 الإنترنت مليء بالمقالات حول نماذج اللغة القائمة على N-gram. في الوقت نفسه ، هناك عدد قليل جدًا من المكتبات الجاهزة للعمل.هناك KenLM و SriLM و IRSTLM . وهي شائعة وتستخدم في العديد من المشاريع الكبيرة. ولكن هناك مشاكل:
الإنترنت مليء بالمقالات حول نماذج اللغة القائمة على N-gram. في الوقت نفسه ، هناك عدد قليل جدًا من المكتبات الجاهزة للعمل.هناك KenLM و SriLM و IRSTLM . وهي شائعة وتستخدم في العديد من المشاريع الكبيرة. ولكن هناك مشاكل:- المكتبات قديمة وليست متطورة.
- ضعف دعم اللغة الروسية.
- العمل فقط مع نص نظيف ومحضر خصيصًا
- دعم ضعيف لـ UTF-8. على سبيل المثال ، يكسر SriLM مع علامة tolower الترميز.
تبرز KenLM قليلاً من القائمة . يتم دعمه بانتظام وليس لديه مشاكل مع UTF-8 ، ولكنه يطالب أيضًا بجودة النص.مرة كنت بحاجة إلى مكتبة لبناء نموذج لغوي. بعد العديد من التجارب والخطأ ، توصلت إلى استنتاج مفاده أن إعداد مجموعة بيانات لتدريس نموذج اللغة أمر معقد للغاية وعملية طويلة. خاصة إذا كانت روسية ! لكنني أردت أتمتة كل شيء بطريقة أو بأخرى.في بحثه ، بدأ من مكتبة SriLM . سألاحظ على الفور أن هذا ليس رمزًا مقترضًا أو شوكة SriLM . كل كود مكتوب بالكامل من الصفر.مثال نصي صغير:
! .
يعد عدم وجود مسافة بين الجمل خطأ مطبعيًا شائعًا إلى حد ما. يصعب العثور على مثل هذا الخطأ في كمية كبيرة من البيانات ، بينما يكسر الرمز المميز.بعد المعالجة ، سيظهر N-gram التالي في نموذج اللغة:
-0.3009452 !
بالطبع ، هناك العديد من المشاكل الأخرى ، الأخطاء المطبعية ، الأحرف الخاصة ، الاختصارات ، الصيغ الرياضية المختلفة ... يجب معالجة كل هذا بشكل صحيح.ANYKS LM ( ALM )
المكتبة فقط يدعم لينكس ، ماكنتوش، و فري أنظمة التشغيل . ليس لدي Windows ولا يوجد تخطيط للدعم.وصف موجز للوظيفة
- دعم UTF-8 بدون تبعيات طرف ثالث.
- دعم تنسيقات البيانات: Arpa ، Vocab ، Map Sequence ، N-grams ، Binary alm Dictionary.
- : Kneser-Nay, Modified Kneser-Nay, Witten-Bell, Additive, Good-Turing, Absolute discounting.
- , , , .
- , N-, N- , N-.
- — N-, .
- : , -.
- N- — N-, backoff .
- N- backoff-.
- , : , , , , Python3.
- « », .
- 〈unk〉 .
- N- Python3.
- , .
- . : , , .
- على عكس نماذج اللغات الأخرى ، يضمن ALM جمع كل N-grams من النص ، بغض النظر عن طولها (باستثناء Kneser-Nay المعدل). هناك أيضًا إمكانية التسجيل الإلزامي لجميع N-gram النادرة ، حتى لو التقوا مرة واحدة فقط.
من تنسيقات نموذج اللغة القياسية ، يتم دعم تنسيق ARPA فقط . بصراحة ، لا أرى أي سبب لدعم حديقة الحيوان بأكملها بجميع أنواع التنسيقات.تنسيق ARPA حساس لحالة الأحرف وهذه أيضًا مشكلة محددة.في بعض الأحيان يكون من المفيد معرفة وجود بيانات محددة فقط في N-gram. على سبيل المثال ، تحتاج إلى فهم وجود الأرقام في N-gram ، ومعناها ليس مهمًا جدًا.مثال:
, 2
ونتيجة لذلك ، يدخل N-gram في نموذج اللغة:
-0.09521468 2
الرقم المحدد ، في هذه الحالة ، لا يهم. يمكن أن تذهب التخفيضات في المتجر 1 و 3 وأي عدد تريده من الأيام.لحل هذه المشكلة ، يستخدم ALM رمز الفئة.الرموز المدعومة
قياسي:〈s〉 - رمز بداية الجملة〈/s〉 - رمز نهاية الجملةendunk〉 - الرمز المميز لكلمةغير معروفة غير قياسي:〈url Tok - الرمز المميز لعنوان url〈num〉 - الرمز المميز للأرقام (العربية أو الرومانية)〉date〉 - تاريخ الرمز المميز (18 يوليو 2004 | 18/18/2004)〈time〉 - رمز الوقت (15:44:56)〉abbr〉 - رمز الاختصار (الأول | الثاني | 20)〉anum〉 - الزائفة أرقام (T34 | 895-M-86 | 39km)〈math〉 - رمز العمليات الرياضية (+ | - | = | / | * | ^)〈range〉 - رمز نطاق الأرقام (1-2 | 100-200 | 300- 400)〈ابروكس〉- رقم تقريبي للرقم (~ 93 | ~ 95.86 | 10 ~ 20)〈score〉 - الرمز المميز للحساب الرقمي (4: 3 | 01:04)〈 dimen to - الرمز العام (200x300 | 1920x1080) "كسر" - رمز كسر بسيط (5/20 | 192/864) unpunct〉 - الرمز المميز لعلامة الترقيم (. | ... |، |! |؟ |: |؛)〈Specl〉 - الرمز المميز للحرف الخاص (~ | @ | # | رقم |٪ | & | $ | § | ±)olisolat〉 - الرمز المميز لعزل ("|" | "|" | "|" | "| (|) | [|] | {|})بالطبع ، يمكن تعطيل دعم كل من الرموز المميزة إذا هناكحاجة إلى N-grams. إذا كنت بحاجة إلى معالجة علامات أخرى (على سبيل المثال ، تحتاج إلى العثور على أسماء البلدان في النص) ، ALM يدعم اتصال البرامج النصية الخارجية في Python3.مثال على البرنامج النصي لاكتشاف الرمز المميز:
def init():
"""
:
"""
def run(token, word):
"""
:
@token
@word
"""
if token and (token == "<usa>"):
if word and (word.lower() == ""): return "ok"
elif token and (token == "<russia>"):
if word and (word.lower() == ""): return "ok"
return "no"
يضيف مثل هذا البرنامج النصي علامتين إضافيتين إلى قائمة العلامات القياسية: 〈usa〉 و 〈russia〉 .بالإضافة إلى البرنامج النصي لاكتشاف الرموز المميزة ، هناك دعم لبرنامج نصي للمعالجة المسبقة للكلمات المعالجة. يمكن لهذا البرنامج النصي تغيير الكلمة قبل إضافة الكلمة إلى نموذج اللغة.مثال على برنامج نصي لمعالجة الكلمات:
def init():
"""
:
"""
def run(word, context):
"""
:
@word
@context
"""
return word
هذا النهج يمكن أن تكون مفيدة إذا كان ذلك ضروريا لتجميع نموذج اللغة التي تتكون من lemmas أو stemms .تنسيقات نص نموذج اللغة المدعومة من ALM
ARPA:
\data\
ngram 1=52
ngram 2=68
ngram 3=15
\1-grams:
-1.807052 1- -0.30103
-1.807052 2 -0.30103
-1.807052 3~4 -0.30103
-2.332414 -0.394770
-3.185530 -0.311249
-3.055896 -0.441649
-1.150508 </s>
-99 <s> -0.3309932
-2.112406 <unk>
-1.807052 T358 -0.30103
-1.807052 VII -0.30103
-1.503878 -0.39794
-1.807052 -0.30103
-1.62953 -0.30103
...
\2-grams:
-0.29431 1-
-0.29431 2
-0.29431 3~4
-0.8407791 <s>
-1.328447 -0.477121
...
\3-grams:
-0.09521468
-0.166590
...
\end\
ARPA هو تنسيق النص القياسي لنموذج لغة اللغة الطبيعية المستخدمة من قبل Sphinx / CMU و Kaldi .NGRAMS:
\data\
ad=1
cw=23832
unq=9390
ngram 1=9905
ngram 2=21907
ngram 3=306
\1-grams:
<s> 2022 | 1
<num> 117 | 1
<unk> 19 | 1
<abbr> 16 | 1
<range> 7 | 1
</s> 2022 | 1
244 | 1
244 | 1
11 | 1
762 | 1
112 | 1
224 | 1
1 | 1
86 | 1
978 | 1
396 | 1
108 | 1
77 | 1
32 | 1
...
\2-grams:
<s> <num> 7 | 1
<s> <unk> 1 | 1
<s> 84 | 1
<s> 83 | 1
<s> 57 | 1
82 | 1
11 | 1
24 | 1
18 | 1
31 | 1
45 | 1
97 | 1
71 | 1
...
\3-grams:
<s> <num> </s> 3 | 1
<s> 6 | 1
<s> 4 | 1
<s> 2 | 1
<s> 3 | 1
2 | 1
</s> 2 | 1
2 | 1
2 | 1
2 | 1
2 | 1
2 | 1
</s> 2 | 1
</s> 3 | 1
2 | 1
...
\end\
Ngrams - تنسيق نص غير قياسي لنموذج اللغة ، هو تعديل تنسيق ARPA .وصف:- م - عدد الوثائق في الضميمة
- cw - عدد الكلمات في جميع الوثائق في الجسم
- unq - عدد الكلمات الفريدة التي تم جمعها
VOCAB:
\data\
ad=1
cw=23832
unq=9390
\words:
33 244 | 1 | 0.010238 | 0.000000 | -3.581616
34 11 | 1 | 0.000462 | 0.000000 | -6.680889
35 762 | 1 | 0.031974 | 0.000000 | -2.442838
40 12 | 1 | 0.000504 | 0.000000 | -6.593878
330344 47 | 1 | 0.001972 | 0.000000 | -5.228637
335190 17 | 1 | 0.000713 | 0.000000 | -6.245571
335192 1 | 1 | 0.000042 | 0.000000 | -9.078785
335202 22 | 1 | 0.000923 | 0.000000 | -5.987742
335206 7 | 1 | 0.000294 | 0.000000 | -7.132874
335207 29 | 1 | 0.001217 | 0.000000 | -5.711489
2282019644 1 | 1 | 0.000042 | 0.000000 | -9.078785
2282345502 10 | 1 | 0.000420 | 0.000000 | -6.776199
2282416889 2 | 1 | 0.000084 | 0.000000 | -8.385637
3009239976 1 | 1 | 0.000042 | 0.000000 | -9.078785
3009763109 1 | 1 | 0.000042 | 0.000000 | -9.078785
3013240091 1 | 1 | 0.000042 | 0.000000 | -9.078785
3014009989 1 | 1 | 0.000042 | 0.000000 | -9.078785
3015727462 2 | 1 | 0.000084 | 0.000000 | -8.385637
3025113549 1 | 1 | 0.000042 | 0.000000 | -9.078785
3049820849 1 | 1 | 0.000042 | 0.000000 | -9.078785
3061388599 1 | 1 | 0.000042 | 0.000000 | -9.078785
3063804798 1 | 1 | 0.000042 | 0.000000 | -9.078785
3071212736 1 | 1 | 0.000042 | 0.000000 | -9.078785
3074971025 1 | 1 | 0.000042 | 0.000000 | -9.078785
3075044360 1 | 1 | 0.000042 | 0.000000 | -9.078785
3123271427 1 | 1 | 0.000042 | 0.000000 | -9.078785
3123322362 1 | 1 | 0.000042 | 0.000000 | -9.078785
3126399411 1 | 1 | 0.000042 | 0.000000 | -9.078785
…
Vocab هو تنسيق قاموس نصي غير قياسي في نموذج اللغة.وصف:- حدوث حالة oc
- العاصمة - حدوث في الوثائق
- tf - (term frequency — ) — . , , : [tf = oc / cw]
- idf - (inverse document frequency — ) — , , : [idf = log(ad / dc)]
- tf-idf - : [tf-idf = tf * idf]
- wltf - , : [wltf = 1 + log(tf * dc)]
MAP:
1:{2022,1,0}|42:{57,1,0}|279603:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|320749:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|351283:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|379815:{3,1,0}
1:{2022,1,0}|42:{57,1,0}|26122748:{3,1,0}
1:{2022,1,0}|44:{6,1,0}
1:{2022,1,0}|48:{1,1,0}
1:{2022,1,0}|51:{11,1,0}|335967:{3,1,0}
1:{2022,1,0}|53:{14,1,0}|371327:{3,1,0}
1:{2022,1,0}|53:{14,1,0}|40260976:{7,1,0}
1:{2022,1,0}|65:{68,1,0}|34:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|3277:{3,1,0}
1:{2022,1,0}|65:{68,1,0}|278003:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|320749:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|11353430797:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|34270133320:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|51652356484:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|66967237546:{2,1,0}
1:{2022,1,0}|2842:{11,1,0}|42:{7,1,0}
…
الخريطة - محتويات الملف لها معنى تقني محض. يمكن استخدامه جنبًا إلى جنب مع ملف vocab ، يمكنك الجمع بين العديد من نماذج اللغات وتعديلها وتخزينها وتوزيعها وتصديرها إلى أي تنسيق ( arpa ، ngrams ، binary alm ).تنسيقات الملفات النصية المساعدة التي يدعمها ALM
في كثير من الأحيان ، عند تجميع نموذج لغوي ، يتم العثور على أخطاء إملائية في النص ، وهي عبارة عن بدائل للأحرف (بأحرف مماثلة بصريًا لأبجدية أخرى). يحلALM هذه المشكلة مع ملف بأحرف متشابهة.p
c
o
t
k
e
a
h
x
b
m
إذا ، عند تدريس نموذج اللغة ، نقل الملفات بقائمة من نطاقات المستوى الأول والاختصارات ، يمكن لـ ALM المساعدة في الكشف الأكثر دقة لعلامات فئة 〉url〉 و 〉abbr〉 .ملف قائمة الاختصارات:
…
ملف قائمة منطقة المجال:
ru
su
cc
net
com
org
info
…
لاكتشاف أكثر دقة لرمز 〈url〉 ، يجب عليك إضافة مناطق نطاق المستوى الأول (جميع مناطق النطاق من المثال مثبتة مسبقًا بالفعل) .حاوية ثنائية لنموذج لغة ALM
لإنشاء حاوية ثنائية لنموذج اللغة ، تحتاج إلى إنشاء ملف JSON مع وصف المعلمات الخاصة بك.خيارات JSON:
{
"aes": 128,
"name": "Name dictionary",
"author": "Name author",
"lictype": "License type",
"lictext": "License text",
"contacts": "Contacts data",
"password": "Password if needed",
"copyright": "Copyright author"
}
وصف:- aes - حجم تشفير AES (128 ، 192 ، 256) بت
- الاسم - اسم القاموس
- المؤلف - مؤلف القاموس
- lictype - نوع الترخيص
- lictext - نص الترخيص
- اتصالات - تفاصيل الاتصال المؤلف
- كلمة المرور - كلمة مرور التشفير (إذا لزم الأمر) ، يتم إجراء التشفير فقط عند تعيين كلمة مرور
- حقوق الطبع والنشر - حقوق الطبع والنشر لمالك القاموس
جميع المعلمات اختيارية باستثناء اسم الحاوية.أمثلة مكتبة ALM
عملية الرمز المميز
يتلقى الرمز المميز النص عند الإدخال ، وينشئ JSON عند الإخراج.$ echo 'Hello World?' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
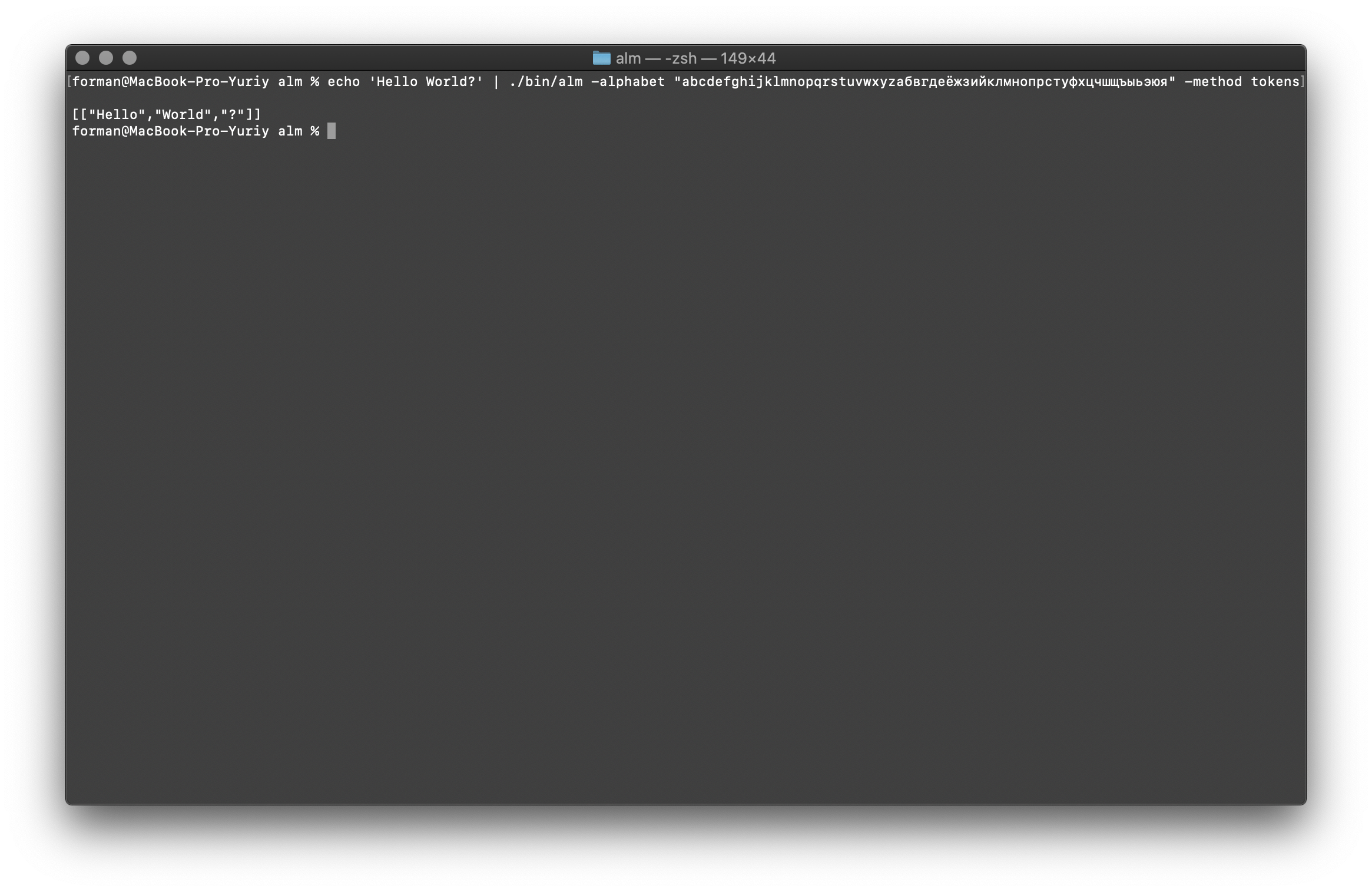 اختبار:
اختبار:Hello World?
نتيجة:[
["Hello","World","?"]
]
لنجرب شيئًا أكثر صعوبة ...$ echo ' ??? ....' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
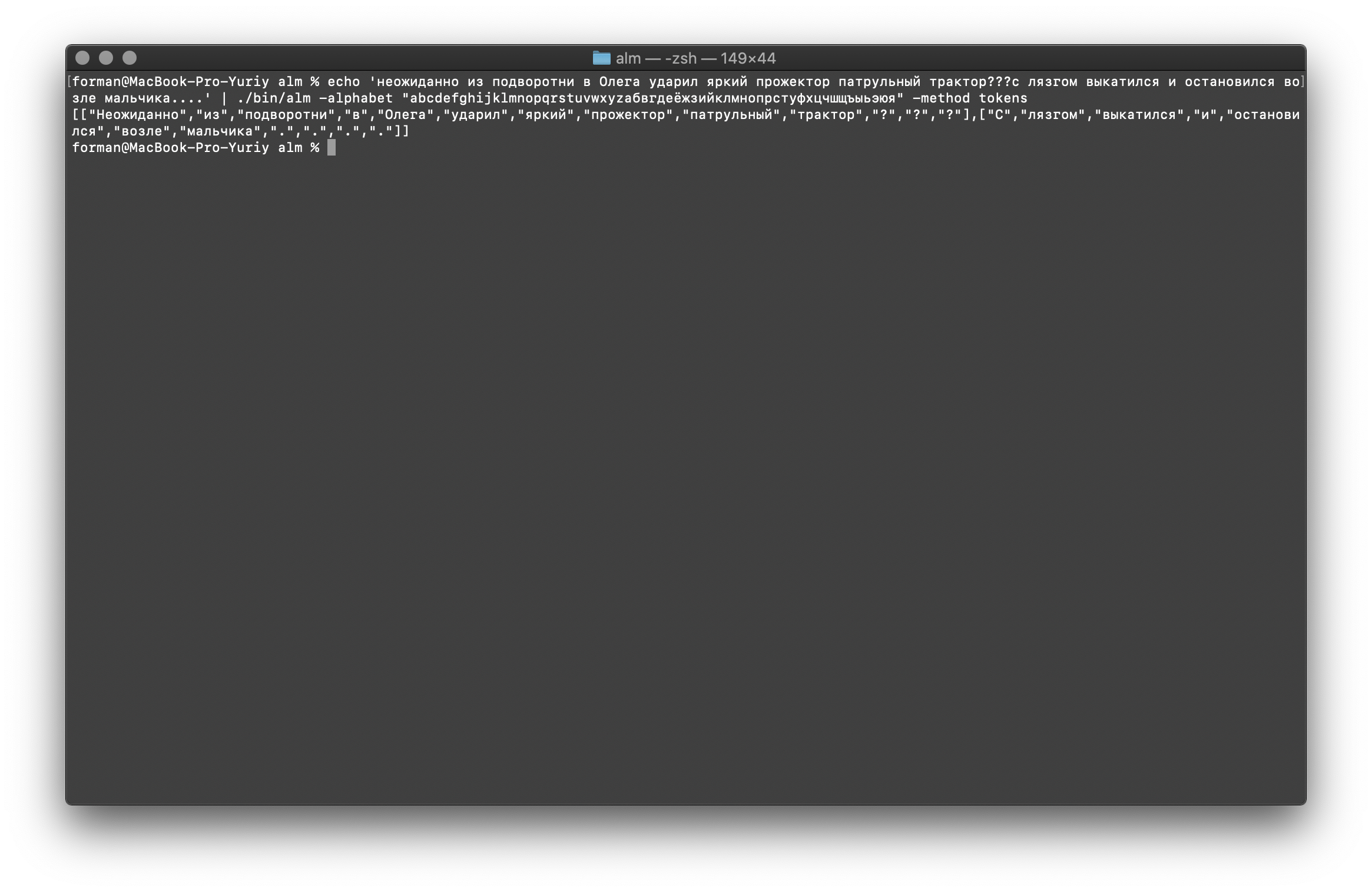 اختبار:
اختبار: ??? ....
نتيجة:[
[
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"?",
"?",
"?"
],[
"",
"",
"",
"",
"",
"",
"",
".",
".",
".",
"."
]
]
كما ترى ، عمل الرمز المميز بشكل صحيح وأصلح الأخطاء الأساسية.قم بتغيير النص قليلاً ورؤية النتيجة.$ echo ' ... .' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
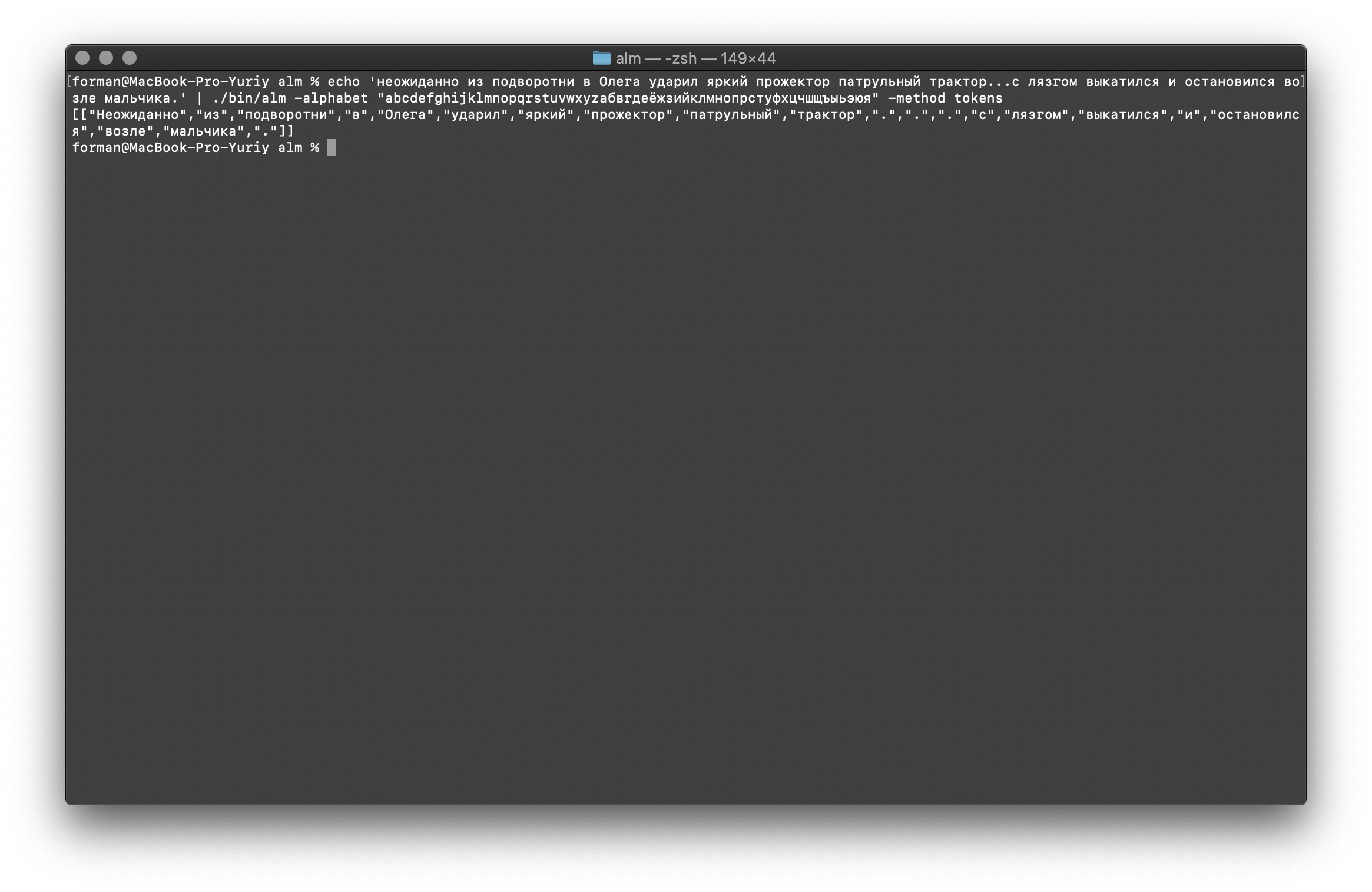 اختبار:
اختبار: ... .
نتيجة:[
[
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
".",
".",
".",
"",
"",
"",
"",
"",
"",
"",
"."
]
]
كما ترون ، تغيرت النتيجة. جرب الآن شيئًا آخر.$ echo ' 5–7 . : 1 . ( +37–38°), 5–10 . – ( +12–15°) ..»| |()' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 اختبار:
اختبار: 5–7 . : 1 . ( +37–38°), 5–10 . – ( +12–15°) ..»| |()
نتيجة:[
[
"",
"",
"",
"",
"5–7",
".",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
":",
"1",
".",
"",
"",
"(",
"+37–38°",
")",
",",
"",
"5–10",
".",
"–",
"",
"",
"(",
"+12–15°",
")",
"",
"..",
"»",
"|",
"|",
"(",
")"
]
]
اجمع كل شيء في النص
أولاً ، قم باستعادة الاختبار الأول.$ echo '[["Hello","World","?"]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
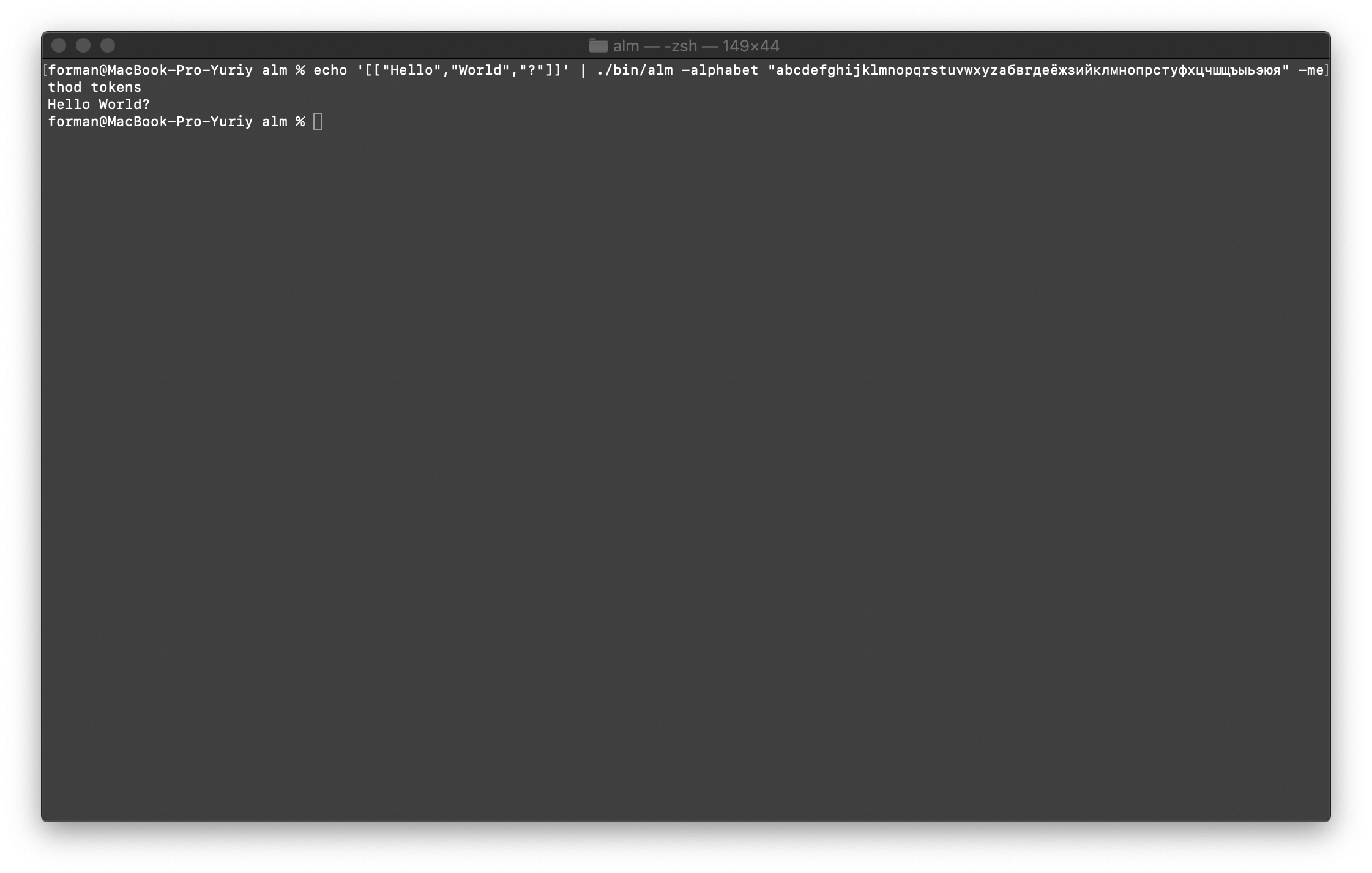 اختبار:
اختبار:[["Hello","World","?"]]
نتيجة:Hello World?
سنستعيد الآن الاختبار الأكثر تعقيدًا.$ echo '[["","","","","","","","","","","?","?","?"],["","","","","","","",".",".",".","."]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
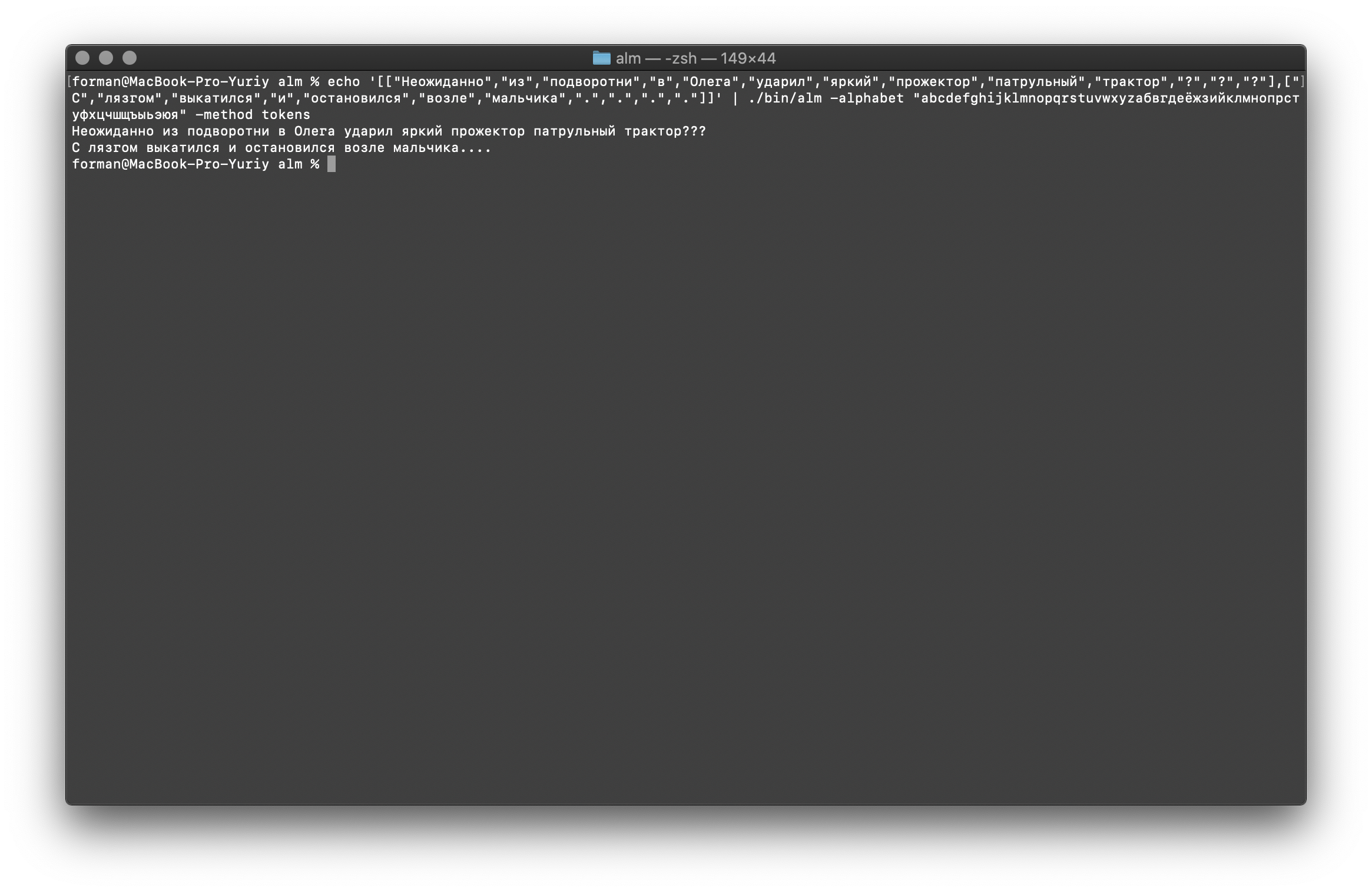 اختبار:
اختبار:[["","","","","","","","","","","?","?","?"],["","","","","","","",".",".",".","."]]
نتيجة: ???
….
كما ترى ، كان الرمز المميز قادرًا على استعادة النص المكسور في البداية.اكمل في.$ echo '[["","","","","","","","","","",".",".",".","","","","","","","","."]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 اختبار:
اختبار:[["","","","","","","","","","",".",".",".","","","","","","","","."]]
نتيجة: ... .
وأخيرًا ، تحقق من الخيار الأكثر صعوبة.$ echo '[["","","","","5–7",".","","","","","","","","","","","","","",":","1",".","","","(","+37–38°",")",",","","5–10",".","–","","","(","+12–15°",")","","..","»","|","|","(",")"]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
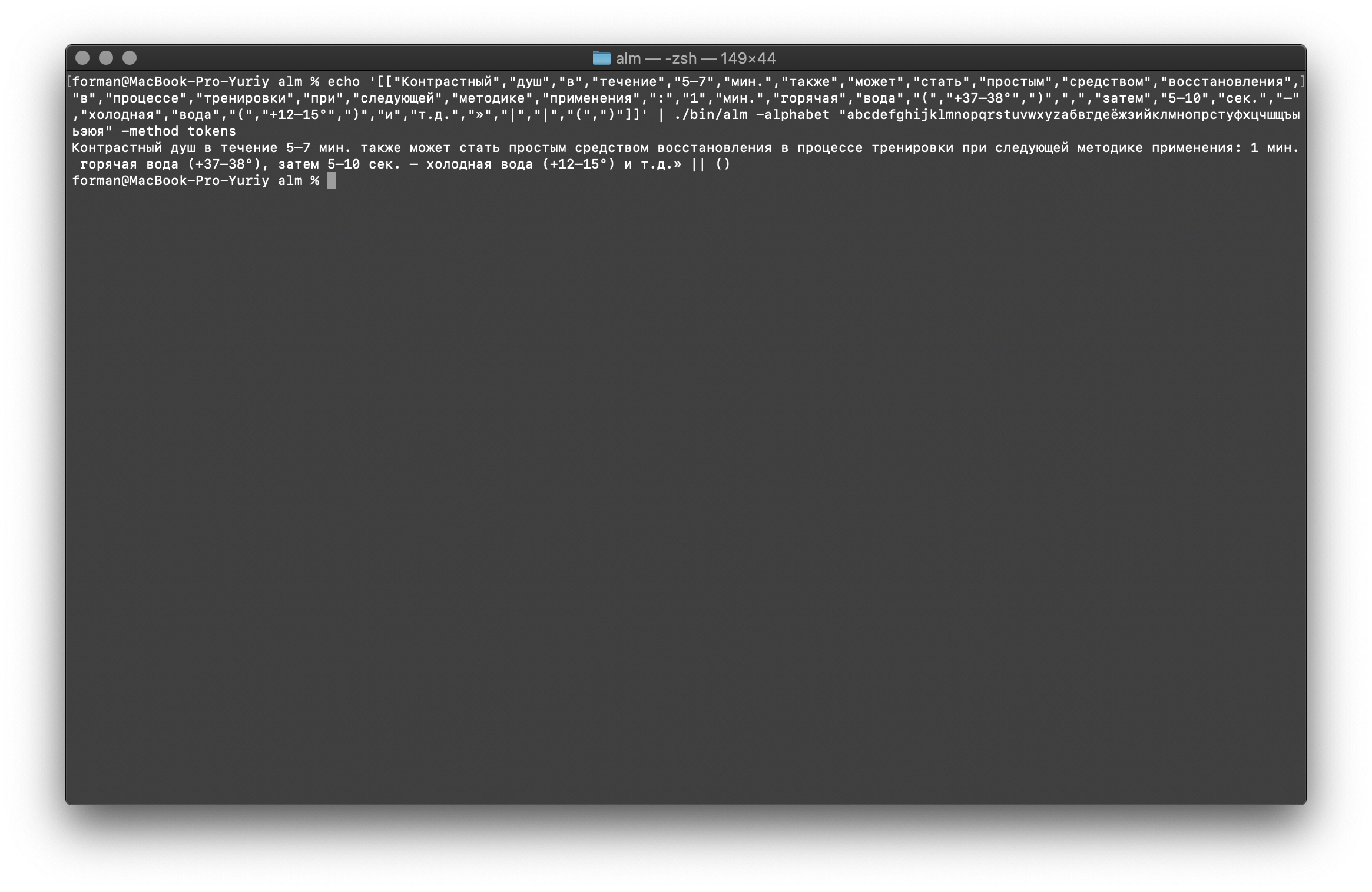 اختبار:
اختبار:[["","","","","5–7",".","","","","","","","","","","","","","",":","1",".","","","(","+37–38°",")",",","","5–10",".","–","","","(","+12–15°",")","","..","»","|","|","(",")"]]
نتيجة: 5–7 . : 1 . (+37–38°), 5–10 . – (+12–15°) ..» || ()
كما يتبين من النتائج ، يمكن للرمز المميز إصلاح معظم الأخطاء في تصميم النص.تدريب نموذج اللغة
$ ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -size 3 -smoothing wittenbell -method train -debug 1 -w-arpa ./lm.arpa -w-map ./lm.map -w-vocab ./lm.vocab -w-ngram ./lm.ngrams -allow-unk -interpolate -corpus ./text.txt -threads 0 -train-segments
سوف أصف معلمات التجميع بمزيد من التفصيل.- الحجم - حجم طول N-grams (يتم تعيين الحجم على 3 جرام )
- تنعيم - خوارزمية تنعيم (خوارزمية تم تحديدها بواسطة Witten-Bell )
- طريقة - طريقة العمل (طريقة تدريب محددة )
- debug - وضع التصحيح (تم تعيين مؤشر حالة التعلم)
- w-arpa — ARPA
- w-map — MAP
- w-vocab — VOCAB
- w-ngram — NGRAM
- allow-unk — 〈unk〉
- interpolate —
- corpus — . ,
- الخيوط - استخدام مؤشرات متعددة للتدريب (0 - للتدريب ، سيتم منح جميع نوى المعالج المتاحة ،> 0 عدد النوى المشاركة في التدريب)
- أجزاء القطار - سيتم تقسيم مبنى التدريب بالتساوي عبر جميع النوى
يمكن الحصول على مزيد من المعلومات باستخدام علامة [-مساعدة] .
حساب الحيرة
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method ppl -debug 2 -r-arpa ./lm.arpa -confidence -threads 0
 اختبار:
اختبار: ??? ….
نتيجة:info: <s> <punct> <punct> <punct> </s>
info: p( | <s> ) = [2gram] 0.00209192 [ -2.67945500 ] / 0.99999999
info: p( | ...) = [3gram] 0.91439744 [ -0.03886500 ] / 1.00000035
info: p( | ...) = [3gram] 0.86302624 [ -0.06397600 ] / 0.99999998
info: p( | ...) = [3gram] 0.98003368 [ -0.00875900 ] / 1.00000088
info: p( | ...) = [3gram] 0.85783547 [ -0.06659600 ] / 0.99999955
info: p( | ...) = [3gram] 0.95238819 [ -0.02118600 ] / 0.99999897
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( <punct> | ...) = [3gram] 0.78127873 [ -0.10719400 ] / 1.00000031
info: p( <punct> | <punct> ...) = [2gram] 0.29417110 [ -0.53140000 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( </s> | <punct> ...) = [3gram] 0.45569787 [ -0.34132300 ] / 0.99999998
info: 1 sentences, 13 words, 0 OOVs
info: 0 zeroprobs, logprob= -4.18477000 ppl= 1.99027067 ppl1= 2.09848266
info: <s> <punct> <punct> <punct> <punct> </s>
info: p( | <s> ) = [2gram] 0.00809597 [ -2.09173100 ] / 0.99999999
info: p( | ...) = [3gram] 0.19675329 [ -0.70607800 ] / 0.99999972
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.98007204 [ -0.00874200 ] / 0.99999931
info: p( | ...) = [3gram] 0.85785325 [ -0.06658700 ] / 1.00000018
info: p( | ...) = [3gram] 0.81482810 [ -0.08893400 ] / 1.00000027
info: p( | ...) = [3gram] 0.93507404 [ -0.02915400 ] / 1.00000058
info: p( <punct> | ...) = [3gram] 0.76391493 [ -0.11695500 ] / 0.99999971
info: p( <punct> | <punct> ...) = [2gram] 0.29417110 [ -0.53140000 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( </s> | <punct> ...) = [3gram] 0.45569787 [ -0.34132300 ] / 0.99999998
info: 1 sentences, 11 words, 0 OOVs
info: 0 zeroprobs, logprob= -4.57026500 ppl= 2.40356248 ppl1= 2.60302678
info: 2 sentences, 24 words, 0 OOVs
info: 0 zeroprobs, logprob= -8.75503500 ppl= 2.23975957 ppl1= 2.31629103
info: work time shifting: 0 seconds
أعتقد أنه لا يوجد شيء خاص للتعليق عليه ، لذلك سنواصل المزيد.التحقق من وجود السياق
$ echo "<s> </s>" | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method checktext -debug 1 -r-arpa ./lm.arpa -confidence
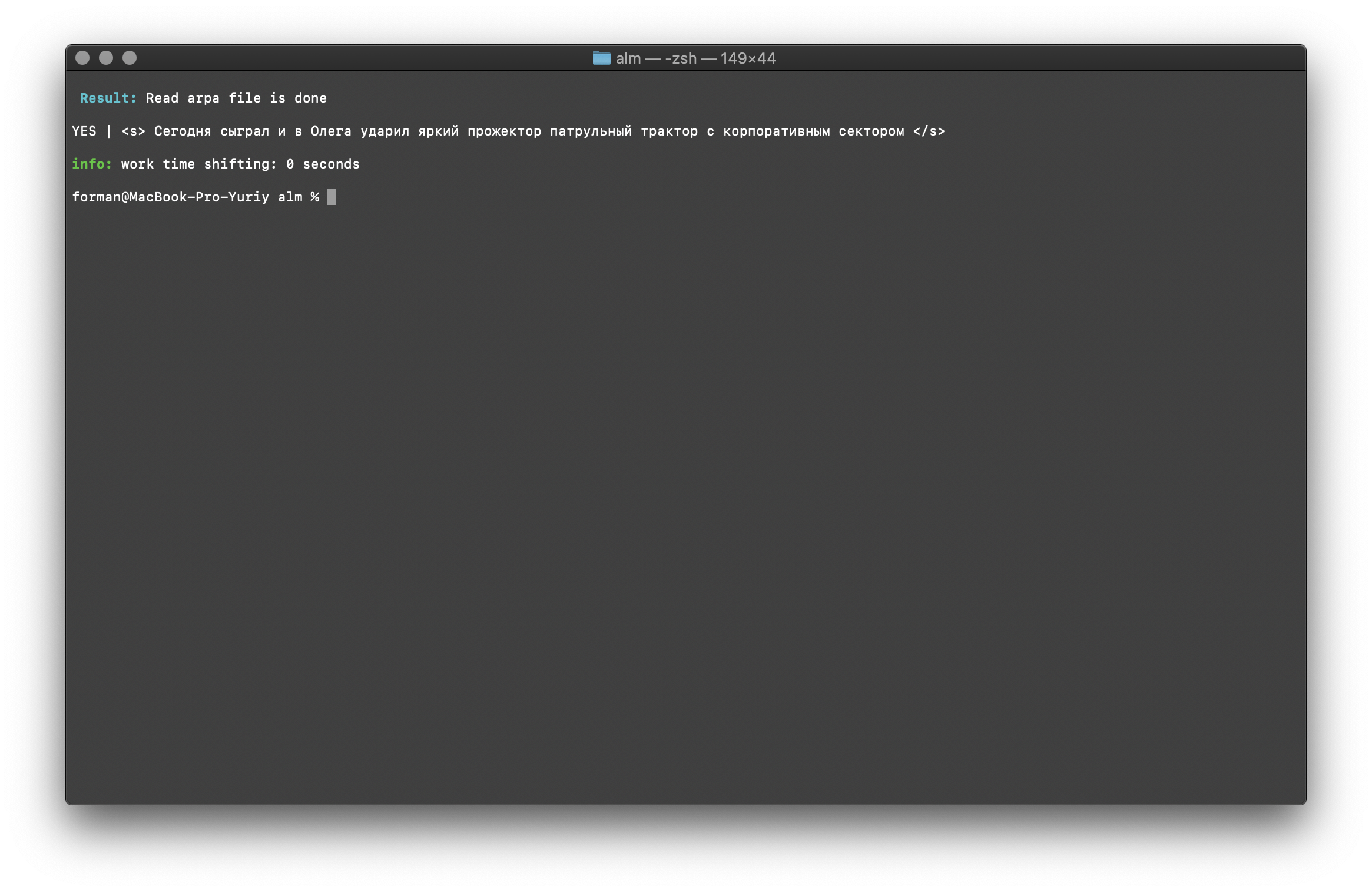 اختبار:
اختبار:<s> </s>
نتيجة:YES | <s> </s>
تظهر النتيجة أن النص الذي يتم التحقق منه يحتوي على السياق الصحيح من حيث نموذج اللغة المجمعة.العلم [- الثقة ] - يعني أنه سيتم تحميل نموذج اللغة كما تم إنشاؤه ، دون الإفراط في الكلام.تصحيح حالة الكلمة
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method fixcase -debug 1 -r-arpa ./lm.arpa -confidence
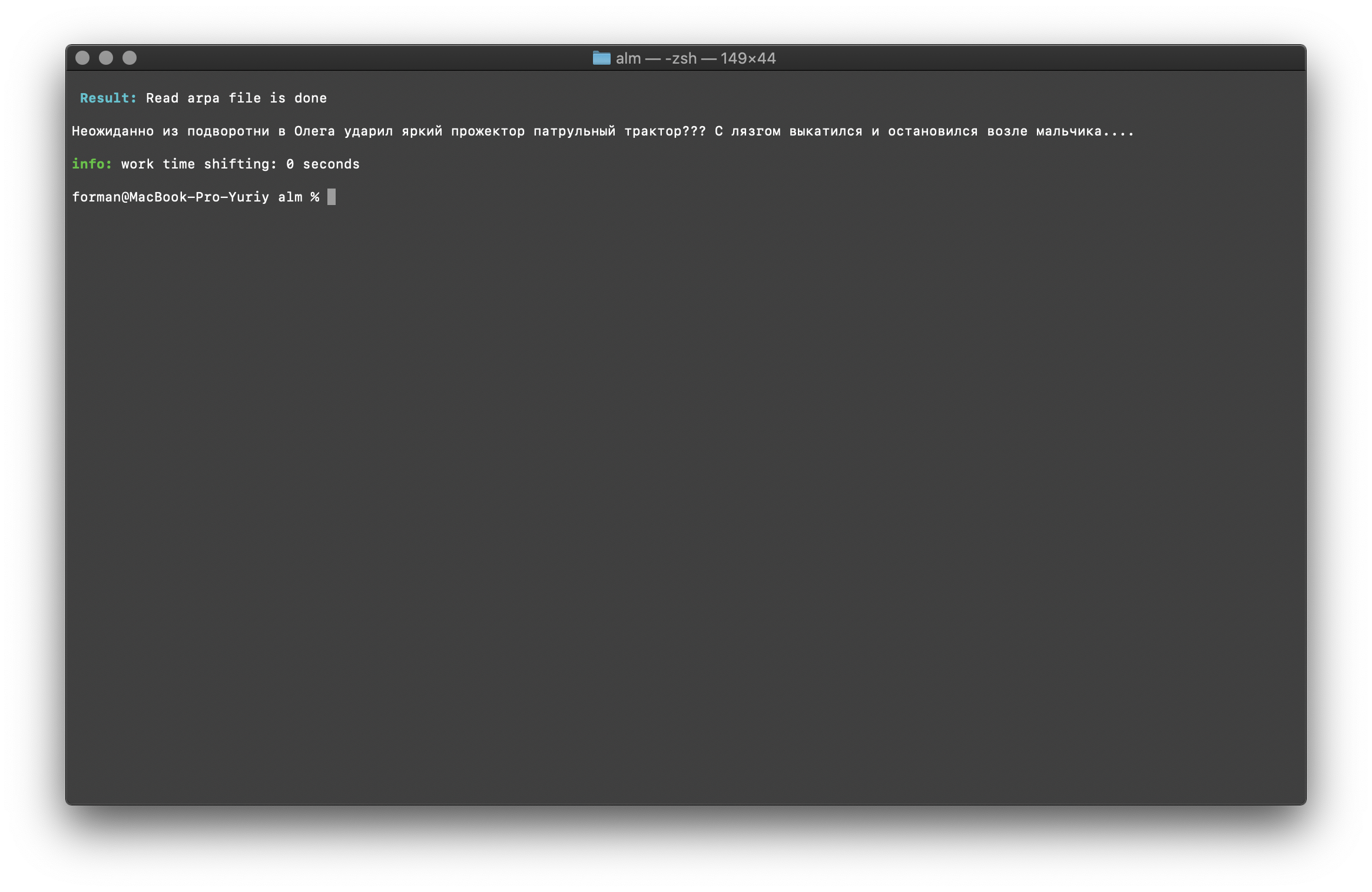 اختبار:
اختبار: ??? ....
نتيجة: ??? ....
يتم استعادة السجلات في النص مع مراعاة سياق نموذج اللغة.المكتبات الموضحة أعلاه للعمل مع نماذج اللغة الإحصائية حساسة لحالة الأحرف. على سبيل المثال ، N-gram " في موسكو غدًا ستمطر " ليس مثل N-gram " في موسكو ستمطر غدًا " ، فهذه N-grams مختلفة تمامًا. ولكن ماذا لو كان مطلوبًا من الحالة أن تكون حساسة لحالة الأحرف ، وفي نفس الوقت ، فإن تكرار نفس N-grams غير منطقي؟ يمثل ALM جميع N-grams بالأحرف الصغيرة. هذا يلغي إمكانية تكرار N-grams. تحتفظ ALM أيضًا بتصنيفها لسجلات الكلمات في كل N-gram. عند التصدير إلى تنسيق النص لنموذج اللغة ، تتم استعادة السجلات حسب تصنيفها.التحقق من عدد N-grams
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -debug 1 -r-arpa ./lm.arpa -confidence
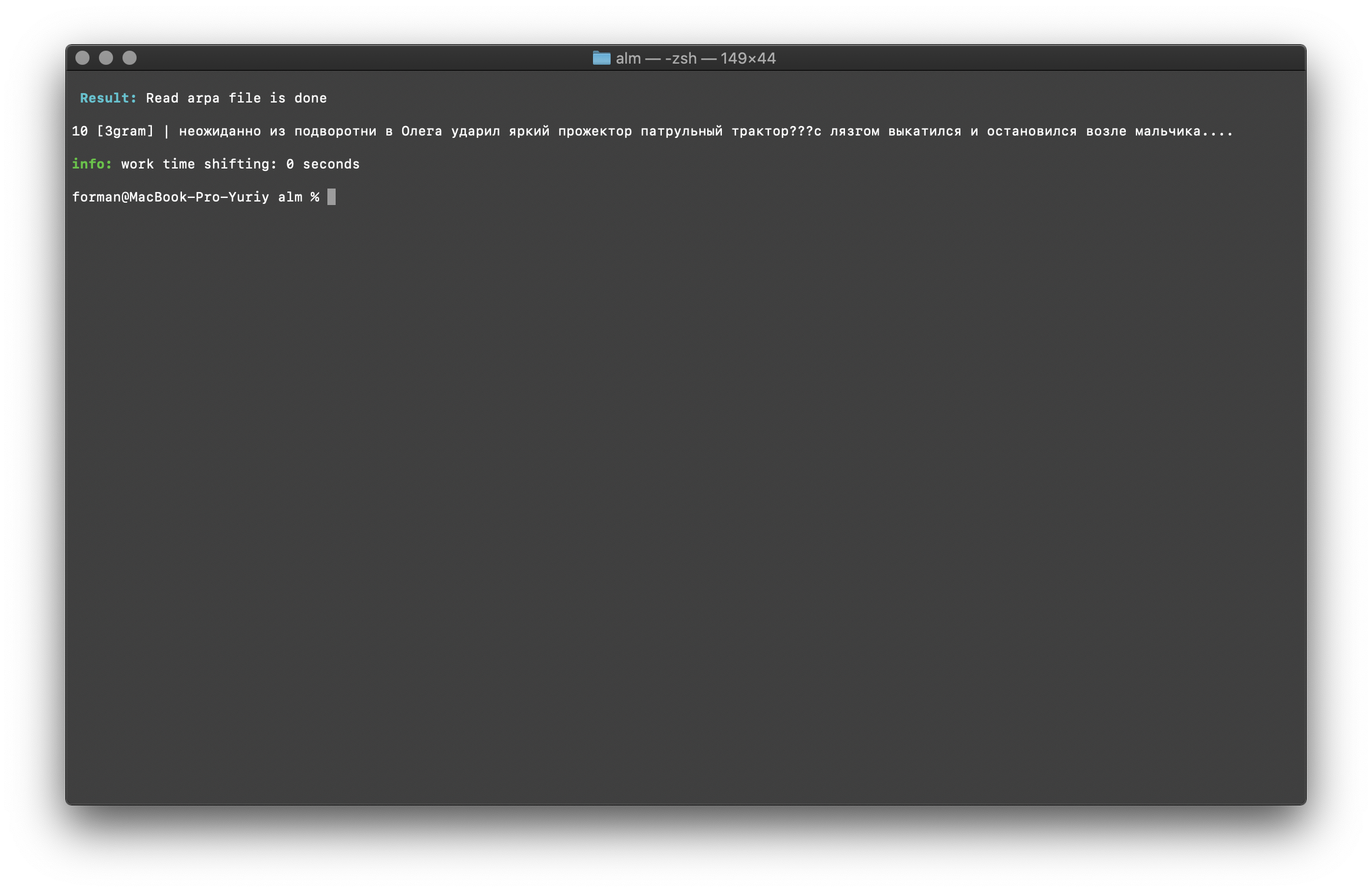 اختبار:
اختبار: ??? ....
نتيجة:10 [3gram] |
N- , .
يتم التحقق من عدد N-grams من خلال حجم N-gram في نموذج اللغة. هناك أيضًا فرصة للتحقق من وجود bigrams و trigrams .تحقق Bigram
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -ngrams bigram -debug 1 -r-arpa ./lm.arpa -confidence
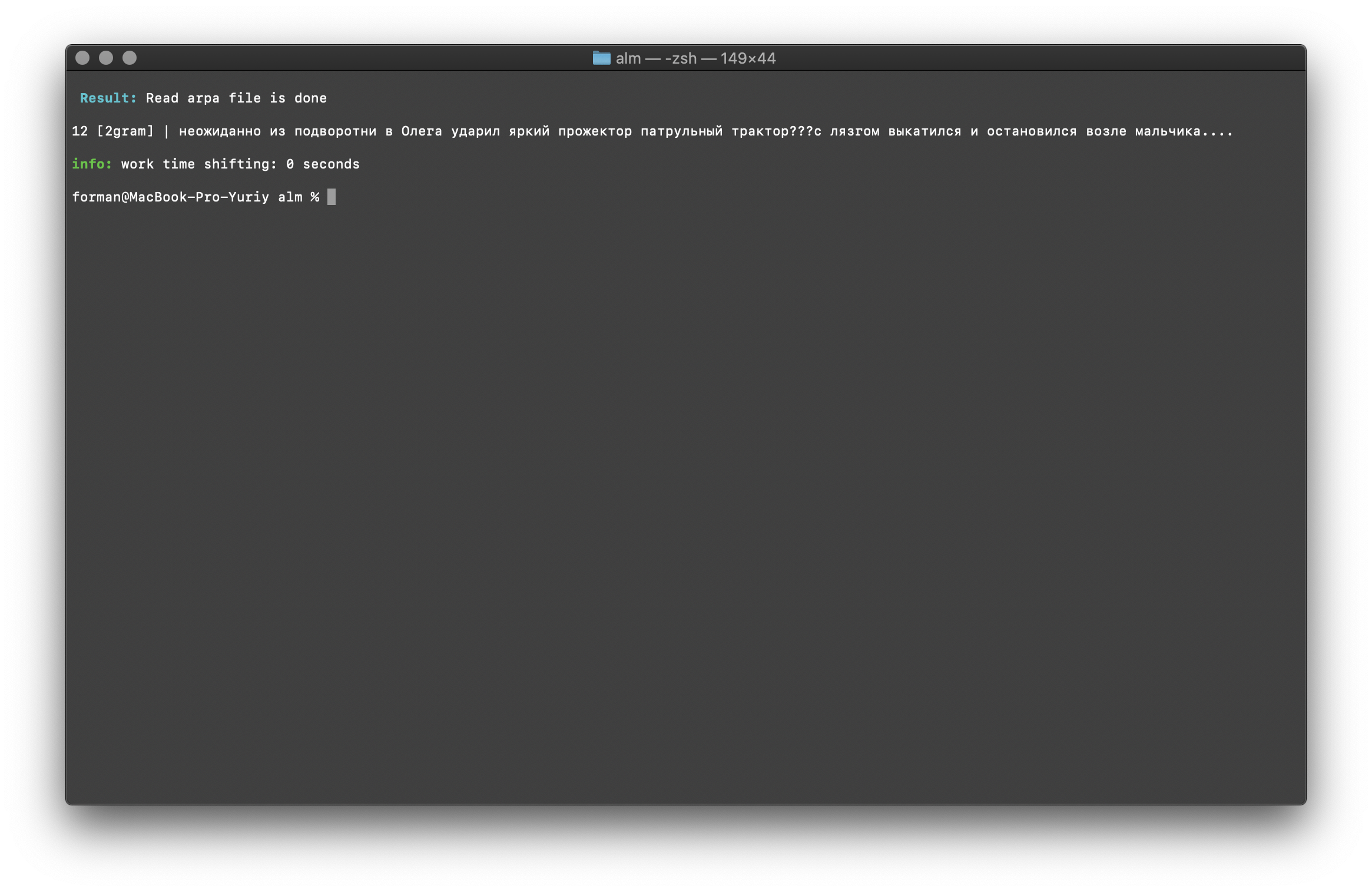 اختبار:
اختبار: ??? ....
نتيجة:12 [2gram] | ??? ….
التحقق من Trigram
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -ngrams trigram -debug 1 -r-arpa ./lm.arpa -confidence
اختبار: ??? ....
نتيجة:10 [3gram] | ??? ….
ابحث عن N-grams في النص
$ echo " " | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method find -debug 1 -r-arpa ./lm.arpa -confidence
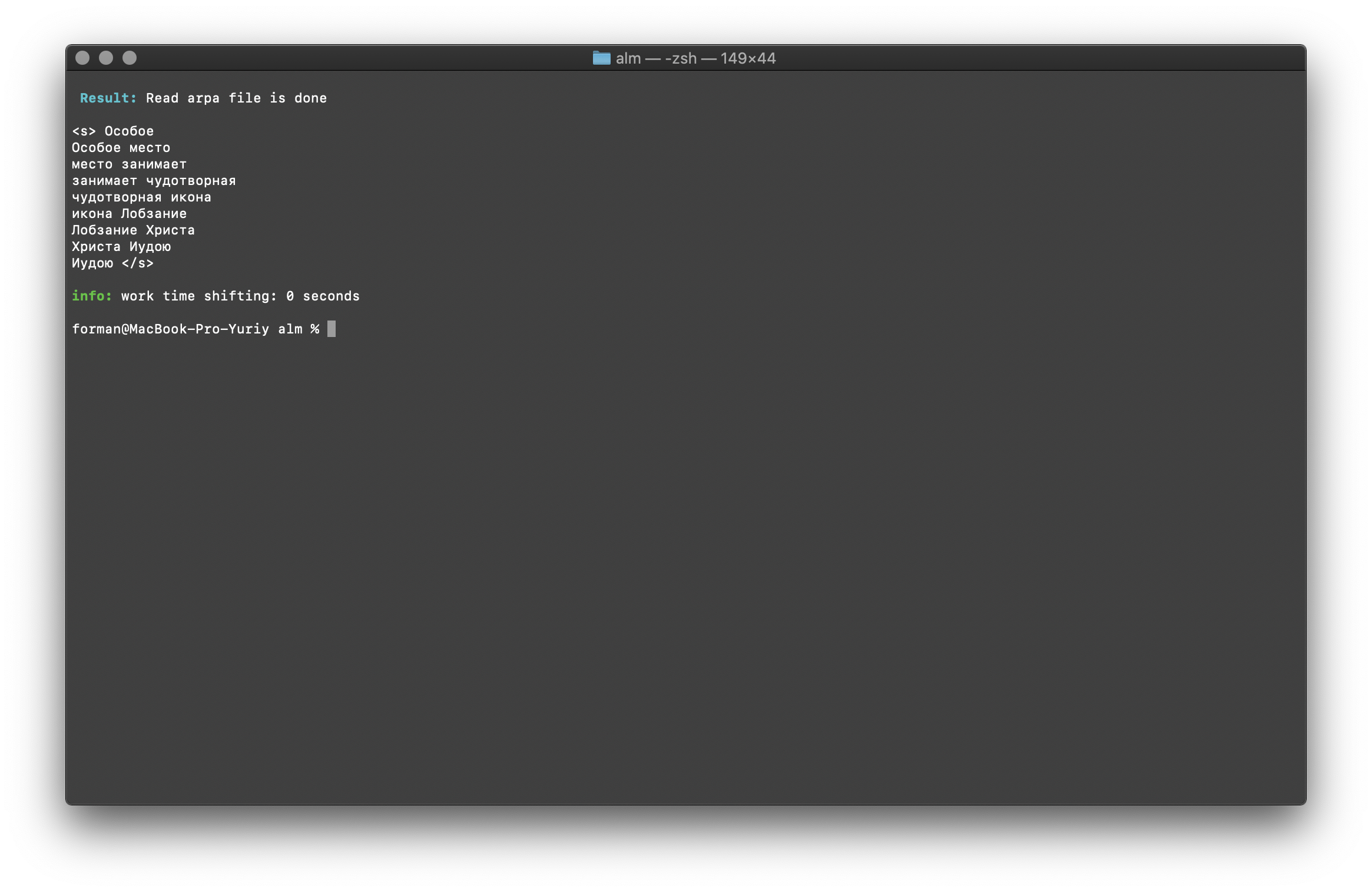 اختبار:
اختبار:
نتيجة:<s>
</s>
قائمة N-grams الموجودة في النص. لا يوجد شيء خاص لشرح هنا.متغيرات البيئة
يمكن تمرير جميع المعلمات من خلال متغيرات البيئة. تبدأ المتغيرات بالبادئة ALM_ ويجب كتابتها بأحرف كبيرة. خلاف ذلك ، تتوافق أسماء المتغيرات مع معلمات التطبيق.إذا تم تحديد كل من معلمات التطبيق ومتغيرات البيئة ، فسيتم إعطاء معلمات التطبيق الأولوية.$ export $ALM_SMOOTHING=wittenbell
$ export $ALM_W-ARPA=./lm.arpa
وبالتالي ، يمكن أتمتة عملية التجميع. على سبيل المثال ، من خلال مخطوطات BASH.استنتاج
أفهم أن هناك تقنيات واعدة مثل RnnLM أو Bert . لكنني متأكد من أن نماذج N-gram الإحصائية ستكون ذات صلة لفترة طويلة.استغرق هذا العمل الكثير من الوقت والجهد. كان يعمل في المكتبة في وقت فراغه من العمل الأساسي ليلاً وفي عطلات نهاية الأسبوع. لم يغط الكود الاختبارات والأخطاء والأخطاء المحتملة. سأكون ممتنا للاختبار. أنا منفتح أيضًا على اقتراحات التحسين ووظائف المكتبة الجديدة. يتم توزيع ALM بموجب ترخيص MIT ، والذي يسمح لك باستخدامه بدون أي قيود تقريبًا.نأمل في الحصول على التعليقات والنقد والاقتراحات.موقع المشروع مشروعمستودع