في أنظمة ERP المعقدة ، تتمتع العديد من الكيانات بطابع هرمي ، عندما تصطف الكائنات المتجانسة في شجرة العلاقات بين الجد والسليل - هذا هو الهيكل التنظيمي للمشروع (كل هذه الفروع والأقسام ومجموعات العمل) ، وكتالوج المنتج ، ومجالات العمل ، والجغرافيا نقاط البيع ، ... في الواقع ، لا يوجد مجال واحد لأتمتة الأعمال حيث لن تكون النتيجة بعض التسلسل الهرمي على الأقل. ولكن حتى إذا كنت لا تعمل "للأعمال التجارية" ، فلا يزال بإمكانك العثور على علاقات هرمية. مبتذلة ، حتى شجرة عائلتك أو مخطط أرضية المبنى في مركز التسوق هو نفس الهيكل. هناك العديد من الطرق لتخزين هذه الشجرة في نظام إدارة قواعد البيانات ، ولكننا سنركز اليوم على خيار واحد فقط:
CREATE TABLE hier(
id
integer
PRIMARY KEY
, pid
integer
REFERENCES hier
, data
json
);
CREATE INDEX ON hier(pid);
وبينما تنظر إلى أعماق التسلسل الهرمي ، فإنها تنتظر بصبر كيف ستصبح طرقك "الساذجة" للعمل مع مثل هذا الهيكل فعّالة.دعونا نحلل المهام الناشئة النموذجية ، وتنفيذها في SQL ومحاولة تحسين أدائها.رقم 1. كم عمق حفرة الارنب؟
دعنا نأخذ ، على وجه الدقة ، أن هذا الهيكل سيعكس خضوع الأقسام في هيكل المنظمة: الإدارات والأقسام والقطاعات والفروع ومجموعات العمل ... أيا كان ما تسمونه.أولاً ، ننشئ "شجرتنا" المكونة من 10 آلاف عنصرINSERT INTO hier
WITH RECURSIVE T AS (
SELECT
1::integer id
, '{1}'::integer[] pids
UNION ALL
SELECT
id + 1
, pids[1:(random() * array_length(pids, 1))::integer] || (id + 1)
FROM
T
WHERE
id < 10000
)
SELECT
pids[array_length(pids, 1)] id
, pids[array_length(pids, 1) - 1] pid
FROM
T;
لنبدأ بأبسط مهمة - للعثور على جميع الموظفين الذين يعملون في قطاع معين ، أو من حيث التسلسل الهرمي - للعثور على جميع أحفاد العقدة . سيكون من الجيد أيضًا الحصول على "عمق" السليل ... كل هذا قد يكون ضروريًا ، على سبيل المثال ، لبناء نوع من الاختيار المعقد من قائمة معرفات هؤلاء الموظفين .سيكون كل شيء على ما يرام إذا كان هؤلاء الأحفاد لا يوجد سوى مستويين وكميًا في العشرات ، ولكن إذا كان هناك أكثر من 5 مستويات ، وهناك بالفعل العشرات من الأحفاد ، فقد تكون هناك مشاكل. دعونا نرى كيف تتم كتابة (والبحث عن) خيارات البحث التقليدية "أسفل الشاشة". لكن أولاً ، نحدد أي العقد ستكون الأكثر إثارة للاهتمام في بحثنا.و "أعمق" الأشجار الفرعية:WITH RECURSIVE T AS (
SELECT
id
, pid
, ARRAY[id] path
FROM
hier
WHERE
pid IS NULL
UNION ALL
SELECT
hier.id
, hier.pid
, T.path || hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABLE T ORDER BY array_length(path, 1) DESC;
id | pid | path
---------------------------------------------
7624 | 7623 | {7615,7620,7621,7622,7623,7624}
4995 | 4994 | {4983,4985,4988,4993,4994,4995}
4991 | 4990 | {4983,4985,4988,4989,4990,4991}
...
و "أوسع" الأشجار الفرعية:...
SELECT
path[1] id
, count(*)
FROM
T
GROUP BY
1
ORDER BY
2 DESC;
id | count
------------
5300 | 30
450 | 28
1239 | 27
1573 | 25
بالنسبة إلى هذه الاستفسارات ، استخدمنا JOIN العودي النموذجي : من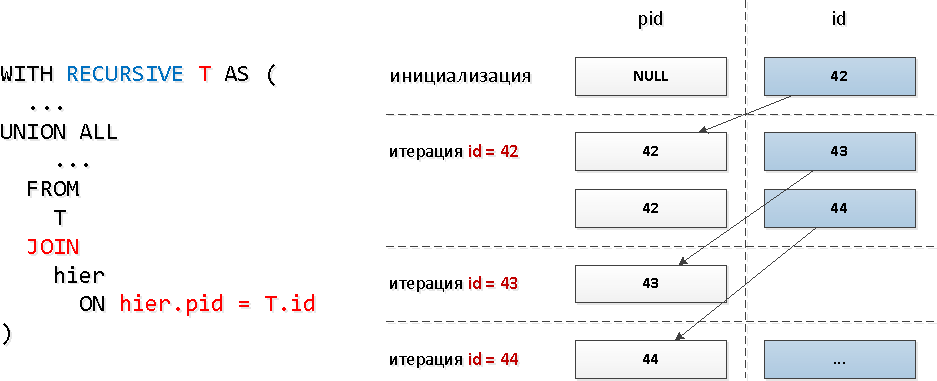 الواضح ، مع نموذج الاستعلام هذا ، سيتزامن عدد التكرارات مع العدد الإجمالي للأحفاد (وهناك عدة عشرات منهم) ، وهذا يمكن أن يستغرق موارد كبيرة جدًا ، ونتيجة لذلك ، الوقت.دعنا نتحقق من الشجرة الفرعية "الأوسع":
الواضح ، مع نموذج الاستعلام هذا ، سيتزامن عدد التكرارات مع العدد الإجمالي للأحفاد (وهناك عدة عشرات منهم) ، وهذا يمكن أن يستغرق موارد كبيرة جدًا ، ونتيجة لذلك ، الوقت.دعنا نتحقق من الشجرة الفرعية "الأوسع":WITH RECURSIVE T AS (
SELECT
id
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABLE T;
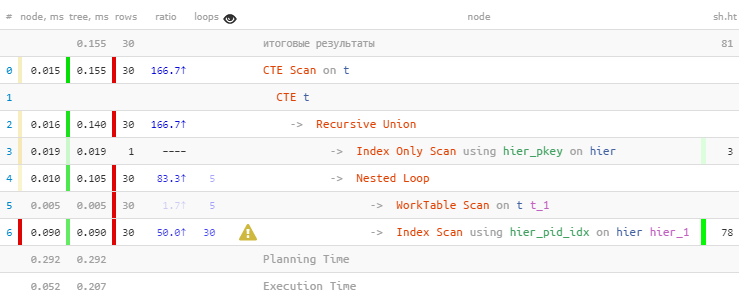 [إلقاء نظرة على Expl.tensor.ru]كما هو متوقع ، وجدنا جميع الإدخالات الثلاثين. لكنهم قضوا 60٪ من الوقت كله في ذلك - لأنهم أجروا 30 بحثًا على الفهرس. وأقل - هل هذا ممكن؟
[إلقاء نظرة على Expl.tensor.ru]كما هو متوقع ، وجدنا جميع الإدخالات الثلاثين. لكنهم قضوا 60٪ من الوقت كله في ذلك - لأنهم أجروا 30 بحثًا على الفهرس. وأقل - هل هذا ممكن؟التدقيق الشامل بواسطة الفهرس
ولكل عقدة ، هل نحن بحاجة لتقديم طلب فهرس منفصل؟ اتضح أنه لا يوجد - يمكننا أن نقرأ من المؤشر على عدة مفاتيح في وقت واحد مع مكالمة واحدة= ANY(array) .وفي كل مجموعة من هذه المعرّفات ، يمكننا أخذ جميع المعرّفات الموجودة في الخطوة السابقة بواسطة "العقد". أي أننا سنبحث في كل خطوة تالية على الفور عن جميع أحفاد مستوى معين دفعة واحدة .ولكن ، إنه لسوء الحظ ، في التحديد العودي ، لا يمكنك الرجوع إلى نفسك في استعلام متداخل ، ولكننا نحتاج فقط إلى حد ما تحديد ما تم العثور عليه بالضبط في المستوى السابق ... اتضح أنه من المستحيل إجراء استعلام متداخل للعينة بأكملها ، ولكن إلى مجالها المحدد - يستطيع. ويمكن أن يكون هذا الحقل أيضًا مصفوفة - وهو ما نحتاج إلى استخدامهANY.يبدو البرية قليلا ، ولكن على الرسم البياني - كل شيء بسيط.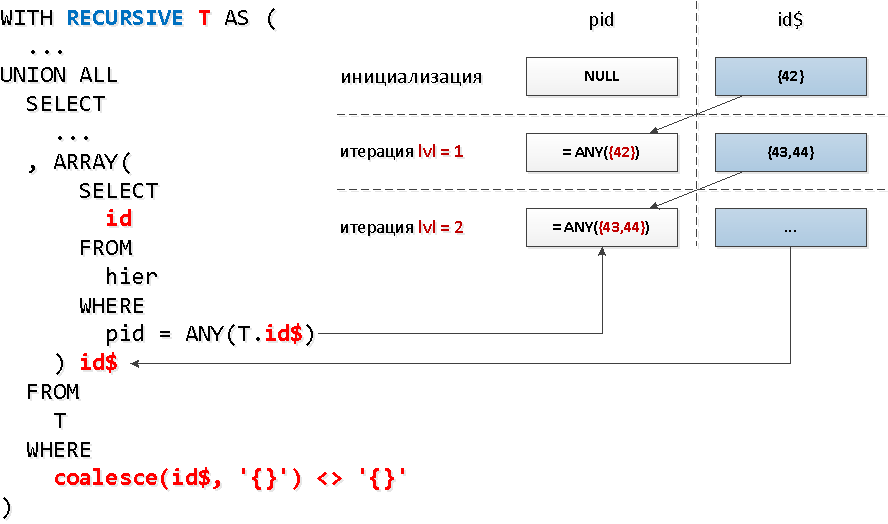
WITH RECURSIVE T AS (
SELECT
ARRAY[id] id$
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
ARRAY(
SELECT
id
FROM
hier
WHERE
pid = ANY(T.id$)
) id$
FROM
T
WHERE
coalesce(id$, '{}') <> '{}'
)
SELECT
unnest(id$) id
FROM
T;
 [إلقاء نظرة على Expl.tensor.ru]وهنا أهم شيء هو عدم الفوز حتى 1.5 مرة في الوقت المناسب ، ولكننا طرحنا عددًا أقل من المخازن المؤقتة ، نظرًا لأن لدينا 5 مكالمات فقط إلى الفهرس بدلاً من 30!مكافأة إضافية هي حقيقة أنه بعد معرفات unnest النهائية ستبقى مرتبة حسب "المستويات".
[إلقاء نظرة على Expl.tensor.ru]وهنا أهم شيء هو عدم الفوز حتى 1.5 مرة في الوقت المناسب ، ولكننا طرحنا عددًا أقل من المخازن المؤقتة ، نظرًا لأن لدينا 5 مكالمات فقط إلى الفهرس بدلاً من 30!مكافأة إضافية هي حقيقة أنه بعد معرفات unnest النهائية ستبقى مرتبة حسب "المستويات".علامة العقدة
الاعتبار التالي الذي سيساعد على تحسين الإنتاجية هو أن "الأوراق" لا يمكن أن يكون لديها أطفال ، أي أنهم لا يحتاجون إلى البحث عن أي شيء. في صياغة مهمتنا ، هذا يعني أنه إذا ذهبنا على طول سلسلة الأقسام ووصلنا إلى الموظف ، فلا حاجة للبحث أكثر في هذا الفرع.دعنا ندخل حقلًا إضافيًاboolean في طاولتنا ، والذي سيخبرنا على الفور ما إذا كان هذا الإدخال المحدد في شجرتنا هو "عقدة" - أي أنه إذا كان يمكن أن يكون لديه أي أطفال على الإطلاق.ALTER TABLE hier
ADD COLUMN branch boolean;
UPDATE
hier T
SET
branch = TRUE
WHERE
EXISTS(
SELECT
NULL
FROM
hier
WHERE
pid = T.id
LIMIT 1
);
غرامة! اتضح أن ما يزيد قليلاً عن 30 ٪ فقط من جميع عناصر الأشجار لديهم أحفاد. سنقومالآن بتطبيق ميكانيكا مختلفة قليلاً - الاتصال بالجزء العودي من خلاله LATERAL، مما سيسمح لنا بالوصول على الفور إلى حقول "الجدول" العودي ، واستخدام الدالة التجميعية مع شرط الفلتر بواسطة سمة العقدة لتقليل مجموعة المفاتيح: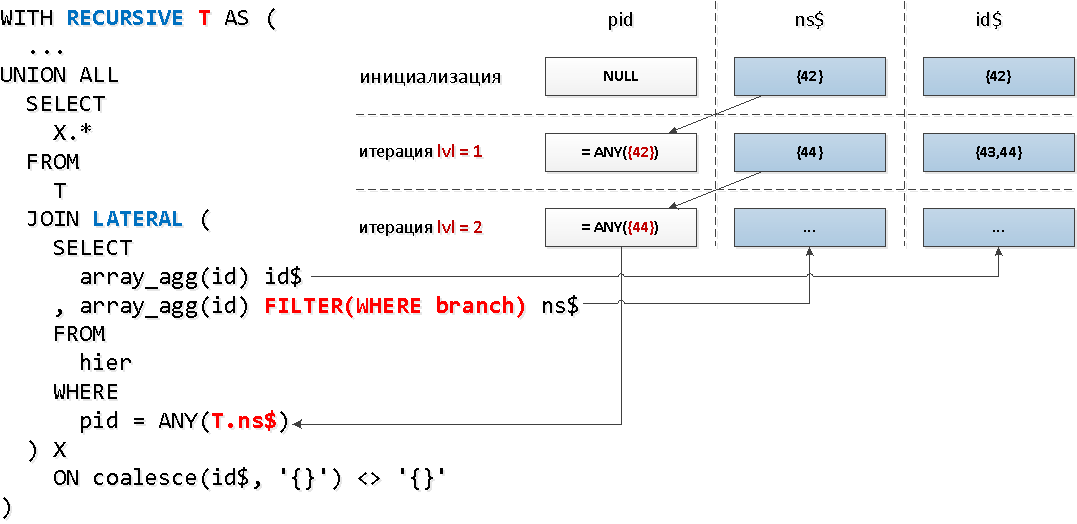
WITH RECURSIVE T AS (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
X.*
FROM
T
JOIN LATERAL (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
pid = ANY(T.ns$)
) X
ON coalesce(T.ns$, '{}') <> '{}'
)
SELECT
unnest(id$) id
FROM
T;
 [إلقاء نظرة على Expl.tensor.ru]تمكنا من تقليل جاذبية أخرى إلى المؤشر وربحنا أكثر من مرتين من حيث المبلغ المخصوم .
[إلقاء نظرة على Expl.tensor.ru]تمكنا من تقليل جاذبية أخرى إلى المؤشر وربحنا أكثر من مرتين من حيث المبلغ المخصوم .# 2 عودة إلى الأصل
ستكون هذه الخوارزمية مفيدة إذا كنت بحاجة إلى جمع سجلات لجميع العناصر "في أعلى الشجرة" ، مع الحفاظ على معلومات حول أي ورقة مصدر (وأي مؤشرات) تسببت في سقوطها في العينة - على سبيل المثال ، لإنشاء تقرير موجز مع تجميع العقد.يجب أن يؤخذ المزيد حصريًا كإثبات للمفهوم ، لأن الطلب مرهق للغاية. ولكن إذا كانت تهيمن على قاعدة البيانات الخاصة بك - يجدر النظر في استخدام مثل هذه التقنيات.لنبدأ ببعض العبارات البسيطة:- من الأفضل قراءة نفس السجل من قاعدة البيانات مرة واحدة فقط .
- تتم قراءة الإدخالات من قاعدة البيانات بكفاءة أكبر في "حزمة" من كل على حدة.
الآن دعنا نحاول تصميم الاستعلام الذي نحتاجه.الخطوة 1
من الواضح ، عند تهيئة العودية (حيث بدونها!) ، سيتعين علينا طرح سجلات الأوراق نفسها من مجموعة معرفات المصدر:WITH RECURSIVE tree AS (
SELECT
rec
, id::text chld
FROM
hier rec
WHERE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNION ALL
...
إذا بدا غريباً أن يتم تخزين "المجموعة" في سلسلة ، وليس في مصفوفة ، فهناك تفسير بسيط. بالنسبة للسلاسل ، توجد وظيفة تجميع "لصق" مضمنة string_agg، ولكن بالنسبة للمصفوفات ، لا. على الرغم من أنه ليس من الصعب تنفيذه بنفسك .الخطوة 2
الآن سنحصل على مجموعة من معرفات القسم التي يجب طرحها بشكل أكبر. دائمًا ، سيتم نسخها في سجلات مختلفة لمجموعة المصادر - لذلك سنقوم بتجميعها ، مع الحفاظ على معلومات حول أوراق المصدر.لكن هنا ثلاث مشاكل تنتظرنا:- لا يمكن أن يحتوي الجزء "العودية الفرعية" من الاستعلام على دالات تجميعية ج
GROUP BY. - لا يمكن أن يكون استدعاء "جدول" متكرر في استعلام فرعي متداخل.
- لا يمكن أن يحتوي الاستعلام في الجزء العودي على CTE.
لحسن الحظ ، يتم تجاوز كل هذه المشاكل بسهولة تامة. لنبدأ من النهاية.CTE في الجزء العودي
هذه ليست الطريقة التي يعمل بها:WITH RECURSIVE tree AS (
...
UNION ALL
WITH T (...)
SELECT ...
)
وهكذا يعمل ، تقرر الأقواس!WITH RECURSIVE tree AS (
...
UNION ALL
(
WITH T (...)
SELECT ...
)
)
استعلام متداخل لـ "جدول" عودي
همم ... لا يمكن أن تكون استدعاء CTE العودية في استعلام فرعي. ولكن يمكن أن يكون داخل CTE! يمكن أن يشير الطلب الفرعي بالفعل إلى CTE!التجميع حسب العودية الداخلية
إنه أمر غير سار ، ولكن ... لدينا أيضًا طريقة بسيطة لمحاكاة GROUP BY باستخدام DISTINCT ONوظائف النافذة!SELECT
(rec).pid id
, string_agg(chld::text, ',') chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
GROUP BY 1
وهكذا يعمل!SELECT DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
الآن نرى لماذا تحول المعرف الرقمي إلى نص - بحيث يمكن لصقها مع فاصلة!الخطوه 3
في النهاية ، لم يبق لنا شيء:- نقرأ سجلات "الأقسام" في مجموعة من المعرّفات المجمعة
- مطابقة الأقسام المطروحة مع "مجموعات" أوراق المصدر
- "توسيع" السلسلة المحددة باستخدام
unnest(string_to_array(chld, ',')::integer[])
WITH RECURSIVE tree AS (
SELECT
rec
, id::text chld
FROM
hier rec
WHERE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNION ALL
(
WITH prnt AS (
SELECT DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
)
, nodes AS (
SELECT
rec
FROM
hier rec
WHERE
id = ANY(ARRAY(
SELECT
id
FROM
prnt
))
)
SELECT
nodes.rec
, prnt.chld
FROM
prnt
JOIN
nodes
ON (nodes.rec).id = prnt.id
)
)
SELECT
unnest(string_to_array(chld, ',')::integer[]) leaf
, (rec).*
FROM
tree;
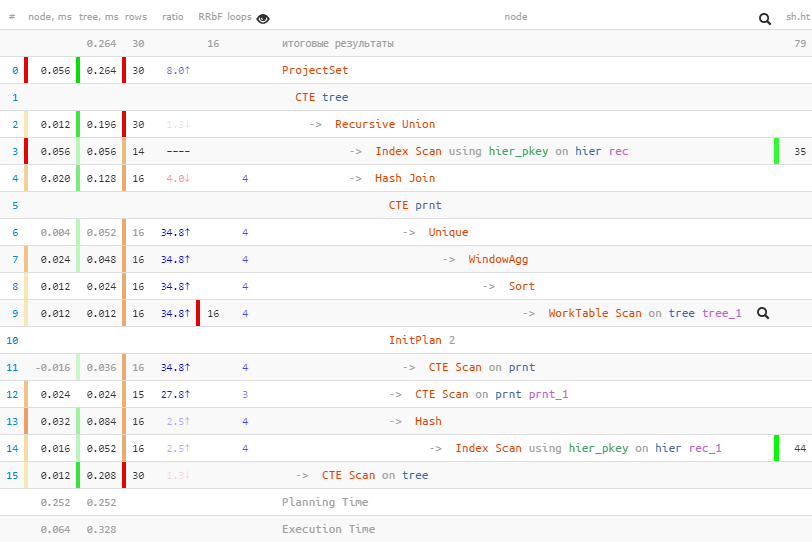 [ explain.tensor.ru]
[ explain.tensor.ru]