يحدث أن الأنظمة عربات التي تجرها الدواب ، تبطئ ، تنهار. كلما كبر النظام ، زادت صعوبة العثور على السبب. لمعرفة سبب عدم عمل شيء كما هو متوقع ، لإصلاح المشكلات المستقبلية أو منعها ، تحتاج إلى النظر في الداخل. لهذا ، يجب أن تمتلك الأنظمة خاصية قابلية الملاحظة ، والتي يتم تحقيقها عن طريق الأجهزة بالمعنى الواسع للكلمة.في HighLoad ++ ، قام بيتر زايتسيف (Percona) بمراجعة البنية التحتية المتاحة للتتبع في Linux وتحدث عن bpfTrace ، والتي (كما يوحي الاسم) تقدم العديد من المزايا. لقد أنشأنا نسخة نصية من التقرير ، حتى يكون من الملائم لك مراجعة التفاصيل وكانت المواد الإضافية في متناول اليد دائمًا.يمكن تقسيم الأجهزة إلى كتلتين كبيرتين:- ثابت ، عندما يتم توصيل مجموعة المعلومات في رمز: تسجيل السجلات ، العدادات ، الوقت ، إلخ.
- ديناميكي ، عندما لا يكون الكود معدًا بنفسه ، ولكن من الممكن القيام بذلك عند الضرورة.
يعتمد خيار تصنيف آخر على نهج تسجيل البيانات:- التتبع - يتم إنشاء الأحداث إذا نجح رمز معين.
- أخذ العينات - يتم التحقق من حالة النظام ، على سبيل المثال ، 100 مرة في الثانية ويحدد ما يحدث فيه.
توجد أدوات ثابتة لسنوات عديدة وهي في كل شيء تقريبًا. على لينكس ، تستخدم العديد من الأدوات القياسية مثل Vmstat أو top. يقرأون البيانات من procfs ، حيث ، بشكل تقريبي ، يتم كتابة أجهزة توقيت وعدادات مختلفة من كود النواة.لكن لا يمكنك إدراج الكثير من هذه العدادات ؛ لا يمكنك تغطية كل شيء في العالم معهم. لذلك ، يمكن أن تكون الأجهزة الديناميكية مفيدة ، مما يسمح لك بمشاهدة ما تحتاج إليه بالضبط. على سبيل المثال ، إذا كانت هناك أية مشكلات في مكدس TCP / IP ، فيمكنك التعمق في الأمر وإرشاد تفاصيل محددة.
Dtrace
DTrace هي واحدة من أولى أطر التتبع الديناميكية المعروفة التي أنشأتها Sun Microsystems. بدأ صنعه في عام 2001 ، وللمرة الأولى تم إصداره في Solaris 10 في عام 2005. اتضح أن هذا النهج شائع جدًا وذهب لاحقًا إلى العديد من التوزيعات الأخرى.ومن المثير للاهتمام أن DTrace يسمح لك بصنع مساحة النواة ومساحة المستخدم. يمكنك وضع آثار على أي مكالمات وظيفية وإرشاد البرامج تحديدًا: تقديم نقاط تتبع DTrace خاصة ، والتي يمكن للمستخدمين فهمها أكثر من أسماء الوظائف.كان هذا مهمًا بشكل خاص لـ Solaris ، لأنه ليس نظام تشغيل مفتوحًا. لم يكن من الممكن مجرد إلقاء نظرة على الكود وفهم أن نقطة التتبع تحتاج إلى وضع مثل هذه الوظيفة ، حيث يمكن القيام بذلك الآن في برنامج Linux الجديد مفتوح المصدر.واحدة من الميزات الفريدة ، خاصة في ذلك الوقت ، من DTrace هي أنه في حين لم يتم تمكين التتبع ، فإنه لا يكلف شيئًا . يعمل بطريقة تستبدل ببساطة بعض تعليمات وحدة المعالجة المركزية بمكالمة DTrace ، والتي تنفذ هذه التعليمات عند عودتها.في DTrace ، تتم كتابة الأجهزة بلغة D خاصة ، على غرار C و Awk.ظهر DTrace لاحقًا في كل مكان تقريبًا باستثناء Linux: على MacOS في 2007 ، على FreeBSD في 2008 ، في NetBSD في 2010. قامت Oracle في 2011 بتضمين DTrace في Oracle Unbreakable Linux. لكن قلة من الناس يستخدمون Oracle Linux ، ولم يدخل DTrace أبدًا Linux الرئيسي.ومن المثير للاهتمام ، أنه في عام 2017 ، قامت Oracle في النهاية بترخيص DTrace بموجب GPLv2 ، مما جعل من الممكن من حيث المبدأ تضمينها في لينكس الرئيسي دون صعوبات الترخيص ، ولكن كان قد فات الأوان بالفعل. في ذلك الوقت ، كان لينكس لديه BPF جيد ، والذي تم استخدامه بشكل أساسي للتوحيد القياسي.سيتم تضمين DTrace في Windows ؛ والآن يتوفر في بعض إصدارات الاختبار.تتبع لينكس
ما هو لينكس بدلاً من DTrace؟ في الواقع ، يوجد في لينكس الكثير من الأشياء في أفضل (أو أسوأ) مظهر لروح المصدر المفتوح ، وقد تراكمت مجموعة من أطر التتبع المختلفة خلال هذا الوقت. لذلك ، معرفة ما ليس بهذه البساطة.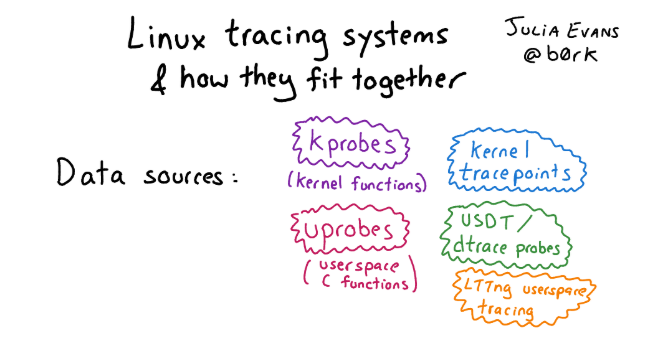 إذا كنت ترغب في التعرف على هذا التنوع وتهتم بالتاريخ ، فراجع المقالة التي تحتوي على صور ووصف مفصل لمناهج التتبع في Linux.إذا تحدثنا عن البنية الأساسية للتتبع في Linux بشكل عام ، فهناك ثلاثة مستويات:
إذا كنت ترغب في التعرف على هذا التنوع وتهتم بالتاريخ ، فراجع المقالة التي تحتوي على صور ووصف مفصل لمناهج التتبع في Linux.إذا تحدثنا عن البنية الأساسية للتتبع في Linux بشكل عام ، فهناك ثلاثة مستويات:- واجهة أجهزة kernel: Kprobe ، Uprobe ، Dtrace مسبار ، إلخ.
- «», . , probe, , user space . : , user space, Kernel Module, - , eBPF.
- -, , : Perf, SystemTap, SysDig, BCC .. bpfTtrace , , .
eBPF — Linux
مع كل هذه الأطر ، أصبح eBPF المعيار في Linux في السنوات الأخيرة. إنها أداة أكثر تقدمًا ومرونة وفعالية تسمح بكل شيء تقريبًا.ما هو eBPF ومن أين أتت؟ في الواقع ، eBPF هو مرشح حزمة Berkeley Extended ، وقد تم تطوير BPF في عام 1992 كآلة افتراضية لتصفية الحزمة الفعالة بواسطة جدار الحماية. في البداية ، لم يكن لديه أي علاقة بالرصد أو الملاحظة أو التتبع.في الإصدارات الأكثر حداثة ، تم توسيع eBPF (وبالتالي الكلمة الموسعة) ، كإطار مشترك للتعامل مع الأحداث . يتم دمج الإصدارات الحالية مع مترجم JIT لزيادة الكفاءة.اختلافات eBPF عن BPF الكلاسيكي:- وأضاف السجلات ؛
- ظهرت كومة.
- هناك هياكل بيانات إضافية (خرائط).
 الآن ينسى الناس في الغالب أنه كان هناك BPF قديم ، ويسمى eBPF ببساطة BPF. في معظم التعبيرات الحديثة ، eBPF و BPF متماثلان. لذلك ، تسمى الأداة bpfTrace ، وليس eBpfTrace.تم تضمين eBPF في Linux الرئيسي منذ 2014 وتم تضمينه تدريجيًا في العديد من أدوات Linux ، بما في ذلك Perf و SystemTap و SysDig. هناك توحيد.ومن المثير للاهتمام أن التنمية لا تزال جارية. النواة الحديثة تدعم eBPF بشكل أفضل وأفضل.
الآن ينسى الناس في الغالب أنه كان هناك BPF قديم ، ويسمى eBPF ببساطة BPF. في معظم التعبيرات الحديثة ، eBPF و BPF متماثلان. لذلك ، تسمى الأداة bpfTrace ، وليس eBpfTrace.تم تضمين eBPF في Linux الرئيسي منذ 2014 وتم تضمينه تدريجيًا في العديد من أدوات Linux ، بما في ذلك Perf و SystemTap و SysDig. هناك توحيد.ومن المثير للاهتمام أن التنمية لا تزال جارية. النواة الحديثة تدعم eBPF بشكل أفضل وأفضل.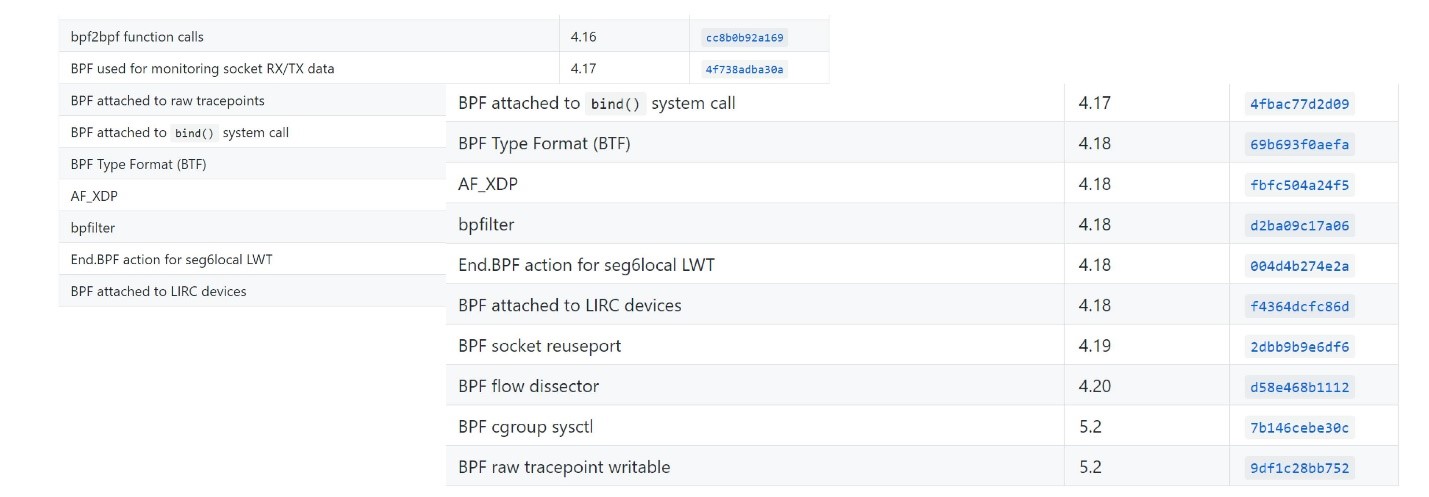 يمكنك أن ترى ما ظهرت إصدارات النواة الحديثة هنا .
يمكنك أن ترى ما ظهرت إصدارات النواة الحديثة هنا .برامج EBPF
إذن ما هو eBPF ولماذا هو مثير للاهتمام؟eBPF هو برنامج في رمزه الثانوي الخاص ، والذي يتم تضمينه مباشرة في النواة ويقوم بمعالجة أحداث التتبع. علاوة على ذلك ، فإن حقيقة أنه مصنوع في رمز ثانوي خاص يسمح للنواة بإجراء تحقق معين من أن الرمز آمن تمامًا. على سبيل المثال ، تحقق من أنه لا يستخدم حلقات ، لأن الحلقة في القسم الحرج في النواة يمكن أن تتسبب في تعليق النظام بأكمله.لكن هذا لا يسمح بأن يكون آمنًا تمامًا. على سبيل المثال ، إذا كتبت برنامج eBPF معقدًا جدًا ، فأدخله في حدث في النواة يحدث 10 ملايين مرة في الثانية ، ثم يمكن أن يتباطأ كل شيء كثيرًا. ولكن في الوقت نفسه ، يعد eBPF أكثر أمانًا من النهج القديم ، عندما تم إدخال بعض وحدات Kernel فقط من خلال insmod ، ويمكن أن يكون أي شيء في هذه الوحدات. إذا أخطأ شخص ما ، أو ببساطة بسبب عدم التوافق الثنائي ، يمكن أن يسقط اللب بأكمله.يمكن تجميع كود eBPF بواسطة LLVM Clang ، أي بشكل عام ، استخدام مجموعة فرعية من C لإنشاء برامج eBPF ، والتي ، بالطبع ، معقدة للغاية. ومن المهم أن يعتمد التجميع على النواة: تُستخدم الرؤوس لفهم الهياكل التي تُستخدم وما الغرض من استخدامها ، وما إلى ذلك. هذا ليس مناسبًا جدًا بمعنى أنه يتم دائمًا توفير بعض الوحدات المتعلقة بنواة معينة ، أو تحتاج إلى إعادة الترجمة.يوضح الرسم البياني كيفية عمل eBPF. http://www.brendangregg.com/ebpf.htmlيقوم المستخدم بإنشاء برنامج eBPF. علاوة على ذلك ، تقوم النواة ، من جانبها ، بفحصها وتحميلها. بعد ذلك ، يمكن لـ eBPF الاتصال بأدوات مختلفة للتتبع ومعالجة المعلومات وحفظها في الخرائط (بنية البيانات للتخزين المؤقت). ثم يمكن لبرنامج المستخدم قراءة الإحصائيات ، وتلقي أحداث الأداء ، وما إلى ذلك.يعرض ميزات eBPF التي توجد فيها إصدارات حِزم Linux.
http://www.brendangregg.com/ebpf.htmlيقوم المستخدم بإنشاء برنامج eBPF. علاوة على ذلك ، تقوم النواة ، من جانبها ، بفحصها وتحميلها. بعد ذلك ، يمكن لـ eBPF الاتصال بأدوات مختلفة للتتبع ومعالجة المعلومات وحفظها في الخرائط (بنية البيانات للتخزين المؤقت). ثم يمكن لبرنامج المستخدم قراءة الإحصائيات ، وتلقي أحداث الأداء ، وما إلى ذلك.يعرض ميزات eBPF التي توجد فيها إصدارات حِزم Linux.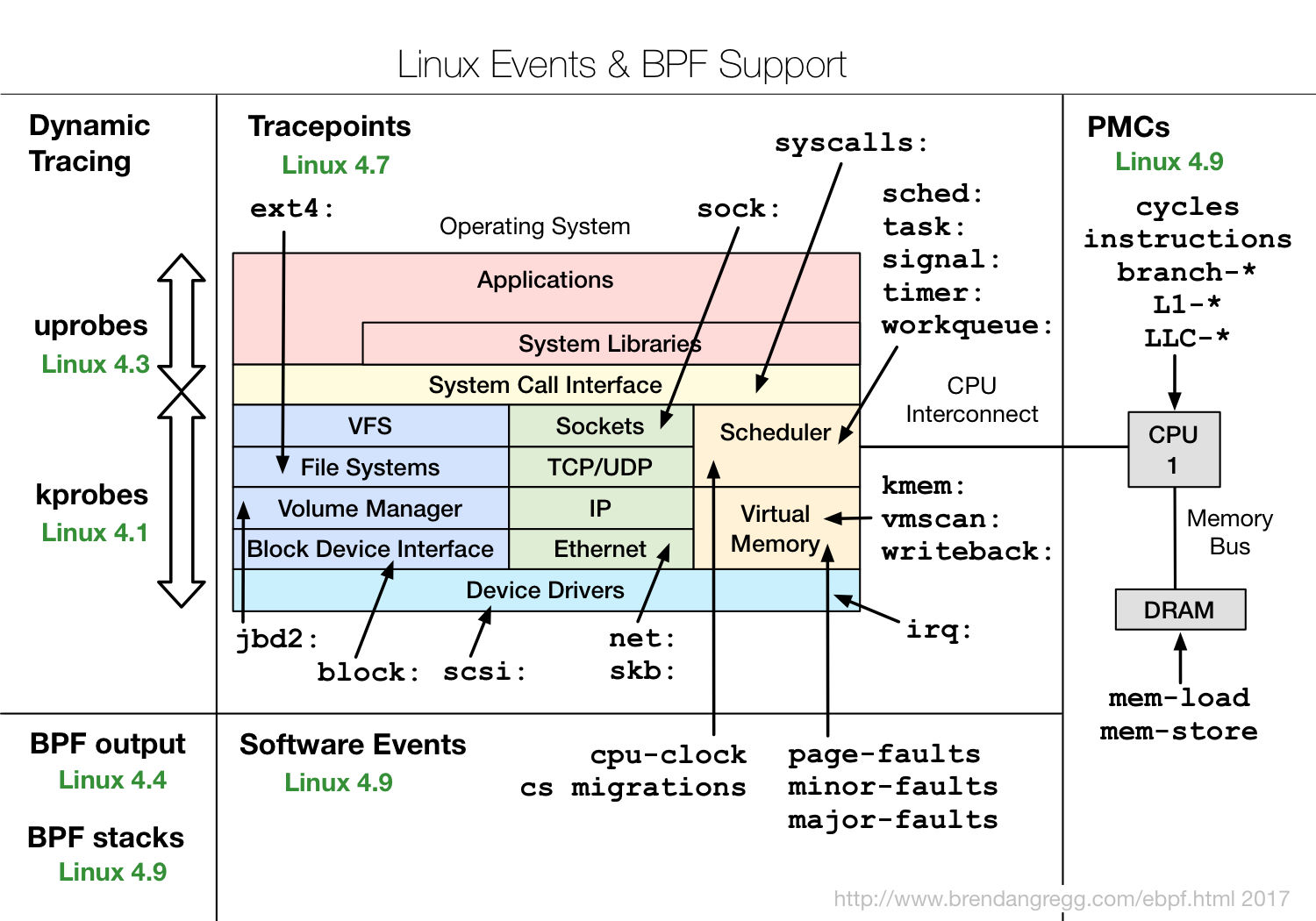 يمكن ملاحظة أن جميع الأنظمة الفرعية لنواة Linux مغطاة تقريبًا ، بالإضافة إلى وجود تكامل جيد مع بيانات الأجهزة ، و eBPF لديه إمكانية الوصول إلى جميع أنواع أخطاء ذاكرة التخزين المؤقت أو تنبؤات أخطاء الفروع ، وما إلى ذلك.إذا كنت مهتمًا بـ eBPF ، فراجع مشروع IO Visor، يحتوي على معظم الأدوات. تشارك شركة IO Visor في تطويرها ، وسيكون لديهم أحدث الإصدارات ووثائق جيدة جدًا. تظهر المزيد والمزيد من أدوات eBPF على توزيعات Linux ، لذا أوصي بأن تستخدم دائمًا أحدث الإصدارات المتاحة.
يمكن ملاحظة أن جميع الأنظمة الفرعية لنواة Linux مغطاة تقريبًا ، بالإضافة إلى وجود تكامل جيد مع بيانات الأجهزة ، و eBPF لديه إمكانية الوصول إلى جميع أنواع أخطاء ذاكرة التخزين المؤقت أو تنبؤات أخطاء الفروع ، وما إلى ذلك.إذا كنت مهتمًا بـ eBPF ، فراجع مشروع IO Visor، يحتوي على معظم الأدوات. تشارك شركة IO Visor في تطويرها ، وسيكون لديهم أحدث الإصدارات ووثائق جيدة جدًا. تظهر المزيد والمزيد من أدوات eBPF على توزيعات Linux ، لذا أوصي بأن تستخدم دائمًا أحدث الإصدارات المتاحة.أداء EBPF
من حيث الأداء ، فإن eBPF فعال للغاية. لفهم مقدار ما إذا كان هناك حمل علوي وما إذا كان هناك حمل ، يمكنك إضافة مسبار ، والذي ينقلب عدة مرات في الثانية ، والتحقق من الوقت المستغرق في تنفيذه.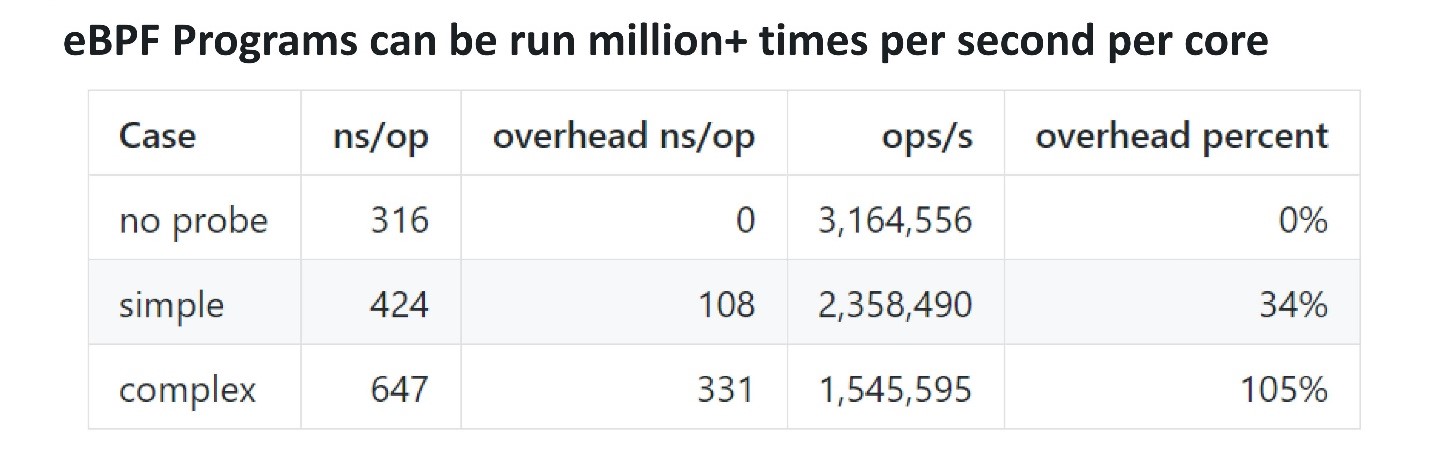 جعل الرجال من Cloudflare معيارًا . أخذهم مسبار eBPF بسيط حوالي 100 نانوثانية ، بينما استغرق مسبار أكثر تعقيدًا 300 نانوثانية. هذا يعني أنه حتى المسبار المعقد يمكن استدعاؤه على قلب واحد حوالي 3 ملايين مرة في الثانية. إذا هز المسبار 100 ألف أو مليون مرة في الثانية على معالج متعدد النواة ، فلن يؤثر ذلك على الأداء كثيرًا.
جعل الرجال من Cloudflare معيارًا . أخذهم مسبار eBPF بسيط حوالي 100 نانوثانية ، بينما استغرق مسبار أكثر تعقيدًا 300 نانوثانية. هذا يعني أنه حتى المسبار المعقد يمكن استدعاؤه على قلب واحد حوالي 3 ملايين مرة في الثانية. إذا هز المسبار 100 ألف أو مليون مرة في الثانية على معالج متعدد النواة ، فلن يؤثر ذلك على الأداء كثيرًا.الواجهة الأمامية لـ eBPF
إذا كنت مهتمًا بـ eBPF وموضوع الملاحظة بشكل عام ، فربما تكون قد سمعت عن Brendan Gregg. يكتب ويتحدث كثيرًا عن هذا الأمر وقام بعمل صورة جميلة تظهر أدوات eBPF. هنا يمكنك أن ترى ذلك ، على سبيل المثال ، يمكنك استخدام Raw BPF - فقط اكتب كود البايت - سيعطي هذا مجموعة كاملة من الميزات ، ولكن سيكون من الصعب جدًا العمل معه. يدور Raw BPF حول كيفية كتابة تطبيق ويب في المجمع - من حيث المبدأ ، من الممكن ، ولكن دون الحاجة إلى القيام بذلك.من المثير للاهتمام ، أن bpfTrace ، من ناحية ، يسمح لك بالحصول على كل شيء تقريبًا من BCC و BPF الخام ، ولكن من الأسهل بكثير استخدامه.في رأيي ، هناك أداتان أكثر فائدة:
هنا يمكنك أن ترى ذلك ، على سبيل المثال ، يمكنك استخدام Raw BPF - فقط اكتب كود البايت - سيعطي هذا مجموعة كاملة من الميزات ، ولكن سيكون من الصعب جدًا العمل معه. يدور Raw BPF حول كيفية كتابة تطبيق ويب في المجمع - من حيث المبدأ ، من الممكن ، ولكن دون الحاجة إلى القيام بذلك.من المثير للاهتمام ، أن bpfTrace ، من ناحية ، يسمح لك بالحصول على كل شيء تقريبًا من BCC و BPF الخام ، ولكن من الأسهل بكثير استخدامه.في رأيي ، هناك أداتان أكثر فائدة:- نسخة مخفية الوجهة. على الرغم من حقيقة أنه وفقًا لمخطط جريج ، فإن BCC معقدة ، فهي تحتوي على العديد من الوظائف الجاهزة التي يمكن إطلاقها ببساطة من سطر الأوامر.
- BpfTrace . يسمح لك ببساطة بكتابة مجموعة أدواتك الخاصة أو استخدام حلول جاهزة.
يمكنك أن تتخيل مدى سهولة الكتابة على bpfTrace إذا نظرت إلى رمز الأداة نفسها في نسختين.
DTrace مقابل bpfTrace
بشكل عام ، يتم استخدام DTrace و bpfTrace لنفس الشيء. http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.htmlالفرق هو أن هناك أيضًا نسخة مخفية الوجهة في نظام BPF البيئي يمكن استخدامها للأدوات المعقدة. لا يوجد مكافئ BCC في DTrace ، لذلك ، لإنشاء مجموعات أدوات معقدة ، عادة ما تستخدم حزمة Shell + DTrace.عند إنشاء bpfTrace ، لم تكن هناك مهمة لمحاكاة DTrace بالكامل. أي أنه لا يمكنك أخذ برنامج نصي DTrace وتشغيله على bpfTrace. لكن هذا لا معنى له ، لأن المنطق في أدوات المستوى الأدنى بسيط للغاية. عادة ما يكون أكثر أهمية لفهم نقاط التتبع التي تحتاج إلى الاتصال بها ، وأسماء مكالمات النظام وما تفعله مباشرة على مستوى منخفض تختلف في Linux و Solaris و FreeBSD. هنا ينشأ الاختلاف.في هذه الحالة ، يتم إجراء bpfTrace بعد 15 عامًا من DTrace. لديها بعض الميزات الإضافية التي لا تمتلكها DTrace. على سبيل المثال ، يمكنه القيام بتتبعات المكدس.ولكن بالطبع ، الكثير موروث من DTrace. على سبيل المثال ، أسماء الدوال والبناء متشابهة ، على الرغم من أنها ليست متكافئة تمامًا.مخطوطات DTrace و bpfTrace قريبة في حجم الشفرة ومتشابهة في قدرات التعقيد واللغة.
http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.htmlالفرق هو أن هناك أيضًا نسخة مخفية الوجهة في نظام BPF البيئي يمكن استخدامها للأدوات المعقدة. لا يوجد مكافئ BCC في DTrace ، لذلك ، لإنشاء مجموعات أدوات معقدة ، عادة ما تستخدم حزمة Shell + DTrace.عند إنشاء bpfTrace ، لم تكن هناك مهمة لمحاكاة DTrace بالكامل. أي أنه لا يمكنك أخذ برنامج نصي DTrace وتشغيله على bpfTrace. لكن هذا لا معنى له ، لأن المنطق في أدوات المستوى الأدنى بسيط للغاية. عادة ما يكون أكثر أهمية لفهم نقاط التتبع التي تحتاج إلى الاتصال بها ، وأسماء مكالمات النظام وما تفعله مباشرة على مستوى منخفض تختلف في Linux و Solaris و FreeBSD. هنا ينشأ الاختلاف.في هذه الحالة ، يتم إجراء bpfTrace بعد 15 عامًا من DTrace. لديها بعض الميزات الإضافية التي لا تمتلكها DTrace. على سبيل المثال ، يمكنه القيام بتتبعات المكدس.ولكن بالطبع ، الكثير موروث من DTrace. على سبيل المثال ، أسماء الدوال والبناء متشابهة ، على الرغم من أنها ليست متكافئة تمامًا.مخطوطات DTrace و bpfTrace قريبة في حجم الشفرة ومتشابهة في قدرات التعقيد واللغة.
bpfTrace
دعونا نرى بمزيد من التفصيل ما هو في bpfTrace ، وكيف يمكن استخدامه وما هو مطلوب لذلك.متطلبات Linux لاستخدام bpfTrace: لاستخدام جميع الميزات ، تحتاج إلى إصدار 4.9 على الأقل. يسمح لك BpfTrace بعمل الكثير من المسابير المختلفة ، بدءًا من خزانة الملابس لإجراء مكالمة وظيفية في تطبيق المستخدم ، ومسابقات kernel ، وما إلى ذلك.
لاستخدام جميع الميزات ، تحتاج إلى إصدار 4.9 على الأقل. يسمح لك BpfTrace بعمل الكثير من المسابير المختلفة ، بدءًا من خزانة الملابس لإجراء مكالمة وظيفية في تطبيق المستخدم ، ومسابقات kernel ، وما إلى ذلك. من المثير للاهتمام ، أن هناك ما يعادل uretprobe لوظيفة خزانة ملابس مخصصة. بالنسبة للنواة ، الشيء نفسه هو kprobe و kretprobe. هذا يعني أنه في الواقع في إطار التتبع يمكنك إنشاء الأحداث عندما يتم استدعاء الوظيفة وعند الانتهاء من هذه الوظيفة - غالبًا ما يُستخدم هذا للتوقيت. أو يمكنك تحليل القيم التي أعادت الدالة وتجميعها وفقًا للمعلمات التي تم استدعاء الدالة بها. إذا تلقيت مكالمة وظيفية وعادت منها ، يمكنك القيام بالكثير من الأشياء الرائعة.يعمل bpfTrace في الداخل على النحو التالي: نكتب برنامج bpf يتم تحليله وتحويله إلى C ثم معالجته من خلال Clang ، والذي يولد كود بايت bpf ، وبعد ذلك يتم تحميل البرنامج.
من المثير للاهتمام ، أن هناك ما يعادل uretprobe لوظيفة خزانة ملابس مخصصة. بالنسبة للنواة ، الشيء نفسه هو kprobe و kretprobe. هذا يعني أنه في الواقع في إطار التتبع يمكنك إنشاء الأحداث عندما يتم استدعاء الوظيفة وعند الانتهاء من هذه الوظيفة - غالبًا ما يُستخدم هذا للتوقيت. أو يمكنك تحليل القيم التي أعادت الدالة وتجميعها وفقًا للمعلمات التي تم استدعاء الدالة بها. إذا تلقيت مكالمة وظيفية وعادت منها ، يمكنك القيام بالكثير من الأشياء الرائعة.يعمل bpfTrace في الداخل على النحو التالي: نكتب برنامج bpf يتم تحليله وتحويله إلى C ثم معالجته من خلال Clang ، والذي يولد كود بايت bpf ، وبعد ذلك يتم تحميل البرنامج. العملية صعبة للغاية ، لذلك هناك قيود. على الخوادم القوية ، يعمل bpfTrace بشكل جيد. لكن سحب Clang إلى جهاز صغير مدمج لمعرفة ما يجري ليس فكرة جيدة. رقائق مناسبة لهذا . وبطبيعة الحال ، لا يحتوي على جميع ميزات bpfTrace ، ولكنه يولد رمز البايت مباشرة.
العملية صعبة للغاية ، لذلك هناك قيود. على الخوادم القوية ، يعمل bpfTrace بشكل جيد. لكن سحب Clang إلى جهاز صغير مدمج لمعرفة ما يجري ليس فكرة جيدة. رقائق مناسبة لهذا . وبطبيعة الحال ، لا يحتوي على جميع ميزات bpfTrace ، ولكنه يولد رمز البايت مباشرة.دعم لينكس
تم إصدار إصدار ثابت من bpfTrace منذ عام تقريبًا ، لذا فهو غير متوفر في توزيعات Linux القديمة. من الأفضل أخذ الحزم أو تجميع أحدث إصدار يوزعه IO Visor.ومن المثير للاهتمام ، أن أحدث إصدار من Ubuntu LTS 18.04 لا يحتوي على bpfTrace ، ولكن يمكن توصيله باستخدام حزمة snap. من ناحية ، هذا أمر مريح ، ولكن من ناحية أخرى ، نظرًا للطريقة التي يتم بها صنع حزم المفاجئة وعزلها ، لن تعمل جميع الوظائف. لتتبع النواة ، تعمل الحزمة ذات الأداة الإضافية بشكل جيد ؛ وقد لا تعمل بشكل صحيح لتتبع المستخدم.
مثال لتتبع العملية
فكر في أبسط مثال يسمح لك بالحصول على إحصائيات حول طلبات IO:bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; }
kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'
هنا نقوم بتوصيل الوظيفة vfs_read، kretprobe و kprobe. علاوة على ذلك ، لكل معرف مؤشر ترابط (tid) ، أي لكل طلب ، نتعقب بداية ونهاية تنفيذه. يمكن تجميع البيانات ليس فقط من خلال مجمل النظام بأكمله ، ولكن أيضًا من خلال عمليات مختلفة. فيما يلي إخراج IO لـ MySQL. توزيع الإدخال / الإخراج الثنائي التقليدي مرئي. عدد كبير من الطلبات السريعة هي البيانات التي تتم قراءتها من ذاكرة التخزين المؤقت. القمة الثانية هي قراءة البيانات من القرص ، حيث يكون الكمون أعلى بكثير.يمكنك حفظ هذا كبرنامج نصي (يستخدم ملحق bt عادة) ، وكتابة التعليقات ، وتنسيقها واستخدامها فقط
توزيع الإدخال / الإخراج الثنائي التقليدي مرئي. عدد كبير من الطلبات السريعة هي البيانات التي تتم قراءتها من ذاكرة التخزين المؤقت. القمة الثانية هي قراءة البيانات من القرص ، حيث يكون الكمون أعلى بكثير.يمكنك حفظ هذا كبرنامج نصي (يستخدم ملحق bt عادة) ، وكتابة التعليقات ، وتنسيقها واستخدامها فقط #bpftrace read.bt.// read.bt file
tracepoint:syscalls:sys_enter_read
{
@start[tid] = nsecs;
}
tracepoint:syscalls:sys_exit_read / @start[tid]/
{
@times = hist(nsecs - @start[tid]);
delete(@start[tid]);
}
المفهوم العام للغة بسيط للغاية.- بناء الجملة: حدد المسبار للاتصال
probe[,probe,...] /filter/ { action }. - عامل التصفية : حدد عامل تصفية ، على سبيل المثال ، البيانات فقط على عملية معينة من معرف المنتج.
- الإجراء: برنامج صغير يتحول مباشرة إلى برنامج bpf ويعمل عند استدعاء bpfTrace.
يمكن العثور على مزيد من التفاصيل هنا .أدوات Bpftrace
يحتوي BpfTrace أيضًا على صندوق أدوات. يتم الآن تنفيذ العديد من الأدوات البسيطة إلى حد ما على BCC على bpfTrace. المجموعة لا تزال صغيرة ، ولكن هناك شيء غير موجود في نسخة مخفية الوجهة. على سبيل المثال ، يتيح لك killsnoop تتبع الإشارات التي تسببها kill ().إذا كنت مهتمًا بالنظر إلى كود bpf ، فيمكنك في bpfTrace أن
المجموعة لا تزال صغيرة ، ولكن هناك شيء غير موجود في نسخة مخفية الوجهة. على سبيل المثال ، يتيح لك killsnoop تتبع الإشارات التي تسببها kill ().إذا كنت مهتمًا بالنظر إلى كود bpf ، فيمكنك في bpfTrace أن -vترى كود البايت الذي تم إنشاؤه من خلاله . هذا مفيد إذا كنت تريد فهم مسبار ثقيل أم لا. بعد الاطلاع على الشفرة وبعد تقدير حجمها (صفحة واحدة أو صفحتين) ، يمكنك فهم مدى تعقيدها.
مثال لتتبع MySQL
دعني أريكم مثالاً على MySQL ، كيف يعمل. يحتوي MySQL على وظيفة تحدث dispatch_commandفيها جميع عمليات تنفيذ استعلام MySQL.bpftrace -e 'uprobe:/usr/sbin/mysqld:dispatch_command { printf("%s\n", str(arg2)); }'
failed to stat uprobe target file /usr/sbin/mysqld: No such file or directory
أردت فقط توصيل خزانة ملابس لطباعة نص الاستفسارات التي تأتي إلى MySQL - وهي مهمة بدائية. حصلت على مشكلة - تقول أنه لا يوجد مثل هذا الملف. ليس كما لو كان هنا:root@mysql1:/# ls -la /usr/sbin/mysqld
-rwxr-xr-x 1 root root 60718384 Oct 25 09:19 /usr/sbin/mysqld
هذه مجرد مفاجآت مع المفاجئة. إذا تم الضبط عبر snap ، فقد تكون هناك مشاكل على مستوى التطبيق.ثم قمت بتثبيت الإصدار apt ، وهو أحدث إصدار من Ubuntu ، بدأ مرة أخرى:root@mysql1:~# bpftrace -e 'uprobe:/usr/sbin/mysqld:dispatch_command { printf("%s\n", str(arg2)); }'
Attaching 1 probe...
Could not resolve symbol: /usr/sbin/mysqld:dispatch_command
"لا يوجد مثل هذا الرمز" - كيف لا ؟! ألقي نظرة على nmما إذا كان هناك مثل هذا الرمز أم لا:root@mysql1:~# nm -D /usr/sbin/mysqld | grep dispatch_command
00000000005af770 T
_Z16dispatch_command19enum_server_commandP3THDPcjbb
root@localhost:~# bpftrace -e 'uprobe:/usr/sbin/mysqld:_Z16dispatch_command19enum_server_commandP3THDPcjbb { printf("%s\n", str(arg2)); }'
Attaching 1 probe...
select @@version_comment limit 1
select 1
يوجد مثل هذا الرمز ، ولكن بما أن MySQL يتم تجميعه من C ++ ، فإنه يتم استخدام mangling هناك. في الواقع، فإن الاسم الحالي للوظيفة التي يتم استخدامها في هذا الأمر، وفيما يلي: _Z16dispatch_command19enum_server_commandP3THDPcjbb. إذا كنت تستخدمه في وظيفة ، فيمكنك الاتصال والحصول على النتيجة. في النظام البيئي المثالي ، تجعل العديد من الأدوات فك التشفير تلقائيًا ، و bpfTrace ليست قادرة بعد.انتبه أيضًا إلى العلم -Dالخاص بـ nm. من المهم أن MySQL ، والعديد من الحزم الأخرى ، تأتي بدون رموز ديناميكية (رموز التصحيح) - تأتي في حزم أخرى. إذا كنت تريد استخدام هذه الأحرف ، فأنت بحاجة إلى علامة -D، وإلا فلن يشاهدها nm.: ++ 25–26 , . , , .
: ++ Online . 5 900 , , -.
: DevOpsConf 2019 HighLoad++ 2019 — , .
— , .