تحية للجميع! كما تعلم بالفعل ، نحن في SE منخرطون في التعرف على النص (وليس فقط) في وثائق مختلفة. نود اليوم أن نتحدث عن مشكلة أخرى عند التعرف على نص على خلفيات معقدة - حول التعرف على المسافات. بشكل عام ، سنتحدث عن الاسم على البطاقات المصرفية ، ولكن أولاً ، مثال مع "شبح" الحرف. كما ترى هنا ، على يمين D ، فإن التشوهات والخلفية تكون واضحة إلى حد ما .. علاوة على ذلك ، إذا قمت بإظهار هذه الخلية بشكل منفصل عن أي شيء آخر ، فإن الشخص (أو الشبكة العصبية) سيقول بالتأكيد أن هناك رسالة.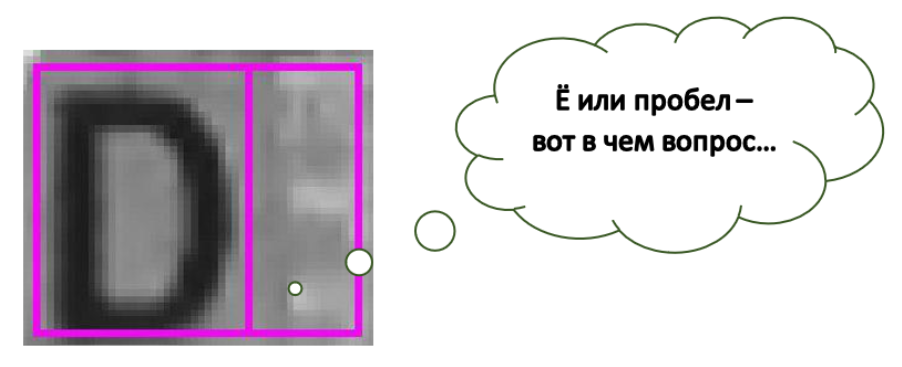 كما ترى في الصورة ، نحن نعمل على الصورة الأصلية بخلفيات معقدة ، لذا فإن مساحاتنا متنوعة للغاية. إنها تأتي في أنماط وشعارات وأحيانًا نص. على سبيل المثال ، VISA أو MAESTRO على البطاقات. ونحن مهتمون فقط بهذه "المساحات المعقدة" ، وليس فقط المستطيلات البيضاء. وفي أنظمتنا ، نعتبر مستطيلات الرموز المقطوعة بدقة منفصلة [1].
كما ترى في الصورة ، نحن نعمل على الصورة الأصلية بخلفيات معقدة ، لذا فإن مساحاتنا متنوعة للغاية. إنها تأتي في أنماط وشعارات وأحيانًا نص. على سبيل المثال ، VISA أو MAESTRO على البطاقات. ونحن مهتمون فقط بهذه "المساحات المعقدة" ، وليس فقط المستطيلات البيضاء. وفي أنظمتنا ، نعتبر مستطيلات الرموز المقطوعة بدقة منفصلة [1].وما هي الصعوبة؟
المسافة هي رمز بدون علامات خاصة. على الخلفيات المعقدة ، كما في الصورة ، قد يكون من الصعب التمييز بين المساحة المقطوعة بشكل منفصل حتى بالنسبة للشخص.من ناحية أخرى ، في الجوهر ، تختلف المساحة عن الشخصيات الأخرى. إذا تم التعرف على ABIA في الاسم بدلاً من ASIA ، فهناك فرصة لإصلاحه بعد المعالجة. ولكن ، إذا ظهرت هناك وكالة دولية مستقلة ، فمن غير المحتمل أن يساعدك شيء.الأساليب غير المستخدمة من قبلنا
غالبًا ما يتم تصفية المسافات باستخدام إحصائيات محسوبة من الصورة. على سبيل المثال ، يعتبرون متوسط القيمة المطلقة للتدرج في الصورة أو تباين شدة وحدات البكسل وتقسيم الصور إلى مسافات وحروف حسب قيمة العتبة. ومع ذلك ، كما يمكن رؤيته من الرسوم البيانية ، فإن هذه الأساليب ليست مناسبة للصور الرمادية ذات الخلفيات المعقدة. وبسبب الارتباط الواضح للقيم ، لن تعمل حتى مجموعة من هذه الأساليب.لن يساعد ثنائية الترميز الثنائي للجميع هنا أيضًا. على سبيل المثال ، في هذه الصورة:لذا ، كيف يمكن تحسين الاعتراف؟
نظرًا لأن الشخص يحتاج إلى بيئة من الفضاء لرؤيته ، فمن المنطقي أن تعرض الشبكة حرفين متجاورين على الأقل. لا نريد زيادة مدخلات شبكة التعرف ، التي تعمل بشكل جيد بشكل عام (وتدرك العديد من الثغرات). لذا سنحصل على شبكة أخرى - أبسط. ستتنبأ الشبكة الجديدة بما هو في الصورة: مسافتان ، وحرفان ، ومسافة وحرف ، أو حرف ومسافة. ووفقًا لذلك ، يتم استخدام هذه الشبكة جنبًا إلى جنب مع شبكة التعرف. تُظهر الصورة البنيات المستخدمة: على اليسار هي بنية شبكة التعرف ، على اليمين هي بنية الشبكة المقترحة. تعمل شبكة التعرف على صورة بحرف واحد ، وتعمل الجديدة على صورة مزدوجة العرض تحتوي على حرفين متجاورين.اختبار؟
للاختبار ، كان لدينا 4320 سطرًا بأسماء تحتوي على 130،149 حرفًا ، منها 68،246 مسافة. بالنسبة للمبتدئين ، لدينا طريقتان. الطريقة الأساسية: نقطع سلسلة إلى أحرف ونتعرف على كل حرف على حدة. طريقة جديدة: نقوم أيضًا بقص سلسلة من الأحرف ، والعثور على جميع المسافات بشبكة جديدة ، والتعرف على الأحرف المتبقية كالمعتاد. يوضح الجدول أن جودة التعرف على المساحات ، بالإضافة إلى الجودة الإجمالية ، آخذة في الازدياد ، ولكن جودة التعرف على الحروف متدنية قليلاً.ومع ذلك ، فإن شبكتنا الأساسية تتعرف أيضًا على المساحات (وإن كانت أسوأ مما نود). ويمكننا أن نحاول الاستفادة من ذلك. دعونا نلقي نظرة على أخطاء كلتا الطريقتين. وأيضًا - على جودة الطريقة الجديدة القائمة على الأخطاء الأساسية والعكس صحيح.بالنسبة للطريقة الأساسية:للطريقة الجديدة:من الجداول الثلاثة الأخيرة يمكن ملاحظة أنه لتحسين النظام يجدر استخدام مزيج متوازن من تقييمات الشبكة. في الوقت نفسه ، تعد جودة الحرف الذي تلو الآخر مثيرة للاهتمام ، ولكن الخط تلو الآخر أكثر إثارة للاهتمام.استنتاج
مسافة - مشكلة كبيرة في طريقها إلى جودة التعرف على المستندات بنسبة 100٪ =) يوضح مثال المسافات بوضوح أهمية النظر ليس فقط إلى الشخصيات الفردية ، ولكن أيضًا إلى مجموعاتها. ومع ذلك ، لا تمسك بالمدفعية الثقيلة على الفور وتعلم شبكات عملاقة تعالج سلاسل كاملة. في بعض الأحيان يكفي شبكة صغيرة أخرى.تم عمل هذا المنشور باستخدام مواد من تقرير من المؤتمر الأوروبي لنمذجة ECMS 2015 (بلغاريا ، فارنا): Sheshkus ، A. & Arlazarov ، VL (2015). كشف رمز الفضاء على خلفية معقدة باستخدام السياق المرئي.قائمة المصادر المستخدمة1. YS Chernyshova و AV Sheshkus و VV Arlazarov ، "إطار CNN من خطوتين للتعرف على سطر النص في الصور الملتقطة بواسطة الكاميرا" ، IEEE Access ، المجلد. 8 ، ص. 32587-32600 ، 2020 ، DOI: 10.1109 / ACCESS.2020.2974051.