 في العامين الماضيين في وقت فراغي كنت أقوم بممارسة الترياتلون. تحظى هذه الرياضة بشعبية كبيرة في العديد من دول العالم ، وخاصة في الولايات المتحدة الأمريكية وأستراليا وأوروبا. تكتسب حاليًا شعبية سريعة في روسيا ودول رابطة الدول المستقلة. إنه يتعلق بإشراك الهواة وليس المحترفين. على عكس مجرد السباحة في المسبح وركوب الدراجات والركض في الصباح ، تتضمن الترياتلون المشاركة في المسابقات والتحضير المنتظم لها ، حتى دون أن تكون محترفًا. بالتأكيد بين أصدقائك هناك بالفعل "رجل حديدي" واحد على الأقل أو شخص يخطط ليصبح واحدًا. ضخمة ، مجموعة متنوعة من المسافات والظروف ، ثلاث رياضات في واحدة - كل هذا لديه القدرة على تكوين كمية كبيرة من البيانات. في كل عام ، تجري عدة مئات من مسابقات الترياتلون في العالم ، حيث يشارك فيها مئات الآلاف من الأشخاص.تقام المسابقات من قبل العديد من المنظمين. كل منهم ، بالطبع ، ينشر النتائج في حد ذاته. ولكن بالنسبة للرياضيين من روسيا وبعض دول رابطة الدول المستقلة ، الفريقتجمع tristats.ru جميع النتائج في مكان واحد - على موقعها الإلكتروني الذي يحمل نفس الاسم. هذا يجعل من السهل جدًا البحث عن النتائج ، سواء الخاصة بك أو أصدقائك ومنافسيك ، أو حتى أصنامك. ولكن بالنسبة لي ، فقد أعطت الفرصة أيضًا لتحليل عدد كبير من النتائج برمجيًا. النتائج المنشورة على trilife: قراءة .كان هذا هو أول مشروع لي من هذا النوع ، لأنني بدأت مؤخرًا فقط في إجراء تحليل البيانات من حيث المبدأ ، وكذلك استخدام الثعبان. لذلك ، أود أن أخبركم عن التنفيذ الفني لهذا العمل ، خاصة أنه في هذه العملية ، ظهرت فروق دقيقة مختلفة ، تتطلب أحيانًا نهجًا خاصًا. ستتمحور حول التخريد والتحليل وأنواع الصب والتنسيقات واستعادة البيانات غير المكتملة وإنشاء عينة تمثيلية والتصور والتحويل وحتى الحوسبة المتوازية.تحول الحجم إلى حجم كبير ، لذلك قمت بتقسيم كل شيء إلى خمسة أجزاء حتى أتمكن من أخذ المعلومات وتذكر من أين أبدأ بعد الفاصل.قبل المضي قدمًا ، من الأفضل أن تقرأ مقالتي أولاً بنتائج الدراسة ، لأنه هنا وصف المطبخ بشكل أساسي لإنشائه. يستغرق 10-15 دقيقة.هل قرأت؟ إذا دعنا نذهب!
في العامين الماضيين في وقت فراغي كنت أقوم بممارسة الترياتلون. تحظى هذه الرياضة بشعبية كبيرة في العديد من دول العالم ، وخاصة في الولايات المتحدة الأمريكية وأستراليا وأوروبا. تكتسب حاليًا شعبية سريعة في روسيا ودول رابطة الدول المستقلة. إنه يتعلق بإشراك الهواة وليس المحترفين. على عكس مجرد السباحة في المسبح وركوب الدراجات والركض في الصباح ، تتضمن الترياتلون المشاركة في المسابقات والتحضير المنتظم لها ، حتى دون أن تكون محترفًا. بالتأكيد بين أصدقائك هناك بالفعل "رجل حديدي" واحد على الأقل أو شخص يخطط ليصبح واحدًا. ضخمة ، مجموعة متنوعة من المسافات والظروف ، ثلاث رياضات في واحدة - كل هذا لديه القدرة على تكوين كمية كبيرة من البيانات. في كل عام ، تجري عدة مئات من مسابقات الترياتلون في العالم ، حيث يشارك فيها مئات الآلاف من الأشخاص.تقام المسابقات من قبل العديد من المنظمين. كل منهم ، بالطبع ، ينشر النتائج في حد ذاته. ولكن بالنسبة للرياضيين من روسيا وبعض دول رابطة الدول المستقلة ، الفريقتجمع tristats.ru جميع النتائج في مكان واحد - على موقعها الإلكتروني الذي يحمل نفس الاسم. هذا يجعل من السهل جدًا البحث عن النتائج ، سواء الخاصة بك أو أصدقائك ومنافسيك ، أو حتى أصنامك. ولكن بالنسبة لي ، فقد أعطت الفرصة أيضًا لتحليل عدد كبير من النتائج برمجيًا. النتائج المنشورة على trilife: قراءة .كان هذا هو أول مشروع لي من هذا النوع ، لأنني بدأت مؤخرًا فقط في إجراء تحليل البيانات من حيث المبدأ ، وكذلك استخدام الثعبان. لذلك ، أود أن أخبركم عن التنفيذ الفني لهذا العمل ، خاصة أنه في هذه العملية ، ظهرت فروق دقيقة مختلفة ، تتطلب أحيانًا نهجًا خاصًا. ستتمحور حول التخريد والتحليل وأنواع الصب والتنسيقات واستعادة البيانات غير المكتملة وإنشاء عينة تمثيلية والتصور والتحويل وحتى الحوسبة المتوازية.تحول الحجم إلى حجم كبير ، لذلك قمت بتقسيم كل شيء إلى خمسة أجزاء حتى أتمكن من أخذ المعلومات وتذكر من أين أبدأ بعد الفاصل.قبل المضي قدمًا ، من الأفضل أن تقرأ مقالتي أولاً بنتائج الدراسة ، لأنه هنا وصف المطبخ بشكل أساسي لإنشائه. يستغرق 10-15 دقيقة.هل قرأت؟ إذا دعنا نذهب!الجزء 1. الكشط والتحليل
تعطى: موقع tristats.ru . هناك نوعان من الجداول التي تهمنا. هذا في الواقع جدول ملخص لجميع الأجناس وبروتوكول لنتائج كل منها.
 كانت المهمة الأولى هي الحصول على هذه البيانات برمجيًا وحفظها لمزيد من المعالجة. حدث ذلك أنني في ذلك الوقت كنت جديدًا في تقنيات الويب ، وبالتالي لم أكن أعرف على الفور كيفية القيام بذلك. لقد بدأت وفقًا لما عرفته - انظر إلى رمز الصفحة. يمكن القيام بذلك باستخدام زر الفأرة الأيمن أو مفتاح F12 .
كانت المهمة الأولى هي الحصول على هذه البيانات برمجيًا وحفظها لمزيد من المعالجة. حدث ذلك أنني في ذلك الوقت كنت جديدًا في تقنيات الويب ، وبالتالي لم أكن أعرف على الفور كيفية القيام بذلك. لقد بدأت وفقًا لما عرفته - انظر إلى رمز الصفحة. يمكن القيام بذلك باستخدام زر الفأرة الأيمن أو مفتاح F12 . تحتوي القائمة في Chrome على خيارين: عرض رمز الصفحة وعرض الرمز . ليس الانقسام الأكثر وضوحا. بطبيعة الحال ، يعطون نتائج مختلفة. تلك التي تعرض الرمز، إنها تمامًا مثل F12 - النص النصي المباشر بتنسيق html- لما يتم عرضه في المتصفح هو عنصر حكيم.
تحتوي القائمة في Chrome على خيارين: عرض رمز الصفحة وعرض الرمز . ليس الانقسام الأكثر وضوحا. بطبيعة الحال ، يعطون نتائج مختلفة. تلك التي تعرض الرمز، إنها تمامًا مثل F12 - النص النصي المباشر بتنسيق html- لما يتم عرضه في المتصفح هو عنصر حكيم.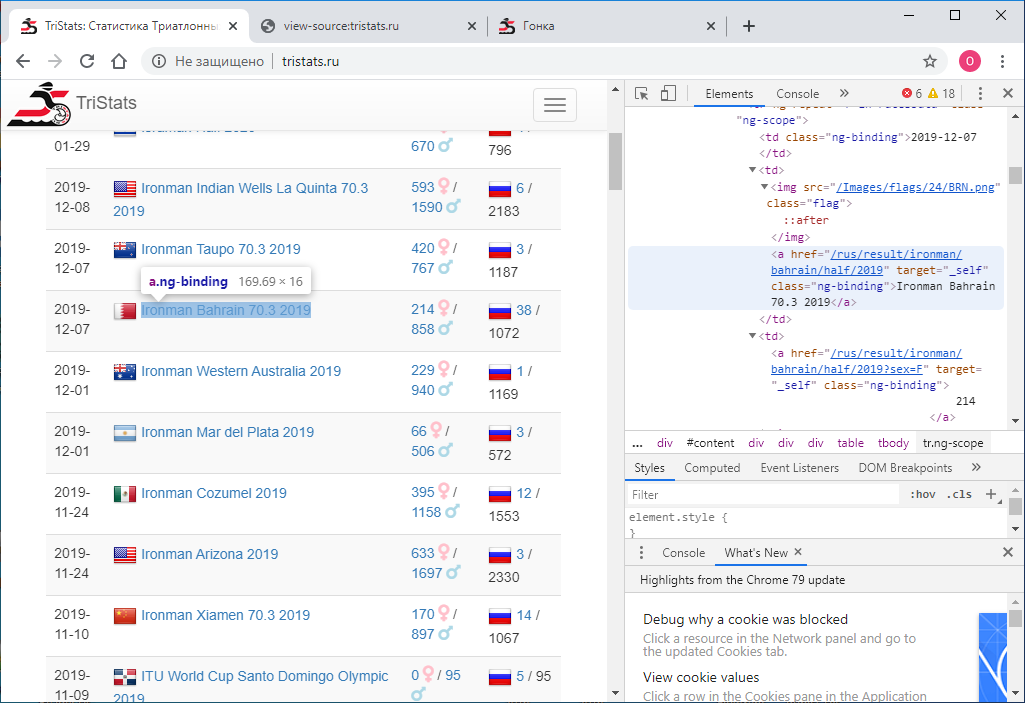 في المقابل ، عرض كود الصفحة يعطي كود المصدر للصفحة. أيضًا html ، ولكن لا توجد بيانات هناك ، فقط أسماء نصوص JS التي تفرغها. حسنا.
في المقابل ، عرض كود الصفحة يعطي كود المصدر للصفحة. أيضًا html ، ولكن لا توجد بيانات هناك ، فقط أسماء نصوص JS التي تفرغها. حسنا. الآن نحن بحاجة إلى فهم كيفية استخدام python لحفظ رمز كل صفحة كملف نصي منفصل. أحاول هذا:
الآن نحن بحاجة إلى فهم كيفية استخدام python لحفظ رمز كل صفحة كملف نصي منفصل. أحاول هذا:import requests
r = requests.get(url='http://tristats.ru/')
print(r.content)
وأحصل على ... كود المصدر. لكني أحتاج إلى نتيجة تنفيذها. بعد الدراسة والبحث والسؤال ، أدركت أنني بحاجة إلى أداة لأتمتة إجراءات المتصفح ، على سبيل المثال ، السيلينيوم . وضعتها. وأيضًا ChromeDriver للعمل مع Google Chrome . ثم استخدمته على النحو التالي:from selenium import webdriver
from selenium.webdriver.chrome.service import Service
service = Service(r'C:\ChromeDriver\chromedriver.exe')
service.start()
driver = webdriver.Remote(service.service_url)
driver.get('http://www.tristats.ru/')
print(driver.page_source)
driver.quit()
يعمل هذا الرمز على تشغيل نافذة متصفح وفتح صفحة فيه على عنوان URL المحدد. ونتيجة لذلك ، نحصل على كود html بالفعل مع البيانات المطلوبة. ولكن هناك عقبة واحدة. والنتيجة 100 إدخال فقط ، ويبلغ إجمالي عدد السباقات 2000 تقريبًا. كيف ذلك؟ والحقيقة هي أنه في البداية يتم عرض أول 100 إدخال فقط في المتصفح ، وفقط إذا قمت بالتمرير إلى أسفل الصفحة تمامًا ، فسيتم تحميل المائة التالية ، وهكذا. لذلك ، من الضروري تنفيذ التمرير برمجياً. للقيام بذلك ، استخدم الأمر:driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
ومع كل تمرير ، سنتحقق مما إذا كان رمز الصفحة المحملة قد تغير أم لا. إذا لم تتغير ، فسنقوم بالتحقق عدة مرات من الموثوقية ، على سبيل المثال 10 ، ثم يتم تحميل الصفحة بأكملها ويمكنك التوقف. بين المخطوطات ، نقوم بتعيين المهلة على ثانية واحدة بحيث يكون للصفحة وقت للتحميل. (حتى لو لم يكن لديها الوقت ، لدينا احتياطي - تسع ثوان أخرى).وسيبدو الرمز الكامل كما يلي:from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
service = Service(r'C:\ChromeDriver\chromedriver.exe')
service.start()
driver = webdriver.Remote(service.service_url)
driver.get('http://www.tristats.ru/')
prev_html = ''
scroll_attempt = 0
while scroll_attempt < 10:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
if prev_html == driver.page_source:
scroll_attempt += 1
else:
prev_html = driver.page_source
scroll_attempt = 0
with open(r'D:\tri\summary.txt', 'w') as f:
f.write(prev_html)
driver.quit()
لذلك ، لدينا ملف html مع جدول ملخص لجميع الأجناس. بحاجة لتحليلها. للقيام بذلك ، استخدم مكتبة lxml .from lxml import html
أولاً نجد جميع صفوف الجدول. لتحديد علامة سلسلة ، ما عليك سوى إلقاء نظرة على ملف html في محرر النصوص. يمكن أن يكون ، على سبيل المثال ، "tr ng-تكرار = 'r في racesData' class = 'ng-نطاق' ' أو جزء لا يمكن العثور عليه في أي علامات.
يمكن أن يكون ، على سبيل المثال ، "tr ng-تكرار = 'r في racesData' class = 'ng-نطاق' ' أو جزء لا يمكن العثور عليه في أي علامات.with open(r'D:\tri\summary.txt', 'r') as f:
sum_html = f.read()
tree = html.fromstring(sum_html)
rows = tree.findall(".//*[@ng-repeat='r in racesData']")
ثم نبدأ dataframe pandas وكل عنصر من كل صف من الجدول مكتوب على هذا dataframe.import pandas as pd
rs = pd.DataFrame(columns=['date','name','link','males','females','rus','total'], index=range(len(rows)))
لمعرفة مكان إخفاء كل عنصر محدد ، ما عليك سوى إلقاء نظرة على رمز html لأحد عناصر صفوفنا في محرر النصوص نفسه.<tr ng-repeat="r in racesData" class="ng-scope">
<td class="ng-binding">2015-04-26</td>
<td>
<img src="/Images/flags/24/USA.png" class="flag">
<a href="/rus/result/ironman/texas/half/2015" target="_self" class="ng-binding">Ironman Texas 70.3 2015</a>
</td>
<td>
<a href="/rus/result/ironman/texas/half/2015?sex=F" target="_self" class="ng-binding">605</a>
<i class="fas fa-venus fa-lg" style="color:Pink"></i>
/
<a href="/rus/result/ironman/texas/half/2015?sex=M" target="_self" class="ng-binding">1539</a>
<i class="fas fa-mars fa-lg" style="color:LightBlue"></i>
</td>
<td class="ng-binding">
<img src="/Images/flags/24/rus.png" class="flag">
<a ng-if="r.CountryCount > 0" href="/rus/result/ironman/texas/half/2015?country=rus" target="_self" class="ng-binding ng-scope">2</a>
/ 2144
</td>
</tr>
أسهل طريقة للتنقل باستخدام رمز ثابت للأطفال هنا هي أنه لا يوجد الكثير منها.for i in range(len(rows)):
rs.loc[i,'date'] = rows[i].getchildren()[0].text.strip()
rs.loc[i,'name'] = rows[i].getchildren()[1].getchildren()[1].text.strip()
rs.loc[i,'link'] = rows[i].getchildren()[1].getchildren()[1].attrib['href'].strip()
rs.loc[i,'males'] = rows[i].getchildren()[2].getchildren()[2].text.strip()
rs.loc[i,'females'] = rows[i].getchildren()[2].getchildren()[0].text.strip()
rs.loc[i,'rus'] = rows[i].getchildren()[3].getchildren()[3].text.strip()
rs.loc[i,'total'] = rows[i].getchildren()[3].text_content().split('/')[1].strip()
ها هي النتيجة: حفظ إطار البيانات هذا في ملف. يمكنني استخدام المخلل ، ولكن يمكن أن يكون CSV ، أو أي شيء آخر.import pickle as pkl
with open(r'D:\tri\summary.pkl', 'wb') as f:
pkl.dump(df,f)
في هذه المرحلة ، تكون جميع البيانات من نوع سلسلة. سنتحول لاحقًا. أهم شيء نحتاجه الآن هو الروابط. سنستخدمها لإلغاء بروتوكولات جميع الأجناس. نصنعها في الصورة وشبه كيف تم إجراؤها للجدول المحوري. في الدورة لجميع السباقات لكل منها ، سنفتح الصفحة حسب المرجع ، وننتقل ونحصل على رمز الصفحة. في جدول الملخص لدينا معلومات عن العدد الإجمالي للمشاركين في السباق - المجموع، سنستخدمها لنفهم حتى النقطة التي تحتاجها لمتابعة التمرير. للقيام بذلك ، سنقوم مباشرة في عملية إلغاء كل صفحة بتحديد عدد السجلات في الجدول ومقارنتها بالقيمة المتوقعة للمجموع. بمجرد أن تكون متساوية ، ننتقل إلى النهاية ويمكنك الانتقال إلى السباق التالي. قمنا أيضًا بتعيين مهلة 60 ثانية. أكلنا خلال هذا الوقت ، لا نصل إلى المجموع ، نذهب إلى السباق التالي. سيتم حفظ رمز الصفحة في ملف. سنحفظ ملفات جميع الأجناس في مجلد واحد ، ونطلق عليها اسم السباقات ، أي بالقيمة في عمود الحدث في جدول الملخص. لتجنب تضارب الأسماء ، من الضروري أن يكون لجميع الأجناس أسماء مختلفة في الجدول المحوري. افحص هذا:df[df.duplicated(subset = 'event', keep=False)]
service.start()
driver = webdriver.Remote(service.service_url)
timeout = 60
for index, row in df.iterrows():
try:
driver.get('http://www.tristats.ru' + row['link'])
start = time.time()
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
race_html = driver.page_source
tree = html.fromstring(race_html)
race_rows = tree.findall(".//*[@ng-repeat='r in resultsData']")
if len(race_rows) == int(row['total']):
break
if time.time() - start > timeout:
print('timeout')
break
with open(os.path.join(r'D:\tri\races', row['event'] + '.txt'), 'w') as f:
f.write(race_html)
except:
traceback.print_exc()
time.sleep(1)
driver.quit()
هذه عملية طويلة. ولكن عندما يتم إعداد كل شيء وتبدأ هذه الآلية الثقيلة في الدوران ، وإضافة ملفات البيانات واحدة تلو الأخرى ، يأتي الشعور بالإثارة اللطيفة. يتم تحميل حوالي ثلاثة بروتوكولات فقط في الدقيقة ، ببطء شديد. غادر لتدور ليلا. استغرق حوالي 10 ساعات. في الصباح ، تم تحميل معظم البروتوكولات. كما يحدث عادة عند العمل مع شبكة ، يفشل عدد قليل. استأنفها بسرعة بمحاولة ثانية.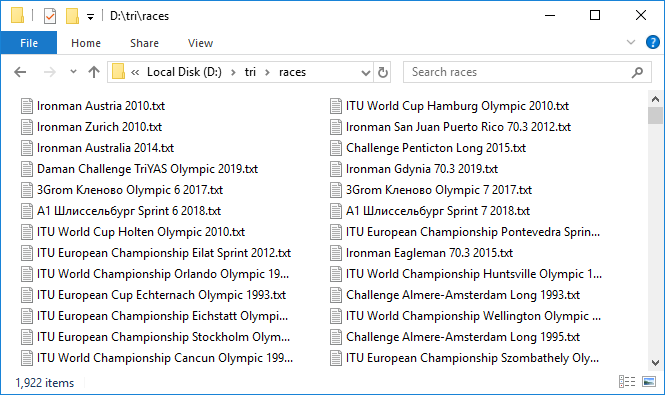 لذا ، لدينا 1،922 ملفًا بسعة إجمالية تبلغ 3 غيغابايت تقريبًا. رائع! لكن التعامل مع ما يقرب من 300 سباق انتهى بمهلة. ما المشكلة؟ تحقق بشكل انتقائي ، وتبين أن القيمة الإجمالية من الجدول المحوري وعدد الإدخالات في بروتوكول السباق التي قمنا بفحصها قد لا تتوافق بالفعل. هذا أمر محزن لأنه لم يتضح سبب هذا التناقض. إما أن هذا يرجع إلى حقيقة أنه لن ينتهي الجميع ، أو نوع من الأخطاء في قاعدة البيانات. بشكل عام ، الإشارة الأولى لنقص البيانات. على أي حال ، نتحقق من تلك التي يكون فيها عدد الإدخالات 100 أو 0 ، هؤلاء هم أكثر المرشحين المشبوهة. كان هناك ثمانية منهم. قم بتنزيلها مرة أخرى تحت تحكم وثيق. بالمناسبة ، يوجد اثنان منهم في الواقع 100 إدخال.حسنًا ، لدينا جميع البيانات. ننتقل إلى التحليل. مرة أخرى ، في دورة سنجري كل سباق ، ونقرأ الملف ونحفظ المحتويات في DataFrame من الباندا . سنقوم بدمج إطارات البيانات هذه في إملاء ، حيث تكون أسماء الأجناس هي المفاتيح - أي أن قيم الأحداث من الجدول المحوري أو أسماء الملفات مع كود html لصفحات السباق ، تتطابق.
لذا ، لدينا 1،922 ملفًا بسعة إجمالية تبلغ 3 غيغابايت تقريبًا. رائع! لكن التعامل مع ما يقرب من 300 سباق انتهى بمهلة. ما المشكلة؟ تحقق بشكل انتقائي ، وتبين أن القيمة الإجمالية من الجدول المحوري وعدد الإدخالات في بروتوكول السباق التي قمنا بفحصها قد لا تتوافق بالفعل. هذا أمر محزن لأنه لم يتضح سبب هذا التناقض. إما أن هذا يرجع إلى حقيقة أنه لن ينتهي الجميع ، أو نوع من الأخطاء في قاعدة البيانات. بشكل عام ، الإشارة الأولى لنقص البيانات. على أي حال ، نتحقق من تلك التي يكون فيها عدد الإدخالات 100 أو 0 ، هؤلاء هم أكثر المرشحين المشبوهة. كان هناك ثمانية منهم. قم بتنزيلها مرة أخرى تحت تحكم وثيق. بالمناسبة ، يوجد اثنان منهم في الواقع 100 إدخال.حسنًا ، لدينا جميع البيانات. ننتقل إلى التحليل. مرة أخرى ، في دورة سنجري كل سباق ، ونقرأ الملف ونحفظ المحتويات في DataFrame من الباندا . سنقوم بدمج إطارات البيانات هذه في إملاء ، حيث تكون أسماء الأجناس هي المفاتيح - أي أن قيم الأحداث من الجدول المحوري أو أسماء الملفات مع كود html لصفحات السباق ، تتطابق.rd = {}
for e in rs['event']:
place = []
... sex = [], name=..., country, group, place_in_group, swim, t1, bike, t2, run
result = []
with open(os.path.join(r'D:\tri\races', e + '.txt'), 'r')
race_html = f.read()
tree = html.fromstring(race_html)
rows = tree.findall(".//*[@ng-repeat='r in resultsData']")
for j in range(len(rows)):
row = rows[j]
parts = row.text_content().split('\n')
parts = [r.strip() for r in parts if r.strip() != '']
place.append(parts[0])
if len([a for a in row.findall('.//i')]) > 0:
sex.append([a for a in row.findall('.//i')][0].attrib['ng-if'][10:-1])
else:
sex.append('')
name.append(parts[1])
if len(parts) > 10:
country.append(parts[2].strip())
k=0
else:
country.append('')
k=1
group.append(parts[3-k])
... place_in_group.append(...), swim.append ..., t1, bike, t2, run
result.append(parts[10-k])
race = pd.DataFrame()
race['place'] = place
... race['sex'] = sex, race['name'] = ..., 'country', 'group', 'place_in_group', 'swim', ' t1', 'bike', 't2', 'run'
race['result'] = result
rd[e] = race
with open(r'D:\tri\details.pkl', 'wb') as f:
pkl.dump(rd,f)
for index, row in rs.iterrows():
e = row['event']
with open(os.path.join(r'D:\tri\races', e + '.txt'), 'r') as f:
race_html = f.read()
tree = html.fromstring(race_html)
header_elem = [tb for tb in tree.findall('.//tbody') if tb.getchildren()[0].getchildren()[0].text == ''][0]
location = header_elem.getchildren()[1].getchildren()[1].text.strip()
rs.loc[index, 'loc'] = location
with open(r'D:\tri\summary1.pkl', 'wb') as f:
pkl.dump(df,f)
الجزء 2. اكتب الصب والتنسيق
لذا ، قمنا بتنزيل جميع البيانات ووضعناها في إطارات البيانات. ومع ذلك ، فإن جميع القيم من نوع str . ينطبق هذا على التاريخ ، وعلى النتائج ، والموقع ، وجميع المعلمات الأخرى. يجب تحويل جميع المعلمات إلى الأنواع المناسبة.لنبدأ بالجدول المحوري.التاريخ و الوقت
الحدث ، في الموضع و صلة ستترك كما هي. تحويل التاريخ إلى تاريخ الباندا كما يلي:rs['date'] = pd.to_datetime(rs['date'])
الباقي يلقي إلى نوع صحيح:cols = ['males', 'females', 'rus', 'total']
rs[cols] = rs[cols].astype(int)
كل شيء سار بسلاسة ، لم تنشأ أخطاء. لذلك كل شيء على ما يرام - احفظ:with open(r'D:\tri\summary2.pkl', 'wb') as f:
pkl.dump(rs, f)
الآن سباقات الإطارات. نظرًا لأن جميع السباقات أكثر ملاءمة وأسرع في المعالجة في وقت واحد ، وليست واحدة في كل مرة ، فسوف نجمعها في إطار بيانات ar واحد كبير (قصير لجميع السجلات ) باستخدام طريقة concat .ar = pd.concat(rd)
يحتوي ar على 1،416،365 إدخالات.الآن قم بتحويل المكان والمكان في المجموعة إلى قيمة صحيحة.ar[['place', 'place in group']] = ar[['place', 'place in group']].astype(int))
بعد ذلك ، نعالج الأعمدة بقيم مؤقتة. سنلقيها في النوع Timedelta من الباندا . ولكن لكي ينجح التحويل ، تحتاج إلى إعداد البيانات بشكل صحيح. يمكنك أن ترى أن بعض القيم التي تستغرق أقل من ساعة تذهب دون تحديد النصيحة ذاتها. تحتاج لإضافته.for col in ['swim', 't1', 'bike', 't2', 'run', 'result']:
strlen = ar[col].str.len()
ar.loc[strlen==5, col] = '0:' + ar.loc[strlen==5, col]
ar.loc[strlen==4, col] = '0:0' + ar.loc[strlen==4, col]
الآن ، لا تزال السلاسل المتبقية ، تبدو كما يلي: التحويل إلى Timedelta :for col in ['swim', 't1', 'bike', 't2', 'run', 'result']:
ar[col] = pd.to_timedelta(ar[col])
أرضية
استمر. تحقق من وجود قيم M و F فقط في عمود الجنس :ar['sex'].unique()
Out: ['M', 'F', '']
في الواقع ، لا تزال هناك سلسلة فارغة ، أي لم يتم تحديد الجنس. دعونا نرى كم عدد هذه الحالات:len(ar[ar['sex'] == ''])
Out: 2538
ليس الكثير جيد. في المستقبل ، سنحاول تقليل هذه القيمة بشكل أكبر. في هذه الأثناء ، اترك عمود الجنس كما هو في شكل خطوط. سنحفظ النتيجة قبل الانتقال إلى تحولات أكثر خطورة وخطورة. من أجل الحفاظ على الاستمرارية بين الملفات ، نقوم بتحويل إطار البيانات المدمج ar إلى قاموس إطارات البيانات rd :for event in ar.index.get_level_values(0).unique():
rd[event] = ar.loc[event]
with open(r'D:\tri\details1.pkl', 'wb') as f:
pkl.dump(rd,f)
بالمناسبة ، بسبب تحويل أنواع بعض الأعمدة ، انخفضت أحجام الملفات من 367 كيلوبايت إلى 295 كيلوبايت للجدول المحوري ومن 251 ميجابايت إلى 168 ميجابايت لبروتوكولات السباق.الرقم الدولي
الآن دعنا نرى البلد.ar['country'].unique()
Out: ['CRO', 'CZE', 'SLO', 'SRB', 'BUL', 'SVK', 'SWE', 'BIH', 'POL', 'MK', 'ROU', 'GRE', 'FRA', 'HUN', 'NOR', 'AUT', 'MNE', 'GBR', 'RUS', 'UAE', 'USA', 'GER', 'URU', 'CRC', 'ITA', 'DEN', 'TUR', 'SUI', 'MEX', 'BLR', 'EST', 'NED', 'AUS', 'BGI', 'BEL', 'ESP', 'POR', 'UKR', 'CAN', 'IRL', 'JPN', 'HKG', 'JEY', 'SGP', 'BRA', 'QAT', 'LUX', 'RSA', 'NZL', 'LAT', 'PHI', 'KSA', 'SEY', 'MAS', 'OMA', 'ARG', 'ECU', 'THA', 'JOR', 'BRN', 'CIV', 'FIN', 'IRN', 'BER', 'LBA', 'KUW', 'LTU', 'SRI', 'HON', 'INA', 'LBN', 'PAN', 'EGY', 'MLT', 'WAL', 'ISL', 'CYP', 'DOM', 'IND', 'VIE', 'MRI', 'AZE', 'MLD', 'LIE', 'VEN', 'ALG', 'SYR', 'MAR', 'KZK', 'PER', 'COL', 'IRQ', 'PAK', 'CZK', 'KAZ', 'CHN', 'NEP', 'ISR', 'MKD', 'FRO', 'BAN', 'ARU', 'CPV', 'ALB', 'BIZ', 'TPE', 'KGZ', 'BNN', 'CUB', 'SNG', 'VTN', 'THI', 'PRG', 'KOR', 'RE', 'TW', 'VN', 'MOL', 'FRE', 'AND', 'MDV', 'GUA', 'MON', 'ARM', 'F.I.TRI.', 'BAHREIN', 'SUECIA', 'REPUBLICA CHECA', 'BRASIL', 'CHI', 'MDA', 'TUN', 'NDL', 'Danish(Dane)', 'Welsh', 'Austrian', 'Unknown', 'AFG', 'Argentinean', 'Pitcairn', 'South African', 'Greenland', 'ESTADOS UNIDOS', 'LUXEMBURGO', 'SUDAFRICA', 'NUEVA ZELANDA', 'RUMANIA', 'PM', 'BAH', 'LTV', 'ESA', 'LAB', 'GIB', 'GUT', 'SAR', 'ita', 'aut', 'ger', 'esp', 'gbr', 'hun', 'den', 'usa', 'sui', 'slo', 'cze', 'svk', 'fra', 'fin', 'isr', 'irn', 'irl', 'bel', 'ned', 'sco', 'pol', 'SMR', 'mex', 'STEEL T BG', 'KINO MANA', 'IVB', 'TCH', 'SCO', 'KEN', 'BAS', 'ZIM', 'Joe', 'PUR', 'SWZ', 'Mark', 'WLS', 'MYA', 'BOT', 'REU', 'NAM', 'NCL', 'BOL', 'GGY', 'ISV', 'TWN', 'GUM', 'FIJ', 'COK', 'NGR', 'IRI', 'GAB', 'ANT', 'GEO', 'COG', 'sue', 'SUD', 'BAR', 'CAY', 'BO', 'VE', 'AX', 'MD', 'PAR', 'UM', 'SEN', 'NIG', 'RWA', 'YEM', 'PLE', 'GHA', 'ITU', 'UZB', 'MGL', 'MAC', 'DMA', 'TAH', 'TTO', 'AHO', 'JAM', 'SKN', 'GRN', 'PRK', 'NFK', 'SOL', 'Sandy', 'SAM', 'PNG', 'SGS', 'Suchy, Jorg', 'SOG', 'GEQ', 'BVT', 'DJI', 'CHA', 'ANG', 'YUG', 'IOT', 'HAI', 'SJM', 'CUW', 'BHU', 'ERI', 'FLK', 'HMD', 'GUF', 'ESH', 'sandy', 'UMI', 'selsmark, 'Alise', 'Eddie', '31/3, Colin', 'CC', '', '', '', '', '', ' ', '', '', '', '-', '', 'GRL', 'UGA', 'VAT', 'ETH', 'ASA', 'PYF', 'ATA', 'ALA', 'MTQ', 'ZZ', 'CXR', 'AIA', 'TJK', 'GUY', 'KR', 'PF', 'BN', 'MO', 'LA', 'CAM', 'NCA', 'ZAM', 'MAD', 'TOG', 'VIR', 'ATF', 'VAN', 'SLE', 'GLP', 'SCG', 'LAO', 'IMN', 'BUR', 'IR', 'SY', 'CMR', 'GBS', 'SUR', 'MOZ', 'BLM', 'MSR', 'CAF', 'BEN', 'COD', 'CCK', 'TUV', 'TGA', 'GI', 'XKX', 'NRU', 'NC', 'LBR', 'TAN', 'VIN', 'SSD', 'GP', 'PS', 'IM', 'JE', '', 'MLI', 'FSM', 'LCA', 'GMB', 'MHL', 'NH', 'FL', 'CT', 'UT', 'AQ', 'Korea', 'Taiwan', 'NewCaledonia', 'Czech Republic', 'PLW', 'BRU', 'RUN', 'NIU', 'KIR', 'SOM', 'TKM', 'SPM', 'BDI', 'COM', 'TCA', 'SHN', 'DO2', 'DCF', 'PCN', 'MNP', 'MYT', 'SXM', 'MAF', 'GUI', 'AN', 'Slovak republic', 'Channel Islands', 'Reunion', 'Wales', 'Scotland', 'ica', 'WLF', 'D', 'F', 'I', 'B', 'L', 'E', 'A', 'S', 'N', 'H', 'R', 'NU', 'BES', 'Bavaria', 'TLS', 'J', 'TKL', 'Tirol"', 'P', '?????', 'EU', 'ES-IB', 'ES-CT', '', 'SOO', 'LZE', '', '', '', '', '', '']
412 قيمة فريدة.بشكل أساسي ، يشار إلى البلد برمز إلكتروني مكون من ثلاثة أرقام في حالة الأحرف الكبيرة. لكن على ما يبدو ، ليس دائمًا. في الواقع ، هناك معيار دولي ISO 3166 ، حيث يتم تحديد الرموز المكونة من ثلاثة أرقام والرقمين لجميع البلدان ، بما في ذلك حتى تلك التي لم تعد موجودة. بالنسبة إلى python ، يمكن العثور على أحد تطبيقات هذا المعيار في حزمة pycountry . وإليك كيف يعمل:import pycountry as pyco
pyco.countries.get(alpha_3 = 'RUS')
Out: Country(alpha_2='RU', alpha_3='RUS', name='Russian Federation', numeric='643')
وبالتالي ، سوف نتحقق من جميع الرموز المكونة من ثلاثة أرقام ، مما يؤدي إلى الأحرف الكبيرة ، والتي تعطي استجابة في countries.get (...) و historical_countries.get (...) :valid_a3 = [c for c in ar['country'].unique() if pyco.countries.get(alpha_3 = c.upper()) != None or pyco.historic_countries.get(alpha_3 = c.upper()) != None])
كان هناك 190 من أصل 412 منهم ، أي أقل من النصف.بالنسبة لـ 222 المتبقية (نشير إلى قائمتهم بواسطة tofix ) ، سننشئ قاموس مطابقة الإصلاح ، حيث سيكون المفتاح هو الاسم الأصلي ، وتكون القيمة هي رمز مكون من ثلاثة أرقام وفقًا لمعيار ISO.tofix = list(set(ar['country'].unique()) - set(valid_a3))
أولاً ، تحقق من الرموز المكونة من رقمين باستخدام pycountry.countries.get (alpha_2 = ...) ، مما يؤدي إلى الأحرف الكبيرة:for icc in tofix:
if pyco.countries.get(alpha_2 = icc.upper()) != None:
fix[icc] = pyco.countries.get(alpha_2 = icc.upper()).alpha_3
else:
if pyco.historic_countries.get(alpha_2 = icc.upper()) != None:
fix[icc] = pyco.historic_countries.get(alpha_2 = icc.upper()).alpha_3
ثم الأسماء الكاملة من خلال pycountry.countries.get (name = ...) ، pycountry.countries.get (common_name = ...) ، مما يؤدي إلى النموذج str.title () :for icc in tofix:
if pyco.countries.get(common_name = icc.title()) != None:
fix[icc] = pyco.countries.get(common_name = icc.title()).alpha_3
else:
if pyco.countries.get(name = icc.title()) != None:
fix[icc] = pyco.countries.get(name = icc.title()).alpha_3
else:
if pyco.historic_countries.get(name = icc.title()) != None:
fix[icc] = pyco.historic_countries.get(name = icc.title()).alpha_3
وبالتالي ، قمنا بتقليل عدد القيم غير المعترف بها إلى 190. لا يزال كثيرًا جدًا: قد تلاحظ أنه لا يزال هناك العديد من الرموز المكونة من ثلاثة أرقام ، ولكن هذا ليس ISO. ماذا بعد؟ اتضح أن هناك معيار آخر - الأولمبية . لسوء الحظ ، لم يتم تضمين تنفيذه في pycountry وعليك البحث عن شيء آخر. تم العثور على الحل في شكل ملف csv على datahub.io . وضع محتويات هذا الملف في DataFrame الباندا يسمى قوات الدفاع المدني . ioc - اللجنة الأولمبية الدولية (IOC)['URU', '', 'PAR', 'SUECIA', 'KUW', 'South African', '', 'Austrian', 'ISV', 'H', 'SCO', 'ES-CT', ', 'GUI', 'BOT', 'SEY', 'BIZ', 'LAB', 'PUR', ' ', 'Scotland', '', '', 'TCH', 'TGA', 'UT', 'BAH', 'GEQ', 'NEP', 'TAH', 'ica', 'FRE', 'E', 'TOG', 'MYA', '', 'Danish (Dane)', 'SAM', 'TPE', 'MON', 'ger', 'Unknown', 'sui', 'R', 'SUI', 'A', 'GRN', 'KZK', 'Wales', '', 'GBS', 'ESA', 'Bavaria', 'Czech Republic', '31/3, Colin', 'SOL', 'SKN', '', 'MGL', 'XKX', 'WLS', 'MOL', 'FIJ', 'CAY', 'ES-IB', 'BER', 'PLE', 'MRI', 'B', 'KSA', '', '', 'LAT', 'GRE', 'ARU', '', 'THI', 'NGR', 'MAD', 'SOG', 'MLD', '?????', 'AHO', 'sco', 'UAE', 'RUMANIA', 'CRO', 'RSA', 'NUEVA ZELANDA', 'KINO MANA', 'PHI', 'sue', 'Tirol"', 'IRI', 'POR', 'CZK', 'SAR', 'D', 'BRASIL', 'DCF', 'HAI', 'ned', 'N', 'BAHREIN', 'VTN', 'EU', 'CAM', 'Mark', 'BUL', 'Welsh', 'VIN', 'HON', 'ESTADOS UNIDOS', 'I', 'GUA', 'OMA', 'CRC', 'PRG', 'NIG', 'BHU', 'Joe', 'GER', 'RUN', 'ALG', '', 'Channel Islands', 'Reunion', 'REPUBLICA CHECA', 'slo', 'ANG', 'NewCaledonia', 'GUT', 'VIE', 'ASA', 'BAR', 'SRI', 'L', '', 'J', 'BAS', 'LUXEMBURGO', 'S', 'CHI', 'SNG', 'BNN', 'den', 'F.I.TRI.', 'STEEL T BG', 'NCA', 'Slovak republic', 'MAS', 'LZE', '-', 'F', 'BRU', '', 'LBA', 'NDL', 'DEN', 'IVB', 'BAN', 'Sandy', 'ZAM', 'sandy', 'Korea', 'SOO', 'BGI', '', 'LTV', 'selsmark, Alise', 'TAN', 'NED', '', 'Suchy, Jorg', 'SLO', 'SUDAFRICA', 'ZIM', 'Eddie', 'INA', '', 'SUD', 'VAN', 'FL', 'P', 'ITU', 'ZZ', 'Argentinean', 'CHA', 'DO2', 'WAL']
len(([x for x in tofix if x.upper() in list(cdf['ioc'])]))
Out: 82
من بين الرموز الثلاثة المكونة من tofix ، تم العثور على 82 بطاقة IOC مقابلة. أضفهم إلى قاموسنا المطابق.for icc in tofix:
if icc.upper() in list(cdf['ioc']):
ind = cdf[cdf['ioc'] == icc.upper()].index[0]
fix[icc] = cdf.loc[ind, 'iso3']
108 القيم الخام المتبقية. يتم إنهاءها يدويًا ، وأحيانًا تلجأ إلى Google للمساعدة. ولكن حتى التحكم اليدوي لا يحل المشكلة بالكامل. لا تزال هناك 49 قيمة من المستحيل بالفعل تفسيرها. ربما تكون معظم هذه القيم مجرد أخطاء في البيانات.{'BGI': 'BRB', 'WAL': 'GBR', 'MLD': 'MDA', 'KZK': 'KAZ', 'CZK': 'CZE', 'BNN': 'BEN', 'SNG': 'SGP', 'VTN': 'VNM', 'THI': 'THA', 'PRG': 'PRT', 'MOL': 'MDA', 'FRE': 'FRA', 'F.I.TRI.': 'ITA', 'BAHREIN': 'BHR', 'SUECIA': 'SWE', 'REPUBLICA CHECA': 'CZE', 'BRASIL': 'BRA', 'NDL': 'NLD', 'Danish (Dane)': 'DNK', 'Welsh': 'GBR', 'Austrian': 'AUT', 'Argentinean': 'ARG', 'South African': 'ZAF', 'ESTADOS UNIDOS': 'USA', 'LUXEMBURGO': 'LUX', 'SUDAFRICA': 'ZAF', 'NUEVA ZELANDA': 'NZL', 'RUMANIA': 'ROU', 'sco': 'GBR', 'SCO': 'GBR', 'WLS': 'GBR', '': 'IND', '': 'IRL', '': 'ARM', '': 'BGR', '': 'SRB', ' ': 'BLR', '': 'GBR', '': 'FRA', '': 'HND', '-': 'CRI', '': 'AZE', 'Korea': 'KOR', 'NewCaledonia': 'FRA', 'Czech Republic': 'CZE', 'Slovak republic': 'SVK', 'Channel Islands': 'FRA', 'Reunion': 'FRA', 'Wales': 'GBR', 'Scotland': 'GBR', 'Bavaria': 'DEU', 'Tirol"': 'AUT', '': 'KGZ', '': 'BLR', '': 'BLR', '': 'BLR', '': 'RUS', '': 'BLR', '': 'RUS'}
unfixed = [x for x in tofix if x not in fix.keys()]
Out: ['', 'H', 'ES-CT', 'LAB', 'TCH', 'UT', 'TAH', 'ica', 'E', 'Unknown', 'R', 'A', '31/3, Colin', 'XKX', 'ES-IB','B','SOG','?????','KINO MANA','sue','SAR','D', 'DCF', 'N', 'EU', 'Mark', 'I', 'Joe', 'RUN', 'GUT', 'L', 'J', 'BAS', 'S', 'STEEL T BG', 'LZE', 'F', 'Sandy', 'DO2', 'sandy', 'SOO', 'LTV', 'selsmark, Alise', 'Suchy, Jorg' 'Eddie', 'FL', 'P', 'ITU', 'ZZ']
ستحتوي هذه المفاتيح على سلسلة فارغة في القاموس المطابق.for cc in unfixed:
fix[cc] = ''
أخيرًا ، نضيف إلى رموز القاموس المتطابقة الصالحة ولكنها مكتوبة بأحرف صغيرة.for cc in valid_a3:
if cc.upper() != cc:
fix[cc] = cc.upper()
حان الوقت الآن لتطبيق البدائل الموجودة. لحفظ البيانات الأولية لمزيد من المقارنة، نسخ البلاد العمود إلى خام البلاد . ثم ، باستخدام القاموس المطابق الذي تم إنشاؤه ، نقوم بتصحيح القيم في عمود البلد التي لا تتوافق مع ISO.for cc in fix:
ind = ar[ar['country'] == cc].index
ar.loc[ind,'country'] = fix[cc]
هنا ، بالطبع ، لا يمكن للمرء الاستغناء عن الرسم البياني ، الجدول يحتوي على مليون ونصف صف تقريبًا. ولكن حسب القاموس نقوم بدورة ، ولكن كيف؟ تحقق من عدد السجلات التي تم تغييرها:len(ar[ar['country'] != ar['country raw']])
Out: 315955
أي أكثر من 20٪ من الإجمالي.ar[ar['country'] != ar['country raw']].sample(10)
len(ar[ar['country'] == ''])
Out: 3221
هذا هو عدد السجلات بدون دولة أو مع دولة غير رسمية. انخفض عدد البلدان الفريدة من 412 إلى 250. ها هي: الآن لا توجد انحرافات. نحفظ النتيجة في ملف details2.pkl جديد ، بعد تحويل إطار البيانات المدمج مرة أخرى إلى قاموس لإطارات البيانات ، كما حدث سابقًا.['', 'ABW', 'AFG', 'AGO', 'AIA', 'ALA', 'ALB', 'AND', 'ANT', 'ARE', 'ARG', 'ARM', 'ASM', 'ATA', 'ATF', 'AUS', 'AUT', 'AZE', 'BDI', 'BEL', 'BEN', 'BES', 'BGD', 'BGR', 'BHR', 'BHS', 'BIH', 'BLM', 'BLR', 'BLZ', 'BMU', 'BOL', 'BRA', 'BRB', 'BRN', 'BTN', 'BUR', 'BVT', 'BWA', 'CAF', 'CAN', 'CCK', 'CHE', 'CHL', 'CHN', 'CIV', 'CMR', 'COD', 'COG', 'COK', 'COL', 'COM', 'CPV', 'CRI', 'CTE', 'CUB', 'CUW', 'CXR', 'CYM', 'CYP', 'CZE', 'DEU', 'DJI', 'DMA', 'DNK', 'DOM', 'DZA', 'ECU', 'EGY', 'ERI', 'ESH', 'ESP', 'EST', 'ETH', 'FIN', 'FJI', 'FLK', 'FRA', 'FRO', 'FSM', 'GAB', 'GBR', 'GEO', 'GGY', 'GHA', 'GIB', 'GIN', 'GLP', 'GMB', 'GNB', 'GNQ', 'GRC', 'GRD', 'GRL', 'GTM', 'GUF', 'GUM', 'GUY', 'HKG', 'HMD', 'HND', 'HRV', 'HTI', 'HUN', 'IDN', 'IMN', 'IND', 'IOT', 'IRL', 'IRN', 'IRQ', 'ISL', 'ISR', 'ITA', 'JAM', 'JEY', 'JOR', 'JPN', 'KAZ', 'KEN', 'KGZ', 'KHM', 'KIR', 'KNA', 'KOR', 'KWT', 'LAO', 'LBN', 'LBR', 'LBY', 'LCA', 'LIE', 'LKA', 'LTU', 'LUX', 'LVA', 'MAC', 'MAF', 'MAR', 'MCO', 'MDA', 'MDG', 'MDV', 'MEX', 'MHL', 'MKD', 'MLI', 'MLT', 'MMR', 'MNE', 'MNG', 'MNP', 'MOZ', 'MSR', 'MTQ', 'MUS', 'MYS', 'MYT', 'NAM', 'NCL', 'NER', 'NFK', 'NGA', 'NHB', 'NIC', 'NIU', 'NLD', 'NOR', 'NPL', 'NRU', 'NZL', 'OMN', 'PAK', 'PAN', 'PCN', 'PER', 'PHL', 'PLW', 'PNG', 'POL', 'PRI', 'PRK', 'PRT', 'PRY', 'PSE', 'PYF', 'QAT', 'REU', 'ROU', 'RUS', 'RWA', 'SAU', 'SCG', 'SDN', 'SEN', 'SGP', 'SGS', 'SHN', 'SJM', 'SLB', 'SLE', 'SLV', 'SMR', 'SOM', 'SPM', 'SRB', 'SSD', 'SUR', 'SVK', 'SVN', 'SWE', 'SWZ', 'SXM', 'SYC', 'SYR', 'TCA', 'TCD', 'TGO', 'THA', 'TJK', 'TKL', 'TKM', 'TLS', 'TON', 'TTO', 'TUN', 'TUR', 'TUV', 'TWN', 'TZA', 'UGA', 'UKR', 'UMI', 'URY', 'USA', 'UZB', 'VAT', 'VCT', 'VEN', 'VGB', 'VIR', 'VNM', 'VUT', 'WLF', 'WSM', 'YEM', 'YUG', 'ZAF', 'ZMB', 'ZWE']
موقعك
تذكر الآن أن ذكر البلدان موجود أيضًا في الجدول المحوري في العمود loc . كما أنه يحتاج إلى تقديم نظرة قياسية. فيما يلي قصة مختلفة قليلاً: لا يمكن رؤية رموز ISO أو الأولمبية. يتم وصف كل شيء في شكل حر إلى حد ما. يتم سرد المدينة والبلد والمكونات الأخرى للعنوان باستخدام فاصلة ، وترتيب عشوائي. في مكان ما في المقام الأول ، في مكان ما في الأخير. لن يساعد pycountry هنا. وهناك الكثير من السجلات - لسباق 1922 525 موقعًا فريدًا (في شكله الأصلي). ولكن هنا تم العثور على أداة مناسبة. هذا هو geopy ، وهي geolocator Nominatim . يعمل مثل هذا:from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent='triathlon results researcher')
geolocator.geocode(' , , ', language='en')
Out: Location( , – , , Altaysky District, Altai Krai, Siberian Federal District, Russia, (51.78897945, 85.73956296106752, 0.0))
عند الطلب ، في شكل عشوائي ، يعطي إجابة منظمة - العنوان والإحداثيات. إذا قمت بتعيين اللغة ، كما هو الحال هنا - الإنجليزية ، فإن ما يمكنها - ستترجم. بادئ ذي بدء ، نحتاج إلى الاسم القياسي للدولة للترجمة اللاحقة إلى رمز ISO. يأخذ فقط المكان الأخير في خاصية العنوان . نظرًا لأن الموقع الجغرافي يرسل طلبًا إلى الخادم في كل مرة ، فإن هذه العملية ليست سريعة وتستغرق 500 دقيقة لـ 500 سجل. علاوة على ذلك ، يحدث أن الجواب لا يأتي. في هذه الحالة ، يساعد الطلب الثاني أحيانًا. في ردي الأول لم يصل إلى 130 طلبًا. تم معالجة معظمها بمحاولتين. ومع ذلك ، لم تتم معالجة 34 اسمًا حتى من خلال عدة محاولات أخرى. ها هم:['Tongyeong, Korea, Korea, South', 'Constanta, Mamaia, Romania, Romania', 'Weihai, China, China', '. , .', 'Odaiba Marin Park, Tokyo, Japan, Japan', 'Sweden, Smaland, Kalmar', 'Cholpon-Ata city, Resort Center "Kapriz", Kyrgyzstan', 'Luxembourg, Region Moselle, Moselle', 'Chita Peninsula, Japan', 'Kraichgau Region, Germany', 'Jintang, Chengdu, Sichuan Province, China, China', 'Madrid, Spain, Spain', 'North American Pro Championship, St. George, Utah, USA', 'Milan Idroscalo Linate, Italy', 'Dexing, Jiangxi Province, China, China', 'Mooloolaba, Australia, Australia', 'Nathan Benderson Park (NBP), 5851 Nathan Benderson Circle, Sarasota, FL 34235., United States', 'Strathclyde Country Park, North Lanarkshire, Glasgow, Great Britain', 'Quijing, China', 'United States of America , Hawaii, Kohala Coast', 'Buffalo City, East London, South Africa', 'Spain, Vall de Cardener', ', . ', 'Asian TriClub Championship, Hefei, China', 'Taizhou, Jiangsu Province, China, China', ', , «»', 'Buffalo, Gallagher Beach, Furhmann Blvd, United States', 'North American Pro Championship | St. George, Utah, USA', 'Weihai, Shandong, China, China', 'Tarzo - Revine Lago, Italy', 'Lausanee, Switzerland', 'Queenstown, New Zealand, New Zealand', 'Makuhari, Japan, Japan', 'Szombathlely, Hungary']
يمكن ملاحظة أنه في كثير من البلدان هناك ذكر مزدوج للبلد ، وهذا يتدخل في الواقع. بشكل عام ، كان علي معالجة هذه الأسماء المتبقية وتم الحصول على العناوين القياسية للجميع. علاوة على ذلك ، من هذه العناوين ، اخترت دولة وكتبت هذه الدولة في عمود جديد في الجدول المحوري. نظرًا لأن ، كما قلت ، فإن العمل مع geopy ليس سريعًا ، فقد قررت على الفور حفظ إحداثيات الموقع - خط العرض وخط الطول. سيكونون في متناول اليد لاحقًا للتصور على الخريطة. بعد ذلك ، باستخدام pyco.countries.get (name = '...') ، بحث Alpha_3 عن البلد بالاسم وخصص رمزًا مكونًا من ثلاثة أرقام.مسافة
إجراء آخر مهم يجب القيام به على الطاولة المحورية هو تحديد المسافة لكل سباق. هذا مفيد لنا لحساب السرعات في المستقبل. في الترياتلون ، هناك أربع مسافات رئيسية - العدو ، والأوليمبية ، وشبه الحديد والحديد. يمكنك أن ترى أنه في أسماء السباقات عادة ما يكون هناك مؤشر على المسافة - هذه هي Sprint ، Olympic ، Half ، Full Words . بالإضافة إلى ذلك ، لدى المنظمين المختلفين تعييناتهم الخاصة للمسافات. نصف الرجل الحديدي ، على سبيل المثال ، تم تعيينه على أنه 70.3 - من خلال عدد الأميال في المسافة ، والأوليمبية - 5150 بعدد الكيلومترات (51.5) ، ويمكن تعيين الحديد على أنه كاملأو بشكل عام ، لعدم وجود تفسير - على سبيل المثال ، Ironman Arizona 2019 . الرجل الحديدي - إنه حديد! في التحدي ، يتم تعيين المسافة الحديدية على أنها طويلة ، والمسافة شبه الحديدية على أنها متوسطة . لدينا IronStar الروسي يعني كامل 226 ، ونصف 113 - من خلال عدد الكيلومترات ، ولكن عادة ما تكون الكلمات Full and Half موجودة أيضًا. الآن قم بتطبيق كل هذه المعرفة وقم بتمييز جميع السباقات وفقًا للكلمات الرئيسية الموجودة في الأسماء.sprints = rs.loc[[i for i in rs.index if 'sprint' in rs.loc[i, 'event'].lower()]]
olympics1 = rs.loc[[i for i in rs.index if 'olympic' in rs.loc[i, 'event'].lower()]]
olympics2 = rs.loc[[i for i in rs.index if '5150' in rs.loc[i, 'event'].lower()]]
olympics = pd.concat([olympics1, olympics2])
rsd = pd.concat([sprints, olympics, halfs, fulls])
في rsd ، تبين أنه تم تسجيل 1 925 سجلًا ، أي ثلاثة أكثر من إجمالي عدد السباقات ، لذلك سقط بعضها تحت معيارين. دعونا نلقي نظرة عليها:rsd[rsd.duplicated(keep=False)]['event'].sort_index()
olympics.drop(65)
سنفعل نفس الشيء مع تقاطع Ironman Dun Laoghaire Full Swim 70.3 2019 إليك أفضل وقت 4:00. هذا نموذجي للنصف. حذف السجل مع فهرس 85 من الامتلاء .fulls.drop(85)
الآن سنكتب معلومات المسافة في إطار البيانات الرئيسي ونرى ما حدث:rs['dist'] = ''
rs.loc[sprints.index,'dist'] = 'sprint'
rs.loc[olympics.index,'dist'] = 'olympic'
rs.loc[halfs.index,'dist'] = 'half'
rs.loc[fulls.index,'dist'] = 'full'
rs.sample(10)
len(rs[rs['dist'] == ''])
Out: 0
وتحقق من مشاكلنا الغامضة:rs.loc[[38,65,82],['event','dist']]
pkl.dump(rs, open(r'D:\tri\summary5.pkl', 'wb'))
الفئات العمرية
الآن نعود إلى بروتوكولات السباق.لقد قمنا بالفعل بتحليل جنس المشاركين وبلدهم ونتائجهم ، وأدخلناهم إلى نموذج قياسي. لكن بقي عمودين آخرين - المجموعة ، وفي الواقع ، الاسم نفسه. لنبدأ بالمجموعات. في الترياتلون ، من المعتاد تقسيم المشاركين حسب الفئات العمرية. غالباً ما تبرز مجموعة من المحترفين. في الواقع ، تكون الإزاحة في كل مجموعة على حدة - يتم منح الأماكن الثلاثة الأولى في كل مجموعة. في المجموعات ، يتم اختيار التأهيل للبطولات ، على سبيل المثال ، على Konu.قم بدمج جميع السجلات ومعرفة المجموعات الموجودة بشكل عام.rd = pkl.load(open(r'D:\tri\details2.pkl', 'rb'))
ar = pd.concat(rd)
ar['group'].unique()
اتضح أن هناك عددًا هائلاً من المجموعات - 581. تبدو مائة مختارة عشوائيًا على النحو التالي: لنرى أيها أكثر عددًا:['MSenior', 'FAmat.', 'M20', 'M65-59', 'F25-29', 'F18-22', 'M75-59', 'MPro', 'F24', 'MCORP M', 'F21-30', 'MSenior 4', 'M40-50', 'FAWAD', 'M16-29', 'MK40-49', 'F65-70', 'F65-70', 'M12-15', 'MK18-29', 'M50up', 'FSEMIFINAL 2 PRO', 'F16', 'MWhite', 'MOpen 25-29', 'F', 'MPT TRI-2', 'M16-24', 'FQUALIFIER 1 PRO', 'F15-17', 'FSEMIFINAL 2 JUNIOR', 'FOpen 60-64', 'M75-80', 'F60-69', 'FJUNIOR A', 'F17-18', 'FAWAD BLIND', 'M75-79', 'M18-29', 'MJUN19-23', 'M60-up', 'M70', 'MPTS5', 'F35-40', "M'S PT1", 'M50-54', 'F65-69', 'F17-20', 'MP4', 'M16-29', 'F18up', 'MJU', 'MPT4', 'MPT TRI-3', 'MU24-39', 'MK35-39', 'F18-20', "M'S", 'F50-55', 'M75-80', 'MXTRI', 'F40-45', 'MJUNIOR B', 'F15', 'F18-19', 'M20-29', 'MAWAD PC4', 'M30-37', 'F21-30', 'Mpro', 'MSEMIFINAL 1 JUNIOR', 'M25-34', 'MAmat.', 'FAWAD PC5', 'FA', 'F50-60', 'FSenior 1', 'M80-84', 'FK45-49', 'F75-79', 'M<23', 'MPTS3', 'M70-75', 'M50-60', 'FQUALIFIER 3 PRO', 'M9', 'F31-40', 'MJUN16-19', 'F18-19', 'M PARA', 'F35-44', 'MParaathlete', 'F18-34', 'FA', 'FAWAD PC2', 'FAll Ages', 'M PARA', 'F31-40', 'MM85', 'M25-39']
ar['group'].value_counts()[:30]
Out:
M40-44 199157
M35-39 183738
M45-49 166796
M30-34 154732
M50-54 107307
M25-29 88980
M55-59 50659
F40-44 48036
F35-39 47414
F30-34 45838
F45-49 39618
MPRO 38445
F25-29 31718
F50-54 26253
M18-24 24534
FPRO 23810
M60-64 20773
M 12799
F55-59 12470
M65-69 8039
F18-24 7772
MJUNIOR 6605
F60-64 5067
M20-24 4580
FJUNIOR 4105
M30-39 3964
M40-49 3319
F 3306
M70-74 3072
F20-24 2522
يمكنك أن ترى أن هذه المجموعات هي خمس سنوات ، بشكل منفصل للرجال وبشكل منفصل للنساء ، وكذلك المجموعات المهنية MPRO و FPRO .لذا سيكون معيارنا:ag = ['MPRO', 'M18-24', 'M25-29', 'M30-34', 'M35-39', 'M40-44', 'M45-49', 'M50-54', 'M55-59', 'M60-64', 'M65-69', 'M70-74', 'M75-79', 'M80-84', 'M85-90', 'FPRO', 'F18-24', 'F25-29', 'F30-34', 'F35-39', 'F40-44', 'F45-49', 'F50-54', 'F55-59', 'F60-64', 'F65-69', 'F70-74', 'F75-79', 'F80-84', 'F85-90']
تغطي هذه المجموعة ما يقرب من 95٪ من جميع اللمسات النهائية.بالطبع ، لن نتمكن من جلب جميع المجموعات إلى هذا المعيار. لكننا نبحث عن تلك التي تشبههم ونعطي جزءًا على الأقل. أولاً ، سنقوم بإحضار الأحرف الكبيرة وإزالة المسافات. إليك ما حدث: قم بتحويلها إلى معاييرنا القياسية.['F25-29F', 'F30-34F', 'F30-34-34', 'F35-39F', 'F40-44F', 'F45-49F', 'F50-54F', 'F55-59F', 'FAG:FPRO', 'FK30-34', 'FK35-39', 'FK40-44', 'FK45-49', 'FOPEN50-54', 'FOPEN60-64', 'MAG:MPRO', 'MK30-34', 'MK30-39', 'MK35-39', 'MK40-44', 'MK40-49', 'MK50-59', 'M40-44', 'MM85-89', 'MOPEN25-29', 'MOPEN30-34', 'MOPEN35-39', 'MOPEN40-44', 'MOPEN45-49', 'MOPEN50-54', 'MOPEN70-74', 'MPRO:', 'MPROM', 'M0-44"']
fix = { 'F25-29F': 'F25-29', 'F30-34F' : 'F30-34', 'F30-34-34': 'F30-34', 'F35-39F': 'F35-39', 'F40-44F': 'F40-44', 'F45-49F': 'F45-49', 'F50-54F': 'F50-54', 'F55-59F': 'F55-59', 'FAG:FPRO': 'FPRO', 'FK30-34': 'F30-34', 'FK35-39': 'F35-39', 'FK40-44': 'F40-44', 'FK45-49': 'F45-49', 'FOPEN50-54': 'F50-54', 'FOPEN60-64': 'F60-64', 'MAG:MPRO': 'MPRO', 'MK30-34': 'M30-34', 'MK30-39': 'M30-39', 'MK35-39': 'M35-39', 'MK40-44': 'M40-44', 'MK40-49': 'M40-49', 'MK50-59': 'M50-59', 'M40-44': 'M40-44', 'MM85-89': 'M85-89', 'MOPEN25-29': 'M25-29', 'MOPEN30-34': 'M30-34', 'MOPEN35-39': 'M35-39', 'MOPEN40-44': 'M40-44', 'MOPEN45-49': 'M45-49', 'MOPEN50-54': 'M50-54', 'MOPEN70-74': 'M70- 74', 'MPRO:' :'MPRO', 'MPROM': 'MPRO', 'M0-44"' : 'M40-44'}
الآن نقوم بتطبيق تحويلنا على إطار البيانات الرئيسي ar ، ولكن أولاً نحفظ قيم المجموعة الأصلية في العمود الخام الجديد للمجموعة .ar['group raw'] = ar['group']
في عمود المجموعة ، نترك فقط تلك القيم التي تتوافق مع معاييرنا.الآن يمكننا أن نقدر جهودنا:len(ar[(ar['group'] != ar['group raw'])&(ar['group']!='')])
Out: 273
فقط قليلا على مستوى مليون ونصف. لكنك لن تعرف حتى تحاول.الشكل 10 المحدد على النحو التالي : احفظ الإصدار الجديد من إطار البيانات ، بعد تحويله مرة أخرى إلى القاموس rd .pkl.dump(rd, open(r'D:\tri\details3.pkl', 'wb'))
اسم
الآن دعنا نعتني بالأسماء. دعونا نرى بشكل انتقائي 100 اسم من أعراق مختلفة:list(ar['name'].sample(100))
Out: ['Case, Christine', 'Van der westhuizen, Wouter', 'Grace, Scott', 'Sader, Markus', 'Schuller, Gunnar', 'Juul-Andersen, Jeppe', 'Nelson, Matthew', ' ', 'Westman, Pehr', 'Becker, Christoph', 'Bolton, Jarrad', 'Coto, Ricardo', 'Davies, Luke', 'Daniltchev, Alexandre', 'Escobar Labastida, Emmanuelle', 'Idzikowski, Jacek', 'Fairaislova Iveta', 'Fisher, Kulani', 'Didenko, Viktor', 'Osborne, Jane', 'Kadralinov, Zhalgas', 'Perkins, Chad', 'Caddell, Martha', 'Lynaire PARISH', 'Busing, Lynn', 'Nikitin, Evgeny', 'ANSON MONZON, ROBERTO', 'Kaub, Bernd', 'Bank, Morten', 'Kennedy, Ian', 'Kahl, Stephen', 'Vossough, Andreas', 'Gale, Karen', 'Mullally, Kristin', 'Alex FRASER', 'Dierkes, Manuela', 'Gillett, David', 'Green, Erica', 'Cunnew, Elliott', 'Sukk, Gaspar', 'Markina Veronika', 'Thomas KVARICS', 'Wu, Lewen', 'Van Enk, W.J.J', 'Escobar, Rosario', 'Healey, Pat', 'Scheef, Heike', 'Ancheta, Marlon', 'Heck, Andreas', 'Vargas Iii, Raul', 'Seferoglou, Maria', 'chris GUZMAN', 'Casey, Timothy', 'Olshanikov Konstantin', 'Rasmus Nerrand', 'Lehmann Bence', 'Amacker, Kirby', 'Parks, Chris', 'Tom, Troy', 'Karlsson, Ulf', 'Halfkann, Dorothee', 'Szabo, Gergely', 'Antipov Mikhail', 'Von Alvensleben, Alvo', 'Gruber, Peter', 'Leblanc, Jean-Philippe', 'Bouchard, Jean-Francois', 'Marchiotto MASSIMO', 'Green, Molly', 'Alder, Christoph', 'Morris, Huw', 'Deceur, Marc', 'Queenan, Derek', 'Krause, Carolin', 'Cockings, Antony', 'Ziehmer Chris', 'Stiene, John', 'Chmet Daniela', 'Chris RIORDAN', 'Wintle, Mel', ' ', 'GASPARINI CHRISTIAN', 'Westbrook, Christohper', 'Martens, Wim', 'Papson, Chris', 'Burdess, Shaun', 'Proctor, Shane', 'Cruzinha, Pedro', 'Hamard, Jacques', 'Petersen, Brett', 'Sahyoun, Sebastien', "O'Connell, Keith", 'Symoshenko, Zhan', 'Luternauer, Jan', 'Coronado, Basil', 'Smith, Alex', 'Dittberner, Felix', 'N?sman, Henrik', 'King, Malisa', 'PUHLMANN Andre']
انها معقدة. هناك مجموعة متنوعة من الخيارات للإدخالات: الاسم الأول اسم العائلة ، الاسم الأخير الاسم الأول ، الاسم الأخير ، الاسم الأول ، الاسم الأخير ، الاسم الأول ، إلخ. أي ترتيب مختلف ، تسجيل مختلف ، في مكان ما يوجد فاصل - فاصلة. هناك أيضًا العديد من البروتوكولات التي يذهب فيها السيريلية. لا يوجد أيضًا تجانس ، ويمكن العثور على هذه التنسيقات: "اسم العائلة الاسم الأول" ، "الاسم الأول اسم العائلة" ، "الاسم الأول الاسم الأوسط الاسم الأخير" ، "الاسم الأخير الاسم الأول الاسم الأوسط". على الرغم من أنه في الواقع ، تم العثور على الاسم الأوسط أيضًا في الهجاء اللاتيني. وهنا ، بالمناسبة ، تنشأ مشكلة أخرى - الترجمة الصوتية. وتجدر الإشارة أيضًا إلى أنه حتى في حالة عدم وجود اسم وسط ، فقد لا يقتصر السجل على كلمتين. على سبيل المثال ، بالنسبة إلى اللاتينيين ، يتكون الاسم بالإضافة إلى اللقب عادة من ثلاث أو أربع كلمات. يمتلك الهولنديون البادئة فان والصينيون والكوريون لديهم أسماء مركبة تتكون عادة من ثلاث كلمات. بشكل عام ، تحتاج إلى الكشف عن هذا التوبيخ بالكامل وتوحيده إلى أقصى حد. كقاعدة عامة ، في تنسيق واحد ، يكون تنسيق الاسم هو نفسه للجميع ، ولكن حتى هنا توجد أخطاء لن نتعامل معها. لنبدأ بتخزين القيم الموجودة في اسم العمود الجديد الخام :ar['name raw'] = ar['name']
الغالبية العظمى من البروتوكولات مكتوبة باللاتينية ، لذا فإن أول شيء أود القيام به هو التحويل الصوتي. دعونا نرى ما هي الأحرف التي يمكن تضمينها في اسم المشارك.set( ''.join(ar['name'].unique()))
Out: [' ', '!', '"', '#', '&', "'", '(', ')', '*', '+', ',', '-', '.', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '>', '?', '@', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '[', '\\', ']', '^', '_', '`', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '|', '\x7f', '\xa0', '¤', '¦', '§', '', '«', '\xad', '', '°', '±', 'µ', '¶', '·', '»', '', 'І', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', 'є', 'і', 'ў', '–', '—', '‘', '’', '‚', '“', '”', '„', '†', '‡', '…', '‰', '›', '']
ما هو موجود فقط! بالإضافة إلى الأحرف والمسافات الفعلية ، لا تزال هناك مجموعة من الشخصيات الغريبة المختلفة. من هذه ، يمكن اعتبار الفترة "." ، والواصلة "-" والفاصلة العليا "" صالحة ، وهذا غير موجود عن طريق الخطأ. بالإضافة إلى ذلك ، لوحظ أنه في العديد من الأسماء والألقاب الألمانية والنرويجية توجد علامة استفهام "؟". يبدو أنهم يستبدلون الحروف من الأبجدية اللاتينية الموسعة - "؟" ، "أ" ، "س" ، "ش" ،؟ وغيرها: فيما يلي أمثلة: الفاصلة ، على الرغم من أنها تحدث في كثير من الأحيان ، هي مجرد فاصل تم اعتماده في أعراق معينة ، لذلك ستقع أيضًا في فئة غير مقبولة. يجب ألا تظهر الأرقام في الأسماء أيضًا.Pierre-Alexandre Petit, Jean-louis Lafontaine, Faris Al-Sultan, Jean-Francois Evrard, Paul O'Mahony, Aidan O'Farrell, John O'Neill, Nick D'Alton, Ward D'Hulster, Hans P.J. Cami, Luis E. Benavides, Maximo Jr. Rueda, Prof. Dr. Tim-Nicolas Korf, Dr. Boris Scharlowsk, Eberhard Gro?mann, Magdalena Wei?, Gro?er Axel, Meyer-Szary Krystian, Morten Halkj?r, RASMUSSEN S?ren Balle
bs = [s for s in symbols if not (s.isalpha() or s in " . - ' ? ,")]
bs
Out: ['!', '"', '#', '&', '(', ')', '*', '+', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '>', '@', '[', '\\', ']', '^', '_', '`', '|', '\x7f', '\xa0', '¤', '¦', '§', '', '«', '\xad', '', '°', '±', '¶', '·', '»', '–', '—', '‘', '’', '‚', '“', '”', '„', '†', '‡', '…', '‰', '›', '']
سنقوم بإزالة جميع هذه الأحرف مؤقتًا لمعرفة عدد الإدخالات الموجودة:for s in bs:
ar['name'] = ar['name'].str.replace(s, '')
corr = ar[ar['name'] != ar['name raw']]
هناك 2184 مثل هذه السجلات ، أي 0.15 ٪ فقط من العدد الإجمالي - قليل جدًا. دعونا نلقي نظرة على 100 منهم:list(corr['name raw'].sample(100))
Out: ['Scha¶ffl, Ga?nter', 'Howard, Brian &', 'Chapiewski, Guilherme (Gc)', 'Derkach 1svd_mail_ru', 'Parker H1 Lauren', 'Leal le?n, Yaneri', 'TencA, David', 'Cortas La?pez, Alejandro', 'Strid, Bja¶rn', '(Crutchfield) Horan, Katie', 'Vigneron, Jean-Michel.Vigneron@gmail.Com', '\xa0', 'Telahr, J†rgen', 'St”rmer, Melanie', 'Nagai B1 Keiji', 'Rinc?n, Mariano', 'Arkalaki, Angela (Evangelia)', 'Barbaro B1 Bonin Anna G:Charlotte', 'Ra?esch, Ja¶rg', "CAVAZZI NICCOLO\\'", 'D„nzel, Thomas', 'Ziska, Steffen (Gerhard)', 'Kobilica B1 Alen', 'Mittelholcz, Bala', 'Jimanez Aguilar, Juan Antonio', 'Achenza H1 Giovanni', 'Reppe H2 Christiane', 'Filipovic B2 Lazar', 'Machuca Ka?hnel, Ruban Alejandro', 'Gellert (Silberprinz), Christian', 'Smith (Guide), Matt', 'Lenatz H1 Benjamin', 'Da¶llinger, Christian', 'Mc Carthy B1 Patrick Donnacha G:Bryan', 'Fa¶llmer, Chris', 'Warner (Rivera), Lisa', 'Wang, Ruijia (Ray)', 'Mc Carthy B1 Donnacha', 'Jones, Nige (Paddy)', 'Sch”ler, Christoph', '\xa0', 'Holthaus, Adelhard (Allard)', 'Mi;Arro, Ana', 'Dr: Koch Stefan', '\xa0', '\xa0', 'Ziska, Steffen (Gerhard)', 'Albarraca\xadn Gonza?lez, Juan Francisco', 'Ha¶fling, Imke', 'Johnston, Eddie (Edwin)', 'Mulcahy, Bob (James)', 'Gottschalk, Bj”rn', '\xa0', 'Gretsch H2 Kendall', 'Scorse, Christopher (Chris)', 'Kiel‚basa, Pawel', 'Kalan, Magnus', 'Roderick "eric" SIMBULAN', 'Russell;, Mark', 'ROPES AND GRAY TEAM 3', 'Andrade, H?¦CTOR DANIEL', 'Landmann H2 Joshua', 'Reyes Rodra\xadguez, Aithami', 'Ziska, Steffen (Gerhard)', 'Ziska, Steffen (Gerhard)', 'Heuza, Pierre', 'Snyder B1 Riley Brad G:Colin', 'Feldmann, Ja¶rg', 'Beveridge H1 Nic', 'FAGES`, perrine', 'Frank", Dieter', 'Saarema¤el, Indrek', 'Betancort Morales, Arida–y', 'Ridderberg, Marie_Louise', '\xa0', 'Ka¶nig, Johannes', 'W Van(der Klugt', 'Ziska, Steffen (Gerhard)', 'Johnson, Nick26', 'Heinz JOHNER03', 'Ga¶rg, Andra', 'Maruo B2 Atsuko', 'Moral Pedrero H1 Eva Maria', '\xa0', 'MATUS SANTIAGO Osc1r', 'Stenbrink, Bja¶rn', 'Wangkhan, Sm1.Thaworn', 'Pullerits, Ta¶nu', 'Clausner, 8588294149', 'Castro Miranda, Josa Ignacio', 'La¶fgren, Pontuz', 'Brown, Jann ( Janine )', 'Ziska, Steffen (Gerhard)', 'Koay, Sa¶ren', 'Ba¶hm, Heiko', 'Oleksiuk B2 Vita', 'G Van(de Grift', 'Scha¶neborn, Guido', 'Mandez, A?lvaro', 'Garca\xada Fla?rez, Daniel']
ونتيجة لذلك ، بعد الكثير من البحث ، تقرر: استبدال جميع الأحرف الأبجدية ، بالإضافة إلى مسافة ، واصلة ، فاصلة عليا وعلامة استفهام ، بفاصلة ، نقطة ورمز \ xa0 ومسافات ، واستبدال جميع الأحرف الأخرى بسلسلة فارغة ، أي حذف فقط.ar['name'] = ar['name raw']
for s in symbols:
if s.isalpha() or s in " - ? '":
continue
if s in ".,\xa0":
ar['name'] = ar['name'].str.replace(s, ' ')
else:
ar['name'] = ar['name'].str.replace(s, '')
ثم تخلص من المساحات الإضافية:ar['name'] = ar['name'].str.split().str.join(' ')
ar['name'] = ar['name'].str.strip()
دعونا نرى ما حدث:ar.loc[corr.index].sample(10)
qmon = ar[(ar['name'].str.replace('?', '').str.strip() == '')&(ar['name']!='')]
يوجد 3429 منهم ، ويشبه ذلك: هدفنا من جعل الأسماء على نفس المستوى هو جعل نفس الأسماء تبدو متشابهة ، ولكن مختلفة بطرق مختلفة. في حالة الأسماء التي تتكون من علامات استفهام فقط ، فإنها تختلف فقط في عدد الأحرف ، ولكن هذا لا يعطي الثقة الكاملة في أن الأسماء التي تحمل نفس الرقم هي نفسها حقًا. لذلك ، نستبدلهم جميعًا بسلسلة فارغة ولن يتم النظر فيها في المستقبل.ar.loc[qmon.index, 'name'] = ''
العدد الإجمالي للإدخالات حيث يكون الاسم هو السلسلة الفارغة 3454. ليس كثيرًا - سننجو. الآن بعد أن تخلصنا من الشخصيات غير الضرورية ، يمكننا المضي قدمًا في التحويل الصوتي. للقيام بذلك ، قم أولاً بإحضار كل شيء إلى أحرف صغيرة حتى لا تقوم بعمل مزدوج.ar['name'] = ar['name'].str.lower()
بعد ذلك ، قم بإنشاء قاموس:trans = {'':'a', '':'b', '':'v', '':'g', '':'d', '':'e', '':'e', '':'zh', '':'z', '':'i', '':'y', '':'k', '':'l', '':'m', '':'n', '':'o', '':'p', '':'r', '':'s', '':'t', '':'u', '':'f', '':'kh', '':'ts', '':'ch', '':'sh', '':'shch', '':'', '':'y', '':'', '':'e', '':'yu', '':'ya', 'є':'e', 'і': 'i','ў':'w','µ':'m'}
كما تضمن أيضًا رسائل من ما يسمى الأبجدية السيريلية الممتدة - "є" و "і" و "ў" ، والتي تُستخدم باللغتين البيلاروسية والأوكرانية ، بالإضافة إلى الحرف اليوناني "µ" . تطبيق التحول:for s in trans:
ar['name'] = ar['name'].str.replace(s, trans[s])
الآن ، من الأحرف الصغيرة العاملة ، سنترجم كل شيء إلى التنسيق المألوف ، حيث يبدأ الاسم الأول والأخير بحرف كبير:ar['name'] = ar['name'].str.title()
دعونا نرى ما حدث.ar[ar['name raw'].str.lower().str[0].isin(trans.keys())].sample(10)
set( ''.join(ar['name'].unique()))
Out: [' ', "'", '-', '?', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J','K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
كله صحيح. ونتيجة لذلك ، أثرت التصحيحات على 1،253،882 أو 89 ٪ من السجلات ، وانخفض عدد الأسماء الفريدة من 660،207 إلى 599،186 ، أي بنسبة 61 ألفًا أو ما يقرب من 10 ٪. رائع! حفظ إلى ملف جديد ، بعد ترجمة اتحاد سجلات ar مرة أخرى إلى قاموس بروتوكول rd .pkl.dump(rd, open(r'D:\tri\details4.pkl', 'wb'))
الآن نحن بحاجة إلى استعادة النظام. أي أن جميع السجلات ستبدو - الاسم الأول اسم العائلة أو اسم العائلة الاسم الأول . أيهما سيتم تحديده. صحيح ، بالإضافة إلى الاسم واللقب ، تحتوي بعض البروتوكولات أيضًا على الأسماء الوسطى. وقد يحدث أن يتم كتابة نفس الشخص بشكل مختلف في بروتوكولات مختلفة - في مكان ما باسم وسط ، في مكان ما بدون. سيتداخل ذلك مع هويته ، لذا حاول إزالة الاسم الأوسط. عادة ما يكون للرعاية الأبوية للرجال نهاية "hiv" ، وبالنسبة للنساء - "vna" . لكن هناك استثناءات. على سبيل المثال - Ilyich ، Ilyinichna ، Nikitich ، Nikitichna. صحيح أن هناك استثناءات قليلة جدًا. كما ذكرنا سابقًا ، يمكن اعتبار تنسيق الأسماء في بروتوكول واحد دائمًا. لذلك ، للتخلص من علم الأبناء ، تحتاج إلى العثور على السباق الذي هم فيه. للقيام بذلك ، ابحث عن إجمالي عدد الأجزاء "vich" و "vna" في اسم العمودومقارنتها بالعدد الإجمالي للإدخالات في كل بروتوكول. إذا كانت هذه الأرقام قريبة ، فهناك اسم الأوسط ، وإلا لا. من غير المعقول أن نبحث عن الامتثال الصارم ، حتى في السباقات حيث يتم تسجيل الأسماء الوسطى ، على سبيل المثال ، يمكن للأجانب المشاركة ، وسيتم تسجيلهم بدونه. يحدث أيضًا أن المشارك نسيت أو لم يرغب في الإشارة إلى اسمه الأوسط. من ناحية أخرى ، هناك أيضًا ألقاب تنتهي بـ "vich" ، وهناك الكثير منها في بيلاروسيا وبلدان أخرى بلغات المجموعة السلافية. بالإضافة إلى ذلك ، قمنا بعمل تحويل صوتي. كان من الممكن إجراء هذا التحليل قبل التحويل الصوتي ، ولكن بعد ذلك هناك فرصة لتفويت بروتوكول فيه أسماء متوسطة ، ولكن في البداية كان بالفعل في اللاتينية. لذلك كل شيء على ما يرام.لذا ، سنبحث عن جميع البروتوكولات التي يوجد فيها عدد الأجزاء "vich" و "vna" في العمودالاسم هو أكثر من 50٪ من إجمالي عدد الإدخالات في البروتوكول.wp = {}
for e in rd:
nvich = (''.join(rd[e]['name'])).count('vich')
nvna = (''.join(rd[e]['name'])).count('vna')
if nvich + nvna > 0.5*len(rd[e]):
wp[e] = rd[e]
يوجد 29 بروتوكولًا ، أحدها هو: ومن المثير للاهتمام أنه إذا أخذنا 20٪ أو العكس بالعكس 70٪ ، فلن تتغير النتيجة ، سيظل هناك 29 ، لذا قمنا بالاختيار الصحيح. وفقًا لذلك ، أقل من 20٪ - تأثير الألقاب ، أكثر من 70٪ - تأثير السجلات الفردية بدون أسماء وسط. بعد فحص البلاد بمساعدة طاولة محورية ، اتضح أن 25 منهم كانوا في روسيا ، و 4 في أبخازيا. الانتقال. سنقوم فقط بمعالجة السجلات التي تحتوي على ثلاثة مكونات ، وهي تلك التي يوجد فيها (من المفترض) اللقب والاسم والاسم الأوسط.sum_n3w = 0
sum_nnot3w = 0
for e in wp:
sum_n3w += len([n for n in wp[e]['name'] if len(n.split()) == 3])
sum_nnot3w += len(wp[e]) - n3w
غالبية هذه السجلات هي 86٪. الآن تلك التي تنقسم فيها المكونات الثلاثة إلى أعمدة name0 ، name1 ، name2 :for e in wp:
ind3 = [i for i in rd[e].index if len(rd[e].loc[i,'name'].split()) == 3]
rd[e]['name0'] = ''
rd[e]['name1'] = ''
rd[e]['name2'] = ''
rd[e].loc[ind3, 'name0'] = rd[e].loc[ind3,'name'].str.split().str[0]
rd[e].loc[ind3, 'name1'] = rd[e].loc[ind3,'name'].str.split().str[1]
rd[e].loc[ind3, 'name2'] = rd[e].loc[ind3,'name'].str.split().str[2]
إليك ما يبدو عليه أحد البروتوكولات: هنا ، على وجه الخصوص ، من الواضح أن تسجيل المكونين لم تتم معالجته. الآن ، لكل بروتوكول ، تحتاج إلى تحديد العمود الذي له اسم الأوسط. هناك خياران فقط - name1 ، name2 ، لأنه لا يمكن أن يكون في المقام الأول. بمجرد تحديد ذلك ، سنقوم بجمع اسم جديد بالفعل بدونه.for e in wp:
n1=(''.join(rd[e]['name1'])).count('vich')+(''.join(rd[e]['name1'])).count('vna')
n2=(''.join(rd[e]['name2'])).count('vich')+(''.join(rd[e]['name2'])).count('vna')
if (n1 > n2):
rd[e]['new name'] = rd[e]['name0'] + ' ' + rd[e]['name2']
else:
rd[e]['new name'] = rd[e]['name0'] + ' ' + rd[e]['name1']
for e in wp:
ind = rd[e][rd[e]['new name'].str.strip() != ''].index
rd[e].loc[ind, 'name'] = rd[e].loc[ind, 'new name']
rd[e] = rd[e].drop(columns = ['name0','name1','name2','new name'])
pkl.dump(rd, open(r'D:\tri\details5.pkl', 'wb'))
تحتاج الآن إلى إحضار الأسماء إلى نفس الترتيب. أي أنه من الضروري في جميع البروتوكولات أن يكون الاسم متبوعًا أولاً بالاسم الأخير ، أو العكس بالعكس - أولاً الاسم الأخير ، ثم الاسم الأول ، أيضًا في جميع البروتوكولات. يعتمد على المزيد ، الآن سنكتشف. الوضع معقد قليلاً بسبب حقيقة أن الاسم الكامل يمكن أن يتكون من أكثر من كلمتين ، حتى بعد إزالة الاسم الأوسط.ar['nwin'] = ar['name'].str.count(' ') + 1
ar.loc[ar['name'] == '','nwin'] = 0
100*ar['nwin'].value_counts()/len(ar)
عدد الكلمات في الاسم عدد السجلات حصة السجلات (٪) بالطبع ، الغالبية العظمى (91٪) كلمتان - مجرد اسم ولقب. لكن الإدخالات التي تحتوي على ثلاث وأربع كلمات هي أيضًا كثيرة جدًا. دعونا نلقي نظرة على جنسية مثل هذه السجلات:ar[ar['nwin'] >= 3]['country'].value_counts()[:12]
Out:
ESP 28435
MEX 10561
USA 7608
DNK 7178
BRA 6321
NLD 5748
DEU 4310
PHL 3941
ZAF 3862
ITA 3691
BEL 3596
FRA 3323
حسنًا ، في المقام الأول إسبانيا ، في المرتبة الثانية - المكسيك ، بلد من أصل إسباني ، أبعد من الولايات المتحدة ، حيث يوجد أيضًا تاريخًا الكثير من اللاتينيين. البرازيل والفلبين أيضا أسماء الإسبانية (والبرتغالية). الدنمارك وهولندا وألمانيا وجنوب إفريقيا وإيطاليا وبلجيكا وفرنسا هي مسألة أخرى ، فهناك ببساطة نوع من البادئة لللقب ، وبالتالي هناك أكثر من كلمتين. في جميع هذه الحالات ، ومع ذلك ، عادة ما يتكون الاسم نفسه من كلمة واحدة ، والاسم الأخير لكلمتين ، ثلاثة. بالطبع ، هناك استثناءات لهذه القاعدة ، لكننا لن نعالجها بعد الآن. أولاً ، لكل بروتوكول ، تحتاج إلى تحديد نوع النظام: اسم اللقب أو العكس. كيف افعلها؟ حدثت لي الفكرة التالية: أولاً ، عادةً ما يكون تنوع الألقاب أكبر بكثير من تنوع الأسماء. يجب أن يكون الأمر كذلك حتى في إطار بروتوكول واحد. ثانيا،عادة ما يكون طول الاسم أقل من طول اللقب (حتى بالنسبة للألقاب غير المركبة). سنستخدم مجموعة من هذه المعايير لتحديد الترتيب الأولي.حدد الكلمات الأولى والأخيرة بالاسم الكامل:ar['new name'] = ar['name']
ind = ar[ar['nwin'] < 2].index
ar.loc[ind, 'new name'] = '. .'
ar['wfin'] = ar['new name'].str.split().str[0]
ar['lwin'] = ar['new name'].str.split().str[-1]
قم بتحويل إطار بيانات ar المدمج مرة أخرى إلى القاموس rd بحيث تقع الأعمدة الجديدة nwin، ns0، ns في إطار البيانات لكل سباق. بعد ذلك ، نحدد عدد البروتوكولات بالترتيب " First Name Last Name" وعدد البروتوكولات بالترتيب العكسي وفقًا لمعيارنا. سننظر فقط في الإدخالات حيث يتكون الاسم الكامل من كلمتين. في نفس الوقت ، احفظ الاسم (الاسم الأول) في عمود جديد:name_surname = {}
surname_name = {}
for e in rd:
d = rd[e][rd[e]['nwin'] == 2]
if len(d['fwin'].unique()) < len(d['lwin'].unique()) and len(''.join(d['fwin'])) < len(''.join(d['lwin'])):
name_surname[e] = d
rd[e]['first name'] = rd[e]['fwin']
if len(d['fwin'].unique()) > len(d['lwin'].unique()) and len(''.join(d['fwin'])) > len(''.join(d['lwin'])):
surname_name[e] = d
rd[e]['first name'] = rd[e]['lwin']
اتضح ما يلي: ترتيب الاسم الأول اسم العائلة - 244 بروتوكول ، ترتيب الاسم الأخير أولاً - 1508 بروتوكول.وفقًا لذلك ، سنؤدي إلى التنسيق الأكثر شيوعًا. اتضح أن المبلغ أقل من المبلغ الإجمالي ، لأننا تحققنا من استيفاء معيارين في نفس الوقت ، وحتى مع عدم المساواة الصارمة. هناك بروتوكولات يتم فيها تحقيق معيار واحد فقط ، أو أنه ممكن ، ولكن من غير المحتمل أن تحدث المساواة. ولكن هذا غير مهم على الإطلاق حيث يتم تعريف التنسيق.الآن ، بافتراض أننا حددنا الطلب بدقة عالية بما فيه الكفاية ، مع عدم نسيان أنه ليس دقيقًا بنسبة 100٪ ، سنستخدم هذه المعلومات. اعثر على الأسماء الأكثر شهرة من عمود الاسم الأول :vc = ar['first name'].value_counts()
خذ أولئك الذين التقوا أكثر من مائة مرة:pfn=vc[vc>100]
كان هناك 1673 منهم ، وإليك المئات منها مرتبة بترتيب تنازلي للشعبية: الآن ، وباستخدام هذه القائمة ، سنجري جميع البروتوكولات ونقارن حيث يوجد المزيد من التطابقات - في الكلمة الأولى من الاسم أو في الأخيرة. سننظر فقط في الأسماء المكونة من كلمتين. إذا كان هناك المزيد من التطابقات مع الكلمة الأخيرة ، فإن الترتيب صحيح ، إذا كان مع الكلمة الأولى ، فهذا يعني العكس. علاوة على ذلك ، نحن هنا أكثر ثقة بالفعل ، لذا يمكنك استخدام هذه المعرفة ، وسنضيف قائمة بأسماء بروتوكولهم التالي إلى القائمة الأولية للأسماء الشائعة مع كل تمريرة. نقوم بفرز البروتوكولات مسبقًا حسب تكرار ظهور الأسماء من القائمة الأولية من أجل تجنب الأخطاء العشوائية وإعداد قائمة أكثر شمولاً لتلك البروتوكولات التي يوجد بها عدد قليل من التطابقات والتي سيتم معالجتها بالقرب من نهاية الدورة.['Michael', 'David', 'Thomas', 'John', 'Daniel', 'Mark', 'Peter', 'Paul', 'Christian', 'Robert', 'Martin', 'James', 'Andrew', 'Chris', 'Richard', 'Andreas', 'Matthew', 'Brian', 'Patrick', 'Scott', 'Kevin', 'Stefan', 'Jason', 'Eric', 'Christopher', 'Alexander', 'Simon', 'Mike', 'Tim', 'Frank', 'Stephen', 'Steve', 'Andrea', 'Jonathan', 'Markus', 'Marco', 'Adam', 'Ryan', 'Jan', 'Tom', 'Marc', 'Carlos', 'Jennifer', 'Matt', 'Steven', 'Jeff', 'Sergey', 'William', 'Aleksandr', 'Sarah', 'Alex', 'Jose', 'Andrey', 'Benjamin', 'Sebastian', 'Ian', 'Anthony', 'Ben', 'Oliver', 'Antonio', 'Ivan', 'Sean', 'Manuel', 'Matthias', 'Nicolas', 'Dan', 'Craig', 'Dmitriy', 'Laura', 'Luis', 'Lisa', 'Kim', 'Anna', 'Nick', 'Rob', 'Maria', 'Greg', 'Aleksey', 'Javier', 'Michelle', 'Andre', 'Mario', 'Joseph', 'Christoph', 'Justin', 'Jim', 'Gary', 'Erik', 'Andy', 'Joe', 'Alberto', 'Roberto', 'Jens', 'Tobias', 'Lee', 'Nicholas', 'Dave', 'Tony', 'Olivier', 'Philippe']
sbpn = pd.DataFrame(columns = ['event', 'num pop names'], index=range(len(rd)))
for i in range(len(rd)):
e = list(rd.keys())[i]
sbpn.loc[i, 'event'] = e
sbpn.loc[i, 'num pop names'] = len(set(pfn).intersection(rd[e]['first name']))
sbnp=sbnp.sort_values(by = 'num pop names',ascending=False)
sbnp = sbnp.reset_index(drop=True)
tofix = []
for i in range(len(rd)):
e = sbpn.loc[i, 'event']
if len(set(list(rd[e]['fwin'])).intersection(pfn)) > len(set(list(rd[e]['lwin'])).intersection(pfn)):
tofix.append(e)
pfn = list(set(pfn + list(rd[e]['fwin'])))
else:
pfn = list(set(pfn + list(rd[e]['lwin'])))
كان هناك 235 بروتوكولات. وهذا هو ، تقريبًا نفس ما حدث في التقريب الأول (244). للتأكد ، نظرت بشكل انتقائي في السجلات الثلاثة الأولى من كل منها ، وتأكدت من أن كل شيء كان صحيحًا. تحقق أيضًا من أن المرحلة الأولى من التصنيف أعطت 36 إدخالًا كاذبًا من اسم اسم الفصل الدراسي واثنين خطأ من اسم اسم الفصل الدراسي . نظرت إلى السجلات الثلاثة الأولى من كل منها ، والواقع أن المرحلة الثانية عملت بشكل مثالي. الآن ، في الواقع ، يبقى إصلاح تلك البروتوكولات حيث تم العثور على ترتيب خاطئ:for e in tofix:
ind = rd[e][rd[e]['nwin'] > 1].index
rd[e].loc[ind,'name'] = rd[e].loc[ind,'name'].str.split(n=1).str[1] + ' ' + rd[e].loc[ind,'name'].str.split(n=1).str[0]
هنا في الانقسام ، حددنا عدد القطع باستخدام المعلمة n . المنطق هو: الاسم كلمة واحدة ، الأولى في الاسم الكامل. كل شيء آخر هو لقب (قد يتكون من عدة كلمات). فقط قم بتبديلها.الآن نتخلص من الأعمدة غير الضرورية ونوفر:for e in rd:
rd[e] = rd[e].drop(columns = ['new name', 'first name', 'fwin','lwin', 'nwin'])
pkl.dump(rd, open(r'D:\tri\details6.pkl', 'wb'))
تحقق من النتيجة. عشرات السجلات الثابتة العشوائية: تم إصلاح ما مجموعه 108 ألف سجل. وانخفض عدد الأسماء الكاملة الفريدة من 598 إلى 547 ألفًا. غرامة! مع الانتهاء من التنسيق.الجزء 3. استعادة البيانات غير مكتملة
انتقل الآن إلى استعادة البيانات المفقودة. وهناك مثل هذا.بلد
لنبدأ بالبلد. البحث عن جميع السجلات التي لم يُشر فيها البلد:arnc = ar[ar['country'] == '']
منهم 3221 منهم 10 عشوائية:nnc = arnc['name'].unique()
عدد الأسماء الفريدة بين السجلات بدون بلد هو 0551. لنرى ما إذا كان يمكن تقليل هذا الرقم.والحقيقة هي أنه في نادٍ ما يقتصر الأشخاص في الترياثلون على سباق واحد فقط ، وعادة ما يشاركون في المسابقات بشكل دوري ، عدة مرات في الموسم ، من سنة إلى أخرى ، يتدربون باستمرار. لذلك ، بالنسبة للعديد من الأسماء في البيانات ، هناك على الأرجح أكثر من سجل واحد. لاستعادة معلومات حول البلد ، حاول العثور على سجلات بنفس الاسم من بين تلك التي يشار إليها البلد.arwc = ar[ar['country'] != '']
nwc = arwc['name'].unique()
tofix = set(nnc).intersection(nwc)
Out: ['Kleber-Schad Ute Cathrin', 'Sellner Peter', 'Pfeiffer Christian', 'Scholl Thomas', 'Petersohn Sandra', 'Marchand Kurt', 'Janneck Britta', 'Angheben Riccardo', 'Thiele Yvonne', 'Kie?Wetter Martin', 'Schymik Gerhard', 'Clark Donald', 'Berod Brigitte', 'Theile Markus', 'Giuliattini Burbui Margherita', 'Wehrum Alexander', 'Kenny Oisin', 'Schwieger Peter', 'Grosse Bianca', 'Schafter Carsten', 'Breck Dirk', 'Mautes Christoph', 'Herrmann Andreas', 'Gilbert Kai', 'Steger Peter', 'Jirouskova Jana', 'Jehrke Michael', 'Valentine David', 'Reis Michael', 'Wanka Michael', 'Schomburg Jonas', 'Giehl Caprice', 'Zinser Carsten', 'Schumann Marcus', 'Magoni Livio', 'Lauden Yann', 'Mayer Dieter', 'Krisa Stefan', 'Haberecht Bernd', 'Schneider Achim', 'Gibanel Curto Antonio', 'Miranda Antonio', 'Juarez Pedro', 'Prelle Gerrit', 'Wuste Kay', 'Bullock Graeme', 'Hahner Martin', 'Kahl Maik', 'Schubnell Frank', 'Hastenteufel Marco', …]
كان هناك 2236 منهم ، أي ما يقرب من ثلاثة أرباع. الآن ، لكل اسم من هذه القائمة ، تحتاج إلى تحديد البلد من خلال السجلات التي توجد فيها. ولكن يحدث أن الاسم نفسه موجود في العديد من السجلات وفي بلدان مختلفة. هذا إما يحمل الاسم نفسه ، أو ربما انتقل الشخص. لذلك ، نقوم أولاً بمعالجة تلك التي يكون فيها كل شيء فريدًا.fix = {}
for n in tofix:
nr = arwc[arwc['name'] == n]
if len(nr['country'].unique()) == 1:
fix[n] = nr['country'].iloc[0]
صنع في حلقة. ولكن ، بصراحة ، يعمل لمدة طويلة - حوالي ثلاث دقائق. إذا كان هناك ترتيب بمزيد من الإدخالات ، فربما يتعين عليك التوصل إلى تنفيذ متجه. كان هناك 2،013 إدخال ، أو 90 ٪ من الإمكانات.الأسماء التي قد تظهر بلدان مختلفة في سجلات مختلفة ، تأخذ البلد الذي يحدث في أغلب الأحيان.if n not in fix:
nr = arwc[arwc['name'] == n]
vc = nr['country'].value_counts()
if vc[0] > vc[1]:
fix[n] = vc.index[0]
وبالتالي ، تم العثور على تطابقات لـ 2،208 اسمًا ، أو 99٪ من جميع الأسماء المحتملة. نطبق هذه المراسلات:{'Kleber-Schad Ute Cathrin': 'DEU', 'Sellner Peter': 'AUT', 'Pfeiffer Christian': 'AUT', 'Scholl Thomas': 'DEU', 'Petersohn Sandra': 'DEU', 'Marchand Kurt': 'BEL', 'Janneck Britta': 'DEU', 'Angheben Riccardo': 'ITA', 'Thiele Yvonne': 'DEU', 'Kie?Wetter Martin': 'DEU', 'Clark Donald': 'GBR', 'Berod Brigitte': 'FRA', 'Theile Markus': 'DEU', 'Giuliattini Burbui Margherita': 'ITA', 'Wehrum Alexander': 'DEU', 'Kenny Oisin': 'IRL', 'Schwieger Peter': 'DEU', 'Schafter Carsten': 'DEU', 'Breck Dirk': 'DEU', 'Mautes Christoph': 'DEU', 'Herrmann Andreas': 'DEU', 'Gilbert Kai': 'DEU', 'Steger Peter': 'AUT', 'Jirouskova Jana': 'CZE', 'Jehrke Michael': 'DEU', 'Wanka Michael': 'DEU', 'Giehl Caprice': 'DEU', 'Zinser Carsten': 'DEU', 'Schumann Marcus': 'DEU', 'Magoni Livio': 'ITA', 'Lauden Yann': 'FRA', 'Mayer Dieter': 'DEU', 'Krisa Stefan': 'DEU', 'Haberecht Bernd': 'DEU', 'Schneider Achim': 'DEU', 'Gibanel Curto Antonio': 'ESP', 'Juarez Pedro': 'ESP', 'Prelle Gerrit': 'DEU', 'Wuste Kay': 'DEU', 'Bullock Graeme': 'GBR', 'Hahner Martin': 'DEU', 'Kahl Maik': 'DEU', 'Schubnell Frank': 'DEU', 'Hastenteufel Marco': 'DEU', 'Tedde Roberto': 'ITA', 'Minervini Domenico': 'ITA', 'Respondek Markus': 'DEU', 'Kramer Arne': 'DEU', 'Schreck Alex': 'DEU', 'Bichler Matthias': 'DEU', …}
for n in fix:
ind = arnc[arnc['name'] == n].index
ar.loc[ind, 'country'] = fix[n]
pkl.dump(rd, open(r'D:\tri\details7.pkl', 'wb'))
أرضية
كما هو الحال في البلدان ، هناك سجلات لا يشار فيها إلى جنس المشارك.ar[ar['sex'] == '']
يوجد 2538 منهم ، قليل نسبياً ، ولكن مرة أخرى سنحاول أن نجعل أقل. احفظ القيم الأصلية في عمود جديد.ar['sex raw'] =ar['sex']
على عكس البلدان التي استرجعنا فيها معلومات بالاسم من البروتوكولات الأخرى ، كل شيء أكثر تعقيدًا هنا. والحقيقة هي أن البيانات مليئة بالأخطاء وهناك العديد من الأسماء (مجموع 2101) التي تم العثور عليها بعلامات لكلا الجنسين.arws = ar[(ar['sex'] != '')&(ar['name'] != '')]
snds = arws[arws.duplicated(subset='name',keep=False)]
snds = snds.drop_duplicates(subset=['name','sex'], keep = 'first')
snds = snds.sort_values(by='name')
snds = snds[snds.duplicated(subset = 'name', keep=False)]
snds
rss = [rd[e] for e in rd if len(rd[e][rd[e]['sex'] != '']['sex'].unique()) == 1]
يوجد 633 منهم ، يبدو أن هذا ممكن تمامًا ، مجرد بروتوكول منفصل للنساء ، بشكل منفصل للرجال. لكن الحقيقة هي أن جميع هذه البروتوكولات تقريبًا تحتوي على فئات عمرية من كلا الجنسين (تبدأ الفئات العمرية للذكور بالحرف M ، الإناث - بالحرف F ). على سبيل المثال: من المتوقع أن يبدأ اسم الفئة العمرية بالحرف M للرجال والحرف F للنساء. في المثالين السابقين ، على الرغم من الأخطاء في عمود الجنس'ITU World Cup Tiszaujvaros Olympic 2002'
، لا يزال يبدو أن اسم المجموعة يصف جنس العضو بشكل صحيح. استنادًا إلى العديد من أمثلة الأمثلة ، نفترض أن المجموعة مُشار إليها بشكل صحيح ، وقد يُشار إلى الجنس بشكل خاطئ. ابحث عن جميع الإدخالات حيث لا يتطابق الحرف الأول في اسم المجموعة مع الجنس. سنأخذ الاسم الأولي لمجموعة المجموعة الخام ، حيث أنه خلال التوحيد القياسي تركت العديد من السجلات بدون مجموعة ، لكننا الآن بحاجة فقط إلى الحرف الأول ، لذا فإن المعيار ليس مهمًا.ar['grflc'] = ar['group raw'].str.upper().str[0]
grncs = ar[(ar['grflc'].isin(['M','F']))&(ar['sex']!=ar['grflc'])]
هناك 26 161 مثل هذه السجلات. حسنًا ، دعنا نصحح الجنس وفقًا لاسم الفئة العمرية:ar.loc[grncs.index, 'sex'] = grncs['grflc']
دعونا نلقي نظرة على النتيجة: جيد. كم عدد السجلات المتبقية الآن بدون جنس؟ar[(ar['sex'] == '')&(ar['name'] != '')]
اتضح بالضبط واحد! حسنًا ، لم يتم تحديد المجموعة حقًا ، ولكن ، على ما يبدو ، هذه امرأة. Emily هو اسم أنثى ، إلى جانب هذه المشاركة (أو التي تحمل اسمها) التي انتهت قبل عام ، وفي هذا البروتوكول يشار إلى الجنس والمجموعة. قم بالاستعادة هنا يدويًا وانتقل.ar.loc[arns.index, 'sex'] = 'F'
الآن جميع السجلات مع الجنس.* بشكل عام ، بالطبع ، من الخطأ القيام بذلك - مع الجري المتكرر ، إذا تغير شيء ما في السلسلة من قبل ، على سبيل المثال ، في تحويل الاسم ، فقد يكون هناك أكثر من سجل واحد بدون جنس ، ولن يكون جميعهم من الإناث ، سيحدث خطأ. لذلك ، يجب عليك إما إدراج منطق ثقيل للبحث عن مشارك بنفس الاسم والجنس في البروتوكولات الأخرى ، مثل استعادة بلد ما ، واختباره بطريقة أو بأخرى ، أو حتى لا يعقد الأمر بشكل غير ضروري ، أضف إلى هذا المنطق التحقق من وجود سجل واحد فقط والاسم على هذا النحو ، أو خلاف ذلك ، من خلال استبعاد استثناء من شأنه إيقاف الكمبيوتر المحمول بأكمله ، يمكنك ملاحظة انحراف عن الخطة والتدخل.if len(arns) == 1 and arns['name'].iloc[0] == 'Stather Emily':
ar.loc[arns.index, 'sex'] = 'F'
else:
raise Exception('Different scenario!')
يبدو أن هذا يمكن أن يهدأ. لكن الحقيقة هي أن التصحيحات تستند إلى افتراض أن المجموعة يشار إليها بشكل صحيح. وهو كذلك بالفعل. تقريبا دائما. تقريبا. ومع ذلك ، تم ملاحظة العديد من التناقضات عن طريق الخطأ ، لذلك الآن دعونا نحاول تحديدها جميعًا ، جيدًا أو قدر الإمكان. كما ذكرنا من قبل ، في المثال الأول ، كان على وجه التحديد حقيقة أن الجنس لا يتوافق مع الاسم على أساس أفكاره الخاصة حول أسماء الذكور والإناث التي تحرسنا.البحث عن جميع الأسماء في سجلات الذكور والإناث. هنا ، يُفهم الاسم على أنه الاسم ، وليس الاسم الكامل ، أي بدون اسم ، ما يسمى الاسم الأول باللغة الإنجليزية .ar['fn'] = ar['name'].str.split().str[-1]
mfn = list(ar[ar['sex'] == 'M']['fn'].unique())
يتم سرد ما مجموعه 32508 أسماء الذكور. فيما يلي أكثر 50 شركة شعبية:['Michael', 'David', 'Thomas', 'John', 'Daniel', 'Mark', 'Peter', 'Paul', 'Christian', 'Robert', 'Martin', 'James', 'Andrew', 'Chris', 'Richard', 'Andreas', 'Matthew', 'Brian', 'Kevin', 'Patrick', 'Scott', 'Stefan', 'Jason', 'Eric', 'Alexander', 'Christopher', 'Simon', 'Mike', 'Tim', 'Frank', 'Stephen', 'Steve', 'Jonathan', 'Marco', 'Markus', 'Adam', 'Ryan', 'Tom', 'Jan', 'Marc', 'Carlos', 'Matt', 'Steven', 'Jeff', 'Sergey', 'William', 'Aleksandr', 'Andrey', 'Benjamin', 'Jose']
ffn = list(ar[ar['sex'] == 'F']['fn'].unique())
عدد أقل من النساء - 14 423 الأكثر شيوعًا: جيد ، يبدو أنه يبدو منطقيًا. دعونا نرى ما إذا كانت هناك تقاطعات.['Jennifer', 'Sarah', 'Laura', 'Lisa', 'Anna', 'Michelle', 'Maria', 'Andrea', 'Nicole', 'Jessica', 'Julie', 'Elizabeth', 'Stephanie', 'Karen', 'Christine', 'Amy', 'Rebecca', 'Susan', 'Rachel', 'Anne', 'Heather', 'Kelly', 'Barbara', 'Claudia', 'Amanda', 'Sandra', 'Julia', 'Lauren', 'Melissa', 'Emma', 'Sara', 'Katie', 'Melanie', 'Kim', 'Caroline', 'Erin', 'Kate', 'Linda', 'Mary', 'Alexandra', 'Christina', 'Emily', 'Angela', 'Catherine', 'Claire', 'Elena', 'Patricia', 'Charlotte', 'Megan', 'Daniela']
mffn = set(mfn).intersection(ffn)
يوجد. وهناك 2811 منهم دعنا ننظر إليهم عن كثب. بادئ ذي بدء ، نجد عدد السجلات التي تحمل هذه الأسماء:armfn = ar[ar['fn'].isin(mffn)]
يوجد 725 562 هذا نصف! انه رائع! يوجد ما يقرب من 37000 اسم فريد ، ولكن نصف السجلات بها 2800 اسمًا. لنر ما هي هذه الأسماء ، وهي الأكثر شيوعًا. للقيام بذلك ، قم بإنشاء إطار بيانات جديد حيث ستكون هذه الأسماء مؤشرات:df = pd.DataFrame(armfn['fn'].value_counts())
df = df.rename(columns={'fn':'total'})
نحن نحسب عدد السجلات من الذكور والإناث مع كل منها.df['M'] = armfn[armfn['sex'] == 'M']['fn'].value_counts()
df['F'] = armfn[armfn['sex'] == 'F']['fn'].value_counts()
df.sort_values(by = 'F', ascending=False)
import gender_guesser.detector as gg
d = gg.Detector()
d.get_gender(u'Oleg')
Out: 'male'
d.get_gender(u'Evgeniya')
Out: 'female'
كل شيء على ما يرام. ولكن إذا تحققت من اسم أندريا ، فإنه يعطي أيضًا أنثى ، وهذا ليس صحيحًا تمامًا. صحيح ، هناك مخرج. إذا نظرت إلى خاصية أسماء الكاشف ، فإن كل الغموض يصبح مرئيًا هناك.d.names['Andrea']
Out: {'female': ' 4 4 3 4788 64 579 34 1 7 ',
'mostly_female': '5 6 7 ',
'male': ' 7 '}
نعم ، هذا هو ، get_gender يمنحك الخيار الأكثر احتمالًا ، ولكن في الواقع يمكن أن يكون أكثر تعقيدًا. تحقق من الأسماء الأخرى:d.names['Maria']
Out: {'female': '686 6 A 85986 A BA 3B98A75457 6 ',
'mostly_female': ' BBC A 678A9 '}
d.names['Oleg']
Out: {'male': ' 6 2 99894737 3 '}
أي أن قائمة أسماء كل اسم تقابل واحدًا أو أكثر من أزواج القيمة الرئيسية ، حيث المفتاح - هو الجنس: ذكر ، أنثى ، معظمهم من الذكور ، معظمهم من الإناث ، وأندي ، والقيمة - قائمة قيم البلد المقابل: 1،2،3 ... .. 9ABC . البلدان هي:d.COUNTRIES
Out: ['great_britain', 'ireland', 'usa', 'italy', 'malta', 'portugal', 'spain', 'france', 'belgium', 'luxembourg', 'the_netherlands', 'east_frisia', 'germany', 'austria', 'swiss', 'iceland', 'denmark', 'norway', 'sweden', 'finland', 'estonia', 'latvia', 'lithuania', 'poland', 'czech_republic', 'slovakia', 'hungary', 'romania', 'bulgaria', 'bosniaand', 'croatia', 'kosovo', 'macedonia', 'montenegro', 'serbia', 'slovenia', 'albania', 'greece', 'russia', 'belarus', 'moldova', 'ukraine', 'armenia', 'azerbaijan', 'georgia', 'the_stans', 'turkey', 'arabia', 'israel', 'china', 'india', 'japan', 'korea', 'vietnam', 'other_countries']
لم أفهم تمامًا ما تعنيه المعاني الأبجدية الرقمية أو غيابها في القائمة على وجه التحديد. لكن هذا لم يكن مهمًا ، لأنني قررت أن أقتصر فقط على استخدام تلك الأسماء التي لها تفسير واضح. أي أنه يوجد زوج واحد فقط من القيمة الرئيسية والمفتاح إما ذكر أو أنثى . لكل اسم من dataframe لدينا ، اكتب تفسيره لمحاكي الجنس :df['sex from gg'] = ''
for n in df.index:
if n in list(d.names.keys()):
options = list(d.names[n].keys())
if len(options) == 1 and options[0] == 'male':
df.loc[n, 'sex from gg'] = 'M'
if len(options) == 1 and options[0] == 'female':
df.loc[n, 'sex from gg'] = 'F'
تبين 1150 اسما. فيما يلي الأكثر شيوعًا التي تمت مناقشتها أعلاه: حسنًا ، ليس سيئًا. الآن قم بتطبيق هذا المنطق على جميع السجلات.all_names = ar['fn'].unique()
male_names = []
female_names = []
for n in all_names:
if n in list(d.names.keys()):
options = list(d.names[n].keys())
if len(options) == 1:
if options[0] == 'male':
male_names.append(n)
if options[0] == 'female':
female_names.append(n)
العثور على 7 091 أسماء ذكور و 0554 أنثى. تطبيق التحول:tofixm = ar[ar['fn'].isin(male_names)]
ar.loc[tofixm.index, 'sex'] = 'M'
tofixf = ar[ar['fn'].isin(female_names)]
ar.loc[tofixf.index, 'sex'] = 'F'
ننظر إلى النتيجة:ar[ar['sex']!=ar['sex raw']]
تصحيح إدخالات 30،352 (مع التصحيح باسم المجموعة). كالعادة ، 10 عشوائية: الآن بعد أن تأكدنا من أننا حددنا الجنس بشكل صحيح ، سنقوم أيضًا بجعل المجموعات القياسية في خط. دعونا نرى أين لا تتطابق:ar['gfl'] = ar['group'].str[0]
gncws = ar[(ar['sex'] != ar['gfl']) & (ar['group']!='')]
4،248 إدخالات. يستبدل الحرف الأول:ar.loc[gncws.index, 'group'] = ar.loc[gncws.index, 'sex'] + ar.loc[gncws.index, 'group'].str[1:].index, 'sex']
pkl.dump(rd, open(r'D:\tri\details8.pkl', 'wb'))
هذا كل شيء ، مع استعادة البيانات غير المكتملة.تحديث النشرة
يبقى تحديث الجدول الموجز ببيانات محدثة حول عدد الرجال والنساء ، إلخ.rs['total raw'] = rs['total']
rs['males raw'] = rs['males']
rs['females raw'] = rs['females']
rs['rus raw'] = rs['rus']
for i in rs.index:
e = rs.loc[i,'event']
rs.loc[i,'total'] = len(rd[e])
rs.loc[i,'males'] = len(rd[e][rd[e]['sex'] == 'M'])
rs.loc[i,'females'] = len(rd[e][rd[e]['sex'] == 'F'])
rs.loc[i,'rus'] = len(rd[e][rd[e]['country'] == 'RUS'])
len(rs[rs['total'] != rs['total raw']])
Out: 288
len(rs[rs['males'] != rs['males raw']])
Out:962
len(rs[rs['females'] != rs['females raw']])
Out: 836
len(rs[rs['rus'] != rs['rus raw']])
Out: 8
pkl.dump(rs, open(r'D:\tri\summary6.pkl', 'wb'))
الجزء 4. أخذ العينات
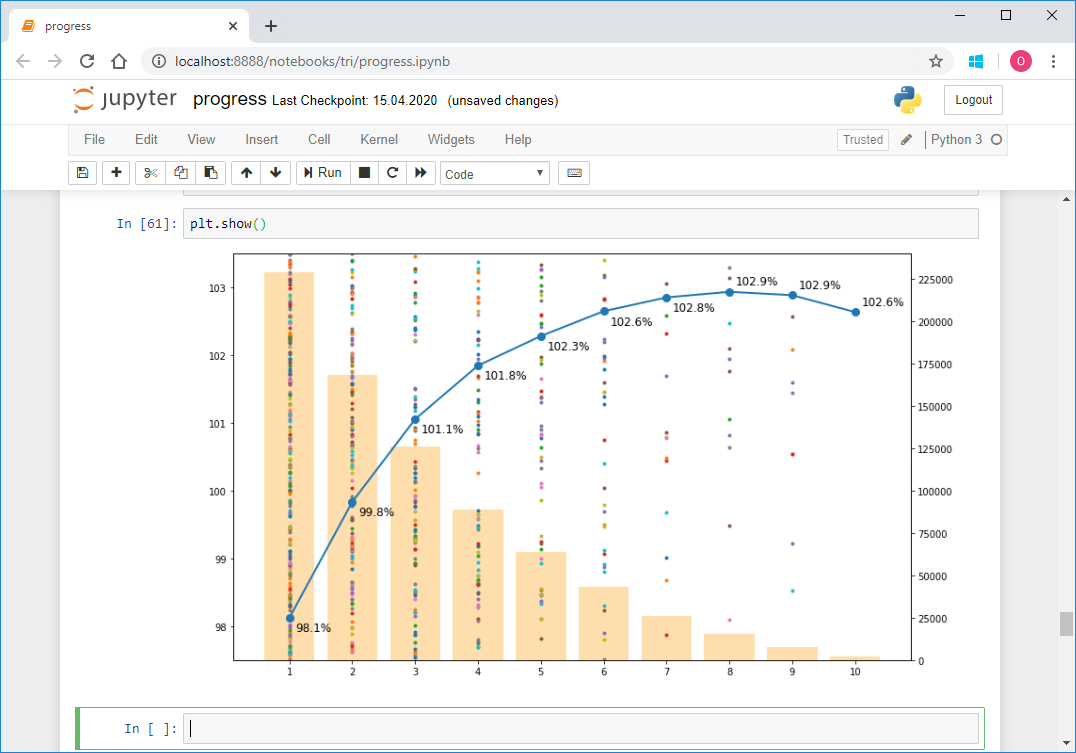
الآن الترياتلون تحظى بشعبية كبيرة. خلال الموسم ، هناك العديد من المسابقات المفتوحة التي يشارك فيها عدد كبير من الرياضيين ، وخاصة الهواة. ولكنها لم تكن كذلك دائما. هناك سجلات في بياناتنا منذ عام 1990. بالتمرير عبر tristats.ru ، لاحظت أن هناك المزيد من السباقات في السنوات الأخيرة ، وعدد قليل جدًا في الأول. ولكن الآن بعد أن تم إعداد بياناتنا ، يمكنك الاطلاع عليها عن كثب.فترة عشر سنوات
احسب عدد السباقات والانهاءات في كل عام:rs['year'] = pd.DatetimeIndex(rs['date']).year
years = range(rs['year'].min(),rs['year'].max())
rsy = pd.DataFrame(columns = ['races', 'finishers', 'rus', 'RUS'], index = years)
for y in rsy.index:
rsy.loc[y,'races'] = len(rs[rs['year'] == y])
rsy.loc[y,'finishers'] = sum(rs[rs['year'] == y]['total'])
rsy.loc[y,'rus'] = sum(rs[rs['year'] == y]['rus'])
rsy.loc[y,'RUS'] = len(rs[(rs['year'] == y)&(rs['country'] == 'RUS')])
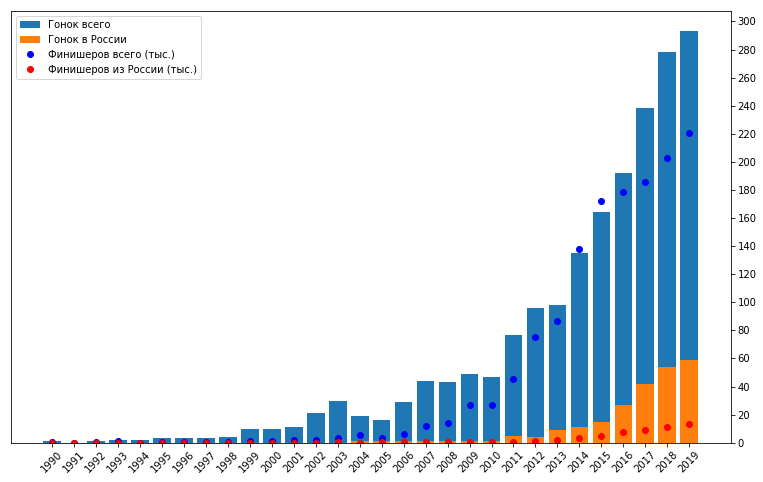 يمكن ملاحظة أن عدد السباقات والمشاركين في بداية الفترة وفي النهاية هو ببساطة لا يقاس. تبدأ الزيادة الكبيرة في إجمالي عدد السباقات في عام 2011 ، بينما يزداد عدد السباقات في روسيا أيضًا. علاوة على ذلك ، يمكن ملاحظة زيادة في عدد المشاركين في عام 2009. قد يشير هذا إلى زيادة الاهتمام بين المشاركين ، أي زيادة الطلب ، وبعد ذلك بعامين زاد العرض ، أي عدد مرات البدء. ومع ذلك ، لا تنس أن البيانات قد لا تكون كاملة وبعضها ، وربما العديد من السباقات مفقودة. بما في ذلك حقيقة أن مشروع جمع هذه البيانات بدأ فقط في عام 2010 ، والذي يمكن أن يفسر أيضًا قفزة كبيرة في الرسم البياني في هذه اللحظة بالذات. بما في ذلك ، لمزيد من التحليل ، قررت أن يستغرق السنوات العشر الماضية. هذه فترة طويلة إلى حد ما ،من أجل تتبع أي اتجاهات على مدى عدة سنوات ، في حين أنها قصيرة بما يكفي لعدم الوصول إلى هناك ، بشكل رئيسي المسابقات المهنية من 90s وأوائل 2000s.
يمكن ملاحظة أن عدد السباقات والمشاركين في بداية الفترة وفي النهاية هو ببساطة لا يقاس. تبدأ الزيادة الكبيرة في إجمالي عدد السباقات في عام 2011 ، بينما يزداد عدد السباقات في روسيا أيضًا. علاوة على ذلك ، يمكن ملاحظة زيادة في عدد المشاركين في عام 2009. قد يشير هذا إلى زيادة الاهتمام بين المشاركين ، أي زيادة الطلب ، وبعد ذلك بعامين زاد العرض ، أي عدد مرات البدء. ومع ذلك ، لا تنس أن البيانات قد لا تكون كاملة وبعضها ، وربما العديد من السباقات مفقودة. بما في ذلك حقيقة أن مشروع جمع هذه البيانات بدأ فقط في عام 2010 ، والذي يمكن أن يفسر أيضًا قفزة كبيرة في الرسم البياني في هذه اللحظة بالذات. بما في ذلك ، لمزيد من التحليل ، قررت أن يستغرق السنوات العشر الماضية. هذه فترة طويلة إلى حد ما ،من أجل تتبع أي اتجاهات على مدى عدة سنوات ، في حين أنها قصيرة بما يكفي لعدم الوصول إلى هناك ، بشكل رئيسي المسابقات المهنية من 90s وأوائل 2000s.rs = rs[(rs['year']>=2010)&(rs['year']<= 2019)]
 بالمناسبة ، انخفض 84٪ من السباقات و 94٪ من الإنهاءات خلال الفترة المحددة.
بالمناسبة ، انخفض 84٪ من السباقات و 94٪ من الإنهاءات خلال الفترة المحددة.يبدأ الهواة
لذا ، فإن الغالبية العظمى من المشاركين في البداية المختارة هم رياضيون هواة ، لذا يمكن الحصول على إحصائيات جيدة منهم. بصراحة ، كان هذا الأمر محل اهتمام رئيسي بالنسبة لي ، لأنني أشارك في مثل هذه البدايات ، ولكن في المستوى بعيدًا جدًا عن أبطال الألعاب الأولمبية. ومع ذلك ، من الواضح أن المسابقات المهنية جرت أيضًا في الفترة المختارة. لكي لا يتم مزج مؤشرات سباقات الهواة والمحترفين ، تقرر حذف هذا الأخير من الاعتبار. كيفية التعرف عليهم؟ بالسرعة. نحسبها. في إحدى المراحل الأولية لإعداد البيانات ، حددنا بالفعل نوع المسافة التي كانت في كل سباق - العدو ، الأولمبي ، النصف ، الحديد. لكل واحد منهم ، تم تحديد المسافة المقطوعة للمراحل بوضوح - السباحة وركوب الدراجات والجري. هذا هو 0.75 + 20 + 5 للسباق ، 1.5 + 40 + 10 للأولمبياد ، 1.9 + 90 + 21.1 للنصف و 3.8 + 180 + 42.2 للحديد. بالطبع ، في الواقع ، بالنسبة لأي نوع ، يمكن أن تختلف الأرقام الحقيقية من سباق إلى آخر مشروطًا بنسبة تصل إلى واحد بالمائة ، ولكن لا توجد معلومات حول هذا ، لذلك سنفترض أن كل شيء كان دقيقًا.rs['km'] = ''
rs.loc[rs['dist'] == 'sprint', 'km'] = 0.75+20+5
rs.loc[rs['dist'] == 'olympic', 'km'] = 1.5+40+10
rs.loc[rs['dist'] == 'half', 'km'] = 1.9+90+21.1
rs.loc[rs['dist'] == 'full', 'km'] = 3.8+180+42.2
نحسب متوسط السرعات القصوى لكل سباق. الحد الأقصى هنا يشير إلى متوسط سرعة الرياضي الذي فاز بالمركز الأول.for index, row in rs.iterrows():
e = row['event']
rd[e]['th'] = pd.TimedeltaIndex(rd[e]['result']).seconds/3600
rd[e]['v'] = rs.loc[i, 'km'] / rd[e]['th']
for index, row in rs.iterrows():
e = row['event']
rs.loc[index,'vmax'] = rd[e]['v'].max()
rs.loc[index,'vavg'] = rd[e]['v'].mean()
 حسنًا ، يمكنك أن ترى أن معظم السرعات التي تم تجميعها في أكوام ما بين حوالي 15 كم / ساعة و 30 كم / ساعة ، ولكن هناك عدد معين من القيم "الكونية" تمامًا. فرز حسب متوسط السرعة ونرى كم منهم:
حسنًا ، يمكنك أن ترى أن معظم السرعات التي تم تجميعها في أكوام ما بين حوالي 15 كم / ساعة و 30 كم / ساعة ، ولكن هناك عدد معين من القيم "الكونية" تمامًا. فرز حسب متوسط السرعة ونرى كم منهم:rs = rs.sort_values(by='vavg')
 هنا قمنا بتغيير المقياس ويمكننا تقدير النطاق بشكل أكثر دقة. بالنسبة للسرعات المتوسطة ، فهي تتراوح من حوالي 17 كم / ساعة إلى 27 كم / ساعة ، كحد أقصى - من 18 كم / ساعة إلى 32 كم / ساعة. بالإضافة إلى وجود "ذيول" بسرعات منخفضة جدًا وعالية جدًا. من المحتمل أن تتوافق السرعات المنخفضة مع المنافسات الشديدة مثل Norseman ، ويمكن أن تكون السرعات العالية في حالة السباحة الملغاة ، حيث كان هناك عداء سريع ، أو ببساطة بيانات خاطئة. نقطة أخرى مهمة هي الخطوة السلسة في منطقة 1200 على طول المحور X، وقيم أعلى لمتوسط السرعة بعده. هناك يمكنك أن ترى اختلافًا أقل بكثير بين المتوسط والسرعة القصوى مقارنة بالثلثي الأول من الرسم البياني. على ما يبدو ، هذه منافسة مهنية. لتمييزها بشكل أكثر وضوحًا ، نحسب نسبة السرعة القصوى إلى المتوسط. في المسابقات المهنية حيث لا يوجد أشخاص عشوائيين ولدى جميع المشاركين مستوى عالٍ جدًا من اللياقة البدنية ، يجب أن تكون هذه النسبة ضئيلة.
هنا قمنا بتغيير المقياس ويمكننا تقدير النطاق بشكل أكثر دقة. بالنسبة للسرعات المتوسطة ، فهي تتراوح من حوالي 17 كم / ساعة إلى 27 كم / ساعة ، كحد أقصى - من 18 كم / ساعة إلى 32 كم / ساعة. بالإضافة إلى وجود "ذيول" بسرعات منخفضة جدًا وعالية جدًا. من المحتمل أن تتوافق السرعات المنخفضة مع المنافسات الشديدة مثل Norseman ، ويمكن أن تكون السرعات العالية في حالة السباحة الملغاة ، حيث كان هناك عداء سريع ، أو ببساطة بيانات خاطئة. نقطة أخرى مهمة هي الخطوة السلسة في منطقة 1200 على طول المحور X، وقيم أعلى لمتوسط السرعة بعده. هناك يمكنك أن ترى اختلافًا أقل بكثير بين المتوسط والسرعة القصوى مقارنة بالثلثي الأول من الرسم البياني. على ما يبدو ، هذه منافسة مهنية. لتمييزها بشكل أكثر وضوحًا ، نحسب نسبة السرعة القصوى إلى المتوسط. في المسابقات المهنية حيث لا يوجد أشخاص عشوائيين ولدى جميع المشاركين مستوى عالٍ جدًا من اللياقة البدنية ، يجب أن تكون هذه النسبة ضئيلة.rs['vmdbva'] = rs['vmax']/rs['vavg']
rs = rs.sort_values(by='vmdbva')
 على هذا الرسم البياني ، يبرز الربع الأول بوضوح شديد: نسبة السرعة القصوى إلى المتوسط صغيرة ، متوسط السرعة العالية ، عدد قليل من المشاركين. هذه مسابقة مهنية. الخطوة على المنحنى الأخضر في مكان ما حول 1.2. سنترك السجلات فقط مع نسبة نسبة أكبر من 1.2 في عينتنا.
على هذا الرسم البياني ، يبرز الربع الأول بوضوح شديد: نسبة السرعة القصوى إلى المتوسط صغيرة ، متوسط السرعة العالية ، عدد قليل من المشاركين. هذه مسابقة مهنية. الخطوة على المنحنى الأخضر في مكان ما حول 1.2. سنترك السجلات فقط مع نسبة نسبة أكبر من 1.2 في عينتنا.rs = rs[rs['vmdbva'] > 1.2]
نقوم أيضًا بإزالة السجلات بسرعات منخفضة وعالية غير معتادة. في ما هي "الأرقام القياسية" العالمية الثلاثية لكل مسافة؟ نشر أوقات قياسية لتمرير مسافات مختلفة لعام 2019. إذا كنت تحسبها بسرعات متوسطة ، يمكنك أن ترى أنه لا يمكن أن يكون أعلى من 33 كم / ساعة حتى الأسرع. لذلك سنأخذ في الاعتبار البروتوكولات التي تكون فيها متوسط السرعات أعلى ، غير صالحة ، وإزالتها من الاعتبار.rs = rs[(rs['vavg'] > 17)&(rs['vmax'] < 33)]
إليك ما تبقى:
 الآن كل شيء يبدو متجانسًا تمامًا ولا يثير أسئلة. نتيجة لكل هذا التحديد ، فقدنا 777 من بروتوكولات 1922 ، أو 40٪. في الوقت نفسه ، لم ينخفض إجمالي عدد اللمسات النهائية كثيرًا - فقط 13 ٪.لذا ، هناك 1145 سباقا متبقيا مع 1،231،772 نهائي. أصبحت هذه العينة مادة لتحليلي وتصوري.
الآن كل شيء يبدو متجانسًا تمامًا ولا يثير أسئلة. نتيجة لكل هذا التحديد ، فقدنا 777 من بروتوكولات 1922 ، أو 40٪. في الوقت نفسه ، لم ينخفض إجمالي عدد اللمسات النهائية كثيرًا - فقط 13 ٪.لذا ، هناك 1145 سباقا متبقيا مع 1،231،772 نهائي. أصبحت هذه العينة مادة لتحليلي وتصوري.الجزء 5. التحليل والتصور
في هذا العمل ، كان التحليل والتصور الصحيح أبسط الأجزاء. رأس جبل الجليد ، والذي كان الجزء تحت الماء هو مجرد إعداد البيانات. كان التحليل ، في الواقع ، عملية حسابية بسيطة على سلسلة الباندا ، وحساب المتوسطات ، والتصفية - كل هذا يتم عن طريق أدوات الباندا الابتدائية والشفرة أعلاه مليئة بالأمثلة. في المقابل ، تم عمل التصور بشكل أساسي باستخدام matplotlib الأكثر القياسية . تستخدم مؤامرة ، بار ، فطيرة . ولكن في بعض الأماكن ، كان عليّ أن العبث بتوقيعات المحاور ، في حالة التواريخ والرسوم التوضيحية ، ولكن هذا ليس شيئًا يعتمد على وصف مفصل هنا. الشيء الوحيد الذي يستحق الحديث عنه هو عرض البيانات الجغرافية. على الأقل ليس كذلكماتبلوتليب .البيانات الجغرافية
لكل سباق لدينا معلومات حول المكان. في البداية ، باستخدام geopy ، قمنا بحساب الإحداثيات لكل موقع. تقام العديد من السباقات سنويا في نفس المكان. أداة سهلة الاستخدام للغاية لعرض البيانات الجغرافية في الثعبان هي folium . وإليك كيف يعمل:import folium
m = folium.Map()
folium.Marker(['55.7522200', '37.6155600'], popup='').add_to(m)
ونحصل على خريطة تفاعلية مباشرة في كمبيوتر محمول المشتري. الآن ، لبياناتنا. أولاً ، سنبدأ عمودًا جديدًا من مجموعة إحداثياتنا:
الآن ، لبياناتنا. أولاً ، سنبدأ عمودًا جديدًا من مجموعة إحداثياتنا:rs['coords'] = rs['latitude'].astype(str) + ', ' + rs['longitude'].astype(str)
إحداثيات فريدة من احداثيات هي 291. ومواقع فريدة من نوعها في الموضع هم 324، مما يعني أن بعض الأسماء مختلفة قليلا، بينما في الوقت نفسه أنها تتوافق مع نفس النقطة. هذا ليس مخيفًا ، سننظر في التفرد من خلال الحبال . نحن نحسب عدد الأحداث التي مرت طوال الوقت في كل موقع (بإحداثيات فريدة):vc = rs['coords'].value_counts()
vc
Out:
43.7009358, 7.2683912 22
43.5854823, 39.723109 20
29.03970805, -13.636291 16
47.3723941, 8.5423328 16
59.3110918, 24.420907 15
51.0834196, 10.4234469 15
54.7585694, 38.8818137 14
20.4317585, -86.9202745 13
52.3727598, 4.8936041 12
41.6132925, 2.6576102 12
... ...
الآن قم بإنشاء خريطة ، وإضافة علامات عليها في شكل دوائر ، والتي يعتمد نصف قطرها على عدد الأحداث التي تقام على الموقع. أضف علامات باسم الموقع إلى العلامات.m = folium.Map(location=[25,10], zoom_start=2)
for c in rs['coords'].unique():
row = [r[1] for r in rs.iterrows() if r[1]['coords'] == c][0]
folium.Circle([row['latitude'], row['longitude']],
popup=(row['location']+'\n('+str(vc[c])+' races)'),
radius = 10000*int(vc[c]),
color='darkorange',
fill=True,
stroke=True,
weight=1).add_to(m)
منجز. يمكنك رؤية النتيجة:
تقدم المشاركين
في الواقع ، بالإضافة إلى التوجيه ، كان العمل على جدول زمني آخر غير تافه أيضًا. هذا هو أحدث رسم بياني لتقدم المشاركين. ها هي: دعنا نحللها ، وفي نفس الوقت سأعطي كود العرض ، كمثال على استخدام matplotlib :
دعنا نحللها ، وفي نفس الوقت سأعطي كود العرض ، كمثال على استخدام matplotlib :fig = plt.figure()
fig.set_size_inches(10, 6)
ax = fig.add_axes([0,0,1,1])
b = ax.bar(exp,numrecs, color = 'navajowhite')
ax1 = ax.twinx()
for i in range(len(exp_samp)):
ax1.plot(exp_samp[i], vproc_samp[i], '.')
p, = ax1.plot(exp, vpm, 'o-',markersize=8, linewidth=2, color='C0')
for i in range(len(exp)):
if i < len(exp)-1 and (vpm[i] < vpm[i+1]):
ax1.text(x = exp[i]+0.1, y = vpm[i]-0.2, s = '{0:3.1f}%'.format(vpm[i]),size=12)
else:
ax1.text(x = exp[i]+0.1, y = vpm[i]+0.1, s = '{0:3.1f}%'.format(vpm[i]),size=12)
ax.legend((b,p), (' ', ''),loc='center right')
ax.set_xlabel(' ')
ax.set_ylabel('')
ax1.set_ylabel('% ')
ax.set_xticks(np.arange(1, 11, step=1))
ax.set_yticks(np.arange(0, 230000, step=25000))
ax1.set_ylim(97.5,103.5)
ax.yaxis.set_label_position("right")
ax.yaxis.tick_right()
ax1.yaxis.set_label_position("left")
ax1.yaxis.tick_left()
plt.show()
الآن حول كيفية حساب البيانات له. أولاً ، كان عليك اختيار أسماء المشاركين الذين أنهوا على الأقل في سباقين ، وفي سنوات تقويمية مختلفة ، وفي الوقت نفسه ليسوا محترفين.أولاً ، لكل بروتوكول ، املأ عمودًا جديدًا يسمى التاريخ ، والذي سيشير إلى تاريخ السباق. وسوف نحتاج أيضا بعد عام من هذا التاريخ، وسوف نبذل عمود العام . نظرًا لأننا سنقوم بتحليل سرعة كل رياضي بالنسبة لمتوسط السرعة في السباق ، فإننا نحسب هذه السرعة على الفور في العمود الجديد vproc - السرعة كنسبة مئوية من المتوسط.for index, row in rs.iterrows():
e = row['event']
rd[e]['date'] = row['date']
rd[e]['year'] = row['year']
rd[e]['vproc'] = 100 * rd[e]['v'] / rd[e]['v'].mean()
إليك ما تبدو عليه البروتوكولات الآن: بعد ذلك ، اجمع جميع البروتوكولات في إطار بيانات واحد.' Sprint 2019'ar = pd.concat(rd)
لكل مشارك ، سنترك إدخال واحد فقط في كل سنة تقويمية:ar1 = ar.drop_duplicates(subset = ['name','year'], keep='first')
بعد ذلك ، من جميع الأسماء الفريدة لهذه الإدخالات ، نجد تلك التي تحدث مرتين على الأقل:nvc = ar1['name'].value_counts()
names = list(nvc[nvc > 1].index)
يوجد 219،890 منهم دعنا نزيل أسماء الرياضيين المحترفين من هذه القائمة:pro_names = ar[ar['group'].isin(['MPRO','FPRO'])]['name'].unique()
names = list(set(names) - set(pro_names))
وكذلك أسماء الرياضيين الذين بدأوا في الأداء قبل عام 2010. للقيام بذلك ، قم بتحميل البيانات التي تم حفظها قبل أخذ عينات على مدى السنوات العشر الماضية. ضعهم في كائنات rsa (ملخص الأجناس كلها) و rda (تفاصيل السباق كلها).rdo = {}
for e in rda:
if rsa[rsa['event'] == e]['year'].iloc[0] < 2010:
rdo[e] = rda[e]
aro = pd.concat(rdo)
old_names = aro['name'].unique()
names = list(set(names) - set(old_names))
وأخيرًا ، نجد أسماء تحدث أكثر من مرة في نفس اليوم. وبالتالي ، فإننا نقلل من وجود الاسماء الكاملة في عينتنا.namesakes = ar[ar.duplicated(subset = ['name','date'], keep = False)]['name'].unique()
names = list(set(names) - set(namesakes))
إذن هناك 198،075 اسم متبقي. من مجموعة البيانات بأكملها ، نختار فقط السجلات التي تحتوي على الأسماء:ars = ar[ar['name'].isin(names)]
الآن ، لكل سجل ، تحتاج إلى تحديد العام الذي تقابله في مهنة الرياضي - الأول أو الثاني أو الثالث أو العاشر. نقوم بعمل حلقة بكل الأسماء وحسابها.ars['exp'] = ''
for n in names:
ind = ars[ars['name'] == n].index
yos = ars.loc[ind, 'year'].min()
ars.loc[ind, 'exp'] = ars.loc[ind, 'year'] - yos + 1
فيما يلي مثال على ما حدث: على ما يبدو ، لا تزال الأسماء نفسها قائمة. هذا أمر متوقع ، لكنه ليس مخيفًا ، لأننا سنحسب متوسط كل شيء ، ولا ينبغي أن يكون هناك الكثير. بعد ذلك ، نبني مصفوفات للرسم البياني:exp = []
vpm = []
numrecs = []
for x in range(ars['exp'].min(), ars['exp'].max() + 1):
exp.append(x)
vpm.append(ars[ars['exp'] == x]['vproc'].mean())
numrecs.append(len(ars[ars['exp'] == x]))
هذا كل شيء ، هناك أساس: الآن ، لتزيينه بنقاط تتوافق مع نتائج محددة ، سنختار 1000 اسم عشوائي وننشئ صفائف مع النتائج الخاصة بها.
الآن ، لتزيينه بنقاط تتوافق مع نتائج محددة ، سنختار 1000 اسم عشوائي وننشئ صفائف مع النتائج الخاصة بها.names_samp = random.sample(names,1000)
ars_samp = ars[ars['name'].isin(names_samp)]
ars_samp = ars_samp.reset_index(drop = True)
exp_samp = []
vproc_samp = []
for n in names_samp:
nr = ars_samp[ars_samp['name'] == n]
nr = nr.sort_values('exp')
exp_samp.append(list(nr['exp']))
vproc_samp.append(list(nr['vproc']))
أضف حلقة لبناء الرسوم البيانية من هذه العينة العشوائية.for i in range(len(exp_samp)):
ax1.plot(exp_samp[i], vproc_samp[i], '.')
الآن كل شيء جاهز: بشكل عام ، ليس صعبًا. ولكن هناك مشكلة واحدة. لحساب إكسب خبرة في الدورة، وجميع الأسماء، والتي هي تقريبا 200 ألف، واتخاذ ثماني ساعات. اضطررت إلى تصحيح الخوارزمية على عينات صغيرة ، ثم إجراء العملية الحسابية ليلا. من حيث المبدأ ، يمكن القيام بذلك مرة واحدة ، ولكن إذا وجدت نوعًا من الخطأ أو تريد تغيير شيء ما ، وتحتاج إلى إعادة سرده مرة أخرى ، فإنه يبدأ في الضغط. وهكذا ، عندما كنت سأنشر تقريرًا في المساء ، اتضح أنه من الضروري إعادة سرد كل شيء مرة أخرى. لم يكن الانتظار حتى الصباح جزءًا من خططي ، وبدأت أبحث عن طريقة لجعل الحساب أسرع. قررت موازية.وجدت في مكان ما طريقة للقيام بذلك مع المعالجة المتعددة. من أجل العمل على Windows ، كنا بحاجة إلى وضع المنطق الرئيسي لكل مهمة متوازية في ملف worker.py منفصل :
بشكل عام ، ليس صعبًا. ولكن هناك مشكلة واحدة. لحساب إكسب خبرة في الدورة، وجميع الأسماء، والتي هي تقريبا 200 ألف، واتخاذ ثماني ساعات. اضطررت إلى تصحيح الخوارزمية على عينات صغيرة ، ثم إجراء العملية الحسابية ليلا. من حيث المبدأ ، يمكن القيام بذلك مرة واحدة ، ولكن إذا وجدت نوعًا من الخطأ أو تريد تغيير شيء ما ، وتحتاج إلى إعادة سرده مرة أخرى ، فإنه يبدأ في الضغط. وهكذا ، عندما كنت سأنشر تقريرًا في المساء ، اتضح أنه من الضروري إعادة سرد كل شيء مرة أخرى. لم يكن الانتظار حتى الصباح جزءًا من خططي ، وبدأت أبحث عن طريقة لجعل الحساب أسرع. قررت موازية.وجدت في مكان ما طريقة للقيام بذلك مع المعالجة المتعددة. من أجل العمل على Windows ، كنا بحاجة إلى وضع المنطق الرئيسي لكل مهمة متوازية في ملف worker.py منفصل :import pickle as pkl
def worker(args):
names = args[0]
ars=args[1]
num=args[2]
ars = ars.sort_values(by='name')
ars = ars.reset_index(drop=True)
for n in names:
ind = ars[ars['name'] == n].index
yos = ars.loc[ind, 'year'].min()
ars.loc[ind, 'exp'] = ars.loc[ind, 'year'] - yos + 1
with open(r'D:\tri\par\prog' + str(num) + '.pkl', 'wb') as f:
pkl.dump(ars,f)
يتم نقل الإجراء إلى جزء من أسماء الأسماء ، الجزء datafreyma ar فقط مع هذه الأسماء ، والرقم التسلسلي للمهام المتوازية - num . تتم كتابة الحسابات في إطار البيانات ، وفي النهاية ، تتم كتابة إطار البيانات في الملف. في الكمبيوتر المحمول الذي يستدعي هذا العامل ، نقوم بإعداد الحجج وفقًا لذلك:num_proc = 8
args = []
for i in range(num_proc):
step = int(len(names_samp)/num_proc) + 1
names_i = names_samp[i*step:min((i+1)*step, len(names_samp))]
ars_i = ars[ars['name'].isin(names_i)]
args.append([names_i, ars_i, i])
نبدأ الحوسبة المتوازية:from multiprocessing import Pool
import workers
if __name__ == '__main__':
p=Pool(processes = num_proc)
p.map(workers.worker,args)
وفي النهاية نقرأ النتائج من الملفات ونجمع القطع مرة أخرى في إطار البيانات بالكامل:ars=pd.DataFrame(columns = ars.columns)
for i in range(num_proc):
with open(r'D:\tri\par\prog'+str(i)+'.pkl', 'rb') as f:
arsi = pkl.load(f)
print(len(arsi))
ars = pd.concat([ars, arsi])
وبالتالي ، كان من الممكن الحصول على تسارع 40 مرة ، وبدلاً من 8 ساعات لإكمال الحساب في 11 دقيقة ونشر تقرير في ذلك المساء. في الوقت نفسه ، تعلمت كيفية موازاة الثعبان ، أعتقد أنه سيكون مفيدًا. هنا ، تحول التسارع إلى أكثر من 8 أضعاف عدد النوى ، نظرًا لأن كل مهمة تستخدم إطار بيانات صغيرًا ، مما يجعل البحث أسرع. من حيث المبدأ ، يمكن تسريع الحسابات المتسلسلة بهذه الطريقة ، ولكن السؤال هو ، كيف تخمن؟ومع ذلك ، لم أستطع الهدوء ، وحتى بعد النشر كنت أفكر باستمرار في كيفية إجراء الحساب باستخدام المتجه ، أي العمليات على أعمدة كاملة من إطار بيانات سلسلة الباندا. هذه الحسابات هي ترتيب حجم أسرع من أي دورات متوازية ، حتى على الكتلة الفائقة. وخرج. اتضح أنه لكل اسم للعثور على عام بداية المهنة ، من الضروري على العكس - لكل عام للعثور على المشاركين الذين بدأوا فيه. للقيام بذلك ، يجب عليك أولاً تحديد جميع الأسماء للسنة الأولى من نموذجنا ، وهذا هو عام 2010. وبناءً على ذلك ، نقوم بمعالجة جميع السجلات بهذه الأسماء باستخدام هذا العام. بعد ذلك ، نأخذ العام المقبل - 2011.مرة أخرى نجد جميع الأسماء التي تحتوي على إدخالات هذا العام ، لكننا نأخذ منها فقط الأسماء غير المجهزة ، أي تلك التي لم يتم الوفاء بها في عام 2010 وتتم معالجتها باستخدامها في عام 2011. وهكذا بالنسبة لبقية العام. نفس الدورة ، ولكن ليس مائتي ألف تكرار ، ولكن تسعة في المجموع.for y in range(ars['year'].min(),ars['year'].max()):
arsynp = ars[(ars['exp'] == '') & (ars['year'] == y)]
namesy = arsynp['name'].unique()
ind = ars[ars['name'].isin(namesy)].index
ars.loc[ind, 'exp'] = ars.loc[ind,'year'] - y + 1
تنجز هذه الدورة في بضع ثوانٍ فقط. وتبين أن الرمز أكثر إيجازًا بكثير.استنتاج
حسنًا ، أخيرًا ، تم إنجاز الكثير من العمل. بالنسبة لي ، كان هذا ، في الواقع ، أول مشروع من نوعه. عندما أخذتها ، كان الهدف الرئيسي هو التدرب على استخدام الثعبان ومكتباته. هذه المهمة أكثر من أن تكتمل. وكانت النتائج نفسها قابلة للعرض. ما هي النتائج التي استخلصتها لنفسي عند الانتهاء؟أولاً: البيانات غير كاملة. ربما يكون هذا صحيحًا لأي مهمة تحليل تقريبًا. حتى إذا كانت منظمة تمامًا ، وغالبًا ما يحدث ذلك بشكل مختلف ، فأنت بحاجة إلى الاستعداد للتعامل معها قبل البدء في حساب الخصائص والبحث عن الاتجاهات - العثور على الأخطاء ، والقيم المتطرفة ، والانحرافات عن المعايير ، وما إلى ذلك.ثانيًا:أي مهمة لها حل. هذا أشبه بالشعار ، لكنه في كثير من الأحيان. الأمر فقط أن هذا الحل قد لا يكون واضحًا جدًا ولا يكمن في البيانات نفسها ، ولكن خارج الصندوق ، إذا جاز التعبير. كمثال - معالجة أسماء المشاركين الموصوفة أعلاه ، أو كشط موقع الويب.ثالثا: معرفة المجال أمر حاسم. سيجعل هذا من الممكن إعداد البيانات بشكل أفضل ، وإزالة البيانات غير الصحيحة أو غير القياسية الواضحة ، وتجنب أخطاء التفسير ، واستخدام المعلومات غير الموجودة في البيانات ، على سبيل المثال ، المسافات في هذا المشروع ، وتقديم النتائج في النموذج المقبول في المجتمع ، مع تجنب الاستنتاجات الغبية غير الصحيحة.رابعاً: العمل في الثعبانهناك مجموعة غنية من الأدوات. في بعض الأحيان يبدو أنه يجدر التفكير في شيء ما ، تبدأ في البحث - إنه موجود بالفعل. هذا رائع! شكرًا جزيلاً للمبدعين على هذه المساهمة ، خاصةً للأدوات التي جاءت في متناول اليد هنا: السيلينيوم من أجل الكشط ، pycountry لتحديد رمز البلد وفقًا لمعيار ISO ، رموز البلد (datahub) للرموز الأولمبية ، geopy لتحديد الإحداثيات في العنوان ، folium - لتصور البيانات الجغرافية وتخمين الجنس - لتحليل الأسماء والمعالجة المتعددة - للحوسبة المتوازية و matplotlib و numpy ، وبالطبع الباندا - دون أن يكون هناك مكان للذهاب إليه.خامساً: التوجه إلى كل شيء. من المهم للغاية أن تكون قادرًا على استخدام أدوات الباندا المدمجة ، فهي فعالة للغاية. أفترض ، في معظم الحالات ، عندما يتم قياس عدد السجلات بدءًا من عشرات الآلاف ، تصبح هذه المهارة ضرورية ببساطة.السادس:معالجة البيانات فكرة سيئة. من الضروري محاولة تقليل أي تدخل يدوي - أولاً ، لا يتم قياسه ، أي عندما تزيد كمية البيانات عدة مرات ، سيزداد وقت المعالجة اليدوية إلى قيم غير مقبولة ، وثانيًا ، سيكون هناك تكرار متكرر - ستنسى شيئًا ، سترتكب خطأ في مكان ما . كل شيء برمجي فقط ، إذا كان هناك شيء خارج المعيار العام لحل البرنامج ، حسنًا ، لا بأس ، يمكنك التضحية بجزء من البيانات ، فسيظل هناك المزيد من الإيجابيات.سابعا:يجب حفظ الكود في حالة صالحة للعمل. يبدو أنه يمكن أن يكون أكثر وضوحا! في الواقع ، عندما يتعلق الأمر بالتعليمات البرمجية الخاصة بك ، والتي تهدف إلى نشر نتائج هذا الرمز ، فكل شيء ليس صارمًا هنا. لقد عملت في Jupiter Notebooks ، وهذه البيئة ، في رأيي ، لا تحتاج إلى إنشاء منتجات برمجية متكاملة. تم تكوينه لإطلاق كل سطر على حدة ، وهذا له مزاياه - إنه سريع: التطوير والتصحيح والتنفيذ في نفس الوقت. ولكن غالبًا ما يكون الإغراء هو مجرد تعديل سطر ما والحصول بسرعة على نتيجة جديدة ، بدلاً من التكرار أو الالتفاف في الدفاع. بالطبع ، يجب تجنب مثل هذا الإغراء. يجب أن يسعى المرء للحصول على رمز جيد ، حتى "لنفسه" ، على الأقل لأنه حتى في عمل تحليلي واحد ، يتم الإطلاق عدة مرات ، ومن المؤكد أن استثمار الوقت في البداية سيؤتي ثماره في المستقبل. ويمكنك إضافة اختبارات ، حتى على أجهزة الكمبيوتر المحمولة ، في شكل تدقيق للمعلمات الهامة ورمي الاستثناءات - إنها مفيدة جدًا.ثامناً: وفر أكثر. في كل خطوة ، قمت بحفظ نسخة جديدة من الملف. في المجموع ، تبين أنها حوالي 10. هذا أمر مريح ، لأنه عندما يتم اكتشاف خطأ ، فإنه يساعد على التحديد السريع في أي مرحلة حدث. بالإضافة إلى ذلك ، قمت بحفظ بيانات المصدر في الأعمدة المميزة بعلامة خام - وهذا يسمح لك بالتحقق من النتيجة بسرعة ورؤية التناقض.تاسع:من الضروري قياس استثمار الوقت والنتيجة. في بعض الأماكن ، استغرقت وقتًا طويلاً جدًا لاستعادة البيانات ، والتي تشكل جزءًا من نسبة مئوية من الإجمالي. في الواقع ، هذا لا معنى له ، كان عليك فقط التخلص منهم ، وهذا كل شيء. وسأفعل ذلك إذا كان مشروعًا تجاريًا ، وليس تدريبًا ذاتيًا. هذا سيسمح لك بالحصول على النتيجة بشكل أسرع. يعمل مبدأ باريتو هنا - يتم تحقيق 80 ٪ من النتيجة في 20 ٪ من الوقت.وآخر واحد:العمل في مثل هذه المشاريع يوسع الآفاق بشكل كبير. عن طيب خاطر ، تتعلم شيئًا جديدًا - على سبيل المثال ، أسماء دول غريبة - مثل جزر بيتكيرن ، أن رمز ISO لسويسرا هو CHE ، من اللاتينية "Confoederatio Helvetica" ، ما هو الاسم الإسباني ، حسنًا ، في الواقع عن الترياتلون نفسه - السجلات ، أصحابها ، أماكن السباقات ، تاريخ الأحداث وما إلى ذلك.ربما يكفي. هذا كل شئ. شكرا لكل من قرأ حتى النهاية!