نحاول في Uchi.ru طرح حتى التحسينات الصغيرة باستخدام اختبار A / B ، حيث كان هناك أكثر من 250 منهم خلال هذا العام الدراسي. اختبار A / B هو أداة اختبار قوية للتغيير ، والتي بدونها يصعب تصور التطور الطبيعي لمنتج الإنترنت. في الوقت نفسه ، على الرغم من البساطة الواضحة ، يمكن ارتكاب أخطاء خطيرة أثناء اختبار أ / ب في مرحلة التصميم من التجربة وفي تلخيص النتائج. في هذه المقالة سأتحدث عن بعض الجوانب التقنية للاختبار: كيف نحدد فترة الاختبار ونلخص وكيف نتجنب النتائج الخاطئة عند اكتمال الاختبارات قبل الموعد المحدد وعند اختبار العديد من الفرضيات دفعة واحدة. يبدو مخطط اختبار A / B النموذجي لنا (وبالنسبة للكثيرين) كما يلي:
يبدو مخطط اختبار A / B النموذجي لنا (وبالنسبة للكثيرين) كما يلي:- نحن نطور ميزة ، ولكن قبل طرحها على الجمهور بأكمله ، نريد التأكد من أنها تحسن المقياس المستهدف ، على سبيل المثال ، التفاعل.
- نحدد الفترة التي يبدأ فيها الاختبار.
- نقسم المستخدمين بشكل عشوائي إلى مجموعتين.
- نعرض على إحدى المجموعات إصدار المنتج مع الميزات (المجموعة التجريبية) ، والآخر - المجموعة القديمة (التحكم).
- في هذه العملية ، نراقب المقياس من أجل إيقاف اختبار غير ناجح بشكل خاص في الوقت المناسب.
- بعد انتهاء صلاحية الاختبار ، نقارن المقياس في المجموعتين التجريبية والضابطة.
- إذا كان المقياس في المجموعة التجريبية أفضل إحصائيًا بشكل ملحوظ منه في المجموعة الضابطة ، فإننا نطرح الميزة المختبرة على الإطلاق. إذا لم يكن هناك دلالة إحصائية ، فإننا ننهي الاختبار بنتيجة سلبية.
كل شيء يبدو منطقيًا وبسيطًا ، الشيطان ، كما هو الحال دائمًا ، في التفاصيل.الأهمية الإحصائية والمعايير والأخطاء
هناك عنصر للعشوائية في أي اختبار أ / ب: تعتمد المقاييس الجماعية ليس فقط على وظائفها ، ولكن أيضًا على ما يدخل إليه المستخدمون وكيف يتصرفون. للحصول على استنتاجات موثوق بها حول تفوق المجموعة ، تحتاج إلى جمع ما يكفي من الملاحظات في الاختبار ، ولكن حتى ذلك الحين لست محصنًا من الأخطاء. وتتميز بنوعين:- يحدث خطأ من النوع الأول إذا قمنا بإصلاح الفرق بين المجموعات ، على الرغم من أنه غير موجود في الواقع. سيحتوي النص أيضًا على مصطلح مكافئ - نتيجة إيجابية خاطئة. المقالة مخصصة لمثل هذه الأخطاء فقط.
- يحدث خطأ من النوع الثاني إذا قمنا بإصلاح عدم وجود فرق ، على الرغم من أنه في الواقع.
مع وجود عدد كبير من التجارب ، من المهم أن يكون احتمال الخطأ من النوع الأول صغيرًا. يمكن التحكم فيه باستخدام الطرق الإحصائية. على سبيل المثال ، نريد ألا يتجاوز احتمال حدوث خطأ من النوع الأول في كل تجربة 5٪ (هذه مجرد قيمة مناسبة ، يمكنك أن تأخذ أخرى لاحتياجاتك الخاصة). ثم سنقوم بتجارب على مستوى أهمية 0.05:- هناك اختبار A / B مع مجموعة التحكم A والمجموعة التجريبية B. الهدف هو التحقق من أن المجموعة B تختلف عن المجموعة A في بعض المقاييس.
- نقوم بصياغة الفرضية الإحصائية الفارغة: لا تختلف المجموعتان A و B ، ويتم تفسير الاختلافات الملحوظة بالضوضاء. افتراضيًا ، نعتقد دائمًا أنه لا يوجد فرق حتى يثبت العكس.
- نتحقق من الفرضية بقاعدة رياضية صارمة - معيار إحصائي ، على سبيل المثال ، معيار الطالب.
- ونتيجة لذلك ، نحصل على القيمة الاحتمالية. يقع في النطاق من 0 إلى 1 ويعني احتمال رؤية الفرق الحالي أو الأكثر تطرفاً بين المجموعات ، بشرط أن تكون الفرضية الصفرية صحيحة ، أي في غياب فرق بين المجموعات.
- تتم مقارنة القيمة الاحتمالية بمستوى أهمية يبلغ 0.05. إذا كانت أكبر ، فنحن نقبل الفرضية الصفرية بأنه لا توجد فروق ، وإلا فإننا نعتقد أن هناك فرقًا مهمًا إحصائيًا بين المجموعات.
يمكن اختبار الفرضية بمعيار حدودي أو غير معياري. تعتمد المعلمات البارامترية على معلمات توزيع العينة لمتغير عشوائي ولديها قوة أكبر (يرتكبون أخطاء من النوع الثاني أقل) ، لكنهم يفرضون متطلبات على توزيع المتغير العشوائي قيد الدراسة.اختبار المعلمات الأكثر شيوعًا هو اختبار الطالب. لعينتين مستقلتين (حالة اختبار A / B) ، يطلق عليه أحيانًا معيار ويلش. يعمل هذا المعيار بشكل صحيح إذا تم توزيع الكميات المدروسة بشكل طبيعي. قد يبدو أنه في البيانات الحقيقية لا يتم الوفاء بهذا المطلب تقريبًا ، ولكن في الواقع يتطلب الاختبار توزيعًا طبيعيًا لمتوسطات العينات ، وليس العينات نفسها. من الناحية العملية ، هذا يعني أنه يمكن تطبيق المعيار إذا كان لديك الكثير من الملاحظات في الاختبار (عشرات إلى مئات) وليس هناك ذيول طويلة جدًا في التوزيعات. إن طبيعة توزيع الملاحظات الأولية غير مهمة. يمكن للقارئ التحقق بشكل مستقل من أن معيار الطالب يعمل بشكل صحيح حتى في العينات التي تم إنشاؤها من برنولي أو التوزيعات الأسية.من بين المعايير غير البارامترية ، فإن معيار مان ويتني شائع. يجب استخدامه إذا كانت عيناتك صغيرة جدًا أو تحتوي على قيم متطرفة كبيرة (الطريقة تقارن المتوسطات ، وبالتالي فهي مقاومة للقيم المتطرفة). أيضًا ، لكي يعمل المعيار بشكل صحيح ، يجب أن تحتوي العينات على قيم مطابقة قليلة. من الناحية العملية ، لم نضطر أبدًا إلى تطبيق معايير غير معلمية ، وفي اختباراتنا نستخدم دائمًا معيار الطالب.مشكلة اختبار الفرضيات المتعددة
المشكلة الأكثر وضوحًا وأبسط: إذا كان في الاختبار ، بالإضافة إلى المجموعة الضابطة ، هناك العديد من التجارب التجريبية ، ثم تلخيص النتائج بمستوى أهمية 0.05 سيؤدي إلى زيادة متعددة في نسبة الأخطاء من النوع الأول. يحدث هذا لأنه مع كل تطبيق للمعيار الإحصائي ، فإن احتمال حدوث خطأ من النوع الأول سيكون 5 ٪. مع عدد المجموعات ومستوى الأهمية احتمال أن تفوز بعض المجموعات التجريبية بالصدفة هو:
على سبيل المثال ، بالنسبة للمجموعات التجريبية الثلاث ، نحصل على 14.3٪ بدلاً من 5٪ المتوقعة. يتم حل المشكلة عن طريق تصحيح Bonferroni لاختبار الفرضيات المتعددة: تحتاج فقط إلى تقسيم مستوى الدلالة على عدد المقارنات (أي المجموعات) والعمل معها. بالنسبة للمثال أعلاه ، مستوى الأهمية ، مع مراعاة التعديل ، سيكون 0.05 / 3 = 0.0167 ، واحتمال خطأ واحد على الأقل من النوع الأول مقبول بنسبة 4.9٪.طريقة هيل - بونفيروني— , , , .
p-value ,
:
P-value
. , p-value
, . - , . ( , ) p-value, . A/B- — , — .
بالمعنى الدقيق للكلمة ، فإن مقارنات المجموعات بمقاييس أو أقسام مختلفة من الجمهور تخضع أيضًا لمشكلة الاختبارات المتعددة. من الناحية الرسمية ، من الصعب جدًا مراعاة جميع الشيكات ، لأن من الصعب التنبؤ بأرقامها مقدمًا وأحيانًا تكون غير مستقلة (خاصة عندما يتعلق الأمر بمقاييس مختلفة ، وليس شرائح). لا توجد وصفة عالمية ، وتعتمد على الحس السليم وتذكر أنه إذا قمت بفحص الكثير من الشرائح باستخدام مقاييس مختلفة ، فعندئذٍ يمكنك في أي اختبار رؤية نتيجة ذات دلالة إحصائية. لذلك ، يجب على المرء أن يكون حذرا ، على سبيل المثال ، إلى الزيادة الكبيرة في الاحتفاظ باليوم الخامس لمستخدمي الهواتف المحمولة الجدد من المدن الكبيرة.مشكلة مختلس النظر
مشكلة معينة من اختبار الفرضيات المتعددة هي مشكلة النظر. النقطة هي أن القيمة الاحتمالية أثناء الاختبار يمكن أن تنخفض دون مستوى الأهمية المقبول. إذا كنت تراقب التجربة بعناية ، يمكنك التقاط هذه اللحظة وارتكاب خطأ حول الدلالة الإحصائية.لنفترض أننا ابتعدنا عن إعداد الاختبار الموصوف في بداية المشاركة وقررنا إجراء تقييم عند مستوى أهمية يبلغ 5٪ كل يوم (أو أكثر من مرة واحدة فقط أثناء الاختبار). من خلال التلخيص ، أفهم أن الاختبار إيجابي إذا كانت قيمة p أقل من 0.05 ، واستمراريته على خلاف ذلك. باستخدام هذه الإستراتيجية ، ستكون حصة النتائج الإيجابية الزائفة متناسبة مع عدد الشيكات وستصل في الشهر الأول إلى 28٪. يبدو هذا الاختلاف الضخم غير بديهي ، لذلك ننتقل إلى منهجية اختبارات A / A ، التي لا غنى عنها لتطوير مخططات اختبار A / B.فكرة اختبار A / A بسيطة: لمحاكاة الكثير من اختبارات A / B على البيانات العشوائية مع تجميع عشوائي. من الواضح أنه لا يوجد فرق بين المجموعات ، لذا يمكنك تقدير نسبة الأخطاء من النوع الأول بدقة في مخطط اختبار A / B الخاص بك. يوضح gif أدناه كيف تتغير قيمة p حسب اليوم لأربعة اختبارات من هذا القبيل. يشار إلى مستوى دلالة يساوي 0.05 بخط متقطع. عندما تنخفض قيمة p أدناه ، نقوم بتلوين مؤامرة الاختبار باللون الأحمر. إذا تم تلخيص نتائج الاختبار في هذا الوقت ، فسيعتبر ناجحًا.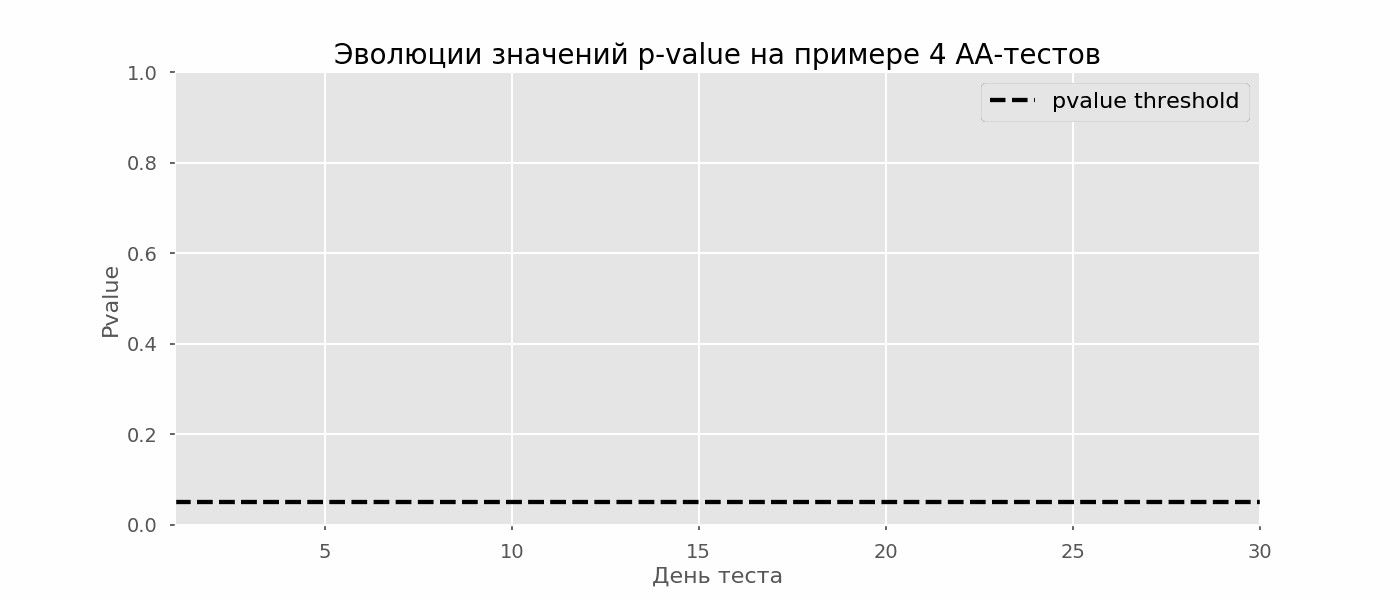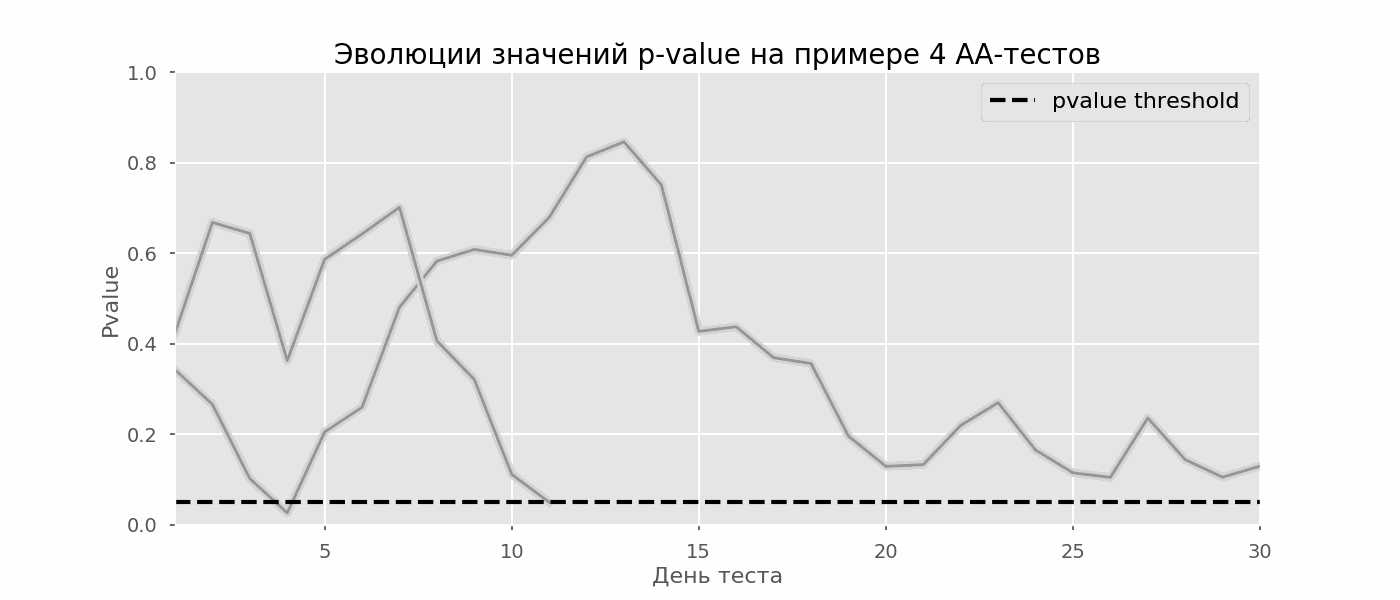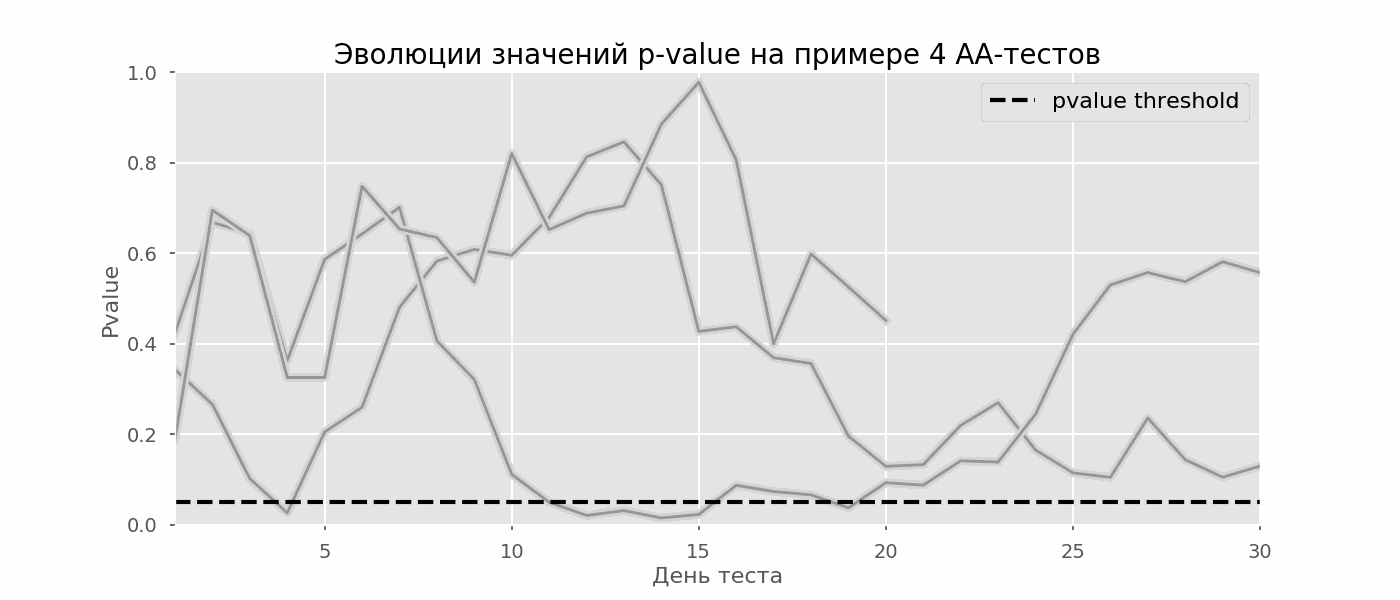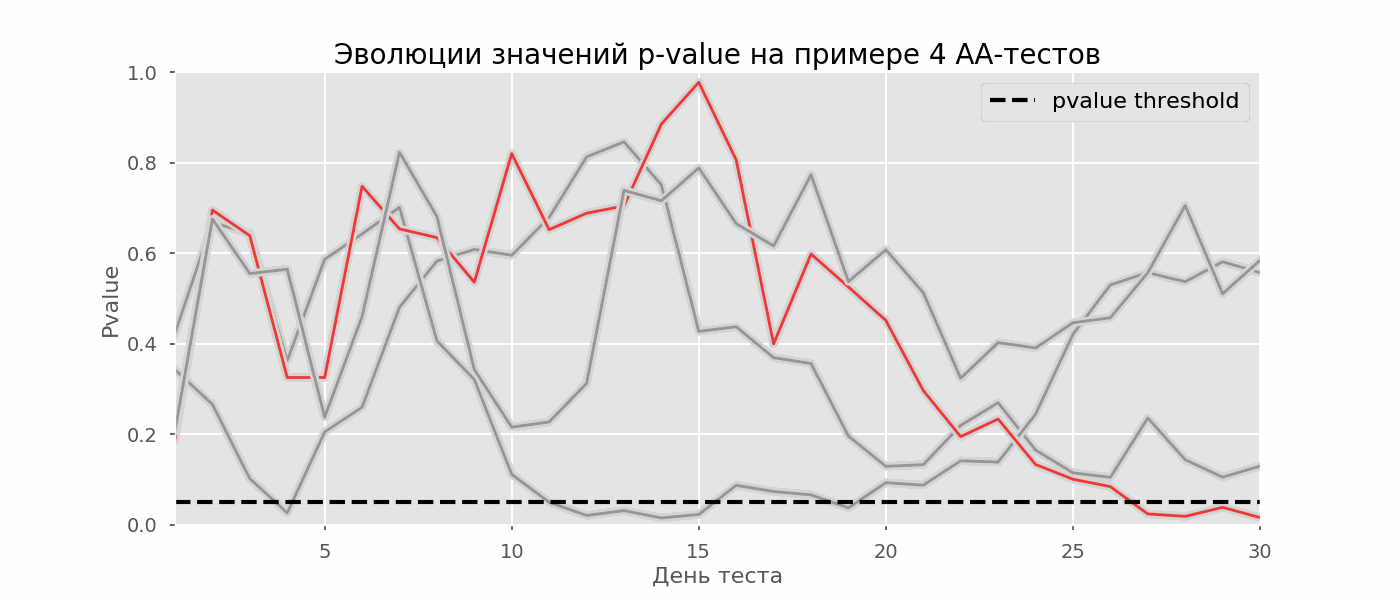 وبالمثل ، نحسب 10 آلاف اختبار A / A تستمر لمدة شهر واحد ونقارن كسور النتائج الإيجابية الكاذبة في المخطط مع التلخيص في نهاية الفصل وكل يوم. للتوضيح ، فيما يلي جداول تجوال القيمة p حسب اليوم لأول 100 محاكاة. كل سطر هو قيمة p لاختبار واحد ، ويتم تمييز مسارات الاختبارات باللون الأحمر ، والتي تعتبر في النهاية خاطئة عن طريق الخطأ (كلما كان أصغر كلما كان ذلك أفضل) ، فإن الخط المتقطع هو قيمة p المطلوبة للتعرف على الاختبار على أنه ناجح.
وبالمثل ، نحسب 10 آلاف اختبار A / A تستمر لمدة شهر واحد ونقارن كسور النتائج الإيجابية الكاذبة في المخطط مع التلخيص في نهاية الفصل وكل يوم. للتوضيح ، فيما يلي جداول تجوال القيمة p حسب اليوم لأول 100 محاكاة. كل سطر هو قيمة p لاختبار واحد ، ويتم تمييز مسارات الاختبارات باللون الأحمر ، والتي تعتبر في النهاية خاطئة عن طريق الخطأ (كلما كان أصغر كلما كان ذلك أفضل) ، فإن الخط المتقطع هو قيمة p المطلوبة للتعرف على الاختبار على أنه ناجح.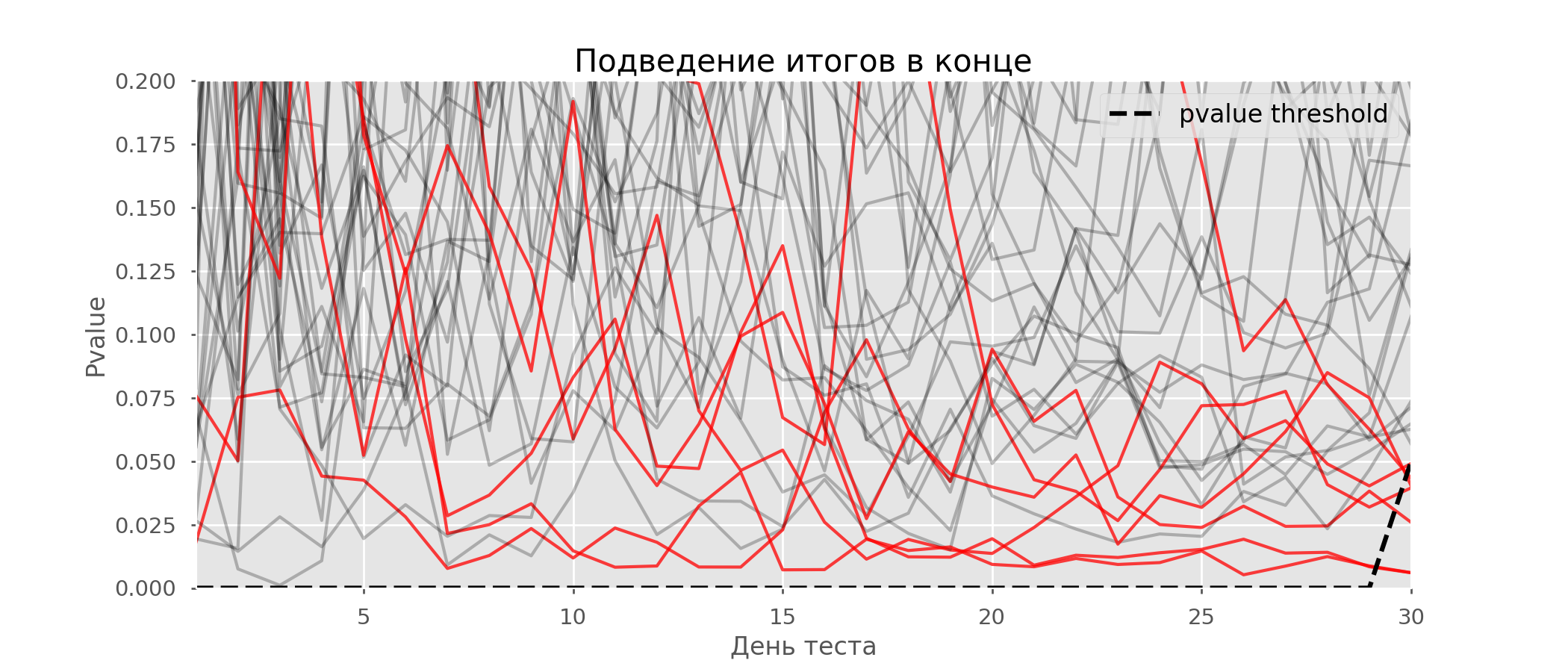 على الرسم البياني ، يمكنك حساب 7 اختبارات إيجابية كاذبة ، وإجماليًا من بين 10 آلاف كان هناك 502 ، أو 5 ٪. وتجدر الإشارة إلى أن قيمة p للعديد من الاختبارات أثناء سير الملاحظات انخفضت إلى أقل من 0.05 ، ولكن بنهاية الملاحظات تجاوزت مستوى الأهمية. الآن دعونا نقيم مخطط الاختبار مع استخلاص المعلومات كل يوم:
على الرسم البياني ، يمكنك حساب 7 اختبارات إيجابية كاذبة ، وإجماليًا من بين 10 آلاف كان هناك 502 ، أو 5 ٪. وتجدر الإشارة إلى أن قيمة p للعديد من الاختبارات أثناء سير الملاحظات انخفضت إلى أقل من 0.05 ، ولكن بنهاية الملاحظات تجاوزت مستوى الأهمية. الآن دعونا نقيم مخطط الاختبار مع استخلاص المعلومات كل يوم: هناك الكثير من الخطوط الحمراء بحيث لا يوجد شيء واضح. سنعيد الرسم من خلال كسر خطوط الاختبار بمجرد أن تصل قيمة p إلى قيمة حرجة:
هناك الكثير من الخطوط الحمراء بحيث لا يوجد شيء واضح. سنعيد الرسم من خلال كسر خطوط الاختبار بمجرد أن تصل قيمة p إلى قيمة حرجة: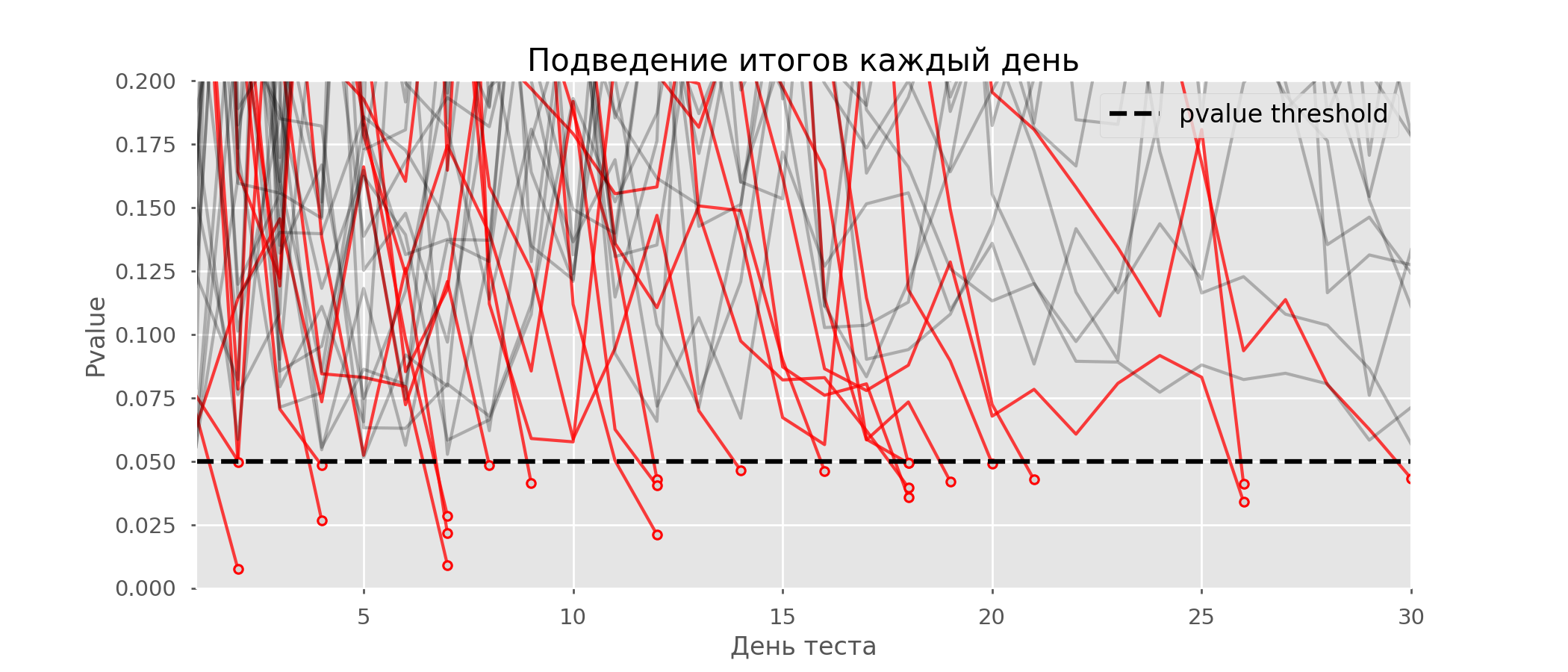 سيكون هناك ما مجموعه 2813 اختبارًا إيجابيًا كاذبًا من أصل 10 آلاف ، أو 28٪. من الواضح أن مثل هذا المخطط غير قابل للتطبيق.على الرغم من أن مشكلة اللمحات هي حالة خاصة من الاختبارات المتعددة ، إلا أنه ليس من المجدي تطبيق التصحيحات القياسية (Bonferroni وغيرها) لأنها ستظهر أنها محافظة بشكل مفرط. يوضح الرسم البياني أدناه النسبة المئوية للنتائج الإيجابية الكاذبة اعتمادًا على عدد المجموعات المختبرة (الخط الأحمر) وعدد اللمحات (الخط الأخضر).
سيكون هناك ما مجموعه 2813 اختبارًا إيجابيًا كاذبًا من أصل 10 آلاف ، أو 28٪. من الواضح أن مثل هذا المخطط غير قابل للتطبيق.على الرغم من أن مشكلة اللمحات هي حالة خاصة من الاختبارات المتعددة ، إلا أنه ليس من المجدي تطبيق التصحيحات القياسية (Bonferroni وغيرها) لأنها ستظهر أنها محافظة بشكل مفرط. يوضح الرسم البياني أدناه النسبة المئوية للنتائج الإيجابية الكاذبة اعتمادًا على عدد المجموعات المختبرة (الخط الأحمر) وعدد اللمحات (الخط الأخضر).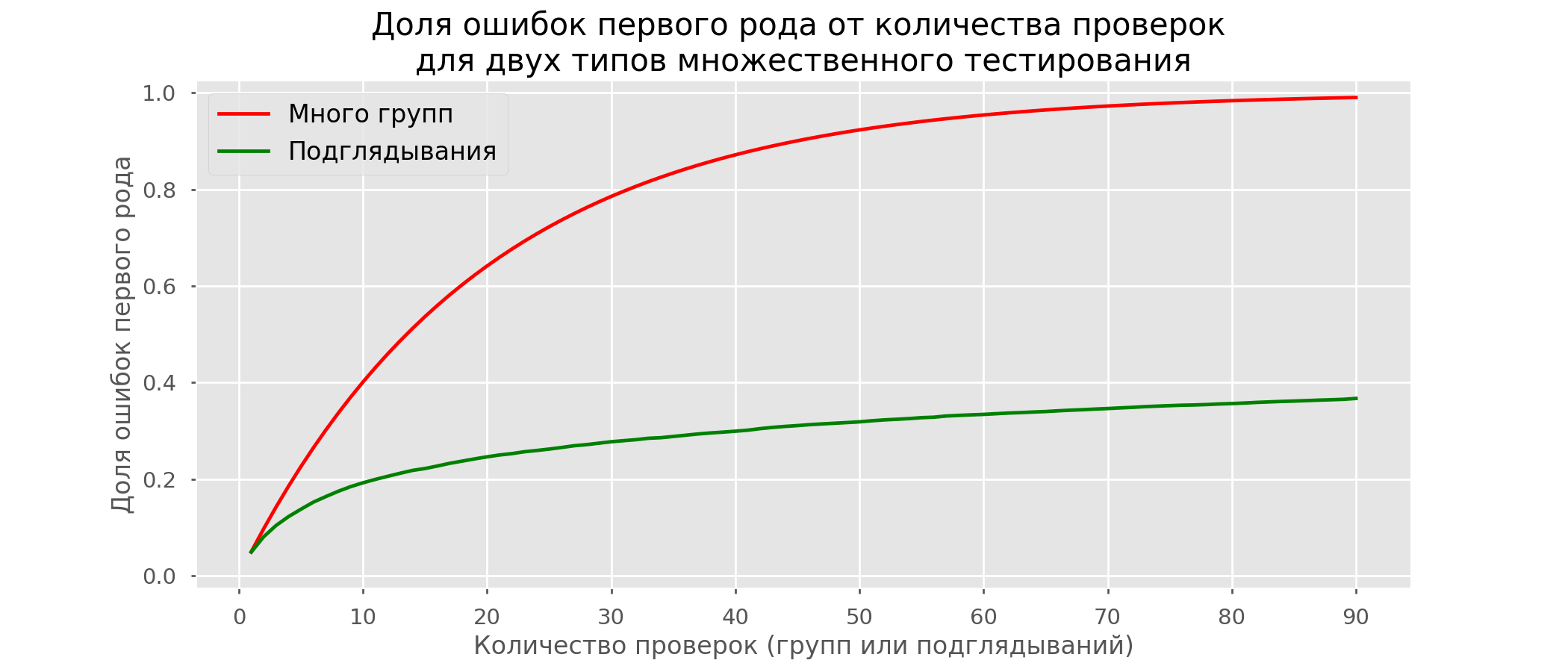 على الرغم من اقترابنا من اللانهاية وفي نظرة خاطفة ، فإن نسبة الأخطاء تنمو ببطء أكثر. هذا لأن المقارنات في هذه الحالة لم تعد مستقلة.
على الرغم من اقترابنا من اللانهاية وفي نظرة خاطفة ، فإن نسبة الأخطاء تنمو ببطء أكثر. هذا لأن المقارنات في هذه الحالة لم تعد مستقلة.نهج بايزي ومشكلة مختلس النظر طرق الاختبار المبكر
هناك خيارات اختبار تسمح لك بإجراء الاختبار قبل الأوان. سأخبرك عن اثنين منهم: مع مستوى ثابت من الأهمية (تصحيح بوكوك) ويعتمد على عدد من اللمحات (تصحيح أوبراين-فليمينغ). بالمعنى الدقيق للكلمة ، بالنسبة لكل من التصحيحات ، يجب أن تعرف مقدمًا الحد الأقصى لفترة الاختبار وعدد الفحوصات بين بداية الاختبار ونهايته. علاوة على ذلك ، يجب أن تحدث الشيكات على فترات زمنية متساوية تقريبًا (أو بكميات متساوية من الملاحظات).بوكوك
الطريقة هي أن نلخص نتائج الاختبارات كل يوم ، ولكن بمستوى أهمية أقل (أكثر صرامة). على سبيل المثال ، إذا علمنا أننا لن نقوم بأكثر من 30 فحصًا ، فيجب تعيين مستوى الدلالة مساوياً 0.006 (يتم تحديده بناءً على عدد الأشخاص الذين يستخدمون طريقة مونت كارلو ، أي تجريبيًا). في محاكاة لدينا ، نحصل على 4٪ نتائج إيجابية خاطئة - على ما يبدو ، يمكن زيادة العتبة. على الرغم من السذاجة الواضحة ، تستخدم بعض الشركات الكبيرة هذه الطريقة الخاصة. إنها بسيطة وموثوقة للغاية إذا اتخذت قرارات بشأن المقاييس الحساسة والكثير من الزيارات. على سبيل المثال ، في Avito ، بشكل افتراضي ، يتم تعيين مستوى الأهمية إلى 0.005 .
على الرغم من السذاجة الواضحة ، تستخدم بعض الشركات الكبيرة هذه الطريقة الخاصة. إنها بسيطة وموثوقة للغاية إذا اتخذت قرارات بشأن المقاييس الحساسة والكثير من الزيارات. على سبيل المثال ، في Avito ، بشكل افتراضي ، يتم تعيين مستوى الأهمية إلى 0.005 .أوبراين فليمينج
في هذه الطريقة ، يختلف مستوى الدلالة اعتمادًا على رقم التحقق. من الضروري تحديد عدد الخطوات (أو اللمحات) في الاختبار مسبقًا وحساب مستوى الأهمية لكل منها. كلما حاولنا إتمام الاختبار بشكل أسرع ، كلما تم تطبيق المعايير بشكل أكثر صرامة. عتبات إحصاءات الطلاب (بما في ذلك القيمة في الخطوة الأخيرة ) المقابلة لمستوى الأهمية المطلوبة تعتمد على رقم التحقق (يأخذ القيم من 1 إلى إجمالي عدد الشيكات شاملًا) ويتم حسابها وفقًا للصيغة التي تم الحصول عليها تجريبيًا:
كود الاحتمالاتfrom sklearn.linear_model import LinearRegression
from sklearn.metrics import explained_variance_score
import matplotlib.pyplot as plt
total_steps = [
2, 3, 4, 5, 6, 8, 10, 15, 20, 25, 30, 50, 60
]
last_z = [
1.969, 1.993, 2.014, 2.031, 2.045, 2.066, 2.081,
2.107, 2.123, 2.134, 2.143, 2.164, 2.17
]
features = [
[1/t, 1/t**0.5] for t in total_steps
]
lr = LinearRegression()
lr.fit(features, last_z)
print(lr.coef_)
print(lr.intercept_)
print(explained_variance_score(lr.predict(features), last_z))
total_steps_extended = np.arange(2, 80)
features_extended = [ [1/t, 1/t**0.5] for t in total_steps_extended ]
plt.plot(total_steps_extended, lr.predict(features_extended))
plt.scatter(total_steps, last_z, s=30, color='black')
plt.show()
يتم حساب مستويات الدلالة ذات الصلة من خلال النسبة المئوية التوزيع القياسي المقابل لقيمة إحصاءات الطلاب :perc = scipy.stats.norm.cdf(Z)
pval_thresholds = (1 − perc) * 2
في نفس المحاكاة ، يبدو هذا: النتائج الإيجابية الكاذبة كانت 501 من أصل 10 آلاف ، أو 5٪ المتوقعة. يرجى ملاحظة أن مستوى الأهمية لا يصل إلى قيمة 5٪ حتى في النهاية ، حيث يجب "تلطيخ" هذه الـ 5٪ على جميع الفحوصات. في الشركة ، نستخدم هذا التصحيح نفسه إذا أجرينا اختبارًا مع إمكانية التوقف المبكر. يمكنك أن تقرأ عن نفس التعديلات وغيرها هنا .
النتائج الإيجابية الكاذبة كانت 501 من أصل 10 آلاف ، أو 5٪ المتوقعة. يرجى ملاحظة أن مستوى الأهمية لا يصل إلى قيمة 5٪ حتى في النهاية ، حيث يجب "تلطيخ" هذه الـ 5٪ على جميع الفحوصات. في الشركة ، نستخدم هذا التصحيح نفسه إذا أجرينا اختبارًا مع إمكانية التوقف المبكر. يمكنك أن تقرأ عن نفس التعديلات وغيرها هنا .الطريقة المثلىOptimizely , , . , . , . O'Brien-Fleming’a .
حاسبة اختبار A / B
تفاصيل المنتج هي أن توزيع أي مقياس يختلف اختلافًا كبيرًا حسب جمهور الاختبار (على سبيل المثال ، رقم الفصل) والوقت من العام. لذلك ، لن يكون من الممكن قبول القواعد الخاصة بتاريخ انتهاء الاختبار بروح "سينتهي الاختبار عند كتابة مليون مستخدم في كل مجموعة" أو "سينتهي الاختبار عندما يصل عدد المهام التي تم حلها إلى 100 مليون". أي أنها ستعمل ، ولكن من الناحية العملية ، سيكون من الضروري مراعاة العديد من العوامل:- ما هي الفصول التي تدخل في الاختبار ؛
- يتم توزيع الاختبار على المعلمين أو الطلاب ؛
- وقت العام الدراسي
- اختبار لجميع المستخدمين أو فقط للمستخدمين الجدد.
ومع ذلك ، في مخططات اختبار A / B الخاصة بنا ، تحتاج دائمًا إلى تحديد تاريخ الانتهاء مسبقًا. للتنبؤ بمدة الاختبار ، قمنا بتطوير تطبيق داخلي - حاسبة اختبار A / B. استنادًا إلى نشاط المستخدمين من الجزء المحدد خلال العام الماضي ، يحسب التطبيق الفترة التي يجب تشغيل الاختبار فيها من أجل إصلاح الزيادة في X٪ بشكل كبير بواسطة المقياس المحدد. يتم أيضًا أخذ تصحيح الاختبارات المتعددة في الاعتبار تلقائيًا ويتم احتساب مستويات أهمية العتبة لإيقاف اختبار مبكر.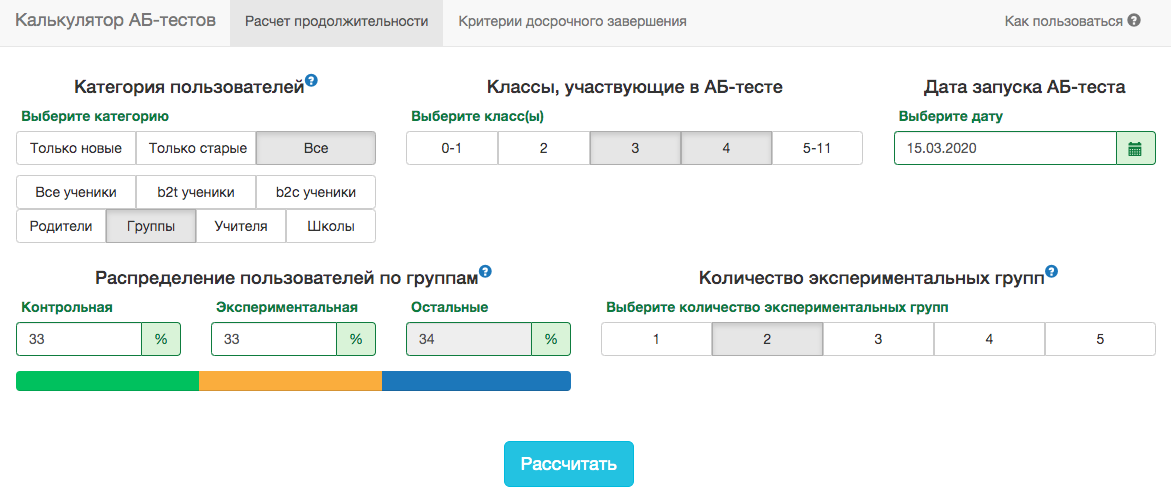 يتم حساب جميع المقاييس على مستوى كائنات الاختبار. إذا كان المقياس هو عدد المشكلات التي تم حلها ، فسيكون في الاختبار على مستوى المعلم هذا مجموع المشكلات التي تم حلها بواسطة طلابه. نظرًا لأننا نستخدم معيار الطالب ، يمكننا حساب الوحدات التي تحتاجها الآلة الحاسبة مسبقًا لجميع الشرائح الممكنة. لكل يوم من بداية الاختبار ، تحتاج إلى معرفة عدد الأشخاص في الاختبار، متوسط قيمة المقياس وتنوعها . تحديد أسهم المجموعة الضابطةالمجموعة التجريبية والمكسب المتوقع من الاختبار في المئة ، يمكنك حساب القيم المتوقعة لإحصاءات الطلاب والقيمة p المقابلة لكل يوم من أيام الاختبار:
يتم حساب جميع المقاييس على مستوى كائنات الاختبار. إذا كان المقياس هو عدد المشكلات التي تم حلها ، فسيكون في الاختبار على مستوى المعلم هذا مجموع المشكلات التي تم حلها بواسطة طلابه. نظرًا لأننا نستخدم معيار الطالب ، يمكننا حساب الوحدات التي تحتاجها الآلة الحاسبة مسبقًا لجميع الشرائح الممكنة. لكل يوم من بداية الاختبار ، تحتاج إلى معرفة عدد الأشخاص في الاختبار، متوسط قيمة المقياس وتنوعها . تحديد أسهم المجموعة الضابطةالمجموعة التجريبية والمكسب المتوقع من الاختبار في المئة ، يمكنك حساب القيم المتوقعة لإحصاءات الطلاب والقيمة p المقابلة لكل يوم من أيام الاختبار:
بعد ذلك ، من السهل الحصول على قيم p لكل يوم:pvalue = (1 − scipy.stats.norm.cdf(ttest_stat_value)) * 2
بمعرفة قيمة p ومستوى الأهمية ، مع مراعاة جميع التصحيحات لكل يوم من أيام الاختبار ، لأي مدة من الاختبار ، يمكنك حساب الحد الأدنى للرفع الذي يمكن اكتشافه (في الأدب الإنجليزي - MDE ، الحد الأدنى من التأثير القابل للكشف). بعد ذلك ، من السهل حل المشكلة العكسية - لتحديد عدد الأيام المطلوبة لتحديد الارتفاع المتوقع.استنتاج
في الختام ، أود أن أذكر الرسائل الرئيسية للمقال:- إذا قارنت متوسط قيم المقياس في مجموعات ، فمن المرجح أن يناسبك معيار الطالب. الاستثناء هو أحجام عينات صغيرة للغاية (عشرات المشاهدات) أو توزيعات مترية غير طبيعية (في الواقع ، لم أر مثل هذا).
- إذا كان هناك عدة مجموعات في الاختبار ، فاستخدم التصحيحات لاختبار الفرضيات المتعددة. أبسط تصحيح بونفيروني سيفعله.
- .
- . .
- . , , , , O'Brien-Fleming.
- A/B-, A/A-.
على الرغم من كل ما سبق ، لا ينبغي أن يعاني العمل والمنطق من أجل الصرامة الرياضية. في بعض الأحيان ، من الممكن طرح وظائف لجميع الذين لم يظهروا زيادة كبيرة في الاختبار ، وتحدث بعض التغييرات حتمًا دون اختبار على الإطلاق. ولكن إذا أجريت مئات الاختبارات سنويًا ، فإن تحليلها الدقيق مهم بشكل خاص. خلاف ذلك ، هناك خطر من أن عدد الاختبارات الإيجابية الكاذبة يمكن مقارنتها باختبارات مفيدة حقًا.