مرحبًا ، اسمي ألكسندر فاسين ، وأنا مطور خلفية في Edadil. بدأت فكرة هذه المادة بحقيقة أنني أردت تحليل المهمة التمهيدية ( Ya.Disk ) في مدرسة Yandex Backend Development School. لقد بدأت في وصف كل التفاصيل الدقيقة لاختيار تقنيات معينة ، ومنهجية الاختبار ... واتضح أنه لا يوجد تحليل على الإطلاق ، ولكنه دليل تفصيلي للغاية حول كيفية كتابة الواجهات الخلفية في Python. من الفكرة الأولية ، كانت هناك متطلبات فقط للخدمة ، على سبيل المثال ، من المناسب تفكيك الأدوات والتقنيات. ونتيجة لذلك ، استيقظت على مائة ألف حرف. كان هناك الكثير المطلوب للنظر في كل شيء بتفصيل كبير. لذا ، فإن برنامج الـ 100 كيلوبايت التالي: كيفية بناء خلفية للخدمة ، من اختيار الأدوات إلى النشر. TL ؛ DR: هنا هو مندوب GitHub مع التطبيق، ومن يحب الخيوط الطويلة (الحقيقية) - من فضلك ، تحت القط.سنقوم بتطوير واختبار خدمة REST API في Python ، وحزمها في حاوية Docker خفيفة الوزن ونشرها باستخدام Ansible.
TL ؛ DR: هنا هو مندوب GitHub مع التطبيق، ومن يحب الخيوط الطويلة (الحقيقية) - من فضلك ، تحت القط.سنقوم بتطوير واختبار خدمة REST API في Python ، وحزمها في حاوية Docker خفيفة الوزن ونشرها باستخدام Ansible.يمكنك تنفيذ خدمة REST API بطرق مختلفة باستخدام أدوات مختلفة. الحل الموصوف ليس هو الحل الوحيد الصحيح ، لقد اخترت التنفيذ والأدوات بناءً على تجربتي الشخصية وتفضيلاتي.
ماذا نفعل؟
تخيل أن متجر هدايا عبر الإنترنت يخطط لإطلاق حدث في مناطق مختلفة. لكي تكون استراتيجية المبيعات فعالة ، هناك حاجة إلى تحليل السوق. يحتوي المتجر على مورد يرسل بانتظام (على سبيل المثال ، عن طريق البريد) تفريغ البيانات بمعلومات عن المقيمين.دعنا نطور خدمة Python REST API التي ستحلل البيانات المقدمة وتحدد الطلب على الهدايا من المقيمين من مختلف الفئات العمرية في مدن مختلفة حسب الشهر.نقوم بتنفيذ المعالجات التالية في الخدمة:POST /imports
يضيف تحميل جديد بالبيانات ؛
GET /imports/$import_id/citizens
إرجاع سكان التفريغ المحدد ؛
PATCH /imports/$import_id/citizens/$citizen_id
تغيير معلومات المقيم (وأقاربه) في التفريغ المحدد ؛
GET /imports/$import_id/citizens/birthdays
, ( ), ;
GET /imports/$import_id/towns/stat/percentile/age
50-, 75- 99- ( ) .
?
لذلك ، نحن نكتب خدمة في Python باستخدام أطر العمل المألوفة والمكتبات و DBMS.في 4 محاضرات لدورة الفيديو ، تم وصف DBMSs المختلفة وخصائصها. بالنسبة للتنفيذ ، اخترت PostgreSQL DBMS ، التي أثبتت نفسها كحل موثوق به مع وثائق ممتازة باللغة الروسية ، مجتمع روسي قوي (يمكنك دائمًا العثور على إجابة سؤال باللغة الروسية) ، وحتى الدورات المجانية . النموذج العلائقي متعدد الاستخدامات ومفهوم جيدًا من قبل العديد من المطورين. على الرغم من أنه يمكن القيام بنفس الشيء على أي NoSQL DBMS ، في هذه المقالة سننظر في PostgreSQL.الهدف الرئيسي من الخدمة - نقل البيانات عبر الشبكة بين قاعدة البيانات والعملاء - لا ينطوي على حمل كبير على المعالج ، ولكنه يتطلب القدرة على معالجة طلبات متعددة في وقت واحد. في 10 محاضرات تعتبر نهج غير متزامن. يسمح لك بخدمة العديد من العملاء بكفاءة في نفس عملية نظام التشغيل (على عكس ، على سبيل المثال ، نموذج ما قبل الشوكة المستخدم في Flask / Django ، والذي يخلق العديد من العمليات لمعالجة الطلبات من المستخدمين ، كل منهم يستهلك ذاكرة ، ولكنه خامل معظم الوقت ) لذلك ، كمكتبة لكتابة الخدمة ، اخترت aiohttp غير المتزامن . في محاضرة 5TH لل دورة فيديو يحكي أن SQLAlchemy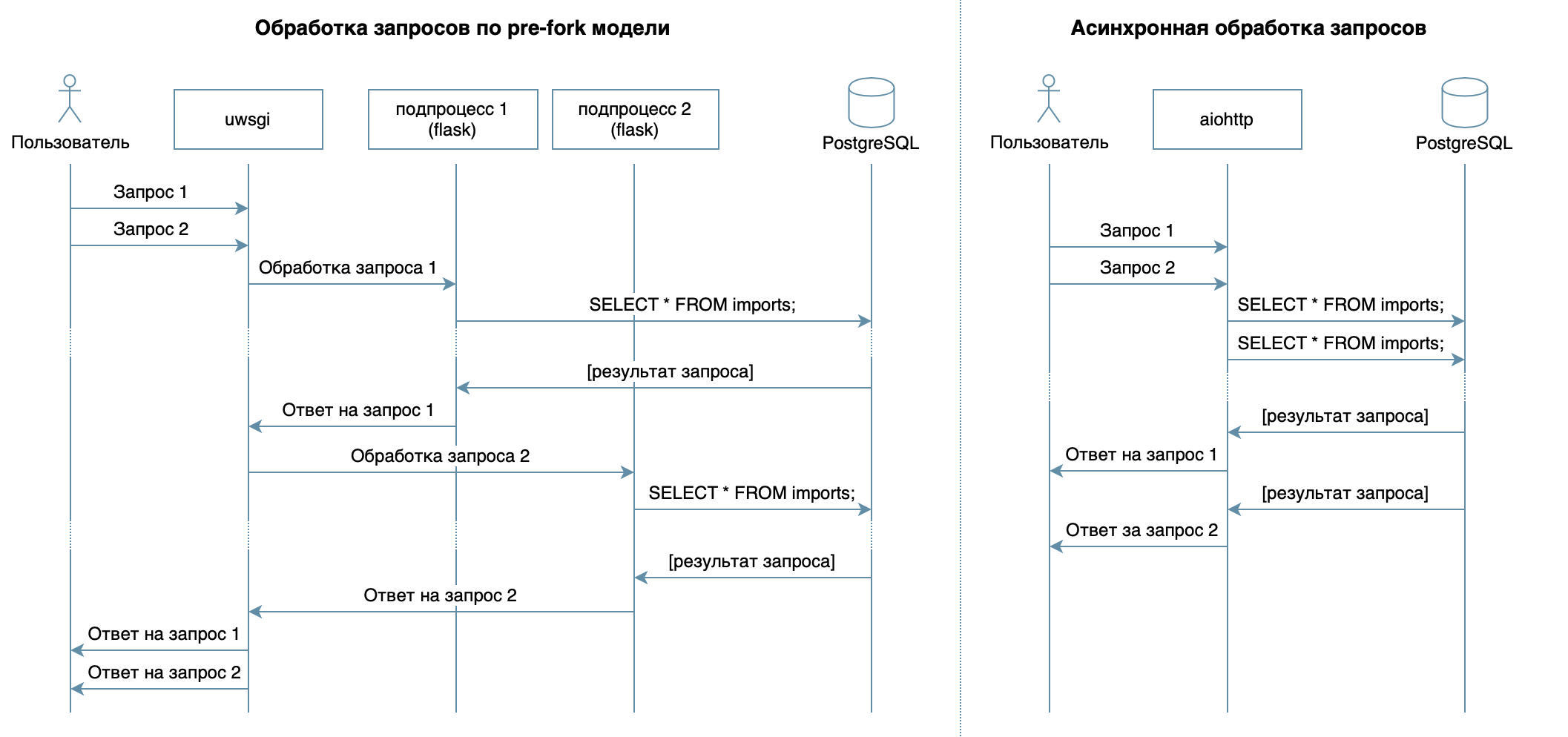 يسمح لك بتحليل الاستعلامات المعقدة إلى أجزاء ، وإعادة استخدامها ، وإنشاء استعلامات بمجموعة ديناميكية من الحقول (على سبيل المثال ، يتيح معالج PATCH التحديث الجزئي للمقيم ذي الحقول العشوائية) والتركيز مباشرة على منطق الأعمال. يمكن لبرنامج تشغيل asyncpg معالجة هذه الطلبات ونقل البيانات بشكل أسرع ، وسيساعدهم asyncpgsa على تكوين صداقات .الأداة المفضلة لدي لإدارة حالة قاعدة البيانات والعمل مع عمليات الترحيل هي Alembic . بالمناسبة ، لقد تحدثت عنه مؤخرًا في Python في موسكو .تم وصف منطق التحقق بإيجاز بواسطة مخططات Marshmallow (بما في ذلك التحقق من الروابط العائلية). استخدام وحدة المواصفات aiohttpلقد ربطت معالجات ومخططات aiohttp للتحقق من صحة البيانات ، وكانت المكافأة هي إنشاء وثائق بتنسيق Swagger وعرضها في واجهة رسومية .لكتابة الاختبارات ، اخترت
يسمح لك بتحليل الاستعلامات المعقدة إلى أجزاء ، وإعادة استخدامها ، وإنشاء استعلامات بمجموعة ديناميكية من الحقول (على سبيل المثال ، يتيح معالج PATCH التحديث الجزئي للمقيم ذي الحقول العشوائية) والتركيز مباشرة على منطق الأعمال. يمكن لبرنامج تشغيل asyncpg معالجة هذه الطلبات ونقل البيانات بشكل أسرع ، وسيساعدهم asyncpgsa على تكوين صداقات .الأداة المفضلة لدي لإدارة حالة قاعدة البيانات والعمل مع عمليات الترحيل هي Alembic . بالمناسبة ، لقد تحدثت عنه مؤخرًا في Python في موسكو .تم وصف منطق التحقق بإيجاز بواسطة مخططات Marshmallow (بما في ذلك التحقق من الروابط العائلية). استخدام وحدة المواصفات aiohttpلقد ربطت معالجات ومخططات aiohttp للتحقق من صحة البيانات ، وكانت المكافأة هي إنشاء وثائق بتنسيق Swagger وعرضها في واجهة رسومية .لكتابة الاختبارات ، اخترت pytest، المزيد عنها في 3 محاضرات .لتصحيح هذا المشروع ووضع ملف تعريف له ، استخدمت مصحح PyCharm ( المحاضرة 9 ).في 7 محاضرة تصف كيفية تشغيل أي جهاز كمبيوتر Docker (أو حتى على نظام تشغيل مختلف) في حزم دون الحاجة إلى ضبط بيئة التطبيق لبدء التشغيل وسهولة تثبيت / تحديث / حذف التطبيق على الخادم.للنشر ، اخترت Ansible. يسمح لك بوصف الحالة المرغوبة للخادم وخدماته بشكل معلن ، ويعمل عبر ssh ولا يتطلب برامج خاصة.تطوير
قررت تسمية حزمة Python analyzerواستخدام البنية التالية: في الملف
في الملف analyzer/__init__.pyقمت بنشر معلومات عامة حول الحزمة: الوصف ( docstring ) ، الإصدار ، الترخيص ، جهات اتصال المطور.يمكن عرضه بمساعدة مدمجة$ python
>>> import analyzer
>>> help(analyzer)
Help on package analyzer:
NAME
analyzer
DESCRIPTION
REST API, .
PACKAGE CONTENTS
api (package)
db (package)
utils (package)
DATA
__all__ = ('__author__', '__email__', '__license__', '__maintainer__',...
__email__ = 'alvassin@yandex.ru'
__license__ = 'MIT'
__maintainer__ = 'Alexander Vasin'
VERSION
0.0.1
AUTHOR
Alexander Vasin
FILE
/Users/alvassin/Work/backendschool2019/analyzer/__init__.py
تحتوي الحزمة على نقطتي إدخال - خدمة REST API ( analyzer/api/__main__.py) وأداة إدارة حالة قاعدة البيانات ( analyzer/db/__main__.py). يتم استدعاء الملفات __main__.pyلسبب ما - أولاً ، مثل هذا الاسم يجذب الانتباه ، ويوضح أن الملف هو نقطة دخول.ثانيًا ، بفضل هذا النهج لنقاط الدخول python -m:
$ python -m analyzer.api --help
$ python -m analyzer.db --help
لماذا تحتاج إلى البدء بـ setup.py؟
بالنظر إلى المستقبل ، سنفكر في كيفية توزيع التطبيق: يمكن تعبئته في أرشيف مضغوط (وكذلك عجلة / بيضة) ، حزمة rpm ، ملف pkg لنظام macOS وتثبيته على جهاز كمبيوتر بعيد أو جهاز افتراضي أو MacBook أو Docker- حاوية.الغرض الرئيسي من الملف setup.pyهو وصف الحزمة مع التطبيق . يجب أن يحتوي الملف على معلومات عامة حول الحزمة (الاسم ، الإصدار ، المؤلف ، وما إلى ذلك) ، ولكن يمكنك أيضًا تحديد الوحدات المطلوبة للعمل ، والتبعيات "الإضافية" (على سبيل المثال ، للاختبار) ، ونقاط الإدخال (على سبيل المثال ، الأوامر القابلة للتنفيذ ) ومتطلبات المترجم. تسمح لك مكونات Setuptools بجمع القطع الأثرية من الحزمة الموصوفة. هناك إضافات مدمجة: zip ، egg ، rpm ، macOS pkg. يتم توزيع الإضافات المتبقية عبر PyPI: wheel ،distutils/setuptoolsxar ، pex .في الخلاصة ، لوصف ملف واحد ، نحصل على فرص رائعة. لهذا السبب يجب أن يبدأ تطوير مشروع جديد setup.py.في الوظيفة ، setup()يشار إلى الوحدات التابعة بقائمة:setup(..., install_requires=["aiohttp", "SQLAlchemy"])
ولكن وصفت التبعيات في ملفات منفصلة requirements.txtو requirements.dev.txtالتي تستخدم في محتويات setup.py. يبدو لي أكثر مرونة ، بالإضافة إلى وجود سر: في وقت لاحق سيسمح لك ببناء صورة Docker بشكل أسرع. سيتم تعيين التبعيات كخطوة منفصلة قبل تثبيت التطبيق نفسه ، وعند إعادة بناء حاوية Docker ، تكون في ذاكرة التخزين المؤقت.أن يكون setup.pyقادرا على قراءة تبعيات من الملفات requirements.txtو requirements.dev.txt، يتم كتابة الدالة:def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
ومن الجدير بالذكر أن setuptoolsعندما يتضمن توزيع مصدر التجمع الافتراضي فقط الملفات التجميع .py، .c، .cppو .h. إلى ملف التبعية requirements.txtو requirements.dev.txtضرب كيس، وينبغي أن تكون محددة بشكل واضح في الملف MANIFEST.in.setup.py بالكاملimport os
from importlib.machinery import SourceFileLoader
from pkg_resources import parse_requirements
from setuptools import find_packages, setup
module_name = 'analyzer'
module = SourceFileLoader(
module_name, os.path.join(module_name, '__init__.py')
).load_module()
def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
setup(
name=module_name,
version=module.__version__,
author=module.__author__,
author_email=module.__email__,
license=module.__license__,
description=module.__doc__,
long_description=open('README.rst').read(),
url='https://github.com/alvassin/backendschool2019',
platforms='all',
classifiers=[
'Intended Audience :: Developers',
'Natural Language :: Russian',
'Operating System :: MacOS',
'Operating System :: POSIX',
'Programming Language :: Python',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.8',
'Programming Language :: Python :: Implementation :: CPython'
],
python_requires='>=3.8',
packages=find_packages(exclude=['tests']),
install_requires=load_requirements('requirements.txt'),
extras_require={'dev': load_requirements('requirements.dev.txt')},
entry_points={
'console_scripts': [
'{0}-api = {0}.api.__main__:main'.format(module_name),
'{0}-db = {0}.db.__main__:main'.format(module_name)
]
},
include_package_data=True
)
يمكنك تثبيت المشروع في وضع التطوير باستخدام الأمر التالي (في الوضع القابل للتحرير ، لن تقوم Python بتثبيت الحزمة بأكملها في مجلد site-packages، ولكن فقط تنشئ روابط ، لذلك ستكون أي تغييرات يتم إجراؤها على ملفات الحزمة مرئية على الفور):
pip install -e '.[dev]'
pip install -e .
كيفية تحديد إصدارات التبعية؟
إنه أمر رائع عندما يعمل المطورون بنشاط على حزمهم - يتم إصلاح الأخطاء بشكل نشط فيها ، وتظهر وظائف جديدة ويمكن الحصول على التعليقات بشكل أسرع. ولكن في بعض الأحيان لا تكون التغييرات في المكتبات التابعة متوافقة مع الإصدارات السابقة ويمكن أن تؤدي إلى أخطاء في تطبيقك إذا لم تفكر في ذلك مسبقًا.لكل حزمة تابعة ، يمكنك تحديد إصدار معين ، على سبيل المثال aiohttp==3.6.2. ثم سيتم ضمان بناء التطبيق على وجه التحديد مع تلك الإصدارات من المكتبات التابعة التي تم اختبارها معها. لكن هذا النهج له عيب - إذا قام المطورون بإصلاح خطأ هام في حزمة تابعة لا تؤثر على التوافق مع الإصدارات السابقة ، فلن يدخل هذا الإصلاح في التطبيق.هناك نهج لإصدار الإصدار الدلالي، التي تقترح إرسال النسخة بالتنسيق MAJOR.MINOR.PATCH:MAJOR - يزيد عند إضافة تغييرات غير متوافقة مع الإصدارات السابقة ؛MINOR - زيادة عند إضافة وظائف جديدة مع دعم التوافق العكسي ؛PATCH - يزيد عند إضافة إصلاحات الأخطاء مع دعم التوافق مع الإصدارات السابقة.
إذا كان حزمة تعتمد يتبع هذا النهج (التي يتم الإبلاغ عنها المؤلفون عادة في ملفات README والتغيير)، فإنه يكفي لإصلاح قيمة MAJOR، MINORوالحد من قيمة الحد الأدنى للPATCH الإصدار: >= MAJOR.MINOR.PATCH, == MAJOR.MINOR.*.يمكن تنفيذ مثل هذا الشرط باستخدام عامل التشغيل ~ = . على سبيل المثال ، aiohttp~=3.6.2سيسمح بتثبيت PIP aiohttpللإصدار 3.6.3 ، وليس 3.7.إذا قمت بتحديد الفاصل الزمني لإصدارات التبعية ، فسيعطي هذا ميزة إضافية أخرى - لن يكون هناك تعارض في الإصدار بين المكتبات التابعة.إذا كنت تقوم بتطوير مكتبة تتطلب حزمة تبعية مختلفة ، فلا تسمح لها بإصدار واحد محدد ، بل بفاصل زمني. ثم سيكون من الأسهل بكثير على مستخدمي مكتبتك استخدامها (فجأة يتطلب تطبيقهم نفس حزمة التبعية ، ولكن من إصدار مختلف).الإصدار الدلالي هو مجرد اتفاق بين مؤلفي ومستهلكي الحزم. لا يضمن أن المؤلفين يكتبون التعليمات البرمجية بدون أخطاء ولا يمكنهم ارتكاب خطأ في الإصدار الجديد من الحزمة الخاصة بهم.قاعدة البيانات
نقوم بتصميم المخطط
يقدم وصف معالج POST / الواردات مثالاً على التفريغ بمعلومات عن المقيمين:مثال للتحميل{
"citizens": [
{
"citizen_id": 1,
"town": "",
"street": " ",
"building": "1675",
"apartment": 7,
"name": " ",
"birth_date": "26.12.1986",
"gender": "male",
"relatives": [2]
},
{
"citizen_id": 2,
"town": "",
"street": " ",
"building": "1675",
"apartment": 7,
"name": " ",
"birth_date": "01.04.1997",
"gender": "male",
"relatives": [1]
},
{
"citizen_id": 3,
"town": "",
"street": " ",
"building": "2",
"apartment": 11,
"name": " ",
"birth_date": "23.11.1986",
"gender": "female",
"relatives": []
},
...
]
}
كان الفكر الأول هو تخزين جميع المعلومات حول المقيم في جدول واحد citizens، حيث سيتم تمثيل العلاقة بحقل relativesفي شكل قائمة أعداد صحيحة .لكن هذه الطريقة لها عيوب عديدةGET /imports/$import_id/citizens/birthdays , , citizens . relatives UNNEST.
, 10- :
SELECT
relations.citizen_id,
relations.relative_id,
date_part('month', relatives.birth_date) as relative_birth_month
FROM (
SELECT
citizens.import_id,
citizens.citizen_id,
UNNEST(citizens.relatives) as relative_id
FROM citizens
WHERE import_id = 1
) as relations
INNER JOIN citizens as relatives ON
relations.import_id = relatives.import_id AND
relations.relative_id = relatives.citizen_id
relatives PostgreSQL, : relatives , . ( ) .
علاوة على ذلك ، قررت إحضار جميع البيانات المطلوبة للعمل إلى شكل عادي ثالث ، وتم الحصول على الهيكل التالي:
- يتكون جدول الاستيراد من عمود متزايد تلقائيًا
import_id. هناك حاجة لإنشاء تدقيق مفتاح خارجي في الجدول citizens.
- يقوم جدول المواطنين بتخزين البيانات العددية عن المقيم (جميع المجالات باستثناء المعلومات حول العلاقات الأسرية).
يتم استخدام الزوج ( import_id، citizen_id) كمفتاح أساسي ، مما يضمن تفرد المقيمين citizen_idداخل الإطار import_id. يضمن
المفتاح الخارجي citizens.import_id -> imports.import_idاحتواء الحقل citizens.import_idعلى عمليات إلغاء التحميل الموجودة فقط.
- relations .
( ): citizens relations .
(import_id, citizen_id, relative_id) , import_id citizen_id c relative_id.
: (relations.import_id, relations.citizen_id) -> (citizens.import_id, citizens.citizen_id) (relations.import_id, relations.relative_id) -> (citizens.import_id, citizens.citizen_id), , citizen_id relative_id .
يضمن هذا الهيكل تكامل البيانات باستخدام أدوات PostgreSQL ، ويتيح لك الحصول على المقيمين بكفاءة مع الأقارب من قاعدة البيانات ، ولكنه يخضع لشرط سباق عند تحديث المعلومات حول المقيمين الذين لديهم استعلامات تنافسية (سنلقي نظرة فاحصة على تنفيذ معالج PATCH).وصف المخطط في SQLAlchemy
في الفصل الخامس ، تحدثت عن كيفية إنشاء استعلامات باستخدام SQLAlchemy ، تحتاج إلى وصف مخطط قاعدة البيانات باستخدام كائنات خاصة: الجداول موصوفة باستخدام sqlalchemy.Tableوملزمة بسجل sqlalchemy.MetaDataيقوم بتخزين جميع المعلومات الوصفية حول قاعدة البيانات. بالمناسبة ، MetaDataلا يمكن للسجل فقط تخزين المعلومات الوصفية الموضحة في Python ، ولكن أيضًا يمثل الحالة الحقيقية لقاعدة البيانات في شكل كائنات SQLAlchemy.تسمح هذه الميزة أيضًا لـ Alembic بمقارنة الشروط وإنشاء رمز الترحيل تلقائيًا.بالمناسبة ، كل قاعدة بيانات لديها نظام تسمية القيود الافتراضية الخاصة بها. حتى لا تضيع الوقت في تسمية قيود جديدة أو البحث / تذكر القيود التي توشك على إزالتها ، تقترح SQLAlchemy استخدام أنماط تسمية أنماط التسمية . يمكن تعريفها في التسجيل MetaData.قم بإنشاء سجل MetaData وقم بتمرير أنماط التسمية إليه
from sqlalchemy import MetaData
convention = {
'all_column_names': lambda constraint, table: '_'.join([
column.name for column in constraint.columns.values()
]),
'ix': 'ix__%(table_name)s__%(all_column_names)s',
'uq': 'uq__%(table_name)s__%(all_column_names)s',
'ck': 'ck__%(table_name)s__%(constraint_name)s',
'fk': 'fk__%(table_name)s__%(all_column_names)s__%(referred_table_name)s',
'pk': 'pk__%(table_name)s'
}
metadata = MetaData(naming_convention=convention)
إذا حددت أنماط تسمية ، فسوف تستخدمها Alembic أثناء التوليد التلقائي لعمليات الترحيل وستقوم بتسمية جميع القيود وفقًا لها. في المستقبل ، MetaDataسيطلب التسجيل الذي تم إنشاؤه لوصف الجداول:نصف مخطط قاعدة البيانات مع كائنات SQLAlchemy
from enum import Enum, unique
from sqlalchemy import (
Column, Date, Enum as PgEnum, ForeignKey, ForeignKeyConstraint, Integer,
String, Table
)
@unique
class Gender(Enum):
female = 'female'
male = 'male'
imports_table = Table(
'imports',
metadata,
Column('import_id', Integer, primary_key=True)
)
citizens_table = Table(
'citizens',
metadata,
Column('import_id', Integer, ForeignKey('imports.import_id'),
primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('town', String, nullable=False, index=True),
Column('street', String, nullable=False),
Column('building', String, nullable=False),
Column('apartment', Integer, nullable=False),
Column('name', String, nullable=False),
Column('birth_date', Date, nullable=False),
Column('gender', PgEnum(Gender, name='gender'), nullable=False),
)
relations_table = Table(
'relations',
metadata,
Column('import_id', Integer, primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('relative_id', Integer, primary_key=True),
ForeignKeyConstraint(
('import_id', 'citizen_id'),
('citizens.import_id', 'citizens.citizen_id')
),
ForeignKeyConstraint(
('import_id', 'relative_id'),
('citizens.import_id', 'citizens.citizen_id')
),
)
تخصيص Alembic
عندما يتم وصف مخطط قاعدة البيانات ، فمن الضروري إنشاء عمليات الترحيل ، ولكن لهذا تحتاج أولاً إلى تكوين Alembic ، والذي تمت مناقشته أيضًا في الفصل 5 .لاستخدام الأمر alembic، يجب تنفيذ الخطوات التالية:- ثبت المجموعة:
pip install alembic - تهيئة الإنبيق:
cd analyzer && alembic init db/alembic.
سيقوم هذا الأمر بإنشاء ملف تكوين analyzer/alembic.iniومجلد analyzer/db/alembicبالمحتويات التالية:
env.py- يسمى في كل مرة تبدأ فيها Alembic. يتصل بتسجيل Alembic sqlalchemy.MetaDataمع وصف الحالة المرغوبة لقاعدة البيانات ويحتوي على إرشادات لبدء عمليات الترحيل.
script.py.mako - القالب الذي يتم على أساسه إنشاء عمليات الترحيل.versions - المجلد الذي ستبحث فيه Alembic (وتولد) عمليات الترحيل.
- حدد عنوان قاعدة البيانات في ملف alembic.ini:
; analyzer/alembic.ini
[alembic]
sqlalchemy.url = postgresql://user:hackme@localhost/analyzer
- حدد وصفًا للحالة المطلوبة لقاعدة البيانات (التسجيل
sqlalchemy.MetaData) بحيث يمكن لـ Alembic إنشاء عمليات الترحيل تلقائيًا:
from analyzer.db import schema
target_metadata = schema.metadata
تم تكوين Alembic ويمكن استخدامه بالفعل ، ولكن في حالتنا هذه التهيئة لها عيوب عديدة:- تقوم الأداة المساعدة
alembicبالبحث alembic.iniفي دليل العمل الحالي. يمكنك alembic.iniتحديد المسار إلى وسيطة سطر الأوامر ، ولكن هذا غير مريح: أريد أن أكون قادرًا على استدعاء الأمر من أي مجلد بدون معلمات إضافية. - لتكوين Alembic للعمل مع قاعدة بيانات محددة ، تحتاج إلى تغيير الملف
alembic.ini. سيكون من الأنسب تحديد إعدادات قاعدة البيانات لمتغير البيئة و / أو وسيطة سطر الأوامر ، على سبيل المثال --pg-url. alembicلا يرتبط اسم الأداة بشكل جيد مع اسم خدمتنا (وقد لا يكون لدى المستخدم Python على الإطلاق ولا يعرف شيئًا عن Alembic). سيكون أكثر ملاءمة للمستخدم النهائي إذا كانت جميع الأوامر القابلة للتنفيذ للخدمة لها بادئة مشتركة ، على سبيل المثال analyzer-*.
يتم حل هذه المشاكل باستخدام غلاف صغير. analyzer/db/__main__.py:- تستخدم Alembic وحدة نمطية قياسية لمعالجة وسيطات سطر الأوامر
argparse. يسمح لك بإضافة وسيطة اختيارية --pg-urlبقيمة افتراضية من متغير بيئة ANALYZER_PG_URL.
الرمزimport os
from alembic.config import CommandLine, Config
from analyzer.utils.pg import DEFAULT_PG_URL
def main():
alembic = CommandLine()
alembic.parser.add_argument(
'--pg-url', default=os.getenv('ANALYZER_PG_URL', DEFAULT_PG_URL),
help='Database URL [env var: ANALYZER_PG_URL]'
)
options = alembic.parser.parse_args()
config = Config(file_=options.config, ini_section=options.name,
cmd_opts=options)
config.set_main_option('sqlalchemy.url', options.pg_url)
exit(alembic.run_cmd(config, options))
if __name__ == '__main__':
main()
alembic.iniيمكن حساب مسار الملف بالنسبة لموقع الملف القابل للتنفيذ ، وليس دليل العمل الحالي للمستخدم.
الرمزimport os
from alembic.config import CommandLine, Config
from pathlib import Path
PROJECT_PATH = Path(__file__).parent.parent.resolve()
def main():
alembic = CommandLine()
options = alembic.parser.parse_args()
if not os.path.isabs(options.config):
options.config = os.path.join(PROJECT_PATH, options.config)
config = Config(file_=options.config, ini_section=options.name,
cmd_opts=options)
alembic_location = config.get_main_option('script_location')
if not os.path.isabs(alembic_location):
config.set_main_option('script_location',
os.path.join(PROJECT_PATH, alembic_location))
exit(alembic.run_cmd(config, options))
if __name__ == '__main__':
main()
عندما تكون الأداة المساعدة لإدارة حالة قاعدة البيانات جاهزة ، يمكن تسجيلها setup.pyكأمر قابل للتنفيذ باسم يمكن للمستخدم النهائي فهمه ، على سبيل المثال analyzer-db:قم بتسجيل أمر تنفيذي في setup.pyfrom setuptools import setup
setup(..., entry_points={
'console_scripts': [
'analyzer-db = analyzer.db.__main__:main'
]
})
بعد إعادة تثبيت الوحدة النمطية ، سيتم إنشاء ملف وسيصبح env/bin/analyzer-dbالأمر analyzer-dbمتاحًا:$ pip install -e '.[dev]'
نحن نولد الهجرات
لإنشاء عمليات الترحيل ، يلزم وجود حالتين: الحالة المرغوبة (التي وصفناها مع كائنات SQLAlchemy) والحالة الحقيقية (قاعدة البيانات ، في حالتنا ، فارغة).قررت أن أسهل طريقة لرفع Postgres كانت مع Docker ، ومن أجل الراحة ، أضفت أمرًا يشغل make postgresحاوية في الخلفية باستخدام PostgreSQL على المنفذ 5432:رفع PostgreSQL وإنشاء الترحيل$ make postgres
...
$ analyzer-db revision --message="Initial" --autogenerate
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'imports'
INFO [alembic.autogenerate.compare] Detected added table 'citizens'
INFO [alembic.autogenerate.compare] Detected added index 'ix__citizens__town' on '['town']'
INFO [alembic.autogenerate.compare] Detected added table 'relations'
Generating /Users/alvassin/Work/backendschool2019/analyzer/db/alembic/versions/d5f704ed4610_initial.py ... done
بشكل عام ، تقوم Alembic بعمل جيد في العمل الروتيني لتوليد الهجرة ، ولكن أود أن ألفت الانتباه إلى ما يلي:- يتم إنشاء أنواع بيانات المستخدم المحددة في الجداول التي تم إنشاؤها تلقائيًا (في حالتنا -
gender) ، ولكن downgradeلم يتم إنشاء الرمز لحذفها . إذا قمت بتطبيق التراجع ، ثم التراجع ، ثم تطبيق الترحيل مرة أخرى ، سيؤدي ذلك إلى حدوث خطأ لأن نوع البيانات المحدد موجود بالفعل.
احذف نوع بيانات الجنس في طريقة الرجوع إلى إصدار أقدمfrom alembic import op
from sqlalchemy import Column, Enum
GenderType = Enum('female', 'male', name='gender')
def upgrade():
...
op.create_table('citizens', ...,
Column('gender', GenderType, nullable=False))
...
def downgrade():
op.drop_table('citizens')
GenderType.drop(op.get_bind())
- في الطريقة ،
downgradeيمكن في بعض الأحيان إزالة بعض الإجراءات (إذا حذفنا الجدول بأكمله ، لا يمكنك حذف فهارسه بشكل منفصل):
على سبيل المثالdef downgrade():
op.drop_table('relations')
op.drop_index(op.f('ix__citizens__town'), table_name='citizens')
op.drop_table('citizens')
op.drop_table('imports')
عندما يكون الترحيل ثابتًا وجاهزًا ، نطبقه:$ analyzer-db upgrade head
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> d5f704ed4610, Initial
تطبيق
قبل البدء في إنشاء معالجات ، يجب عليك تكوين تطبيق aiohttp.إذا نظرت إلى aiohttp quickstart ، يمكنك كتابة شيء من هذا القبيلimport logging
from aiohttp import web
def main():
logging.basicConfig(level=logging.DEBUG)
app = web.Application()
app.router.add_route(...)
web.run_app(app)
يثير هذا الرمز عددًا من الأسئلة ولديه عدد من العيوب:- كيفية تكوين التطبيق؟ كحد أدنى ، يجب عليك تحديد المضيف والمنفذ لتوصيل العملاء ، بالإضافة إلى معلومات الاتصال بقاعدة البيانات.
أحب حقًا حل هذه المشكلة بمساعدة الوحدة النمطية ConfigArgParse: فهي تمد المشكلة القياسية argparseوتسمح باستخدام وسيطات سطر الأوامر ومتغيرات البيئة (التي لا غنى عنها لتكوين حاويات Docker) وحتى ملفات التكوين (بالإضافة إلى دمج هذه الأساليب) للتكوين. باستخدامه ConfigArgParse، يمكنك أيضًا التحقق من قيم معلمات تكوين التطبيق.
مثال على معلمات المعالجة باستخدام ConfigArgParsefrom aiohttp import web
from configargparse import ArgumentParser, ArgumentDefaultsHelpFormatter
from analyzer.utils.argparse import positive_int
parser = ArgumentParser(
auto_env_var_prefix='ANALYZER_',
formatter_class=ArgumentDefaultsHelpFormatter
)
parser.add_argument('--api-address', default='0.0.0.0',
help='IPv4/IPv6 address API server would listen on')
parser.add_argument('--api-port', type=positive_int, default=8081,
help='TCP port API server would listen on')
def main():
args = parser.parse_args()
app = web.Application()
web.run_app(app, host=args.api_address, port=args.api_port)
if __name__ == '__main__':
main()
, ConfigArgParse, argparse, ( -h --help). :
$ python __main__.py --help
usage: __main__.py [-h] [--api-address API_ADDRESS] [--api-port API_PORT]
If an arg is specified in more than one place, then commandline values override environment variables which override defaults.
optional arguments:
-h, --help show this help message and exit
--api-address API_ADDRESS
IPv4/IPv6 address API server would listen on [env var: ANALYZER_API_ADDRESS] (default: 0.0.0.0)
--api-port API_PORT TCP port API server would listen on [env var: ANALYZER_API_PORT] (default: 8081)
- — , «» . , .
os.environ.clear(), Python (, asyncio?), , ConfigArgParser.
import os
from typing import Callable
from configargparse import ArgumentParser
from yarl import URL
from analyzer.api.app import create_app
from analyzer.utils.pg import DEFAULT_PG_URL
ENV_VAR_PREFIX = 'ANALYZER_'
parser = ArgumentParser(auto_env_var_prefix=ENV_VAR_PREFIX)
parser.add_argument('--pg-url', type=URL, default=URL(DEFAULT_PG_URL),
help='URL to use to connect to the database')
def clear_environ(rule: Callable):
"""
,
rule
"""
for name in filter(rule, tuple(os.environ)):
os.environ.pop(name)
def main():
args = parser.parse_args()
clear_environ(lambda i: i.startswith(ENV_VAR_PREFIX))
app = create_app(args)
...
if __name__ == '__main__':
main()
- stderr/ .
9 , logging.basicConfig() stderr.
, . aiomisc.
aiomiscimport logging
from aiomisc.log import basic_config
basic_config(logging.DEBUG, buffered=True)
- , ? ,
fork , (, Windows ).
import os
from sys import argv
import forklib
from aiohttp.web import Application, run_app
from aiomisc import bind_socket
from setproctitle import setproctitle
def main():
sock = bind_socket(address='0.0.0.0', port=8081, proto_name='http')
setproctitle(f'[Master] {os.path.basename(argv[0])}')
def worker():
setproctitle(f'[Worker] {os.path.basename(argv[0])}')
app = Application()
run_app(app, sock=sock)
forklib.fork(os.cpu_count(), worker, auto_restart=True)
if __name__ == '__main__':
main()
- - ? , ( — ) ,
nobody. — .
import os
import pwd
from aiohttp.web import run_app
from aiomisc import bind_socket
from analyzer.api.app import create_app
def main():
sock = bind_socket(address='0.0.0.0', port=8085, proto_name='http')
user = pwd.getpwnam('nobody')
os.setgid(user.pw_gid)
os.setuid(user.pw_uid)
app = create_app(...)
run_app(app, sock=sock)
if __name__ == '__main__':
main()
create_app, .
سيتم إرجاع جميع استجابات المعالج الناجحة بتنسيق JSON. سيكون من الملائم أيضًا للعملاء تلقي معلومات حول الأخطاء في نموذج متسلسل (على سبيل المثال ، لمعرفة الحقول التي لم تنجح في التحقق من الصحة). تقدمالوثائق aiohttpطريقة json_responseتأخذ كائنًا ، تسلسله في JSON ، وترجع كائنًا جديدًا aiohttp.web.Responseبرأس Content-Type: application/jsonوبيانات متسلسلة بداخله.كيفية إجراء تسلسل للبيانات باستخدام json_responsefrom aiohttp.web import Application, View, run_app
from aiohttp.web_response import json_response
class SomeView(View):
async def get(self):
return json_response({'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
ولكن هناك طريقة أخرى: aiohttp يسمح لك بتسجيل مُسلسِل عشوائي لنوع محدد من بيانات الاستجابة في التسجيل aiohttp.PAYLOAD_REGISTRY. على سبيل المثال ، يمكنك تحديد مُسلسِل aiohttp.JsonPayloadلكائنات من نوع التعيين .في هذه الحالة ، سيكون كافيًا أن يقوم المعالج بإرجاع كائن Responseببيانات الاستجابة في المعلمة body. سيعثر aiohttp على مُسلسل يطابق نوع البيانات ويسلسل الاستجابة.بالإضافة إلى حقيقة أن تسلسل الكائنات موصوف في مكان واحد ، فإن هذا النهج أكثر مرونة أيضًا - فهو يسمح لك بتنفيذ حلول مثيرة للاهتمام للغاية (سننظر في إحدى حالات الاستخدام في المعالج GET /imports/$import_id/citizens).كيفية إجراء تسلسل للبيانات باستخدام aiohttp.PAYLOAD_REGISTRYfrom types import MappingProxyType
from typing import Mapping
from aiohttp import PAYLOAD_REGISTRY, JsonPayload
from aiohttp.web import run_app, Application, Response, View
PAYLOAD_REGISTRY.register(JsonPayload, (Mapping, MappingProxyType))
class SomeView(View):
async def get(self):
return Response(body={'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
من المهم أن نفهم أن json_responseمثل aiohttp.JsonPayload، فإنها تستخدم معيار طريقة json.dumpsالتي يمكن أن أنواع البيانات يست معقدة تسلسل، على سبيل المثال، datetime.dateأو asyncpg.Record( asyncpgعوائد السجلات من قاعدة البيانات كما مثيلات هذه الفئة). علاوة على ذلك ، قد تحتوي بعض الكائنات المعقدة على أشياء أخرى: في سجل واحد من قاعدة البيانات قد يكون هناك حقل نوع datetime.date.عالج مطورو Python هذه المشكلة: json.dumpsتتيح لك الطريقة استخدام الوسيطة defaultلتحديد دالة يتم استدعاؤها عندما يكون من الضروري إجراء تسلسل لكائن غير مألوف. يُتوقع أن تقوم الوظيفة بإرسال كائن غير مألوف إلى نوع يمكنه إجراء تسلسل لوحدة json.كيفية تمديد JsonPayload لتسلسل الأشياء التعسفيةimport json
from datetime import date
from functools import partial, singledispatch
from typing import Any
from aiohttp.payload import JsonPayload as BaseJsonPayload
from aiohttp.typedefs import JSONEncoder
@singledispatch
def convert(value):
raise NotImplementedError(f'Unserializable value: {value!r}')
@convert.register(Record)
def convert_asyncpg_record(value: Record):
"""
,
asyncpg
"""
return dict(value)
@convert.register(date)
def convert_date(value: date):
"""
date —
.
..
"""
return value.strftime('%d.%m.%Y')
dumps = partial(json.dumps, default=convert)
class JsonPayload(BaseJsonPayload):
def __init__(self,
value: Any,
encoding: str = 'utf-8',
content_type: str = 'application/json',
dumps: JSONEncoder = dumps,
*args: Any,
**kwargs: Any) -> None:
super().__init__(value, encoding, content_type, dumps, *args, **kwargs)
معالجات
يسمح لك aiohttp بتنفيذ معالجات بوظائف وفئات غير متزامنة. تعد الفصول أكثر قابلية للتوسعة: أولاً ، يمكن وضع الرمز الذي ينتمي إلى معالج واحد في مكان واحد ، وثانيًا ، تسمح لك الفئات باستخدام الوراثة للتخلص من تكرار التعليمات البرمجية (على سبيل المثال ، يتطلب كل معالج اتصال قاعدة بيانات).فئة قاعدة المعالجfrom aiohttp.web_urldispatcher import View
from asyncpgsa import PG
class BaseView(View):
URL_PATH: str
@property
def pg(self) -> PG:
return self.request.app['pg']
نظرًا لصعوبة قراءة ملف واحد كبير ، فقد قررت تقسيم المعالجات إلى ملفات. تشجع الملفات الصغيرة على ضعف الاتصال ، وإذا كانت هناك ، على سبيل المثال ، عمليات استيراد حلقية داخل المعالجات ، فهذا يعني أن شيئًا ما قد يكون خطأ في تكوين الكيانات.ما بعد / الواردات
يتلقى معالج الإدخال json مع بيانات حول السكان. الحد الأقصى المسموح به حجم الطلب ويتم التحكم في aiohttp بواسطة الخيار client_max_sizeو هو 2 MB افتراضيا . إذا تم تجاوز الحد ، فسوف يعرض aiohttp استجابة HTTP بالحالة 413: طلب كيان خطأ كبير جدًا.في الوقت نفسه ، سيبلغ حجم json الصحيح مع أطول الخطوط والأرقام ~ 63 ميغابايت ، لذا يجب توسيع القيود على حجم الطلب.بعد ذلك ، تحتاج إلى التحقق من البيانات وإلغاء تسلسلها . إذا كانت غير صحيحة ، فستحتاج إلى إرجاع استجابة HTTP 400: Bad Request.كنت بحاجة إلى نظامين Marhsmallow. الأول CitizenSchema، يتحقق من بيانات كل فرد مقيم ، ويزيل أيضًا سلسلة عيد ميلاد سعيد إلى الكائن datetime.date:- نوع البيانات وتنسيق وتوافر جميع الحقول المطلوبة ؛
- عدم وجود حقول غير مألوفة ؛
- يجب تحديد تاريخ الميلاد بالصيغة
DD.MM.YYYYولا يمكن أن يكون له أي أهمية من المستقبل ؛ - يجب أن تحتوي قائمة أقارب كل مقيم على معرفات فريدة للمقيمين الموجودين في هذا التحميل.
المخطط الثاني ImportSchema، يتحقق من التفريغ ككل:citizen_id يجب أن يكون كل مقيم في التفريغ فريدًا ؛- يجب أن تكون الروابط العائلية ثنائية الاتجاه (إذا كان المقيم رقم 1 لديه مقيم رقم 2 في قائمة الأقارب ، فيجب أن يكون للمقيم رقم 2 أيضًا قريب رقم 1).
إذا كانت البيانات صحيحة ، فيجب إضافتها إلى قاعدة البيانات بقاعدة جديدة فريدة import_id.لإضافة البيانات ، ستحتاج إلى إجراء العديد من الاستعلامات في جداول مختلفة. لتجنب البيانات المضافة جزئيًا جزئيًا في قاعدة البيانات في حالة حدوث خطأ أو استثناء (على سبيل المثال ، عند قطع اتصال عميل لم يتلق استجابة كاملة ، سيقوم aiohttp بطرح استثناء CancelledError ) ، يجب عليك استخدام معاملة .من الضروري إضافة البيانات إلى الجداول في أجزاء ، لأنه في استعلام واحد إلى PostgreSQL لا يمكن أن يكون هناك أكثر من 32767 وسيطة. يوجد citizens9 حقول في الجدول . وفقًا لذلك ، بالنسبة لاستعلام واحد ، يمكن فقط إدراج 32،767 / 9 = 3،640 صفًا في هذا الجدول ، وفي عملية تحميل واحدة يمكن أن يصل عدد سكانها إلى 10000.الحصول على / الواردات / $ import_id / المواطنين
يقوم المعالج بإرجاع كافة المقيمين لتفريغ مع المحدد import_id. إذا كان التحميل المحدد غير موجود ، فيجب عليك إرجاع استجابة 404: لم يتم العثور على HTTP. يبدو أن هذا السلوك شائع بالنسبة للمعالجات التي تحتاج إلى إلغاء تحميل موجود ، لذلك قمت بسحب رمز التحقق إلى فصل دراسي منفصل.الفئة الأساسية للمعالجات التي تحتوي على حمولاتfrom aiohttp.web_exceptions import HTTPNotFound
from sqlalchemy import select, exists
from analyzer.db.schema import imports_table
class BaseImportView(BaseView):
@property
def import_id(self):
return int(self.request.match_info.get('import_id'))
async def check_import_exists(self):
query = select([
exists().where(imports_table.c.import_id == self.import_id)
])
if not await self.pg.fetchval(query):
raise HTTPNotFound()
للحصول على قائمة أقارب لكل مقيم ، ستحتاج إلى إجراء LEFT JOINمن جدول citizensإلى جدول relations، وتجميع الحقل relations.relative_idمجمعة حسب import_idو citizen_id.إذا لم يكن للمقيم أقارب ، LEFT JOINفسوف يعيد relations.relative_idالقيمة له في الحقل NULL، ونتيجة للتجمع ، ستبدو قائمة الأقارب [NULL].لإصلاح هذه القيمة غير الصحيحة ، استخدمت الدالة array_remove .تخزن قاعدة البيانات التاريخ بتنسيق YYYY-MM-DD، ولكننا بحاجة إلى تنسيق DD.MM.YYYY.من الناحية الفنية ، يمكنك تنسيق التاريخ إما باستخدام استعلام SQL أو على جانب Python في وقت إجراء تسلسل الاستجابة باستخدام json.dumps(إرجاع asyncpg قيمة الحقل birth_dateكمثيل للفئةdatetime.date)لقد اخترت التسلسل على جانب Python ، نظرًا لأنه birth_dateالكائن الوحيد datetime.dateفي المشروع بتنسيق واحد (انظر قسم "تسلسل البيانات" ).على الرغم من حقيقة أن المعالج ينفذ طلبين (التحقق من وجود تفريغ وطلب للحصول على قائمة بالمقيمين) ، ليس من الضروري استخدام معاملة . بشكل افتراضي ، يستخدم PostgreSQL مستوى العزل ، READ COMMITTEDوحتى في إحدى المعاملات ، ستكون جميع التغييرات على المعاملات الأخرى المكتملة بنجاح مرئية (إضافة صفوف جديدة وتغيير القائمة).يمكن أن يستغرق التحميل الأكبر في عرض النص حوالي 63 ميغابايت - وهذا كثير جدًا ، خاصة بالنظر إلى أن العديد من الطلبات لاستلام البيانات قد تصل في نفس الوقت. هناك طريقة مثيرة للاهتمام للحصول على البيانات من قاعدة البيانات باستخدام المؤشر وإرسالها إلى العميل في أجزاء .للقيام بذلك ، نحتاج إلى تنفيذ شيئين:- عنصر
SelectQueryنوع يقوم AsyncIterableبارجاع السجلات من قاعدة البيانات. في المكالمة الأولى ، يتصل بقاعدة البيانات ، ويفتح المعاملات وينشئ المؤشر ؛ وأثناء التكرار الإضافي ، يقوم بإرجاع السجلات من قاعدة البيانات. يتم إرجاعها بواسطة المعالج.
حدد رمز الاستعلامfrom collections import AsyncIterable
from asyncpgsa.transactionmanager import ConnectionTransactionContextManager
from sqlalchemy.sql import Select
class SelectQuery(AsyncIterable):
"""
, PostgreSQL
, ,
"""
PREFETCH = 500
__slots__ = (
'query', 'transaction_ctx', 'prefetch', 'timeout'
)
def __init__(self, query: Select,
transaction_ctx: ConnectionTransactionContextManager,
prefetch: int = None,
timeout: float = None):
self.query = query
self.transaction_ctx = transaction_ctx
self.prefetch = prefetch or self.PREFETCH
self.timeout = timeout
async def __aiter__(self):
async with self.transaction_ctx as conn:
cursor = conn.cursor(self.query, prefetch=self.prefetch,
timeout=self.timeout)
async for row in cursor:
yield row
- مُسلسل
AsyncGenJSONListPayloadيمكنه التكرار عبر المولدات غير المتزامنة ، وتسلسل البيانات من المولد غير المتزامن إلى JSON وإرسال البيانات إلى العملاء في أجزاء. يتم تسجيله aiohttp.PAYLOAD_REGISTRYكمسلسل للأشياء AsyncIterable.
كود AsyncGenJSONListPayloadimport json
from functools import partial
from aiohttp import Payload
dumps = partial(json.dumps, default=convert, ensure_ascii=False)
class AsyncGenJSONListPayload(Payload):
"""
AsyncIterable,
JSON
"""
def __init__(self, value, encoding: str = 'utf-8',
content_type: str = 'application/json',
root_object: str = 'data',
*args, **kwargs):
self.root_object = root_object
super().__init__(value, content_type=content_type, encoding=encoding,
*args, **kwargs)
async def write(self, writer):
await writer.write(
('{"%s":[' % self.root_object).encode(self._encoding)
)
first = True
async for row in self._value:
if not first:
await writer.write(b',')
else:
first = False
await writer.write(dumps(row).encode(self._encoding))
await writer.write(b']}')
علاوة على ذلك ، في المعالج سيكون من الممكن إنشاء كائن SelectQuery، وتمرير استعلام SQL ووظيفة له لفتح المعاملة ، وإعادته إلى Response body:رمز المعالج
from aiohttp.web_response import Response
from aiohttp_apispec import docs, response_schema
from analyzer.api.schema import CitizensResponseSchema
from analyzer.db.schema import citizens_table as citizens_t
from analyzer.utils.pg import SelectQuery
from .query import CITIZENS_QUERY
from .base import BaseImportView
class CitizensView(BaseImportView):
URL_PATH = r'/imports/{import_id:\d+}/citizens'
@docs(summary=' ')
@response_schema(CitizensResponseSchema())
async def get(self):
await self.check_import_exists()
query = CITIZENS_QUERY.where(
citizens_t.c.import_id == self.import_id
)
body = SelectQuery(query, self.pg.transaction())
return Response(body=body)
aiohttpيكشف aiohttp.PAYLOAD_REGISTRYالتسلسل المسجل AsyncGenJSONListPayloadلكائنات من النوع في التسجيل AsyncIterable. ثم يقوم المتسلسل بتكرار الكائن SelectQueryوإرسال البيانات إلى العميل. في المكالمة الأولى ، SelectQueryيتلقى الكائن اتصالاً بقاعدة البيانات ، ويفتح معاملة وينشئ المؤشر ؛ وأثناء التكرار الإضافي ، سيتلقى بيانات من قاعدة البيانات مع المؤشر ويعيدها سطراً بسطر.يسمح هذا النهج بعدم تخصيص ذاكرة لكامل البيانات مع كل طلب ، ولكن له خصوصية: لن يتمكن التطبيق من إعادة حالة HTTP المقابلة إلى العميل في حالة حدوث خطأ (بعد كل شيء ، حالة HTTP ، تم إرسال الرؤوس بالفعل إلى العميل ، ويتم كتابة البيانات).عندما يحدث استثناء ، لم يبق شيء سوى قطع الاتصال. يمكن بالطبع تأمين استثناء ، ولكن لن يتمكن العميل من فهم الخطأ الذي حدث بالضبط.من ناحية أخرى ، قد تنشأ حالة مماثلة حتى إذا كان المعالج يتلقى جميع البيانات من قاعدة البيانات ، ولكن الشبكة يومض أثناء نقل البيانات إلى العميل - لا أحد في مأمن من ذلك.التصحيح / الواردات / $ import_id / للمواطنين / $ مواطن_المعروف
يتلقى المعالج معرف التفريغ ، import_idالمقيم citizen_id، وكذلك json مع البيانات الجديدة حول المقيم. في حالة وجود تفريغ غير موجود أو مقيم ، يجب إرجاع استجابة HTTP 404: Not Found.يجب التحقق من البيانات المرسلة من قبل العميل وإلغاء تسلسلها . إذا كانت غير صحيحة ، يجب عليك إرجاع استجابة HTTP 400: Bad Request. نفذت مخطط Marshmallow PatchCitizenSchemaيتحقق:- نوع وتنسيق البيانات للحقول المحددة.
- تاريخ الولادة. يجب تحديده بتنسيق
DD.MM.YYYYولا يمكن أن يكون ذا أهمية من المستقبل. - قائمة أقارب كل مقيم. يجب أن يكون لها معرفات فريدة للمقيمين.
relativesلا يمكن التحقق من وجود الأقارب المشار إليهم في الحقل بشكل منفصل: إذا تمت إضافة relationsمقيم غير موجود إلى الجدول ، فسوف تُرجع PostgreSQL خطأً ForeignKeyViolationErrorيمكن معالجته ويمكن إرجاع حالة HTTP 400: Bad Request.ما هي الحالة التي يجب إرجاعها إذا أرسل العميل بيانات غير صحيحة لمقيم غير موجود أو تفريغ ؟ من الأصح دلالة للتحقق أولاً من وجود تفريغ ومقيم (إذا لم يكن هناك ، عودة 404: Not Found) وعندئذ فقط ما إذا كان العميل قد أرسل البيانات الصحيحة (إن لم يكن ، العودة 400: Bad Request). عمليًا ، غالبًا ما يكون التحقق من البيانات أولاً أرخص ، وفقط إذا كانت صحيحة ، قم بالوصول إلى قاعدة البيانات.كلا الخيارين مقبول ، لكنني قررت اختيار خيار ثاني أرخص ، لأن نتيجة العملية على أي حال هي خطأ لا يؤثر على أي شيء (سيقوم العميل بتصحيح البيانات ثم يكتشف أيضًا أن المقيم غير موجود).إذا كانت البيانات صحيحة ، فمن الضروري تحديث المعلومات حول المقيم في قاعدة البيانات . في المعالج ، ستحتاج إلى إجراء العديد من الاستعلامات لجداول مختلفة. في حالة حدوث خطأ أو استثناء ، يجب التراجع عن التغييرات التي تم إجراؤها على قاعدة البيانات ، لذا يجب إجراء الاستعلامات في المعاملة . تسمح لكالطريقة PATCH بنقل بعض الحقول فقط للمقيم.يجب كتابة المعالج بطريقة لا تتعطل عند الوصول إلى البيانات التي لم يحددها العميل ، ولا يقوم أيضًا بتنفيذ الاستعلامات على الجداول التي لم تتغير فيها البيانات.إذا حدد العميل الحقل relatives، فمن الضروري الحصول على قائمة بالأقارب الحاليين. إذا تم تغييره ، حدد السجلات التي relativesيجب حذفها من الجدول وأيها يجب إضافتها من أجل جعل قاعدة البيانات تتماشى مع طلب العميل. بشكل افتراضي ، يستخدم PostgreSQL عزل المعاملات READ COMMITTED. وهذا يعني أنه كجزء من المعاملة الحالية ، ستكون التغييرات مرئية للسجلات الحالية (وكذلك الجديدة) للمعاملات المكتملة الأخرى. هذا يمكن أن يؤدي إلى حالة سباق بين الطلبات التنافسية .افترض أن هناك تفريغ مع السكان#1. #2، #3دون القرابة. تتلقى الخدمة طلبين متزامنين لتغيير المقيم رقم 1: {"relatives": [2]}و {"relatives": [3]}. سيقوم aiohttp بإنشاء معالجين يستقبلان في الوقت نفسه الحالة الحالية للمقيم من PostgreSQL.لن يكتشف كل معالج علاقة واحدة ذات صلة وسيقرر إضافة علاقة جديدة مع القريب المحدد. نتيجة لذلك ، المقيم رقم 1 لديه نفس مجال الأقارب [2,3]. لا يمكن وصف هذا السلوك بأنه واضح. هناك خياران متوقعان لتقرير نتيجة السباق: لإكمال الطلب الأول فقط ، والثاني لإرجاع استجابة HTTP
لا يمكن وصف هذا السلوك بأنه واضح. هناك خياران متوقعان لتقرير نتيجة السباق: لإكمال الطلب الأول فقط ، والثاني لإرجاع استجابة HTTP409: Conflict(بحيث يكرر العميل الطلب) ، أو لتنفيذ الطلبات بدوره (سيتم معالجة الطلب الثاني فقط بعد اكتمال الأول).يمكن تنفيذ الخيار الأول عن طريق تشغيل وضع العزلSERIALIZABLE. إذا تمكن شخص بالفعل أثناء معالجة الطلب من تغيير البيانات وتنفيذها ، فسيتم طرح استثناء ، والذي يمكن معالجته وإرجاع حالة HTTP المقابلة.سيء هذا الحل - عدد كبير من الأقفال في PostgreSQL ، SERIALIZABLEسيعطي استثناء ، حتى إذا غيرت الاستعلامات التنافسية سجلات السكان من عمليات التفريغ المختلفة.يمكنك أيضًا استخدام آلية قفل التوصية . إذا حصلت على مثل هذا القفل import_id، فستكون الطلبات التنافسية لعمليات التفريغ المختلفة قادرة على العمل بالتوازي.لمعالجة الطلبات التنافسية في تحميل واحد ، يمكنك تنفيذ سلوك أي من الخيارات: pg_try_advisory_xact_lockتحاول الوظيفة الحصول على قفل وتقوم بإرجاع النتيجة المنطقية على الفور (إذا لم يكن من الممكن الحصول على القفل ، يمكن طرح استثناء) ، pg_advisory_xact_lockوتنتظر حتىيتوفر المورد للحظر (في هذه الحالة ، سيتم تنفيذ الطلبات بالتسلسل ، لقد استقرت على هذا الخيار).نتيجة لذلك ، يجب على المعالج إرجاع المعلومات الحالية حول المقيم المحدث . كان من الممكن قصر أنفسنا على إعادة البيانات من طلبه إلى العميل (نظرًا لأننا نعيد الرد على العميل ، فهذا يعني أنه لم تكن هناك استثناءات وتم إكمال جميع الطلبات بنجاح). أو - استخدم الكلمة الرئيسية RETURNING في الاستعلامات التي تعدل قاعدة البيانات وتولد استجابة من النتائج. لكن كلا النهجين لن يسمح لنا برؤية الحالة واختبارها مع سباق الدول.لم تكن هناك متطلبات تحميل عالية للخدمة ، لذلك قررت أن أطلب جميع البيانات عن المقيم مرة أخرى وأعيد للعميل نتيجة صادقة من قاعدة البيانات.الحصول على / الواردات / $ import_id / المواطنين / أعياد الميلاد
يقوم المعالج بحساب عدد الهدايا التي سيحصل عليها كل مقيم في التفريغ لأقاربه (الطلب الأول). يتم تجميع الرقم حسب الشهر للتحميل مع المحدد import_id. في حالة التحميل غير الموجود ، يجب إعادة استجابة HTTP 404: Not Found.هناك خياران للتنفيذ:- احصل على بيانات للمقيمين مع الأقارب من قاعدة البيانات ، وعلى جانب Python ، قم بتجميع البيانات حسب الشهر وإنشاء قوائم لتلك الأشهر التي لا توجد بيانات لها في قاعدة البيانات.
- تجميع طلب json في قاعدة البيانات وإضافة بذرة للأشهر المفقودة.
استقرت على الخيار الأول - يبدو بصريًا أكثر قابلية للفهم ودعمه. يمكن الحصول على عدد أعياد الميلاد في شهر معين بجعل JOINمن الجدول مع الروابط العائلية ( relations.citizen_id- المقيم الذي نعتبره أعياد ميلاد الأقارب) في الجدول citizens(يحتوي على تاريخ الميلاد الذي تريد الحصول على الشهر منه).يجب ألا تحتوي قيم الشهر على أصفار بادئة. قد يحتوي الشهر الذي تم الحصول عليه من الحقل birth_dateباستخدام الدالة date_partعلى صفر بادئ. لإزالته، أديت castل integerفي الاستعلام SQL.على الرغم من حقيقة أن المعالج يحتاج إلى تلبية طلبين (تحقق من وجود تفريغ والحصول على معلومات حول أعياد الميلاد والهدايا) ، فإن المعاملة غير مطلوبة .بشكل افتراضي ، تستخدم PostgreSQL وضع READ COMMITTED ، حيث تظهر جميع السجلات الجديدة (المضافة بواسطة المعاملات الأخرى) والسجلات الحالية (المعدلة بواسطة معاملات أخرى) في المعاملة الحالية بعد إتمامها بنجاح.على سبيل المثال ، إذا تمت إضافة تحميل جديد في وقت استلام البيانات ، فلن يؤثر ذلك على التحميلات الحالية. إذا تم تنفيذ طلب تغيير المقيم وقت استلام البيانات ، فإما أن البيانات لن تكون مرئية بعد (إذا لم تكتمل المعاملة المتغيرة للبيانات) ، أو ستكتمل المعاملة بالكامل وستكون جميع التغييرات مرئية على الفور. لن يتم انتهاك النزاهة التي تم الحصول عليها من قاعدة البيانات.الحصول على / الواردات / $ import_id / المدن / ستات / النسبة المئوية / العمر
يقوم المعالج بحساب النسب المئوية 50 و 75 و 99 من الأعمار (سنوات كاملة) للمقيمين حسب المدينة في العينة مع معرف الاستيراد المحدد. في حالة التحميل غير الموجود ، يجب إعادة استجابة HTTP 404: Not Found.على الرغم من حقيقة أن المعالج ينفذ طلبين (التحقق من وجود تفريغ والحصول على قائمة المقيمين) ، ليس من الضروري استخدام المعاملة .هناك خياران للتنفيذ:- احصل على عمر السكان من قاعدة البيانات ، مجمعة حسب المدينة ، ثم على جانب Python ، احسب النسب المئوية باستخدام numpy (الذي تم تحديده كمرجع في المهمة) وقرب ما يصل إلى منزلين عشريين.
- PostgreSQL: percentile_cont , SQL-, numpy .
يتطلب الخيار الثاني نقل بيانات أقل بين التطبيق و PostgreSQL ، ولكن ليس لديه مشكلة واضحة للغاية: في PostgreSQL ، التقريب رياضي ، ( SELECT ROUND(2.5)إرجاع 3) ، وفي Python - المحاسبة ، إلى أقرب عدد صحيح ( round(2.5)إرجاع 2).لاختبار المعالج ، يجب أن يكون التنفيذ هو نفسه في كل من PostgreSQL و Python (يبدو أن تنفيذ دالة بالتقريب الرياضي في Python أسهل). تجدر الإشارة إلى أنه عند حساب النسبة المئوية ، يمكن أن يعيد numpy و PostgreSQL أرقامًا مختلفة قليلاً ، ولكن بالنظر إلى التقريب ، لن يكون هذا الاختلاف ملحوظًا.اختبارات
ما الذي يجب التحقق منه في هذا التطبيق؟ أولاً ، أن المستوفين يلبون المتطلبات ويؤدون العمل المطلوب في بيئة قريبة قدر الإمكان من بيئة القتال. ثانيًا ، تعمل عمليات الترحيل التي تغير حالة قاعدة البيانات بدون أخطاء. ثالثًا ، هناك عدد من الوظائف الإضافية التي يمكن أيضًا تغطيتها بشكل صحيح من خلال الاختبارات.قررت استخدام إطار pytest بسبب مرونته وسهولة استخدامه. يوفر آلية قوية لتحضير البيئة للاختبارات - التركيبات ، أي تعمل مع مصممpytest.mark.fixtureيمكن تحديد أسماءهم بواسطة المعلمة في الاختبار. إذا اكتشف pytest معلمة باسم تثبيت في التعليق التوضيحي للاختبار ، فستقوم بتنفيذ هذه التركيبات وتمرير النتيجة في قيمة هذه المعلمة. وإذا كانت المباراة عبارة عن مولد ، فستأخذ معلمة الاختبار القيمة التي تم إرجاعها yield، وبعد انتهاء الاختبار ، سيتم تنفيذ الجزء الثاني من المباراة ، والذي يمكنه مسح الموارد أو إغلاق الاتصالات.بالنسبة لمعظم الاختبارات ، نحتاج إلى قاعدة بيانات PostgreSQL. لعزل الاختبارات عن بعضها البعض ، يمكنك إنشاء قاعدة بيانات منفصلة قبل كل اختبار ، وحذفها بعد التنفيذ.إنشاء قاعدة بيانات تركيبات لكل اختبارimport os
import uuid
import pytest
from sqlalchemy import create_engine
from sqlalchemy_utils import create_database, drop_database
from yarl import URL
from analyzer.utils.pg import DEFAULT_PG_URL
PG_URL = os.getenv('CI_ANALYZER_PG_URL', DEFAULT_PG_URL)
@pytest.fixture
def postgres():
tmp_name = '.'.join([uuid.uuid4().hex, 'pytest'])
tmp_url = str(URL(PG_URL).with_path(tmp_name))
create_database(tmp_url)
try:
yield tmp_url
finally:
drop_database(tmp_url)
def test_db(postgres):
"""
, PostgreSQL
"""
engine = create_engine(postgres)
assert engine.execute('SELECT 1').scalar() == 1
engine.dispose()
قامت وحدة sqlalchemy_utils بعمل رائع في هذه المهمة ، مع مراعاة ميزات قواعد البيانات وبرامج التشغيل المختلفة. على سبيل المثال ، لا يسمح PostgreSQL بالتنفيذ CREATE DATABASEفي كتلة المعاملات. عند إنشاء قاعدة بيانات ، فإنه sqlalchemy_utilsيترجم psycopg2(الذي عادة ما ينفذ جميع الطلبات في المعاملة) إلى وضع الإلغاء التلقائي.ميزة أخرى مهمة: إذا كان هناك عميل واحد على الأقل متصلاً بـ PostgreSQL ، فلا يمكن حذف قاعدة البيانات ، ولكن يتم sqlalchemy_utilsفصل جميع العملاء قبل حذف قاعدة البيانات. سيتم حذف قاعدة البيانات بنجاح حتى إذا توقف بعض الاختبارات مع الاتصالات النشطة لها.نحتاج إلى PostgreSQL في حالات مختلفة: لاختبار الترحيلات ، نحتاج إلى قاعدة بيانات نظيفة ، بينما تتطلب المعالجات تطبيق جميع عمليات الترحيل. يمكنك تغيير حالة قاعدة البيانات برمجيًا باستخدام أوامر Alembic ؛ فهي تتطلب كائن تكوين Alembic للاتصال بها.إنشاء كائن تكوين Alembic لاعبا اساسياfrom types import SimpleNamespace
import pytest
from analyzer.utils.pg import make_alembic_config
@pytest.fixture()
def alembic_config(postgres):
cmd_options = SimpleNamespace(config='alembic.ini', name='alembic',
pg_url=postgres, raiseerr=False, x=None)
return make_alembic_config(cmd_options)
يرجى ملاحظة أن التركيبات alembic_configلها معلمة postgres- pytestلا تسمح فقط بالإشارة إلى اعتماد الاختبار على التركيبات ، ولكن أيضًا إلى التبعيات بين التركيبات.تسمح لك هذه الآلية بفصل المنطق بمرونة وكتابة كود موجز للغاية وقابل لإعادة الاستخدام.معالجات
تتطلب معالجات الاختبار قاعدة بيانات مع الجداول وأنواع البيانات التي تم إنشاؤها. لتطبيق عمليات الترحيل ، يجب عليك استدعاء أمر الترقية Alembic برمجيًا. لتسمية ذلك ، تحتاج إلى كائن بتكوين Alembic ، الذي حددناه بالفعل بالتركيبات alembic_config. تبدو قاعدة البيانات مع عمليات الترحيل كيانًا مستقلاً تمامًا ، ويمكن تمثيلها على أنها تركيبات:from alembic.command import upgrade
@pytest.fixture
async def migrated_postgres(alembic_config, postgres):
upgrade(alembic_config, 'head')
return postgres
عندما يكون هناك العديد من عمليات الترحيل في المشروع ، قد يستغرق تطبيقهم لكل اختبار الكثير من الوقت. لتسريع العملية ، يمكنك إنشاء قاعدة بيانات مع عمليات الترحيل مرة واحدة ثم استخدامها كقالب .بالإضافة إلى قاعدة البيانات لاختبار المعالجات ، ستحتاج إلى تطبيق قيد التشغيل ، بالإضافة إلى عميل تم تكوينه للعمل مع هذا التطبيق. لتسهيل اختبار التطبيق ، أضع إنشائه في وظيفة create_appتتطلب تشغيل المعلمات: قاعدة بيانات ، ومنفذ لـ REST API ، وغيرها.يمكن أيضًا تمثيل الحجج لبدء تشغيل التطبيق على أنها تركيبات منفصلة. لإنشائها ، ستحتاج إلى تحديد المنفذ المجاني لتشغيل تطبيق الاختبار والعنوان إلى قاعدة البيانات المؤقتة التي تم ترحيلها.لتحديد المنفذ المجاني ، استخدمت aiomisc_unused_portالتركيب من حزمة aiomisc. سيكونالتثبيت القياسي aiohttp_unused_portجيدًا أيضًا ، ولكنه يُرجع وظيفة لتحديد المنافذ المجانية ، بينما aiomisc_unused_portيُرجع على الفور رقم المنفذ. بالنسبة لتطبيقنا ، نحتاج إلى تحديد منفذ مجاني واحد فقط ، لذلك قررت عدم كتابة سطر إضافي من التعليمات البرمجية مع مكالمة aiohttp_unused_port.@pytest.fixture
def arguments(aiomisc_unused_port, migrated_postgres):
return parser.parse_args(
[
'--log-level=debug',
'--api-address=127.0.0.1',
f'--api-port={aiomisc_unused_port}',
f'--pg-url={migrated_postgres}'
]
)
تتضمن جميع الاختبارات باستخدام معالجات طلبات إلى REST API ؛ aiohttpولا يلزم العمل مباشرة مع التطبيق . لذلك ، قمت بعمل تثبيت واحد يقوم بتشغيل التطبيق واستخدام المصنع aiohttp_clientيقوم بإنشاء وإرجاع عميل اختبار قياسي متصل بالتطبيق aiohttp.test_utils.TestClient.from analyzer.api.app import create_app
@pytest.fixture
async def api_client(aiohttp_client, arguments):
app = create_app(arguments)
client = await aiohttp_client(app, server_kwargs={
'port': arguments.api_port
})
try:
yield client
finally:
await client.close()
الآن ، إذا حددت تركيبات في معلمات الاختبار api_client، فسيحدث ما يلي:postgres ( migrated_postgres).alembic_config Alembic, ( migrated_postgres).migrated_postgres ( arguments).aiomisc_unused_port ( arguments).arguments ( api_client).api_client .- .
api_client .postgres .
تسمح لك التركيبات بتجنب تكرار التعليمات البرمجية ، ولكن بالإضافة إلى إعداد البيئة في الاختبارات ، هناك مكان محتمل آخر حيث سيكون هناك الكثير من نفس التعليمات البرمجية - طلبات التطبيق.أولاً ، عند تقديم طلب ، نتوقع الحصول على حالة HTTP معينة. ثانيًا ، إذا كانت الحالة تتطابق مع الحالة المتوقعة ، فقبل العمل مع البيانات ، تحتاج إلى التأكد من أن لديهم التنسيق الصحيح. من السهل ارتكاب خطأ هنا وكتابة معالج يقوم بإجراء العمليات الحسابية الصحيحة ويعيد النتيجة الصحيحة ، ولكنه لا ينجح في التحقق التلقائي بسبب تنسيق الاستجابة غير الصحيح (على سبيل المثال ، ننسى أن تلف الإجابة في القاموس بمفتاح data). كل هذه الفحوصات يمكن أن تتم في مكان واحد.في الوحدةanalyzer.testing لقد أعددت لكل مساعد وظيفة مساعد تتحقق من حالة HTTP ، بالإضافة إلى تنسيق الاستجابة باستخدام Marshmallow.الحصول على / الواردات / $ import_id / المواطنين
قررت أن أبدأ باستخدام معالج يقوم بإرجاع المقيمين ، لأنه مفيد للغاية للتحقق من نتائج معالجات أخرى تغير حالة قاعدة البيانات.عمدًا لم أستخدم رمزًا يضيف البيانات إلى قاعدة البيانات من المعالج POST /imports، على الرغم من أنه ليس من الصعب تحويلها إلى وظيفة منفصلة. يحتوي رمز المعالج على خاصية للتغيير ، وإذا كان هناك أي خطأ في الرمز يضيف إلى قاعدة البيانات ، فهناك احتمال أن يتوقف الاختبار عن العمل على النحو المنشود وسيتوقف المطورون ضمنيًا عن عرض الأخطاء.في هذا الاختبار ، حددت مجموعات بيانات الاختبار التالية:- التفريغ مع عدة أقارب. يتحقق من أنه سيتم تشكيل قائمة لكل مقيم مع معرفات الأقارب بشكل صحيح.
- التفريغ مع مقيم واحد بدون أقارب. للتحقق من أن الحقل
relativesعبارة عن قائمة فارغة (نظرًا LEFT JOINلاستعلام SQL ، قد تكون قائمة الأقارب متساوية [None]). - التفريغ مع مقيم من أقاربه.
- تفريغ فارغ. التحقق من أن المعالج يسمح بإضافة تفريغ فارغ ولا يتلف مع وجود خطأ.
لتشغيل نفس الاختبار بشكل منفصل في كل عملية تحميل ، استخدمت آلية pytest أخرى قوية جدًا - المعلمة . تسمح لك هذه الآلية بلف وظيفة الاختبار في الديكور pytest.mark.parametrizeووصفها المعلمات التي يجب أن تتخذها وظيفة الاختبار لكل حالة اختبار فردية.كيفية تحديد اختبارimport pytest
from analyzer.utils.testing import generate_citizen
datasets = [
[
generate_citizen(citizen_id=1, relatives=[2, 3]),
generate_citizen(citizen_id=2, relatives=[1]),
generate_citizen(citizen_id=3, relatives=[1])
],
[
generate_citizen(relatives=[])
],
[
generate_citizen(citizen_id=1, name='', gender='male',
birth_date='17.02.2020', relatives=[1])
],
[],
]
@pytest.mark.parametrize('dataset', datasets)
async def test_get_citizens(api_client, dataset):
"""
4 ,
"""
لذلك ، سيضيف الاختبار التحميل إلى قاعدة البيانات ، ثم ، باستخدام طلب إلى المعالج ، سيتلقى معلومات حول المقيمين ومقارنة التحميل المرجعي مع التحميل المستلم. ولكن كيف تقارن السكان؟يتكون كل مقيم من الحقول العددية وحقل relatives- قائمة معرفات الأقارب. القائمة في Python هي نوع مرتبة ، وعند مقارنة ترتيب عناصر كل قائمة ، ولكن عند مقارنة القوائم مع الأشقاء ، لا يهم الترتيب.إذا أحضرت relativesإلى المجموعة قبل المقارنة ، فعند المقارنة لا تعمل على إيجاد موقف حيث يوجد لدى أحد السكان في الميدان relativesتكرارات. إذا قمت بفرز القائمة بمعرفات الأقارب ، فسوف يتغلب هذا على مشكلة الترتيب المختلف لمعرفات الأقارب ، ولكن في نفس الوقت يكتشف التكرارات.عند مقارنة قائمتين مع المقيمين ، قد يواجه أحدهما مشكلة مماثلة: من الناحية الفنية ، ليس ترتيب السكان في التفريغ مهمًا ، ولكن من المهم اكتشاف ما إذا كان هناك ساكنان لهما نفس المعرفات في تفريغ واحد وليس في الآخر. لذلك بالإضافة إلى تنظيم القائمة مع الأقارب ، يحتاج الأقارب لكل مقيم إلى ترتيب السكان في كل تفريغ.نظرًا لأن مهمة مقارنة السكان ستنشأ أكثر من مرة ، فقد قمت بتنفيذ وظيفتين: واحدة لمقارنة اثنين من المقيمين ، والثانية لمقارنة قائمتين مع المقيمين:قارن بين السكانfrom typing import Iterable, Mapping
def normalize_citizen(citizen):
"""
"""
return {**citizen, 'relatives': sorted(citizen['relatives'])}
def compare_citizens(left: Mapping, right: Mapping) -> bool:
"""
"""
return normalize_citizen(left) == normalize_citizen(right)
def compare_citizen_groups(left: Iterable, right: Iterable) -> bool:
"""
,
"""
left = [normalize_citizen(citizen) for citizen in left]
left.sort(key=lambda citizen: citizen['citizen_id'])
right = [normalize_citizen(citizen) for citizen in right]
right.sort(key=lambda citizen: citizen['citizen_id'])
return left == right
للتأكد من أن هذا المعالج لا يعيد سكان عمليات التفريغ الأخرى ، قررت إضافة تفريغ إضافي مع ساكن واحد قبل كل اختبار.ما بعد / الواردات
قمت بتعريف مجموعات البيانات التالية لاختبار المعالج:- البيانات الصحيحة ، المتوقع إضافتها بنجاح إلى قاعدة البيانات.
- ( ).
. , , insert , . - ( , ).
, .
- .
, . :)
, aiohttp PostgreSQL 32 767 ( ).
- تفريغ فارغ
يجب على المعالج أن يأخذ في الاعتبار مثل هذه الحالة وألا يسقط ، محاولاً إجراء إدراج فارغ في الجدول مع السكان.
- البيانات التي بها أخطاء ، توقع استجابة HTTP 400: طلب غير صحيح.
- تاريخ الميلاد غير صحيح (زمن المستقبل).
- سيتيزنيد ليست فريدة في التحميل.
- يشار إلى القرابة بشكل غير صحيح (لا يوجد سوى من مقيم لآخر ، ولكن لا توجد تعليقات).
- المقيم لديه قريب غير موجود في التفريغ.
- العلاقات الأسرية ليست فريدة من نوعها.
إذا كان المعالج يعمل بنجاح وتمت إضافة البيانات ، فأنت بحاجة إلى إضافة المقيمين إلى قاعدة البيانات ومقارنتهم بالتفريغ القياسي. للحصول على المقيمين ، استخدمت المعالج الذي تم اختباره بالفعل GET /imports/$import_id/citizens، وللمقارنة ، وظيفة compare_citizen_groups.التصحيح / الواردات / $ import_id / للمواطنين / $ مواطن_المعروف
يشبه التحقق من صحة البيانات من نواح كثيرة تلك الموصوفة في المعالج POST /importsمع بعض الاستثناءات: هناك مقيم واحد فقط ويمكن للعميل فقط تمرير الحقول التي يريدها .قررت استخدام المجموعات التالية مع بيانات غير صحيحة للتحقق من أن المعالج سيعرض استجابة HTTP 400: Bad request:- تم تحديد الحقل ، ولكن به نوع بيانات و / أو تنسيق غير صحيح
- تاريخ الميلاد غير صحيح (في المستقبل).
relativesيحتوي الحقل على قريب غير موجود في التفريغ.
من الضروري أيضًا التحقق من أن المعالج يقوم بتحديث المعلومات بشكل صحيح عن المقيم وأقاربه.للقيام بذلك ، قم بإنشاء تحميل مع ثلاثة سكان ، اثنان منهم أقارب ، وأرسل طلبًا بقيم جديدة لجميع الحقول العددية ومعرف نسبي جديد في الحقل relatives.للتأكد من أن المعالج يميز بين سكان عمليات التفريغ المختلفة قبل الاختبار (وعلى سبيل المثال ، لا يغير السكان الذين لديهم نفس المعرفات من تفريغ آخر) ، قمت بإنشاء تفريغ إضافي مع ثلاثة سكان لديهم نفس المعرفات.يجب على المعالج حفظ القيم الجديدة للحقول العددية وإضافة قريب جديد محدد وإزالة العلاقة مع قريب قديم غير محدد. يجب أن تكون جميع التغييرات في القرابة ثنائية. يجب ألا تكون هناك تغييرات في عمليات التفريغ الأخرى.نظرًا لأن مثل هذا المعالج قد يخضع لظروف السباق (تمت مناقشة ذلك في قسم التطوير) ، أضفت اختبارين إضافيين . واحد يعيد إنتاج المشكلة مع حالة السباق (يمتد فئة المعالج ويزيل القفل) ، والثاني يثبت أن المشكلة مع حالة السباق لا تتكرر.الحصول على / الواردات / $ import_id / المواطنين / أعياد الميلاد
لاختبار هذا المعالج ، حددت مجموعات البيانات التالية:- تفريغ يكون للمقيم فيه قريب في شهر واحد واثنين من أقاربه في آخر.
- التفريغ مع مقيم واحد بدون أقارب. التحقق من أن المعالج لا يأخذها في الاعتبار في الحسابات.
- تفريغ فارغ. التحقق من أن المعالج لن يفشل وسيعيد القاموس الصحيح خلال 12 شهرًا من الاستجابة.
- التفريغ مع مقيم من أقاربه. الشيكات أن المقيم سيشتري هدية لشهر ولادته.
يجب على المعالج إرجاع كافة الأشهر في الاستجابة ، حتى إذا لم يكن هناك أعياد ميلاد في هذه الأشهر. لتجنب الازدواجية ، قمت بعمل وظيفة يمكنك تمرير القاموس إليها بحيث يكملها بقيم الأشهر المفقودة.للتأكد من أن المعالج يميز بين سكان عمليات التفريغ المختلفة ، أضفت تفريغًا إضافيًا مع اثنين من الأقارب. إذا استخدمها المعالج عن طريق الخطأ في الحسابات ، فستكون النتائج غير صحيحة وسيقع المعالج مع وجود خطأ.الحصول على / الواردات / $ import_id / المدن / ستات / النسبة المئوية / العمر
تكمن خصوصية هذا الاختبار في أن نتائج عمله تعتمد على الوقت الحالي: يتم حساب عمر السكان بناءً على التاريخ الحالي. للتأكد من أن نتائج الاختبار لا تتغير بمرور الوقت ، يجب تسجيل التاريخ الحالي وتواريخ ميلاد السكان والنتائج المتوقعة. هذا سيجعل من السهل إعادة إنتاج أي ، حتى حالات الحافة.ما هو أفضل تاريخ للتثبيت؟ في المعالج ، لحساب عمر المقيمين ، يتم استخدام وظيفة PostgreSQL AGE، والتي تأخذ المعلمة الأولى كتاريخ ضروري لحساب العمر ، والثانية كتاريخ أساسي (محدد بواسطة ثابت TownAgeStatView.CURRENT_DATE).نستبدل التاريخ الأساسي في المعالج بوقت الاختبارfrom unittest.mock import patch
import pytz
CURRENT_DATE = datetime(2020, 2, 17, tzinfo=pytz.utc)
@patch('analyzer.api.handlers.TownAgeStatView.CURRENT_DATE', new=CURRENT_DATE)
async def test_get_ages(...):
...
لاختبار المعالج ، حددت مجموعات البيانات التالية (لجميع المقيمين الذين أشرت إليهم في مدينة واحدة ، لأن المعالج يجمع النتائج حسب المدينة):- التفريغ مع العديد من السكان الذين غدا عيد ميلادهم (العمر - عدة سنوات و 364 يومًا). يتحقق من أن المعالج يستخدم عدد السنوات الكاملة فقط في الحسابات.
- التفريغ مع مقيم عيد ميلاده اليوم (العمر - بضع سنوات بالضبط). ويتحقق من الحالة الإقليمية - يجب ألا يحسب عمر المقيم الذي يكون عيد ميلاده اليوم مخفضًا بمقدار عام واحد.
- تفريغ فارغ. يجب ألا يقع المعالج عليه.
numpyالمعيار لحساب المئات - مع الاستكمال الخطي ، ونتائج الاختبار للاختبار الذي قمت بحسابه لهم.تحتاج أيضًا إلى تقريب القيم المئوية الكسرية إلى منزلتين عشريتين. إذا استخدمت PostgreSQL للتقريب في المعالج ، و Python لحساب البيانات المرجعية ، فقد تلاحظ أن التقريب في Python 3 و PostgreSQL يمكن أن يعطي نتائج مختلفة .على سبيل المثال# Python 3
round(2.5)
> 2
-- PostgreSQL
SELECT ROUND(2.5)
> 3
والحقيقة هي أن Python تستخدم التقريب البنكي إلى أقرب زوج ، وتستخدم PostgreSQL الرياضيات (نصف إلى نصف). إذا تم إجراء العمليات الحسابية والتقريب في PostgreSQL ، فسيكون من الصحيح استخدام التقريب الرياضي في الاختبارات أيضًا.في البداية وصفت مجموعات البيانات بتواريخ الميلاد بتنسيق نصي ، ولكن كان من غير الملائم قراءة اختبار بهذا التنسيق: في كل مرة كان عليّ حساب عمر كل ساكن في ذهني لكي أتذكر ما كانت مجموعة بيانات معينة تتحقق منه. بالطبع ، يمكنك الحصول على التعليقات في الكود ، لكنني قررت الذهاب إلى أبعد من ذلك قليلاً وكتبت وظيفة age2dateتسمح لك بوصف تاريخ الميلاد في شكل العمر: عدد السنوات والأيام.على سبيل المثال ، مثل هذاimport pytz
from analyzer.utils.testing import generate_citizen
CURRENT_DATE = datetime(2020, 2, 17, tzinfo=pytz.utc)
def age2date(years: int, days: int = 0, base_date=CURRENT_DATE) -> str:
birth_date = copy(base_date).replace(year=base_date.year - years)
birth_date -= timedelta(days=days)
return birth_date.strftime(BIRTH_DATE_FORMAT)
generate_citizen(birth_date='17.02.2009')
generate_citizen(birth_date=age2date(years=11))
للتأكد من أن المعالج يميز بين سكان عمليات التفريغ المختلفة ، أضفت تفريغًا إضافيًا مع أحد المقيمين من مدينة أخرى: إذا استخدمه المعالج عن طريق الخطأ ، ستظهر مدينة إضافية في النتائج وسيفشل الاختبار.حقيقة مثيرة للاهتمام: عندما كتبت هذا الاختبار في 29 فبراير 2020 ، توقفت فجأة عن توليد حمولات مع المقيمين بسبب خطأ في Faker (2020 هي سنة كبيسة ، والسنوات الأخرى التي اختارها Faker لم تكن دائمًا قفزة فيها أيضًا لم يكن 29 فبراير). تذكر تسجيل التواريخ وحالات حافة الاختبار!
الهجرات
يبدو رمز الهجرة للوهلة الأولى واضحًا والأقل عرضة للخطأ ، فلماذا نختبره؟ هذا خطأ خطير للغاية: يمكن أن تتجلى أكثر الأخطاء الخادعة للهجرة في أكثر الأوقات غير المناسبة. حتى إذا لم يفسدوا البيانات ، يمكن أن يتسببوا في تعطل غير ضروري. يغير الترحيل الأوليالموجود في المشروع بنية قاعدة البيانات ، ولكنه لا يغير البيانات. ما هي الأخطاء الشائعة التي يمكن حمايتها من مثل هذه الهجرات؟downgrade ( , , ).
, (--): , — .
- C .
- ( ).
سيتم اكتشاف معظم هذه الأخطاء عن طريق اختبار الدرج . فكرته - لاستخدام هجرة واحدة، وأداء باستمرار الأساليب upgrade، downgrade، upgradeلكل الهجرة. هذا الاختبار يكفي لإضافته إلى المشروع مرة واحدة ، ولا يتطلب دعمًا وسيخدم بأمانة.ولكن إذا كان الترحيل ، بالإضافة إلى الهيكل ، سيغير البيانات ، فسيكون من الضروري كتابة اختبار منفصل واحد على الأقل ، والتحقق من أن البيانات تتغير بشكل صحيح في الطريقة upgradeوتعود إلى الحالة الأولية في downgrade. فقط في حالة: مشروع بأمثلة لاختبار الهجرات المختلفة ، التي أعددتها لتقرير حول Alembic في موسكو بايثون.المجسم
الأداة النهائية التي سننشرها والتي نريد الحصول عليها نتيجة التجميع هي صورة Docker. للبناء ، يجب عليك تحديد الصورة الأساسية باستخدام Python. python:latestتزن الصورة الرسمية ~ 1 غيغابايت ، وإذا تم استخدامها كصورة أساسية ، فستكون الصورة مع التطبيق ضخمة. هناك صور تعتمد على نظام Alpine OS ، حجمه أصغر بكثير. ولكن مع العدد المتزايد من الحزم المثبتة ، سيزداد حجم الصورة النهائية ، ونتيجة لذلك ، لن تكون الصورة المجمعة على أساس جبال الألب صغيرة جدًا. اخترت snakepacker / python كصورة أساسية - فهي تزن أكثر بقليل من صور جبال الألب ، ولكنها تستند إلى Ubuntu ، التي تقدم مجموعة كبيرة من الحزم والمكتبات.طريق اخرقلل حجم الصورة مع التطبيق - لا تُدرج في الصورة النهائية المترجم والمكتبات والملفات التي تحتوي على رؤوس للتجميع ، وهي غير مطلوبة لكي يعمل التطبيق.للقيام بذلك ، يمكنك استخدام التجميع متعدد المراحل من Docker:- باستخدام صورة "ثقيلة"
snakepacker/python:all(~ 1 جيجا بايت ، ~ 500 ميجا بايت مضغوطة) ، قم بإنشاء بيئة افتراضية ، وقم بتثبيت كل التبعيات وحزمة التطبيق فيها. هذه الصورة مطلوبة حصريًا للتجميع ، ويمكن أن تحتوي على مترجم ، وجميع المكتبات والملفات الضرورية ذات الرؤوس.
FROM snakepacker/python:all as builder
RUN python3.8 -m venv /usr/share/python3/app
COPY dist/ /mnt/dist/
RUN /usr/share/python3/app/bin/pip install /mnt/dist/*
- نقوم بنسخ البيئة الافتراضية النهائية إلى صورة "خفيفة"
snakepacker/python:3.8(~ 100 ميجابايت ، مضغوطة ~ 50 ميجابايت) ، والتي تحتوي فقط على مترجم الإصدار المطلوب من Python.
هام: في البيئة الافتراضية ، يتم استخدام المسارات المطلقة ، لذلك يجب نسخها إلى نفس العنوان الذي تم تجميعها فيه في حاوية المجمع.
FROM snakepacker/python:3.8 as api
COPY --from=builder /usr/share/python3/app /usr/share/python3/app
RUN ln -snf /usr/share/python3/app/bin/analyzer-* /usr/local/bin/
CMD ["analyzer-api"]
ل تقليل الوقت الذي يستغرقه لبناء صورة ، يمكن تثبيت وحدات تعتمد التطبيق قبل تثبيته في بيئة افتراضية. ثم ستقوم Docker بتخزينها مؤقتًا ولن يتم إعادة تثبيتها إذا لم تتغير.ملف Dockerfile بالكامل
FROM snakepacker/python:all as builder
RUN python3.8 -m venv /usr/share/python3/app
RUN /usr/share/python3/app/bin/pip install -U pip
COPY requirements.txt /mnt/
RUN /usr/share/python3/app/bin/pip install -Ur /mnt/requirements.txt
COPY dist/ /mnt/dist/
RUN /usr/share/python3/app/bin/pip install /mnt/dist/* \
&& /usr/share/python3/app/bin/pip check
FROM snakepacker/python:3.8 as api
COPY --from=builder /usr/share/python3/app /usr/share/python3/app
RUN ln -snf /usr/share/python3/app/bin/analyzer-* /usr/local/bin/
CMD ["analyzer-api"]
لسهولة التجميع ، أضفت أمرًا make uploadيجمع صورة Docker ويحملها على hub.docker.com.Ci
الآن بعد أن تم تغطية الرمز بالاختبارات ويمكننا بناء صورة Docker ، حان الوقت لأتمتة هذه العمليات. أول شيء يتبادر إلى الذهن: إجراء اختبارات لإنشاء طلبات التجمع ، وعند إضافة التغييرات إلى الفرع الرئيسي ، قم بتجميع صورة Docker جديدة وتحميلها إلى Docker Hub (أو حزم GitHub ، إذا كنت لن تقوم بتوزيع الصورة علنًا).لقد قمت بحل هذه المشكلة مع GitHub Actions . للقيام بذلك ، كان من الضروري إنشاء ملف YAML في مجلد .github/workflowsووصف سير العمل فيه (مع مهمتين: testو publish) ، الذي قمت بتسميته CI. يتم تنفيذالمهمة في testكل مرة يتم فيها بدء سير العمل CI، باستخدام الخدماتتلتقط حاوية مع PostgreSQL ، تنتظر أن تصبح متاحة ، ويتم إطلاقها pytestفي الحاوية snakepacker/python:all. يتم تنفيذالمهمة publishفقط إذا تم إضافة التغييرات إلى الفرع masterوإذا كانت المهمة testناجحة. يجمع توزيع المصدر حسب الحاوية snakepacker/python:all، ثم يجمع ويحمل صورة Docker docker/build-push-action@v1.الوصف الكامل لسير العملname: CI
# Workflow
# - master
on:
push:
branches: [ master ]
pull_request:
branches: [ master ]
jobs:
# workflow
test:
runs-on: ubuntu-latest
services:
postgres:
image: docker://postgres
ports:
- 5432:5432
env:
POSTGRES_USER: user
POSTGRES_PASSWORD: hackme
POSTGRES_DB: analyzer
steps:
- uses: actions/checkout@v2
- name: test
uses: docker://snakepacker/python:all
env:
CI_ANALYZER_PG_URL: postgresql://user:hackme@postgres/analyzer
with:
args: /bin/bash -c "pip install -U '.[dev]' && pylama && wait-for-port postgres:5432 && pytest -vv --cov=analyzer --cov-report=term-missing tests"
# Docker-
publish:
# master
if: github.event_name == 'push' && github.ref == 'refs/heads/master'
# , test
needs: test
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: sdist
uses: docker://snakepacker/python:all
with:
args: make sdist
- name: build-push
uses: docker/build-push-action@v1
with:
username: ${{ secrets.REGISTRY_LOGIN }}
password: ${{ secrets.REGISTRY_TOKEN }}
repository: alvassin/backendschool2019
target: api
tags: 0.0.1, latest
الآن ، عند إضافة التغييرات إلى الشريحة الرئيسية في علامة التبويب الإجراءات على GitHub ، يمكنك رؤية بدء الاختبارات وتجميع وتحميل صورة Docker: وعند إنشاء طلب تجمع في الفرع الرئيسي ، سيتم أيضًا عرض نتائج المهمة فيه
وعند إنشاء طلب تجمع في الفرع الرئيسي ، سيتم أيضًا عرض نتائج المهمة فيه test:
نشر
لنشر التطبيق على الخادم المقدم ، تحتاج إلى تثبيت Docker و Docker Compose وبدء تشغيل الحاويات مع التطبيق و PostgreSQL وتطبيق عمليات الترحيل.يمكن أتمتة هذه الخطوات باستخدام نظام إدارة تكوين Ansible. إنه مكتوب بلغة Python ، ولا يتطلب وكلاء خاصين (يتصل مباشرة عبر ssh) ، ويستخدم قوالب jinja ويسمح بشكل صريح لوصف الحالة المطلوبة في ملفات YAML. يسمح لك النهج التصريحي بعدم التفكير في الحالة الحالية للنظام والإجراءات اللازمة لإحضار النظام إلى الحالة المطلوبة. كل هذا العمل يقع على أكتاف وحدات Ansible.يسمح لك Ansible بتجميع المهام ذات الصلة المنطقية في أدوار ثم إعادة استخدامها. سنحتاج دورين:docker(تثبيت وتكوين Docker) و analyzer(تثبيت وتكوين التطبيق). يضيفالدورdocker مستودعًا مع Docker إلى النظام ، ويقوم بتثبيت وتكوين الحزم docker-ceو docker-compose.بشكل اختياري ، يمكنك تعيين REST API للاستئناف تلقائيًا بعد إعادة تشغيل الخادم. يتيح لك Ubuntu حل هذه المشكلة بمساعدة نظام التهيئة systemd. يتحكم في الوحدات التي تمثل الموارد المختلفة (الشياطين والمآخذ ونقاط التحميل وغيرها). لإضافة وحدة جديدة إلى systemd ، يجب عليك وصف تكوينها في ملف خدمة. منفصل ووضع هذا الملف في أحد المجلدات الخاصة ، على سبيل المثال ، في /etc/systemd/system. ثم يمكن تشغيل الوحدة ، بالإضافة إلى تمكين التحميل التلقائي لها.صفقةdocker-ceأثناء التثبيت ، سيقوم تلقائيًا بإنشاء ملف بتكوين الوحدة - ما عليك سوى التأكد من تشغيله وتشغيله عند بدء تشغيل النظام. docker-compose@.serviceسيتم إنشاء Docker Compose بواسطة Ansible. يشير الرمز الموجود @في الاسم إلى systemd أن الوحدة عبارة عن قالب. يتيح لك ذلك بدء الخدمة docker-composeباستخدام معلمة - على سبيل المثال ، باسم خدمتنا ، والتي سيتم استبدالها بدلاً من %iملف تكوين الوحدة:[Unit]
Description=%i service with docker compose
Requires=docker.service
After=docker.service
[Service]
Type=oneshot
RemainAfterExit=true
WorkingDirectory=/etc/docker/compose/%i
ExecStart=/usr/local/bin/docker-compose up -d --remove-orphans
ExecStop=/usr/local/bin/docker-compose down
[Install]
WantedBy=multi-user.target
سيقوم الدورanalyzer بإنشاء ملف من القالب docker-compose.ymlعلى العنوان /etc/docker/compose/analyzerوتسجيل التطبيق كخدمة يتم تشغيلها تلقائيًا systemdوتطبيق الترحيل. عندما تكون الأدوار جاهزة ، تحتاج إلى وصف كتاب اللعب.---
- name: Gathering facts
hosts: all
become: yes
gather_facts: yes
- name: Install docker
hosts: docker
become: yes
gather_facts: no
roles:
- docker
- name: Install analyzer
hosts: api
become: yes
gather_facts: no
roles:
- analyzer
يمكن تحديد قائمة المضيفين ، بالإضافة إلى المتغيرات المستخدمة في الأدوار ، في ملف الجرد hosts.ini.[api]
130.193.51.154
[docker:children]
api
[api:vars]
analyzer_image = alvassin/backendschool2019
analyzer_pg_user = user
analyzer_pg_password = hackme
analyzer_pg_dbname = analyzer
بعد أن تصبح جميع الملفات Ansible جاهزة ، قم بتشغيلها:$ ansible-playbook -i hosts.ini deploy.yml
حول اختبار الإجهاد, , . , -
. : , — , 10 . , (, , CI-): .
, , , 10 . ? , , . , , .
RPS, : . , ,
import_id,
POST /imports . .
, Python 3,
Locust.
,
locustfile.py locust. - .
Locust . , .
self.round .
locustfile.py
import logging
from http import HTTPStatus
from locust import HttpLocust, constant, task, TaskSet
from locust.exception import RescheduleTask
from analyzer.api.handlers import (
CitizenBirthdaysView, CitizensView, CitizenView, TownAgeStatView
)
from analyzer.utils.testing import generate_citizen, generate_citizens, url_for
class AnalyzerTaskSet(TaskSet):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.round = 0
def make_dataset(self):
citizens = [
generate_citizen(citizen_id=1, relatives=[2]),
generate_citizen(citizen_id=2, relatives=[1]),
*generate_citizens(citizens_num=9998, relations_num=1000,
start_citizen_id=3)
]
return {citizen['citizen_id']: citizen for citizen in citizens}
def request(self, method, path, expected_status, **kwargs):
with self.client.request(
method, path, catch_response=True, **kwargs
) as resp:
if resp.status_code != expected_status:
resp.failure(f'expected status {expected_status}, '
f'got {resp.status_code}')
logging.info(
'round %r: %s %s, http status %d (expected %d), took %rs',
self.round, method, path, resp.status_code, expected_status,
resp.elapsed.total_seconds()
)
return resp
def create_import(self, dataset):
resp = self.request('POST', '/imports', HTTPStatus.CREATED,
json={'citizens': list(dataset.values())})
if resp.status_code != HTTPStatus.CREATED:
raise RescheduleTask
return resp.json()['data']['import_id']
def get_citizens(self, import_id):
url = url_for(CitizensView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens')
def update_citizen(self, import_id):
url = url_for(CitizenView.URL_PATH, import_id=import_id, citizen_id=1)
self.request('PATCH', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens/{citizen_id}',
json={'relatives': [i for i in range(3, 10)]})
def get_birthdays(self, import_id):
url = url_for(CitizenBirthdaysView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens/birthdays')
def get_town_stats(self, import_id):
url = url_for(TownAgeStatView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/towns/stat/percentile/age')
@task
def workflow(self):
self.round += 1
dataset = self.make_dataset()
import_id = self.create_import(dataset)
self.get_citizens(import_id)
self.update_citizen(import_id)
self.get_birthdays(import_id)
self.get_town_stats(import_id)
class WebsiteUser(HttpLocust):
task_set = AnalyzerTaskSet
wait_time = constant(1)
100 c , , :

, ( — 95 , — ). .

— Ansible ~20.15 ~20.30 Locust.

ما الذي يمكن فعله أيضًا؟
أظهر الملف الشخصي للتطبيق أن حوالي ربع إجمالي وقت تنفيذ طلب البحث يتم إنفاقه على تسلسل JSON وإلغاء تسلسله: هناك الكثير من البيانات المرسلة والمستلمة من الخدمة. يمكن تسريع هذه العمليات بشكل كبير باستخدام مكتبة orjson ، ولكن يجب تحضير الخدمة قليلاً - orjsonفهي ليست بديلاً عن الوحدة النمطية القياسية. jsonعادةً ، يتطلب الإنتاج عدة نسخ من الخدمة لضمان تحمل الخطأ والتعامل مع الحمل. لإدارة مجموعة من الخدمات ، تحتاج إلى أداة توضح ما إذا كانت نسخة الخدمة "حية" أم لا. يمكن حل هذه المشكلة عن طريق معالج يقوم /healthباستقصاء جميع الموارد المطلوبة للعمل ، في حالتنا ، قاعدة بيانات. إذاSELECT 1يتم تنفيذها في أقل من ثانية ، تكون الخدمة على قيد الحياة. إذا لم يكن الأمر كذلك ، فأنت بحاجة إلى الانتباه إليه.عندما يعمل التطبيق بشكل مكثف للغاية مع شبكة ، يمكن أن يزيد uvloop الأداء ببرودة .عامل مهم هو سهولة قراءة التعليمات البرمجية. كتب أحد زملائي ، يوري شيكانوف ، وحدة رمادية تجمع بين عدة أدوات للتحقق التلقائي وتنفيذ التعليمات البرمجية ، والتي من السهل إضافتها إلى pre-commitربط Git ، والتي تم إعدادها بملف تكوين واحد أو متغيرات بيئة. يسمح لك اللون الرمادي بفرز عمليات الاستيراد ( التصنيف ) ، وتحسين تعبيرات python وفقًا للإصدارات الجديدة من اللغة ( pyupgrade ) ، وإضافة فواصل في نهاية استدعاءات الوظائف ، وعمليات الاستيراد ، والقوائم ، وما إلى ذلك (add-trailing-comma ) ، وأيضًا اقتباسات إلى نموذج واحد ( توحيد ).* * *
هذا كل شيء بالنسبة لي: لقد قمنا بتطوير الخدمة وتغطيتها وتجميعها ونشرها ، كما أجرينا اختبار الحمل.شكر وتقدير
أود أن أعبر عن امتناني العميق للرجال الذين قضوا وقتًا في كتابة هذا المقال ، لمراجعة الكود ، لتقديم أفكاري وتعليقاتي: إلى Maria Zelenova زيلما، فلاديمير سولوماتين لينر، أناستاسيا سيمينوفا موركوفيوري شيكانوف dizballanzeميخائيل شوشبانوف mishushبافيل موسين pavkazzz وخاصة ديمتري أورلوف orlovdl.