 مرحبا ، هابروجيتلي! يقدم Paul و Harvey Daytels نظرة جديدة على Python ويستخدمان نهجًا فريدًا لحل المشكلات التي تواجه الأشخاص المعاصرين في تكنولوجيا المعلومات بسرعة.تحت تصرفك أكثر من خمسمائة مهمة حقيقية - من الأجزاء إلى 40 سيناريو وأمثلة كبيرة مع التنفيذ الكامل. يسمح لك IPython مع Jupyter Notebooks بتعلم مصطلحات لغة Python الحديثة بسرعة. توضح الفصول من 1 إلى 5 وأجزاء من الفصول من 6 إلى 7 أمثلة واضحة على حل مشكلات الذكاء الاصطناعي من الفصول من 11 إلى 16. سوف تتعلم عن معالجة اللغة الطبيعية ، وتحليل الانفعالات على Twitter ، والحوسبة المعرفية لـ IBM Watson ، والتعلم الآلي مع مدرس في مشاكل التصنيف والانحدار ، والتعلم الآلي بدون معلم في التجميع ، والتعرف على الأنماط مع التعلم العميق والشبكات العصبية التلافيفية ، والشبكات العصبية المتكررة ، الكبيرة البيانات من Hadoop و Spark و NoSQL و IoT والمزيد. ستعمل (بشكل مباشر أو غير مباشر) مع الخدمات السحابية ، بما في ذلك Twitter ، و Google Translate ، و IBM Watson ،Microsoft Azure و OpenMapQuest و PubNub وما إلى ذلك.
مرحبا ، هابروجيتلي! يقدم Paul و Harvey Daytels نظرة جديدة على Python ويستخدمان نهجًا فريدًا لحل المشكلات التي تواجه الأشخاص المعاصرين في تكنولوجيا المعلومات بسرعة.تحت تصرفك أكثر من خمسمائة مهمة حقيقية - من الأجزاء إلى 40 سيناريو وأمثلة كبيرة مع التنفيذ الكامل. يسمح لك IPython مع Jupyter Notebooks بتعلم مصطلحات لغة Python الحديثة بسرعة. توضح الفصول من 1 إلى 5 وأجزاء من الفصول من 6 إلى 7 أمثلة واضحة على حل مشكلات الذكاء الاصطناعي من الفصول من 11 إلى 16. سوف تتعلم عن معالجة اللغة الطبيعية ، وتحليل الانفعالات على Twitter ، والحوسبة المعرفية لـ IBM Watson ، والتعلم الآلي مع مدرس في مشاكل التصنيف والانحدار ، والتعلم الآلي بدون معلم في التجميع ، والتعرف على الأنماط مع التعلم العميق والشبكات العصبية التلافيفية ، والشبكات العصبية المتكررة ، الكبيرة البيانات من Hadoop و Spark و NoSQL و IoT والمزيد. ستعمل (بشكل مباشر أو غير مباشر) مع الخدمات السحابية ، بما في ذلك Twitter ، و Google Translate ، و IBM Watson ،Microsoft Azure و OpenMapQuest و PubNub وما إلى ذلك.9.12.2. قراءة ملفات CSV في مكتبة DataFrame بمكتبة الباندا
قدم قسم "مقدمة لعلوم البيانات" في الفصلين السابقين أساسيات العمل مع حيوانات الباندا. الآن سنوضح أدوات الباندا لتنزيل ملفات CSV ، ثم نقوم بإجراء عمليات تحليل البيانات الأساسية.مجموعات البيانات
في أمثلة علم البيانات العملية ، سيتم استخدام العديد من مجموعات البيانات المجانية والمفتوحة لتوضيح مفاهيم التعلم الآلي ومعالجة اللغة الطبيعية. تتوفر مجموعة كبيرة ومتنوعة من مجموعات البيانات المجانية على الإنترنت. يحتوي مستودع Rdatasets الشهير على روابط لأكثر من 1100 مجموعة بيانات CSV مجانية. تم شحن هذه المجموعات في الأصل مع لغة البرمجة R لتبسيط دراسة البرامج الإحصائية وتطويرها ، ومع ذلك ، فهي لا تتعلق بلغة R. الآن هذه المجموعات متاحة على GitHub على:https://vincentarelbundock.imtqy.com/Rdatasets/ datasets.htmlيحظى هذا المستودع بشعبية كبيرة بحيث توجد وحدة pydataset مصممة خصيصًا للوصول إلى مجموعات البيانات. للحصول على تعليمات حول تثبيت مجموعة بيانات pydataset والوصول إلى مجموعات البيانات ، انتقل إلى:https://github.com/iamaziz/PyDataset
مصدر آخر رائع لمجموعات البيانات:https://github.com/awesomedata/awesome-public-datasetsمجموعة بيانات تعلُم الآلة شائعة الاستخدام للمبتدئين هي مجموعة بيانات تايتانيك ، والتي تسرد جميع الركاب وما إذا كانوا قد نجوا عندما اصطدمت تيتانيك بجبل جليدي وغرقت في 14-15 أبريل 1912. سنستخدم هذه المجموعة لإظهار كيفية تحميل مجموعة بيانات وعرض بياناتها واشتقاق إحصائيات وصفية. سيتم استكشاف مجموعات البيانات الشائعة الأخرى في فصول أمثلة علوم البيانات لاحقًا في هذا الكتاب.العمل مع ملفات CSV المحليةلتحميل مجموعة بيانات CSV في DataFrame ، يمكنك استخدام وظيفة read_csv بمكتبة pandas. يقوم المقتطف التالي بتنزيل ملف CSV accounts.csv الذي تم إنشاؤه سابقًا في هذا الفصل وعرضه:In [1]: import pandas as pd
In [2]: df = pd.read_csv('accounts.csv',
...: names=['account', 'name', 'balance'])
...:
In [3]: df
Out[3]:
account name balance
0 100 Jones 24.98
1 200 Doe 345.67
2 300 White 0.00
3 400 Stone -42.16
4 500 Rich 224.62
تحدد وسيطة الأسماء أسماء الأعمدة في DataFrame. بدون هذه الحجة ، يعتبر read_csv السطر الأول من ملف CSV الذي يحتوي على قائمة مفصولة بفواصل لأسماء الأعمدة.لحفظ بيانات DataFrame في ملف CSV ، اتصل بطريقة to_csv لمجموعة DataFrame:In [4]: df.to_csv('accounts_from_dataframe.csv', index=False)
مؤشر الوسيطة الرئيسية = خطأ يعني أن أسماء الصفوف (0-4 على الجانب الأيسر من إخراج DataFrame في الجزء [3]) لا يجب كتابتها إلى الملف. يحتوي السطر الأول من الملف الناتج على أسماء الأعمدة:account,name,balance
100,Jones,24.98
200,Doe,345.67
300,White,0.0
400,Stone,-42.16
500,Rich,224.62
9.12.3. قراءة مجموعة بيانات الكوارث تيتانيك
تعد مجموعة بيانات تايتانيك للكوارث واحدة من أكثر مجموعات بيانات التعلم الآلي شيوعًا وهي متوفرة في العديد من التنسيقات ، بما في ذلك CSV.قم بتنزيل مجموعة بيانات تايتانيك للكوارث على عنوان URL
إذا كان لديك عنوان URL يمثل مجموعة بيانات بتنسيق CSV ، فيمكنك تحميله في DataFrame مع وظيفة read_csv - دعنا نقول من GitHub:In [1]: import pandas as pd
In [2]: titanic = pd.read_csv('https://vincentarelbundock.imtqy.com/' +
...: 'Rdatasets/csv/carData/TitanicSurvival.csv')
...:
عرض بعض خطوط مجموعة بيانات الكوارث في Titanicتحتوي مجموعة البيانات على أكثر من 1300 خط ، ويمثل كل سطر راكبًا واحدًا. وفقًا لويكيبيديا ، كان هناك حوالي 1317 راكبًا على متنها ، وتوفي 815 منهم 1. بالنسبة لمجموعات البيانات الكبيرة ، يتم عرض أول 30 سطرًا فقط عند إخراج إطار البيانات ، ثم يتم عرض علامة القطع "..." وآخر 30 سطرًا. لتوفير مساحة ، سنلقي نظرة على السطور الخمسة الأولى والأخيرة باستخدام طرق الرأس والذيل لمجموعة DataFrame. تعيد كلتا الطريقتين خمسة أسطر افتراضيًا ، ولكن يمكن تمرير عدد الأسطر المعروضة في الوسيطة:في [3]: pd.set_option ('الدقة' ، 2) # تنسيق لقيم الفاصلة العائمةيرجى ملاحظة: الباندا يضبط عرض كل عمود على أساس أكبر قيمة في العمود أو اسم العمود (اعتمادًا على أكبر عرض) ؛ في العمود العمري للصف 1305 هو NaN - علامة على قيمة مفقودة في مجموعة البيانات.تعيين أسماء الأعمدةيبدو اسم العمود الأول في مجموعة البيانات غريبًا نوعًا ما ('لم يذكر اسمه: 0'). يمكن حل هذه المشكلة عن طريق تخصيص أسماء الأعمدة. استبدل "لم يذكر اسمه: 0" بـ "اسم" وخفض "راكب الفئة" إلى "فئة":

9.12.4. تحليل بيانات بسيط باستخدام مجموعة بيانات الكوارث تايتانيك كمثال
الآن سنستخدم الباندا لإجراء تحليل بسيط للبيانات باستخدام بعض خصائص الإحصائيات الوصفية كمثال. عندما تتصل بوصف لمجموعة DataFrame تحتوي على أعمدة رقمية وغير رقمية ، قم بوصف الخصائص الإحصائية للأعمدة الرقمية فقط - في هذه الحالة ، فقط للعمود العمري: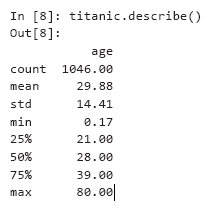 لاحظ الاختلافات في قيمة العد (1046) وعدد خطوط البيانات في مجموعة البيانات (1309 - عند استدعاء الذيل ، كان مؤشر السطر الأخير 1308). يحتوي 1046 صفًا فقط من البيانات (قيمة العد) على قيمة عمرية. كانت النتائج المتبقية مفقودة وتم تمييزها بـ NaN ، كما في السطر 1305. عند إجراء العمليات الحسابية ، تتجاهل مكتبة الباندا البيانات المفقودة (NaN) بشكل افتراضي. بالنسبة إلى 1046 راكبًا بعمر صالح ، كان متوسط العمر (المتوقع) 29.88 سنة. كان أصغر الركاب (دقيقة) يبلغ من العمر شهرين فقط (0.17 * 12 يعطي 2.04) ، وكان الأكبر (الأقصى) يبلغ من العمر 80 عامًا. كان متوسط العمر 28 عامًا (يشار إليه بنسبة 50 في المائة). يصف الربع 25 في المائة متوسط العمر في النصف الأول من الركاب (مرتبة حسب العمر) ،والربع 75 في المائة هو المتوسط في النصف الثاني من الركاب.افترض أنك تريد حساب إحصائيات عن الركاب الناجين. يمكننا مقارنة العمود المتبقي مع القيمة "نعم" للحصول على مجموعة سلسلة جديدة بقيم True / False ، ثم استخدام الوصف لوصف النتائج:
لاحظ الاختلافات في قيمة العد (1046) وعدد خطوط البيانات في مجموعة البيانات (1309 - عند استدعاء الذيل ، كان مؤشر السطر الأخير 1308). يحتوي 1046 صفًا فقط من البيانات (قيمة العد) على قيمة عمرية. كانت النتائج المتبقية مفقودة وتم تمييزها بـ NaN ، كما في السطر 1305. عند إجراء العمليات الحسابية ، تتجاهل مكتبة الباندا البيانات المفقودة (NaN) بشكل افتراضي. بالنسبة إلى 1046 راكبًا بعمر صالح ، كان متوسط العمر (المتوقع) 29.88 سنة. كان أصغر الركاب (دقيقة) يبلغ من العمر شهرين فقط (0.17 * 12 يعطي 2.04) ، وكان الأكبر (الأقصى) يبلغ من العمر 80 عامًا. كان متوسط العمر 28 عامًا (يشار إليه بنسبة 50 في المائة). يصف الربع 25 في المائة متوسط العمر في النصف الأول من الركاب (مرتبة حسب العمر) ،والربع 75 في المائة هو المتوسط في النصف الثاني من الركاب.افترض أنك تريد حساب إحصائيات عن الركاب الناجين. يمكننا مقارنة العمود المتبقي مع القيمة "نعم" للحصول على مجموعة سلسلة جديدة بقيم True / False ، ثم استخدام الوصف لوصف النتائج:In [9]: (titanic.survived == 'yes').describe()
Out[9]:
count 1309
unique 2
top False
freq 809
Name: survived, dtype: object
بالنسبة للبيانات غير الرقمية ، يعرض الوصف خصائص مختلفة للإحصاءات الوصفية:- العد - العدد الإجمالي للعناصر في النتيجة ؛
- فريد - عدد القيم الفريدة (2) نتيجة لذلك - صحيح (نجا الراكب) أو خطأ (مات الراكب) ؛
- أعلى - القيمة الأكثر شيوعًا نتيجة لذلك ؛
- freq - عدد تكرارات القيمة الأعلى.
9.12.5. رسم بياني لأعمار الركاب
التصور طريقة جيدة للتعرف على البيانات بشكل أفضل. يحتوي Pandas على العديد من أدوات التصور المدمجة القائمة على Matplotlib. لاستخدامها ، قم أولاً بتمكين دعم Matplotlib في IPython:In [10]: %matplotlib
يظهر الرسم البياني بوضوح توزيع البيانات العددية عبر مجموعة من القيم. تحلل الطريقة السابقة لمجموعة DataFrame تلقائيًا بيانات كل عمود رقمي وتبني الرسم البياني المقابل. لعرض الرسوم البيانية لكل عمود عددي من البيانات ، اتصل بـ Hist لمجموعة DataFrame الخاصة بك:In [11]: histogram = titanic.hist()
تحتوي مجموعة بيانات الكوارث Titanic على عمود رقمي واحد فقط من البيانات ، لذلك يعرض الرسم البياني مخططًا بيانيًا لتوزيع الأعمار. بالنسبة لمجموعات البيانات التي تحتوي على أعمدة رقمية متعددة ، ينشئ hist رسمًا بيانيًا منفصلاً لكل عمود رقمي.»يمكن العثور على مزيد من المعلومات حول الكتاب على موقع الناشر على الويب» المحتويات» مقتطفات منخصم قسيمة 25٪ من Khabrozhiteley - Pythonعند دفع النسخة الورقية من الكتاب (تاريخ الإصدار - 5 يونيو ) ، يتم إرسال كتاب إلكتروني عبر البريد الإلكتروني.