 إن تأثير الجداول والفهارس المنتفخة (النفخ) معروف على نطاق واسع ولا يوجد فقط في Postgres. هناك طرق للتعامل معها "خارج الصندوق" مثل VACUUM FULL أو CLUSTER ، لكنها تحجب الجداول أثناء التشغيل وبالتالي لا يمكن استخدامها دائمًا.ستحتوي المقالة على القليل من النظرية حول كيفية حدوث الانتفاخ ، وكيفية التعامل معه ، حول القيود المؤجلة والمشاكل التي تجلبها لاستخدام امتداد pg_repack.تستند هذه المقالة على عرضي التقديمي في PgConf.Russia 2020.
إن تأثير الجداول والفهارس المنتفخة (النفخ) معروف على نطاق واسع ولا يوجد فقط في Postgres. هناك طرق للتعامل معها "خارج الصندوق" مثل VACUUM FULL أو CLUSTER ، لكنها تحجب الجداول أثناء التشغيل وبالتالي لا يمكن استخدامها دائمًا.ستحتوي المقالة على القليل من النظرية حول كيفية حدوث الانتفاخ ، وكيفية التعامل معه ، حول القيود المؤجلة والمشاكل التي تجلبها لاستخدام امتداد pg_repack.تستند هذه المقالة على عرضي التقديمي في PgConf.Russia 2020.لماذا يحدث سخام
يعتمد Postgres على نموذج متعدد الإصدارات ( MVCC ). جوهره هو أن كل صف في الجدول يمكن أن يكون له عدة إصدارات ، في حين أن المعاملات لا ترى أكثر من واحد من هذه الإصدارات ، ولكن ليس بالضرورة نفس الإصدار. هذا يسمح لمعاملات متعددة للعمل في وقت واحد وليس لها أي تأثير فعليًا على بعضها البعض.من الواضح أنه يجب تخزين كل هذه الإصدارات. يعمل Postgres مع الذاكرة صفحة بصفحة ، والصفحة هي الحد الأدنى من البيانات التي يمكن قراءتها من القرص أو كتابتها. دعونا نلقي نظرة على مثال صغير لفهم كيف يحدث هذا.لنفترض أن لدينا جدول أضفنا فيه عدة سجلات. في الصفحة الأولى من الملف حيث تم تخزين الجدول ، ظهرت بيانات جديدة. هذه هي إصدارات مباشرة من السلاسل المتوفرة للمعاملات الأخرى بعد الالتزام (للتبسيط ، سنفترض أن مستوى العزل قراءة ملتزم).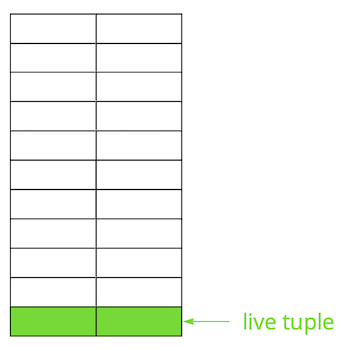 ثم قمنا بتحديث أحد الإدخالات وبالتالي وضع علامة على الإصدار القديم على أنه غير ذي صلة.
ثم قمنا بتحديث أحد الإدخالات وبالتالي وضع علامة على الإصدار القديم على أنه غير ذي صلة.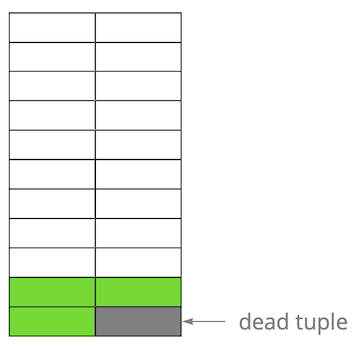 خطوة بخطوة ، تحديث وحذف نسخة من السطور ، حصلنا على صفحة يكون فيها حوالي نصف البيانات "القمامة". هذه البيانات غير مرئية لأي معاملة.
خطوة بخطوة ، تحديث وحذف نسخة من السطور ، حصلنا على صفحة يكون فيها حوالي نصف البيانات "القمامة". هذه البيانات غير مرئية لأي معاملة.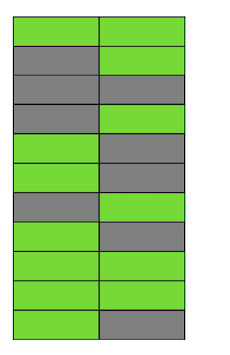 يحتوي Postgres على آلية فراغ، الذي ينظف الإصدارات غير ذات الصلة ويوفر المساحة للبيانات الجديدة. ولكن إذا لم يتم تكوينها بقوة كافية أو أنها مشغولة بالعمل في جداول أخرى ، فستبقى "البيانات غير المرغوب فيها" ، وعلينا استخدام صفحات إضافية للبيانات الجديدة.لذا في مثالنا ، في وقت ما ، سيتألف الجدول من أربع صفحات ، ولكن لن يكون هناك سوى نصف البيانات الحية فيه. ونتيجة لذلك ، عند الوصول إلى الجدول ، سنقرأ بيانات أكثر بكثير من اللازم.
يحتوي Postgres على آلية فراغ، الذي ينظف الإصدارات غير ذات الصلة ويوفر المساحة للبيانات الجديدة. ولكن إذا لم يتم تكوينها بقوة كافية أو أنها مشغولة بالعمل في جداول أخرى ، فستبقى "البيانات غير المرغوب فيها" ، وعلينا استخدام صفحات إضافية للبيانات الجديدة.لذا في مثالنا ، في وقت ما ، سيتألف الجدول من أربع صفحات ، ولكن لن يكون هناك سوى نصف البيانات الحية فيه. ونتيجة لذلك ، عند الوصول إلى الجدول ، سنقرأ بيانات أكثر بكثير من اللازم.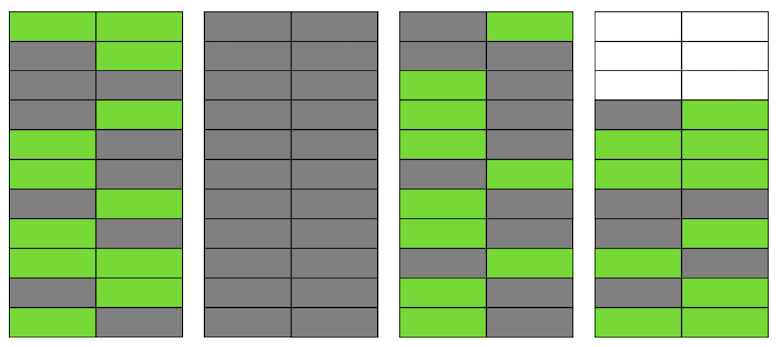 حتى لو حذف VACUUM الآن جميع الإصدارات غير ذات الصلة من السلاسل ، فلن يتحسن الوضع بشكل كبير. سيكون لدينا مساحة خالية في الصفحات أو حتى صفحات كاملة للخطوط الجديدة ، لكننا سنستمر في قراءة بيانات أكثر من اللازم.بالمناسبة ، إذا كانت هناك صفحة فارغة تمامًا (الثانية في مثالنا) في نهاية الملف ، فإن VACUUM يمكن أن يقطعها. لكنها الآن في الوسط ، لذلك لا يمكن فعل أي شيء معها.
حتى لو حذف VACUUM الآن جميع الإصدارات غير ذات الصلة من السلاسل ، فلن يتحسن الوضع بشكل كبير. سيكون لدينا مساحة خالية في الصفحات أو حتى صفحات كاملة للخطوط الجديدة ، لكننا سنستمر في قراءة بيانات أكثر من اللازم.بالمناسبة ، إذا كانت هناك صفحة فارغة تمامًا (الثانية في مثالنا) في نهاية الملف ، فإن VACUUM يمكن أن يقطعها. لكنها الآن في الوسط ، لذلك لا يمكن فعل أي شيء معها. عندما يصبح عدد هذه الصفحات الفارغة أو المسطحة كبيرًا ، والذي يسمى النفخ ، فإنه يبدأ في التأثير على الأداء.كل ما هو موضح أعلاه هو آليات حدوث النفخ في الجداول. في الفهارس ، يحدث هذا بنفس الطريقة تقريبًا.
عندما يصبح عدد هذه الصفحات الفارغة أو المسطحة كبيرًا ، والذي يسمى النفخ ، فإنه يبدأ في التأثير على الأداء.كل ما هو موضح أعلاه هو آليات حدوث النفخ في الجداول. في الفهارس ، يحدث هذا بنفس الطريقة تقريبًا.هل لدي انتفاخ؟
هناك عدة طرق لتحديد ما إذا كان لديك انتفاخ. الفكرة الأولى هي استخدام إحصائيات Postgres الداخلية ، والتي تحتوي على معلومات تقريبية حول عدد الصفوف في الجداول ، وعدد الصفوف "الحية" ، وما إلى ذلك. على الإنترنت ، يمكنك العثور على العديد من الأشكال المختلفة للنصوص الجاهزة. لقد اتخذنا كأساس برنامج نصي من خبراء PostgreSQL ، والذي يمكنه تقييم جداول الانتفاخ جنبًا إلى جنب مع فهارس الخبز المحمص ومنتفخ. في تجربتنا ، خطأها هو 10-20٪.طريقة أخرى هي استخدام ملحق pgstattuple ، والذي يسمح لك بالنظر داخل الصفحات والحصول على قيم النفخ المقدرة والدقيقة. ولكن في الحالة الثانية ، يجب عليك مسح الجدول بأكمله.قيمة سخام صغيرة ، تصل إلى 20٪ ، نعتبرها مقبولة. ويمكن أن يعتبر التناظرية من fillfactor عن الجداول و الفهارس . عند 50٪ وما فوق ، قد تبدأ مشاكل الأداء.طرق التعامل مع النفخ
هناك عدة طرق للتعامل مع الانتفاخ خارج الصندوق في Postgres ، لكنها بعيدة عن أن تكون مناسبة للجميع دائمًا.اضبط AUTOVACUUM بحيث لا يحدث الانتفاخ . وبشكل أكثر دقة ، للحفاظ على مستوى مقبول لك. تبدو هذه نصيحة "القبطان" ، ولكن في الواقع ليس من السهل دائمًا تحقيق ذلك. على سبيل المثال ، أنت تعمل بنشاط على تطوير تغييرات منتظمة في مخطط البيانات أو حدوث نوع من ترحيل البيانات. ونتيجة لذلك ، يمكن أن يتغير ملف تعريف التحميل بشكل متكرر ، وكقاعدة عامة ، يمكن أن يكون مختلفًا للجداول المختلفة. هذا يعني أنك بحاجة إلى العمل باستمرار قليلاً قبل المنحنى وضبط AUTOVACUUM على الوضع المتغير لكل جدول. لكن من الواضح أن هذا ليس بالأمر السهل.سبب آخر شائع أن AUTOVACUUM ليس لديها الوقت الكافي لمعالجة الجداول هو وجود معاملات طويلة تمنعه من مسح البيانات نظرًا لأنها متاحة لهذه المعاملات. التوصية هنا واضحة أيضًا - تخلص من المعاملات المعلقة وتقليل وقت المعاملات النشطة. ولكن إذا كان الحمل على التطبيق الخاص بك عبارة عن مزيج من OLAP و OLTP ، فيمكنك في الوقت نفسه الحصول على العديد من التحديثات المتكررة والطلبات القصيرة ، بالإضافة إلى العمليات الطويلة - على سبيل المثال ، إنشاء تقرير. في مثل هذه الحالة ، يجدر التفكير في توزيع الحمل على قواعد مختلفة ، مما سيسمح بضبط أدق لكل منها.مثال آخر - حتى لو كان ملف التعريف موحدًا ، ولكن قاعدة البيانات تحت حمولة عالية جدًا ، حتى AUTOVACUUM الأكثر عدوانية قد لا يتأقلم ، وسيحدث سخام. التحجيم (الرأسي أو الأفقي) هو الحل الوحيد.ولكن ماذا عن الموقف عندما قمت بتكوين AUTOVACUUM ، ولكن الانتفاخ مستمر في النمو. الفراغ الكاملالقيادةيعيد بناء محتويات الجداول والفهارس ويترك فقط البيانات ذات الصلة بها. للتخلص من الانتفاخ ، يعمل بشكل مثالي ، ولكن أثناء تنفيذه ، يتم التقاط قفل حصري على الطاولة (AccessExclusiveLock) ، والذي لن يسمح بالاستعلامات إلى هذا الجدول ، حتى إنه يحدد. إذا كنت تستطيع إيقاف خدمتك أو جزء منها لفترة (من عشرات الدقائق إلى عدة ساعات ، اعتمادًا على حجم قاعدة البيانات والأجهزة الخاصة بك) ، فإن هذا الخيار هو الأفضل. لسوء الحظ ، ليس لدينا وقت لتشغيل VACUUM FULL أثناء الصيانة المجدولة ، لذا فإن هذه الطريقة لا تناسبنا. العنقوديةالقيادةكما أنه يعيد بناء محتويات الجداول ، كما يفعل VACUUM FULL ، في نفس الوقت يسمح لك بتحديد الفهرس الذي سيتم بموجبه ترتيب البيانات فعليًا على القرص (ولكن في المستقبل لا يتم ضمان الطلب). في حالات معينة ، يعد هذا تحسينًا جيدًا لعدد من الاستعلامات - مع قراءة العديد من السجلات حسب الفهرس. عيوب الأمر هو نفسه VACUUM FULL - يؤمن الجدول أثناء العملية. يشبهالأمر REINDEX الاثنين السابقين ، لكنه يعيد بناء فهرس معين أو كل الفهارس على الجدول. الأقفال أضعف قليلاً: ShareLock على الطاولة (يمنع التعديلات ، لكن يسمح بالتحديد) و AccessExclusiveLock على فهرس قابل لإعادة البناء (يمنع الطلبات باستخدام هذا الفهرس). ومع ذلك ، في الإصدار 12 من Postgres ، المعلمة CONCURRENTLY، الذي يسمح لك بإعادة بناء الفهرس دون منع إضافة أو تعديل أو حذف السجلات بشكل متواز.في الإصدارات السابقة من Postgres ، يمكنك تحقيق نتيجة مشابهة لـ REINDEX بالتوافق مع CREATE INDEX CONCURRENTLY . يسمح لك بإنشاء فهرس دون حظر صارم (ShareUpdateExclusiveLock ، الذي لا يتداخل مع الاستعلامات المتوازية) ، ثم استبدل الفهرس القديم بفهرس جديد وحذف الفهرس القديم. هذا يزيل فهارس الانتفاخ دون التدخل في التطبيق الخاص بك. من المهم مراعاة أنه عند إعادة بناء الفهارس سيكون هناك تحميل إضافي على النظام الفرعي للقرص.وبالتالي ، إذا كانت هناك طرق لفهارس للقضاء على الانتفاخ "الساخن" ، فلا توجد جداول. هنا تدخل العديد من الملحقات الخارجية: pg_repack(سابقًا pg_reorg) و pgcompact و pgcompacttable وغيرها. في إطار هذه المقالة ، لن أقارنها وسأتحدث فقط عن pg_repack ، التي نستخدمها في المنزل بعد بعض التحسينات.كيف يعمل pg_repack
لنفترض أن لدينا جدولًا عاديًا جدًا لأنفسنا - مع الفهارس والقيود ، وللأسف ، مع سخام. الخطوة الأولى هي pg_repack إنشاء جدول سجل لتخزين البيانات حول جميع التغييرات أثناء العملية. سيعمل المشغل على تكرار هذه التغييرات في كل إدراج وتحديث وحذف. ثم يتم إنشاء جدول مشابه للأصل في الهيكل ، ولكن بدون فهارس وقيود ، حتى لا تبطئ عملية إدراج البيانات.بعد ذلك ، تقوم pg_repack بنقل البيانات من الجدول القديم إلى الجدول الجديد ، وتصفية جميع الصفوف غير ذات الصلة تلقائيًا ، ثم إنشاء فهارس للجدول الجديد. أثناء تنفيذ كل هذه العمليات ، يتم تجميع التغييرات في جدول السجل.الخطوة التالية هي نقل التغييرات إلى الجدول الجديد. يتم تنفيذ الترحيل في العديد من التكرارات ، وعندما يبقى أقل من 20 إدخال في جدول السجل ، يلتقط pg_repack قفلًا صارمًا ، وينقل أحدث البيانات ويستبدل الجدول القديم بالجدول الجديد في جداول نظام Postgres. هذه هي النقطة الوحيدة والقصيرة للغاية في الوقت الذي لا يمكنك فيه العمل مع الجدول. بعد ذلك ، يتم حذف الجدول القديم والجدول الذي يحتوي على السجلات ويتم تحرير مساحة في نظام الملفات. اكتمال العملية.من الناحية النظرية ، كل شيء يبدو رائعًا ، ماذا في الواقع؟ اختبرنا pg_repack بدون تحميل وتحت الحمل ، تحققنا من تشغيله في حالة التوقف المبكر (بعبارة أخرى ، Ctrl + C). كانت جميع الاختبارات إيجابية.ذهبنا إلى همز - ثم حدث كل شيء على النحو المتوقع.أول فطيرة على همز
في المجموعة الأولى ، تلقينا خطأ حول انتهاك تقييد فريد:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
يحتوي هذا التقييد على index_16508 اسم تم إنشاؤه تلقائيًا - تم إنشاؤه بواسطة pg_repack. من خلال السمات المدرجة في تكوينه ، قررنا تقييد "لدينا" ، الذي يتوافق معه. تحولت المشكلة إلى أن هذا ليس تقييدًا عاديًا تمامًا ، ولكنه قيد مؤجل ، أي يتم تنفيذ التحقق منه في وقت لاحق من الأمر sql ، مما يؤدي إلى عواقب غير متوقعة.القيود المؤجلة: لماذا هم بحاجة إليها وكيف يعملون
القليل من النظرية حول القيود المؤجلة.لنأخذ مثالاً بسيطًا: لدينا جدول مرجعي للسيارة به صفتان - اسم وترتيب السيارة في الدليل.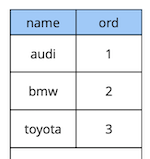
create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique
);
لنفترض أننا بحاجة إلى تبديل السيارتين الأولى والثانية. الحل "في الجبهة" هو تحديث القيمة الأولى إلى الثانية ، والثانية إلى الأولى:begin;
update cars set ord = 2 where name = 'audi';
update cars set ord = 1 where name = 'bmw';
commit;
ولكن عند تنفيذ هذا الرمز ، نتوقع حدوث انتهاك للقيد ، لأن ترتيب القيم في الجدول فريد:[23305] ERROR: duplicate key value violates unique constraint “uk_cars”
Detail: Key (ord)=(2) already exists.
كيف تفعل ذلك بشكل مختلف؟ الخيار الأول: إضافة استبدال إضافي للقيمة بأمر يضمن عدم وجوده في الجدول ، على سبيل المثال ، "-1". في البرمجة ، يسمى هذا "تبادل قيم متغيرين من خلال المتغير الثالث". العيب الوحيد لهذه الطريقة هو التحديث الإضافي.الخيار الثاني: إعادة تصميم الجدول لاستخدام نوع بيانات فاصلة عائمة لقيمة الأمر بدلاً من الأعداد الصحيحة. وبعد ذلك ، عند تحديث القيمة من 1 ، على سبيل المثال ، إلى 2.5 ، "سيقوم" السجل الأول تلقائيًا "الوقوف" بين الثاني والثالث. يعمل هذا الحل ، ولكن هناك نوعان من القيود. أولاً ، لن تعمل لك إذا تم استخدام القيمة في مكان ما في الواجهة. ثانيًا ، بناءً على دقة نوع البيانات ، سيكون لديك عدد محدود من الإدخالات المحتملة قبل إعادة حساب قيم جميع السجلات.الخيار الثالث: جعل القيد مؤجلًا بحيث يتم التحقق منه فقط في وقت الالتزام:create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique deferrable initially deferred
);
نظرًا لأن منطق طلبنا الأولي يضمن أن جميع القيم فريدة من نوعها في وقت الالتزام ، فستنجح.المثال أعلاه هو بالطبع الاصطناعية للغاية ، لكنه يكشف عن الفكرة. في تطبيقنا ، نستخدم قيودًا مؤجلة لتنفيذ المنطق المسؤول عن حل التعارضات مع العمل في الوقت نفسه مع كائنات عناصر واجهة التعامل الشائعة على اللوحة. يسمح لنا استخدام مثل هذه القيود بجعل رمز التطبيق أسهل قليلاً.بشكل عام ، اعتمادًا على نوع القيد في Postgres ، هناك ثلاثة مستويات من الدقة للتحقق منها: مستوى الصف والمعاملة والتعبير.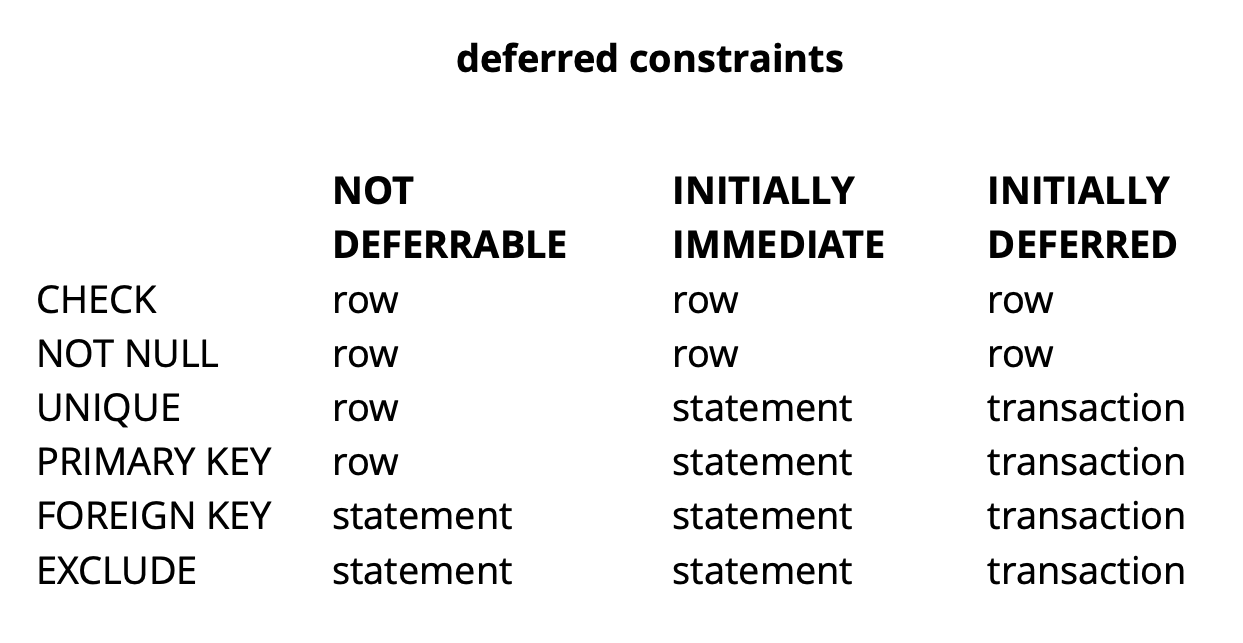 المصدر: begriffsدائمًا ما يتم التحقق من CHECK و NOT NULL على مستوى الصف ، لقيود أخرى ، كما يمكن رؤيته من الجدول ، هناك خيارات مختلفة. اقرأ المزيد هنا .للتلخيص بإيجاز ، تعطي القيود المعلقة في بعض المواقف رمزًا أكثر قابلية للقراءة وأوامر أقل. ومع ذلك ، يجب عليك الدفع مقابل ذلك عن طريق تعقيد عملية التصحيح ، حيث إن لحظة حدوث الخطأ ولحظة اكتشافك له يتم فصلها في الوقت المناسب. مشكلة أخرى محتملة هي أن المجدول لا يمكنه دائمًا بناء الخطة المثلى إذا كان هناك قيد مؤجل في الطلب.
المصدر: begriffsدائمًا ما يتم التحقق من CHECK و NOT NULL على مستوى الصف ، لقيود أخرى ، كما يمكن رؤيته من الجدول ، هناك خيارات مختلفة. اقرأ المزيد هنا .للتلخيص بإيجاز ، تعطي القيود المعلقة في بعض المواقف رمزًا أكثر قابلية للقراءة وأوامر أقل. ومع ذلك ، يجب عليك الدفع مقابل ذلك عن طريق تعقيد عملية التصحيح ، حيث إن لحظة حدوث الخطأ ولحظة اكتشافك له يتم فصلها في الوقت المناسب. مشكلة أخرى محتملة هي أن المجدول لا يمكنه دائمًا بناء الخطة المثلى إذا كان هناك قيد مؤجل في الطلب.صقل pg_repack
لقد اكتشفنا ما هي القيود المعلقة ، ولكن كيف ترتبط بمشكلتنا؟ تذكر الخطأ الذي تلقيناه سابقًا:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
يحدث في وقت نسخ البيانات من جدول السجل إلى الجدول الجديد. يبدو غريبا لأنه يتم الالتزام بالبيانات الموجودة في جدول السجل مع البيانات الموجودة في الجدول الأصلي. إذا استوفوا قيود الجدول الأصلي ، فكيف يمكنهم انتهاك نفس القيود في الجدول الجديد؟كما اتضح ، فإن جذر المشكلة يكمن في الخطوة السابقة من pg_repack ، التي تنشئ الفهارس فقط ، وليس القيود: الجدول القديم كان له قيود فريدة ، والجديد أنشأ فهرسًا فريدًا بدلاً من ذلك. من المهم أن نلاحظ هنا أنه إذا كان التقييد عاديًا ولم يتم تأجيله ، فإن المؤشر الفريد الذي تم إنشاؤه بدلاً منه يعادل هذا التقييد ، لأن يتم تنفيذ قيود Postgres الفريدة من خلال إنشاء فهرس فريد. ولكن في حالة القيد المؤجل ، فإن السلوك ليس هو نفسه ، لأنه لا يمكن تأجيل الفهرس ويتم فحصه دائمًا في وقت تنفيذ الأمر sql.وبالتالي ، فإن جوهر المشكلة يكمن في "تأجيل" الشيك: في الجدول الأصلي يحدث في وقت الالتزام ، وفي الجدول الجديد - في وقت تنفيذ الأمر sql. لذا نحتاج إلى التأكد من أن عمليات الفحص تتم بنفس الطريقة في كلتا الحالتين: إما مؤجلة دائمًا ، أو دائمًا على الفور.ما الأفكار التي لدينا؟
من المهم أن نلاحظ هنا أنه إذا كان التقييد عاديًا ولم يتم تأجيله ، فإن المؤشر الفريد الذي تم إنشاؤه بدلاً منه يعادل هذا التقييد ، لأن يتم تنفيذ قيود Postgres الفريدة من خلال إنشاء فهرس فريد. ولكن في حالة القيد المؤجل ، فإن السلوك ليس هو نفسه ، لأنه لا يمكن تأجيل الفهرس ويتم فحصه دائمًا في وقت تنفيذ الأمر sql.وبالتالي ، فإن جوهر المشكلة يكمن في "تأجيل" الشيك: في الجدول الأصلي يحدث في وقت الالتزام ، وفي الجدول الجديد - في وقت تنفيذ الأمر sql. لذا نحتاج إلى التأكد من أن عمليات الفحص تتم بنفس الطريقة في كلتا الحالتين: إما مؤجلة دائمًا ، أو دائمًا على الفور.ما الأفكار التي لدينا؟إنشاء فهرس مشابه المؤجل
الفكرة الأولى هي إجراء كلا الفحصين في الوضع الفوري. قد يؤدي هذا إلى العديد من المحفزات الإيجابية الكاذبة للتقييد ، ولكن إذا كان هناك عدد قليل منها ، فلا ينبغي أن يؤثر ذلك على عمل المستخدمين ، لأن مثل هذه النزاعات تعتبر حالة طبيعية. تحدث ، على سبيل المثال ، عندما يبدأ مستخدمان تحرير نفس الأداة في نفس الوقت ، ولا يتوفر لدى عميل المستخدم الثاني الوقت للحصول على معلومات تفيد بأن الأداة مقفلة بالفعل لتحريرها بواسطة المستخدم الأول. في هذه الحالة ، يرفض الخادم المستخدم الثاني ، ويعيد عميله التغييرات ويعيد الأداة. بعد ذلك بقليل ، عندما ينتهي المستخدم الأول من التحرير ، سيتلقى الثاني معلومات تفيد بأن الأداة لم تعد مؤمنة ، وسيكون قادرًا على تكرار عملها.للتأكد من أن عمليات الفحص دائمًا في وضع الطوارئ ، أنشأنا فهرسًا جديدًا مشابهًا للقيد المؤجل الأصلي:CREATE UNIQUE INDEX CONCURRENTLY uk_tablename__immediate ON tablename (id, index);
DROP INDEX CONCURRENTLY uk_tablename__immediate;
في بيئة الاختبار ، تلقينا فقط بعض الأخطاء المتوقعة. نجاح! أطلقنا مرة أخرى pg_repack على همز وحصلنا على 5 أخطاء في المجموعة الأولى في ساعة عمل. هذه نتيجة مقبولة. ومع ذلك ، في المجموعة الثانية بالفعل ، زاد عدد الأخطاء عدة مرات واضطررنا إلى إيقاف pg_repack.لماذا حصل هذا؟ يعتمد احتمال حدوث خطأ على عدد المستخدمين الذين يعملون في وقت واحد مع نفس الأدوات. على ما يبدو ، في تلك اللحظة مع البيانات المخزنة في المجموعة الأولى ، كانت هناك تغييرات تنافسية أقل بكثير من بقية البيانات ، أي كنا فقط "محظوظين".لم تنجح الفكرة. في تلك اللحظة ، رأينا خيارين آخرين للحل: إعادة كتابة رمز التطبيق الخاص بنا للتخلي عن القيود المعلقة ، أو "تعليم" pg_repack للعمل معهم. لقد اخترنا الثاني.استبدل الفهارس في جدول جديد بقيود مؤجلة من جدول المصدر
كان الغرض من المراجعة واضحًا - إذا كان الجدول الأصلي يحتوي على قيد مؤجل ، فعندئذٍ للجدول الجديد تحتاج إلى إنشاء مثل هذا القيد ، وليس الفهرس.لاختبار تغييراتنا ، كتبنا اختبارًا بسيطًا:- جدول مع قيود مؤجلة وسجل واحد ؛
- إدراج البيانات في الحلقة التي تتعارض مع السجل الحالي ؛
- إجراء تحديث - لم تعد البيانات تتعارض ؛
- ارتكاب التغيير.
create table test_table
(
id serial,
val int,
constraint uk_test_table__val unique (val) deferrable initially deferred
);
INSERT INTO test_table (val) VALUES (0);
FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (0) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
COMMIT;
END;
END LOOP;
تعطلت النسخة الأصلية من pg_repack دائمًا عند الإدخال الأول ، عملت النسخة المنقحة دون أخطاء. غرامة.نذهب إلى prod ومرة أخرى نحصل على خطأ في نفس المرحلة من نسخ البيانات من جدول السجل إلى الجدول الجديد:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
الوضع الكلاسيكي: كل شيء يعمل في بيئات الاختبار ، ولكن ليس على همز ؟!APPLY_COUNT والمفصل من دفعتين
بدأنا في تحليل الشفرة حرفياً سطراً بسطر ووجدنا نقطة مهمة: يتم نقل البيانات من جدول السجل إلى الجدول الجديد مع دفعات ، يشير ثابت APPLY_COUNT إلى حجم الدفعات:for (;;)
{
num = apply_log(connection, table, APPLY_COUNT);
if (num > MIN_TUPLES_BEFORE_SWITCH)
continue;
...
}
تكمن المشكلة في أن بيانات المعاملة الأصلية ، التي يمكن أن تنتهك فيها عدة عمليات القيد ، يمكن نقلها إلى مفصل دفعتين أثناء التحويل - سيتم تخصيص نصف الفرق في المباراة الأولى والنصف الآخر في الثانية. وإليك كيف محظوظ: إذا لم تنتهك الفرق في الدفعة الأولى أي شيء ، فإن كل شيء على ما يرام ، ولكن إذا انتهكوا - يحدث خطأ.APPLY_COUNT يساوي 1000 إدخال ، وهو ما يفسر سبب نجاح اختباراتنا - لم يغطيوا حالة "تقاطع الدُفعات". استخدمنا أمرين - إدراج وتحديث ، لذلك تم وضع 500 معاملة بالضبط لفريقين دائمًا في الدفعة ولم نواجه مشاكل. بعد إضافة التحديث الثاني ، توقف التحرير عن العمل:FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (1) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
UPDATE test_table set val = i where id = v_id;
COMMIT;
END;
END LOOP;
لذا ، فإن المهمة التالية هي التأكد من أن البيانات من الجدول المصدر التي تغيرت في معاملة واحدة تقع في الجدول الجديد أيضًا داخل نفس المعاملة.رفض الجزار
ومرة أخرى كان لدينا حلان. أولاً: دعنا نتخلى تمامًا عن التجميع ونقوم بنقل البيانات في معاملة واحدة. لصالح هذا الحل كانت بساطته - كانت التغييرات البرمجية المطلوبة ضئيلة (بالمناسبة ، في الإصدارات القديمة ثم عملت pg_reorg بهذه الطريقة). لكن هناك مشكلة - نحن ننشئ صفقة طويلة ، وهذا ، كما قيل سابقًا ، يشكل تهديدًا لظهور منتفخ جديد.الحل الثاني أكثر تعقيدًا ، ولكن ربما يكون أكثر صحة: قم بإنشاء عمود في جدول السجل بمعرف المعاملة الذي أضاف البيانات إلى الجدول. بعد ذلك ، عند نسخ البيانات ، سنتمكن من تجميعها حسب هذه السمة والتأكد من نقل التغييرات ذات الصلة معًا. سيتم تشكيل الدفعة من عدة معاملات (أو واحدة كبيرة) وسيختلف حجمها اعتمادًا على مقدار البيانات التي تم تغييرها في هذه المعاملات. من المهم ملاحظة أنه نظرًا لأن بيانات المعاملات المختلفة تقع في جدول السجل بترتيب عشوائي ، فلن يكون من الممكن قراءتها بالتسلسل ، كما كان من قبل. إن seqscan لكل طلب تمت تصفيته بواسطة tx_id باهظ الثمن ، فأنت بحاجة إلى فهرس ، ولكنه سيبطئ الطريقة بسبب النفقات العامة لتحديثه. بشكل عام ، كما هو الحال دائمًا ، تحتاج إلى التضحية بشيء ما.لذا ، قررنا البدء بالخيار الأول كخيار أبسط. أولاً ، كان من الضروري فهم ما إذا كانت الصفقة الطويلة ستكون مشكلة حقيقية. نظرًا لأن النقل الرئيسي للبيانات من الجدول القديم إلى الجدول الجديد يحدث أيضًا في معاملة واحدة طويلة ، فقد تحول السؤال إلى "كم سنزيد هذه المعاملة؟" تعتمد مدة المعاملة الأولى بشكل أساسي على حجم الجدول. تعتمد مدة التغيير الجديد على عدد التغييرات المتراكمة في الجدول أثناء نقل البيانات ، أي من شدة الحمل. حدث تشغيل pg_repack أثناء الحد الأدنى للحمل على الخدمة ، وكان مقدار التغيير صغيرًا بشكل لا يقارن مقارنة بحجم الجدول الأصلي. قررنا أنه يمكننا إهمال وقت المعاملة الجديدة (للمقارنة ، هذا متوسط ساعة واحدة و 2-3 دقائق).كانت التجارب إيجابية. يعمل على همز أيضا. للتوضيح ، صورة بحجم إحدى القواعد بعد التشغيل: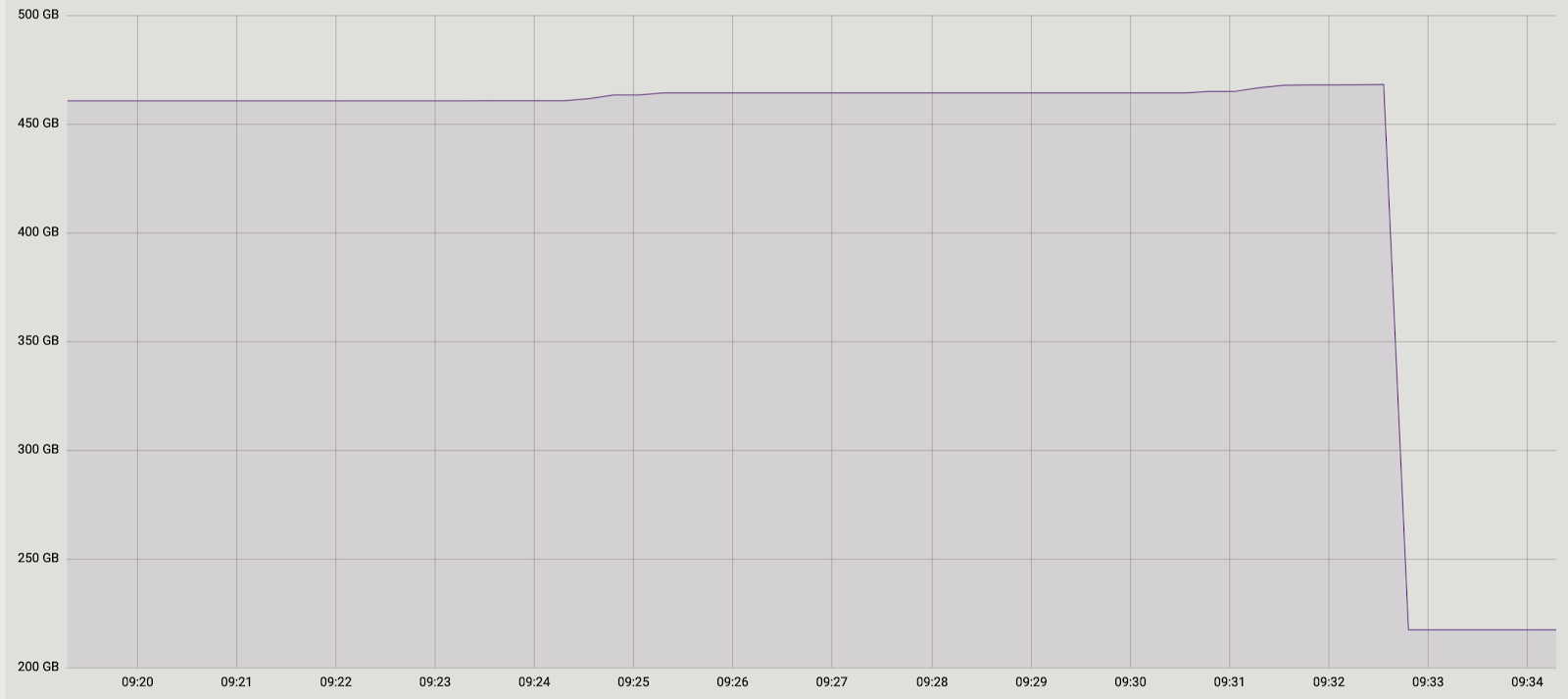 نظرًا لأن هذا الحل يناسبنا تمامًا ، فإننا لم نحاول تنفيذ الثانية ، ولكننا نفكر في مناقشتها مع مطوري الإضافة. لسوء الحظ ، فإن مراجعتنا الحالية ليست جاهزة للنشر بعد ، لأننا لم نحل المشكلة إلا من خلال قيود معلقة فريدة ، ومن أجل تصحيح كامل ، من الضروري تقديم الدعم لأنواع أخرى. نأمل أن نكون قادرين على القيام بذلك في المستقبل.ربما لديك سؤال ، لماذا شاركنا في هذه القصة مع الانتهاء من pg_repack ، ولم نستخدم ، على سبيل المثال ، نظائرها؟ في مرحلة ما ، فكرنا أيضًا في ذلك ، لكن التجربة الإيجابية لاستخدامه في وقت سابق ، على طاولات دون قيود معلقة ، حفزتنا على محاولة فهم جوهر المشكلة وإصلاحها. بالإضافة إلى ذلك ، لاستخدام حلول أخرى ، يستغرق الأمر أيضًا وقتًا لإجراء الاختبارات ، لذلك قررنا أولاً أننا سنحاول إصلاح المشكلة فيها ، وإذا أدركنا أنه لا يمكننا القيام بذلك في فترة زمنية معقولة ، فسنبدأ في التفكير في نظائرها.
نظرًا لأن هذا الحل يناسبنا تمامًا ، فإننا لم نحاول تنفيذ الثانية ، ولكننا نفكر في مناقشتها مع مطوري الإضافة. لسوء الحظ ، فإن مراجعتنا الحالية ليست جاهزة للنشر بعد ، لأننا لم نحل المشكلة إلا من خلال قيود معلقة فريدة ، ومن أجل تصحيح كامل ، من الضروري تقديم الدعم لأنواع أخرى. نأمل أن نكون قادرين على القيام بذلك في المستقبل.ربما لديك سؤال ، لماذا شاركنا في هذه القصة مع الانتهاء من pg_repack ، ولم نستخدم ، على سبيل المثال ، نظائرها؟ في مرحلة ما ، فكرنا أيضًا في ذلك ، لكن التجربة الإيجابية لاستخدامه في وقت سابق ، على طاولات دون قيود معلقة ، حفزتنا على محاولة فهم جوهر المشكلة وإصلاحها. بالإضافة إلى ذلك ، لاستخدام حلول أخرى ، يستغرق الأمر أيضًا وقتًا لإجراء الاختبارات ، لذلك قررنا أولاً أننا سنحاول إصلاح المشكلة فيها ، وإذا أدركنا أنه لا يمكننا القيام بذلك في فترة زمنية معقولة ، فسنبدأ في التفكير في نظائرها.الموجودات
ما يمكن أن نوصي به بناءً على تجربتنا الخاصة:- راقب انتفاخك. استنادًا إلى بيانات المراقبة ، يمكنك فهم مدى جودة تكوين الفراغ التلقائي.
- اضبط AUTOVACUUM للحفاظ على الانتفاخ عند مستوى معقول.
- bloat “ ”, . – .
- – , .