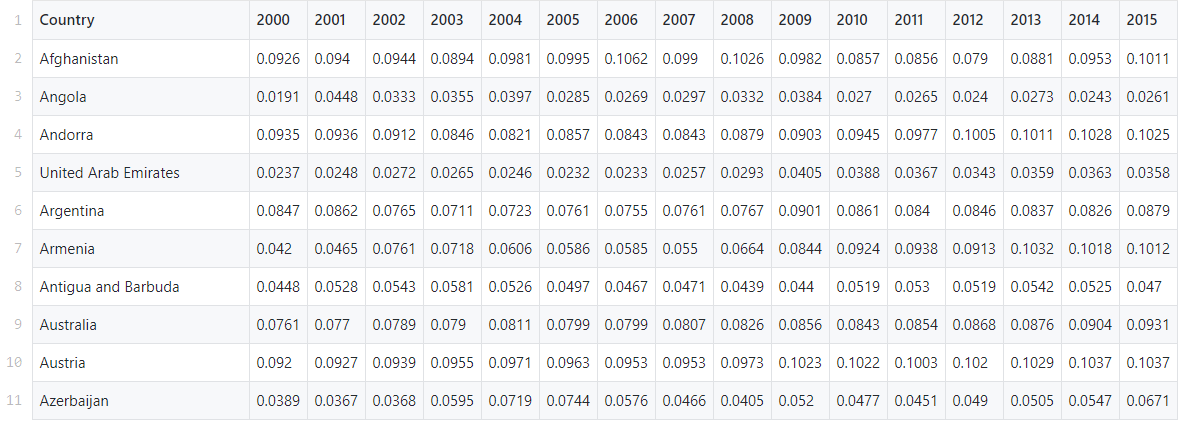
لذا ، لنبدأ
الآن بعد أن قمت بإعداد بيئة Anaconda ، وتثبيت PyCaret ، فإنك تفهم أساسيات تحليل الكتلة وسياق الأعمال ، لقد حان الوقت لبدء العمل.1. الحصول على البيانات
الخطوة الأولى هي استيراد مجموعة البيانات إلى Power BI Desktop. يمكنك تنزيل البيانات باستخدام موصل الويب. (Power BI Desktop → الحصول على البيانات → من الويب ). رابط إلى ملف csv: https://github.com/pycaret/powerbi-clustering/blob/master/clustering.csv .
رابط إلى ملف csv: https://github.com/pycaret/powerbi-clustering/blob/master/clustering.csv .2. التدريب النموذجي
لتعلم نموذج التجميع في Power BI ، نحتاج إلى تنفيذ نص Python النصي في Power Query Editor ( Power Query Editor → Transform → Run python script ). استخدم الكود التالي كبرنامج نصي:from pycaret.clustering import *
dataset = get_clusters(dataset, num_clusters=5, ignore_features=['Country'])
 لقد تجاهلنا عمود "البلد" للمجموعة باستخدام المعلمة
لقد تجاهلنا عمود "البلد" للمجموعة باستخدام المعلمة ignore_features. هناك العديد من الأسباب التي قد تجعلك بحاجة إلى استبعاد أعمدة معينة لتدريب نموذج التعلم الآلي بشكل أفضل.يسمح لك PyCaret بإخفاء الأعمدة غير الضرورية بدلاً من حذفها ، لأنك قد تحتاج إليها في المستقبل لمزيد من التحليل. على سبيل المثال ، في الوقت الحالي لم نرغب في استخدام "البلد" للتدريب وتمرير هذا العمود إلى ignore_features.هناك 8 خوارزميات للتعلم الآلي جاهزة للاستخدام في PyCaret.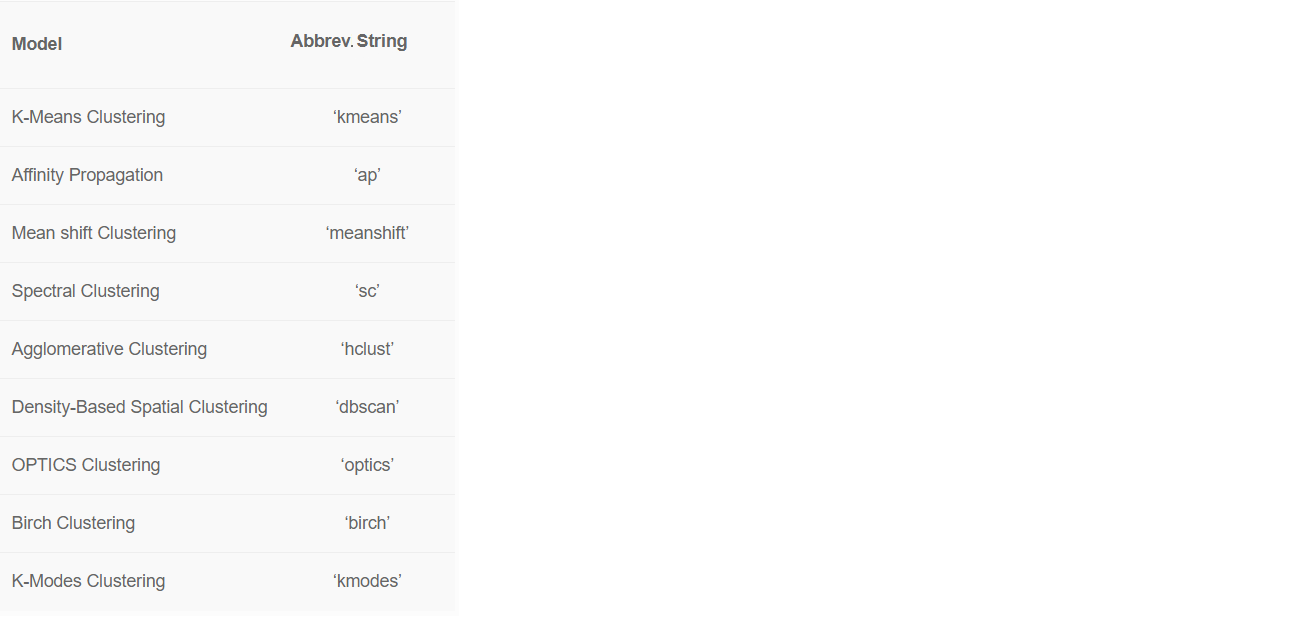 بشكل افتراضي ، يقوم PyCaret بتدريب نموذج تجميع k-يعني على أربع مجموعات. ولكن يمكن تغيير القيم الافتراضية بسهولة:
بشكل افتراضي ، يقوم PyCaret بتدريب نموذج تجميع k-يعني على أربع مجموعات. ولكن يمكن تغيير القيم الافتراضية بسهولة:- لتغيير نوع النموذج ، استخدم معلمة النموذج في
get_clusters(). - لتغيير عدد المجموعات ، استخدم الخيار
num_clusters.
على سبيل المثال ، هذه هي الطريقة التي يمكنك من خلالها تجميع k-يعني في 6 مجموعات.from pycaret.clustering import *
dataset = get_clusters(dataset, model='kmodes', num_clusters=6, ignore_features=['Country'])
الخلاصة: تمت إضافة
 عمود آخر مع تسمية عنقود إلى مجموعة البيانات الأصلية. ثم يتم استخدام جميع القيم في عمود السنة لتطبيع البيانات والتصور بشكل أكبر في Power BI.هكذا ستبدو النتيجة النهائية في Power BI.
عمود آخر مع تسمية عنقود إلى مجموعة البيانات الأصلية. ثم يتم استخدام جميع القيم في عمود السنة لتطبيع البيانات والتصور بشكل أكبر في Power BI.هكذا ستبدو النتيجة النهائية في Power BI.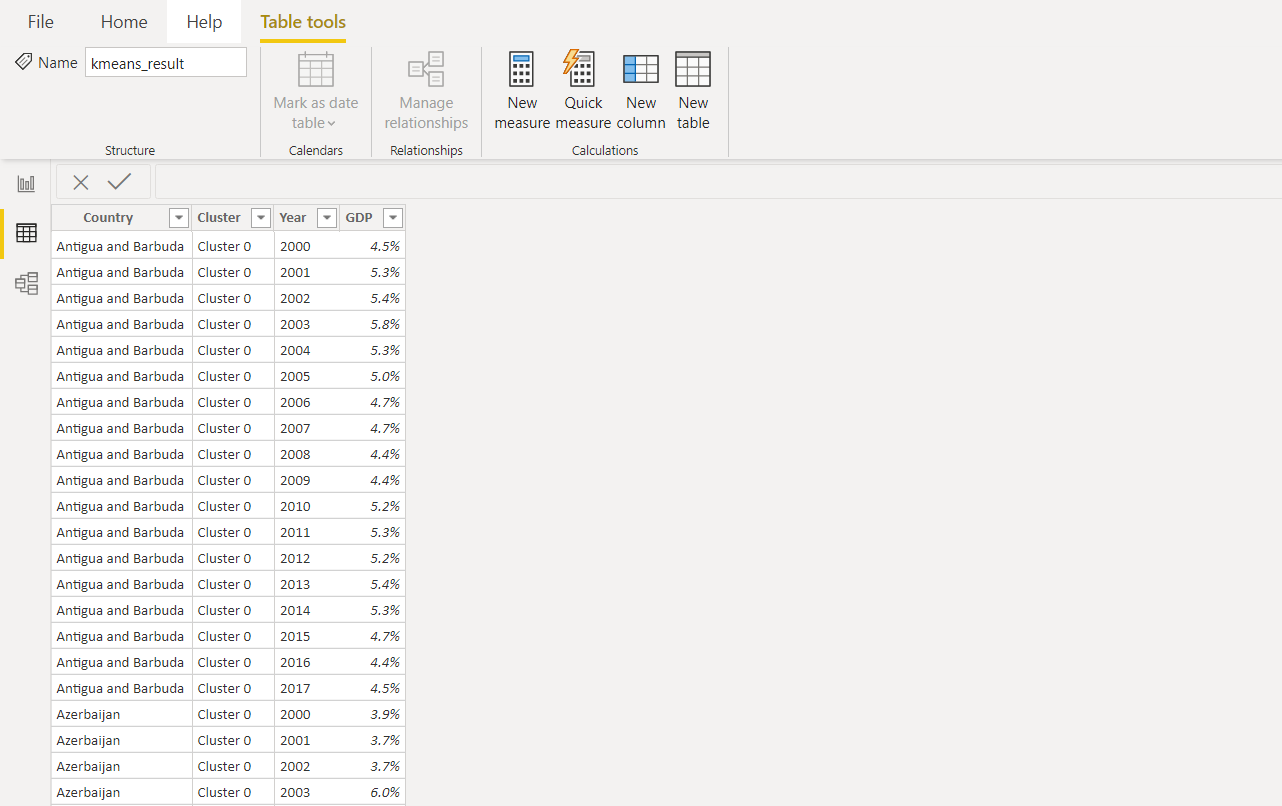
3. لوحة القيادة
عندما تحصل على تصنيفات الكتلة في Power BI ، يمكنك تصورها في لوحة التحكم في Power BI للتحليلات: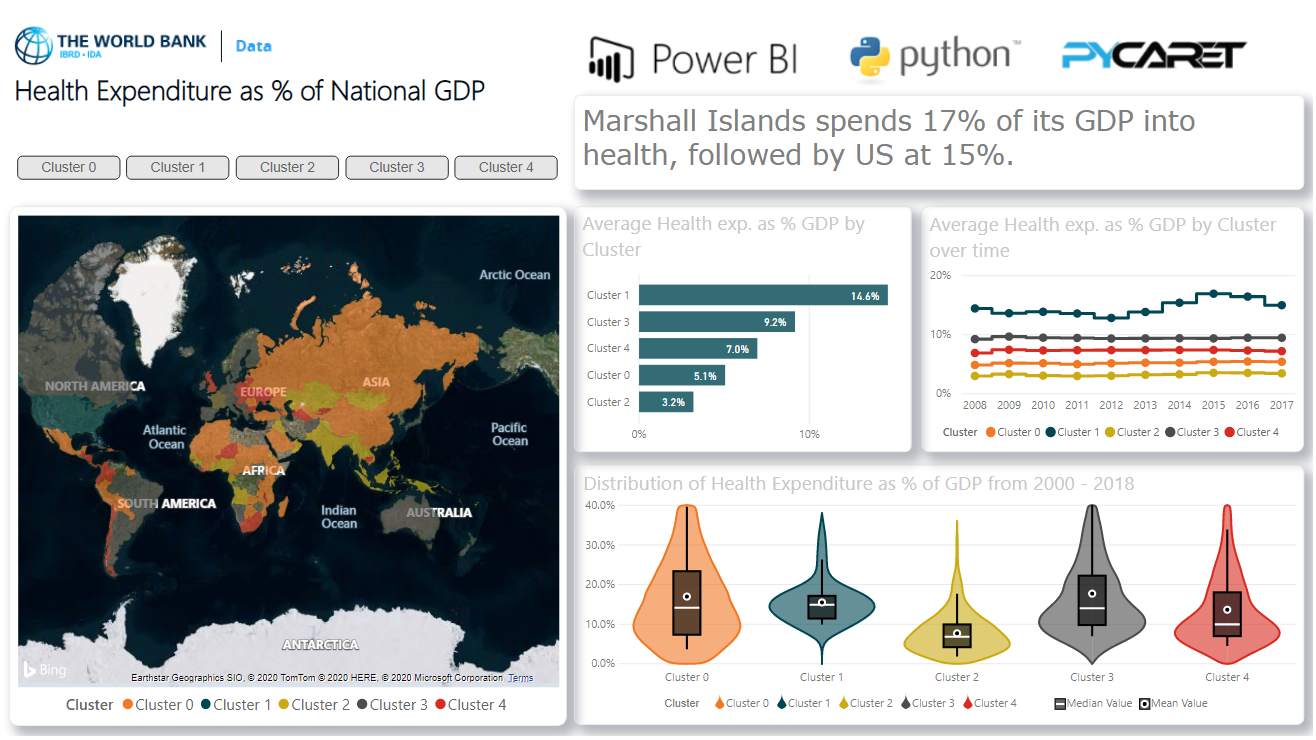
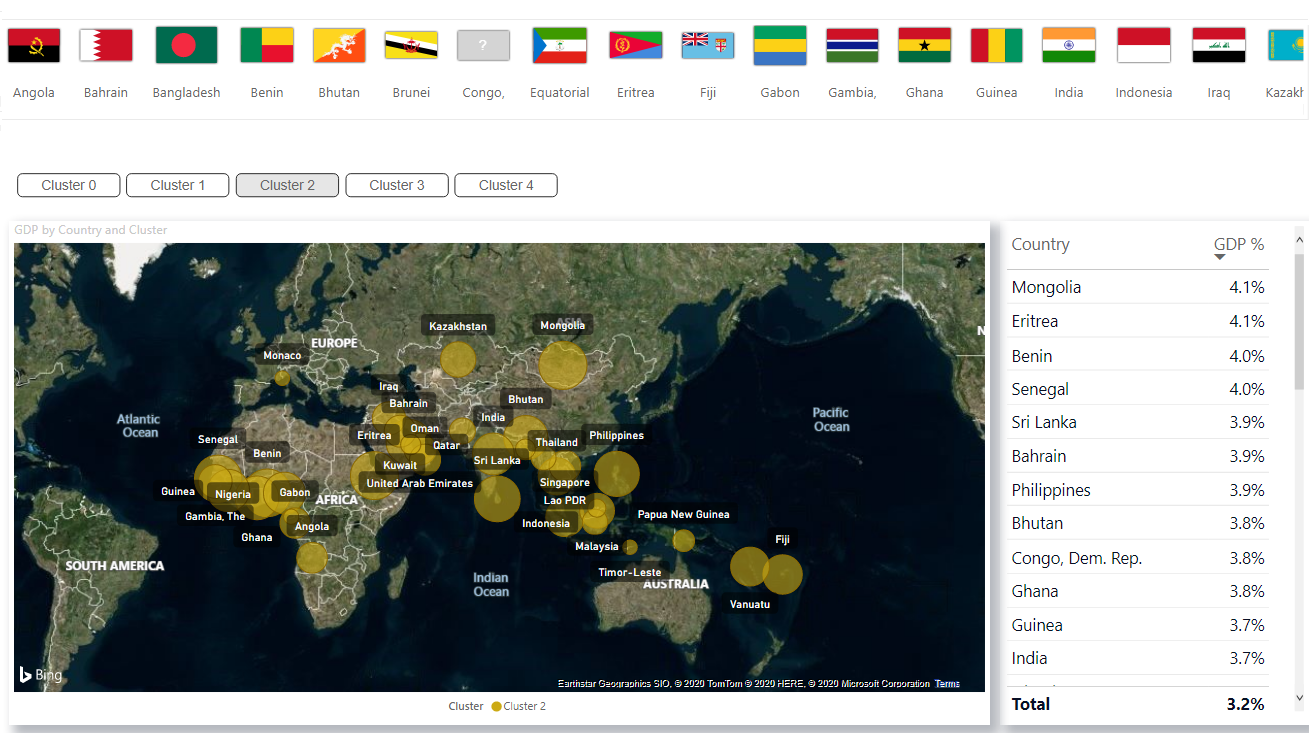 يمكنك تنزيل ملف PBIX ومجموعة البيانات من GitHub .
يمكنك تنزيل ملف PBIX ومجموعة البيانات من GitHub .تنفيذ التجميع
أعلاه ، أظهرنا أبسط تنفيذ التجميع في Power BI. ألاحظ أن هذه الطريقة تدرب نموذج التجميع في كل مرة يتم فيها تحديث مجموعة بيانات في Power BI. يمكن أن يكون هذا مشكلة للأسباب التالية:- عندما يتم إعادة تدريب النموذج على البيانات الجديدة ، يمكن أن تتغير تسميات الكتلة (أي إذا تم تعيين بعض نقاط البيانات في المجموعة الأولى في وقت سابق ، ثم عند إعادة التدريب ، يمكن تعيينها إلى المجموعة الثانية) ؛
- لن ترغب في قضاء عدة ساعات في كل مرة إعادة تدريب النموذج.
هناك طريقة أكثر فاعلية لتطبيق التجميع في Power BI بدلاً من إعادة التعلم مرارًا وتكرارًا ، وهي استخدام نموذج مدرب مسبقًا لإنشاء تسميات عنقودية.تدريب النموذج المبكر
يمكنك استخدام أي بيئة تطوير متكاملة (IDE) أو مفكرة لتدريب النموذج. في هذا المثال ، قمنا بتدريب نموذج التجميع في Visual Studio Code.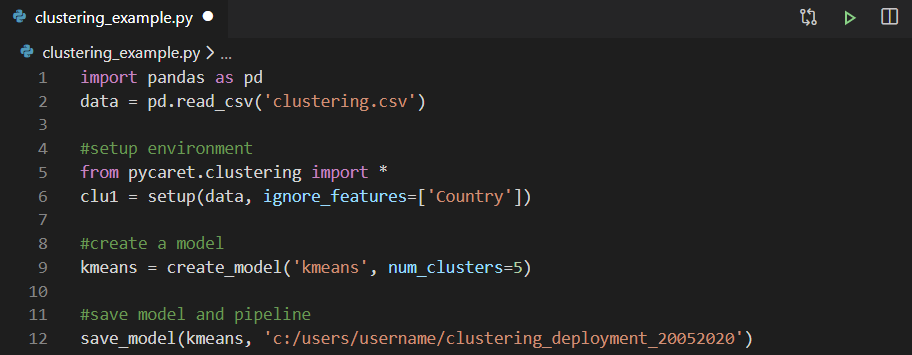 ثم ، يتم حفظ النموذج المدرب كملف مخلل واستيراده في Power Query لإنشاء تسميات عنقودية.
ثم ، يتم حفظ النموذج المدرب كملف مخلل واستيراده في Power Query لإنشاء تسميات عنقودية. إذا كنت تريد معرفة المزيد حول تنفيذ تحليل الكتلة في دفتر ملاحظات Jupyter مع PyCaret ، شاهد هذا الفيديو لمدة دقيقتين.
إذا كنت تريد معرفة المزيد حول تنفيذ تحليل الكتلة في دفتر ملاحظات Jupyter مع PyCaret ، شاهد هذا الفيديو لمدة دقيقتين.باستخدام نموذج التدريب المسبق
قم بتشغيل الكود أدناه لإنشاء علامات من النموذج المدرب مسبقًا:from pycaret.clustering import *
dataset = predict_model('c:/.../clustering_deployment_20052020, data = dataset)
ستكون النتيجة هي نفسها كما لاحظنا سابقًا. والفرق الوحيد هو أنه عند استخدام النموذج الذي تم تدريبه مسبقًا ، سيتم إنشاء العلامات استنادًا إلى مجموعة البيانات الجديدة باستخدام النموذج القديم ، وليس على النموذج الذي تمت إعادة تدريبه.العمل مع خدمة Power BI
بعد تحميل ملف .pbix إلى خدمة Power BI ، ستحتاج إلى اتباع بعض الخطوات الإضافية لضمان الدمج السلس لخط تعلم الآلة في خط بياناتك. ستكون الخطوات على النحو التالي:- قم بتشغيل التحديث المجدول لمجموعة البيانات - سيسمح لك هذا بجدولة المصنف مع مجموعة البيانات الخاصة بك ليتم تحديثها باستخدام برنامج Python النصي ، ألق نظرة على قسم تكوين التحديث المجدول ، والذي يحتوي أيضًا على معلومات حول البوابة الشخصية.
- قم بتثبيت البوابة الشخصية - ستحتاج إلى بوابة شخصية ، والتي يجب تثبيتها في نفس الدليل حيث تم تثبيت Python. يجب أن يكون لخدمة Power BI حق الوصول إلى بيئة Python. هنا يمكنك معرفة المزيد حول كيفية تثبيت البوابة الشخصية وتكوينها.
إذا كنت تريد معرفة المزيد عن تحليل الكتلة ، فيمكنك التعرف على دليلنا في هذا الكمبيوتر المحمول .
احصل على الدورة.