يكشف الوصول إلى GPU من Java قوة هائلة. يصف كيفية عمل GPU وكيفية الوصول من Java.برمجة GPU هي عالم عالي لمبرمجي Java. هذا أمر مفهوم لأن مهام Java العادية ليست مناسبة لوحدة معالجة الرسومات. ومع ذلك ، فإن GPUs لديها أداء قوي ، لذلك دعونا نستكشف قدراتها.من أجل جعل الموضوع متاحًا ، سأقضي بعض الوقت في شرح بنية وحدة معالجة الرسومات جنبًا إلى جنب مع القليل من التاريخ الذي سيسهل الانغماس في برمجة الحديد.بمجرد أن ظهرت لي الاختلافات بين GPU وحوسبة وحدة المعالجة المركزية (CPU) ، سأوضح كيفية استخدام GPU في عالم Java. أخيرًا ، سأصف الأطر والمكتبات الرئيسية المتاحة لكتابة كود Java وتشغيلها على GPU ، وسأقدم بعض الأمثلة على الكود.القليل من الخلفية
تم نشر GPU لأول مرة بواسطة NVIDIA في عام 1999. وهو معالج خاص مصمم لمعالجة البيانات الرسومية قبل نقلها إلى الشاشة. في كثير من الحالات ، يسمح هذا ببعض الحسابات لتفريغ وحدة المعالجة المركزية ، وبالتالي تحرير موارد وحدة المعالجة المركزية التي تسرع هذه الحسابات غير المحملة. والنتيجة هي أنه يمكن معالجة المدخلات الكبيرة وتقديمها بدقة إخراج أعلى ، مما يجعل العرض المرئي أكثر جاذبية ومعدل الإطار أكثر سلاسة.جوهر المعالجة ثنائية الأبعاد / ثلاثية الأبعاد هو بشكل رئيسي في معالجة المصفوفات ، ويمكن التحكم في ذلك باستخدام نهج موزع. ما هو النهج الفعال لمعالجة الصور؟ للإجابة على ذلك ، دعنا نقارن بنية وحدة المعالجة المركزية القياسية (كما هو موضح في الشكل 1.) ووحدة معالجة الرسومات.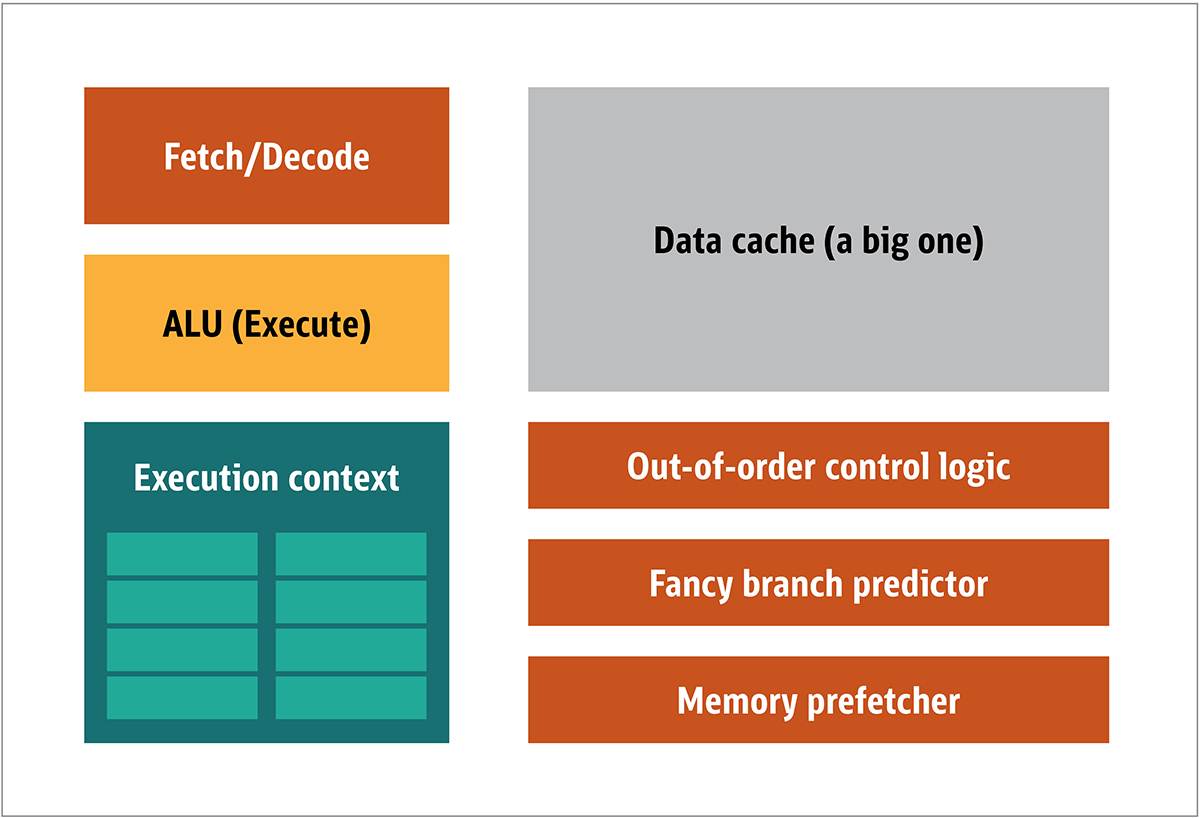 تين. 1. كتل بنية وحدة المعالجة المركزيةفي وحدة المعالجة المركزية ، فإن عناصر المعالجة الفعلية - السجلات ووحدة المنطق الحسابي (ALU) وسياقات التنفيذ - ليست سوى أجزاء صغيرة من النظام بأكمله. لتسريع المدفوعات غير المنتظمة التي تأتي في ترتيب غير متوقع ، هناك ذاكرة تخزين مؤقت كبيرة وسريعة ومكلفة ؛ أنواع مختلفة من جامعي. والمتنبئين الفروع.لا تحتاج إلى كل هذا على GPU ، لأنه يتم تلقي البيانات بطريقة يمكن التنبؤ بها ، وتقوم GPU بتنفيذ مجموعة محدودة جدًا من العمليات على البيانات. وبالتالي ، من الممكن جعلها صغيرة جدًا ومعالج غير مكلف مع بنية كتلة مماثلة لتلك المبينة في الشكل. 2.
تين. 1. كتل بنية وحدة المعالجة المركزيةفي وحدة المعالجة المركزية ، فإن عناصر المعالجة الفعلية - السجلات ووحدة المنطق الحسابي (ALU) وسياقات التنفيذ - ليست سوى أجزاء صغيرة من النظام بأكمله. لتسريع المدفوعات غير المنتظمة التي تأتي في ترتيب غير متوقع ، هناك ذاكرة تخزين مؤقت كبيرة وسريعة ومكلفة ؛ أنواع مختلفة من جامعي. والمتنبئين الفروع.لا تحتاج إلى كل هذا على GPU ، لأنه يتم تلقي البيانات بطريقة يمكن التنبؤ بها ، وتقوم GPU بتنفيذ مجموعة محدودة جدًا من العمليات على البيانات. وبالتالي ، من الممكن جعلها صغيرة جدًا ومعالج غير مكلف مع بنية كتلة مماثلة لتلك المبينة في الشكل. 2.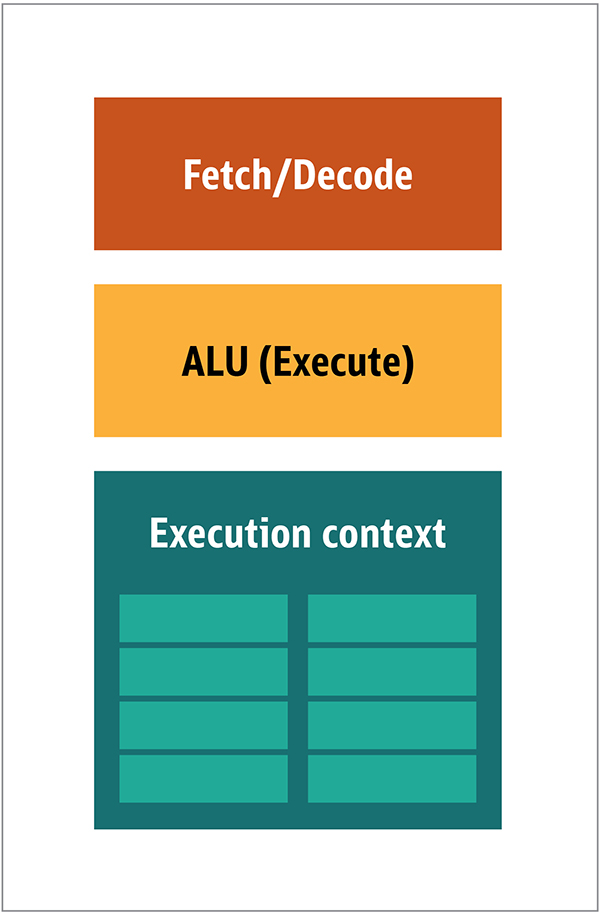 الشكل. 2. كتلة العمارة لنواة GPU بسيطةنظرًا لأن مثل هذه المعالجات أرخص والبيانات التي تتم معالجتها بها في أجزاء متوازية ، فمن السهل جعل العديد منها يعمل بالتوازي. تم تصميمه بالإشارة إلى تعليمات متعددة أو بيانات متعددة أو MIMD (تنطق "mim-dee").يعتمد النهج الثاني على حقيقة أنه غالبًا ما يتم تطبيق تعليمات واحدة على أجزاء متعددة من البيانات. يُعرف هذا بإرشادات فردية أو بيانات متعددة أو SIMD (تُنطق "sim-dee"). في هذا التصميم ، تحتوي وحدة معالجة رسومات واحدة على وحدات ALU متعددة وسياقات تنفيذ ، ويتم نقل مناطق صغيرة إلى بيانات السياق المشتركة ، كما هو موضح في الشكل 3.
الشكل. 2. كتلة العمارة لنواة GPU بسيطةنظرًا لأن مثل هذه المعالجات أرخص والبيانات التي تتم معالجتها بها في أجزاء متوازية ، فمن السهل جعل العديد منها يعمل بالتوازي. تم تصميمه بالإشارة إلى تعليمات متعددة أو بيانات متعددة أو MIMD (تنطق "mim-dee").يعتمد النهج الثاني على حقيقة أنه غالبًا ما يتم تطبيق تعليمات واحدة على أجزاء متعددة من البيانات. يُعرف هذا بإرشادات فردية أو بيانات متعددة أو SIMD (تُنطق "sim-dee"). في هذا التصميم ، تحتوي وحدة معالجة رسومات واحدة على وحدات ALU متعددة وسياقات تنفيذ ، ويتم نقل مناطق صغيرة إلى بيانات السياق المشتركة ، كما هو موضح في الشكل 3.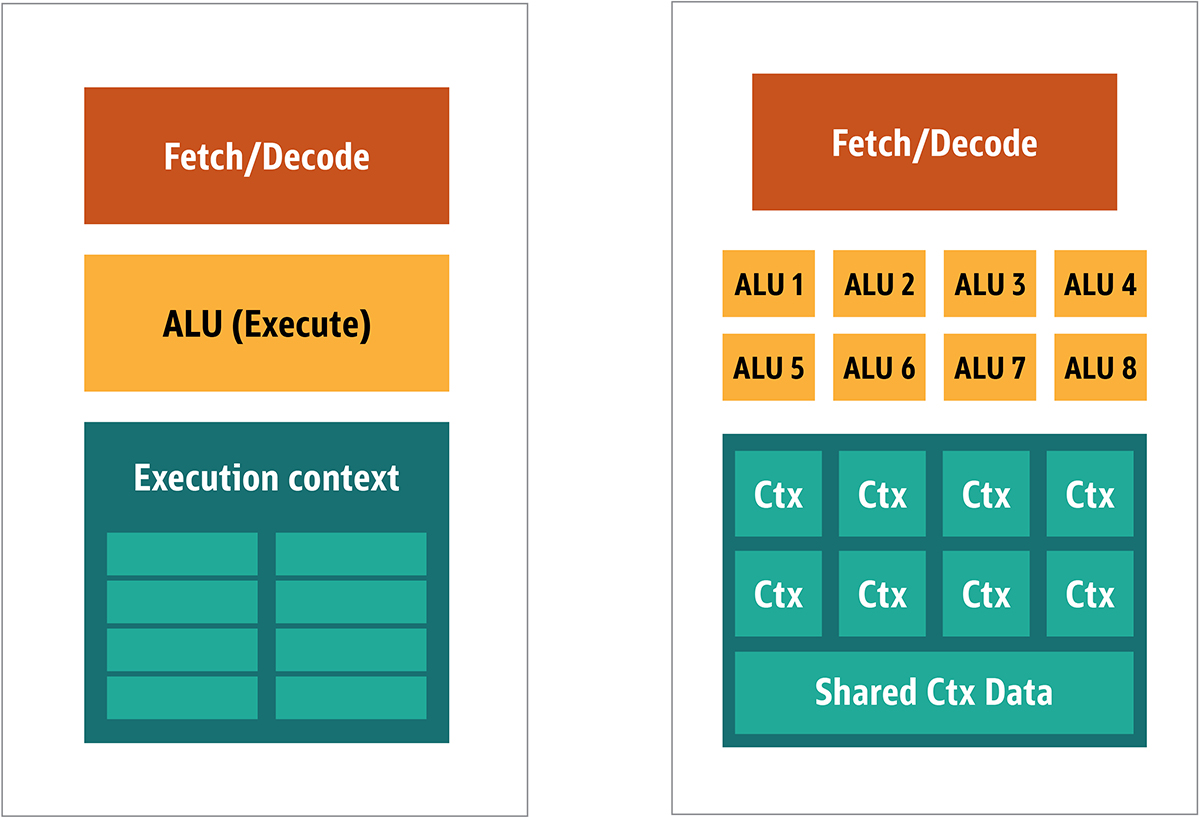 الشكل. 3. مقارنة بين بنية نمط MIMD لكتل GPU (من اليسار) ، مع تصميم SIMD (من اليمين)يوفر خلط معالجة SIMD و MIMD الحد الأقصى لعرض النطاق الترددي الذي سأتجاوزه. في هذا التصميم ، لديك العديد من معالجات SIMD تعمل بالتوازي ، كما في الشكل 4.
الشكل. 3. مقارنة بين بنية نمط MIMD لكتل GPU (من اليسار) ، مع تصميم SIMD (من اليمين)يوفر خلط معالجة SIMD و MIMD الحد الأقصى لعرض النطاق الترددي الذي سأتجاوزه. في هذا التصميم ، لديك العديد من معالجات SIMD تعمل بالتوازي ، كما في الشكل 4. الشكل. 4. العمل معالجات SIMD متعددة بالتوازي. هناك 16 نواة مع 128 وحدة ALUنظرًا لأن لديك مجموعة من المعالجات الصغيرة والبسيطة ، يمكنك برمجتها للحصول على تأثير خاص في الإخراج.
الشكل. 4. العمل معالجات SIMD متعددة بالتوازي. هناك 16 نواة مع 128 وحدة ALUنظرًا لأن لديك مجموعة من المعالجات الصغيرة والبسيطة ، يمكنك برمجتها للحصول على تأثير خاص في الإخراج.تشغيل البرامج على GPU
كانت معظم التأثيرات الرسومية المبكرة في الألعاب عبارة عن برامج صغيرة مشفرة في الواقع تعمل على وحدة معالجة الرسومات ويتم تطبيقها على تدفقات البيانات من وحدة المعالجة المركزية.كان هذا واضحًا ، حتى عندما كانت الخوارزميات ذات الترميز الصلب غير كافية ، خاصة في تصميم الألعاب ، حيث تعد التأثيرات المرئية أحد الاتجاهات السحرية الرئيسية. واستجابة لذلك ، فتح البائعون الكبار إمكانية الوصول إلى GPU ، ومن ثم يمكن لمطوري الجهات الخارجية برمجتها.كان النهج النموذجي هو كتابة برنامج صغير يسمى تظليل في لغة خاصة (عادة نوع فرعي من C) وتجميعها باستخدام مترجمين خاصين للعمارة المطلوبة. تم اختيار مصطلح تظليل لأن الظلال غالبًا ما تستخدم للتحكم في تأثيرات الضوء والظل ، ولكن هذا لا يعني أنه يمكنهم التحكم في التأثيرات الخاصة الأخرى.كان لكل بائع GPU لغة برمجة وبنية أساسية خاصة به لإنشاء تظليل لهندسته. على هذا النهج ، تم إنشاء العديد من المنصات.أهمها:- DirectCompute: لغة تظليل / واجهة برمجة تطبيقات خاصة لـ Microsoft والتي تعد جزءًا من Direct3D ، بدءًا من DirectX 10.
- AMD FireStream: تقنيات ATI / Radeon الخاصة التي عفا عليها الزمن من قبل AMD.
- OpenACC: اتحاد متعدد البائعين ، حل الحوسبة المتوازية
- ++ AMP: Microsoft C++
- CUDA: Nvidia,
- OpenL: , Apple, Khronos Group
في معظم الأحيان ، يكون العمل مع وحدة معالجة الرسومات هو برمجة منخفضة المستوى. من أجل جعل هذا أكثر قابلية للفهم للمطورين ، للتشفير ، تم توفير العديد من الملخصات. أشهرها DirectX ، من Microsoft ، و OpenGL ، من مجموعة Khronos Group. هذه هي واجهات برمجة التطبيقات لكتابة رمز عالي المستوى ، والتي يمكن بعد ذلك تبسيطها لوحدة معالجة الرسومات ، بشكل أكثر دلالة ، للمبرمج.على حد علمي ، لا توجد بنية أساسية لـ Java لـ DirectX ، ولكن هناك حل جيد لـ OpenGL. بدأ JSR 231 في عام 2002 وهو موجه لمبرمجي GPU ، ولكن تم التخلي عنه في عام 2008 ويدعم OpenGL 2.0 فقط.يستمر دعم OpenGL في مشروع JOCL المستقل (الذي يدعم أيضًا OpenCL) وهو متاح للجمهور. وهكذا ، تم كتابة لعبة Minecraft الشهيرة باستخدام JOCL.GPGPU القادمة
حتى الآن ، لم يكن لدى Java و GPU أرضية مشتركة ، على الرغم من أنه يجب أن يكون. غالبًا ما يتم استخدام Java في المؤسسات وعلوم البيانات وفي القطاع المالي ، حيث يوجد الكثير من الحوسبة وحيث هناك حاجة إلى الكثير من قوة الحوسبة. هذه هي فكرة GPU للأغراض العامة (GPGPU). بدأت فكرة استخدام GPU على هذا المسار عندما بدأ مصنعو محولات الفيديو في الوصول إلى المخزن المؤقت لإطار البرنامج ، مما يسمح للمطورين بقراءة المحتويات. حدد بعض المتسللين أنه يمكنهم استخدام القوة الكاملة لوحدة معالجة الرسومات للحوسبة الشاملة.كانت الوصفة على هذا النحو:- ترميز البيانات كمصفوفة نقطية.
- اكتب تظليل للتعامل معها.
- أرسلهما إلى بطاقة الجرافيكس.
- احصل على نتيجة من الإطار العازل
- فك شفرة البيانات من مصفوفة نقطية.
هذا تفسير بسيط للغاية. لست متأكدًا مما إذا كان هذا سيعمل في الإنتاج ، ولكنه يعمل حقًا.بعد ذلك ، بدأت العديد من الدراسات من معهد ستانفورد في تبسيط استخدام GPUs. في عام 2005 ، صنعوا BrookGPU ، الذي كان نظامًا بيئيًا صغيرًا يتضمن لغة برمجة ومترجم ووقت تشغيل.قامت BrookGPU بتجميع البرامج المكتوبة بلغة برمجة مؤشر ترابط Brook ، والتي كانت من متغيرات ANSI C. يمكنها استهداف OpenGL v1.3 + أو DirectX v9 + أو AMD Close to Metal في جزء حوسبة الخادم ، ويتم تشغيله على Microsoft Windows و Linux. للتصحيح ، يمكن لـ BrookGPU أيضًا محاكاة بطاقة رسومات افتراضية على وحدة المعالجة المركزية.ومع ذلك ، لم تقلع هذه ، بسبب المعدات المتاحة في ذلك الوقت. في عالم GPGPU ، تحتاج إلى نسخ البيانات إلى الجهاز (في هذا السياق ، يشير الجهاز إلى GPU والجهاز الذي يقع عليه) ، وانتظر GPU لحساب البيانات ، ثم نسخ البيانات مرة أخرى إلى برنامج التحكم. هذا يخلق الكثير من التأخير. وفي منتصف العقد الأول من القرن الحالي ، عندما كان المشروع قيد التطوير النشط ، استبعدت هذه التأخيرات أيضًا الاستخدام المكثف لوحدة معالجة الرسومات للحوسبة الأساسية.ومع ذلك ، شهدت العديد من الشركات المستقبل في هذه التكنولوجيا. بدأ العديد من مطوري محولات الفيديو في تزويد وحدات GPGPU بتقنياتها الخاصة ، وقدمت تحالفات مشكلة أخرى نماذج برمجة أقل تنوعًا وعملية تعمل على كمية كبيرة من الأجهزة.الآن بعد أن أخبرتك بكل شيء ، دعنا نتحقق من أنجح تقنيات الحوسبة GPU - OpenCL و CUDA - انظر أيضًا كيف تعمل Java معهم.OpenCL وجافا
مثل حزم البنية التحتية الأخرى ، يوفر OpenCL تطبيقًا أساسيًا في C. يتوفر هذا من الناحية الفنية باستخدام Java Native Interface (JNI) أو Java Native Access (JNA) ، ولكن هذا النهج سيكون صعبًا للغاية بالنسبة لمعظم المطورين.لحسن الحظ ، تم تنفيذ هذا العمل بالفعل من قبل العديد من المكتبات: JOCL و JogAmp و JavaCL. لسوء الحظ ، أصبح JavaCL مشروعًا ميتًا. لكن مشروع JOCL حي ومكيف للغاية. سأستخدمه في الأمثلة التالية.ولكن يجب علي أولا أن أشرح ما هو OpenCL. ذكرت في وقت سابق أن OpenCL يوفر نموذجًا أساسيًا جدًا مناسبًا لبرمجة جميع أنواع الأجهزة - ليس فقط وحدات معالجة الرسومات ووحدات المعالجة المركزية ، ولكن حتى معالجات DSP و FPGA.دعونا نلقي نظرة على أبسط مثال: ربما تكون المتجهات القابلة للطي هي المثال الأكثر سطوعًا وبساطة. لديك صفيفين من الأرقام للإضافة وواحد للنتيجة. تأخذ عنصرًا من الصفيف الأول وعنصرًا من الصفيف الثاني ، ثم تضع المجموع في صفيف النتائج ، كما هو موضح في الشكل. 5.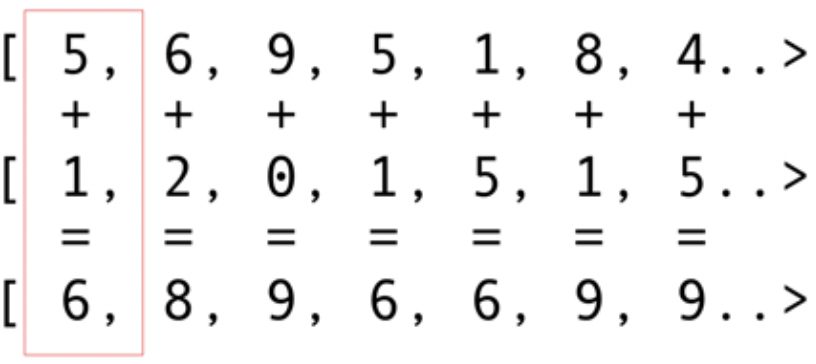 الشكل. 5. إضافة عناصر صفيفين وتخزين المجموع في الصفيف الناتجكما ترى ، العملية متسقة للغاية ومع ذلك يتم توزيعها. يمكنك دفع كل عملية إضافة إلى وحدات معالجة رسومات أساسية مختلفة. هذا يعني أنه إذا كان لديك 2048 مركزًا ، كما هو الحال في Nvidia 1080 ، فيمكنك إجراء عمليات إضافة 2048 في نفس الوقت. هذا يعني أنه هنا تنتظرك Teraflops المحتملة من طاقة الكمبيوتر. هذا الكود لمجموعة من 10 مليون رقم مأخوذ من موقع JOCL:
الشكل. 5. إضافة عناصر صفيفين وتخزين المجموع في الصفيف الناتجكما ترى ، العملية متسقة للغاية ومع ذلك يتم توزيعها. يمكنك دفع كل عملية إضافة إلى وحدات معالجة رسومات أساسية مختلفة. هذا يعني أنه إذا كان لديك 2048 مركزًا ، كما هو الحال في Nvidia 1080 ، فيمكنك إجراء عمليات إضافة 2048 في نفس الوقت. هذا يعني أنه هنا تنتظرك Teraflops المحتملة من طاقة الكمبيوتر. هذا الكود لمجموعة من 10 مليون رقم مأخوذ من موقع JOCL:public class ArrayGPU {
private static String programSource =
"__kernel void "+
"sampleKernel(__global const float *a,"+
" __global const float *b,"+
" __global float *c)"+
"{"+
" int gid = get_global_id(0);"+
" c[gid] = a[gid] + b[gid];"+
"}";
public static void main(String args[])
{
int n = 10_000_000;
float srcArrayA[] = new float[n];
float srcArrayB[] = new float[n];
float dstArray[] = new float[n];
for (int i=0; i<n; i++)
{
srcArrayA[i] = i;
srcArrayB[i] = i;
}
Pointer srcA = Pointer.to(srcArrayA);
Pointer srcB = Pointer.to(srcArrayB);
Pointer dst = Pointer.to(dstArray);
final int platformIndex = 0;
final long deviceType = CL.CL_DEVICE_TYPE_ALL;
final int deviceIndex = 0;
CL.setExceptionsEnabled(true);
int numPlatformsArray[] = new int[1];
CL.clGetPlatformIDs(0, null, numPlatformsArray);
int numPlatforms = numPlatformsArray[0];
cl_platform_id platforms[] = new cl_platform_id[numPlatforms];
CL.clGetPlatformIDs(platforms.length, platforms, null);
cl_platform_id platform = platforms[platformIndex];
cl_context_properties contextProperties = new cl_context_properties();
contextProperties.addProperty(CL.CL_CONTEXT_PLATFORM, platform);
int numDevicesArray[] = new int[1];
CL.clGetDeviceIDs(platform, deviceType, 0, null, numDevicesArray);
int numDevices = numDevicesArray[0];
cl_device_id devices[] = new cl_device_id[numDevices];
CL.clGetDeviceIDs(platform, deviceType, numDevices, devices, null);
cl_device_id device = devices[deviceIndex];
cl_context context = CL.clCreateContext(
contextProperties, 1, new cl_device_id[]{device},
null, null, null);
cl_command_queue commandQueue =
CL.clCreateCommandQueue(context, device, 0, null);
cl_mem memObjects[] = new cl_mem[3];
memObjects[0] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_ONLY | CL.CL_MEM_COPY_HOST_PTR,
Sizeof.cl_float * n, srcA, null);
memObjects[1] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_ONLY | CL.CL_MEM_COPY_HOST_PTR,
Sizeof.cl_float * n, srcB, null);
memObjects[2] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_WRITE,
Sizeof.cl_float * n, null, null);
cl_program program = CL.clCreateProgramWithSource(context,
1, new String[]{ programSource }, null, null);
CL.clBuildProgram(program, 0, null, null, null, null);
cl_kernel kernel = CL.clCreateKernel(program, "sampleKernel", null);
CL.clSetKernelArg(kernel, 0,
Sizeof.cl_mem, Pointer.to(memObjects[0]));
CL.clSetKernelArg(kernel, 1,
Sizeof.cl_mem, Pointer.to(memObjects[1]));
CL.clSetKernelArg(kernel, 2,
Sizeof.cl_mem, Pointer.to(memObjects[2]));
long global_work_size[] = new long[]{n};
long local_work_size[] = new long[]{1};
CL.clEnqueueNDRangeKernel(commandQueue, kernel, 1, null,
global_work_size, local_work_size, 0, null, null);
CL.clEnqueueReadBuffer(commandQueue, memObjects[2], CL.CL_TRUE, 0,
n * Sizeof.cl_float, dst, 0, null, null);
CL.clReleaseMemObject(memObjects[0]);
CL.clReleaseMemObject(memObjects[1]);
CL.clReleaseMemObject(memObjects[2]);
CL.clReleaseKernel(kernel);
CL.clReleaseProgram(program);
CL.clReleaseCommandQueue(commandQueue);
CL.clReleaseContext(context);
}
private static String getString(cl_device_id device, int paramName) {
long size[] = new long[1];
CL.clGetDeviceInfo(device, paramName, 0, null, size);
byte buffer[] = new byte[(int)size[0]];
CL.clGetDeviceInfo(device, paramName, buffer.length, Pointer.to(buffer), null);
return new String(buffer, 0, buffer.length-1);
}
}
هذا الرمز ليس مثل كود Java ، ولكنه كذلك. سأشرح الكود أكثر ؛ لا تقضي الكثير من الوقت في ذلك الآن ، لأنني سأناقش بإيجاز الحلول المعقدة.سيتم توثيق الكود ، لكن لنقم ببعض الإرشادات. كما ترون ، فإن الكود مشابه جدًا للكود الموجود في C. وهذا أمر طبيعي لأن JOCL هو OpenCL فقط. في البداية ، إليك بعض التعليمات البرمجية في السطر ، وهذا الرمز هو الجزء الأكثر أهمية: يتم تجميعه باستخدام OpenCL ثم يتم إرساله إلى بطاقة الفيديو ، حيث يتم تنفيذه. يسمى هذا الرمز Kernel. لا تخلط بين هذا المصطلح و OC Kernel ؛ هذا هو رمز الجهاز. تم كتابة هذا الرمز في مجموعة فرعية من C.بعد أن يأتي kernel برمز Java لتثبيت الجهاز وتكوينه ، وتقسيم البيانات ، وإنشاء مخازن الذاكرة المؤقتة المناسبة للبيانات الناتجة.لتلخيص: هنا هو "رمز المضيف" ، والذي عادة ما يكون ربط اللغة (في حالتنا ، في جافا) ، و "رمز الجهاز". تقوم دائمًا بتمييز ما سيعمل على المضيف وما يجب أن يعمل على الجهاز ، لأن المضيف يتحكم في الجهاز.يجب أن يُظهر الرمز السابق وحدة معالجة الرسومات المكافئة لـ "Hello World!" كما ترون ، معظمها ضخم.دعونا لا ننسى ميزات SIMD. إذا كان جهازك يدعم ملحق SIMD ، فيمكنك جعل الرمز الحسابي أسرع. على سبيل المثال ، دعنا نلقي نظرة على كود ضرب مصفوفة النواة. هذا الرمز موجود في خط جافا بسيط في التطبيق.__kernel void MatrixMul_kernel_basic(int dim,
__global float *A,
__global float *B,
__global float *C){
int iCol = get_global_id(0);
int iRow = get_global_id(1);
float result = 0.0;
for(int i=0; i< dim; ++i)
{
result +=
A[iRow*dim + i]*B[i*dim + iCol];
}
C[iRow*dim + iCol] = result;
}
من الناحية الفنية ، سيعمل هذا الرمز على أجزاء من البيانات التي تم تثبيتها لك بواسطة إطار عمل OpenCL ، مع التعليمات التي طلبتها في الجزء التحضيري.إذا كانت بطاقة الفيديو الخاصة بك تدعم تعليمات SIMD ويمكنها معالجة متجه لأربعة أرقام عائمة ، يمكن للتحسينات الصغيرة تحويل الرمز السابق إلى ما يلي:#define VECTOR_SIZE 4
__kernel void MatrixMul_kernel_basic_vector4(
size_t dim,
const float4 *A,
const float4 *B,
float4 *C)
{
size_t globalIdx = get_global_id(0);
size_t globalIdy = get_global_id(1);
float4 resultVec = (float4){ 0, 0, 0, 0 };
size_t dimVec = dim / 4;
for(size_t i = 0; i < dimVec; ++i) {
float4 Avector = A[dimVec * globalIdy + i];
float4 Bvector[4];
Bvector[0] = B[dimVec * (i * 4 + 0) + globalIdx];
Bvector[1] = B[dimVec * (i * 4 + 1) + globalIdx];
Bvector[2] = B[dimVec * (i * 4 + 2) + globalIdx];
Bvector[3] = B[dimVec * (i * 4 + 3) + globalIdx];
resultVec += Avector[0] * Bvector[0];
resultVec += Avector[1] * Bvector[1];
resultVec += Avector[2] * Bvector[2];
resultVec += Avector[3] * Bvector[3];
}
C[dimVec * globalIdy + globalIdx] = resultVec;
}
مع هذا الرمز يمكنك مضاعفة الأداء.رائع. لقد فتحت للتو GPU لعالم Java! ولكن كمطور Java ، هل تريد حقًا القيام بكل هذا العمل القذر ، باستخدام C code ، والعمل مع مثل هذه التفاصيل منخفضة المستوى؟ لا أريد. ولكن الآن بعد أن أصبحت لديك بعض المعرفة بكيفية استخدام GPU ، دعنا ننظر إلى حل آخر مختلف عن رمز JOCL الذي قدمته للتو.كودا وجافا
CUDA هو حل Nvidia لمشكلة البرمجة هذه. توفر CUDA العديد من المكتبات الجاهزة للاستخدام لعمليات GPU القياسية ، مثل المصفوفات والمخططات البيانية وحتى الشبكات العصبية العميقة. ظهرت قائمة من المكتبات بالفعل مع مجموعة من الحلول الجاهزة. هذا كله من مشروع JCuda:- JCublas: كل شيء للمصفوفات
- JCufft: تحويل فورييه السريع
- JCurand: كل شيء للأرقام العشوائية
- JCusparse: مصفوفات نادرة
- JCusolver: عامل الأرقام
- JNvgraph: كل شيء للرسوم البيانية
- JCudpp: مكتبة CUDA للبيانات الموازية البدائية وبعض خوارزميات الفرز
- JNpp: معالجة صور GPU
- JCudnn: مكتبة الشبكة العصبية العميقة
أنا أفكر في استخدام JCurand ، الذي يولد أرقام عشوائية. يمكنك استخدام هذا من كود Java بدون لغة Kernel خاصة أخرى. فمثلا:...
int n = 100;
curandGenerator generator = new curandGenerator();
float hostData[] = new float[n];
Pointer deviceData = new Pointer();
cudaMalloc(deviceData, n * Sizeof.FLOAT);
curandCreateGenerator(generator, CURAND_RNG_PSEUDO_DEFAULT);
curandSetPseudoRandomGeneratorSeed(generator, 1234);
curandGenerateUniform(generator, deviceData, n);
cudaMemcpy(Pointer.to(hostData), deviceData,
n * Sizeof.FLOAT, cudaMemcpyDeviceToHost);
System.out.println(Arrays.toString(hostData));
curandDestroyGenerator(generator);
cudaFree(deviceData);
...
يستخدم GPU لإنشاء عدد كبير من الأرقام العشوائية بجودة عالية جدًا ، استنادًا إلى الرياضيات القوية جدًا.في JCuda ، يمكنك أيضًا كتابة كود CUDA عام واستدعائه من Java عن طريق استدعاء بعض ملفات JAR في مسار الفصل الدراسي الخاص بك. راجع وثائق JCuda للحصول على أمثلة رائعة.البقاء فوق رمز المستوى المنخفض
يبدو كل شيء رائعًا ، ولكن هناك الكثير من التعليمات البرمجية ، والكثير من التثبيت ، والعديد من اللغات المختلفة لتشغيلها كلها. هل هناك طريقة لاستخدام GPU جزئيًا على الأقل؟ماذا لو كنت لا ترغب في التفكير في كل هذا OpenCL ، CUDA ، وغيرها من الأشياء غير الضرورية؟ ماذا لو كنت تريد فقط البرمجة في Java وعدم التفكير في كل شيء غير واضح؟ يمكن أن يساعد مشروع Aparapi. يعتمد Aparapi على "واجهة برمجة تطبيقات متوازية". أعتقد أنه جزء من Hibernate لبرمجة GPU التي تستخدم OpenCL تحت الغطاء. دعونا نلقي نظرة على مثال لإضافة المتجهات.public static void main(String[] _args) {
final int size = 512;
final float[] a = new float[size];
final float[] b = new float[size];
for (int i = 0; i < size; i++){
a[i] = (float) (Math.random() * 100);
b[i] = (float) (Math.random() * 100);
}
final float[] sum = new float[size];
Kernel kernel = new Kernel(){
@Override public void run() {
I int gid = getGlobalId();
sum[gid] = a[gid] + b[gid];
}
};
kernel.execute(Range.create(size));
for(int i = 0; i < size; i++) {
System.out.printf("%6.2f + %6.2f = %8.2f\n", a[i], b[i], sum[i])
}
kernel.dispose();
}
هنا كود Java خالص (مأخوذ من وثائق Aparapi) ، هنا وهناك أيضًا ، يمكنك رؤية مصطلح معين Kernel و getGlobalId. لا تزال بحاجة إلى فهم كيفية برمجة GPU ، ولكن يمكنك استخدام نهج GPGPU بطريقة تشبه جافا. علاوة على ذلك ، يوفر Aparapi طريقة سهلة لاستخدام سياق OpenGL لطبقة OpenCL - وبالتالي السماح للبيانات بالبقاء تمامًا على بطاقة الرسومات - وبالتالي تجنب مشاكل الكمون في الذاكرة.إذا كنت بحاجة إلى القيام بالكثير من الحسابات المستقلة ، فابحث في Aparapi. هناك العديد من الأمثلة على كيفية استخدام الحوسبة المتوازية.بالإضافة إلى ذلك ، هناك بعض المشاريع تسمى TornadoVM - تقوم تلقائيًا بنقل الحسابات المناسبة من وحدة المعالجة المركزية إلى وحدة معالجة الرسومات ، مما يوفر تحسينًا كبيرًا للخروج من الصندوق.الموجودات
هناك العديد من التطبيقات حيث يمكن لوحدات معالجة الرسومات أن تجلب بعض المزايا ، ولكن يمكنك القول أنه لا تزال هناك بعض العقبات. ومع ذلك ، يمكن لـ Java و GPU القيام بأشياء رائعة معًا. في هذه المقالة ، تطرقت فقط إلى هذا الموضوع الشامل. كنت أنوي إظهار العديد من الخيارات ذات المستوى العالي والمنخفض للوصول إلى GPU من Java. سيوفر استكشاف هذه المنطقة فوائد أداء هائلة ، خاصة للمهام المعقدة التي تتطلب حسابات متعددة يمكن إجراؤها بالتوازي.رابط المصدر