في هذه المقالة سأخبر وأظهر مثالًا على كيف استطاع شخص يتمتع بخبرة بسيطة في مجال علوم البيانات جمع البيانات من المنتدى وعمل نماذج موضوعية للمشاركات باستخدام نموذج LDA ، وكشف عن مواضيع مؤلمة للأشخاص الذين يعانون من عدم تحمل الاضطرابات الهضمية.في العام الماضي ، كنت بحاجة إلى تحسين معرفتي بشكل عاجل في مجال التعلم الآلي. أنا مدير منتجات لعلوم البيانات والتعلم الآلي والذكاء الاصطناعي ، أو بطريقة أخرى مدير المنتجات التقنية AI / ML. مهارات الأعمال والقدرة على تطوير المنتجات ، كما هو الحال عادة في المشاريع التي تستهدف المستخدمين من خارج المجال التقني ، ليست كافية. تحتاج إلى فهم المفاهيم التقنية الأساسية لصناعة ML ، وإذا لزم الأمر ، يمكنك كتابة مثال بنفسك لتوضيح المنتج.منذ حوالي 5 سنوات ، كنت أقوم بتطوير مشروعات Front-End ، وتطوير تطبيقات ويب معقدة على JS و React ، لكنني لم أتعامل أبدًا مع التعلم الآلي وأجهزة الكمبيوتر المحمولة والخوارزميات. لذلك ، عندما رأيت الأخبار من Otus أنها افتتحت دورة تجريبية مدتها خمسة أشهر حول التعلم الآلي ، دون تردد ، قررت الخضوع لاختبار تجريبي وحصلت على الدورة.لمدة خمسة أشهر ، كل أسبوع كانت هناك محاضرات لمدة ساعتين واجبات منزلية لهم. هناك تعلمت عن أساسيات ML: خوارزميات الانحدار المختلفة ، والتصنيفات ، ومجموعات النماذج ، وتعزيز التدرج ، وحتى التقنيات السحابية المتأثرة قليلاً. من حيث المبدأ ، إذا كنت تستمع بعناية لكل محاضرة ، فهناك أمثلة وتفسيرات كافية للواجب المنزلي. ولكن مع ذلك ، في بعض الأحيان ، كما هو الحال في أي مشروع ترميز آخر ، كان علي أن أنتقل إلى الوثائق. بالنظر إلى عملي بدوام كامل ، كان من الملائم للغاية الدراسة ، حيث كان بإمكاني دائمًا مراجعة سجل محاضرة عبر الإنترنت.في نهاية التدريب لهذه الدورة ، كان على الجميع أخذ المشروع النهائي. نشأت فكرة المشروع بشكل عفوي تمامًا ، وفي ذلك الوقت بدأت التدريب في ريادة الأعمال في ستانفورد ، حيث انضممت إلى الفريق الذي عمل في المشروع للأشخاص الذين يعانون من عدم تحمل الاضطرابات الهضمية. أثناء بحث السوق ، كنت مهتمًا بمعرفة المخاوف ، وما الذي يتحدثون عنه ، وما الذي يشكو منه الأشخاص الذين لديهم هذه الميزة.مع تقدم الدراسة ، وجدت منتدى على celiac.comمع كمية كبيرة من المواد عن مرض الاضطرابات الهضمية. كان من الواضح أن التمرير يدويًا وقراءة أكثر من 100 ألف مشاركة غير عملي. لذلك جاءتني الفكرة لتطبيق المعرفة التي تلقيتها في هذه الدورة: جمع جميع الأسئلة والتعليقات من المنتدى من موضوع معين وجعل النمذجة المواضيعية مع الكلمات الأكثر شيوعًا في كل منها.الخطوة 1. جمع البيانات من المنتدى
يتكون المنتدى من عدة مواضيع بأحجام مختلفة. في المجموع ، يحتوي هذا المنتدى على حوالي 115000 موضوع وحوالي مليون مشاركة ، مع تعليقات عليها. كنت مهتمًا بموضوع فرعي محدد "التعامل مع مرض الاضطرابات الهضمية" ، والذي يعني حرفياً "التعامل مع مرض الاضطرابات الهضمية" ، إذا كان باللغة الروسية ، فهذا يعني المزيد "لمواصلة العيش مع تشخيص مرض الاضطرابات الهضمية والتعامل مع الصعوبات بطريقة ما". يحتوي هذا الموضوع الفرعي على حوالي 175000 تعليق.حدث تنزيل البيانات على مرحلتين. بادئ ذي بدء ، كان علي أن أتصفح جميع الصفحات تحت الموضوع وأجمع كل الروابط إلى جميع المشاركات ، حتى أنه في الخطوة التالية ، يمكنني بالفعل جمع تعليق.url_coping = 'https://www.celiac.com/forums/forum/5-coping-with-celiac-disease/'
نظرًا لأن المنتدى أصبح قديمًا جدًا ، فقد كنت محظوظًا للغاية ولم يكن هناك أي مشاكل أمنية في الموقع ، لذلك كان من الضروري جمع البيانات ، من خلال استخدام مجموعة وكيل المستخدم من مكتبة fake_useragent ، Beautiful Soup للعمل مع ترميز html ومعرفة عدد الصفحات:
def get_pages_count(url):
response = requests.get(url, headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
last_page_section = soup.find('li', attrs = {'class':'ipsPagination_last'})
if (last_page_section):
count_link = last_page_section.find('a')
return int(count_link['data-page'])
else:
return 1
coping_pages_count = get_pages_count(url_coping)
ثم قم بتنزيل HTML DOM لكل صفحة لسحب البيانات منها بسهولة ويسر باستخدام مكتبة BeautifulSoup Python .
def retrieve_pages(pages_count, url):
pages = []
for page in range(pages_count):
response = requests.get('{}page/{}'.format(url, page), headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
pages.append(soup)
return pages
coping_pages = retrieve_pages(coping_pages_count, url_coping)
لتنزيل البيانات ، كنت بحاجة إلى تحديد الحقول اللازمة للتحليل: ابحث عن قيم هذه الحقول في DOM واحفظها في القاموس. جئت بنفسي من خلفية الواجهة الأمامية ، لذلك كان العمل مع المنزل والأشياء تافهة بالنسبة لي.def collect_post_info(pages):
posts = []
for page in pages:
posts_list_soup = page.find('ol', attrs = {'class': 'ipsDataList'}).findAll('li', attrs = {'class': 'ipsDataItem'})
for post_soup in posts_list_soup:
post = {}
post['id'] = uuid.uuid4()
title_section = post_soup.find('span', attrs = {'class':'ipsType_break ipsContained'})
if (title_section):
title_section_a = title_section.find('a')
post['title'] = title_section_a['title']
post['url'] = title_section_a['data-ipshover-target']
author_section = post_soup.find('div', attrs = {'class':'ipsDataItem_meta'})
if (author_section):
author_section_a = post_soup.find('a')
author_section_time = post_soup.find('time')
post['author'] = author_section_a['data-ipshover-target']
post['last_action'] = author_section_time['datetime']
stats_section = post_soup.find('ul', attrs = {'class':'ipsDataItem_stats'})
if (stats_section):
stats_section_replies = post_soup.find('span', attrs = {'class':'ipsDataItem_stats_number'})
if (stats_section_replies):
post['replies'] = stats_section_replies.getText()
stats_section_views = post_soup.find('li', attrs = {'class':'ipsType_light'})
if (stats_section_views):
post['views'] = stats_section_views.find('span', attrs = {'class':'ipsDataItem_stats_number'}).getText()
posts.append(post)
return posts
في المجموع ، جمعت حوالي 15،450 مشاركة في هذا الموضوع.coping_posts_info = collect_post_info(coping_pages)
الآن يمكن نقلها إلى DataFrame بحيث يتم وضعها بشكل جميل ، وفي الوقت نفسه حفظها في ملف csv بحيث لا تضطر إلى الانتظار مرة أخرى عندما يتم جمع البيانات من الموقع إذا انقطع الكمبيوتر المحمول عن طريق الخطأ أو قمت بإعادة تعريف متغير عن طريق الخطأ.df_coping = pd.DataFrame(coping_posts_info,
columns =['title', 'url', 'author', 'last_action', 'replies', 'views'])
df_coping['replies'] = df_coping['replies'].astype(int)
df_coping['views'] = df_coping['views'].apply(lambda x: int(x.replace(',','')))
df_coping.to_csv('celiac_forum_coping.csv', sep=',')
بعد جمع مجموعة من المشاركات ، شرعت في جمع التعليقات بأنفسهم.def collect_postpage_details(pages, df):
comments = []
for i, page in enumerate(pages):
articles = page.findAll('article')
for k, article in enumerate(articles):
comment = {
'url': df['url'][i]
}
if(k == 0):
comment['question'] = 1
else:
comment['question'] = 0
comment_section = article.find('div', attrs = {'class':'ipsComment_content'})
if (comment_section):
comment_section_p = comment_section.find('p')
if(comment_section_p):
comment['comment'] = comment_section_p.getText()
comment['date'] = comment_section.find('time')['datetime']
author_section = article.find('strong')
if (author_section):
author_section_url = author_section.find('a')
if (author_section_url):
comment['author'] = author_section_url['data-ipshover-target']
comments.append(comment)
return comments
coping_data = collect_postpage_details(coping_comments_pages, df_coping)
df_coping_comments.to_csv('celiac_forum_coping_comments_1.csv', sep=',')
الخطوة 2 تحليل البيانات والنمذجة المواضيعية
في الخطوة السابقة ، قمنا بجمع البيانات من المنتدى واستلمنا البيانات النهائية في شكل 153777 سطر من الأسئلة والتعليقات.ولكن فقط البيانات التي تم جمعها ليست مثيرة للاهتمام ، لذلك كان أول شيء أردت القيام به هو تحليلات بسيطة للغاية: لقد اشتقت إحصائيات لأهم 30 موضوعًا وأكثر 30 تعليقًا.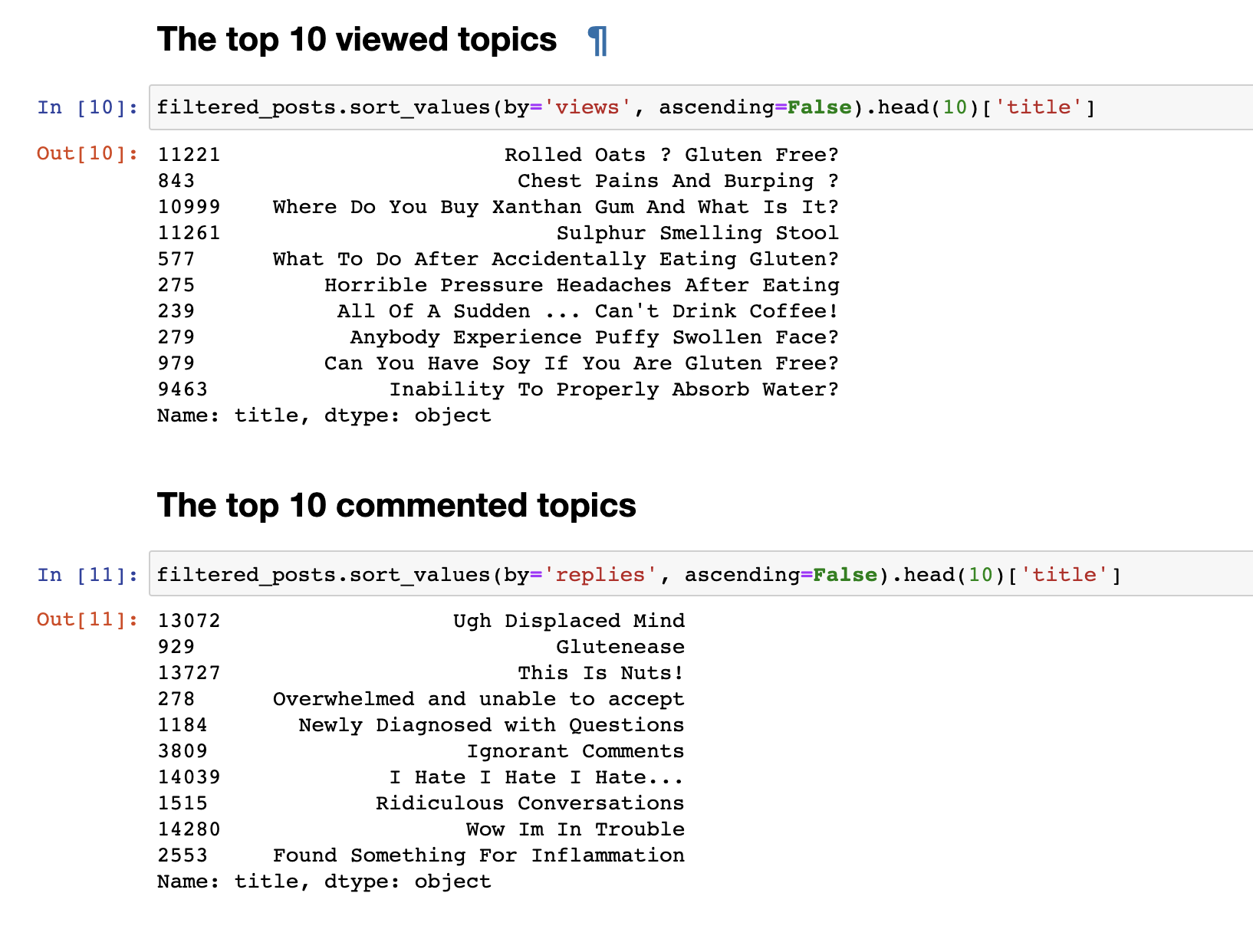 المنشورات الأكثر مشاهدة لا تتطابق مع المنشورات الأكثر تعليقًا. ملحوظة عناوين المنشورات ، حتى للوهلة الأولى. أسمائهم أكثر عاطفية: "أكره ، أكره ، أكره" أو " تعليقات متغطرسة" أو "واو ، أنا في مشكلة" . والأكثر مشاهدة هو تنسيق السؤال: "هل يمكنني أكل الصويا؟" ، "لماذا لا أستطيع امتصاص الماء بشكل صحيح؟"آخر.قمنا بتحليل نص بسيط. للانتقال مباشرةً إلى تحليل أكثر تعقيدًا ، تحتاج إلى إعداد البيانات نفسها قبل إرسالها إلى مدخلات نموذج LDA للحصول على تصنيف حسب الموضوع. للقيام بذلك ، تخلص من التعليقات التي تحتوي على أقل من 30 كلمة ، لتصفية الرسائل غير المرغوب فيها والتعليقات القصيرة التي لا معنى لها. نأتي بهم إلى صغيرة.
المنشورات الأكثر مشاهدة لا تتطابق مع المنشورات الأكثر تعليقًا. ملحوظة عناوين المنشورات ، حتى للوهلة الأولى. أسمائهم أكثر عاطفية: "أكره ، أكره ، أكره" أو " تعليقات متغطرسة" أو "واو ، أنا في مشكلة" . والأكثر مشاهدة هو تنسيق السؤال: "هل يمكنني أكل الصويا؟" ، "لماذا لا أستطيع امتصاص الماء بشكل صحيح؟"آخر.قمنا بتحليل نص بسيط. للانتقال مباشرةً إلى تحليل أكثر تعقيدًا ، تحتاج إلى إعداد البيانات نفسها قبل إرسالها إلى مدخلات نموذج LDA للحصول على تصنيف حسب الموضوع. للقيام بذلك ، تخلص من التعليقات التي تحتوي على أقل من 30 كلمة ، لتصفية الرسائل غير المرغوب فيها والتعليقات القصيرة التي لا معنى لها. نأتي بهم إلى صغيرة.
def filter_text_words(text, min_words = 30):
text = str(text)
return len(text.split()) > 30
filtered_comments = filtered_comments[filtered_comments['comment'].apply(filter_text_words)]
comments_only = filtered_comments['comment']
comments_only= comments_only.apply(lambda x: x.lower())
comments_only.head()
احذف كلمات التوقف غير الضرورية لمسح تحديد النص الخاص بناstop_words = stopwords.words('english')
def remove_stop_words(tokens):
new_tokens = []
for t in tokens:
token = []
for word in t:
if word not in stop_words:
token.append(word)
new_tokens.append(token)
return new_tokens
tokens = remove_stop_words(data_words)
نضيف أيضًا bigrams ونشكل مجموعة من الكلمات لإبراز العبارات الثابتة ، على سبيل المثال ، مثل gluten_free و support_group والعبارات الأخرى التي عند تجميعها ، لها معنى معين.
bigram = gensim.models.Phrases(tokens, min_count=5, threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
bigram_mod.save('bigram_mod.pkl')
bag_of_words = [bigram_mod[w] for w in tokens]
with open('bigrams.pkl', 'wb') as f:
pickle.dump(bag_of_words, f)
الآن نحن جاهزون أخيرًا لتدريب نموذج LDA نفسه مباشرةً.
id2word = corpora.Dictionary(bag_of_words)
id2word.save('id2word.pkl')
id2word.filter_extremes(no_below=3, no_above=0.4, keep_n=3*10**6)
corpus = [id2word.doc2bow(text) for text in bag_of_words]
lda_model = gensim.models.ldamodel.LdaModel(
corpus,
id2word=id2word,
eval_every=20,
random_state=42,
num_topics=30,
passes=5
)
lda_model.save('lda_default_2.pkl')
topics = lda_model.show_topics(num_topics=30, num_words=100, formatted=False)
في نهاية التدريب ، نحصل في النهاية على نتيجة المواضيع المشكلة. التي أرفقتها في نهاية هذا المنشور.for t in range(lda_model.num_topics):
plt.figure(figsize=(15, 10))
plt.imshow(WordCloud(background_color="white", max_words=100, width=900, height=900, collocations=False)
.fit_words(dict(topics[t][1])))
plt.axis("off")
plt.title("Topic #" + themes_headers[t])
plt.show()
كما قد يكون ملحوظًا ، اتضح أن المواضيع مميزة تمامًا في المحتوى عن بعضها البعض. وفقا لهم ، يصبح من الواضح ما الذي يتحدث عنه الناس مع التعصب البطني. بشكل أساسي ، حول الطعام ، الذهاب إلى المطاعم ، الطعام الملوث بالجلوتين ، الآلام الرهيبة ، العلاج ، الذهاب إلى الأطباء ، العائلة ، سوء الفهم وأشياء أخرى يجب أن يواجهها الناس كل يوم فيما يتعلق بمشكلتهم.هذا كل شئ. شكرا لكم جميعا على اهتمامكم. آمل أن تجد هذه المواد مثيرة للاهتمام ومفيدة. ومع ذلك ، نظرًا لأنني لست مطورًا في DS ، فلا تحكم بدقة. إذا كان هناك شيء لإضافته أو تحسينه ، فأنا دائمًا أرحب بالنقد البناء ، أكتب.لعرض 30 موضوعًا